রাস্ট প্রোগ্রামিং ভাষা (The Rust Programming Language)
স্টিভ ক্লাবনিক, ক্যারল নিকোলস এবং ক্রিস ক্রিচো কর্তৃক রচিত, রাস্ট কমিউনিটির অবদানে সমৃদ্ধ
এই পাঠ্যটির এই সংস্করণটি ধরে নিচ্ছে যে আপনি Rust 1.85.0 (প্রকাশিত 2025-02-17) বা তার পরের সংস্করণ ব্যবহার করছেন। Rust ইনস্টল বা আপডেট করার জন্য অধ্যায় ১-এর "ইনস্টলেশন" বিভাগ দেখুন।
HTML ফরম্যাটটি অনলাইনে https://doc.rust-lang.org/stable/book/ এ উপলব্ধ এবং rustup দিয়ে তৈরি Rust ইনস্টলেশনের সাথে অফলাইনেও উপলব্ধ; এটি খুলতে rustup doc --book চালান।
বেশ কয়েকটি কমিউনিটি অনুবাদও উপলব্ধ।
এই পাঠ্যটি নো স্টার্চ প্রেস থেকে পেপারব্যাক এবং ইবুক ফরম্যাটে পাওয়া যায়।
🚨 আরও ইন্টারেক্টিভ শিক্ষার অভিজ্ঞতা চান? Rust বইয়ের একটি ভিন্ন সংস্করণ ব্যবহার করে দেখুন, যেখানে রয়েছে: কুইজ, হাইলাইটিং, ভিজ্যুয়ালাইজেশন এবং আরও অনেক কিছু: https://rust-book.cs.brown.edu
মুখবন্ধ (Foreword)
এটা সব সময় স্পষ্ট ছিল না, কিন্তু Rust প্রোগ্রামিং ভাষাটি মৌলিকভাবে ক্ষমতায়ন সম্পর্কে: আপনি এখন যে ধরনের কোডই লিখছেন না কেন, Rust আপনাকে আরও দূরে পৌঁছাতে, আরও আত্মবিশ্বাসের সাথে প্রোগ্রাম করতে এবং আগের চেয়ে আরও বিস্তৃত ডোমেইনে কাজ করতে সক্ষম করে।
উদাহরণস্বরূপ, "সিস্টেম-লেভেল"-এর কাজ, যা মেমরি ম্যানেজমেন্ট, ডেটা রিপ্রেজেন্টেশন এবং কনকারেন্সির নিম্ন-স্তরের বিবরণ নিয়ে কাজ করে। ঐতিহ্যগতভাবে, প্রোগ্রামিংয়ের এই ক্ষেত্রটিকে রহস্যময় বলে মনে করা হয়, যা শুধুমাত্র কয়েকজনের কাছে অ্যাক্সেসযোগ্য যারা এর কুখ্যাত অসুবিধাগুলি এড়াতে প্রয়োজনীয় বছর ধরে শেখার জন্য উৎসর্গ করেছে। এবং এমনকি যারা এটি অনুশীলন করে তারাও সতর্কতার সাথে করে, যাতে তাদের কোড শোষণ, ক্র্যাশ বা দুর্নীতির শিকার না হয়।
Rust পুরানো অসুবিধাগুলি দূর করে এবং আপনাকে সাহায্য করার জন্য একটি বন্ধুত্বপূর্ণ, পরিশীলিত টুলসেট সরবরাহ করে এই বাধাগুলি ভেঙে দেয়। যেসব প্রোগ্রামারদের নিম্ন-স্তরের নিয়ন্ত্রণে "ডিপ ডাউন" করতে হবে তারা Rust-এর সাথে তা করতে পারে, ক্র্যাশ বা নিরাপত্তা ত্রুটির চিরাচরিত ঝুঁকি না নিয়ে এবং একটি পরিবর্তনশীল টুলচেইনের সূক্ষ্ম বিষয়গুলি না শিখেই। আরও ভাল, ভাষাটি আপনাকে স্বাভাবিকভাবে নির্ভরযোগ্য কোডের দিকে পরিচালিত করার জন্য ডিজাইন করা হয়েছে যা গতি এবং মেমরি ব্যবহারের ক্ষেত্রে দক্ষ।
যেসব প্রোগ্রামার ইতিমধ্যেই নিম্ন-স্তরের কোড নিয়ে কাজ করছেন তারা তাদের উচ্চাকাঙ্ক্ষা বাড়াতে Rust ব্যবহার করতে পারেন। উদাহরণস্বরূপ, Rust-এ প্যারালেলিজম চালু করা তুলনামূলকভাবে কম ঝুঁকিপূর্ণ কাজ: কম্পাইলার আপনার জন্য চিরাচরিত ভুলগুলি ধরবে। এবং আপনি আপনার কোডে আরও আক্রমণাত্মক অপটিমাইজেশান মোকাবেলা করতে পারেন এই আত্মবিশ্বাসের সাথে যে আপনি দুর্ঘটনাক্রমে ক্র্যাশ বা দুর্বলতা তৈরি করবেন না।
কিন্তু Rust শুধুমাত্র নিম্ন-স্তরের সিস্টেম প্রোগ্রামিংয়ে সীমাবদ্ধ নয়। এটি CLI অ্যাপস, ওয়েব সার্ভার এবং আরও অনেক ধরনের কোড লেখার জন্য যথেষ্ট অভিব্যক্তিপূর্ণ এবং সুবিধাজনক — আপনি বইটির পরবর্তী অংশে উভয়ের সহজ উদাহরণ পাবেন। Rust-এর সাথে কাজ করা আপনাকে এমন দক্ষতা তৈরি করতে দেয় যা এক ডোমেইন থেকে অন্য ডোমেইনে স্থানান্তরিত হয়; আপনি একটি ওয়েব অ্যাপ লিখে Rust শিখতে পারেন, তারপর সেই একই দক্ষতাগুলি আপনার Raspberry Pi-কে টার্গেট করার জন্য প্রয়োগ করতে পারেন।
এই বইটি তার ব্যবহারকারীদের ক্ষমতায়নের জন্য Rust-এর সম্ভাবনাকে সম্পূর্ণরূপে গ্রহণ করে। এটি একটি বন্ধুত্বপূর্ণ এবং সহজবোধ্য পাঠ্য যা আপনাকে কেবল Rust সম্পর্কে আপনার জ্ঞানই নয়, সাধারণভাবে একজন প্রোগ্রামার হিসাবে আপনার নাগাল এবং আত্মবিশ্বাসকেও বাড়িয়ে তুলতে সহায়তা করে। সুতরাং, ঝাঁপিয়ে পড়ুন, শিখতে প্রস্তুত হন—এবং Rust কমিউনিটিতে স্বাগতম!
— নিকোলাস মাতসাকিস এবং অ্যারন তুরোন
সূচনা (Introduction)
দ্রষ্টব্য: এই বইয়ের এই সংস্করণটি No Starch Press থেকে ছাপানো এবং ই-বুক আকারে পাওয়া The Rust Programming Language বইটির অনুরূপ।
The Rust Programming Language বইটিতে আপনাকে স্বাগতম। এটি Rust প্রোগ্রামিং ভাষা সম্পর্কে একটি প্রাথমিক ধারণা দেয়। Rust প্রোগ্রামিং ল্যাঙ্গুয়েজ আপনাকে দ্রুত এবং নির্ভরযোগ্য সফটওয়্যার লিখতে সাহায্য করে। প্রোগ্রামিং ল্যাঙ্গুয়েজ ডিজাইনের ক্ষেত্রে, উচ্চ-স্তরের এরগোনোমিক্স (ergonomics) এবং নিম্ন-স্তরের কন্ট্রোল প্রায়শই একসাথে পাওয়া যায় না, কিন্তু Rust এই দ্বন্দ্বের সমাধান করে। একদিকে যেমন এটি শক্তিশালী প্রযুক্তিগত ক্ষমতা দেয়, তেমনই ডেভেলপারদের জন্য একটি দুর্দান্ত অভিজ্ঞতাও প্রদান করে। Rust-এর মাধ্যমে আপনি মেমরি ব্যবহারের মতো নিম্ন-স্তরের বিষয়গুলোকেও সহজে নিয়ন্ত্রণ করতে পারবেন, যা সাধারণত অনেক জটিলতার সাথে জড়িত থাকে।
কাদের জন্য Rust? (Who Rust Is For)
Rust বিভিন্ন কারণে অনেকের জন্যই উপযুক্ত। আসুন, এর মধ্যে কয়েকটি প্রধান দল/গোষ্ঠী সম্পর্কে জেনে নিই।
ডেভেলপারদের দল (Teams of Developers)
সিস্টেম প্রোগ্রামিং সম্পর্কে কম-বেশি জ্ঞান রাখা বড় ডেভেলপার দলগুলোর মধ্যে সহযোগিতার জন্য Rust একটি কার্যকর টুল হিসেবে প্রমাণিত। নিম্ন-স্তরের কোডে নানা ধরনের সূক্ষ্ম বাগ (bug) থাকার সম্ভাবনা থাকে। অন্যান্য ল্যাঙ্গুয়েজে এই বাগগুলো ধরতে প্রচুর টেস্টিং এবং অভিজ্ঞ ডেভেলপারদের কোড রিভিউ প্রয়োজন হয়। কিন্তু Rust-এ, কম্পাইলার নিজেই এই ধরনের বাগ থাকা কোড কম্পাইল করতে বাধা দেয়, যার মধ্যে concurrency বাগ-ও রয়েছে। কম্পাইলারের সাথে মিলেমিশে কাজ করার ফলে ডেভেলপারদের দল বাগ খোঁজার বদলে প্রোগ্রামের লজিকের দিকে বেশি মনোযোগ দিতে পারে।
Rust সিস্টেম প্রোগ্রামিংয়ের জগতে আধুনিক সব ডেভেলপার টুল নিয়ে এসেছে:
- Cargo হল একটি অন্তর্নির্মিত dependency ম্যানেজার এবং বিল্ড টুল। এটি Rust ইকোসিস্টেমের মধ্যে dependency যোগ করা, কম্পাইল করা এবং সেগুলোকে ম্যানেজ করা সহজ করে তোলে।
- Rustfmt টুলটি ডেভেলপারদের মধ্যে কোডিং স্টাইলের সামঞ্জস্য বজায় রাখতে সাহায্য করে।
- rust-analyzer কোড কমপ্লিশন এবং ইনলাইন এরর মেসেজের জন্য ইন্টিগ্রেটেড ডেভেলপমেন্ট এনভায়রনমেন্ট (IDE) ইন্টিগ্রেশনকে আরও শক্তিশালী করে তোলে।
Rust ইকোসিস্টেমের এই টুলগুলো এবং অন্যান্য টুল ব্যবহার করে ডেভেলপাররা সিস্টেম-লেভেল কোড লেখার সময় নিজেদের উৎপাদনশীলতা বজায় রাখতে পারে।
শিক্ষার্থী (Students)
যারা সিস্টেম কনসেপ্ট সম্পর্কে জানতে আগ্রহী, Rust সেই সব শিক্ষার্থী এবং ব্যক্তিদের জন্য। Rust ব্যবহার করে অনেকেই অপারেটিং সিস্টেম ডেভেলপমেন্টের মতো বিভিন্ন বিষয় শিখেছেন। এখানকার কমিউনিটি খুবই বন্ধুত্বপূর্ণ এবং শিক্ষার্থীদের প্রশ্নের উত্তর দিতে তারা সব সময়েই প্রস্তুত। এই বইটির মতো বিভিন্ন উদ্যোগের মাধ্যমে, Rust টিম সিস্টেমের ধারণাগুলোকে আরও বেশি মানুষের কাছে, বিশেষ করে যারা প্রোগ্রামিংয়ে নতুন, তাদের কাছে পৌঁছে দিতে চায়।
কোম্পানি (Companies)
ছোট-বড় কয়েকশো কোম্পানি তাদের প্রোডাকশনে বিভিন্ন ধরনের কাজের জন্য Rust ব্যবহার করে। এই কাজগুলোর মধ্যে রয়েছে কমান্ড লাইন টুল, ওয়েব সার্ভিস, DevOps টুলিং, এমবেডেড ডিভাইস, অডিও ও ভিডিও অ্যানালিসিস এবং ট্রান্সকোডিং, ক্রিপ্টোকারেন্সি, বায়োইনফরমেটিক্স, সার্চ ইঞ্জিন, ইন্টারনেট অফ থিংস অ্যাপ্লিকেশন, মেশিন লার্নিং, এমনকি ফায়ারফক্স (Firefox) ওয়েব ব্রাউজারের প্রধান কিছু অংশ।
ওপেন সোর্স ডেভেলপার (Open Source Developers)
যারা Rust প্রোগ্রামিং ল্যাঙ্গুয়েজ, কমিউনিটি, ডেভেলপার টুল এবং লাইব্রেরি তৈরি করতে চান, Rust তাদের জন্য। আপনি যদি Rust ল্যাঙ্গুয়েজে অবদান রাখেন তবে আমরা অত্যন্ত খুশি হব।
যারা গতি এবং স্থিতিশীলতাকে গুরুত্ব দেন (People Who Value Speed and Stability)
যারা একটি প্রোগ্রামিং ল্যাঙ্গুয়েজে গতি এবং স্থিতিশীলতা দুটোই চান, Rust তাদের জন্য। এখানে গতি বলতে বোঝানো হয়েছে, Rust কোড কত দ্রুত চলতে পারে এবং আপনি কত দ্রুত Rust ব্যবহার করে প্রোগ্রাম লিখতে পারেন। Rust-এর কম্পাইলার বিভিন্ন চেকের মাধ্যমে ফিচার যোগ এবং রিফ্যাক্টরিং (refactoring) করার সময় কোডের স্থায়িত্ব নিশ্চিত করে। অন্যান্য ল্যাঙ্গুয়েজে যেখানে এই ধরনের চেক থাকে না, সেখানে পুরনো কোড পরিবর্তন করতে ডেভেলপাররা প্রায়ই ভয় পান। অন্যদিকে, Rust চেষ্টা করে "শূন্য-খরচের অ্যাবস্ট্রাকশন" তৈরি করতে। এর মানে হল, উচ্চ-স্তরের ফিচারগুলো এমনভাবে নিম্ন-স্তরের কোডে কম্পাইল হবে, যেন মনে হয় সেগুলো হাতে লেখা হয়েছে এবং এর জন্য বাড়তি কোনো খরচ হবে না। Rust-এর লক্ষ্য হল নিরাপদ কোডকে দ্রুতগতির কোডে পরিণত করা।
Rust ল্যাঙ্গুয়েজ আরও অনেক ব্যবহারকারীকে সমর্থন করার আশা রাখে; উপরে যাদের উল্লেখ করা হয়েছে তারা কেবল প্রধান স্টেকহোল্ডারদের মধ্যে কয়েকজন। Rust-এর মূল লক্ষ্য হল নিরাপত্তা এবং উৎপাদনশীলতা, গতি এবং এরগোনোমিক্স (ergonomics) একসাথে সরবরাহ করে প্রোগ্রামারদের এতদিন ধরে যে আপস করতে হয়েছে সেটা দূর করা। Rust ব্যবহার করে দেখুন এবং এর বৈশিষ্ট্যগুলো আপনার জন্য কতটা উপযোগী তা যাচাই করুন।
এই বইটি কাদের জন্য (Who This Book Is For)
এই বইটি লেখার সময় ধরে নেওয়া হয়েছে যে আপনি অন্য কোনো প্রোগ্রামিং ল্যাঙ্গুয়েজে কোড লিখেছেন, তবে সেটি কোন ল্যাঙ্গুয়েজ তা নির্দিষ্ট করা হয়নি। আমরা চেষ্টা করেছি বইটির বিষয়বস্তু যাতে বিভিন্ন প্রোগ্রামিং ব্যাকগ্রাউন্ডের ব্যক্তিরা সহজে বুঝতে পারেন। প্রোগ্রামিং কী বা এটি নিয়ে কীভাবে চিন্তা করতে হয়, সে বিষয়ে আমরা খুব বেশি আলোচনা করিনি। আপনি যদি প্রোগ্রামিংয়ে একেবারে নতুন হন, তবে আপনার জন্য এমন একটি বই পড়া ভালো হবে যেখানে প্রোগ্রামিংয়ের প্রাথমিক বিষয়গুলো নিয়ে আলোচনা করা হয়েছে।
এই বইটি কীভাবে ব্যবহার করবেন (How to Use This Book)
সাধারণভাবে, ধরে নেওয়া হয়েছে যে আপনি এই বইটি শুরু থেকে শেষ পর্যন্ত ধারাবাহিকভাবে পড়বেন। পরের দিকের চ্যাপ্টারগুলো আগের চ্যাপ্টারের ধারণার ওপর ভিত্তি করে লেখা হয়েছে। আবার, কোনো কোনো ক্ষেত্রে আগের চ্যাপ্টারে কোনো বিষয়ের বিস্তারিত আলোচনা না থাকলেও পরের চ্যাপ্টারে সেই বিষয়ে ফিরে আসা হয়েছে।
এই বইটিতে আপনি দুই ধরনের চ্যাপ্টার পাবেন: কনসেপ্ট (ধারণা) চ্যাপ্টার এবং প্রোজেক্ট চ্যাপ্টার। কনসেপ্ট চ্যাপ্টারে আপনি Rust-এর কোনো একটি দিক সম্পর্কে জানতে পারবেন। প্রোজেক্ট চ্যাপ্টারে, আমরা একসাথে ছোট ছোট প্রোগ্রাম তৈরি করব এবং সেখানে আপনি যা শিখেছেন তা প্রয়োগ করার সুযোগ পাবেন। ২, ১২ এবং ২১ নম্বর চ্যাপ্টারগুলো হল প্রোজেক্ট চ্যাপ্টার; বাকিগুলো কনসেপ্ট চ্যাপ্টার।
চ্যাপ্টার ১-এ Rust ইন্সটল করার পদ্ধতি, “Hello, world!” প্রোগ্রাম লেখার নিয়ম এবং Rust-এর প্যাকেজ ম্যানেজার ও বিল্ড টুল Cargo ব্যবহারের উপায় বলা হয়েছে। চ্যাপ্টার ২-তে Rust দিয়ে একটি প্রোগ্রাম লেখার হাতে-কলমে অভিজ্ঞতা দেওয়া হয়েছে, যেখানে আপনি একটি সংখ্যা অনুমান করার গেম তৈরি করবেন। এখানে আমরা বিভিন্ন কনসেপ্ট নিয়ে ওপর-ওপর আলোচনা করেছি, পরের চ্যাপ্টারগুলোতে বিস্তারিত আলোচনা করা হবে। আপনি যদি শুরুতেই হাতে-কলমে কিছু করতে চান, তাহলে চ্যাপ্টার ২ আপনার জন্য। চ্যাপ্টার ৩-এ Rust-এর এমন সব ফিচার নিয়ে আলোচনা করা হয়েছে, যেগুলো অন্যান্য প্রোগ্রামিং ল্যাঙ্গুয়েজের মতোই। চ্যাপ্টার ৪-এ আপনি Rust-এর ownership সিস্টেম সম্পর্কে জানতে পারবেন। আপনি যদি এমন কেউ হন যিনি প্রতিটি খুঁটিনাটি বিষয় না জেনে এগোতে চান না, তাহলে আপনি চ্যাপ্টার ২ বাদ দিয়ে সরাসরি চ্যাপ্টার ৩-এ চলে যেতে পারেন। তারপর যখন আপনি নিজের শেখা বিষয়গুলো কাজে লাগিয়ে কোনো প্রোজেক্টে কাজ করতে চাইবেন, তখন চ্যাপ্টার ২-এ ফিরে আসতে পারেন।
চ্যাপ্টার ৫-এ structs এবং methods নিয়ে আলোচনা করা হয়েছে। চ্যাপ্টার ৬-এ রয়েছে enums, match এক্সপ্রেশন এবং if let কন্ট্রোল ফ্লো কনস্ট্রাক্ট। Rust-এ আপনি কাস্টম টাইপ তৈরি করার জন্য structs এবং enums ব্যবহার করবেন।
চ্যাপ্টার ৭-এ আপনি Rust-এর মডিউল সিস্টেম এবং আপনার কোড ও এর পাবলিক অ্যাপ্লিকেশন প্রোগ্রামিং ইন্টারফেস (API) সাজানোর জন্য প্রাইভেসি রুলস সম্পর্কে জানতে পারবেন। চ্যাপ্টার ৮-এ স্ট্যান্ডার্ড লাইব্রেরিতে থাকা কিছু কমন কালেকশন ডেটা স্ট্রাকচার, যেমন ভেক্টর, স্ট্রিং এবং হ্যাশ ম্যাপ নিয়ে আলোচনা করা হয়েছে। চ্যাপ্টার ৯-এ Rust-এর এরর-হ্যান্ডলিংয়ের ফিলোসফি এবং টেকনিকগুলো আলোচনা করা হয়েছে।
চ্যাপ্টার ১০-এ জেনেরিকস (generics), ট্রেইটস (traits) এবং লাইফটাইম (lifetimes) নিয়ে বিস্তারিত আলোচনা করা হয়েছে, যা আপনাকে এমন কোড লেখার ক্ষমতা দেয় যা একাধিক টাইপের জন্য ব্যবহার করা যায়। চ্যাপ্টার ১১-এর মূল বিষয় হল টেস্টিং। Rust-এর নিজস্ব নিরাপত্তা ব্যবস্থা থাকা সত্ত্বেও আপনার প্রোগ্রামের লজিক ঠিক আছে কিনা, তা নিশ্চিত করার জন্য টেস্টিং প্রয়োজন। চ্যাপ্টার ১২-তে আমরা grep কমান্ড লাইন টুলের কার্যকারিতার একটি অংশ নিজেরা তৈরি করব, যেটি ফাইলগুলোর মধ্যে টেক্সট খুঁজে বের করে। এর জন্য আমরা আগের চ্যাপ্টারগুলোতে আলোচনা করা অনেক কনসেপ্ট ব্যবহার করব।
চ্যাপ্টার ১৩-তে ক্লোজার (closures) এবং ইটারেটর (iterators) নিয়ে আলোচনা করা হয়েছে। এগুলো Rust-এর এমন কিছু ফিচার যেগুলো ফাংশনাল প্রোগ্রামিং ল্যাঙ্গুয়েজ থেকে নেওয়া হয়েছে। চ্যাপ্টার ১৪-তে আমরা Cargo নিয়ে আরও বিস্তারিত আলোচনা করব এবং অন্যদের সাথে আপনার লাইব্রেরি শেয়ার করার সেরা উপায়গুলো জানব। চ্যাপ্টার ১৫-তে স্ট্যান্ডার্ড লাইব্রেরির স্মার্ট পয়েন্টার এবং সেই পয়েন্টারগুলোর কার্যকারিতার জন্য দায়ী ট্রেইটগুলো নিয়ে আলোচনা করা হয়েছে।
চ্যাপ্টার ১৬-তে আমরা কনকারেন্ট প্রোগ্রামিংয়ের বিভিন্ন মডেল নিয়ে আলোচনা করব এবং Rust কীভাবে আপনাকে নির্ভয়ে মাল্টিপল থ্রেডে প্রোগ্রাম করতে সাহায্য করে, সে বিষয়ে কথা বলব। চ্যাপ্টার 17-এ আমরা Rust-এর async এবং await সিনট্যাক্স এবং এরা যে লাইটওয়েট কনকারেন্সি মডেল সমর্থন করে সে বিষয়ে জানবো।
চ্যাপ্টার ১৮-তে অবজেক্ট-ওরিয়েন্টেড প্রোগ্রামিংয়ের যে প্রিন্সিপালগুলোর সঙ্গে আপনি হয়তো পরিচিত, Rust-এর ইডিয়ামগুলো সেগুলোর থেকে কতটা আলাদা, তা দেখানো হয়েছে।
চ্যাপ্টার ১৯ হল প্যাটার্ন এবং প্যাটার্ন ম্যাচিং-এর একটি রেফারেন্স। Rust প্রোগ্রামগুলোতে আইডিয়া প্রকাশের জন্য এগুলো খুবই শক্তিশালী উপায়। চ্যাপ্টার ২০-তে আরও কিছু অ্যাডভান্সড বিষয় নিয়ে আলোচনা করা হয়েছে, যেমন আনসেফ (unsafe) Rust, ম্যাক্রো (macros), এবং লাইফটাইম, ট্রেইট, টাইপ, ফাংশন ও ক্লোজার সম্পর্কে আরও বিস্তারিত তথ্য।
চ্যাপ্টার ২১-এ আমরা একটি প্রোজেক্ট শেষ করব, যেখানে আমরা একটি নিম্ন-স্তরের মাল্টিথ্রেডেড ওয়েব সার্ভার তৈরি করব!
সবশেষে, কিছু অ্যাপেন্ডিক্সে (appendices) ল্যাঙ্গুয়েজটি সম্পর্কে আরও কিছু দরকারী তথ্য দেওয়া হয়েছে, যেগুলো অনেকটা রেফারেন্সের মতো কাজ করবে। Appendix A-তে Rust-এর কীওয়ার্ড, Appendix B-তে Rust-এর অপারেটর ও সিম্বল, Appendix C-তে স্ট্যান্ডার্ড লাইব্রেরি থেকে পাওয়া ডিরাইভেবল ট্রেইট, Appendix D-তে কিছু দরকারী ডেভেলপমেন্ট টুল এবং Appendix E-তে Rust-এর এডিশনগুলো নিয়ে আলোচনা করা হয়েছে। Appendix F-এ আপনি বইটির অন্যান্য অনুবাদ খুঁজে পাবেন এবং Appendix G-এ আমরা Rust কীভাবে তৈরি হয়েছে এবং নাইটলি Rust কী, সে বিষয়ে আলোচনা করব।
এই বইটি পড়ার কোনো নির্দিষ্ট নিয়ম নেই: আপনি যদি কোনো অংশ বাদ দিয়ে এগিয়ে যেতে চান, তাহলে যেতে পারেন! তবে কোনো কিছু বুঝতে অসুবিধা হলে আপনাকে হয়তো আগের চ্যাপ্টারগুলোতে ফিরে যেতে হতে পারে। আপনার যেভাবে সুবিধা হয়, সেভাবেই পড়ুন।
Rust শেখার প্রক্রিয়ার একটি গুরুত্বপূর্ণ অংশ হল কম্পাইলারের দেখানো এরর মেসেজগুলো পড়তে শেখা। এই মেসেজগুলোই আপনাকে সঠিক কোডের দিকে নিয়ে যাবে। তাই, আমরা এখানে অনেক উদাহরণ দিয়েছি যেখানে কোড কম্পাইল হবে না এবং প্রতিটি ক্ষেত্রে কম্পাইলার আপনাকে কী এরর মেসেজ দেখাবে, সেটাও বলা হয়েছে। মনে রাখবেন, আপনি যদি কোনো একটি উদাহরণ নিয়ে কাজ করেন, তাহলে সেটি কম্পাইল নাও হতে পারে! আপনি যে উদাহরণটি নিয়ে কাজ করছেন, সেটি এরর দেওয়ার জন্য তৈরি কিনা, তা বোঝার জন্য আশেপাশের লেখাগুলো অবশ্যই পড়বেন। যেসব কোড কাজ করার কথা নয়, Ferris সেগুলোকে আলাদা করতে আপনাকে সাহায্য করবে:
| Ferris | অর্থ (Meaning) |
|---|---|
 | এই কোড কম্পাইল হবে না! |
 | এই কোড প্যানিক (panic) করবে! |
 | এই কোড প্রত্যাশিত আচরণ করবে না। |
বেশিরভাগ ক্ষেত্রে, যেসব কোড কম্পাইল হয় না, সেগুলোর সঠিক ভার্সন কোনটি, তা আমরা আপনাকে দেখিয়ে দেব।
সোর্স কোড (Source Code)
এই বইটি তৈরি করার জন্য যে সোর্স ফাইলগুলো ব্যবহার করা হয়েছে, সেগুলো GitHub-এ পাওয়া যাবে।
শুরু করা যাক (Getting Started)
চলুন আপনার Rust যাত্রা শুরু করা যাক! শেখার অনেক কিছু আছে, কিন্তু প্রতিটি যাত্রাই কোথাও না কোথাও থেকে শুরু হয়। এই চ্যাপ্টারে, আমরা আলোচনা করব:
- Linux, macOS, এবং Windows-এ Rust ইন্সটল করা
- একটি প্রোগ্রাম লেখা যা
Hello, world!প্রিন্ট করে cargoব্যবহার করা, Rust-এর প্যাকেজ ম্যানেজার এবং বিল্ড সিস্টেম
ইন্সটলেশন (Installation)
প্রথম ধাপ হল Rust ইন্সটল করা। আমরা rustup-এর মাধ্যমে Rust ডাউনলোড করব। rustup হল একটি কমান্ড লাইন টুল, যা Rust-এর বিভিন্ন ভার্সন এবং এর সাথে সম্পর্কিত টুলগুলো ম্যানেজ করে। ডাউনলোড করার জন্য আপনার ইন্টারনেট কানেকশন লাগবে।
দ্রষ্টব্য: যদি আপনি কোনো কারণে
rustupব্যবহার করতে না চান, তাহলে অন্যান্য ইন্সটলেশন পদ্ধতির জন্য Other Rust Installation Methods page দেখুন।
নিচের ধাপগুলো Rust কম্পাইলারের সর্বশেষ স্থিতিশীল (stable) ভার্সন ইন্সটল করবে। Rust-এর স্টেবিলিটি গ্যারান্টি নিশ্চিত করে যে, বইয়ের যেসব উদাহরণ কম্পাইল হয়েছে, সেগুলো Rust-এর নতুন ভার্সনেও কম্পাইল হবে। ভার্সন অনুযায়ী আউটপুট সামান্য ভিন্ন হতে পারে, কারণ Rust প্রায়ই এরর মেসেজ এবং ওয়ার্নিং উন্নত করে। অর্থাৎ, আপনি এই ধাপগুলো অনুসরণ করে Rust-এর যে কোনো নতুন স্থিতিশীল ভার্সন ইন্সটল করুন না কেন, তা এই বইয়ের কন্টেন্টের সাথে ঠিকঠাক কাজ করবে।
কমান্ড লাইন নোটেশন (Command Line Notation)
এই চ্যাপ্টারে এবং পুরো বইজুড়ে, আমরা টার্মিনালে ব্যবহৃত কিছু কমান্ড দেখাব। টার্মিনালে যেসব লাইন আপনার টাইপ করা উচিত, সেগুলো সবই
$দিয়ে শুরু হয়। আপনাকে$ক্যারেক্টারটি টাইপ করতে হবে না; এটি হল কমান্ড লাইন প্রম্পট, যা প্রতিটি কমান্ডের শুরু বোঝানোর জন্য দেখানো হয়। যেসব লাইন$দিয়ে শুরু হয় না, সেগুলো সাধারণত আগের কমান্ডের আউটপুট দেখায়। এছাড়াও, PowerShell-এর জন্য নির্দিষ্ট উদাহরণগুলোতে$-এর পরিবর্তে>ব্যবহার করা হবে।
Linux বা macOS-এ rustup ইন্সটল করা (Installing rustup on Linux or macOS)
আপনি যদি Linux বা macOS ব্যবহার করেন, তাহলে একটি টার্মিনাল খুলুন এবং নিচের কমান্ডটি লিখুন:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
এই কমান্ডটি একটি স্ক্রিপ্ট ডাউনলোড করে এবং rustup টুলটির ইন্সটলেশন শুরু করে। এই rustup টুলটি Rust-এর সর্বশেষ স্থিতিশীল ভার্সন ইন্সটল করে। আপনাকে হয়তো আপনার পাসওয়ার্ড দিতে বলা হতে পারে। ইন্সটলেশন সফল হলে, নিচের লাইনটি দেখতে পাবেন:
Rust is installed now. Great!
আপনার একটি লিঙ্কার (linker)-এরও প্রয়োজন হবে। লিঙ্কার হল এমন একটি প্রোগ্রাম, যা Rust তার কম্পাইল করা আউটপুটগুলোকে একটি ফাইলে যুক্ত করতে ব্যবহার করে। সম্ভবত আপনার কাছে এটি ইতিমধ্যেই আছে। আপনি যদি লিঙ্কার এরর পান, তাহলে আপনার একটি C কম্পাইলার ইন্সটল করা উচিত, যার মধ্যে সাধারণত একটি লিঙ্কার অন্তর্ভুক্ত থাকে। একটি C কম্পাইলার থাকাও দরকারি, কারণ কিছু সাধারণ Rust প্যাকেজ C কোডের উপর নির্ভরশীল এবং তাদের একটি C কম্পাইলার প্রয়োজন হবে।
macOS-এ, আপনি নিচের কমান্ডটি চালিয়ে একটি C কম্পাইলার পেতে পারেন:
$ xcode-select --install
Linux ব্যবহারকারীদের সাধারণত তাদের ডিস্ট্রিবিউশনের ডকুমেন্টেশন অনুযায়ী GCC বা Clang ইন্সটল করা উচিত। উদাহরণস্বরূপ, আপনি যদি Ubuntu ব্যবহার করেন, তাহলে আপনি build-essential প্যাকেজটি ইন্সটল করতে পারেন।
Windows-এ rustup ইন্সটল করা (Installing rustup on Windows)
Windows-এ, https://www.rust-lang.org/tools/install-এ যান এবং Rust ইন্সটল করার জন্য দেওয়া নির্দেশাবলী অনুসরণ করুন। ইন্সটলেশনের কোনো এক সময়ে, আপনাকে Visual Studio ইন্সটল করতে বলা হবে। এটি একটি লিঙ্কার এবং প্রোগ্রাম কম্পাইল করার জন্য প্রয়োজনীয় নেটিভ লাইব্রেরি সরবরাহ করে। এই ধাপে আরও সাহায্যের প্রয়োজন হলে, https://rust-lang.github.io/rustup/installation/windows-msvc.html দেখুন।
এই বইয়ের বাকি অংশে ব্যবহৃত কমান্ডগুলো cmd.exe এবং PowerShell, দুটোতেই কাজ করে। যদি নির্দিষ্ট কোনো পার্থক্য থাকে, তাহলে আমরা কোনটি ব্যবহার করতে হবে তা ব্যাখ্যা করব।
সমস্যা সমাধান (Troubleshooting)
আপনার Rust সঠিকভাবে ইন্সটল হয়েছে কিনা, তা পরীক্ষা করার জন্য একটি শেল খুলুন এবং এই লাইনটি লিখুন:
$ rustc --version
আপনি নিচের ফরম্যাটে প্রকাশিত সর্বশেষ স্থিতিশীল ভার্সনের ভার্সন নম্বর, কমিট হ্যাশ এবং কমিট ডেট দেখতে পাবেন:
rustc x.y.z (abcabcabc yyyy-mm-dd)
আপনি যদি এই তথ্য দেখতে পান, তাহলে আপনি সফলভাবে Rust ইন্সটল করেছেন! যদি এই তথ্য দেখতে না পান, তাহলে নিচের মতো করে পরীক্ষা করুন যে Rust আপনার %PATH% সিস্টেম ভেরিয়েবলে আছে কিনা।
Windows CMD-তে, এটি ব্যবহার করুন:
> echo %PATH%
PowerShell-এ, এটি ব্যবহার করুন:
> echo $env:Path
Linux এবং macOS-এ, এটি ব্যবহার করুন:
$ echo $PATH
যদি সব ঠিক থাকে এবং Rust তবুও কাজ না করে, তাহলে আপনি বেশ কয়েকটি জায়গা থেকে সাহায্য পেতে পারেন। অন্যান্য Rustacean-দের (আমরা নিজেদের এই মজার নামে ডাকি) সাথে কীভাবে যোগাযোগ করবেন, তা জানতে কমিউনিটি পেজ দেখুন।
আপডেট এবং আনইন্সটল করা (Updating and Uninstalling)
rustup-এর মাধ্যমে Rust ইন্সটল হয়ে গেলে, নতুন প্রকাশিত ভার্সনে আপডেট করা সহজ। আপনার শেল থেকে, নিচের আপডেট স্ক্রিপ্টটি চালান:
$ rustup update
Rust এবং rustup আনইন্সটল করতে, আপনার শেল থেকে নিচের আনইন্সটল স্ক্রিপ্টটি চালান:
$ rustup self uninstall
লোকাল ডকুমেন্টেশন (Local Documentation)
Rust ইন্সটলেশনের সাথে ডকুমেন্টেশনের একটি লোকাল কপিও অন্তর্ভুক্ত থাকে, যাতে আপনি অফলাইনে পড়তে পারেন। লোকাল ডকুমেন্টেশন আপনার ব্রাউজারে খুলতে rustup doc চালান।
স্ট্যান্ডার্ড লাইব্রেরি থেকে যখনই কোনো টাইপ বা ফাংশন দেওয়া হয় এবং আপনি যদি নিশ্চিত না হন যে এটি কী করে বা কীভাবে ব্যবহার করতে হয়, তাহলে জানার জন্য অ্যাপ্লিকেশন প্রোগ্রামিং ইন্টারফেস (API) ডকুমেন্টেশন ব্যবহার করুন!
টেক্সট এডিটর এবং ইন্টিগ্রেটেড ডেভেলপমেন্ট এনভায়রনমেন্ট (Text Editors and Integrated Development Environments)
এই বইটিতে আপনি Rust কোড লেখার জন্য কোন টুল ব্যবহার করবেন সে সম্পর্কে কোনো অনুমান করা হয়নি। প্রায় যেকোনো টেক্সট এডিটর দিয়েই কাজ চালানো যাবে! তবে, অনেক টেক্সট এডিটর এবং ইন্টিগ্রেটেড ডেভেলপমেন্ট এনভায়রনমেন্ট (IDE)-এর Rust-এর জন্য বিল্ট-ইন সাপোর্ট রয়েছে। আপনি Rust ওয়েবসাইটের টুলস পেজে বিভিন্ন এডিটর এবং IDE-এর একটি আপ-টু-ডেট তালিকা দেখতে পারেন।
হ্যালো, ওয়ার্ল্ড! (Hello, World!)
এখন যেহেতু আপনি Rust ইন্সটল করেছেন, তাই আপনার প্রথম Rust প্রোগ্রাম লেখার সময় এসেছে। নতুন কোনো প্রোগ্রামিং ল্যাঙ্গুয়েজ শেখার সময় পর্দায় Hello, world! লেখাটি প্রিন্ট করার একটি ছোট প্রোগ্রাম লেখা ঐতিহ্য, তাই আমরা এখানে সেটাই করব!
দ্রষ্টব্য: এই বইটি লেখার সময় ধরে নেওয়া হয়েছে যে আপনি কমান্ড লাইনের সাথে পরিচিত। আপনার এডিটিং, টুলিং, বা আপনার কোড কোথায় থাকবে, এইসব বিষয়ে Rust-এর নির্দিষ্ট কোনো বাধ্যবাধকতা নেই। তাই আপনি যদি কমান্ড লাইনের পরিবর্তে কোনো ইন্টিগ্রেটেড ডেভেলপমেন্ট এনভায়রনমেন্ট (IDE) ব্যবহার করতে পছন্দ করেন, তবে নির্দ্বিধায় আপনার পছন্দের IDE ব্যবহার করতে পারেন। এখন অনেক IDE-তেই Rust-এর সাপোর্ট রয়েছে; বিস্তারিত জানতে IDE-এর ডকুমেন্টেশন দেখুন। Rust টিম
rust-analyzer-এর মাধ্যমে മികച്ച IDE সাপোর্ট দেওয়ার ওপর জোর দিচ্ছে। আরও বিস্তারিত জানতে Appendix D দেখুন।
একটি প্রোজেক্ট ডিরেক্টরি তৈরি করা (Creating a Project Directory)
শুরুতে, আপনাকে আপনার Rust কোড রাখার জন্য একটি ডিরেক্টরি তৈরি করতে হবে। আপনার কোড কোথায় থাকবে তাতে Rust-এর কিছু যায় আসে না। তবে এই বইয়ের অনুশীলন এবং প্রোজেক্টগুলোর জন্য, আমরা পরামর্শ দিই যে আপনি আপনার হোম ডিরেক্টরিতে একটি projects নামে ডিরেক্টরি তৈরি করুন এবং আপনার সমস্ত প্রোজেক্ট সেখানেই রাখুন।
একটি টার্মিনাল খুলুন এবং projects ডিরেক্টরি এবং এর ভেতরে "Hello, world!" প্রোজেক্টের জন্য একটি ডিরেক্টরি তৈরি করতে নিচের কমান্ডগুলো লিখুন।
Linux, macOS এবং Windows-এর PowerShell-এর জন্য, এই কমান্ডটি লিখুন:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
Windows CMD-এর জন্য, এই কমান্ডটি লিখুন:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
একটি Rust প্রোগ্রাম লেখা এবং চালানো (Writing and Running a Rust Program)
এরপর, একটি নতুন সোর্স ফাইল তৈরি করুন এবং সেটির নাম দিন main.rs। Rust ফাইলগুলো সবসময় .rs এক্সটেনশন দিয়ে শেষ হয়। যদি ফাইলের নামে একাধিক শব্দ ব্যবহার করেন, তাহলে সেগুলোকে আলাদা করার জন্য আন্ডারস্কোর (_) ব্যবহার করার নিয়ম রয়েছে। উদাহরণস্বরূপ, helloworld.rs-এর পরিবর্তে hello_world.rs ব্যবহার করুন।
এবার, আপনার তৈরি করা main.rs ফাইলটি খুলুন এবং Listing 1-1-এর কোডটি লিখুন।
fn main() { println!("Hello, world!"); }
ফাইলটি সেভ করুন এবং ~/projects/hello_world ডিরেক্টরিতে আপনার টার্মিনাল উইন্ডোতে ফিরে যান। Linux বা macOS-এ, ফাইলটি কম্পাইল এবং রান করার জন্য নিচের কমান্ডগুলো লিখুন:
$ rustc main.rs
$ ./main
Hello, world!
Windows-এ, ./main-এর পরিবর্তে .\main.exe কমান্ডটি লিখুন:
> rustc main.rs
> .\main.exe
Hello, world!
আপনার অপারেটিং সিস্টেম যাই হোক না কেন, টার্মিনালে Hello, world! স্ট্রিংটি প্রিন্ট হওয়া উচিত। যদি এই আউটপুটটি দেখতে না পান, তাহলে সাহায্য পাওয়ার উপায় জানতে ইন্সটলেশন অংশের “সমস্যা সমাধান” অংশটি দেখুন।
যদি Hello, world! প্রিন্ট হয়ে থাকে, তাহলে অভিনন্দন! আপনি আনুষ্ঠানিকভাবে একটি Rust প্রোগ্রাম লিখেছেন। এর মানে আপনি এখন একজন Rust প্রোগ্রামার—স্বাগতম!
একটি Rust প্রোগ্রামের অ্যানাটমি (Anatomy of a Rust Program)
আসুন, এই “Hello, world!” প্রোগ্রামটি বিস্তারিতভাবে পর্যালোচনা করি। নিচে এই ধাঁধার প্রথম অংশটি দেওয়া হলো:
fn main() { }
এই লাইনগুলো main নামের একটি ফাংশন সংজ্ঞায়িত করে। main ফাংশনটি বিশেষ: এটি প্রতিটি এক্সিকিউটেবল Rust প্রোগ্রামে সবার প্রথমে রান হওয়া কোড। এখানে, প্রথম লাইনটি main নামের একটি ফাংশন ঘোষণা করে, যার কোনো প্যারামিটার নেই এবং এটি কিছুই রিটার্ন করে না। যদি কোনো প্যারামিটার থাকত, তবে সেগুলো () বন্ধনীর মধ্যে যেত।
ফাংশনের বডি {}-এর মধ্যে আবদ্ধ। Rust-এ সমস্ত ফাংশন বডির চারপাশে কার্লি ব্র্যাকেট থাকা আবশ্যক। ফাংশন ঘোষণার লাইনেই, একটি স্পেস দিয়ে ওপেনিং কার্লি ব্র্যাকেট ({) বসানো একটি ভালো অভ্যাস।
দ্রষ্টব্য: আপনি যদি Rust প্রোজেক্ট জুড়ে একটি স্ট্যান্ডার্ড স্টাইল অনুসরণ করতে চান, তাহলে আপনি
rustfmtনামক একটি অটোমেটিক ফরম্যাটার টুল ব্যবহার করতে পারেন। এটি আপনার কোডকে একটি নির্দিষ্ট স্টাইলে ফরম্যাট করবে (rustfmtসম্পর্কে আরও জানতে Appendix D দেখুন)। Rust টিম এই টুলটিকে স্ট্যান্ডার্ড Rust ডিস্ট্রিবিউশনের সাথে যুক্ত করেছে, যেমনrustcআছে, তাই এটি আপনার কম্পিউটারে ইতিমধ্যেই ইন্সটল হয়ে থাকার কথা!
main ফাংশনের বডিতে নিচের কোডটি রয়েছে:
#![allow(unused)] fn main() { println!("Hello, world!"); }
এই লাইনটি এই ছোট প্রোগ্রামটির সমস্ত কাজ করে: এটি স্ক্রিনে টেক্সট প্রিন্ট করে। এখানে তিনটি গুরুত্বপূর্ণ বিষয় লক্ষ্য করার আছে।
প্রথমত, println! একটি Rust ম্যাক্রো কল করে। যদি এটি একটি ফাংশন কল করত, তবে এটিকে println (! ছাড়া) লেখা হত। আমরা চ্যাপ্টার ২০-তে Rust ম্যাক্রোগুলো নিয়ে আরও বিস্তারিত আলোচনা করব। আপাতত, আপনাকে শুধু এটুকু জানলেই চলবে যে ! ব্যবহার করার অর্থ হল আপনি একটি ম্যাক্রো কল করছেন, সাধারণ ফাংশন নয় এবং ম্যাক্রোগুলি সবসময় ফাংশনের মতো একই নিয়ম অনুসরণ করে না।
দ্বিতীয়ত, আপনি "Hello, world!" স্ট্রিংটি দেখতে পাচ্ছেন। আমরা এই স্ট্রিংটিকে println!-এর আর্গুমেন্ট হিসেবে পাঠাই এবং এই স্ট্রিংটি স্ক্রিনে প্রিন্ট হয়।
তৃতীয়ত, আমরা লাইনটি একটি সেমিকোলন (;) দিয়ে শেষ করি। এটি নির্দেশ করে যে এই এক্সপ্রেশনটি শেষ এবং পরেরটি শুরু হওয়ার জন্য প্রস্তুত। Rust কোডের বেশিরভাগ লাইন সেমিকোলন দিয়ে শেষ হয়।
কম্পাইল করা এবং চালানো আলাদা ধাপ (Compiling and Running Are Separate Steps)
আপনি সবেমাত্র একটি নতুন তৈরি করা প্রোগ্রাম চালিয়েছেন, তাই চলুন এই প্রক্রিয়ার প্রতিটি ধাপ পরীক্ষা করি।
একটি Rust প্রোগ্রাম চালানোর আগে, আপনাকে rustc কমান্ড ব্যবহার করে এবং আপনার সোর্স ফাইলের নাম দিয়ে Rust কম্পাইলার ব্যবহার করে কম্পাইল করতে হবে, এইভাবে:
$ rustc main.rs
যদি আপনার C বা C++ ব্যাকগ্রাউন্ড থাকে, তাহলে আপনি দেখবেন যে এটি gcc বা clang-এর মতোই। সফলভাবে কম্পাইল করার পরে, Rust একটি বাইনারি এক্সিকিউটেবল আউটপুট দেয়।
Linux, macOS এবং Windows-এর PowerShell-এ, আপনি আপনার শেলে ls কমান্ডটি লিখে এক্সিকিউটেবলটি দেখতে পারেন:
$ ls
main main.rs
Linux এবং macOS-এ, আপনি দুটি ফাইল দেখতে পাবেন। Windows-এর PowerShell-এ, আপনি CMD ব্যবহার করলে যে তিনটি ফাইল দেখতে পেতেন, সেগুলোই দেখতে পাবেন। Windows-এর CMD-তে, আপনি নিচের কমান্ডটি লিখবেন:
> dir /B %= the /B option says to only show the file names =%
main.exe
main.pdb
main.rs
এটি .rs এক্সটেনশন সহ সোর্স কোড ফাইল, এক্সিকিউটেবল ফাইল (Windows-এ main.exe, কিন্তু অন্য সব প্ল্যাটফর্মে main) এবং Windows ব্যবহার করার সময়, .pdb এক্সটেনশন সহ ডিবাগিং তথ্য সম্বলিত একটি ফাইল দেখায়। এখান থেকে, আপনি main বা main.exe ফাইলটি চালান, এইভাবে:
$ ./main # or .\main.exe on Windows
যদি আপনার main.rs ফাইলটি আপনার “Hello, world!” প্রোগ্রাম হয়, তাহলে এই লাইনটি আপনার টার্মিনালে Hello, world! প্রিন্ট করবে।
আপনি যদি রুবি (Ruby), পাইথন (Python) বা জাভাস্ক্রিপ্টের (JavaScript) মতো ডায়নামিক ল্যাঙ্গুয়েজের সাথে বেশি পরিচিত হন, তাহলে আপনি হয়তো একটি প্রোগ্রাম কম্পাইল এবং চালানোকে আলাদা ধাপ হিসেবে নাও দেখতে পারেন। Rust হল একটি অ্যাওয়েড-অফ-টাইম কম্পাইল্ড (ahead-of-time compiled) ল্যাঙ্গুয়েজ। এর মানে হল, আপনি একটি প্রোগ্রাম কম্পাইল করে এক্সিকিউটেবল ফাইলটি অন্য কাউকে দিতে পারেন এবং তারা Rust ইন্সটল না করেও সেটি চালাতে পারবেন। আপনি যদি কাউকে একটি .rb, .py বা .js ফাইল দেন, তবে তাদের যথাক্রমে রুবি, পাইথন বা জাভাস্ক্রিপ্ট ইন্সটল করা থাকতে হবে। কিন্তু সেইসব ল্যাঙ্গুয়েজে, আপনার প্রোগ্রাম কম্পাইল এবং চালানোর জন্য আপনার কেবল একটি কমান্ডই যথেষ্ট। ল্যাঙ্গুয়েজ ডিজাইনের ক্ষেত্রে সবকিছুই একটি আপস।
শুধুমাত্র rustc দিয়ে কম্পাইল করা ছোট প্রোগ্রামগুলোর জন্য ঠিক আছে, কিন্তু আপনার প্রোজেক্ট বড় হওয়ার সাথে সাথে আপনি সমস্ত অপশনগুলো পরিচালনা করতে এবং আপনার কোড শেয়ার করা সহজ করতে চাইবেন। এরপর, আমরা আপনাকে Cargo টুলের সাথে পরিচয় করিয়ে দেব, যা আপনাকে বাস্তব-বিশ্বের Rust প্রোগ্রাম লিখতে সাহায্য করবে।
হ্যালো, কার্গো! (Hello, Cargo!)
কার্গো (Cargo) হল Rust-এর বিল্ড সিস্টেম এবং প্যাকেজ ম্যানেজার। বেশিরভাগ Rustacean তাদের Rust প্রোজেক্টগুলো ম্যানেজ করার জন্য এই টুলটি ব্যবহার করেন, কারণ Cargo আপনার হয়ে অনেক কাজ করে দেয়। যেমন, আপনার কোড বিল্ড করা, আপনার কোডের জন্য প্রয়োজনীয় লাইব্রেরিগুলো ডাউনলোড করা এবং সেই লাইব্রেরিগুলো বিল্ড করা। (যে লাইব্রেরিগুলোর ওপর আপনার কোড নির্ভর করে, সেগুলোকে আমরা ডিপেন্ডেন্সি (dependencies) বলি।)
সবচেয়ে সহজ Rust প্রোগ্রামগুলো, যেমনটি আমরা এতক্ষণ লিখেছি, সেগুলোর কোনো ডিপেন্ডেন্সি নেই। আমরা যদি “Hello, world!” প্রোজেক্টটি Cargo দিয়ে তৈরি করতাম, তাহলে Cargo-র কেবল সেই অংশটি ব্যবহৃত হত যেটি আপনার কোড বিল্ড করার দায়িত্বে রয়েছে। আপনি যখন আরও জটিল Rust প্রোগ্রাম লিখবেন, তখন আপনাকে ডিপেন্ডেন্সি যোগ করতে হবে। আর আপনি যদি Cargo ব্যবহার করে একটি প্রোজেক্ট শুরু করেন, তাহলে ডিপেন্ডেন্সি যোগ করা অনেক সহজ হয়ে যাবে।
যেহেতু বেশিরভাগ Rust প্রোজেক্ট Cargo ব্যবহার করে, তাই এই বইয়ের বাকি অংশে ধরে নেওয়া হবে যে আপনিও Cargo ব্যবহার করছেন। আপনি যদি “ইন্সটলেশন” বিভাগে আলোচিত অফিশিয়াল ইন্সটলারগুলো ব্যবহার করে থাকেন, তাহলে Cargo Rust-এর সাথেই ইন্সটল হয়ে যায়। আপনি যদি অন্য কোনো উপায়ে Rust ইন্সটল করে থাকেন, তাহলে আপনার টার্মিনালে নিচের কমান্ডটি লিখে পরীক্ষা করুন যে Cargo ইন্সটল করা আছে কিনা:
$ cargo --version
যদি আপনি একটি ভার্সন নম্বর দেখতে পান, তাহলে বুঝবেন যে এটি ইন্সটল করা আছে! যদি command not found-এর মতো কোনো এরর দেখতে পান, তাহলে Cargo আলাদাভাবে ইন্সটল করার পদ্ধতি জানার জন্য আপনার ইন্সটলেশন পদ্ধতির ডকুমেন্টেশন দেখুন।
Cargo দিয়ে একটি প্রোজেক্ট তৈরি করা (Creating a Project with Cargo)
আসুন, Cargo ব্যবহার করে একটি নতুন প্রোজেক্ট তৈরি করি এবং দেখি যে এটি আমাদের আগের “Hello, world!” প্রোজেক্ট থেকে কীভাবে আলাদা। আপনার projects ডিরেক্টরিতে (অথবা আপনি যেখানে আপনার কোড রাখার সিদ্ধান্ত নিয়েছেন সেখানে) ফিরে যান। তারপর, যেকোনো অপারেটিং সিস্টেমে, নিচের কমান্ডগুলো চালান:
$ cargo new hello_cargo
$ cd hello_cargo
প্রথম কমান্ডটি hello_cargo নামে একটি নতুন ডিরেক্টরি এবং প্রোজেক্ট তৈরি করে। আমরা আমাদের প্রোজেক্টের নাম দিয়েছি hello_cargo, এবং Cargo একই নামের একটি ডিরেক্টরিতে এর ফাইলগুলো তৈরি করে।
hello_cargo ডিরেক্টরিতে যান এবং ফাইলগুলোর তালিকা দেখুন। আপনি দেখতে পাবেন যে Cargo আমাদের জন্য দুটি ফাইল এবং একটি ডিরেক্টরি তৈরি করেছে: একটি Cargo.toml ফাইল এবং একটি src ডিরেক্টরি, যার ভেতরে একটি main.rs ফাইল রয়েছে।
এটি একটি নতুন Git রিপোজিটরি এবং একটি .gitignore ফাইলও ইনিশিয়ালাইজ করেছে। আপনি যদি একটি বিদ্যমান Git রিপোজিটরির মধ্যে cargo new চালান, তাহলে Git ফাইলগুলো তৈরি হবে না; আপনি cargo new --vcs=git ব্যবহার করে এই আচরণটিকে ওভাররাইড করতে পারেন।
দ্রষ্টব্য: Git হল একটি বহুল ব্যবহৃত ভার্সন কন্ট্রোল সিস্টেম। আপনি
cargo new-কে অন্য কোনো ভার্সন কন্ট্রোল সিস্টেম ব্যবহার করতে বা কোনো ভার্সন কন্ট্রোল সিস্টেম ব্যবহার না করার জন্য--vcsফ্ল্যাগ ব্যবহার করতে পারেন। উপলব্ধ অপশনগুলো দেখতেcargo new --helpচালান।
আপনার পছন্দের টেক্সট এডিটরে Cargo.toml খুলুন। এটি Listing 1-2-এর কোডের মতো হওয়া উচিত।
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
এই ফাইলটি TOML (Tom’s Obvious, Minimal Language) ফরম্যাটে রয়েছে, যেটি Cargo-র কনফিগারেশন ফরম্যাট।
প্রথম লাইন, [package], হল একটি সেকশন হেডিং, যা নির্দেশ করে যে নিচের স্টেটমেন্টগুলো একটি প্যাকেজ কনফিগার করছে। আমরা যখন এই ফাইলে আরও তথ্য যোগ করব, তখন আমরা অন্যান্য সেকশনও যোগ করব।
পরের তিনটি লাইন আপনার প্রোগ্রাম কম্পাইল করার জন্য Cargo-র প্রয়োজনীয় কনফিগারেশন তথ্য সেট করে: নাম, ভার্সন এবং ব্যবহার করার জন্য Rust-এর এডিশন। আমরা Appendix E-তে edition কী সম্পর্কে আলোচনা করব।
শেষ লাইন, [dependencies], হল আপনার প্রোজেক্টের যেকোনো ডিপেন্ডেন্সি তালিকাভুক্ত করার জন্য একটি সেকশনের শুরু। Rust-এ, কোডের প্যাকেজগুলোকে ক্রেটস (crates) বলা হয়। এই প্রোজেক্টের জন্য আমাদের অন্য কোনো ক্রেটের প্রয়োজন হবে না, কিন্তু চ্যাপ্টার ২-এর প্রথম প্রোজেক্টে আমাদের প্রয়োজন হবে, তাই আমরা তখন এই ডিপেন্ডেন্সি সেকশনটি ব্যবহার করব।
এবার src/main.rs খুলুন এবং দেখুন:
Filename: src/main.rs
fn main() { println!("Hello, world!"); }
Cargo আপনার জন্য একটি “Hello, world!” প্রোগ্রাম তৈরি করেছে, ঠিক যেমনটি আমরা Listing 1-1-এ লিখেছিলাম! এখনও পর্যন্ত, আমাদের প্রোজেক্ট এবং Cargo-র তৈরি করা প্রোজেক্টের মধ্যে পার্থক্য হল, Cargo কোডটিকে src ডিরেক্টরির মধ্যে রেখেছে এবং আমাদের টপ ডিরেক্টরিতে একটি Cargo.toml কনফিগারেশন ফাইল রয়েছে।
Cargo আশা করে যে আপনার সোর্স ফাইলগুলো src ডিরেক্টরির মধ্যে থাকবে। টপ-লেভেল প্রোজেক্ট ডিরেক্টরিটি শুধুমাত্র README ফাইল, লাইসেন্স তথ্য, কনফিগারেশন ফাইল এবং আপনার কোডের সাথে সম্পর্কিত নয় এমন যেকোনো কিছুর জন্য। Cargo ব্যবহার করা আপনাকে আপনার প্রোজেক্টগুলো সংগঠিত করতে সাহায্য করে। সবকিছুর জন্য একটি নির্দিষ্ট জায়গা রয়েছে এবং সবকিছু তার নিজের জায়গায় থাকে।
আপনি যদি এমন একটি প্রোজেক্ট শুরু করেন যেটি Cargo ব্যবহার করে না, যেমনটি আমরা “Hello, world!” প্রোজেক্টের ক্ষেত্রে করেছিলাম, তাহলে আপনি এটিকে Cargo ব্যবহার করে এমন একটি প্রোজেক্টে রূপান্তর করতে পারেন। প্রোজেক্ট কোডটিকে src ডিরেক্টরির মধ্যে সরিয়ে নিন এবং একটি উপযুক্ত Cargo.toml ফাইল তৈরি করুন। cargo init চালালে সহজেই সেই Cargo.toml ফাইলটি পেয়ে যাবেন, এটি আপনার জন্য স্বয়ংক্রিয়ভাবে ফাইলটি তৈরি করে দেবে।
একটি Cargo প্রোজেক্ট বিল্ড এবং রান করা (Building and Running a Cargo Project)
এখন দেখা যাক, Cargo দিয়ে “Hello, world!” প্রোগ্রাম বিল্ড এবং রান করলে কী কী পার্থক্য হয়! আপনার hello_cargo ডিরেক্টরি থেকে, নিচের কমান্ডটি লিখে আপনার প্রোজেক্ট বিল্ড করুন:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
এই কমান্ডটি আপনার বর্তমান ডিরেক্টরির পরিবর্তে target/debug/hello_cargo-তে (অথবা Windows-এ target\debug\hello_cargo.exe) একটি এক্সিকিউটেবল ফাইল তৈরি করে। ডিফল্ট বিল্ডটি যেহেতু একটি ডিবাগ বিল্ড, তাই Cargo বাইনারিটিকে debug নামের একটি ডিরেক্টরিতে রাখে। আপনি এই কমান্ডটি দিয়ে এক্সিকিউটেবলটি চালাতে পারেন:
$ ./target/debug/hello_cargo # or .\target\debug\hello_cargo.exe on Windows
Hello, world!
যদি সবকিছু ঠিকঠাক চলে, তাহলে টার্মিনালে Hello, world! প্রিন্ট হওয়া উচিত। প্রথমবারের মতো cargo build চালালে, Cargo টপ লেভেলে একটি নতুন ফাইলও তৈরি করে: Cargo.lock। এই ফাইলটি আপনার প্রোজেক্টের ডিপেন্ডেন্সিগুলোর সঠিক ভার্সন ট্র্যাক করে। এই প্রোজেক্টে কোনো ডিপেন্ডেন্সি নেই, তাই ফাইলটি কিছুটা ফাঁকা। আপনাকে কখনোই এই ফাইলটি ম্যানুয়ালি পরিবর্তন করতে হবে না; Cargo নিজেই এর বিষয়বস্তু পরিচালনা করে।
আমরা cargo build দিয়ে একটি প্রোজেক্ট বিল্ড করলাম এবং ./target/debug/hello_cargo দিয়ে চালালাম। কিন্তু আমরা cargo run ব্যবহার করেও কোড কম্পাইল করতে পারি এবং তারপর ஒரே কমান্ডে প্রাপ্ত এক্সিকিউটেবল চালাতে পারি:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
cargo build চালানোর পরে বাইনারির পুরো পাথ ব্যবহার করার পরিবর্তে cargo run ব্যবহার করা বেশি সুবিধাজনক। তাই বেশিরভাগ ডেভেলপার cargo run ব্যবহার করেন।
লক্ষ্য করুন যে, এবার আমরা Cargo-কে hello_cargo কম্পাইল করছে এমন কোনো আউটপুট দেখতে পাইনি। Cargo বুঝতে পেরেছে যে ফাইলগুলো পরিবর্তন হয়নি, তাই এটি রি-বিল্ড না করেই বাইনারিটি চালিয়ে দিয়েছে। আপনি যদি আপনার সোর্স কোড পরিবর্তন করতেন, তাহলে Cargo চালানোর আগে প্রোজেক্টটি রি-বিল্ড করত এবং আপনি এই আউটপুটটি দেখতে পেতেন:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo cargo check নামেও একটি কমান্ড সরবরাহ করে। এই কমান্ডটি দ্রুত আপনার কোড পরীক্ষা করে দেখে যে এটি কম্পাইল হয় কিনা, কিন্তু কোনো এক্সিকিউটেবল তৈরি করে না:
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
আপনি কেন একটি এক্সিকিউটেবল চাইবেন না? প্রায়শই, cargo check, cargo build-এর চেয়ে অনেক দ্রুত, কারণ এটি এক্সিকিউটেবল তৈরির ধাপটি এড়িয়ে যায়। কোড লেখার সময় আপনি যদি ক্রমাগত আপনার কাজ পরীক্ষা করতে থাকেন, তাহলে cargo check ব্যবহার করলে আপনার প্রোজেক্ট কম্পাইল হচ্ছে কিনা, তা জানার প্রক্রিয়াটি দ্রুত হবে! তাই, অনেক Rustacean তাদের প্রোগ্রাম লেখার সময় নিয়মিতভাবে cargo check চালান, যাতে এটি কম্পাইল হচ্ছে কিনা তা নিশ্চিত করা যায়। তারপর যখন তারা এক্সিকিউটেবল ব্যবহার করতে প্রস্তুত হন, তখন তারা cargo build চালান।
আসুন, Cargo সম্পর্কে আমরা এ পর্যন্ত যা শিখেছি তার পুনরাবৃত্তি করি:
- আমরা
cargo newব্যবহার করে একটি প্রোজেক্ট তৈরি করতে পারি। - আমরা
cargo buildব্যবহার করে একটি প্রোজেক্ট বিল্ড করতে পারি। - আমরা
cargo runব্যবহার করে এক ধাপে একটি প্রোজেক্ট বিল্ড এবং রান করতে পারি। - আমরা
cargo checkব্যবহার করে কোনো বাইনারি তৈরি না করে এরর আছে কিনা তা পরীক্ষা করার জন্য একটি প্রোজেক্ট বিল্ড করতে পারি। - আমাদের কোডের মতোই একই ডিরেক্টরিতে বিল্ডের ফলাফল সংরক্ষণ করার পরিবর্তে, Cargo এটিকে target/debug ডিরেক্টরিতে সংরক্ষণ করে।
Cargo ব্যবহারের আরেকটি সুবিধা হল, আপনি কোন অপারেটিং সিস্টেমে কাজ করছেন তা নির্বিশেষে কমান্ডগুলো একই থাকে। তাই, এখন থেকে, আমরা Linux এবং macOS-এর জন্য আলাদা এবং Windows-এর জন্য আলাদা কোনো সুনির্দিষ্ট নির্দেশ দেব না।
রিলিজের জন্য বিল্ড করা (Building for Release)
যখন আপনার প্রোজেক্টটি অবশেষে রিলিজের জন্য প্রস্তুত হবে, তখন আপনি অপটিমাইজেশন সহ কম্পাইল করার জন্য cargo build --release ব্যবহার করতে পারেন। এই কমান্ডটি target/debug-এর পরিবর্তে target/release-এ একটি এক্সিকিউটেবল তৈরি করবে। অপটিমাইজেশনগুলো আপনার Rust কোডকে দ্রুততর করে, কিন্তু এগুলো চালু করলে আপনার প্রোগ্রাম কম্পাইল হতে বেশি সময় লাগে। এই কারণেই দুটি ভিন্ন প্রোফাইল রয়েছে: একটি ডেভেলপমেন্টের জন্য, যখন আপনি দ্রুত এবং ঘন ঘন রি-বিল্ড করতে চান এবং অন্যটি ফাইনাল প্রোগ্রাম বিল্ড করার জন্য, যেটি আপনি একজন ব্যবহারকারীকে দেবেন, যা বারবার রি-বিল্ড করা হবে না এবং যত দ্রুত সম্ভব চলবে। আপনি যদি আপনার কোডের চলার সময় বেঞ্চমার্ক করেন, তাহলে cargo build --release চালাতে এবং target/release-এর এক্সিকিউটেবল দিয়ে বেঞ্চমার্ক করতে ভুলবেন না।
Cargo-কে নিয়ম হিসেবে ধরা (Cargo as Convention)
সরল প্রোজেক্টগুলোর ক্ষেত্রে, Cargo শুধু rustc ব্যবহারের চেয়ে বেশি কিছু সুবিধা দেয় না, তবে আপনার প্রোগ্রামগুলো আরও জটিল হয়ে উঠলে এটি নিজের কার্যকারিতা প্রমাণ করবে। একবার প্রোগ্রামগুলো একাধিক ফাইলে বড় হয়ে গেলে বা কোনো ডিপেন্ডেন্সির প্রয়োজন হলে, Cargo-কে দিয়ে বিল্ডের সমন্বয় করানো অনেক সহজ।
যদিও hello_cargo প্রোজেক্টটি সহজ, তবুও এটি এখন আপনার বাকি Rust ক্যারিয়ারে আপনি যে আসল টুলিং ব্যবহার করবেন তার অনেকটাই ব্যবহার করে। আসলে, যেকোনো বিদ্যমান প্রোজেক্টে কাজ করার জন্য, আপনি Git ব্যবহার করে কোডটি চেক আউট করতে, সেই প্রোজেক্টের ডিরেক্টরিতে যেতে এবং বিল্ড করতে নিচের কমান্ডগুলো ব্যবহার করতে পারেন:
$ git clone example.org/someproject
$ cd someproject
$ cargo build
Cargo সম্পর্কে আরও তথ্যের জন্য, এর ডকুমেন্টেশন দেখুন।
সারসংক্ষেপ (Summary)
আপনি ইতিমধ্যেই আপনার Rust যাত্রায় একটি দুর্দান্ত সূচনা করেছেন! এই চ্যাপ্টারে, আপনি শিখেছেন কীভাবে:
rustupব্যবহার করে Rust-এর সর্বশেষ স্থিতিশীল ভার্সন ইন্সটল করবেন- একটি নতুন Rust ভার্সনে আপডেট করবেন
- লোকালি ইন্সটল করা ডকুমেন্টেশন খুলবেন
- সরাসরি
rustcব্যবহার করে একটি “Hello, world!” প্রোগ্রাম লিখবেন এবং চালাবেন - Cargo-র নিয়ম ব্যবহার করে একটি নতুন প্রোজেক্ট তৈরি করবেন এবং চালাবেন
Rust কোড পড়া এবং লেখার অভ্যাসের জন্য এটি একটি আরও বড় প্রোগ্রাম তৈরি করার উপযুক্ত সময়। তাই, চ্যাপ্টার ২-তে, আমরা একটি অনুমান করার গেম (guessing game) প্রোগ্রাম তৈরি করব। আপনি যদি Rust-এ সাধারণ প্রোগ্রামিং কনসেপ্টগুলো কীভাবে কাজ করে তা শিখে শুরু করতে চান, তাহলে চ্যাপ্টার ৩ দেখুন এবং তারপর চ্যাপ্টার ২-এ ফিরে আসুন।
একটি সংখ্যা অনুমানের গেম প্রোগ্রামিং (Programming a Guessing Game)
আসুন, একসাথে একটি হ্যান্ডস-অন প্রোজেক্টে কাজ করার মাধ্যমে Rust-এর জগতে প্রবেশ করি! এই চ্যাপ্টারটি আপনাকে কিছু সাধারণ Rust কনসেপ্টের সাথে পরিচয় করিয়ে দেবে, একটি বাস্তব প্রোগ্রামে সেগুলো কীভাবে ব্যবহার করা হয় তা দেখিয়ে। আপনি let, match, মেথড, অ্যাসোসিয়েটেড ফাংশন, এক্সটার্নাল ক্রেট এবং আরও অনেক কিছু সম্পর্কে জানতে পারবেন! নিচের চ্যাপ্টারগুলোতে, আমরা এই ধারণাগুলো আরও বিস্তারিতভাবে আলোচনা করব। এই চ্যাপ্টারে, আপনি শুধুমাত্র মৌলিক বিষয়গুলো অনুশীলন করবেন।
আমরা একটি ক্লাসিক বিগিনার প্রোগ্রামিং সমস্যা সমাধান করব: একটি সংখ্যা অনুমানের গেম। এটি কীভাবে কাজ করে তা নিচে বলা হলো: প্রোগ্রামটি 1 থেকে 100-এর মধ্যে একটি র্যান্ডম সংখ্যা তৈরি করবে। তারপর এটি প্লেয়ারকে একটি সংখ্যা অনুমান করতে বলবে। একটি সংখ্যা অনুমান করার পরে, প্রোগ্রামটি জানাবে যে অনুমানটি খুব কম না বেশি হয়েছে। যদি অনুমানটি সঠিক হয়, তাহলে গেমটি একটি অভিনন্দন বার্তা প্রিন্ট করবে এবং শেষ হয়ে যাবে।
একটি নতুন প্রোজেক্ট সেট আপ করা (Setting Up a New Project)
একটি নতুন প্রোজেক্ট সেট আপ করতে, চ্যাপ্টার ১-এ তৈরি করা projects ডিরেক্টরিতে যান এবং Cargo ব্যবহার করে নিচের মতো একটি নতুন প্রোজেক্ট তৈরি করুন:
$ cargo new guessing_game
$ cd guessing_game
প্রথম কমান্ড, cargo new, প্রোজেক্টের নাম (guessing_game) প্রথম আর্গুমেন্ট হিসেবে নেয়। দ্বিতীয় কমান্ডটি নতুন প্রোজেক্টের ডিরেক্টরিতে যাওয়া নির্দেশ করে।
জেনারেট হওয়া Cargo.toml ফাইলটি দেখুন:
Filename: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
[dependencies]
আপনি যেমন চ্যাপ্টার ১-এ দেখেছেন, cargo new আপনার জন্য একটি “Hello, world!” প্রোগ্রাম তৈরি করে। src/main.rs ফাইলটি দেখুন:
Filename: src/main.rs
fn main() { println!("Hello, world!"); }
এবার চলুন, এই “Hello, world!” প্রোগ্রামটি কম্পাইল করি এবং cargo run কমান্ড ব্যবহার করে একই ধাপে চালাই:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `file:///projects/guessing_game/target/debug/guessing_game`
Hello, world!
run কমান্ডটি তখন কাজে আসে যখন আপনাকে একটি প্রোজেক্টে দ্রুত পুনরাবৃত্তি করতে হয়, যেমনটি আমরা এই গেমে করব। অর্থাৎ, পরবর্তী ধাপে যাওয়ার আগে প্রতিটি পুনরাবৃত্তি দ্রুত পরীক্ষা করে নেওয়া যাবে।
src/main.rs ফাইলটি আবার খুলুন। আপনি এই ফাইলেই সমস্ত কোড লিখবেন।
একটি অনুমান প্রক্রিয়া করা (Processing a Guess)
অনুমান করার গেম প্রোগ্রামটির প্রথম অংশ ব্যবহারকারীর ইনপুট চাইবে, সেই ইনপুটটি প্রক্রিয়া করবে এবং ইনপুটটি প্রত্যাশিত ফর্ম্যাটে আছে কিনা তা পরীক্ষা করবে। শুরু করার জন্য, আমরা প্লেয়ারকে একটি সংখ্যা অনুমান করতে দেব। Listing 2-1-এর কোডটি src/main.rs-এ লিখুন।
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}এই কোডটিতে অনেক তথ্য রয়েছে, তাই চলুন লাইন ধরে ধরে আলোচনা করি। ব্যবহারকারীর ইনপুট নিতে এবং তারপর ফলাফলটি আউটপুট হিসেবে প্রিন্ট করতে, আমাদের io ইনপুট/আউটপুট লাইব্রেরিটিকে স্কোপের মধ্যে আনতে হবে। io লাইব্রেরিটি স্ট্যান্ডার্ড লাইব্রেরি থেকে আসে, যাকে std বলা হয়:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}ডিফল্টরূপে, Rust-এর স্ট্যান্ডার্ড লাইব্রেরিতে সংজ্ঞায়িত আইটেমগুলোর একটি সেট রয়েছে, যা প্রতিটি প্রোগ্রামের স্কোপে আনা হয়। এই সেটটিকে প্রেলিউড (prelude) বলা হয়, এবং আপনি স্ট্যান্ডার্ড লাইব্রেরি ডকুমেন্টেশনে prelude-এর সবকিছু দেখতে পারেন।
যদি আপনি যে টাইপটি ব্যবহার করতে চান সেটি প্রেলিউডে না থাকে, তাহলে আপনাকে use স্টেটমেন্ট ব্যবহার করে সেই টাইপটিকে স্পষ্টতই স্কোপে আনতে হবে। std::io লাইব্রেরি ব্যবহার করলে আপনি বেশ কিছু দরকারী ফিচার পাবেন, যার মধ্যে ব্যবহারকারীর ইনপুট নেওয়ার ক্ষমতাও রয়েছে।
আপনি যেমন চ্যাপ্টার ১-এ দেখেছেন, main ফাংশনটি প্রোগ্রামে প্রবেশের পথ:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}fn সিনট্যাক্স একটি নতুন ফাংশন ঘোষণা করে; বন্ধনী, (), নির্দেশ করে যে কোনও প্যারামিটার নেই; এবং কার্লি ব্র্যাকেট, {}, ফাংশনের বডি শুরু করে।
আপনি চ্যাপ্টার ১-এ আরও শিখেছেন যে, println! হল একটি ম্যাক্রো যা স্ক্রিনে একটি স্ট্রিং প্রিন্ট করে:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}এই কোডটি একটি প্রম্পট প্রিন্ট করছে, যাতে গেমটি কী তা বলা হয়েছে এবং ব্যবহারকারীর কাছ থেকে ইনপুট চাওয়া হয়েছে।
ভেরিয়েবল ব্যবহার করে মান সংরক্ষণ করা (Storing Values with Variables)
এরপর, আমরা ব্যবহারকারীর ইনপুট সংরক্ষণ করার জন্য একটি ভেরিয়েবল তৈরি করব, এইভাবে:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}এবার প্রোগ্রামটি আরও মজাদার হচ্ছে! এই ছোট লাইনে অনেক কিছু ঘটছে। আমরা ভেরিয়েবল তৈরি করতে let স্টেটমেন্ট ব্যবহার করি। আরেকটি উদাহরণ নিচে দেওয়া হলো:
let apples = 5;এই লাইনটি apples নামের একটি নতুন ভেরিয়েবল তৈরি করে এবং এটিকে 5 মানের সাথে বাইন্ড করে। Rust-এ, ভেরিয়েবলগুলো ডিফল্টরূপে ইমিউটেবল (immutable) হয়, অর্থাৎ একবার আমরা ভেরিয়েবলকে একটি মান দিলে, সেই মানটি পরিবর্তন হবে না। আমরা চ্যাপ্টার ৩-এর “ভেরিয়েবল এবং মিউটেবিলিটি” বিভাগে এই ধারণাটি নিয়ে বিস্তারিত আলোচনা করব। একটি ভেরিয়েবলকে মিউটেবল (mutable) করতে, আমরা ভেরিয়েবলের নামের আগে mut যোগ করি:
let apples = 5; // immutable
let mut bananas = 5; // mutableদ্রষ্টব্য:
//সিনট্যাক্স একটি কমেন্ট শুরু করে, যা লাইনের শেষ পর্যন্ত চলতে থাকে। Rust কমেন্টের ভেতরের সবকিছু উপেক্ষা করে। আমরা চ্যাপ্টার ৩-এ কমেন্ট নিয়ে আরও বিস্তারিত আলোচনা করব।
অনুমানের গেমের প্রোগ্রামে ফিরে আসা যাক। আপনি এখন জানেন যে let mut guess guess নামের একটি মিউটেবল ভেরিয়েবল তৈরি করবে। সমান চিহ্ন (=) Rust-কে বলে যে আমরা এখনই ভেরিয়েবলের সাথে কিছু বাইন্ড করতে চাই। সমান চিহ্নের ডানদিকে guess-এর মান রয়েছে, যেটি String::new কল করার ফলাফল। String::new একটি ফাংশন, যা একটি String-এর নতুন ইন্সট্যান্স রিটার্ন করে। String হল স্ট্যান্ডার্ড লাইব্রেরি থেকে পাওয়া একটি স্ট্রিং টাইপ, যা প্রসারণযোগ্য (growable), UTF-8 এনকোডেড টেক্সট।
::new লাইনের :: সিনট্যাক্স নির্দেশ করে যে new হল String টাইপের একটি অ্যাসোসিয়েটেড ফাংশন। একটি অ্যাসোসিয়েটেড ফাংশন হল এমন একটি ফাংশন যা একটি টাইপের উপর ইমপ্লিমেন্ট করা হয়, এক্ষেত্রে String। এই new ফাংশনটি একটি নতুন, খালি স্ট্রিং তৈরি করে। আপনি অনেক টাইপের ওপর new ফাংশন দেখতে পাবেন, কারণ এটি একটি সাধারণ নাম, যা কোনো কিছুর একটি নতুন মান তৈরি করে।
পুরো let mut guess = String::new(); লাইনটি একটি মিউটেবল ভেরিয়েবল তৈরি করেছে, যা বর্তমানে একটি String-এর নতুন, খালি ইন্সট্যান্সের সাথে বাইন্ড করা আছে।
ব্যবহারকারীর ইনপুট গ্রহণ করা (Receiving User Input)
মনে করে দেখুন, আমরা প্রোগ্রামের প্রথম লাইনে use std::io; দিয়ে স্ট্যান্ডার্ড লাইব্রেরি থেকে ইনপুট/আউটপুট ফাংশনালিটি অন্তর্ভুক্ত করেছিলাম। এবার আমরা io মডিউল থেকে stdin ফাংশনটি কল করব, যা আমাদের ব্যবহারকারীর ইনপুট হ্যান্ডেল করতে দেবে:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}যদি আমরা প্রোগ্রামের শুরুতে use std::io; দিয়ে io লাইব্রেরি ইম্পোর্ট না করতাম, তাহলেও আমরা এই ফাংশনটিকে std::io::stdin লিখে ব্যবহার করতে পারতাম। stdin ফাংশনটি std::io::Stdin-এর একটি ইন্সট্যান্স রিটার্ন করে, যেটি আপনার টার্মিনালের স্ট্যান্ডার্ড ইনপুটের হ্যান্ডেলের প্রতিনিধিত্ব করে।
এরপর, .read_line(&mut guess) লাইনটি ব্যবহারকারীর কাছ থেকে ইনপুট নেওয়ার জন্য স্ট্যান্ডার্ড ইনপুট হ্যান্ডেলে read_line মেথড কল করে। আমরা read_line-কে আর্গুমেন্ট হিসেবে &mut guess পাস করছি, যাতে এটি ব্যবহারকারীর ইনপুট কোন স্ট্রিংয়ে সংরক্ষণ করবে তা বলতে পারে। read_line-এর মূল কাজ হল ব্যবহারকারী স্ট্যান্ডার্ড ইনপুটে যা টাইপ করে, সেটি একটি স্ট্রিংয়ে যুক্ত করা (স্ট্রিংয়ের আগের কনটেন্ট মুছে না দিয়ে)। তাই আমরা সেই স্ট্রিংটিকে আর্গুমেন্ট হিসেবে পাস করি। স্ট্রিং আর্গুমেন্টটিকে অবশ্যই মিউটেবল হতে হবে, যাতে মেথডটি স্ট্রিংয়ের কনটেন্ট পরিবর্তন করতে পারে।
& নির্দেশ করে যে এই আর্গুমেন্টটি একটি রেফারেন্স, যা আপনাকে আপনার কোডের একাধিক অংশকে মেমরিতে ডেটা একাধিকবার কপি না করেই ডেটার একটি অংশ অ্যাক্সেস করার সুবিধা দেয়। রেফারেন্স একটি জটিল ফিচার, এবং Rust-এর অন্যতম প্রধান সুবিধা হল রেফারেন্স ব্যবহার করা কতটা নিরাপদ এবং সহজ। এই প্রোগ্রামটি শেষ করার জন্য আপনাকে সেই সমস্ত বিবরণ জানার দরকার নেই। আপাতত, আপনার শুধু এটুকু জানলেই চলবে যে ভেরিয়েবলের মতো রেফারেন্সগুলোও ডিফল্টরূপে ইমিউটেবল হয়। তাই, এটিকে মিউটেবল করার জন্য আপনাকে &guess-এর পরিবর্তে &mut guess লিখতে হবে। (চ্যাপ্টার ৪ রেফারেন্স আরও বিশদভাবে ব্যাখ্যা করবে।)
Result দিয়ে সম্ভাব্য ত্রুটি সামলানো (Handling Potential Failure with Result)
আমরা এখনও এই লাইনেই কাজ করছি। আমরা এখন টেক্সটের তৃতীয় লাইন নিয়ে আলোচনা করছি, কিন্তু মনে রাখবেন যে এটি এখনও কোডের একটি একক লজিক্যাল লাইনের অংশ। পরের অংশটি হল এই মেথড:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}আমরা এই কোডটিকে এভাবে লিখতে পারতাম:
io::stdin().read_line(&mut guess).expect("Failed to read line");কিন্তু, একটি লম্বা লাইন পড়া কঠিন, তাই এটিকে ভাগ করে নেওয়া ভালো। .method_name() সিনট্যাক্স দিয়ে যখন আপনি একটি মেথড কল করেন, তখন প্রায়ই একটি নতুন লাইন এবং অন্যান্য হোয়াইটস্পেস যোগ করে লম্বা লাইনগুলোকে ভেঙে ফেলা বুদ্ধিমানের কাজ। এবার আলোচনা করা যাক এই লাইনটি কী করে।
আগে যেমন উল্লেখ করা হয়েছে, read_line ব্যবহারকারী যা ইনপুট দেয়, সেটি আমাদের দেওয়া স্ট্রিংয়ে রাখে। কিন্তু এটি একটি Result মানও রিটার্ন করে। Result হল একটি গণনা (enumeration), যাকে প্রায়শই enum বলা হয়। এটি এমন একটি টাইপ, যা একাধিক সম্ভাব্য অবস্থার মধ্যে একটিতে থাকতে পারে। আমরা প্রতিটি সম্ভাব্য অবস্থাকে একটি ভেরিয়েন্ট বলি।
চ্যাপ্টার ৬-এ enum সম্পর্কে আরও বিস্তারিত আলোচনা করা হবে। এই Result টাইপগুলোর উদ্দেশ্য হল এরর-হ্যান্ডলিং তথ্য এনকোড করা।
Result-এর ভেরিয়েন্টগুলো হল Ok এবং Err। Ok ভেরিয়েন্ট নির্দেশ করে যে অপারেশন সফল হয়েছে এবং এর মধ্যে সফলভাবে জেনারেট হওয়া মান রয়েছে। Err ভেরিয়েন্ট মানে অপারেশন ব্যর্থ হয়েছে এবং এর মধ্যে অপারেশনটি কীভাবে বা কেন ব্যর্থ হয়েছে সে সম্পর্কে তথ্য রয়েছে।
যেকোনো টাইপের মানের মতোই Result টাইপের মানগুলোরও নিজস্ব মেথড ডিফাইন করা থাকে। Result-এর একটি ইন্সট্যান্সের একটি expect মেথড রয়েছে, যাকে আপনি কল করতে পারেন। যদি Result-এর এই ইন্সট্যান্সটি একটি Err মান হয়, তাহলে expect প্রোগ্রামটিকে ক্র্যাশ করাবে এবং আপনি expect-এর আর্গুমেন্ট হিসেবে যে মেসেজটি পাস করেছেন সেটি প্রদর্শন করবে। যদি read_line মেথড একটি Err রিটার্ন করে, তাহলে সম্ভবত এটি অন্তর্নিহিত অপারেটিং সিস্টেম থেকে আসা কোনো এররের ফলাফল। যদি Result-এর এই ইন্সট্যান্সটি একটি Ok মান হয়, তাহলে expect Ok-এর মধ্যে থাকা রিটার্ন মানটি গ্রহণ করবে এবং শুধুমাত্র সেই মানটি আপনাকে রিটার্ন করবে, যাতে আপনি সেটি ব্যবহার করতে পারেন। এক্ষেত্রে, সেই মানটি হল ব্যবহারকারীর ইনপুটের বাইটের সংখ্যা।
আপনি যদি expect কল না করেন, তাহলে প্রোগ্রামটি কম্পাইল হবে, কিন্তু আপনি একটি ওয়ার্নিং পাবেন:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut guess);
| +++++++
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.59s
Rust সতর্ক করে যে আপনি read_line থেকে রিটার্ন হওয়া Result মানটি ব্যবহার করেননি, যা নির্দেশ করে যে প্রোগ্রামটি একটি সম্ভাব্য এরর হ্যান্ডেল করেনি।
ওয়ার্নিংটি দমন করার সঠিক উপায় হল আসলে এরর-হ্যান্ডলিং কোড লেখা। কিন্তু আমাদের ক্ষেত্রে, কোনো সমস্যা হলে আমরা শুধু এই প্রোগ্রামটিকে ক্র্যাশ করাতে চাই, তাই আমরা expect ব্যবহার করতে পারি। আপনি চ্যাপ্টার ৯-এ এরর থেকে পুনরুদ্ধার সম্পর্কে জানতে পারবেন।
println! প্লেসহোল্ডার দিয়ে মান প্রিন্ট করা (Printing Values with println! Placeholders)
ক্লোজিং কার্লি ব্র্যাকেট ছাড়াও, এখনও পর্যন্ত কোডটিতে আলোচনা করার মতো আর একটি লাইন রয়েছে:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}এই লাইনটি সেই স্ট্রিংটিকে প্রিন্ট করে, যেখানে এখন ব্যবহারকারীর ইনপুট রয়েছে। {} কার্লি ব্র্যাকেটের সেটটি হল একটি প্লেসহোল্ডার: {}-কে কাঁকড়ার ছোট সাঁড়াশি হিসেবে ভাবতে পারেন, যা একটি মানকে ধরে রাখে। যখন একটি ভেরিয়েবলের মান প্রিন্ট করা হয়, তখন কার্লি ব্র্যাকেটের ভেতরে ভেরিয়েবলের নাম দেওয়া যেতে পারে। যখন একটি এক্সপ্রেশনের মূল্যায়ন করা ফলাফল প্রিন্ট করা হয়, তখন ফরম্যাট স্ট্রিংয়ে খালি কার্লি ব্র্যাকেট বসানো হয়। তারপর ফরম্যাট স্ট্রিংয়ের পরে, প্রতিটি খালি কার্লি ব্র্যাকেট প্লেসহোল্ডারে প্রিন্ট করার জন্য কমা দিয়ে আলাদা করা এক্সপ্রেশনের একটি তালিকা একই ক্রমে দেওয়া হয়। println!-এর একটি কলে একটি ভেরিয়েবল এবং একটি এক্সপ্রেশনের ফলাফল প্রিন্ট করা এমন দেখাবে:
#![allow(unused)] fn main() { let x = 5; let y = 10; println!("x = {x} and y + 2 = {}", y + 2); }
এই কোডটি x = 5 and y + 2 = 12 প্রিন্ট করবে।
প্রথম অংশের পরীক্ষা (Testing the First Part)
আসুন, অনুমানের গেমের প্রথম অংশটি পরীক্ষা করি। cargo run ব্যবহার করে এটি চালান:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/guessing_game`
Guess the number!
Please input your guess.
6
You guessed: 6
এই পর্যন্ত, গেমের প্রথম অংশটি সম্পন্ন হয়েছে: আমরা কীবোর্ড থেকে ইনপুট নিচ্ছি এবং সেটি প্রিন্ট করছি।
একটি সংখ্যা অনুমানের গেম প্রোগ্রামিং (Programming a Guessing Game)
আসুন, একসাথে একটি হ্যান্ডস-অন প্রোজেক্টে কাজ করার মাধ্যমে Rust-এর জগতে ঝাঁপ দেই! এই চ্যাপ্টারটি আপনাকে কিছু সাধারণ Rust কনসেপ্টের সাথে পরিচয় করিয়ে দেবে, একটি বাস্তব প্রোগ্রামে সেগুলো কীভাবে ব্যবহার করা হয় তা দেখিয়ে। আপনি let, match, মেথড, অ্যাসোসিয়েটেড ফাংশন, এক্সটার্নাল ক্রেট এবং আরও অনেক কিছু সম্পর্কে জানতে পারবেন! নিচের চ্যাপ্টারগুলোতে, আমরা এই ধারণাগুলো আরও বিস্তারিতভাবে আলোচনা করব। এই চ্যাপ্টারে, আপনি শুধুমাত্র মৌলিক বিষয়গুলো অনুশীলন করবেন।
আমরা একটি ক্লাসিক বিগিনার প্রোগ্রামিং সমস্যা সমাধান করব: একটি সংখ্যা অনুমানের গেম। এটি কীভাবে কাজ করে তা নিচে বলা হলো: প্রোগ্রামটি 1 থেকে 100-এর মধ্যে একটি র্যান্ডম সংখ্যা তৈরি করবে। তারপর এটি প্লেয়ারকে একটি সংখ্যা অনুমান করতে বলবে। একটি সংখ্যা অনুমান করার পরে, প্রোগ্রামটি জানাবে যে অনুমানটি খুব কম না বেশি হয়েছে। যদি অনুমানটি সঠিক হয়, তাহলে গেমটি একটি অভিনন্দন বার্তা প্রিন্ট করবে এবং শেষ হয়ে যাবে।
একটি নতুন প্রোজেক্ট সেট আপ করা (Setting Up a New Project)
একটি নতুন প্রোজেক্ট সেট আপ করতে, চ্যাপ্টার ১-এ তৈরি করা projects ডিরেক্টরিতে যান এবং Cargo ব্যবহার করে নিচের মতো একটি নতুন প্রোজেক্ট তৈরি করুন:
$ cargo new guessing_game
$ cd guessing_game
প্রথম কমান্ড, cargo new, প্রোজেক্টের নাম (guessing_game) প্রথম আর্গুমেন্ট হিসেবে নেয়। দ্বিতীয় কমান্ডটি নতুন প্রোজেক্টের ডিরেক্টরিতে যাওয়া নির্দেশ করে।
জেনারেট হওয়া Cargo.toml ফাইলটি দেখুন:
Filename: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
[dependencies]
আপনি যেমন চ্যাপ্টার ১-এ দেখেছেন, cargo new আপনার জন্য একটি “Hello, world!” প্রোগ্রাম তৈরি করে। src/main.rs ফাইলটি দেখুন:
Filename: src/main.rs
fn main() { println!("Hello, world!"); }
এবার চলুন, এই “Hello, world!” প্রোগ্রামটি কম্পাইল করি এবং cargo run কমান্ড ব্যবহার করে একই ধাপে চালাই:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `file:///projects/guessing_game/target/debug/guessing_game`
Hello, world!
run কমান্ডটি তখন কাজে আসে যখন আপনাকে একটি প্রোজেক্টে দ্রুত পুনরাবৃত্তি করতে হয়, যেমনটি আমরা এই গেমে করব। অর্থাৎ, পরবর্তী ধাপে যাওয়ার আগে প্রতিটি পুনরাবৃত্তি দ্রুত পরীক্ষা করে নেওয়া যাবে।
src/main.rs ফাইলটি আবার খুলুন। আপনি এই ফাইলেই সমস্ত কোড লিখবেন।
একটি অনুমান প্রক্রিয়া করা (Processing a Guess)
অনুমান করার গেম প্রোগ্রামটির প্রথম অংশ ব্যবহারকারীর ইনপুট চাইবে, সেই ইনপুটটি প্রক্রিয়া করবে এবং ইনপুটটি প্রত্যাশিত ফর্ম্যাটে আছে কিনা তা পরীক্ষা করবে। শুরু করার জন্য, আমরা প্লেয়ারকে একটি সংখ্যা অনুমান করতে দেব। Listing 2-1-এর কোডটি src/main.rs-এ লিখুন।
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}এই কোডটিতে অনেক তথ্য রয়েছে, তাই চলুন লাইন ধরে ধরে আলোচনা করি। ব্যবহারকারীর ইনপুট নিতে এবং তারপর ফলাফলটি আউটপুট হিসেবে প্রিন্ট করতে, আমাদের io ইনপুট/আউটপুট লাইব্রেরিটিকে স্কোপের মধ্যে আনতে হবে। io লাইব্রেরিটি স্ট্যান্ডার্ড লাইব্রেরি থেকে আসে, যাকে std বলা হয়:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}ডিফল্টরূপে, Rust-এর স্ট্যান্ডার্ড লাইব্রেরিতে সংজ্ঞায়িত আইটেমগুলোর একটি সেট রয়েছে, যা প্রতিটি প্রোগ্রামের স্কোপে আনা হয়। এই সেটটিকে প্রেলিউড (prelude) বলা হয়, এবং আপনি স্ট্যান্ডার্ড লাইব্রেরি ডকুমেন্টেশনে prelude-এর সবকিছু দেখতে পারেন।
যদি আপনি যে টাইপটি ব্যবহার করতে চান সেটি প্রেলিউডে না থাকে, তাহলে আপনাকে use স্টেটমেন্ট ব্যবহার করে সেই টাইপটিকে স্পষ্টতই স্কোপে আনতে হবে। std::io লাইব্রেরি ব্যবহার করলে আপনি বেশ কিছু দরকারী ফিচার পাবেন, যার মধ্যে ব্যবহারকারীর ইনপুট নেওয়ার ক্ষমতাও রয়েছে।
আপনি যেমন চ্যাপ্টার ১-এ দেখেছেন, main ফাংশনটি প্রোগ্রামে প্রবেশের পথ:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}fn সিনট্যাক্স একটি নতুন ফাংশন ঘোষণা করে; বন্ধনী, (), নির্দেশ করে যে কোনও প্যারামিটার নেই; এবং কার্লি ব্র্যাকেট, {}, ফাংশনের বডি শুরু করে।
আপনি চ্যাপ্টার ১-এ আরও শিখেছেন যে, println! হল একটি ম্যাক্রো যা স্ক্রিনে একটি স্ট্রিং প্রিন্ট করে:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}এই কোডটি একটি প্রম্পট প্রিন্ট করছে, যাতে গেমটি কী তা বলা হয়েছে এবং ব্যবহারকারীর কাছ থেকে ইনপুট চাওয়া হয়েছে।
ভেরিয়েবল ব্যবহার করে মান সংরক্ষণ করা (Storing Values with Variables)
এরপর, আমরা ব্যবহারকারীর ইনপুট সংরক্ষণ করার জন্য একটি ভেরিয়েবল তৈরি করব, এইভাবে:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}এবার প্রোগ্রামটি আরও মজাদার হচ্ছে! এই ছোট লাইনে অনেক কিছু ঘটছে। আমরা ভেরিয়েবল তৈরি করতে let স্টেটমেন্ট ব্যবহার করি। আরেকটি উদাহরণ নিচে দেওয়া হলো:
let apples = 5;এই লাইনটি apples নামের একটি নতুন ভেরিয়েবল তৈরি করে এবং এটিকে 5 মানের সাথে বাইন্ড করে। Rust-এ, ভেরিয়েবলগুলো ডিফল্টরূপে ইমিউটেবল (immutable) হয়, অর্থাৎ একবার আমরা ভেরিয়েবলকে একটি মান দিলে, সেই মানটি পরিবর্তন হবে না। আমরা চ্যাপ্টার ৩-এর “ভেরিয়েবল এবং মিউটেবিলিটি” বিভাগে এই ধারণাটি নিয়ে বিস্তারিত আলোচনা করব। একটি ভেরিয়েবলকে মিউটেবল (mutable) করতে, আমরা ভেরিয়েবলের নামের আগে mut যোগ করি:
let apples = 5; // immutable
let mut bananas = 5; // mutableদ্রষ্টব্য:
//সিনট্যাক্স একটি কমেন্ট শুরু করে, যা লাইনের শেষ পর্যন্ত চলতে থাকে। Rust কমেন্টের ভেতরের সবকিছু উপেক্ষা করে। আমরা চ্যাপ্টার ৩-এ কমেন্ট নিয়ে আরও বিস্তারিত আলোচনা করব।
অনুমানের গেমের প্রোগ্রামে ফিরে আসা যাক। আপনি এখন জানেন যে let mut guess guess নামের একটি মিউটেবল ভেরিয়েবল তৈরি করবে। সমান চিহ্ন (=) Rust-কে বলে যে আমরা এখনই ভেরিয়েবলের সাথে কিছু বাইন্ড করতে চাই। সমান চিহ্নের ডানদিকে guess-এর মান রয়েছে, যেটি String::new কল করার ফলাফল। String::new একটি ফাংশন, যা একটি String-এর নতুন ইন্সট্যান্স রিটার্ন করে। String হল স্ট্যান্ডার্ড লাইব্রেরি থেকে পাওয়া একটি স্ট্রিং টাইপ, যা প্রসারণযোগ্য (growable), UTF-8 এনকোডেড টেক্সট।
::new লাইনের :: সিনট্যাক্স নির্দেশ করে যে new হল String টাইপের একটি অ্যাসোসিয়েটেড ফাংশন। একটি অ্যাসোসিয়েটেড ফাংশন হল এমন একটি ফাংশন যা একটি টাইপের উপর ইমপ্লিমেন্ট করা হয়, এক্ষেত্রে String। এই new ফাংশনটি একটি নতুন, খালি স্ট্রিং তৈরি করে। আপনি অনেক টাইপের ওপর new ফাংশন দেখতে পাবেন, কারণ এটি একটি সাধারণ নাম, যা কোনো কিছুর একটি নতুন মান তৈরি করে।
পুরো let mut guess = String::new(); লাইনটি একটি মিউটেবল ভেরিয়েবল তৈরি করেছে, যা বর্তমানে একটি String-এর নতুন, খালি ইন্সট্যান্সের সাথে বাইন্ড করা আছে।
ব্যবহারকারীর ইনপুট গ্রহণ করা (Receiving User Input)
মনে করে দেখুন, আমরা প্রোগ্রামের প্রথম লাইনে use std::io; দিয়ে স্ট্যান্ডার্ড লাইব্রেরি থেকে ইনপুট/আউটপুট ফাংশনালিটি অন্তর্ভুক্ত করেছিলাম। এবার আমরা io মডিউল থেকে stdin ফাংশনটি কল করব, যা আমাদের ব্যবহারকারীর ইনপুট হ্যান্ডেল করতে দেবে:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}যদি আমরা প্রোগ্রামের শুরুতে use std::io; দিয়ে io লাইব্রেরি ইম্পোর্ট না করতাম, তাহলেও আমরা এই ফাংশনটিকে std::io::stdin লিখে ব্যবহার করতে পারতাম। stdin ফাংশনটি std::io::Stdin-এর একটি ইন্সট্যান্স রিটার্ন করে, যেটি আপনার টার্মিনালের স্ট্যান্ডার্ড ইনপুটের হ্যান্ডেলের প্রতিনিধিত্ব করে।
এরপর, .read_line(&mut guess) লাইনটি ব্যবহারকারীর কাছ থেকে ইনপুট নেওয়ার জন্য স্ট্যান্ডার্ড ইনপুট হ্যান্ডেলে read_line মেথড কল করে। আমরা read_line-কে আর্গুমেন্ট হিসেবে &mut guess পাস করছি, যাতে এটি ব্যবহারকারীর ইনপুট কোন স্ট্রিংয়ে সংরক্ষণ করবে তা বলতে পারে। read_line-এর মূল কাজ হল ব্যবহারকারী স্ট্যান্ডার্ড ইনপুটে যা টাইপ করে, সেটি একটি স্ট্রিংয়ে যুক্ত করা (স্ট্রিংয়ের আগের কনটেন্ট মুছে না দিয়ে)। তাই আমরা সেই স্ট্রিংটিকে আর্গুমেন্ট হিসেবে পাস করি। স্ট্রিং আর্গুমেন্টটিকে অবশ্যই মিউটেবল হতে হবে, যাতে মেথডটি স্ট্রিংয়ের কনটেন্ট পরিবর্তন করতে পারে।
& নির্দেশ করে যে এই আর্গুমেন্টটি একটি রেফারেন্স, যা আপনাকে আপনার কোডের একাধিক অংশকে মেমরিতে ডেটা একাধিকবার কপি না করেই ডেটার একটি অংশ অ্যাক্সেস করার সুবিধা দেয়। রেফারেন্স একটি জটিল ফিচার, এবং Rust-এর অন্যতম প্রধান সুবিধা হল রেফারেন্স ব্যবহার করা কতটা নিরাপদ এবং সহজ। এই প্রোগ্রামটি শেষ করার জন্য আপনাকে সেই সমস্ত বিবরণ জানার দরকার নেই। আপাতত, আপনার শুধু এটুকু জানলেই চলবে যে ভেরিয়েবলের মতো রেফারেন্সগুলোও ডিফল্টরূপে ইমিউটেবল হয়। তাই, এটিকে মিউটেবল করার জন্য আপনাকে &guess-এর পরিবর্তে &mut guess লিখতে হবে। (চ্যাপ্টার ৪ রেফারেন্স আরও বিশদভাবে ব্যাখ্যা করবে।)
Result দিয়ে সম্ভাব্য ত্রুটি সামলানো (Handling Potential Failure with Result)
আমরা এখনও এই লাইনেই কাজ করছি। আমরা এখন টেক্সটের তৃতীয় লাইন নিয়ে আলোচনা করছি, কিন্তু মনে রাখবেন যে এটি এখনও কোডের একটি একক লজিক্যাল লাইনের অংশ। পরের অংশটি হল এই মেথড:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}আমরা এই কোডটিকে এভাবে লিখতে পারতাম:
io::stdin().read_line(&mut guess).expect("Failed to read line");কিন্তু, একটি লম্বা লাইন পড়া কঠিন, তাই এটিকে ভাগ করে নেওয়া ভালো। .method_name() সিনট্যাক্স দিয়ে যখন আপনি একটি মেথড কল করেন, তখন প্রায়ই একটি নতুন লাইন এবং অন্যান্য হোয়াইটস্পেস যোগ করে লম্বা লাইনগুলোকে ভেঙে ফেলা বুদ্ধিমানের কাজ। এবার আলোচনা করা যাক এই লাইনটি কী করে।
আগে যেমন উল্লেখ করা হয়েছে, read_line ব্যবহারকারী যা ইনপুট দেয়, সেটি আমাদের দেওয়া স্ট্রিংয়ে রাখে। কিন্তু এটি একটি Result মানও রিটার্ন করে। Result হল একটি গণনা (enumeration), যাকে প্রায়শই enum বলা হয়। এটি এমন একটি টাইপ, যা একাধিক সম্ভাব্য অবস্থার মধ্যে একটিতে থাকতে পারে। আমরা প্রতিটি সম্ভাব্য অবস্থাকে একটি ভেরিয়েন্ট বলি।
চ্যাপ্টার ৬-এ enum সম্পর্কে আরও বিস্তারিত আলোচনা করা হবে। এই Result টাইপগুলোর উদ্দেশ্য হল এরর-হ্যান্ডলিং তথ্য এনকোড করা।
Result-এর ভেরিয়েন্টগুলো হল Ok এবং Err। Ok ভেরিয়েন্ট নির্দেশ করে যে অপারেশন সফল হয়েছে এবং এর মধ্যে সফলভাবে জেনারেট হওয়া মান রয়েছে। Err ভেরিয়েন্ট মানে অপারেশন ব্যর্থ হয়েছে এবং এর মধ্যে অপারেশনটি কীভাবে বা কেন ব্যর্থ হয়েছে সে সম্পর্কে তথ্য রয়েছে।
যেকোনো টাইপের মানের মতোই Result টাইপের মানগুলোরও নিজস্ব মেথড ডিফাইন করা থাকে। Result-এর একটি ইন্সট্যান্সের একটি expect মেথড রয়েছে, যাকে আপনি কল করতে পারেন। যদি Result-এর এই ইন্সট্যান্সটি একটি Err মান হয়, তাহলে expect প্রোগ্রামটিকে ক্র্যাশ করাবে এবং আপনি expect-এর আর্গুমেন্ট হিসেবে যে মেসেজটি পাস করেছেন সেটি প্রদর্শন করবে। যদি read_line মেথড একটি Err রিটার্ন করে, তাহলে সম্ভবত এটি অন্তর্নিহিত অপারেটিং সিস্টেম থেকে আসা কোনো এররের ফলাফল। যদি Result-এর এই ইন্সট্যান্সটি একটি Ok মান হয়, তাহলে expect Ok-এর মধ্যে থাকা রিটার্ন মানটি গ্রহণ করবে এবং শুধুমাত্র সেই মানটি আপনাকে রিটার্ন করবে, যাতে আপনি সেটি ব্যবহার করতে পারেন। এক্ষেত্রে, সেই মানটি হল ব্যবহারকারীর ইনপুটের বাইটের সংখ্যা।
আপনি যদি expect কল না করেন, তাহলে প্রোগ্রামটি কম্পাইল হবে, কিন্তু আপনি একটি ওয়ার্নিং পাবেন:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut guess);
| +++++++
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.59s
Rust সতর্ক করে যে আপনি read_line থেকে রিটার্ন হওয়া Result মানটি ব্যবহার করেননি, যা নির্দেশ করে যে প্রোগ্রামটি একটি সম্ভাব্য এরর হ্যান্ডেল করেনি।
ওয়ার্নিংটি দমন করার সঠিক উপায় হল আসলে এরর-হ্যান্ডলিং কোড লেখা। কিন্তু আমাদের ক্ষেত্রে, কোনো সমস্যা হলে আমরা শুধু এই প্রোগ্রামটিকে ক্র্যাশ করাতে চাই, তাই আমরা expect ব্যবহার করতে পারি। আপনি চ্যাপ্টার ৯-এ এরর থেকে পুনরুদ্ধার সম্পর্কে জানতে পারবেন।
println! প্লেসহোল্ডার দিয়ে মান প্রিন্ট করা (Printing Values with println! Placeholders)
ক্লোজিং কার্লি ব্র্যাকেট ছাড়াও, এখনও পর্যন্ত কোডটিতে আলোচনা করার মতো আর একটি লাইন রয়েছে:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {}", guess);
}এই লাইনটি সেই স্ট্রিংটিকে প্রিন্ট করে, যেখানে এখন ব্যবহারকারীর ইনপুট রয়েছে। {} কার্লি ব্র্যাকেটের সেটটি হল একটি প্লেসহোল্ডার: {}-কে কাঁকড়ার ছোট সাঁড়াশি হিসেবে ভাবতে পারেন, যা একটি মানকে ধরে রাখে। যখন একটি ভেরিয়েবলের মান প্রিন্ট করা হয়, তখন কার্লি ব্র্যাকেটের ভেতরে ভেরিয়েবলের নাম দেওয়া যেতে পারে। যখন একটি এক্সপ্রেশনের মূল্যায়ন করা ফলাফল প্রিন্ট করা হয়, তখন ফরম্যাট স্ট্রিংয়ে খালি কার্লি ব্র্যাকেট বসানো হয়। তারপর ফরম্যাট স্ট্রিংয়ের পরে, প্রতিটি খালি কার্লি ব্র্যাকেট প্লেসহোল্ডারে প্রিন্ট করার জন্য কমা দিয়ে আলাদা করা এক্সপ্রেশনের একটি তালিকা একই ক্রমে দেওয়া হয়। println!-এর একটি কলে একটি ভেরিয়েবল এবং একটি এক্সপ্রেশনের ফলাফল প্রিন্ট করা এমন দেখাবে:
#![allow(unused)] fn main() { let x = 5; let y = 10; println!("x = {x} and y + 2 = {}", y + 2); }
এই কোডটি x = 5 and y + 2 = 12 প্রিন্ট করবে।
প্রথম অংশের পরীক্ষা (Testing the First Part)
আসুন, অনুমানের গেমের প্রথম অংশটি পরীক্ষা করি। cargo run ব্যবহার করে এটি চালান:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/guessing_game`
Guess the number!
Please input your guess.
6
You guessed: 6
এই পর্যন্ত, গেমের প্রথম অংশটি সম্পন্ন হয়েছে: আমরা কীবোর্ড থেকে ইনপুট নিচ্ছি এবং সেটি প্রিন্ট করছি।
একটি গোপন সংখ্যা তৈরি করা (Generating a Secret Number)
এরপর, আমাদের একটি গোপন সংখ্যা তৈরি করতে হবে, যেটি ব্যবহারকারী অনুমান করার চেষ্টা করবে। গোপন সংখ্যাটি প্রত্যেকবার আলাদা হওয়া উচিত, যাতে গেমটি একাধিকবার খেলতে মজা লাগে। আমরা 1 থেকে 100-এর মধ্যে একটি র্যান্ডম সংখ্যা ব্যবহার করব, যাতে গেমটি খুব কঠিন না হয়। Rust-এর স্ট্যান্ডার্ড লাইব্রেরিতে এখনও র্যান্ডম সংখ্যার কার্যকারিতা অন্তর্ভুক্ত নেই। তবে, Rust টিম এই কার্যকারিতা সহ একটি rand ক্রেট সরবরাহ করে।
আরও কার্যকারিতা পেতে একটি ক্রেট ব্যবহার করা (Using a Crate to Get More Functionality)
মনে রাখবেন যে একটি ক্রেট হল Rust সোর্স কোড ফাইলগুলোর একটি সংগ্রহ। আমরা যে প্রোজেক্টটি তৈরি করছি সেটি হল একটি বাইনারি ক্রেট, যেটি একটি এক্সিকিউটেবল। rand ক্রেটটি হল একটি লাইব্রেরি ক্রেট, যেটিতে কোড রয়েছে যা অন্য প্রোগ্রামগুলোতে ব্যবহার করার উদ্দেশ্যে তৈরি এবং নিজে থেকে চালানো যায় না।
Cargo-র এক্সটার্নাল ক্রেটগুলোর সমন্বয় হল সেই জায়গা যেখানে Cargo সত্যিই சிறந்து (তামিল শব্দ, অর্থ 'shines') দেখায়। rand ব্যবহার করে এমন কোড লেখার আগে, আমাদের Cargo.toml ফাইলটিকে পরিবর্তন করতে হবে, যাতে rand ক্রেটটি একটি ডিপেন্ডেন্সি হিসেবে অন্তর্ভুক্ত হয়। এখন সেই ফাইলটি খুলুন এবং Cargo আপনার জন্য তৈরি করা [dependencies] সেকশন হেডারের নিচে, নিচের লাইনটি যোগ করুন। এখানে যেভাবে rand নির্দিষ্ট করা হয়েছে, ঠিক সেভাবে এই ভার্সন নম্বর সহ নির্দিষ্ট করতে ভুলবেন না, নাহলে এই টিউটোরিয়ালের কোড উদাহরণগুলো কাজ নাও করতে পারে:
Filename: Cargo.toml
[dependencies]
rand = "0.8.5"
Cargo.toml ফাইলে, একটি হেডারের পরে যা কিছু থাকে তা সেই বিভাগের অংশ যা অন্য একটি বিভাগ শুরু না হওয়া পর্যন্ত চলতে থাকে। [dependencies]-এ আপনি Cargo-কে জানান যে আপনার প্রোজেক্ট কোন এক্সটার্নাল ক্রেটগুলোর উপর নির্ভর করে এবং সেই ক্রেটগুলোর কোন ভার্সন আপনার প্রয়োজন। এক্ষেত্রে, আমরা rand ক্রেটটিকে সেমান্টিক ভার্সন স্পেসিফায়ার 0.8.5 দিয়ে নির্দিষ্ট করি। Cargo সেমান্টিক ভার্সনিং (কখনও কখনও SemVer বলা হয়) বোঝে, যা ভার্সন নম্বর লেখার একটি স্ট্যান্ডার্ড। স্পেসিফায়ার 0.8.5 আসলে ^0.8.5-এর শর্টহ্যান্ড, যার অর্থ হল যেকোনো ভার্সন যা কমপক্ষে 0.8.5 কিন্তু 0.9.0-এর নিচে।
Cargo এই ভার্সনগুলোকে 0.8.5 ভার্সনের সাথে সঙ্গতিপূর্ণ পাবলিক API-এর অধিকারী বলে মনে করে এবং এই স্পেসিফিকেশন নিশ্চিত করে যে আপনি সর্বশেষ প্যাচ রিলিজ পাবেন যা এখনও এই চ্যাপ্টারের কোডের সাথে কম্পাইল হবে। 0.9.0 বা তার বেশি কোনো ভার্সনের ক্ষেত্রে, নিচের উদাহরণগুলোতে ব্যবহৃত API-এর মতো একই API থাকার কোনো গ্যারান্টি নেই।
এখন, কোডের কোনো পরিবর্তন না করেই, চলুন প্রোজেক্টটি বিল্ড করি, যেমনটি Listing 2-2-তে দেখানো হয়েছে।
$ cargo build
Updating crates.io index
Locking 15 packages to latest Rust 1.85.0 compatible versions
Adding rand v0.8.5 (available: v0.9.0)
Compiling proc-macro2 v1.0.93
Compiling unicode-ident v1.0.17
Compiling libc v0.2.170
Compiling cfg-if v1.0.0
Compiling byteorder v1.5.0
Compiling getrandom v0.2.15
Compiling rand_core v0.6.4
Compiling quote v1.0.38
Compiling syn v2.0.98
Compiling zerocopy-derive v0.7.35
Compiling zerocopy v0.7.35
Compiling ppv-lite86 v0.2.20
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.48s
আপনি হয়তো ভিন্ন ভার্সন নম্বর দেখতে পারেন (কিন্তু সেগুলো সবই কোডের সাথে সঙ্গতিপূর্ণ হবে, SemVer-এর কারণে!) এবং ভিন্ন লাইন (অপারেটিং সিস্টেমের উপর নির্ভর করে), এবং লাইনগুলো ভিন্ন ক্রমে থাকতে পারে।
যখন আমরা একটি এক্সটার্নাল ডিপেন্ডেন্সি অন্তর্ভুক্ত করি, Cargo সেই ডিপেন্ডেন্সির প্রয়োজনীয় সবকিছুর সর্বশেষ ভার্সন রেজিস্ট্রি থেকে নিয়ে আসে, যেটি Crates.io থেকে ডেটার একটি কপি। Crates.io হল সেই জায়গা যেখানে Rust ইকোসিস্টেমের লোকেরা তাদের ওপেন সোর্স Rust প্রোজেক্টগুলো অন্যদের ব্যবহারের জন্য পোস্ট করে।
রেজিস্ট্রি আপডেট করার পরে, Cargo [dependencies] সেকশনটি পরীক্ষা করে এবং তালিকাভুক্ত যেকোনো ক্রেট ডাউনলোড করে, যেগুলো ইতিমধ্যেই ডাউনলোড করা হয়নি। এই ক্ষেত্রে, যদিও আমরা শুধুমাত্র rand-কে ডিপেন্ডেন্সি হিসেবে তালিকাভুক্ত করেছি, Cargo rand কাজ করার জন্য যে অন্যান্য ক্রেটগুলোর উপর নির্ভর করে সেগুলোও নিয়ে এসেছে। ক্রেটগুলো ডাউনলোড করার পরে, Rust সেগুলোকে কম্পাইল করে এবং তারপর ডিপেন্ডেন্সিগুলো উপলব্ধ করে প্রোজেক্টটি কম্পাইল করে।
আপনি যদি কোনো পরিবর্তন না করেই আবার cargo build চালান, তাহলে আপনি Finished লাইনটি ছাড়া আর কোনো আউটপুট পাবেন না। Cargo জানে যে এটি ইতিমধ্যেই ডিপেন্ডেন্সিগুলো ডাউনলোড এবং কম্পাইল করেছে, এবং আপনি আপনার Cargo.toml ফাইলে সেগুলো সম্পর্কে কোনো পরিবর্তন করেননি। Cargo আরও জানে যে আপনি আপনার কোড সম্পর্কে কোনো পরিবর্তন করেননি, তাই এটি সেটিও পুনরায় কম্পাইল করে না। করার মতো কিছু না থাকায়, এটি কেবল শেষ হয়ে যায়।
আপনি যদি src/main.rs ফাইলটি খোলেন, একটি সামান্য পরিবর্তন করেন, এবং তারপর সংরক্ষণ করে আবার বিল্ড করেন, তাহলে আপনি কেবল দুটি লাইনের আউটপুট দেখতে পাবেন:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
এই লাইনগুলো দেখায় যে Cargo শুধুমাত্র src/main.rs ফাইলে আপনার ছোট পরিবর্তনের সাথে বিল্ডটি আপডেট করে। আপনার ডিপেন্ডেন্সিগুলো পরিবর্তন হয়নি, তাই Cargo জানে যে এটি ইতিমধ্যেই সেগুলোর জন্য যা ডাউনলোড এবং কম্পাইল করেছে তা পুনরায় ব্যবহার করতে পারে।
Cargo.lock ফাইল দিয়ে রিপ্রোডিউসিবল বিল্ড নিশ্চিত করা (Ensuring Reproducible Builds with the Cargo.lock File)
Cargo-র একটি মেকানিজম রয়েছে যা নিশ্চিত করে যে আপনি বা অন্য কেউ যখনই আপনার কোড বিল্ড করবেন, তখনই যেন একই আর্টিফ্যাক্ট পুনরায় তৈরি করা যায়: আপনি অন্যথায় নির্দেশ না দেওয়া পর্যন্ত Cargo শুধুমাত্র আপনার নির্দিষ্ট করা ডিপেন্ডেন্সিগুলোর ভার্সনগুলোই ব্যবহার করবে। উদাহরণস্বরূপ, ধরা যাক পরের সপ্তাহে rand ক্রেটের 0.8.6 ভার্সন প্রকাশিত হল, এবং সেই ভার্সনে একটি গুরুত্বপূর্ণ বাগ ফিক্স রয়েছে, কিন্তু এটিতে একটি রিগ্রেশনও রয়েছে যা আপনার কোডকে ভেঙে দেবে। এটি হ্যান্ডেল করার জন্য, আপনি যখন প্রথমবার cargo build চালান তখন Rust Cargo.lock ফাইলটি তৈরি করে, তাই এখন আমাদের guessing_game ডিরেক্টরিতে এটি রয়েছে।
আপনি যখন প্রথমবার একটি প্রোজেক্ট বিল্ড করেন, Cargo মানদণ্ড পূরণ করে এমন ডিপেন্ডেন্সিগুলোর সমস্ত ভার্সন খুঁজে বের করে এবং তারপর সেগুলোকে Cargo.lock ফাইলে লিখে রাখে। ভবিষ্যতে যখন আপনি আপনার প্রোজেক্ট বিল্ড করবেন, Cargo দেখবে যে Cargo.lock ফাইলটি বিদ্যমান এবং ভার্সনগুলো পুনরায় বের করার সমস্ত কাজ না করে সেখানে নির্দিষ্ট করা ভার্সনগুলো ব্যবহার করবে। এটি আপনাকে স্বয়ংক্রিয়ভাবে একটি রিপ্রোডিউসিবল বিল্ড করতে দেয়। অন্য কথায়, আপনার প্রোজেক্টটি 0.8.5-এই থাকবে যতক্ষণ না আপনি স্পষ্টতই আপগ্রেড করেন, Cargo.lock ফাইলের কারণে। যেহেতু রিপ্রোডিউসিবল বিল্ডের জন্য Cargo.lock ফাইলটি গুরুত্বপূর্ণ, তাই এটিকে প্রায়শই আপনার প্রোজেক্টের বাকি কোডের সাথে সোর্স কন্ট্রোলে চেক ইন করা হয়।
একটি নতুন ভার্সন পেতে একটি ক্রেট আপডেট করা (Updating a Crate to Get a New Version)
যখন আপনি একটি ক্রেট আপডেট করতে চান, Cargo update কমান্ড সরবরাহ করে, যেটি Cargo.lock ফাইলটিকে উপেক্ষা করবে এবং Cargo.toml-এ আপনার স্পেসিফিকেশন পূরণ করে এমন সমস্ত সর্বশেষ ভার্সন খুঁজে বের করবে। তারপর Cargo সেই ভার্সনগুলোকে Cargo.lock ফাইলে লিখবে। এই ক্ষেত্রে, Cargo শুধুমাত্র 0.8.5-এর চেয়ে বড় এবং 0.9.0-এর চেয়ে ছোট ভার্সনগুলো খুঁজবে। যদি rand ক্রেট দুটি নতুন ভার্সন 0.8.6 এবং 0.9.0 প্রকাশ করে, তাহলে আপনি যদি cargo update চালান তবে আপনি নিম্নলিখিতটি দেখতে পাবেন:
$ cargo update
Updating crates.io index
Locking 1 package to latest Rust 1.85.0 compatible version
Updating rand v0.8.5 -> v0.8.6 (available: v0.9.0)
Cargo 0.9.0 রিলিজটিকে উপেক্ষা করে। এই সময়ে, আপনি আপনার Cargo.lock ফাইলে একটি পরিবর্তনও লক্ষ্য করবেন, যেখানে উল্লেখ করা হয়েছে যে আপনি এখন যে rand ক্রেট ভার্সনটি ব্যবহার করছেন সেটি হল 0.8.6। rand ভার্সন 0.9.0 বা 0.9.x সিরিজের যেকোনো ভার্সন ব্যবহার করতে, আপনাকে Cargo.toml ফাইলটিকে এর পরিবর্তে এইরকম দেখাতে আপডেট করতে হবে:
[dependencies]
rand = "0.9.0"
পরের বার যখন আপনি cargo build চালাবেন, Cargo উপলব্ধ ক্রেটগুলোর রেজিস্ট্রি আপডেট করবে এবং আপনার নির্দিষ্ট করা নতুন ভার্সন অনুযায়ী আপনার rand প্রয়োজনীয়তাগুলো পুনরায় মূল্যায়ন করবে।
Cargo এবং এর ইকোসিস্টেম সম্পর্কে আরও অনেক কিছু বলার আছে, যা আমরা চ্যাপ্টার 14-তে আলোচনা করব, কিন্তু আপাতত, আপনার এটুকুই জানা দরকার। Cargo লাইব্রেরিগুলোকে পুনরায় ব্যবহার করা খুব সহজ করে তোলে, তাই Rustacean-রা বেশ কয়েকটি প্যাকেজ থেকে একত্রিত করে ছোট প্রোজেক্ট লিখতে সক্ষম।
একটি র্যান্ডম সংখ্যা তৈরি করা (Generating a Random Number)
আসুন, অনুমান করার জন্য একটি সংখ্যা তৈরি করতে rand ব্যবহার করা শুরু করি। পরবর্তী ধাপ হল src/main.rs আপডেট করা, যেমনটি Listing 2-3-তে দেখানো হয়েছে।
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}প্রথমে আমরা use rand::Rng; লাইনটি যোগ করি। Rng ট্রেইট সেই মেথডগুলো সংজ্ঞায়িত করে যেগুলো র্যান্ডম সংখ্যা জেনারেটররা প্রয়োগ করে এবং সেই মেথডগুলো ব্যবহার করার জন্য এই ট্রেইটটি আমাদের স্কোপে থাকতে হবে। চ্যাপ্টার ১০-এ ট্রেইটগুলো বিস্তারিতভাবে আলোচনা করা হবে।
এরপর, আমরা মাঝখানে দুটি লাইন যোগ করছি। প্রথম লাইনে, আমরা rand::thread_rng ফাংশনটি কল করি যা আমাদের নির্দিষ্ট র্যান্ডম সংখ্যা জেনারেটর দেয় যা আমরা ব্যবহার করতে যাচ্ছি: যেটি এক্সিকিউশনের বর্তমান থ্রেডের জন্য লোকাল এবং অপারেটিং সিস্টেম দ্বারা সিডেড। তারপর আমরা র্যান্ডম সংখ্যা জেনারেটরের উপর gen_range মেথডটি কল করি। এই মেথডটি Rng ট্রেইট দ্বারা সংজ্ঞায়িত করা হয়েছে যা আমরা use rand::Rng; স্টেটমেন্ট দিয়ে স্কোপে এনেছি। gen_range মেথডটি একটি রেঞ্জ এক্সপ্রেশনকে আর্গুমেন্ট হিসেবে নেয় এবং রেঞ্জের মধ্যে একটি র্যান্ডম সংখ্যা তৈরি করে। আমরা এখানে যে ধরনের রেঞ্জ এক্সপ্রেশন ব্যবহার করছি সেটি start..=end ফর্ম নেয় এবং নিম্ন ও উচ্চ উভয় সীমানাতেই অন্তর্ভুক্ত থাকে, তাই আমাদের 1 থেকে 100-এর মধ্যে একটি সংখ্যা অনুরোধ করতে 1..=100 নির্দিষ্ট করতে হবে।
দ্রষ্টব্য: আপনি শুধু কোন ট্রেইট ব্যবহার করবেন এবং কোন মেথড এবং ফাংশন একটি ক্রেট থেকে কল করবেন তা এমনি এমনি জানবেন না, তাই প্রতিটি ক্রেটের ডকুমেন্টেশন থাকে যাতে এটি ব্যবহারের নির্দেশাবলী থাকে। Cargo-র আরেকটি দারুণ ফিচার হল
cargo doc --openকমান্ড চালালে আপনার সমস্ত ডিপেন্ডেন্সির দেওয়া ডকুমেন্টেশন লোকালি তৈরি হবে এবং আপনার ব্রাউজারে খুলবে। উদাহরণস্বরূপ, আপনি যদিrandক্রেটের অন্যান্য কার্যকারিতা সম্পর্কে আগ্রহী হন, তাহলেcargo doc --openচালান এবং বাম দিকের সাইডবারেrand-এ ক্লিক করুন।
দ্বিতীয় নতুন লাইনটি গোপন সংখ্যাটি প্রিন্ট করে। এটি দরকারী যখন আমরা প্রোগ্রামটি ডেভেলপ করছি তখন এটি পরীক্ষা করতে, কিন্তু আমরা ফাইনাল ভার্সন থেকে এটি মুছে ফেলব। প্রোগ্রামটি শুরু হওয়ার সাথে সাথেই উত্তর প্রিন্ট করলে সেটি আর তেমন কোনো গেম থাকে না!
কয়েকবার প্রোগ্রামটি চালানোর চেষ্টা করুন:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 7
Please input your guess.
4
You guessed: 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 83
Please input your guess.
5
You guessed: 5
আপনার ভিন্ন র্যান্ডম সংখ্যা পাওয়া উচিত, এবং সেগুলো সবই 1 থেকে 100-এর মধ্যে সংখ্যা হওয়া উচিত। দারুন কাজ!
অনুমানের সাথে গোপন সংখ্যার তুলনা করা (Comparing the Guess to the Secret Number)
এখন আমাদের কাছে ব্যবহারকারীর ইনপুট এবং একটি র্যান্ডম সংখ্যা রয়েছে, আমরা সেগুলোর তুলনা করতে পারি। সেই ধাপটি Listing 2-4-এ দেখানো হয়েছে। মনে রাখবেন যে এই কোডটি এখনই কম্পাইল হবে না, যেমনটি আমরা ব্যাখ্যা করব।
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
// --snip--
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}প্রথমে আমরা আরেকটি use স্টেটমেন্ট যোগ করি, স্ট্যান্ডার্ড লাইব্রেরি থেকে std::cmp::Ordering নামক একটি টাইপকে স্কোপে আনি। Ordering টাইপটি হল আরেকটি enum এবং এর ভেরিয়েন্টগুলো হল Less, Greater, এবং Equal। আপনি যখন দুটি মান তুলনা করেন তখন এই তিনটি ফলাফল সম্ভব।
তারপর আমরা নিচে পাঁচটি নতুন লাইন যোগ করি যা Ordering টাইপ ব্যবহার করে। cmp মেথড দুটি মান তুলনা করে এবং যে কোনো কিছুর উপর কল করা যেতে পারে যা তুলনা করা যায়। এটি আপনি যেটির সাথে তুলনা করতে চান তার একটি রেফারেন্স নেয়: এখানে এটি guess-কে secret_number-এর সাথে তুলনা করছে। তারপর এটি Ordering enum-এর একটি ভেরিয়েন্ট রিটার্ন করে যা আমরা use স্টেটমেন্ট দিয়ে স্কোপে এনেছি। আমরা একটি match এক্সপ্রেশন ব্যবহার করি, guess এবং secret_number-এর মান সহ cmp-এর কলে কোন Ordering-এর ভেরিয়েন্ট রিটার্ন করা হয়েছিল তার উপর ভিত্তি করে পরবর্তীতে কী করতে হবে তা নির্ধারণ করতে।
একটি match এক্সপ্রেশন আর্ম দিয়ে তৈরি। একটি আর্ম একটি প্যাটার্ন নিয়ে গঠিত, যার সাথে ম্যাচ করতে হবে, এবং কোডটি চালানো উচিত যদি match-কে দেওয়া মান সেই আর্মের প্যাটার্নের সাথে মেলে। Rust match-কে দেওয়া মান নেয় এবং প্রতিটি আর্মের প্যাটার্নের মধ্য দিয়ে যায়। প্যাটার্ন এবং match কনস্ট্রাক্ট হল Rust-এর শক্তিশালী ফিচার: এগুলো আপনাকে বিভিন্ন পরিস্থিতি প্রকাশ করতে দেয় যা আপনার কোড সম্মুখীন হতে পারে এবং নিশ্চিত করে যে আপনি সেগুলোর সবই হ্যান্ডেল করেছেন। এই ফিচারগুলো যথাক্রমে চ্যাপ্টার ৬ এবং চ্যাপ্টার 19-এ বিস্তারিতভাবে আলোচনা করা হবে।
আসুন, আমরা এখানে যে match এক্সপ্রেশনটি ব্যবহার করি তার একটি উদাহরণ দেখি। ধরা যাক যে ব্যবহারকারী 50 অনুমান করেছে এবং র্যান্ডমভাবে তৈরি গোপন সংখ্যাটি এবার 38।
কোড যখন 50-কে 38-এর সাথে তুলনা করে, তখন cmp মেথডটি Ordering::Greater রিটার্ন করবে, কারণ 50, 38-এর চেয়ে বড়। match এক্সপ্রেশনটি Ordering::Greater মান পায় এবং প্রতিটি আর্মের প্যাটার্ন পরীক্ষা করতে শুরু করে। এটি প্রথম আর্মের প্যাটার্ন, Ordering::Less-এর দিকে তাকায় এবং দেখে যে Ordering::Greater মানটি Ordering::Less-এর সাথে মেলে না, তাই এটি সেই আর্মের কোডটিকে উপেক্ষা করে এবং পরের আর্মে চলে যায়। পরের আর্মের প্যাটার্নটি হল Ordering::Greater, যেটি Ordering::Greater-এর সাথে মিলে যায়! সেই আর্মের সাথে সম্পর্কিত কোডটি এক্সিকিউট হবে এবং স্ক্রিনে Too big! প্রিন্ট করবে। প্রথম সফল ম্যাচের পরেই match এক্সপ্রেশনটি শেষ হয়ে যায়, তাই এই পরিস্থিতিতে এটি শেষ আর্মের দিকে তাকাবে না।
কিন্তু, Listing 2-4-এর কোডটি এখনও কম্পাইল হবে না। চলুন চেষ্টা করি:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
error[E0308]: mismatched types
--> src/main.rs:22:21
|
22 | match guess.cmp(&secret_number) {
| --- ^^^^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/cmp.rs:964:8
|
964 | fn cmp(&self, other: &Self) -> Ordering;
| ^^^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `guessing_game` (bin "guessing_game") due to 1 previous error
এররের মূল অংশে বলা হয়েছে যে এখানে টাইপ মিলছে না (mismatched types)। Rust-এ একটি শক্তিশালী, স্ট্যাটিক টাইপ সিস্টেম রয়েছে। তবে, এতে টাইপ ইনফারেন্সও (type inference) রয়েছে। যখন আমরা let mut guess = String::new() লিখেছিলাম, তখন Rust অনুমান করতে পেরেছিল যে guess একটি String হওয়া উচিত এবং আমাদের টাইপ লিখতে বাধ্য করেনি। অন্যদিকে, secret_number হল একটি সংখ্যা টাইপ। Rust-এর কয়েকটি সংখ্যা টাইপের মান 1 থেকে 100-এর মধ্যে হতে পারে: i32, একটি 32-বিট সংখ্যা; u32, একটি আনসাইনড 32-বিট সংখ্যা; i64, একটি 64-বিট সংখ্যা; এবং আরও অনেক কিছু। অন্যভাবে উল্লেখ না করা পর্যন্ত, Rust ডিফল্টভাবে i32 ব্যবহার করে, যেটি secret_number-এর টাইপ, যদি না আপনি অন্য কোথাও টাইপ সম্পর্কিত তথ্য যোগ করেন যা Rust-কে ভিন্ন সাংখ্যিক টাইপ অনুমান করতে বাধ্য করে। এররের কারণ হল Rust একটি স্ট্রিং এবং একটি সংখ্যা টাইপের তুলনা করতে পারে না।
শেষ পর্যন্ত, আমরা চাই যে প্রোগ্রামটি ইনপুট হিসেবে যে String পড়ে, সেটিকে একটি সংখ্যা টাইপে রূপান্তর করতে, যাতে আমরা এটিকে সংখ্যাগতভাবে গোপন সংখ্যার সাথে তুলনা করতে পারি। আমরা main ফাংশন বডিতে এই লাইনটি যোগ করে তা করি:
Filename: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}লাইনটি হল:
let guess: u32 = guess.trim().parse().expect("অনুগ্রহ করে একটি সংখ্যা টাইপ করুন!");আমরা guess নামে একটি ভেরিয়েবল তৈরি করি। কিন্তু, প্রোগ্রামে কি ইতিমধ্যেই guess নামে একটি ভেরিয়েবল নেই? আছে, কিন্তু সুবিধাজনকভাবে Rust আমাদের guess-এর আগের মানটিকে একটি নতুন মান দিয়ে শ্যাডো (shadow) করার অনুমতি দেয়। শ্যাডোয়িং (Shadowing) আমাদের guess ভেরিয়েবলের নামটি পুনরায় ব্যবহার করার সুযোগ দেয়, guess_str এবং guess-এর মতো দুটি আলাদা ভেরিয়েবল তৈরি করতে বাধ্য করার পরিবর্তে। আমরা চ্যাপ্টার ৩-এ এটি আরও বিশদে আলোচনা করব, তবে আপাতত, জেনে রাখুন যে এই ফিচারটি প্রায়শই ব্যবহৃত হয় যখন আপনি একটি মানকে এক টাইপ থেকে অন্য টাইপে রূপান্তর করতে চান।
আমরা এই নতুন ভেরিয়েবলটিকে guess.trim().parse() এক্সপ্রেশনের সাথে বাইন্ড করি। এক্সপ্রেশনের guess সেই আসল guess ভেরিয়েবলকে বোঝায়, যেখানে ইনপুটটি একটি স্ট্রিং হিসাবে ছিল। একটি String ইন্সট্যান্সের উপর trim মেথডটি শুরু এবং শেষের যেকোনো হোয়াইটস্পেস সরিয়ে দেবে, যা স্ট্রিংটিকে u32-তে রূপান্তর করার আগে আমাদের অবশ্যই করতে হবে, কারণ u32 শুধুমাত্র সংখ্যাসূচক ডেটা ধারণ করতে পারে। ব্যবহারকারীকে read_line সম্পূর্ণ করতে এবং তাদের অনুমান ইনপুট করতে enter চাপতে হবে, যা স্ট্রিংটিতে একটি নতুন লাইন ক্যারেক্টার যুক্ত করে। উদাহরণস্বরূপ, যদি ব্যবহারকারী 5 টাইপ করে এবং enter চাপে, তাহলে guess দেখতে এরকম হবে: 5\n। \n মানে “newline”। (Windows-এ, enter চাপলে একটি ক্যারেজ রিটার্ন এবং একটি নতুন লাইন আসে, \r\n।) trim মেথডটি \n বা \r\n সরিয়ে দেয়, ফলে শুধুমাত্র 5 থাকে।
স্ট্রিং-এর উপর parse মেথড একটি স্ট্রিংকে অন্য টাইপে রূপান্তর করে। এখানে, আমরা এটিকে একটি স্ট্রিং থেকে একটি সংখ্যায় রূপান্তর করতে ব্যবহার করি। let guess: u32 ব্যবহার করে আমাদের Rust-কে জানাতে হবে যে আমরা ঠিক কোন সংখ্যা টাইপ চাই। guess-এর পরে কোলন (:) Rust-কে বলে যে আমরা ভেরিয়েবলের টাইপ অ্যানোটেট করব। Rust-এর কয়েকটি বিল্ট-ইন সংখ্যা টাইপ রয়েছে; এখানে দেখানো u32 হল একটি আনসাইনড, 32-বিট ইন্টিজার। এটি একটি ছোট ধনাত্মক সংখ্যার জন্য একটি ভালো ডিফল্ট পছন্দ। আপনি চ্যাপ্টার ৩-এ অন্যান্য সংখ্যা টাইপ সম্পর্কে জানতে পারবেন।
অতিরিক্তভাবে, এই উদাহরণ প্রোগ্রামে u32 অ্যানোটেশন এবং secret_number-এর সাথে তুলনা করার অর্থ হল Rust অনুমান করবে যে secret_number-ও একটি u32 হওয়া উচিত। তাই এখন তুলনাটি একই টাইপের দুটি মানের মধ্যে হবে!
parse মেথডটি কেবল সেইসব ক্যারেক্টারের উপর কাজ করবে যেগুলোকে যুক্তিযুক্তভাবে সংখ্যায় রূপান্তর করা যেতে পারে এবং তাই সহজেই এরর ঘটাতে পারে। উদাহরণস্বরূপ, যদি স্ট্রিংটিতে A👍% থাকে, তাহলে এটিকে একটি সংখ্যায় রূপান্তর করার কোনো উপায় থাকবে না। যেহেতু এটি ব্যর্থ হতে পারে, তাই parse মেথডটি একটি Result টাইপ রিটার্ন করে, অনেকটা read_line মেথডের মতোই (আগে “Result দিয়ে সম্ভাব্য ত্রুটি সামলানো”)-তে আলোচনা করা হয়েছে)। আমরা এই Result-টিকে আবার expect মেথড ব্যবহার করে একইভাবে পরিচালনা করব। যদি parse একটি Err Result ভেরিয়েন্ট রিটার্ন করে কারণ এটি স্ট্রিং থেকে একটি সংখ্যা তৈরি করতে পারেনি, তাহলে expect কলটি গেমটিকে ক্র্যাশ করাবে এবং আমরা যে মেসেজটি দেব সেটি প্রিন্ট করবে। যদি parse সফলভাবে স্ট্রিংটিকে একটি সংখ্যায় রূপান্তর করতে পারে, তাহলে এটি Result-এর Ok ভেরিয়েন্ট রিটার্ন করবে এবং expect Ok মান থেকে আমাদের কাঙ্ক্ষিত সংখ্যাটি রিটার্ন করবে।
চলুন এবার প্রোগ্রামটি চালানো যাক:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 58
Please input your guess.
76
You guessed: 76
Too big!
দারুণ! অনুমানের আগে স্পেস যোগ করা হলেও, প্রোগ্রামটি বুঝতে পেরেছে যে ব্যবহারকারী 76 অনুমান করেছে। বিভিন্ন ধরনের ইনপুট দিয়ে ভিন্ন আচরণ যাচাই করতে কয়েকবার প্রোগ্রামটি চালান: সঠিকভাবে সংখ্যাটি অনুমান করুন, খুব বেশি একটি সংখ্যা অনুমান করুন এবং খুব কম একটি সংখ্যা অনুমান করুন।
আমাদের গেমের বেশিরভাগ অংশ এখন কাজ করছে, কিন্তু ব্যবহারকারী কেবল একটি অনুমান করতে পারে। চলুন একটি লুপ যোগ করে এটি পরিবর্তন করি!
লুপিংয়ের মাধ্যমে একাধিক অনুমানের সুযোগ (Allowing Multiple Guesses with Looping)
loop কীওয়ার্ডটি একটি অসীম লুপ তৈরি করে। ব্যবহারকারীদের সংখ্যা অনুমান করার আরও সুযোগ দিতে আমরা একটি লুপ যোগ করব:
Filename: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
}আপনি দেখতে পাচ্ছেন, আমরা অনুমান ইনপুট প্রম্পট থেকে শুরু করে সবকিছু একটি লুপের মধ্যে নিয়ে এসেছি। লুপের ভেতরের লাইনগুলোকে আরও চারটি স্পেস দিয়ে ইনডেন্ট করতে ভুলবেন না এবং আবার প্রোগ্রামটি চালান। প্রোগ্রামটি এখন চিরকালের জন্য আরেকটি অনুমানের জন্য জিজ্ঞাসা করবে, যা আসলে একটি নতুন সমস্যা তৈরি করে। মনে হচ্ছে ব্যবহারকারী গেমটি বন্ধ করতে পারবে না!
ব্যবহারকারী সবসময় কীবোর্ড শর্টকাট ctrl-c ব্যবহার করে প্রোগ্রামটি থামাতে পারে। কিন্তু এই অতৃপ্ত দৈত্য থেকে বাঁচার আরেকটি উপায় আছে, যেমনটি “অনুমানের সাথে গোপন সংখ্যার তুলনা করা”-তে parse আলোচনায় উল্লেখ করা হয়েছে: যদি ব্যবহারকারী একটি অ-সংখ্যাসূচক উত্তর প্রবেশ করান, তাহলে প্রোগ্রামটি ক্র্যাশ করবে। ব্যবহারকারীকে গেম বন্ধ করার অনুমতি দেওয়ার জন্য আমরা সেটি কাজে লাগাতে পারি, যেমনটি এখানে দেখানো হয়েছে:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 59
Please input your guess.
45
You guessed: 45
Too small!
Please input your guess.
60
You guessed: 60
Too big!
Please input your guess.
59
You guessed: 59
You win!
Please input your guess.
quit
thread 'main' panicked at src/main.rs:28:47:
Please type a number!: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
quit টাইপ করলে গেমটি বন্ধ হয়ে যাবে, কিন্তু আপনি যেমন লক্ষ্য করবেন, অন্য কোনো অ-সংখ্যাসূচক ইনপুট দিলেও এটি বন্ধ হয়ে যাবে। অন্তত বলতে গেলে, এটি আদর্শ নয়; আমরা চাই যে গেমটি তখনই বন্ধ হোক যখন সঠিক সংখ্যাটি অনুমান করা হয়।
সঠিক অনুমানের পরে বন্ধ হওয়া (Quitting After a Correct Guess)
আসুন, একটি break স্টেটমেন্ট যোগ করে গেমটি এমনভাবে প্রোগ্রাম করি যাতে ব্যবহারকারী জিতলে বন্ধ হয়ে যায়:
Filename: src/main.rs
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}You win!-এর পরে break লাইনটি যোগ করলে, ব্যবহারকারী যখন গোপন সংখ্যাটি সঠিকভাবে অনুমান করে, তখন প্রোগ্রামটি লুপ থেকে বেরিয়ে আসে। লুপ থেকে বেরিয়ে আসার অর্থ প্রোগ্রাম থেকেও বেরিয়ে আসা, কারণ লুপটি হল main-এর শেষ অংশ।
অবৈধ ইনপুট হ্যান্ডেল করা (Handling Invalid Input)
গেমের আচরণকে আরও উন্নত করতে, ব্যবহারকারী যখন একটি অ-সংখ্যা ইনপুট দেয় তখন প্রোগ্রামটি ক্র্যাশ করার পরিবর্তে, আসুন গেমটিকে অ-সংখ্যা উপেক্ষা করতে দিই যাতে ব্যবহারকারী অনুমান চালিয়ে যেতে পারে। আমরা guess-কে String থেকে u32-তে রূপান্তর করা লাইনটি পরিবর্তন করে তা করতে পারি, যেমনটি Listing 2-5-এ দেখানো হয়েছে।
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}এররে ক্র্যাশ করা থেকে এরর হ্যান্ডেলিংয়ে যেতে আমরা একটি expect কল থেকে একটি match এক্সপ্রেশনে পরিবর্তন করি। মনে রাখবেন যে parse একটি Result টাইপ রিটার্ন করে এবং Result হল একটি enum যার ভেরিয়েন্টগুলো হল Ok এবং Err। আমরা এখানে একটি match এক্সপ্রেশন ব্যবহার করছি, যেমনটি আমরা cmp মেথডের Ordering ফলাফলের সাথে করেছিলাম।
যদি parse সফলভাবে স্ট্রিংটিকে একটি সংখ্যায় পরিণত করতে সক্ষম হয়, তাহলে এটি একটি Ok মান রিটার্ন করবে, যেটিতে প্রাপ্ত সংখ্যাটি থাকবে। সেই Ok মানটি প্রথম আর্মের প্যাটার্নের সাথে মিলবে, এবং match এক্সপ্রেশনটি কেবল parse যে num মানটি তৈরি করেছে এবং Ok মানের ভিতরে রেখেছে সেটি রিটার্ন করবে। সেই সংখ্যাটি যেখানে আমাদের দরকার, অর্থাৎ আমরা যে নতুন guess ভেরিয়েবল তৈরি করছি, সেখানেই চলে যাবে।
যদি parse স্ট্রিংটিকে একটি সংখ্যায় পরিণত করতে সক্ষম না হয়, তাহলে এটি একটি Err মান রিটার্ন করবে, যেটিতে এরর সম্পর্কে আরও তথ্য থাকবে। Err মানটি প্রথম match আর্মের Ok(num) প্যাটার্নের সাথে মেলে না, তবে এটি দ্বিতীয় আর্মের Err(_) প্যাটার্নের সাথে মেলে। আন্ডারস্কোর, _, হল একটি ক্যাচ-অল মান; এই উদাহরণে, আমরা বলছি যে আমরা সমস্ত Err মানের সাথে মেলাতে চাই, সেগুলোর ভিতরে যাই তথ্য থাকুক না কেন। তাই প্রোগ্রামটি দ্বিতীয় আর্মের কোড, continue, চালাবে, যেটি প্রোগ্রামটিকে loop-এর পরবর্তী পুনরাবৃত্তিতে যেতে এবং আরেকটি অনুমানের জন্য জিজ্ঞাসা করতে বলে। সুতরাং, কার্যকরভাবে, প্রোগ্রামটি parse-এর সম্মুখীন হতে পারে এমন সমস্ত এরর উপেক্ষা করে!
এবার প্রোগ্রামের সবকিছু প্রত্যাশিতভাবে কাজ করা উচিত। চলুন চেষ্টা করি:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 61
Please input your guess.
10
You guessed: 10
Too small!
Please input your guess.
99
You guessed: 99
Too big!
Please input your guess.
foo
Please input your guess.
61
You guessed: 61
You win!
দারুণ! একটি ছোট্ট ফাইনাল টুইক দিয়ে, আমরা অনুমানের গেমটি শেষ করব। মনে রাখবেন যে প্রোগ্রামটি এখনও গোপন সংখ্যাটি প্রিন্ট করছে। সেটি পরীক্ষার জন্য ভাল কাজ করেছিল, কিন্তু এটি গেমটিকে নষ্ট করে দেয়। চলুন println!-টি মুছে ফেলি যেটি গোপন সংখ্যাটি আউটপুট করে। Listing 2-6 চূড়ান্ত কোডটি দেখায়।
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}এই পর্যায়ে, আপনি সফলভাবে অনুমানের গেমটি তৈরি করেছেন। অভিনন্দন!
সারসংক্ষেপ (Summary)
এই প্রোজেক্টটি আপনাকে অনেকগুলো নতুন Rust কনসেপ্টের সাথে পরিচয় করিয়ে দেওয়ার একটি হ্যান্ডস-অন উপায় ছিল: let, match, ফাংশন, এক্সটার্নাল ক্রেটগুলোর ব্যবহার এবং আরও অনেক কিছু। পরের কয়েকটি চ্যাপ্টারে, আপনি এই কনসেপ্টগুলো সম্পর্কে আরও বিস্তারিত জানতে পারবেন। চ্যাপ্টার ৩-এ বেশিরভাগ প্রোগ্রামিং ল্যাঙ্গুয়েজের কনসেপ্টগুলো, যেমন ভেরিয়েবল, ডেটা টাইপ এবং ফাংশন কভার করে এবং সেগুলো Rust-এ কীভাবে ব্যবহার করতে হয় তা দেখায়। চ্যাপ্টার ৪-এ ওনারশিপ (ownership) নিয়ে আলোচনা করা হয়েছে, একটি ফিচার যা Rust-কে অন্যান্য ল্যাঙ্গুয়েজ থেকে আলাদা করে। চ্যাপ্টার ৫-এ স্ট্রাক্ট এবং মেথড সিনট্যাক্স নিয়ে আলোচনা করা হয়েছে এবং চ্যাপ্টার ৬ ব্যাখ্যা করে যে কীভাবে enum কাজ করে।
সাধারণ প্রোগ্রামিং ধারণা (Common Programming Concepts)
এই চ্যাপ্টারে প্রায় প্রতিটি প্রোগ্রামিং ল্যাঙ্গুয়েজে ব্যবহৃত ধারণাগুলো এবং সেগুলো Rust-এ কীভাবে কাজ করে তা আলোচনা করা হয়েছে। অনেক প্রোগ্রামিং ল্যাঙ্গুয়েজের মূলে অনেক মিল রয়েছে। এই চ্যাপ্টারে উপস্থাপিত ধারণাগুলোর কোনোটিই Rust-এর জন্য অনন্য নয়, তবে আমরা সেগুলোকে Rust-এর পরিপ্রেক্ষিতে আলোচনা করব এবং এই ধারণাগুলো ব্যবহারের নিয়মগুলো ব্যাখ্যা করব।
বিশেষ করে, আপনি ভেরিয়েবল, বেসিক টাইপ, ফাংশন, কমেন্ট এবং কন্ট্রোল ফ্লো সম্পর্কে জানতে পারবেন। এই ভিত্তিগুলো প্রতিটি Rust প্রোগ্রামে থাকবে এবং এগুলো আগেভাগে শিখে নিলে আপনার শুরুটা অনেক শক্ত হবে।
কীওয়ার্ড (Keywords)
Rust ল্যাঙ্গুয়েজে কিছু কীওয়ার্ড (keywords) রয়েছে, যেগুলো শুধুমাত্র ল্যাঙ্গুয়েজের ব্যবহারের জন্য সংরক্ষিত, অনেকটা অন্যান্য ল্যাঙ্গুয়েজের মতোই। মনে রাখবেন যে আপনি এই শব্দগুলোকে ভেরিয়েবল বা ফাংশনের নাম হিসেবে ব্যবহার করতে পারবেন না। বেশিরভাগ কীওয়ার্ডের বিশেষ অর্থ রয়েছে এবং আপনি সেগুলোকে আপনার Rust প্রোগ্রামগুলোতে বিভিন্ন কাজ করার জন্য ব্যবহার করবেন; কয়েকটির সাথে বর্তমানে কোনো কার্যকারিতা যুক্ত নেই, তবে ভবিষ্যতে Rust-এ যোগ করা হতে পারে এমন কার্যকারিতার জন্য সংরক্ষিত রাখা হয়েছে। আপনি Appendix A-তে কীওয়ার্ডগুলোর একটি তালিকা খুঁজে পেতে পারেন।
ভেরিয়েবল এবং মিউটেবিলিটি (Variables and Mutability)
“ভেরিয়েবল ব্যবহার করে মান সংরক্ষণ করা” বিভাগে যেমন উল্লেখ করা হয়েছে, ডিফল্টভাবে ভেরিয়েবলগুলো ইমিউটেবল (immutable) হয়। Rust আপনাকে যে নিরাপত্তা এবং সহজে কনকারেন্সি (concurrency) ব্যবহারের সুবিধা দেয়, সেটির সুবিধা নিতে আপনার কোড লেখার ক্ষেত্রে এটি Rust-এর দেওয়া অনেকগুলো কৌশলের মধ্যে একটি। তবে, আপনার কাছে এখনও আপনার ভেরিয়েবলগুলোকে মিউটেবল (mutable) করার অপশন রয়েছে। চলুন, অনুসন্ধান করি কেন Rust আপনাকে ইমিউটেবিলিটিকে প্রাধান্য দিতে উৎসাহিত করে এবং কেন আপনি কখনও কখনও এর থেকে বেরিয়ে আসতে চাইতে পারেন।
যখন একটি ভেরিয়েবল ইমিউটেবল হয়, তখন একটি মান একটি নামের সাথে বাইন্ড হয়ে গেলে, আপনি সেই মান পরিবর্তন করতে পারবেন না। এটি বোঝানোর জন্য, cargo new variables ব্যবহার করে আপনার projects ডিরেক্টরিতে variables নামে একটি নতুন প্রোজেক্ট তৈরি করুন।
তারপর, আপনার নতুন variables ডিরেক্টরিতে, src/main.rs খুলুন এবং এর কোডটি নিচের কোড দিয়ে প্রতিস্থাপন করুন, যেটি এখনই কম্পাইল হবে না:
Filename: src/main.rs
fn main() {
let x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}cargo run ব্যবহার করে প্রোগ্রামটি সংরক্ষণ করুন এবং চালান। আপনি এই আউটপুটে দেখানো ইমিউটেবিলিটি এরর সম্পর্কিত একটি এরর মেসেজ পাবেন:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` (bin "variables") due to 1 previous error
এই উদাহরণটি দেখায় যে কম্পাইলার কীভাবে আপনার প্রোগ্রামের এররগুলো খুঁজে পেতে সহায়তা করে। কম্পাইলার এররগুলো বিরক্তিকর হতে পারে, কিন্তু আসলে এগুলো কেবল বোঝায় যে আপনার প্রোগ্রামটি আপনি যা করতে চান তা এখনও নিরাপদে করছে না; এগুলোর মানে এই নয় যে আপনি ভালো প্রোগ্রামার নন! অভিজ্ঞ Rustacean-রাও কম্পাইলার এরর পান।
আপনি cannot assign twice to immutable variable `x` এরর মেসেজটি পেয়েছেন কারণ আপনি ইমিউটেবল x ভেরিয়েবলে দ্বিতীয়বার মান অ্যাসাইন করার চেষ্টা করেছিলেন।
আমরা যখন এমন একটি মান পরিবর্তন করার চেষ্টা করি যা ইমিউটেবল হিসাবে নির্ধারিত, তখন কম্পাইল-টাইম এরর পাওয়া গুরুত্বপূর্ণ, কারণ এই পরিস্থিতি বাগের কারণ হতে পারে। যদি আমাদের কোডের একটি অংশ এই ধারণার উপর কাজ করে যে একটি মান কখনই পরিবর্তন হবে না এবং আমাদের কোডের অন্য অংশ সেই মান পরিবর্তন করে, তাহলে এটি সম্ভব যে কোডের প্রথম অংশটি যেভাবে ডিজাইন করা হয়েছিল সেভাবে কাজ করবে না। এই ধরনের বাগের কারণ পরে খুঁজে বের করা কঠিন হতে পারে, বিশেষ করে যখন কোডের দ্বিতীয় অংশটি শুধুমাত্র কখনও কখনও মান পরিবর্তন করে। Rust কম্পাইলার গ্যারান্টি দেয় যে, যখন আপনি বলেন যে একটি মান পরিবর্তন হবে না, তখন সেটি সত্যিই পরিবর্তন হবে না, তাই আপনাকে নিজে থেকে সেটি ট্র্যাক রাখতে হবে না। এইভাবে আপনার কোড বোঝা সহজ হয়।
কিন্তু মিউটেবিলিটি খুব দরকারী হতে পারে এবং কোড লেখাকে আরও সুবিধাজনক করে তুলতে পারে। যদিও ভেরিয়েবলগুলো ডিফল্টরূপে ইমিউটেবল হয়, আপনি চ্যাপ্টার ২-এ যেমন করেছেন, তেমন ভেরিয়েবলের নামের সামনে mut যোগ করে সেগুলোকে মিউটেবল করতে পারেন। mut যোগ করা কোডের ভবিষ্যত পাঠকদের কাছে অভিপ্রায় প্রকাশ করে, এটি নির্দেশ করে যে কোডের অন্যান্য অংশগুলো এই ভেরিয়েবলের মান পরিবর্তন করবে।
উদাহরণস্বরূপ, চলুন src/main.rs পরিবর্তন করে নিচের মতো করি:
Filename: src/main.rs
fn main() { let mut x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); }
আমরা যখন এখন প্রোগ্রামটি চালাই, তখন আমরা এটি পাই:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
The value of x is: 5
The value of x is: 6
mut ব্যবহার করা হলে আমরা x-এর সাথে বাইন্ড করা মান 5 থেকে 6-এ পরিবর্তন করার অনুমতি পাই। শেষ পর্যন্ত, মিউটেবিলিটি ব্যবহার করবেন কিনা তা আপনার উপর নির্ভর করে এবং সেই নির্দিষ্ট পরিস্থিতিতে কোনটি সবচেয়ে পরিষ্কার বলে আপনি মনে করেন তার উপর নির্ভর করে।
কনস্ট্যান্ট (Constants)
ইমিউটেবল ভেরিয়েবলের মতো, কনস্ট্যান্টগুলোও (constants) এমন মান যেগুলো একটি নামের সাথে বাইন্ড করা থাকে এবং পরিবর্তন করার অনুমতি নেই, তবে কনস্ট্যান্ট এবং ভেরিয়েবলের মধ্যে কয়েকটি পার্থক্য রয়েছে।
প্রথমত, আপনি কনস্ট্যান্টগুলোর সাথে mut ব্যবহার করতে পারবেন না। কনস্ট্যান্টগুলো শুধুমাত্র ডিফল্টভাবে ইমিউটেবল নয়—এগুলো সর্বদাই ইমিউটেবল। আপনি let কীওয়ার্ডের পরিবর্তে const কীওয়ার্ড ব্যবহার করে কনস্ট্যান্ট ঘোষণা করেন এবং মানের টাইপটি অবশ্যই অ্যানোটেট করতে হবে। আমরা পরের বিভাগে, “ডেটা টাইপস”-এ টাইপ এবং টাইপ অ্যানোটেশন নিয়ে আলোচনা করব, তাই এখনই বিস্তারিত বিবরণ নিয়ে চিন্তা করবেন না। শুধু জেনে রাখুন যে আপনাকে সর্বদাই টাইপ অ্যানোটেট করতে হবে।
কনস্ট্যান্টগুলো যেকোনো স্কোপে ঘোষণা করা যেতে পারে, গ্লোবাল স্কোপ সহ, যা সেগুলোকে এমন মানগুলোর জন্য দরকারী করে তোলে যেগুলো কোডের অনেক অংশের জানার প্রয়োজন।
শেষ পার্থক্য হল কনস্ট্যান্টগুলোকে শুধুমাত্র একটি কনস্ট্যান্ট এক্সপ্রেশনে সেট করা যেতে পারে, এমন কোনো মানের ফলাফলে নয় যা শুধুমাত্র রানটাইমে গণনা করা যেতে পারে।
এখানে একটি কনস্ট্যান্ট ঘোষণার উদাহরণ দেওয়া হল:
#![allow(unused)] fn main() { const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3; }
কনস্ট্যান্টের নাম হল THREE_HOURS_IN_SECONDS এবং এর মান 60 (এক মিনিটের সেকেন্ড সংখ্যা) গুণ 60 (এক ঘন্টার মিনিটের সংখ্যা) গুণ 3 (এই প্রোগ্রামে আমরা যত ঘন্টা গণনা করতে চাই) এর ফলাফলে সেট করা হয়েছে। কনস্ট্যান্টগুলোর জন্য Rust-এর নামকরণের নিয়ম হল শব্দগুলোর মধ্যে আন্ডারস্কোর সহ সমস্ত আপারকেস ব্যবহার করা। কম্পাইলার কম্পাইল টাইমে সীমিত সংখ্যক অপারেশন মূল্যায়ন করতে সক্ষম, যা আমাদের এই কনস্ট্যান্টটিকে 10,800 মানে সেট করার পরিবর্তে, এই মানটিকে এমনভাবে লিখতে দেয় যা বোঝা এবং যাচাই করা সহজ। কনস্ট্যান্ট ঘোষণা করার সময় কোন অপারেশনগুলো ব্যবহার করা যেতে পারে সে সম্পর্কে আরও তথ্যের জন্য Rust রেফারেন্সের কনস্ট্যান্ট মূল্যায়ন বিভাগটি দেখুন।
কনস্ট্যান্টগুলো যে স্কোপে ঘোষণা করা হয়েছে, তার মধ্যে একটি প্রোগ্রাম চলার পুরো সময়ের জন্য বৈধ। এই বৈশিষ্ট্যটি কনস্ট্যান্টগুলোকে আপনার অ্যাপ্লিকেশন ডোমেইনের এমন মানগুলোর জন্য দরকারী করে তোলে যেগুলো প্রোগ্রামের একাধিক অংশের জানার প্রয়োজন হতে পারে, যেমন একটি গেমের কোনো খেলোয়াড়কে সর্বাধিক যত পয়েন্ট অর্জন করার অনুমতি দেওয়া হয়েছে, বা আলোর গতি।
আপনার প্রোগ্রাম জুড়ে ব্যবহৃত হার্ডকোডেড মানগুলোকে কনস্ট্যান্ট হিসেবে নামকরণ করা কোডের ভবিষ্যত রক্ষণাবেক্ষণকারীদের কাছে সেই মানের অর্থ বোঝানোর ক্ষেত্রে দরকারী। ভবিষ্যতে যদি হার্ডকোডেড মান পরিবর্তন করার প্রয়োজন হয় তবে আপনার কোডে শুধুমাত্র একটি জায়গায় পরিবর্তন করতে হবে, এটিও সহায়ক।
শ্যাডোয়িং (Shadowing)
আপনি যেমন চ্যাপ্টার ২-তে অনুমান করার গেম টিউটোরিয়ালে দেখেছেন, আপনি আগের ভেরিয়েবলের মতো একই নামে একটি নতুন ভেরিয়েবল ঘোষণা করতে পারেন। Rustacean-রা বলে যে প্রথম ভেরিয়েবলটি দ্বিতীয়টি দ্বারা শ্যাডো (shadow) হয়েছে, যার অর্থ হল আপনি যখন ভেরিয়েবলের নামটি ব্যবহার করবেন তখন কম্পাইলার দ্বিতীয় ভেরিয়েবলটি দেখবে। কার্যত, দ্বিতীয় ভেরিয়েবলটি প্রথমটিকে ছাপিয়ে যায়, ভেরিয়েবলের নামের যেকোনো ব্যবহার নিজের দিকে নিয়ে যায় যতক্ষণ না এটি নিজে শ্যাডো হয় বা স্কোপ শেষ হয়। আমরা একই ভেরিয়েবলের নাম ব্যবহার করে এবং let কীওয়ার্ডের ব্যবহার পুনরাবৃত্তি করে একটি ভেরিয়েবলকে শ্যাডো করতে পারি, এইভাবে:
Filename: src/main.rs
fn main() { let x = 5; let x = x + 1; { let x = x * 2; println!("The value of x in the inner scope is: {x}"); } println!("The value of x is: {x}"); }
এই প্রোগ্রামটি প্রথমে x-কে 5 মানের সাথে বাইন্ড করে। তারপর এটি let x = পুনরাবৃত্তি করে একটি নতুন ভেরিয়েবল x তৈরি করে, আসল মান নিয়ে এবং 1 যোগ করে, তাই x-এর মান তখন 6 হয়। তারপর, কার্লি ব্র্যাকেট দিয়ে তৈরি একটি অভ্যন্তরীণ স্কোপের মধ্যে, তৃতীয় let স্টেটমেন্টটিও x-কে শ্যাডো করে এবং একটি নতুন ভেরিয়েবল তৈরি করে, আগের মানকে 2 দিয়ে গুণ করে x-কে 12 মান দেয়। যখন সেই স্কোপটি শেষ হয়ে যায়, তখন অভ্যন্তরীণ শ্যাডোয়িং শেষ হয়ে যায় এবং x আবার 6 হয়ে যায়। যখন আমরা এই প্রোগ্রামটি চালাই, তখন এটি নিম্নলিখিত আউটপুট দেবে:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
The value of x in the inner scope is: 12
The value of x is: 6
শ্যাডোয়িং একটি ভেরিয়েবলকে mut হিসাবে চিহ্নিত করার চেয়ে আলাদা, কারণ let কীওয়ার্ড ব্যবহার না করে আমরা যদি ভুলবশত এই ভেরিয়েবলটিতে পুনরায় অ্যাসাইন করার চেষ্টা করি তবে আমরা একটি কম্পাইল-টাইম এরর পাব। let ব্যবহার করে, আমরা একটি মানের উপর কয়েকটি রূপান্তর করতে পারি, কিন্তু সেই রূপান্তরগুলো সম্পন্ন হওয়ার পরে ভেরিয়েবলটি ইমিউটেবল থাকবে।
mut এবং শ্যাডোয়িংয়ের মধ্যে আরেকটি পার্থক্য হল, যেহেতু আমরা যখন আবার let কীওয়ার্ড ব্যবহার করি তখন কার্যকরভাবে একটি নতুন ভেরিয়েবল তৈরি করি, তাই আমরা মানের টাইপ পরিবর্তন করতে পারি কিন্তু একই নাম পুনরায় ব্যবহার করতে পারি। উদাহরণস্বরূপ, ধরা যাক আমাদের প্রোগ্রাম একজন ব্যবহারকারীকে কিছু টেক্সটের মধ্যে কতগুলো স্পেস চায় তা স্পেস ক্যারেক্টার ইনপুট করে দেখাতে বলে এবং তারপর আমরা সেই ইনপুটটিকে একটি সংখ্যা হিসাবে সংরক্ষণ করতে চাই:
fn main() { let spaces = " "; let spaces = spaces.len(); }
প্রথম spaces ভেরিয়েবলটি হল একটি স্ট্রিং টাইপ এবং দ্বিতীয় spaces ভেরিয়েবলটি হল একটি সংখ্যা টাইপ। এইভাবে শ্যাডোয়িং আমাদেরকে spaces_str এবং spaces_num-এর মতো আলাদা নাম নিয়ে আসার ঝামেলা থেকে বাঁচায়; পরিবর্তে, আমরা সহজ spaces নামটি পুনরায় ব্যবহার করতে পারি। তবে, যদি আমরা এর জন্য mut ব্যবহার করার চেষ্টা করি, যেমনটি এখানে দেখানো হয়েছে, তাহলে আমরা একটি কম্পাইল-টাইম এরর পাব:
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}এরর বলছে যে আমাদের একটি ভেরিয়েবলের টাইপ মিউটেট করার অনুমতি নেই:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut spaces = " ";
| ----- expected due to this value
3 | spaces = spaces.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` (bin "variables") due to 1 previous error
এখন যেহেতু আমরা অনুসন্ধান করেছি যে ভেরিয়েবলগুলো কীভাবে কাজ করে, আসুন তারা যে আরও ডেটা টাইপ রাখতে পারে সেগুলোর দিকে তাকাই।
ডেটা টাইপ (Data Types)
Rust-এর প্রতিটি মানের একটি নির্দিষ্ট ডেটা টাইপ রয়েছে, যা Rust-কে জানায় যে কী ধরনের ডেটা নির্দিষ্ট করা হচ্ছে, যাতে এটি জানতে পারে যে সেই ডেটা নিয়ে কীভাবে কাজ করতে হবে। আমরা দুটি ডেটা টাইপ সাবসেট দেখব: স্কেলার (scalar) এবং কম্পাউন্ড (compound)।
মনে রাখবেন যে Rust হল একটি স্ট্যাটিকালি টাইপড (statically typed) ল্যাঙ্গুয়েজ, যার মানে হল কম্পাইল করার সময় এটিকে সমস্ত ভেরিয়েবলের টাইপ জানতে হবে। কম্পাইলার সাধারণত মান এবং আমরা কীভাবে এটি ব্যবহার করি তার উপর ভিত্তি করে আমরা কোন টাইপ ব্যবহার করতে চাই তা অনুমান করতে পারে। যেসব ক্ষেত্রে অনেকগুলো টাইপ সম্ভব, যেমন আমরা যখন চ্যাপ্টার ২-এর “অনুমানের সাথে গোপন সংখ্যার তুলনা করা” বিভাগে parse ব্যবহার করে একটি String-কে সাংখ্যিক টাইপে রূপান্তর করেছি, তখন আমাদের অবশ্যই একটি টাইপ অ্যানোটেশন যোগ করতে হবে, এইভাবে:
#![allow(unused)] fn main() { let guess: u32 = "42".parse().expect("সংখ্যা নয়!"); }
আমরা যদি উপরের কোডে দেখানো : u32 টাইপ অ্যানোটেশন যোগ না করি, তাহলে Rust নিম্নলিখিত এররটি প্রদর্শন করবে, যার মানে হল কম্পাইলারের আমাদের কাছ থেকে আরও তথ্য প্রয়োজন যাতে আমরা কোন টাইপ ব্যবহার করতে চাই তা জানা যায়:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0284]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `guess` an explicit type
|
2 | let guess: /* Type */ = "42".parse().expect("Not a number!");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `no_type_annotations` (bin "no_type_annotations") due to 1 previous error
আপনি অন্যান্য ডেটা টাইপের জন্য ভিন্ন টাইপ অ্যানোটেশন দেখতে পাবেন।
স্কেলার টাইপ (Scalar Types)
একটি স্কেলার টাইপ একটি একক মান উপস্থাপন করে। Rust-এ চারটি প্রাথমিক স্কেলার টাইপ রয়েছে: ইন্টিজার (integers), ফ্লোটিং-পয়েন্ট সংখ্যা (floating-point numbers), বুলিয়ান (Booleans) এবং ক্যারেক্টার (characters)। আপনি হয়তো এগুলো অন্যান্য প্রোগ্রামিং ল্যাঙ্গুয়েজ থেকে চিনতে পারেন। চলুন, দেখি এগুলো Rust-এ কীভাবে কাজ করে।
ইন্টিজার টাইপ (Integer Types)
একটি ইন্টিজার হল ভগ্নাংশ ছাড়া একটি সংখ্যা। আমরা চ্যাপ্টার ২-এ একটি ইন্টিজার টাইপ ব্যবহার করেছি, u32 টাইপ। এই টাইপ ডিক্লারেশন নির্দেশ করে যে এর সাথে সম্পর্কিত মানটি একটি আনসাইনড ইন্টিজার হওয়া উচিত (সাইনড ইন্টিজার টাইপগুলো u-এর পরিবর্তে i দিয়ে শুরু হয়) যা 32 বিট জায়গা নেয়। টেবিল 3-1 Rust-এর বিল্ট-ইন ইন্টিজার টাইপগুলো দেখায়। আমরা একটি ইন্টিজার মানের টাইপ ঘোষণা করতে এই ভেরিয়েন্টগুলোর যেকোনো একটি ব্যবহার করতে পারি।
Table 3-1: Integer Types in Rust
| Length | Signed | Unsigned |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
প্রতিটি ভেরিয়েন্ট সাইনড বা আনসাইনড হতে পারে এবং একটি স্পষ্ট আকার রয়েছে। সাইনড এবং আনসাইনড বলতে বোঝায় যে সংখ্যাটি ঋণাত্মক হতে পারে কিনা—অন্য কথায়, সংখ্যাটির সাথে একটি চিহ্ন থাকা দরকার কিনা (সাইনড) অথবা এটি সর্বদা ধনাত্মক হবে কিনা এবং তাই চিহ্ন ছাড়াই উপস্থাপন করা যেতে পারে কিনা (আনসাইনড)। এটি কাগজে সংখ্যা লেখার মতো: যখন চিহ্নটি গুরুত্বপূর্ণ, তখন একটি সংখ্যা প্লাস চিহ্ন বা মাইনাস চিহ্ন দিয়ে দেখানো হয়; তবে, যখন এটি ধনাত্মক বলে ধরে নেওয়া নিরাপদ, তখন এটি কোনো চিহ্ন ছাড়াই দেখানো হয়। সাইনড সংখ্যাগুলো টু’স কমপ্লিমেন্ট উপস্থাপনা ব্যবহার করে সংরক্ষণ করা হয়।
প্রতিটি সাইনড ভেরিয়েন্ট −(2n − 1) থেকে 2n − 1 − 1 পর্যন্ত সংখ্যা সংরক্ষণ করতে পারে, যেখানে n হল সেই ভেরিয়েন্টটি ব্যবহার করা বিটের সংখ্যা। সুতরাং একটি i8 −(27) থেকে 27 − 1 পর্যন্ত সংখ্যা সংরক্ষণ করতে পারে, যা −128 থেকে 127 এর সমান। আনসাইনড ভেরিয়েন্টগুলো 0 থেকে 2n − 1 পর্যন্ত সংখ্যা সংরক্ষণ করতে পারে, তাই একটি u8 0 থেকে 28 − 1 পর্যন্ত সংখ্যা সংরক্ষণ করতে পারে, যা 0 থেকে 255 এর সমান।
অতিরিক্তভাবে, isize এবং usize টাইপগুলো আপনার প্রোগ্রামটি যে কম্পিউটারের আর্কিটেকচারের উপর চলছে তার উপর নির্ভর করে, যা টেবিলে “arch” হিসাবে চিহ্নিত করা হয়েছে: আপনি যদি 64-বিট আর্কিটেকচারে থাকেন তবে 64 বিট এবং আপনি যদি 32-বিট আর্কিটেকচারে থাকেন তবে 32 বিট।
আপনি টেবিল 3-2-তে দেখানো যেকোনো ফর্ম্যাটে ইন্টিজার লিটারেল লিখতে পারেন। মনে রাখবেন যে সংখ্যা লিটারেলগুলো, যেগুলো একাধিক সাংখ্যিক টাইপ হতে পারে, টাইপ নির্ধারণ করতে 57u8-এর মতো একটি টাইপ সাফিক্স ব্যবহার করার অনুমতি দেয়। সংখ্যা লিটারেলগুলো সংখ্যাটিকে সহজে পড়ার জন্য _ কে ভিজ্যুয়াল বিভাজক হিসাবেও ব্যবহার করতে পারে, যেমন 1_000, যেটির মান 1000 নির্দিষ্ট করার মতোই হবে।
Table 3-2: Integer Literals in Rust
| Number literals | Example |
|---|---|
| Decimal | 98_222 |
| Hex | 0xff |
| Octal | 0o77 |
| Binary | 0b1111_0000 |
Byte (u8 only) | b'A' |
তাহলে আপনি কীভাবে জানবেন কোন ধরনের ইন্টিজার ব্যবহার করতে হবে? আপনি যদি নিশ্চিত না হন, তাহলে Rust-এর ডিফল্টগুলো সাধারণত শুরু করার জন্য ভালো জায়গা: ইন্টিজার টাইপগুলো ডিফল্টভাবে i32 হয়। isize বা usize ব্যবহার করার প্রাথমিক পরিস্থিতি হল যখন কোনো ধরনের কালেকশন ইনডেক্স করা হয়।
ইন্টিজার ওভারফ্লো (Integer Overflow)
ধরা যাক আপনার কাছে
u8টাইপের একটি ভেরিয়েবল রয়েছে যা 0 থেকে 255-এর মধ্যে মান ধারণ করতে পারে। আপনি যদি সেই ভেরিয়েবলের মান সেই সীমার বাইরের কোনো মানে পরিবর্তন করার চেষ্টা করেন, যেমন 256, তাহলে ইন্টিজার ওভারফ্লো ঘটবে, যার ফলে দুটি আচরণের মধ্যে একটি হতে পারে। আপনি যখন ডিবাগ মোডে কম্পাইল করছেন, তখন Rust ইন্টিজার ওভারফ্লোর জন্য চেক অন্তর্ভুক্ত করে যা এই আচরণ ঘটলে আপনার প্রোগ্রামটিকে রানটাইমে প্যানিক (panic) ঘটায়। Rust প্যানিকিং শব্দটি ব্যবহার করে যখন একটি প্রোগ্রাম এরর-সহ প্রস্থান করে; আমরা চ্যাপ্টার ৯-এর “panic!দিয়ে পুনরুদ্ধার করা যায় না এমন এরর” বিভাগে প্যানিক নিয়ে আরও বিস্তারিত আলোচনা করব।আপনি যখন
--releaseফ্ল্যাগ দিয়ে রিলিজ মোডে কম্পাইল করছেন, তখন Rust ইন্টিজার ওভারফ্লোর জন্য চেক অন্তর্ভুক্ত করে না যা প্যানিকের কারণ হয়। পরিবর্তে, যদি ওভারফ্লো ঘটে, তাহলে Rust টু’স কমপ্লিমেন্ট র্যাপিং (two’s complement wrapping) সম্পাদন করে। সংক্ষেপে, টাইপটি যে মানগুলো ধারণ করতে পারে তার সর্বাধিক মানের চেয়ে বড় মানগুলো টাইপটি যে মানগুলো ধারণ করতে পারে তার সর্বনিম্ন মানে “র্যাপ অ্যারাউন্ড” করে।u8-এর ক্ষেত্রে, 256 মানটি 0 হয়ে যায়, 257 মানটি 1 হয়ে যায়, এবং এইভাবে চলতে থাকে। প্রোগ্রামটি প্যানিক করবে না, তবে ভেরিয়েবলের একটি মান থাকবে যা সম্ভবত আপনি যা আশা করছিলেন তা নয়। ইন্টিজার ওভারফ্লোর র্যাপিং আচরণের উপর নির্ভর করা একটি এরর হিসাবে বিবেচিত হয়।ওভারফ্লোর সম্ভাবনা স্পষ্টভাবে হ্যান্ডেল করতে, আপনি প্রিমিটিভ সাংখ্যিক টাইপগুলোর জন্য স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা এই ফ্যামিলি অফ মেথডগুলো ব্যবহার করতে পারেন:
- সমস্ত মোডে র্যাপ করার জন্য
wrapping_*মেথডগুলো ব্যবহার করুন, যেমনwrapping_add।- যদি
checked_*মেথডগুলোর সাথে ওভারফ্লো হয় তবেNoneমানটি রিটার্ন করুন।overflowing_*মেথডগুলোর সাথে মান এবং একটি বুলিয়ান রিটার্ন করুন যা নির্দেশ করে যে ওভারফ্লো হয়েছে কিনা।saturating_*মেথডগুলোর সাথে মানের সর্বনিম্ন বা সর্বোচ্চ মানগুলোতে স্যাচুরেট করুন।
ফ্লোটিং-পয়েন্ট টাইপ (Floating-Point Types)
Rust-এ ফ্লোটিং-পয়েন্ট সংখ্যার জন্য দুটি প্রিমিটিভ টাইপ রয়েছে, যেগুলি দশমিক বিন্দু সহ সংখ্যা। Rust-এর ফ্লোটিং-পয়েন্ট টাইপগুলো হল f32 এবং f64, যেগুলোর আকার যথাক্রমে 32 বিট এবং 64 বিট। ডিফল্ট টাইপ হল f64 কারণ আধুনিক CPU-গুলোতে, এটি প্রায় f32-এর মতোই দ্রুত কিন্তু আরও নির্ভুলতা দিতে সক্ষম। সমস্ত ফ্লোটিং-পয়েন্ট টাইপ সাইনড।
এখানে একটি উদাহরণ দেওয়া হল যা ফ্লোটিং-পয়েন্ট সংখ্যাগুলো অ্যাকশনে দেখায়:
Filename: src/main.rs
fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 }
ফ্লোটিং-পয়েন্ট সংখ্যাগুলো IEEE-754 স্ট্যান্ডার্ড অনুযায়ী উপস্থাপন করা হয়।
সাংখ্যিক অপারেশন (Numeric Operations)
Rust সমস্ত সংখ্যা টাইপের জন্য আপনার প্রত্যাশিত বেসিক গাণিতিক অপারেশনগুলো সমর্থন করে: যোগ, বিয়োগ, গুণ, ভাগ এবং অবশিষ্টাংশ (remainder)। ইন্টিজার বিভাজন শূন্যের দিকে নিকটতম ইন্টিজারে ছোট হয়। নিম্নলিখিত কোডটি দেখায় যে আপনি কীভাবে একটি let স্টেটমেন্টে প্রতিটি সাংখ্যিক অপারেশন ব্যবহার করবেন:
Filename: src/main.rs
fn main() { // addition let sum = 5 + 10; // subtraction let difference = 95.5 - 4.3; // multiplication let product = 4 * 30; // division let quotient = 56.7 / 32.2; let truncated = -5 / 3; // Results in -1 // remainder let remainder = 43 % 5; }
এই স্টেটমেন্টগুলোর প্রতিটি এক্সপ্রেশন একটি গাণিতিক অপারেটর ব্যবহার করে এবং একটি একক মানে মূল্যায়ন করে, যা তারপর একটি ভেরিয়েবলের সাথে বাইন্ড করা হয়। Appendix B-তে Rust যে সমস্ত অপারেটর সরবরাহ করে তার একটি তালিকা রয়েছে।
বুলিয়ান টাইপ (The Boolean Type)
বেশিরভাগ অন্যান্য প্রোগ্রামিং ল্যাঙ্গুয়েজের মতো, Rust-এ একটি বুলিয়ান টাইপের দুটি সম্ভাব্য মান রয়েছে: true এবং false। বুলিয়ানগুলোর আকার এক বাইট। Rust-এ বুলিয়ান টাইপ bool ব্যবহার করে নির্দিষ্ট করা হয়। উদাহরণস্বরূপ:
Filename: src/main.rs
fn main() { let t = true; let f: bool = false; // with explicit type annotation }
বুলিয়ান মানগুলো ব্যবহার করার প্রধান উপায় হল কন্ডিশনালের মাধ্যমে, যেমন একটি if এক্সপ্রেশন। আমরা “কন্ট্রোল ফ্লো” বিভাগে Rust-এ if এক্সপ্রেশনগুলো কীভাবে কাজ করে তা আলোচনা করব।
ক্যারেক্টার টাইপ (The Character Type)
Rust-এর char টাইপ হল ভাষার সবচেয়ে প্রিমিটিভ আলফাবেটিক টাইপ। char মান ঘোষণার কয়েকটি উদাহরণ নিচে দেওয়া হলো:
Filename: src/main.rs
fn main() { let c = 'z'; let z: char = 'ℤ'; // with explicit type annotation let heart_eyed_cat = '😻'; }
লক্ষ্য করুন যে আমরা char লিটারেলগুলোকে সিঙ্গেল কোট দিয়ে নির্দিষ্ট করি, স্ট্রিং লিটারেলগুলোর বিপরীতে, যেগুলো ডাবল কোট ব্যবহার করে। Rust-এর char টাইপের আকার চার বাইট এবং এটি একটি ইউনিকোড স্কেলার মান (Unicode Scalar Value) উপস্থাপন করে, যার মানে এটি কেবল ASCII-এর চেয়ে আরও অনেক কিছু উপস্থাপন করতে পারে। অ্যাকসেন্টেড অক্ষর; চীনা, জাপানি এবং কোরিয়ান অক্ষর; ইমোজি; এবং জিরো-উইথ স্পেস সবই Rust-এ বৈধ char মান। ইউনিকোড স্কেলার মানগুলো U+0000 থেকে U+D7FF এবং U+E000 থেকে U+10FFFF পর্যন্ত। তবে, একটি “ক্যারেক্টার” আসলে ইউনিকোডে একটি ধারণা নয়, তাই “ক্যারেক্টার” বলতে আপনি যা বোঝেন, সেটি Rust-এর char-এর সাথে নাও মিলতে পারে। আমরা চ্যাপ্টার ৮-এ “স্ট্রিং দিয়ে UTF-8 এনকোডেড টেক্সট সংরক্ষণ করা”-তে এই বিষয়টি নিয়ে বিস্তারিত আলোচনা করব।
কম্পাউন্ড টাইপ (Compound Types)
কম্পাউন্ড টাইপগুলো একাধিক মানকে একটি টাইপে গ্রুপ করতে পারে। Rust-এর দুটি প্রিমিটিভ কম্পাউন্ড টাইপ রয়েছে: টাপল (tuples) এবং অ্যারে (arrays)।
টাপল টাইপ (The Tuple Type)
একটি টাপল হল বিভিন্ন টাইপের বেশ কয়েকটি মানকে একটি কম্পাউন্ড টাইপে একত্রিত করার একটি সাধারণ উপায়। টাপলগুলোর একটি নির্দিষ্ট দৈর্ঘ্য থাকে: একবার ঘোষণা করা হলে, সেগুলোর আকার বাড়তে বা কমতে পারে না।
আমরা প্যারেনথেসিসের মধ্যে কমা-দ্বারা-বিচ্ছিন্ন মানগুলোর একটি তালিকা লিখে একটি টাপল তৈরি করি। টাপলের প্রতিটি অবস্থানের একটি টাইপ রয়েছে এবং টাপলের বিভিন্ন মানের টাইপগুলো একই হতে হবে না। আমরা এই উদাহরণে ঐচ্ছিক টাইপ অ্যানোটেশন যোগ করেছি:
Filename: src/main.rs
fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); }
ভেরিয়েবল tup সম্পূর্ণ টাপলের সাথে বাইন্ড করে, কারণ একটি টাপলকে একটি একক কম্পাউন্ড উপাদান হিসাবে বিবেচনা করা হয়। টাপল থেকে தனி মানগুলো পেতে, আমরা প্যাটার্ন ম্যাচিং ব্যবহার করে একটি টাপল মানকে ডিস্ট্রাকচার করতে পারি, এইভাবে:
Filename: src/main.rs
fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; println!("The value of y is: {y}"); }
এই প্রোগ্রামটি প্রথমে একটি টাপল তৈরি করে এবং এটিকে tup ভেরিয়েবলের সাথে বাইন্ড করে। তারপর এটি let-এর সাথে একটি প্যাটার্ন ব্যবহার করে tup-কে তিনটি আলাদা ভেরিয়েবল, x, y এবং z-এ পরিণত করে। এটিকে ডিস্ট্রাকচারিং বলা হয়, কারণ এটি একক টাপলকে তিনটি ভাগে ভেঙে দেয়। অবশেষে, প্রোগ্রামটি y-এর মান প্রিন্ট করে, যেটি হল 6.4।
আমরা একটি পিরিয়ড (.) ব্যবহার করে সরাসরি একটি টাপল এলিমেন্ট অ্যাক্সেস করতে পারি, তারপরে আমরা যে মানটি অ্যাক্সেস করতে চাই তার ইনডেক্স দিতে পারি। উদাহরণস্বরূপ:
Filename: src/main.rs
fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let five_hundred = x.0; let six_point_four = x.1; let one = x.2; }
এই প্রোগ্রামটি টাপল x তৈরি করে এবং তারপর তাদের নিজ নিজ ইনডেক্স ব্যবহার করে টাপলের প্রতিটি এলিমেন্ট অ্যাক্সেস করে। বেশিরভাগ প্রোগ্রামিং ল্যাঙ্গুয়েজের মতো, একটি টাপলের প্রথম ইনডেক্স হল 0।
কোনো মান ছাড়া টাপলের একটি বিশেষ নাম আছে, ইউনিট (unit)। এই মান এবং এর সংশ্লিষ্ট টাইপ উভয়ই () লেখা হয় এবং একটি খালি মান বা একটি খালি রিটার্ন টাইপ উপস্থাপন করে। এক্সপ্রেশনগুলো যদি অন্য কোনো মান রিটার্ন না করে তবে অন্তর্নিহিতভাবে ইউনিট মান রিটার্ন করে।
অ্যারে টাইপ (The Array Type)
একাধিক মানের একটি সংগ্রহ রাখার আরেকটি উপায় হল একটি অ্যারে (array)। টাপলের মতো নয়, একটি অ্যারের প্রতিটি উপাদানের একই টাইপ হতে হবে। অন্য কিছু ল্যাঙ্গুয়েজের অ্যারের মতো নয়, Rust-এর অ্যারেগুলোর একটি নির্দিষ্ট দৈর্ঘ্য রয়েছে।
আমরা একটি অ্যারের মানগুলোকে স্কোয়ার ব্র্যাকেটের ভিতরে কমা-দ্বারা-বিচ্ছিন্ন তালিকা হিসাবে লিখি:
Filename: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; }
অ্যারেগুলো দরকারী যখন আপনি চান আপনার ডেটা হিপের (heap) পরিবর্তে স্ট্যাকে (stack) বরাদ্দ করা হোক (আমরা স্ট্যাক এবং হিপ সম্পর্কে আরও আলোচনা করব চ্যাপ্টার ৪-এ), অথবা যখন আপনি নিশ্চিত করতে চান যে আপনার কাছে সর্বদা একটি নির্দিষ্ট সংখ্যক উপাদান রয়েছে। একটি অ্যারে ভেক্টর টাইপের মতো নমনীয় নয়। একটি ভেক্টর (vector) হল স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা একটি অনুরূপ কালেকশন টাইপ যা আকারে বাড়তে বা কমতে পারে। আপনি যদি অ্যারে বা ভেক্টর ব্যবহার করবেন কিনা তা নিয়ে অনিশ্চিত হন, তাহলে সম্ভবত আপনার ভেক্টর ব্যবহার করা উচিত। চ্যাপ্টার ৮-এ ভেক্টর সম্পর্কে আরও বিস্তারিত আলোচনা করা হয়েছে।
তবে, অ্যারেগুলো আরও দরকারী যখন আপনি জানেন যে উপাদানগুলোর সংখ্যা পরিবর্তন করার প্রয়োজন হবে না। উদাহরণস্বরূপ, আপনি যদি একটি প্রোগ্রামে মাসের নামগুলো ব্যবহার করেন, তাহলে আপনি সম্ভবত ভেক্টরের পরিবর্তে একটি অ্যারে ব্যবহার করবেন কারণ আপনি জানেন যে এটিতে সর্বদা 12টি উপাদান থাকবে:
#![allow(unused)] fn main() { let months = ["জানুয়ারি", "ফেব্রুয়ারি", "মার্চ", "এপ্রিল", "মে", "জুন", "জুলাই", "আগস্ট", "সেপ্টেম্বর", "অক্টোবর", "নভেম্বর", "ডিসেম্বর"]; }
আপনি একটি অ্যারের টাইপ লেখেন স্কয়ার ব্র্যাকেট ব্যবহার করে, যার মধ্যে প্রতিটি উপাদানের টাইপ, একটি সেমিকোলন এবং তারপর অ্যারেতে থাকা উপাদানগুলোর সংখ্যা থাকে, এইভাবে:
#![allow(unused)] fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; }
এখানে, i32 হল প্রতিটি উপাদানের টাইপ। সেমিকোলনের পরে, সংখ্যা 5 নির্দেশ করে যে অ্যারেটিতে পাঁচটি উপাদান রয়েছে।
আপনি প্রতিটি উপাদানের জন্য একই মান রাখতে একটি অ্যারে ইনিশিয়ালাইজ করতে পারেন, প্রাথমিক মানটি নির্দিষ্ট করে, তারপর একটি সেমিকোলন এবং তারপর স্কয়ার ব্র্যাকেটে অ্যারের দৈর্ঘ্য উল্লেখ করে, যেমনটি এখানে দেখানো হয়েছে:
#![allow(unused)] fn main() { let a = [3; 5]; }
a নামের অ্যারেটিতে 5টি উপাদান থাকবে যা প্রাথমিকভাবে 3 মানে সেট করা হবে। এটি let a = [3, 3, 3, 3, 3]; লেখার মতোই, কিন্তু আরও সংক্ষিপ্ত উপায়ে।
অ্যারে এলিমেন্ট অ্যাক্সেস করা (Accessing Array Elements)
একটি অ্যারে হল একটি পরিচিত, নির্দিষ্ট আকারের মেমরির একটি একক অংশ যা স্ট্যাকে বরাদ্দ করা যেতে পারে। আপনি ইনডেক্সিং ব্যবহার করে একটি অ্যারের উপাদানগুলো অ্যাক্সেস করতে পারেন, এইভাবে:
Filename: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; let first = a[0]; let second = a[1]; }
এই উদাহরণে, first নামের ভেরিয়েবলটি 1 মান পাবে কারণ অ্যারের [0] ইনডেক্সে সেই মানটি রয়েছে। second নামের ভেরিয়েবলটি অ্যারের [1] ইনডেক্স থেকে 2 মান পাবে।
অবৈধ অ্যারে এলিমেন্ট অ্যাক্সেস (Invalid Array Element Access)
দেখা যাক কী ঘটে যদি আপনি অ্যারের শেষের বাইরের কোনো উপাদান অ্যাক্সেস করার চেষ্টা করেন। ধরুন আপনি এই কোডটি চালান, চ্যাপ্টার ২-এর অনুমান করার গেমের মতো, ব্যবহারকারীর কাছ থেকে একটি অ্যারে ইনডেক্স পেতে:
Filename: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}এই কোডটি সফলভাবে কম্পাইল হয়। আপনি যদি cargo run ব্যবহার করে এই কোডটি চালান এবং 0, 1, 2, 3, বা 4 প্রবেশ করেন, তাহলে প্রোগ্রামটি অ্যারের সেই ইনডেক্সে সংশ্লিষ্ট মানটি প্রিন্ট করবে। আপনি যদি এর পরিবর্তে অ্যারের শেষের বাইরের কোনো সংখ্যা প্রবেশ করেন, যেমন 10, তাহলে আপনি এইরকম আউটপুট দেখতে পাবেন:
thread 'main' panicked at src/main.rs:19:19:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
প্রোগ্রামটি ইনডেক্সিং অপারেশনে একটি অবৈধ মান ব্যবহার করার কারণে একটি রানটাইম এরর-এ পর্যবসিত হয়েছিল। প্রোগ্রামটি একটি এরর মেসেজ দিয়ে প্রস্থান করেছিল এবং ফাইনাল println! স্টেটমেন্টটি চালায়নি। আপনি যখন ইনডেক্সিং ব্যবহার করে একটি উপাদান অ্যাক্সেস করার চেষ্টা করেন, তখন Rust পরীক্ষা করবে যে আপনি যে ইনডেক্সটি নির্দিষ্ট করেছেন সেটি অ্যারের দৈর্ঘ্যের চেয়ে কম কিনা। যদি ইনডেক্সটি দৈর্ঘ্যের চেয়ে বেশি বা সমান হয়, তাহলে Rust প্যানিক করবে। এই পরীক্ষাটি রানটাইমে ঘটতে হবে, বিশেষ করে এই ক্ষেত্রে, কারণ কম্পাইলারের পক্ষে জানা সম্ভব নয় যে ব্যবহারকারী পরে কোড চালানোর সময় কী মান প্রবেশ করবে।
এটি হল Rust-এর মেমরি সুরক্ষা নীতির একটি উদাহরণ। অনেক নিম্ন-স্তরের ল্যাঙ্গুয়েজে, এই ধরনের পরীক্ষা করা হয় না এবং আপনি যখন একটি ভুল ইনডেক্স দেন, তখন অবৈধ মেমরি অ্যাক্সেস করা যেতে পারে। Rust আপনাকে এই ধরনের এরর থেকে রক্ষা করে মেমরি অ্যাক্সেসের অনুমতি দেওয়ার পরিবর্তে এবং চালিয়ে যাওয়ার পরিবর্তে অবিলম্বে প্রস্থান করে। চ্যাপ্টার ৯-এ Rust-এর এরর হ্যান্ডলিং সম্পর্কে আরও আলোচনা করা হয়েছে এবং কীভাবে আপনি সুস্পষ্ট, নিরাপদ কোড লিখতে পারেন যা প্যানিক করে না বা অবৈধ মেমরি অ্যাক্সেসের অনুমতি দেয় না।
ফাংশন (Functions)
Rust কোডে ফাংশন সর্বত্র বিদ্যমান। আপনি ইতিমধ্যেই ভাষার সবচেয়ে গুরুত্বপূর্ণ ফাংশনগুলোর মধ্যে একটি দেখেছেন: main ফাংশন, যেটি অনেক প্রোগ্রামের এন্ট্রি পয়েন্ট। আপনি fn কীওয়ার্ডটিও দেখেছেন, যেটি আপনাকে নতুন ফাংশন ঘোষণা করতে দেয়।
Rust কোড ফাংশন এবং ভেরিয়েবলের নামের জন্য প্রচলিত স্টাইল হিসাবে স্নেক কেস (snake case) ব্যবহার করে, যেখানে সমস্ত অক্ষর ছোট হাতের হয় এবং শব্দগুলো আন্ডারস্কোর দিয়ে আলাদা করা হয়। এখানে একটি প্রোগ্রাম রয়েছে যাতে একটি উদাহরণ ফাংশন সংজ্ঞা রয়েছে:
Filename: src/main.rs
fn main() { println!("Hello, world!"); another_function(); } fn another_function() { println!("Another function."); }
আমরা Rust-এ একটি ফাংশন সংজ্ঞায়িত করি fn লিখে, তারপর একটি ফাংশনের নাম এবং এক সেট প্যারেন্থেসিস দিয়ে। কার্লি ব্র্যাকেটগুলো কম্পাইলারকে বলে যে ফাংশন বডি কোথায় শুরু এবং শেষ হয়।
আমরা যে কোনো ফাংশনকে তার নাম লিখে এবং তারপর এক সেট প্যারেন্থেসিস দিয়ে কল করতে পারি। যেহেতু another_function প্রোগ্রামটিতে সংজ্ঞায়িত করা হয়েছে, তাই এটিকে main ফাংশনের ভিতর থেকে কল করা যেতে পারে। লক্ষ্য করুন যে আমরা সোর্স কোডে main ফাংশনের পরে another_function সংজ্ঞায়িত করেছি; আমরা এটিকে আগেও সংজ্ঞায়িত করতে পারতাম। Rust-এ আপনি কোথায় আপনার ফাংশনগুলো সংজ্ঞায়িত করছেন সেটি গুরুত্বপূর্ণ নয়, শুধুমাত্র সেগুলোকে এমন কোথাও সংজ্ঞায়িত করা দরকার যা কলার (caller) দেখতে পায়।
ফাংশনগুলো আরও বিশদে জানতে চলুন functions নামে একটি নতুন বাইনারি প্রোজেক্ট শুরু করি। src/main.rs-এ another_function উদাহরণটি রাখুন এবং এটি চালান। আপনার নিম্নলিখিত আউটপুট দেখা উচিত:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Another function.
লাইনগুলো main ফাংশনে যে ক্রমে প্রদর্শিত হয় সেই ক্রমে এক্সিকিউট হয়। প্রথমে “Hello, world!” মেসেজটি প্রিন্ট হয়, এবং তারপর another_function কল করা হয় এবং এর মেসেজ প্রিন্ট হয়।
প্যারামিটার (Parameters)
আমরা ফাংশনগুলোকে প্যারামিটার রাখার জন্য সংজ্ঞায়িত করতে পারি, যেগুলো হল বিশেষ ভেরিয়েবল যা একটি ফাংশনের সিগনেচারের অংশ। যখন একটি ফাংশনের প্যারামিটার থাকে, তখন আপনি সেগুলোকে সেই প্যারামিটারগুলোর জন্য নির্দিষ্ট মান সরবরাহ করতে পারেন। টেকনিক্যালি, নির্দিষ্ট মানগুলোকে আর্গুমেন্ট (arguments) বলা হয়, কিন্তু সাধারণ কথোপকথনে, লোকেরা ফাংশনের সংজ্ঞার ভেরিয়েবল বা ফাংশন কল করার সময় দেওয়া নির্দিষ্ট মান, উভয়ের জন্যই প্যারামিটার এবং আর্গুমেন্ট শব্দগুলো ব্যবহার করে।
another_function-এর এই ভার্সনে আমরা একটি প্যারামিটার যোগ করি:
Filename: src/main.rs
fn main() { another_function(5); } fn another_function(x: i32) { println!("The value of x is: {x}"); }
এই প্রোগ্রামটি চালানোর চেষ্টা করুন; আপনার নিম্নলিখিত আউটপুট পাওয়া উচিত:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
The value of x is: 5
another_function-এর ঘোষণায় x নামে একটি প্যারামিটার রয়েছে। x-এর টাইপ i32 হিসাবে নির্দিষ্ট করা হয়েছে। যখন আমরা another_function-এ 5 পাস করি, তখন println! ম্যাক্রো ফরম্যাট স্ট্রিং-এ x ধারণকারী কার্লি ব্র্যাকেটের জোড়ার জায়গায় 5 বসিয়ে দেয়।
ফাংশন সিগনেচারে, আপনাকে অবশ্যই প্রতিটি প্যারামিটারের টাইপ ঘোষণা করতে হবে। এটি Rust-এর ডিজাইনের একটি ইচ্ছাকৃত সিদ্ধান্ত: ফাংশন সংজ্ঞায় টাইপ অ্যানোটেশন প্রয়োজন হওয়ার অর্থ হল কম্পাইলারকে আপনার বোঝানো টাইপটি বের করার জন্য কোডের অন্য কোথাও সেগুলো ব্যবহার করার প্রয়োজন প্রায় কখনই হয় না। কম্পাইলার আরও সহায়ক এরর মেসেজ দিতে সক্ষম হয় যদি এটি জানে যে ফাংশনটি কোন টাইপ আশা করে।
একাধিক প্যারামিটার সংজ্ঞায়িত করার সময়, প্যারামিটার ঘোষণাগুলোকে কমা দিয়ে আলাদা করুন, এইভাবে:
Filename: src/main.rs
fn main() { print_labeled_measurement(5, 'h'); } fn print_labeled_measurement(value: i32, unit_label: char) { println!("The measurement is: {value}{unit_label}"); }
এই উদাহরণটি print_labeled_measurement নামে দুটি প্যারামিটার সহ একটি ফাংশন তৈরি করে। প্রথম প্যারামিটারের নাম value এবং এটি একটি i32। দ্বিতীয়টির নাম unit_label এবং টাইপ char। ফাংশনটি তারপর value এবং unit_label উভয় ধারণকারী টেক্সট প্রিন্ট করে।
চলুন এই কোডটি চালানোর চেষ্টা করি। আপনার functions প্রোজেক্টের src/main.rs ফাইলে বর্তমানে থাকা প্রোগ্রামটিকে উপরের উদাহরণ দিয়ে প্রতিস্থাপন করুন এবং cargo run ব্যবহার করে এটি চালান:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
The measurement is: 5h
যেহেতু আমরা ফাংশনটিকে value-এর জন্য 5 এবং unit_label-এর জন্য 'h' মান দিয়ে কল করেছি, তাই প্রোগ্রাম আউটপুটে সেই মানগুলো রয়েছে।
স্টেটমেন্ট এবং এক্সপ্রেশন (Statements and Expressions)
ফাংশন বডিগুলো স্টেটমেন্টের (statements) একটি সিরিজ দিয়ে গঠিত, যা ঐচ্ছিকভাবে একটি এক্সপ্রেশন (expression) দিয়ে শেষ হতে পারে। ఇప్పటి পর্যন্ত, আমরা যেসব ফাংশন কভার করেছি, সেগুলোতে কোনো শেষ এক্সপ্রেশন ছিল না, কিন্তু আপনি একটি স্টেটমেন্টের অংশ হিসাবে একটি এক্সপ্রেশন দেখেছেন। যেহেতু Rust একটি এক্সপ্রেশন-ভিত্তিক ভাষা, তাই এটি একটি গুরুত্বপূর্ণ পার্থক্য যা বোঝা দরকার। অন্যান্য ভাষার একই পার্থক্য নেই, তাই দেখা যাক স্টেটমেন্ট এবং এক্সপ্রেশন কী এবং তাদের পার্থক্যগুলো ফাংশনের বডিগুলোকে কীভাবে প্রভাবিত করে।
- স্টেটমেন্ট হল নির্দেশাবলী যা কিছু কাজ সম্পাদন করে এবং কোনো মান রিটার্ন করে না।
- এক্সপ্রেশন একটি ফলাফলের মান মূল্যায়ন করে। চলুন কিছু উদাহরণ দেখি।
আমরা আসলে ইতিমধ্যেই স্টেটমেন্ট এবং এক্সপ্রেশন ব্যবহার করেছি। let কীওয়ার্ড দিয়ে একটি ভেরিয়েবল তৈরি করা এবং এতে একটি মান অ্যাসাইন করা হল একটি স্টেটমেন্ট। Listing 3-1-এ, let y = 6; হল একটি স্টেটমেন্ট।
fn main() { let y = 6; }
ফাংশন ডেফিনিশনগুলোও স্টেটমেন্ট; উপরের সম্পূর্ণ উদাহরণটি নিজেই একটি স্টেটমেন্ট। (আমরা নিচে দেখতে পাব, একটি ফাংশনকে কল করা স্টেটমেন্ট নয়।)
স্টেটমেন্টগুলো মান রিটার্ন করে না। অতএব, আপনি অন্য ভেরিয়েবলে একটি let স্টেটমেন্ট অ্যাসাইন করতে পারবেন না, যেমনটি নিম্নলিখিত কোড করার চেষ্টা করে; আপনি একটি এরর পাবেন:
Filename: src/main.rs
fn main() {
let x = (let y = 6);
}আপনি যখন এই প্রোগ্রামটি চালাবেন, তখন আপনি যে এররটি পাবেন তা দেখতে এরকম হবে:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` (bin "functions") due to 1 previous error; 1 warning emitted
let y = 6 স্টেটমেন্টটি কোনো মান রিটার্ন করে না, তাই x-এর সাথে বাইন্ড করার মতো কিছু নেই। এটি অন্যান্য ভাষা, যেমন C এবং Ruby-তে যা ঘটে তার থেকে ভিন্ন, যেখানে অ্যাসাইনমেন্টটি অ্যাসাইনমেন্টের মান রিটার্ন করে। সেই ভাষাগুলোতে, আপনি x = y = 6 লিখতে পারেন এবং x এবং y উভয়ের মান 6 হতে পারে; Rust-এর ক্ষেত্রে তা হয় না।
এক্সপ্রেশনগুলো একটি মান মূল্যায়ন করে এবং আপনি Rust-এ লিখবেন এমন বেশিরভাগ কোড তৈরি করে। একটি গাণিতিক অপারেশন বিবেচনা করুন, যেমন 5 + 6, যেটি একটি এক্সপ্রেশন যা 11 মানে মূল্যায়ন করে। এক্সপ্রেশনগুলো স্টেটমেন্টের অংশ হতে পারে: Listing 3-1-এ, let y = 6; স্টেটমেন্টের 6 হল একটি এক্সপ্রেশন যা 6 মানে মূল্যায়ন করে। একটি ফাংশন কল করা একটি এক্সপ্রেশন। একটি ম্যাক্রো কল করা একটি এক্সপ্রেশন। কার্লি ব্র্যাকেট দিয়ে তৈরি একটি নতুন স্কোপ ব্লক হল একটি এক্সপ্রেশন, উদাহরণস্বরূপ:
Filename: src/main.rs
fn main() { let y = { let x = 3; x + 1 }; println!("The value of y is: {y}"); }
এই এক্সপ্রেশনটি:
{
let x = 3;
x + 1
}হল একটি ব্লক, যা এই ক্ষেত্রে, 4 মূল্যায়ন করে। সেই মানটি let স্টেটমেন্টের অংশ হিসাবে y-এর সাথে বাইন্ড করা হয়। লক্ষ্য করুন যে x + 1 লাইনের শেষে একটি সেমিকোলন নেই, যা আপনি ఇప్పటి পর্যন্ত দেখেছেন এমন বেশিরভাগ লাইনের থেকে আলাদা। এক্সপ্রেশনগুলোর শেষে সেমিকোলন থাকে না। আপনি যদি একটি এক্সপ্রেশনের শেষে একটি সেমিকোলন যোগ করেন, তাহলে আপনি এটিকে একটি স্টেটমেন্টে পরিণত করবেন এবং এটি তখন কোনো মান রিটার্ন করবে না। এরপর ফাংশন রিটার্ন ভ্যালু এবং এক্সপ্রেশনগুলো অন্বেষণ করার সময় এটি মনে রাখবেন।
রিটার্ন ভ্যালু সহ ফাংশন (Functions with Return Values)
ফাংশনগুলো সেই কোডে মান রিটার্ন করতে পারে যেখান থেকে সেগুলোকে কল করা হয়েছে। আমরা রিটার্ন ভ্যালুগুলোর নাম দিই না, তবে একটি তীর চিহ্নের (->) পরে আমাদের তাদের টাইপ ঘোষণা করতে হবে। Rust-এ, ফাংশনের রিটার্ন ভ্যালু, ফাংশনের বডির ব্লকের ফাইনাল এক্সপ্রেশনের মানের সমার্থক। আপনি return কীওয়ার্ড ব্যবহার করে এবং একটি মান নির্দিষ্ট করে একটি ফাংশন থেকে তাড়াতাড়ি রিটার্ন করতে পারেন, তবে বেশিরভাগ ফাংশন শেষ এক্সপ্রেশনটিকেই রিটার্ন করে। এখানে একটি ফাংশনের উদাহরণ দেওয়া হল যা একটি মান রিটার্ন করে:
Filename: src/main.rs
fn five() -> i32 { 5 } fn main() { let x = five(); println!("The value of x is: {x}"); }
five ফাংশনে কোনো ফাংশন কল, ম্যাক্রো বা এমনকি let স্টেটমেন্টও নেই—শুধু সংখ্যা 5 নিজে। Rust-এ এটি একটি সম্পূর্ণ বৈধ ফাংশন। মনে রাখবেন যে ফাংশনের রিটার্ন টাইপও নির্দিষ্ট করা হয়েছে, -> i32 হিসাবে। এই কোডটি চালানোর চেষ্টা করুন; আউটপুটটি এইরকম হওয়া উচিত:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
The value of x is: 5
five-এর 5 হল ফাংশনের রিটার্ন ভ্যালু, যে কারণে রিটার্ন টাইপ হল i32। চলুন এটিকে আরও বিশদে পরীক্ষা করি। দুটি গুরুত্বপূর্ণ অংশ রয়েছে: প্রথমত, let x = five(); লাইনটি দেখায় যে আমরা একটি ভেরিয়েবল ইনিশিয়ালাইজ করার জন্য একটি ফাংশনের রিটার্ন ভ্যালু ব্যবহার করছি। যেহেতু five ফাংশনটি 5 রিটার্ন করে, তাই সেই লাইনটি নিম্নলিখিতটির মতোই:
#![allow(unused)] fn main() { let x = 5; }
দ্বিতীয়ত, five ফাংশনের কোনো প্যারামিটার নেই এবং রিটার্ন ভ্যালুর টাইপ সংজ্ঞায়িত করে, কিন্তু ফাংশনের বডি হল একটি নিঃসঙ্গ 5 যেখানে কোনো সেমিকোলন নেই, কারণ এটি একটি এক্সপ্রেশন যার মান আমরা রিটার্ন করতে চাই।
চলুন আরেকটি উদাহরণ দেখি:
Filename: src/main.rs
fn main() { let x = plus_one(5); println!("The value of x is: {x}"); } fn plus_one(x: i32) -> i32 { x + 1 }
এই কোডটি চালালে The value of x is: 6 প্রিন্ট হবে। কিন্তু যদি আমরা x + 1 সম্বলিত লাইনের শেষে একটি সেমিকোলন বসিয়ে দিই, এটিকে একটি এক্সপ্রেশন থেকে একটি স্টেটমেন্টে পরিবর্তন করি, তাহলে আমরা একটি এরর পাব:
Filename: src/main.rs
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1;
}এই কোডটি কম্পাইল করলে একটি এরর তৈরি হবে, যা নিচে দেওয়া হলো:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_one(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` (bin "functions") due to 1 previous error
প্রধান এরর মেসেজ, mismatched types, এই কোডের মূল সমস্যা প্রকাশ করে। plus_one ফাংশনের সংজ্ঞা বলে যে এটি একটি i32 রিটার্ন করবে, কিন্তু স্টেটমেন্টগুলো কোনো মান মূল্যায়ন করে না, যেটি (), ইউনিট টাইপ দ্বারা প্রকাশ করা হয়। অতএব, কিছুই রিটার্ন করা হয়নি, যা ফাংশনের সংজ্ঞার বিপরীত এবং এর ফলে একটি এরর হয়। এই আউটপুটে, Rust সম্ভবত এই সমস্যাটি সংশোধন করতে সাহায্য করার জন্য একটি মেসেজ প্রদান করে: এটি সেমিকোলনটি সরানোর পরামর্শ দেয়, যা এররটি ঠিক করবে।
কমেন্ট (Comments)
সমস্ত প্রোগ্রামার তাদের কোড সহজে বোধগম্য করার চেষ্টা করে, কিন্তু কখনও কখনও অতিরিক্ত ব্যাখ্যার প্রয়োজন হয়। এই ক্ষেত্রগুলোতে, প্রোগ্রামাররা তাদের সোর্স কোডে কমেন্ট (comments) রেখে যান, যা কম্পাইলার উপেক্ষা করবে কিন্তু সোর্স কোড পড়া লোকেরা দরকারী বলে মনে করতে পারে।
এখানে একটি সহজ কমেন্ট দেওয়া হলো:
#![allow(unused)] fn main() { // hello, world }
Rust-এ, প্রচলিত কমেন্ট স্টাইল দুটি স্ল্যাশ দিয়ে একটি কমেন্ট শুরু করে এবং কমেন্টটি লাইনের শেষ পর্যন্ত চলতে থাকে। যেসব কমেন্ট একটি লাইনের চেয়ে বেশি বিস্তৃত, সেগুলোর জন্য আপনাকে প্রতিটি লাইনে // অন্তর্ভুক্ত করতে হবে, এইভাবে:
#![allow(unused)] fn main() { // সুতরাং আমরা এখানে জটিল কিছু করছি, যথেষ্ট দীর্ঘ যে এটি করার জন্য // আমাদের একাধিক লাইনের কমেন্টের প্রয়োজন! যাক বাবা! আশা করি, এই কমেন্টটি // ব্যাখ্যা করবে কী ঘটছে। }
কোড ধারণকারী লাইনের শেষেও কমেন্ট রাখা যেতে পারে:
Filename: src/main.rs
fn main() { let lucky_number = 7; // I'm feeling lucky today }
কিন্তু আপনি সেগুলোকে প্রায়শই এই ফর্ম্যাটে ব্যবহৃত হতে দেখবেন, যেখানে কমেন্টটি যে কোডটিকে অ্যানোটেট করছে তার উপরে একটি আলাদা লাইনে থাকে:
Filename: src/main.rs
fn main() { // I'm feeling lucky today let lucky_number = 7; }
Rust-এ আরও এক ধরনের কমেন্ট রয়েছে, ডকুমেন্টেশন কমেন্ট, যা নিয়ে আমরা চ্যাপ্টার 14-এর “Crates.io-তে একটি ক্রেট প্রকাশ করা” বিভাগে আলোচনা করব।
The translation is perfect, short and accurate.
কন্ট্রোল ফ্লো (Control Flow)
কোনো শর্ত true কিনা তার উপর নির্ভর করে কিছু কোড চালানোর ক্ষমতা এবং একটি শর্ত true থাকা অবস্থায় কিছু কোড বারবার চালানোর ক্ষমতা বেশিরভাগ প্রোগ্রামিং ভাষার মৌলিক বিল্ডিং ব্লক। Rust কোডের এক্সিকিউশনের ফ্লো নিয়ন্ত্রণ করার জন্য সবচেয়ে সাধারণ যে কনস্ট্রাক্টগুলো ব্যবহার করা হয় সেগুলো হল if এক্সপ্রেশন এবং লুপ।
if এক্সপ্রেশন (if Expressions)
একটি if এক্সপ্রেশন আপনাকে শর্তের উপর নির্ভর করে আপনার কোডকে শাখা (branch) করতে দেয়। আপনি একটি শর্ত দেন এবং তারপর বলেন, “যদি এই শর্তটি পূরণ হয়, তাহলে কোডের এই ব্লকটি চালাও। যদি শর্তটি পূরণ না হয়, তাহলে কোডের এই ব্লকটি চালিও না।”
if এক্সপ্রেশনটি আরও ভালোভাবে বোঝার জন্য আপনার projects ডিরেক্টরিতে branches নামে একটি নতুন প্রোজেক্ট তৈরি করুন। src/main.rs ফাইলে, নিম্নলিখিতটি ইনপুট দিন:
Filename: src/main.rs
fn main() { let number = 3; if number < 5 { println!("condition was true"); } else { println!("condition was false"); } }
সমস্ত if এক্সপ্রেশন if কীওয়ার্ড দিয়ে শুরু হয়, তারপরে একটি শর্ত থাকে। এই ক্ষেত্রে, শর্তটি পরীক্ষা করে যে number ভেরিয়েবলের মান 5-এর কম কিনা। শর্তটি যদি true হয় তাহলে যে কোড ব্লকটি চালাতে হবে সেটি আমরা শর্তের ঠিক পরেই কার্লি ব্র্যাকেটের ভিতরে রাখি। if এক্সপ্রেশনের শর্তগুলোর সাথে সম্পর্কিত কোডের ব্লকগুলোকে কখনও কখনও আর্মস (arms) বলা হয়, ঠিক যেমনটি আমরা চ্যাপ্টার ২-এর “অনুমানের সাথে গোপন সংখ্যার তুলনা করা” বিভাগে আলোচনা করা match এক্সপ্রেশনের আর্মগুলোর মতো।
ঐচ্ছিকভাবে, আমরা একটি else এক্সপ্রেশনও অন্তর্ভুক্ত করতে পারি, যেটি আমরা এখানে করেছি, যদি শর্তটি false হয় তবে প্রোগ্রামটিকে চালানোর জন্য একটি বিকল্প কোড ব্লক দিতে। আপনি যদি একটি else এক্সপ্রেশন সরবরাহ না করেন এবং শর্তটি false হয়, তাহলে প্রোগ্রামটি কেবল if ব্লকটি এড়িয়ে যাবে এবং কোডের পরবর্তী অংশে চলে যাবে।
এই কোডটি চালানোর চেষ্টা করুন; আপনার নিম্নলিখিত আউটপুট দেখা উচিত:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was true
চলুন number-এর মান এমন একটি মানে পরিবর্তন করার চেষ্টা করি যা শর্তটিকে false করে, কী ঘটে তা দেখার জন্য:
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}প্রোগ্রামটি আবার চালান এবং আউটপুট দেখুন:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was false
এটিও লক্ষ্য করার মতো যে এই কোডের শর্তটি অবশ্যই একটি bool হতে হবে। শর্তটি যদি bool না হয়, তাহলে আমরা একটি এরর পাব। উদাহরণস্বরূপ, নিম্নলিখিত কোডটি চালানোর চেষ্টা করুন:
Filename: src/main.rs
fn main() {
let number = 3;
if number {
println!("number was three");
}
}if শর্তটি এবার 3 মান মূল্যায়ন করে এবং Rust একটি এরর দেয়:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if number {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
এররটি নির্দেশ করে যে Rust একটি bool আশা করেছিল কিন্তু একটি ইন্টিজার পেয়েছে। Ruby এবং JavaScript-এর মতো ভাষাগুলোর বিপরীতে, Rust স্বয়ংক্রিয়ভাবে নন-বুলিয়ান টাইপগুলোকে বুলিয়ানে রূপান্তর করার চেষ্টা করবে না। আপনাকে স্পষ্ট হতে হবে এবং সর্বদাই if-কে এর শর্ত হিসাবে একটি বুলিয়ান দিতে হবে। উদাহরণস্বরূপ, যদি আমরা চাই যে if কোড ব্লকটি তখনই চলুক যখন একটি সংখ্যা 0-এর সমান না হয়, তাহলে আমরা if এক্সপ্রেশনটিকে নিম্নলিখিতভাবে পরিবর্তন করতে পারি:
Filename: src/main.rs
fn main() { let number = 3; if number != 0 { println!("number was something other than zero"); } }
এই কোডটি চালালে number was something other than zero প্রিন্ট হবে।
else if দিয়ে একাধিক শর্ত হ্যান্ডেল করা (Handling Multiple Conditions with else if)
আপনি else if এক্সপ্রেশনে if এবং else একত্রিত করে একাধিক শর্ত ব্যবহার করতে পারেন। উদাহরণস্বরূপ:
Filename: src/main.rs
fn main() { let number = 6; if number % 4 == 0 { println!("number is divisible by 4"); } else if number % 3 == 0 { println!("number is divisible by 3"); } else if number % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } }
এই প্রোগ্রামটির চারটি সম্ভাব্য পথ রয়েছে যা এটি নিতে পারে। এটি চালানোর পরে, আপনার নিম্নলিখিত আউটপুট দেখা উচিত:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
number is divisible by 3
যখন এই প্রোগ্রামটি এক্সিকিউট হয়, তখন এটি প্রতিটি if এক্সপ্রেশন পরীক্ষা করে এবং প্রথম বডিটি এক্সিকিউট করে যার শর্তটি true তে মূল্যায়ন করে। লক্ষ্য করুন যে 6, 2 দ্বারা বিভাজ্য হওয়া সত্ত্বেও, আমরা number is divisible by 2 আউটপুট দেখতে পাই না, বা আমরা else ব্লক থেকে number is not divisible by 4, 3, or 2 টেক্সটটিও দেখতে পাই না। কারণ হল Rust শুধুমাত্র প্রথম true শর্তের জন্য ব্লকটি এক্সিকিউট করে এবং একবার এটি একটি খুঁজে পেলে, এটি বাকিগুলোও পরীক্ষা করে না।
অত্যধিক else if এক্সপ্রেশন ব্যবহার করলে আপনার কোড এলোমেলো হয়ে যেতে পারে, তাই আপনার যদি একের বেশি থাকে, তাহলে আপনি হয়তো আপনার কোড রিফ্যাক্টর করতে চাইতে পারেন। এই ক্ষেত্রগুলোর জন্য চ্যাপ্টার ৬-এ match নামক একটি শক্তিশালী Rust ব্রাঞ্চিং কনস্ট্রাক্ট বর্ণনা করা হয়েছে।
let স্টেটমেন্টে if ব্যবহার করা (Using if in a let Statement)
যেহেতু if একটি এক্সপ্রেশন, তাই আমরা এটিকে একটি let স্টেটমেন্টের ডান পাশে ব্যবহার করতে পারি, ফলাফলটিকে একটি ভেরিয়েবলের সাথে অ্যাসাইন করতে, যেমনটি Listing 3-2-তে রয়েছে।
fn main() { let condition = true; let number = if condition { 5 } else { 6 }; println!("The value of number is: {number}"); }
number ভেরিয়েবলটি if এক্সপ্রেশনের ফলাফলের উপর ভিত্তি করে একটি মানের সাথে বাইন্ড করা হবে। কী ঘটে তা দেখতে এই কোডটি চালান:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
The value of number is: 5
মনে রাখবেন যে কোডের ব্লকগুলো তাদের ভেতরের শেষ এক্সপ্রেশনটিতে মূল্যায়ন করে এবং সংখ্যাগুলোও নিজে থেকে এক্সপ্রেশন। এই ক্ষেত্রে, সম্পূর্ণ if এক্সপ্রেশনের মান নির্ভর করে কোন কোড ব্লকটি এক্সিকিউট হয় তার উপর। এর মানে হল if-এর প্রতিটি আর্ম (arm) থেকে ফলাফলের সম্ভাব্য মানগুলো অবশ্যই একই টাইপের হতে হবে; Listing 3-2-তে, if আর্ম এবং else আর্ম উভয়ের ফলাফলই ছিল i32 ইন্টিজার। যদি টাইপগুলো মেলানো না থাকে, যেমনটি নিম্নলিখিত উদাহরণে রয়েছে, তাহলে আমরা একটি এরর পাব:
Filename: src/main.rs
fn main() {
let condition = true;
let number = if condition { 5 } else { "six" };
println!("The value of number is: {number}");
}আমরা যখন এই কোডটি কম্পাইল করার চেষ্টা করি, তখন আমরা একটি এরর পাব। if এবং else আর্মগুলোর মান টাইপগুলো অসঙ্গতিপূর্ণ, এবং Rust ঠিক কোথায় সমস্যাটি খুঁজে বের করতে হবে তা নির্দেশ করে:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let number = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
if ব্লকের এক্সপ্রেশনটি একটি ইন্টিজারে মূল্যায়ন করে এবং else ব্লকের এক্সপ্রেশনটি একটি স্ট্রিংয়ে মূল্যায়ন করে। এটি কাজ করবে না কারণ ভেরিয়েবলগুলোর অবশ্যই একটি একক টাইপ থাকতে হবে এবং Rust-কে কম্পাইল করার সময় নিশ্চিতভাবে জানতে হবে যে number ভেরিয়েবলটির টাইপ কী। number-এর টাইপ জানা কম্পাইলারকে আমরা যেখানেই number ব্যবহার করি সেখানেই টাইপটি বৈধ কিনা তা যাচাই করতে দেয়। Rust সেটি করতে সক্ষম হবে না যদি number-এর টাইপ শুধুমাত্র রানটাইমে নির্ধারিত হত; কম্পাইলার আরও জটিল হবে এবং কোড সম্পর্কে কম গ্যারান্টি দিতে পারবে যদি এটিকে কোনো ভেরিয়েবলের জন্য একাধিক কাল্পনিক টাইপ ট্র্যাক রাখতে হত।
লুপের সাহায্যে পুনরাবৃত্তি (Repetition with Loops)
প্রায়শই কোডের একটি ব্লক একাধিকবার চালানো দরকারি। এই কাজের জন্য, Rust-এ বেশ কয়েকটি লুপ (loops) রয়েছে, যেগুলো লুপ বডির ভেতরের কোড শেষ পর্যন্ত চালাবে এবং তারপর অবিলম্বে আবার শুরুতে ফিরে যাবে। লুপ নিয়ে পরীক্ষা করার জন্য, আসুন loops নামে একটি নতুন প্রোজেক্ট তৈরি করি।
Rust-এ তিন ধরনের লুপ রয়েছে: loop, while, এবং for। চলুন প্রতিটি ব্যবহার করে দেখি।
loop দিয়ে কোড পুনরাবৃত্তি করা (Repeating Code with loop)
loop কীওয়ার্ডটি Rust-কে কোডের একটি ব্লক বারবার চালানোর নির্দেশ দেয়, যতক্ষণ না আপনি স্পষ্টতই এটিকে থামতে বলেন।
উদাহরণস্বরূপ, আপনার loops ডিরেক্টরির src/main.rs ফাইলটিকে নিচের মতো পরিবর্তন করুন:
Filename: src/main.rs
fn main() {
loop {
println!("again!");
}
}আমরা যখন এই প্রোগ্রামটি চালাই, তখন আমরা again! লেখাটি বারবার প্রিন্ট হতে দেখব যতক্ষণ না আমরা ম্যানুয়ালি প্রোগ্রামটি বন্ধ করি। বেশিরভাগ টার্মিনাল একটি ক্রমাগত লুপে আটকে থাকা একটি প্রোগ্রামকে বাধা দেওয়ার জন্য কীবোর্ড শর্টকাট ctrl-c সমর্থন করে। চেষ্টা করে দেখুন:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/loops`
again!
again!
again!
again!
^Cagain!
^C প্রতীকটি উপস্থাপন করে যেখানে আপনি ctrl-c টিপেছেন। আপনি ^C-এর পরে again! শব্দটি প্রিন্ট করা দেখতে পারেন বা নাও পারেন, এটি নির্ভর করে যে কোডটি লুপের কোথায় ছিল যখন এটি বাধার সংকেত পেয়েছিল।
সৌভাগ্যবশত, Rust কোড ব্যবহার করে একটি লুপ থেকে বেরিয়ে আসার একটি উপায়ও সরবরাহ করে। আপনি লুপের মধ্যে break কীওয়ার্ডটি রাখতে পারেন, প্রোগ্রামটিকে কখন লুপ চালানো বন্ধ করতে হবে তা বলার জন্য। মনে করে দেখুন যে, আমরা চ্যাপ্টার ২-এর “সঠিক অনুমানের পরে বন্ধ হওয়া” বিভাগে অনুমান করার গেমে এটি করেছিলাম, যখন ব্যবহারকারী সঠিক সংখ্যা অনুমান করে গেমটি জিতেছিলেন তখন প্রোগ্রামটি বন্ধ করার জন্য।
আমরা অনুমান করার গেমে continue ব্যবহার করেছি, যা একটি লুপের মধ্যে প্রোগ্রামটিকে সেই পুনরাবৃত্তির (iteration) অবশিষ্ট কোডগুলো এড়িয়ে যেতে এবং পরবর্তী পুনরাবৃত্তিতে যেতে বলে।
লুপ থেকে মান রিটার্ন করা (Returning Values from Loops)
loop-এর একটি ব্যবহার হল এমন একটি অপারেশন পুনরায় চেষ্টা করা যা আপনি জানেন যে ব্যর্থ হতে পারে, যেমন একটি থ্রেড তার কাজ সম্পন্ন করেছে কিনা তা পরীক্ষা করা। আপনাকে সেই অপারেশনের ফলাফল লুপের বাইরে আপনার কোডের বাকি অংশে পাস করতে হতে পারে। এটি করার জন্য, আপনি লুপ বন্ধ করার জন্য ব্যবহৃত break এক্সপ্রেশনের পরে যে মানটি রিটার্ন করতে চান সেটি যোগ করতে পারেন; সেই মানটি লুপ থেকে রিটার্ন করা হবে যাতে আপনি এটি ব্যবহার করতে পারেন, যেমনটি এখানে দেখানো হয়েছে:
fn main() { let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; println!("The result is {result}"); }
লুপের আগে, আমরা counter নামে একটি ভেরিয়েবল ঘোষণা করি এবং এটিকে 0 দিয়ে ইনিশিয়ালাইজ করি। তারপর আমরা লুপ থেকে রিটার্ন করা মান রাখার জন্য result নামে একটি ভেরিয়েবল ঘোষণা করি। লুপের প্রতিটি পুনরাবৃত্তিতে, আমরা counter ভেরিয়েবলে 1 যোগ করি এবং তারপর পরীক্ষা করি যে counter 10-এর সমান কিনা। যখন এটি হয়, তখন আমরা counter * 2 মান সহ break কীওয়ার্ডটি ব্যবহার করি। লুপের পরে, আমরা result-এ মান অ্যাসাইন করা স্টেটমেন্টটি শেষ করতে একটি সেমিকোলন ব্যবহার করি। অবশেষে, আমরা result-এর মান প্রিন্ট করি, যা এই ক্ষেত্রে 20।
আপনি একটি লুপের ভেতর থেকেও return করতে পারেন। break শুধুমাত্র বর্তমান লুপ থেকে বের হয়, return সর্বদাই বর্তমান ফাংশন থেকে বের হয়।
একাধিক লুপের মধ্যে পার্থক্য করার জন্য লুপ লেবেল (Loop Labels to Disambiguate Between Multiple Loops)
যদি আপনার লুপের মধ্যে লুপ থাকে, তাহলে break এবং continue সেই সময়ে সবচেয়ে ভেতরের লুপে প্রযোজ্য হয়। আপনি ঐচ্ছিকভাবে একটি লুপে একটি লুপ লেবেল নির্দিষ্ট করতে পারেন যা আপনি তারপর break বা continue-এর সাথে ব্যবহার করতে পারেন, যাতে সেই কীওয়ার্ডগুলো সবচেয়ে ভেতরের লুপের পরিবর্তে লেবেলযুক্ত লুপে প্রযোজ্য হয় তা নির্দিষ্ট করতে। লুপ লেবেলগুলো অবশ্যই একটি সিঙ্গেল কোট দিয়ে শুরু হতে হবে। দুটি নেস্টেড লুপ সহ এখানে একটি উদাহরণ দেওয়া হল:
fn main() { let mut count = 0; 'counting_up: loop { println!("count = {count}"); let mut remaining = 10; loop { println!("remaining = {remaining}"); if remaining == 9 { break; } if count == 2 { break 'counting_up; } remaining -= 1; } count += 1; } println!("End count = {count}"); }
বাইরের লুপটির লেবেল হল 'counting_up, এবং এটি 0 থেকে 2 পর্যন্ত গণনা করবে। লেবেল ছাড়া ভেতরের লুপটি 10 থেকে 9 পর্যন্ত গণনা করবে। প্রথম break যেটি একটি লেবেল নির্দিষ্ট করে না সেটি শুধুমাত্র ভেতরের লুপ থেকে বেরিয়ে আসবে। break 'counting_up; স্টেটমেন্টটি বাইরের লুপ থেকে বেরিয়ে আসবে। এই কোডটি প্রিন্ট করে:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
count = 0
remaining = 10
remaining = 9
count = 1
remaining = 10
remaining = 9
count = 2
remaining = 10
End count = 2
while দিয়ে শর্তসাপেক্ষ লুপ (Conditional Loops with while)
একটি প্রোগ্রামের প্রায়শই একটি লুপের মধ্যে একটি শর্ত মূল্যায়ন করার প্রয়োজন হয়। যখন শর্তটি true হয়, তখন লুপটি চলে। যখন শর্তটি আর true থাকে না, তখন প্রোগ্রামটি break কল করে, লুপটি বন্ধ করে। loop, if, else, এবং break-এর সমন্বয় ব্যবহার করে এইরকম আচরণ বাস্তবায়ন করা সম্ভব; আপনি চাইলে এখনই একটি প্রোগ্রামে সেটি চেষ্টা করতে পারেন। তবে, এই প্যাটার্নটি এতটাই সাধারণ যে Rust-এর এর জন্য একটি বিল্ট-ইন ল্যাঙ্গুয়েজ কনস্ট্রাক্ট রয়েছে, যাকে while লুপ বলা হয়। Listing 3-3-তে, আমরা প্রোগ্রামটিকে তিনবার লুপ করতে, প্রতিবার কাউন্ট ডাউন করতে এবং তারপর লুপের পরে একটি মেসেজ প্রিন্ট করে প্রস্থান করতে while ব্যবহার করি।
fn main() { let mut number = 3; while number != 0 { println!("{number}!"); number -= 1; } println!("LIFTOFF!!!"); }
এই কনস্ট্রাক্টটি loop, if, else, এবং break ব্যবহার করলে প্রয়োজনীয় অনেক নেস্টিং দূর করে এবং এটি আরও সুস্পষ্ট। যখন একটি শর্ত true তে মূল্যায়ন করে, তখন কোডটি চলে; অন্যথায়, এটি লুপ থেকে বেরিয়ে যায়।
for দিয়ে একটি কালেকশনের মধ্যে লুপ করা (Looping Through a Collection with for)
আপনি একটি কালেকশনের উপাদানগুলোর ওপর লুপ করার জন্য while কনস্ট্রাক্টটিও ব্যবহার করতে পারেন, যেমন একটি অ্যারে। উদাহরণস্বরূপ, Listing 3-4-এর লুপটি অ্যারে a-এর প্রতিটি উপাদান প্রিন্ট করে।
fn main() { let a = [10, 20, 30, 40, 50]; let mut index = 0; while index < 5 { println!("the value is: {}", a[index]); index += 1; } }
এখানে, কোডটি অ্যারের উপাদানগুলোর মধ্যে গণনা করে। এটি ইনডেক্স 0 থেকে শুরু হয় এবং তারপর লুপটি অ্যারের শেষ ইনডেক্সে পৌঁছানো পর্যন্ত চলতে থাকে (অর্থাৎ, যখন index < 5 আর true থাকে না)। এই কোডটি চালালে অ্যারের প্রতিটি উপাদান প্রিন্ট হবে:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
the value is: 10
the value is: 20
the value is: 30
the value is: 40
the value is: 50
প্রত্যাশিতভাবে, অ্যারের পাঁচটি মানই টার্মিনালে প্রদর্শিত হয়। যদিও index কোনো এক সময়ে 5 মানে পৌঁছাবে, লুপটি অ্যারে থেকে ষষ্ঠ মান আনার চেষ্টা করার আগেই চালানো বন্ধ করে দেয়।
তবে, এই পদ্ধতিটি এরর-প্রবণ; ইনডেক্স মান বা পরীক্ষার শর্তটি ভুল হলে আমরা প্রোগ্রামটিকে প্যানিক করাতে পারি। উদাহরণস্বরূপ, আপনি যদি a অ্যারের সংজ্ঞাকে চারটি উপাদান রাখার জন্য পরিবর্তন করেন কিন্তু শর্তটিকে while index < 4-এ আপডেট করতে ভুলে যান, তাহলে কোডটি প্যানিক করবে। এটি ধীরও, কারণ কম্পাইলার রানটাইম কোড যোগ করে, লুপের প্রতিটি পুনরাবৃত্তিতে ইনডেক্সটি অ্যারের সীমার মধ্যে আছে কিনা তার শর্তসাপেক্ষ পরীক্ষা করতে।
আরও সংক্ষিপ্ত বিকল্প হিসাবে, আপনি একটি for লুপ ব্যবহার করতে পারেন এবং একটি কালেকশনের প্রতিটি আইটেমের জন্য কিছু কোড চালাতে পারেন। একটি for লুপ Listing 3-5-এর কোডের মতো দেখায়।
fn main() { let a = [10, 20, 30, 40, 50]; for element in a { println!("the value is: {element}"); } }
আমরা যখন এই কোডটি চালাই, তখন আমরা Listing 3-4-এর মতোই একই আউটপুট দেখতে পাব। আরও গুরুত্বপূর্ণভাবে, আমরা এখন কোডের নিরাপত্তা বাড়িয়েছি এবং বাগের সম্ভাবনা দূর করেছি যা অ্যারের শেষের বাইরে যাওয়া বা যথেষ্ট দূরে না যাওয়া এবং কিছু আইটেম মিস করার ফলে হতে পারে।
for লুপ ব্যবহার করলে, আপনি যদি অ্যারের মানের সংখ্যা পরিবর্তন করেন তবে আপনাকে অন্য কোনো কোড পরিবর্তন করতে মনে রাখতে হবে না, যেমনটি Listing 3-4-এ ব্যবহৃত পদ্ধতির সাথে করতে হত।
for লুপগুলোর নিরাপত্তা এবং সংক্ষিপ্ততা সেগুলোকে Rust-এ সর্বাধিক ব্যবহৃত লুপ কনস্ট্রাক্ট করে তোলে। এমনকী যে পরিস্থিতিতে আপনি কিছু কোড একটি নির্দিষ্ট সংখ্যক বার চালাতে চান, যেমন কাউন্টডাউন উদাহরণ যা Listing 3-3-তে একটি while লুপ ব্যবহার করেছে, বেশিরভাগ Rustacean-রা একটি for লুপ ব্যবহার করবে। সেটি করার উপায় হল একটি Range ব্যবহার করা, যা স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা হয়, যা একটি সংখ্যা থেকে শুরু করে অন্য সংখ্যার আগে শেষ হওয়া সমস্ত সংখ্যা ক্রমানুসারে তৈরি করে।
এখানে for লুপ এবং আরেকটি মেথড যা আমরা এখনও আলোচনা করিনি, rev, রেঞ্জটিকে বিপরীত করতে ব্যবহার করে কাউন্টডাউনটি দেখতে কেমন হবে:
Filename: src/main.rs
fn main() { for number in (1..4).rev() { println!("{number}!"); } println!("LIFTOFF!!!"); }
এই কোডটি একটু সুন্দর, তাই না?
সারসংক্ষেপ (Summary)
আপনি পেরেছেন! এটি একটি বড় চ্যাপ্টার ছিল: আপনি ভেরিয়েবল, স্কেলার এবং কম্পাউন্ড ডেটা টাইপ, ফাংশন, কমেন্ট, if এক্সপ্রেশন এবং লুপ সম্পর্কে শিখেছেন! এই চ্যাপ্টারে আলোচিত কনসেপ্টগুলো অনুশীলন করতে, নিম্নলিখিতগুলো করার জন্য প্রোগ্রাম তৈরি করার চেষ্টা করুন:
- ফারেনহাইট এবং সেলসিয়াসের মধ্যে তাপমাত্রা রূপান্তর করুন।
- nতম ফিবোনাচ্চি সংখ্যা তৈরি করুন।
- "The Twelve Days of Christmas" ক্রিসমাস ক্যারোলের লিরিকগুলো প্রিন্ট করুন, গানের পুনরাবৃত্তির সুবিধা নিন।
আপনি যখন આગળ (গুজরাটি শব্দ, অর্থ 'move on') বাড়াতে প্রস্তুত হবেন, তখন আমরা Rust-এর একটি কনসেপ্ট নিয়ে আলোচনা করব যা অন্যান্য প্রোগ্রামিং ল্যাঙ্গুয়েজে সাধারণত থাকে না: ওনারশিপ (ownership)।
ওনারশিপ বোঝা (Understanding Ownership)
ওনারশিপ হল Rust-এর সবচেয়ে অনন্য বৈশিষ্ট্য এবং এটি ভাষার বাকি অংশের জন্য গভীর প্রভাব ফেলে। এটি Rust-কে গারবেজ কালেক্টর (garbage collector) ছাড়াই মেমরি নিরাপত্তার গ্যারান্টি দিতে সক্ষম করে, তাই ওনারশিপ কীভাবে কাজ করে তা বোঝা গুরুত্বপূর্ণ। এই চ্যাপ্টারে, আমরা ওনারশিপ এবং সেইসাথে এর সাথে সম্পর্কিত বেশ কয়েকটি ফিচার নিয়ে আলোচনা করব: বোরোয়িং (borrowing), স্লাইস (slices), এবং Rust কীভাবে মেমরিতে ডেটা সাজায়।
ওনারশিপ কী? (What Is Ownership?)
ওনারশিপ হল নিয়মের একটি সেট যা নির্ধারণ করে কিভাবে একটি Rust প্রোগ্রাম মেমরি পরিচালনা করে। সব প্রোগ্রামকেই রান করার সময় কম্পিউটারের মেমরি ব্যবহারের পদ্ধতি পরিচালনা করতে হয়। কিছু ল্যাঙ্গুয়েজে গারবেজ কালেকশন (garbage collection) থাকে, যা প্রোগ্রাম চলার সময় নিয়মিতভাবে অব্যবহৃত মেমরি খুঁজে বের করে; অন্য ল্যাঙ্গুয়েজগুলোতে, প্রোগ্রামারকে স্পষ্টতই মেমরি বরাদ্দ (allocate) এবং মুক্ত (free) করতে হয়। Rust একটি তৃতীয় পদ্ধতি ব্যবহার করে: মেমরি ওনারশিপের একটি সিস্টেমের মাধ্যমে পরিচালিত হয়, যেখানে কম্পাইলার নিয়মের একটি সেট পরীক্ষা করে। যদি কোনো নিয়ম লঙ্ঘন করা হয়, তাহলে প্রোগ্রামটি কম্পাইল হবে না। ওনারশিপের কোনো ফিচারই আপনার প্রোগ্রাম চলার সময় এটিকে ধীর করবে না।
যেহেতু ওনারশিপ অনেক প্রোগ্রামারের কাছে একটি নতুন ধারণা, তাই এটিতে অভ্যস্ত হতে কিছুটা সময় লাগে। ভালো খবর হল, আপনি Rust এবং ওনারশিপ সিস্টেমের নিয়মগুলোর সাথে যত বেশি অভিজ্ঞ হবেন, আপনার জন্য স্বাভাবিকভাবেই নিরাপদ এবং দক্ষ কোড তৈরি করা তত সহজ হবে। চেষ্টা চালিয়ে যান!
আপনি যখন ওনারশিপ বুঝতে পারবেন, তখন আপনি Rust-কে অনন্য করে তোলে এমন ফিচারগুলো বোঝার জন্য একটি শক্ত ভিত্তি পাবেন। এই চ্যাপ্টারে, আপনি স্ট্রিং-এর মতো খুব সাধারণ ডেটা স্ট্রাকচারের উপর ফোকাস করে এমন কিছু উদাহরণের মাধ্যমে ওনারশিপ শিখবেন।
স্ট্যাক এবং হিপ (The Stack and the Heap)
অনেক প্রোগ্রামিং ল্যাঙ্গুয়েজে আপনাকে স্ট্যাক এবং হিপ সম্পর্কে খুব বেশি চিন্তা করতে হয় না। কিন্তু Rust-এর মতো সিস্টেম প্রোগ্রামিং ল্যাঙ্গুয়েজে, একটি মান স্ট্যাকে আছে নাকি হিপে আছে, তা ভাষার আচরণকে প্রভাবিত করে এবং আপনাকে কেন কিছু সিদ্ধান্ত নিতে হবে তা নির্ধারণ করে। ওনারশিপের অংশগুলো এই চ্যাপ্টারের শেষের দিকে স্ট্যাক এবং হিপের সাথে সম্পর্কিত করে বর্ণনা করা হবে, তাই প্রস্তুতির জন্য এখানে একটি সংক্ষিপ্ত ব্যাখ্যা দেওয়া হল।
স্ট্যাক এবং হিপ উভয়ই মেমরির অংশ যা রানটাইমে আপনার কোড ব্যবহার করতে পারে, তবে সেগুলো ভিন্নভাবে গঠিত। স্ট্যাক মানগুলোকে যে ক্রমে পায় সেই ক্রমে সংরক্ষণ করে এবং বিপরীত ক্রমে মানগুলো সরিয়ে দেয়। এটিকে লাস্ট ইন, ফার্স্ট আউট (last in, first out) বলা হয়। প্লেটের স্তূপের কথা চিন্তা করুন: আপনি যখন আরও প্লেট যোগ করেন, আপনি সেগুলোকে স্তূপের উপরে রাখেন এবং যখন আপনার একটি প্লেট প্রয়োজন হয়, আপনি উপরের দিক থেকে একটি প্লেট নেন। মাঝখান থেকে বা নিচ থেকে প্লেট যোগ করা বা সরানো কাজ করবে না! ডেটা যোগ করাকে স্ট্যাকের উপর পুশ করা (pushing onto the stack) বলা হয় এবং ডেটা সরিয়ে দেওয়াকে স্ট্যাক থেকে পপ করা (popping off the stack) বলা হয়। স্ট্যাকে সংরক্ষিত সমস্ত ডেটার একটি পরিচিত, নির্দিষ্ট আকার থাকতে হবে। কম্পাইল করার সময় অজানা আকারের ডেটা বা আকার পরিবর্তন হতে পারে এমন ডেটা অবশ্যই হিপে সংরক্ষণ করতে হবে।
হিপ কম সংগঠিত: আপনি যখন হিপে ডেটা রাখেন, তখন আপনি একটি নির্দিষ্ট পরিমাণ জায়গা অনুরোধ করেন। মেমরি অ্যালোকেটর (memory allocator) হিপে যথেষ্ট বড় একটি খালি জায়গা খুঁজে বের করে, এটিকে ব্যবহৃত হচ্ছে বলে চিহ্নিত করে এবং একটি পয়েন্টার (pointer) রিটার্ন করে, যেটি হল সেই অবস্থানের ঠিকানা। এই প্রক্রিয়াটিকে হিপে অ্যালোকেট করা (allocating on the heap) বলা হয় এবং কখনও কখনও এটিকে সংক্ষেপে শুধু অ্যালোকেটিং (allocating) বলা হয় (স্ট্যাকের উপর মান পুশ করা অ্যালোকেটিং হিসাবে বিবেচিত হয় না)। কারণ হিপের পয়েন্টারটি একটি পরিচিত, নির্দিষ্ট আকারের, আপনি পয়েন্টারটি স্ট্যাকে সংরক্ষণ করতে পারেন, কিন্তু যখন আপনি আসল ডেটা চান, তখন আপনাকে পয়েন্টারটি অনুসরণ করতে হবে। একটি রেস্তোরাঁয় বসার কথা চিন্তা করুন। আপনি যখন প্রবেশ করেন, তখন আপনি আপনার গ্রুপের লোকের সংখ্যা জানান এবং হোস্ট সবার জন্য উপযুক্ত একটি খালি টেবিল খুঁজে বের করে আপনাকে সেখানে নিয়ে যায়। যদি আপনার গ্রুপের কেউ দেরিতে আসে, তাহলে তারা আপনাকে খুঁজে বের করার জন্য জিজ্ঞাসা করতে পারে যে আপনাকে কোথায় বসানো হয়েছে।
স্ট্যাকে পুশ করা হিপে অ্যালোকেট করার চেয়ে দ্রুত, কারণ অ্যালোকেটরকে কখনই নতুন ডেটা সংরক্ষণ করার জন্য জায়গা খুঁজতে হয় না; সেই অবস্থানটি সর্বদা স্ট্যাকের শীর্ষে থাকে। তুলনামূলকভাবে, হিপে জায়গা বরাদ্দ করার জন্য আরও বেশি কাজ প্রয়োজন, কারণ অ্যালোকেটরকে প্রথমে ডেটা রাখার জন্য যথেষ্ট বড় জায়গা খুঁজে বের করতে হবে এবং তারপর পরবর্তী বরাদ্দের জন্য প্রস্তুতি নিতে বুককিপিং করতে হবে।
হিপের ডেটা অ্যাক্সেস করা স্ট্যাকের ডেটা অ্যাক্সেস করার চেয়ে ধীর, কারণ আপনাকে সেখানে যাওয়ার জন্য একটি পয়েন্টার অনুসরণ করতে হবে। সমসাময়িক প্রসেসরগুলো দ্রুততর হয় যদি সেগুলো মেমরিতে কম লাফিয়ে চলে। উপমাটি চালিয়ে গেলে, একটি রেস্তোরাঁর একজন সার্ভারের কথা বিবেচনা করুন যিনি অনেক টেবিল থেকে অর্ডার নিচ্ছেন। পরবর্তী টেবিলে যাওয়ার আগে একটি টেবিলের সমস্ত অর্ডার নেওয়া সবচেয়ে কার্যকর। টেবিল A থেকে একটি অর্ডার নেওয়া, তারপর টেবিল B থেকে একটি অর্ডার, তারপর আবার A থেকে একটি, এবং তারপর আবার B থেকে একটি অর্ডার নেওয়া অনেক ধীর প্রক্রিয়া হবে। একইভাবে, একটি প্রসেসর তার কাজটি আরও ভালভাবে করতে পারে যদি এটি এমন ডেটাতে কাজ করে যা অন্যান্য ডেটার কাছাকাছি থাকে (যেমন এটি স্ট্যাকে থাকে) দূরে থাকার পরিবর্তে (যেমন এটি হিপে থাকতে পারে)।
যখন আপনার কোড একটি ফাংশন কল করে, তখন ফাংশনে পাস করা মানগুলো (সম্ভাব্যভাবে, হিপের ডেটার পয়েন্টার সহ) এবং ফাংশনের লোকাল ভেরিয়েবলগুলো স্ট্যাকের উপর পুশ করা হয়। যখন ফাংশনটি শেষ হয়ে যায়, তখন সেই মানগুলো স্ট্যাক থেকে পপ করা হয়।
কোডের কোন অংশগুলো হিপের কোন ডেটা ব্যবহার করছে তা ট্র্যাক রাখা, হিপে ডুপ্লিকেট ডেটার পরিমাণ কমানো এবং অব্যবহৃত ডেটা পরিষ্কার করা যাতে আপনার জায়গা শেষ না হয়ে যায়, এই সমস্ত সমস্যাগুলো ওনারশিপ সমাধান করে। একবার আপনি ওনারশিপ বুঝতে পারলে, আপনাকে স্ট্যাক এবং হিপ সম্পর্কে খুব বেশি চিন্তা করতে হবে না, কিন্তু ওনারশিপের মূল উদ্দেশ্য হল হিপ ডেটা পরিচালনা করা, এটি যেভাবে কাজ করে তা ব্যাখ্যা করতে সাহায্য করতে পারে।
ওনারশিপের নিয়ম (Ownership Rules)
প্রথমে, চলুন ওনারশিপের নিয়মগুলো দেখি। এই নিয়মগুলো মনে রাখুন যখন আমরা উদাহরণের মাধ্যমে কাজ করব:
- Rust-এ প্রতিটি মানের একজন ওনার (owner) থাকে।
- একবারে কেবল একজন ওনার থাকতে পারে।
- যখন ওনার স্কোপের বাইরে চলে যায়, তখন মানটি ড্রপ (drop) হয়ে যাবে।
ভেরিয়েবল স্কোপ (Variable Scope)
যেহেতু আমরা এখন বেসিক Rust সিনট্যাক্স অতিক্রম করেছি, তাই আমরা উদাহরণগুলোতে সমস্ত fn main() { কোড অন্তর্ভুক্ত করব না, তাই আপনি যদি অনুসরণ করেন তবে নিম্নলিখিত উদাহরণগুলো নিজে থেকে একটি main ফাংশনের ভিতরে রাখতে ভুলবেন না। ফলস্বরূপ, আমাদের উদাহরণগুলো আরও সংক্ষিপ্ত হবে, যা আমাদের বয়লারপ্লেট কোডের পরিবর্তে আসল বিবরণে ফোকাস করতে দেবে।
ওনারশিপের প্রথম উদাহরণ হিসাবে, আমরা কিছু ভেরিয়েবলের স্কোপ (scope) দেখব। একটি স্কোপ হল একটি প্রোগ্রামের মধ্যে একটি পরিসর যার জন্য একটি আইটেম বৈধ। নিম্নলিখিত ভেরিয়েবলটি বিবেচনা করুন:
#![allow(unused)] fn main() { let s = "hello"; }
s ভেরিয়েবলটি একটি স্ট্রিং লিটারেলকে নির্দেশ করে, যেখানে স্ট্রিংয়ের মানটি আমাদের প্রোগ্রামের টেক্সটে হার্ডকোড করা আছে। ভেরিয়েবলটি যে বিন্দুতে ঘোষণা করা হয়েছে সেখান থেকে বর্তমান স্কোপ শেষ হওয়া পর্যন্ত বৈধ। Listing 4-1-এ একটি প্রোগ্রাম দেখানো হলো, যেখানে s ভেরিয়েবলটি কোথায় বৈধ হবে তা টীকা দিয়ে দেখানো হয়েছে।
fn main() { { // s is not valid here, it’s not yet declared let s = "hello"; // s is valid from this point forward // do stuff with s } // this scope is now over, and s is no longer valid }
অন্য কথায়, এখানে দুটি গুরুত্বপূর্ণ সময় বিন্দু রয়েছে:
- যখন
sস্কোপের মধ্যে আসে, তখন এটি বৈধ। - এটি স্কোপের বাইরে যাওয়া পর্যন্ত বৈধ থাকে।
এই সময়ে, স্কোপ এবং কখন ভেরিয়েবলগুলো বৈধ তার মধ্যে সম্পর্ক অন্যান্য প্রোগ্রামিং ল্যাঙ্গুয়েজের মতোই। এবার আমরা String টাইপ প্রবর্তন করে এই বোধগম্যতার উপর ভিত্তি করে তৈরি করব।
String টাইপ (The String Type)
ওনারশিপের নিয়মগুলো ব্যাখ্যা করার জন্য, আমাদের এমন একটি ডেটা টাইপ দরকার যা আমরা চ্যাপ্টার ৩-এর “ডেটা টাইপস” বিভাগে কভার করা ডেটা টাইপগুলোর চেয়ে আরও জটিল। পূর্বে কভার করা টাইপগুলো একটি পরিচিত আকারের, স্ট্যাকে সংরক্ষণ করা যেতে পারে এবং তাদের স্কোপ শেষ হয়ে গেলে স্ট্যাক থেকে পপ করা যেতে পারে এবং অন্য কোনো কোডের অংশের যদি ভিন্ন স্কোপে একই মান ব্যবহার করার প্রয়োজন হয় তবে দ্রুত এবং তুচ্ছভাবে একটি নতুন, স্বাধীন ইন্সট্যান্স তৈরি করতে কপি করা যেতে পারে। কিন্তু আমরা হিপে সংরক্ষিত ডেটা দেখতে চাই এবং Rust কীভাবে জানে কখন সেই ডেটা পরিষ্কার করতে হবে তা অনুসন্ধান করতে চাই, এবং String টাইপ হল একটি দুর্দান্ত উদাহরণ।
আমরা String-এর সেই অংশগুলোর উপর মনোযোগ দেব যেগুলো ওনারশিপের সাথে সম্পর্কিত। এই দিকগুলো অন্যান্য জটিল ডেটা টাইপের ক্ষেত্রেও প্রযোজ্য, সেগুলো স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা হোক বা আপনার তৈরি করা হোক। আমরা চ্যাপ্টার ৮-এ String নিয়ে আরও বিস্তারিত আলোচনা করব।
আমরা ইতিমধ্যেই স্ট্রিং লিটারেল দেখেছি, যেখানে একটি স্ট্রিং মান আমাদের প্রোগ্রামে হার্ডকোড করা থাকে। স্ট্রিং লিটারেলগুলো সুবিধাজনক, কিন্তু সেগুলো প্রতিটি পরিস্থিতিতে উপযুক্ত নয় যেখানে আমরা টেক্সট ব্যবহার করতে চাইতে পারি। একটি কারণ হল সেগুলো ইমিউটেবল। আরেকটি কারণ হল, আমরা যখন কোড লিখি তখন প্রতিটি স্ট্রিং মান জানা সম্ভব নয়: উদাহরণস্বরূপ, আমরা যদি ব্যবহারকারীর ইনপুট নিতে এবং এটি সংরক্ষণ করতে চাই? এই পরিস্থিতিগুলোর জন্য, Rust-এর একটি দ্বিতীয় স্ট্রিং টাইপ রয়েছে, String। এই টাইপটি হিপে বরাদ্দ করা ডেটা পরিচালনা করে এবং সেইজন্য কম্পাইল করার সময় আমাদের কাছে অজানা পরিমাণের টেক্সট সংরক্ষণ করতে সক্ষম। আপনি from ফাংশন ব্যবহার করে একটি স্ট্রিং লিটারেল থেকে একটি String তৈরি করতে পারেন, এইভাবে:
#![allow(unused)] fn main() { let s = String::from("hello"); }
ডাবল কোলন :: অপারেটর আমাদের String টাইপের অধীনে এই বিশেষ from ফাংশনটিকে নেমস্পেস করতে দেয়, string_from-এর মতো কোনো নাম ব্যবহার করার পরিবর্তে। আমরা চ্যাপ্টার ৫-এর “মেথড সিনট্যাক্স” বিভাগে এবং চ্যাপ্টার ৭-এ “মডিউল ট্রিতে একটি আইটেমের উল্লেখ করার জন্য পাথ”-তে মডিউল সহ নেমস্পেসিং সম্পর্কে কথা বলার সময় এই সিনট্যাক্সটি নিয়ে আরও আলোচনা করব।
এই ধরনের স্ট্রিং পরিবর্তন করা যেতে পারে:
fn main() { let mut s = String::from("hello"); s.push_str(", world!"); // push_str() appends a literal to a String println!("{s}"); // This will print `hello, world!` }
তাহলে, এখানে পার্থক্য কী? কেন String পরিবর্তন করা যেতে পারে কিন্তু লিটারেলগুলো পারে না? পার্থক্য হল এই দুটি টাইপ কীভাবে মেমরি নিয়ে কাজ করে।
মেমরি এবং অ্যালোকেশন (Memory and Allocation)
স্ট্রিং লিটারেলের ক্ষেত্রে, আমরা কম্পাইল করার সময় বিষয়বস্তু জানি, তাই টেক্সটটি সরাসরি চূড়ান্ত এক্সিকিউটেবলে হার্ডকোড করা হয়। এই কারণেই স্ট্রিং লিটারেলগুলো দ্রুত এবং দক্ষ। কিন্তু এই বৈশিষ্ট্যগুলো শুধুমাত্র স্ট্রিং লিটারেলের অপরিবর্তনীয়তা থেকে আসে। দুর্ভাগ্যবশত, আমরা প্রতিটি টেক্সট অংশের জন্য বাইনারিতে মেমরির একটি অংশ রাখতে পারি না যার আকার কম্পাইল করার সময় অজানা এবং প্রোগ্রাম চলার সময় যার আকার পরিবর্তন হতে পারে।
String টাইপের সাথে, একটি পরিবর্তনযোগ্য, প্রসারণযোগ্য টেক্সট সমর্থন করার জন্য, আমাদের হিপে কম্পাইল করার সময় অজানা পরিমাণে মেমরি বরাদ্দ করতে হবে, বিষয়বস্তু রাখার জন্য। এর মানে হল:
- মেমরিটি অবশ্যই রানটাইমে মেমরি অ্যালোকেটর থেকে অনুরোধ করতে হবে।
- আমাদের
String-এর কাজ শেষ হয়ে গেলে এই মেমরিটি অ্যালোকেটরকে ফিরিয়ে দেওয়ার একটি উপায় প্রয়োজন।
সেই প্রথম অংশটি আমাদের দ্বারা সম্পন্ন হয়: যখন আমরা String::from কল করি, তখন এর ইমপ্লিমেন্টেশন প্রয়োজনীয় মেমরির অনুরোধ করে। এটি প্রোগ্রামিং ল্যাঙ্গুয়েজগুলোতে প্রায় সর্বজনীন।
তবে, দ্বিতীয় অংশটি ভিন্ন। গারবেজ কালেক্টর (GC) সহ ভাষাগুলোতে, GC অব্যবহৃত মেমরি ট্র্যাক করে এবং পরিষ্কার করে, এবং আমাদের এটি নিয়ে চিন্তা করতে হবে না। GC ছাড়া বেশিরভাগ ল্যাঙ্গুয়েজে, কখন মেমরি আর ব্যবহার করা হচ্ছে না তা শনাক্ত করা এবং এটিকে অনুরোধ করার মতোই স্পষ্টভাবে মুক্ত করার জন্য কোড কল করা আমাদের দায়িত্ব। এটি সঠিকভাবে করা ঐতিহাসিকভাবে একটি কঠিন প্রোগ্রামিং সমস্যা। যদি আমরা ভুলে যাই, তাহলে আমরা মেমরি নষ্ট করব। যদি আমরা এটি খুব তাড়াতাড়ি করি, তাহলে আমাদের একটি অবৈধ ভেরিয়েবল থাকবে। যদি আমরা এটি দুবার করি, সেটিও একটি বাগ। আমাদের ঠিক একটি allocate-কে ঠিক একটি free-এর সাথে যুক্ত করতে হবে।
Rust একটি ভিন্ন পথ নেয়: মেমরির মালিক ভেরিয়েবলটি স্কোপের বাইরে চলে গেলে স্বয়ংক্রিয়ভাবে মেমরি ফেরত দেওয়া হয়। এখানে স্ট্রিং লিটারেলের পরিবর্তে একটি String ব্যবহার করে Listing 4-1 থেকে আমাদের স্কোপ উদাহরণের একটি ভার্সন দেওয়া হলো:
fn main() { { let s = String::from("hello"); // s is valid from this point forward // do stuff with s } // this scope is now over, and s is no // longer valid }
একটি স্বাভাবিক বিন্দু আছে যেখানে আমরা আমাদের String-এর প্রয়োজনীয় মেমরি অ্যালোকেটরকে ফিরিয়ে দিতে পারি: যখন s স্কোপের বাইরে চলে যায়। যখন একটি ভেরিয়েবল স্কোপের বাইরে চলে যায়, তখন Rust আমাদের জন্য একটি বিশেষ ফাংশন কল করে। এই ফাংশনটিকে drop বলা হয় এবং এখানেই String-এর লেখক মেমরি ফেরত দেওয়ার কোড রাখতে পারেন। Rust ক্লোজিং কার্লি ব্র্যাকেটে স্বয়ংক্রিয়ভাবে drop কল করে।
দ্রষ্টব্য: C++-এ, একটি আইটেমের জীবনকালের শেষে রিসোর্স ডিলোকেট করার এই প্যাটার্নটিকে কখনও কখনও রিসোর্স অ্যাকুইজিশন ইজ ইনিশিয়ালাইজেশন (Resource Acquisition Is Initialization - RAII) বলা হয়। আপনি যদি RAII প্যাটার্ন ব্যবহার করে থাকেন তবে Rust-এর
dropফাংশনটি আপনার কাছে পরিচিত হবে।
এই প্যাটার্নটি Rust কোড লেখার পদ্ধতির উপর গভীর প্রভাব ফেলে। এটি এখনই সহজ মনে হতে পারে, তবে আরও জটিল পরিস্থিতিতে কোডের আচরণ অপ্রত্যাশিত হতে পারে যখন আমরা চাই যে একাধিক ভেরিয়েবল হিপে বরাদ্দ করা ডেটা ব্যবহার করুক। চলুন এখন সেই পরিস্থিতিগুলোর মধ্যে কয়েকটি অন্বেষণ করি।
ভেরিয়েবল এবং ডেটার মধ্যে মিথস্ক্রিয়া: মুভ (Variables and Data Interacting with Move)
Rust-এ একাধিক ভেরিয়েবল একই ডেটার সাথে ভিন্নভাবে ইন্টারঅ্যাক্ট করতে পারে। চলুন Listing 4-2-এর একটি ইন্টিজার ব্যবহার করে একটি উদাহরণ দেখি।
fn main() { let x = 5; let y = x; }
আমরা সম্ভবত অনুমান করতে পারি এটি কী করছে: "x-এ 5 মান বাইন্ড করো; তারপর x-এর মানের একটি কপি তৈরি করো এবং এটিকে y-এ বাইন্ড করো।" আমাদের এখন দুটি ভেরিয়েবল আছে, x এবং y, এবং উভয়ই 5-এর সমান। உண்மையில் এটিই ঘটছে, কারণ ইন্টিজারগুলো হল পরিচিত, নির্দিষ্ট আকারের সহজ মান এবং এই দুটি 5 মান স্ট্যাকের উপর পুশ করা হয়।
এবার চলুন String ভার্সনটি দেখি:
fn main() { let s1 = String::from("hello"); let s2 = s1; }
এটি দেখতে অনেকটা একই রকম, তাই আমরা অনুমান করতে পারি যে এটি একইভাবে কাজ করবে: অর্থাৎ, দ্বিতীয় লাইনটি s1-এর মানের একটি কপি তৈরি করবে এবং এটিকে s2-তে বাইন্ড করবে। কিন্তু আসলে এটি ঘটে না।
String-এর ক্ষেত্রে পর্দার আড়ালে কী ঘটছে তা দেখতে Figure 4-1 দেখুন। একটি String তিনটি অংশ নিয়ে গঠিত, যা বাম দিকে দেখানো হয়েছে: স্ট্রিংয়ের কনটেন্ট ধারণকারী মেমরির একটি পয়েন্টার, একটি দৈর্ঘ্য (length) এবং একটি ধারণক্ষমতা (capacity)। ডেটার এই গ্রুপটি স্ট্যাকে সংরক্ষণ করা হয়। ডানদিকে হিপের মেমরি রয়েছে যা কনটেন্ট ধারণ করে।

Figure 4-1: "hello" মান ধারণকারী একটি String-এর মেমরি উপস্থাপনা, যা s1-এর সাথে বাইন্ড করা
দৈর্ঘ্য হল String-এর কনটেন্টগুলো বর্তমানে কত বাইট মেমরি ব্যবহার করছে। ধারণক্ষমতা হল মোট মেমরির পরিমাণ, বাইটে, যা String অ্যালোকেটর থেকে পেয়েছে। দৈর্ঘ্য এবং ধারণক্ষমতার মধ্যে পার্থক্য গুরুত্বপূর্ণ, কিন্তু এই প্রসঙ্গে নয়, তাই আপাতত, ধারণক্ষমতা উপেক্ষা করা যেতে পারে।
যখন আমরা s1-কে s2-তে অ্যাসাইন করি, তখন String ডেটা কপি করা হয়, অর্থাৎ আমরা পয়েন্টার, দৈর্ঘ্য এবং ধারণক্ষমতা কপি করি যা স্ট্যাকের উপর রয়েছে। আমরা হিপের ডেটা কপি করি না যেখানে পয়েন্টারটি নির্দেশ করে। অন্য কথায়, মেমরিতে ডেটার উপস্থাপনাটি Figure 4-2-এর মতো দেখায়।

Figure 4-2: ভেরিয়েবল s2-এর মেমরি উপস্থাপনা, যেখানে s1-এর পয়েন্টার, দৈর্ঘ্য এবং ধারণক্ষমতার একটি কপি রয়েছে
উপস্থাপনাটি Figure 4-3-এর মতো নয়, যেটি মেমরি দেখতে কেমন হত যদি Rust হিপ ডেটাও কপি করত। যদি Rust এটি করত, তাহলে হিপের ডেটা বড় হলে s2 = s1 অপারেশনটি রানটাইম পারফরম্যান্সের ক্ষেত্রে খুব ব্যয়বহুল হতে পারত।

Figure 4-3: s2 = s1 কী করতে পারে তার আরেকটি সম্ভাবনা, যদি Rust হিপ ডেটাও কপি করত
আগে, আমরা বলেছিলাম যে যখন একটি ভেরিয়েবল স্কোপের বাইরে চলে যায়, তখন Rust স্বয়ংক্রিয়ভাবে drop ফাংশনটিকে কল করে এবং সেই ভেরিয়েবলের জন্য হিপ মেমরি পরিষ্কার করে। কিন্তু Figure 4-2-তে দেখানো হয়েছে যে উভয় ডেটা পয়েন্টার একই অবস্থানের দিকে নির্দেশ করছে। এটি একটি সমস্যা: যখন s2 এবং s1 স্কোপের বাইরে চলে যায়, তখন তারা উভয়ই একই মেমরি মুক্ত করার চেষ্টা করবে। এটি ডাবল ফ্রি (double free) এরর হিসাবে পরিচিত এবং এটি মেমরি নিরাপত্তার বাগগুলোর মধ্যে একটি যা আমরা আগে উল্লেখ করেছি। দুবার মেমরি মুক্ত করলে মেমরি ক্ষতিগ্রস্ত হতে পারে, যা সম্ভাব্য নিরাপত্তা দুর্বলতার দিকে পরিচালিত করতে পারে।
মেমরির নিরাপত্তা নিশ্চিত করতে, let s2 = s1; লাইনের পরে, Rust s1-কে আর বৈধ বলে মনে করে না। অতএব, s1 যখন স্কোপের বাইরে চলে যায় তখন Rust-কে কিছু মুক্ত করতে হবে না। s2 তৈরি হওয়ার পরে আপনি যখন s1 ব্যবহার করার চেষ্টা করবেন তখন কী ঘটে তা দেখুন; এটি কাজ করবে না:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}, world!");
}আপনি এইরকম একটি এরর পাবেন কারণ Rust আপনাকে অবৈধ রেফারেন্স ব্যবহার করা থেকে বিরত রাখে:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:15
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{s1}, world!");
| ^^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
আপনি যদি অন্য ল্যাঙ্গুয়েজের সাথে কাজ করার সময় শ্যালো কপি (shallow copy) এবং ডিপ কপি (deep copy) শব্দগুলো শুনে থাকেন, তাহলে ডেটা কপি না করে পয়েন্টার, দৈর্ঘ্য এবং ধারণক্ষমতা কপি করার ধারণাটি সম্ভবত শ্যালো কপি করার মতো শোনাবে। কিন্তু যেহেতু Rust প্রথম ভেরিয়েবলটিকেও অকার্যকর করে, তাই এটিকে শ্যালো কপি বলার পরিবর্তে, এটি মুভ (move) নামে পরিচিত। এই উদাহরণে, আমরা বলব যে s1 s2-তে মুভ করা হয়েছে। সুতরাং, আসলে যা ঘটে তা Figure 4-4-এ দেখানো হয়েছে।

Figure 4-4: s1 অকার্যকর হওয়ার পরে মেমরিতে উপস্থাপনা
এটি আমাদের সমস্যার সমাধান করে! শুধুমাত্র s2 বৈধ থাকায়, যখন এটি স্কোপের বাইরে চলে যাবে তখন এটি একাই মেমরি মুক্ত করবে এবং আমরা সম্পন্ন করব।
উপরন্তু, এর দ্বারা বোঝানো একটি ডিজাইন পছন্দ রয়েছে: Rust স্বয়ংক্রিয়ভাবে আপনার ডেটার “ডিপ” কপি তৈরি করবে না। অতএব, যেকোনো স্বয়ংক্রিয় কপিং রানটাইম পারফরম্যান্সের ক্ষেত্রে সস্তা বলে ধরে নেওয়া যেতে পারে।
স্কোপ এবং অ্যাসাইনমেন্ট (Scope and Assignment)
স্কোপিং, ওনারশিপ এবং drop ফাংশনের মাধ্যমে মেমরি মুক্ত হওয়ার মধ্যে সম্পর্ক এর বিপরীত। যখন আপনি একটি বিদ্যমান ভেরিয়েবলে একটি সম্পূর্ণ নতুন মান নির্ধারণ করেন, তখন Rust drop কল করবে এবং মূল মানের মেমরি অবিলম্বে মুক্ত করবে। উদাহরণস্বরূপ, এই কোডটি বিবেচনা করুন:
fn main() { let mut s = String::from("hello"); s = String::from("ahoy"); println!("{s}, world!"); }
আমরা প্রাথমিকভাবে একটি ভেরিয়েবল s ঘোষণা করি এবং "hello" মান সহ একটি String-এর সাথে আবদ্ধ করি। তারপর আমরা "ahoy" মান সহ একটি নতুন String তৈরি করি এবং s-এ বরাদ্দ করি। এই সময়ে, হিপের মূল মানটিকে কিছুই নির্দেশ করছে না।

Figure 4-5: মূল মানটি সম্পূর্ণরূপে প্রতিস্থাপিত হওয়ার পরে মেমরিতে উপস্থাপনা।
মূল স্ট্রিংটি অবিলম্বে স্কোপের বাইরে চলে যায়। Rust এটির উপর drop ফাংশন চালাবে এবং এর মেমরি অবিলম্বে মুক্ত করা হবে। যখন আমরা শেষে মানটি প্রিন্ট করি, তখন এটি "ahoy, world!" হবে।
ভেরিয়েবল এবং ডেটার মধ্যে মিথস্ক্রিয়া: ক্লোন (Variables and Data Interacting with Clone)
আমরা যদি String-এর হিপ ডেটার ডিপ কপি করতে চাই, শুধু স্ট্যাক ডেটা নয়, তাহলে আমরা clone নামক একটি সাধারণ মেথড ব্যবহার করতে পারি। আমরা চ্যাপ্টার ৫-এ মেথড সিনট্যাক্স নিয়ে আলোচনা করব, কিন্তু যেহেতু মেথডগুলো অনেক প্রোগ্রামিং ল্যাঙ্গুয়েজের একটি সাধারণ ফিচার, তাই আপনি সম্ভবত সেগুলো আগে দেখেছেন।
এখানে clone মেথডের একটি উদাহরণ দেওয়া হল:
fn main() { let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {s1}, s2 = {s2}"); }
এটি ঠিকঠাক কাজ করে এবং স্পষ্টতই Figure 4-3-তে দেখানো আচরণ তৈরি করে, যেখানে হিপ ডেটা কপি করা হয়।
আপনি যখন clone-এর একটি কল দেখেন, তখন আপনি জানেন যে কিছু নির্বিচার কোড এক্সিকিউট করা হচ্ছে এবং সেই কোডটি ব্যয়বহুল হতে পারে। এটি একটি ভিজ্যুয়াল ইন্ডিকেটর যে ভিন্ন কিছু ঘটছে।
শুধুমাত্র স্ট্যাক-ডেটা: কপি (Stack-Only Data: Copy)
আরেকটি বিষয় রয়েছে যা নিয়ে আমরা এখনও কথা বলিনি। ইন্টিজার ব্যবহার করে এই কোডটি—যার অংশ Listing 4-2-তে দেখানো হয়েছিল—কাজ করে এবং বৈধ:
fn main() { let x = 5; let y = x; println!("x = {x}, y = {y}"); }
কিন্তু এই কোডটি আমরা যা শিখেছি তার বিপরীত বলে মনে হচ্ছে: আমাদের কাছে clone-এর কোনো কল নেই, তবুও x বৈধ এবং y-তে সরানো হয়নি।
কারণ হল, ইন্টিজারের মতো টাইপগুলোর কম্পাইল করার সময় একটি পরিচিত আকার থাকে, সেগুলো সম্পূর্ণরূপে স্ট্যাকে সংরক্ষণ করা হয়, তাই আসল মানগুলোর কপি তৈরি করা দ্রুত। তার মানে আমরা y ভেরিয়েবল তৈরি করার পরে x-কে অবৈধ করতে চাইব এমন কোনো কারণ নেই। অন্য কথায়, এখানে ডিপ এবং শ্যালো কপি করার মধ্যে কোনো পার্থক্য নেই, তাই clone কল করা வழக்கী শ্যালো কপি করার থেকে আলাদা কিছু করবে না এবং আমরা এটিকে বাদ দিতে পারি।
Rust-এর একটি বিশেষ অ্যানোটেশন রয়েছে যাকে Copy ট্রেইট বলা হয়, যা আমরা ইন্টিজারের মতো স্ট্যাকে সংরক্ষিত টাইপগুলোতে রাখতে পারি (আমরা চ্যাপ্টার 10-এ ট্রেইট সম্পর্কে আরও কথা বলব)। যদি একটি টাইপ Copy ট্রেইট ইমপ্লিমেন্ট করে, তাহলে সেটি ব্যবহার করা ভেরিয়েবলগুলো মুভ করে না, বরং তুচ্ছভাবে কপি করা হয়, অন্য ভেরিয়েবলে অ্যাসাইন করার পরেও সেগুলো বৈধ থাকে।
যদি টাইপ বা এর কোনো অংশ Drop ট্রেইট ইমপ্লিমেন্ট করে, তাহলে Rust আমাদের Copy দিয়ে একটি টাইপ অ্যানোটেট করতে দেবে না। যদি টাইপটির মান স্কোপের বাইরে চলে গেলে কিছু বিশেষ ঘটার প্রয়োজন হয় এবং আমরা সেই টাইপে Copy অ্যানোটেশন যোগ করি, তাহলে আমরা একটি কম্পাইল-টাইম এরর পাব। ট্রেইট ইমপ্লিমেন্ট করার জন্য আপনার টাইপে কীভাবে Copy অ্যানোটেশন যোগ করবেন সে সম্পর্কে জানতে, Appendix C-এর “ডেরিভেবল ট্রেইটস” দেখুন।
তাহলে, কোন টাইপগুলো Copy ট্রেইট ইমপ্লিমেন্ট করে? আপনি নিশ্চিত হওয়ার জন্য প্রদত্ত টাইপের জন্য ডকুমেন্টেশন পরীক্ষা করতে পারেন, তবে একটি সাধারণ নিয়ম হিসাবে, সহজ স্কেলার মানগুলোর যেকোনো গ্রুপ Copy ইমপ্লিমেন্ট করতে পারে এবং অ্যালোকেশন প্রয়োজন বা কোনো ধরনের রিসোর্স এমন কিছু Copy ইমপ্লিমেন্ট করতে পারে না। এখানে কয়েকটি টাইপ রয়েছে যা Copy ইমপ্লিমেন্ট করে:
- সমস্ত ইন্টিজার টাইপ, যেমন
u32। - বুলিয়ান টাইপ,
bool, যার মানtrueএবংfalse। - সমস্ত ফ্লোটিং-পয়েন্ট টাইপ, যেমন
f64। - ক্যারেক্টার টাইপ,
char। - টাপল, যদি সেগুলোতে শুধুমাত্র এমন টাইপ থাকে যেগুলো
Copyইমপ্লিমেন্ট করে। উদাহরণস্বরূপ,(i32, i32)Copyইমপ্লিমেন্ট করে, কিন্তু(i32, String)করে না।
ওনারশিপ এবং ফাংশন (Ownership and Functions)
একটি ফাংশনে একটি মান পাস করার মেকানিক্স একটি ভেরিয়েবলে একটি মান অ্যাসাইন করার মতোই। একটি ফাংশনে একটি ভেরিয়েবল পাস করা অ্যাসাইনমেন্টের মতোই মুভ বা কপি করবে। Listing 4-3-তে কিছু টীকা সহ একটি উদাহরণ রয়েছে যা দেখায় যে কোথায় ভেরিয়েবলগুলো স্কোপের মধ্যে যায় এবং বাইরে যায়।
fn main() { let s = String::from("hello"); // s comes into scope takes_ownership(s); // s's value moves into the function... // ... and so is no longer valid here let x = 5; // x comes into scope makes_copy(x); // because i32 implements the Copy trait, // x does NOT move into the function, println!("{}", x); // so it's okay to use x afterward } // Here, x goes out of scope, then s. But because s's value was moved, nothing // special happens. fn takes_ownership(some_string: String) { // some_string comes into scope println!("{some_string}"); } // Here, some_string goes out of scope and `drop` is called. The backing // memory is freed. fn makes_copy(some_integer: i32) { // some_integer comes into scope println!("{some_integer}"); } // Here, some_integer goes out of scope. Nothing special happens.
আমরা যদি takes_ownership কলে s ব্যবহার করার চেষ্টা করতাম, তাহলে Rust একটি কম্পাইল-টাইম এরর দিত। এই স্ট্যাটিক চেকগুলো আমাদের ভুল থেকে রক্ষা করে। main-এ কোড যোগ করার চেষ্টা করুন যা s এবং x ব্যবহার করে, এটা দেখার জন্য যে আপনি কোথায় সেগুলো ব্যবহার করতে পারেন এবং কোথায় ওনারশিপের নিয়মগুলো আপনাকে তা করতে বাধা দেয়।
রিটার্ন ভ্যালু এবং স্কোপ (Return Values and Scope)
মান রিটার্ন করাও ওনারশিপ স্থানান্তর করতে পারে। Listing 4-4 Listing 4-3-এর মতো একই টীকা সহ কিছু মান রিটার্ন করে এমন একটি ফাংশনের উদাহরণ দেখায়।
fn main() { let s1 = gives_ownership(); // gives_ownership moves its return // value into s1 let s2 = String::from("hello"); // s2 comes into scope let s3 = takes_and_gives_back(s2); // s2 is moved into // takes_and_gives_back, which also // moves its return value into s3 } // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing // happens. s1 goes out of scope and is dropped. fn gives_ownership() -> String { // gives_ownership will move its // return value into the function // that calls it let some_string = String::from("yours"); // some_string comes into scope some_string // some_string is returned and // moves out to the calling // function } // This function takes a String and returns a String. fn takes_and_gives_back(a_string: String) -> String { // a_string comes into // scope a_string // a_string is returned and moves out to the calling function }
একটি ভেরিয়েবলের ওনারশিপ প্রতিবার একই প্যাটার্ন অনুসরণ করে: অন্য ভেরিয়েবলে একটি মান অ্যাসাইন করা এটিকে সরিয়ে দেয়। যখন একটি ভেরিয়েবল যাতে হিপের ডেটা রয়েছে, স্কোপের বাইরে চলে যায়, তখন drop দ্বারা মানটি পরিষ্কার করা হবে, যদি না ডেটার ওনারশিপ অন্য কোনো ভেরিয়েবলে সরানো হয়।
যদিও এটি কাজ করে, ওনারশিপ নেওয়া এবং তারপর প্রতিটি ফাংশনের সাথে ওনারশিপ ফিরিয়ে দেওয়া একটু ক্লান্তিকর। আমরা যদি একটি ফাংশনকে একটি মান ব্যবহার করতে দিতে চাই কিন্তু ওনারশিপ নিতে না চাই? এটি বেশ বিরক্তিকর যে আমরা যা কিছু পাস করি তাও ফিরিয়ে দিতে হবে যদি আমরা এটি আবার ব্যবহার করতে চাই, সেইসাথে ফাংশনের বডি থেকে প্রাপ্ত ডেটা যা আমরা রিটার্ন করতে চাইতে পারি।
Rust আমাদের একটি টাপল ব্যবহার করে একাধিক মান রিটার্ন করতে দেয়, যেমনটি Listing 4-5-এ দেখানো হয়েছে।
fn main() { let s1 = String::from("hello"); let (s2, len) = calculate_length(s1); println!("The length of '{s2}' is {len}."); } fn calculate_length(s: String) -> (String, usize) { let length = s.len(); // len() returns the length of a String (s, length) }
কিন্তু এটি খুব বেশি আনুষ্ঠানিকতা এবং এমন একটি ধারণার জন্য অনেক কাজ যা সাধারণ হওয়া উচিত। আমাদের সৌভাগ্য যে, Rust-এর ওনারশিপ স্থানান্তর না করে একটি মান ব্যবহার করার জন্য একটি ফিচার রয়েছে, যাকে রেফারেন্স (references) বলা হয়।
রেফারেন্স এবং বোরোয়িং (References and Borrowing)
Listing 4-5-এর টাপল কোডের সমস্যা হল, calculate_length ফাংশন কল করার পরেও আমরা যাতে String ব্যবহার করতে পারি, সেজন্য আমাদের এটিকে কলিং ফাংশনে (calling function) ফেরত দিতে হবে, কারণ String-টি calculate_length-এর মধ্যে সরানো (move) হয়েছিল। এর পরিবর্তে, আমরা String মানের একটি রেফারেন্স দিতে পারি। একটি রেফারেন্স হল একটি পয়েন্টারের মতো, এটি একটি ঠিকানা যা অনুসরণ করে আমরা সেই ঠিকানায় সংরক্ষিত ডেটা অ্যাক্সেস করতে পারি; সেই ডেটার মালিক অন্য কোনো ভেরিয়েবল। পয়েন্টারের বিপরীতে, একটি রেফারেন্স গ্যারান্টি দেয় যে এটি তার লাইফটাইম (lifetime)-এর জন্য একটি নির্দিষ্ট টাইপের বৈধ মানকে নির্দেশ করবে।
এখানে একটি calculate_length ফাংশন কীভাবে সংজ্ঞায়িত এবং ব্যবহার করা যেতে পারে, যা মানের ওনারশিপ নেওয়ার পরিবর্তে প্যারামিটার হিসাবে একটি অবজেক্টের রেফারেন্স নেয়:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{s1}' is {len}."); } fn calculate_length(s: &String) -> usize { s.len() }
প্রথমত, লক্ষ্য করুন যে ভেরিয়েবল ডিক্লারেশন এবং ফাংশন রিটার্ন ভ্যালুর সমস্ত টাপল কোড চলে গেছে। দ্বিতীয়ত, লক্ষ্য করুন যে আমরা calculate_length-এ &s1 পাস করি এবং এর সংজ্ঞায়, আমরা String-এর পরিবর্তে &String নিই। এই অ্যাম্পারস্যান্ডগুলো (ampersands) রেফারেন্স উপস্থাপন করে এবং এগুলো আপনাকে কোনো মান এর ওনারশিপ না নিয়ে সেটি ব্যবহার করতে দেয়। Figure 4-6 এই ধারণাটি চিত্রিত করে।

Figure 4-6: &String s-এর একটি ডায়াগ্রাম যা String s1-এর দিকে নির্দেশ করছে
দ্রষ্টব্য:
&ব্যবহার করে রেফারেন্সিংয়ের বিপরীত হল ডিরেফারেন্সিং (dereferencing), যা ডিরেফারেন্স অপারেটর,*দিয়ে সম্পন্ন করা হয়। আমরা চ্যাপ্টার ৮-এ ডিরেফারেন্স অপারেটরের কিছু ব্যবহার দেখব এবং চ্যাপ্টার ১৫-তে ডিরেফারেন্সিংয়ের বিশদ আলোচনা করব।
আসুন এখানে ফাংশন কলটি আরও ঘনিষ্ঠভাবে দেখি:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{s1}' is {len}."); } fn calculate_length(s: &String) -> usize { s.len() }
&s1 সিনট্যাক্স আমাদের একটি রেফারেন্স তৈরি করতে দেয় যা s1-এর মানকে রেফার করে কিন্তু এটির মালিকানা নেয় না। যেহেতু রেফারেন্সটির মালিকানা নেই, তাই রেফারেন্সটি ব্যবহার করা বন্ধ হয়ে গেলে এটি যে মানটির দিকে নির্দেশ করে সেটি ড্রপ হবে না।
একইভাবে, ফাংশনের সিগনেচার & ব্যবহার করে বোঝায় যে প্যারামিটার s-এর টাইপ হল একটি রেফারেন্স। চলুন কিছু ব্যাখ্যামূলক টীকা যোগ করি:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{s1}' is {len}."); } fn calculate_length(s: &String) -> usize { // s is a reference to a String s.len() } // Here, s goes out of scope. But because s does not have ownership of what // it refers to, the value is not dropped.
ভেরিয়েবল s যে স্কোপে বৈধ সেটি যেকোনো ফাংশন প্যারামিটারের স্কোপের মতোই, কিন্তু s ব্যবহার করা বন্ধ হয়ে গেলে রেফারেন্স দ্বারা নির্দেশিত মানটি ড্রপ হয় না, কারণ s-এর ওনারশিপ নেই। যখন ফাংশনগুলো প্রকৃত মানের পরিবর্তে প্যারামিটার হিসাবে রেফারেন্স নেয়, তখন আমাদের ওনারশিপ ফিরিয়ে দেওয়ার জন্য মানগুলো রিটার্ন করার প্রয়োজন হবে না, কারণ আমাদের কখনই ওনারশিপ ছিল না।
আমরা একটি রেফারেন্স তৈরির ক্রিয়াকে বোরোয়িং (borrowing) বলি। বাস্তব জীবনের মতো, যদি কোনো ব্যক্তির কাছে কোনো কিছু থাকে, তাহলে আপনি সেটি তার কাছ থেকে ধার নিতে পারেন। আপনার কাজ শেষ হয়ে গেলে, আপনাকে এটি ফিরিয়ে দিতে হবে। আপনি এটির মালিক নন।
তাহলে, আমরা যদি কোনো কিছু ধার করে পরিবর্তন করার চেষ্টা করি তাহলে কী হবে? Listing 4-6-এর কোডটি চেষ্টা করুন। স্পয়লার অ্যালার্ট: এটি কাজ করে না!
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}এখানে এররটি দেওয়া হলো:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | some_string.push_str(", world");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn change(some_string: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
ভেরিয়েবলগুলো যেমন ডিফল্টরূপে ইমিউটেবল, তেমনই রেফারেন্সগুলোও। আমরা যেটির রেফারেন্স নিয়েছি সেটি পরিবর্তন করার অনুমতি নেই।
মিউটেবল রেফারেন্স (Mutable References)
আমরা Listing 4-6-এর কোডটিকে কয়েকটি ছোট পরিবর্তনের মাধ্যমে ঠিক করতে পারি, যাতে একটি ধার করা মান পরিবর্তন করা যায়। এর জন্য, আমরা একটি মিউটেবল রেফারেন্স ব্যবহার করব:
fn main() { let mut s = String::from("hello"); change(&mut s); } fn change(some_string: &mut String) { some_string.push_str(", world"); }
প্রথমে আমরা s-কে mut করি। তারপর আমরা change ফাংশন কল করার সময় &mut s দিয়ে একটি মিউটেবল রেফারেন্স তৈরি করি এবং some_string: &mut String দিয়ে একটি মিউটেবল রেফারেন্স গ্রহণ করার জন্য ফাংশন সিগনেচার আপডেট করি। এটি খুব স্পষ্ট করে তোলে যে change ফাংশনটি যে মানটি ধার করে সেটি পরিবর্তন করবে।
মিউটেবল রেফারেন্সগুলোর একটি বড় সীমাবদ্ধতা রয়েছে: যদি আপনার কাছে একটি মানের মিউটেবল রেফারেন্স থাকে, তাহলে আপনি সেই মানের অন্য কোনো রেফারেন্স রাখতে পারবেন না। s-এর দুটি মিউটেবল রেফারেন্স তৈরি করার চেষ্টা করা এই কোডটি ব্যর্থ হবে:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
}এখানে এররটি দেওয়া হলো:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
এই এররটি বলে যে এই কোডটি অবৈধ কারণ আমরা s-কে একবারে একাধিকবার মিউটেবল হিসাবে ধার করতে পারি না। প্রথম মিউটেবল ধার r1-এ রয়েছে এবং println!-এ ব্যবহৃত হওয়া পর্যন্ত এটি অবশ্যই স্থায়ী হতে হবে, কিন্তু সেই মিউটেবল রেফারেন্স তৈরি এবং এর ব্যবহারের মধ্যে, আমরা r2-তে আরেকটি মিউটেবল রেফারেন্স তৈরি করার চেষ্টা করেছি যা r1-এর মতো একই ডেটা ধার করে।
একই সময়ে একই ডেটার একাধিক মিউটেবল রেফারেন্স প্রতিরোধ করার সীমাবদ্ধতা মিউটেশনের অনুমতি দেয় কিন্তু খুব নিয়ন্ত্রিত পদ্ধতিতে। এটি এমন কিছু যা নিয়ে নতুন Rustacean-রা সংগ্রাম করে কারণ বেশিরভাগ ল্যাঙ্গুয়েজ আপনাকে যখন খুশি মিউটেট করতে দেয়। এই সীমাবদ্ধতা থাকার সুবিধা হল Rust কম্পাইল করার সময় ডেটা রেস (data races) প্রতিরোধ করতে পারে। একটি ডেটা রেস একটি রেস কন্ডিশনের অনুরূপ এবং এটি ঘটে যখন এই তিনটি আচরণ ঘটে:
- দুই বা ততোধিক পয়েন্টার একই ডেটা অ্যাক্সেস করে।
- অন্তত একটি পয়েন্টার ডেটাতে লেখার জন্য ব্যবহার করা হচ্ছে।
- ডেটাতে অ্যাক্সেস সিঙ্ক্রোনাইজ করার জন্য কোনো মেকানিজম ব্যবহার করা হচ্ছে না।
ডেটা রেস অনির্ধারিত আচরণ ঘটায় এবং রানটাইমে সেগুলোকে ট্র্যাক করার চেষ্টা করার সময় নির্ণয় এবং ঠিক করা কঠিন হতে পারে; Rust ডেটা রেস সহ কোড কম্পাইল করতে অস্বীকার করে এই সমস্যাটি প্রতিরোধ করে!
বরাবরের মতো, আমরা একাধিক মিউটেবল রেফারেন্সের অনুমতি দেওয়ার জন্য একটি নতুন স্কোপ তৈরি করতে কার্লি ব্র্যাকেট ব্যবহার করতে পারি, তবে একযোগে নয়:
fn main() { let mut s = String::from("hello"); { let r1 = &mut s; } // r1 goes out of scope here, so we can make a new reference with no problems. let r2 = &mut s; }
মিউটেবল এবং ইমিউটেবল রেফারেন্স একত্রিত করার জন্য Rust একই ধরনের নিয়ম প্রয়োগ করে। এই কোডটির ফলে একটি এরর হয়:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{}, {}, and {}", r1, r2, r3);
}এখানে এররটি দেওয়া হলো:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{}, {}, and {}", r1, r2, r3);
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
যাক বাবা! আমরা একই মানের একটি ইমিউটেবল রেফারেন্স থাকাকালীন একটি মিউটেবল রেফারেন্স রাখতে পারি না।
একটি ইমিউটেবল রেফারেন্সের ব্যবহারকারীরা আশা করে না যে মানটি হঠাৎ করে তাদের অজান্তেই পরিবর্তিত হয়ে যাবে! তবে, একাধিক ইমিউটেবল রেফারেন্স অনুমোদিত কারণ যারা শুধুমাত্র ডেটা পড়ছে তাদের কারও ডেটা পড়ার উপর প্রভাব ফেলার ক্ষমতা নেই।
মনে রাখবেন যে একটি রেফারেন্সের স্কোপ শুরু হয় যেখানে এটি প্রবর্তিত হয় এবং সেই রেফারেন্সটি শেষবার ব্যবহার করা পর্যন্ত চলতে থাকে। উদাহরণস্বরূপ, এই কোডটি কম্পাইল হবে কারণ ইমিউটেবল রেফারেন্সগুলোর শেষ ব্যবহার println!-এ, মিউটেবল রেফারেন্স প্রবর্তিত হওয়ার আগে:
fn main() { let mut s = String::from("hello"); let r1 = &s; // no problem let r2 = &s; // no problem println!("{r1} and {r2}"); // Variables r1 and r2 will not be used after this point. let r3 = &mut s; // no problem println!("{r3}"); }
ইমিউটেবল রেফারেন্স r1 এবং r2-এর স্কোপগুলো println!-এর পরে শেষ হয় যেখানে সেগুলো শেষবার ব্যবহার করা হয়েছে, যা মিউটেবল রেফারেন্স r3 তৈরি হওয়ার আগে। এই স্কোপগুলো ওভারল্যাপ করে না, তাই এই কোডটি অনুমোদিত: কম্পাইলার বলতে পারে যে রেফারেন্সটি স্কোপের শেষ হওয়ার আগে একটি বিন্দুতে আর ব্যবহার করা হচ্ছে না।
এমনকি যদি বোরোয়িং এররগুলো মাঝে মাঝে হতাশাজনক হতে পারে, মনে রাখবেন যে এটি হল Rust কম্পাইলার একটি সম্ভাব্য বাগ তাড়াতাড়ি (রানটাইমের পরিবর্তে কম্পাইল করার সময়) নির্দেশ করছে এবং আপনাকে ঠিক কোথায় সমস্যাটি রয়েছে তা দেখাচ্ছে। তাহলে আপনাকে ট্র্যাক করতে হবে না কেন আপনার ডেটা আপনার ভাবনার মতো নয়।
ড্যাংলিং রেফারেন্স (Dangling References)
পয়েন্টার সহ ভাষাগুলোতে, ভুলবশত একটি ড্যাংলিং পয়েন্টার (dangling pointer)—একটি পয়েন্টার যা মেমরির এমন একটি লোকেশনকে নির্দেশ করে যা হয়তো অন্য কাউকে দেওয়া হয়েছে—তৈরি করা সহজ, কিছু মেমরি মুক্ত করার সময় সেই মেমরির একটি পয়েন্টার সংরক্ষণ করে। অন্যদিকে, Rust-এ, কম্পাইলার গ্যারান্টি দেয় যে রেফারেন্সগুলো কখনই ড্যাংলিং রেফারেন্স হবে না: যদি আপনার কাছে কিছু ডেটার রেফারেন্স থাকে, তাহলে কম্পাইলার নিশ্চিত করবে যে ডেটার রেফারেন্স শেষ হওয়ার আগে ডেটা স্কোপের বাইরে যাবে না।
আসুন একটি ড্যাংলিং রেফারেন্স তৈরি করার চেষ্টা করি, এটা দেখতে যে Rust কীভাবে কম্পাইল-টাইম এরর দিয়ে সেগুলো প্রতিরোধ করে:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}এখানে এররটি দেওয়া হলো:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn dangle() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn dangle() -> &String {
5 + fn dangle() -> String {
|
error[E0515]: cannot return reference to local variable `s`
--> src/main.rs:8:5
|
8 | &s
| ^^ returns a reference to data owned by the current function
Some errors have detailed explanations: E0106, E0515.
For more information about an error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 2 previous errors
এই এরর মেসেজটি এমন একটি ফিচারের কথা বলে যা আমরা এখনও কভার করিনি: লাইফটাইম। আমরা চ্যাপ্টার ১০-এ লাইফটাইম নিয়ে বিস্তারিত আলোচনা করব। কিন্তু, আপনি যদি লাইফটাইম সম্পর্কিত অংশগুলো উপেক্ষা করেন, তাহলে মেসেজটিতে এই কোডটি কেন সমস্যাযুক্ত তার মূল বিষয় রয়েছে:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
আসুন আরও ঘনিষ্ঠভাবে দেখি আমাদের dangle কোডের প্রতিটি পর্যায়ে ঠিক কী ঘটছে:
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // we return a reference to the String, s
} // Here, s goes out of scope, and is dropped, so its memory goes away.
// Danger!যেহেতু s dangle-এর ভিতরে তৈরি করা হয়েছে, তাই dangle-এর কোড শেষ হয়ে গেলে, s ডিলোক্যাট করা হবে। কিন্তু আমরা এটির একটি রেফারেন্স রিটার্ন করার চেষ্টা করেছি। এর মানে হল এই রেফারেন্সটি একটি অকার্যকর String-এর দিকে নির্দেশ করবে। সেটি ভালো নয়! Rust আমাদের এটি করতে দেবে না।
এখানে সমাধান হল সরাসরি String রিটার্ন করা:
fn main() { let string = no_dangle(); } fn no_dangle() -> String { let s = String::from("hello"); s }
এটি কোনো সমস্যা ছাড়াই কাজ করে। ওনারশিপ সরানো হয়েছে এবং কিছুই ডিলোক্যাট করা হয়নি।
রেফারেন্সের নিয়ম (The Rules of References)
আসুন, রেফারেন্স সম্পর্কে আমরা যা আলোচনা করেছি তার পুনরাবৃত্তি করি:
- যেকোনো সময়ে, আপনি হয় একটি মিউটেবল রেফারেন্স অথবা যেকোনো সংখ্যক ইমিউটেবল রেফারেন্স রাখতে পারেন।
- রেফারেন্সগুলো সর্বদাই বৈধ হতে হবে।
এরপর, আমরা একটি ভিন্ন ধরনের রেফারেন্স দেখব: স্লাইস।
স্লাইস টাইপ (The Slice Type)
স্লাইস (slices) আপনাকে সম্পূর্ণ কালেকশনের পরিবর্তে কালেকশনের উপাদানগুলোর একটি ধারাবাহিক অংশকে রেফারেন্স করতে দেয়। একটি স্লাইস হল এক ধরনের রেফারেন্স, তাই এর ওনারশিপ নেই।
এখানে একটি ছোট প্রোগ্রামিং সমস্যা রয়েছে: এমন একটি ফাংশন লিখুন যা স্পেস দ্বারা পৃথক করা শব্দের একটি স্ট্রিং নেয় এবং সেই স্ট্রিংটিতে পাওয়া প্রথম শব্দটি রিটার্ন করে। যদি ফাংশনটি স্ট্রিংটিতে কোনো স্পেস খুঁজে না পায়, তাহলে পুরো স্ট্রিংটি অবশ্যই একটি শব্দ হবে, তাই সম্পূর্ণ স্ট্রিংটি রিটার্ন করা উচিত।
স্লাইস ব্যবহার না করে আমরা কীভাবে এই ফাংশনের সিগনেচার লিখব তা নিয়ে কাজ করি, যাতে স্লাইসগুলো যে সমস্যার সমাধান করবে তা বোঝা যায়:
fn first_word(s: &String) -> ?first_word ফাংশনটির প্যারামিটার হিসাবে একটি &String রয়েছে। আমাদের ওনারশিপের প্রয়োজন নেই, তাই এটি ঠিক আছে। (প্রচলিত Rust-এ, ফাংশনগুলো তাদের আর্গুমেন্টের ওনারশিপ নেয় না যদি না তাদের প্রয়োজন হয়, এবং এর কারণগুলো আমরা যত এগোব ততই স্পষ্ট হয়ে উঠবে!) কিন্তু আমরা কী রিটার্ন করব? আমাদের কাছে স্ট্রিং-এর অংশ সম্পর্কে কথা বলার কোনো উপায় নেই। তবে, আমরা একটি স্পেস দ্বারা নির্দেশিত শব্দের শেষের ইনডেক্সটি রিটার্ন করতে পারি। চলুন Listing 4-7-এ দেখানো মতো সেটি চেষ্টা করি।
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() {}
যেহেতু আমাদের String-এর প্রতিটি এলিমেন্টের মধ্যে গিয়ে পরীক্ষা করতে হবে যে কোনো মান স্পেস কিনা, তাই আমরা as_bytes মেথড ব্যবহার করে আমাদের String-কে বাইটের অ্যারেতে রূপান্তর করব।
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}এরপর, আমরা iter মেথড ব্যবহার করে বাইটের অ্যারের উপর একটি ইটারেটর তৈরি করি:
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}আমরা চ্যাপ্টার 13-এ ইটারেটরগুলো নিয়ে আরও বিস্তারিত আলোচনা করব। আপাতত, জেনে রাখুন যে iter হল একটি মেথড যা একটি কালেকশনের প্রতিটি এলিমেন্ট রিটার্ন করে এবং enumerate iter-এর ফলাফলকে র্যাপ করে এবং প্রতিটি এলিমেন্টকে একটি টাপলের অংশ হিসাবে রিটার্ন করে। enumerate থেকে রিটার্ন করা টাপলের প্রথম এলিমেন্টটি হল ইনডেক্স এবং দ্বিতীয় এলিমেন্টটি হল এলিমেন্টের একটি রেফারেন্স। এটি নিজে থেকে ইনডেক্স গণনা করার চেয়ে একটু বেশি সুবিধাজনক।
যেহেতু enumerate মেথড একটি টাপল রিটার্ন করে, তাই আমরা সেই টাপলটিকে ডিস্ট্রাকচার করতে প্যাটার্ন ব্যবহার করতে পারি। আমরা চ্যাপ্টার 6-এ প্যাটার্নগুলো নিয়ে আরও আলোচনা করব। for লুপে, আমরা একটি প্যাটার্ন নির্দিষ্ট করি যেখানে টাপলের ইনডেক্সের জন্য i এবং টাপলের একক বাইটের জন্য &item রয়েছে। যেহেতু আমরা .iter().enumerate() থেকে এলিমেন্টের একটি রেফারেন্স পাই, তাই আমরা প্যাটার্নে & ব্যবহার করি।
for লুপের ভিতরে, আমরা বাইট লিটারেল সিনট্যাক্স ব্যবহার করে স্পেস উপস্থাপন করে এমন বাইটটি খুঁজি। যদি আমরা একটি স্পেস খুঁজে পাই, তাহলে আমরা অবস্থানটি রিটার্ন করি। অন্যথায়, আমরা s.len() ব্যবহার করে স্ট্রিংটির দৈর্ঘ্য রিটার্ন করি।
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}আমাদের কাছে এখন স্ট্রিং-এর প্রথম শব্দের শেষের ইনডেক্স খুঁজে বের করার একটি উপায় আছে, কিন্তু একটি সমস্যা আছে। আমরা নিজে থেকে একটি usize রিটার্ন করছি, কিন্তু এটি শুধুমাত্র &String-এর পরিপ্রেক্ষিতে একটি অর্থপূর্ণ সংখ্যা। অন্য কথায়, যেহেতু এটি String থেকে একটি পৃথক মান, তাই ভবিষ্যতে এটি বৈধ থাকবে এমন কোনো নিশ্চয়তা নেই। Listing 4-8-এর প্রোগ্রামটি বিবেচনা করুন, যেটি Listing 4-7 থেকে first_word ফাংশন ব্যবহার করে।
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() { let mut s = String::from("hello world"); let word = first_word(&s); // word will get the value 5 s.clear(); // this empties the String, making it equal to "" // `word` still has the value `5` here, but `s` no longer has any content // that we could meaningfully use with the value `5`, so `word` is now // totally invalid! }
এই প্রোগ্রামটি কোনো এরর ছাড়াই কম্পাইল হয় এবং s.clear() কল করার পরেও যদি আমরা word ব্যবহার করি তাহলেও কম্পাইল হবে। যেহেতু word কোনোভাবেই s-এর অবস্থার সাথে সংযুক্ত নয়, তাই word-এ এখনও 5 মান রয়েছে। আমরা সেই 5 মানটি s ভেরিয়েবলের সাথে ব্যবহার করে প্রথম শব্দটি বের করার চেষ্টা করতে পারি, কিন্তু এটি একটি বাগ হবে কারণ আমরা word-এ 5 সংরক্ষণ করার পর থেকে s-এর কনটেন্ট পরিবর্তন হয়েছে।
word-এর ইনডেক্সটি s-এর ডেটার সাথে সিঙ্কের বাইরে চলে যাওয়া নিয়ে চিন্তা করা ক্লান্তিকর এবং এরর-প্রবণ! আমরা যদি একটি second_word ফাংশন লিখি তাহলে এই ইনডেক্সগুলো পরিচালনা করা আরও কঠিন। এর সিগনেচারটি এমন হতে হবে:
fn second_word(s: &String) -> (usize, usize) {এখন আমরা একটি শুরুর এবং একটি শেষের ইনডেক্স ট্র্যাক করছি এবং আমাদের কাছে আরও বেশি মান রয়েছে যা একটি নির্দিষ্ট অবস্থার ডেটা থেকে গণনা করা হয়েছে কিন্তু সেই অবস্থার সাথে কোনোভাবেই সংযুক্ত নয়। আমাদের কাছে তিনটি সম্পর্কহীন ভেরিয়েবল রয়েছে যেগুলোকে সিঙ্কে রাখতে হবে।
সৌভাগ্যবশত, Rust-এর এই সমস্যার একটি সমাধান রয়েছে: স্ট্রিং স্লাইস।
স্ট্রিং স্লাইস (String Slices)
একটি স্ট্রিং স্লাইস হল একটি String-এর অংশের একটি রেফারেন্স, এবং এটি দেখতে এরকম:
fn main() { let s = String::from("hello world"); let hello = &s[0..5]; let world = &s[6..11]; }
সম্পূর্ণ String-এর রেফারেন্সের পরিবর্তে, hello হল String-এর একটি অংশের রেফারেন্স, যা অতিরিক্ত [0..5] বিটে নির্দিষ্ট করা হয়েছে। আমরা [starting_index..ending_index] নির্দিষ্ট করে ব্র্যাকেটের মধ্যে একটি রেঞ্জ ব্যবহার করে স্লাইস তৈরি করি, যেখানে starting_index হল স্লাইসের প্রথম অবস্থান এবং ending_index হল স্লাইসের শেষ অবস্থানের চেয়ে এক বেশি। অভ্যন্তরীণভাবে, স্লাইস ডেটা স্ট্রাকচারটি শুরুর অবস্থান এবং স্লাইসের দৈর্ঘ্য সংরক্ষণ করে, যা ending_index বিয়োগ starting_index-এর সাথে সঙ্গতিপূর্ণ। সুতরাং, let world = &s[6..11];-এর ক্ষেত্রে, world হবে একটি স্লাইস যাতে s-এর 6 ইনডেক্সের বাইটের একটি পয়েন্টার থাকবে এবং দৈর্ঘ্য হবে 5।
Figure 4-7 এটি একটি ডায়াগ্রামে দেখায়।

Figure 4-7: একটি String-এর অংশকে রেফারেন্স করা স্ট্রিং স্লাইস
Rust-এর .. রেঞ্জ সিনট্যাক্সের সাথে, আপনি যদি 0 ইনডেক্স থেকে শুরু করতে চান, তাহলে আপনি দুটি পিরিয়ডের আগের মানটি বাদ দিতে পারেন। অন্য কথায়, এগুলো সমান:
#![allow(unused)] fn main() { let s = String::from("hello"); let slice = &s[0..2]; let slice = &s[..2]; }
একইভাবে, যদি আপনার স্লাইসটিতে String-এর শেষ বাইট অন্তর্ভুক্ত থাকে, তাহলে আপনি ট্রেইলিং সংখ্যাটি বাদ দিতে পারেন। তার মানে এগুলো সমান:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[3..len]; let slice = &s[3..]; }
আপনি সম্পূর্ণ স্ট্রিং-এর একটি স্লাইস নিতে উভয় মানও বাদ দিতে পারেন। তাই এগুলো সমান:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[0..len]; let slice = &s[..]; }
দ্রষ্টব্য: স্ট্রিং স্লাইস রেঞ্জ ইনডেক্সগুলো অবশ্যই বৈধ UTF-8 ক্যারেক্টার সীমানায় ঘটতে হবে। আপনি যদি একটি মাল্টিবাইট ক্যারেক্টারের মাঝখানে একটি স্ট্রিং স্লাইস তৈরি করার চেষ্টা করেন, তাহলে আপনার প্রোগ্রামটি একটি এরর দিয়ে প্রস্থান করবে। স্ট্রিং স্লাইস প্রবর্তনের উদ্দেশ্যে, আমরা এই বিভাগে শুধুমাত্র ASCII অনুমান করছি; UTF-8 হ্যান্ডলিং-এর আরও বিশদ আলোচনা চ্যাপ্টার 8-এর “স্ট্রিং দিয়ে UTF-8 এনকোডেড টেক্সট সংরক্ষণ করা” বিভাগে রয়েছে।
এই সমস্ত তথ্য মাথায় রেখে, চলুন first_word পুনরায় লিখি যাতে এটি একটি স্লাইস রিটার্ন করে। "স্ট্রিং স্লাইস" বোঝায় এমন টাইপটি &str হিসাবে লেখা হয়:
fn first_word(s: &String) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() {}
আমরা Listing 4-7-এর মতোই শব্দের শেষের ইনডেক্সটি পাই, একটি স্পেসের প্রথম ঘটনাটি সন্ধান করে। যখন আমরা একটি স্পেস খুঁজে পাই, তখন আমরা স্ট্রিং-এর শুরু এবং স্পেসের ইনডেক্সটিকে শুরুর এবং শেষের ইনডেক্স হিসাবে ব্যবহার করে একটি স্ট্রিং স্লাইস রিটার্ন করি।
এখন যখন আমরা first_word কল করি, তখন আমরা একটি একক মান ফিরে পাই যা অন্তর্নিহিত ডেটার সাথে সংযুক্ত। মানটি স্লাইসের শুরুর বিন্দুর একটি রেফারেন্স এবং স্লাইসের উপাদানগুলোর সংখ্যা নিয়ে গঠিত।
একটি second_word ফাংশনের জন্যও একটি স্লাইস রিটার্ন করা কাজ করবে:
fn second_word(s: &String) -> &str {আমাদের কাছে এখন একটি সরল API রয়েছে যা এলোমেলো করা অনেক কঠিন, কারণ কম্পাইলার নিশ্চিত করবে যে String-এর রেফারেন্সগুলো বৈধ থাকবে। Listing 4-8-এর প্রোগ্রামের বাগটি মনে আছে, যখন আমরা প্রথম শব্দের শেষের ইনডেক্স পেয়েছিলাম কিন্তু তারপর স্ট্রিংটি পরিষ্কার করেছিলাম যাতে আমাদের ইনডেক্সটি অবৈধ হয়ে গিয়েছিল? সেই কোডটি যুক্তিগতভাবে ভুল ছিল কিন্তু কোনো তাৎক্ষণিক এরর দেখায়নি। সমস্যাগুলো পরে দেখা যেত যদি আমরা খালি স্ট্রিং দিয়ে প্রথম শব্দের ইনডেক্স ব্যবহার করতে থাকতাম। স্লাইসগুলো এই বাগটিকে অসম্ভব করে তোলে এবং আমাদের কোডে কোনো সমস্যা থাকলে তা অনেক আগেই জানিয়ে দেয়। first_word-এর স্লাইস ভার্সন ব্যবহার করলে একটি কম্পাইল-টাইম এরর হবে:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {word}");
}এখানে কম্পাইলার এররটি দেওয়া হলো:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {word}");
| ------ immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
বোরোয়িং-এর নিয়ম থেকে মনে করুন যে যদি আমাদের কাছে কোনো কিছুর ইমিউটেবল রেফারেন্স থাকে, তাহলে আমরা একটি মিউটেবল রেফারেন্সও নিতে পারি না। যেহেতু clear-এর String ছোট করা দরকার, তাই এটিকে একটি মিউটেবল রেফারেন্স নিতে হবে। clear কলের পরে println! word-এর রেফারেন্স ব্যবহার করে, তাই সেই সময়ে ইমিউটেবল রেফারেন্সটি এখনও সক্রিয় থাকতে হবে। Rust clear-এর মিউটেবল রেফারেন্স এবং word-এর ইমিউটেবল রেফারেন্সকে একই সময়ে বিদ্যমান থাকতে দেয় না এবং কম্পাইলেশন ব্যর্থ হয়। Rust শুধুমাত্র আমাদের API ব্যবহার করা সহজ করেনি, এটি কম্পাইল করার সময়ই এক শ্রেণীর এরর সম্পূর্ণরূপে দূর করেছে!
স্ট্রিং লিটারেলগুলো স্লাইস (String Literals as Slices)
মনে করে দেখুন যে আমরা স্ট্রিং লিটারেলগুলো বাইনারির ভিতরে সংরক্ষিত থাকার বিষয়ে কথা বলেছি। এখন যেহেতু আমরা স্লাইস সম্পর্কে জানি, তাই আমরা স্ট্রিং লিটারেলগুলোকে সঠিকভাবে বুঝতে পারি:
#![allow(unused)] fn main() { let s = "Hello, world!"; }
এখানে s-এর টাইপ হল &str: এটি বাইনারির সেই নির্দিষ্ট পয়েন্টকে নির্দেশ করা একটি স্লাইস। এই কারণেই স্ট্রিং লিটারেলগুলো ইমিউটেবল; &str হল একটি ইমিউটেবল রেফারেন্স।
প্যারামিটার হিসাবে স্ট্রিং স্লাইস (String Slices as Parameters)
লিটারেল এবং String মানগুলোর স্লাইস নিতে পারা আমাদের first_word-এ আরও একটি উন্নতির দিকে নিয়ে যায়, এবং সেটি হল এর সিগনেচার:
fn first_word(s: &String) -> &str {একজন আরও অভিজ্ঞ Rustacean পরিবর্তে Listing 4-9-এ দেখানো সিগনেচারটি লিখবেন কারণ এটি আমাদের একই ফাংশনটি &String মান এবং &str মান, উভয়ের উপর ব্যবহার করার অনুমতি দেয়।
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}যদি আমাদের কাছে একটি স্ট্রিং স্লাইস থাকে, তাহলে আমরা সেটি সরাসরি পাস করতে পারি। যদি আমাদের কাছে একটি String থাকে, তাহলে আমরা String-এর একটি স্লাইস বা String-এর একটি রেফারেন্স পাস করতে পারি। এই নমনীয়তা ডিরেফ কোয়েরশনস (deref coercions)-এর সুবিধা নেয়, একটি ফিচার যা আমরা চ্যাপ্টার ১৫-এর “ফাংশন এবং মেথড সহ ইমপ্লিসিট ডিরেফ কোয়েরশনস” বিভাগে কভার করব।
একটি String-এর রেফারেন্সের পরিবর্তে একটি স্ট্রিং স্লাইস নেওয়ার জন্য একটি ফাংশন সংজ্ঞায়িত করা আমাদের API-কে আরও সাধারণ এবং দরকারী করে তোলে, কোনো কার্যকারিতা না হারিয়ে:
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // `first_word` works on slices of `String`s, whether partial or whole. let word = first_word(&my_string[0..6]); let word = first_word(&my_string[..]); // `first_word` also works on references to `String`s, which are equivalent // to whole slices of `String`s. let word = first_word(&my_string); let my_string_literal = "hello world"; // `first_word` works on slices of string literals, whether partial or // whole. let word = first_word(&my_string_literal[0..6]); let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
অন্যান্য স্লাইস (Other Slices)
আপনি যেমন কল্পনা করতে পারেন, স্ট্রিং স্লাইসগুলো স্ট্রিং-এর জন্য নির্দিষ্ট। কিন্তু আরও একটি সাধারণ স্লাইস টাইপও রয়েছে। এই অ্যারেটি বিবেচনা করুন:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; }
যেমন আমরা একটি স্ট্রিং-এর অংশের উল্লেখ করতে চাইতে পারি, তেমনি আমরা একটি অ্যারের অংশের উল্লেখ করতে চাইতে পারি। আমরা এটি এইভাবে করব:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; let slice = &a[1..3]; assert_eq!(slice, &[2, 3]); }
এই স্লাইসটির টাইপ হল &[i32]। এটি স্ট্রিং স্লাইসগুলোর মতোই কাজ করে, প্রথম উপাদানের একটি রেফারেন্স এবং একটি দৈর্ঘ্য সংরক্ষণ করে। আপনি অন্যান্য সমস্ত ধরণের কালেকশনের জন্য এই ধরনের স্লাইস ব্যবহার করবেন। আমরা চ্যাপ্টার ৮-এ ভেক্টর নিয়ে কথা বলার সময় এই কালেকশনগুলো নিয়ে বিস্তারিত আলোচনা করব।
সারসংক্ষেপ (Summary)
ওনারশিপ, বোরোয়িং এবং স্লাইসের ধারণাগুলো কম্পাইল করার সময় Rust প্রোগ্রামগুলোতে মেমরির নিরাপত্তা নিশ্চিত করে। Rust ল্যাঙ্গুয়েজ আপনাকে অন্যান্য সিস্টেম প্রোগ্রামিং ল্যাঙ্গুয়েজের মতোই আপনার মেমরি ব্যবহারের উপর নিয়ন্ত্রণ দেয়, কিন্তু ডেটার ওনার স্বয়ংক্রিয়ভাবে সেই ডেটা পরিষ্কার করার মানে হল আপনাকে এই নিয়ন্ত্রণ পেতে অতিরিক্ত কোড লিখতে এবং ডিবাগ করতে হবে না।
ওনারশিপ Rust-এর আরও অনেক অংশের কাজকে প্রভাবিত করে, তাই আমরা বই জুড়ে এই ধারণাগুলো নিয়ে আরও কথা বলব। চলুন চ্যাপ্টার ৫-এ যাই এবং একটি struct-এ ডেটার অংশগুলোকে একত্রিত করা দেখি।
স্ট্রাকট ব্যবহার করে সম্পর্কিত ডেটা স্ট্রাকচার করা (Using Structs to Structure Related Data)
একটি স্ট্রাকট (struct), বা স্ট্রাকচার (structure), হল একটি কাস্টম ডেটা টাইপ যা আপনাকে একাধিক সম্পর্কিত মানকে একসাথে প্যাকেজ করতে এবং নাম দিতে দেয়, যা একটি অর্থপূর্ণ গ্রুপ তৈরি করে। আপনি যদি অবজেক্ট-ওরিয়েন্টেড ভাষার সাথে পরিচিত হন, তাহলে একটি স্ট্রাকট হল একটি অবজেক্টের ডেটা অ্যাট্রিবিউটের মতো। এই চ্যাপ্টারে, আপনি ইতিমধ্যেই যা জানেন তার উপর ভিত্তি করে আমরা টাপলগুলোর সাথে স্ট্রাকটগুলোর তুলনা করব এবং কখন ডেটা গ্রুপ করার জন্য স্ট্রাকটগুলো একটি ভাল উপায় তা প্রদর্শন করব।
আমরা স্ট্রাকটগুলো কীভাবে সংজ্ঞায়িত এবং ইন্সট্যানশিয়েট (instantiate) করতে হয় তা প্রদর্শন করব। আমরা অ্যাসোসিয়েটেড ফাংশনগুলো কীভাবে সংজ্ঞায়িত করতে হয় তা নিয়ে আলোচনা করব, বিশেষ করে মেথড (methods) নামক অ্যাসোসিয়েটেড ফাংশনগুলো, যা একটি স্ট্রাকট টাইপের সাথে সম্পর্কিত আচরণ নির্দিষ্ট করে। স্ট্রাকট এবং এনাম (enum) (চ্যাপ্টার ৬-এ আলোচিত) হল আপনার প্রোগ্রামের ডোমেনে নতুন টাইপ তৈরি করার বিল্ডিং ব্লক, যাতে Rust-এর কম্পাইল-টাইম টাইপ চেকিং-এর সম্পূর্ণ সুবিধা নেওয়া যায়।
স্ট্রাকট সংজ্ঞায়িত এবং ইন্সট্যানশিয়েট করা (Defining and Instantiating Structs)
স্ট্রাকটগুলো টাপলগুলোর মতোই, যা “টাপল টাইপ” বিভাগে আলোচিত হয়েছে। উভয়ই একাধিক সম্পর্কিত মান ধারণ করে। টাপলগুলোর মতো, একটি স্ট্রাকটের অংশগুলো বিভিন্ন টাইপের হতে পারে। টাপলগুলোর বিপরীতে, একটি স্ট্রাকটে আপনি ডেটার প্রতিটি অংশের নাম দেবেন যাতে মানগুলোর অর্থ স্পষ্ট হয়। এই নামগুলো যুক্ত করার অর্থ হল স্ট্রাকটগুলো টাপলগুলোর চেয়ে বেশি নমনীয়: একটি ইন্সট্যান্সের মান নির্দিষ্ট করতে বা অ্যাক্সেস করতে আপনাকে ডেটার ক্রমের উপর নির্ভর করতে হবে না।
একটি স্ট্রাকট সংজ্ঞায়িত করতে, আমরা struct কীওয়ার্ডটি লিখি এবং পুরো স্ট্রাকটটির নাম দিই। একটি স্ট্রাকটের নাম ডেটার অংশগুলোকে একত্রিত করার তাৎপর্য বর্ণনা করবে। তারপর, কার্লি ব্র্যাকেটের ভিতরে, আমরা ডেটার অংশগুলোর নাম এবং টাইপ সংজ্ঞায়িত করি, যাকে আমরা ফিল্ড (fields) বলি। উদাহরণস্বরূপ, Listing 5-1 একটি ব্যবহারকারী অ্যাকাউন্ট সম্পর্কে তথ্য সংরক্ষণ করে এমন একটি স্ট্রাকট দেখায়।
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() {}
একটি স্ট্রাকট সংজ্ঞায়িত করার পরে সেটি ব্যবহার করতে, আমরা প্রতিটি ফিল্ডের জন্য নির্দিষ্ট মান উল্লেখ করে সেই স্ট্রাকটের একটি ইন্সট্যান্স (instance) তৈরি করি। আমরা স্ট্রাকটের নাম উল্লেখ করে এবং তারপর কী (key): মান (value) জোড়া ধারণকারী কার্লি ব্র্যাকেট যুক্ত করে একটি ইন্সট্যান্স তৈরি করি, যেখানে কীগুলো হল ফিল্ডগুলোর নাম এবং মানগুলো হল সেই ফিল্ডগুলোতে আমরা যে ডেটা সংরক্ষণ করতে চাই। আমাদেরকে স্ট্রাকটে যে ক্রমে ফিল্ডগুলো ঘোষণা করেছি সেই একই ক্রমে নির্দিষ্ট করতে হবে না। অন্য কথায়, স্ট্রাকট সংজ্ঞাটি টাইপের জন্য একটি সাধারণ টেমপ্লেটের মতো এবং ইন্সট্যান্সগুলো সেই টেমপ্লেটটিকে নির্দিষ্ট ডেটা দিয়ে পূরণ করে টাইপের মান তৈরি করে। উদাহরণস্বরূপ, আমরা Listing 5-2-তে দেখানো একটি নির্দিষ্ট ব্যবহারকারী ঘোষণা করতে পারি।
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let user1 = User { active: true, username: String::from("someusername123"), email: String::from("someone@example.com"), sign_in_count: 1, }; }
একটি স্ট্রাকট থেকে একটি নির্দিষ্ট মান পেতে, আমরা ডট নোটেশন ব্যবহার করি। উদাহরণস্বরূপ, এই ব্যবহারকারীর ইমেল ঠিকানা অ্যাক্সেস করতে, আমরা user1.email ব্যবহার করি। যদি ইন্সট্যান্সটি মিউটেবল হয়, তাহলে আমরা ডট নোটেশন ব্যবহার করে এবং একটি নির্দিষ্ট ফিল্ডে অ্যাসাইন করে একটি মান পরিবর্তন করতে পারি। Listing 5-3 একটি মিউটেবল User ইন্সট্যান্সের email ফিল্ডের মান কীভাবে পরিবর্তন করতে হয় তা দেখায়।
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let mut user1 = User { active: true, username: String::from("someusername123"), email: String::from("someone@example.com"), sign_in_count: 1, }; user1.email = String::from("anotheremail@example.com"); }
মনে রাখবেন যে সম্পূর্ণ ইন্সট্যান্সটি অবশ্যই মিউটেবল হতে হবে; Rust আমাদেরকে শুধুমাত্র নির্দিষ্ট ফিল্ডগুলোকে মিউটেবল হিসাবে চিহ্নিত করার অনুমতি দেয় না। যেকোনো এক্সপ্রেশনের মতো, আমরা ফাংশন বডির শেষ এক্সপ্রেশন হিসাবে স্ট্রাকটের একটি নতুন ইন্সট্যান্স তৈরি করতে পারি, পরোক্ষভাবে সেই নতুন ইন্সট্যান্সটি রিটার্ন করতে পারি।
Listing 5-4 একটি build_user ফাংশন দেখায় যা প্রদত্ত ইমেল এবং ব্যবহারকারীর নাম সহ একটি User ইন্সট্যান্স রিটার্ন করে। active ফিল্ডটি true মান পায় এবং sign_in_count 1 মান পায়।
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn build_user(email: String, username: String) -> User { User { active: true, username: username, email: email, sign_in_count: 1, } } fn main() { let user1 = build_user( String::from("someone@example.com"), String::from("someusername123"), ); }
ফাংশন প্যারামিটারগুলোর নাম স্ট্রাকট ফিল্ডগুলোর মতোই রাখা অর্থপূর্ণ, কিন্তু email এবং username ফিল্ডের নাম এবং ভেরিয়েবলগুলো পুনরাবৃত্তি করা কিছুটা ক্লান্তিকর। যদি স্ট্রাকটে আরও ফিল্ড থাকত, তাহলে প্রতিটি নাম পুনরাবৃত্তি করা আরও বিরক্তিকর হয়ে উঠত। সৌভাগ্যবশত, একটি সুবিধাজনক শর্টহ্যান্ড রয়েছে!
ফিল্ড ইনিট শর্টহ্যান্ড ব্যবহার করা (Using the Field Init Shorthand)
যেহেতু Listing 5-4-এ প্যারামিটারের নাম এবং স্ট্রাকট ফিল্ডের নামগুলো হুবহু একই, তাই আমরা ফিল্ড ইনিট শর্টহ্যান্ড (field init shorthand) সিনট্যাক্স ব্যবহার করে build_user পুনরায় লিখতে পারি যাতে এটি একই আচরণ করে কিন্তু username এবং email-এর পুনরাবৃত্তি না থাকে, যেমনটি Listing 5-5-এ দেখানো হয়েছে।
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn build_user(email: String, username: String) -> User { User { active: true, username, email, sign_in_count: 1, } } fn main() { let user1 = build_user( String::from("someone@example.com"), String::from("someusername123"), ); }
এখানে, আমরা User স্ট্রাকটের একটি নতুন ইন্সট্যান্স তৈরি করছি, যার একটি ফিল্ডের নাম email। আমরা email ফিল্ডের মান build_user ফাংশনের email প্যারামিটারের মানটিতে সেট করতে চাই। যেহেতু email ফিল্ড এবং email প্যারামিটারের নাম একই, তাই আমাদের email: email-এর পরিবর্তে শুধুমাত্র email লিখতে হবে।
স্ট্রাকট আপডেট সিনট্যাক্স সহ অন্যান্য ইন্সট্যান্স থেকে ইন্সট্যান্স তৈরি করা (Creating Instances from Other Instances with Struct Update Syntax)
প্রায়শই একটি স্ট্রাকটের একটি নতুন ইন্সট্যান্স তৈরি করা দরকারী যা অন্য ইন্সট্যান্সের বেশিরভাগ মান অন্তর্ভুক্ত করে, কিন্তু কিছু পরিবর্তন করে। আপনি এটি স্ট্রাকট আপডেট সিনট্যাক্স (struct update syntax) ব্যবহার করে করতে পারেন।
প্রথমে, Listing 5-6-এ আমরা দেখাই কিভাবে user2-তে একটি নতুন User ইন্সট্যান্স নিয়মিতভাবে তৈরি করা যায়, আপডেট সিনট্যাক্স ছাড়া। আমরা email-এর জন্য একটি নতুন মান সেট করি কিন্তু অন্যথায় Listing 5-2-তে তৈরি করা user1 থেকে একই মান ব্যবহার করি।
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { // --snip-- let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { active: user1.active, username: user1.username, email: String::from("another@example.com"), sign_in_count: user1.sign_in_count, }; }
স্ট্রাকট আপডেট সিনট্যাক্স ব্যবহার করে, আমরা কম কোড দিয়ে একই প্রভাব অর্জন করতে পারি, যেমনটি Listing 5-7-এ দেখানো হয়েছে। সিনট্যাক্স .. নির্দিষ্ট করে যে অবশিষ্ট ফিল্ডগুলো যেগুলো স্পষ্টভাবে সেট করা হয়নি সেগুলোর মান প্রদত্ত ইন্সট্যান্সের ফিল্ডগুলোর মতোই হওয়া উচিত।
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { // --snip-- let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { email: String::from("another@example.com"), ..user1 }; }
Listing 5-7-এর কোডটিও user2-তে একটি ইন্সট্যান্স তৈরি করে যার email-এর জন্য একটি ভিন্ন মান রয়েছে কিন্তু user1 থেকে username, active এবং sign_in_count ফিল্ডগুলোর জন্য একই মান রয়েছে। ..user1 অবশ্যই শেষে আসতে হবে যাতে এটি নির্দিষ্ট করা যায় যে অবশিষ্ট ক্ষেত্রগুলির মান user1-এর সংশ্লিষ্ট ক্ষেত্রগুলি থেকে পাওয়া উচিত, তবে আমরা স্ট্রাকটের সংজ্ঞায় ক্ষেত্রগুলির ক্রম নির্বিশেষে, যে কোনও ক্রমে যতগুলি ক্ষেত্রের জন্য মান নির্দিষ্ট করতে পারি।
লক্ষ্য করুন যে স্ট্রাকট আপডেট সিনট্যাক্স একটি অ্যাসাইনমেন্টের মতো = ব্যবহার করে; এর কারণ হল এটি ডেটা মুভ করে, যেমনটি আমরা “ভেরিয়েবল এবং ডেটার মধ্যে মিথস্ক্রিয়া: মুভ” বিভাগে দেখেছি। এই উদাহরণে, user2 তৈরি করার পরে আমরা আর user1 ব্যবহার করতে পারি না কারণ user1-এর username ফিল্ডের String user2-তে সরানো হয়েছে। যদি আমরা email এবং username উভয়ের জন্য user2-কে নতুন String মান দিতাম এবং এইভাবে শুধুমাত্র user1 থেকে active এবং sign_in_count মান ব্যবহার করতাম, তাহলে user2 তৈরি করার পরেও user1 বৈধ থাকত। active এবং sign_in_count উভয়ই এমন টাইপ যা Copy ট্রেইট ইমপ্লিমেন্ট করে, তাই “শুধুমাত্র স্ট্যাক-ডেটা: কপি” বিভাগে আমরা যে আচরণ নিয়ে আলোচনা করেছি তা প্রযোজ্য হবে। এই উদাহরণে আমরা এখনও user1.email ব্যবহার করতে পারি, কারণ এর মান সরানো হয়নি।
নামযুক্ত ক্ষেত্র ছাড়া টাপল স্ট্রাকট ব্যবহার করে ভিন্ন টাইপ তৈরি করা (Using Tuple Structs Without Named Fields to Create Different Types)
Rust টাপলের মতো দেখতে স্ট্রাকটগুলোকেও সমর্থন করে, যাকে টাপল স্ট্রাকট (tuple structs) বলা হয়। টাপল স্ট্রাকটগুলোর অতিরিক্ত অর্থ রয়েছে যা স্ট্রাকটের নাম সরবরাহ করে কিন্তু তাদের ক্ষেত্রগুলোর সাথে যুক্ত নাম নেই; বরং, তাদের কেবল ক্ষেত্রগুলোর টাইপ রয়েছে। টাপল স্ট্রাকটগুলো দরকারী যখন আপনি পুরো টাপলটিকে একটি নাম দিতে চান এবং টাপলটিকে অন্যান্য টাপল থেকে আলাদা টাইপ করতে চান এবং যখন প্রতিটি ক্ষেত্রের নামকরণ করা নিয়মিত স্ট্রাকটের মতো শব্দবহুল বা অপ্রয়োজনীয় হবে।
একটি টাপল স্ট্রাকট সংজ্ঞায়িত করতে, struct কীওয়ার্ড এবং স্ট্রাকটের নাম দিয়ে শুরু করুন এবং তারপরে টাপলের টাইপগুলো দিন। উদাহরণস্বরূপ, এখানে আমরা Color এবং Point নামে দুটি টাপল স্ট্রাকট সংজ্ঞায়িত এবং ব্যবহার করি:
struct Color(i32, i32, i32); struct Point(i32, i32, i32); fn main() { let black = Color(0, 0, 0); let origin = Point(0, 0, 0); }
লক্ষ্য করুন যে black এবং origin মানগুলো ভিন্ন টাইপের, কারণ সেগুলো ভিন্ন টাপল স্ট্রাকটের ইন্সট্যান্স। আপনি সংজ্ঞায়িত করা প্রতিটি স্ট্রাকট তার নিজস্ব টাইপ, যদিও স্ট্রাকটের ভেতরের ক্ষেত্রগুলোর একই টাইপ থাকতে পারে। উদাহরণস্বরূপ, Color টাইপের একটি প্যারামিটার নেয় এমন একটি ফাংশন Point-কে আর্গুমেন্ট হিসাবে নিতে পারে না, যদিও উভয় টাইপ তিনটি i32 মান দিয়ে তৈরি। অন্যথায়, টাপল স্ট্রাকট ইন্সট্যান্সগুলো টাপলের মতোই, যেখানে আপনি সেগুলোকে তাদের পৃথক অংশে ডিস্ট্রাকচার করতে পারেন এবং আপনি একটি . ব্যবহার করতে পারেন। ইনডেক্স দ্বারা একটি পৃথক মান অ্যাক্সেস করতে পারেন। টাপলের মতন, টাপল স্ট্রাকটগুলিকে ডিস্ট্রাকচার করার সময় আপনাকে স্ট্রাকটের টাইপের নাম দিতে হবে। উদাহরণস্বরূপ, আমরা let Point(x, y, z) = point লিখব।
কোনো ক্ষেত্র ছাড়া ইউনিট-সদৃশ স্ট্রাকট (Unit-Like Structs Without Any Fields)
আপনি এমন স্ট্রাকটও সংজ্ঞায়িত করতে পারেন যেগুলোর কোনো ক্ষেত্র নেই! এগুলোকে ইউনিট-সদৃশ স্ট্রাকট (unit-like structs) বলা হয় কারণ সেগুলো ()-এর মতোই আচরণ করে, ইউনিট টাইপ যা আমরা “টাপল টাইপ” বিভাগে উল্লেখ করেছি। ইউনিট-সদৃশ স্ট্রাকটগুলো কার্যকর হতে পারে যখন আপনাকে কোনো টাইপের উপর একটি ট্রেইট ইমপ্লিমেন্ট করতে হবে কিন্তু টাইপের মধ্যে নিজে কোনো ডেটা সংরক্ষণ করতে চান না। আমরা চ্যাপ্টার ১০-এ ট্রেইট নিয়ে আলোচনা করব। এখানে AlwaysEqual নামক একটি ইউনিট স্ট্রাকট ঘোষণা এবং ইন্সট্যানশিয়েট করার একটি উদাহরণ দেওয়া হল:
struct AlwaysEqual; fn main() { let subject = AlwaysEqual; }
AlwaysEqual সংজ্ঞায়িত করতে, আমরা struct কীওয়ার্ড, আমাদের কাঙ্ক্ষিত নাম এবং তারপর একটি সেমিকোলন ব্যবহার করি। কোঁকড়া ধনুর্বন্ধনী বা বৃত্তাকার বন্ধনীর প্রয়োজন নেই! তারপর আমরা subject ভেরিয়েবলে AlwaysEqual-এর একটি ইন্সট্যান্স একইভাবে পেতে পারি: আমরা যে নামটি সংজ্ঞায়িত করেছি সেটি ব্যবহার করে, কোনো কোঁকড়া ধনুর্বন্ধনী বা বৃত্তাকার বন্ধনী ছাড়াই। কল্পনা করুন যে পরবর্তীতে আমরা এই টাইপের জন্য এমন আচরণ প্রয়োগ করব যাতে AlwaysEqual-এর প্রতিটি ইন্সট্যান্স অন্য যেকোনো টাইপের প্রতিটি ইন্সট্যান্সের সমান হয়, সম্ভবত পরীক্ষার উদ্দেশ্যে একটি পরিচিত ফলাফল পাওয়ার জন্য। সেই আচরণ বাস্তবায়ন করার জন্য আমাদের কোনো ডেটার প্রয়োজন হবে না! আপনি চ্যাপ্টার ১০-এ দেখতে পাবেন কীভাবে ট্রেইট সংজ্ঞায়িত করতে হয় এবং সেগুলো ইউনিট-সদৃশ স্ট্রাকট সহ যেকোনো টাইপে প্রয়োগ করতে হয়।
স্ট্রাকট ডেটার ওনারশিপ (Ownership of Struct Data)
Listing 5-1-এর
Userস্ট্রাকট সংজ্ঞায়, আমরা&strস্ট্রিং স্লাইস টাইপের পরিবর্তে ওনড (owned)Stringটাইপ ব্যবহার করেছি। এটি একটি ইচ্ছাকৃত পছন্দ কারণ আমরা চাই এই স্ট্রাকটের প্রতিটি ইন্সট্যান্স তার সমস্ত ডেটার মালিক হোক এবং সেই ডেটা যতদিন পর্যন্ত সম্পূর্ণ স্ট্রাকটটি বৈধ ততদিন পর্যন্ত বৈধ থাকুক।স্ট্রাকটগুলোর জন্য অন্য কিছুর মালিকানাধীন ডেটার রেফারেন্স সংরক্ষণ করাও সম্ভব, কিন্তু সেটি করার জন্য লাইফটাইম (lifetimes) ব্যবহার করতে হবে, একটি Rust ফিচার যা আমরা চ্যাপ্টার ১০-এ আলোচনা করব। লাইফটাইম নিশ্চিত করে যে একটি স্ট্রাকট দ্বারা রেফারেন্স করা ডেটা যতদিন স্ট্রাকটটি বৈধ ততদিন পর্যন্ত বৈধ। ধরুন আপনি লাইফটাইম নির্দিষ্ট না করে একটি স্ট্রাকটে একটি রেফারেন্স সংরক্ষণ করার চেষ্টা করছেন, যেমনটি নিচে দেওয়া হলো; এটি কাজ করবে না:
struct User { active: bool, username: &str, email: &str, sign_in_count: u64, } fn main() { let user1 = User { active: true, username: "someusername123", email: "someone@example.com", sign_in_count: 1, }; }কম্পাইলার অভিযোগ করবে যে এটির লাইফটাইম স্পেসিফায়ার প্রয়োজন:
$ cargo run Compiling structs v0.1.0 (file:///projects/structs) error[E0106]: missing lifetime specifier --> src/main.rs:3:15 | 3 | username: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 ~ username: &'a str, | error[E0106]: missing lifetime specifier --> src/main.rs:4:12 | 4 | email: &str, | ^ expected named lifetime parameter | help: consider introducing a named lifetime parameter | 1 ~ struct User<'a> { 2 | active: bool, 3 | username: &str, 4 ~ email: &'a str, | For more information about this error, try `rustc --explain E0106`. error: could not compile `structs` (bin "structs") due to 2 previous errorsচ্যাপ্টার ১০-এ, আমরা এই এররগুলো কীভাবে ঠিক করতে হয় তা নিয়ে আলোচনা করব যাতে আপনি স্ট্রাকটগুলোতে রেফারেন্স সংরক্ষণ করতে পারেন, কিন্তু আপাতত, আমরা
&str-এর মতো রেফারেন্সের পরিবর্তেString-এর মতো ওনড টাইপ ব্যবহার করে এইরকম এররগুলো ঠিক করব।
স্ট্রাকট ব্যবহার করে একটি উদাহরণ প্রোগ্রাম (An Example Program Using Structs)
কখন আমরা স্ট্রাকট ব্যবহার করতে চাইতে পারি তা বোঝার জন্য, আসুন একটি প্রোগ্রাম লিখি যা একটি আয়তক্ষেত্রের ক্ষেত্রফল গণনা করে। আমরা প্রথমে আলাদা ভেরিয়েবল ব্যবহার করে শুরু করব, এবং তারপর স্ট্রাকট ব্যবহার না করা পর্যন্ত প্রোগ্রামটিকে রিফ্যাক্টর (refactor) করব।
আসুন, Cargo দিয়ে rectangles নামে একটি নতুন বাইনারি প্রোজেক্ট তৈরি করি, যেটি পিক্সেলের সাপেক্ষে একটি আয়তক্ষেত্রের প্রস্থ এবং উচ্চতা নেবে এবং আয়তক্ষেত্রটির ক্ষেত্রফল গণনা করবে। Listing 5-8 আমাদের প্রোজেক্টের src/main.rs-এ ঠিক এটি করার একটি সংক্ষিপ্ত প্রোগ্রাম দেখায়।
fn main() { let width1 = 30; let height1 = 50; println!( "The area of the rectangle is {} square pixels.", area(width1, height1) ); } fn area(width: u32, height: u32) -> u32 { width * height }
এবার, cargo run ব্যবহার করে এই প্রোগ্রামটি চালান:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
The area of the rectangle is 1500 square pixels.
এই কোডটি প্রতিটি ডাইমেনশন (dimension) দিয়ে area ফাংশন কল করে আয়তক্ষেত্রের ক্ষেত্রফল বের করতে সফল হয়, কিন্তু আমরা এই কোডটিকে আরও স্পষ্ট এবং পাঠযোগ্য করতে পারি।
এই কোডের সমস্যাটি area-এর সিগনেচারে স্পষ্ট:
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}area ফাংশনটি একটি আয়তক্ষেত্রের ক্ষেত্রফল গণনা করার কথা, কিন্তু আমরা যে ফাংশনটি লিখেছি তাতে দুটি প্যারামিটার রয়েছে এবং আমাদের প্রোগ্রামে এটি কোথাও স্পষ্ট নয় যে প্যারামিটারগুলো সম্পর্কিত। প্রস্থ এবং উচ্চতাকে একসাথে গ্রুপ করা আরও পাঠযোগ্য এবং পরিচালনাযোগ্য হবে। আমরা ইতিমধ্যেই চ্যাপ্টার ৩-এর “টাপল টাইপ” বিভাগে এটি করার একটি উপায় নিয়ে আলোচনা করেছি: টাপল ব্যবহার করে।
টাপল দিয়ে রিফ্যাক্টরিং (Refactoring with Tuples)
Listing 5-9 আমাদের প্রোগ্রামের আরেকটি ভার্সন দেখায় যা টাপল ব্যবহার করে।
fn main() { let rect1 = (30, 50); println!( "The area of the rectangle is {} square pixels.", area(rect1) ); } fn area(dimensions: (u32, u32)) -> u32 { dimensions.0 * dimensions.1 }
একভাবে, এই প্রোগ্রামটি ভাল। টাপলগুলো আমাদের কিছুটা স্ট্রাকচার যুক্ত করতে দেয় এবং আমরা এখন কেবল একটি আর্গুমেন্ট পাস করছি। কিন্তু অন্যভাবে, এই ভার্সনটি কম স্পষ্ট: টাপলগুলো তাদের উপাদানগুলোর নাম দেয় না, তাই আমাদেরকে টাপলের অংশগুলোতে ইনডেক্স করতে হবে, যা আমাদের গণনাকে কম সুস্পষ্ট করে তোলে।
ক্ষেত্রফল গণনার জন্য প্রস্থ এবং উচ্চতা মিশিয়ে ফেললে কিছু যায় আসে না, কিন্তু আমরা যদি স্ক্রিনে আয়তক্ষেত্রটি আঁকতে চাই, তাহলে সেটি গুরুত্বপূর্ণ হবে! আমাদের মনে রাখতে হবে যে width হল টাপল ইনডেক্স 0 এবং height হল টাপল ইনডেক্স 1। অন্য কারও জন্য এটি বোঝা এবং মনে রাখা আরও কঠিন হবে যদি তারা আমাদের কোড ব্যবহার করে। যেহেতু আমরা আমাদের কোডে আমাদের ডেটার অর্থ প্রকাশ করিনি, তাই এখন এরর আনা সহজ।
স্ট্রাকট দিয়ে রিফ্যাক্টরিং: আরও অর্থ যোগ করা (Refactoring with Structs: Adding More Meaning)
আমরা ডেটাকে লেবেল করে অর্থ যোগ করতে স্ট্রাকট ব্যবহার করি। আমরা যে টাপলটি ব্যবহার করছি সেটিকে আমরা সম্পূর্ণ অংশের জন্য একটি নাম এবং অংশগুলোর জন্য নাম সহ একটি স্ট্রাকটে রূপান্তর করতে পারি, যেমনটি Listing 5-10-এ দেখানো হয়েছে।
struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", area(&rect1) ); } fn area(rectangle: &Rectangle) -> u32 { rectangle.width * rectangle.height }
এখানে আমরা একটি স্ট্রাকট সংজ্ঞায়িত করেছি এবং এর নাম দিয়েছি Rectangle। কার্লি ব্র্যাকেটের ভিতরে, আমরা ফিল্ডগুলোকে width এবং height হিসাবে সংজ্ঞায়িত করেছি, যেগুলোর উভয়ের টাইপ u32। তারপর, main-এ, আমরা Rectangle-এর একটি নির্দিষ্ট ইন্সট্যান্স তৈরি করেছি যার প্রস্থ 30 এবং উচ্চতা 50।
আমাদের area ফাংশনটি এখন একটি প্যারামিটার দিয়ে সংজ্ঞায়িত করা হয়েছে, যার নাম আমরা দিয়েছি rectangle, যার টাইপ হল একটি স্ট্রাকট Rectangle ইন্সট্যান্সের ইমিউটেবল বোরো। চ্যাপ্টার ৪-এ যেমন উল্লেখ করা হয়েছে, আমরা স্ট্রাকটটির ওনারশিপ নেওয়ার পরিবর্তে বোরো করতে চাই। এইভাবে, main তার ওনারশিপ বজায় রাখে এবং rect1 ব্যবহার করা চালিয়ে যেতে পারে, যে কারণে আমরা ফাংশন সিগনেচারে এবং যেখানে আমরা ফাংশনটি কল করি সেখানে & ব্যবহার করি।
area ফাংশনটি Rectangle ইন্সট্যান্সের width এবং height ফিল্ড অ্যাক্সেস করে (মনে রাখবেন যে একটি ধার করা স্ট্রাকট ইন্সট্যান্সের ফিল্ডগুলো অ্যাক্সেস করলে ফিল্ডের মানগুলো সরানো হয় না, যে কারণে আপনি প্রায়শই স্ট্রাকটগুলোর বোরো দেখতে পান)। area-এর জন্য আমাদের ফাংশন সিগনেচারটি এখন ঠিক সেটাই বলে যা আমরা বোঝাতে চাই: Rectangle-এর ক্ষেত্রফল গণনা করুন, এর width এবং height ফিল্ড ব্যবহার করে। এটি প্রকাশ করে যে প্রস্থ এবং উচ্চতা একে অপরের সাথে সম্পর্কিত এবং এটি 0 এবং 1-এর টাপল ইনডেক্স মানগুলো ব্যবহার করার পরিবর্তে মানগুলোকে বর্ণনামূলক নাম দেয়। এটি স্পষ্টতার জন্য একটি জয়।
ডিরাইভড ট্রেইট দিয়ে দরকারী কার্যকারিতা যোগ করা (Adding Useful Functionality with Derived Traits)
আমরা যখন আমাদের প্রোগ্রাম ডিবাগ করছি তখন Rectangle-এর একটি ইন্সট্যান্স প্রিন্ট করতে এবং এর সমস্ত ফিল্ডের মান দেখতে পারা দরকারী হবে। Listing 5-11 আগের চ্যাপ্টারগুলোতে ব্যবহৃত println! ম্যাক্রো ব্যবহার করার চেষ্টা করে। তবে, এটি কাজ করবে না।
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {}", rect1);
}আমরা যখন এই কোডটি কম্পাইল করি, তখন আমরা এই মূল মেসেজ সহ একটি এরর পাই:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
println! ম্যাক্রো অনেক ধরনের ফরম্যাটিং করতে পারে এবং ডিফল্টরূপে, কার্লি ব্র্যাকেটগুলো println!-কে Display নামে পরিচিত ফরম্যাটিং ব্যবহার করতে বলে: সরাসরি শেষ ব্যবহারকারীর ব্যবহারের জন্য উদ্দিষ্ট আউটপুট। আমরা ఇప్పటి পর্যন্ত যে প্রিমিটিভ টাইপগুলো দেখেছি সেগুলো ডিফল্টরূপে Display ইমপ্লিমেন্ট করে কারণ ব্যবহারকারীর কাছে 1 বা অন্য কোনো প্রিমিটিভ টাইপ দেখানোর একটিমাত্র উপায় রয়েছে। কিন্তু স্ট্রাকটগুলোর সাথে, println! কীভাবে আউটপুট ফরম্যাট করবে তা কম স্পষ্ট কারণ আরও প্রদর্শনের সম্ভাবনা রয়েছে: আপনি কি কমা চান নাকি চান না? আপনি কি কার্লি ব্র্যাকেটগুলো প্রিন্ট করতে চান? সমস্ত ফিল্ড দেখানো উচিত? এই অস্পষ্টতার কারণে, Rust আমরা কী চাই তা অনুমান করার চেষ্টা করে না এবং স্ট্রাকটগুলোতে println! এবং {} প্লেসহোল্ডারের সাথে ব্যবহার করার জন্য Display-এর কোনো প্রদত্ত ইমপ্লিমেন্টেশন নেই।
আমরা যদি এররগুলো পড়া চালিয়ে যাই, তাহলে আমরা এই সহায়ক নোটটি খুঁজে পাব:
= help: the trait `std::fmt::Display` is not implemented for `Rectangle`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
চলুন চেষ্টা করি! println! ম্যাক্রো কলটি এখন println!("rect1 is {rect1:?}");-এর মতো হবে। কার্লি ব্র্যাকেটগুলোর ভিতরে :? স্পেসিফায়ার রাখলে println!-কে বলা হয় যে আমরা Debug নামক একটি আউটপুট ফর্ম্যাট ব্যবহার করতে চাই। Debug ট্রেইটটি আমাদের স্ট্রাকটটিকে এমনভাবে প্রিন্ট করতে সক্ষম করে যা ডেভেলপারদের জন্য দরকারী, যাতে আমরা আমাদের কোড ডিবাগ করার সময় এর মান দেখতে পারি।
এই পরিবর্তন সহ কোড কম্পাইল করুন। ধুর! আমরা এখনও একটি এরর পাই:
error[E0277]: `Rectangle` doesn't implement `Debug`
কিন্তু আবারও, কম্পাইলার আমাদের একটি সহায়ক নোট দেয়:
= help: the trait `Debug` is not implemented for `Rectangle`
= note: add `#[derive(Debug)]` to `Rectangle` or manually `impl Debug for Rectangle`
Rust-এ ডিবাগিং তথ্য প্রিন্ট করার কার্যকারিতা অন্তর্ভুক্ত, কিন্তু আমাদের স্ট্রাকটের জন্য সেই কার্যকারিতা উপলব্ধ করতে স্পষ্টভাবে অপ্ট ইন করতে হবে। সেটি করার জন্য, আমরা স্ট্রাকট সংজ্ঞার ঠিক আগে আউটার অ্যাট্রিবিউট #[derive(Debug)] যোগ করি, যেমনটি Listing 5-12-তে দেখানো হয়েছে।
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!("rect1 is {rect1:?}"); }
এখন আমরা যখন প্রোগ্রামটি চালাই, তখন আমরা কোনো এরর পাব না এবং আমরা নিম্নলিখিত আউটপুট দেখতে পাব:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle { width: 30, height: 50 }
দারুণ! এটি সবচেয়ে সুন্দর আউটপুট নয়, তবে এটি এই ইন্সট্যান্সের সমস্ত ফিল্ডের মান দেখায়, যা অবশ্যই ডিবাগিংয়ের সময় সাহায্য করবে। যখন আমাদের কাছে বড় স্ট্রাকট থাকে, তখন এমন আউটপুট পাওয়া দরকারী যা পড়া একটু সহজ; সেই ক্ষেত্রগুলোতে, আমরা println! স্ট্রিং-এ {:?}-এর পরিবর্তে {:#?} ব্যবহার করতে পারি। এই উদাহরণে, {:#?} স্টাইল ব্যবহার করলে নিম্নলিখিত আউটপুট আসবে:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle {
width: 30,
height: 50,
}
Debug ফর্ম্যাট ব্যবহার করে একটি মান প্রিন্ট করার আরেকটি উপায় হল dbg! ম্যাক্রো ব্যবহার করা, যা একটি এক্সপ্রেশনের ওনারশিপ নেয় (println!-এর বিপরীতে, যেটি একটি রেফারেন্স নেয়), সেই dbg! ম্যাক্রো কলটি আপনার কোডের কোথায় ঘটছে তার ফাইল এবং লাইন নম্বর প্রিন্ট করে, সেই এক্সপ্রেশনের ফলাফলের মান সহ এবং মানের ওনারশিপ ফিরিয়ে দেয়।
দ্রষ্টব্য:
dbg!ম্যাক্রো কলটি স্ট্যান্ডার্ড এরর কনসোল স্ট্রিমে (stderr) প্রিন্ট করে,println!-এর বিপরীতে, যেটি স্ট্যান্ডার্ড আউটপুট কনসোল স্ট্রিমে (stdout) প্রিন্ট করে। আমরা চ্যাপ্টার ১২-এর “স্ট্যান্ডার্ড আউটপুটের পরিবর্তে স্ট্যান্ডার্ড এরর-এ এরর মেসেজ লেখা” বিভাগেstderrএবংstdoutসম্পর্কে আরও কথা বলব।
এখানে একটি উদাহরণ দেওয়া হল যেখানে আমরা width ফিল্ডে অ্যাসাইন করা মান এবং rect1-এর সম্পূর্ণ স্ট্রাকটের মান জানতে আগ্রহী:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let scale = 2; let rect1 = Rectangle { width: dbg!(30 * scale), height: 50, }; dbg!(&rect1); }
আমরা 30 * scale এক্সপ্রেশনের চারপাশে dbg! রাখতে পারি এবং যেহেতু dbg! এক্সপ্রেশনের মানের ওনারশিপ রিটার্ন করে, তাই width ফিল্ডটি একই মান পাবে যেন আমাদের সেখানে dbg! কল না থাকে। আমরা চাই না dbg! rect1-এর ওনারশিপ নিক, তাই আমরা পরের কলে rect1-এর একটি রেফারেন্স ব্যবহার করি। এই উদাহরণের আউটপুট দেখতে কেমন তা এখানে দেওয়া হল:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10:16] 30 * scale = 60
[src/main.rs:14:5] &rect1 = Rectangle {
width: 60,
height: 50,
}
আমরা দেখতে পাচ্ছি যে আউটপুটের প্রথম অংশটি src/main.rs লাইন ১০ থেকে এসেছে যেখানে আমরা 30 * scale এক্সপ্রেশনটি ডিবাগ করছি এবং এর ফলাফলের মান হল 60 (ইন্টিজারগুলোর জন্য ইমপ্লিমেন্ট করা Debug ফরম্যাটিং হল শুধুমাত্র তাদের মান প্রিন্ট করা)। src/main.rs-এর ১৪ লাইনে dbg! কলটি &rect1-এর মান আউটপুট করে, যেটি হল Rectangle স্ট্রাকট। এই আউটপুটটি Rectangle টাইপের প্রিটি Debug ফরম্যাটিং ব্যবহার করে। আপনার কোড কী করছে তা বোঝার চেষ্টা করার সময় dbg! ম্যাক্রো সত্যিই সহায়ক হতে পারে!
Debug ট্রেইট ছাড়াও, Rust আমাদের derive অ্যাট্রিবিউট দিয়ে ব্যবহার করার জন্য বেশ কয়েকটি ট্রেইট সরবরাহ করেছে যা আমাদের কাস্টম টাইপগুলোতে দরকারী আচরণ যোগ করতে পারে। সেই ট্রেইটগুলো এবং তাদের আচরণগুলো Appendix C-তে তালিকাভুক্ত করা হয়েছে। আমরা চ্যাপ্টার ১০-এ কাস্টম আচরণ সহ এই ট্রেইটগুলো কীভাবে ইমপ্লিমেন্ট করতে হয় এবং সেইসাথে কীভাবে আপনার নিজের ট্রেইট তৈরি করতে হয় তা কভার করব। derive ছাড়াও আরও অনেক অ্যাট্রিবিউট রয়েছে; আরও তথ্যের জন্য, Rust রেফারেন্সের “অ্যাট্রিবিউটস” বিভাগ দেখুন।
আমাদের area ফাংশনটি খুব নির্দিষ্ট: এটি শুধুমাত্র আয়তক্ষেত্রের ক্ষেত্রফল গণনা করে। এই আচরণটিকে আমাদের Rectangle স্ট্রাকটের সাথে আরও ঘনিষ্ঠভাবে যুক্ত করা সহায়ক হবে কারণ এটি অন্য কোনো টাইপের সাথে কাজ করবে না। চলুন দেখি কিভাবে আমরা এই কোডটিকে রিফ্যাক্টর করে area ফাংশনকে আমাদের Rectangle টাইপে সংজ্ঞায়িত একটি area মেথডে পরিণত করতে পারি।
মেথড সিনট্যাক্স (Method Syntax)
মেথডগুলো (Methods) ফাংশনের মতোই: আমরা সেগুলোকে fn কীওয়ার্ড এবং একটি নাম দিয়ে ঘোষণা করি, সেগুলোর প্যারামিটার এবং একটি রিটার্ন মান থাকতে পারে এবং সেগুলোর মধ্যে কিছু কোড থাকে যা অন্য কোথাও থেকে মেথড কল করা হলে চালানো হয়। ফাংশনগুলোর বিপরীতে, মেথডগুলো একটি স্ট্রাকটের (অথবা একটি এনাম বা একটি ট্রেইট অবজেক্ট, যা আমরা যথাক্রমে চ্যাপ্টার ৬ এবং চ্যাপ্টার 18-এ কভার করব) প্রেক্ষাপটে সংজ্ঞায়িত করা হয় এবং তাদের প্রথম প্যারামিটার সর্বদাই self হয়, যা স্ট্রাকটের ইন্সট্যান্সটিকে উপস্থাপন করে যেটিতে মেথড কল করা হচ্ছে।
মেথড সংজ্ঞায়িত করা (Defining Methods)
চলুন, area ফাংশনটিকে পরিবর্তন করি, যেখানে একটি Rectangle ইন্সট্যান্স প্যারামিটার হিসেবে আছে। এর পরিবর্তে, Rectangle স্ট্রাকটে একটি area মেথড সংজ্ঞায়িত করি, যেমনটি Listing 5-13-তে দেখানো হয়েছে।
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", rect1.area() ); }
Rectangle-এর পরিপ্রেক্ষিতে ফাংশনটি সংজ্ঞায়িত করতে, আমরা Rectangle-এর জন্য একটি impl (ইমপ্লিমেন্টেশন) ব্লক শুরু করি। এই impl ব্লকের ভেতরের সবকিছু Rectangle টাইপের সাথে সম্পর্কিত হবে। তারপর আমরা area ফাংশনটিকে impl-এর কার্লি ব্র্যাকেটের মধ্যে সরিয়ে নিই এবং সিগনেচারে ও বডির সর্বত্র প্রথম (এবং এই ক্ষেত্রে, একমাত্র) প্যারামিটারটিকে self করি। main-এ, যেখানে আমরা area ফাংশনটিকে কল করেছি এবং rect1-কে আর্গুমেন্ট হিসাবে পাস করেছি, সেখানে আমরা পরিবর্তে আমাদের Rectangle ইন্সট্যান্সে area মেথড কল করার জন্য মেথড সিনট্যাক্স ব্যবহার করতে পারি। মেথড সিনট্যাক্স একটি ইন্সট্যান্সের পরে বসে: আমরা একটি ডট এবং তারপর মেথডের নাম, প্যারেন্থেসিস এবং যেকোনো আর্গুমেন্ট যোগ করি।
area-এর সিগনেচারে, আমরা rectangle: &Rectangle-এর পরিবর্তে &self ব্যবহার করি। &self আসলে self: &Self-এর সংক্ষিপ্ত রূপ। একটি impl ব্লকের মধ্যে, Self টাইপটি হল সেই টাইপের উপনাম (alias) যার জন্য impl ব্লকটি রয়েছে। মেথডগুলোর প্রথম প্যারামিটার হিসেবে Self টাইপের self নামের একটি প্যারামিটার থাকা আবশ্যক, তাই Rust আপনাকে প্রথম প্যারামিটারের জায়গায় শুধুমাত্র self নামটি দিয়ে এটিকে সংক্ষিপ্ত করতে দেয়। মনে রাখবেন যে, rectangle: &Rectangle-এ আমরা যেভাবে করেছিলাম, ঠিক সেভাবেই এই মেথডটি যে Self ইন্সট্যান্স ধার করে তা নির্দেশ করার জন্য আমাদের এখনও self শর্টহ্যান্ডের সামনে & ব্যবহার করতে হবে। মেথডগুলো self-এর ওনারশিপ নিতে পারে, self ইমিউটেবলভাবে ধার করতে পারে, যেমনটি আমরা এখানে করেছি, অথবা self মিউটেবলভাবে ধার করতে পারে, ঠিক যেমন তারা অন্য কোনো প্যারামিটার নিতে পারে।
আমরা এখানে &self বেছে নিয়েছি সেই একই কারণে যে কারণে আমরা ফাংশন ভার্সনে &Rectangle ব্যবহার করেছি: আমরা ওনারশিপ নিতে চাই না এবং আমরা কেবল স্ট্রাকটের ডেটা পড়তে চাই, লিখতে নয়। যদি আমরা ইন্সট্যান্সটিকে পরিবর্তন করতে চাইতাম যেটিতে আমরা মেথড কল করেছি, তাহলে আমরা প্রথম প্যারামিটার হিসাবে &mut self ব্যবহার করতাম। শুধুমাত্র self-কে প্রথম প্যারামিটার হিসাবে ব্যবহার করে ইন্সট্যান্সের ওনারশিপ নেয় এমন মেথড থাকা বিরল; এই কৌশলটি সাধারণত তখনই ব্যবহার করা হয় যখন মেথডটি self-কে অন্য কিছুতে রূপান্তরিত করে এবং আপনি রূপান্তরের পরে কলারকে মূল ইন্সট্যান্সটি ব্যবহার করতে বাধা দিতে চান।
মেথড সিনট্যাক্স সরবরাহ করা এবং প্রতিটি মেথডের সিগনেচারে self-এর টাইপ পুনরাবৃত্তি না করা ছাড়াও, ফাংশনের পরিবর্তে মেথড ব্যবহার করার প্রধান কারণ হল সংগঠন। আমরা একটি টাইপের ইন্সট্যান্সের সাথে যা করতে পারি তার সমস্ত কিছু একটি impl ব্লকে রেখেছি, যাতে আমাদের কোডের ভবিষ্যত ব্যবহারকারীদেরকে আমাদের দেওয়া লাইব্রেরির বিভিন্ন জায়গায় Rectangle-এর ক্ষমতাগুলো খুঁজতে না হয়।
লক্ষ্য করুন যে আমরা একটি মেথডকে স্ট্রাকটের একটি ফিল্ডের মতোই একই নাম দিতে পারি। উদাহরণস্বরূপ, আমরা Rectangle-এ একটি মেথড সংজ্ঞায়িত করতে পারি যার নামও width:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn width(&self) -> bool { self.width > 0 } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; if rect1.width() { println!("The rectangle has a nonzero width; it is {}", rect1.width); } }
এখানে, আমরা width মেথডটিকে true রিটার্ন করার জন্য বেছে নিচ্ছি যদি ইন্সট্যান্সের width ফিল্ডের মান 0-এর চেয়ে বড় হয় এবং false রিটার্ন করার জন্য যদি মান 0 হয়: আমরা একই নামের একটি মেথডের মধ্যে একটি ফিল্ড যেকোনো উদ্দেশ্যে ব্যবহার করতে পারি। main-এ, যখন আমরা rect1.width-এর পরে প্যারেন্থেসিস দিই, তখন Rust বোঝে যে আমরা width মেথডকে বোঝাতে চেয়েছি। যখন আমরা প্যারেন্থেসিস ব্যবহার করি না, তখন Rust বোঝে যে আমরা width ফিল্ডকে বোঝাতে চেয়েছি।
প্রায়শই, সব সময় নয়, যখন আমরা একটি ফিল্ডের মতো একই নাম একটি মেথডকে দিই তখন আমরা চাই যে এটি শুধুমাত্র ফিল্ডের মান রিটার্ন করুক এবং অন্য কিছু না করুক। এই ধরনের মেথডগুলোকে গেটার (getters) বলা হয় এবং Rust অন্য কিছু ভাষার মতো স্ট্রাকট ফিল্ডের জন্য এগুলো স্বয়ংক্রিয়ভাবে প্রয়োগ করে না। গেটারগুলো দরকারী কারণ আপনি ফিল্ডটিকে প্রাইভেট কিন্তু মেথডটিকে পাবলিক করতে পারেন এবং এইভাবে টাইপের পাবলিক API-এর অংশ হিসাবে সেই ফিল্ডে রিড-অনলি অ্যাক্সেস সক্রিয় করতে পারেন। পাবলিক এবং প্রাইভেট কী এবং কীভাবে একটি ফিল্ড বা মেথডকে পাবলিক বা প্রাইভেট হিসাবে মনোনীত করতে হয় তা নিয়ে আমরা চ্যাপ্টার 7-এ আলোচনা করব।
->অপারেটরটি কোথায়?C এবং C++-এ, মেথড কল করার জন্য দুটি ভিন্ন অপারেটর ব্যবহার করা হয়: আপনি যদি সরাসরি অবজেক্টে একটি মেথড কল করেন তবে আপনি
.ব্যবহার করেন এবং যদি আপনি অবজেক্টের পয়েন্টারে মেথড কল করেন এবং প্রথমে পয়েন্টারটিকে ডিরেফারেন্স করতে হয় তবে আপনি->ব্যবহার করেন। অন্য কথায়, যদিobjectএকটি পয়েন্টার হয়, তাহলেobject->something()হল(*object).something()-এর অনুরূপ।Rust-এর
->অপারেটরের সমতুল্য নেই; পরিবর্তে, Rust-এর অটোমেটিক রেফারেন্সিং এবং ডিরেফারেন্সিং (automatic referencing and dereferencing) নামক একটি ফিচার রয়েছে। মেথড কল করা Rust-এর কয়েকটি জায়গার মধ্যে একটি যেখানে এই আচরণ রয়েছে।এটি এইভাবে কাজ করে: যখন আপনি
object.something()দিয়ে একটি মেথড কল করেন, তখন Rust স্বয়ংক্রিয়ভাবে&,&mut, বা*যোগ করে যাতেobjectমেথডের সিগনেচারের সাথে মেলে। অন্য কথায়, নিম্নলিখিতগুলো একই:#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Point { x: f64, y: f64, } impl Point { fn distance(&self, other: &Point) -> f64 { let x_squared = f64::powi(other.x - self.x, 2); let y_squared = f64::powi(other.y - self.y, 2); f64::sqrt(x_squared + y_squared) } } let p1 = Point { x: 0.0, y: 0.0 }; let p2 = Point { x: 5.0, y: 6.5 }; p1.distance(&p2); (&p1).distance(&p2); }প্রথমটি অনেক বেশি পরিষ্কার দেখায়। এই স্বয়ংক্রিয় রেফারেন্সিং আচরণটি কাজ করে কারণ মেথডগুলোর একটি পরিষ্কার রিসিভার রয়েছে—
self-এর টাইপ। একটি মেথডের রিসিভার এবং নাম দেওয়া থাকলে, Rust নিশ্চিতভাবে বের করতে পারে যে মেথডটি পড়ছে (&self), পরিবর্তন করছে (&mut self), নাকি কনজিউম করছে (self। মেথড রিসিভারদের জন্য Rust-এর অন্তর্নিহিতভাবে ধার করা (borrowing) ওনারশিপকে বাস্তবে ব্যবহারের উপযোগী করে তোলার একটি বড় অংশ।
আরও প্যারামিটার সহ মেথড (Methods with More Parameters)
আসুন Rectangle স্ট্রাকটে একটি দ্বিতীয় মেথড প্রয়োগ করে মেথডগুলো ব্যবহার করার অনুশীলন করি। এবার আমরা চাই যে একটি Rectangle-এর ইন্সট্যান্স Rectangle-এর আরেকটি ইন্সট্যান্স নেবে এবং true রিটার্ন করবে যদি দ্বিতীয় Rectangle সম্পূর্ণরূপে self-এর (প্রথম Rectangle) মধ্যে ফিট করে; অন্যথায়, এটি false রিটার্ন করবে। অর্থাৎ, আমরা can_hold মেথড সংজ্ঞায়িত করার পরে, আমরা Listing 5-14-তে দেখানো প্রোগ্রামটি লিখতে সক্ষম হতে চাই।
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}প্রত্যাশিত আউটপুটটি দেখতে নিচের মতো হবে কারণ rect2-এর উভয় ডাইমেনশন rect1-এর ডাইমেনশনের চেয়ে ছোট, কিন্তু rect3 rect1-এর চেয়ে প্রশস্ত:
Can rect1 hold rect2? true
Can rect1 hold rect3? false
আমরা জানি যে আমরা একটি মেথড সংজ্ঞায়িত করতে চাই, তাই এটি impl Rectangle ব্লকের মধ্যে থাকবে। মেথডটির নাম হবে can_hold এবং এটি প্যারামিটার হিসাবে অন্য একটি Rectangle-এর ইমিউটেবল বোরো নেবে। আমরা মেথডটি যে কোড থেকে কল করা হবে সেটি দেখে প্যারামিটারের টাইপ কী হবে তা বলতে পারি: rect1.can_hold(&rect2) &rect2 পাস করে, যেটি হল rect2-এর একটি ইমিউটেবল বোরো, Rectangle-এর একটি ইন্সট্যান্স। এটি বোধগম্য কারণ আমাদের কেবল rect2 পড়তে হবে (লেখার পরিবর্তে, যার অর্থ আমাদের একটি মিউটেবল বোরো প্রয়োজন হবে) এবং আমরা চাই main rect2-এর ওনারশিপ বজায় রাখুক যাতে আমরা can_hold মেথড কল করার পরেও এটি ব্যবহার করতে পারি। can_hold-এর রিটার্ন মান হবে একটি বুলিয়ান এবং ইমপ্লিমেন্টেশনটি পরীক্ষা করবে যে self-এর প্রস্থ এবং উচ্চতা যথাক্রমে অন্য Rectangle-এর প্রস্থ এবং উচ্চতার চেয়ে বেশি কিনা। চলুন Listing 5-13 থেকে impl ব্লকে নতুন can_hold মেথড যোগ করি, যা Listing 5-15-এ দেখানো হয়েছে।
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; let rect2 = Rectangle { width: 10, height: 40, }; let rect3 = Rectangle { width: 60, height: 45, }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
আমরা যখন Listing 5-14-এর main ফাংশন দিয়ে এই কোডটি চালাব, তখন আমরা আমাদের কাঙ্ক্ষিত আউটপুট পাব। মেথডগুলো একাধিক প্যারামিটার নিতে পারে যা আমরা self প্যারামিটারের পরে সিগনেচারে যোগ করি এবং সেই প্যারামিটারগুলো ফাংশনের প্যারামিটারগুলোর মতোই কাজ করে।
অ্যাসোসিয়েটেড ফাংশন (Associated Functions)
impl ব্লকের মধ্যে সংজ্ঞায়িত সমস্ত ফাংশনকে অ্যাসোসিয়েটেড ফাংশন (associated functions) বলা হয় কারণ সেগুলো impl-এর পরে থাকা টাইপের সাথে সম্পর্কিত। আমরা অ্যাসোসিয়েটেড ফাংশন সংজ্ঞায়িত করতে পারি যেগুলোর প্রথম প্যারামিটার হিসাবে self নেই (এবং এইভাবে সেগুলো মেথড নয়) কারণ তাদের কাজ করার জন্য টাইপের কোনো ইন্সট্যান্সের প্রয়োজন নেই। আমরা ইতিমধ্যেই এইরকম একটি ফাংশন ব্যবহার করেছি: String::from ফাংশন যা String টাইপে সংজ্ঞায়িত।
যে অ্যাসোসিয়েটেড ফাংশনগুলো মেথড নয় সেগুলো প্রায়শই কনস্ট্রাক্টরগুলোর জন্য ব্যবহৃত হয় যা স্ট্রাকটের একটি নতুন ইন্সট্যান্স রিটার্ন করবে। এগুলোকে প্রায়শই new বলা হয়, কিন্তু new কোনো বিশেষ নাম নয় এবং এটি ভাষার মধ্যে তৈরি করা নয়। উদাহরণস্বরূপ, আমরা square নামে একটি অ্যাসোসিয়েটেড ফাংশন সরবরাহ করতে পারি যার একটি ডাইমেনশন প্যারামিটার থাকবে এবং এটিকে প্রস্থ এবং উচ্চতা উভয় হিসাবে ব্যবহার করবে, এইভাবে একটি বর্গক্ষেত্র Rectangle তৈরি করা সহজ করে তুলবে, যেখানে একই মান দুবার উল্লেখ করার প্রয়োজন হবে না:
Filename: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn square(size: u32) -> Self { Self { width: size, height: size, } } } fn main() { let sq = Rectangle::square(3); }
রিটার্ন টাইপ এবং ফাংশনের বডিতে Self কীওয়ার্ডগুলো হল সেই টাইপের উপনাম যা impl কীওয়ার্ডের পরে প্রদর্শিত হয়, যা এই ক্ষেত্রে Rectangle।
এই অ্যাসোসিয়েটেড ফাংশনটিকে কল করতে, আমরা স্ট্রাকটের নাম সহ :: সিনট্যাক্স ব্যবহার করি; let sq = Rectangle::square(3); হল একটি উদাহরণ। এই ফাংশনটি স্ট্রাকট দ্বারা নেমস্পেস করা হয়: :: সিনট্যাক্সটি অ্যাসোসিয়েটেড ফাংশন এবং মডিউল দ্বারা তৈরি নেমস্পেস উভয়ের জন্য ব্যবহৃত হয়। আমরা চ্যাপ্টার 7-এ মডিউল নিয়ে আলোচনা করব।
একাধিক impl ব্লক (Multiple impl Blocks)
প্রতিটি স্ট্রাকটের একাধিক impl ব্লক থাকতে পারে। উদাহরণস্বরূপ, Listing 5-15 Listing 5-16-তে দেখানো কোডের সমতুল্য, যেখানে প্রতিটি মেথড তার নিজস্ব impl ব্লকে রয়েছে।
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } impl Rectangle { fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; let rect2 = Rectangle { width: 10, height: 40, }; let rect3 = Rectangle { width: 60, height: 45, }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
এখানে এই মেথডগুলোকে একাধিক impl ব্লকে আলাদা করার কোনো কারণ নেই, তবে এটি বৈধ সিনট্যাক্স। আমরা চ্যাপ্টার ১০-এ একাধিক impl ব্লক দরকারী এমন একটি ক্ষেত্র দেখব, যেখানে আমরা জেনেরিক টাইপ এবং ট্রেইট নিয়ে আলোচনা করব।
সারসংক্ষেপ (Summary)
স্ট্রাকটগুলো আপনাকে কাস্টম টাইপ তৈরি করতে দেয় যা আপনার ডোমেনের জন্য অর্থপূর্ণ। স্ট্রাকট ব্যবহার করে, আপনি সম্পর্কিত ডেটার অংশগুলোকে একে অপরের সাথে সংযুক্ত রাখতে পারেন এবং আপনার কোডকে স্পষ্ট করতে প্রতিটি অংশের নাম দিতে পারেন। impl ব্লকগুলোতে, আপনি আপনার টাইপের সাথে সম্পর্কিত ফাংশনগুলো সংজ্ঞায়িত করতে পারেন এবং মেথডগুলো হল এক ধরনের অ্যাসোসিয়েটেড ফাংশন যা আপনাকে আপনার স্ট্রাকটগুলোর ইন্সট্যান্সের আচরণ নির্দিষ্ট করতে দেয়।
কিন্তু স্ট্রাকটগুলোই কাস্টম টাইপ তৈরি করার একমাত্র উপায় নয়: আসুন Rust-এর এনাম (enum) ফিচারে যাই যাতে আপনার টুলবক্সে আরেকটি টুল যুক্ত করা যায়।
এনাম এবং প্যাটার্ন ম্যাচিং (Enums and Pattern Matching)
এই চ্যাপ্টারে, আমরা এনিউমারেশন (enumerations) দেখব, যাকে এনাম (enums)-ও বলা হয়। এনামগুলো আপনাকে এর সম্ভাব্য ভেরিয়েন্ট (variants) গণনা করে একটি টাইপ সংজ্ঞায়িত করতে দেয়। প্রথমে আমরা একটি এনাম সংজ্ঞায়িত করব এবং ব্যবহার করব, এটি দেখানোর জন্য যে কীভাবে একটি এনাম ডেটার সাথে অর্থ এনকোড করতে পারে। এরপর, আমরা একটি বিশেষভাবে দরকারী এনাম অন্বেষণ করব, যার নাম Option, যা প্রকাশ করে যে একটি মান কিছু হতে পারে অথবা কিছুই না। তারপর আমরা দেখব কিভাবে match এক্সপ্রেশনের প্যাটার্ন ম্যাচিং, এনামের বিভিন্ন মানের জন্য আলাদা কোড চালানো সহজ করে তোলে। সবশেষে, আমরা দেখব কিভাবে if let কনস্ট্রাক্ট আপনার কোডে এনামগুলো হ্যান্ডেল করার জন্য আরেকটি সুবিধাজনক এবং সংক্ষিপ্ত উপায়।
একটি এনাম সংজ্ঞায়িত করা (Defining an Enum)
স্ট্রাকটগুলো যেমন আপনাকে সম্পর্কিত ফিল্ড এবং ডেটা একত্রিত করার একটি উপায় দেয়, যেমন width এবং height সহ একটি Rectangle, এনামগুলো আপনাকে সম্ভাব্য মানগুলোর একটি সেট থেকে একটি মান বলার উপায় দেয়। উদাহরণস্বরূপ, আমরা বলতে চাইতে পারি যে Rectangle হল সম্ভাব্য আকারগুলোর একটি সেটের মধ্যে একটি, যার মধ্যে Circle এবং Triangle-ও রয়েছে। এটি করার জন্য, Rust আমাদের এই সম্ভাবনাগুলোকে একটি এনাম হিসাবে এনকোড করার অনুমতি দেয়।
আসুন এমন একটি পরিস্থিতি দেখি যা আমরা কোডে প্রকাশ করতে চাইতে পারি এবং দেখি কেন এই ক্ষেত্রে এনামগুলো দরকারী এবং স্ট্রাকটগুলোর চেয়ে বেশি উপযুক্ত। ধরুন আমাদের IP অ্যাড্রেস নিয়ে কাজ করতে হবে। বর্তমানে, IP অ্যাড্রেসের জন্য দুটি প্রধান স্ট্যান্ডার্ড ব্যবহার করা হয়: ভার্সন চার এবং ভার্সন ছয়। যেহেতু এগুলোই আমাদের প্রোগ্রামের সামনে আসতে পারে এমন IP অ্যাড্রেসের একমাত্র সম্ভাবনা, তাই আমরা সমস্ত সম্ভাব্য ভেরিয়েন্টগুলো গণনা করতে পারি, যেখান থেকে এনিউমারেশন (enumeration) নামটি এসেছে।
যেকোনো IP অ্যাড্রেস হয় একটি ভার্সন চার বা একটি ভার্সন ছয় অ্যাড্রেস হতে পারে, কিন্তু একই সময়ে উভয়ই নয়। IP অ্যাড্রেসের এই বৈশিষ্ট্যটি এনাম ডেটা স্ট্রাকচারকে উপযুক্ত করে তোলে কারণ একটি এনাম মান শুধুমাত্র তার ভেরিয়েন্টগুলোর মধ্যে একটি হতে পারে। ভার্সন চার এবং ভার্সন ছয় উভয় অ্যাড্রেসই এখনও মৌলিকভাবে IP অ্যাড্রেস, তাই কোড যখন যেকোনো ধরনের IP অ্যাড্রেসের ক্ষেত্রে প্রযোজ্য পরিস্থিতিগুলো পরিচালনা করে তখন তাদের একই টাইপ হিসাবে বিবেচনা করা উচিত।
আমরা কোডে এই ধারণাটি প্রকাশ করতে পারি একটি IpAddrKind এনিউমারেশন সংজ্ঞায়িত করে এবং একটি IP অ্যাড্রেস হতে পারে এমন সম্ভাব্য প্রকারগুলো তালিকাভুক্ত করে, V4 এবং V6। এগুলো হল এনামের ভেরিয়েন্ট:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
IpAddrKind এখন একটি কাস্টম ডেটা টাইপ যা আমরা আমাদের কোডের অন্য কোথাও ব্যবহার করতে পারি।
এনাম মান (Enum Values)
আমরা IpAddrKind-এর দুটি ভেরিয়েন্টের প্রত্যেকটির ইন্সট্যান্স তৈরি করতে পারি এইভাবে:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
লক্ষ্য করুন যে এনামের ভেরিয়েন্টগুলো এর আইডেন্টিফায়ারের অধীনে নেমস্পেস করা হয়েছে এবং আমরা দুটিকে আলাদা করতে একটি ডাবল কোলন ব্যবহার করি। এটি দরকারী কারণ এখন IpAddrKind::V4 এবং IpAddrKind::V6 উভয় মান একই টাইপের: IpAddrKind। তারপর আমরা, উদাহরণস্বরূপ, এমন একটি ফাংশন সংজ্ঞায়িত করতে পারি যা যেকোনো IpAddrKind নেয়:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
এবং আমরা এই ফাংশনটিকে যেকোনো ভেরিয়েন্ট দিয়ে কল করতে পারি:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
এনাম ব্যবহারের আরও সুবিধা রয়েছে। আমাদের IP অ্যাড্রেস টাইপ সম্পর্কে আরও চিন্তা করলে, এই মুহূর্তে আমাদের কাছে প্রকৃত IP অ্যাড্রেস ডেটা সংরক্ষণ করার কোনো উপায় নেই; আমরা কেবল জানি এটি কোন ধরনের। যেহেতু আপনি এইমাত্র চ্যাপ্টার ৫-এ স্ট্রাকট সম্পর্কে শিখেছেন, তাই আপনি হয়তো Listing 6-1-এ দেখানো স্ট্রাকটগুলো দিয়ে এই সমস্যার সমাধান করতে চাইতে পারেন।
fn main() { enum IpAddrKind { V4, V6, } struct IpAddr { kind: IpAddrKind, address: String, } let home = IpAddr { kind: IpAddrKind::V4, address: String::from("127.0.0.1"), }; let loopback = IpAddr { kind: IpAddrKind::V6, address: String::from("::1"), }; }
এখানে, আমরা একটি স্ট্রাকট IpAddr সংজ্ঞায়িত করেছি যাতে দুটি ফিল্ড রয়েছে: একটি kind ফিল্ড যার টাইপ IpAddrKind (আমরা পূর্বে সংজ্ঞায়িত করা এনাম) এবং একটি address ফিল্ড যার টাইপ String। আমাদের কাছে এই স্ট্রাকটের দুটি ইন্সট্যান্স রয়েছে। প্রথমটি হল home, এবং এর kind-এর মান হল IpAddrKind::V4 যার সাথে 127.0.0.1-এর সংশ্লিষ্ট অ্যাড্রেস ডেটা রয়েছে। দ্বিতীয় ইন্সট্যান্সটি হল loopback। এটির kind মান হিসাবে IpAddrKind-এর অন্য ভেরিয়েন্টটি রয়েছে, V6, এবং এর সাথে ::1 অ্যাড্রেস যুক্ত রয়েছে। আমরা kind এবং address মানগুলোকে একসাথে বান্ডিল করার জন্য একটি স্ট্রাকট ব্যবহার করেছি, তাই এখন ভেরিয়েন্টটি মানের সাথে সম্পর্কিত।
যাইহোক, শুধুমাত্র একটি এনাম ব্যবহার করে একই ধারণাটি উপস্থাপন করা আরও সংক্ষিপ্ত: একটি স্ট্রাকটের ভিতরে একটি এনামের পরিবর্তে, আমরা সরাসরি প্রতিটি এনাম ভেরিয়েন্টের মধ্যে ডেটা রাখতে পারি। IpAddr এনামের এই নতুন সংজ্ঞাটি বলে যে V4 এবং V6 উভয় ভেরিয়েন্টের সাথেই String মান যুক্ত থাকবে:
fn main() { enum IpAddr { V4(String), V6(String), } let home = IpAddr::V4(String::from("127.0.0.1")); let loopback = IpAddr::V6(String::from("::1")); }
আমরা সরাসরি এনামের প্রতিটি ভেরিয়েন্টের সাথে ডেটা সংযুক্ত করি, তাই একটি অতিরিক্ত স্ট্রাকটের প্রয়োজন নেই। এখানে, এনামগুলো কীভাবে কাজ করে তার আরেকটি বিশদ বিবরণ দেখাও সহজ: আমরা যে প্রতিটি এনাম ভেরিয়েন্টের নাম সংজ্ঞায়িত করি সেটিও একটি ফাংশন হয়ে যায় যা এনামের একটি ইন্সট্যান্স তৈরি করে। অর্থাৎ, IpAddr::V4() হল একটি ফাংশন কল যা একটি String আর্গুমেন্ট নেয় এবং IpAddr টাইপের একটি ইন্সট্যান্স রিটার্ন করে। এনাম সংজ্ঞায়িত করার ফলে আমরা স্বয়ংক্রিয়ভাবে এই কনস্ট্রাক্টর ফাংশনটি সংজ্ঞায়িত করি।
একটি স্ট্রাকটের পরিবর্তে একটি এনাম ব্যবহার করার আরেকটি সুবিধা রয়েছে: প্রতিটি ভেরিয়েন্টের বিভিন্ন টাইপ এবং পরিমাণের ডেটা থাকতে পারে। ভার্সন চার IP অ্যাড্রেসগুলোতে সর্বদা চারটি সংখ্যাসূচক উপাদান থাকবে যার মান 0 থেকে 255 এর মধ্যে থাকবে। যদি আমরা V4 অ্যাড্রেসগুলোকে চারটি u8 মান হিসাবে সংরক্ষণ করতে চাইতাম কিন্তু এখনও V6 অ্যাড্রেসগুলোকে একটি String মান হিসাবে প্রকাশ করতে চাইতাম, তাহলে আমরা একটি স্ট্রাকট দিয়ে তা করতে পারতাম না। এনামগুলো এই ক্ষেত্রটি সহজে পরিচালনা করে:
fn main() { enum IpAddr { V4(u8, u8, u8, u8), V6(String), } let home = IpAddr::V4(127, 0, 0, 1); let loopback = IpAddr::V6(String::from("::1")); }
আমরা ভার্সন চার এবং ভার্সন ছয় IP অ্যাড্রেস সংরক্ষণ করার জন্য ডেটা স্ট্রাকচার সংজ্ঞায়িত করার বিভিন্ন উপায় দেখিয়েছি। যাইহোক, দেখা যাচ্ছে যে, IP অ্যাড্রেস সংরক্ষণ করা এবং সেগুলো কোন ধরনের তা এনকোড করা এতটাই সাধারণ যে স্ট্যান্ডার্ড লাইব্রেরিতে আমাদের ব্যবহারের জন্য একটি সংজ্ঞা রয়েছে! চলুন দেখি কিভাবে স্ট্যান্ডার্ড লাইব্রেরি IpAddr সংজ্ঞায়িত করে: এতে ঠিক সেই এনাম এবং ভেরিয়েন্টগুলো রয়েছে যা আমরা সংজ্ঞায়িত করেছি এবং ব্যবহার করেছি, কিন্তু এটি অ্যাড্রেস ডেটাকে দুটি ভিন্ন স্ট্রাকটের আকারে ভেরিয়েন্টগুলোর ভিতরে এমবেড করে, যা প্রতিটি ভেরিয়েন্টের জন্য ভিন্নভাবে সংজ্ঞায়িত করা হয়েছে:
#![allow(unused)] fn main() { struct Ipv4Addr { // --snip-- } struct Ipv6Addr { // --snip-- } enum IpAddr { V4(Ipv4Addr), V6(Ipv6Addr), } }
এই কোডটি ব্যাখ্যা করে যে আপনি একটি এনাম ভেরিয়েন্টের ভিতরে যেকোনো ধরনের ডেটা রাখতে পারেন: উদাহরণস্বরূপ, স্ট্রিং, সাংখ্যিক টাইপ বা স্ট্রাকট। আপনি এমনকি অন্য একটি এনামও অন্তর্ভুক্ত করতে পারেন! এছাড়াও, স্ট্যান্ডার্ড লাইব্রেরির টাইপগুলো প্রায়শই আপনার তৈরি করা জিনিসের চেয়ে বেশি জটিল হয় না।
লক্ষ্য করুন যে যদিও স্ট্যান্ডার্ড লাইব্রেরিতে IpAddr-এর জন্য একটি সংজ্ঞা রয়েছে, তবুও আমরা কোনো বিরোধ ছাড়াই আমাদের নিজস্ব সংজ্ঞা তৈরি এবং ব্যবহার করতে পারি কারণ আমরা স্ট্যান্ডার্ড লাইব্রেরির সংজ্ঞাটিকে আমাদের স্কোপে আনিনি। আমরা চ্যাপ্টার ৭-এ স্কোপে টাইপ আনার বিষয়ে আরও কথা বলব।
Listing 6-2-তে এনামের আরেকটি উদাহরণ দেখা যাক: এটির ভেরিয়েন্টগুলোতে বিভিন্ন ধরনের ডেটা এমবেড করা আছে।
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() {}
এই এনামটিতে চারটি ভেরিয়েন্ট রয়েছে যাদের বিভিন্ন টাইপ রয়েছে:
Quit-এর সাথে কোনো ডেটা যুক্ত নেই।Move-এর নামযুক্ত ফিল্ড রয়েছে, যেমন একটি স্ট্রাকটে থাকে।Writeএকটি এককStringঅন্তর্ভুক্ত করে।ChangeColor-এ তিনটিi32মান রয়েছে।
Listing 6-2-এর মতো ভেরিয়েন্ট সহ একটি এনাম সংজ্ঞায়িত করা বিভিন্ন ধরণের স্ট্রাকট সংজ্ঞা সংজ্ঞায়িত করার মতোই, পার্থক্য হল এনামটি struct কীওয়ার্ড ব্যবহার করে না এবং সমস্ত ভেরিয়েন্ট Message টাইপের অধীনে একত্রিত হয়। নিম্নলিখিত স্ট্রাকটগুলো পূর্ববর্তী এনাম ভেরিয়েন্টগুলোর মতো একই ডেটা ধারণ করতে পারে:
struct QuitMessage; // unit struct struct MoveMessage { x: i32, y: i32, } struct WriteMessage(String); // tuple struct struct ChangeColorMessage(i32, i32, i32); // tuple struct fn main() {}
কিন্তু যদি আমরা বিভিন্ন স্ট্রাকট ব্যবহার করতাম, যেগুলোর প্রত্যেকের নিজস্ব টাইপ রয়েছে, তাহলে আমরা Listing 6-2-তে সংজ্ঞায়িত Message এনামের মতো এই সমস্ত ধরণের মেসেজ নিতে পারে এমন একটি ফাংশন সংজ্ঞায়িত করতে পারতাম না, যেটি একটি একক টাইপ।
এনাম এবং স্ট্রাকটগুলোর মধ্যে আরও একটি মিল রয়েছে: যেমন আমরা impl ব্যবহার করে স্ট্রাকটগুলোতে মেথড সংজ্ঞায়িত করতে পারি, তেমনই আমরা এনামগুলোতেও মেথড সংজ্ঞায়িত করতে পারি। এখানে call নামে একটি মেথড রয়েছে যা আমরা আমাদের Message এনামে সংজ্ঞায়িত করতে পারি:
fn main() { enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } impl Message { fn call(&self) { // method body would be defined here } } let m = Message::Write(String::from("hello")); m.call(); }
মেথডের বডি self ব্যবহার করে সেই মানটি পেতে পারে যেটিতে আমরা মেথডটি কল করেছি। এই উদাহরণে, আমরা একটি ভেরিয়েবল m তৈরি করেছি যার মান Message::Write(String::from("hello")), এবং m.call() রান করার সময় call মেথডের বডিতে self হবে এটি।
আসুন স্ট্যান্ডার্ড লাইব্রেরির আরেকটি এনাম দেখি যা খুব সাধারণ এবং দরকারী: Option।
Option এনাম এবং নাল (Null) মানের উপর এর সুবিধা (The Option Enum and Its Advantages Over Null Values)
এই বিভাগে Option-এর একটি কেস স্টাডি অন্বেষণ করা হয়েছে, যেটি স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সংজ্ঞায়িত আরেকটি এনাম। Option টাইপটি খুব সাধারণ পরিস্থিতিকে এনকোড করে যেখানে একটি মান কিছু হতে পারে বা কিছুই নাও হতে পারে।
উদাহরণস্বরূপ, আপনি যদি একটি খালি নয় এমন তালিকার প্রথম আইটেমটির অনুরোধ করেন, তাহলে আপনি একটি মান পাবেন। আপনি যদি একটি খালি তালিকার প্রথম আইটেমটির অনুরোধ করেন, তাহলে আপনি কিছুই পাবেন না। টাইপ সিস্টেমের পরিপ্রেক্ষিতে এই ধারণাটি প্রকাশ করার অর্থ হল কম্পাইলার পরীক্ষা করতে পারে যে আপনি যে সমস্ত ক্ষেত্রগুলো হ্যান্ডেল করা উচিত সেগুলো হ্যান্ডেল করেছেন কিনা; এই কার্যকারিতা অন্যান্য প্রোগ্রামিং ল্যাঙ্গুয়েজে অত্যন্ত সাধারণ বাগগুলো প্রতিরোধ করতে পারে।
প্রোগ্রামিং ল্যাঙ্গুয়েজ ডিজাইন প্রায়শই কোন ফিচারগুলো আপনি অন্তর্ভুক্ত করেন তার পরিপ্রেক্ষিতে ভাবা হয়, তবে আপনি যে ফিচারগুলো বাদ দেন সেগুলোও গুরুত্বপূর্ণ। Rust-এর নাল (null) ফিচার নেই যা অন্য অনেক ভাষার আছে। নাল হল এমন একটি মান যার অর্থ সেখানে কোনো মান নেই। নাল সহ ভাষাগুলোতে, ভেরিয়েবলগুলো সর্বদাই দুটি অবস্থার মধ্যে একটিতে থাকতে পারে: নাল বা নাল-নয়।
২০০৯ সালে তার উপস্থাপনা “Null References: The Billion Dollar Mistake,”-এ নালের উদ্ভাবক টনি হোর (Tony Hoare) এটি বলেছেন:
আমি এটিকে আমার বিলিয়ন-ডলার ভুল বলি। সেই সময়ে, আমি একটি অবজেক্ট-ওরিয়েন্টেড ভাষায় রেফারেন্সের জন্য প্রথম ব্যাপক টাইপ সিস্টেম ডিজাইন করছিলাম। আমার লক্ষ্য ছিল নিশ্চিত করা যে রেফারেন্সের সমস্ত ব্যবহার যেন একেবারে নিরাপদ হয়, কম্পাইলার দ্বারা স্বয়ংক্রিয়ভাবে পরীক্ষা করা হয়। কিন্তু আমি একটি নাল রেফারেন্স রাখার প্রলোভন প্রতিরোধ করতে পারিনি, কারণ এটি বাস্তবায়ন করা খুব সহজ ছিল। এটি অসংখ্য এরর, দুর্বলতা এবং সিস্টেম ক্র্যাশের দিকে পরিচালিত করেছে, যা সম্ভবত গত চল্লিশ বছরে এক বিলিয়ন ডলারের কষ্ট এবং ক্ষতির কারণ হয়েছে।
নাল মানগুলোর সমস্যা হল যে আপনি যদি একটি নাল মানকে নাল-নয় মান হিসাবে ব্যবহার করার চেষ্টা করেন, তাহলে আপনি কোনো না কোনো ধরনের এরর পাবেন। যেহেতু এই নাল বা নাল-নয় বৈশিষ্ট্যটি ব্যাপক, তাই এই ধরনের এরর করা অত্যন্ত সহজ।
যাইহোক, নাল যে ধারণাটি প্রকাশ করার চেষ্টা করছে সেটি এখনও একটি দরকারী ধারণা: একটি নাল হল এমন একটি মান যা বর্তমানে কোনো কারণে অবৈধ বা অনুপস্থিত।
সমস্যাটি আসলে ধারণার সাথে নয়, নির্দিষ্ট বাস্তবায়নের সাথে। সেই অনুযায়ী, Rust-এর নাল নেই, তবে এটিতে একটি এনাম রয়েছে যা একটি মান উপস্থিত বা অনুপস্থিত থাকার ধারণাটিকে এনকোড করতে পারে। এই এনামটি হল Option<T>, এবং এটি স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সংজ্ঞায়িত করা হয়েছে এইভাবে:
#![allow(unused)] fn main() { enum Option<T> { None, Some(T), } }
Option<T> এনামটি এতটাই দরকারী যে এটি প্রেলিউডে (prelude) অন্তর্ভুক্ত করা হয়েছে; আপনাকে এটিকে স্পষ্টতই স্কোপে আনতে হবে না। এর ভেরিয়েন্টগুলোও প্রেলিউডে অন্তর্ভুক্ত করা হয়েছে: আপনি সরাসরি Option:: উপসর্গ ছাড়াই Some এবং None ব্যবহার করতে পারেন। Option<T> এনামটি এখনও একটি নিয়মিত এনাম এবং Some(T) এবং None এখনও Option<T> টাইপের ভেরিয়েন্ট।
<T> সিনট্যাক্স হল Rust-এর একটি ফিচার যা নিয়ে আমরা এখনও কথা বলিনি। এটি একটি জেনেরিক টাইপ প্যারামিটার এবং আমরা চ্যাপ্টার ১০-এ জেনেরিকগুলো নিয়ে আরও বিস্তারিত আলোচনা করব। আপাতত, আপনাকে শুধু জানতে হবে যে <T> মানে হল Option এনামের Some ভেরিয়েন্টটি যেকোনো টাইপের এক টুকরো ডেটা ধারণ করতে পারে এবং T-এর পরিবর্তে ব্যবহৃত প্রতিটি কংক্রিট টাইপ সামগ্রিক Option<T> টাইপটিকে একটি ভিন্ন টাইপ করে তোলে। এখানে সংখ্যা টাইপ এবং অক্ষর টাইপ ধারণ করতে Option মান ব্যবহারের কিছু উদাহরণ দেওয়া হল:
fn main() { let some_number = Some(5); let some_char = Some('e'); let absent_number: Option<i32> = None; }
some_number-এর টাইপ হল Option<i32>। some_char-এর টাইপ হল Option<char>, যেটি একটি ভিন্ন টাইপ। Rust এই টাইপগুলো অনুমান করতে পারে কারণ আমরা Some ভেরিয়েন্টের ভিতরে একটি মান নির্দিষ্ট করেছি। absent_number-এর জন্য, Rust আমাদের সামগ্রিক Option টাইপটি অ্যানোটেট করতে বলে: কম্পাইলার শুধুমাত্র একটি None মান দেখে সংশ্লিষ্ট Some ভেরিয়েন্টটি কী টাইপ ধারণ করবে তা অনুমান করতে পারে না। এখানে, আমরা Rust-কে বলি যে আমরা চাই absent_number-এর টাইপ Option<i32> হোক।
যখন আমাদের কাছে একটি Some মান থাকে, তখন আমরা জানি যে একটি মান উপস্থিত রয়েছে এবং মানটি Some-এর মধ্যে রয়েছে। যখন আমাদের কাছে একটি None মান থাকে, তখন এক অর্থে এর অর্থ নালের মতোই: আমাদের কাছে একটি বৈধ মান নেই। তাহলে Option<T> থাকা নাল থাকার চেয়ে ভালো কেন?
সংক্ষেপে, যেহেতু Option<T> এবং T (যেখানে T যেকোনো টাইপ হতে পারে) ভিন্ন টাইপ, তাই কম্পাইলার আমাদের একটি Option<T> মানকে নিশ্চিতভাবে একটি বৈধ মান হিসাবে ব্যবহার করতে দেবে না। উদাহরণস্বরূপ, এই কোডটি কম্পাইল হবে না, কারণ এটি একটি i8-এর সাথে একটি Option<i8> যোগ করার চেষ্টা করছে:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
}যদি আমরা এই কোডটি চালাই, তাহলে আমরা এইরকম একটি এরর মেসেজ পাব:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let sum = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
`&i8` implements `Add<i8>`
`&i8` implements `Add`
`i8` implements `Add<&i8>`
`i8` implements `Add`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
দারুণ! আসলে, এই এরর মেসেজটির অর্থ হল Rust বুঝতে পারছে না কিভাবে একটি i8 এবং একটি Option<i8> যোগ করতে হয়, কারণ তারা ভিন্ন টাইপ। যখন Rust-এ আমাদের i8-এর মতো একটি টাইপের মান থাকে, তখন কম্পাইলার নিশ্চিত করবে যে আমাদের কাছে সর্বদাই একটি বৈধ মান রয়েছে। আমরা সেই মানটি ব্যবহার করার আগে নালের জন্য পরীক্ষা না করেই আত্মবিশ্বাসের সাথে এগিয়ে যেতে পারি। শুধুমাত্র যখন আমাদের কাছে একটি Option<i8> থাকে (অথবা আমরা যে মানের টাইপ নিয়ে কাজ করছি) তখনই আমাদের একটি মান নাও থাকতে পারে এমন বিষয়ে চিন্তা করতে হবে এবং কম্পাইলার নিশ্চিত করবে যে আমরা মানটি ব্যবহার করার আগে সেই ক্ষেত্রটি হ্যান্ডেল করেছি।
অন্য কথায়, আপনি Option<T>-এর সাথে T অপারেশনগুলো সম্পাদন করার আগে আপনাকে এটিকে T-তে রূপান্তর করতে হবে। সাধারণত, এটি নালের সাথে সবচেয়ে সাধারণ সমস্যাগুলোর মধ্যে একটি ধরতে সাহায্য করে: এমন কিছুকে নাল নয় বলে ধরে নেওয়া যা আসলে নাল।
একটি নাল-নয় মান ভুলভাবে ধরে নেওয়ার ঝুঁকি দূর করা আপনাকে আপনার কোডে আরও আত্মবিশ্বাসী হতে সাহায্য করে। এমন একটি মান থাকতে যা সম্ভবত নাল হতে পারে, আপনাকে অবশ্যই স্পষ্টতই অপ্ট ইন করতে হবে সেই মানটির টাইপ Option<T> করে। তারপর, যখন আপনি সেই মানটি ব্যবহার করেন, তখন আপনাকে স্পষ্টতই সেই ক্ষেত্রটি হ্যান্ডেল করতে হবে যখন মানটি নাল হয়। যেখানেই একটি মানের টাইপ Option<T> নয়, সেখানে আপনি নিরাপদে ধরে নিতে পারেন যে মানটি নাল নয়। Rust-এর জন্য এটি একটি ইচ্ছাকৃত ডিজাইনের সিদ্ধান্ত ছিল নালের ব্যাপকতা সীমিত করতে এবং Rust কোডের নিরাপত্তা বাড়াতে।
তাহলে আপনি কীভাবে একটি Option<T> টাইপের মান থাকলে Some ভেরিয়েন্ট থেকে T মানটি বের করবেন যাতে আপনি সেই মানটি ব্যবহার করতে পারেন? Option<T> এনামের বিভিন্ন পরিস্থিতিতে দরকারী প্রচুর সংখ্যক মেথড রয়েছে; আপনি এর ডকুমেন্টেশনে সেগুলো দেখতে পারেন। Option<T>-এর মেথডগুলোর সাথে পরিচিত হওয়া আপনার Rust যাত্রায় অত্যন্ত দরকারী হবে।
সাধারণভাবে, একটি Option<T> মান ব্যবহার করার জন্য, আপনি প্রতিটি ভেরিয়েন্ট হ্যান্ডেল করার জন্য কোড রাখতে চান। আপনি কিছু কোড চান যা শুধুমাত্র তখনই চলবে যখন আপনার কাছে একটি Some(T) মান থাকবে এবং এই কোডটিকে ভিতরের T ব্যবহার করার অনুমতি দেওয়া হয়। আপনার কাছে যদি একটি None মান থাকে তবে আপনি অন্য কিছু কোড চালাতে চান এবং সেই কোডে একটি T মান উপলব্ধ নেই। match এক্সপ্রেশন হল একটি কন্ট্রোল ফ্লো কনস্ট্রাক্ট যা এনামগুলোর সাথে ব্যবহার করার সময় ঠিক এটিই করে: এটি এনামের কোন ভেরিয়েন্ট রয়েছে তার উপর নির্ভর করে ভিন্ন কোড চালাবে এবং সেই কোডটি মিলিত মানের ভিতরের ডেটা ব্যবহার করতে পারে।
match কন্ট্রোল ফ্লো কনস্ট্রাক্ট (The match Control Flow Construct)
Rust-এ match নামক একটি অত্যন্ত শক্তিশালী কন্ট্রোল ফ্লো কনস্ট্রাক্ট রয়েছে যা আপনাকে একটি মানকে একাধিক প্যাটার্নের সাথে তুলনা করতে এবং কোন প্যাটার্নটি মেলে তার উপর ভিত্তি করে কোড এক্সিকিউট করতে দেয়। প্যাটার্নগুলো লিটারেল মান, ভেরিয়েবলের নাম, ওয়াইল্ডকার্ড এবং আরও অনেক কিছু দিয়ে তৈরি হতে পারে; চ্যাপ্টার 19-এ সমস্ত ভিন্ন ধরনের প্যাটার্ন এবং সেগুলো কী করে তা কভার করা হয়েছে। match-এর ক্ষমতা আসে প্যাটার্নগুলোর এক্সপ্রেসিভনেস (expressiveness) থেকে এবং কম্পাইলার নিশ্চিত করে যে সমস্ত সম্ভাব্য ক্ষেত্র হ্যান্ডেল করা হয়েছে।
একটি match এক্সপ্রেশনকে একটি কয়েন-সর্টিং মেশিনের মতো ভাবতে পারেন: কয়েনগুলো বিভিন্ন আকারের গর্তযুক্ত একটি ট্র্যাকের নিচে গড়িয়ে পড়ে এবং প্রতিটি কয়েন প্রথম যে গর্তটিতে ফিট করে সেটিতে পড়ে যায়। একইভাবে, মানগুলো match-এর প্রতিটি প্যাটার্নের মধ্য দিয়ে যায় এবং প্রথম প্যাটার্নে যে মানটি "ফিট" করে, সেটি এক্সিকিউশনের সময় ব্যবহার করার জন্য সংশ্লিষ্ট কোড ব্লকে চলে যায়।
কয়েনের কথা যখন উঠলই, তখন আসুন match ব্যবহার করে সেগুলোকে একটি উদাহরণ হিসাবে ব্যবহার করি! আমরা এমন একটি ফাংশন লিখতে পারি যা একটি অজানা US কয়েন নেয় এবং গণনা মেশিনের মতোই নির্ধারণ করে যে এটি কোন কয়েন এবং সেন্টে এর মান রিটার্ন করে, যেমনটি Listing 6-3-তে দেখানো হয়েছে।
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } fn main() {}
আসুন value_in_cents ফাংশনের match টি ভেঙে দেখি। প্রথমে আমরা match কীওয়ার্ডটি লিখি এবং তারপর একটি এক্সপ্রেশন, যা এই ক্ষেত্রে coin মান। এটি if দিয়ে ব্যবহৃত কন্ডিশনাল এক্সপ্রেশনের মতোই মনে হয়, কিন্তু একটি বড় পার্থক্য রয়েছে: if-এর সাথে, কন্ডিশনটি একটি বুলিয়ান মান মূল্যায়ন করতে হবে, কিন্তু এখানে এটি যেকোনো টাইপের হতে পারে। এই উদাহরণে coin-এর টাইপ হল Coin এনাম যা আমরা প্রথম লাইনে সংজ্ঞায়িত করেছি।
এরপর রয়েছে match আর্মগুলো। একটি আর্মের দুটি অংশ রয়েছে: একটি প্যাটার্ন এবং কিছু কোড। এখানে প্রথম আর্মটিতে একটি প্যাটার্ন রয়েছে যা হল Coin::Penny মান এবং তারপর => অপারেটর যা প্যাটার্ন এবং চালানোর জন্য কোডকে আলাদা করে। এই ক্ষেত্রে কোডটি হল শুধুমাত্র 1 মান। প্রতিটি আর্মকে একটি কমা দিয়ে পরেরটি থেকে আলাদা করা হয়।
যখন match এক্সপ্রেশনটি এক্সিকিউট হয়, তখন এটি ফলাফলের মানটিকে প্রতিটি আর্মের প্যাটার্নের সাথে তুলনা করে, ক্রমানুসারে। যদি একটি প্যাটার্ন মানের সাথে মেলে, তাহলে সেই প্যাটার্নের সাথে সম্পর্কিত কোডটি এক্সিকিউট করা হয়। যদি সেই প্যাটার্নটি মানের সাথে না মেলে, তাহলে এক্সিকিউশন পরবর্তী আর্মে চলতে থাকে, অনেকটা কয়েন-সর্টিং মেশিনের মতো। আমাদের যতগুলো প্রয়োজন ততগুলো আর্ম থাকতে পারে: Listing 6-3-তে, আমাদের match-এর চারটি আর্ম রয়েছে।
প্রতিটি আর্মের সাথে সম্পর্কিত কোড হল একটি এক্সপ্রেশন এবং ম্যাচিং আর্মের এক্সপ্রেশনের ফলাফলের মান হল সেই মান যা সম্পূর্ণ match এক্সপ্রেশনের জন্য রিটার্ন করা হয়।
যদি ম্যাচ আর্মের কোড ছোট হয় তবে আমরা সাধারণত কার্লি ব্র্যাকেট ব্যবহার করি না, যেমনটি Listing 6-3-তে রয়েছে যেখানে প্রতিটি আর্ম শুধুমাত্র একটি মান রিটার্ন করে। আপনি যদি একটি ম্যাচ আর্মে একাধিক লাইনের কোড চালাতে চান, তাহলে আপনাকে অবশ্যই কার্লি ব্র্যাকেট ব্যবহার করতে হবে এবং আর্মের পরে কমাটি তখন ঐচ্ছিক। উদাহরণস্বরূপ, নিম্নলিখিত কোডটি প্রতিবার Coin::Penny দিয়ে মেথড কল করা হলে “Lucky penny!” প্রিন্ট করে, কিন্তু তবুও ব্লকের শেষ মান, 1 রিটার্ন করে:
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => { println!("Lucky penny!"); 1 } Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } fn main() {}
মানগুলোর সাথে বাইন্ড করা প্যাটার্ন (Patterns That Bind to Values)
ম্যাচ আর্মগুলোর আরেকটি দরকারী ফিচার হল যে তারা প্যাটার্নের সাথে মেলে এমন মানগুলোর অংশের সাথে বাইন্ড করতে পারে। এইভাবে আমরা এনাম ভেরিয়েন্টগুলো থেকে মান বের করতে পারি।
উদাহরণ হিসাবে, আসুন আমাদের এনাম ভেরিয়েন্টগুলোর মধ্যে একটি পরিবর্তন করি যাতে এর ভিতরে ডেটা থাকে। ১৯৯৯ থেকে ২০০৮ সাল পর্যন্ত, মার্কিন যুক্তরাষ্ট্র প্রতিটি ৫০টি রাজ্যের জন্য একদিকে ভিন্ন ডিজাইন সহ কোয়ার্টার তৈরি করেছিল। অন্য কোনো কয়েনের স্টেট ডিজাইন ছিল না, তাই শুধুমাত্র কোয়ার্টারেই এই অতিরিক্ত মান রয়েছে। আমরা আমাদের enum-এ এই তথ্য যোগ করতে পারি Quarter ভেরিয়েন্টটিকে পরিবর্তন করে এর ভিতরে একটি UsState মান সংরক্ষণ করতে, যা আমরা Listing 6-4-এ করেছি।
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() {}
আসুন কল্পনা করি যে একজন বন্ধু সমস্ত ৫০টি রাজ্যের কোয়ার্টার সংগ্রহ করার চেষ্টা করছেন। আমরা যখন আমাদের খুচরো পয়সাগুলো কয়েনের ধরন অনুসারে বাছাই করি, তখন আমরা প্রতিটি কোয়ার্টারের সাথে সম্পর্কিত রাজ্যের নামও বলব যাতে যদি এটি এমন কোনো রাজ্য হয় যা আমাদের বন্ধুর নেই, তাহলে তারা সেটি তাদের সংগ্রহে যোগ করতে পারে।
এই কোডের ম্যাচ এক্সপ্রেশনে, আমরা Coin::Quarter ভেরিয়েন্টের মানগুলোর সাথে মেলে এমন প্যাটার্নে state নামক একটি ভেরিয়েবল যোগ করি। যখন একটি Coin::Quarter মেলে, তখন state ভেরিয়েবলটি সেই কোয়ার্টারের রাজ্যের মানের সাথে বাইন্ড হবে। তারপর আমরা সেই আর্মের কোডে state ব্যবহার করতে পারি, এইভাবে:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter(state) => { println!("State quarter from {state:?}!"); 25 } } } fn main() { value_in_cents(Coin::Quarter(UsState::Alaska)); }
যদি আমরা value_in_cents(Coin::Quarter(UsState::Alaska)) কল করি, তাহলে coin হবে Coin::Quarter(UsState::Alaska)। যখন আমরা সেই মানটিকে প্রতিটি ম্যাচ আর্মের সাথে তুলনা করি, তখন সেগুলোর কোনোটিই মেলে না যতক্ষণ না আমরা Coin::Quarter(state)-এ পৌঁছাই। সেই সময়ে, state-এর জন্য বাইন্ডিং হবে UsState::Alaska মান। তারপর আমরা println! এক্সপ্রেশনে সেই বাইন্ডিংটি ব্যবহার করতে পারি, এইভাবে Quarter-এর জন্য Coin এনাম ভেরিয়েন্ট থেকে অভ্যন্তরীণ রাজ্যের মান পেতে পারি।
Option<T>-এর সাথে ম্যাচিং (Matching with Option<T>)
আগের বিভাগে, আমরা Option<T> ব্যবহার করার সময় Some কেস থেকে অভ্যন্তরীণ T মানটি পেতে চেয়েছিলাম; আমরা Coin এনামের সাথে যেভাবে করেছি, সেভাবে match ব্যবহার করে Option<T> হ্যান্ডেল করতে পারি! কয়েনগুলোর তুলনা করার পরিবর্তে, আমরা Option<T>-এর ভেরিয়েন্টগুলোর তুলনা করব, কিন্তু match এক্সপ্রেশন যেভাবে কাজ করে তা একই থাকে।
ধরুন আমরা এমন একটি ফাংশন লিখতে চাই যা একটি Option<i32> নেয় এবং যদি ভিতরে একটি মান থাকে তবে সেই মানের সাথে 1 যোগ করে। যদি ভিতরে কোনো মান না থাকে, তাহলে ফাংশনটির None মান রিটার্ন করা উচিত এবং কোনো অপারেশন করার চেষ্টা করা উচিত নয়।
match-এর কারণে এই ফাংশনটি লেখা খুব সহজ এবং এটি Listing 6-5-এর মতো দেখতে হবে।
fn main() { fn plus_one(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), } } let five = Some(5); let six = plus_one(five); let none = plus_one(None); }
আসুন plus_one-এর প্রথম এক্সিকিউশনটি আরও বিশদে পরীক্ষা করি। যখন আমরা plus_one(five) কল করি, তখন plus_one-এর বডিতে x ভেরিয়েবলের মান হবে Some(5)। তারপর আমরা এটিকে প্রতিটি ম্যাচ আর্মের সাথে তুলনা করি:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Some(5) মানটি None প্যাটার্নের সাথে মেলে না, তাই আমরা পরবর্তী আর্মে চালিয়ে যাই:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Some(5) কি Some(i)-এর সাথে মেলে? অবশ্যই মেলে! আমাদের একই ভেরিয়েন্ট রয়েছে। i, Some-এর মধ্যে থাকা মানের সাথে বাইন্ড করে, তাই i 5 মান নেয়। তারপর ম্যাচ আর্মের কোডটি এক্সিকিউট করা হয়, তাই আমরা i-এর মানের সাথে 1 যোগ করি এবং আমাদের মোট 6 সহ একটি নতুন Some মান তৈরি করি।
এবার Listing 6-5-এ plus_one-এর দ্বিতীয় কলটি বিবেচনা করি, যেখানে x হল None। আমরা match-এ প্রবেশ করি এবং প্রথম আর্মের সাথে তুলনা করি:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}এটি মিলে যায়! যোগ করার মতো কোনো মান নেই, তাই প্রোগ্রামটি বন্ধ হয়ে যায় এবং =>-এর ডানদিকের None মানটি রিটার্ন করে। যেহেতু প্রথম আর্মটি মিলে গেছে, তাই অন্য কোনো আর্ম তুলনা করা হয় না।
অনেক পরিস্থিতিতে match এবং এনামগুলোকে একত্রিত করা দরকারী। আপনি Rust কোডে এই প্যাটার্নটি অনেক দেখতে পাবেন: একটি এনামের বিপরীতে match, ভিতরের ডেটার সাথে একটি ভেরিয়েবল বাইন্ড করা এবং তারপর এর উপর ভিত্তি করে কোড এক্সিকিউট করা। এটি প্রথমে একটু জটিল, কিন্তু একবার আপনি এতে অভ্যস্ত হয়ে গেলে, আপনি চাইবেন যে এটি সমস্ত ভাষায় থাকুক। এটি ধারাবাহিকভাবে ব্যবহারকারীর প্রিয়।
ম্যাচগুলো এক্সহস্টিভ (Matches Are Exhaustive)
match-এর আরেকটি দিক রয়েছে যা আমাদের আলোচনা করতে হবে: আর্মগুলোর প্যাটার্নগুলোকে অবশ্যই সমস্ত সম্ভাবনা কভার করতে হবে। আমাদের plus_one ফাংশনের এই ভার্সনটি বিবেচনা করুন, যেটিতে একটি বাগ রয়েছে এবং কম্পাইল হবে না:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}আমরা None কেসটি হ্যান্ডেল করিনি, তাই এই কোডটি একটি বাগের কারণ হবে। সৌভাগ্যবশত, এটি এমন একটি বাগ যা Rust কীভাবে ধরতে হয় তা জানে। আমরা যদি এই কোডটি কম্পাইল করার চেষ্টা করি, তাহলে আমরা এই এররটি পাব:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/option.rs:572:1
|
572 | pub enum Option<T> {
| ^^^^^^^^^^^^^^^^^^
...
576 | None,
| ---- not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Rust জানে যে আমরা প্রতিটি সম্ভাব্য ক্ষেত্র কভার করিনি, এবং এমনকি জানে যে আমরা কোন প্যাটার্নটি ভুলে গেছি! Rust-এ ম্যাচগুলো এক্সহস্টিভ (exhaustive): কোডটি বৈধ হওয়ার জন্য আমাদের অবশ্যই প্রতিটি শেষ সম্ভাবনা শেষ করতে হবে। বিশেষ করে Option<T>-এর ক্ষেত্রে, যখন Rust আমাদের None কেসটি স্পষ্টভাবে হ্যান্ডেল করতে ভোলা থেকে বিরত রাখে, তখন এটি আমাদের এমন একটি মান আছে বলে ধরে নেওয়া থেকে রক্ষা করে যখন আমাদের কাছে নাল থাকতে পারে, এইভাবে পূর্বে আলোচিত বিলিয়ন-ডলারের ভুলটিকে অসম্ভব করে তোলে।
ক্যাচ-অল প্যাটার্ন এবং _ প্লেসহোল্ডার (Catch-All Patterns and the _ Placeholder)
এনামগুলো ব্যবহার করে, আমরা কয়েকটি নির্দিষ্ট মানের জন্য বিশেষ অ্যাকশন নিতে পারি, কিন্তু অন্য সমস্ত মানের জন্য একটি ডিফল্ট অ্যাকশন নিতে পারি। কল্পনা করুন যে আমরা একটি গেম ইমপ্লিমেন্ট করছি যেখানে, আপনি যদি ডাইস রোলে 3 পান, তাহলে আপনার প্লেয়ার সরবে না, কিন্তু পরিবর্তে একটি নতুন অভিনব টুপি পায়। আপনি যদি 7 রোল করেন, তাহলে আপনার প্লেয়ার একটি অভিনব টুপি হারায়। অন্য সমস্ত মানের জন্য, আপনার প্লেয়ার গেম বোর্ডে সেই সংখ্যক স্পেস সরবে। এখানে একটি match রয়েছে যা সেই লজিকটি ইমপ্লিমেন্ট করে, ডাইস রোলের ফলাফলটি র্যান্ডম মানের পরিবর্তে হার্ডকোড করা হয়েছে এবং অন্য সমস্ত লজিক বডি ছাড়া ফাংশন দ্বারা উপস্থাপিত হয়েছে কারণ সেগুলো বাস্তবায়ন করা এই উদাহরণের সুযোগের বাইরে:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), other => move_player(other), } fn add_fancy_hat() {} fn remove_fancy_hat() {} fn move_player(num_spaces: u8) {} }
প্রথম দুটি আর্মের জন্য, প্যাটার্নগুলো হল আক্ষরিক মান 3 এবং 7। শেষ আর্মের জন্য যা অন্য সমস্ত সম্ভাব্য মান কভার করে, প্যাটার্নটি হল other নামক ভেরিয়েবল। other আর্মের জন্য যে কোডটি চলে সেটি move_player ফাংশনে ভেরিয়েবলটি পাস করে সেটি ব্যবহার করে।
এই কোডটি কম্পাইল হয়, যদিও আমরা u8 যে সমস্ত সম্ভাব্য মান নিতে পারে তা তালিকাভুক্ত করিনি, কারণ শেষ প্যাটার্নটি বিশেষভাবে তালিকাভুক্ত নয় এমন সমস্ত মানের সাথে মিলবে। এই ক্যাচ-অল প্যাটার্নটি match অবশ্যই এক্সহস্টিভ হতে হবে সেই প্রয়োজনীয়তা পূরণ করে। মনে রাখবেন যে আমাদের ক্যাচ-অল আর্মটিকে শেষে রাখতে হবে কারণ প্যাটার্নগুলো ক্রমানুসারে মূল্যায়ন করা হয়। আমরা যদি ক্যাচ-অল আর্মটিকে আগে রাখি, তাহলে অন্য আর্মগুলো কখনই চলবে না, তাই আমরা যদি একটি ক্যাচ-অলের পরে আর্ম যোগ করি তবে Rust আমাদের সতর্ক করবে!
Rust-এ একটি প্যাটার্নও রয়েছে যা আমরা ব্যবহার করতে পারি যখন আমরা একটি ক্যাচ-অল চাই কিন্তু ক্যাচ-অল প্যাটার্নের মানটি ব্যবহার করতে চাই না: _ হল একটি বিশেষ প্যাটার্ন যা যেকোনো মানের সাথে মেলে এবং সেই মানের সাথে বাইন্ড করে না। এটি Rust-কে বলে যে আমরা মানটি ব্যবহার করতে যাচ্ছি না, তাই Rust আমাদের একটি অব্যবহৃত ভেরিয়েবল সম্পর্কে সতর্ক করবে না।
আসুন গেমের নিয়ম পরিবর্তন করি: এখন, আপনি যদি 3 বা 7 ছাড়া অন্য কিছু রোল করেন, তাহলে আপনাকে অবশ্যই আবার রোল করতে হবে। আমাদের আর ক্যাচ-অল মানটি ব্যবহার করার প্রয়োজন নেই, তাই আমরা আমাদের কোড পরিবর্তন করে other নামক ভেরিয়েবলের পরিবর্তে _ ব্যবহার করতে পারি:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), _ => reroll(), } fn add_fancy_hat() {} fn remove_fancy_hat() {} fn reroll() {} }
এই উদাহরণটিও এক্সহস্টিভনেসের প্রয়োজনীয়তা পূরণ করে কারণ আমরা স্পষ্টভাবে শেষ আর্মে অন্য সমস্ত মান উপেক্ষা করছি; আমরা কোনো কিছু ভুলে যাইনি।
অবশেষে, আমরা গেমের নিয়মগুলো আরও একবার পরিবর্তন করব যাতে আপনি যদি 3 বা 7 ছাড়া অন্য কিছু রোল করেন তাহলে আপনার টার্নে আর কিছুই ঘটবে না। আমরা _ আর্মের সাথে থাকা কোড হিসাবে ইউনিট মান (খালি টাপল টাইপ যা আমরা “টাপল টাইপ” বিভাগে উল্লেখ করেছি) ব্যবহার করে তা প্রকাশ করতে পারি:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), _ => (), } fn add_fancy_hat() {} fn remove_fancy_hat() {} }
এখানে, আমরা Rust-কে স্পষ্টভাবে বলছি যে আমরা অন্য কোনো মান ব্যবহার করতে যাচ্ছি না যা আগের কোনো আর্মে একটি প্যাটার্নের সাথে মেলে না এবং আমরা এই ক্ষেত্রে কোনো কোড চালাতে চাই না।
প্যাটার্ন এবং ম্যাচিং সম্পর্কে আরও অনেক কিছু রয়েছে যা আমরা চ্যাপ্টার 19-এ কভার করব। আপাতত, আমরা if let সিনট্যাক্সে চলে যাচ্ছি, যা এমন পরিস্থিতিতে দরকারী হতে পারে যেখানে match এক্সপ্রেশনটি একটু শব্দবহুল।
if let এবং let else দিয়ে সংক্ষিপ্ত কন্ট্রোল ফ্লো (Concise Control Flow with if let and let else)
if let সিনট্যাক্স আপনাকে if এবং let-কে একত্রিত করে কম শব্দ ব্যবহার করে এমন মানগুলো হ্যান্ডেল করতে দেয়, যেগুলো একটি প্যাটার্নের সাথে মেলে এবং বাকিগুলো উপেক্ষা করে। Listing 6-6-এর প্রোগ্রামটি বিবেচনা করুন, যেটি config_max ভেরিয়েবলের একটি Option<u8> মানের উপর ম্যাচ করে, কিন্তু শুধুমাত্র তখনই কোড এক্সিকিউট করতে চায় যদি মানটি Some ভেরিয়েন্ট হয়।
fn main() { let config_max = Some(3u8); match config_max { Some(max) => println!("The maximum is configured to be {max}"), _ => (), } }
যদি মানটি Some হয়, তাহলে আমরা প্যাটার্নের max ভেরিয়েবলের সাথে মান বাইন্ড করে Some ভেরিয়েন্টের মানটি প্রিন্ট করি। আমরা None মান নিয়ে কিছু করতে চাই না। match এক্সপ্রেশনটিকে সন্তুষ্ট করার জন্য, শুধুমাত্র একটি ভেরিয়েন্ট প্রক্রিয়া করার পরে আমাদের _ => () যোগ করতে হবে, যা যোগ করার জন্য বিরক্তিকর বয়লারপ্লেট কোড।
পরিবর্তে, আমরা if let ব্যবহার করে এটিকে আরও সংক্ষিপ্তভাবে লিখতে পারি। নিম্নলিখিত কোডটি Listing 6-6-এর match-এর মতোই আচরণ করে:
fn main() { let config_max = Some(3u8); if let Some(max) = config_max { println!("The maximum is configured to be {max}"); } }
if let সিনট্যাক্স একটি প্যাটার্ন এবং একটি এক্সপ্রেশন নেয়, যা একটি সমান চিহ্ন দ্বারা পৃথক করা হয়। এটি match-এর মতোই কাজ করে, যেখানে এক্সপ্রেশনটি match-কে দেওয়া হয় এবং প্যাটার্নটি হল এর প্রথম আর্ম। এই ক্ষেত্রে, প্যাটার্নটি হল Some(max), এবং max Some-এর ভিতরের মানের সাথে বাইন্ড করে। তারপর আমরা if let ব্লকের বডিতে max ব্যবহার করতে পারি, একইভাবে আমরা সংশ্লিষ্ট match আর্মে max ব্যবহার করেছি। if let ব্লকের কোড শুধুমাত্র তখনই চলে যদি মানটি প্যাটার্নের সাথে মেলে।
if let ব্যবহার করার অর্থ হল কম টাইপিং, কম ইন্ডেন্টেশন এবং কম বয়লারপ্লেট কোড। তবে, আপনি match যে এক্সহস্টিভ চেকিং (exhaustive checking) প্রয়োগ করে সেটি হারাবেন। match এবং if let-এর মধ্যে বেছে নেওয়া আপনার নির্দিষ্ট পরিস্থিতিতে আপনি কী করছেন এবং এক্সহস্টিভ চেকিং হারানো সংক্ষিপ্ততা অর্জনের জন্য উপযুক্ত কিনা তার উপর নির্ভর করে।
অন্য কথায়, আপনি if let-কে একটি match-এর সিনট্যাক্স সুগার হিসাবে ভাবতে পারেন যা মানটি একটি প্যাটার্নের সাথে মিললে কোড চালায় এবং তারপর অন্য সমস্ত মান উপেক্ষা করে।
আমরা if let-এর সাথে একটি else অন্তর্ভুক্ত করতে পারি। else-এর সাথে থাকা কোডের ব্লকটি match এক্সপ্রেশনের _ কেসের সাথে থাকা কোড ব্লকের মতোই, যেটি if let এবং else-এর সমতুল্য। Listing 6-4-এর Coin এনামের সংজ্ঞাটি স্মরণ করুন, যেখানে Quarter ভেরিয়েন্টটিতে একটি UsState মানও ছিল। আমরা যদি কোয়ার্টারগুলোর রাজ্যের ঘোষণা করার পাশাপাশি সমস্ত নন-কোয়ার্টার কয়েন গণনা করতে চাই, তাহলে আমরা এটি একটি match এক্সপ্রেশন দিয়ে করতে পারি, এইভাবে:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let coin = Coin::Penny; let mut count = 0; match coin { Coin::Quarter(state) => println!("State quarter from {state:?}!"), _ => count += 1, } }
অথবা আমরা একটি if let এবং else এক্সপ্রেশন ব্যবহার করতে পারি, এইভাবে:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let coin = Coin::Penny; let mut count = 0; if let Coin::Quarter(state) = coin { println!("State quarter from {state:?}!"); } else { count += 1; } }
"হ্যাপি পাথ"-এ থাকা let else দিয়ে ("Staying on the “happy path” with let else)
একটি সাধারণ প্যাটার্ন হল যখন একটি মান উপস্থিত থাকে তখন কিছু গণনা সম্পাদন করা এবং অন্যথায় একটি ডিফল্ট মান ফেরত দেওয়া। একটি UsState মান সহ কয়েনের আমাদের উদাহরণটি চালিয়ে যাওয়া, যদি আমরা কোয়ার্টারের রাজ্যের বয়স কতটা তার উপর নির্ভর করে মজার কিছু বলতে চাই, তাহলে আমরা একটি রাজ্যে বয়স পরীক্ষা করার জন্য UsState-এ একটি মেথড প্রবর্তন করতে পারি, এইভাবে:
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { if let Coin::Quarter(state) = coin { if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } else { None } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
তারপর আমরা কয়েনের টাইপের উপর ম্যাচ করার জন্য if let ব্যবহার করতে পারি, Listing 6-7-এর মতো, কন্ডিশনের বডিতে একটি state ভেরিয়েবল প্রবর্তন করতে পারি।
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { if let Coin::Quarter(state) = coin { if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } else { None } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
এতে কাজটি সম্পন্ন হয়, কিন্তু এটি কাজটিকে if let স্টেটমেন্টের বডিতে ঠেলে দিয়েছে এবং যদি কাজটি আরও জটিল হয়, তাহলে টপ-লেভেল ব্রাঞ্চগুলো কীভাবে সম্পর্কিত তা অনুসরণ করা কঠিন হতে পারে। আমরা এই বিষয়টিও বিবেচনায় নিতে পারি যে এক্সপ্রেশনগুলো একটি মান তৈরি করে, if let থেকে state তৈরি করতে বা তাড়াতাড়ি রিটার্ন করতে, যেমনটি Listing 6-8-এ রয়েছে। (আপনি একটি match দিয়েও একই কাজ করতে পারেন, অবশ্যই!)
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { let state = if let Coin::Quarter(state) = coin { state } else { return None; }; if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
এটি তার নিজস্ব উপায়ে অনুসরণ করা কিছুটা বিরক্তিকর! if let-এর একটি শাখা একটি মান তৈরি করে এবং অন্যটি সম্পূর্ণরূপে ফাংশন থেকে রিটার্ন করে।
এই সাধারণ প্যাটার্নটিকে আরও সুন্দরভাবে প্রকাশ করার জন্য, Rust-এর let-else রয়েছে। let-else সিনট্যাক্স বাম দিকে একটি প্যাটার্ন এবং ডানদিকে একটি এক্সপ্রেশন নেয়, if let-এর মতোই, কিন্তু এটির কোনো if শাখা নেই, শুধুমাত্র একটি else শাখা রয়েছে। যদি প্যাটার্নটি মেলে, তাহলে এটি বাইরের স্কোপে প্যাটার্ন থেকে মানটিকে বাইন্ড করবে। যদি প্যাটার্নটি মেলে না, তাহলে প্রোগ্রামটি else আর্মের মধ্যে চলে যাবে, যেটিকে অবশ্যই ফাংশন থেকে রিটার্ন করতে হবে।
Listing 6-9-এ, আপনি দেখতে পারেন কিভাবে Listing 6-8 if let-এর পরিবর্তে let-else ব্যবহার করলে কেমন দেখায়। লক্ষ্য করুন যে এটি ফাংশনের মূল বডিতে "হ্যাপি পাথে" থাকে, দুটি শাখার জন্য উল্লেখযোগ্যভাবে ভিন্ন কন্ট্রোল ফ্লো না রেখে যেভাবে if let করেছিল।
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { let Coin::Quarter(state) = coin else { return None; }; if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
যদি আপনার এমন পরিস্থিতি থাকে যেখানে আপনার প্রোগ্রামের লজিক একটি match ব্যবহার করে প্রকাশ করা খুব শব্দবহুল হয়, তাহলে মনে রাখবেন যে if let এবং let else আপনার Rust টুলবক্সে রয়েছে।
সারসংক্ষেপ (Summary)
আমরা এখন এনামগুলো ব্যবহার করে কীভাবে কাস্টম টাইপ তৈরি করতে হয় তা কভার করেছি, যেগুলো গণনাকৃত মানগুলোর একটি সেটের মধ্যে একটি হতে পারে। আমরা দেখেছি কিভাবে স্ট্যান্ডার্ড লাইব্রেরির Option<T> টাইপ আপনাকে এরর প্রতিরোধ করতে টাইপ সিস্টেম ব্যবহার করতে সাহায্য করে। যখন এনাম মানগুলোর ভিতরে ডেটা থাকে, তখন আপনি কতগুলো ক্ষেত্র হ্যান্ডেল করতে হবে তার উপর নির্ভর করে সেই মানগুলো বের করতে এবং ব্যবহার করতে match বা if let ব্যবহার করতে পারেন।
আপনার Rust প্রোগ্রামগুলো এখন স্ট্রাকট এবং এনাম ব্যবহার করে আপনার ডোমেনে ধারণাগুলো প্রকাশ করতে পারে। আপনার API-তে ব্যবহার করার জন্য কাস্টম টাইপ তৈরি করা টাইপ নিরাপত্তা নিশ্চিত করে: কম্পাইলার নিশ্চিত করবে যে আপনার ফাংশনগুলো শুধুমাত্র সেই টাইপের মানগুলো পাবে যা প্রতিটি ফাংশন আশা করে।
আপনার ব্যবহারকারীদের কাছে একটি সুসংগঠিত API সরবরাহ করার জন্য যা ব্যবহার করা সহজ এবং শুধুমাত্র আপনার ব্যবহারকারীদের যা প্রয়োজন সেটাই প্রকাশ করে, আসুন এবার Rust-এর মডিউলগুলোর দিকে যাই।
প্যাকেজ, ক্রেট এবং মডিউল ব্যবহার করে ক্রমবর্ধমান প্রোজেক্ট পরিচালনা করা (Managing Growing Projects with Packages, Crates, and Modules)
আপনি যখন বড় প্রোগ্রাম লিখবেন, তখন আপনার কোড সংগঠিত করা ক্রমবর্ধমান গুরুত্বপূর্ণ হয়ে উঠবে। সম্পর্কিত কার্যকারিতা গ্রুপ করে এবং স্বতন্ত্র বৈশিষ্ট্যযুক্ত কোড আলাদা করার মাধ্যমে, আপনি স্পষ্ট করবেন যে কোনো নির্দিষ্ট ফিচার ইমপ্লিমেন্ট করে এমন কোড কোথায় পাওয়া যাবে এবং কোনো ফিচারের কাজ পরিবর্তন করতে কোথায় যেতে হবে।
আমরা இதுவரை যে প্রোগ্রামগুলো লিখেছি সেগুলো একটি ফাইলের মধ্যে একটি মডিউলে ছিল। একটি প্রোজেক্ট বাড়ার সাথে সাথে, আপনাকে কোডটিকে একাধিক মডিউল এবং তারপর একাধিক ফাইলে বিভক্ত করে সংগঠিত করা উচিত। একটি প্যাকেজে একাধিক বাইনারি ক্রেট এবং ঐচ্ছিকভাবে একটি লাইব্রেরি ক্রেট থাকতে পারে। একটি প্যাকেজ বাড়ার সাথে সাথে, আপনি অংশগুলোকে আলাদা ক্রেট হিসেবে বের করে নিতে পারেন যা এক্সটার্নাল ডিপেন্ডেন্সি (external dependencies) হয়ে যায়। এই চ্যাপ্টারটি এই সমস্ত কৌশল কভার করে। খুব বড় প্রোজেক্টগুলোর জন্য, যেখানে সম্পর্কযুক্ত প্যাকেজের একটি সেট একসাথে বিকশিত হয়, Cargo ওয়ার্কস্পেস (workspaces) সরবরাহ করে, যা আমরা চ্যাপ্টার 14-এর “কার্গো ওয়ার্কস্পেস”-এ কভার করব।
আমরা ইমপ্লিমেন্টেশনের বিবরণ এনক্যাপসুলেট (encapsulate) করা নিয়েও আলোচনা করব, যা আপনাকে উচ্চ স্তরে কোড পুনরায় ব্যবহার করতে দেয়: একবার আপনি একটি অপারেশন ইমপ্লিমেন্ট করলে, অন্য কোড তার পাবলিক ইন্টারফেসের মাধ্যমে আপনার কোডকে কল করতে পারে, ইমপ্লিমেন্টেশন কীভাবে কাজ করে তা না জেনেই। আপনি যেভাবে কোড লেখেন তা নির্ধারণ করে যে কোন অংশগুলো অন্য কোডের ব্যবহারের জন্য পাবলিক এবং কোন অংশগুলো প্রাইভেট ইমপ্লিমেন্টেশন বিবরণ যা পরিবর্তন করার অধিকার আপনি সংরক্ষণ করেন। এটি আপনার মাথায় রাখতে হবে এমন বিস্তারিত বিবরণের পরিমাণ সীমিত করার আরেকটি উপায়।
একটি সম্পর্কিত ধারণা হল স্কোপ: কোড যে নেস্টেড প্রসঙ্গে লেখা হয় সেখানে "স্কোপের মধ্যে" হিসাবে সংজ্ঞায়িত নামের একটি সেট রয়েছে। কোড পড়ার, লেখার এবং কম্পাইল করার সময়, প্রোগ্রামার এবং কম্পাইলারদের জানা দরকার যে কোনো নির্দিষ্ট স্থানের একটি নির্দিষ্ট নাম একটি ভেরিয়েবল, ফাংশন, স্ট্রাকট, এনাম, মডিউল, কনস্ট্যান্ট বা অন্য কোনো আইটেমকে নির্দেশ করে কিনা এবং সেই আইটেমটির অর্থ কী। আপনি স্কোপ তৈরি করতে পারেন এবং কোন নামগুলো স্কোপের ভিতরে বা বাইরে আছে তা পরিবর্তন করতে পারেন। আপনি একই স্কোপে একই নামের দুটি আইটেম রাখতে পারবেন না; নামের দ্বন্দ্ব সমাধানের জন্য টুল উপলব্ধ রয়েছে।
Rust-এর বেশ কয়েকটি ফিচার রয়েছে যা আপনাকে আপনার কোডের সংগঠন পরিচালনা করতে দেয়, যার মধ্যে কোন বিবরণগুলো উন্মুক্ত, কোন বিবরণগুলো প্রাইভেট এবং আপনার প্রোগ্রামগুলোর প্রতিটি স্কোপে কোন নামগুলো রয়েছে তা সহ। এই ফিচারগুলো, কখনও কখনও সম্মিলিতভাবে মডিউল সিস্টেম (module system) হিসাবে উল্লেখ করা হয়, এর মধ্যে নিম্নলিখিতগুলো অন্তর্ভুক্ত:
- প্যাকেজ (Packages): একটি Cargo ফিচার যা আপনাকে ক্রেট তৈরি, পরীক্ষা এবং শেয়ার করতে দেয়।
- ক্রেট (Crates): মডিউলের একটি ট্রি যা একটি লাইব্রেরি বা এক্সিকিউটেবল তৈরি করে।
- মডিউল (Modules) এবং use: আপনাকে পাথগুলোর সংগঠন, স্কোপ এবং গোপনীয়তা নিয়ন্ত্রণ করতে দেয়।
- পাথ (Paths): একটি আইটেম, যেমন একটি স্ট্রাকট, ফাংশন বা মডিউলের নামকরণের একটি উপায়।
এই চ্যাপ্টারে, আমরা এই সমস্ত ফিচারগুলো কভার করব, সেগুলো কীভাবে ইন্টারঅ্যাক্ট করে তা নিয়ে আলোচনা করব এবং স্কোপ পরিচালনা করতে সেগুলো কীভাবে ব্যবহার করতে হয় তা ব্যাখ্যা করব। শেষ পর্যন্ত, আপনার মডিউল সিস্টেম সম্পর্কে একটি দৃঢ় বোধ থাকা উচিত এবং একজন পেশাদারের মতো স্কোপ নিয়ে কাজ করতে সক্ষম হওয়া উচিত!
প্যাকেজ এবং ক্রেট (Packages and Crates)
মডিউল সিস্টেমের প্রথম যে অংশগুলো আমরা কভার করব সেগুলো হল প্যাকেজ এবং ক্রেট।
একটি ক্রেট (crate) হল কোডের সবচেয়ে ছোট অংশ যা Rust কম্পাইলার একবারে বিবেচনা করে। এমনকি যদি আপনি cargo-র পরিবর্তে rustc চালান এবং একটি একক সোর্স কোড ফাইল পাস করেন (যেমনটি আমরা চ্যাপ্টার ১-এর "রাইটিং অ্যান্ড রানিং এ রাস্ট প্রোগ্রাম"-এ করেছিলাম), কম্পাইলার সেই ফাইলটিকে একটি ক্রেট হিসাবে বিবেচনা করে। ক্রেটগুলোতে মডিউল থাকতে পারে এবং মডিউলগুলো অন্যান্য ফাইলে সংজ্ঞায়িত করা যেতে পারে যা ক্রেটের সাথে কম্পাইল করা হয়, যেমনটি আমরা আসন্ন বিভাগগুলোতে দেখব।
একটি ক্রেট দুটি ফর্মের মধ্যে একটি হতে পারে: একটি বাইনারি ক্রেট বা একটি লাইব্রেরি ক্রেট। বাইনারি ক্রেটগুলো হল এমন প্রোগ্রাম যা আপনি একটি এক্সিকিউটেবলে কম্পাইল করতে পারেন, যা আপনি চালাতে পারেন, যেমন একটি কমান্ড লাইন প্রোগ্রাম বা একটি সার্ভার। প্রতিটি বাইনারি ক্রেটে অবশ্যই main নামক একটি ফাংশন থাকতে হবে যা এক্সিকিউটেবল চালানোর সময় কী ঘটবে তা নির্ধারণ করে। আমরা এ পর্যন্ত যতগুলো ক্রেট তৈরি করেছি তার সবই বাইনারি ক্রেট।
লাইব্রেরি ক্রেটগুলোতে একটি main ফাংশন থাকে না এবং সেগুলো একটি এক্সিকিউটেবলে কম্পাইল হয় না। পরিবর্তে, তারা কার্যকারিতা সংজ্ঞায়িত করে যা একাধিক প্রোজেক্টের সাথে শেয়ার করার উদ্দেশ্যে তৈরি। উদাহরণস্বরূপ, চ্যাপ্টার ২-তে আমরা যে rand ক্রেটটি ব্যবহার করেছি সেটি র্যান্ডম সংখ্যা তৈরি করার কার্যকারিতা সরবরাহ করে। বেশিরভাগ সময় যখন Rustacean-রা "ক্রেট" বলে, তখন তারা লাইব্রেরি ক্রেট বোঝায় এবং তারা "লাইব্রেরি"-এর সাধারণ প্রোগ্রামিং ধারণার সাথে "ক্রেট" শব্দটিকে বিনিময়যোগ্যভাবে ব্যবহার করে।
ক্রেট রুট (crate root) হল একটি সোর্স ফাইল যেখান থেকে Rust কম্পাইলার শুরু করে এবং আপনার ক্রেটের রুট মডিউল তৈরি করে (আমরা “স্কোপ এবং গোপনীয়তা নিয়ন্ত্রণ করতে মডিউল সংজ্ঞায়িত করা”-তে মডিউলগুলো বিস্তারিতভাবে ব্যাখ্যা করব)।
একটি প্যাকেজ (package) হল এক বা একাধিক ক্রেটের একটি বান্ডিল যা কার্যকারিতার একটি সেট সরবরাহ করে। একটি প্যাকেজে একটি Cargo.toml ফাইল থাকে যা বর্ণনা করে কিভাবে সেই ক্রেটগুলো তৈরি করতে হয়। Cargo আসলে একটি প্যাকেজ যাতে কমান্ড লাইন টুলের জন্য বাইনারি ক্রেট রয়েছে যা আপনি আপনার কোড তৈরি করতে ব্যবহার করেছেন। Cargo প্যাকেজে একটি লাইব্রেরি ক্রেটও রয়েছে যার উপর বাইনারি ক্রেট নির্ভর করে। অন্য প্রোজেক্টগুলো Cargo লাইব্রেরি ক্রেটের উপর নির্ভর করতে পারে যাতে Cargo কমান্ড লাইন টুল যে লজিক ব্যবহার করে সেটি ব্যবহার করা যায়। একটি প্যাকেজে আপনি যত খুশি বাইনারি ক্রেট থাকতে পারে, কিন্তু সর্বাধিক শুধুমাত্র একটি লাইব্রেরি ক্রেট থাকতে পারে। একটি প্যাকেজে অবশ্যই অন্তত একটি ক্রেট থাকতে হবে, সেটি লাইব্রেরি হোক বা বাইনারি ক্রেট।
আসুন আমরা যখন একটি প্যাকেজ তৈরি করি তখন কী ঘটে তা দেখি। প্রথমে আমরা cargo new my-project কমান্ডটি প্রবেশ করাই:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
আমরা cargo new my-project চালানোর পরে, Cargo কী তৈরি করে তা দেখতে আমরা ls ব্যবহার করি। প্রোজেক্ট ডিরেক্টরিতে, একটি Cargo.toml ফাইল রয়েছে, যা আমাদের একটি প্যাকেজ দেয়। এছাড়াও একটি src ডিরেক্টরি রয়েছে যাতে main.rs রয়েছে। আপনার টেক্সট এডিটরে Cargo.toml খুলুন এবং লক্ষ্য করুন যে src/main.rs-এর কোনো উল্লেখ নেই। Cargo একটি নিয়ম অনুসরণ করে যে src/main.rs হল প্যাকেজের নামের সাথে একই নামের একটি বাইনারি ক্রেটের ক্রেট রুট। একইভাবে, Cargo জানে যে যদি প্যাকেজ ডিরেক্টরিতে src/lib.rs থাকে, তাহলে প্যাকেজটিতে প্যাকেজের নামের সাথে একই নামের একটি লাইব্রেরি ক্রেট রয়েছে এবং src/lib.rs হল এর ক্রেট রুট। Cargo লাইব্রেরি বা বাইনারি তৈরি করতে ক্রেট রুট ফাইলগুলো rustc-তে পাস করে।
এখানে, আমাদের কাছে এমন একটি প্যাকেজ রয়েছে যাতে শুধুমাত্র src/main.rs রয়েছে, অর্থাৎ এটিতে শুধুমাত্র my-project নামের একটি বাইনারি ক্রেট রয়েছে। যদি একটি প্যাকেজে src/main.rs এবং src/lib.rs থাকে, তবে এতে দুটি ক্রেট রয়েছে: একটি বাইনারি এবং একটি লাইব্রেরি, উভয়ের নামই প্যাকেজের নামের মতো। একটি প্যাকেজে src/bin ডিরেক্টরিতে ফাইল রেখে একাধিক বাইনারি ক্রেট থাকতে পারে: প্রতিটি ফাইল একটি পৃথক বাইনারি ক্রেট হবে।
স্কোপ এবং গোপনীয়তা নিয়ন্ত্রণ করতে মডিউল সংজ্ঞায়িত করা (Defining Modules to Control Scope and Privacy)
এই বিভাগে, আমরা মডিউল এবং মডিউল সিস্টেমের অন্যান্য অংশগুলো নিয়ে কথা বলব, যেমন পাথ (paths), যা আপনাকে আইটেমগুলোর নাম দিতে দেয়; use কীওয়ার্ড যা একটি পাথকে স্কোপে নিয়ে আসে; এবং pub কীওয়ার্ড যা আইটেমগুলোকে পাবলিক করে। আমরা as কীওয়ার্ড, এক্সটার্নাল প্যাকেজ এবং গ্লোব অপারেটর নিয়েও আলোচনা করব।
মডিউল চিট শিট (Modules Cheat Sheet)
মডিউল এবং পাথের বিশদ বিবরণে যাওয়ার আগে, এখানে মডিউল, পাথ, use কীওয়ার্ড এবং pub কীওয়ার্ড কম্পাইলারে কীভাবে কাজ করে এবং বেশিরভাগ ডেভেলপাররা কীভাবে তাদের কোড সংগঠিত করে তার একটি দ্রুত রেফারেন্স দেওয়া হলো। আমরা এই চ্যাপ্টার জুড়ে এই প্রতিটি নিয়মের উদাহরণ দেখব, তবে মডিউলগুলো কীভাবে কাজ করে তার একটি অনুস্মারক হিসাবে এটি মনে রাখার জন্য একটি দুর্দান্ত জায়গা।
- ক্রেট রুট থেকে শুরু করুন: একটি ক্রেট কম্পাইল করার সময়, কম্পাইলার প্রথমে কোড কম্পাইল করার জন্য ক্রেট রুট ফাইলে (সাধারণত একটি লাইব্রেরি ক্রেটের জন্য src/lib.rs বা একটি বাইনারি ক্রেটের জন্য src/main.rs) খোঁজে।
- মডিউল ঘোষণা করা: ক্রেট রুট ফাইলে, আপনি নতুন মডিউল ঘোষণা করতে পারেন; ধরুন আপনি
mod garden;দিয়ে একটি "গার্ডেন" মডিউল ঘোষণা করছেন। কম্পাইলার এই জায়গাগুলোতে মডিউলের কোড খুঁজবে:- ইনলাইন, কার্লি ব্র্যাকেটের মধ্যে যা
mod garden-এর পরে সেমিকোলন প্রতিস্থাপন করে - src/garden.rs ফাইলে
- src/garden/mod.rs ফাইলে
- ইনলাইন, কার্লি ব্র্যাকেটের মধ্যে যা
- সাবমডিউল ঘোষণা করা: ক্রেট রুট ছাড়া অন্য যেকোনো ফাইলে, আপনি সাবমডিউল ঘোষণা করতে পারেন। উদাহরণস্বরূপ, আপনি src/garden.rs-এ
mod vegetables;ঘোষণা করতে পারেন। কম্পাইলার প্যারেন্ট মডিউলের জন্য নির্ধারিত ডিরেক্টরির মধ্যে নিম্নলিখিত জায়গাগুলোতে সাবমডিউলের কোড খুঁজবে:- ইনলাইন, সরাসরি
mod vegetables-এর পরে, কার্লি ব্র্যাকেটের মধ্যে, সেমিকোলনের পরিবর্তে - src/garden/vegetables.rs ফাইলে
- src/garden/vegetables/mod.rs ফাইলে
- ইনলাইন, সরাসরি
- মডিউলের কোডের পাথ: একবার একটি মডিউল আপনার ক্রেটের অংশ হয়ে গেলে, আপনি সেই মডিউলের কোডটি সেই একই ক্রেটের অন্য যেকোনো জায়গা থেকে রেফার করতে পারেন, যতক্ষণ গোপনীয়তার নিয়মগুলো অনুমতি দেয়, কোডের পাথ ব্যবহার করে। উদাহরণস্বরূপ, গার্ডেন ভেজিটেবলস মডিউলের একটি
Asparagusটাইপcrate::garden::vegetables::Asparagus-এ পাওয়া যাবে। - প্রাইভেট বনাম পাবলিক: একটি মডিউলের ভেতরের কোড ডিফল্টরূপে তার প্যারেন্ট মডিউলগুলো থেকে প্রাইভেট থাকে। একটি মডিউলকে পাবলিক করতে,
mod-এর পরিবর্তেpub modদিয়ে এটি ঘোষণা করুন। একটি পাবলিক মডিউলের ভেতরের আইটেমগুলোকেও পাবলিক করতে, তাদের ঘোষণার আগেpubব্যবহার করুন। useকীওয়ার্ড: একটি স্কোপের মধ্যে,useকীওয়ার্ডটি আইটেমগুলোর শর্টকাট তৈরি করে যাতে লম্বা পথের পুনরাবৃত্তি কমানো যায়। যেকোনো স্কোপে যাcrate::garden::vegetables::Asparagus-কে রেফার করতে পারে, আপনিuse crate::garden::vegetables::Asparagus;দিয়ে একটি শর্টকাট তৈরি করতে পারেন এবং তারপর থেকে আপনাকে স্কোপে সেই টাইপটি ব্যবহার করার জন্য শুধুমাত্রAsparagusলিখতে হবে।
এখানে, আমরা backyard নামে একটি বাইনারি ক্রেট তৈরি করি যা এই নিয়মগুলো ব্যাখ্যা করে। ক্রেটের ডিরেক্টরি, যার নামও backyard, এই ফাইল এবং ডিরেক্টরিগুলো ধারণ করে:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
এই ক্ষেত্রে ক্রেট রুট ফাইলটি হল src/main.rs, এবং এতে রয়েছে:
use crate::garden::vegetables::Asparagus;
pub mod garden;
fn main() {
let plant = Asparagus {};
println!("I'm growing {plant:?}!");
}pub mod garden; লাইনটি কম্পাইলারকে src/garden.rs-এ পাওয়া কোড অন্তর্ভুক্ত করতে বলে, যেটি হল:
pub mod vegetables;এখানে, pub mod vegetables; মানে src/garden/vegetables.rs-এর কোডও অন্তর্ভুক্ত করা হয়েছে। সেই কোডটি হল:
#[derive(Debug)]
pub struct Asparagus {}এবার চলুন এই নিয়মগুলোর বিস্তারিত বিবরণে যাই এবং সেগুলোকে অ্যাকশনে দেখি!
মডিউলে সম্পর্কিত কোড গ্রুপ করা (Grouping Related Code in Modules)
মডিউলগুলো আমাদের পঠনযোগ্যতা এবং সহজে পুনরায় ব্যবহারের জন্য একটি ক্রেটের মধ্যে কোড সংগঠিত করতে দেয়। মডিউলগুলো আমাদের আইটেমগুলোর গোপনীয়তা (privacy) নিয়ন্ত্রণ করতে দেয়, কারণ একটি মডিউলের ভেতরের কোড ডিফল্টরূপে প্রাইভেট থাকে। প্রাইভেট আইটেমগুলো হল অভ্যন্তরীণ ইমপ্লিমেন্টেশনের বিবরণ যা বাইরের ব্যবহারের জন্য উপলব্ধ নয়। আমরা মডিউল এবং সেগুলোর ভেতরের আইটেমগুলোকে পাবলিক করতে পারি, যা সেগুলোকে এক্সটার্নাল কোডের ব্যবহার এবং সেগুলোর উপর নির্ভর করার অনুমতি দেয়।
উদাহরণস্বরূপ, আসুন একটি লাইব্রেরি ক্রেট লিখি যা একটি রেস্তোরাঁর কার্যকারিতা সরবরাহ করে। আমরা ফাংশনগুলোর সিগনেচার সংজ্ঞায়িত করব কিন্তু তাদের বডি খালি রাখব যাতে রেস্তোরাঁর ইমপ্লিমেন্টেশনের পরিবর্তে কোডের সংগঠনের উপর মনোযোগ দেওয়া যায়।
রেস্তোরাঁ শিল্পে, একটি রেস্তোরাঁর কিছু অংশকে ফ্রন্ট অফ হাউস (front of house) এবং অন্যগুলোকে ব্যাক অফ হাউস (back of house) হিসাবে উল্লেখ করা হয়। ফ্রন্ট অফ হাউস হল যেখানে গ্রাহকরা থাকে; এর মধ্যে রয়েছে যেখানে হোস্টরা গ্রাহকদের বসায়, সার্ভাররা অর্ডার এবং পেমেন্ট নেয় এবং বারটেন্ডাররা পানীয় তৈরি করে। ব্যাক অফ হাউস হল যেখানে শেফ এবং বাবুর্চিরা রান্নাঘরে কাজ করে, ডিশওয়াশাররা পরিষ্কার করে এবং ম্যানেজাররা প্রশাসনিক কাজ করে।
এইভাবে আমাদের ক্রেটটিকে স্ট্রাকচার করার জন্য, আমরা এর ফাংশনগুলোকে নেস্টেড মডিউলে সংগঠিত করতে পারি। cargo new restaurant --lib চালিয়ে restaurant নামে একটি নতুন লাইব্রেরি তৈরি করুন। তারপর Listing 7-1-এর কোডটি src/lib.rs-এ লিখুন কিছু মডিউল এবং ফাংশন সিগনেচার সংজ্ঞায়িত করতে; এই কোডটি হল ফ্রন্ট অফ হাউস বিভাগ।
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}আমরা mod কীওয়ার্ড দিয়ে একটি মডিউল সংজ্ঞায়িত করি এবং তারপর মডিউলের নাম দিই (এই ক্ষেত্রে, front_of_house)। মডিউলের বডি তারপর কার্লি ব্র্যাকেটের ভিতরে যায়। মডিউলগুলোর ভিতরে, আমরা অন্যান্য মডিউল রাখতে পারি, যেমনটি এই ক্ষেত্রে hosting এবং serving মডিউলগুলোর সাথে করা হয়েছে। মডিউলগুলো অন্যান্য আইটেমগুলোর জন্যও সংজ্ঞা রাখতে পারে, যেমন স্ট্রাকট, এনাম, কনস্ট্যান্ট, ট্রেইট এবং—Listing 7-1-এর মতো—ফাংশন।
মডিউল ব্যবহার করে, আমরা সম্পর্কিত সংজ্ঞাগুলোকে একসাথে গ্রুপ করতে পারি এবং কেন সেগুলো সম্পর্কিত তার নাম দিতে পারি। এই কোডটি ব্যবহার করা প্রোগ্রামাররা সমস্ত সংজ্ঞা পড়ার পরিবর্তে গ্রুপগুলোর উপর ভিত্তি করে কোডটি নেভিগেট করতে পারে, যা তাদের জন্য প্রাসঙ্গিক সংজ্ঞাগুলো খুঁজে পাওয়া সহজ করে তোলে। এই কোডে নতুন কার্যকারিতা যোগ করা প্রোগ্রামাররা জানবে যে প্রোগ্রামটিকে সংগঠিত রাখতে কোথায় কোড রাখতে হবে।
আগে, আমরা উল্লেখ করেছি যে src/main.rs এবং src/lib.rs-কে ক্রেট রুট বলা হয়। তাদের নামের কারণ হল এই দুটি ফাইলের যেকোনো একটির কনটেন্ট ক্রেটের মডিউল কাঠামোর রুটে crate নামক একটি মডিউল তৈরি করে, যা মডিউল ট্রি (module tree) নামে পরিচিত।
Listing 7-2 Listing 7-1-এর কাঠামোর জন্য মডিউল ট্রি দেখায়।
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
এই ট্রিটি দেখায় কিভাবে কিছু মডিউল অন্য মডিউলের ভিতরে নেস্ট করা হয়; উদাহরণস্বরূপ, hosting front_of_house-এর ভিতরে নেস্ট করা আছে। ট্রিটি আরও দেখায় যে কিছু মডিউল হল সিবলিং (siblings), মানে সেগুলো একই মডিউলে সংজ্ঞায়িত; hosting এবং serving হল front_of_house-এর মধ্যে সংজ্ঞায়িত সিবলিং। যদি মডিউল A মডিউল B-এর মধ্যে থাকে, তাহলে আমরা বলি যে মডিউল A হল মডিউল B-এর চাইল্ড (child) এবং মডিউল B হল মডিউল A-এর প্যারেন্ট (parent)। লক্ষ্য করুন যে সম্পূর্ণ মডিউল ট্রিটি crate নামক অন্তর্নিহিত মডিউলের অধীনে রয়েছে।
মডিউল ট্রি আপনাকে আপনার কম্পিউটারের ফাইল সিস্টেমের ডিরেক্টরি ট্রির কথা মনে করিয়ে দিতে পারে; এটি একটি খুব উপযুক্ত তুলনা! ফাইল সিস্টেমের ডিরেক্টরিগুলোর মতোই, আপনি আপনার কোড সংগঠিত করতে মডিউল ব্যবহার করেন। এবং একটি ডিরেক্টরির ফাইলগুলোর মতোই, আমাদের মডিউলগুলো খুঁজে বের করার একটি উপায় দরকার।
মডিউল ট্রিতে একটি আইটেমকে রেফার করার জন্য পাথ (Paths for Referring to an Item in the Module Tree)
একটি মডিউল ট্রিতে একটি আইটেম কোথায় খুঁজতে হবে তা Rust-কে দেখানোর জন্য, আমরা ফাইল সিস্টেমে নেভিগেট করার সময় যেভাবে পাথ ব্যবহার করি সেভাবেই একটি পাথ ব্যবহার করি। একটি ফাংশন কল করার জন্য, আমাদের এর পাথ জানতে হবে।
একটি পাথ দুটি রূপ নিতে পারে:
- একটি অ্যাবসোলিউট পাথ (absolute path) হল একটি ক্রেট রুট থেকে শুরু হওয়া সম্পূর্ণ পাথ; এক্সটার্নাল ক্রেটের কোডের জন্য, অ্যাবসোলিউট পাথ ক্রেটের নাম দিয়ে শুরু হয় এবং বর্তমান ক্রেটের কোডের জন্য, এটি লিটারেল
crateদিয়ে শুরু হয়। - একটি রিলেটিভ পাথ (relative path) বর্তমান মডিউল থেকে শুরু হয় এবং
self,super, বা বর্তমান মডিউলের একটি আইডেন্টিফায়ার ব্যবহার করে।
অ্যাবসোলিউট এবং রিলেটিভ উভয় পাথই ডাবল কোলন (::) দ্বারা পৃথক করা এক বা একাধিক আইডেন্টিফায়ার অনুসরণ করে।
Listing 7-1-এ ফিরে গিয়ে, ধরা যাক আমরা add_to_waitlist ফাংশনটি কল করতে চাই। এটি একই প্রশ্ন: add_to_waitlist ফাংশনের পাথ কী? Listing 7-3-তে Listing 7-1-এর কিছু মডিউল এবং ফাংশন সরিয়ে দেওয়া হয়েছে।
আমরা ক্রেট রুটে সংজ্ঞায়িত একটি নতুন ফাংশন, eat_at_restaurant থেকে add_to_waitlist ফাংশনটিকে কল করার দুটি উপায় দেখাব। এই পাথগুলো সঠিক, কিন্তু অন্য একটি সমস্যা রয়েছে যা এই উদাহরণটিকে কম্পাইল হতে বাধা দেবে। আমরা একটু পরেই এর কারণ ব্যাখ্যা করব।
eat_at_restaurant ফাংশনটি আমাদের লাইব্রেরি ক্রেটের পাবলিক API-এর অংশ, তাই আমরা এটিকে pub কীওয়ার্ড দিয়ে চিহ্নিত করি। “pub কীওয়ার্ড দিয়ে পাথ এক্সপোজ করা” বিভাগে, আমরা pub সম্পর্কে আরও বিস্তারিত আলোচনা করব।
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}প্রথমবার যখন আমরা eat_at_restaurant-এ add_to_waitlist ফাংশনটি কল করি, তখন আমরা একটি অ্যাবসোলিউট পাথ ব্যবহার করি। add_to_waitlist ফাংশনটি eat_at_restaurant-এর মতোই একই ক্রেটে সংজ্ঞায়িত করা হয়েছে, যার মানে হল আমরা একটি অ্যাবসোলিউট পাথ শুরু করতে crate কীওয়ার্ড ব্যবহার করতে পারি। তারপর আমরা add_to_waitlist-এ পৌঁছানো পর্যন্ত ক্রমাগত প্রতিটি মডিউল অন্তর্ভুক্ত করি। আপনি একই কাঠামোর একটি ফাইল সিস্টেম কল্পনা করতে পারেন: add_to_waitlist প্রোগ্রামটি চালানোর জন্য আমরা /front_of_house/hosting/add_to_waitlist পাথটি নির্দিষ্ট করব; ক্রেট রুট থেকে শুরু করার জন্য crate নামটি ব্যবহার করা আপনার শেলে ফাইল সিস্টেম রুট থেকে শুরু করার জন্য / ব্যবহার করার মতো।
দ্বিতীয়বার যখন আমরা eat_at_restaurant-এ add_to_waitlist কল করি, তখন আমরা একটি রিলেটিভ পাথ ব্যবহার করি। পাথটি front_of_house দিয়ে শুরু হয়, যে মডিউলটির নাম eat_at_restaurant-এর মতোই মডিউল ট্রির একই স্তরে সংজ্ঞায়িত করা হয়েছে। এখানে ফাইল সিস্টেমের সমতুল্য হবে front_of_house/hosting/add_to_waitlist পাথ ব্যবহার করা। একটি মডিউলের নাম দিয়ে শুরু করার অর্থ হল পাথটি রিলেটিভ।
রিলেটিভ বা অ্যাবসোলিউট পাথ ব্যবহার করবেন কিনা তা বেছে নেওয়া আপনার প্রোজেক্টের উপর ভিত্তি করে একটি সিদ্ধান্ত, এবং এটি নির্ভর করে আপনি আইটেম সংজ্ঞার কোডটি আইটেমটি ব্যবহার করা কোড থেকে আলাদাভাবে নাকি একসাথে সরানোর সম্ভাবনা বেশি কিনা। উদাহরণস্বরূপ, যদি আমরা front_of_house মডিউল এবং eat_at_restaurant ফাংশনটিকে customer_experience নামক একটি মডিউলে সরিয়ে নিই, তাহলে আমাদের add_to_waitlist-এর অ্যাবসোলিউট পাথ আপডেট করতে হবে, কিন্তু রিলেটিভ পাথটি এখনও বৈধ থাকবে। যাইহোক, যদি আমরা eat_at_restaurant ফাংশনটিকে আলাদাভাবে dining নামক একটি মডিউলে সরিয়ে নিই, তাহলে add_to_waitlist কলের অ্যাবসোলিউট পাথ একই থাকবে, কিন্তু রিলেটিভ পাথটি আপডেট করতে হবে। সাধারণভাবে আমাদের পছন্দ হল অ্যাবসোলিউট পাথগুলো নির্দিষ্ট করা কারণ আমরা কোড সংজ্ঞা এবং আইটেম কলগুলো একে অপরের থেকে স্বাধীনভাবে সরাতে চাইতে পারি।
আসুন Listing 7-3 কম্পাইল করার চেষ্টা করি এবং জেনে নিই কেন এটি এখনও কম্পাইল হবে না! আমরা যে এররগুলো পাই সেগুলো Listing 7-4-এ দেখানো হয়েছে।
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
error[E0603]: module `hosting` is private
--> src/lib.rs:12:21
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
এরর মেসেজগুলো বলে যে hosting মডিউলটি প্রাইভেট। অন্য কথায়, আমাদের কাছে hosting মডিউল এবং add_to_waitlist ফাংশনের জন্য সঠিক পাথ রয়েছে, কিন্তু Rust আমাদের সেগুলো ব্যবহার করতে দেবে না কারণ এটির প্রাইভেট বিভাগে অ্যাক্সেস নেই। Rust-এ, সমস্ত আইটেম (ফাংশন, মেথড, স্ট্রাকট, এনাম, মডিউল এবং কনস্ট্যান্ট) ডিফল্টরূপে প্যারেন্ট মডিউলগুলোর কাছে প্রাইভেট। আপনি যদি একটি ফাংশন বা স্ট্রাকটের মতো একটি আইটেমকে প্রাইভেট করতে চান তবে আপনি এটিকে একটি মডিউলে রাখবেন।
প্যারেন্ট মডিউলের আইটেমগুলো চাইল্ড মডিউলের ভেতরের প্রাইভেট আইটেমগুলো ব্যবহার করতে পারে না, তবে চাইল্ড মডিউলের আইটেমগুলো তাদের পূর্বপুরুষ মডিউলগুলোর আইটেমগুলো ব্যবহার করতে পারে। এর কারণ হল চাইল্ড মডিউলগুলো তাদের ইমপ্লিমেন্টেশনের বিবরণ র্যাপ করে এবং লুকিয়ে রাখে, কিন্তু চাইল্ড মডিউলগুলো সেই প্রেক্ষাপটটি দেখতে পারে যেখানে সেগুলো সংজ্ঞায়িত করা হয়েছে। আমাদের রূপকটি চালিয়ে যেতে, গোপনীয়তার নিয়মগুলোকে একটি রেস্তোরাঁর ব্যাক অফিসের মতো ভাবুন: সেখানে যা ঘটে তা রেস্তোরাঁর গ্রাহকদের কাছে প্রাইভেট, কিন্তু অফিসের ম্যানেজাররা তারা যে রেস্তোরাঁটি পরিচালনা করেন তার সবকিছু দেখতে এবং করতে পারেন।
Rust মডিউল সিস্টেমটিকে এমনভাবে কাজ করার জন্য বেছে নিয়েছে যাতে অভ্যন্তরীণ ইমপ্লিমেন্টেশনের বিবরণ লুকানো ডিফল্ট হয়। এইভাবে, আপনি জানেন যে আপনি বাইরের কোড না ভেঙে ভিতরের কোডের কোন অংশগুলো পরিবর্তন করতে পারেন। যাইহোক, Rust আপনাকে একটি আইটেমকে পাবলিক করতে pub কীওয়ার্ড ব্যবহার করে চাইল্ড মডিউলের কোডের ভেতরের অংশগুলো বাইরের পূর্বপুরুষ মডিউলগুলোতে প্রকাশ করার অপশন দেয়।
pub কীওয়ার্ড দিয়ে পাথ এক্সপোজ করা (Exposing Paths with the pub Keyword)
আসুন Listing 7-4-এর এররটিতে ফিরে যাই যা আমাদের বলেছিল যে hosting মডিউলটি প্রাইভেট। আমরা চাই প্যারেন্ট মডিউলের eat_at_restaurant ফাংশনটির চাইল্ড মডিউলের add_to_waitlist ফাংশনে অ্যাক্সেস থাকুক, তাই আমরা hosting মডিউলটিকে pub কীওয়ার্ড দিয়ে চিহ্নিত করি, যেমনটি Listing 7-5-এ দেখানো হয়েছে।
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}দুর্ভাগ্যবশত, Listing 7-5-এর কোডটি এখনও কম্পাইলার এরর দেয়, যেমনটি Listing 7-6-এ দেখানো হয়েছে।
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:10:37
|
10 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:13:30
|
13 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
কী ঘটল? mod hosting-এর সামনে pub কীওয়ার্ড যোগ করলে মডিউলটি পাবলিক হয়। এই পরিবর্তনের সাথে, যদি আমরা front_of_house অ্যাক্সেস করতে পারি, তাহলে আমরা hosting অ্যাক্সেস করতে পারব। কিন্তু hosting-এর কনটেন্টগুলো এখনও প্রাইভেট; মডিউলটিকে পাবলিক করা এর কনটেন্টগুলোকে পাবলিক করে না। একটি মডিউলে pub কীওয়ার্ড শুধুমাত্র তার পূর্বপুরুষ মডিউলগুলোর কোডকে এটি রেফার করার অনুমতি দেয়, এর ভেতরের কোড অ্যাক্সেস করতে নয়। যেহেতু মডিউলগুলো হল কন্টেইনার, তাই শুধুমাত্র মডিউলটিকে পাবলিক করে আমরা খুব বেশি কিছু করতে পারি না; আমাদের আরও এগিয়ে যেতে হবে এবং মডিউলের ভেতরের এক বা একাধিক আইটেমকেও পাবলিক করতে হবে।
Listing 7-6-এর এররগুলো বলে যে add_to_waitlist ফাংশনটি প্রাইভেট। গোপনীয়তার নিয়মগুলো স্ট্রাকট, এনাম, ফাংশন এবং মেথডের পাশাপাশি মডিউলগুলোর ক্ষেত্রেও প্রযোজ্য।
আসুন Listing 7-7-এর মতো add_to_waitlist ফাংশনটিকেও এর সংজ্ঞার আগে pub কীওয়ার্ড যোগ করে পাবলিক করি।
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}এখন কোডটি কম্পাইল হবে! গোপনীয়তার নিয়মগুলোর সাপেক্ষে pub কীওয়ার্ড যোগ করলে কেন আমাদের eat_at_restaurant-এ এই পাথগুলো ব্যবহার করার অনুমতি দেয় তা দেখতে, আসুন অ্যাবসোলিউট এবং রিলেটিভ পাথগুলো দেখি।
অ্যাবসোলিউট পাথে, আমরা crate দিয়ে শুরু করি, আমাদের ক্রেটের মডিউল ট্রির রুট। front_of_house মডিউলটি ক্রেট রুটে সংজ্ঞায়িত করা হয়েছে। যদিও front_of_house পাবলিক নয়, কারণ eat_at_restaurant ফাংশনটি front_of_house-এর মতোই একই মডিউলে সংজ্ঞায়িত করা হয়েছে (অর্থাৎ, eat_at_restaurant এবং front_of_house হল সিবলিং), আমরা eat_at_restaurant থেকে front_of_house-কে রেফার করতে পারি। এরপর hosting মডিউলটি pub দিয়ে চিহ্নিত করা হয়েছে। আমরা hosting-এর প্যারেন্ট মডিউল অ্যাক্সেস করতে পারি, তাই আমরা hosting অ্যাক্সেস করতে পারি। অবশেষে, add_to_waitlist ফাংশনটি pub দিয়ে চিহ্নিত করা হয়েছে এবং আমরা এর প্যারেন্ট মডিউল অ্যাক্সেস করতে পারি, তাই এই ফাংশন কলটি কাজ করে!
রিলেটিভ পাথের ক্ষেত্রে, লজিকটি অ্যাবসোলিউট পাথের মতোই, প্রথম ধাপটি ছাড়া: ক্রেট রুট থেকে শুরু করার পরিবর্তে, পাথটি front_of_house থেকে শুরু হয়। front_of_house মডিউলটি eat_at_restaurant-এর মতোই একই মডিউলে সংজ্ঞায়িত করা হয়েছে, তাই eat_at_restaurant যে মডিউলে সংজ্ঞায়িত করা হয়েছে সেখান থেকে শুরু হওয়া রিলেটিভ পাথটি কাজ করে। তারপর, যেহেতু hosting এবং add_to_waitlist pub দিয়ে চিহ্নিত করা হয়েছে, তাই পাথের বাকি অংশটি কাজ করে এবং এই ফাংশন কলটি বৈধ!
যদি আপনি আপনার লাইব্রেরি ক্রেট শেয়ার করার পরিকল্পনা করেন যাতে অন্য প্রোজেক্টগুলো আপনার কোড ব্যবহার করতে পারে, তাহলে আপনার পাবলিক API হল আপনার ক্রেটের ব্যবহারকারীদের সাথে আপনার চুক্তি যা নির্ধারণ করে যে তারা কীভাবে আপনার কোডের সাথে ইন্টারঅ্যাক্ট করতে পারে। আপনার ক্রেটের উপর নির্ভর করা লোকেদের জন্য এটিকে সহজতর করার জন্য আপনার পাবলিক API-তে পরিবর্তনগুলো পরিচালনা করার বিষয়ে অনেক বিবেচনা রয়েছে। এই বিবেচনাগুলো এই বইয়ের সুযোগের বাইরে; আপনি যদি এই বিষয়ে আগ্রহী হন, তাহলে The Rust API Guidelines দেখুন।
বাইনারি এবং লাইব্রেরি সহ প্যাকেজগুলোর জন্য সর্বোত্তম অনুশীলন (Best Practices for Packages with a Binary and a Library)
আমরা উল্লেখ করেছি যে একটি প্যাকেজে একটি src/main.rs বাইনারি ক্রেট রুট এবং সেইসাথে একটি src/lib.rs লাইব্রেরি ক্রেট রুট উভয়ই থাকতে পারে এবং উভয় ক্রেটের নাম ডিফল্টরূপে প্যাকেজের নামের মতো হবে। সাধারণত, লাইব্রেরি এবং বাইনারি ক্রেট উভয়ই ধারণকারী এই প্যাটার্নের প্যাকেজগুলোতে বাইনারি ক্রেটে শুধুমাত্র একটি এক্সিকিউটেবল শুরু করার জন্য যথেষ্ট কোড থাকবে যা লাইব্রেরি ক্রেটের মধ্যে কোড কল করে। এটি অন্য প্রোজেক্টগুলোকে প্যাকেজ যে কার্যকারিতা সরবরাহ করে তার বেশিরভাগ থেকে উপকৃত হতে দেয় কারণ লাইব্রেরি ক্রেটের কোড শেয়ার করা যেতে পারে।
মডিউল ট্রিটি src/lib.rs-এ সংজ্ঞায়িত করা উচিত। তারপর, যেকোনো পাবলিক আইটেম প্যাকেজের নাম দিয়ে পাথ শুরু করে বাইনারি ক্রেটে ব্যবহার করা যেতে পারে। বাইনারি ক্রেটটি লাইব্রেরি ক্রেটের একজন ব্যবহারকারী হয়ে ওঠে ঠিক যেমন একটি সম্পূর্ণ এক্সটার্নাল ক্রেট লাইব্রেরি ক্রেট ব্যবহার করবে: এটি শুধুমাত্র পাবলিক API ব্যবহার করতে পারে। এটি আপনাকে একটি ভাল API ডিজাইন করতে সহায়তা করে; আপনি কেবল লেখক নন, আপনি একজন ক্লায়েন্টও!
চ্যাপ্টার 12-এ, আমরা একটি কমান্ড লাইন প্রোগ্রাম দিয়ে এই সাংগঠনিক অনুশীলনটি প্রদর্শন করব যাতে একটি বাইনারি ক্রেট এবং একটি লাইব্রেরি ক্রেট উভয়ই থাকবে।
super দিয়ে রিলেটিভ পাথ শুরু করা (Starting Relative Paths with super)
আমরা super দিয়ে পাথের শুরুতে প্যারেন্ট মডিউল থেকে শুরু হওয়া রিলেটিভ পাথ তৈরি করতে পারি, কারেন্ট মডিউল বা ক্রেট রুট থেকে নয়। এটি ফাইল সিস্টেমের পাথ .. সিনট্যাক্স দিয়ে শুরু করার মতো। super ব্যবহার করা আমাদের এমন একটি আইটেমকে রেফার করতে দেয় যা আমরা জানি প্যারেন্ট মডিউলে রয়েছে, যা মডিউল ট্রিকে পুনরায় সাজানো সহজ করে তুলতে পারে যখন মডিউলটি প্যারেন্টের সাথে ঘনিষ্ঠভাবে সম্পর্কিত কিন্তু প্যারেন্টকে হয়তো কোনো একদিন মডিউল ট্রির অন্য কোথাও সরানো হতে পারে।
Listing 7-8-এর কোডটি বিবেচনা করুন যা এমন পরিস্থিতিকে মডেল করে যেখানে একজন শেফ একটি ভুল অর্ডার ঠিক করে এবং ব্যক্তিগতভাবে সেটি গ্রাহকের কাছে নিয়ে আসে। back_of_house মডিউলে সংজ্ঞায়িত fix_incorrect_order ফাংশনটি প্যারেন্ট মডিউলে সংজ্ঞায়িত deliver_order ফাংশনটিকে কল করে, super দিয়ে শুরু করে deliver_order-এর পাথ নির্দিষ্ট করে।
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order();
}
fn cook_order() {}
}fix_incorrect_order ফাংশনটি back_of_house মডিউলে রয়েছে, তাই আমরা super ব্যবহার করে back_of_house-এর প্যারেন্ট মডিউলে যেতে পারি, যা এই ক্ষেত্রে crate, অর্থাৎ রুট। সেখান থেকে, আমরা deliver_order খুঁজি এবং এটি খুঁজে পাই। সফল! আমরা মনে করি back_of_house মডিউল এবং deliver_order ফাংশন একে অপরের সাথে একই সম্পর্কে থাকবে এবং যদি আমরা ক্রেটের মডিউল ট্রি পুনরায় সংগঠিত করার সিদ্ধান্ত নিই তবে একসাথে সরানো হবে। অতএব, আমরা super ব্যবহার করেছি যাতে ভবিষ্যতে যদি এই কোডটি অন্য কোনো মডিউলে সরানো হয় তবে আমাদের কম জায়গায় কোড আপডেট করতে হবে।
স্ট্রাকট এবং এনামগুলোকে পাবলিক করা (Making Structs and Enums Public)
আমরা স্ট্রাকট এবং এনামগুলোকেও পাবলিক হিসাবে মনোনীত করতে pub ব্যবহার করতে পারি, কিন্তু স্ট্রাকট এবং এনামগুলোর সাথে pub ব্যবহারের কয়েকটি অতিরিক্ত বিবরণ রয়েছে। যদি আমরা একটি স্ট্রাকট সংজ্ঞার আগে pub ব্যবহার করি, তাহলে আমরা স্ট্রাকটটিকে পাবলিক করি, কিন্তু স্ট্রাকটের ফিল্ডগুলো এখনও প্রাইভেট থাকবে। আমরা প্রতিটি ফিল্ডকে কেস-বাই-কেস ভিত্তিতে পাবলিক করতে পারি বা নাও করতে পারি। Listing 7-9-এ, আমরা একটি পাবলিক toast ফিল্ড কিন্তু একটি প্রাইভেট seasonal_fruit ফিল্ড সহ একটি পাবলিক back_of_house::Breakfast স্ট্রাকট সংজ্ঞায়িত করেছি। এটি একটি রেস্তোরাঁর ক্ষেত্রটিকে মডেল করে যেখানে গ্রাহক খাবারের সাথে আসা রুটির টাইপ বেছে নিতে পারে, কিন্তু শেফ সিদ্ধান্ত নেন কোন ফল পরিবেশন করা হবে, সেটি সিজনে কী আছে এবং স্টকে কী আছে তার উপর ভিত্তি করে। উপলব্ধ ফল দ্রুত পরিবর্তন হয়, তাই গ্রাহকরা ফল বেছে নিতে পারে না বা এমনকি তারা কোন ফল পাবে তাও দেখতে পায় না।
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Order a breakfast in the summer with Rye toast.
let mut meal = back_of_house::Breakfast::summer("Rye");
// Change our mind about what bread we'd like.
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// The next line won't compile if we uncomment it; we're not allowed
// to see or modify the seasonal fruit that comes with the meal.
// meal.seasonal_fruit = String::from("blueberries");
}যেহেতু back_of_house::Breakfast স্ট্রাকটের toast ফিল্ডটি পাবলিক, তাই eat_at_restaurant-এ আমরা ডট নোটেশন ব্যবহার করে toast ফিল্ডে লিখতে এবং পড়তে পারি। লক্ষ্য করুন যে আমরা eat_at_restaurant-এ seasonal_fruit ফিল্ডটি ব্যবহার করতে পারি না, কারণ seasonal_fruit প্রাইভেট। seasonal_fruit ফিল্ডের মান পরিবর্তন করার লাইনটি আনকমেন্ট করার চেষ্টা করুন, দেখুন আপনি কী এরর পান!
এছাড়াও, মনে রাখবেন যে যেহেতু back_of_house::Breakfast-এর একটি প্রাইভেট ফিল্ড রয়েছে, তাই স্ট্রাকটটির একটি পাবলিক অ্যাসোসিয়েটেড ফাংশন সরবরাহ করা দরকার যা Breakfast-এর একটি ইন্সট্যান্স তৈরি করে (আমরা এখানে এটির নাম দিয়েছি summer)। যদি Breakfast-এর এমন কোনো ফাংশন না থাকত, তাহলে আমরা eat_at_restaurant-এ Breakfast-এর একটি ইন্সট্যান্স তৈরি করতে পারতাম না কারণ আমরা eat_at_restaurant-এ প্রাইভেট seasonal_fruit ফিল্ডের মান সেট করতে পারতাম না।
বিপরীতে, যদি আমরা একটি এনামকে পাবলিক করি, তাহলে এর সমস্ত ভেরিয়েন্ট পাবলিক হয়ে যায়। আমাদের শুধুমাত্র enum কীওয়ার্ডের আগে pub প্রয়োজন, যেমনটি Listing 7-10-এ দেখানো হয়েছে।
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}যেহেতু আমরা Appetizer এনামটিকে পাবলিক করেছি, তাই আমরা eat_at_restaurant-এ Soup এবং Salad ভেরিয়েন্টগুলো ব্যবহার করতে পারি।
এনামগুলো খুব একটা দরকারী নয় যদি না তাদের ভেরিয়েন্টগুলো পাবলিক হয়; প্রতিটি ক্ষেত্রে সমস্ত এনাম ভেরিয়েন্টকে pub দিয়ে অ্যানোটেট করতে হলে বিরক্তিকর হবে, তাই এনাম ভেরিয়েন্টগুলোর জন্য ডিফল্ট হল পাবলিক হওয়া। স্ট্রাকটগুলো প্রায়শই তাদের ফিল্ডগুলো পাবলিক না করেই দরকারী, তাই স্ট্রাকট ফিল্ডগুলো সবকিছু ডিফল্টরূপে প্রাইভেট হওয়ার সাধারণ নিয়ম অনুসরণ করে, যদি না pub দিয়ে অ্যানোটেট করা হয়।
pub জড়িত আরও একটি পরিস্থিতি রয়েছে যা আমরা কভার করিনি, এবং সেটি হল আমাদের শেষ মডিউল সিস্টেম ফিচার: use কীওয়ার্ড। আমরা প্রথমে use নিয়ে নিজে থেকেই আলোচনা করব, এবং তারপর আমরা দেখাব কিভাবে pub এবং use একত্রিত করতে হয়।
use কীওয়ার্ড দিয়ে পাথগুলোকে স্কোপে আনা (Bringing Paths into Scope with the use Keyword)
ফাংশন কল করার জন্য পাথগুলো লিখতে থাকা অসুবিধাজনক এবং পুনরাবৃত্তিমূলক মনে হতে পারে। Listing 7-7-এ, আমরা add_to_waitlist ফাংশনে যাওয়ার জন্য অ্যাবসোলিউট পাথ বা রিলেটিভ পাথ যাই বেছে নিই না কেন, প্রতিবার যখন আমরা add_to_waitlist কল করতে চেয়েছি, তখনও আমাদের front_of_house এবং hosting উল্লেখ করতে হয়েছে। সৌভাগ্যবশত, এই প্রক্রিয়াটিকে সহজ করার একটি উপায় রয়েছে: আমরা একবার use কীওয়ার্ড দিয়ে একটি পাথের শর্টকাট তৈরি করতে পারি এবং তারপর স্কোপের অন্য সব জায়গায় ছোট নামটি ব্যবহার করতে পারি।
Listing 7-11-এ, আমরা crate::front_of_house::hosting মডিউলটিকে eat_at_restaurant ফাংশনের স্কোপে নিয়ে আসি যাতে eat_at_restaurant-এ add_to_waitlist ফাংশনটিকে কল করার জন্য আমাদের কেবল hosting::add_to_waitlist উল্লেখ করতে হয়।
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}একটি স্কোপে use এবং একটি পাথ যোগ করা ফাইল সিস্টেমে একটি সিম্বলিক লিঙ্ক (symbolic link) তৈরি করার মতোই। ক্রেট রুটে use crate::front_of_house::hosting যোগ করে, hosting এখন সেই স্কোপে একটি বৈধ নাম, যেন hosting মডিউলটি ক্রেট রুটে সংজ্ঞায়িত করা হয়েছে। use দিয়ে স্কোপে আনা পাথগুলোও অন্য যেকোনো পাথের মতোই গোপনীয়তা পরীক্ষা করে।
লক্ষ্য করুন যে use শুধুমাত্র সেই বিশেষ স্কোপের জন্য শর্টকাট তৈরি করে যেখানে use সংঘটিত হয়। Listing 7-12 eat_at_restaurant ফাংশনটিকে customer নামক একটি নতুন চাইল্ড মডিউলে সরিয়ে দেয়, যেটি তখন use স্টেটমেন্ট থেকে আলাদা একটি স্কোপ, তাই ফাংশন বডি কম্পাইল হবে না।
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
mod customer {
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
}কম্পাইলার এরর দেখায় যে শর্টকাটটি আর customer মডিউলের মধ্যে প্রযোজ্য নয়:
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0433]: failed to resolve: use of undeclared crate or module `hosting`
--> src/lib.rs:11:9
|
11 | hosting::add_to_waitlist();
| ^^^^^^^ use of undeclared crate or module `hosting`
|
help: consider importing this module through its public re-export
|
10 + use crate::hosting;
|
warning: unused import: `crate::front_of_house::hosting`
--> src/lib.rs:7:5
|
7 | use crate::front_of_house::hosting;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` (lib) due to 1 previous error; 1 warning emitted
লক্ষ্য করুন যে একটি ওয়ার্নিংও রয়েছে যে use আর তার স্কোপে ব্যবহৃত হচ্ছে না! এই সমস্যাটি সমাধান করতে, use-কেও customer মডিউলের মধ্যে সরিয়ে নিন, অথবা চাইল্ড customer মডিউলের মধ্যে super::hosting দিয়ে প্যারেন্ট মডিউলের শর্টকাটটিকে রেফারেন্স করুন।
ইডিওমেটিক use পাথ তৈরি করা (Creating Idiomatic use Paths)
Listing 7-11-এ, আপনি হয়তো ভাবছেন কেন আমরা use crate::front_of_house::hosting নির্দিষ্ট করেছি এবং তারপর eat_at_restaurant-এ hosting::add_to_waitlist কল করেছি, Listing 7-13-এর মতো একই ফলাফল অর্জন করার জন্য add_to_waitlist ফাংশন পর্যন্ত পুরো use পাথ নির্দিষ্ট না করে।
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
}যদিও Listing 7-11 এবং Listing 7-13 উভয়ই একই কাজ সম্পন্ন করে, Listing 7-11 হল use দিয়ে একটি ফাংশনকে স্কোপে আনার ইডিওমেটিক উপায়। use দিয়ে ফাংশনের প্যারেন্ট মডিউলটিকে স্কোপে আনার অর্থ হল ফাংশনটি কল করার সময় আমাদের প্যারেন্ট মডিউলটি নির্দিষ্ট করতে হবে। ফাংশনটি কল করার সময় প্যারেন্ট মডিউলটি নির্দিষ্ট করা এটি স্পষ্ট করে যে ফাংশনটি লোকালি সংজ্ঞায়িত নয়, তবুও সম্পূর্ণ পাথের পুনরাবৃত্তি কমিয়ে আনা হয়। Listing 7-13-এর কোডটি অস্পষ্ট যে add_to_waitlist কোথায় সংজ্ঞায়িত করা হয়েছে।
অন্যদিকে, use দিয়ে স্ট্রাকট, এনাম এবং অন্যান্য আইটেম আনার সময়, সম্পূর্ণ পাথ নির্দিষ্ট করা ইডিওমেটিক। Listing 7-14 স্ট্যান্ডার্ড লাইব্রেরির HashMap স্ট্রাকটটিকে একটি বাইনারি ক্রেটের স্কোপে আনার ইডিওমেটিক উপায় দেখায়।
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); map.insert(1, 2); }
এই ইডিয়মের পিছনে কোনো জোরালো কারণ নেই: এটি কেবল সেই রীতি যা বিকশিত হয়েছে এবং লোকেরা এইভাবে Rust কোড পড়তে এবং লিখতে অভ্যস্ত হয়ে উঠেছে।
এই ইডিয়মের ব্যতিক্রম হল যদি আমরা use স্টেটমেন্ট দিয়ে একই নামের দুটি আইটেমকে স্কোপে আনি, কারণ Rust এটির অনুমতি দেয় না। Listing 7-15 দেখায় কিভাবে একই নামের কিন্তু ভিন্ন প্যারেন্ট মডিউল সহ দুটি Result টাইপকে স্কোপে আনতে হয় এবং কীভাবে সেগুলোকে রেফার করতে হয়।
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
Ok(())
}
fn function2() -> io::Result<()> {
// --snip--
Ok(())
}আপনি যেমন দেখতে পাচ্ছেন, প্যারেন্ট মডিউলগুলো ব্যবহার করে দুটি Result টাইপকে আলাদা করা হয়। যদি পরিবর্তে আমরা use std::fmt::Result এবং use std::io::Result নির্দিষ্ট করতাম, তাহলে আমাদের একই স্কোপে দুটি Result টাইপ থাকত এবং যখন আমরা Result ব্যবহার করতাম তখন Rust জানত না আমরা কোনটি বোঝাতে চেয়েছি।
as কীওয়ার্ড দিয়ে নতুন নাম প্রদান করা (Providing New Names with the as Keyword)
use দিয়ে একই নামের দুটি টাইপকে একই স্কোপে আনার সমস্যার আরেকটি সমাধান রয়েছে: পাথের পরে, আমরা as এবং টাইপের জন্য একটি নতুন লোকাল নাম বা এলিয়াস (alias) নির্দিষ্ট করতে পারি। Listing 7-16 Listing 7-15-এর কোডটি লেখার আরেকটি উপায় দেখায়, as ব্যবহার করে দুটি Result টাইপের মধ্যে একটির নাম পরিবর্তন করে।
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
Ok(())
}
fn function2() -> IoResult<()> {
// --snip--
Ok(())
}দ্বিতীয় use স্টেটমেন্টে, আমরা std::io::Result টাইপের জন্য নতুন নাম IoResult বেছে নিয়েছি, যেটি std::fmt থেকে আনা Result-এর সাথে সাংঘর্ষিক হবে না। Listing 7-15 এবং Listing 7-16 ইডিওমেটিক হিসাবে বিবেচিত হয়, তাই পছন্দ আপনার উপর নির্ভর করে!
pub use দিয়ে নামগুলো পুনরায় এক্সপোর্ট করা (Re-exporting Names with pub use)
যখন আমরা use কীওয়ার্ড দিয়ে একটি নাম স্কোপে আনি, তখন নতুন স্কোপে উপলব্ধ নামটি প্রাইভেট হয়। আমাদের কোডকে কল করা কোডটিকে সেই নামটি রেফার করার অনুমতি দেওয়ার জন্য যেন এটি সেই কোডের স্কোপে সংজ্ঞায়িত করা হয়েছে, আমরা pub এবং use একত্রিত করতে পারি। এই কৌশলটিকে রি-এক্সপোর্টিং (re-exporting) বলা হয় কারণ আমরা একটি আইটেমকে স্কোপে আনছি কিন্তু সেই আইটেমটিকে অন্যদের তাদের স্কোপে আনার জন্যও উপলব্ধ করছি।
Listing 7-17 Listing 7-11-এর কোডটি দেখায় যেখানে রুট মডিউলে use-কে pub use-এ পরিবর্তন করা হয়েছে।
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}এই পরিবর্তনের আগে, এক্সটার্নাল কোডকে add_to_waitlist ফাংশনটিকে restaurant::front_of_house::hosting::add_to_waitlist() পাথ ব্যবহার করে কল করতে হত, যেটিতে front_of_house মডিউলটিকেও pub হিসাবে চিহ্নিত করার প্রয়োজন হত। এখন যে এই pub use রুট মডিউল থেকে hosting মডিউলটিকে পুনরায় এক্সপোর্ট করেছে, এক্সটার্নাল কোড পরিবর্তে restaurant::hosting::add_to_waitlist() পাথ ব্যবহার করতে পারে।
রি-এক্সপোর্টিং দরকারী যখন আপনার কোডের অভ্যন্তরীণ কাঠামো আপনার কোডকে কল করা প্রোগ্রামাররা ডোমেন সম্পর্কে যেভাবে ভাবেন তার থেকে ভিন্ন হয়। উদাহরণস্বরূপ, এই রেস্তোরাঁর রূপকটিতে, রেস্তোরাঁ চালানো লোকেরা "ফ্রন্ট অফ হাউস" এবং "ব্যাক অফ হাউস" সম্পর্কে চিন্তা করে। কিন্তু একটি রেস্তোরাঁয় আসা গ্রাহকরা সম্ভবত রেস্তোরাঁর অংশগুলো সম্পর্কে সেই পরিভাষায় ভাববেন না। pub use দিয়ে, আমরা আমাদের কোড একটি কাঠামো দিয়ে লিখতে পারি কিন্তু একটি ভিন্ন কাঠামো এক্সপোজ করতে পারি। এটি করলে আমাদের লাইব্রেরিটি লাইব্রেরিতে কাজ করা প্রোগ্রামার এবং লাইব্রেরি কল করা প্রোগ্রামার উভয়ের জন্যই সুসংগঠিত হয়। আমরা চ্যাপ্টার 14-এর “pub use দিয়ে একটি সুবিধাজনক পাবলিক API এক্সপোর্ট করা”-তে pub use-এর আরেকটি উদাহরণ এবং এটি কীভাবে আপনার ক্রেটের ডকুমেন্টেশনকে প্রভাবিত করে তা দেখব।
এক্সটার্নাল প্যাকেজ ব্যবহার করা (Using External Packages)
চ্যাপ্টার ২-এ, আমরা একটি অনুমান করার গেম প্রোজেক্ট প্রোগ্রাম করেছি যা র্যান্ডম সংখ্যা পেতে rand নামক একটি এক্সটার্নাল প্যাকেজ ব্যবহার করেছে। আমাদের প্রোজেক্টে rand ব্যবহার করার জন্য, আমরা Cargo.toml-এ এই লাইনটি যোগ করেছি:
rand = "0.8.5"
Cargo.toml-এ rand-কে ডিপেন্ডেন্সি হিসাবে যোগ করা Cargo-কে crates.io থেকে rand প্যাকেজ এবং যেকোনো ডিপেন্ডেন্সি ডাউনলোড করতে এবং rand-কে আমাদের প্রোজেক্টের জন্য উপলব্ধ করতে বলে।
তারপর, rand সংজ্ঞাগুলোকে আমাদের প্যাকেজের স্কোপে আনতে, আমরা use লাইন যোগ করেছি যা ক্রেটের নাম, rand দিয়ে শুরু হয় এবং আমরা যে আইটেমগুলোকে স্কোপে আনতে চেয়েছিলাম সেগুলো তালিকাভুক্ত করেছি। “একটি র্যান্ডম সংখ্যা তৈরি করা”-তে স্মরণ করুন যে, চ্যাপ্টার ২-এ, আমরা Rng ট্রেইটটিকে স্কোপে এনেছি এবং rand::thread_rng ফাংশনটিকে কল করেছি:
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Rust কমিউনিটির সদস্যরা crates.io-তে অনেকগুলি প্যাকেজ উপলব্ধ করেছেন এবং সেগুলোর যেকোনোটিকে আপনার প্যাকেজে যুক্ত করার জন্য একই ধাপগুলো জড়িত: সেগুলোকে আপনার প্যাকেজের Cargo.toml ফাইলে তালিকাভুক্ত করা এবং তাদের ক্রেট থেকে আইটেমগুলোকে স্কোপে আনতে use ব্যবহার করা।
মনে রাখবেন যে স্ট্যান্ডার্ড লাইব্রেরি (std)ও আমাদের প্যাকেজের জন্য একটি এক্সটার্নাল ক্রেট। যেহেতু স্ট্যান্ডার্ড লাইব্রেরিটি Rust ভাষার সাথে পাঠানো হয়, তাই আমাদের std অন্তর্ভুক্ত করার জন্য Cargo.toml পরিবর্তন করার প্রয়োজন নেই। কিন্তু আমাদের প্যাকেজের স্কোপে সেখান থেকে আইটেমগুলো আনতে use দিয়ে এটিকে রেফার করতে হবে। উদাহরণস্বরূপ, HashMap-এর সাথে আমরা এই লাইনটি ব্যবহার করব:
#![allow(unused)] fn main() { use std::collections::HashMap; }
এটি স্ট্যান্ডার্ড লাইব্রেরি ক্রেটের নাম std দিয়ে শুরু হওয়া একটি অ্যাবসোলিউট পাথ।
বড় use তালিকা পরিষ্কার করতে নেস্টেড পাথ ব্যবহার করা (Using Nested Paths to Clean Up Large use Lists)
যদি আমরা একই ক্রেট বা একই মডিউলে সংজ্ঞায়িত একাধিক আইটেম ব্যবহার করি, তাহলে প্রতিটি আইটেমকে নিজস্ব লাইনে তালিকাভুক্ত করা আমাদের ফাইলগুলোতে অনেক উল্লম্ব জায়গা নিতে পারে। উদাহরণস্বরূপ, Listing 2-4-এ অনুমান করার গেমে আমাদের দুটি use স্টেটমেন্ট ছিল যা std থেকে আইটেমগুলোকে স্কোপে এনেছিল:
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}পরিবর্তে, আমরা একই আইটেমগুলোকে এক লাইনে স্কোপে আনতে নেস্টেড পাথ ব্যবহার করতে পারি। আমরা এটি করি পাথের সাধারণ অংশটি নির্দিষ্ট করে, তারপর দুটি কোলন এবং তারপর কার্লি ব্র্যাকেটের মধ্যে পাথের ভিন্ন অংশগুলোর একটি তালিকা, যেমনটি Listing 7-18-এ দেখানো হয়েছে।
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}বড় প্রোগ্রামগুলোতে, একই ক্রেট বা মডিউল থেকে অনেকগুলো আইটেমকে স্কোপে আনতে নেস্টেড পাথ ব্যবহার করা প্রয়োজনীয় use স্টেটমেন্টের সংখ্যা অনেক কমাতে পারে!
আমরা একটি পাথের যেকোনো স্তরে একটি নেস্টেড পাথ ব্যবহার করতে পারি, যা দুটি use স্টেটমেন্টকে একত্রিত করার সময় দরকারী যেখানে একটি সাবপাথ শেয়ার করা হয়। উদাহরণস্বরূপ, Listing 7-19 দুটি use স্টেটমেন্ট দেখায়: একটি যা std::io-কে স্কোপে আনে এবং একটি যা std::io::Write-কে স্কোপে আনে।
use std::io;
use std::io::Write;এই দুটি পাথের সাধারণ অংশ হল std::io, এবং সেটি হল সম্পূর্ণ প্রথম পাথ। এই দুটি পাথকে একটি use স্টেটমেন্টে মার্জ করতে, আমরা নেস্টেড পাথে self ব্যবহার করতে পারি, যেমনটি Listing 7-20-তে দেখানো হয়েছে।
use std::io::{self, Write};এই লাইনটি std::io এবং std::io::Write-কে স্কোপে নিয়ে আসে।
গ্লোব অপারেটর (The Glob Operator)
আমরা যদি একটি পাথে সংজ্ঞায়িত সমস্ত পাবলিক আইটেমকে স্কোপে আনতে চাই, তাহলে আমরা সেই পাথটি নির্দিষ্ট করতে পারি এবং তারপর * গ্লোব অপারেটরটি ব্যবহার করতে পারি:
#![allow(unused)] fn main() { use std::collections::*; }
এই use স্টেটমেন্টটি std::collections-এ সংজ্ঞায়িত সমস্ত পাবলিক আইটেমকে বর্তমান স্কোপে নিয়ে আসে। গ্লোব অপারেটর ব্যবহার করার সময় সতর্ক থাকুন! গ্লোব কোন নামগুলো স্কোপে রয়েছে এবং আপনার প্রোগ্রামে ব্যবহৃত একটি নাম কোথায় সংজ্ঞায়িত করা হয়েছিল তা বলা কঠিন করে তুলতে পারে।
গ্লোব অপারেটরটি প্রায়শই পরীক্ষার সময় ব্যবহার করা হয় যাতে পরীক্ষার অধীনে থাকা সমস্ত কিছুকে tests মডিউলে আনা যায়; আমরা চ্যাপ্টার 11-এর “কিভাবে পরীক্ষা লিখতে হয়”-তে এটি নিয়ে কথা বলব। গ্লোব অপারেটরটি কখনও কখনও প্রেলিউড প্যাটার্নের (prelude pattern) অংশ হিসাবেও ব্যবহৃত হয়: সেই প্যাটার্ন সম্পর্কে আরও তথ্যের জন্য স্ট্যান্ডার্ড লাইব্রেরি ডকুমেন্টেশন দেখুন।
মডিউলগুলোকে বিভিন্ন ফাইলে আলাদা করা (Separating Modules into Different Files)
এখন পর্যন্ত, এই চ্যাপ্টারের সমস্ত উদাহরণে একটি ফাইলের মধ্যে একাধিক মডিউল সংজ্ঞায়িত করা হয়েছে। যখন মডিউলগুলো বড় হয়ে যায়, তখন আপনি কোড নেভিগেট করা সহজ করার জন্য সেগুলোর সংজ্ঞাগুলো একটি পৃথক ফাইলে সরিয়ে নিতে চাইতে পারেন।
উদাহরণস্বরূপ, আসুন Listing 7-17-এর কোড থেকে শুরু করি যেখানে একাধিক রেস্তোরাঁ মডিউল ছিল। আমরা সমস্ত মডিউলকে ক্রেট রুট ফাইলে সংজ্ঞায়িত করার পরিবর্তে মডিউলগুলোকে ফাইলে এক্সট্র্যাক্ট করব। এই ক্ষেত্রে, ক্রেট রুট ফাইলটি হল src/lib.rs, কিন্তু এই পদ্ধতিটি বাইনারি ক্রেটগুলোর সাথেও কাজ করে যাদের ক্রেট রুট ফাইল src/main.rs।
প্রথমে আমরা front_of_house মডিউলটিকে তার নিজস্ব ফাইলে এক্সট্র্যাক্ট করব। front_of_house মডিউলের কোঁকড়া ধনুর্বন্ধনীর ভিতরের কোডটি সরিয়ে ফেলুন, শুধুমাত্র mod front_of_house; ঘোষণাটি রেখে দিন, যাতে src/lib.rs-এ Listing 7-21-এ দেখানো কোড থাকে। মনে রাখবেন যে এটি কম্পাইল হবে না যতক্ষণ না আমরা Listing 7-22-এ src/front_of_house.rs ফাইল তৈরি করি।
mod front_of_house;
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}এরপর, কোঁকড়া ধনুর্বন্ধনীর মধ্যে থাকা কোডটি src/front_of_house.rs নামে একটি নতুন ফাইলে রাখুন, যেমনটি Listing 7-22-এ দেখানো হয়েছে। কম্পাইলার জানে যে এই ফাইলটিতে খুঁজতে হবে কারণ এটি ক্রেট রুটে front_of_house নামের মডিউল ঘোষণার সম্মুখীন হয়েছে।
pub mod hosting {
pub fn add_to_waitlist() {}
}লক্ষ্য করুন যে আপনাকে আপনার মডিউল ট্রিতে একটি mod ঘোষণা ব্যবহার করে শুধুমাত্র একবার একটি ফাইল লোড করতে হবে। কম্পাইলার যখন জানে যে ফাইলটি প্রোজেক্টের অংশ (এবং আপনি যেখানে mod স্টেটমেন্ট রেখেছেন তার কারণে মডিউল ট্রিতে কোডটি কোথায় রয়েছে তা জানে), তখন আপনার প্রোজেক্টের অন্যান্য ফাইলগুলোর লোড করা ফাইলের কোডটিকে রেফার করা উচিত যেখানে এটি ঘোষণা করা হয়েছিল, যেমনটি “মডিউল ট্রিতে একটি আইটেমকে রেফার করার জন্য পাথ” বিভাগে আলোচনা করা হয়েছে। অন্য কথায়, mod একটি "অন্তর্ভুক্ত (include)" অপারেশন নয় যা আপনি হয়তো অন্য প্রোগ্রামিং ভাষাগুলোতে দেখেছেন।
এরপর, আমরা hosting মডিউলটিকে তার নিজস্ব ফাইলে এক্সট্র্যাক্ট করব। প্রক্রিয়াটি একটু ভিন্ন কারণ hosting হল রুট মডিউলের চাইল্ড মডিউল নয়, front_of_house-এর চাইল্ড মডিউল। আমরা hosting-এর জন্য ফাইলটিকে একটি নতুন ডিরেক্টরিতে রাখব যার নাম মডিউল ট্রিতে এর পূর্বপুরুষদের নামে হবে, এই ক্ষেত্রে src/front_of_house।
hosting সরানো শুরু করতে, আমরা src/front_of_house.rs পরিবর্তন করে শুধুমাত্র hosting মডিউলের ঘোষণা রাখি:
pub mod hosting;তারপর আমরা একটি src/front_of_house ডিরেক্টরি এবং hosting মডিউলে তৈরি করা সংজ্ঞাগুলো ধারণ করার জন্য একটি hosting.rs ফাইল তৈরি করি:
pub fn add_to_waitlist() {}যদি আমরা পরিবর্তে hosting.rs কে src ডিরেক্টরিতে রাখতাম, তাহলে কম্পাইলার আশা করত যে hosting.rs কোডটি ক্রেট রুটে ঘোষিত একটি hosting মডিউলে রয়েছে, front_of_house মডিউলের চাইল্ড হিসাবে ঘোষিত নয়। কোন মডিউলের কোডের জন্য কোন ফাইলগুলো পরীক্ষা করতে হবে সে সম্পর্কে কম্পাইলারের নিয়মগুলোর অর্থ হল ডিরেক্টরি এবং ফাইলগুলো মডিউল ট্রির সাথে আরও ঘনিষ্ঠভাবে মেলে।
বিকল্প ফাইলের পাথ (Alternate File Paths)
ఇప్పటి পর্যন্ত আমরা Rust কম্পাইলার ব্যবহার করে এমন সবচেয়ে ইডিওমেটিক ফাইলের পাথগুলো কভার করেছি, কিন্তু Rust একটি পুরানো স্টাইলের ফাইল পাথও সমর্থন করে। ক্রেট রুটে ঘোষিত
front_of_houseনামক একটি মডিউলের জন্য, কম্পাইলার মডিউলের কোড খুঁজবে:
- src/front_of_house.rs-এ (যা আমরা কভার করেছি)
- src/front_of_house/mod.rs-এ (পুরানো স্টাইল, এখনও সমর্থিত পাথ)
front_of_house-এর একটি সাবমডিউলhostingনামক মডিউলের জন্য, কম্পাইলার মডিউলের কোড খুঁজবে:
- src/front_of_house/hosting.rs-এ (যা আমরা কভার করেছি)
- src/front_of_house/hosting/mod.rs-এ (পুরানো স্টাইল, এখনও সমর্থিত পাথ)
আপনি যদি একই মডিউলের জন্য উভয় স্টাইল ব্যবহার করেন, তাহলে আপনি একটি কম্পাইলার এরর পাবেন। একই প্রোজেক্টে বিভিন্ন মডিউলের জন্য উভয় স্টাইলের মিশ্রণ ব্যবহার করার অনুমতি রয়েছে, তবে এটি আপনার প্রোজেক্ট নেভিগেট করা লোকেদের জন্য বিভ্রান্তিকর হতে পারে।
mod.rs নামে ফাইলগুলো ব্যবহার করা স্টাইলের প্রধান অসুবিধা হল আপনার প্রোজেক্টে mod.rs নামে অনেকগুলো ফাইল থাকতে পারে, যা আপনার এডিটরে একসাথে খোলা থাকলে বিভ্রান্তিকর হতে পারে।
আমরা প্রতিটি মডিউলের কোডকে একটি পৃথক ফাইলে সরিয়ে নিয়েছি এবং মডিউল ট্রি একই রয়েছে। eat_at_restaurant-এর ফাংশন কলগুলো কোনো পরিবর্তন ছাড়াই কাজ করবে, যদিও সংজ্ঞাগুলো ভিন্ন ফাইলে রয়েছে। এই কৌশলটি আপনাকে মডিউলগুলোর আকার বাড়ার সাথে সাথে সেগুলোকে নতুন ফাইলে সরিয়ে নিতে দেয়।
লক্ষ্য করুন যে src/lib.rs-এ pub use crate::front_of_house::hosting স্টেটমেন্টটিও পরিবর্তিত হয়নি, use-এরও ক্রেটের অংশ হিসাবে কোন ফাইলগুলো কম্পাইল করা হয় তার উপর কোনো প্রভাব নেই। mod কীওয়ার্ড মডিউলগুলো ঘোষণা করে এবং Rust সেই মডিউলের নামের সাথে একই নামের একটি ফাইলে সেই মডিউলে যাওয়া কোডের জন্য সন্ধান করে।
সারসংক্ষেপ (Summary)
Rust আপনাকে একটি প্যাকেজকে একাধিক ক্রেট এবং একটি ক্রেটকে মডিউলে বিভক্ত করতে দেয় যাতে আপনি একটি মডিউলে সংজ্ঞায়িত আইটেমগুলোকে অন্য মডিউল থেকে রেফার করতে পারেন। আপনি অ্যাবসোলিউট বা রিলেটিভ পাথ নির্দিষ্ট করে এটি করতে পারেন। এই পাথগুলো একটি use স্টেটমেন্ট দিয়ে স্কোপে আনা যেতে পারে যাতে আপনি সেই স্কোপে আইটেমটির একাধিক ব্যবহারের জন্য একটি সংক্ষিপ্ত পাথ ব্যবহার করতে পারেন। মডিউল কোড ডিফল্টরূপে প্রাইভেট, কিন্তু আপনি pub কীওয়ার্ড যোগ করে সংজ্ঞাগুলোকে পাবলিক করতে পারেন।
পরবর্তী চ্যাপ্টারে, আমরা স্ট্যান্ডার্ড লাইব্রেরির কিছু কালেকশন ডেটা স্ট্রাকচার দেখব যা আপনি আপনার সুসংগঠিত কোডে ব্যবহার করতে পারেন।
সাধারণ কালেকশন (Common Collections)
Rust-এর স্ট্যান্ডার্ড লাইব্রেরিতে বেশ কিছু দরকারী ডেটা স্ট্রাকচার রয়েছে, যেগুলোকে কালেকশন (collections) বলা হয়। বেশিরভাগ অন্যান্য ডেটা টাইপ একটি নির্দিষ্ট মান উপস্থাপন করে, কিন্তু কালেকশনগুলো একাধিক মান ধারণ করতে পারে। বিল্ট-ইন অ্যারে এবং টাপল টাইপের বিপরীতে, এই কালেকশনগুলো যে ডেটা নির্দেশ করে তা হিপে (heap) সংরক্ষণ করা হয়, যার মানে ডেটার পরিমাণ কম্পাইল করার সময় জানার প্রয়োজন নেই এবং প্রোগ্রাম চলার সাথে সাথে এটি বাড়তে বা কমতে পারে। প্রতিটি ধরণের কালেকশনের বিভিন্ন ক্ষমতা এবং খরচ রয়েছে এবং আপনার বর্তমান পরিস্থিতির জন্য উপযুক্ত একটি বেছে নেওয়া এমন একটি দক্ষতা যা আপনি সময়ের সাথে সাথে বিকশিত করবেন। এই চ্যাপ্টারে, আমরা তিনটি কালেকশন নিয়ে আলোচনা করব যা Rust প্রোগ্রামগুলোতে প্রায়শই ব্যবহৃত হয়:
- একটি ভেক্টর (vector) আপনাকে একে অপরের পাশে পরিবর্তনশীল সংখ্যক মান সংরক্ষণ করতে দেয়।
- একটি স্ট্রিং (string) হল অক্ষরের একটি কালেকশন। আমরা আগে
Stringটাইপ উল্লেখ করেছি, কিন্তু এই চ্যাপ্টারে আমরা এটি সম্পর্কে বিস্তারিত আলোচনা করব। - একটি হ্যাশ ম্যাপ (hash map) আপনাকে একটি নির্দিষ্ট কী (key)-এর সাথে একটি মান যুক্ত করতে দেয়। এটি ম্যাপ (map) নামক আরও সাধারণ ডেটা স্ট্রাকচারের একটি বিশেষ বাস্তবায়ন।
স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা অন্যান্য ধরণের কালেকশন সম্পর্কে জানতে, ডকুমেন্টেশন দেখুন।
আমরা ভেক্টর, স্ট্রিং এবং হ্যাশ ম্যাপ কীভাবে তৈরি এবং আপডেট করতে হয়, সেইসাথে কী প্রত্যেকটিকে বিশেষ করে তোলে তা নিয়ে আলোচনা করব।
ভেক্টর ব্যবহার করে মানগুলোর তালিকা সংরক্ষণ করা (Storing Lists of Values with Vectors)
আমরা প্রথমে যে কালেকশন টাইপটি দেখব তা হল Vec<T>, যাকে ভেক্টর (vector) বলা হয়। ভেক্টর আপনাকে মেমরিতে একে অপরের পাশে সমস্ত মান স্থাপন করে একটি একক ডেটা স্ট্রাকচারে একাধিক মান সংরক্ষণ করতে দেয়। ভেক্টরগুলো শুধুমাত্র একই টাইপের মান সংরক্ষণ করতে পারে। যখন আপনার কাছে আইটেমগুলোর একটি তালিকা থাকে, যেমন একটি ফাইলের টেক্সটের লাইন বা শপিং কার্টের আইটেমগুলোর দাম, তখন এগুলো দরকারী।
একটি নতুন ভেক্টর তৈরি করা (Creating a New Vector)
একটি নতুন খালি ভেক্টর তৈরি করতে, আমরা Vec::new ফাংশনটি কল করি, যেমনটি Listing 8-1-এ দেখানো হয়েছে।
fn main() { let v: Vec<i32> = Vec::new(); }
লক্ষ্য করুন যে আমরা এখানে একটি টাইপ অ্যানোটেশন যুক্ত করেছি। যেহেতু আমরা এই ভেক্টরে কোনো মান সন্নিবেশ করাচ্ছি না, তাই Rust জানে না যে আমরা কোন ধরনের উপাদান সংরক্ষণ করতে চাই। এটি একটি গুরুত্বপূর্ণ বিষয়। ভেক্টরগুলো জেনেরিক ব্যবহার করে ইমপ্লিমেন্ট করা হয়; আমরা চ্যাপ্টার ১০-এ আপনার নিজের টাইপের সাথে জেনেরিক কীভাবে ব্যবহার করতে হয় তা কভার করব। আপাতত, জেনে রাখুন যে স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা Vec<T> টাইপ যেকোনো টাইপ ধারণ করতে পারে। যখন আমরা একটি নির্দিষ্ট টাইপ ধারণ করার জন্য একটি ভেক্টর তৈরি করি, তখন আমরা অ্যাঙ্গেল ব্র্যাকেটের মধ্যে টাইপটি নির্দিষ্ট করতে পারি। Listing 8-1-এ, আমরা Rust-কে বলেছি যে v-এর Vec<T> i32 টাইপের উপাদান ধারণ করবে।
প্রায়শই, আপনি প্রাথমিক মান সহ একটি Vec<T> তৈরি করবেন এবং Rust আপনি যে মান সংরক্ষণ করতে চান তার টাইপ অনুমান করবে, তাই আপনাকে খুব কমই এই টাইপ অ্যানোটেশন করতে হবে। Rust সুবিধাজনকভাবে vec! ম্যাক্রো সরবরাহ করে, যা আপনার দেওয়া মানগুলো ধারণ করে এমন একটি নতুন ভেক্টর তৈরি করবে। Listing 8-2 1, 2 এবং 3 মান ধারণ করে এমন একটি নতুন Vec<i32> তৈরি করে। ইন্টিজার টাইপ হল i32 কারণ এটি ডিফল্ট ইন্টিজার টাইপ, যেমনটি আমরা চ্যাপ্টার ৩-এর “ডেটা টাইপস” বিভাগে আলোচনা করেছি।
fn main() { let v = vec![1, 2, 3]; }
যেহেতু আমরা প্রাথমিক i32 মান দিয়েছি, তাই Rust অনুমান করতে পারে যে v-এর টাইপ হল Vec<i32>, এবং টাইপ অ্যানোটেশনটি প্রয়োজনীয় নয়। এরপর, আমরা দেখব কিভাবে একটি ভেক্টর পরিবর্তন করতে হয়।
একটি ভেক্টর আপডেট করা (Updating a Vector)
একটি ভেক্টর তৈরি করতে এবং তারপর এতে উপাদান যোগ করতে, আমরা push মেথড ব্যবহার করতে পারি, যেমনটি Listing 8-3-তে দেখানো হয়েছে।
fn main() { let mut v = Vec::new(); v.push(5); v.push(6); v.push(7); v.push(8); }
যেকোনো ভেরিয়েবলের মতো, যদি আমরা এর মান পরিবর্তন করতে চাই, তাহলে আমাদের mut কীওয়ার্ড ব্যবহার করে এটিকে মিউটেবল করতে হবে, যেমনটি চ্যাপ্টার ৩-এ আলোচনা করা হয়েছে। আমরা ভিতরে যে সংখ্যাগুলো রাখি সেগুলো সবই i32 টাইপের, এবং Rust ডেটা থেকে এটি অনুমান করে, তাই আমাদের Vec<i32> অ্যানোটেশনের প্রয়োজন নেই।
ভেক্টরের উপাদানগুলো পড়া (Reading Elements of Vectors)
একটি ভেক্টরে সংরক্ষিত একটি মান রেফারেন্স করার দুটি উপায় রয়েছে: ইনডেক্সিংয়ের মাধ্যমে অথবা get মেথড ব্যবহার করে। নিম্নলিখিত উদাহরণগুলোতে, আমরা অতিরিক্ত স্পষ্টতার জন্য এই ফাংশনগুলো থেকে রিটার্ন করা মানগুলোর টাইপ অ্যানোটেট করেছি।
Listing 8-4 একটি ভেক্টরের একটি মান অ্যাক্সেস করার উভয় পদ্ধতি দেখায়, ইনডেক্সিং সিনট্যাক্স এবং get মেথড দিয়ে।
fn main() { let v = vec![1, 2, 3, 4, 5]; let third: &i32 = &v[2]; println!("The third element is {third}"); let third: Option<&i32> = v.get(2); match third { Some(third) => println!("The third element is {third}"), None => println!("There is no third element."), } }
এখানে কয়েকটি বিবরণ লক্ষ্য করুন। আমরা তৃতীয় উপাদানটি পেতে 2-এর ইনডেক্স মান ব্যবহার করি কারণ ভেক্টরগুলো সংখ্যা দ্বারা ইনডেক্স করা হয়, শূন্য থেকে শুরু করে। & এবং [] ব্যবহার করা আমাদের ইনডেক্স মানের এলিমেন্টের একটি রেফারেন্স দেয়। যখন আমরা আর্গুমেন্ট হিসাবে পাস করা ইনডেক্স সহ get মেথড ব্যবহার করি, তখন আমরা একটি Option<&T> পাই যা আমরা match-এর সাথে ব্যবহার করতে পারি।
Rust এলিমেন্টকে রেফারেন্স করার এই দুটি উপায় সরবরাহ করে যাতে আপনি প্রোগ্রামটি কীভাবে আচরণ করবে তা বেছে নিতে পারেন যখন আপনি বিদ্যমান এলিমেন্টগুলোর সীমার বাইরের একটি ইনডেক্স মান ব্যবহার করার চেষ্টা করেন। উদাহরণস্বরূপ, আসুন দেখি কী ঘটে যখন আমাদের পাঁচটি এলিমেন্টসহ একটি ভেক্টর থাকে এবং তারপর আমরা প্রতিটি কৌশল দিয়ে ১০০ ইনডেক্সে একটি এলিমেন্ট অ্যাক্সেস করার চেষ্টা করি, যেমনটি Listing 8-5-এ দেখানো হয়েছে।
fn main() { let v = vec![1, 2, 3, 4, 5]; let does_not_exist = &v[100]; let does_not_exist = v.get(100); }
যখন আমরা এই কোডটি চালাই, তখন প্রথম [] মেথডটি প্রোগ্রামটিকে প্যানিক (panic) ঘটাবে কারণ এটি একটি অস্তিত্বহীন এলিমেন্টকে রেফারেন্স করে। এই মেথডটি তখনই ব্যবহার করা ভাল যখন আপনি চান যে আপনার প্রোগ্রামটি ক্র্যাশ করুক যদি ভেক্টরের শেষের বাইরের কোনো এলিমেন্ট অ্যাক্সেস করার চেষ্টা করা হয়।
যখন get মেথডটিকে ভেক্টরের বাইরের একটি ইনডেক্স পাস করা হয়, তখন এটি প্যানিক না করে None রিটার্ন করে। আপনি এই মেথডটি ব্যবহার করবেন যদি ভেক্টরের সীমার বাইরের একটি এলিমেন্ট অ্যাক্সেস করা স্বাভাবিক পরিস্থিতিতে মাঝে মাঝে ঘটতে পারে। আপনার কোডে তখন Some(&element) বা None হ্যান্ডেল করার জন্য লজিক থাকবে, যেমনটি চ্যাপ্টার ৬-এ আলোচনা করা হয়েছে। উদাহরণস্বরূপ, ইনডেক্সটি একজন ব্যক্তির কাছ থেকে একটি সংখ্যা প্রবেশ করানো থেকে আসতে পারে। যদি তারা ভুলবশত খুব বড় একটি সংখ্যা প্রবেশ করায় এবং প্রোগ্রামটি একটি None মান পায়, তাহলে আপনি ব্যবহারকারীকে বলতে পারেন যে বর্তমান ভেক্টরে কতগুলো আইটেম রয়েছে এবং তাদের একটি বৈধ মান প্রবেশ করার আরেকটি সুযোগ দিতে পারেন। একটি টাইপোর কারণে প্রোগ্রামটি ক্র্যাশ করার চেয়ে এটি আরও ব্যবহারকারী-বান্ধব হবে!
যখন প্রোগ্রামের একটি বৈধ রেফারেন্স থাকে, তখন বোরো চেকার (borrow checker) ওনারশিপ এবং বোরোয়িং-এর নিয়মগুলো (চ্যাপ্টার ৪-এ কভার করা হয়েছে) প্রয়োগ করে যাতে এই রেফারেন্স এবং ভেক্টরের কনটেন্টের অন্য কোনো রেফারেন্স বৈধ থাকে। সেই নিয়মটি স্মরণ করুন যা বলে যে আপনি একই স্কোপে মিউটেবল এবং ইমিউটেবল রেফারেন্স রাখতে পারবেন না। সেই নিয়মটি Listing 8-6-এ প্রযোজ্য, যেখানে আমরা ভেক্টরের প্রথম এলিমেন্টের একটি ইমিউটেবল রেফারেন্স রাখি এবং শেষে একটি এলিমেন্ট যোগ করার চেষ্টা করি। যদি আমরা ফাংশনের পরেও সেই এলিমেন্টটিকে রেফার করার চেষ্টা করি তবে এই প্রোগ্রামটি কাজ করবে না।
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}এই কোডটি কম্পাইল করলে এই এররটি আসবে:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {first}");
| ------- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Listing 8-6-এর কোডটি কাজ করা উচিত বলে মনে হতে পারে: প্রথম এলিমেন্টের একটি রেফারেন্স কেন ভেক্টরের শেষের পরিবর্তনগুলোর বিষয়ে চিন্তা করবে? এই এররটি ভেক্টরগুলো যেভাবে কাজ করে তার কারণে: যেহেতু ভেক্টরগুলো মেমরিতে মানগুলোকে একে অপরের পাশে রাখে, তাই ভেক্টরের শেষে একটি নতুন এলিমেন্ট যোগ করার জন্য নতুন মেমরি বরাদ্দ করার এবং পুরানো এলিমেন্টগুলোকে নতুন জায়গায় কপি করার প্রয়োজন হতে পারে, যদি ভেক্টরটি বর্তমানে যেখানে সংরক্ষণ করা হয়েছে সেখানে সমস্ত এলিমেন্টগুলোকে একে অপরের পাশে রাখার জন্য যথেষ্ট জায়গা না থাকে। সেই ক্ষেত্রে, প্রথম এলিমেন্টের রেফারেন্সটি ডিলোক্যাট করা মেমরির দিকে নির্দেশ করবে। বোরোয়িং-এর নিয়মগুলো প্রোগ্রামগুলোকে সেই পরিস্থিতিতে পড়তে বাধা দেয়।
দ্রষ্টব্য:
Vec<T>টাইপের ইমপ্লিমেন্টেশনের বিস্তারিত বিবরণের জন্য, “The Rustonomicon” দেখুন।
একটি ভেক্টরের মানগুলোর উপর ইটারেট করা (Iterating Over the Values in a Vector)
একটি ভেক্টরের প্রতিটি এলিমেন্ট অ্যাক্সেস করার জন্য, আমরা একবারে একটি অ্যাক্সেস করার জন্য ইনডেক্স ব্যবহার করার পরিবর্তে সমস্ত এলিমেন্টের মধ্য দিয়ে ইটারেট করব। Listing 8-7 দেখায় কিভাবে i32 মানগুলোর একটি ভেক্টরের প্রতিটি এলিমেন্টে ইমিউটেবল রেফারেন্স পেতে এবং সেগুলো প্রিন্ট করতে একটি for লুপ ব্যবহার করতে হয়।
fn main() { let v = vec![100, 32, 57]; for i in &v { println!("{i}"); } }
সমস্ত এলিমেন্টে পরিবর্তন করার জন্য আমরা একটি মিউটেবল ভেক্টরের প্রতিটি এলিমেন্টে মিউটেবল রেফারেন্সের উপরও ইটারেট করতে পারি। Listing 8-8-এর for লুপ প্রতিটি এলিমেন্টে 50 যোগ করবে।
fn main() { let mut v = vec![100, 32, 57]; for i in &mut v { *i += 50; } }
মিউটেবল রেফারেন্স যে মানটিকে রেফার করে সেটি পরিবর্তন করতে, += অপারেটর ব্যবহার করার আগে আমাদের i-এর মান পেতে * ডিরেফারেন্স অপারেটর ব্যবহার করতে হবে। আমরা চ্যাপ্টার ১৫-এর “ভ্যালুতে পয়েন্টার অনুসরণ করা” বিভাগে ডিরেফারেন্স অপারেটর সম্পর্কে আরও কথা বলব।
একটি ভেক্টরের উপর ইটারেট করা, ইমিউটেবল বা মিউটেবল যাই হোক না কেন, বোরো চেকারের নিয়মের কারণে নিরাপদ। যদি আমরা Listing 8-7 এবং Listing 8-8-এর for লুপ বডিতে আইটেমগুলো সন্নিবেশ বা অপসারণ করার চেষ্টা করতাম, তাহলে আমরা Listing 8-6-এর কোডের সাথে পাওয়া এররের মতো একটি কম্পাইলার এরর পেতাম। for লুপ যে ভেক্টরটির রেফারেন্স ধরে রাখে সেটি সম্পূর্ণ ভেক্টরের যুগপৎ পরিবর্তন প্রতিরোধ করে।
একাধিক টাইপ সংরক্ষণ করতে একটি এনাম ব্যবহার করা (Using an Enum to Store Multiple Types)
ভেক্টরগুলো শুধুমাত্র একই টাইপের মান সংরক্ষণ করতে পারে। এটি অসুবিধাজনক হতে পারে; বিভিন্ন টাইপের আইটেমগুলোর একটি তালিকা সংরক্ষণ করার প্রয়োজনের জন্য অবশ্যই ব্যবহারের ক্ষেত্র রয়েছে। সৌভাগ্যবশত, একটি এনামের ভেরিয়েন্টগুলো একই এনাম টাইপের অধীনে সংজ্ঞায়িত করা হয়, তাই যখন আমাদের বিভিন্ন টাইপের এলিমেন্ট উপস্থাপন করার জন্য একটি টাইপ প্রয়োজন হয়, তখন আমরা একটি এনাম সংজ্ঞায়িত এবং ব্যবহার করতে পারি!
উদাহরণস্বরূপ, ধরা যাক আমরা একটি স্প্রেডশিটের একটি সারি থেকে মান পেতে চাই যেখানে সারির কিছু কলামে ইন্টিজার, কিছুতে ফ্লোটিং-পয়েন্ট সংখ্যা এবং কিছুতে স্ট্রিং রয়েছে। আমরা একটি এনাম সংজ্ঞায়িত করতে পারি যার ভেরিয়েন্টগুলো বিভিন্ন মানের টাইপ ধারণ করবে এবং সমস্ত এনাম ভেরিয়েন্ট একই টাইপ হিসাবে বিবেচিত হবে: এনামের টাইপ। তারপর আমরা সেই এনামটি ধারণ করার জন্য একটি ভেক্টর তৈরি করতে পারি এবং শেষ পর্যন্ত, বিভিন্ন টাইপ ধারণ করতে পারি। আমরা Listing 8-9-এ এটি প্রদর্শন করেছি।
fn main() { enum SpreadsheetCell { Int(i32), Float(f64), Text(String), } let row = vec![ SpreadsheetCell::Int(3), SpreadsheetCell::Text(String::from("blue")), SpreadsheetCell::Float(10.12), ]; }
Rust-কে কম্পাইল করার সময় জানতে হবে ভেক্টরে কোন টাইপগুলো থাকবে যাতে এটি জানে যে প্রতিটি এলিমেন্ট সংরক্ষণ করার জন্য হিপে ঠিক কতটা মেমরির প্রয়োজন হবে। আমাদের অবশ্যই স্পষ্ট হতে হবে যে এই ভেক্টরে কোন টাইপগুলো অনুমোদিত। যদি Rust একটি ভেক্টরকে যেকোনো টাইপ ধারণ করার অনুমতি দিত, তাহলে ভেক্টরের এলিমেন্টগুলোতে করা অপারেশনের সাথে এক বা একাধিক টাইপ এরর ঘটাতে পারত। একটি এনাম প্লাস একটি match এক্সপ্রেশন ব্যবহার করার অর্থ হল Rust কম্পাইল করার সময় নিশ্চিত করবে যে প্রতিটি সম্ভাব্য ক্ষেত্র হ্যান্ডেল করা হয়েছে, যেমনটি চ্যাপ্টার ৬-এ আলোচনা করা হয়েছে।
আপনি যদি জানেন না যে একটি প্রোগ্রাম রানটাইমে একটি ভেক্টরে সংরক্ষণ করার জন্য কোন টাইপের সম্পূর্ণ সেট পাবে, তাহলে এনাম কৌশলটি কাজ করবে না। পরিবর্তে, আপনি একটি ট্রেইট অবজেক্ট ব্যবহার করতে পারেন, যা আমরা চ্যাপ্টার 18-এ কভার করব।
এখন আমরা ভেক্টর ব্যবহার করার সবচেয়ে সাধারণ উপায়গুলো নিয়ে আলোচনা করেছি, API ডকুমেন্টেশন পর্যালোচনা করতে ভুলবেন না, স্ট্যান্ডার্ড লাইব্রেরি দ্বারা Vec<T>-তে সংজ্ঞায়িত আরও অনেক দরকারী মেথডের জন্য। উদাহরণস্বরূপ, push ছাড়াও, একটি pop মেথড শেষ এলিমেন্টটিকে সরিয়ে দেয় এবং রিটার্ন করে।
একটি ভেক্টর ড্রপ করলে এর এলিমেন্টগুলো ড্রপ হয় (Dropping a Vector Drops Its Elements)
অন্য যেকোনো struct-এর মতো, একটি ভেক্টর যখন স্কোপের বাইরে চলে যায় তখন মুক্ত হয়ে যায়, যেমনটি Listing 8-10-এ টীকা দেওয়া হয়েছে।
fn main() { { let v = vec![1, 2, 3, 4]; // do stuff with v } // <- v goes out of scope and is freed here }
যখন ভেক্টরটি ড্রপ করা হয়, তখন এর সমস্ত কনটেন্টও ড্রপ করা হয়, যার অর্থ এটি যে ইন্টিজারগুলো ধারণ করে সেগুলো পরিষ্কার করা হবে। বোরো চেকার নিশ্চিত করে যে একটি ভেক্টরের কনটেন্টের যেকোনো রেফারেন্স শুধুমাত্র তখনই ব্যবহার করা হয় যখন ভেক্টরটি নিজেই বৈধ থাকে।
আসুন পরবর্তী কালেকশন টাইপে যাওয়া যাক: String!
স্ট্রিং দিয়ে UTF-8 এনকোডেড টেক্সট সংরক্ষণ করা (Storing UTF-8 Encoded Text with Strings)
আমরা চ্যাপ্টার ৪-এ স্ট্রিং নিয়ে কথা বলেছি, কিন্তু এখন আমরা সেগুলোর দিকে আরও গভীরভাবে দেখব। নতুন Rustacean-রা সাধারণত স্ট্রিং নিয়ে সমস্যায় পড়েন তিনটি কারণে: Rust-এর সম্ভাব্য এররগুলো প্রকাশ করার প্রবণতা, স্ট্রিং অনেকের ধারণার চেয়ে বেশি জটিল ডেটা স্ট্রাকচার এবং UTF-8। এই বিষয়গুলো একত্রিত হয়ে এমন একটি পরিস্থিতির সৃষ্টি করে যা অন্যান্য প্রোগ্রামিং ভাষা থেকে আসা লোকেদের কাছে কঠিন মনে হতে পারে।
আমরা কালেকশনের পরিপ্রেক্ষিতে স্ট্রিং নিয়ে আলোচনা করি কারণ স্ট্রিংগুলো বাইটের একটি কালেকশন হিসাবে প্রয়োগ করা হয়, সেইসাথে কিছু মেথড যা সেই বাইটগুলোকে টেক্সট হিসাবে ব্যাখ্যা করা হলে দরকারী কার্যকারিতা প্রদান করে। এই বিভাগে, আমরা String-এর অপারেশনগুলো নিয়ে কথা বলব যা প্রতিটি কালেকশন টাইপের আছে, যেমন তৈরি করা, আপডেট করা এবং পড়া। আমরা আরও আলোচনা করব কিভাবে String অন্যান্য কালেকশন থেকে আলাদা, অর্থাৎ কিভাবে একটি String-এ ইনডেক্সিং করা মানুষের এবং কম্পিউটারের String ডেটা ব্যাখ্যা করার পার্থক্যের কারণে জটিল।
স্ট্রিং কী? (What Is a String?)
আমরা প্রথমে স্ট্রিং (string) বলতে কী বোঝায় তা সংজ্ঞায়িত করব। Rust-এর কোর ল্যাঙ্গুয়েজে শুধুমাত্র একটি স্ট্রিং টাইপ রয়েছে, সেটি হল স্ট্রিং স্লাইস str যা সাধারণত এর বোরোড (borrowed) ফর্ম &str-এ দেখা যায়। চ্যাপ্টার ৪-এ, আমরা স্ট্রিং স্লাইস নিয়ে কথা বলেছি, যেগুলো অন্য কোথাও সংরক্ষিত কিছু UTF-8 এনকোডেড স্ট্রিং ডেটার রেফারেন্স। উদাহরণস্বরূপ, স্ট্রিং লিটারেলগুলো প্রোগ্রামের বাইনারিতে সংরক্ষণ করা হয় এবং তাই সেগুলো স্ট্রিং স্লাইস।
String টাইপ, যা Rust-এর স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা হয়, কোর ল্যাঙ্গুয়েজের মধ্যে কোড করা হয়নি, এটি একটি প্রসারণযোগ্য, পরিবর্তনযোগ্য, ওনড (owned), UTF-8 এনকোডেড স্ট্রিং টাইপ। যখন Rustacean-রা Rust-এ "স্ট্রিং" উল্লেখ করে, তখন তারা String বা স্ট্রিং স্লাইস &str টাইপ উভয়কেই বোঝাতে পারে, শুধু একটি টাইপকে নয়। যদিও এই বিভাগটি মূলত String সম্পর্কে, উভয় টাইপই Rust-এর স্ট্যান্ডার্ড লাইব্রেরিতে প্রচুর ব্যবহৃত হয় এবং String ও স্ট্রিং স্লাইস উভয়ই UTF-8 এনকোডেড।
একটি নতুন স্ট্রিং তৈরি করা (Creating a New String)
Vec<T>-এর সাথে উপলব্ধ অনেকগুলি অপারেশন String-এর সাথেও উপলব্ধ, কারণ String আসলে কিছু অতিরিক্ত গ্যারান্টি, সীমাবদ্ধতা এবং ক্ষমতা সহ বাইটের একটি ভেক্টরের চারপাশে একটি র্যাপার (wrapper) হিসাবে প্রয়োগ করা হয়। Vec<T> এবং String-এর সাথে একইভাবে কাজ করে এমন একটি ফাংশনের উদাহরণ হল একটি ইন্সট্যান্স তৈরি করার জন্য new ফাংশন, যা Listing 8-11-তে দেখানো হয়েছে।
fn main() { let mut s = String::new(); }
এই লাইনটি s নামে একটি নতুন, খালি স্ট্রিং তৈরি করে, যেখানে আমরা ডেটা লোড করতে পারি। প্রায়শই, আমাদের কাছে কিছু প্রাথমিক ডেটা থাকবে যা দিয়ে আমরা স্ট্রিং শুরু করতে চাই। এর জন্য, আমরা to_string মেথড ব্যবহার করি, যা যেকোনো টাইপে উপলব্ধ যা Display ট্রেইট ইমপ্লিমেন্ট করে, যেমনটি স্ট্রিং লিটারেলগুলো করে। Listing 8-12 দুটি উদাহরণ দেখায়।
fn main() { let data = "initial contents"; let s = data.to_string(); // The method also works on a literal directly: let s = "initial contents".to_string(); }
এই কোডটি initial contents ধারণকারী একটি স্ট্রিং তৈরি করে।
আমরা একটি স্ট্রিং লিটারেল থেকে একটি String তৈরি করতে String::from ফাংশনটিও ব্যবহার করতে পারি। Listing 8-13-এর কোডটি Listing 8-12-এর কোডের সমতুল্য যা to_string ব্যবহার করে।
fn main() { let s = String::from("initial contents"); }
যেহেতু স্ট্রিংগুলো অনেক কিছুর জন্য ব্যবহার করা হয়, তাই আমরা স্ট্রিংয়ের জন্য অনেকগুলি ভিন্ন জেনেরিক API ব্যবহার করতে পারি, যা আমাদের অনেক অপশন সরবরাহ করে। এগুলোর মধ্যে কিছু অপ্রয়োজনীয় মনে হতে পারে, তবে সবারই নিজস্ব স্থান রয়েছে! এই ক্ষেত্রে, String::from এবং to_string একই কাজ করে, তাই আপনি কোনটি বেছে নেবেন তা স্টাইল এবং পঠনযোগ্যতার উপর নির্ভর করে।
মনে রাখবেন যে স্ট্রিংগুলো UTF-8 এনকোডেড, তাই আমরা সেগুলোর মধ্যে যেকোনো সঠিকভাবে এনকোড করা ডেটা অন্তর্ভুক্ত করতে পারি, যেমনটি Listing 8-14-তে দেখানো হয়েছে।
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שלום"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
এগুলো সবই বৈধ String মান।
একটি স্ট্রিং আপডেট করা (Updating a String)
একটি String আকারে বাড়তে পারে এবং এর কনটেন্ট পরিবর্তন হতে পারে, ঠিক Vec<T>-এর কনটেন্টের মতোই, যদি আপনি এতে আরও ডেটা পুশ করেন। এছাড়াও, আপনি সুবিধাজনকভাবে + অপারেটর বা format! ম্যাক্রো ব্যবহার করে String মানগুলোকে সংযুক্ত করতে পারেন।
push_str এবং push দিয়ে একটি স্ট্রিং-এ যুক্ত করা (Appending to a String with push_str and push)
আমরা একটি স্ট্রিং স্লাইস যুক্ত করতে push_str মেথড ব্যবহার করে একটি String বাড়াতে পারি, যেমনটি Listing 8-15-তে দেখানো হয়েছে।
fn main() { let mut s = String::from("foo"); s.push_str("bar"); }
এই দুটি লাইনের পরে, s-এ foobar থাকবে। push_str মেথডটি একটি স্ট্রিং স্লাইস নেয় কারণ আমরা অপরিহার্যভাবে প্যারামিটারের ওনারশিপ নিতে চাই না। উদাহরণস্বরূপ, Listing 8-16-এর কোডে, আমরা s1-এ এর কনটেন্ট যুক্ত করার পরে s2 ব্যবহার করতে সক্ষম হতে চাই।
fn main() { let mut s1 = String::from("foo"); let s2 = "bar"; s1.push_str(s2); println!("s2 is {s2}"); }
যদি push_str মেথডটি s2-এর ওনারশিপ নিত, তাহলে আমরা শেষ লাইনে এর মান প্রিন্ট করতে পারতাম না। যাইহোক, এই কোডটি আমাদের প্রত্যাশা অনুযায়ী কাজ করে!
push মেথডটি একটি একক অক্ষরকে প্যারামিটার হিসাবে নেয় এবং এটিকে String-এ যুক্ত করে। Listing 8-17 push মেথড ব্যবহার করে একটি String-এ l অক্ষর যোগ করে।
fn main() { let mut s = String::from("lo"); s.push('l'); }
ফলস্বরূপ, s-এ lol থাকবে।
+ অপারেটর বা format! ম্যাক্রো দিয়ে কনক্যাটেনেশন (Concatenation with the + Operator or the format! Macro)
প্রায়শই, আপনি দুটি বিদ্যমান স্ট্রিংকে একত্রিত করতে চাইবেন। এটি করার একটি উপায় হল + অপারেটর ব্যবহার করা, যেমনটি Listing 8-18-এ দেখানো হয়েছে।
fn main() { let s1 = String::from("Hello, "); let s2 = String::from("world!"); let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used }
স্ট্রিং s3-তে থাকবে Hello, world!। s1 যোগ করার পরে আর বৈধ না হওয়ার কারণ এবং আমরা s2-এর একটি রেফারেন্স ব্যবহার করার কারণ হল আমরা যখন + অপারেটর ব্যবহার করি তখন যে মেথডটি কল করা হয় তার সিগনেচার। + অপারেটর add মেথড ব্যবহার করে, যার সিগনেচার অনেকটা এরকম দেখায়:
fn add(self, s: &str) -> String {স্ট্যান্ডার্ড লাইব্রেরিতে, আপনি add কে জেনেরিক এবং অ্যাসোসিয়েটেড টাইপ ব্যবহার করে সংজ্ঞায়িত দেখতে পাবেন। এখানে, আমরা কংক্রিট টাইপগুলোতে প্রতিস্থাপিত করেছি, যা ঘটে যখন আমরা এই মেথডটিকে String মান দিয়ে কল করি। আমরা চ্যাপ্টার ১০-এ জেনেরিক নিয়ে আলোচনা করব। এই সিগনেচারটি আমাদের + অপারেটরের জটিল বিটগুলো বোঝার জন্য প্রয়োজনীয় ক্লু দেয়।
প্রথমত, s2-এর একটি & রয়েছে, যার অর্থ হল আমরা দ্বিতীয় স্ট্রিংটির একটি রেফারেন্স প্রথম স্ট্রিংটিতে যুক্ত করছি। এটি add ফাংশনের s প্যারামিটারের কারণে: আমরা শুধুমাত্র একটি String-এর সাথে একটি &str যোগ করতে পারি; আমরা দুটি String মান একসাথে যোগ করতে পারি না। কিন্তু অপেক্ষা করুন—&s2-এর টাইপ হল &String, &str নয়, যেমনটি add-এর দ্বিতীয় প্যারামিটারে নির্দিষ্ট করা হয়েছে। তাহলে Listing 8-18 কেন কম্পাইল হয়?
আমরা add কলে &s2 ব্যবহার করতে সক্ষম হওয়ার কারণ হল কম্পাইলার &String আর্গুমেন্টটিকে একটি &str-এ কোয়ার্স (coerce) করতে পারে। যখন আমরা add মেথডটি কল করি, তখন Rust একটি ডিরেফ কোয়েরশন (deref coercion) ব্যবহার করে, যা এখানে &s2 কে &s2[..]-তে পরিণত করে। আমরা চ্যাপ্টার ১৫-এ ডিরেফ কোয়েরশন নিয়ে আরও বিস্তারিত আলোচনা করব। যেহেতু add s প্যারামিটারের ওনারশিপ নেয় না, তাই s2 এই অপারেশনের পরেও একটি বৈধ String থাকবে।
দ্বিতীয়ত, আমরা সিগনেচারে দেখতে পাচ্ছি যে add self-এর ওনারশিপ নেয় কারণ self-এর & নেই। এর মানে Listing 8-18-এর s1 add কলে সরানো হবে এবং তার পরে আর বৈধ থাকবে না। সুতরাং, যদিও let s3 = s1 + &s2; দেখে মনে হচ্ছে এটি উভয় স্ট্রিং কপি করবে এবং একটি নতুন তৈরি করবে, এই স্টেটমেন্টটি আসলে s1-এর ওনারশিপ নেয়, s2-এর কনটেন্টের একটি কপি যুক্ত করে এবং তারপর ফলাফলের ওনারশিপ ফিরিয়ে দেয়। অন্য কথায়, এটি দেখতে অনেকগুলো কপি তৈরি করার মতো, কিন্তু তা নয়; ইমপ্লিমেন্টেশনটি কপি করার চেয়ে বেশি কার্যকরী।
যদি আমাদের একাধিক স্ট্রিংকে কনক্যাটেনেট করতে হয়, তাহলে + অপারেটরের আচরণ জটিল হয়ে যায়:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = s1 + "-" + &s2 + "-" + &s3; }
এই পর্যায়ে, s হবে tic-tac-toe। সমস্ত + এবং " অক্ষরগুলোর সাথে, কী ঘটছে তা দেখা কঠিন। আরও জটিল উপায়ে স্ট্রিংগুলোকে একত্রিত করার জন্য, আমরা পরিবর্তে format! ম্যাক্রো ব্যবহার করতে পারি:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = format!("{s1}-{s2}-{s3}"); }
এই কোডটিও s-কে tic-tac-toe-তে সেট করে। format! ম্যাক্রো println!-এর মতোই কাজ করে, কিন্তু স্ক্রিনে আউটপুট প্রিন্ট করার পরিবর্তে, এটি কনটেন্ট সহ একটি String রিটার্ন করে। format! ব্যবহার করে কোডের ভার্সনটি পড়া অনেক সহজ এবং format! ম্যাক্রো দ্বারা জেনারেট করা কোড রেফারেন্স ব্যবহার করে যাতে এই কলটি এর কোনো প্যারামিটারের ওনারশিপ না নেয়।
স্ট্রিংগুলোতে ইনডেক্সিং (Indexing into Strings)
অন্যান্য অনেক প্রোগ্রামিং ল্যাঙ্গুয়েজে, ইনডেক্সের মাধ্যমে রেফারেন্স করে একটি স্ট্রিংয়ের পৃথক অক্ষরগুলো অ্যাক্সেস করা একটি বৈধ এবং সাধারণ অপারেশন। যাইহোক, আপনি যদি Rust-এ ইনডেক্সিং সিনট্যাক্স ব্যবহার করে একটি String-এর অংশগুলো অ্যাক্সেস করার চেষ্টা করেন, তাহলে আপনি একটি এরর পাবেন। Listing 8-19-এর অবৈধ কোডটি বিবেচনা করুন।
fn main() {
let s1 = String::from("hello");
let h = s1[0];
}এই কোডটির ফলে নিম্নলিখিত এরর হবে:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:3:16
|
3 | let h = s1[0];
| ^ string indices are ranges of `usize`
|
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
but trait `SliceIndex<[_]>` is implemented for `usize`
= help: for that trait implementation, expected `[_]`, found `str`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` (bin "collections") due to 1 previous error
এরর এবং নোটটি গল্পটি বলে: Rust স্ট্রিংগুলো ইনডেক্সিং সমর্থন করে না। কিন্তু কেন নয়? এই প্রশ্নের উত্তর দেওয়ার জন্য, আমাদের আলোচনা করতে হবে কিভাবে Rust মেমরিতে স্ট্রিংগুলো সংরক্ষণ করে।
অভ্যন্তরীণ উপস্থাপনা (Internal Representation)
একটি String হল একটি Vec<u8>-এর উপর একটি র্যাপার। Listing 8-14 থেকে আমাদের সঠিকভাবে এনকোড করা UTF-8 উদাহরণের কিছু স্ট্রিং দেখা যাক। প্রথমে, এটি:
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שלום"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
এই ক্ষেত্রে, len হবে 4, যার অর্থ "Hola" স্ট্রিংটি সংরক্ষণ করা ভেক্টরটি 4 বাইট লম্বা। UTF-8-এ এনকোড করা হলে এই প্রতিটি অক্ষর এক বাইট নেয়। নিম্নলিখিত লাইনটি, যাইহোক, আপনাকে অবাক করতে পারে (মনে রাখবেন যে এই স্ট্রিংটি বড় হাতের সিরিলিক অক্ষর Ze দিয়ে শুরু হয়, সংখ্যা 3 নয়):
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שלום"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
আপনাকে যদি জিজ্ঞাসা করা হয় স্ট্রিংটি কত লম্বা, তাহলে আপনি হয়তো বলবেন 12। আসলে, Rust-এর উত্তর হল 24: UTF-8-এ “Здравствуйте” এনকোড করতে যত বাইট লাগে, কারণ সেই স্ট্রিংয়ের প্রতিটি ইউনিকোড স্কেলার মান 2 বাইট স্টোরেজ নেয়। অতএব, স্ট্রিংয়ের বাইটগুলোতে একটি ইনডেক্স সর্বদাই একটি বৈধ ইউনিকোড স্কেলার মানের সাথে সম্পর্কযুক্ত হবে না। এটি প্রদর্শন করতে, এই অবৈধ Rust কোডটি বিবেচনা করুন:
let hello = "Здравствуйте";
let answer = &hello[0];আপনি ইতিমধ্যেই জানেন যে answer З হবে না, প্রথম অক্ষর। UTF-8-এ এনকোড করা হলে, З-এর প্রথম বাইট হল 208 এবং দ্বিতীয়টি হল 151, তাই মনে হতে পারে যে answer আসলে 208 হওয়া উচিত, কিন্তু 208 নিজে থেকে একটি বৈধ অক্ষর নয়। 208 রিটার্ন করা সম্ভবত ব্যবহারকারী যা চাইবেন তা নয় যদি তারা এই স্ট্রিংটির প্রথম অক্ষরটি জিজ্ঞাসা করে; তবে, Rust-এর কাছে বাইট ইনডেক্স 0-তে সেই ডেটাই রয়েছে। ব্যবহারকারীরা সাধারণত বাইট মান রিটার্ন চান না, এমনকী যদি স্ট্রিংটিতে শুধুমাত্র ল্যাটিন অক্ষর থাকে: যদি &"hi"[0] বৈধ কোড হত যা বাইট মান রিটার্ন করত, তাহলে এটি h নয়, 104 রিটার্ন করত।
তাহলে, উত্তর হল, একটি অপ্রত্যাশিত মান রিটার্ন করা এবং বাগগুলো এড়াতে যা অবিলম্বে আবিষ্কার নাও হতে পারে, Rust এই কোডটি কম্পাইল করে না এবং ডেভেলপমেন্ট প্রক্রিয়ার শুরুতেই ভুল বোঝাবুঝি প্রতিরোধ করে।
বাইট এবং স্কেলার মান এবং গ্রাফিম ক্লাস্টার! ওহ মাই! (Bytes and Scalar Values and Grapheme Clusters! Oh My!)
UTF-8 সম্পর্কে আরেকটি বিষয় হল যে Rust-এর দৃষ্টিকোণ থেকে স্ট্রিংগুলো দেখার জন্য আসলে তিনটি প্রাসঙ্গিক উপায় রয়েছে: বাইট হিসাবে, স্কেলার মান হিসাবে এবং গ্রাফিম ক্লাস্টার হিসাবে (আমরা যাকে অক্ষর বলব তার সবচেয়ে কাছের জিনিস)।
আমরা যদি দেবনাগরী লিপিতে লেখা হিন্দি শব্দ “नमस्ते”-এর দিকে তাকাই, তাহলে এটি u8 মানগুলোর একটি ভেক্টর হিসাবে সংরক্ষিত হয় যা দেখতে এইরকম:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
এটি 18 বাইট এবং কম্পিউটারগুলো শেষ পর্যন্ত এই ডেটা এভাবেই সংরক্ষণ করে। আমরা যদি সেগুলোকে ইউনিকোড স্কেলার মান হিসাবে দেখি, যেগুলো Rust-এর char টাইপ, তাহলে সেই বাইটগুলো দেখতে এইরকম:
['न', 'म', 'स', '्', 'त', 'े']
এখানে ছয়টি char মান রয়েছে, কিন্তু চতুর্থ এবং ষষ্ঠটি অক্ষর নয়: সেগুলো হল ডায়াক্রিটিকস (diacritics) যেগুলোর নিজস্ব কোনো অর্থ নেই। অবশেষে, যদি আমরা সেগুলোকে গ্রাফিম ক্লাস্টার হিসাবে দেখি, তাহলে আমরা একজন ব্যক্তি যাকে হিন্দি শব্দটি তৈরি করা চারটি অক্ষর বলবে তা পাব:
["न", "म", "स्", "ते"]
Rust কম্পিউটারগুলোর সংরক্ষণ করা কাঁচা স্ট্রিং ডেটা ব্যাখ্যা করার বিভিন্ন উপায় সরবরাহ করে যাতে প্রতিটি প্রোগ্রাম তার প্রয়োজনীয় ব্যাখ্যাটি বেছে নিতে পারে, ডেটাটি কোন মানব ভাষা হোক না কেন।
Rust আমাদের একটি অক্ষর পাওয়ার জন্য একটি String-এ ইনডেক্স করার অনুমতি দেয় না তার একটি শেষ কারণ হল ইনডেক্সিং অপারেশনগুলো সর্বদাই কনস্ট্যান্ট টাইমে (O(1)) নেওয়ার আশা করা হয়। কিন্তু একটি String দিয়ে সেই পারফরম্যান্স গ্যারান্টি দেওয়া সম্ভব নয়, কারণ Rust-কে শুরু থেকে ইনডেক্স পর্যন্ত কনটেন্টের মধ্যে দিয়ে যেতে হবে যাতে কতগুলো বৈধ অক্ষর ছিল তা নির্ধারণ করতে হয়।
স্ট্রিং স্লাইসিং (Slicing Strings)
একটি স্ট্রিং-এ ইনডেক্সিং করা প্রায়শই একটি খারাপ ধারণা কারণ এটি স্পষ্ট নয় যে স্ট্রিং-ইনডেক্সিং অপারেশনের রিটার্ন টাইপ কী হওয়া উচিত: একটি বাইট মান, একটি অক্ষর, একটি গ্রাফিম ক্লাস্টার বা একটি স্ট্রিং স্লাইস। অতএব, যদি আপনার সত্যিই স্ট্রিং স্লাইস তৈরি করতে ইনডেক্স ব্যবহার করার প্রয়োজন হয়, তাহলে Rust আপনাকে আরও নির্দিষ্ট হতে বলে।
একটি একক সংখ্যা সহ [] ব্যবহার করে ইনডেক্সিং করার পরিবর্তে, আপনি নির্দিষ্ট বাইট ধারণকারী একটি স্ট্রিং স্লাইস তৈরি করতে একটি রেঞ্জ সহ [] ব্যবহার করতে পারেন:
#![allow(unused)] fn main() { let hello = "Здравствуйте"; let s = &hello[0..4]; }
এখানে, s হবে একটি &str যাতে স্ট্রিং-এর প্রথম চারটি বাইট রয়েছে। এর আগে, আমরা উল্লেখ করেছি যে এই অক্ষরগুলোর প্রতিটি দুই বাইট ছিল, যার মানে s হবে Зд।
যদি আমরা &hello[0..1]-এর মতো কিছু দিয়ে একটি অক্ষরের বাইটের শুধুমাত্র অংশ স্লাইস করার চেষ্টা করতাম, তাহলে Rust রানটাইমে প্যানিক করবে, যেমনটি একটি ভেক্টরে একটি অবৈধ ইনডেক্স অ্যাক্সেস করা হলে ঘটে:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at src/main.rs:4:19:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
রেঞ্জ দিয়ে স্ট্রিং স্লাইস তৈরি করার সময় আপনার সতর্কতা অবলম্বন করা উচিত, কারণ এটি করলে আপনার প্রোগ্রাম ক্র্যাশ করতে পারে।
স্ট্রিংগুলোর উপর ইটারেট করার মেথড (Methods for Iterating Over Strings)
স্ট্রিং-এর অংশগুলোতে কাজ করার সর্বোত্তম উপায় হল আপনি অক্ষর চান নাকি বাইট চান সে সম্পর্কে স্পষ্ট হওয়া। পৃথক ইউনিকোড স্কেলার মানগুলোর জন্য, chars মেথড ব্যবহার করুন। “Зд”-তে chars কল করা আলাদা করে এবং char টাইপের দুটি মান রিটার্ন করে এবং আপনি প্রতিটি এলিমেন্ট অ্যাক্সেস করতে ফলাফলের উপর ইটারেট করতে পারেন:
#![allow(unused)] fn main() { for c in "Зд".chars() { println!("{c}"); } }
এই কোডটি নিম্নলিখিতগুলো প্রিন্ট করবে:
З
д
বিকল্পভাবে, bytes মেথড প্রতিটি কাঁচা বাইট রিটার্ন করে, যা আপনার ডোমেনের জন্য উপযুক্ত হতে পারে:
#![allow(unused)] fn main() { for b in "Зд".bytes() { println!("{b}"); } }
এই কোডটি এই স্ট্রিং তৈরি করা চারটি বাইট প্রিন্ট করবে:
208
151
208
180
কিন্তু মনে রাখতে ভুলবেন না যে বৈধ ইউনিকোড স্কেলার মানগুলো একাধিক বাইট দিয়ে তৈরি হতে পারে।
স্ট্রিং থেকে গ্রাফিম ক্লাস্টার পাওয়া, যেমন দেবনাগরী লিপির সাথে, জটিল, তাই এই কার্যকারিতা স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা হয় না। আপনার যদি এই কার্যকারিতার প্রয়োজন হয় তবে crates.io-তে ক্রেট উপলব্ধ রয়েছে।
স্ট্রিংগুলো এত সহজ নয় (Strings Are Not So Simple)
সংক্ষেপে, স্ট্রিংগুলো জটিল। বিভিন্ন প্রোগ্রামিং ভাষাগুলো প্রোগ্রামারের কাছে এই জটিলতা কীভাবে উপস্থাপন করতে হয় সে সম্পর্কে বিভিন্ন পছন্দ করে। Rust সমস্ত Rust প্রোগ্রামের জন্য String ডেটার সঠিক হ্যান্ডলিংকে ডিফল্ট আচরণ হিসাবে তৈরি করতে বেছে নিয়েছে, যার অর্থ হল প্রোগ্রামারদের সামনে UTF-8 ডেটা হ্যান্ডেল করার বিষয়ে আরও বেশি চিন্তা করতে হবে। এই ট্রেড-অফটি অন্যান্য প্রোগ্রামিং ভাষাগুলোর তুলনায় স্ট্রিংগুলোর আরও জটিলতা প্রকাশ করে, তবে এটি আপনাকে আপনার ডেভেলপমেন্ট লাইফ সাইকেলের পরে নন-ASCII অক্ষর জড়িত এররগুলো হ্যান্ডেল করা থেকে বিরত রাখে।
ভাল খবর হল স্ট্যান্ডার্ড লাইব্রেরি এই জটিল পরিস্থিতিগুলোকে সঠিকভাবে পরিচালনা করতে সহায়তা করার জন্য String এবং &str টাইপের উপর নির্মিত প্রচুর কার্যকারিতা সরবরাহ করে। স্ট্রিং-এ অনুসন্ধানের জন্য contains-এর মতো এবং একটি স্ট্রিং-এর অংশগুলোকে অন্য স্ট্রিং দিয়ে প্রতিস্থাপন করার জন্য replace-এর মতো দরকারী মেথডগুলোর জন্য ডকুমেন্টেশন পরীক্ষা করতে ভুলবেন না।
আসুন একটু কম জটিল কিছুতে যাই: হ্যাশ ম্যাপ!
হ্যাশ ম্যাপে অ্যাসোসিয়েটেড ভ্যালু সহ কী সংরক্ষণ করা (Storing Keys with Associated Values in Hash Maps)
আমাদের সাধারণ কালেকশনগুলোর মধ্যে সর্বশেষ হল হ্যাশ ম্যাপ (hash map)। HashMap<K, V> টাইপ একটি হ্যাশিং ফাংশন (hashing function) ব্যবহার করে K টাইপের কী (key)-গুলোকে V টাইপের ভ্যালু (value)-তে ম্যাপ করে। এই হ্যাশিং ফাংশন নির্ধারণ করে যে কীভাবে এই কী এবং ভ্যালুগুলোকে মেমরিতে রাখা হবে। অনেক প্রোগ্রামিং ল্যাঙ্গুয়েজ এই ধরনের ডেটা স্ট্রাকচার সমর্থন করে, কিন্তু সেগুলোতে প্রায়শই ভিন্ন নাম ব্যবহার করা হয়, যেমন হ্যাশ (hash), ম্যাপ (map), অবজেক্ট (object), হ্যাশ টেবিল (hash table), ডিকশনারি (dictionary), বা অ্যাসোসিয়েটিভ অ্যারে (associative array)।
হ্যাশ ম্যাপগুলো দরকারী যখন আপনি ইনডেক্স ব্যবহার করে ডেটা খুঁজতে চান না, যেমনটি ভেক্টরের ক্ষেত্রে করা হয়, বরং এমন একটি কী ব্যবহার করে ডেটা খুঁজতে চান যা যেকোনো টাইপের হতে পারে। উদাহরণস্বরূপ, একটি গেমে, আপনি একটি হ্যাশ ম্যাপে প্রতিটি দলের স্কোর ট্র্যাক রাখতে পারেন যেখানে প্রতিটি কী হল একটি দলের নাম এবং ভ্যালুগুলো হল প্রতিটি দলের স্কোর। একটি দলের নাম দিলে, আপনি তার স্কোর পুনরুদ্ধার করতে পারবেন।
আমরা এই বিভাগে হ্যাশ ম্যাপের বেসিক API নিয়ে আলোচনা করব, তবে স্ট্যান্ডার্ড লাইব্রেরি দ্বারা HashMap<K, V>-তে সংজ্ঞায়িত ফাংশনগুলোতে আরও অনেক কিছু রয়েছে। যথারীতি, আরও তথ্যের জন্য স্ট্যান্ডার্ড লাইব্রেরির ডকুমেন্টেশন দেখুন।
একটি নতুন হ্যাশ ম্যাপ তৈরি করা (Creating a New Hash Map)
খালি হ্যাশ ম্যাপ তৈরি করার একটি উপায় হল new ব্যবহার করা এবং insert দিয়ে এলিমেন্ট যোগ করা। Listing 8-20-তে, আমরা দুটি দলের স্কোর ট্র্যাক করছি যাদের নাম Blue এবং Yellow। Blue টিম 10 পয়েন্ট দিয়ে শুরু করে এবং Yellow টিম 50 পয়েন্ট দিয়ে শুরু করে।
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); }
লক্ষ্য করুন যে আমাদের প্রথমে স্ট্যান্ডার্ড লাইব্রেরির কালেকশন অংশ থেকে HashMap ব্যবহার (use) করতে হবে। আমাদের তিনটি সাধারণ কালেকশনের মধ্যে, এটি সবচেয়ে কম ব্যবহৃত হয়, তাই এটিকে প্রেলিউডে স্বয়ংক্রিয়ভাবে স্কোপে আনা ফিচারগুলোর মধ্যে অন্তর্ভুক্ত করা হয়নি। হ্যাশ ম্যাপগুলোর স্ট্যান্ডার্ড লাইব্রেরি থেকে কম সাপোর্টও রয়েছে; উদাহরণস্বরূপ, এগুলো তৈরি করার জন্য কোনো বিল্ট-ইন ম্যাক্রো নেই।
ভেক্টরের মতোই, হ্যাশ ম্যাপগুলো তাদের ডেটা হিপে সংরক্ষণ করে। এই HashMap-এর String টাইপের কী এবং i32 টাইপের ভ্যালু রয়েছে। ভেক্টরের মতো, হ্যাশ ম্যাপগুলোও হোমোজিনিয়াস (homogeneous): সমস্ত কী-এর একই টাইপ হতে হবে এবং সমস্ত ভ্যালুর একই টাইপ হতে হবে।
হ্যাশ ম্যাপের ভ্যালু অ্যাক্সেস করা (Accessing Values in a Hash Map)
আমরা হ্যাশ ম্যাপ থেকে একটি ভ্যালু পেতে পারি get মেথডে তার কী প্রদান করে, যেমনটি Listing 8-21-এ দেখানো হয়েছে।
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); let team_name = String::from("Blue"); let score = scores.get(&team_name).copied().unwrap_or(0); }
এখানে, score-এ Blue টিমের সাথে সম্পর্কিত মান থাকবে এবং ফলাফল হবে 10। get মেথড একটি Option<&V> রিটার্ন করে; যদি হ্যাশ ম্যাপে সেই কী-এর জন্য কোনো মান না থাকে, তাহলে get None রিটার্ন করবে। এই প্রোগ্রামটি Option হ্যান্ডেল করে copied কল করে একটি Option<&i32>-এর পরিবর্তে একটি Option<i32> পেতে, তারপর unwrap_or ব্যবহার করে score-কে শূন্যে সেট করে যদি scores-এ কী-এর জন্য কোনো এন্ট্রি না থাকে।
আমরা ভেক্টরের মতোই হ্যাশ ম্যাপের প্রতিটি কী-ভ্যালু পেয়ারের উপর ইটারেট করতে পারি, একটি for লুপ ব্যবহার করে:
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); for (key, value) in &scores { println!("{key}: {value}"); } }
এই কোডটি প্রতিটি পেয়ারকে একটি নির্বিচার ক্রমে প্রিন্ট করবে:
Yellow: 50
Blue: 10
হ্যাশ ম্যাপ এবং ওনারশিপ (Hash Maps and Ownership)
i32-এর মতো Copy ট্রেইট ইমপ্লিমেন্ট করে এমন টাইপের জন্য, মানগুলো হ্যাশ ম্যাপে কপি করা হয়। String-এর মতো ওনড (owned) ভ্যালুগুলোর জন্য, ভ্যালুগুলো সরানো হবে এবং হ্যাশ ম্যাপ সেই ভ্যালুগুলোর ওনার হবে, যেমনটি Listing 8-22-এ দেখানো হয়েছে।
fn main() { use std::collections::HashMap; let field_name = String::from("Favorite color"); let field_value = String::from("Blue"); let mut map = HashMap::new(); map.insert(field_name, field_value); // field_name and field_value are invalid at this point, try using them and // see what compiler error you get! }
insert কলে হ্যাশ ম্যাপে স্থানান্তরিত হওয়ার পরে আমরা field_name এবং field_value ভেরিয়েবলগুলো ব্যবহার করতে পারব না।
যদি আমরা হ্যাশ ম্যাপে ভ্যালুগুলোর রেফারেন্স ইনসার্ট করি, তাহলে ভ্যালুগুলো হ্যাশ ম্যাপে সরানো হবে না। রেফারেন্সগুলো যে মানগুলোর দিকে নির্দেশ করে সেগুলো অবশ্যই হ্যাশ ম্যাপটি বৈধ থাকা পর্যন্ত বৈধ থাকতে হবে। আমরা চ্যাপ্টার ১০-এ “লাইফটাইম দিয়ে রেফারেন্স বৈধ করা”-তে এই বিষয়গুলো নিয়ে আরও কথা বলব।
একটি হ্যাশ ম্যাপ আপডেট করা (Updating a Hash Map)
যদিও কী এবং ভ্যালু পেয়ারের সংখ্যা বাড়তে পারে, প্রতিটি ইউনিক কী-এর সাথে একবারে শুধুমাত্র একটি ভ্যালু যুক্ত থাকতে পারে (কিন্তু বিপরীতটি সত্য নয়: উদাহরণস্বরূপ, Blue টিম এবং Yellow টিম উভয়েরই scores হ্যাশ ম্যাপে 10 মান সংরক্ষিত থাকতে পারে)।
আপনি যখন একটি হ্যাশ ম্যাপের ডেটা পরিবর্তন করতে চান, তখন আপনাকে সিদ্ধান্ত নিতে হবে যে একটি কী-তে ইতিমধ্যেই একটি ভ্যালু অ্যাসাইন করা থাকলে কীভাবে সেই পরিস্থিতিটি পরিচালনা করবেন। আপনি পুরানো ভ্যালুটিকে নতুন ভ্যালু দিয়ে প্রতিস্থাপন করতে পারেন, পুরানো ভ্যালুটিকে সম্পূর্ণরূপে উপেক্ষা করে। আপনি পুরানো ভ্যালুটি রাখতে পারেন এবং নতুন ভ্যালুটিকে উপেক্ষা করতে পারেন, শুধুমাত্র তখনই নতুন ভ্যালু যোগ করতে পারেন যদি কী-টিতে ইতিমধ্যেই কোনো ভ্যালু না থাকে। অথবা আপনি পুরানো ভ্যালু এবং নতুন ভ্যালুকে একত্রিত করতে পারেন। চলুন দেখি কিভাবে এই প্রতিটি কাজ করতে হয়!
একটি ভ্যালু ওভাররাইট করা (Overwriting a Value)
যদি আমরা একটি হ্যাশ ম্যাপে একটি কী এবং একটি ভ্যালু ইনসার্ট করি এবং তারপর সেই একই কী-তে একটি ভিন্ন ভ্যালু ইনসার্ট করি, তাহলে সেই কী-এর সাথে সম্পর্কিত ভ্যালুটি প্রতিস্থাপিত হবে। যদিও Listing 8-23-এর কোডটি দুবার insert কল করে, হ্যাশ ম্যাপটিতে কেবল একটি কী-ভ্যালু পেয়ার থাকবে কারণ আমরা উভয়বারই Blue টিমের কী-এর জন্য ভ্যালু ইনসার্ট করছি।
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Blue"), 25); println!("{scores:?}"); }
এই কোডটি {"Blue": 25} প্রিন্ট করবে। 10-এর আসল মানটি ওভাররাইট করা হয়েছে।
একটি কী এবং ভ্যালু যোগ করা শুধুমাত্র যদি একটি কী উপস্থিত না থাকে (Adding a Key and Value Only If a Key Isn’t Present)
একটি নির্দিষ্ট কী-এর ஏற்கனவே একটি ভ্যালু সহ হ্যাশ ম্যাপে আছে কিনা তা পরীক্ষা করা এবং তারপর নিম্নলিখিত পদক্ষেপগুলো নেওয়া সাধারণ: যদি কী-টি হ্যাশ ম্যাপে বিদ্যমান থাকে, তাহলে বিদ্যমান মানটি যেমন আছে তেমনই থাকা উচিত। যদি কী-টি বিদ্যমান না থাকে, তাহলে এটি এবং এর জন্য একটি ভ্যালু ইনসার্ট করুন।
হ্যাশ ম্যাপগুলোর জন্য এই কাজের জন্য একটি বিশেষ API রয়েছে যাকে entry বলা হয়, যা আপনি যে কী-টি পরীক্ষা করতে চান সেটি প্যারামিটার হিসাবে নেয়। entry মেথডের রিটার্ন মান হল Entry নামক একটি এনাম, যা এমন একটি মান উপস্থাপন করে যা বিদ্যমান থাকতে পারে বা নাও থাকতে পারে। ধরা যাক, আমরা পরীক্ষা করতে চাই যে Yellow টিমের কী-টির সাথে কোনো ভ্যালু যুক্ত আছে কিনা। যদি না থাকে, তাহলে আমরা 50 মানটি ইনসার্ট করতে চাই, এবং Blue টিমের জন্যও একই কাজ করতে চাই। entry API ব্যবহার করে, কোডটি Listing 8-24-এর মতো দেখায়।
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.entry(String::from("Yellow")).or_insert(50); scores.entry(String::from("Blue")).or_insert(50); println!("{scores:?}"); }
Entry-তে or_insert মেথডটি সংজ্ঞায়িত করা হয়েছে সংশ্লিষ্ট Entry কী-এর জন্য ভ্যালুর একটি মিউটেবল রেফারেন্স (&mut V) রিটার্ন করার জন্য যদি সেই কী বিদ্যমান থাকে, এবং যদি না থাকে, তাহলে এটি এই কী-এর জন্য নতুন ভ্যালু হিসাবে প্যারামিটারটি ইনসার্ট করে এবং নতুন ভ্যালুতে একটি মিউটেবল রেফারেন্স রিটার্ন করে। এই কৌশলটি নিজে থেকে লজিক লেখার চেয়ে অনেক বেশি পরিষ্কার এবং এছাড়াও, বোরো চেকারের (borrow checker) সাথে আরও ভালোভাবে কাজ করে।
Listing 8-24-এর কোড চালালে {"Yellow": 50, "Blue": 10} প্রিন্ট হবে। entry-তে প্রথম কলটি Yellow টিমের কী-এর জন্য 50 মান ইনসার্ট করবে কারণ Yellow টিমের ইতিমধ্যেই কোনো ভ্যালু ছিল না। entry-তে দ্বিতীয় কলটি হ্যাশ ম্যাপ পরিবর্তন করবে না কারণ Blue টিমের ইতিমধ্যেই 10 মান রয়েছে।
পুরানো মানের উপর ভিত্তি করে একটি মান আপডেট করা (Updating a Value Based on the Old Value)
হ্যাশ ম্যাপের জন্য আরেকটি সাধারণ ব্যবহারের ক্ষেত্র হল একটি কী-এর মান সন্ধান করা এবং তারপর পুরানো মানের উপর ভিত্তি করে এটি আপডেট করা। উদাহরণস্বরূপ, Listing 8-25 এমন কোড দেখায় যা গণনা করে যে কিছু টেক্সটে প্রতিটি শব্দ কতবার এসেছে। আমরা শব্দগুলোকে কী হিসাবে ব্যবহার করে একটি হ্যাশ ম্যাপ ব্যবহার করি এবং আমরা কতবার সেই শব্দটি দেখেছি তা ট্র্যাক রাখতে মান বৃদ্ধি করি। যদি এটি এমন একটি শব্দ হয় যা আমরা প্রথমবার দেখেছি, তাহলে আমরা প্রথমে 0 মানটি ইনসার্ট করব।
fn main() { use std::collections::HashMap; let text = "hello world wonderful world"; let mut map = HashMap::new(); for word in text.split_whitespace() { let count = map.entry(word).or_insert(0); *count += 1; } println!("{map:?}"); }
এই কোডটি {"world": 2, "hello": 1, "wonderful": 1} প্রিন্ট করবে। আপনি হয়তো একই কী-ভ্যালু পেয়ারগুলো ভিন্ন ক্রমে প্রিন্ট হতে দেখতে পারেন: “হ্যাশ ম্যাপের ভ্যালু অ্যাক্সেস করা” থেকে মনে রাখবেন যে একটি হ্যাশ ম্যাপের উপর ইটারেটিং একটি নির্বিচার ক্রমে ঘটে।
split_whitespace মেথডটি text-এর মানের হোয়াইটস্পেস দ্বারা পৃথক করা সাবস্লাইসের উপর একটি ইটারেটর রিটার্ন করে। or_insert মেথডটি নির্দিষ্ট কী-এর জন্য মানের একটি মিউটেবল রেফারেন্স (&mut V) রিটার্ন করে। এখানে, আমরা সেই মিউটেবল রেফারেন্সটি count ভেরিয়েবলে সংরক্ষণ করি, তাই সেই মানটিতে অ্যাসাইন করার জন্য, আমাদের প্রথমে তারকাচিহ্ন (*) ব্যবহার করে count ডিরেফারেন্স করতে হবে। মিউটেবল রেফারেন্সটি for লুপের শেষে স্কোপের বাইরে চলে যায়, তাই এই সমস্ত পরিবর্তনগুলো নিরাপদ এবং বোরোয়িং নিয়ম দ্বারা অনুমোদিত।
হ্যাশিং ফাংশন (Hashing Functions)
ডিফল্টরূপে, HashMap SipHash নামক একটি হ্যাশিং ফাংশন ব্যবহার করে যা হ্যাশ টেবিল1 জড়িত ডিনায়াল-অফ-সার্ভিস (DoS) আক্রমণের বিরুদ্ধে প্রতিরোধ প্রদান করতে পারে। এটি উপলব্ধ দ্রুততম হ্যাশিং অ্যালগরিদম নয়, তবে পারফরম্যান্সের ড্রপের সাথে আসা আরও ভাল নিরাপত্তার জন্য ট্রেড-অফটি মূল্যবান। আপনি যদি আপনার কোড প্রোফাইল করেন এবং দেখেন যে ডিফল্ট হ্যাশ ফাংশনটি আপনার উদ্দেশ্যের জন্য খুব ধীর, তাহলে আপনি একটি ভিন্ন হ্যাশার (hasher) নির্দিষ্ট করে অন্য ফাংশনে স্যুইচ করতে পারেন। একটি হ্যাশার হল এমন একটি টাইপ যা BuildHasher ট্রেইট ইমপ্লিমেন্ট করে। আমরা চ্যাপ্টার 10-এ ট্রেইটস এবং কিভাবে সেগুলো ইমপ্লিমেন্ট করতে হয় সে সম্পর্কে কথা বলব। আপনাকে শুরু থেকেই নিজের হ্যাশার ইমপ্লিমেন্ট করতে হবে না; crates.io-তে অন্যান্য Rust ব্যবহারকারীদের শেয়ার করা লাইব্রেরি রয়েছে যা অনেক সাধারণ হ্যাশিং অ্যালগরিদম ইমপ্লিমেন্ট করে এমন হ্যাশার সরবরাহ করে।
সারসংক্ষেপ (Summary)
ভেক্টর, স্ট্রিং এবং হ্যাশ ম্যাপগুলো এমন প্রোগ্রামগুলোতে প্রয়োজনীয় কার্যকারিতার একটি বড় অংশ সরবরাহ করবে যেখানে আপনাকে ডেটা সংরক্ষণ, অ্যাক্সেস এবং পরিবর্তন করতে হবে। এখানে কিছু অনুশীলন রয়েছে যা সমাধান করার জন্য আপনার এখন সজ্জিত হওয়া উচিত:
- পূর্ণসংখ্যার একটি তালিকা দেওয়া হলে, একটি ভেক্টর ব্যবহার করুন এবং তালিকার মিডিয়ান (median) (সাজানো হলে, মাঝের অবস্থানের মান) এবং মোড (mode) (যে মানটি সবচেয়ে বেশি ঘটে; এখানে একটি হ্যাশ ম্যাপ সহায়ক হবে) রিটার্ন করুন।
- স্ট্রিংগুলোকে পিগ ল্যাটিনে (pig latin) রূপান্তর করুন। প্রতিটি শব্দের প্রথম ব্যঞ্জনবর্ণটি শব্দের শেষে সরানো হয় এবং ay যোগ করা হয়, তাই first হয়ে যায় irst-fay। যেসব শব্দ স্বরবর্ণ দিয়ে শুরু হয় সেগুলোর পরিবর্তে শেষে hay যোগ করা হয় (apple হয়ে যায় apple-hay)। UTF-8 এনকোডিং সম্পর্কে বিস্তারিত মনে রাখবেন!
- একটি হ্যাশ ম্যাপ এবং ভেক্টর ব্যবহার করে, একটি টেক্সট ইন্টারফেস তৈরি করুন যাতে একজন ব্যবহারকারী একটি কোম্পানিতে একটি বিভাগে কর্মচারীর নাম যোগ করতে পারে; উদাহরণস্বরূপ, “Add Sally to Engineering” বা “Add Amir to Sales”। তারপর ব্যবহারকারীকে একটি বিভাগের সমস্ত লোকের তালিকা বা কোম্পানির সমস্ত লোককে বিভাগ অনুসারে, বর্ণানুক্রমে সাজানো তালিকা পুনরুদ্ধার করতে দিন।
স্ট্যান্ডার্ড লাইব্রেরি API ডকুমেন্টেশন ভেক্টর, স্ট্রিং এবং হ্যাশ ম্যাপের মেথডগুলো বর্ণনা করে যা এই অনুশীলনগুলোর জন্য সহায়ক হবে!
আমরা আরও জটিল প্রোগ্রামগুলোর মধ্যে যাচ্ছি যেখানে অপারেশনগুলো ব্যর্থ হতে পারে, তাই এরর হ্যান্ডলিং নিয়ে আলোচনা করার জন্য এটি একটি উপযুক্ত সময়। আমরা এরপর সেটাই করব!
এরর হ্যান্ডলিং (Error Handling)
সফটওয়্যারে এরর একটি বাস্তব ঘটনা, তাই Rust-এ এমন পরিস্থিতিগুলো হ্যান্ডেল করার জন্য বেশ কিছু ফিচার রয়েছে যেখানে কোনো কিছু ভুল হয়। অনেক ক্ষেত্রে, Rust চায় যে আপনি এররের সম্ভাবনা স্বীকার করুন এবং আপনার কোড কম্পাইল করার আগে কোনো পদক্ষেপ নিন। এই প্রয়োজনীয়তা আপনার প্রোগ্রামকে আরও শক্তিশালী করে তোলে, এটি নিশ্চিত করে যে আপনি প্রোডাকশনে আপনার কোড ডিপ্লয় (deploy) করার আগে এররগুলো আবিষ্কার করবেন এবং সেগুলোকে যথাযথভাবে হ্যান্ডেল করবেন!
Rust এররগুলোকে দুটি প্রধান বিভাগে ভাগ করে: রিকভারেবল (recoverable) এবং আনরিকভারেবল (unrecoverable) এরর। একটি রিকভারেবল এরর, যেমন file not found এররের ক্ষেত্রে, আমরা সম্ভবত শুধুমাত্র ব্যবহারকারীকে সমস্যাটি জানাতে চাই এবং অপারেশনটি পুনরায় চেষ্টা করতে চাই। আনরিকভারেবল এররগুলো সর্বদাই বাগের লক্ষণ, যেমন একটি অ্যারের শেষের বাইরের কোনো লোকেশন অ্যাক্সেস করার চেষ্টা করা, এবং তাই আমরা অবিলম্বে প্রোগ্রামটি বন্ধ করতে চাই।
বেশিরভাগ ভাষা এই দুটি ধরণের এররের মধ্যে পার্থক্য করে না এবং এক্সেপশন (exception)-এর মতো মেকানিজম ব্যবহার করে উভয়কেই একইভাবে হ্যান্ডেল করে। Rust-এ এক্সেপশন নেই। পরিবর্তে, এটির রিকভারেবল এররের জন্য Result<T, E> টাইপ এবং panic! ম্যাক্রো রয়েছে, যা প্রোগ্রামটি কোনো আনরিকভারেবল এররের সম্মুখীন হলে এক্সিকিউশন বন্ধ করে দেয়। এই চ্যাপ্টারটি প্রথমে panic! কল করা এবং তারপর Result<T, E> মান রিটার্ন করা নিয়ে আলোচনা করে। উপরন্তু, আমরা একটি এরর থেকে পুনরুদ্ধার করার চেষ্টা করব নাকি এক্সিকিউশন বন্ধ করব, তা সিদ্ধান্ত নেওয়ার সময় বিবেচ্য বিষয়গুলো অন্বেষণ করব।
panic! দিয়ে আনরিকভারেবল এরর (Unrecoverable Errors with panic!)
কখনও কখনও আপনার কোডে খারাপ কিছু ঘটে এবং আপনি এটি সম্পর্কে কিছুই করতে পারেন না। এই ক্ষেত্রগুলোতে, Rust-এর panic! ম্যাক্রো রয়েছে। কার্যত প্যানিক ঘটানোর দুটি উপায় রয়েছে: এমন কোনো কাজ করা যা আমাদের কোডকে প্যানিক করে (যেমন অ্যারের শেষের বাইরে অ্যাক্সেস করা) অথবা স্পষ্টতই panic! ম্যাক্রো কল করা। উভয় ক্ষেত্রেই, আমরা আমাদের প্রোগ্রামে একটি প্যানিক ঘটাই। ডিফল্টরূপে, এই প্যানিকগুলো একটি ব্যর্থতার মেসেজ প্রিন্ট করবে, আনওয়াইন্ড (unwind) করবে, স্ট্যাক পরিষ্কার করবে এবং বন্ধ হয়ে যাবে। একটি এনভায়রনমেন্ট ভেরিয়েবলের মাধ্যমে, আপনি Rust-কে প্যানিক ঘটলে কল স্ট্যাক (call stack) প্রদর্শন করতে বলতে পারেন যাতে প্যানিকের উৎস খুঁজে বের করা সহজ হয়।
প্যানিকের প্রতিক্রিয়ায় স্ট্যাক আনওয়াইন্ড করা বা অ্যাবোর্ট করা (Unwinding the Stack or Aborting in Response to a Panic)
ডিফল্টরূপে, যখন একটি প্যানিক ঘটে তখন প্রোগ্রামটি আনওয়াইন্ডিং (unwinding) শুরু করে, যার অর্থ হল Rust স্ট্যাকের উপরে উঠে যায় এবং প্রতিটি ফাংশনের ডেটা পরিষ্কার করে। যাইহোক, ফিরে যাওয়া এবং পরিষ্কার করা অনেক কাজ। তাই, Rust আপনাকে অবিলম্বে অ্যাবোর্টিং (aborting)-এর বিকল্প বেছে নেওয়ার অনুমতি দেয়, যা পরিষ্কার না করেই প্রোগ্রামটি শেষ করে।
প্রোগ্রামটি যে মেমরি ব্যবহার করছিল তা অপারেটিং সিস্টেম দ্বারা পরিষ্কার করতে হবে। যদি আপনার প্রোজেক্টে আপনাকে ফলাফল বাইনারিটিকে যতটা সম্ভব ছোট করতে হয়, তাহলে আপনি আপনার Cargo.toml ফাইলের উপযুক্ত
[profile]বিভাগেpanic = 'abort'যোগ করে প্যানিক হওয়ার পরে আনওয়াইন্ডিং থেকে অ্যাবোর্টিং-এ পরিবর্তন করতে পারেন। উদাহরণস্বরূপ, আপনি যদি রিলিজ মোডে প্যানিকের সময় অ্যাবোর্ট করতে চান তবে এটি যোগ করুন:[profile.release] panic = 'abort'
আসুন একটি সহজ প্রোগ্রামে panic! কল করার চেষ্টা করি:
fn main() { panic!("crash and burn"); }
আপনি যখন প্রোগ্রামটি চালাবেন, তখন আপনি এইরকম কিছু দেখতে পাবেন:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:2:5:
crash and burn
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
panic! কলের কারণে শেষ দুটি লাইনে থাকা এরর মেসেজটি এসেছে। প্রথম লাইনটি আমাদের প্যানিক মেসেজ এবং আমাদের সোর্স কোডের সেই স্থানটি দেখায় যেখানে প্যানিক ঘটেছে: src/main.rs:2:5 নির্দেশ করে যে এটি আমাদের src/main.rs ফাইলের দ্বিতীয় লাইনের পঞ্চম অক্ষর।
এই ক্ষেত্রে, নির্দেশিত লাইনটি আমাদের কোডের অংশ, এবং যদি আমরা সেই লাইনে যাই, তাহলে আমরা panic! ম্যাক্রো কলটি দেখতে পাব। অন্য ক্ষেত্রে, panic! কলটি এমন কোডে থাকতে পারে যা আমাদের কোড কল করে এবং এরর মেসেজ দ্বারা রিপোর্ট করা ফাইলের নাম এবং লাইন নম্বর অন্য কারও কোড হতে পারে যেখানে panic! ম্যাক্রো কল করা হয়েছে, আমাদের কোডের সেই লাইন নয় যা শেষ পর্যন্ত panic! কলের দিকে পরিচালিত করেছে।
আমরা panic! কলের ফাংশনগুলোর ব্যাকট্রেস ব্যবহার করে আমাদের কোডের কোন অংশটি সমস্যার কারণ তা বের করতে পারি। panic! ব্যাকট্রেস কীভাবে ব্যবহার করতে হয় তা বোঝার জন্য, আসুন আরেকটি উদাহরণ দেখি এবং দেখি যখন আমাদের কোডের সরাসরি ম্যাক্রো কল করার পরিবর্তে আমাদের কোডের কোনো বাগের কারণে একটি লাইব্রেরি থেকে panic! কল আসে তখন এটি কেমন হয়। Listing 9-1-এ কিছু কোড রয়েছে যা ভেক্টরের বৈধ ইনডেক্সের সীমার বাইরে একটি ইনডেক্স অ্যাক্সেস করার চেষ্টা করে।
fn main() { let v = vec![1, 2, 3]; v[99]; }
এখানে, আমরা আমাদের ভেক্টরের 100তম এলিমেন্টটি অ্যাক্সেস করার চেষ্টা করছি (যা 99 ইনডেক্সে রয়েছে কারণ ইনডেক্সিং শূন্য থেকে শুরু হয়), কিন্তু ভেক্টরটিতে কেবল তিনটি এলিমেন্ট রয়েছে। এই পরিস্থিতিতে, Rust প্যানিক করবে। [] ব্যবহার করলে একটি এলিমেন্ট রিটার্ন করার কথা, কিন্তু আপনি যদি একটি অবৈধ ইনডেক্স পাস করেন, তাহলে Rust এখানে সঠিক এমন কোনো এলিমেন্ট রিটার্ন করতে পারবে না।
C-তে, একটি ডেটা স্ট্রাকচারের শেষের বাইরে পড়ার চেষ্টা করা অনির্ধারিত আচরণ (undefined behavior)। আপনি মেমরির সেই লোকেশনে যা আছে তা পেতে পারেন যা ডেটা স্ট্রাকচারের সেই এলিমেন্টের সাথে সঙ্গতিপূর্ণ হবে, যদিও মেমরি সেই কাঠামোর অন্তর্গত নয়। এটিকে বাফার ওভাররিড (buffer overread) বলা হয় এবং এটি নিরাপত্তা দুর্বলতার দিকে পরিচালিত করতে পারে যদি একজন আক্রমণকারী ইনডেক্সটিকে এমনভাবে ম্যানিপুলেট করতে সক্ষম হয় যাতে ডেটা স্ট্রাকচারের পরে সংরক্ষিত ডেটা যা তাদের পড়ার অনুমতি নেই তা পড়তে পারে।
এই ধরনের দুর্বলতা থেকে আপনার প্রোগ্রামকে রক্ষা করার জন্য, আপনি যদি এমন একটি ইনডেক্সে একটি এলিমেন্ট পড়ার চেষ্টা করেন যা বিদ্যমান নেই, তাহলে Rust এক্সিকিউশন বন্ধ করে দেবে এবং চালিয়ে যেতে অস্বীকার করবে। চলুন চেষ্টা করে দেখি:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
এই এররটি আমাদের main.rs-এর ৪ নম্বর লাইনের দিকে নির্দেশ করে যেখানে আমরা ভেক্টরের v-এর 99 ইনডেক্স অ্যাক্সেস করার চেষ্টা করি।
note: লাইনটি আমাদের বলে যে আমরা RUST_BACKTRACE এনভায়রনমেন্ট ভেরিয়েবল সেট করে এররটির কারণ কী ঘটেছিল তার একটি ব্যাকট্রেস পেতে পারি। একটি ব্যাকট্রেস (backtrace) হল সেই সমস্ত ফাংশনগুলোর একটি তালিকা যা এই পয়েন্ট পর্যন্ত কল করা হয়েছে। Rust-এ ব্যাকট্রেসগুলো অন্যান্য ভাষার মতোই কাজ করে: ব্যাকট্রেস পড়ার মূল চাবিকাঠি হল ওপর থেকে শুরু করা এবং আপনি যে ফাইলগুলো লিখেছেন সেগুলো না দেখা পর্যন্ত পড়া। সেটি হল সেই স্থান যেখানে সমস্যাটির উদ্ভব হয়েছে। সেই স্থানের উপরের লাইনগুলো হল কোড যা আপনার কোড কল করেছে; নিচের লাইনগুলো হল সেই কোড যা আপনার কোডকে কল করেছে। এই আগের এবং পরের লাইনগুলোতে কোর Rust কোড, স্ট্যান্ডার্ড লাইব্রেরি কোড বা আপনি যে ক্রেটগুলো ব্যবহার করছেন সেগুলো অন্তর্ভুক্ত থাকতে পারে। আসুন RUST_BACKTRACE এনভায়রনমেন্ট ভেরিয়েবলটিকে 0 ছাড়া অন্য কোনো মানে সেট করে একটি ব্যাকট্রেস পাওয়ার চেষ্টা করি। Listing 9-2 আপনি যা দেখবেন তার অনুরূপ আউটপুট দেখায়।
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/std/src/panicking.rs:692:5
1: core::panicking::panic_fmt
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:273:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:16:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3361:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
এটি অনেক আউটপুট! আপনি যে সঠিক আউটপুটটি দেখতে পান তা আপনার অপারেটিং সিস্টেম এবং Rust ভার্সনের উপর নির্ভর করে ভিন্ন হতে পারে। এই তথ্য সহ ব্যাকট্রেস পেতে, ডিবাগ সিম্বল (debug symbols) সক্রিয় থাকতে হবে। ডিবাগ সিম্বলগুলো ডিফল্টরূপে সক্রিয় থাকে যখন --release ফ্ল্যাগ ছাড়া cargo build বা cargo run ব্যবহার করা হয়, যেমনটি আমরা এখানে করেছি।
Listing 9-2-এর আউটপুটে, ব্যাকট্রেসের লাইন ৬ আমাদের প্রোজেক্টের সেই লাইনের দিকে নির্দেশ করে যা সমস্যার কারণ: src/main.rs-এর লাইন ৪। আমরা যদি আমাদের প্রোগ্রামটিকে প্যানিক করতে না চাই, তাহলে আমাদের লেখা একটি ফাইলের উল্লেখ করা প্রথম লাইন দ্বারা নির্দেশিত অবস্থানে আমাদের অনুসন্ধান শুরু করা উচিত। Listing 9-1-এ, যেখানে আমরা ইচ্ছাকৃতভাবে কোড লিখেছি যা প্যানিক করবে, প্যানিক ঠিক করার উপায় হল ভেক্টরের ইনডেক্সের সীমার বাইরের কোনো এলিমেন্টের অনুরোধ না করা। ভবিষ্যতে যখন আপনার কোড প্যানিক করবে, তখন আপনাকে বের করতে হবে যে কোডটি কী অ্যাকশন নিচ্ছে এবং কী মান নিয়ে প্যানিক ঘটাচ্ছে এবং কোডের পরিবর্তে কী করা উচিত।
আমরা panic!-এ ফিরে আসব এবং কখন আমাদের এরর পরিস্থিতি হ্যান্ডেল করার জন্য panic! ব্যবহার করা উচিত এবং কখন করা উচিত নয়, এই চ্যাপ্টারের “panic! নাকি panic! নয়” বিভাগে। এরপর, আমরা দেখব কিভাবে Result ব্যবহার করে একটি এরর থেকে পুনরুদ্ধার করা যায়।
Result সহ পুনরুদ্ধারযোগ্য ত্রুটি (Recoverable Errors with Result)
বেশিরভাগ এররই এত গুরুতর নয় যে প্রোগ্রামটিকে সম্পূর্ণরূপে বন্ধ করে দিতে হবে। কখনও কখনও যখন একটি ফাংশন ব্যর্থ হয়, তখন এটি এমন একটি কারণে হয় যা আপনি সহজেই ব্যাখ্যা করতে এবং প্রতিক্রিয়া জানাতে পারেন। উদাহরণস্বরূপ, আপনি যদি একটি ফাইল খোলার চেষ্টা করেন এবং সেই অপারেশনটি ব্যর্থ হয় কারণ ফাইলটি বিদ্যমান নেই, তাহলে আপনি প্রক্রিয়াটি বন্ধ করার পরিবর্তে ফাইলটি তৈরি করতে চাইতে পারেন।
চ্যাপ্টার ২-এর “Result দিয়ে সম্ভাব্য ব্যর্থতা হ্যান্ডেল করা” থেকে স্মরণ করুন যে Result এনামটি দুটি ভেরিয়েন্ট, Ok এবং Err সহ সংজ্ঞায়িত করা হয়েছে, নিম্নরূপ:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
T এবং E হল জেনেরিক টাইপ প্যারামিটার: আমরা চ্যাপ্টার ১০-এ জেনেরিক নিয়ে আরও বিস্তারিত আলোচনা করব। এখনই আপনার যা জানা দরকার তা হল T সেই টাইপের মান উপস্থাপন করে যা Ok ভেরিয়েন্টের মধ্যে একটি সফলতার ক্ষেত্রে রিটার্ন করা হবে এবং E সেই টাইপের এরর উপস্থাপন করে যা Err ভেরিয়েন্টের মধ্যে একটি ব্যর্থতার ক্ষেত্রে রিটার্ন করা হবে। যেহেতু Result-এর এই জেনেরিক টাইপ প্যারামিটারগুলো রয়েছে, তাই আমরা Result টাইপ এবং এতে সংজ্ঞায়িত ফাংশনগুলো বিভিন্ন পরিস্থিতিতে ব্যবহার করতে পারি যেখানে সাফল্যের মান এবং এররের মান যা আমরা রিটার্ন করতে চাই তা ভিন্ন হতে পারে।
আসুন এমন একটি ফাংশন কল করি যা একটি Result মান রিটার্ন করে কারণ ফাংশনটি ব্যর্থ হতে পারে। Listing 9-3-তে আমরা একটি ফাইল খোলার চেষ্টা করি।
use std::fs::File; fn main() { let greeting_file_result = File::open("hello.txt"); }
File::open-এর রিটার্ন টাইপ হল একটি Result<T, E>। জেনেরিক প্যারামিটার T-কে File::open-এর ইমপ্লিমেন্টেশন দ্বারা সাফল্যের মানের টাইপ, std::fs::File দিয়ে পূরণ করা হয়েছে, যা একটি ফাইল হ্যান্ডেল। এরর মানে ব্যবহৃত E-এর টাইপ হল std::io::Error। এই রিটার্ন টাইপের অর্থ হল File::open-এর কলটি সফল হতে পারে এবং একটি ফাইল হ্যান্ডেল রিটার্ন করতে পারে যা থেকে আমরা পড়তে বা লিখতে পারি। ফাংশন কলটিও ব্যর্থ হতে পারে: উদাহরণস্বরূপ, ফাইলটি বিদ্যমান নাও থাকতে পারে, অথবা আমাদের ফাইলটি অ্যাক্সেস করার অনুমতি নাও থাকতে পারে। File::open ফাংশনটির আমাদের বলার একটি উপায় থাকতে হবে যে এটি সফল হয়েছে নাকি ব্যর্থ হয়েছে এবং একই সাথে আমাদের ফাইল হ্যান্ডেল বা এরর সম্পর্কিত তথ্য দিতে হবে। এই তথ্যটিই Result এনাম প্রকাশ করে।
যেখানে File::open সফল হয়, সেখানে greeting_file_result ভেরিয়েবলের মান হবে একটি Ok-এর ইন্সট্যান্স যাতে একটি ফাইল হ্যান্ডেল রয়েছে। যেখানে এটি ব্যর্থ হয়, সেখানে greeting_file_result-এর মান হবে একটি Err-এর ইন্সট্যান্স যাতে কী ধরনের এরর ঘটেছে সে সম্পর্কে আরও তথ্য রয়েছে।
আমাদের Listing 9-3-এর কোডে File::open যে মান রিটার্ন করে তার উপর নির্ভর করে ভিন্ন ভিন্ন পদক্ষেপ নিতে কোড যোগ করতে হবে। Listing 9-4 একটি বেসিক টুল ব্যবহার করে Result হ্যান্ডেল করার একটি উপায় দেখায়, সেটি হল match এক্সপ্রেশন যা আমরা চ্যাপ্টার ৬-এ আলোচনা করেছি।
use std::fs::File; fn main() { let greeting_file_result = File::open("hello.txt"); let greeting_file = match greeting_file_result { Ok(file) => file, Err(error) => panic!("Problem opening the file: {error:?}"), }; }
লক্ষ্য করুন যে, Option এনামের মতো, Result এনাম এবং এর ভেরিয়েন্টগুলো প্রেলিউড (prelude) দ্বারা স্কোপে আনা হয়েছে, তাই আমাদের match আর্মগুলোতে Ok এবং Err ভেরিয়েন্টগুলোর আগে Result:: উল্লেখ করার প্রয়োজন নেই।
যখন ফলাফল Ok হয়, তখন এই কোডটি Ok ভেরিয়েন্টের ভেতরের file মানটি রিটার্ন করবে এবং আমরা তারপর সেই ফাইল হ্যান্ডেল মানটিকে greeting_file ভেরিয়েবলে অ্যাসাইন করি। match-এর পরে, আমরা পড়ার বা লেখার জন্য ফাইল হ্যান্ডেলটি ব্যবহার করতে পারি।
match-এর অন্য আর্মটি সেই ক্ষেত্রটি হ্যান্ডেল করে যেখানে আমরা File::open থেকে একটি Err মান পাই। এই উদাহরণে, আমরা panic! ম্যাক্রো কল করতে বেছে নিয়েছি। যদি আমাদের বর্তমান ডিরেক্টরিতে hello.txt নামে কোনো ফাইল না থাকে এবং আমরা এই কোডটি চালাই, তাহলে আমরা panic! ম্যাক্রো থেকে নিম্নলিখিত আউটপুট দেখতে পাব:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at src/main.rs:8:23:
Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
যথারীতি, এই আউটপুটটি আমাদের বলে যে ঠিক কী ভুল হয়েছে।
বিভিন্ন এররের সাথে ম্যাচিং (Matching on Different Errors)
Listing 9-4-এর কোডটি File::open যে কারণেই ব্যর্থ হোক না কেন panic! করবে। যাইহোক, আমরা বিভিন্ন ব্যর্থতার কারণে ভিন্ন ভিন্ন পদক্ষেপ নিতে চাই: যদি File::open ব্যর্থ হয় কারণ ফাইলটি বিদ্যমান নেই, তাহলে আমরা ফাইলটি তৈরি করতে এবং নতুন ফাইলের হ্যান্ডেলটি রিটার্ন করতে চাই। যদি File::open অন্য কোনো কারণে ব্যর্থ হয়—উদাহরণস্বরূপ, আমাদের ফাইলটি খোলার অনুমতি না থাকার কারণে—তাহলে আমরা এখনও Listing 9-4-এর মতোই কোডটিকে panic! করাতে চাই। এর জন্য, আমরা একটি ভেতরের match এক্সপ্রেশন যোগ করি, যা Listing 9-5-এ দেখানো হয়েছে।
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {e:?}"),
},
other_error => {
panic!("Problem opening the file: {other_error:?}");
}
},
};
}File::open Err ভেরিয়েন্টের মধ্যে যে মানটি রিটার্ন করে তার টাইপ হল io::Error, যেটি স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা একটি স্ট্রাকট। এই স্ট্রাকটে একটি kind মেথড রয়েছে যা আমরা কল করে একটি io::ErrorKind মান পেতে পারি। io::ErrorKind এনামটি স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা হয়েছে এবং এর ভেরিয়েন্টগুলো io অপারেশনের ফলে হতে পারে এমন বিভিন্ন ধরনের এরর উপস্থাপন করে। আমরা যে ভেরিয়েন্টটি ব্যবহার করতে চাই সেটি হল ErrorKind::NotFound, যা নির্দেশ করে যে আমরা যে ফাইলটি খোলার চেষ্টা করছি সেটি এখনও বিদ্যমান নেই। তাই আমরা greeting_file_result-এর উপর match করি, কিন্তু আমাদের error.kind()-এর উপরও একটি ভেতরের match রয়েছে।
ভেতরের ম্যাচে আমরা যে শর্তটি পরীক্ষা করতে চাই তা হল error.kind() দ্বারা রিটার্ন করা মানটি ErrorKind এনামের NotFound ভেরিয়েন্ট কিনা। যদি তাই হয়, তাহলে আমরা File::create দিয়ে ফাইলটি তৈরি করার চেষ্টা করি। যাইহোক, যেহেতু File::createও ব্যর্থ হতে পারে, তাই আমাদের ভেতরের match এক্সপ্রেশনে একটি দ্বিতীয় আর্ম প্রয়োজন। যখন ফাইলটি তৈরি করা যায় না, তখন একটি ভিন্ন এরর মেসেজ প্রিন্ট করা হয়। বাইরের match-এর দ্বিতীয় আর্মটি একই থাকে, তাই প্রোগ্রামটি ফাইল অনুপস্থিতির এরর (missing file error) ছাড়া অন্য কোনো এররের ক্ষেত্রে প্যানিক করে।
Result<T, E>-এর সাথেmatchব্যবহারের বিকল্পঅনেকগুলো
match!matchএক্সপ্রেশনটি খুব দরকারী কিন্তু এটি একটি খুব আদিম (primitive) প্রক্রিয়া। চ্যাপ্টার 13-এ, আপনি ক্লোজার (closures) সম্পর্কে জানতে পারবেন, যেগুলোResult<T, E>-তে সংজ্ঞায়িত অনেকগুলো মেথডের সাথে ব্যবহার করা হয়। আপনার কোডেResult<T, E>মানগুলো হ্যান্ডেল করার সময় এই মেথডগুলোmatchব্যবহারের চেয়ে আরও সংক্ষিপ্ত হতে পারে।উদাহরণস্বরূপ, Listing 9-5-এর মতোই একই লজিক লেখার আরেকটি উপায় এখানে দেওয়া হল, এবার ক্লোজার এবং
unwrap_or_elseমেথড ব্যবহার করে:use std::fs::File; use std::io::ErrorKind; fn main() { let greeting_file = File::open("hello.txt").unwrap_or_else(|error| { if error.kind() == ErrorKind::NotFound { File::create("hello.txt").unwrap_or_else(|error| { panic!("Problem creating the file: {error:?}"); }) } else { panic!("Problem opening the file: {error:?}"); } }); }যদিও এই কোডটির Listing 9-5-এর মতোই আচরণ রয়েছে, তবে এতে কোনো
matchএক্সপ্রেশন নেই এবং এটি পড়া আরও সহজ। আপনি চ্যাপ্টার 13 পড়ার পরে এই উদাহরণটিতে ফিরে আসুন এবং স্ট্যান্ডার্ড লাইব্রেরি ডকুমেন্টেশনেunwrap_or_elseমেথডটি দেখুন। এরর নিয়ে কাজ করার সময় আরও অনেকগুলো মেথড বিশাল নেস্টেডmatchএক্সপ্রেশনগুলোকে পরিষ্কার করতে পারে।
এরর-এ প্যানিকের জন্য শর্টকাট: unwrap এবং expect (Shortcuts for Panic on Error: unwrap and expect)
match ব্যবহার করা যথেষ্ট ভাল কাজ করে, কিন্তু এটি কিছুটা শব্দবহুল হতে পারে এবং সর্বদাই অভিপ্রায়টি ভালভাবে প্রকাশ করে না। Result<T, E> টাইপে বিভিন্ন, আরও নির্দিষ্ট কাজ করার জন্য অনেকগুলি হেল্পার মেথড সংজ্ঞায়িত করা হয়েছে। unwrap মেথড হল একটি শর্টকাট মেথড যা আমরা Listing 9-4-এ লিখেছি এমন match এক্সপ্রেশনের মতোই ইমপ্লিমেন্ট করা। যদি Result মানটি Ok ভেরিয়েন্ট হয়, তাহলে unwrap Ok-এর ভেতরের মানটি রিটার্ন করবে। যদি Result Err ভেরিয়েন্ট হয়, তাহলে unwrap আমাদের জন্য panic! ম্যাক্রো কল করবে। এখানে অ্যাকশনে unwrap-এর একটি উদাহরণ দেওয়া হল:
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt").unwrap(); }
যদি আমরা এই কোডটি hello.txt ফাইল ছাড়া চালাই, তাহলে আমরা unwrap মেথডের করা panic! কল থেকে একটি এরর মেসেজ দেখতে পাব:
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
একইভাবে, expect মেথড আমাদের panic! এরর মেসেজটিও বেছে নিতে দেয়। unwrap-এর পরিবর্তে expect ব্যবহার করা এবং ভাল এরর মেসেজ প্রদান করা আপনার অভিপ্রায় প্রকাশ করতে পারে এবং প্যানিকের উৎস ট্র্যাক করা সহজ করে তুলতে পারে। expect-এর সিনট্যাক্সটি এইরকম দেখায়:
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt") .expect("hello.txt should be included in this project"); }
আমরা expect কে unwrap-এর মতোই ব্যবহার করি: ফাইল হ্যান্ডেল রিটার্ন করতে বা panic! ম্যাক্রো কল করতে। expect তার panic! কলে যে এরর মেসেজটি ব্যবহার করে সেটি হল সেই প্যারামিটার যা আমরা expect-কে পাস করি, unwrap যে ডিফল্ট panic! মেসেজ ব্যবহার করে তার পরিবর্তে। এটি দেখতে এইরকম:
thread 'main' panicked at src/main.rs:5:10:
hello.txt should be included in this project: Os { code: 2, kind: NotFound, message: "No such file or directory" }
প্রোডাকশন-কোয়ালিটি কোডে, বেশিরভাগ Rustacean-রা unwrap-এর চেয়ে expect বেছে নেয় এবং অপারেশনটি সর্বদা সফল হবে বলে আশা করার কারণ সম্পর্কে আরও প্রসঙ্গ দেয়। এইভাবে, যদি আপনার অনুমানগুলো কখনও ভুল প্রমাণিত হয়, তাহলে আপনার কাছে ডিবাগিংয়ে ব্যবহার করার জন্য আরও তথ্য থাকবে।
এরর প্রচার করা (Propagating Errors)
যখন একটি ফাংশনের ইমপ্লিমেন্টেশন এমন কিছু কল করে যা ব্যর্থ হতে পারে, তখন ফাংশনের মধ্যেই এরর হ্যান্ডেল করার পরিবর্তে আপনি এররটিকে কলিং কোডে রিটার্ন করতে পারেন যাতে এটি সিদ্ধান্ত নিতে পারে কী করতে হবে। এটিকে এরর প্রোপাগেটিং (propagating) বলা হয় এবং এটি কলিং কোডকে আরও নিয়ন্ত্রণ দেয়, যেখানে আপনার কোডের প্রেক্ষাপটে আপনার কাছে উপলব্ধ তথ্যের চেয়ে বেশি তথ্য বা লজিক থাকতে পারে যা নির্দেশ করে যে কীভাবে এররটি হ্যান্ডেল করা উচিত।
উদাহরণস্বরূপ, Listing 9-6 এমন একটি ফাংশন দেখায় যা একটি ফাইল থেকে একটি ব্যবহারকারীর নাম পড়ে। যদি ফাইলটি বিদ্যমান না থাকে বা পড়া না যায়, তাহলে এই ফাংশনটি সেই এররগুলোকে ফাংশনটিকে কল করা কোডে রিটার্ন করবে।
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let username_file_result = File::open("hello.txt"); let mut username_file = match username_file_result { Ok(file) => file, Err(e) => return Err(e), }; let mut username = String::new(); match username_file.read_to_string(&mut username) { Ok(_) => Ok(username), Err(e) => Err(e), } } }
এই ফাংশনটি অনেক সংক্ষিপ্ত উপায়ে লেখা যেতে পারে, কিন্তু আমরা এরর হ্যান্ডলিং অন্বেষণ করার জন্য এটির অনেকগুলি ম্যানুয়ালি করতে যাচ্ছি; শেষে, আমরা সংক্ষিপ্ত উপায়টি দেখাব। আসুন প্রথমে ফাংশনের রিটার্ন টাইপটি দেখি: Result<String, io::Error>। এর মানে হল ফাংশনটি Result<T, E> টাইপের একটি মান রিটার্ন করছে, যেখানে জেনেরিক প্যারামিটার T-কে কংক্রিট টাইপ String দিয়ে পূরণ করা হয়েছে এবং জেনেরিক টাইপ E-কে কংক্রিট টাইপ io::Error দিয়ে পূরণ করা হয়েছে।
যদি এই ফাংশনটি কোনো সমস্যা ছাড়াই সফল হয়, তাহলে এই ফাংশনটিকে কল করা কোডটি একটি Ok মান পাবে যাতে একটি String রয়েছে—ফাংশনটি ফাইল থেকে যে username পড়েছে সেটি। যদি এই ফাংশনটি কোনো সমস্যার সম্মুখীন হয়, তাহলে কলিং কোডটি একটি Err মান পাবে যাতে io::Error-এর একটি ইন্সট্যান্স রয়েছে যাতে সমস্যাগুলো কী ছিল সে সম্পর্কে আরও তথ্য রয়েছে। আমরা এই ফাংশনের রিটার্ন টাইপ হিসাবে io::Error বেছে নিয়েছি কারণ এটি এই ফাংশনের বডিতে আমরা যে দুটি অপারেশন কল করছি যেগুলো ব্যর্থ হতে পারে: File::open ফাংশন এবং read_to_string মেথড, উভয়ের থেকেই রিটার্ন করা এরর মানের টাইপ।
ফাংশনের বডি File::open ফাংশন কল করে শুরু হয়। তারপর আমরা Listing 9-4-এর match-এর মতোই একটি match দিয়ে Result মানটি হ্যান্ডেল করি। যদি File::open সফল হয়, তাহলে প্যাটার্ন ভেরিয়েবল file-এর ফাইল হ্যান্ডেলটি মিউটেবল ভেরিয়েবল username_file-এর মান হয়ে যায় এবং ফাংশনটি চলতে থাকে। Err কেসের ক্ষেত্রে, panic! কল করার পরিবর্তে, আমরা ফাংশন থেকে সম্পূর্ণরূপে তাড়াতাড়ি রিটার্ন করার জন্য return কীওয়ার্ড ব্যবহার করি এবং File::open থেকে এরর মানটি, এখন প্যাটার্ন ভেরিয়েবল e-তে, এই ফাংশনের এরর মান হিসাবে কলিং কোডে ফেরত পাঠাই।
সুতরাং, যদি আমাদের username_file-এ একটি ফাইল হ্যান্ডেল থাকে, তাহলে ফাংশনটি ভেরিয়েবল username-এ একটি নতুন String তৈরি করে এবং ফাইল হ্যান্ডেলে read_to_string মেথড কল করে ফাইলের কনটেন্টগুলো username-এ পড়ার জন্য। read_to_string মেথডটিও একটি Result রিটার্ন করে কারণ এটি ব্যর্থ হতে পারে, যদিও File::open সফল হয়েছে। তাই আমাদের সেই Result হ্যান্ডেল করার জন্য আরেকটি match প্রয়োজন: যদি read_to_string সফল হয়, তাহলে আমাদের ফাংশন সফল হয়েছে এবং আমরা ফাইল থেকে ব্যবহারকারীর নাম username-এ থাকা অবস্থায় Ok-তে র্যাপ করে রিটার্ন করি। যদি read_to_string ব্যর্থ হয়, তাহলে আমরা File::open-এর রিটার্ন মান হ্যান্ডেল করা match-এ এরর মান যেভাবে রিটার্ন করেছি সেভাবেই এরর মানটি রিটার্ন করি। তবে, আমাদের স্পষ্টভাবে return বলার দরকার নেই, কারণ এটি ফাংশনের শেষ এক্সপ্রেশন।
যে কোডটি এই কোডটিকে কল করবে সেটি তারপর একটি Ok মান পাবে যাতে একটি ব্যবহারকারীর নাম রয়েছে অথবা একটি Err মান যাতে একটি io::Error রয়েছে। কলিং কোডটি সেই মানগুলো নিয়ে কী করবে তা তাদের উপর নির্ভর করে। যদি কলিং কোডটি একটি Err মান পায়, তাহলে এটি panic! কল করতে পারে এবং প্রোগ্রামটি ক্র্যাশ করাতে পারে, একটি ডিফল্ট ব্যবহারকারীর নাম ব্যবহার করতে পারে, অথবা উদাহরণস্বরূপ, একটি ফাইল ছাড়া অন্য কোথাও থেকে ব্যবহারকারীর নাম খুঁজতে পারে। কলিং কোডটি আসলে কী করার চেষ্টা করছে সে সম্পর্কে আমাদের কাছে পর্যাপ্ত তথ্য নেই, তাই আমরা সমস্ত সাফল্য বা এররের তথ্য উপরের দিকে প্রচার করি যাতে এটি যথাযথভাবে হ্যান্ডেল করা যায়।
Rust-এ এরর প্রচার করার এই প্যাটার্নটি এতটাই সাধারণ যে Rust এটিকে সহজ করার জন্য প্রশ্নবোধক চিহ্ন অপারেটর ? সরবরাহ করে।
এরর প্রচার করার জন্য একটি শর্টকাট: ? অপারেটর (A Shortcut for Propagating Errors: the ? Operator)
Listing 9-7 read_username_from_file-এর একটি ইমপ্লিমেন্টেশন দেখায় যা Listing 9-6-এর মতোই একই কার্যকারিতা সম্পন্ন করে, কিন্তু এই ইমপ্লিমেন্টেশনটি ? অপারেটর ব্যবহার করে।
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username_file = File::open("hello.txt")?; let mut username = String::new(); username_file.read_to_string(&mut username)?; Ok(username) } }
একটি Result মানের পরে স্থাপিত ? প্রায় Listing 9-6-এ Result মানগুলো হ্যান্ডেল করার জন্য আমরা যে match এক্সপ্রেশনগুলো সংজ্ঞায়িত করেছি তার মতোই কাজ করার জন্য সংজ্ঞায়িত করা হয়েছে। যদি Result-এর মানটি একটি Ok হয়, তাহলে Ok-এর ভিতরের মানটি এই এক্সপ্রেশন থেকে রিটার্ন করা হবে এবং প্রোগ্রামটি চলতে থাকবে। যদি মানটি একটি Err হয়, তাহলে Err টি সম্পূর্ণ ফাংশন থেকে রিটার্ন করা হবে যেন আমরা return কীওয়ার্ড ব্যবহার করেছি যাতে এরর মানটি কলিং কোডে প্রচারিত হয়।
Listing 9-6 থেকে match এক্সপ্রেশন যা করে এবং ? অপারেটর যা করে তার মধ্যে একটি পার্থক্য রয়েছে: এরর মানগুলোতে ? অপারেটর কল করা হলে সেগুলো স্ট্যান্ডার্ড লাইব্রেরির From ট্রেইটে সংজ্ঞায়িত from ফাংশনের মধ্য দিয়ে যায়, যা একটি টাইপ থেকে অন্য টাইপে মান রূপান্তর করতে ব্যবহৃত হয়। যখন ? অপারেটর from ফাংশনটিকে কল করে, তখন প্রাপ্ত এরর টাইপটি বর্তমান ফাংশনের রিটার্ন টাইপে সংজ্ঞায়িত এরর টাইপে রূপান্তরিত হয়। এটি দরকারী যখন একটি ফাংশন একটি এরর টাইপ রিটার্ন করে যা সমস্ত উপায়ে একটি ফাংশন ব্যর্থ হতে পারে তা উপস্থাপন করে, এমনকী যদি অংশগুলো বিভিন্ন কারণে ব্যর্থ হতে পারে।
উদাহরণস্বরূপ, আমরা Listing 9-7-এর read_username_from_file ফাংশনটিকে পরিবর্তন করে একটি কাস্টম এরর টাইপ OurError রিটার্ন করতে পারি যা আমরা সংজ্ঞায়িত করি। যদি আমরা io::Error থেকে OurError-এর একটি ইন্সট্যান্স তৈরি করতে impl From<io::Error> for OurError সংজ্ঞায়িত করি, তাহলে read_username_from_file-এর বডিতে ? অপারেটর কলগুলো from কল করবে এবং এরর টাইপগুলোকে রূপান্তর করবে, ফাংশনে কোনো অতিরিক্ত কোড যোগ করার প্রয়োজন ছাড়াই।
Listing 9-7-এর প্রসঙ্গে, File::open কলের শেষে ? Ok-এর ভেতরের মানটিকে ভেরিয়েবল username_file-এ রিটার্ন করবে। যদি একটি এরর ঘটে, তাহলে ? অপারেটর পুরো ফাংশন থেকে তাড়াতাড়ি রিটার্ন করবে এবং যেকোনো Err মান কলিং কোডকে দেবে। একই জিনিস read_to_string কলের শেষে ?-এর ক্ষেত্রে প্রযোজ্য।
? অপারেটর অনেক বয়লারপ্লেট দূর করে এবং এই ফাংশনের ইমপ্লিমেন্টেশনকে সহজ করে তোলে। আমরা Listing 9-8-এ দেখানো ?-এর পরে অবিলম্বে মেথড কল চেইন করে এই কোডটিকে আরও ছোট করতে পারি।
use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username = String::new(); File::open("hello.txt")?.read_to_string(&mut username)?; Ok(username) } fn main() { let username = read_username_from_file().expect("Unable to get username"); }
আমরা username-এ নতুন String তৈরি করাটিকে ফাংশনের শুরুতে সরিয়ে দিয়েছি; সেই অংশটি পরিবর্তন হয়নি। username_file ভেরিয়েবল তৈরি করার পরিবর্তে, আমরা File::open("hello.txt")?-এর ফলাফলের উপর সরাসরি read_to_string-এর কলটি চেইন করেছি। আমাদের এখনও read_to_string কলের শেষে একটি ? রয়েছে এবং File::open এবং read_to_string উভয়ই সফল হলে আমরা এখনও username ধারণকারী একটি Ok মান রিটার্ন করি, এরর রিটার্ন করার পরিবর্তে। কার্যকারিতা আবার Listing 9-6 এবং Listing 9-7-এর মতোই; এটি লেখার একটি ভিন্ন, আরও এরগোনমিক উপায়।
Listing 9-9 fs::read_to_string ব্যবহার করে এটিকে আরও ছোট করার একটি উপায় দেখায়।
use std::fs; use std::io; fn read_username_from_file() -> Result<String, io::Error> { fs::read_to_string("hello.txt") } fn main() { let username = read_username_from_file().expect("Unable to get username"); }
একটি ফাইলকে একটি স্ট্রিং-এ পড়া একটি মোটামুটি সাধারণ অপারেশন, তাই স্ট্যান্ডার্ড লাইব্রেরি সুবিধাজনক fs::read_to_string ফাংশন সরবরাহ করে যা ফাইলটি খোলে, একটি নতুন String তৈরি করে, ফাইলের কনটেন্টগুলো পড়ে, কনটেন্টগুলো সেই String-এ রাখে এবং এটি রিটার্ন করে। অবশ্যই, fs::read_to_string ব্যবহার করা আমাদের সমস্ত এরর হ্যান্ডলিং ব্যাখ্যা করার সুযোগ দেয় না, তাই আমরা প্রথমে দীর্ঘ পথটি বেছে নিয়েছিলাম।
? অপারেটর কোথায় ব্যবহার করা যেতে পারে (Where The ? Operator Can Be Used)
? অপারেটরটি শুধুমাত্র এমন ফাংশনগুলোতে ব্যবহার করা যেতে পারে যাদের রিটার্ন টাইপ সেই মানের সাথে সামঞ্জস্যপূর্ণ যেখানে ? ব্যবহার করা হয়েছে। এর কারণ হল ? অপারেটরটি Listing 9-6-এ সংজ্ঞায়িত match এক্সপ্রেশনের মতোই ফাংশন থেকে তাড়াতাড়ি একটি মান রিটার্ন করার জন্য সংজ্ঞায়িত করা হয়েছে। Listing 9-6-এ, match একটি Result মান ব্যবহার করছিল এবং আর্লি রিটার্ন আর্ম একটি Err(e) মান রিটার্ন করছিল। ফাংশনের রিটার্ন টাইপটিকে অবশ্যই একটি Result হতে হবে যাতে এটি এই return-এর সাথে সামঞ্জস্যপূর্ণ হয়।
Listing 9-10-এ, আসুন আমরা একটি main ফাংশনে ? অপারেটর ব্যবহার করলে যে এরর পাব তা দেখি যার রিটার্ন টাইপটি এমন একটি টাইপের সাথে বেমানান, যেখানে আমরা ? ব্যবহার করছি:
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")?;
}এই কোডটি একটি ফাইল খোলে, যা ব্যর্থ হতে পারে। ? অপারেটরটি File::open দ্বারা রিটার্ন করা Result মানটিকে অনুসরণ করে, কিন্তু এই main ফাংশনটির রিটার্ন টাইপ হল (), Result নয়। যখন আমরা এই কোডটি কম্পাইল করি, তখন আমরা নিম্নলিখিত এরর মেসেজটি পাই:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let greeting_file = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
= help: the trait `FromResidual<Result<Infallible, std::io::Error>>` is not implemented for `()`
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let greeting_file = File::open("hello.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` (bin "error-handling") due to 1 previous error
এই এররটি নির্দেশ করে যে আমরা শুধুমাত্র এমন একটি ফাংশনে ? অপারেটর ব্যবহার করার অনুমতি পেয়েছি যা Result, Option, বা অন্য কোনো টাইপ রিটার্ন করে যা FromResidual ইমপ্লিমেন্ট করে।
এররটি ঠিক করতে, আপনার দুটি পছন্দ রয়েছে। একটি পছন্দ হল আপনার ফাংশনের রিটার্ন টাইপ পরিবর্তন করে এমন একটি টাইপ করা যা আপনি ? অপারেটর ব্যবহার করছেন তার সাথে সঙ্গতিপূর্ণ, যদি আপনার কাছে সেটি করতে কোনো বাধা না থাকে। অন্য কৌশলটি হল match বা Result<T, E> মেথডগুলোর মধ্যে একটি ব্যবহার করে Result<T, E>-কে উপযুক্ত উপায়ে হ্যান্ডেল করা।
এরর মেসেজটিতে এটিও উল্লেখ করা হয়েছে যে ? Option<T> মানগুলোর সাথেও ব্যবহার করা যেতে পারে। Result-এ ? ব্যবহার করার মতো, আপনি শুধুমাত্র Option-এর উপর ? ব্যবহার করতে পারেন এমন একটি ফাংশনে যা একটি Option রিটার্ন করে। Option<T>-তে ? অপারেটর কল করার সময় আচরণটি Result<T, E>-তে কল করার সময় এর আচরণের মতোই: যদি মানটি None হয়, তাহলে সেই বিন্দু থেকে ফাংশন থেকে None তাড়াতাড়ি রিটার্ন করা হবে। যদি মানটি Some হয়, তাহলে Some-এর ভিতরের মানটি হল এক্সপ্রেশনের ফলাফল মান এবং ফাংশনটি চলতে থাকে। Listing 9-11-এ একটি ফাংশনের উদাহরণ রয়েছে যা প্রদত্ত টেক্সটের প্রথম লাইনের শেষ অক্ষরটি খুঁজে বের করে।
fn last_char_of_first_line(text: &str) -> Option<char> { text.lines().next()?.chars().last() } fn main() { assert_eq!( last_char_of_first_line("Hello, world\nHow are you today?"), Some('d') ); assert_eq!(last_char_of_first_line(""), None); assert_eq!(last_char_of_first_line("\nhi"), None); }
এই ফাংশনটি Option<char> রিটার্ন করে কারণ সেখানে একটি অক্ষর থাকার সম্ভাবনা রয়েছে, তবে এটিও সম্ভব যে সেখানে কোনো অক্ষর নেই। এই কোডটি text স্ট্রিং স্লাইস আর্গুমেন্ট নেয় এবং এতে lines মেথড কল করে, যা স্ট্রিং-এর লাইনগুলোর উপর একটি ইটারেটর রিটার্ন করে। যেহেতু এই ফাংশনটি প্রথম লাইনটি পরীক্ষা করতে চায়, তাই এটি ইটারেটর থেকে প্রথম মান পেতে next কল করে। যদি text খালি স্ট্রিং হয়, তাহলে next-এর এই কলটি None রিটার্ন করবে, যেক্ষেত্রে আমরা ? ব্যবহার করে থামি এবং last_char_of_first_line থেকে None রিটার্ন করি। যদি text খালি স্ট্রিং না হয়, তাহলে next একটি Some মান রিটার্ন করবে যাতে text-এর প্রথম লাইনের একটি স্ট্রিং স্লাইস রয়েছে।
? স্ট্রিং স্লাইসটি বের করে এবং আমরা সেই স্ট্রিং স্লাইসে chars কল করে এর অক্ষরগুলোর একটি ইটারেটর পেতে পারি। আমরা এই প্রথম লাইনের শেষ অক্ষরটিতে আগ্রহী, তাই আমরা ইটারেটরের শেষ আইটেমটি রিটার্ন করতে last কল করি। এটি একটি Option কারণ এটি সম্ভব যে প্রথম লাইনটি খালি স্ট্রিং; উদাহরণস্বরূপ, যদি text একটি ফাঁকা লাইন দিয়ে শুরু হয় কিন্তু অন্য লাইনগুলোতে অক্ষর থাকে, যেমন "\nhi"-তে। যাইহোক, যদি প্রথম লাইনে একটি শেষ অক্ষর থাকে, তাহলে সেটি Some ভেরিয়েন্টে রিটার্ন করা হবে। মাঝের ? অপারেটরটি আমাদের এই লজিকটি প্রকাশ করার একটি সংক্ষিপ্ত উপায় দেয়, যা আমাদের ফাংশনটিকে এক লাইনে ইমপ্লিমেন্ট করতে দেয়। যদি আমরা Option-এ ? অপারেটর ব্যবহার করতে না পারতাম, তাহলে আমাদের এই লজিকটি আরও মেথড কল বা একটি match এক্সপ্রেশন ব্যবহার করে ইমপ্লিমেন্ট করতে হত।
লক্ষ্য করুন যে আপনি একটি Result রিটার্ন করে এমন একটি ফাংশনে Result-এর উপর ? অপারেটর ব্যবহার করতে পারেন এবং আপনি একটি Option রিটার্ন করে এমন একটি ফাংশনে Option-এর উপর ? অপারেটর ব্যবহার করতে পারেন, কিন্তু আপনি মিশ্রিত করতে পারবেন না। ? অপারেটর স্বয়ংক্রিয়ভাবে একটি Result-কে একটি Option-এ বা বিপরীতভাবে রূপান্তর করবে না; সেই ক্ষেত্রগুলোতে, আপনি Result-এ ok মেথড বা Option-এ ok_or মেথডের মতো মেথডগুলো ব্যবহার করে রূপান্তরটি স্পষ্টভাবে করতে পারেন।
এখন পর্যন্ত, আমরা যে সমস্ত main ফাংশন ব্যবহার করেছি সেগুলো () রিটার্ন করেছে। main ফাংশনটি বিশেষ কারণ এটি একটি এক্সিকিউটেবল প্রোগ্রামের এন্ট্রি পয়েন্ট এবং এক্সিট পয়েন্ট, এবং প্রোগ্রামটি প্রত্যাশিতভাবে আচরণ করার জন্য এর রিটার্ন টাইপ কী হতে পারে তার উপর সীমাবদ্ধতা রয়েছে।
সৌভাগ্যবশত, main একটি Result<(), E> রিটার্ন করতে পারে। Listing 9-12-এ Listing 9-10-এর কোড রয়েছে, কিন্তু আমরা main-এর রিটার্ন টাইপ পরিবর্তন করে Result<(), Box<dyn Error>> করেছি এবং শেষে একটি রিটার্ন ভ্যালু Ok(()) যোগ করেছি। এই কোডটি এখন কম্পাইল হবে।
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?;
Ok(())
}Box<dyn Error> টাইপটি হল একটি ট্রেইট অবজেক্ট (trait object), যা নিয়ে আমরা চ্যাপ্টার 18-এর “ভিন্ন টাইপের মানের জন্য অনুমতি দেয় এমন ট্রেইট অবজেক্ট ব্যবহার করা”-তে কথা বলব। আপাতত, আপনি Box<dyn Error>-কে "যেকোনো ধরনের এরর" হিসাবে পড়তে পারেন। এরর টাইপ Box<dyn Error> সহ একটি main ফাংশনে Result মানের উপর ? ব্যবহার করার অনুমতি রয়েছে কারণ এটি যেকোনো Err মানকে তাড়াতাড়ি রিটার্ন করার অনুমতি দেয়। যদিও এই main ফাংশনের বডি শুধুমাত্র std::io::Error টাইপের এরর রিটার্ন করবে, Box<dyn Error> নির্দিষ্ট করে, এই সিগনেচারটি সঠিক থাকবে এমনকী যদি main-এর বডিতে আরও কোড যোগ করা হয় যা অন্যান্য এরর রিটার্ন করে।
যখন একটি main ফাংশন একটি Result<(), E> রিটার্ন করে, তখন এক্সিকিউটেবলটি 0 মান দিয়ে প্রস্থান করবে যদি main Ok(()) রিটার্ন করে এবং main একটি Err মান রিটার্ন করলে একটি ননজিরো মান দিয়ে প্রস্থান করবে। C-তে লেখা এক্সিকিউটেবলগুলো প্রস্থান করার সময় ইন্টিজার রিটার্ন করে: যেসব প্রোগ্রাম সফলভাবে প্রস্থান করে সেগুলো 0 ইন্টিজার রিটার্ন করে এবং যেসব প্রোগ্রাম এরর করে সেগুলো 0 ছাড়া অন্য কোনো ইন্টিজার রিটার্ন করে। Rust-ও এই কনভেনশনের সাথে সামঞ্জস্যপূর্ণ হওয়ার জন্য এক্সিকিউটেবলগুলো থেকে ইন্টিজার রিটার্ন করে।
main ফাংশন যেকোনো টাইপ রিটার্ন করতে পারে যা the std::process::Termination
trait ইমপ্লিমেন্ট করে, যেটিতে একটি ফাংশন report রয়েছে যা একটি ExitCode রিটার্ন করে। আপনার নিজের টাইপের জন্য Termination ট্রেইট ইমপ্লিমেন্ট করার বিষয়ে আরও তথ্যের জন্য স্ট্যান্ডার্ড লাইব্রেরি ডকুমেন্টেশন দেখুন।
এখন আমরা panic! কল করা বা Result রিটার্ন করার বিশদ বিবরণ নিয়ে আলোচনা করেছি, আসুন কোন ক্ষেত্রে কোনটি ব্যবহার করা উপযুক্ত তা নিয়ে আলোচনা করা যাক।
panic! নাকি panic! নয় (To panic! or Not to panic!)
তাহলে আপনি কীভাবে সিদ্ধান্ত নেবেন যে কখন আপনার panic! কল করা উচিত এবং কখন Result রিটার্ন করা উচিত? যখন কোড প্যানিক করে, তখন পুনরুদ্ধার করার কোনো উপায় থাকে না। আপনি যেকোনো এরর পরিস্থিতির জন্য panic! কল করতে পারেন, পুনরুদ্ধার করার কোনো সম্ভাব্য উপায় থাকুক বা না থাকুক, কিন্তু তখন আপনি কলিং কোডের পক্ষে সিদ্ধান্ত নিচ্ছেন যে পরিস্থিতিটি পুনরুদ্ধারযোগ্য নয়। আপনি যখন একটি Result মান রিটার্ন করতে পছন্দ করেন, তখন আপনি কলিং কোডকে অপশন দেন। কলিং কোডটি তার পরিস্থিতির জন্য উপযুক্ত উপায়ে পুনরুদ্ধার করার চেষ্টা করতে পারে, অথবা এটি সিদ্ধান্ত নিতে পারে যে এই ক্ষেত্রে একটি Err মান পুনরুদ্ধারযোগ্য নয়, তাই এটি panic! কল করতে পারে এবং আপনার পুনরুদ্ধারযোগ্য এররটিকে একটি পুনরুদ্ধার অযোগ্য এররে পরিণত করতে পারে। অতএব, Result রিটার্ন করা একটি ভাল ডিফল্ট পছন্দ যখন আপনি এমন একটি ফাংশন সংজ্ঞায়িত করছেন যা ব্যর্থ হতে পারে।
উদাহরণ, প্রোটোটাইপ কোড এবং পরীক্ষার মতো পরিস্থিতিতে, Result রিটার্ন করার পরিবর্তে প্যানিক করে এমন কোড লেখাই বেশি উপযুক্ত। আসুন অনুসন্ধান করি কেন, তারপর এমন পরিস্থিতি নিয়ে আলোচনা করি যেখানে কম্পাইলার বলতে পারে না যে ব্যর্থতা অসম্ভব, কিন্তু আপনি একজন মানুষ হিসাবে পারেন। চ্যাপ্টারটি লাইব্রেরি কোডে প্যানিক করতে হবে কিনা তা সিদ্ধান্ত নেওয়ার বিষয়ে কিছু সাধারণ নির্দেশিকা দিয়ে শেষ হবে।
উদাহরণ, প্রোটোটাইপ কোড এবং পরীক্ষা (Examples, Prototype Code, and Tests)
আপনি যখন কোনো ধারণা বোঝানোর জন্য একটি উদাহরণ লিখছেন, তখন শক্তিশালী এরর-হ্যান্ডলিং কোড অন্তর্ভুক্ত করা উদাহরণটিকে কম স্পষ্ট করে তুলতে পারে। উদাহরণগুলোতে, এটি বোঝা যায় যে unwrap-এর মতো একটি মেথডের কল যা প্যানিক করতে পারে, তা হল আপনি যেভাবে আপনার অ্যাপ্লিকেশনটিকে এররগুলো হ্যান্ডেল করতে চান তার জন্য একটি স্থানধারক (placeholder), যা আপনার কোডের বাকি অংশ কী করছে তার উপর ভিত্তি করে ভিন্ন হতে পারে।
একইভাবে, unwrap এবং expect মেথডগুলো প্রোটোটাইপ করার সময় খুব সুবিধাজনক, আপনি কীভাবে এররগুলো হ্যান্ডেল করবেন তা সিদ্ধান্ত নেওয়ার আগে। আপনি যখন আপনার প্রোগ্রামটিকে আরও শক্তিশালী করার জন্য প্রস্তুত হবেন তখন তারা আপনার কোডে পরিষ্কার মার্কার রেখে যায়।
যদি একটি টেস্টে একটি মেথড কল ব্যর্থ হয়, তাহলে আপনি চাইবেন পুরো টেস্টটি ব্যর্থ হোক, এমনকী যদি সেই মেথডটি পরীক্ষার অধীনে থাকা কার্যকারিতা নাও হয়। যেহেতু panic! হল একটি টেস্টকে ব্যর্থ হিসাবে চিহ্নিত করার উপায়, তাই unwrap বা expect কল করা ঠিক সেটাই ঘটা উচিত।
যেসব ক্ষেত্রে কম্পাইলারের চেয়ে আপনার কাছে বেশি তথ্য রয়েছে (Cases in Which You Have More Information Than the Compiler)
আপনি যখন unwrap বা expect কল করেন তখনও এটি উপযুক্ত হবে যখন আপনার কাছে অন্য কোনো লজিক থাকে যা নিশ্চিত করে যে Result-এর একটি Ok মান থাকবে, কিন্তু লজিকটি কম্পাইলার বোঝার মতো কিছু নয়। আপনার কাছে তখনও একটি Result মান থাকবে যা আপনাকে হ্যান্ডেল করতে হবে: আপনি যে অপারেশনটি কল করছেন সেটি সাধারণভাবে ব্যর্থ হওয়ার সম্ভাবনা রয়েছে, যদিও এটি আপনার নির্দিষ্ট পরিস্থিতিতে যুক্তিসঙ্গতভাবে অসম্ভব। আপনি যদি ম্যানুয়ালি কোডটি পরিদর্শন করে নিশ্চিত করতে পারেন যে আপনার কখনই একটি Err ভেরিয়েন্ট থাকবে না, তাহলে unwrap কল করা সম্পূর্ণভাবে গ্রহণযোগ্য এবং expect-এর টেক্সটে আপনার কেন কখনই একটি Err ভেরিয়েন্ট থাকবে না বলে মনে করেন তার কারণ নথিভুক্ত করা আরও ভাল। এখানে একটি উদাহরণ দেওয়া হল:
fn main() { use std::net::IpAddr; let home: IpAddr = "127.0.0.1" .parse() .expect("Hardcoded IP address should be valid"); }
আমরা একটি হার্ডকোডেড স্ট্রিং পার্স করে একটি IpAddr ইন্সট্যান্স তৈরি করছি। আমরা দেখতে পাচ্ছি যে 127.0.0.1 হল একটি বৈধ IP অ্যাড্রেস, তাই এখানে expect ব্যবহার করা গ্রহণযোগ্য। যাইহোক, একটি হার্ডকোডেড, বৈধ স্ট্রিং থাকা parse মেথডের রিটার্ন টাইপ পরিবর্তন করে না: আমরা এখনও একটি Result মান পাই এবং কম্পাইলার এখনও আমাদের Result হ্যান্ডেল করতে বাধ্য করবে যেন Err ভেরিয়েন্ট একটি সম্ভাবনা, কারণ কম্পাইলার এতটা স্মার্ট নয় যে এটি দেখতে পায় যে এই স্ট্রিংটি সর্বদাই একটি বৈধ IP অ্যাড্রেস। যদি IP অ্যাড্রেসের স্ট্রিংটি প্রোগ্রামে হার্ডকোড করার পরিবর্তে একজন ব্যবহারকারীর কাছ থেকে আসে এবং সেইজন্য ব্যর্থতার সম্ভাবনা থাকে, তাহলে আমাদের অবশ্যই আরও শক্তিশালী উপায়ে Result হ্যান্ডেল করতে হবে। এই IP অ্যাড্রেসটি হার্ডকোড করা হয়েছে এই ধারণাটি উল্লেখ করা ভবিষ্যতে আমাদের expect-কে আরও ভাল এরর-হ্যান্ডলিং কোডে পরিবর্তন করতে উৎসাহিত করবে, যদি আমাদের পরিবর্তে অন্য কোনো উৎস থেকে IP অ্যাড্রেস পেতে হয়।
এরর হ্যান্ডলিংয়ের জন্য নির্দেশিকা (Guidelines for Error Handling)
আপনার কোড প্যানিক করা বাঞ্ছনীয় যখন এটি সম্ভব যে আপনার কোডটি খারাপ অবস্থায় শেষ হতে পারে। এই প্রসঙ্গে, একটি খারাপ অবস্থা (bad state) হল যখন কিছু অনুমান, গ্যারান্টি, চুক্তি বা ইনভেরিয়েন্ট (invariant) ভেঙে যায়, যেমন যখন অবৈধ মান, অসঙ্গতিপূর্ণ মান বা অনুপস্থিত মান আপনার কোডে পাস করা হয়—এছাড়াও নিম্নলিখিত এক বা একাধিক:
- খারাপ অবস্থাটি এমন কিছু যা অপ্রত্যাশিত, এমন কিছুর বিপরীতে যা মাঝে মাঝে ঘটার সম্ভাবনা রয়েছে, যেমন একজন ব্যবহারকারী ভুল ফর্ম্যাটে ডেটা প্রবেশ করানো।
- এই পয়েন্টের পরে আপনার কোডটিকে এই খারাপ অবস্থায় না থাকার উপর নির্ভর করতে হবে, প্রতিটি ধাপে সমস্যার জন্য পরীক্ষা করার পরিবর্তে।
- আপনি যে টাইপগুলো ব্যবহার করছেন তাতে এই তথ্যটি এনকোড করার কোনো ভাল উপায় নেই। আমরা চ্যাপ্টার 18-এ “স্টেট এবং আচরণকে টাইপ হিসাবে এনকোড করা”-তে এর একটি উদাহরণ নিয়ে কাজ করব।
যদি কেউ আপনার কোড কল করে এবং এমন মান পাস করে যা অর্থবোধক নয়, তাহলে আপনি যদি পারেন তবে একটি এরর রিটার্ন করা সবচেয়ে ভাল যাতে লাইব্রেরির ব্যবহারকারী সিদ্ধান্ত নিতে পারে যে তারা সেই ক্ষেত্রে কী করতে চায়। যাইহোক, যে ক্ষেত্রগুলোতে চালিয়ে যাওয়া অনিরাপদ বা ক্ষতিকারক হতে পারে, সেখানে panic! কল করা এবং আপনার লাইব্রেরি ব্যবহার করা ব্যক্তিকে তাদের কোডের বাগ সম্পর্কে সতর্ক করা সবচেয়ে ভাল হতে পারে যাতে তারা ডেভেলপমেন্টের সময় এটি ঠিক করতে পারে। একইভাবে, আপনি যদি এক্সটার্নাল কোড কল করেন যা আপনার নিয়ন্ত্রণের বাইরে এবং এটি একটি অবৈধ অবস্থা রিটার্ন করে যা আপনার ঠিক করার কোনো উপায় নেই, তাহলে panic! প্রায়শই উপযুক্ত।
তবে, যখন ব্যর্থতা প্রত্যাশিত হয়, তখন একটি panic! কল করার চেয়ে Result রিটার্ন করা আরও উপযুক্ত। উদাহরণগুলোর মধ্যে রয়েছে একটি পার্সারকে বিকৃত ডেটা দেওয়া বা একটি HTTP অনুরোধ একটি স্ট্যাটাস রিটার্ন করা যা নির্দেশ করে যে আপনি একটি রেট লিমিটে পৌঁছে গেছেন। এই ক্ষেত্রগুলোতে, একটি Result রিটার্ন করা ইঙ্গিত দেয় যে ব্যর্থতা একটি প্রত্যাশিত সম্ভাবনা যা কলিং কোডকে কীভাবে হ্যান্ডেল করতে হবে তা অবশ্যই সিদ্ধান্ত নিতে হবে।
যখন আপনার কোড এমন একটি অপারেশন করে যা অবৈধ মান ব্যবহার করে কল করা হলে একজন ব্যবহারকারীকে ঝুঁকিতে ফেলতে পারে, তখন আপনার কোড প্রথমে মানগুলো বৈধ কিনা তা যাচাই করা উচিত এবং যদি মানগুলো বৈধ না হয় তবে প্যানিক করা উচিত। এটি বেশিরভাগ নিরাপত্তার কারণে: অবৈধ ডেটাতে কাজ করার চেষ্টা করা আপনার কোডকে দুর্বলতার দিকে প্রকাশ করতে পারে। আপনি যদি একটি আউট-অফ-বাউন্ডস মেমরি অ্যাক্সেসের চেষ্টা করেন তবে স্ট্যান্ডার্ড লাইব্রেরি panic! কল করার এটি প্রধান কারণ: বর্তমান ডেটা স্ট্রাকচারের অন্তর্গত নয় এমন মেমরি অ্যাক্সেস করার চেষ্টা করা একটি সাধারণ নিরাপত্তা সমস্যা। ফাংশনগুলোতে প্রায়শই চুক্তি (contracts) থাকে: ইনপুটগুলো নির্দিষ্ট প্রয়োজনীয়তা পূরণ করলেই তাদের আচরণ গ্যারান্টিযুক্ত হয়। চুক্তি লঙ্ঘন হলে প্যানিক করা অর্থবোধক কারণ একটি চুক্তি লঙ্ঘন সর্বদাই একটি কলার-সাইড বাগ নির্দেশ করে এবং এটি এমন কোনো ধরনের এরর নয় যা আপনি চান যে কলিং কোডটিকে স্পষ্টতই হ্যান্ডেল করতে হবে। আসলে, কলিং কোডের পুনরুদ্ধার করার কোনো যুক্তিসঙ্গত উপায় নেই; কলিং প্রোগ্রামারদের কোড ঠিক করতে হবে। একটি ফাংশনের জন্য চুক্তিগুলো, বিশেষ করে যখন একটি লঙ্ঘন প্যানিকের কারণ হবে, ফাংশনের জন্য API ডকুমেন্টেশনে ব্যাখ্যা করা উচিত।
যাইহোক, আপনার সমস্ত ফাংশনে প্রচুর এরর চেক থাকা শব্দবহুল এবং বিরক্তিকর হবে। সৌভাগ্যবশত, আপনি আপনার জন্য অনেকগুলি চেক করতে Rust-এর টাইপ সিস্টেম (এবং এইভাবে কম্পাইলার দ্বারা করা টাইপ চেকিং) ব্যবহার করতে পারেন। যদি আপনার ফাংশনে একটি প্যারামিটার হিসাবে একটি নির্দিষ্ট টাইপ থাকে, তাহলে আপনি আপনার কোডের লজিকের সাথে এগিয়ে যেতে পারেন, এটি জেনে যে কম্পাইলার ইতিমধ্যেই নিশ্চিত করেছে যে আপনার কাছে একটি বৈধ মান রয়েছে। উদাহরণস্বরূপ, যদি আপনার একটি টাইপ থাকে Option-এর পরিবর্তে, তাহলে আপনার প্রোগ্রামটি কিছু না থাকার পরিবর্তে কিছু থাকার আশা করে। আপনার কোডটিকে তখন Some এবং None ভেরিয়েন্টগুলোর জন্য দুটি ক্ষেত্র হ্যান্ডেল করতে হবে না: এটির শুধুমাত্র একটি ক্ষেত্র থাকবে যেখানে অবশ্যই একটি মান থাকবে। আপনার ফাংশনে কিছুই পাস করার চেষ্টা করা কোড কম্পাইল হবে না, তাই আপনার ফাংশনকে রানটাইমে সেই ক্ষেত্রের জন্য পরীক্ষা করতে হবে না। আরেকটি উদাহরণ হল একটি আনসাইনড ইন্টিজার টাইপ যেমন u32 ব্যবহার করা, যা নিশ্চিত করে যে প্যারামিটারটি কখনই নেতিবাচক নয়।
বৈধতার জন্য কাস্টম টাইপ তৈরি করা (Creating Custom Types for Validation)
আসুন Rust-এর টাইপ সিস্টেম ব্যবহার করার ধারণাটি আরও এক ধাপ এগিয়ে নিয়ে যাই যাতে আমরা একটি বৈধ মান নিশ্চিত করি এবং বৈধতার জন্য একটি কাস্টম টাইপ তৈরি করার দিকে নজর দিই। চ্যাপ্টার ২-এর অনুমান করার গেমটি স্মরণ করুন যেখানে আমাদের কোড ব্যবহারকারীকে 1 থেকে 100-এর মধ্যে একটি সংখ্যা অনুমান করতে বলেছিল। আমরা আমাদের গোপন সংখ্যার সাথে এটি পরীক্ষা করার আগে ব্যবহারকারীর অনুমান সেই সংখ্যাগুলোর মধ্যে ছিল কিনা তা আমরা কখনই যাচাই করিনি; আমরা শুধুমাত্র যাচাই করেছি যে অনুমানটি ধনাত্মক ছিল। এই ক্ষেত্রে, পরিণতিগুলো খুব ভয়াবহ ছিল না: আমাদের "Too high" বা "Too low"-এর আউটপুট এখনও সঠিক হবে। কিন্তু ব্যবহারকারীকে বৈধ অনুমানের দিকে পরিচালিত করা এবং ব্যবহারকারী যখন সীমার বাইরের কোনো সংখ্যা অনুমান করে তার পরিবর্তে যখন ব্যবহারকারী, উদাহরণস্বরূপ, অক্ষরের টাইপ করে তখন ভিন্ন আচরণ করা একটি দরকারী উন্নতি হবে।
এটি করার একটি উপায় হল অনুমানটিকে শুধুমাত্র একটি u32-এর পরিবর্তে একটি i32 হিসাবে পার্স করা যাতে সম্ভাব্য নেতিবাচক সংখ্যাগুলোর অনুমতি দেওয়া যায় এবং তারপর সংখ্যাটি সীমার মধ্যে আছে কিনা তার জন্য একটি চেক যোগ করা, এইভাবে:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("The secret number will be between 1 and 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}if এক্সপ্রেশনটি পরীক্ষা করে যে আমাদের মান সীমার বাইরে কিনা, ব্যবহারকারীকে সমস্যা সম্পর্কে বলে এবং লুপের পরবর্তী পুনরাবৃত্তি শুরু করতে এবং আরেকটি অনুমানের জন্য জিজ্ঞাসা করতে continue কল করে। if এক্সপ্রেশনের পরে, আমরা guess এবং গোপন সংখ্যার মধ্যে তুলনা চালিয়ে যেতে পারি, এটি জেনে যে guess 1 এবং 100-এর মধ্যে রয়েছে।
যাইহোক, এটি একটি আদর্শ সমাধান নয়: যদি এটি একেবারে গুরুত্বপূর্ণ হয় যে প্রোগ্রামটি শুধুমাত্র 1 থেকে 100-এর মধ্যে মানগুলোর উপর কাজ করে এবং এটির অনেক ফাংশনে এই প্রয়োজনীয়তা থাকে, তাহলে প্রতিটি ফাংশনে এইরকম একটি চেক থাকা ক্লান্তিকর হবে (এবং পারফরম্যান্সকে প্রভাবিত করতে পারে)।
পরিবর্তে, আমরা একটি নতুন টাইপ তৈরি করতে পারি এবং সর্বত্র বৈধতা পুনরাবৃত্তি করার পরিবর্তে টাইপের একটি ইন্সট্যান্স তৈরি করার জন্য একটি ফাংশনে বৈধতা রাখতে পারি। এইভাবে, ফাংশনগুলোর জন্য তাদের সিগনেচারে নতুন টাইপ ব্যবহার করা এবং তারা যে মানগুলো গ্রহণ করে সেগুলো আত্মবিশ্বাসের সাথে ব্যবহার করা নিরাপদ। Listing 9-13 একটি Guess টাইপ সংজ্ঞায়িত করার একটি উপায় দেখায় যা শুধুমাত্র তখনই Guess-এর একটি ইন্সট্যান্স তৈরি করবে যদি new ফাংশনটি 1 থেকে 100-এর মধ্যে একটি মান পায়।
#![allow(unused)] fn main() { pub struct Guess { value: i32, } impl Guess { pub fn new(value: i32) -> Guess { if value < 1 || value > 100 { panic!("Guess value must be between 1 and 100, got {value}."); } Guess { value } } pub fn value(&self) -> i32 { self.value } } }
প্রথমে আমরা Guess নামে একটি স্ট্রাকট সংজ্ঞায়িত করি যাতে value নামে একটি ফিল্ড রয়েছে যা একটি i32 ধারণ করে। এখানেই সংখ্যাটি সংরক্ষণ করা হবে।
তারপর আমরা Guess-এ new নামে একটি অ্যাসোসিয়েটেড ফাংশন ইমপ্লিমেন্ট করি যা Guess মানগুলোর ইন্সট্যান্স তৈরি করে। new ফাংশনটি i32 টাইপের value নামক একটি প্যারামিটার নিতে এবং একটি Guess রিটার্ন করার জন্য সংজ্ঞায়িত করা হয়েছে। new ফাংশনের বডির কোডটি value পরীক্ষা করে নিশ্চিত করে যে এটি 1 থেকে 100-এর মধ্যে রয়েছে। যদি value এই পরীক্ষায় উত্তীর্ণ না হয়, তাহলে আমরা একটি panic! কল করি, যা কলিং কোডটি লিখছেন এমন প্রোগ্রামারকে সতর্ক করবে যে তাদের একটি বাগ রয়েছে যা তাদের ঠিক করতে হবে, কারণ এই সীমার বাইরের একটি value সহ একটি Guess তৈরি করা Guess::new যে চুক্তির উপর নির্ভর করছে তা লঙ্ঘন করবে। যে পরিস্থিতিতে Guess::new প্যানিক করতে পারে তা এর পাবলিক-ফেসিং API ডকুমেন্টেশনে আলোচনা করা উচিত; আমরা চ্যাপ্টার 14-এ আপনার তৈরি করা API ডকুমেন্টেশনে panic!-এর সম্ভাবনা নির্দেশ করে এমন ডকুমেন্টেশন কনভেনশনগুলো কভার করব। যদি value পরীক্ষায় উত্তীর্ণ হয়, তাহলে আমরা value প্যারামিটারে সেট করা এর value ফিল্ড সহ একটি নতুন Guess তৈরি করি এবং Guess রিটার্ন করি।
এরপর, আমরা value নামে একটি মেথড ইমপ্লিমেন্ট করি যা self ধার করে, অন্য কোনো প্যারামিটার নেই এবং একটি i32 রিটার্ন করে। এই ধরনের মেথডকে কখনও কখনও গেটার (getter) বলা হয় কারণ এর উদ্দেশ্য হল এর ফিল্ডগুলো থেকে কিছু ডেটা পাওয়া এবং তা রিটার্ন করা। এই পাবলিক মেথডটি প্রয়োজনীয় কারণ Guess স্ট্রাকটের value ফিল্ডটি প্রাইভেট। value ফিল্ডটি প্রাইভেট হওয়া গুরুত্বপূর্ণ যাতে Guess স্ট্রাকট ব্যবহার করা কোড সরাসরি value সেট করার অনুমতি না পায়: মডিউলের বাইরের কোডকে অবশ্যই Guess-এর একটি ইন্সট্যান্স তৈরি করতে Guess::new ফাংশন ব্যবহার করতে হবে, এইভাবে এটি নিশ্চিত করে যে Guess-এর এমন কোনো value থাকার কোনো উপায় নেই যা Guess::new ফাংশনের শর্তগুলো দ্বারা পরীক্ষা করা হয়নি।
একটি ফাংশন যার একটি প্যারামিটার রয়েছে বা শুধুমাত্র 1 থেকে 100-এর মধ্যে সংখ্যা রিটার্ন করে, তারপর তার সিগনেচারে ঘোষণা করতে পারে যে এটি একটি i32-এর পরিবর্তে একটি Guess নেয় বা রিটার্ন করে এবং এর বডিতে কোনো অতিরিক্ত চেক করার প্রয়োজন হবে না।
সারসংক্ষেপ (Summary)
Rust-এর এরর-হ্যান্ডলিং ফিচারগুলো আপনাকে আরও শক্তিশালী কোড লিখতে সাহায্য করার জন্য ডিজাইন করা হয়েছে। panic! ম্যাক্রো সংকেত দেয় যে আপনার প্রোগ্রামটি এমন একটি অবস্থায় রয়েছে যা এটি হ্যান্ডেল করতে পারে না এবং আপনাকে অবৈধ বা ভুল মান নিয়ে এগিয়ে যাওয়ার চেষ্টা করার পরিবর্তে প্রক্রিয়াটি বন্ধ করতে দেয়। Result এনাম Rust-এর টাইপ সিস্টেম ব্যবহার করে নির্দেশ করে যে অপারেশনগুলো এমনভাবে ব্যর্থ হতে পারে যা থেকে আপনার কোড পুনরুদ্ধার করতে পারে। আপনি আপনার কোডকে কল করা কোডকে জানাতে Result ব্যবহার করতে পারেন যে এটিকে সম্ভাব্য সাফল্য বা ব্যর্থতা উভয়ই হ্যান্ডেল করতে হবে। উপযুক্ত পরিস্থিতিতে panic! এবং Result ব্যবহার করা অনিবার্য সমস্যার মুখে আপনার কোডকে আরও নির্ভরযোগ্য করে তুলবে।
এখন আপনি দেখেছেন যে স্ট্যান্ডার্ড লাইব্রেরি কীভাবে Option এবং Result এনামগুলোর সাথে জেনেরিক ব্যবহার করে, আমরা জেনেরিকগুলো কীভাবে কাজ করে এবং আপনি কীভাবে আপনার কোডে সেগুলো ব্যবহার করতে পারেন সে সম্পর্কে কথা বলব।
জেনেরিক টাইপ, ট্রেইট এবং লাইফটাইম (Generic Types, Traits, and Lifetimes)
প্রায় প্রতিটি প্রোগ্রামিং ল্যাঙ্গুয়েজের ধারণার ডুপ্লিকেশন (duplication) কার্যকরভাবে পরিচালনা করার জন্য টুল রয়েছে। Rust-এ, এই ধরনের একটি টুল হল জেনেরিকস (generics): কংক্রিট টাইপ বা অন্যান্য বৈশিষ্ট্যের জন্য অ্যাবস্ট্রাক্ট স্ট্যান্ড-ইন (abstract stand-ins)। কোড কম্পাইল এবং রান করার সময় তাদের জায়গায় কী থাকবে তা না জেনেই আমরা জেনেরিকগুলোর আচরণ বা অন্যান্য জেনেরিকের সাথে তারা কীভাবে সম্পর্কিত তা প্রকাশ করতে পারি।
ফাংশনগুলো i32 বা String-এর মতো কংক্রিট টাইপের পরিবর্তে কিছু জেনেরিক টাইপের প্যারামিটার নিতে পারে, একইভাবে তারা একাধিক কংক্রিট মানের উপর একই কোড চালানোর জন্য অজানা মান সহ প্যারামিটার নেয়। প্রকৃতপক্ষে, আমরা ইতিমধ্যেই চ্যাপ্টার ৬-এ Option<T>, চ্যাপ্টার ৮-এ Vec<T> এবং HashMap<K, V>, এবং চ্যাপ্টার ৯-এ Result<T, E>-এর সাথে জেনেরিক ব্যবহার করেছি। এই চ্যাপ্টারে, আপনি শিখবেন কিভাবে জেনেরিক ব্যবহার করে আপনার নিজস্ব টাইপ, ফাংশন এবং মেথড সংজ্ঞায়িত করতে হয়!
প্রথমে আমরা কোড ডুপ্লিকেশন কমাতে একটি ফাংশন কীভাবে এক্সট্র্যাক্ট (extract) করতে হয় তা পর্যালোচনা করব। তারপর আমরা একই কৌশল ব্যবহার করে দুটি ফাংশন থেকে একটি জেনেরিক ফাংশন তৈরি করব যা শুধুমাত্র তাদের প্যারামিটারের টাইপের ক্ষেত্রে ভিন্ন। আমরা স্ট্রাকট এবং এনাম সংজ্ঞায় জেনেরিক টাইপ কীভাবে ব্যবহার করতে হয় তাও ব্যাখ্যা করব।
তারপর আপনি শিখবেন কিভাবে একটি জেনেরিক উপায়ে আচরণ সংজ্ঞায়িত করতে ট্রেইট (traits) ব্যবহার করতে হয়। আপনি জেনেরিক টাইপের সাথে ট্রেইটগুলোকে একত্রিত করে একটি জেনেরিক টাইপকে সীমাবদ্ধ করতে পারেন যাতে এটি শুধুমাত্র সেই টাইপগুলো গ্রহণ করে যাদের একটি নির্দিষ্ট আচরণ রয়েছে, যেকোনো টাইপের পরিবর্তে।
অবশেষে, আমরা লাইফটাইম (lifetimes) নিয়ে আলোচনা করব: এক ধরনের জেনেরিক যা কম্পাইলারকে রেফারেন্সগুলো একে অপরের সাথে কীভাবে সম্পর্কিত সে সম্পর্কে তথ্য দেয়। লাইফটাইম আমাদের কম্পাইলারকে ধার করা মান সম্পর্কে যথেষ্ট তথ্য দিতে দেয় যাতে এটি নিশ্চিত করতে পারে যে রেফারেন্সগুলো আমাদের সাহায্য ছাড়াই আরও পরিস্থিতিতে বৈধ হবে।
একটি ফাংশন এক্সট্র্যাক্ট করে ডুপ্লিকেশন অপসারণ করা (Removing Duplication by Extracting a Function)
কোড ডুপ্লিকেশন অপসারণ করতে আমরা জেনেরিক টাইপ ব্যবহার করে একটি ফাংশন তৈরি করব। জেনেরিক সিনট্যাক্সে (syntax) প্রবেশ করার আগে, আসুন প্রথমে দেখি কিভাবে জেনেরিক টাইপ ব্যবহার না করে ডুপ্লিকেশন অপসারণ করা যায়, এমন একটি ফাংশন এক্সট্র্যাক্ট করে যা নির্দিষ্ট মানগুলোকে একটি প্লেসহোল্ডার দিয়ে প্রতিস্থাপন করে যা একাধিক মান উপস্থাপন করে। তারপর আমরা একটি জেনেরিক ফাংশন এক্সট্র্যাক্ট করার জন্য একই কৌশল প্রয়োগ করব! কিভাবে ডুপ্লিকেট কোড শনাক্ত করতে হয় যা আপনি একটি ফাংশনে এক্সট্র্যাক্ট করতে পারেন, তা দেখে আপনি জেনেরিক ব্যবহার করতে পারে এমন ডুপ্লিকেট কোড চিনতে শুরু করবেন।
আমরা Listing 10-1-এর ছোট প্রোগ্রামটি দিয়ে শুরু করব যা একটি তালিকার বৃহত্তম সংখ্যা খুঁজে বের করে।
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); assert_eq!(*largest, 100); }
আমরা number_list ভেরিয়েবলে পূর্ণসংখ্যার একটি তালিকা সংরক্ষণ করি এবং তালিকার প্রথম সংখ্যার একটি রেফারেন্স largest নামক একটি ভেরিয়েবলে রাখি। তারপর আমরা তালিকার সমস্ত সংখ্যার মধ্যে পুনরাবৃত্তি করি, এবং যদি বর্তমান সংখ্যাটি largest-এ সংরক্ষিত সংখ্যার চেয়ে বড় হয়, তাহলে আমরা সেই ভেরিয়েবলের রেফারেন্স প্রতিস্থাপন করি। যাইহোক, যদি বর্তমান সংখ্যাটি ఇప్పటి পর্যন্ত দেখা বৃহত্তম সংখ্যার চেয়ে ছোট বা সমান হয়, তাহলে ভেরিয়েবলটি পরিবর্তন হয় না এবং কোডটি তালিকার পরবর্তী সংখ্যায় চলে যায়। তালিকার সমস্ত সংখ্যা বিবেচনা করার পরে, largest সবচেয়ে বড় সংখ্যাটিকে রেফার করবে, যা এই ক্ষেত্রে 100।
আমাদের এখন দুটি ভিন্ন সংখ্যার তালিকায় বৃহত্তম সংখ্যা খুঁজে বের করার দায়িত্ব দেওয়া হয়েছে। এটি করার জন্য, আমরা Listing 10-1-এর কোডটি ডুপ্লিকেট করতে পারি এবং প্রোগ্রামের দুটি ভিন্ন স্থানে একই লজিক ব্যবহার করতে পারি, যেমনটি Listing 10-2-তে দেখানো হয়েছে।
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); }
যদিও এই কোডটি কাজ করে, কোড ডুপ্লিকেট করা ক্লান্তিকর এবং এরর-প্রবণ। আমরা যখন কোড পরিবর্তন করতে চাই তখন একাধিক স্থানে কোড আপডেট করার কথাও মনে রাখতে হবে।
এই ডুপ্লিকেশন দূর করার জন্য, আমরা একটি অ্যাবস্ট্রাকশন (abstraction) তৈরি করব একটি ফাংশন সংজ্ঞায়িত করে যা প্যারামিটার হিসাবে পাস করা যেকোনো পূর্ণসংখ্যার তালিকার উপর কাজ করে। এই সমাধানটি আমাদের কোডকে আরও পরিষ্কার করে এবং আমাদের একটি তালিকা থেকে বৃহত্তম সংখ্যা খুঁজে বের করার ধারণাটিকে অ্যাবস্ট্রাক্টলি (abstractly) প্রকাশ করতে দেয়।
Listing 10-3-এ, আমরা বৃহত্তম সংখ্যা খুঁজে বের করার কোডটিকে largest নামক একটি ফাংশনে এক্সট্র্যাক্ট করি। তারপর আমরা Listing 10-2 থেকে দুটি তালিকায় বৃহত্তম সংখ্যা খুঁজে বের করার জন্য ফাংশনটিকে কল করি। আমরা ভবিষ্যতে আমাদের কাছে থাকতে পারে এমন i32 মানগুলোর অন্য যেকোনো তালিকাতেও ফাংশনটি ব্যবহার করতে পারি।
fn largest(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 100); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let result = largest(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 6000); }
largest ফাংশনটির list নামক একটি প্যারামিটার রয়েছে, যা যেকোনো i32 মানের কংক্রিট স্লাইসকে উপস্থাপন করে যা আমরা ফাংশনে পাস করতে পারি। ফলস্বরূপ, যখন আমরা ফাংশনটি কল করি, তখন কোডটি আমাদের পাস করা নির্দিষ্ট মানগুলোর উপর চলে।
সংক্ষেপে, এখানে আমরা Listing 10-2 থেকে Listing 10-3-এর কোড পরিবর্তন করার জন্য যে ধাপগুলো নিয়েছি সেগুলো হল:
- ডুপ্লিকেট কোড সনাক্ত করুন।
- ডুপ্লিকেট কোডটিকে ফাংশনের বডিতে এক্সট্র্যাক্ট করুন এবং ফাংশন সিগনেচারে সেই কোডের ইনপুট এবং রিটার্ন মানগুলো নির্দিষ্ট করুন।
- ডুপ্লিকেট কোডের দুটি ইন্সট্যান্স আপডেট করুন যাতে পরিবর্তে ফাংশনটিকে কল করা যায়।
এরপর, আমরা কোড ডুপ্লিকেশন কমাতে জেনেরিক ব্যবহার করে এই একই ধাপগুলো ব্যবহার করব। একইভাবে যে ফাংশন বডিটি নির্দিষ্ট মানগুলোর পরিবর্তে একটি অ্যাবস্ট্রাক্ট list-এর উপর কাজ করতে পারে, জেনেরিকগুলো কোডকে অ্যাবস্ট্রাক্ট টাইপের উপর কাজ করার অনুমতি দেয়।
উদাহরণস্বরূপ, ধরা যাক আমাদের দুটি ফাংশন ছিল: একটি যা i32 মানগুলোর একটি স্লাইসে বৃহত্তম আইটেম খুঁজে বের করে এবং একটি যা char মানগুলোর একটি স্লাইসে বৃহত্তম আইটেম খুঁজে বের করে। আমরা কীভাবে সেই ডুপ্লিকেশন দূর করব? চলুন খুঁজে বের করি!
জেনেরিক ডেটা টাইপ (Generic Data Types)
আমরা ফাংশন সিগনেচার বা স্ট্রাকটের মতো আইটেমগুলোর জন্য সংজ্ঞা তৈরি করতে জেনেরিক ব্যবহার করি, যা আমরা পরে বিভিন্ন কংক্রিট ডেটা টাইপের সাথে ব্যবহার করতে পারি। আসুন প্রথমে দেখি কিভাবে জেনেরিক ব্যবহার করে ফাংশন, স্ট্রাকট, এনাম এবং মেথড সংজ্ঞায়িত করতে হয়। তারপর আমরা আলোচনা করব কিভাবে জেনেরিক কোড পারফরম্যান্সকে প্রভাবিত করে।
ফাংশন সংজ্ঞায় (In Function Definitions)
যখন আমরা জেনেরিক ব্যবহার করে একটি ফাংশন সংজ্ঞায়িত করি, তখন আমরা ফাংশনের সিগনেচারে জেনেরিকগুলো রাখি, যেখানে আমরা সাধারণত প্যারামিটার এবং রিটার্ন মানের ডেটা টাইপগুলো নির্দিষ্ট করি। এটি করা আমাদের কোডকে আরও নমনীয় করে তোলে এবং কোড ডুপ্লিকেশন রোধ করার সময় আমাদের ফাংশনের কলারদের আরও কার্যকারিতা প্রদান করে।
আমাদের largest ফাংশনটি নিয়ে আলোচনা চালিয়ে গেলে, Listing 10-4 দুটি ফাংশন দেখায় যা উভয়ই একটি স্লাইসের বৃহত্তম মান খুঁজে বের করে। আমরা তারপর সেগুলোকে জেনেরিক ব্যবহার করে একটি একক ফাংশনে একত্রিত করব।
fn largest_i32(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn largest_char(list: &[char]) -> &char { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest_i32(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 100); let char_list = vec!['y', 'm', 'a', 'q']; let result = largest_char(&char_list); println!("The largest char is {result}"); assert_eq!(*result, 'y'); }
largest_i32 ফাংশনটি হল সেই ফাংশন যা আমরা Listing 10-3-এ এক্সট্র্যাক্ট করেছি, যেটি একটি স্লাইসের বৃহত্তম i32 খুঁজে বের করে। largest_char ফাংশনটি একটি স্লাইসের বৃহত্তম char খুঁজে বের করে। ফাংশন বডিগুলোর একই কোড রয়েছে, তাই আসুন একটি একক ফাংশনে জেনেরিক টাইপ প্যারামিটার প্রবর্তন করে ডুপ্লিকেশন দূর করি।
একটি নতুন একক ফাংশনে টাইপগুলোকে প্যারামিটারাইজ করার জন্য, আমাদের টাইপ প্যারামিটারের নাম দিতে হবে, ঠিক যেমনটি আমরা একটি ফাংশনের ভ্যালু প্যারামিটারগুলোর জন্য করি। আপনি টাইপ প্যারামিটারের নাম হিসাবে যেকোনো আইডেন্টিফায়ার ব্যবহার করতে পারেন। কিন্তু আমরা T ব্যবহার করব কারণ, কনভেনশন অনুসারে, Rust-এ টাইপ প্যারামিটারের নামগুলো ছোট হয়, প্রায়শই শুধুমাত্র একটি অক্ষর এবং Rust-এর টাইপ-নেমিং কনভেনশন হল CamelCase। টাইপের জন্য সংক্ষিপ্ত, T হল বেশিরভাগ Rust প্রোগ্রামারদের ডিফল্ট পছন্দ।
যখন আমরা ফাংশনের বডিতে একটি প্যারামিটার ব্যবহার করি, তখন আমাদের সিগনেচারে প্যারামিটারের নাম ঘোষণা করতে হবে যাতে কম্পাইলার বুঝতে পারে সেই নামের অর্থ কী। একইভাবে, যখন আমরা একটি ফাংশন সিগনেচারে একটি টাইপ প্যারামিটারের নাম ব্যবহার করি, তখন আমাদের এটি ব্যবহার করার আগে টাইপ প্যারামিটারের নাম ঘোষণা করতে হবে। জেনেরিক largest ফাংশন সংজ্ঞায়িত করতে, আমরা ফাংশনের নাম এবং প্যারামিটার তালিকার মধ্যে অ্যাঙ্গেল ব্র্যাকেট, <>,-এর ভিতরে টাইপের নামের ঘোষণাগুলো রাখি, এইভাবে:
fn largest<T>(list: &[T]) -> &T {আমরা এই সংজ্ঞাটি এভাবে পড়ি: ফাংশন largest কিছু টাইপ T-এর উপর জেনেরিক। এই ফাংশনটির একটি প্যারামিটার রয়েছে যার নাম list, যেটি টাইপ T-এর মানগুলোর একটি স্লাইস। largest ফাংশনটি একই টাইপ T-এর একটি মানের রেফারেন্স রিটার্ন করবে।
Listing 10-5 তার সিগনেচারে জেনেরিক ডেটা টাইপ ব্যবহার করে সম্মিলিত largest ফাংশন সংজ্ঞা দেখায়। লিস্টিংটি আরও দেখায় কিভাবে আমরা ফাংশনটিকে i32 মান বা char মানগুলোর স্লাইস দিয়ে কল করতে পারি। মনে রাখবেন যে এই কোডটি এখনও কম্পাইল হবে না, কিন্তু আমরা এই চ্যাপ্টারের পরে এটি ঠিক করব।
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {result}");
}যদি আমরা এখনই এই কোডটি কম্পাইল করি, তাহলে আমরা এই এররটি পাব:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
হেল্প টেক্সট std::cmp::PartialOrd উল্লেখ করে, যেটি একটি ট্রেইট (trait), এবং আমরা পরবর্তী বিভাগে ট্রেইট নিয়ে কথা বলব। আপাতত, জেনে রাখুন যে এই এররটি বলে যে largest-এর বডি T-এর সম্ভাব্য সমস্ত টাইপের জন্য কাজ করবে না। যেহেতু আমরা বডিতে T টাইপের মানগুলোর তুলনা করতে চাই, তাই আমরা শুধুমাত্র সেই টাইপগুলো ব্যবহার করতে পারি যাদের মানগুলো অর্ডার করা যায়। তুলনা সক্রিয় করতে, স্ট্যান্ডার্ড লাইব্রেরিতে std::cmp::PartialOrd ট্রেইট রয়েছে যা আপনি টাইপগুলোতে ইমপ্লিমেন্ট করতে পারেন (এই ট্রেইট সম্পর্কে আরও জানতে Appendix C দেখুন)। হেল্প টেক্সটের পরামর্শ অনুসরণ করে, আমরা T-এর জন্য বৈধ টাইপগুলোকে শুধুমাত্র তাদের মধ্যে সীমাবদ্ধ করি যারা PartialOrd ইমপ্লিমেন্ট করে এবং এই উদাহরণটি কম্পাইল হবে, কারণ স্ট্যান্ডার্ড লাইব্রেরি i32 এবং char উভয়টিতেই PartialOrd ইমপ্লিমেন্ট করে।
স্ট্রাকট সংজ্ঞায় (In Struct Definitions)
আমরা <> সিনট্যাক্স ব্যবহার করে এক বা একাধিক ফিল্ডে জেনেরিক টাইপ প্যারামিটার ব্যবহার করে স্ট্রাকট সংজ্ঞায়িত করতে পারি। Listing 10-6 যেকোনো টাইপের x এবং y কো-অর্ডিনেট মান ধারণ করার জন্য একটি Point<T> স্ট্রাকট সংজ্ঞায়িত করে।
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }
স্ট্রাকট সংজ্ঞায় জেনেরিক ব্যবহারের সিনট্যাক্স ফাংশন সংজ্ঞায় ব্যবহৃত সিনট্যাক্সের অনুরূপ। প্রথমে আমরা স্ট্রাকটের নামের ঠিক পরেই অ্যাঙ্গেল ব্র্যাকেটের ভিতরে টাইপ প্যারামিটারের নাম ঘোষণা করি। তারপর আমরা স্ট্রাকট সংজ্ঞায় জেনেরিক টাইপ ব্যবহার করি যেখানে আমরা অন্যথায় কংক্রিট ডেটা টাইপ নির্দিষ্ট করতাম।
লক্ষ্য করুন যে যেহেতু আমরা Point<T> সংজ্ঞায়িত করার জন্য শুধুমাত্র একটি জেনেরিক টাইপ ব্যবহার করেছি, এই সংজ্ঞাটি বলে যে Point<T> স্ট্রাকটটি কিছু টাইপ T-এর উপর জেনেরিক, এবং x এবং y ফিল্ডগুলো উভয়ই একই টাইপের, সেই টাইপ যাই হোক না কেন। আমরা যদি Point<T>-এর একটি ইন্সট্যান্স তৈরি করি যেখানে বিভিন্ন টাইপের মান রয়েছে, যেমনটি Listing 10-7-এ রয়েছে, তাহলে আমাদের কোড কম্পাইল হবে না।
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}এই উদাহরণে, যখন আমরা x-এ ইন্টিজার মান 5 অ্যাসাইন করি, তখন আমরা কম্পাইলারকে জানাই যে এই Point<T> ইন্সট্যান্সের জন্য জেনেরিক টাইপ T একটি ইন্টিজার হবে। তারপর যখন আমরা y-এর জন্য 4.0 নির্দিষ্ট করি, যাকে আমরা x-এর মতোই একই টাইপ হিসাবে সংজ্ঞায়িত করেছি, তখন আমরা এইরকম একটি টাইপ মিসম্যাচ এরর পাব:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
একটি Point স্ট্রাকট সংজ্ঞায়িত করতে যেখানে x এবং y উভয়ই জেনেরিক কিন্তু ভিন্ন টাইপ হতে পারে, আমরা একাধিক জেনেরিক টাইপ প্যারামিটার ব্যবহার করতে পারি। উদাহরণস্বরূপ, Listing 10-8-এ, আমরা Point-এর সংজ্ঞা পরিবর্তন করে T এবং U টাইপের উপর জেনেরিক করি যেখানে x হল T টাইপের এবং y হল U টাইপের।
struct Point<T, U> { x: T, y: U, } fn main() { let both_integer = Point { x: 5, y: 10 }; let both_float = Point { x: 1.0, y: 4.0 }; let integer_and_float = Point { x: 5, y: 4.0 }; }
এখন দেখানো Point-এর সমস্ত ইন্সট্যান্স অনুমোদিত! আপনি একটি সংজ্ঞায় যত খুশি জেনেরিক টাইপ প্যারামিটার ব্যবহার করতে পারেন, কিন্তু কয়েকটির বেশি ব্যবহার করলে আপনার কোড পড়া কঠিন হয়ে যায়। আপনি যদি আপনার কোডে প্রচুর জেনেরিক টাইপের প্রয়োজন বোধ করেন, তাহলে এটি ইঙ্গিত করতে পারে যে আপনার কোডটিকে ছোট ছোট অংশে পুনর্গঠন করা দরকার।
এনাম সংজ্ঞায় (In Enum Definitions)
আমরা যেমন স্ট্রাকট দিয়ে করেছি, তেমনি আমরা এনাম সংজ্ঞায়িত করতে পারি যাতে তাদের ভেরিয়েন্টগুলোতে জেনেরিক ডেটা টাইপ থাকে। আসুন স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সরবরাহ করা Option<T> এনামটি আবার দেখি, যা আমরা চ্যাপ্টার ৬-এ ব্যবহার করেছি:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
এই সংজ্ঞাটি এখন আপনার কাছে আরও বোধগম্য হওয়া উচিত। আপনি যেমন দেখতে পাচ্ছেন, Option<T> এনামটি T টাইপের উপর জেনেরিক এবং এর দুটি ভেরিয়েন্ট রয়েছে: Some, যা T টাইপের একটি মান ধারণ করে এবং একটি None ভেরিয়েন্ট যা কোনো মান ধারণ করে না। Option<T> এনাম ব্যবহার করে, আমরা একটি ঐচ্ছিক মানের অ্যাবস্ট্রাক্ট ধারণা প্রকাশ করতে পারি এবং যেহেতু Option<T> জেনেরিক, তাই আমরা এই অ্যাবস্ট্রাকশনটি ব্যবহার করতে পারি ঐচ্ছিক মানের টাইপ যাই হোক না কেন।
এনামগুলো একাধিক জেনেরিক টাইপও ব্যবহার করতে পারে। Result এনামের সংজ্ঞা যা আমরা চ্যাপ্টার ৯-এ ব্যবহার করেছি তার একটি উদাহরণ:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
Result এনামটি দুটি টাইপ, T এবং E-এর উপর জেনেরিক এবং এর দুটি ভেরিয়েন্ট রয়েছে: Ok, যা T টাইপের একটি মান ধারণ করে এবং Err, যা E টাইপের একটি মান ধারণ করে। এই সংজ্ঞাটি Result এনামটিকে যেকোনো জায়গায় ব্যবহার করা সুবিধাজনক করে তোলে যেখানে আমাদের এমন একটি অপারেশন রয়েছে যা সফল হতে পারে (কিছু টাইপ T-এর একটি মান রিটার্ন করে) বা ব্যর্থ হতে পারে (কিছু টাইপ E-এর একটি এরর রিটার্ন করে)। প্রকৃতপক্ষে, এটিই আমরা Listing 9-3-তে একটি ফাইল খুলতে ব্যবহার করেছি, যেখানে ফাইলটি সফলভাবে খোলা হলে T std::fs::File টাইপ দিয়ে পূরণ করা হয়েছিল এবং ফাইলটি খোলার ক্ষেত্রে সমস্যা হলে E std::io::Error টাইপ দিয়ে পূরণ করা হয়েছিল।
আপনি যখন আপনার কোডে এমন পরিস্থিতি চিনতে পারবেন যেখানে একাধিক স্ট্রাকট বা এনাম সংজ্ঞা রয়েছে যা শুধুমাত্র তাদের ধারণ করা মানগুলোর টাইপের মধ্যে ভিন্ন, তখন আপনি জেনেরিক টাইপ ব্যবহার করে ডুপ্লিকেশন এড়াতে পারেন।
মেথড সংজ্ঞায় (In Method Definitions)
আমরা স্ট্রাকট এবং এনামগুলোতে মেথড ইমপ্লিমেন্ট করতে পারি (যেমনটি আমরা চ্যাপ্টার ৫-এ করেছি) এবং তাদের সংজ্ঞায় জেনেরিক টাইপও ব্যবহার করতে পারি। Listing 10-9 Listing 10-6-এ সংজ্ঞায়িত Point<T> স্ট্রাকটটি দেখায় যার উপর x নামক একটি মেথড ইমপ্লিমেন্ট করা হয়েছে।
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
এখানে, আমরা Point<T>-তে x নামে একটি মেথড সংজ্ঞায়িত করেছি যা x ফিল্ডের ডেটার একটি রেফারেন্স রিটার্ন করে।
লক্ষ্য করুন যে আমাদের impl-এর পরেই T ঘোষণা করতে হবে যাতে আমরা Point<T> টাইপে মেথড ইমপ্লিমেন্ট করছি তা নির্দিষ্ট করতে T ব্যবহার করতে পারি। impl-এর পরে T-কে জেনেরিক টাইপ হিসাবে ঘোষণা করে, Rust শনাক্ত করতে পারে যে Point-এর অ্যাঙ্গেল ব্র্যাকেটের টাইপটি একটি কংক্রিট টাইপের পরিবর্তে একটি জেনেরিক টাইপ। আমরা স্ট্রাকট সংজ্ঞায় ঘোষিত জেনেরিক প্যারামিটারের চেয়ে এই জেনেরিক প্যারামিটারের জন্য একটি ভিন্ন নাম বেছে নিতে পারতাম, কিন্তু একই নাম ব্যবহার করা প্রচলিত। একটি impl-এর মধ্যে লেখা মেথড যা জেনেরিক টাইপ ঘোষণা করে, সেটি টাইপের যেকোনো ইন্সট্যান্সে সংজ্ঞায়িত করা হবে, জেনেরিক টাইপের পরিবর্তে শেষ পর্যন্ত কোন কংক্রিট টাইপ ব্যবহার করা হোক না কেন।
আমরা টাইপের উপর মেথড সংজ্ঞায়িত করার সময় জেনেরিক টাইপগুলোতে সীমাবদ্ধতাও নির্দিষ্ট করতে পারি। উদাহরণস্বরূপ, আমরা যেকোনো জেনেরিক টাইপ সহ Point<T> ইন্সট্যান্সের পরিবর্তে শুধুমাত্র Point<f32> ইন্সট্যান্সগুলোতে মেথড ইমপ্লিমেন্ট করতে পারি। Listing 10-10-এ আমরা কংক্রিট টাইপ f32 ব্যবহার করি, যার অর্থ আমরা impl-এর পরে কোনো টাইপ ঘোষণা করি না।
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } impl Point<f32> { fn distance_from_origin(&self) -> f32 { (self.x.powi(2) + self.y.powi(2)).sqrt() } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
এই কোডটির অর্থ হল Point<f32> টাইপের একটি distance_from_origin মেথড থাকবে; Point<T>-এর অন্যান্য ইন্সট্যান্স যেখানে T টাইপ f32 নয়, তাদের এই মেথডটি সংজ্ঞায়িত করা হবে না। মেথডটি পরিমাপ করে যে আমাদের পয়েন্টটি (0.0, 0.0) কো-অর্ডিনেটের পয়েন্ট থেকে কত দূরে এবং গাণিতিক অপারেশন ব্যবহার করে যা শুধুমাত্র ফ্লোটিং-পয়েন্ট টাইপের জন্য উপলব্ধ।
একটি স্ট্রাকট সংজ্ঞায় জেনেরিক টাইপ প্যারামিটারগুলো সর্বদাই সেই একই স্ট্রাকটের মেথড সিগনেচারে আপনি যেগুলো ব্যবহার করেন সেগুলো নয়। Listing 10-11 উদাহরণটিকে আরও স্পষ্ট করার জন্য Point স্ট্রাকটের জন্য জেনেরিক টাইপ X1 এবং Y1 এবং mixup মেথড সিগনেচারের জন্য X2 Y2 ব্যবহার করে। মেথডটি self Point-এর x মান (টাইপ X1) এবং পাস করা Point-এর y মান (টাইপ Y2) দিয়ে একটি নতুন Point ইন্সট্যান্স তৈরি করে।
struct Point<X1, Y1> { x: X1, y: Y1, } impl<X1, Y1> Point<X1, Y1> { fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Hello", y: 'c' }; let p3 = p1.mixup(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
main-এ, আমরা একটি Point সংজ্ঞায়িত করেছি যার x-এর জন্য একটি i32 (মান 5 সহ) এবং y-এর জন্য একটি f64 (মান 10.4 সহ) রয়েছে। p2 ভেরিয়েবল হল একটি Point স্ট্রাকট যার x-এর জন্য একটি স্ট্রিং স্লাইস (মান "Hello" সহ) এবং y-এর জন্য একটি char (মান c সহ) রয়েছে। p1-এ p2 আর্গুমেন্ট সহ mixup কল করা আমাদের p3 দেয়, যার x-এর জন্য একটি i32 থাকবে, কারণ x, p1 থেকে এসেছে। p3 ভেরিয়েবলের y-এর জন্য একটি char থাকবে, কারণ y, p2 থেকে এসেছে। println! ম্যাক্রো কলটি p3.x = 5, p3.y = c প্রিন্ট করবে।
এই উদাহরণের উদ্দেশ্য হল এমন একটি পরিস্থিতি প্রদর্শন করা যেখানে কিছু জেনেরিক প্যারামিটার impl দিয়ে ঘোষণা করা হয় এবং কিছু মেথড সংজ্ঞা দিয়ে ঘোষণা করা হয়। এখানে, জেনেরিক প্যারামিটার X1 এবং Y1 impl-এর পরে ঘোষণা করা হয়েছে কারণ সেগুলো স্ট্রাকট সংজ্ঞার সাথে সম্পর্কিত। জেনেরিক প্যারামিটার X2 এবং Y2 fn mixup-এর পরে ঘোষণা করা হয়েছে কারণ সেগুলো শুধুমাত্র মেথডের সাথে সম্পর্কিত।
জেনেরিক ব্যবহার করা কোডের পারফরম্যান্স (Performance of Code Using Generics)
আপনি হয়তো ভাবছেন যে জেনেরিক টাইপ প্যারামিটার ব্যবহার করার সময় কোনো রানটাইম খরচ আছে কিনা। ভাল খবর হল যে জেনেরিক টাইপ ব্যবহার করা আপনার প্রোগ্রামকে কংক্রিট টাইপ ব্যবহার করার চেয়ে কোনোভাবেই ধীর করবে না।
Rust কম্পাইল করার সময় জেনেরিক ব্যবহার করে কোডের মনোমরফাইজেশন (monomorphization) সম্পাদন করে এটি সম্পন্ন করে। মনোমর্ফাইজেশন হল জেনেরিক কোডকে কংক্রিট টাইপ দিয়ে পূরণ করে নির্দিষ্ট কোডে পরিণত করার প্রক্রিয়া, যেগুলো কম্পাইল করার সময় ব্যবহার করা হয়। এই প্রক্রিয়ায়, কম্পাইলার Listing 10-5-এ জেনেরিক ফাংশন তৈরি করতে আমরা যে ধাপগুলো ব্যবহার করেছি তার বিপরীত কাজ করে: কম্পাইলার সেই সমস্ত জায়গাগুলো দেখে যেখানে জেনেরিক কোড কল করা হয়েছে এবং জেনেরিক কোডটি যে কংক্রিট টাইপগুলোর সাথে কল করা হয়েছে তার জন্য কোড জেনারেট করে।
আসুন দেখি কিভাবে এটি স্ট্যান্ডার্ড লাইব্রেরির জেনেরিক Option<T> এনাম ব্যবহার করে কাজ করে:
#![allow(unused)] fn main() { let integer = Some(5); let float = Some(5.0); }
যখন Rust এই কোডটি কম্পাইল করে, তখন এটি মনোমরফাইজেশন সম্পাদন করে। সেই প্রক্রিয়া চলাকালীন, কম্পাইলার Option<T> ইন্সট্যান্সে ব্যবহৃত মানগুলো পড়ে এবং দুই ধরনের Option<T> শনাক্ত করে: একটি হল i32 এবং অন্যটি হল f64। সেই অনুযায়ী, এটি Option<T>-এর জেনেরিক সংজ্ঞাকে i32 এবং f64-এর জন্য বিশেষায়িত দুটি সংজ্ঞায় প্রসারিত করে, এইভাবে জেনেরিক সংজ্ঞাকে নির্দিষ্ট সংজ্ঞা দিয়ে প্রতিস্থাপন করে।
কোডের মনোমরফাইজড ভার্সনটি দেখতে নিচের মতো (কম্পাইলার এখানে উদাহরণের জন্য আমরা যা ব্যবহার করছি তার চেয়ে ভিন্ন নাম ব্যবহার করে):
enum Option_i32 { Some(i32), None, } enum Option_f64 { Some(f64), None, } fn main() { let integer = Option_i32::Some(5); let float = Option_f64::Some(5.0); }
জেনেরিক Option<T> কম্পাইলার দ্বারা তৈরি করা নির্দিষ্ট সংজ্ঞা দিয়ে প্রতিস্থাপিত হয়। যেহেতু Rust জেনেরিক কোডকে এমন কোডে কম্পাইল করে যা প্রতিটি ইন্সট্যান্সে টাইপ নির্দিষ্ট করে, তাই আমরা জেনেরিক ব্যবহারের জন্য কোনো রানটাইম খরচ দিই না। যখন কোডটি চলে, তখন এটি এমনভাবে কাজ করে যেন আমরা প্রতিটি সংজ্ঞা হাতে ডুপ্লিকেট করেছি। মনোমরফাইজেশনের প্রক্রিয়া Rust-এর জেনেরিকগুলোকে রানটাইমে অত্যন্ত কার্যকরী করে তোলে।
ট্রেইট: সাধারণ আচরণ সংজ্ঞায়িত করা (Traits: Defining Shared Behavior)
একটি ট্রেইট (trait) একটি নির্দিষ্ট টাইপের কার্যকারিতা সংজ্ঞায়িত করে এবং অন্যান্য টাইপের সাথে শেয়ার করতে পারে। আমরা অ্যাবস্ট্রাক্ট উপায়ে সাধারণ আচরণ সংজ্ঞায়িত করতে ট্রেইট ব্যবহার করতে পারি। আমরা ট্রেইট বাউন্ড (trait bounds) ব্যবহার করে নির্দিষ্ট করতে পারি যে একটি জেনেরিক টাইপ যেকোনো টাইপ হতে পারে যার নির্দিষ্ট আচরণ রয়েছে।
দ্রষ্টব্য: ট্রেইটগুলো অন্যান্য ভাষার একটি ফিচারের মতো যাকে প্রায়শই ইন্টারফেস (interfaces) বলা হয়, যদিও কিছু পার্থক্য রয়েছে।
একটি ট্রেইট সংজ্ঞায়িত করা (Defining a Trait)
একটি টাইপের আচরণ সেই টাইপের উপর আমরা যে মেথডগুলো কল করতে পারি তা নিয়ে গঠিত। বিভিন্ন টাইপ একই আচরণ শেয়ার করে যদি আমরা সেই সমস্ত টাইপের উপর একই মেথড কল করতে পারি। ট্রেইট সংজ্ঞাগুলো হল মেথড সিগনেচারগুলোকে একত্রিত করার একটি উপায়, যা কিছু উদ্দেশ্য পূরণের জন্য প্রয়োজনীয় আচরণের একটি সেট সংজ্ঞায়িত করে।
উদাহরণস্বরূপ, ধরা যাক আমাদের কাছে একাধিক স্ট্রাকট রয়েছে যা বিভিন্ন ধরণের এবং পরিমাণের টেক্সট ধারণ করে: একটি NewsArticle স্ট্রাকট যা একটি নির্দিষ্ট স্থানে ফাইল করা একটি সংবাদ ধারণ করে এবং একটি SocialPost যাতে সর্বাধিক 280টি অক্ষর থাকতে পারে, সাথে মেটাডেটা যা নির্দেশ করে যে এটি একটি নতুন পোস্ট, একটি রিপোস্ট, নাকি অন্য কোনো পোস্টের উত্তর।
আমরা aggregator নামে একটি মিডিয়া অ্যাগ্রিগেটর লাইব্রেরি ক্রেট তৈরি করতে চাই যা NewsArticle বা SocialPost ইন্সট্যান্সে সংরক্ষিত ডেটার সারাংশ প্রদর্শন করতে পারে। এটি করার জন্য, আমাদের প্রতিটি টাইপ থেকে একটি সারাংশ প্রয়োজন, এবং আমরা একটি ইন্সট্যান্সে একটি summarize মেথড কল করে সেই সারাংশের অনুরোধ করব। Listing 10-12 একটি পাবলিক Summary ট্রেইটের সংজ্ঞা দেখায় যা এই আচরণটিকে প্রকাশ করে।
pub trait Summary {
fn summarize(&self) -> String;
}এখানে, আমরা trait কীওয়ার্ড এবং তারপর ট্রেইটের নাম ব্যবহার করে একটি ট্রেইট ঘোষণা করি, যা এই ক্ষেত্রে Summary। আমরা ট্রেইটটিকে pub হিসাবেও ঘোষণা করি যাতে এই ক্রেটের উপর নির্ভরশীল ক্রেটগুলোও এই ট্রেইটটি ব্যবহার করতে পারে, যেমনটি আমরা কয়েকটি উদাহরণে দেখব। কোঁকড়া ধনুর্বন্ধনীর ভিতরে, আমরা মেথড সিগনেচারগুলো ঘোষণা করি যা এই ট্রেইটটি ইমপ্লিমেন্ট করে এমন টাইপগুলোর আচরণ বর্ণনা করে, যা এই ক্ষেত্রে fn summarize(&self) -> String।
মেথড সিগনেচারের পরে, কোঁকড়া ধনুর্বন্ধনীর মধ্যে একটি ইমপ্লিমেন্টেশন দেওয়ার পরিবর্তে, আমরা একটি সেমিকোলন ব্যবহার করি। এই ট্রেইটটি ইমপ্লিমেন্ট করা প্রতিটি টাইপকে অবশ্যই মেথডের বডির জন্য নিজস্ব কাস্টম আচরণ প্রদান করতে হবে। কম্পাইলার এনফোর্স (enforce) করবে যে Summary ট্রেইট আছে এমন যেকোনো টাইপের অবশ্যই summarize মেথড সংজ্ঞায়িত থাকবে এবং সিগনেচার হুবহু একই হবে।
একটি ট্রেইটের বডিতে একাধিক মেথড থাকতে পারে: মেথড সিগনেচারগুলো প্রতি লাইনে তালিকাভুক্ত করা হয় এবং প্রতিটি লাইন একটি সেমিকোলন দিয়ে শেষ হয়।
একটি টাইপে একটি ট্রেইট ইমপ্লিমেন্ট করা (Implementing a Trait on a Type)
এখন আমরা Summary ট্রেইটের মেথডগুলোর কাঙ্ক্ষিত সিগনেচার সংজ্ঞায়িত করেছি, আমরা এটিকে আমাদের মিডিয়া অ্যাগ্রিগেটরের টাইপগুলোতে ইমপ্লিমেন্ট করতে পারি। Listing 10-13 NewsArticle স্ট্রাকটে Summary ট্রেইটের একটি ইমপ্লিমেন্টেশন দেখায় যা হেডলাইন, লেখক এবং অবস্থান ব্যবহার করে summarize-এর রিটার্ন ভ্যালু তৈরি করে। SocialPost স্ট্রাকটের জন্য, আমরা summarize-কে ব্যবহারকারীর নাম এবং তারপর পোস্টের সম্পূর্ণ টেক্সট হিসাবে সংজ্ঞায়িত করি, ধরে নিই যে পোস্টের কনটেন্ট ইতিমধ্যেই 280 অক্ষরে সীমাবদ্ধ।
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}একটি টাইপে একটি ট্রেইট ইমপ্লিমেন্ট করা নিয়মিত মেথড ইমপ্লিমেন্ট করার মতোই। পার্থক্য হল impl-এর পরে, আমরা যে ট্রেইটটি ইমপ্লিমেন্ট করতে চাই তার নাম রাখি, তারপর for কীওয়ার্ড ব্যবহার করি এবং তারপর যে টাইপের জন্য আমরা ট্রেইটটি ইমপ্লিমেন্ট করতে চাই তার নাম নির্দিষ্ট করি। impl ব্লকের মধ্যে, আমরা মেথড সিগনেচারগুলো রাখি যা ট্রেইট সংজ্ঞায় সংজ্ঞায়িত করা হয়েছে। প্রতিটি সিগনেচারের পরে একটি সেমিকোলন যোগ করার পরিবর্তে, আমরা কোঁকড়া ধনুর্বন্ধনী ব্যবহার করি এবং মেথড বডিতে নির্দিষ্ট আচরণ পূরণ করি যা আমরা চাই যে ট্রেইটের মেথডগুলোতে নির্দিষ্ট টাইপের জন্য থাকুক।
এখন লাইব্রেরিটি NewsArticle এবং SocialPost-এ Summary ট্রেইট ইমপ্লিমেন্ট করেছে, ক্রেটের ব্যবহারকারীরা NewsArticle এবং SocialPost-এর ইন্সট্যান্সগুলোতে ট্রেইট মেথডগুলোকে একইভাবে কল করতে পারে যেভাবে আমরা নিয়মিত মেথড কল করি। একমাত্র পার্থক্য হল ব্যবহারকারীকে অবশ্যই ট্রেইটটিকে টাইপের মতোই স্কোপে আনতে হবে। এখানে একটি বাইনারি ক্রেট কীভাবে আমাদের aggregator লাইব্রেরি ক্রেট ব্যবহার করতে পারে তার একটি উদাহরণ দেওয়া হল:
use aggregator::{SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new social post: {}", post.summarize());
}এই কোডটি 1 new post: horse_ebooks: of course, as you probably already know, people প্রিন্ট করে।
অন্যান্য ক্রেট যেগুলো aggregator ক্রেটের উপর নির্ভর করে তারাও Summary ট্রেইটটিকে স্কোপে এনে তাদের নিজস্ব টাইপগুলোতে Summary ইমপ্লিমেন্ট করতে পারে। একটি সীমাবদ্ধতা লক্ষ্য করার মতো যে আমরা শুধুমাত্র তখনই একটি টাইপের উপর একটি ট্রেইট ইমপ্লিমেন্ট করতে পারি যদি ট্রেইট বা টাইপ, অথবা উভয়ই, আমাদের ক্রেটের লোকাল হয়। উদাহরণস্বরূপ, আমরা স্ট্যান্ডার্ড লাইব্রেরি ট্রেইট যেমন Display-কে আমাদের aggregator ক্রেট কার্যকারিতার অংশ হিসাবে SocialPost-এর মতো কাস্টম টাইপে ইমপ্লিমেন্ট করতে পারি কারণ SocialPost টাইপটি আমাদের aggregator ক্রেটের লোকাল। আমরা আমাদের aggregator ক্রেটে Vec<T>-তে Summary ইমপ্লিমেন্ট করতে পারি কারণ Summary ট্রেইটটি আমাদের aggregator ক্রেটের লোকাল।
কিন্তু আমরা এক্সটার্নাল টাইপগুলোতে এক্সটার্নাল ট্রেইট ইমপ্লিমেন্ট করতে পারি না। উদাহরণস্বরূপ, আমরা আমাদের aggregator ক্রেটের মধ্যে Vec<T>-তে Display ট্রেইট ইমপ্লিমেন্ট করতে পারি না কারণ Display এবং Vec<T> উভয়ই স্ট্যান্ডার্ড লাইব্রেরিতে সংজ্ঞায়িত করা হয়েছে এবং আমাদের aggregator ক্রেটের লোকাল নয়। এই সীমাবদ্ধতাটি কোহেরেন্স (coherence) নামক একটি বৈশিষ্ট্যের অংশ, এবং আরও নির্দিষ্টভাবে অর্ফান রুল (orphan rule), এটির নামকরণ করা হয়েছে কারণ প্যারেন্ট টাইপ উপস্থিত নেই। এই নিয়মটি নিশ্চিত করে যে অন্য লোকেদের কোড আপনার কোড ভাঙতে পারবে না এবং এর বিপরীতটিও সত্য। নিয়মটি ছাড়া, দুটি ক্রেট একই টাইপের জন্য একই ট্রেইট ইমপ্লিমেন্ট করতে পারত এবং Rust জানত না কোন ইমপ্লিমেন্টেশন ব্যবহার করতে হবে।
ডিফল্ট ইমপ্লিমেন্টেশন (Default Implementations)
কখনও কখনও প্রতিটি টাইপের সমস্ত মেথডের জন্য ইমপ্লিমেন্টেশনের প্রয়োজন হওয়ার পরিবর্তে একটি ট্রেইটের কিছু বা সমস্ত মেথডের জন্য ডিফল্ট আচরণ থাকা দরকারী। তারপর, যখন আমরা একটি নির্দিষ্ট টাইপের উপর ট্রেইটটি ইমপ্লিমেন্ট করি, তখন আমরা প্রতিটি মেথডের ডিফল্ট আচরণ রাখতে বা ওভাররাইড করতে পারি।
Listing 10-14-এ, আমরা Summary ট্রেইটের summarize মেথডের জন্য শুধুমাত্র মেথড সিগনেচার সংজ্ঞায়িত করার পরিবর্তে একটি ডিফল্ট স্ট্রিং নির্দিষ্ট করি, যেমনটি আমরা Listing 10-12-তে করেছি।
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}NewsArticle-এর ইন্সট্যান্সগুলো সংক্ষিপ্ত করতে একটি ডিফল্ট ইমপ্লিমেন্টেশন ব্যবহার করতে, আমরা impl Summary for NewsArticle {} দিয়ে একটি খালি impl ব্লক নির্দিষ্ট করি।
যদিও আমরা সরাসরি NewsArticle-এ summarize মেথড সংজ্ঞায়িত করছি না, তবুও আমরা একটি ডিফল্ট ইমপ্লিমেন্টেশন সরবরাহ করেছি এবং নির্দিষ্ট করেছি যে NewsArticle Summary ট্রেইট ইমপ্লিমেন্ট করে। ফলস্বরূপ, আমরা এখনও NewsArticle-এর একটি ইন্সট্যান্সে summarize মেথড কল করতে পারি, এইভাবে:
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
}এই কোডটি New article available! (Read more...) প্রিন্ট করে।
একটি ডিফল্ট ইমপ্লিমেন্টেশন তৈরি করা Listing 10-13-এ SocialPost-এ Summary-এর ইমপ্লিমেন্টেশন সম্পর্কে আমাদের কোনো কিছু পরিবর্তন করার প্রয়োজন নেই। কারণ হল একটি ডিফল্ট ইমপ্লিমেন্টেশন ওভাররাইড করার সিনট্যাক্স একটি ট্রেইট মেথড ইমপ্লিমেন্ট করার সিনট্যাক্সের মতোই যা একটি ডিফল্ট ইমপ্লিমেন্টেশন নেই।
ডিফল্ট ইমপ্লিমেন্টেশনগুলো একই ট্রেইটের অন্যান্য মেথডগুলোকে কল করতে পারে, এমনকী যদি সেই অন্য মেথডগুলোর ডিফল্ট ইমপ্লিমেন্টেশন না থাকে। এইভাবে, একটি ট্রেইট অনেক দরকারী কার্যকারিতা সরবরাহ করতে পারে এবং ইমপ্লিমেন্টরদের কেবল এটির একটি ছোট অংশ নির্দিষ্ট করতে হয়। উদাহরণস্বরূপ, আমরা Summary ট্রেইটটিকে একটি summarize_author মেথড সংজ্ঞায়িত করতে পারি যার ইমপ্লিমেন্টেশন প্রয়োজন, এবং তারপর একটি summarize মেথড সংজ্ঞায়িত করতে পারি যার একটি ডিফল্ট ইমপ্লিমেন্টেশন রয়েছে যা summarize_author মেথডকে কল করে:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Summary-এর এই ভার্সনটি ব্যবহার করার জন্য, আমাদের শুধুমাত্র একটি টাইপের উপর ট্রেইট ইমপ্লিমেন্ট করার সময় summarize_author সংজ্ঞায়িত করতে হবে:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}আমরা summarize_author সংজ্ঞায়িত করার পরে, আমরা SocialPost স্ট্রাকটের ইন্সট্যান্সগুলোতে summarize কল করতে পারি এবং summarize-এর ডিফল্ট ইমপ্লিমেন্টেশনটি আমাদের দেওয়া summarize_author-এর সংজ্ঞাকে কল করবে। যেহেতু আমরা summarize_author ইমপ্লিমেন্ট করেছি, তাই Summary ট্রেইট আমাদের আরও কোনো কোড লেখার প্রয়োজন ছাড়াই summarize মেথডের আচরণ দিয়েছে। এখানে এটি দেখতে কেমন:
use aggregator::{self, SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new social post: {}", post.summarize());
}এই কোডটি 1 new post: (Read more from @horse_ebooks...) প্রিন্ট করে।
মনে রাখবেন যে একই মেথডের ওভাররাইডিং ইমপ্লিমেন্টেশন থেকে ডিফল্ট ইমপ্লিমেন্টেশনকে কল করা সম্ভব নয়।
প্যারামিটার হিসাবে ট্রেইট (Traits as Parameters)
এখন আপনি জানেন কিভাবে ট্রেইট সংজ্ঞায়িত এবং ইমপ্লিমেন্ট করতে হয়, আমরা এমন ফাংশন সংজ্ঞায়িত করতে ট্রেইটগুলো কীভাবে ব্যবহার করতে হয় তা অন্বেষণ করতে পারি যা বিভিন্ন টাইপ গ্রহণ করে। আমরা Listing 10-13-এ NewsArticle এবং SocialPost টাইপগুলোতে যে Summary ট্রেইট ইমপ্লিমেন্ট করেছি তা ব্যবহার করে একটি notify ফাংশন সংজ্ঞায়িত করব যা তার item প্যারামিটারে summarize মেথড কল করে, যেটি কিছু টাইপের যা Summary ট্রেইট ইমপ্লিমেন্ট করে। এটি করার জন্য, আমরা impl Trait সিনট্যাক্স ব্যবহার করি, এইভাবে:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}item প্যারামিটারের জন্য একটি কংক্রিট টাইপের পরিবর্তে, আমরা impl কীওয়ার্ড এবং ট্রেইটের নাম নির্দিষ্ট করি। এই প্যারামিটারটি নির্দিষ্ট ট্রেইট ইমপ্লিমেন্ট করে এমন যেকোনো টাইপ গ্রহণ করে। notify-এর বডিতে, আমরা item-এ Summary ট্রেইট থেকে আসা যেকোনো মেথড কল করতে পারি, যেমন summarize। আমরা notify কল করতে পারি এবং NewsArticle বা SocialPost-এর যেকোনো ইন্সট্যান্স পাস করতে পারি। এই ফাংশনটিকে অন্য কোনো টাইপ, যেমন একটি String বা একটি i32 দিয়ে কল করা কোড কম্পাইল হবে না কারণ সেই টাইপগুলো Summary ইমপ্লিমেন্ট করে না।
ট্রেইট বাউন্ড সিনট্যাক্স (Trait Bound Syntax)
impl Trait সিনট্যাক্সটি সহজ ক্ষেত্রের জন্য কাজ করে কিন্তু আসলে একটি দীর্ঘ ফর্মের জন্য সিনট্যাক্স সুগার যা ট্রেইট বাউন্ড (trait bound) নামে পরিচিত; এটি দেখতে এইরকম:
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}এই দীর্ঘ ফর্মটি পূর্ববর্তী বিভাগের উদাহরণের সমতুল্য কিন্তু আরও শব্দবহুল। আমরা একটি কোলন এবং অ্যাঙ্গেল ব্র্যাকেটের মধ্যে জেনেরিক টাইপ প্যারামিটারের ঘোষণার সাথে ট্রেইট বাউন্ডগুলো রাখি।
impl Trait সিনট্যাক্সটি সুবিধাজনক এবং সহজ ক্ষেত্রে আরও সংক্ষিপ্ত কোড তৈরি করে, যেখানে সম্পূর্ণ ট্রেইট বাউন্ড সিনট্যাক্স অন্যান্য ক্ষেত্রে আরও জটিলতা প্রকাশ করতে পারে। উদাহরণস্বরূপ, আমাদের দুটি প্যারামিটার থাকতে পারে যা Summary ইমপ্লিমেন্ট করে। impl Trait সিনট্যাক্স দিয়ে এটি করা এইরকম দেখায়:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {যদি আমরা চাই যে এই ফাংশনটি item1 এবং item2-কে বিভিন্ন টাইপের অনুমতি দিক (যতক্ষণ উভয় টাইপ Summary ইমপ্লিমেন্ট করে) ততক্ষণ impl Trait ব্যবহার করা উপযুক্ত। যাইহোক, যদি আমরা উভয় প্যারামিটারকে একই টাইপ হতে বাধ্য করতে চাই, তাহলে আমাদের অবশ্যই একটি ট্রেইট বাউন্ড ব্যবহার করতে হবে, এইভাবে:
pub fn notify<T: Summary>(item1: &T, item2: &T) {item1 এবং item2 প্যারামিটারের টাইপ হিসাবে নির্দিষ্ট করা জেনেরিক টাইপ T ফাংশনটিকে সীমাবদ্ধ করে যাতে item1 এবং item2-এর জন্য আর্গুমেন্ট হিসাবে পাস করা মানের কংক্রিট টাইপ একই হতে হবে।
+ সিনট্যাক্স দিয়ে একাধিক ট্রেইট বাউন্ড নির্দিষ্ট করা (Specifying Multiple Trait Bounds with the + Syntax)
আমরা একাধিক ট্রেইট বাউন্ডও নির্দিষ্ট করতে পারি। ধরা যাক, আমরা চেয়েছিলাম notify item-এ ডিসপ্লে ফরম্যাটিং এবং summarize ব্যবহার করুক: আমরা notify সংজ্ঞায় নির্দিষ্ট করি যে item-কে অবশ্যই Display এবং Summary উভয়ই ইমপ্লিমেন্ট করতে হবে। আমরা + সিনট্যাক্স ব্যবহার করে এটি করতে পারি:
pub fn notify(item: &(impl Summary + Display)) {+ সিনট্যাক্স জেনেরিক টাইপের উপর ট্রেইট বাউন্ডের সাথেও বৈধ:
pub fn notify<T: Summary + Display>(item: &T) {দুটি ট্রেইট বাউন্ড নির্দিষ্ট করার সাথে, notify-এর বডি summarize কল করতে পারে এবং item ফর্ম্যাট করতে {} ব্যবহার করতে পারে।
where ক্লজ সহ ক্লিনার ট্রেইট বাউন্ড (Clearer Trait Bounds with where Clauses)
অত্যধিক ট্রেইট বাউন্ড ব্যবহার করার অসুবিধা রয়েছে। প্রতিটি জেনেরিকের নিজস্ব ট্রেইট বাউন্ড রয়েছে, তাই একাধিক জেনেরিক টাইপ প্যারামিটারযুক্ত ফাংশনগুলোতে ফাংশনের নাম এবং এর প্যারামিটার তালিকার মধ্যে প্রচুর ট্রেইট বাউন্ডের তথ্য থাকতে পারে, যা ফাংশন সিগনেচারকে পড়া কঠিন করে তোলে। এই কারণে, Rust-এর ফাংশন সিগনেচারের পরে একটি where ক্লজের মধ্যে ট্রেইট বাউন্ডগুলো নির্দিষ্ট করার জন্য বিকল্প সিনট্যাক্স রয়েছে। সুতরাং, এটি লেখার পরিবর্তে:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {আমরা একটি where ক্লজ ব্যবহার করতে পারি, এইভাবে:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}এই ফাংশনের সিগনেচারটি কম বিশৃঙ্খল: ফাংশনের নাম, প্যারামিটার তালিকা এবং রিটার্ন টাইপ কাছাকাছি, প্রচুর ট্রেইট বাউন্ড ছাড়া একটি ফাংশনের মতো।
ট্রেইট ইমপ্লিমেন্ট করে এমন টাইপ রিটার্ন করা (Returning Types That Implement Traits)
আমরা রিটার্ন পজিশনে impl Trait সিনট্যাক্স ব্যবহার করে এমন কিছু টাইপের মান রিটার্ন করতে পারি যা একটি ট্রেইট ইমপ্লিমেন্ট করে, যেমনটি এখানে দেখানো হয়েছে:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}রিটার্ন টাইপের জন্য impl Summary ব্যবহার করে, আমরা নির্দিষ্ট করি যে returns_summarizable ফাংশনটি কংক্রিট টাইপের নাম না দিয়েই Summary ট্রেইট ইমপ্লিমেন্ট করে এমন কিছু টাইপ রিটার্ন করে। এই ক্ষেত্রে, returns_summarizable একটি SocialPost রিটার্ন করে, কিন্তু এই ফাংশনটিকে কল করা কোডটি সেটি জানার প্রয়োজন নেই।
শুধুমাত্র যে ট্রেইটটি ইমপ্লিমেন্ট করে তার দ্বারা একটি রিটার্ন টাইপ নির্দিষ্ট করার ক্ষমতা ক্লোজার (closures) এবং ইটারেটরগুলোর (iterators) প্রসঙ্গে বিশেষভাবে কার্যকর, যা আমরা চ্যাপ্টার 13-এ কভার করব। ক্লোজার এবং ইটারেটরগুলো এমন টাইপ তৈরি করে যা শুধুমাত্র কম্পাইলার জানে বা টাইপগুলো উল্লেখ করার জন্য খুব দীর্ঘ। impl Trait সিনট্যাক্স আপনাকে সংক্ষিপ্তভাবে নির্দিষ্ট করতে দেয় যে একটি ফাংশন Iterator ট্রেইট ইমপ্লিমেন্ট করে এমন কিছু টাইপ রিটার্ন করে, খুব দীর্ঘ টাইপ লেখার প্রয়োজন ছাড়াই।
যাইহোক, আপনি শুধুমাত্র তখনই impl Trait ব্যবহার করতে পারেন যদি আপনি একটি একক টাইপ রিটার্ন করেন। উদাহরণস্বরূপ, এই কোডটি যা একটি NewsArticle বা একটি SocialPost রিটার্ন করে এবং রিটার্ন টাইপটিকে impl Summary হিসাবে নির্দিষ্ট করা হয়েছে তা কাজ করবে না:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}
}একটি NewsArticle বা একটি SocialPost রিটার্ন করার অনুমতি নেই কারণ কম্পাইলারে impl Trait সিনট্যাক্স কীভাবে ইমপ্লিমেন্ট করা হয় তার চারপাশে সীমাবদ্ধতা রয়েছে। এই আচরণ সহ একটি ফাংশন কীভাবে লিখতে হয় তা আমরা চ্যাপ্টার 18-এর “ভিন্ন টাইপের মানের জন্য অনুমতি দেয় এমন ট্রেইট অবজেক্ট ব্যবহার করা” বিভাগে কভার করব।
ট্রেইট বাউন্ড ব্যবহার করে শর্তসাপেক্ষে মেথড ইমপ্লিমেন্ট করা (Using Trait Bounds to Conditionally Implement Methods)
জেনেরিক টাইপ প্যারামিটার ব্যবহার করে এমন একটি impl ব্লকের সাথে একটি ট্রেইট বাউন্ড ব্যবহার করে, আমরা নির্দিষ্ট ট্রেইটগুলো ইমপ্লিমেন্ট করে এমন টাইপগুলোর জন্য শর্তসাপেক্ষে মেথড ইমপ্লিমেন্ট করতে পারি। উদাহরণস্বরূপ, Listing 10-15-এর Pair<T> টাইপটি সর্বদাই new ফাংশন ইমপ্লিমেন্ট করে Pair<T>-এর একটি নতুন ইন্সট্যান্স রিটার্ন করার জন্য (চ্যাপ্টার ৫-এর “মেথড সংজ্ঞায়িত করা” বিভাগ থেকে স্মরণ করুন যে Self হল impl ব্লকের টাইপের জন্য একটি টাইপ অ্যালিয়াস, যা এই ক্ষেত্রে Pair<T>)। কিন্তু পরবর্তী impl ব্লকে, Pair<T> শুধুমাত্র তখনই cmp_display মেথড ইমপ্লিমেন্ট করে যদি এর ভেতরের টাইপ T PartialOrd ট্রেইট ইমপ্লিমেন্ট করে যা তুলনা সক্ষম করে এবং Display ট্রেইট যা প্রিন্টিং সক্ষম করে।
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}আমরা যেকোনো টাইপের জন্য শর্তসাপেক্ষে একটি ট্রেইট ইমপ্লিমেন্ট করতে পারি যা অন্য একটি ট্রেইট ইমপ্লিমেন্ট করে। ট্রেইট বাউন্ড সন্তুষ্ট করে এমন যেকোনো টাইপের উপর একটি ট্রেইটের ইমপ্লিমেন্টেশনগুলোকে ব্ল্যাঙ্কেট ইমপ্লিমেন্টেশন (blanket implementations) বলা হয় এবং Rust স্ট্যান্ডার্ড লাইব্রেরিতে ব্যাপকভাবে ব্যবহৃত হয়। উদাহরণস্বরূপ, স্ট্যান্ডার্ড লাইব্রেরি যেকোনো টাইপের উপর ToString ট্রেইট ইমপ্লিমেন্ট করে যা Display ট্রেইট ইমপ্লিমেন্ট করে। স্ট্যান্ডার্ড লাইব্রেরির impl ব্লকটি এই কোডের মতো দেখায়:
impl<T: Display> ToString for T {
// --snip--
}যেহেতু স্ট্যান্ডার্ড লাইব্রেরিতে এই ব্ল্যাঙ্কেট ইমপ্লিমেন্টেশন রয়েছে, তাই আমরা ToString ট্রেইট দ্বারা সংজ্ঞায়িত to_string মেথডটিকে যেকোনো টাইপে কল করতে পারি যা Display ট্রেইট ইমপ্লিমেন্ট করে। উদাহরণস্বরূপ, আমরা ইন্টিজারগুলোকে তাদের সংশ্লিষ্ট String মানগুলোতে পরিণত করতে পারি কারণ ইন্টিজারগুলো Display ইমপ্লিমেন্ট করে:
#![allow(unused)] fn main() { let s = 3.to_string(); }
ব্ল্যাঙ্কেট ইমপ্লিমেন্টেশনগুলো ট্রেইটের জন্য ডকুমেন্টেশনের “Implementors” বিভাগে প্রদর্শিত হয়।
ট্রেইট এবং ট্রেইট বাউন্ড আমাদের জেনেরিক টাইপ প্যারামিটার ব্যবহার করে কোড লিখতে দেয় যাতে ডুপ্লিকেশন কমানো যায়, কিন্তু কম্পাইলারকে এটিও নির্দিষ্ট করতে দেয় যে আমরা চাই জেনেরিক টাইপের নির্দিষ্ট আচরণ থাকুক। কম্পাইলার তখন ট্রেইট বাউন্ডের তথ্য ব্যবহার করে পরীক্ষা করতে পারে যে আমাদের কোডের সাথে ব্যবহৃত সমস্ত কংক্রিট টাইপ সঠিক আচরণ প্রদান করে কিনা। ডায়নামিকালি টাইপ করা ভাষাগুলোতে, আমরা যদি এমন কোনো টাইপে একটি মেথড কল করি যা মেথডটি সংজ্ঞায়িত করে না, তাহলে আমরা রানটাইমে একটি এরর পাব। কিন্তু Rust এই এররগুলোকে কম্পাইল টাইমে নিয়ে যায় তাই আমাদের কোড চালানোর আগেই সমস্যাগুলো ঠিক করতে বাধ্য করা হয়। উপরন্তু, আমাদের এমন কোড লিখতে হবে না যা রানটাইমে আচরণের জন্য পরীক্ষা করে কারণ আমরা ইতিমধ্যেই কম্পাইল টাইমে এটি পরীক্ষা করেছি। এটি জেনেরিকের নমনীয়তা ত্যাগ না করেই পারফরম্যান্স উন্নত করে।
লাইফটাইম দিয়ে রেফারেন্স বৈধ করা (Validating References with Lifetimes)
লাইফটাইম হল আরেক ধরনের জেনেরিক যা আমরা ইতিমধ্যেই ব্যবহার করছি। কোনো টাইপের আমাদের কাঙ্ক্ষিত আচরণ আছে কিনা তা নিশ্চিত করার পরিবর্তে, লাইফটাইম নিশ্চিত করে যে রেফারেন্সগুলো যতক্ষণ আমাদের প্রয়োজন ততক্ষণ বৈধ থাকবে।
চ্যাপ্টার ৪-এর “রেফারেন্স এবং বোরোয়িং” বিভাগে আমরা যে একটি বিশদ আলোচনা করিনি তা হল, Rust-এর প্রতিটি রেফারেন্সের একটি লাইফটাইম (lifetime) রয়েছে, যেটি হল সেই স্কোপ যার জন্য সেই রেফারেন্সটি বৈধ। বেশিরভাগ সময়, লাইফটাইমগুলো উহ্য এবং অনুমিত হয়, ঠিক যেমন বেশিরভাগ সময় টাইপগুলো অনুমিত হয়। একাধিক টাইপ সম্ভব হলেই কেবল আমাদের টাইপগুলো অ্যানোটেট করতে হয়। একইভাবে, যখন রেফারেন্সগুলোর লাইফটাইম কয়েকটি ভিন্ন উপায়ে সম্পর্কিত হতে পারে তখন আমাদের লাইফটাইমগুলো অ্যানোটেট করতে হয়। Rust চায় যে আমরা জেনেরিক লাইফটাইম প্যারামিটার ব্যবহার করে সম্পর্কগুলো অ্যানোটেট করি যাতে এটি নিশ্চিত করা যায় যে রানটাইমে ব্যবহৃত প্রকৃত রেফারেন্সগুলো অবশ্যই বৈধ হবে।
লাইফটাইম অ্যানোটেট করা এমন একটি ধারণা যা বেশিরভাগ অন্য প্রোগ্রামিং ল্যাঙ্গুয়েজের নেই, তাই এটি অপরিচিত মনে হবে। যদিও আমরা এই চ্যাপ্টারে লাইফটাইমগুলো সম্পূর্ণরূপে কভার করব না, তবুও আমরা লাইফটাইম সিনট্যাক্সের সাধারণ উপায়গুলো নিয়ে আলোচনা করব যাতে আপনি এই ধারণার সাথে স্বাচ্ছন্দ্য বোধ করতে পারেন।
লাইফটাইম দিয়ে ড্যাংলিং রেফারেন্স প্রতিরোধ করা (Preventing Dangling References with Lifetimes)
লাইফটাইমের মূল লক্ষ্য হল ড্যাংলিং রেফারেন্স (dangling references) প্রতিরোধ করা, যা একটি প্রোগ্রামকে তার উদ্দিষ্ট ডেটা ছাড়া অন্য ডেটা রেফারেন্স করতে বাধ্য করে। Listing 10-16-এর প্রোগ্রামটি বিবেচনা করুন, যেখানে একটি আউটার স্কোপ (outer scope) এবং একটি ইনার স্কোপ (inner scope) রয়েছে।
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}দ্রষ্টব্য: Listing 10-16, 10-17 এবং 10-23-এর উদাহরণগুলো ভেরিয়েবল ঘোষণা করে সেগুলোকে প্রাথমিক মান না দিয়ে, তাই ভেরিয়েবলের নামটি আউটার স্কোপে বিদ্যমান। প্রথম দেখায়, এটি Rust-এর কোনো নাল মান না থাকার সাথে সাংঘর্ষিক বলে মনে হতে পারে। যাইহোক, যদি আমরা একটি ভেরিয়েবলকে মান দেওয়ার আগে ব্যবহার করার চেষ্টা করি, তাহলে আমরা একটি কম্পাইল-টাইম এরর পাব, যা দেখায় যে Rust প্রকৃতপক্ষে নাল মানগুলোর অনুমতি দেয় না।
আউটার স্কোপটি r নামে একটি ভেরিয়েবল ঘোষণা করে কোনো প্রাথমিক মান ছাড়াই, এবং ইনার স্কোপটি x নামে একটি ভেরিয়েবল ঘোষণা করে 5 প্রাথমিক মান সহ। ইনার স্কোপের ভিতরে, আমরা r-এর মান x-এর রেফারেন্স হিসাবে সেট করার চেষ্টা করি। তারপর ইনার স্কোপটি শেষ হয় এবং আমরা r-এর মান প্রিন্ট করার চেষ্টা করি। এই কোডটি কম্পাইল হবে না কারণ r যে মানটিকে রেফার করছে সেটি আমরা ব্যবহার করার চেষ্টা করার আগেই স্কোপের বাইরে চলে গেছে। এখানে এরর মেসেজটি দেওয়া হল:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| --- borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
এরর মেসেজটি বলে যে x ভেরিয়েবলটি "যথেষ্ট দিন বাঁচে না"। এর কারণ হল ইনার স্কোপটি ৭ নম্বর লাইনে শেষ হয়ে গেলে x স্কোপের বাইরে চলে যাবে। কিন্তু r এখনও আউটার স্কোপের জন্য বৈধ; যেহেতু এর স্কোপটি বড়, তাই আমরা বলি যে এটি "বেশি দিন বাঁচে"। যদি Rust এই কোডটিকে কাজ করার অনুমতি দিত, তাহলে x স্কোপের বাইরে চলে গেলে r এমন মেমরিকে রেফার করত যা ডিলোক্যাট করা হয়েছে এবং আমরা r দিয়ে যা কিছু করার চেষ্টা করতাম তা সঠিকভাবে কাজ করত না। তাহলে Rust কীভাবে নির্ধারণ করে যে এই কোডটি অবৈধ? এটি একটি বোরো চেকার (borrow checker) ব্যবহার করে।
বোরো চেকার (The Borrow Checker)
Rust কম্পাইলারের একটি বোরো চেকার রয়েছে যা স্কোপগুলো তুলনা করে নির্ধারণ করে যে সমস্ত বোরো বৈধ কিনা। Listing 10-17 Listing 10-16-এর মতোই একই কোড দেখায় কিন্তু ভেরিয়েবলগুলোর লাইফটাইম দেখানো অ্যানোটেশন সহ।
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+এখানে, আমরা r-এর লাইফটাইমকে 'a দিয়ে এবং x-এর লাইফটাইমকে 'b দিয়ে অ্যানোটেট করেছি। আপনি দেখতে পাচ্ছেন, ভেতরের 'b ব্লকটি বাইরের 'a লাইফটাইম ব্লকের চেয়ে অনেক ছোট। কম্পাইল করার সময়, Rust দুটি লাইফটাইমের আকার তুলনা করে এবং দেখে যে r-এর 'a লাইফটাইম রয়েছে কিন্তু এটি 'b লাইফটাইম সহ মেমরিকে রেফার করে। প্রোগ্রামটি প্রত্যাখ্যাত হয় কারণ 'b, 'a-এর চেয়ে ছোট: রেফারেন্সের বিষয়বস্তুটি রেফারেন্সের মতো দীর্ঘস্থায়ী হয় না।
Listing 10-18 কোডটি ঠিক করে যাতে এটিতে কোনো ড্যাংলিং রেফারেন্স না থাকে এবং এটি কোনো এরর ছাড়াই কম্পাইল হয়।
fn main() { let x = 5; // ----------+-- 'b // | let r = &x; // --+-- 'a | // | | println!("r: {r}"); // | | // --+ | } // ----------+
এখানে, x-এর লাইফটাইম 'b, যা এই ক্ষেত্রে 'a-এর চেয়ে বড়। এর মানে হল r, x-কে রেফারেন্স করতে পারে কারণ Rust জানে যে r-এর রেফারেন্স সর্বদাই বৈধ থাকবে যখন x বৈধ থাকবে।
এখন আপনি জানেন যে রেফারেন্সগুলোর লাইফটাইম কোথায় এবং Rust কীভাবে লাইফটাইম বিশ্লেষণ করে তা নিশ্চিত করে যে রেফারেন্সগুলো সর্বদাই বৈধ হবে, আসুন ফাংশনের প্রেক্ষাপটে প্যারামিটার এবং রিটার্ন ভ্যালুগুলোর জেনেরিক লাইফটাইম অন্বেষণ করি।
ফাংশনে জেনেরিক লাইফটাইম (Generic Lifetimes in Functions)
আমরা দুটি স্ট্রিং স্লাইসের মধ্যে দীর্ঘতমটি রিটার্ন করে এমন একটি ফাংশন লিখব। এই ফাংশনটি দুটি স্ট্রিং স্লাইস নেবে এবং একটি একক স্ট্রিং স্লাইস রিটার্ন করবে। আমরা longest ফাংশনটি ইমপ্লিমেন্ট করার পরে, Listing 10-19-এর কোডটি The longest string is abcd প্রিন্ট করবে।
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}লক্ষ্য করুন যে আমরা চাই ফাংশনটি স্ট্রিং স্লাইস নিক, যেগুলো রেফারেন্স, স্ট্রিং নয়, কারণ আমরা চাই না যে longest ফাংশনটি তার প্যারামিটারগুলোর ওনারশিপ নিক। আমরা কেন Listing 10-19-এ ব্যবহৃত প্যারামিটারগুলোই চাই, সে সম্পর্কে আরও আলোচনার জন্য চ্যাপ্টার ৪-এর “প্যারামিটার হিসাবে স্ট্রিং স্লাইস” দেখুন।
আমরা যদি Listing 10-20-তে দেখানো longest ফাংশনটি ইমপ্লিমেন্ট করার চেষ্টা করি, তাহলে এটি কম্পাইল হবে না।
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}পরিবর্তে, আমরা নিম্নলিখিত এররটি পাই যা লাইফটাইম সম্পর্কে বলে:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
হেল্প টেক্সট প্রকাশ করে যে রিটার্ন টাইপের উপর একটি জেনেরিক লাইফটাইম প্যারামিটার প্রয়োজন কারণ Rust বলতে পারে না যে রিটার্ন করা রেফারেন্সটি x নাকি y-কে রেফার করছে। আসলে, আমরাও জানি না, কারণ এই ফাংশনের বডির if ব্লকটি x-এর একটি রেফারেন্স রিটার্ন করে এবং else ব্লকটি y-এর একটি রেফারেন্স রিটার্ন করে!
যখন আমরা এই ফাংশনটি সংজ্ঞায়িত করছি, তখন আমরা জানি না যে এই ফাংশনে কোন কংক্রিট মানগুলো পাস করা হবে, তাই আমরা জানি না যে if কেস নাকি else কেস এক্সিকিউট হবে। আমরা যে রেফারেন্সগুলো পাস করা হবে তার কংক্রিট লাইফটাইমও জানি না, তাই আমরা Listing 10-17 এবং 10-18-এ যেভাবে স্কোপগুলো দেখেছি সেভাবে দেখতে পারি না, যাতে আমরা নির্ধারণ করতে পারি যে আমরা যে রেফারেন্সটি রিটার্ন করব সেটি সর্বদাই বৈধ হবে কিনা। বোরো চেকারও এটি নির্ধারণ করতে পারে না, কারণ এটি জানে না যে x এবং y-এর লাইফটাইম রিটার্ন মানের লাইফটাইমের সাথে কীভাবে সম্পর্কিত। এই এররটি ঠিক করার জন্য, আমরা জেনেরিক লাইফটাইম প্যারামিটার যোগ করব যা রেফারেন্সগুলোর মধ্যে সম্পর্ক সংজ্ঞায়িত করে যাতে বোরো চেকার তার বিশ্লেষণ করতে পারে।
লাইফটাইম অ্যানোটেশন সিনট্যাক্স (Lifetime Annotation Syntax)
লাইফটাইম অ্যানোটেশনগুলো কোনো রেফারেন্সের লাইফটাইম পরিবর্তন করে না। বরং, তারা লাইফটাইমকে প্রভাবিত না করে একাধিক রেফারেন্সের লাইফটাইমের সম্পর্ক বর্ণনা করে। ঠিক যেমন ফাংশনগুলো যেকোনো টাইপ গ্রহণ করতে পারে যখন সিগনেচারটি একটি জেনেরিক টাইপ প্যারামিটার নির্দিষ্ট করে, তেমনি ফাংশনগুলো একটি জেনেরিক লাইফটাইম প্যারামিটার নির্দিষ্ট করে যেকোনো লাইফটাইম সহ রেফারেন্স গ্রহণ করতে পারে।
লাইফটাইম অ্যানোটেশনগুলোর একটু অস্বাভাবিক সিনট্যাক্স রয়েছে: লাইফটাইম প্যারামিটারের নামগুলো অবশ্যই একটি অ্যাপোস্ট্রফি (') দিয়ে শুরু হতে হবে এবং সাধারণত সব ছোট হাতের হয় এবং খুব ছোট হয়, জেনেরিক টাইপের মতো। বেশিরভাগ মানুষ প্রথম লাইফটাইম অ্যানোটেশনের জন্য 'a নামটি ব্যবহার করে। আমরা একটি রেফারেন্সের &-এর পরে লাইফটাইম প্যারামিটার অ্যানোটেশনগুলো রাখি, রেফারেন্সের টাইপ থেকে অ্যানোটেশনটিকে আলাদা করতে একটি স্পেস ব্যবহার করে।
এখানে কিছু উদাহরণ দেওয়া হল: লাইফটাইম প্যারামিটার ছাড়া একটি i32-এর রেফারেন্স, 'a নামের একটি লাইফটাইম প্যারামিটার সহ একটি i32-এর রেফারেন্স এবং 'a লাইফটাইম সহ একটি i32-এর মিউটেবল রেফারেন্স।
&i32 // একটি রেফারেন্স
&'a i32 // একটি স্পষ্ট লাইফটাইম সহ একটি রেফারেন্স
&'a mut i32 // একটি স্পষ্ট লাইফটাইম সহ একটি মিউটেবল রেফারেন্সএকা একটি লাইফটাইম অ্যানোটেশনের খুব বেশি অর্থ নেই কারণ অ্যানোটেশনগুলো Rust-কে একাধিক রেফারেন্সের জেনেরিক লাইফটাইম প্যারামিটারগুলো একে অপরের সাথে কীভাবে সম্পর্কিত তা বলতে বোঝানো হয়েছে। আসুন longest ফাংশনের প্রেক্ষাপটে লাইফটাইম অ্যানোটেশনগুলো একে অপরের সাথে কীভাবে সম্পর্কিত তা পরীক্ষা করি।
ফাংশন সিগনেচারে লাইফটাইম অ্যানোটেশন (Lifetime Annotations in Function Signatures)
ফাংশন সিগনেচারে লাইফটাইম অ্যানোটেশন ব্যবহার করার জন্য, আমাদের ফাংশনের নাম এবং প্যারামিটার তালিকার মধ্যে অ্যাঙ্গেল ব্র্যাকেটের ভিতরে জেনেরিক লাইফটাইম প্যারামিটারগুলো ঘোষণা করতে হবে, ঠিক যেমনটি আমরা জেনেরিক টাইপ প্যারামিটারগুলোর সাথে করেছি।
আমরা চাই সিগনেচারটি নিম্নলিখিত সীমাবদ্ধতা প্রকাশ করুক: রিটার্ন করা রেফারেন্সটি বৈধ থাকবে যতক্ষণ উভয় প্যারামিটার বৈধ থাকে। এটি হল প্যারামিটারগুলোর লাইফটাইম এবং রিটার্ন মানের মধ্যে সম্পর্ক। আমরা লাইফটাইমটির নাম দেব 'a এবং তারপর এটিকে প্রতিটি রেফারেন্সে যোগ করব, যেমনটি Listing 10-21-এ দেখানো হয়েছে।
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {result}"); } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
এই কোডটি কম্পাইল করা উচিত এবং Listing 10-19-এর main ফাংশনের সাথে ব্যবহার করলে আমরা যে ফলাফল চাই তা তৈরি করবে।
ফাংশন সিগনেচারটি এখন Rust-কে বলে যে কিছু লাইফটাইম 'a-এর জন্য, ফাংশনটি দুটি প্যারামিটার নেয়, উভয়ই স্ট্রিং স্লাইস যা কমপক্ষে 'a লাইফটাইম পর্যন্ত বাঁচে। ফাংশন সিগনেচারটি Rust-কে আরও বলে যে ফাংশন থেকে রিটার্ন করা স্ট্রিং স্লাইসটি কমপক্ষে 'a লাইফটাইম পর্যন্ত বাঁচবে। বাস্তবে, এর অর্থ হল longest ফাংশন দ্বারা রিটার্ন করা রেফারেন্সের লাইফটাইমটি ফাংশন আর্গুমেন্ট দ্বারা রেফার করা মানগুলোর লাইফটাইমের ছোটটির সমান। এই সম্পর্কগুলোই আমরা চাই যে Rust এই কোডটি বিশ্লেষণ করার সময় ব্যবহার করুক।
মনে রাখবেন, যখন আমরা এই ফাংশন সিগনেচারে লাইফটাইম প্যারামিটারগুলো নির্দিষ্ট করি, তখন আমরা পাস করা বা রিটার্ন করা কোনো মানের লাইফটাইম পরিবর্তন করি না। বরং, আমরা নির্দিষ্ট করছি যে বোরো চেকারের এই সীমাবদ্ধতাগুলো মেনে চলে না এমন যেকোনো মান প্রত্যাখ্যান করা উচিত। মনে রাখবেন যে longest ফাংশনটিকে x এবং y ঠিক কতদিন বাঁচবে তা জানার প্রয়োজন নেই, শুধুমাত্র কিছু স্কোপ যা এই সিগনেচারটিকে সন্তুষ্ট করবে এমন 'a-এর জন্য প্রতিস্থাপিত করা যেতে পারে।
ফাংশনগুলোতে লাইফটাইম অ্যানোটেট করার সময়, অ্যানোটেশনগুলো ফাংশন সিগনেচারে যায়, ফাংশন বডিতে নয়। লাইফটাইম অ্যানোটেশনগুলো ফাংশনের চুক্তির অংশ হয়ে যায়, অনেকটা সিগনেচারের টাইপগুলোর মতো। ফাংশন সিগনেচারে লাইফটাইম চুক্তি থাকা মানে Rust কম্পাইলারের বিশ্লেষণ আরও সহজ হতে পারে। যদি কোনো ফাংশন যেভাবে অ্যানোটেট করা হয়েছে বা যেভাবে কল করা হয়েছে তাতে কোনো সমস্যা থাকে, তাহলে কম্পাইলার এররগুলো আমাদের কোডের অংশ এবং সীমাবদ্ধতার দিকে আরও সুনির্দিষ্টভাবে নির্দেশ করতে পারে। যদি, পরিবর্তে, Rust কম্পাইলার আমাদের উদ্দিষ্ট লাইফটাইমের সম্পর্কগুলো সম্পর্কে আরও অনুমান করে, তাহলে কম্পাইলার হয়তো আমাদের কোডের ব্যবহারকে সমস্যার কারণ থেকে অনেক ধাপ দূরে নির্দেশ করতে সক্ষম হতে পারে।
যখন আমরা longest-এ কংক্রিট রেফারেন্স পাস করি, তখন 'a-এর জন্য প্রতিস্থাপিত কংক্রিট লাইফটাইম হল x-এর স্কোপের সেই অংশ যা y-এর স্কোপের সাথে ওভারল্যাপ করে। অন্য কথায়, জেনেরিক লাইফটাইম 'a কংক্রিট লাইফটাইম পাবে যা x এবং y-এর লাইফটাইমের ছোটটির সমান। যেহেতু আমরা রিটার্ন করা রেফারেন্সটিকে একই লাইফটাইম প্যারামিটার 'a দিয়ে অ্যানোটেট করেছি, তাই রিটার্ন করা রেফারেন্সটিও x এবং y-এর লাইফটাইমের ছোটটির দৈর্ঘ্য পর্যন্ত বৈধ থাকবে।
আসুন দেখি কিভাবে লাইফটাইম অ্যানোটেশনগুলো longest ফাংশনকে সীমাবদ্ধ করে, বিভিন্ন কংক্রিট লাইফটাইমের রেফারেন্স পাস করে। Listing 10-22 একটি সহজবোধ্য উদাহরণ।
fn main() { let string1 = String::from("long string is long"); { let string2 = String::from("xyz"); let result = longest(string1.as_str(), string2.as_str()); println!("The longest string is {result}"); } } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
এই উদাহরণে, string1 আউটার স্কোপের শেষ পর্যন্ত বৈধ, string2 ইনার স্কোপের শেষ পর্যন্ত বৈধ এবং result এমন কিছুকে রেফার করে যা ইনার স্কোপের শেষ পর্যন্ত বৈধ। এই কোডটি চালান এবং আপনি দেখতে পাবেন যে বোরো চেকার অনুমোদন করে; এটি কম্পাইল হবে এবং The longest string is long string is long প্রিন্ট করবে।
এরপর, আসুন এমন একটি উদাহরণ চেষ্টা করি যা দেখায় যে result-এর রেফারেন্সের লাইফটাইম অবশ্যই দুটি আর্গুমেন্টের ছোট লাইফটাইম হতে হবে। আমরা result ভেরিয়েবলের ঘোষণা ইনার স্কোপের বাইরে নিয়ে যাব কিন্তু result ভেরিয়েবলে মান অ্যাসাইনমেন্ট string2-এর সাথে স্কোপের ভিতরে রেখে দেব। তারপর আমরা println! যা result ব্যবহার করে, সেটি ইনার স্কোপের পরে, বাইরের স্কোপে নিয়ে যাব। Listing 10-23-এর কোডটি কম্পাইল হবে না।
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}আমরা যখন এই কোডটি কম্পাইল করার চেষ্টা করি, তখন আমরা এই এররটি পাই:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
5 | let string2 = String::from("xyz");
| ------- binding `string2` declared here
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {result}");
| -------- borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
এররটি দেখায় যে println! স্টেটমেন্টের জন্য result বৈধ হওয়ার জন্য, string2-কে আউটার স্কোপের শেষ পর্যন্ত বৈধ হতে হবে। Rust এটি জানে কারণ আমরা ফাংশন প্যারামিটার এবং রিটার্ন ভ্যালুগুলোর লাইফটাইম একই লাইফটাইম প্যারামিটার 'a ব্যবহার করে অ্যানোটেট করেছি।
মানুষ হিসাবে, আমরা এই কোডটি দেখতে পাচ্ছি এবং জানি যে string1 string2-এর চেয়ে দীর্ঘ এবং সেইজন্য, result-এ string1-এর একটি রেফারেন্স থাকবে। যেহেতু string1 এখনও স্কোপের বাইরে যায়নি, তাই println! স্টেটমেন্টের জন্য string1-এর একটি রেফারেন্স এখনও বৈধ থাকবে। যাইহোক, কম্পাইলার এই ক্ষেত্রে দেখতে পাচ্ছে না যে রেফারেন্সটি বৈধ। আমরা Rust-কে বলেছি যে longest ফাংশন দ্বারা রিটার্ন করা রেফারেন্সের লাইফটাইমটি পাস করা রেফারেন্সগুলোর লাইফটাইমের ছোটটির সমান। অতএব, বোরো চেকার Listing 10-23-এর কোডটিকে সম্ভবত একটি অবৈধ রেফারেন্স হিসাবে বাতিল করে দেয়।
longest ফাংশনে পাস করা রেফারেন্সগুলোর মান এবং লাইফটাইম পরিবর্তন করে এবং রিটার্ন করা রেফারেন্স কীভাবে ব্যবহৃত হয় তা নিয়ে আরও পরীক্ষা ডিজাইন করার চেষ্টা করুন। কম্পাইল করার আগে আপনার পরীক্ষাগুলো বোরো চেকার পাস করবে কিনা সে সম্পর্কে অনুমান করুন; তারপর আপনি সঠিক কিনা তা দেখতে পরীক্ষা করুন!
লাইফটাইমের পরিপ্রেক্ষিতে চিন্তা করা (Thinking in Terms of Lifetimes)
আপনাকে যে উপায়ে লাইফটাইম প্যারামিটারগুলো নির্দিষ্ট করতে হবে তা নির্ভর করে আপনার ফাংশন কী করছে তার উপর। উদাহরণস্বরূপ, যদি আমরা longest ফাংশনের ইমপ্লিমেন্টেশন পরিবর্তন করে সর্বদাই দীর্ঘতম স্ট্রিং স্লাইসের পরিবর্তে প্রথম প্যারামিটারটি রিটার্ন করতাম, তাহলে আমাদের y প্যারামিটারে একটি লাইফটাইম নির্দিষ্ট করার প্রয়োজন হত না। নিম্নলিখিত কোডটি কম্পাইল হবে:
fn main() { let string1 = String::from("abcd"); let string2 = "efghijklmnopqrstuvwxyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {result}"); } fn longest<'a>(x: &'a str, y: &str) -> &'a str { x }
আমরা প্যারামিটার x এবং রিটার্ন টাইপের জন্য একটি লাইফটাইম প্যারামিটার 'a নির্দিষ্ট করেছি, কিন্তু প্যারামিটার y-এর জন্য নয়, কারণ y-এর লাইফটাইমের সাথে x বা রিটার্ন মানের লাইফটাইমের কোনো সম্পর্ক নেই।
যখন একটি ফাংশন থেকে একটি রেফারেন্স রিটার্ন করা হয়, তখন রিটার্ন টাইপের জন্য লাইফটাইম প্যারামিটারটি প্যারামিটারগুলোর মধ্যে একটির লাইফটাইম প্যারামিটারের সাথে মেলানো প্রয়োজন। যদি রিটার্ন করা রেফারেন্সটি প্যারামিটারগুলোর কোনোটিকে রেফার না করে, তাহলে এটি অবশ্যই এই ফাংশনের মধ্যে তৈরি করা একটি মানকে রেফার করবে। যাইহোক, এটি একটি ড্যাংলিং রেফারেন্স হবে কারণ মানটি ফাংশনের শেষে স্কোপের বাইরে চলে যাবে। longest ফাংশনের এই বাস্তবায়নের প্রচেষ্টাটি বিবেচনা করুন যা কম্পাইল হবে না:
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}এখানে, যদিও আমরা রিটার্ন টাইপের জন্য একটি লাইফটাইম প্যারামিটার 'a নির্দিষ্ট করেছি, তবুও এই ইমপ্লিমেন্টেশনটি কম্পাইল করতে ব্যর্থ হবে কারণ রিটার্ন ভ্যালুর লাইফটাইম প্যারামিটারগুলোর লাইফটাইমের সাথে কোনোভাবেই সম্পর্কিত নয়। এখানে আমরা যে এরর মেসেজটি পাই তা হল:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return value referencing local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `result` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
সমস্যা হল result স্কোপের বাইরে চলে যায় এবং longest ফাংশনের শেষে পরিষ্কার হয়ে যায়। আমরা result-এর একটি রেফারেন্সও ফাংশন থেকে রিটার্ন করার চেষ্টা করছি। এমন কোনো উপায় নেই যাতে আমরা লাইফটাইম প্যারামিটারগুলো নির্দিষ্ট করতে পারি যা ড্যাংলিং রেফারেন্স পরিবর্তন করবে এবং Rust আমাদের একটি ড্যাংলিং রেফারেন্স তৈরি করতে দেবে না। এই ক্ষেত্রে, সর্বোত্তম সমাধান হবে একটি ওনড ডেটা টাইপ রিটার্ন করা, রেফারেন্স নয়, যাতে কলিং ফাংশনটি তখন মানের ক্লিনিং আপ করার জন্য দায়ী থাকে।
পরিশেষে, লাইফটাইম সিনট্যাক্স হল ফাংশনের বিভিন্ন প্যারামিটার এবং রিটার্ন মানগুলোর লাইফটাইমগুলোকে সংযুক্ত করার বিষয়ে। একবার সেগুলো সংযুক্ত হয়ে গেলে, Rust-এর কাছে মেমরি-নিরাপদ অপারেশনগুলোর অনুমতি দেওয়ার জন্য এবং ড্যাংলিং পয়েন্টার তৈরি করবে বা অন্যথায় মেমরির নিরাপত্তা লঙ্ঘন করবে এমন অপারেশনগুলোকে বাতিল করার জন্য যথেষ্ট তথ্য থাকে।
স্ট্রাকট সংজ্ঞায় লাইফটাইম অ্যানোটেশন (Lifetime Annotations in Struct Definitions)
এখন পর্যন্ত, আমরা যে স্ট্রাকটগুলো সংজ্ঞায়িত করেছি সেগুলো সবই ওনড টাইপ ধারণ করে। আমরা রেফারেন্স ধারণ করার জন্য স্ট্রাকট সংজ্ঞায়িত করতে পারি, কিন্তু সেই ক্ষেত্রে আমাদের স্ট্রাকটের সংজ্ঞার প্রতিটি রেফারেন্সে একটি লাইফটাইম অ্যানোটেশন যোগ করতে হবে। Listing 10-24-এ ImportantExcerpt নামে একটি স্ট্রাকট রয়েছে যা একটি স্ট্রিং স্লাইস ধারণ করে।
struct ImportantExcerpt<'a> { part: &'a str, } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
এই স্ট্রাকটটিতে part নামক একটি একক ফিল্ড রয়েছে যা একটি স্ট্রিং স্লাইস ধারণ করে, যেটি একটি রেফারেন্স। জেনেরিক ডেটা টাইপের মতো, আমরা স্ট্রাকটের নামের পরে অ্যাঙ্গেল ব্র্যাকেটের ভিতরে জেনেরিক লাইফটাইম প্যারামিটারের নাম ঘোষণা করি যাতে আমরা স্ট্রাকট সংজ্ঞার বডিতে লাইফটাইম প্যারামিটার ব্যবহার করতে পারি। এই অ্যানোটেশনটির অর্থ হল ImportantExcerpt-এর একটি ইন্সট্যান্স তার part ফিল্ডে থাকা রেফারেন্সের চেয়ে বেশি বাঁচতে পারে না।
এখানে main ফাংশনটি ImportantExcerpt স্ট্রাকটের একটি ইন্সট্যান্স তৈরি করে যা novel ভেরিয়েবলের মালিকানাধীন String-এর প্রথম বাক্যের রেফারেন্স ধারণ করে। novel-এর ডেটা ImportantExcerpt ইন্সট্যান্স তৈরি হওয়ার আগেই বিদ্যমান। উপরন্তু, ImportantExcerpt স্কোপের বাইরে না যাওয়া পর্যন্ত novel স্কোপের বাইরে যায় না, তাই ImportantExcerpt ইন্সট্যান্সের রেফারেন্সটি বৈধ।
লাইফটাইম এলিশন (Lifetime Elision)
আপনি শিখেছেন যে প্রতিটি রেফারেন্সের একটি লাইফটাইম রয়েছে এবং আপনাকে সেই ফাংশন বা স্ট্রাকটগুলোর জন্য লাইফটাইম প্যারামিটার নির্দিষ্ট করতে হবে যেগুলো রেফারেন্স ব্যবহার করে। যাইহোক, Listing 4-9-এ আমাদের একটি ফাংশন ছিল, যা Listing 10-25-এ আবারও দেখানো হয়েছে, যেটি লাইফটাইম অ্যানোটেশন ছাড়াই কম্পাইল হয়েছিল।
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // first_word works on slices of `String`s let word = first_word(&my_string[..]); let my_string_literal = "hello world"; // first_word works on slices of string literals let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
এই ফাংশনটি লাইফটাইম অ্যানোটেশন ছাড়াই কম্পাইল হওয়ার কারণ হল এটি ঐতিহাসিক: Rust-এর প্রাথমিক ভার্সনগুলোতে (pre-1.0), এই কোডটি কম্পাইল হত না কারণ প্রতিটি রেফারেন্সের একটি স্পষ্ট লাইফটাইম প্রয়োজন হত। সেই সময়ে, ফাংশন সিগনেচারটি এইভাবে লেখা হত:
fn first_word<'a>(s: &'a str) -> &'a str {অনেক Rust কোড লেখার পরে, Rust টিম দেখেছে যে Rust প্রোগ্রামাররা নির্দিষ্ট পরিস্থিতিতে একই লাইফটাইম অ্যানোটেশনগুলো বারবার লিখছেন। এই পরিস্থিতিগুলো অনুমানযোগ্য ছিল এবং কয়েকটি নির্ধারক (deterministic) প্যাটার্ন অনুসরণ করত। ডেভেলপাররা এই প্যাটার্নগুলোকে কম্পাইলারের কোডে প্রোগ্রাম করেছেন যাতে বোরো চেকার এই পরিস্থিতিতে লাইফটাইমগুলো অনুমান করতে পারে এবং স্পষ্ট অ্যানোটেশনের প্রয়োজন না হয়।
Rust ইতিহাসের এই অংশটি প্রাসঙ্গিক কারণ এটি সম্ভব যে আরও নির্ধারক প্যাটার্ন আবির্ভূত হবে এবং কম্পাইলারে যুক্ত করা হবে। ভবিষ্যতে, আরও কম লাইফটাইম অ্যানোটেশনের প্রয়োজন হতে পারে।
Rust-এর রেফারেন্সের বিশ্লেষণে প্রোগ্রাম করা প্যাটার্নগুলোকে লাইফটাইম এলিশন রুলস (lifetime elision rules) বলা হয়। এগুলো প্রোগ্রামারদের অনুসরণ করার নিয়ম নয়; এগুলো হল বিশেষ ক্ষেত্রের একটি সেট যা কম্পাইলার বিবেচনা করবে এবং যদি আপনার কোড এই ক্ষেত্রগুলোর সাথে খাপ খায়, তাহলে আপনাকে স্পষ্টভাবে লাইফটাইম লিখতে হবে না।
এলিশন নিয়মগুলো সম্পূর্ণ অনুমান সরবরাহ করে না। যদি Rust নিয়মগুলো প্রয়োগ করার পরেও রেফারেন্সগুলোর লাইফটাইম কী হবে তা নিয়ে অস্পষ্টতা থাকে, তাহলে কম্পাইলার অবশিষ্ট রেফারেন্সগুলোর লাইফটাইম কী হওয়া উচিত তা অনুমান করবে না। অনুমান করার পরিবর্তে, কম্পাইলার আপনাকে একটি এরর দেবে যা আপনি লাইফটাইম অ্যানোটেশন যোগ করে সমাধান করতে পারেন।
ফাংশন বা মেথড প্যারামিটারের লাইফটাইমগুলোকে ইনপুট লাইফটাইম (input lifetimes) বলা হয় এবং রিটার্ন ভ্যালুগুলোর লাইফটাইমগুলোকে আউটপুট লাইফটাইম (output lifetimes) বলা হয়।
কম্পাইলার তিনটি নিয়ম ব্যবহার করে রেফারেন্সগুলোর লাইফটাইম বের করে যখন কোনো স্পষ্ট অ্যানোটেশন থাকে না। প্রথম নিয়মটি ইনপুট লাইফটাইমের ক্ষেত্রে প্রযোজ্য এবং দ্বিতীয় ও তৃতীয় নিয়মগুলো আউটপুট লাইফটাইমের ক্ষেত্রে প্রযোজ্য। যদি কম্পাইলার তিনটি নিয়মের শেষে পৌঁছায় এবং তখনও এমন রেফারেন্স থাকে যার জন্য এটি লাইফটাইম বের করতে পারে না, তাহলে কম্পাইলার একটি এরর দিয়ে থামবে। এই নিয়মগুলো fn সংজ্ঞা এবং impl ব্লক উভয়ের ক্ষেত্রেই প্রযোজ্য।
প্রথম নিয়ম হল কম্পাইলার প্রতিটি প্যারামিটারকে একটি লাইফটাইম প্যারামিটার বরাদ্দ করে যা একটি রেফারেন্স। অন্য কথায়, একটি প্যারামিটার সহ একটি ফাংশন একটি লাইফটাইম প্যারামিটার পায়: fn foo<'a>(x: &'a i32); দুটি প্যারামিটার সহ একটি ফাংশন দুটি পৃথক লাইফটাইম প্যারামিটার পায়: fn foo<'a, 'b>(x: &'a i32, y: &'b i32); এবং এভাবে চলতে থাকে।
দ্বিতীয় নিয়ম হল, যদি ঠিক একটি ইনপুট লাইফটাইম প্যারামিটার থাকে, তাহলে সেই লাইফটাইমটি সমস্ত আউটপুট লাইফটাইম প্যারামিটারে বরাদ্দ করা হয়: fn foo<'a>(x: &'a i32) -> &'a i32।
তৃতীয় নিয়ম হল, যদি একাধিক ইনপুট লাইফটাইম প্যারামিটার থাকে, কিন্তু তাদের মধ্যে একটি &self বা &mut self হয় কারণ এটি একটি মেথড, তাহলে self-এর লাইফটাইম সমস্ত আউটপুট লাইফটাইম প্যারামিটারে বরাদ্দ করা হয়। এই তৃতীয় নিয়মটি মেথডগুলোকে পড়তে এবং লিখতে অনেক সুন্দর করে তোলে কারণ কম সংখ্যক চিহ্নের প্রয়োজন হয়।
আসুন ধরে নিই আমরা কম্পাইলার। Listing 10-25-এর first_word ফাংশনের সিগনেচারে রেফারেন্সগুলোর লাইফটাইম বের করতে আমরা এই নিয়মগুলো প্রয়োগ করব। সিগনেচারটি রেফারেন্সগুলোর সাথে কোনো লাইফটাইম যুক্ত না করেই শুরু হয়:
fn first_word(s: &str) -> &str {তারপর কম্পাইলার প্রথম নিয়মটি প্রয়োগ করে, যা নির্দিষ্ট করে যে প্রতিটি প্যারামিটার তার নিজস্ব লাইফটাইম পায়। আমরা এটিকে যথারীতি 'a বলব, তাই এখন সিগনেচারটি হল:
fn first_word<'a>(s: &'a str) -> &str {দ্বিতীয় নিয়মটি প্রযোজ্য কারণ ঠিক একটি ইনপুট লাইফটাইম রয়েছে। দ্বিতীয় নিয়মটি নির্দিষ্ট করে যে একটি ইনপুট প্যারামিটারের লাইফটাইম আউটপুট লাইফটাইমে বরাদ্দ করা হয়, তাই সিগনেচারটি এখন এরকম:
fn first_word<'a>(s: &'a str) -> &'a str {এখন এই ফাংশন সিগনেচারের সমস্ত রেফারেন্সের লাইফটাইম রয়েছে এবং কম্পাইলার প্রোগ্রামারকে এই ফাংশন সিগনেচারে লাইফটাইম অ্যানোটেট করার প্রয়োজন ছাড়াই তার বিশ্লেষণ চালিয়ে যেতে পারে।
আসুন আরেকটি উদাহরণ দেখি, এবার longest ফাংশনটি ব্যবহার করে যেখানে আমরা Listing 10-20-এ কাজ শুরু করার সময় কোনো লাইফটাইম প্যারামিটার ছিল না:
fn longest(x: &str, y: &str) -> &str {আসুন প্রথম নিয়মটি প্রয়োগ করি: প্রতিটি প্যারামিটার তার নিজস্ব লাইফটাইম পায়। এবার আমাদের একটির পরিবর্তে দুটি প্যারামিটার রয়েছে, তাই আমাদের দুটি লাইফটাইম রয়েছে:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {আপনি দেখতে পাচ্ছেন যে দ্বিতীয় নিয়মটি প্রযোজ্য নয় কারণ একাধিক ইনপুট লাইফটাইম রয়েছে। তৃতীয় নিয়মটিও প্রযোজ্য নয়, কারণ longest একটি ফাংশন, মেথড নয়, তাই কোনো প্যারামিটারই self নয়। তিনটি নিয়ম নিয়ে কাজ করার পরেও, আমরা এখনও রিটার্ন টাইপের লাইফটাইম কী তা বের করতে পারিনি। এই কারণেই আমরা Listing 10-20-এর কোড কম্পাইল করার চেষ্টা করার সময় একটি এরর পেয়েছিলাম: কম্পাইলার লাইফটাইম এলিশন নিয়মগুলো নিয়ে কাজ করেছে কিন্তু তবুও সিগনেচারের রেফারেন্সগুলোর সমস্ত লাইফটাইম বের করতে পারেনি।
যেহেতু তৃতীয় নিয়মটি সত্যিই শুধুমাত্র মেথড সিগনেচারে প্রযোজ্য, তাই আমরা পরবর্তীকালে সেই প্রসঙ্গে লাইফটাইমগুলো দেখব, এটা দেখার জন্য যে কেন তৃতীয় নিয়মটির অর্থ হল আমাদের প্রায়শই মেথড সিগনেচারে লাইফটাইম অ্যানোটেট করতে হয় না।
মেথড সংজ্ঞায় লাইফটাইম অ্যানোটেশন (Lifetime Annotations in Method Definitions)
যখন আমরা লাইফটাইম সহ স্ট্রাকটগুলোতে মেথড ইমপ্লিমেন্ট করি, তখন আমরা জেনেরিক টাইপ প্যারামিটারের মতোই সিনট্যাক্স ব্যবহার করি, যেমনটি Listing 10-11-তে দেখানো হয়েছে। আমরা কোথায় লাইফটাইম প্যারামিটারগুলো ঘোষণা করি এবং ব্যবহার করি তা নির্ভর করে সেগুলো স্ট্রাকট ফিল্ডগুলোর সাথে সম্পর্কিত কিনা বা মেথড প্যারামিটার এবং রিটার্ন ভ্যালুগুলোর সাথে।
স্ট্রাকট ফিল্ডগুলোর জন্য লাইফটাইমের নাম সর্বদাই impl কীওয়ার্ডের পরে ঘোষণা করতে হবে এবং তারপর স্ট্রাকটের নামের পরে ব্যবহার করতে হবে কারণ সেই লাইফটাইমগুলো স্ট্রাকটের টাইপের অংশ।
impl ব্লকের ভেতরের মেথড সিগনেচারগুলোতে, রেফারেন্সগুলো স্ট্রাকটের ফিল্ডের রেফারেন্সগুলোর লাইফটাইমের সাথে যুক্ত হতে পারে, অথবা সেগুলো স্বাধীন হতে পারে। উপরন্তু, লাইফটাইম এলিশন নিয়মগুলো প্রায়শই এমন হয় যে মেথড সিগনেচারে লাইফটাইম অ্যানোটেশনের প্রয়োজন হয় না। আসুন Listing 10-24-এ সংজ্ঞায়িত ImportantExcerpt নামক স্ট্রাকটটি ব্যবহার করে কিছু উদাহরণ দেখি।
প্রথমে আমরা level নামক একটি মেথড ব্যবহার করব যার একমাত্র প্যারামিটার হল self-এর একটি রেফারেন্স এবং যার রিটার্ন ভ্যালু হল একটি i32, যা কোনো কিছুর রেফারেন্স নয়:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {announcement}"); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
impl-এর পরে লাইফটাইম প্যারামিটার ঘোষণা এবং টাইপ নামের পরে এর ব্যবহার প্রয়োজনীয়, কিন্তু প্রথম এলিশন নিয়মের কারণে আমাদের self-এর রেফারেন্সের লাইফটাইম অ্যানোটেট করার প্রয়োজন নেই।
এখানে একটি উদাহরণ দেওয়া হল যেখানে তৃতীয় লাইফটাইম এলিশন নিয়মটি প্রযোজ্য:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {announcement}"); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
দুটি ইনপুট লাইফটাইম রয়েছে, তাই Rust প্রথম লাইফটাইম এলিশন নিয়ম প্রয়োগ করে এবং &self এবং announcement উভয়কেই তাদের নিজস্ব লাইফটাইম দেয়। তারপর, যেহেতু প্যারামিটারগুলোর মধ্যে একটি হল &self, তাই রিটার্ন টাইপটি &self-এর লাইফটাইম পায় এবং সমস্ত লাইফটাইম হিসাব করা হয়েছে।
স্ট্যাটিক লাইফটাইম (The Static Lifetime)
আমাদের একটি বিশেষ লাইফটাইম নিয়ে আলোচনা করতে হবে: 'static, যা বোঝায় যে প্রভাবিত রেফারেন্সটি প্রোগ্রামের সম্পূর্ণ সময়কালের জন্য বাঁচতে পারে। সমস্ত স্ট্রিং লিটারেলের 'static লাইফটাইম রয়েছে, যা আমরা নিম্নরূপে অ্যানোটেট করতে পারি:
#![allow(unused)] fn main() { let s: &'static str = "I have a static lifetime."; }
এই স্ট্রিং-এর টেক্সটটি সরাসরি প্রোগ্রামের বাইনারিতে সংরক্ষণ করা হয়, যা সর্বদাই উপলব্ধ। অতএব, সমস্ত স্ট্রিং লিটারেলের লাইফটাইম হল 'static।
আপনি হয়তো এরর মেসেজে 'static লাইফটাইম ব্যবহার করার পরামর্শ দেখতে পারেন। কিন্তু একটি রেফারেন্সের জন্য 'static লাইফটাইম নির্দিষ্ট করার আগে, ভাবুন যে আপনার রেফারেন্সটি আসলে আপনার প্রোগ্রামের পুরো লাইফটাইম ধরে বাঁচে কিনা এবং আপনি তা চান কিনা। বেশিরভাগ সময়, 'static লাইফটাইম সুপারিশ করা একটি এরর মেসেজ একটি ড্যাংলিং রেফারেন্স তৈরি করার চেষ্টা বা উপলব্ধ লাইফটাইমের অমিলের ফলে হয়। এই ধরনের ক্ষেত্রে, সমাধান হল সেই সমস্যাগুলো ঠিক করা, 'static লাইফটাইম নির্দিষ্ট করা নয়।
জেনেরিক টাইপ প্যারামিটার, ট্রেইট বাউন্ড এবং লাইফটাইম একসাথে (Generic Type Parameters, Trait Bounds, and Lifetimes Together)
আসুন সংক্ষেপে একটি ফাংশনে জেনেরিক টাইপ প্যারামিটার, ট্রেইট বাউন্ড এবং লাইফটাইম নির্দিষ্ট করার সিনট্যাক্স দেখি!
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest_with_an_announcement( string1.as_str(), string2, "Today is someone's birthday!", ); println!("The longest string is {result}"); } use std::fmt::Display; fn longest_with_an_announcement<'a, T>( x: &'a str, y: &'a str, ann: T, ) -> &'a str where T: Display, { println!("Announcement! {ann}"); if x.len() > y.len() { x } else { y } }
এটি Listing 10-21-এর longest ফাংশন যা দুটি স্ট্রিং স্লাইসের মধ্যে দীর্ঘতমটি রিটার্ন করে। কিন্তু এখন এটির জেনেরিক টাইপ T-এর একটি অতিরিক্ত প্যারামিটার রয়েছে ann, যা যেকোনো টাইপ দ্বারা পূরণ করা যেতে পারে যা where ক্লজ দ্বারা নির্দিষ্ট করা Display ট্রেইট ইমপ্লিমেন্ট করে। এই অতিরিক্ত প্যারামিটারটি {} ব্যবহার করে প্রিন্ট করা হবে, যে কারণে Display ট্রেইট বাউন্ড প্রয়োজন। যেহেতু লাইফটাইমগুলো এক ধরনের জেনেরিক, তাই লাইফটাইম প্যারামিটার 'a এবং জেনেরিক টাইপ প্যারামিটার T-এর ঘোষণাগুলো ফাংশনের নামের পরে অ্যাঙ্গেল ব্র্যাকেটের মধ্যে একই তালিকায় যায়।
সারসংক্ষেপ (Summary)
আমরা এই চ্যাপ্টারে অনেক কিছু কভার করেছি! এখন আপনি জেনেরিক টাইপ প্যারামিটার, ট্রেইট এবং ট্রেইট বাউন্ড এবং জেনেরিক লাইফটাইম প্যারামিটার সম্পর্কে জানেন, আপনি পুনরাবৃত্তি ছাড়া কোড লিখতে প্রস্তুত যা বিভিন্ন পরিস্থিতিতে কাজ করে। জেনেরিক টাইপ প্যারামিটারগুলো আপনাকে বিভিন্ন টাইপের কোড প্রয়োগ করতে দেয়। ট্রেইট এবং ট্রেইট বাউন্ডগুলো নিশ্চিত করে যে টাইপগুলো জেনেরিক হলেও, কোডের প্রয়োজনীয় আচরণ তাদের থাকবে। আপনি শিখেছেন কিভাবে লাইফটাইম অ্যানোটেশন ব্যবহার করতে হয় যাতে এই নমনীয় কোডে কোনো ড্যাংলিং রেফারেন্স না থাকে। এবং এই সমস্ত বিশ্লেষণ কম্পাইল টাইমে ঘটে, যা রানটাইম পারফরম্যান্সকে প্রভাবিত করে না!
বিশ্বাস করুন বা না করুন, আমরা এই চ্যাপ্টারে যা নিয়ে আলোচনা করেছি সে সম্পর্কে আরও অনেক কিছু শেখার আছে: চ্যাপ্টার 18-এ ট্রেইট অবজেক্ট নিয়ে আলোচনা করা হয়েছে, যা ট্রেইট ব্যবহারের আরেকটি উপায়। এছাড়াও আরও জটিল পরিস্থিতি রয়েছে যেখানে লাইফটাইম অ্যানোটেশনের প্রয়োজন হয় যা আপনার শুধুমাত্র খুব উন্নত পরিস্থিতিতে প্রয়োজন হবে; এগুলোর জন্য, আপনার Rust Reference পড়া উচিত। কিন্তু এরপর, আপনি Rust-এ কিভাবে পরীক্ষা লিখতে হয় তা শিখবেন যাতে আপনি নিশ্চিত করতে পারেন যে আপনার কোড যেভাবে কাজ করার কথা সেভাবেই কাজ করছে।
স্বয়ংক্রিয় পরীক্ষা লেখা (Writing Automated Tests)
১৯৭২ সালে "দ্য হাম্বল প্রোগ্রামার" প্রবন্ধে এডসগার ডাইকস্ট্রা (Edsger W. Dijkstra) বলেছিলেন যে "প্রোগ্রাম টেস্টিং বাগগুলোর উপস্থিতি দেখানোর জন্য খুব কার্যকর উপায় হতে পারে, কিন্তু তাদের অনুপস্থিতি দেখানোর জন্য এটি আশাহীনভাবে অপর্যাপ্ত।" তার মানে এই নয় যে আমরা যতটা সম্ভব পরীক্ষা করার চেষ্টা করব না!
আমাদের প্রোগ্রামগুলো কতটা সঠিক (correctness) তা হল, আমাদের কোডটি আমরা যা করতে চাই তা কতটা করে। Rust প্রোগ্রামগুলোর সঠিকতার বিষয়ে উচ্চ মাত্রার উদ্বেগ নিয়ে ডিজাইন করা হয়েছে, কিন্তু সঠিকতা জটিল এবং প্রমাণ করা সহজ নয়। Rust-এর টাইপ সিস্টেম এই বোঝার একটি বিশাল অংশ বহন করে, কিন্তু টাইপ সিস্টেম সবকিছু ধরতে পারে না। তাই, Rust স্বয়ংক্রিয় সফটওয়্যার পরীক্ষা লেখার জন্য সমর্থন অন্তর্ভুক্ত করে।
ধরা যাক, আমরা একটি add_two ফাংশন লিখি যা যেকোনো সংখ্যার সাথে ২ যোগ করে। এই ফাংশনের সিগনেচার একটি পূর্ণসংখ্যাকে প্যারামিটার হিসাবে গ্রহণ করে এবং একটি পূর্ণসংখ্যাকে ফলাফল হিসাবে রিটার্ন করে। যখন আমরা সেই ফাংশনটি ইমপ্লিমেন্ট এবং কম্পাইল করি, তখন Rust সমস্ত টাইপ চেকিং এবং বোরো চেকিং করে যা আপনি এতক্ষণ শিখেছেন, এটি নিশ্চিত করার জন্য যে, উদাহরণস্বরূপ, আমরা এই ফাংশনে একটি String মান বা একটি অবৈধ রেফারেন্স পাস করছি না। কিন্তু Rust পরীক্ষা করতে পারে না যে এই ফাংশনটি ঠিক সেটাই করবে যা আমরা চাই, অর্থাৎ, প্যারামিটারের সাথে ১০ বা প্যারামিটার বিয়োগ ৫০ যোগ না করে, প্যারামিটারের সাথে ২ যোগ করে রিটার্ন করবে! এখানেই পরীক্ষার প্রয়োজন হয়।
আমরা এমন পরীক্ষা লিখতে পারি যা দাবি করে, উদাহরণস্বরূপ, যখন আমরা add_two ফাংশনে 3 পাস করি, তখন রিটার্ন করা মান 5 হয়। আমরা যখনই আমাদের কোডে পরিবর্তন করি তখনই এই পরীক্ষাগুলো চালাতে পারি যাতে বিদ্যমান সঠিক আচরণ পরিবর্তন না হয় তা নিশ্চিত করা যায়।
টেস্টিং একটি জটিল দক্ষতা: যদিও আমরা একটি চ্যাপ্টারে ভাল পরীক্ষা লেখার প্রতিটি বিবরণ কভার করতে পারি না, এই চ্যাপ্টারে আমরা Rust-এর টেস্টিং সুবিধাগুলোর মেকানিক্স নিয়ে আলোচনা করব। আমরা আপনার পরীক্ষাগুলো লেখার সময় আপনার কাছে উপলব্ধ অ্যানোটেশন এবং ম্যাক্রোগুলো, আপনার পরীক্ষাগুলো চালানোর জন্য দেওয়া ডিফল্ট আচরণ এবং অপশনগুলো এবং কীভাবে পরীক্ষাগুলোকে ইউনিট টেস্ট এবং ইন্টিগ্রেশন টেস্টে সংগঠিত করতে হয় সে সম্পর্কে কথা বলব।
টেস্ট কীভাবে লিখতে হয় (How to Write Tests)
টেস্ট হলো Rust-এর ফাংশন যা যাচাই করে যে নন-টেস্ট কোড প্রত্যাশিতভাবে কাজ করছে কিনা। টেস্ট ফাংশনের বডিতে সাধারণত এই তিনটি কাজ করা হয়:
- প্রয়োজনীয় ডেটা বা স্টেট সেট আপ করা।
- যে কোডটি টেস্ট করতে চান সেটি রান করা।
- ফলাফল আপনার প্রত্যাশা অনুযায়ী হয়েছে কিনা, তা অ্যাসার্ট (assert) করা।
আসুন, Rust-এর সেই ফিচারগুলো দেখি যেগুলো এই কাজগুলো করার জন্য টেস্ট লিখতে বিশেষভাবে সাহায্য করে। এর মধ্যে রয়েছে test অ্যাট্রিবিউট, কিছু ম্যাক্রো, এবং should_panic অ্যাট্রিবিউট।
একটি টেস্ট ফাংশনের গঠন (The Anatomy of a Test Function)
Rust-এ, সবচেয়ে সহজভাবে বলতে গেলে, একটি টেস্ট হল একটি ফাংশন যাকে test অ্যাট্রিবিউট দিয়ে চিহ্নিত করা হয়। অ্যাট্রিবিউট হল Rust কোডের অংশবিশেষ সম্পর্কে মেটাডেটা; একটি উদাহরণ হল derive অ্যাট্রিবিউট, যা আমরা চ্যাপ্টার ৫-এ স্ট্রাক্ট (struct)-এর সাথে ব্যবহার করেছি। একটি ফাংশনকে টেস্ট ফাংশনে পরিণত করতে, fn-এর আগে লাইনে #[test] যোগ করুন। যখন আপনি cargo test কমান্ড দিয়ে আপনার টেস্টগুলো রান করবেন, Rust একটি টেস্ট রানার বাইনারি তৈরি করবে যা চিহ্নিত ফাংশনগুলো রান করে এবং প্রতিটি টেস্ট ফাংশন পাস (pass) করেছে নাকি ফেইল (fail) করেছে তা রিপোর্ট করে।
যখনই আমরা Cargo দিয়ে একটি নতুন লাইব্রেরি প্রোজেক্ট তৈরি করি, আমাদের জন্য স্বয়ংক্রিয়ভাবে একটি টেস্ট মডিউল তৈরি হয়ে যায়, যার মধ্যে একটি টেস্ট ফাংশন থাকে। এই মডিউলটি আপনাকে টেস্ট লেখার জন্য একটি টেমপ্লেট দেয়, তাই আপনাকে প্রতিবার নতুন প্রোজেক্ট শুরু করার সময় সঠিক গঠন এবং সিনট্যাক্স (syntax) খুঁজতে হবে না। আপনি যত খুশি অতিরিক্ত টেস্ট ফাংশন এবং টেস্ট মডিউল যোগ করতে পারেন!
আমরা আসলে কোনো কোড টেস্ট করার আগে, টেমপ্লেট টেস্ট নিয়ে পরীক্ষা-নিরীক্ষা করে টেস্ট কীভাবে কাজ করে তার কিছু দিক অনুসন্ধান করব। তারপর আমরা কিছু বাস্তব-বিশ্বের (real-world) টেস্ট লিখব, যেগুলো আমাদের লেখা কিছু কোড কল করবে এবং অ্যাসার্ট (assert) করবে যে এটির আচরণ (behavior) সঠিক।
আসুন adder নামে একটি নতুন লাইব্রেরি প্রোজেক্ট তৈরি করি, যা দুটি সংখ্যা যোগ করবে:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
আপনার adder লাইব্রেরির src/lib.rs ফাইলের কনটেন্ট (contents) লিস্টিং 11-1-এর মতো হওয়া উচিত।
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}ফাইলটি একটি উদাহরণ add ফাংশন দিয়ে শুরু হয়, যাতে আমাদের টেস্ট করার মতো কিছু থাকে।
আপাতত, আসুন শুধুমাত্র it_works ফাংশনটির উপর ফোকাস করি। #[test] অ্যানোটেশনটি (annotation) লক্ষ্য করুন: এই অ্যাট্রিবিউটটি নির্দেশ করে যে এটি একটি টেস্ট ফাংশন, তাই টেস্ট রানার জানবে যে এই ফাংশনটিকে একটি টেস্ট হিসাবে বিবেচনা করতে হবে। tests মডিউলে আমাদের নন-টেস্ট ফাংশনও থাকতে পারে, যা সাধারণ পরিস্থিতি সেট আপ করতে বা সাধারণ অপারেশনগুলো সম্পাদন করতে সাহায্য করে, তাই আমাদেরকে সবসময় নির্দেশ করতে হয় যে কোন ফাংশনগুলো টেস্ট।
উদাহরণ ফাংশন বডিটি assert_eq! ম্যাক্রো ব্যবহার করে এটা অ্যাসার্ট করে যে result, যার মধ্যে 2 এবং 2 সহ add কল করার ফলাফল রয়েছে, 4 এর সমান। এই অ্যাসারশনটি (assertion) একটি সাধারণ টেস্টের ফরম্যাটের (format) উদাহরণ হিসাবে কাজ করে। আসুন এটি রান করে দেখি যে এই টেস্টটি পাস করে কিনা।
cargo test কমান্ড আমাদের প্রোজেক্টের সমস্ত টেস্ট রান করে, যেমনটি লিস্টিং 11-2-তে দেখানো হয়েছে।
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (file:///projects/adder/target/debug/deps/adder-40313d497ef8f64e)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cargo টেস্টটি কম্পাইল (compile) এবং রান করেছে। আমরা running 1 test লাইনটি দেখতে পাচ্ছি। পরের লাইনটি জেনারেট হওয়া টেস্ট ফাংশনের নাম দেখায়, যাকে বলা হয় tests::it_works, এবং সেই টেস্টটি চালানোর ফলাফল হল ok। সার্বিক সারাংশ test result: ok. মানে হল যে সমস্ত টেস্ট পাস করেছে, এবং 1 passed; 0 failed অংশটি পাস বা ফেইল করা টেস্টের সংখ্যা গণনা করে।
একটি টেস্টকে উপেক্ষা (ignored) হিসাবে চিহ্নিত করা সম্ভব যাতে এটি কোনও নির্দিষ্ট দৃষ্টান্তে (instance) চালানো না হয়; আমরা এই অধ্যায়ের ["Ignoring Some Tests Unless Specifically Requested"][ignoring] বিভাগে এটি কভার করব। যেহেতু আমরা এখানে তা করিনি, সারাংশটি 0 ignored দেখায়। আমরা cargo test কমান্ডে একটি আর্গুমেন্ট (argument) পাস করতে পারি শুধুমাত্র সেই টেস্টগুলি চালানোর জন্য যাদের নাম একটি স্ট্রিং (string)-এর সাথে মেলে; এটিকে ফিল্টারিং (filtering) বলা হয় এবং আমরা ["Running a Subset of Tests by Name"][subset] বিভাগে এটি কভার করব। এখানে আমরা যে টেস্টগুলি চালানো হচ্ছে সেগুলি ফিল্টার করিনি, তাই সারাংশের শেষে 0 filtered out দেখাচ্ছে।
0 measured স্ট্যাটিস্টিকটি (statistic) বেঞ্চমার্ক (benchmark) টেস্টগুলোর জন্য যা পারফরম্যান্স (performance) পরিমাপ করে। বেঞ্চমার্ক টেস্টগুলো, এই লেখার সময় পর্যন্ত, শুধুমাত্র নাইটলি রাস্ট (nightly Rust)-এ উপলব্ধ। আরও জানতে [the documentation about benchmark tests][bench] দেখুন।
টেস্ট আউটপুটের (output) পরবর্তী অংশ Doc-tests adder থেকে শুরু করে যেকোনো ডকুমেন্টেশন (documentation) টেস্টের ফলাফলের জন্য। আমাদের এখনও কোনো ডকুমেন্টেশন টেস্ট নেই, তবে Rust আমাদের API ডকুমেন্টেশনে প্রদর্শিত যেকোনো কোড উদাহরণ কম্পাইল করতে পারে। এই ফিচারটি আপনার ডক্স (docs) এবং আপনার কোডকে সিঙ্ক (sync)-এ রাখতে সাহায্য করে! আমরা চ্যাপ্টার ১৪-এর ["Documentation Comments as Tests"][doc-comments] বিভাগে কীভাবে ডকুমেন্টেশন টেস্ট লিখতে হয় তা নিয়ে আলোচনা করব। আপাতত, আমরা Doc-tests আউটপুট উপেক্ষা করব।
আসুন আমাদের নিজেদের প্রয়োজনে টেস্টটি কাস্টমাইজ (customize) করা শুরু করি। প্রথমে, it_works ফাংশনের নাম পরিবর্তন করে অন্য একটি নাম দিন, যেমন exploration, এইভাবে:
Filename: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}তারপর আবার cargo test রান করুন। আউটপুট এখন it_works-এর পরিবর্তে exploration দেখাবে:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
এখন আমরা আরেকটি টেস্ট যোগ করব, কিন্তু এবার আমরা এমন একটি টেস্ট তৈরি করব যা ফেইল করবে! যখন টেস্ট ফাংশনের মধ্যে কোনো কিছু প্যানিক (panic) করে তখন টেস্টগুলো ফেইল করে। প্রতিটি টেস্ট একটি নতুন থ্রেডে (thread) চালানো হয়, এবং যখন প্রধান থ্রেড (main thread) দেখে যে একটি টেস্ট থ্রেড মারা গেছে, তখন টেস্টটিকে ফেইল (failed) হিসাবে চিহ্নিত করা হয়। চ্যাপ্টার ৯-এ, আমরা আলোচনা করেছি যে কীভাবে প্যানিক করার সবচেয়ে সহজ উপায় হল panic! ম্যাক্রো কল করা। another নামের একটি ফাংশন হিসাবে নতুন টেস্টটি লিখুন, যাতে আপনার src/lib.rs ফাইলটি লিস্টিং 11-3-এর মতো দেখায়।
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}cargo test ব্যবহার করে আবার টেস্টগুলো রান করুন। আউটপুট লিস্টিং 11-4-এর মতো হওয়া উচিত, যেখানে দেখা যাবে যে আমাদের exploration টেস্ট পাস করেছে এবং another ফেইল করেছে।
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'tests::another' panicked at src/lib.rs:17:9:
Make this test fail
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
ok-এর পরিবর্তে, test tests::another লাইনে FAILED দেখাচ্ছে। আলাদা আলাদা ফলাফল এবং সারাংশের মধ্যে দুটি নতুন অংশ (section) দেখা যাচ্ছে: প্রথমটি প্রতিটি টেস্ট ফেইলের বিস্তারিত কারণ প্রদর্শন করে। এই ক্ষেত্রে, আমরা বিস্তারিত পাচ্ছি যে another ফেইল করেছে কারণ এটি src/lib.rs ফাইলের ১৭ নম্বর লাইনে 'Make this test fail'-এ panicked at করেছে। পরের অংশে শুধুমাত্র সমস্ত ফেইলিং (failing) টেস্টের নাম তালিকাভুক্ত করা হয়েছে, যা দরকারী যখন অনেকগুলি টেস্ট থাকে এবং অনেকগুলি বিস্তারিত ফেইলিং টেস্ট আউটপুট থাকে। আমরা একটি ফেইলিং টেস্টের নাম ব্যবহার করতে পারি শুধুমাত্র সেই টেস্টটি চালানোর জন্য যাতে আরও সহজে ডিবাগ (debug) করা যায়; আমরা ["Controlling How Tests Are Run"][controlling-how-tests-are-run] বিভাগে টেস্ট চালানোর উপায় সম্পর্কে আরও কথা বলব।
সারাংশ লাইনটি শেষে প্রদর্শিত হয়: সামগ্রিকভাবে, আমাদের টেস্টের ফলাফল হল FAILED। আমাদের একটি টেস্ট পাস করেছে এবং একটি টেস্ট ফেইল করেছে।
এখন আপনি বিভিন্ন পরিস্থিতিতে টেস্টের ফলাফল দেখতে কেমন হয় তা দেখেছেন, আসুন panic! ছাড়া অন্য কিছু ম্যাক্রো দেখি যা টেস্টে দরকারি।
assert! ম্যাক্রো দিয়ে ফলাফল পরীক্ষা করা (Checking Results with the assert! Macro)
assert! ম্যাক্রো, স্ট্যান্ডার্ড লাইব্রেরি (standard library) দ্বারা সরবরাহ করা, তখন দরকারি যখন আপনি নিশ্চিত করতে চান যে একটি টেস্টের কোনো শর্ত (condition) true কিনা। আমরা assert! ম্যাক্রোকে একটি আর্গুমেন্ট দিই যা একটি বুলিয়ান (Boolean)-এ মূল্যায়ন করে। যদি মানটি true হয়, তবে কিছুই ঘটে না এবং টেস্ট পাস করে। যদি মানটি false হয়, তবে assert! ম্যাক্রো panic! কল করে টেস্টটিকে ফেইল করানোর জন্য। assert! ম্যাক্রো ব্যবহার করা আমাদের কোড আমাদের ইচ্ছামতো কাজ করছে কিনা তা পরীক্ষা করতে সাহায্য করে।
চ্যাপ্টার ৫-এ, লিস্টিং 5-15-তে, আমরা একটি Rectangle স্ট্রাক্ট এবং একটি can_hold মেথড ব্যবহার করেছি, যা এখানে লিস্টিং 11-5-এ পুনরাবৃত্তি করা হয়েছে। আসুন এই কোডটি src/lib.rs ফাইলে রাখি, তারপর assert! ম্যাক্রো ব্যবহার করে এটির জন্য কিছু টেস্ট লিখি।
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}can_hold মেথড একটি বুলিয়ান রিটার্ন করে, যার মানে হল এটি assert! ম্যাক্রোর জন্য একটি উপযুক্ত ব্যবহারের ক্ষেত্র। লিস্টিং 11-6-এ, আমরা একটি টেস্ট লিখি যা can_hold মেথডটি পরীক্ষা করে। একটি Rectangle ইন্সট্যান্স তৈরি করা হয় যার প্রস্থ (width) 8 এবং উচ্চতা (height) 7, এবং অ্যাসার্ট (assert) করা হয় যে এটি অন্য একটি Rectangle ইন্সট্যান্স ধারণ করতে পারে যার প্রস্থ 5 এবং উচ্চতা 1।
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}tests মডিউলের ভিতরে use super::*; লাইনটি লক্ষ করুন। tests মডিউল হল একটি সাধারণ মডিউল যা সাধারণ ভিজিবিলিটি (visibility) নিয়মগুলি অনুসরণ করে যা আমরা চ্যাপ্টার ৭-এ ["Paths for Referring to an Item in the Module Tree"][paths-for-referring-to-an-item-in-the-module-tree] বিভাগে কভার করেছি। কারণ tests মডিউলটি একটি অভ্যন্তরীণ মডিউল (inner module), আমাদেরকে বাইরের মডিউলের টেস্ট করা কোডটিকে অভ্যন্তরীণ মডিউলের স্কোপে (scope) আনতে হবে। আমরা এখানে একটি গ্লোব (glob) ব্যবহার করি, তাই বাইরের মডিউলে আমরা যা কিছু সংজ্ঞায়িত (define) করি তা এই tests মডিউলের জন্য উপলব্ধ।
আমরা আমাদের টেস্টের নাম দিয়েছি larger_can_hold_smaller, এবং আমরা দুটি প্রয়োজনীয় Rectangle ইন্সট্যান্স তৈরি করেছি। তারপর আমরা assert! ম্যাক্রো কল করেছি এবং এটিকে larger.can_hold(&smaller) কল করার ফলাফল পাস করেছি। এই এক্সপ্রেশনটির true রিটার্ন করার কথা, তাই আমাদের টেস্ট পাস করা উচিত। আসুন দেখা যাক!
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
এটি পাস করে! আসুন আরেকটি টেস্ট যোগ করি, এবার অ্যাসার্ট করি যে একটি ছোট আয়তক্ষেত্র একটি বড় আয়তক্ষেত্র ধারণ করতে পারে না:
Filename: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}কারণ এই ক্ষেত্রে can_hold ফাংশনের সঠিক ফলাফল হল false, তাই assert! ম্যাক্রোতে পাস করার আগে আমাদের সেই ফলাফলটিকে নেগেট (negate) করতে হবে। ফলস্বরূপ, আমাদের টেস্ট পাস করবে যদি can_hold false রিটার্ন করে:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
দুটি টেস্ট পাস করেছে! এখন দেখা যাক আমাদের টেস্টের ফলাফলের কী হয় যখন আমরা আমাদের কোডে একটি বাগ (bug) আনি। আমরা can_hold মেথডের ইমপ্লিমেন্টেশন (implementation) পরিবর্তন করব, প্রস্থ তুলনা করার সময় বৃহত্তর-দেন (greater-than) চিহ্নটিকে ছোট-দেন (less-than) চিহ্ন দিয়ে প্রতিস্থাপন করে:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}এখন টেস্টগুলো চালালে নিম্নলিখিত আউটপুট পাওয়া যাবে:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at src/lib.rs:28:9:
assertion failed: larger.can_hold(&smaller)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
আমাদের টেস্ট বাগটি ধরে ফেলেছে! কারণ larger.width হল 8 এবং smaller.width হল 5, can_hold-এ প্রস্থের তুলনা এখন false রিটার্ন করে: 8, 5-এর চেয়ে ছোট নয়।
assert_eq! এবং assert_ne! ম্যাক্রো ব্যবহার করে সমতা পরীক্ষা করা (Testing Equality with the assert_eq! and assert_ne! Macros)
কার্যকারিতা যাচাই করার একটি সাধারণ উপায় হল টেস্ট করা কোডের ফলাফল এবং কোড থেকে প্রত্যাশিত মানের মধ্যে সমতা পরীক্ষা করা। আপনি assert! ম্যাক্রো ব্যবহার করে এবং == অপারেটর ব্যবহার করে একটি এক্সপ্রেশন পাস করে এটি করতে পারেন। তবে, এটি এত সাধারণ একটি টেস্ট যে স্ট্যান্ডার্ড লাইব্রেরি এই টেস্টটি আরও সুবিধাজনকভাবে সম্পাদন করার জন্য দুটি ম্যাক্রো সরবরাহ করে—assert_eq! এবং assert_ne!। এই ম্যাক্রোগুলি যথাক্রমে দুটি আর্গুমেন্টকে সমতা বা অসমতার জন্য তুলনা করে। অ্যাসারশন ব্যর্থ হলে তারা দুটি মানও প্রিন্ট করবে, যার ফলে টেস্টটি কেন ব্যর্থ হয়েছে তা দেখা সহজ হয়; অপরপক্ষে, assert! ম্যাক্রো শুধুমাত্র নির্দেশ করে যে এটি == এক্সপ্রেশনের জন্য একটি false মান পেয়েছে, false মানের দিকে পরিচালিত মানগুলি প্রিন্ট না করেই।
লিস্টিং 11-7-এ, আমরা add_two নামে একটি ফাংশন লিখি যা তার প্যারামিটারে 2 যোগ করে, তারপর আমরা assert_eq! ম্যাক্রো ব্যবহার করে এই ফাংশনটি টেস্ট করি।
pub fn add_two(a: usize) -> usize {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}আসুন পরীক্ষা করি যে এটি পাস করে কিনা!
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
আমরা result নামে একটি ভেরিয়েবল তৈরি করি যেখানে add_two(2) কল করার ফলাফল থাকে। তারপর আমরা result এবং 4 কে assert_eq! এর আর্গুমেন্ট হিসেবে পাস করি। এই টেস্টের জন্য আউটপুট লাইনটি হল test tests::it_adds_two ... ok, এবং ok লেখাটি নির্দেশ করে যে আমাদের টেস্ট পাস করেছে!
আসুন আমাদের কোডে একটি বাগ ঢুকিয়ে দেখি assert_eq! ব্যর্থ হলে দেখতে কেমন হয়। add_two ফাংশনের ইমপ্লিমেন্টেশন পরিবর্তন করে 3 যোগ করি:
pub fn add_two(a: usize) -> usize {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}আবার টেস্ট রান করুন:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'tests::it_adds_two' panicked at src/lib.rs:12:9:
assertion `left == right` failed
left: 5
right: 4
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
আমাদের টেস্ট বাগটি ধরে ফেলেছে! it_adds_two টেস্টটি ব্যর্থ হয়েছে, এবং মেসেজটি আমাদের বলছে যে ব্যর্থ হওয়া অ্যাসারশনটি হল assertion `left == right` failed এবং left এবং right-এর মান কী কী। এই মেসেজটি আমাদের ডিবাগিং শুরু করতে সাহায্য করে: left আর্গুমেন্ট, যেখানে আমাদের add_two(2) কল করার ফলাফল ছিল, সেটি ছিল 5 কিন্তু right আর্গুমেন্টটি ছিল 4। আপনি কল্পনা করতে পারেন যে এটি বিশেষভাবে সহায়ক হবে যখন আমাদের অনেকগুলি টেস্ট চলতে থাকবে।
মনে রাখবেন যে কিছু ভাষা এবং টেস্ট ফ্রেমওয়ার্কে, সমতা অ্যাসারশন ফাংশনের প্যারামিটারগুলিকে expected এবং actual বলা হয় এবং আমরা যে ক্রমে আর্গুমেন্টগুলি নির্দিষ্ট করি তা গুরুত্বপূর্ণ। যাইহোক, Rust-এ, সেগুলিকে left এবং right বলা হয়, এবং আমরা যে ক্রমে প্রত্যাশিত মান এবং কোড যে মান তৈরি করে তা নির্দিষ্ট করি, তাতে কিছু যায় আসে না। আমরা এই টেস্টের অ্যাসারশনটিকে assert_eq!(4, result) হিসাবে লিখতে পারতাম, যার ফলে একই ব্যর্থতার মেসেজ আসবে যা assertion failed: `(left == right)` প্রদর্শন করে।
assert_ne! ম্যাক্রো পাস করবে যদি আমরা যে দুটি মান দিই তা সমান না হয় এবং যদি সেগুলি সমান হয় তবে ব্যর্থ হবে। এই ম্যাক্রোটি সেইসব ক্ষেত্রের জন্য সবচেয়ে দরকারী যখন আমরা নিশ্চিত নই যে একটি মান কী হবে, কিন্তু আমরা জানি মানটি নিশ্চিতভাবে কী হওয়া উচিত নয়। উদাহরণস্বরূপ, যদি আমরা এমন একটি ফাংশন পরীক্ষা করি যা তার ইনপুটকে কোনওভাবে পরিবর্তন করার গ্যারান্টিযুক্ত, কিন্তু ইনপুটটি কীভাবে পরিবর্তন করা হয়েছে তা সপ্তাহের দিনের উপর নির্ভর করে যেদিন আমরা আমাদের টেস্টগুলি চালাই, তাহলে সম্ভবত সেরা জিনিসটি অ্যাসার্ট করা হল যে ফাংশনের আউটপুট ইনপুটের সমান নয়।
ভিতরে ভিতরে, assert_eq! এবং assert_ne! ম্যাক্রোগুলি যথাক্রমে == এবং != অপারেটর ব্যবহার করে। যখন অ্যাসারশনগুলি ব্যর্থ হয়, তখন এই ম্যাক্রোগুলি তাদের আর্গুমেন্টগুলিকে ডিবাগ ফরম্যাটিং ব্যবহার করে প্রিন্ট করে, যার অর্থ হল যে মানগুলির তুলনা করা হচ্ছে সেগুলিতে অবশ্যই PartialEq এবং Debug ট্রেইট (trait) ইমপ্লিমেন্ট (implement) করা থাকতে হবে। সমস্ত প্রিমিটিভ টাইপ (primitive type) এবং স্ট্যান্ডার্ড লাইব্রেরির বেশিরভাগ টাইপ এই ট্রেইটগুলি ইমপ্লিমেন্ট করে। আপনার নিজের সংজ্ঞায়িত করা স্ট্রাক্ট এবং এনামগুলির (enum) জন্য, আপনাকে সেই টাইপগুলির সমতা অ্যাসার্ট করার জন্য PartialEq ইমপ্লিমেন্ট করতে হবে। অ্যাসারশন ব্যর্থ হলে মানগুলি প্রিন্ট করার জন্য আপনাকে Debug ও ইমপ্লিমেন্ট করতে হবে। যেহেতু উভয় ট্রেইটই ডিরাইভেবল (derivable) ট্রেইট, যেমনটি চ্যাপ্টার ৫-এর লিস্টিং 5-12-তে উল্লেখ করা হয়েছে, তাই এটি সাধারণত আপনার স্ট্রাক্ট বা এনাম সংজ্ঞাতে #[derive(PartialEq, Debug)] অ্যানোটেশন যোগ করার মতোই সহজ। এই এবং অন্যান্য ডিরাইভেবল ট্রেইট সম্পর্কে আরও বিশদ বিবরণের জন্য অ্যাপেন্ডিক্স সি, ["ডেরাইভেবল ট্রেইট"][derivable-traits] দেখুন।
কাস্টম ব্যর্থতার বার্তা যোগ করা (Adding Custom Failure Messages)
আপনি assert!, assert_eq!, এবং assert_ne! ম্যাক্রোতে ঐচ্ছিক আর্গুমেন্ট হিসাবে ব্যর্থতার বার্তার সাথে প্রিন্ট করার জন্য একটি কাস্টম মেসেজও যোগ করতে পারেন। প্রয়োজনীয় আর্গুমেন্টগুলির পরে নির্দিষ্ট করা যেকোনো আর্গুমেন্ট format! ম্যাক্রোতে পাঠানো হয় (চ্যাপ্টার ৮-এ ["কনক্যাটেনেশন উইথ দ্যা + অপারেটর অর দ্যা format! ম্যাক্রো"][concatenation-with-the--operator-or-the-format-macro] তে আলোচনা করা হয়েছে), তাই আপনি একটি ফরম্যাট স্ট্রিং পাস করতে পারেন যাতে {} প্লেসহোল্ডার (placeholder) এবং সেই প্লেসহোল্ডারগুলিতে যাওয়ার জন্য মান রয়েছে। কাস্টম মেসেজগুলি একটি অ্যাসারশনের অর্থ কী তা ডকুমেন্ট করার জন্য দরকারী; যখন একটি টেস্ট ব্যর্থ হয়, তখন কোডের সমস্যাটি কী তা সম্পর্কে আপনার আরও ভাল ধারণা থাকবে।
উদাহরণস্বরূপ, ধরা যাক আমাদের কাছে একটি ফাংশন রয়েছে যা লোকেদের নাম দিয়ে অভিবাদন জানায় এবং আমরা পরীক্ষা করতে চাই যে আমরা ফাংশনে যে নামটি পাস করি তা আউটপুটে প্রদর্শিত হবে:
Filename: src/lib.rs
pub fn greeting(name: &str) -> String {
format!("Hello {name}!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}এই প্রোগ্রামটির প্রয়োজনীয়তাগুলি এখনও সম্মত হয়নি, এবং আমরা মোটামুটি নিশ্চিত যে অভিবাদনের শুরুতে Hello লেখাটি পরিবর্তন হবে। আমরা সিদ্ধান্ত নিয়েছি যে প্রয়োজনীয়তা পরিবর্তন হলে আমাদের টেস্ট আপডেট করতে হবে না, তাই greeting ফাংশন থেকে প্রত্যাবর্তিত মানের সাথে সঠিক সমতা পরীক্ষা করার পরিবর্তে, আমরা কেবল অ্যাসার্ট করব যে আউটপুটটিতে ইনপুট প্যারামিটারের টেক্সট রয়েছে।
এখন আসুন name বাদ দেওয়ার জন্য greeting পরিবর্তন করে এই কোডে একটি বাগ ঢুকিয়ে দেখি যে ডিফল্ট টেস্ট ব্যর্থতা দেখতে কেমন হয়:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}এই টেস্ট চালালে নিম্নলিখিত ফলাফল পাওয়া যাবে:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
assertion failed: result.contains("Carol")
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
এই ফলাফলটি কেবল নির্দেশ করে যে অ্যাসারশনটি ব্যর্থ হয়েছে এবং অ্যাসারশনটি কোন লাইনে রয়েছে। একটি আরও দরকারী ব্যর্থতার বার্তা greeting ফাংশন থেকে প্রাপ্ত মানটি প্রিন্ট করবে। আসুন একটি কাস্টম ব্যর্থতার বার্তা যোগ করি যা একটি ফরম্যাট স্ট্রিং নিয়ে গঠিত এবং যাতে greeting ফাংশন থেকে আমরা যে প্রকৃত মান পেয়েছি তার সাথে একটি প্লেসহোল্ডার পূরণ করা হয়েছে:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{result}`"
);
}
}এখন যখন আমরা টেস্টটি চালাব, তখন আমরা একটি আরও তথ্যপূর্ণ ত্রুটির বার্তা পাব:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
Greeting did not contain name, value was `Hello!`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
আমরা টেস্টের আউটপুটে প্রকৃত মানটি দেখতে পাচ্ছি, যা আমাদের কী ঘটার কথা ছিল তার পরিবর্তে কী ঘটেছে তা ডিবাগ করতে সাহায্য করবে।
should_panic দিয়ে প্যানিক পরীক্ষা করা (Checking for Panics with should_panic)
রিটার্ন মান পরীক্ষা করার পাশাপাশি, আমাদের কোড প্রত্যাশিতভাবে ত্রুটির শর্তগুলি (error conditions) পরিচালনা করে কিনা তা পরীক্ষা করা গুরুত্বপূর্ণ। উদাহরণস্বরূপ, চ্যাপ্টার ৯, লিস্টিং 9-13-এ তৈরি করা Guess টাইপটি বিবেচনা করুন। Guess ব্যবহার করে এমন অন্যান্য কোড এই গ্যারান্টির উপর নির্ভর করে যে Guess ইন্সট্যান্সগুলিতে কেবল 1 থেকে 100-এর মধ্যে মান থাকবে। আমরা একটি টেস্ট লিখতে পারি যা নিশ্চিত করে যে সেই সীমার বাইরের মান সহ একটি Guess ইন্সট্যান্স তৈরি করার চেষ্টা করলে প্যানিক (panic) হয়।
আমরা আমাদের টেস্ট ফাংশনে should_panic অ্যাট্রিবিউট যোগ করে এটি করি। ফাংশনের ভিতরের কোড প্যানিক করলে টেস্ট পাস করে; ফাংশনের ভিতরের কোড প্যানিক না করলে টেস্ট ব্যর্থ হয়।
লিস্টিং 11-8 একটি টেস্ট দেখায় যা পরীক্ষা করে যে Guess::new-এর ত্রুটির শর্তগুলি তখনই ঘটে যখন আমরা সেগুলি প্রত্যাশা করি।
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}আমরা #[should_panic] অ্যাট্রিবিউটটি #[test] অ্যাট্রিবিউটের পরে এবং এটি যে টেস্ট ফাংশনটিতে প্রযোজ্য তার আগে রাখি। আসুন এই টেস্টটি পাস করার সময় ফলাফলটি দেখি:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
দারুণ দেখাচ্ছে! এখন আসুন আমাদের কোডে একটি বাগ ঢুকিয়ে দিই, new ফাংশনটি 100-এর বেশি হলে যে প্যানিক করবে সেই শর্তটি সরিয়ে দিয়ে:
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}যখন আমরা লিস্টিং 11-8-এর টেস্টটি চালাই, তখন এটি ব্যর্থ হবে:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
আমরা এই ক্ষেত্রে খুব সহায়ক বার্তা পাই না, কিন্তু যখন আমরা টেস্ট ফাংশনটি দেখি, তখন আমরা দেখতে পাই যে এটি #[should_panic] দিয়ে চিহ্নিত করা হয়েছে। আমরা যে ব্যর্থতা পেয়েছি তার অর্থ হল টেস্ট ফাংশনের কোডটি প্যানিকের কারণ হয়নি।
should_panic ব্যবহার করে এমন টেস্টগুলি সুনির্দিষ্ট (precise) নাও হতে পারে। একটি should_panic টেস্ট পাস করবে এমনকি যদি টেস্টটি আমাদের প্রত্যাশিত কারণ থেকে ভিন্ন কারণে প্যানিক করে। should_panic টেস্টগুলিকে আরও সুনির্দিষ্ট করতে, আমরা should_panic অ্যাট্রিবিউটে একটি ঐচ্ছিক expected প্যারামিটার যোগ করতে পারি। টেস্ট হার্নেস (harness) নিশ্চিত করবে যে ব্যর্থতার বার্তায় প্রদত্ত টেক্সট রয়েছে। উদাহরণস্বরূপ, লিস্টিং 11-9-এ Guess-এর জন্য সংশোধিত কোডটি বিবেচনা করুন যেখানে new ফাংশনটি মানের উপর নির্ভর করে বিভিন্ন বার্তা সহ প্যানিক করে, মানটি খুব ছোট বা খুব বড় কিনা।
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}এই টেস্টটি পাস করবে কারণ আমরা should_panic অ্যাট্রিবিউটের expected প্যারামিটারে যে মানটি রেখেছি তা হল Guess::new ফাংশন যে বার্তার সাথে প্যানিক করে তার একটি সাবস্ট্রিং। আমরা সম্পূর্ণ প্যানিক বার্তাটি নির্দিষ্ট করতে পারতাম যা আমরা আশা করি, যা এই ক্ষেত্রে Guess value must be less than or equal to 100, got 200 হবে। আপনি কী নির্দিষ্ট করতে চান তা নির্ভর করে প্যানিক বার্তার কতটা অনন্য বা ডায়নামিক এবং আপনি আপনার টেস্টটি কতটা সুনির্দিষ্ট করতে চান তার উপর। এই ক্ষেত্রে, প্যানিক বার্তার একটি সাবস্ট্রিং যথেষ্ট যাতে নিশ্চিত করা যায় যে টেস্ট ফাংশনের কোডটি else if value > 100 কেসটি সম্পাদন করে।
একটি should_panic টেস্ট যখন একটি expected মেসেজ সহ ব্যর্থ হয় তখন কী ঘটে তা দেখতে, আসুন আবার আমাদের কোডে একটি বাগ ঢুকিয়ে দিই if value < 1 এবং else if value > 100 ব্লকের বডি অদলবদল করে:
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}এবার যখন আমরা should_panic টেস্ট চালাব, তখন এটি ব্যর্থ হবে:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at src/lib.rs:12:13:
Guess value must be greater than or equal to 1, got 200.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: `"Guess value must be greater than or equal to 1, got 200."`,
expected substring: `"less than or equal to 100"`
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
ব্যর্থতার বার্তাটি নির্দেশ করে যে এই টেস্টটি সত্যিই আমাদের প্রত্যাশা অনুযায়ী প্যানিক করেছে, কিন্তু প্যানিক বার্তায় প্রত্যাশিত স্ট্রিং less than or equal to 100 অন্তর্ভুক্ত ছিল না। আমরা এই ক্ষেত্রে যে প্যানিক বার্তাটি পেয়েছি তা হল Guess value must be greater than or equal to 1, got 200. এখন আমরা বের করতে শুরু করতে পারি আমাদের বাগটি কোথায়!
টেস্টে Result<T, E> ব্যবহার করা (Using Result<T, E> in Tests)
আমাদের এখনও পর্যন্ত সমস্ত টেস্ট ব্যর্থ হলে প্যানিক করে। আমরা Result<T, E> ব্যবহার করে এমন টেস্টও লিখতে পারি! এখানে লিস্টিং 11-1-এর টেস্টটি রয়েছে, Result<T, E> ব্যবহার করার জন্য পুনরায় লেখা হয়েছে এবং প্যানিক করার পরিবর্তে একটি Err রিটার্ন করে:
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() -> Result<(), String> {
let result = add(2, 2);
if result == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}it_works ফাংশনটির এখন Result<(), String> রিটার্ন টাইপ রয়েছে। ফাংশনের বডিতে, assert_eq! ম্যাক্রো কল করার পরিবর্তে, আমরা টেস্ট পাস করলে Ok(()) এবং টেস্ট ব্যর্থ হলে ভিতরে একটি String সহ একটি Err রিটার্ন করি।
টেস্টগুলি যাতে Result<T, E> রিটার্ন করে লেখা আপনাকে টেস্টের বডিতে কোয়েশ্চন মার্ক অপারেটর (?) ব্যবহার করতে সক্ষম করে, যা এমন টেস্ট লেখার একটি সুবিধাজনক উপায় হতে পারে যেগুলির মধ্যে কোনও অপারেশন যদি একটি Err ভেরিয়েন্ট রিটার্ন করে তবে ব্যর্থ হওয়া উচিত।
আপনি Result<T, E> ব্যবহার করে এমন টেস্টগুলিতে #[should_panic] অ্যানোটেশন ব্যবহার করতে পারবেন না। একটি অপারেশন একটি Err ভেরিয়েন্ট রিটার্ন করে তা অ্যাসার্ট করতে, Result<T, E> মানের উপর কোয়েশ্চন মার্ক অপারেটর (?) ব্যবহার করবেন না। পরিবর্তে, assert!(value.is_err()) ব্যবহার করুন।
এখন আপনি টেস্ট লেখার বিভিন্ন উপায় জানেন, আসুন দেখি যখন আমরা আমাদের টেস্টগুলি চালাই তখন কী ঘটে এবং cargo test-এর সাথে আমরা যে বিভিন্ন অপশন ব্যবহার করতে পারি সেগুলি অন্বেষণ করি।
টেস্ট কীভাবে চালানো হয় তা নিয়ন্ত্রণ করা (Controlling How Tests Are Run)
যেমন cargo run আপনার কোড কম্পাইল করে এবং তারপর ফলস্বরূপ বাইনারি চালায়, তেমনি cargo test আপনার কোডকে টেস্ট মোডে কম্পাইল করে এবং ফলস্বরূপ টেস্ট বাইনারি চালায়। cargo test দ্বারা উত্পাদিত বাইনারির ডিফল্ট আচরণ হল সমস্ত টেস্ট সমান্তরালভাবে (parallel) চালানো এবং টেস্ট চলাকালীন উত্পন্ন আউটপুট ক্যাপচার করা, আউটপুট প্রদর্শিত হওয়া রোধ করে এবং টেস্টের ফলাফলের সাথে সম্পর্কিত আউটপুট পড়া সহজ করে তোলে। তবে, আপনি এই ডিফল্ট আচরণ পরিবর্তন করতে কমান্ড লাইন অপশন নির্দিষ্ট করতে পারেন।
কিছু কমান্ড লাইন অপশন cargo test-এ যায় এবং কিছু ফলস্বরূপ টেস্ট বাইনারিতে যায়। এই দুই ধরনের আর্গুমেন্ট আলাদা করতে, আপনি cargo test-এ যাওয়া আর্গুমেন্টগুলি তালিকাভুক্ত করুন, তারপরে বিভাজক -- এবং তারপর টেস্ট বাইনারিতে যাওয়া আর্গুমেন্টগুলি দিন। cargo test --help চালালে cargo test-এর সাথে আপনি যে অপশনগুলি ব্যবহার করতে পারেন সেগুলি প্রদর্শিত হয় এবং cargo test -- --help চালালে বিভাজকের পরে আপনি যে অপশনগুলি ব্যবহার করতে পারেন সেগুলি প্রদর্শিত হয়। সেই অপশনগুলি the rustc book-এর “Tests” section-এও ডকুমেন্ট করা আছে।
সমান্তরালভাবে বা ধারাবাহিকভাবে টেস্ট চালানো (Running Tests in Parallel or Consecutively)
যখন আপনি একাধিক টেস্ট চালান, ডিফল্টরূপে সেগুলি থ্রেড ব্যবহার করে সমান্তরালভাবে চলে, যার অর্থ হল সেগুলি দ্রুত চালানো শেষ হয় এবং আপনি দ্রুত প্রতিক্রিয়া পান। যেহেতু টেস্টগুলি একই সময়ে চলছে, তাই আপনাকে অবশ্যই নিশ্চিত করতে হবে যে আপনার টেস্টগুলি একে অপরের উপর বা কোনও শেয়ার্ড স্টেটের (shared state) উপর নির্ভরশীল নয়, যার মধ্যে একটি শেয়ার্ড এনভায়রনমেন্ট, যেমন বর্তমান ওয়ার্কিং ডিরেক্টরি (working directory) বা এনভায়রনমেন্ট ভেরিয়েবল অন্তর্ভুক্ত রয়েছে।
উদাহরণস্বরূপ, ধরুন আপনার প্রতিটি টেস্ট কিছু কোড চালায় যা ডিস্কে test-output.txt নামে একটি ফাইল তৈরি করে এবং সেই ফাইলে কিছু ডেটা লেখে। তারপর প্রতিটি টেস্ট সেই ফাইলের ডেটা পড়ে এবং অ্যাসার্ট করে যে ফাইলটিতে একটি নির্দিষ্ট মান রয়েছে, যা প্রতিটি টেস্টে আলাদা। যেহেতু টেস্টগুলি একই সময়ে চলে, তাই একটি টেস্ট অন্য টেস্টের লেখার এবং পড়ার সময়ের মধ্যে ফাইলটিকে ওভাররাইট করতে পারে। দ্বিতীয় টেস্টটি তখন ব্যর্থ হবে, কোডটি ভুল হওয়ার কারণে নয়, বরং টেস্টগুলি সমান্তরালভাবে চলার সময় একে অপরের সাথে হস্তক্ষেপ করার কারণে। একটি সমাধান হল নিশ্চিত করা যে প্রতিটি টেস্ট একটি ভিন্ন ফাইলে লেখে; আরেকটি সমাধান হল টেস্টগুলি একবারে একটি করে চালানো।
আপনি যদি সমান্তরালভাবে টেস্ট চালাতে না চান বা আপনি যদি ব্যবহৃত থ্রেডের সংখ্যার উপর আরও সূক্ষ্ম-নিয়ন্ত্রণ (fine-grained control) চান, তাহলে আপনি --test-threads ফ্ল্যাগ এবং আপনি যে সংখ্যক থ্রেড ব্যবহার করতে চান তা টেস্ট বাইনারিতে পাঠাতে পারেন। নিম্নলিখিত উদাহরণটি দেখুন:
$ cargo test -- --test-threads=1
আমরা টেস্ট থ্রেডের সংখ্যা 1-এ সেট করি, প্রোগ্রামটিকে কোনও প্যারালেলিজম (parallelism) ব্যবহার না করতে বলি। একটি থ্রেড ব্যবহার করে টেস্ট চালানো সমান্তরালভাবে চালানোর চেয়ে বেশি সময় নেবে, কিন্তু টেস্টগুলি একে অপরের সাথে হস্তক্ষেপ করবে না যদি তারা স্টেট শেয়ার করে।
ফাংশন আউটপুট দেখানো (Showing Function Output)
ডিফল্টরূপে, যদি একটি টেস্ট পাস করে, তাহলে Rust-এর টেস্ট লাইব্রেরি স্ট্যান্ডার্ড আউটপুটে প্রিন্ট করা যেকোনো কিছু ক্যাপচার করে। উদাহরণস্বরূপ, যদি আমরা একটি টেস্টে println! কল করি এবং টেস্টটি পাস করে, তাহলে আমরা টার্মিনালে println! আউটপুট দেখতে পাব না; আমরা শুধুমাত্র সেই লাইনটি দেখতে পাব যা নির্দেশ করে যে টেস্টটি পাস করেছে। যদি একটি টেস্ট ব্যর্থ হয়, তাহলে আমরা ব্যর্থতার বার্তার বাকি অংশের সাথে স্ট্যান্ডার্ড আউটপুটে যা প্রিন্ট করা হয়েছিল তা দেখতে পাব।
একটি উদাহরণ হিসাবে, লিস্টিং 11-10-এ একটি নিরীহ (silly) ফাংশন রয়েছে যা তার প্যারামিটারের মান প্রিন্ট করে এবং 10 রিটার্ন করে, পাশাপাশি একটি টেস্ট যা পাস করে এবং একটি টেস্ট যা ব্যর্থ হয়।
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {a}");
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(value, 10);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(value, 5);
}
}যখন আমরা cargo test দিয়ে এই টেস্টগুলি চালাই, তখন আমরা নিম্নলিখিত আউটপুট দেখতে পাব:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
লক্ষ্য করুন যে এই আউটপুটের কোথাও আমরা I got the value 4 দেখতে পাচ্ছি না, যেটি প্রিন্ট করা হয় যখন পাস করা টেস্টটি চলে। সেই আউটপুটটি ক্যাপচার করা হয়েছে। ব্যর্থ হওয়া টেস্ট থেকে আউটপুট, I got the value 8, টেস্টের সারাংশ আউটপুটের বিভাগে প্রদর্শিত হয়, যা টেস্ট ব্যর্থতার কারণও দেখায়।
যদি আমরা পাস করা টেস্টগুলির জন্যেও প্রিন্ট করা মানগুলি দেখতে চাই, তাহলে আমরা --show-output দিয়ে Rust কে সফল টেস্টের আউটপুটও দেখাতে বলতে পারি:
$ cargo test -- --show-output
যখন আমরা --show-output ফ্ল্যাগ সহ লিস্টিং 11-10-এর টেস্টগুলি আবার চালাই, তখন আমরা নিম্নলিখিত আউটপুট দেখতে পাই:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
নামের মাধ্যমে টেস্টের একটি উপসেট চালানো (Running a Subset of Tests by Name)
কখনও কখনও, একটি সম্পূর্ণ টেস্ট স্যুট (suite) চালাতে অনেক সময় লাগতে পারে। আপনি যদি কোনও নির্দিষ্ট এলাকার কোডে কাজ করেন, তাহলে আপনি সম্ভবত শুধুমাত্র সেই কোডের সাথে সম্পর্কিত টেস্টগুলি চালাতে চাইতে পারেন। আপনি cargo test-কে একটি আর্গুমেন্ট হিসাবে যে টেস্ট(গুলি) চালাতে চান তার নাম বা নামগুলি পাস করে কোন টেস্টগুলি চালাতে হবে তা বেছে নিতে পারেন।
টেস্টের একটি উপসেট কীভাবে চালানো যায় তা প্রদর্শন করতে, আমরা প্রথমে আমাদের add_two ফাংশনের জন্য তিনটি টেস্ট তৈরি করব, যেমনটি লিস্টিং 11-11-তে দেখানো হয়েছে, এবং কোনটি চালাতে হবে তা বেছে নেব।
pub fn add_two(a: usize) -> usize {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
#[test]
fn add_three_and_two() {
let result = add_two(3);
assert_eq!(result, 5);
}
#[test]
fn one_hundred() {
let result = add_two(100);
assert_eq!(result, 102);
}
}যদি আমরা কোনো আর্গুমেন্ট পাস না করে টেস্ট চালাই, যেমনটি আমরা আগে দেখেছি, সমস্ত টেস্ট সমান্তরালভাবে চলবে:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
একক টেস্ট চালানো (Running Single Tests)
আমরা cargo test-এ যেকোনো টেস্ট ফাংশনের নাম পাস করতে পারি শুধুমাত্র সেই টেস্টটি চালানোর জন্য:
$ cargo test one_hundred
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
শুধুমাত্র one_hundred নামের টেস্টটি চলেছে; অন্য দুটি টেস্ট সেই নামের সাথে মেলেনি। টেস্ট আউটপুট আমাদের জানায় যে আরও টেস্ট ছিল যা চলেনি, শেষে 2 filtered out প্রদর্শন করে।
আমরা এইভাবে একাধিক টেস্টের নাম নির্দিষ্ট করতে পারি না; cargo test-কে দেওয়া শুধুমাত্র প্রথম মানটি ব্যবহার করা হবে। কিন্তু একাধিক টেস্ট চালানোর একটি উপায় আছে।
একাধিক টেস্ট চালানোর জন্য ফিল্টারিং (Filtering to Run Multiple Tests)
আমরা একটি টেস্টের নামের অংশ নির্দিষ্ট করতে পারি, এবং সেই মানের সাথে মেলে এমন নামের যেকোনো টেস্ট চালানো হবে। উদাহরণস্বরূপ, যেহেতু আমাদের দুটি টেস্টের নামে add রয়েছে, তাই আমরা cargo test add চালিয়ে সেই দুটি চালাতে পারি:
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
এই কমান্ডটি add নামের সমস্ত টেস্ট চালিয়েছে এবং one_hundred নামের টেস্টটিকে ফিল্টার করেছে। এছাড়াও লক্ষ্য করুন যে একটি টেস্ট যে মডিউলে প্রদর্শিত হয় সেটি টেস্টের নামের অংশ হয়ে যায়, তাই আমরা মডিউলের নামে ফিল্টার করে একটি মডিউলের সমস্ত টেস্ট চালাতে পারি।
নির্দিষ্টভাবে অনুরোধ না করা পর্যন্ত কিছু টেস্ট উপেক্ষা করা (Ignoring Some Tests Unless Specifically Requested)
কখনও কখনও কয়েকটি নির্দিষ্ট টেস্ট চালানো খুব সময়সাপেক্ষ হতে পারে, তাই আপনি cargo test-এর বেশিরভাগ চালানোর সময় সেগুলিকে বাদ দিতে চাইতে পারেন। আপনি যে সমস্ত টেস্ট চালাতে চান সেগুলিকে আর্গুমেন্ট হিসাবে তালিকাভুক্ত করার পরিবর্তে, আপনি সেগুলিকে বাদ দেওয়ার জন্য ignore অ্যাট্রিবিউট ব্যবহার করে সময়সাপেক্ষ টেস্টগুলিকে চিহ্নিত করতে পারেন, যেমনটি এখানে দেখানো হয়েছে:
Filename: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// code that takes an hour to run
}
}#[test]-এর পরে, আমরা যে টেস্টটিকে বাদ দিতে চাই তাতে #[ignore] লাইন যুক্ত করি। এখন যখন আমরা আমাদের টেস্টগুলি চালাই, তখন it_works চলে, কিন্তু expensive_test চলে না:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::expensive_test ... ignored
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
expensive_test ফাংশনটি ignored হিসাবে তালিকাভুক্ত করা হয়েছে। যদি আমরা শুধুমাত্র উপেক্ষিত (ignored) টেস্টগুলি চালাতে চাই, তাহলে আমরা cargo test -- --ignored ব্যবহার করতে পারি:
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
কোন টেস্টগুলি চালানো হবে তা নিয়ন্ত্রণ করে, আপনি নিশ্চিত করতে পারেন যে আপনার cargo test-এর ফলাফলগুলি দ্রুত পাওয়া যাবে। আপনি যখন এমন একটি বিন্দুতে থাকবেন যেখানে ignored টেস্টগুলির ফলাফলগুলি পরীক্ষা করা অর্থপূর্ণ এবং আপনার ফলাফলের জন্য অপেক্ষা করার সময় আছে, তখন আপনি পরিবর্তে cargo test -- --ignored চালাতে পারেন। আপনি যদি সমস্ত টেস্ট চালাতে চান, সেগুলি উপেক্ষিত হোক বা না হোক, আপনি cargo test -- --include-ignored চালাতে পারেন।
টেস্ট সংগঠন (Test Organization)
এই অধ্যায়ের শুরুতে যেমন উল্লেখ করা হয়েছে, টেস্টিং একটি জটিল বিষয়, এবং ভিন্ন ভিন্ন মানুষ ভিন্ন পরিভাষা (terminology) এবং সংগঠন (organization) ব্যবহার করে। Rust কমিউনিটি টেস্ট সম্পর্কে দুটি প্রধান বিভাগের পরিপ্রেক্ষিতে চিন্তা করে: ইউনিট টেস্ট (unit tests) এবং ইন্টিগ্রেশন টেস্ট (integration tests)। ইউনিট টেস্টগুলি ছোট এবং আরও ফোকাসড (focused), একটি মডিউলকে আলাদাভাবে টেস্ট করে এবং প্রাইভেট ইন্টারফেসগুলিও টেস্ট করতে পারে। ইন্টিগ্রেশন টেস্টগুলি সম্পূর্ণরূপে আপনার লাইব্রেরির বাইরে থাকে এবং আপনার কোডকে একইভাবে ব্যবহার করে যেভাবে অন্য কোনো বহিরাগত (external) কোড ব্যবহার করবে, শুধুমাত্র পাবলিক ইন্টারফেস ব্যবহার করে এবং প্রতিটি টেস্টে সম্ভাব্য একাধিক মডিউল পরীক্ষা করে।
উভয় ধরনের টেস্ট লেখাই গুরুত্বপূর্ণ, এটা নিশ্চিত করার জন্য যে আপনার লাইব্রেরির অংশগুলি আলাদাভাবে এবং একসাথে আপনার প্রত্যাশা অনুযায়ী কাজ করছে।
ইউনিট টেস্ট (Unit Tests)
ইউনিট টেস্টের উদ্দেশ্য হল কোডের প্রতিটি ইউনিটকে বাকি কোড থেকে আলাদা করে টেস্ট করা, যাতে দ্রুত শনাক্ত করা যায় কোথায় কোড প্রত্যাশিতভাবে কাজ করছে এবং কোথায় করছে না। আপনি ইউনিট টেস্টগুলিকে src ডিরেক্টরির মধ্যে প্রতিটি ফাইলে রাখবেন, সেই কোডের সাথে যা তারা টেস্ট করছে। কনভেনশন হল প্রতিটি ফাইলে tests নামে একটি মডিউল তৈরি করা, টেস্ট ফাংশনগুলি ধারণ করার জন্য এবং মডিউলটিকে cfg(test) দিয়ে চিহ্নিত করা।
টেস্ট মডিউল এবং #[cfg(test)] (The Tests Module and #[cfg(test)])
tests মডিউলে #[cfg(test)] অ্যানোটেশন Rust-কে বলে যে টেস্ট কোড শুধুমাত্র তখনই কম্পাইল এবং রান করতে হবে যখন আপনি cargo test চালাবেন, cargo build চালানোর সময় নয়। এটি কম্পাইলের সময় বাঁচায় যখন আপনি শুধুমাত্র লাইব্রেরি তৈরি করতে চান এবং ফলস্বরূপ কম্পাইল করা আর্টিফ্যাক্টে (artifact) জায়গা বাঁচায় কারণ টেস্টগুলি অন্তর্ভুক্ত করা হয় না। আপনি দেখবেন যে ইন্টিগ্রেশন টেস্টগুলি একটি ভিন্ন ডিরেক্টরিতে যায় বলে তাদের #[cfg(test)] অ্যানোটেশনের প্রয়োজন হয় না। যাইহোক, যেহেতু ইউনিট টেস্টগুলি কোডের মতোই একই ফাইলে থাকে, তাই আপনি #[cfg(test)] ব্যবহার করবেন যাতে সেগুলি কম্পাইল করা ফলাফলে অন্তর্ভুক্ত না হয়।
স্মরণ করুন যে যখন আমরা এই অধ্যায়ের প্রথম বিভাগে নতুন adder প্রোজেক্ট তৈরি করেছি, Cargo আমাদের জন্য এই কোডটি তৈরি করেছে:
Filename: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}স্বয়ংক্রিয়ভাবে তৈরি হওয়া tests মডিউলে, cfg অ্যাট্রিবিউটটির অর্থ হল কনফিগারেশন (configuration) এবং Rust-কে বলে যে নিম্নলিখিত আইটেমটি শুধুমাত্র একটি নির্দিষ্ট কনফিগারেশন অপশন দেওয়া হলেই অন্তর্ভুক্ত করা উচিত। এই ক্ষেত্রে, কনফিগারেশন অপশনটি হল test, যা Rust দ্বারা টেস্ট কম্পাইল এবং চালানোর জন্য সরবরাহ করা হয়। cfg অ্যাট্রিবিউট ব্যবহার করে, Cargo আমাদের টেস্ট কোড শুধুমাত্র তখনই কম্পাইল করে যদি আমরা সক্রিয়ভাবে cargo test দিয়ে টেস্ট চালাই। এর মধ্যে এই মডিউলের মধ্যে থাকা যেকোনো হেল্পার (helper) ফাংশন অন্তর্ভুক্ত, #[test] দিয়ে চিহ্নিত ফাংশনগুলি ছাড়াও।
প্রাইভেট ফাংশন টেস্ট করা (Testing Private Functions)
টেস্টিং কমিউনিটির মধ্যে বিতর্ক রয়েছে যে প্রাইভেট ফাংশনগুলি সরাসরি টেস্ট করা উচিত কিনা, এবং অন্যান্য ভাষাগুলি প্রাইভেট ফাংশনগুলি টেস্ট করা কঠিন বা অসম্ভব করে তোলে। আপনি যে টেস্টিং আইডিওলজি (ideology)-ই মেনে চলুন না কেন, Rust-এর প্রাইভেসি (privacy) নিয়মগুলি আপনাকে প্রাইভেট ফাংশনগুলি টেস্ট করার অনুমতি দেয়। internal_adder প্রাইভেট ফাংশন সহ লিস্টিং 11-12-এর কোডটি বিবেচনা করুন।
pub fn add_two(a: usize) -> usize {
internal_adder(a, 2)
}
fn internal_adder(left: usize, right: usize) -> usize {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
let result = internal_adder(2, 2);
assert_eq!(result, 4);
}
}লক্ষ্য করুন যে internal_adder ফাংশনটি pub হিসাবে চিহ্নিত করা হয়নি। টেস্টগুলি শুধুমাত্র Rust কোড, এবং tests মডিউলটি অন্য একটি মডিউল। যেমনটি আমরা ["পাথস ফর রেফারring টু এন আইটেম ইন দা মডিউল ট্রি"][paths] তে আলোচনা করেছি, চাইল্ড মডিউলের আইটেমগুলি তাদের অ্যানসেস্টর (ancestor) মডিউলের আইটেমগুলি ব্যবহার করতে পারে। এই টেস্টে, আমরা tests মডিউলের প্যারেন্টের সমস্ত আইটেমকে use super::* দিয়ে স্কোপে আনি, এবং তারপর টেস্টটি internal_adder কল করতে পারে। আপনি যদি মনে করেন যে প্রাইভেট ফাংশনগুলি টেস্ট করা উচিত নয়, তবে Rust-এ এমন কিছু নেই যা আপনাকে তা করতে বাধ্য করবে।
ইন্টিগ্রেশন টেস্ট (Integration Tests)
Rust-এ, ইন্টিগ্রেশন টেস্টগুলি সম্পূর্ণরূপে আপনার লাইব্রেরির বাইরে থাকে। তারা আপনার লাইব্রেরি ব্যবহার করে একইভাবে যেভাবে অন্য কোনো কোড ব্যবহার করবে, যার মানে হল তারা শুধুমাত্র সেই ফাংশনগুলিকে কল করতে পারে যেগুলি আপনার লাইব্রেরির পাবলিক API-এর অংশ। তাদের উদ্দেশ্য হল আপনার লাইব্রেরির অনেকগুলি অংশ একসাথে সঠিকভাবে কাজ করে কিনা তা পরীক্ষা করা। কোডের ইউনিটগুলি যেগুলি নিজেরা সঠিকভাবে কাজ করে, ইন্টিগ্রেট (integrate) করার সময় সমস্যা হতে পারে, তাই ইন্টিগ্রেটেড কোডের টেস্ট কভারেজও (coverage) গুরুত্বপূর্ণ। ইন্টিগ্রেশন টেস্ট তৈরি করতে, আপনাকে প্রথমে একটি tests ডিরেক্টরি তৈরি করতে হবে।
_tests_ ডিরেক্টরি (The tests Directory)
আমরা আমাদের প্রোজেক্ট ডিরেক্টরির উপরের স্তরে, src-এর পাশে একটি tests ডিরেক্টরি তৈরি করি। Cargo জানে যে এই ডিরেক্টরিতে ইন্টিগ্রেশন টেস্ট ফাইলগুলি খুঁজতে হবে। আমরা তারপর যতগুলি খুশি টেস্ট ফাইল তৈরি করতে পারি, এবং Cargo প্রতিটি ফাইলকে একটি আলাদা ক্রেট হিসাবে কম্পাইল করবে।
আসুন একটি ইন্টিগ্রেশন টেস্ট তৈরি করি। লিস্টিং 11-12-এর কোডটি এখনও src/lib.rs ফাইলে রেখে, একটি tests ডিরেক্টরি তৈরি করুন এবং tests/integration_test.rs নামে একটি নতুন ফাইল তৈরি করুন। আপনার ডিরেক্টরি কাঠামোটি এইরকম হওয়া উচিত:
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
লিস্টিং 11-13-এর কোডটি tests/integration_test.rs ফাইলে লিখুন।
use adder::add_two;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}tests ডিরেক্টরির প্রতিটি ফাইল একটি পৃথক ক্রেট, তাই আমাদের লাইব্রেরিকে প্রতিটি টেস্ট ক্রেটের স্কোপে আনতে হবে। সেই কারণে আমরা কোডের শীর্ষে use adder::add_two; যোগ করি, যা আমাদের ইউনিট টেস্টে প্রয়োজন ছিল না।
আমাদের tests/integration_test.rs-এর কোনো কোডকে #[cfg(test)] দিয়ে চিহ্নিত করার প্রয়োজন নেই। Cargo tests ডিরেক্টরিটিকে বিশেষভাবে বিবেচনা করে এবং এই ডিরেক্টরির ফাইলগুলিকে শুধুমাত্র তখনই কম্পাইল করে যখন আমরা cargo test চালাই। এখন cargo test চালান:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
আউটপুটের তিনটি বিভাগে ইউনিট টেস্ট, ইন্টিগ্রেশন টেস্ট এবং ডক টেস্ট অন্তর্ভুক্ত রয়েছে। লক্ষ্য করুন যে যদি কোনও বিভাগের কোনও টেস্ট ব্যর্থ হয়, তবে নিম্নলিখিত বিভাগগুলি চালানো হবে না। উদাহরণস্বরূপ, যদি একটি ইউনিট টেস্ট ব্যর্থ হয়, তাহলে ইন্টিগ্রেশন এবং ডক টেস্টের জন্য কোনও আউটপুট থাকবে না কারণ সেই টেস্টগুলি শুধুমাত্র তখনই চালানো হবে যদি সমস্ত ইউনিট টেস্ট পাস করে।
ইউনিট টেস্টের জন্য প্রথম বিভাগটি আমরা যেভাবে দেখছি তেমনই: প্রতিটি ইউনিট টেস্টের জন্য একটি লাইন (লিস্টিং 11-12-এ যোগ করা internal নামের একটি) এবং তারপর ইউনিট টেস্টের জন্য একটি সারাংশ লাইন।
ইন্টিগ্রেশন টেস্ট বিভাগটি Running tests/integration_test.rs লাইন দিয়ে শুরু হয়। এর পরে, সেই ইন্টিগ্রেশন টেস্টের প্রতিটি টেস্ট ফাংশনের জন্য একটি লাইন এবং Doc-tests adder বিভাগ শুরু হওয়ার ঠিক আগে ইন্টিগ্রেশন টেস্টের ফলাফলের জন্য একটি সারাংশ লাইন রয়েছে।
প্রতিটি ইন্টিগ্রেশন টেস্ট ফাইলের নিজস্ব বিভাগ রয়েছে, তাই যদি আমরা tests ডিরেক্টরিতে আরও ফাইল যুক্ত করি, তাহলে আরও ইন্টিগ্রেশন টেস্ট বিভাগ থাকবে।
আমরা এখনও একটি নির্দিষ্ট ইন্টিগ্রেশন টেস্ট ফাংশন চালাতে পারি, টেস্ট ফাংশনের নামটিকে cargo test-এর আর্গুমেন্ট হিসাবে নির্দিষ্ট করে। একটি নির্দিষ্ট ইন্টিগ্রেশন টেস্ট ফাইলের সমস্ত টেস্ট চালানোর জন্য, cargo test-এর --test আর্গুমেন্ট এবং ফাইলের নাম ব্যবহার করুন:
$ cargo test --test integration_test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
এই কমান্ডটি শুধুমাত্র tests/integration_test.rs ফাইলের টেস্টগুলি চালায়।
ইন্টিগ্রেশন টেস্টে সাবমডিউল (Submodules in Integration Tests)
আপনি আরও ইন্টিগ্রেশন টেস্ট যোগ করার সাথে সাথে, আপনি সেগুলিকে সংগঠিত করতে সহায়তা করার জন্য tests ডিরেক্টরিতে আরও ফাইল তৈরি করতে চাইতে পারেন; উদাহরণস্বরূপ, আপনি যে কার্যকারিতা পরীক্ষা করছেন তার দ্বারা টেস্ট ফাংশনগুলিকে গ্রুপ করতে পারেন। আগেই যেমন উল্লেখ করা হয়েছে, tests ডিরেক্টরির প্রতিটি ফাইলকে তার নিজস্ব আলাদা ক্রেট হিসাবে কম্পাইল করা হয়, যা আলাদা স্কোপ তৈরি করার জন্য দরকারী, এন্ড ইউজাররা (end users) আপনার ক্রেট কীভাবে ব্যবহার করবে তা আরও ঘনিষ্ঠভাবে অনুকরণ করতে। যাইহোক, এর মানে হল tests ডিরেক্টরির ফাইলগুলি src-এর ফাইলগুলির মতো একই আচরণ শেয়ার করে না, যেমনটি আপনি চ্যাপ্টার ৭-এ শিখেছেন কীভাবে কোডকে মডিউল এবং ফাইলগুলিতে আলাদা করতে হয়।
tests ডিরেক্টরি ফাইলগুলির ভিন্ন আচরণ সবচেয়ে বেশি লক্ষণীয় হয় যখন আপনার কাছে একাধিক ইন্টিগ্রেশন টেস্ট ফাইলে ব্যবহার করার জন্য একগুচ্ছ হেল্পার ফাংশন থাকে এবং আপনি সেগুলিকে একটি সাধারণ মডিউলে এক্সট্রাক্ট (extract) করার জন্য চ্যাপ্টার ৭-এর ["সেপারেটিং মডিউলস ইনটু ডিফারেন্ট ফাইলস"][separating-modules-into-files] বিভাগের ধাপগুলি অনুসরণ করার চেষ্টা করেন। উদাহরণস্বরূপ, যদি আমরা tests/common.rs তৈরি করি এবং এতে setup নামে একটি ফাংশন রাখি, তাহলে আমরা setup-এ কিছু কোড যোগ করতে পারি যা আমরা একাধিক টেস্ট ফাইলের একাধিক টেস্ট ফাংশন থেকে কল করতে চাই:
Filename: tests/common.rs
pub fn setup() {
// setup code specific to your library's tests would go here
}যখন আমরা আবার টেস্টগুলি চালাই, তখন আমরা common.rs ফাইলের জন্য টেস্ট আউটপুটে একটি নতুন বিভাগ দেখতে পাব, যদিও এই ফাইলটিতে কোনও টেস্ট ফাংশন নেই বা আমরা কোথাও থেকে setup ফাংশনটি কল করিনি:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
টেস্ট ফলাফলে common থাকা এবং এর জন্য running 0 tests প্রদর্শিত হওয়া আমরা যা চেয়েছিলাম তা নয়। আমরা শুধু অন্য ইন্টিগ্রেশন টেস্ট ফাইলগুলির সাথে কিছু কোড শেয়ার করতে চেয়েছিলাম। common-কে টেস্ট আউটপুটে আসা থেকে বিরত রাখতে, tests/common.rs তৈরি করার পরিবর্তে, আমরা tests/common/mod.rs তৈরি করব। প্রোজেক্ট ডিরেক্টরিটি এখন এইরকম দেখাচ্ছে:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
এটি পুরোনো নামকরণের নিয়ম যা Rust-ও বোঝে, যা আমরা চ্যাপ্টার ৭-এ ["অল্টারনেট ফাইল পাথস"][alt-paths]-এ উল্লেখ করেছি। ফাইলটির নামকরণ এইভাবে করা Rust-কে বলে যে common মডিউলটিকে একটি ইন্টিগ্রেশন টেস্ট ফাইল হিসাবে বিবেচনা না করতে। যখন আমরা setup ফাংশন কোডটিকে tests/common/mod.rs-এ সরিয়ে নিই এবং tests/common.rs ফাইলটি মুছে ফেলি, তখন টেস্ট আউটপুটের বিভাগটি আর প্রদর্শিত হবে না। tests ডিরেক্টরির সাবডিরেক্টরির ফাইলগুলি আলাদা ক্রেট হিসাবে কম্পাইল করা হয় না বা টেস্ট আউটপুটে তাদের বিভাগ থাকে না।
আমরা tests/common/mod.rs তৈরি করার পরে, আমরা এটিকে যেকোনো ইন্টিগ্রেশন টেস্ট ফাইল থেকে একটি মডিউল হিসাবে ব্যবহার করতে পারি। এখানে tests/integration_test.rs-এর it_adds_two টেস্ট থেকে setup ফাংশন কল করার একটি উদাহরণ রয়েছে:
Filename: tests/integration_test.rs
use adder::add_two;
mod common;
#[test]
fn it_adds_two() {
common::setup();
let result = add_two(2);
assert_eq!(result, 4);
}লক্ষ্য করুন যে mod common; ডিক্লারেশনটি (declaration) লিস্টিং 7-21-এ প্রদর্শিত মডিউল ডিক্লারেশনের মতোই। তারপর, টেস্ট ফাংশনে, আমরা common::setup() ফাংশনটি কল করতে পারি।
বাইনারি ক্রেটের জন্য ইন্টিগ্রেশন টেস্ট (Integration Tests for Binary Crates)
যদি আমাদের প্রোজেক্টটি একটি বাইনারি ক্রেট হয় যাতে শুধুমাত্র একটি src/main.rs ফাইল থাকে এবং একটি src/lib.rs ফাইল না থাকে, তাহলে আমরা tests ডিরেক্টরিতে ইন্টিগ্রেশন টেস্ট তৈরি করতে পারি না এবং use স্টেটমেন্ট দিয়ে src/main.rs ফাইলে সংজ্ঞায়িত ফাংশনগুলিকে স্কোপে আনতে পারি না। শুধুমাত্র লাইব্রেরি ক্রেটগুলি ফাংশন প্রকাশ করে যা অন্য ক্রেটগুলি ব্যবহার করতে পারে; বাইনারি ক্রেটগুলি নিজে থেকেই চালানোর জন্য তৈরি।
এটি একটি কারণ যে Rust প্রোজেক্টগুলি যেগুলি একটি বাইনারি সরবরাহ করে সেগুলির একটি সরল src/main.rs ফাইল থাকে যা src/lib.rs ফাইলে থাকা লজিককে কল করে। সেই কাঠামো ব্যবহার করে, ইন্টিগ্রেশন টেস্টগুলি গুরুত্বপূর্ণ কার্যকারিতা উপলব্ধ করতে use সহ লাইব্রেরি ক্রেট পরীক্ষা করতে পারে। যদি গুরুত্বপূর্ণ কার্যকারিতা কাজ করে, তাহলে src/main.rs ফাইলের অল্প পরিমাণ কোডও কাজ করবে এবং সেই অল্প পরিমাণ কোড টেস্ট করার প্রয়োজন নেই।
সারসংক্ষেপ (Summary)
Rust-এর টেস্টিং ফিচারগুলি কোড কীভাবে কাজ করা উচিত তা নির্দিষ্ট করার একটি উপায় সরবরাহ করে, যাতে আপনি পরিবর্তন করলেও এটি আপনার প্রত্যাশা অনুযায়ী কাজ করে। ইউনিট টেস্টগুলি একটি লাইব্রেরির বিভিন্ন অংশ আলাদাভাবে পরীক্ষা করে এবং প্রাইভেট ইমপ্লিমেন্টেশনের বিস্তারিত পরীক্ষা করতে পারে। ইন্টিগ্রেশন টেস্টগুলি পরীক্ষা করে যে লাইব্রেরির অনেকগুলি অংশ একসাথে সঠিকভাবে কাজ করে কিনা এবং তারা লাইব্রেরির পাবলিক API ব্যবহার করে কোডটিকে একইভাবে পরীক্ষা করে যেভাবে বহিরাগত কোড এটি ব্যবহার করবে। যদিও Rust-এর টাইপ সিস্টেম এবং ওনারশিপ (ownership) নিয়মগুলি কিছু ধরণের বাগ প্রতিরোধ করতে সহায়তা করে, তবুও আপনার কোড কীভাবে আচরণ করবে বলে আশা করা হচ্ছে তার সাথে সম্পর্কিত লজিক বাগগুলি কমাতে টেস্টগুলি গুরুত্বপূর্ণ।
আসুন এই অধ্যায়ে এবং পূর্ববর্তী অধ্যায়গুলিতে আপনি যা শিখেছেন তা একত্রিত করে একটি প্রোজেক্টে কাজ করি!
একটি I/O প্রোজেক্ট: একটি কমান্ড লাইন প্রোগ্রাম তৈরি করা (An I/O Project: Building a Command Line Program)
এই চ্যাপ্টারটি আপনার ఇప్పటి পর্যন্ত শেখা অনেক দক্ষতার একটি সংক্ষিপ্ত পুনরালোচনা (recap) এবং আরও কিছু স্ট্যান্ডার্ড লাইব্রেরি ফিচারের অনুসন্ধান। আমরা একটি কমান্ড লাইন টুল তৈরি করব যা ফাইল এবং কমান্ড লাইন ইনপুট/আউটপুটের সাথে ইন্টারঅ্যাক্ট করে, যাতে আপনার আয়ত্তে থাকা কিছু Rust কনসেপ্ট অনুশীলন করা যায়।
Rust-এর গতি, নিরাপত্তা, একক বাইনারি আউটপুট, এবং ক্রস-প্ল্যাটফর্ম সাপোর্ট এটিকে কমান্ড লাইন টুল তৈরির জন্য একটি আদর্শ ভাষা করে তোলে। তাই আমাদের প্রোজেক্টের জন্য, আমরা ক্লাসিক কমান্ড লাইন সার্চ টুল grep (globally search a regular expression and print)-এর নিজস্ব ভার্সন তৈরি করব। সবচেয়ে সহজ ব্যবহারের ক্ষেত্রে, grep একটি নির্দিষ্ট স্ট্রিংয়ের জন্য একটি নির্দিষ্ট ফাইল অনুসন্ধান করে। এটি করার জন্য, grep তার আর্গুমেন্ট হিসাবে একটি ফাইলের পাথ (path) এবং একটি স্ট্রিং নেয়। তারপর এটি ফাইলটি পড়ে, সেই ফাইলের মধ্যে থাকা যেসব লাইনে স্ট্রিং আর্গুমেন্টটি রয়েছে সেগুলি খুঁজে বের করে এবং সেই লাইনগুলি প্রিন্ট করে।
এই চলার পথে, আমরা দেখাব কীভাবে আমাদের কমান্ড লাইন টুলটিকে টার্মিনালের সেই ফিচারগুলি ব্যবহার করতে হয় যা অন্য অনেক কমান্ড লাইন টুল ব্যবহার করে। ব্যবহারকারীকে আমাদের টুলের আচরণ কনফিগার করার অনুমতি দেওয়ার জন্য আমরা একটি এনভায়রনমেন্ট ভেরিয়েবলের মান পড়ব। আমরা স্ট্যান্ডার্ড আউটপুট (stdout)-এর পরিবর্তে স্ট্যান্ডার্ড এরর কনসোল স্ট্রিমে (stderr) ত্রুটি বার্তাগুলিও প্রিন্ট করব, যাতে, উদাহরণস্বরূপ, ব্যবহারকারী সফল আউটপুট একটি ফাইলে পুনঃনির্দেশিত (redirect) করতে পারে এবং একই সাথে স্ক্রিনে ত্রুটি বার্তাগুলি দেখতে পায়।
Rust কমিউনিটির একজন সদস্য, Andrew Gallant, ইতিমধ্যেই grep-এর একটি সম্পূর্ণ ফিচারযুক্ত, অত্যন্ত দ্রুত ভার্সন তৈরি করেছেন, যার নাম ripgrep। তুলনামূলকভাবে, আমাদের ভার্সনটি বেশ সহজ হবে, কিন্তু এই চ্যাপ্টারটি আপনাকে ripgrep-এর মতো একটি বাস্তব-বিশ্বের (real-world) প্রোজেক্ট বোঝার জন্য প্রয়োজনীয় কিছু পটভূমির জ্ঞান দেবে।
আমাদের grep প্রোজেক্টটি আপনার இதுவரை শেখা বেশ কয়েকটি কনসেপ্টকে একত্রিত করবে:
- কোড অর্গানাইজ করা (চ্যাপ্টার ৭)
- ভেক্টর এবং স্ট্রিং ব্যবহার করা (চ্যাপ্টার ৮)
- ত্রুটি হ্যান্ডেল করা (চ্যাপ্টার ৯)
- উপযুক্ত স্থানে ট্রেইট এবং লাইফটাইম ব্যবহার করা (চ্যাপ্টার ১০)
- টেস্ট লেখা (চ্যাপ্টার ১১)
আমরা সংক্ষেপে ক্লোজার (closure), ইটারেটর (iterator) এবং ট্রেইট অবজেক্টের (trait object) সাথেও পরিচয় করিয়ে দেব, যা চ্যাপ্টার ১৩ এবং চ্যাপ্টার ১৮ তে বিস্তারিতভাবে আলোচনা করা হবে।
কমান্ড লাইন আর্গুমেন্ট গ্রহণ করা
আসুন, বরাবরের মতো, cargo new ব্যবহার করে একটি নতুন project তৈরি করি। আমরা আমাদের projectটির নাম দেব minigrep, যাতে এটিকে আপনার সিস্টেমে ஏற்கனவே থাকা grep tool থেকে আলাদা করা যায়।
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
প্রথম কাজটি হল minigrep-কে দুটি কমান্ড লাইন আর্গুমেন্ট গ্রহণ করতে সক্ষম করা: file path এবং যে string টি অনুসন্ধান করতে হবে সেটি। অর্থাৎ, আমরা চাই আমাদের প্রোগ্রামটি cargo run, দুটি হাইফেন (যা নির্দেশ করে যে নিম্নলিখিত আর্গুমেন্টগুলি cargo-র জন্য নয়, আমাদের প্রোগ্রামের জন্য), একটি search string, এবং যে file-এ অনুসন্ধান করতে হবে তার path সহ চালাতে:
$ cargo run -- searchstring example-filename.txt
এখন, cargo new দ্বারা generate করা প্রোগ্রামটি আমাদের দেওয়া arguments process করতে পারে না। crates.io-তে কিছু existing library আছে যারা কমান্ড লাইন আর্গুমেন্ট গ্রহণ করে এমন প্রোগ্রাম লিখতে সাহায্য করতে পারে, কিন্তু যেহেতু আপনি এই concept টি শিখছেন, তাই আসুন আমরা নিজেরাই এই ক্ষমতাটি implement করি।
আর্গুমেন্ট ভ্যালুগুলো পড়া
minigrep-এ আমরা যে command line argument-গুলো pass করি, সেগুলোর value read করার জন্য, আমরা Rust-এর standard library-তে থাকা std::env::args function টি ব্যবহার করব। এই function টি minigrep-এ pass করা command line argument-গুলোর একটি iterator return করে। আমরা Chapter 13-এ iterator সম্পর্কে বিস্তারিত আলোচনা করব। এখন, আপনার iterator সম্পর্কে শুধুমাত্র দুটি বিষয় জানতে হবে: iterator-গুলো values-এর একটি series produce করে, এবং আমরা একটি iterator-এর উপর collect method call করে এটিকে একটি collection-এ পরিণত করতে পারি, যেমন একটি vector, যেখানে iterator-এর produce করা সমস্ত element থাকবে।
Listing 12-1-এর code আপনার minigrep প্রোগ্রামকে যেকোনো command line argument read করতে এবং তারপর value-গুলোকে একটি vector-এ collect করতে দেয়।
use std::env; fn main() { let args: Vec<String> = env::args().collect(); dbg!(args); }
প্রথমে আমরা std::env module-টিকে use statement-এর মাধ্যমে scope-এ আনি, যাতে আমরা এর args function-টি ব্যবহার করতে পারি। লক্ষ্য করুন যে std::env::args function-টি দুটি স্তরের module-এর মধ্যে nested। আমরা যেমন Chapter
7-এ আলোচনা করেছি, যেসব ক্ষেত্রে desired function একাধিক module-এর মধ্যে nested থাকে, সেক্ষেত্রে আমরা function-এর পরিবর্তে parent module-টিকে scope-এ আনতে চেয়েছি। এটা করার মাধ্যমে, আমরা সহজেই std::env-এর অন্যান্য function-গুলো ব্যবহার করতে পারি। এছাড়াও, use std::env::args যোগ করে শুধুমাত্র args দিয়ে function-টিকে call করার চেয়ে এটি কম ambiguous, কারণ args সহজেই current module-এ defined কোনো function বলে ভুল হতে পারে।
argsফাংশন এবং ইনভ্যালিড ইউনিকোডমনে রাখবেন যে, যদি কোনো argument-এ invalid Unicode থাকে, তাহলে
std::env::argsপ্যানিক করবে। যদি আপনার প্রোগ্রামের invalid Unicode যুক্ত argument গ্রহণ করার প্রয়োজন হয়, তাহলে এর পরিবর্তেstd::env::args_osব্যবহার করুন। সেই function-টি একটি iterator return করে যাStringvalue-এর পরিবর্তেOsStringvalue produce করে। আমরা এখানে সরলতার জন্যstd::env::argsব্যবহার করা বেছে নিয়েছি, কারণOsStringvalue-গুলো platform অনুযায়ী ভিন্ন হয় এবংStringvalue-গুলোর চেয়ে এগুলোর সাথে কাজ করা আরও জটিল।
main-এর প্রথম লাইনে, আমরা env::args call করি, এবং iterator-টিকে তৎক্ষণাৎ collect ব্যবহার করে একটি vector-এ পরিণত করি, যেখানে iterator দ্বারা produced সমস্ত value থাকে। আমরা collect function ব্যবহার করে বিভিন্ন ধরনের collection তৈরি করতে পারি, তাই আমরা args-এর type টি explicit ভাবে annotate করি যাতে বোঝা যায় যে আমরা string-এর একটি vector চাই। যদিও Rust-এ খুব কমই type annotate করার প্রয়োজন হয়, collect এমন একটি function যেখানে প্রায়ই annotate করার প্রয়োজন হয় কারণ Rust নিজে থেকে বুঝতে পারে না যে আপনি কী ধরনের collection চান।
অবশেষে, আমরা debug macro ব্যবহার করে vector-টি print করি। আসুন প্রথমে কোনো argument ছাড়া এবং তারপর দুটি argument দিয়ে code টি run করে দেখি:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
লক্ষ্য করুন যে vector-এর প্রথম value টি হল "target/debug/minigrep", যেটি আমাদের binary-র নাম। এটি C-তে arguments list-এর আচরণের সাথে মেলে, যা প্রোগ্রামগুলোকে execution-এর সময় তাদের যে নামে invoke করা হয়েছিল সেটি ব্যবহার করতে দেয়। প্রোগ্রামের নামটি access করতে পারা সুবিধাজনক হতে পারে যদি আপনি এটিকে message-এ print করতে চান বা প্রোগ্রামের behavior পরিবর্তন করতে চান এই ভিত্তিতে যে প্রোগ্রামটি invoke করার জন্য কোন command line alias ব্যবহার করা হয়েছে। কিন্তু এই chapter-এর উদ্দেশ্যের জন্য, আমরা এটিকে ignore করব এবং শুধুমাত্র আমাদের প্রয়োজনীয় দুটি argument save করব।
আর্গুমেন্ট ভ্যালুগুলো ভেরিয়েবলে সংরক্ষণ করা
প্রোগ্রামটি এখন command line argument হিসেবে specified value-গুলো access করতে পারছে। এখন আমাদের দুটি argument-এর value-গুলোকে variable-এ save করতে হবে যাতে আমরা value-গুলো প্রোগ্রামের বাকি অংশে ব্যবহার করতে পারি। Listing 12-2 তে আমরা সেটাই করব।
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
}আমরা যখন vector-টি print করেছিলাম তখন যেমন দেখেছিলাম, প্রোগ্রামের নামটি vector-এর প্রথম value, args[0] দখল করে, তাই আমরা argument-গুলো index 1 থেকে শুরু করছি। minigrep যে প্রথম argument টি নেয় সেটি হল সেই string যেটি আমরা search করছি, তাই আমরা প্রথম argument-টির একটি reference query variable-এ রাখি। দ্বিতীয় argument টি হবে file path, তাই আমরা দ্বিতীয় argument-টির একটি reference file_path variable-এ রাখি।
আমরা অস্থায়ীভাবে এই variable-গুলোর value print করি এটা প্রমাণ করার জন্য যে code টি আমাদের ইচ্ছা অনুযায়ী কাজ করছে। আসুন test এবং sample.txt argument-গুলো দিয়ে এই প্রোগ্রামটি আবার run করি:
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
দারুণ, প্রোগ্রামটি কাজ করছে! আমাদের প্রয়োজনীয় argument-গুলোর value সঠিক variable-গুলোতে save করা হচ্ছে। পরে আমরা কিছু error handling যোগ করব কিছু সম্ভাব্য ত্রুটিপূর্ণ পরিস্থিতি, যেমন যখন user কোনো argument provide করে না; আপাতত, আমরা সেই পরিস্থিতিটি ignore করব এবং এর পরিবর্তে file-reading ক্ষমতা যোগ করার উপর কাজ করব।
একটি File পড়া
এখন আমরা file_path argument-এ specified file টি read করার functionality যোগ করব। প্রথমে আমাদের test করার জন্য একটি sample file-এর প্রয়োজন: আমরা অল্প কিছু text, multiple line এবং কিছু repeated word সহ একটি file ব্যবহার করব। Listing 12-3-এ Emily Dickinson-এর একটি কবিতা আছে যা এই কাজের জন্য উপযুক্ত! আপনার project-এর root level-এ poem.txt নামে একটি file create করুন, এবং “I’m Nobody! Who are you?” কবিতাটি লিখুন।
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Text টি create করা হয়ে গেলে, src/main.rs edit করুন এবং file read করার জন্য code যোগ করুন, যেমনটি Listing 12-4-এ দেখানো হয়েছে।
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}প্রথমে আমরা use statement-এর মাধ্যমে standard library-এর একটি relevant অংশ import করি: file handle করার জন্য আমাদের std::fs-এর প্রয়োজন।
main-এ, নতুন statement fs::read_to_string, file_path নেয়, সেই file টি open করে, এবং file-এর contents সহ std::io::Result<String> type-এর একটি value return করে।
এরপরে, আমরা আবার একটি temporary println! statement যোগ করি যা file read করার পরে contents-এর value print করে, যাতে আমরা check করতে পারি যে প্রোগ্রামটি এখনও পর্যন্ত ঠিকঠাক কাজ করছে।
আসুন আমরা এই code-টি প্রথম command line argument হিসেবে যেকোনো string (কারণ আমরা এখনও searching অংশটি implement করিনি) এবং দ্বিতীয় argument হিসেবে poem.txt file দিয়ে run করি:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
দারুণ! Code file-এর contents read করে print করেছে। কিন্তু code-টিতে কিছু সমস্যা রয়েছে। বর্তমানে, main function-টির multiple responsibility রয়েছে: সাধারণত, function-গুলো clear এবং maintain করা সহজ হয় যদি প্রতিটি function শুধুমাত্র একটি idea-র জন্য responsible হয়। আরেকটি সমস্যা হল আমরা error গুলোকে যতটা ভালোভাবে handle করা সম্ভব ততটা করছি না। প্রোগ্রামটি এখনও ছোট, তাই এই ত্রুটিগুলো বড় কোনো সমস্যা নয়, কিন্তু প্রোগ্রামটি যত বড় হবে, এগুলোকে পরিষ্কারভাবে ঠিক করা তত কঠিন হবে। প্রোগ্রাম develop করার সময় শুরুতেই refactor করা একটি ভালো অভ্যাস, কারণ অল্প পরিমাণ code refactor করা অনেক সহজ। আমরা এরপরে সেটাই করব।
Modularity এবং Error Handling উন্নত করার জন্য Refactoring
আমাদের প্রোগ্রামটিকে উন্নত করার জন্য, আমরা চারটি সমস্যা সমাধান করব যেগুলির প্রোগ্রামের structure এবং এটি কীভাবে potential error গুলি handle করছে তার সাথে সম্পর্ক রয়েছে। প্রথমত, আমাদের main function এখন দুটি কাজ করে: এটি argument parse করে এবং file read করে। আমাদের প্রোগ্রাম যত বাড়বে, main function-এর handle করা আলাদা কাজের সংখ্যাও বাড়বে। একটি function-এর responsibility যত বাড়ে, সেটি সম্পর্কে reasoning করা, test করা এবং সেটির কোনো একটি অংশ break না করে পরিবর্তন করা তত কঠিন হয়ে পড়ে। Functionality আলাদা করা সবচেয়ে ভালো যাতে প্রতিটি function একটি কাজের জন্য responsible হয়।
এই সমস্যাটি দ্বিতীয় সমস্যার সাথেও জড়িত: যদিও query এবং file_path আমাদের প্রোগ্রামের configuration variable, contents-এর মতো variable গুলো প্রোগ্রামের logic perform করার জন্য ব্যবহৃত হয়। main যত দীর্ঘ হবে, তত বেশি variable আমাদের scope-এ আনতে হবে; আমাদের scope-এ যত বেশি variable থাকবে, প্রতিটির purpose ট্র্যাক রাখা তত কঠিন হবে। Configuration variable গুলোকে একটি structure-এ group করা সবচেয়ে ভালো যাতে তাদের purpose স্পষ্ট হয়।
তৃতীয় সমস্যাটি হল, file read fail করলে আমরা একটি error message print করার জন্য expect ব্যবহার করেছি, কিন্তু error message টি শুধুমাত্র Should have been able to read the file প্রিন্ট করে। File read করার ক্ষেত্রে বিভিন্নভাবে fail হতে পারে: উদাহরণস্বরূপ, file টি missing থাকতে পারে, অথবা আমাদের এটি open করার permission নাও থাকতে পারে। এখন, পরিস্থিতি যাই হোক না কেন, আমরা সবকিছুর জন্য একই error message প্রিন্ট করব, যা user-কে কোনো information দেবে না!
চতুর্থত, আমরা একটি error handle করার জন্য expect ব্যবহার করি, এবং যদি user পর্যাপ্ত argument specify না করে আমাদের প্রোগ্রাম run করে, তাহলে তারা Rust-এর কাছ থেকে একটি index out of bounds error পাবে যা সমস্যাটি স্পষ্ট ভাবে ব্যাখ্যা করে না। Error-handling code-গুলো এক জায়গায় থাকলে সবচেয়ে ভালো হবে, যাতে future-এ maintainer-দের error-handling logic পরিবর্তন করার প্রয়োজন হলে code-এর শুধুমাত্র একটি জায়গাতেই consult করতে হয়। সমস্ত error-handling code এক জায়গায় থাকলে এটাও নিশ্চিত হবে যে আমরা এমন message প্রিন্ট করছি যা আমাদের end user-দের কাছে অর্থপূর্ণ হবে।
আসুন আমাদের project refactor করে এই চারটি সমস্যার সমাধান করি।
বাইনারি প্রোজেক্টের জন্য Separation of Concerns
main function-এ একাধিক কাজের responsibility allocate করার সাংগঠনিক সমস্যাটি অনেক binary project-এর ক্ষেত্রে common। ফলস্বরূপ, Rust community একটি binary program-এর আলাদা concern গুলোকে split করার জন্য guidelines develop করেছে, যখন main বড় হতে শুরু করে। এই process-টিতে নিম্নলিখিত step গুলো রয়েছে:
- আপনার প্রোগ্রামকে একটি main.rs file এবং একটি lib.rs file-এ split করুন এবং আপনার প্রোগ্রামের logic-কে lib.rs-এ move করুন।
- যতক্ষণ আপনার command line parsing logic ছোট থাকে, ততক্ষণ এটি main.rs-এ থাকতে পারে।
- যখন command line parsing logic জটিল হতে শুরু করে, তখন এটিকে main.rs থেকে extract করুন এবং lib.rs-এ move করুন।
এই process-এর পরে main function-এ যে responsibility গুলো থাকা উচিত সেগুলো নিম্নলিখিতগুলির মধ্যে limited হওয়া উচিত:
- Argument value-গুলো দিয়ে command line parsing logic call করা
- অন্যান্য configuration set up করা
- lib.rs-এ একটি
runfunction call করা - যদি
runকোনো error return করে তাহলে error handle করা
এই pattern-টি concern গুলোকে আলাদা করার বিষয়ে: main.rs প্রোগ্রাম run করা handle করে এবং lib.rs বর্তমান task-এর সমস্ত logic handle করে। যেহেতু আপনি সরাসরি main function test করতে পারবেন না, তাই এই structure আপনাকে lib.rs-এর function গুলোতে move করে আপনার প্রোগ্রামের সমস্ত logic test করতে দেয়। main.rs-এ যে code অবশিষ্ট থাকে তা এতটাই ছোট হবে যে এটি পড়ে এর সঠিকতা verify করা যাবে। আসুন এই process টি follow করে আমাদের প্রোগ্রামটিকে পুনরায় কাজ করি।
Argument Parser-কে Extract করা
আমরা argument parse করার functionality-টিকে একটি function-এ extract করব যাকে main call করবে command line parsing logic-কে src/lib.rs-এ move করার জন্য প্রস্তুত করতে। Listing 12-5 main-এর নতুন start দেখায় যা parse_config নামক একটি নতুন function call করে, যেটি আমরা আপাতত src/main.rs-এ define করব।
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, file_path) = parse_config(&args);
// --snip--
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let file_path = &args[2];
(query, file_path)
}আমরা এখনও command line argument-গুলোকে একটি vector-এ collect করছি, কিন্তু main function-এর মধ্যে index 1-এ থাকা argument value-টিকে query variable-এ এবং index 2-এ থাকা argument value-টিকে file_path variable-এ assign করার পরিবর্তে, আমরা পুরো vector-টিকে parse_config function-এ pass করি। parse_config function-টিতে এরপর সেই logic থাকে যা নির্ধারণ করে কোন argument কোন variable-এ যাবে এবং value-গুলো main-এ ফেরত পাঠায়। আমরা এখনও main-এ query এবং file_path variable create করি, কিন্তু command line argument এবং variable গুলো কীভাবে correspond করে তা নির্ধারণ করার responsibility আর main-এর নেই।
আমাদের ছোট প্রোগ্রামের জন্য এই rework টি overkill মনে হতে পারে, কিন্তু আমরা ছোট, incremental step-এ refactor করছি। এই পরিবর্তনটি করার পরে, argument parsing এখনও কাজ করছে কিনা তা verify করার জন্য প্রোগ্রামটি আবার run করুন। আপনার progress প্রায়শই check করা ভালো, যাতে সমস্যা দেখা দিলে তার কারণ সনাক্ত করতে সুবিধা হয়।
Configuration Value গুলো Grouping করা
আমরা parse_config function-টিকে আরও উন্নত করার জন্য আরেকটি ছোট step নিতে পারি। এখন, আমরা একটি tuple return করছি, কিন্তু তারপরে আমরা সেই tuple-টিকে আবার individual part-এ ভেঙে দিচ্ছি। এটি একটি লক্ষণ যে সম্ভবত আমাদের এখনও সঠিক abstraction নেই।
আরেকটি indicator যা দেখায় যে উন্নতির জায়গা রয়েছে তা হল parse_config-এর config অংশটি, যা বোঝায় যে আমরা যে দুটি value return করি সেগুলি related এবং উভয়ই একটি configuration value-এর অংশ। আমরা বর্তমানে data-র structure-এ এই অর্থটি প্রকাশ করছি না, শুধুমাত্র দুটি value-কে একটি tuple-এ group করে; এর পরিবর্তে আমরা দুটি value-কে একটি struct-এ রাখব এবং struct-এর প্রতিটি field-কে একটি অর্থপূর্ণ নাম দেব। এটি করলে future-এ এই code-এর maintainer-দের জন্য এটা বোঝা সহজ হবে যে কীভাবে বিভিন্ন value একে অপরের সাথে related এবং তাদের purpose কী।
Listing 12-6 parse_config function-এর improvement গুলো দেখায়।
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
// --snip--
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
fn parse_config(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}আমরা Config নামের একটি struct যোগ করেছি যার field-গুলোর নাম query এবং file_path হিসেবে define করা হয়েছে। parse_config-এর signature এখন নির্দেশ করে যে এটি একটি Config value return করে। parse_config-এর body-তে, যেখানে আমরা args-এ String value-গুলোকে reference করা string slice return করতাম, সেখানে এখন আমরা Config-কে define করি owned String value ধারণ করার জন্য। main-এর args variable-টি argument value-গুলোর owner এবং parse_config function-কে শুধুমাত্র সেগুলো borrow করতে দিচ্ছে, যার অর্থ হল যদি Config, args-এর value-গুলোর ownership নেওয়ার চেষ্টা করত তাহলে আমরা Rust-এর borrowing rule violate করতাম।
আমরা String data manage করার জন্য বেশ কয়েকটি উপায় অবলম্বন করতে পারি; সবচেয়ে সহজ, যদিও কিছুটা inefficient, উপায় হল value-গুলোর উপর clone method call করা। এটি Config instance-এর own করার জন্য data-র একটি full copy তৈরি করবে, যা string data-র একটি reference store করার চেয়ে বেশি সময় এবং memory নেয়। যাইহোক, data clone করা আমাদের code-কে আরও straightforward করে তোলে কারণ আমাদের reference-গুলোর lifetime manage করতে হয় না; এই পরিস্থিতিতে, simplicity অর্জনের জন্য performance-এর সামান্য ত্যাগ একটি worthwhile trade-off।
cloneব্যবহারের Trade-Offঅনেক Rustaceans-দের মধ্যে ownership-এর সমস্যা সমাধানের জন্য
cloneব্যবহার করা এড়িয়ে যাওয়ার প্রবণতা রয়েছে কারণ এর runtime cost আছে। Chapter 13-এ, আপনি শিখবেন কীভাবে এই ধরনের পরিস্থিতিতে আরও efficient method ব্যবহার করতে হয়। কিন্তু আপাতত, progress চালিয়ে যাওয়ার জন্য কয়েকটি string copy করা ঠিক আছে কারণ আপনি এই copy গুলো শুধুমাত্র একবার করবেন এবং আপনার file path এবং query string খুব ছোট। প্রথম চেষ্টাতেই code hyperoptimize করার চেষ্টা করার চেয়ে একটি working প্রোগ্রাম থাকা ভালো যা কিছুটা inefficient। আপনি Rust-এর সাথে আরও experienced হওয়ার সাথে সাথে, সবচেয়ে efficient solution দিয়ে শুরু করা আরও সহজ হবে, কিন্তু আপাতত,clonecall করা perfectly acceptable।
আমরা main update করেছি যাতে এটি parse_config দ্বারা returned Config-এর instance-টিকে config নামের একটি variable-এ রাখে, এবং আমরা সেই code update করেছি যেটি আগে আলাদা query এবং file_path variable ব্যবহার করত যাতে এটি এখন পরিবর্তে Config struct-এর field গুলো ব্যবহার করে।
এখন আমাদের code আরও স্পষ্টভাবে প্রকাশ করে যে query এবং file_path related এবং তাদের purpose হল প্রোগ্রামটি কীভাবে কাজ করবে তা configure করা। এই value গুলো ব্যবহার করে এমন যেকোনো code জানে যে সেগুলিকে config instance-এর মধ্যে তাদের purpose-এর জন্য named field-গুলোতে খুঁজতে হবে।
Config-এর জন্য একটি Constructor তৈরি করা
এখনও পর্যন্ত, আমরা command line argument parse করার জন্য responsible logic-টিকে main থেকে extract করে parse_config function-এ রেখেছি। এটি করতে গিয়ে আমরা দেখতে পেলাম যে query এবং file_path value গুলো related ছিল, এবং সেই relationship আমাদের code-এ প্রকাশ করা উচিত। তারপরে আমরা query এবং file_path-এর related purpose-টির নাম দেওয়ার জন্য এবং parse_config function থেকে value-গুলোর নাম struct field name হিসেবে return করতে সক্ষম হওয়ার জন্য একটি Config struct যোগ করেছি।
সুতরাং এখন যেহেতু parse_config function-টির purpose হল একটি Config instance create করা, তাই আমরা parse_config-কে একটি plain function থেকে Config struct-এর সাথে associated new নামের একটি function-এ পরিবর্তন করতে পারি। এই পরিবর্তনটি code-টিকে আরও idiomatic করে তুলবে। আমরা standard library-তে type-গুলোর instance create করতে পারি, যেমন String, String::new call করে। একইভাবে, parse_config-কে Config-এর সাথে associated একটি new function-এ পরিবর্তন করে, আমরা Config::new call করে Config-এর instance create করতে পারব। Listing 12-7 আমাদের যে পরিবর্তনগুলো করতে হবে সেগুলো দেখায়।
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
// --snip--
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}আমরা main update করেছি যেখানে আমরা parse_config call করছিলাম, পরিবর্তে Config::new call করার জন্য। আমরা parse_config-এর নাম পরিবর্তন করে new করেছি এবং এটিকে একটি impl block-এর মধ্যে move করেছি, যা new function-টিকে Config-এর সাথে associate করে। এই code টি আবার compile করে দেখুন এটা নিশ্চিত করতে যে এটি কাজ করছে।
Error Handling ঠিক করা
এখন আমরা আমাদের error handling ঠিক করার জন্য কাজ করব। মনে রাখবেন যে vector-এ তিনটির কম item থাকলে args vector-এর index 1 বা index 2-এ value access করার চেষ্টা করলে প্রোগ্রামটি panic করবে। কোনো argument ছাড়া প্রোগ্রামটি run করার চেষ্টা করুন; এটি এইরকম দেখাবে:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:27:21:
index out of bounds: the len is 1 but the index is 1
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
index out of bounds: the len is 1 but the index is 1 লাইনটি programmers-দের জন্য উদ্দিষ্ট একটি error message। এটি আমাদের end user-দের বুঝতে সাহায্য করবে না যে পরিবর্তে তাদের কী করা উচিত। আসুন এখন সেটা ঠিক করি।
Error Message-এর উন্নতি
Listing 12-8-এ, আমরা new function-এ একটি check যোগ করি যা index 1 এবং index 2 access করার আগে verify করবে যে slice-টি যথেষ্ট long কিনা। যদি slice-টি যথেষ্ট long না হয়, তাহলে প্রোগ্রামটি panic করে এবং একটি better error message প্রদর্শন করে।
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("not enough arguments");
}
// --snip--
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}এই code-টি Listing 9-13-এ লেখা আমাদের Guess::new function-এর মতো, যেখানে value argument-টি valid value-গুলোর range-এর বাইরে থাকলে আমরা panic! call করেছিলাম। এখানে value-গুলোর একটি range check করার পরিবর্তে, আমরা check করছি যে args-এর length কমপক্ষে 3 কিনা এবং function-এর বাকি অংশ এই assumption-এর অধীনে operate করতে পারে যে এই condition পূরণ হয়েছে। যদি args-এ তিনটির কম item থাকে, তাহলে এই condition-টি true হবে, এবং আমরা প্রোগ্রামটিকে immediately end করার জন্য panic! macro call করি।
new-তে এই কয়েকটি অতিরিক্ত code line সহ, আসুন আবার কোনো argument ছাড়াই প্রোগ্রামটি run করি এটা দেখতে যে error-টি এখন কেমন দেখায়:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
not enough arguments
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
এই output টি আরও ভালো: আমাদের এখন একটি reasonable error message রয়েছে। যাইহোক, আমাদের কাছে extraneous information-ও রয়েছে যা আমরা আমাদের user-দের দিতে চাই না। সম্ভবত Listing 9-13-এ আমরা যে technique ব্যবহার করেছি সেটি এখানে ব্যবহার করার জন্য সেরা নয়: panic!-এ call করা usage problem-এর চেয়ে programming problem-এর জন্য বেশি উপযুক্ত, যেমন Chapter 9-এ আলোচনা করা হয়েছে। পরিবর্তে, আমরা Chapter 9-এ শেখা অন্য technique টি ব্যবহার করব—একটি Result return করা যা success বা error indicate করে।
panic! Call করার পরিবর্তে একটি Result Return করা
আমরা পরিবর্তে একটি Result value return করতে পারি যাতে successful case-এ একটি Config instance থাকবে এবং error case-এ problem টি describe করবে। আমরা function-টির নামও new থেকে build-এ পরিবর্তন করতে যাচ্ছি কারণ অনেক programmer আশা করেন new function গুলো কখনই fail করবে না। যখন Config::build, main-এর সাথে communicate করছে, তখন আমরা Result type ব্যবহার করে signal দিতে পারি যে একটি problem ছিল। তারপরে আমরা main পরিবর্তন করে Err variant-কে আমাদের user-দের জন্য আরও practical error-এ convert করতে পারি, thread 'main' এবং RUST_BACKTRACE সম্পর্কে আশেপাশের text ছাড়াই যা panic!-এ call করার কারণে ঘটে।
Listing 12-9-এ আমরা এখন যে function টিকে Config::build বলছি, তার return value এবং একটি Result return করার জন্য function-এর body-তে যে পরিবর্তনগুলো করতে হবে সেগুলো দেখানো হলো। মনে রাখবেন যে যতক্ষণ না আমরা main update করি, ততক্ষণ পর্যন্ত এটি compile হবে না, যা আমরা পরবর্তী listing-এ করব।
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}আমাদের build function success case-এ একটি Config instance এবং error case-এ একটি string literal সহ একটি Result return করে। আমাদের error value গুলো সব সময় string literal হবে যাদের 'static lifetime আছে।
আমরা function-এর body-তে দুটি পরিবর্তন করেছি: user পর্যাপ্ত argument pass না করলে panic! call করার পরিবর্তে, আমরা এখন একটি Err value return করি, এবং আমরা Config return value-টিকে একটি Ok-এ wrap করেছি। এই পরিবর্তনগুলো function-টিকে এর new type signature-এর সাথে সঙ্গতিপূর্ণ করে তোলে।
Config::build থেকে একটি Err value return করা main function-কে build function থেকে returned Result value handle করতে এবং error case-এ আরও cleanly process exit করতে দেয়।
Config::build কল করা এবং Error হ্যান্ডেল করা
Error case হ্যান্ডেল করতে এবং একটি user-friendly message প্রিন্ট করতে, আমাদের main update করতে হবে যাতে এটি Config::build দ্বারা returned Result হ্যান্ডেল করতে পারে, যেমনটি Listing 12-10-এ দেখানো হয়েছে। আমরা panic! থেকে nonzero error code সহ command line tool exit করার responsibility-ও সরিয়ে নেব এবং পরিবর্তে এটি নিজে implement করব। একটি nonzero exit status হল এমন একটি convention যা আমাদের প্রোগ্রাম call করা process-কে signal দেয় যে প্রোগ্রামটি একটি error state-এর সাথে exit করেছে।
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}এই listing-এ, আমরা এমন একটি method ব্যবহার করেছি যা আমরা এখনও বিস্তারিতভাবে আলোচনা করিনি: unwrap_or_else, যেটি standard library দ্বারা Result<T, E>-তে define করা হয়েছে। unwrap_or_else ব্যবহার করা আমাদের কিছু custom, non-panic! error handling define করার সুযোগ দেয়। যদি Result একটি Ok value হয়, তাহলে এই method-টির behavior unwrap-এর মতোই: এটি Ok যে inner value-টিকে wrap করে রেখেছে সেটি return করে। যাইহোক, যদি value-টি একটি Err value হয়, তাহলে এই method টি closure-এর মধ্যে থাকা code call করে, যেটি হল একটি anonymous function যা আমরা define করি এবং unwrap_or_else-এ argument হিসেবে pass করি। আমরা Chapter 13-এ closure সম্পর্কে আরও বিস্তারিত আলোচনা করব। আপাতত, আপনার শুধু এটা জানলেই চলবে যে unwrap_or_else, Err-এর inner value, যেটি এই ক্ষেত্রে Listing 12-9-এ যোগ করা static string "not enough arguments", সেটিকে vertical pipe-গুলোর মধ্যে থাকা err argument-এর মাধ্যমে আমাদের closure-এ pass করবে। Closure-এর ভেতরের code তারপর run করার সময় err value-টিকে ব্যবহার করতে পারবে।
আমরা standard library থেকে process কে scope-এ আনার জন্য একটি নতুন use লাইন যোগ করেছি। Error case-এ যে closure-টি run করবে তার code-এ শুধুমাত্র দুটি লাইন রয়েছে: আমরা err value-টি print করি এবং তারপর process::exit call করি। process::exit function প্রোগ্রামটিকে immediately stop করবে এবং exit status code হিসেবে যে number টি pass করা হয়েছিল সেটি return করবে। এটি Listing 12-8-এ ব্যবহৃত panic!-ভিত্তিক handling-এর মতোই, কিন্তু আমরা আর সমস্ত extra output পাচ্ছি না। আসুন চেষ্টা করা যাক:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
দারুণ! এই output টি আমাদের user-দের জন্য অনেক বেশি friendly।
main থেকে Logic Extract করা
এখন যেহেতু আমরা configuration parsing refactor করা শেষ করেছি, আসুন প্রোগ্রামের logic-এর দিকে মনোযোগ দিই। আমরা যেমন “বাইনারি প্রোজেক্টের জন্য Separation of Concerns”-এ উল্লেখ করেছি, আমরা run নামের একটি function extract করব যেটি বর্তমানে main function-এ থাকা সমস্ত logic ধারণ করবে যা configuration set up করা বা error handle করার সাথে জড়িত নয়। যখন আমাদের কাজ শেষ হবে, main সংক্ষিপ্ত হবে এবং inspection-এর মাধ্যমে সহজেই verify করা যাবে, এবং আমরা অন্যান্য সমস্ত logic-এর জন্য test লিখতে পারব।
Listing 12-11-এ extract করা run function দেখানো হয়েছে। আপাতত, আমরা শুধুমাত্র function extract করার ছোট, incremental improvement করছি। আমরা এখনও src/main.rs-এ function-টি define করছি।
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) {
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}run function-এ এখন file read করা থেকে শুরু করে main-এর সমস্ত অবশিষ্ট logic রয়েছে। run function টি Config instance-টিকে argument হিসেবে নেয়।
run Function থেকে Error Return করা
প্রোগ্রামের অবশিষ্ট logic run function-এ আলাদা করার সাথে, আমরা error handling-এর উন্নতি করতে পারি, যেমনটি আমরা Listing 12-9-এ Config::build-এর সাথে করেছিলাম। expect call করে প্রোগ্রামটিকে panic করার অনুমতি দেওয়ার পরিবর্তে, run function টি কোনো কিছু ভুল হলে একটি Result<T, E> return করবে। এটি আমাদেরকে user-friendly উপায়ে error handle করার জন্য logic-কে main-এ আরও consolidate করার সুযোগ দেবে। Listing 12-12 run-এর signature এবং body-তে আমাদের যে পরিবর্তনগুলো করতে হবে সেগুলো দেখায়।
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}আমরা এখানে তিনটি উল্লেখযোগ্য পরিবর্তন করেছি। প্রথমত, আমরা run function-এর return type পরিবর্তন করে Result<(), Box<dyn Error>> করেছি। এই function টি আগে unit type, (), return করত, এবং আমরা Ok case-এ returned value হিসেবে সেটিই রাখছি।
Error type-এর জন্য, আমরা trait object Box<dyn Error> ব্যবহার করেছি (এবং আমরা উপরের দিকে একটি use statement দিয়ে std::error::Error কে scope-এ এনেছি)। আমরা Chapter 18-এ trait object নিয়ে আলোচনা করব। আপাতত, শুধু জেনে রাখুন যে Box<dyn Error> মানে function টি এমন একটি type return করবে যা Error trait implement করে, কিন্তু আমাদের specify করতে হবে না যে return value-টি specific কোন type-এর হবে। এটি আমাদেরকে error value return করার flexibility দেয় যা different error case-এ different type-এর হতে পারে। dyn keyword টি dynamic-এর সংক্ষিপ্ত রূপ।
দ্বিতীয়ত, আমরা Chapter 9-এ আলোচনা করা ? operator-এর পক্ষে expect-এর call সরিয়ে দিয়েছি। কোনো error-এর উপর panic! করার পরিবর্তে, ? current function থেকে error value-টি return করবে যাতে caller সেটি handle করতে পারে।
তৃতীয়ত, run function টি এখন success case-এ একটি Ok value return করে। আমরা signature-এ run function-এর success type () হিসেবে declare করেছি, যার অর্থ হল আমাদের unit type value-টিকে Ok value-তে wrap করতে হবে। এই Ok(()) syntax টি প্রথমে একটু অদ্ভুত লাগতে পারে, কিন্তু এইভাবে () ব্যবহার করা হল idiomatic উপায় এটা indicate করার জন্য যে আমরা run কে শুধুমাত্র এর side effect-গুলোর জন্য call করছি; এটি আমাদের প্রয়োজনীয় কোনো value return করে না।
আপনি যখন এই code run করবেন, এটি compile হবে কিন্তু একটি warning প্রদর্শন করবে:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
19 | let _ = run(config);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Rust আমাদের বলছে যে আমাদের code Result value-টিকে ignore করেছে এবং Result value-টি indicate করতে পারে যে একটি error ঘটেছে। কিন্তু আমরা check করছি না যে কোনো error হয়েছে কিনা, এবং compiler আমাদের মনে করিয়ে দিচ্ছে যে সম্ভবত আমাদের এখানে কিছু error-handling code থাকা উচিত ছিল! আসুন এখনই সেই সমস্যাটি সংশোধন করি।
main-এ run থেকে Returned Error হ্যান্ডেল করা
আমরা error-গুলো check করব এবং Listing 12-10-এ Config::build-এর সাথে ব্যবহৃত পদ্ধতির মতোই একটি technique ব্যবহার করে সেগুলি handle করব, তবে সামান্য ভিন্নতা সহ:
Filename: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}আমরা unwrap_or_else-এর পরিবর্তে if let ব্যবহার করি এটা check করার জন্য যে run একটি Err value return করে কিনা এবং যদি করে তবে process::exit(1) call করার জন্য। run function এমন কোনো value return করে না যা আমরা unwrap করতে চাই, যেমন Config::build, Config instance return করে। যেহেতু run success case-এ () return করে, তাই আমরা শুধুমাত্র একটি error detect করার বিষয়ে আগ্রহী, তাই unwrapped value return করার জন্য আমাদের unwrap_or_else-এর প্রয়োজন নেই, যেটি শুধুমাত্র () হবে।
if let এবং unwrap_or_else function-গুলোর body উভয় ক্ষেত্রেই একই: আমরা error print করি এবং exit করি।
কোডকে একটি Library Crate-এ Split করা
আমাদের minigrep project-টি এখনও পর্যন্ত ভালো দেখাচ্ছে! এখন আমরা src/main.rs file-টিকে split করব এবং কিছু code src/lib.rs file-এ রাখব। এইভাবে, আমরা code test করতে পারব এবং src/main.rs file-টিতে responsibility কম রাখতে পারব।
আসুন src/main.rs থেকে src/lib.rs-এ সমস্ত code সরিয়ে নিই যা main function-এ নেই:
runfunction definition- Relevant
usestatement-গুলো Config-এর definitionConfig::buildfunction definition
src/lib.rs-এর contents-এ Listing 12-13-এ দেখানো signature গুলো থাকা উচিত (সংक्षिप्तতার জন্য আমরা function-গুলোর body বাদ দিয়েছি)। মনে রাখবেন যে যতক্ষণ না আমরা Listing 12-14-এ src/main.rs modify করি, ততক্ষণ পর্যন্ত এটি compile হবে না।
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
// --snip--
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}আমরা pub keyword-টির উদার ব্যবহার করেছি: Config-এ, এর field এবং এর build method-এ এবং run function-এ। আমাদের এখন একটি library crate রয়েছে যার একটি public API রয়েছে যা আমরা test করতে পারি!
এখন আমাদের Listing 12-14-এ দেখানো code-টিকে src/lib.rs-এ সরানো code binary crate-এর scope-এ src/main.rs-এ আনতে হবে।
use std::env;
use std::process;
use minigrep::Config;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = minigrep::run(config) {
// --snip--
println!("Application error: {e}");
process::exit(1);
}
}আমরা library crate থেকে binary crate-এর scope-এ Config type-টি আনার জন্য একটি use minigrep::Config লাইন যোগ করি এবং আমরা run function-টির আগে আমাদের crate-এর নাম prefix করি। এখন সমস্ত functionality সংযুক্ত হওয়া উচিত এবং কাজ করা উচিত। cargo run দিয়ে প্রোগ্রামটি run করুন এবং নিশ্চিত করুন যে সবকিছু সঠিকভাবে কাজ করছে।
উফ! এটা অনেক কাজ ছিল, কিন্তু আমরা ভবিষ্যতে নিজেদের সাফল্যের জন্য প্রস্তুত করেছি। এখন error handle করা অনেক সহজ, এবং আমরা code-টিকে আরও modular করেছি। এখন থেকে আমাদের প্রায় সমস্ত কাজ src/lib.rs-এ করা হবে।
আসুন এই নতুন পাওয়া modularity-র সুবিধা নিই এমন কিছু করে যা পুরানো code-এর সাথে করা কঠিন হত কিন্তু নতুন code-এর সাথে সহজ: আমরা কিছু test লিখব!
Test-Driven Development ব্যবহার করে Library-র Functionality Develop করা
এখন যেহেতু আমরা logic-টিকে src/lib.rs-এ extract করেছি এবং argument সংগ্রহ ও error handling src/main.rs-এ রেখেছি, তাই আমাদের code-এর core functionality-র জন্য test লেখা অনেক সহজ। আমরা command line থেকে আমাদের binary call না করেই বিভিন্ন argument দিয়ে সরাসরি function call করতে পারি এবং return value গুলো check করতে পারি।
এই section-এ, আমরা নিম্নলিখিত step-গুলো সহ test-driven development (TDD) process ব্যবহার করে minigrep প্রোগ্রামে searching logic যোগ করব:
- এমন একটি test লিখুন যেটি fail করে এবং আপনি যে কারণে এটি fail করবে বলে আশা করছেন সেই কারণেই fail করছে কিনা তা নিশ্চিত করতে এটি run করুন।
- নতুন test-টি pass করানোর জন্য যথেষ্ট code লিখুন বা modify করুন।
- আপনি যে code যোগ করেছেন বা পরিবর্তন করেছেন সেটি refactor করুন এবং নিশ্চিত করুন যে test গুলো தொடர்ந்து pass করছে।
- Step 1 থেকে পুনরাবৃত্তি করুন!
যদিও software লেখার এটি অন্যতম একটি উপায়, TDD কোড ডিজাইনকে এগিয়ে নিতে সাহায্য করতে পারে। Test pass করানোর code লেখার আগে test লিখলে প্রক্রিয়া জুড়ে high test coverage বজায় রাখতে সহায়তা করে।
আমরা সেই functionality-র implementation test-drive করব যেটি file-এর contents-এ query string-টির জন্য search করবে এবং query-এর সাথে match করে এমন line-গুলোর একটি list তৈরি করবে। আমরা এই functionality-টি search নামক একটি function-এ যোগ করব।
একটি Failing Test লেখা
যেহেতু আমাদের আর প্রয়োজন নেই, তাই আসুন src/lib.rs এবং src/main.rs থেকে println! statement গুলো সরিয়ে দিই যেগুলো আমরা প্রোগ্রামের behavior check করার জন্য ব্যবহার করতাম। তারপর, src/lib.rs-এ, আমরা একটি tests module যোগ করব একটি test function সহ, যেমনটি আমরা Chapter 11-এ করেছিলাম। Test function টি specify করে যে search function-টির behavior আমরা কেমন চাই: এটি একটি query এবং যে text-এ search করতে হবে সেটি নেবে এবং text-এর শুধুমাত্র সেই line গুলো return করবে যেগুলিতে query রয়েছে। Listing 12-15 এই test টি দেখায়, যেটি এখনও compile হবে না।
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}এই test টি "duct" string-টির জন্য search করে। আমরা যে text-এ search করছি সেটি তিনটি লাইন, যার মধ্যে শুধুমাত্র একটিতে "duct" রয়েছে (লক্ষ্য করুন যে opening double quote-এর পরের backslash টি Rust-কে বলে এই string literal-এর contents-এর শুরুতে একটি newline character না রাখতে)। আমরা assert করি যে search function থেকে returned value-টিতে শুধুমাত্র সেই line-টি রয়েছে যা আমরা আশা করি।
আমরা এখনও এই test টি run করে fail হতে দেখতে পাচ্ছি না কারণ test টি এখনও compile-ই হচ্ছে না: search function-টি এখনও নেই! TDD নীতি অনুসারে, আমরা Listing 12-16-এ দেখানো search function-এর একটি definition যোগ করে test টিকে compile এবং run করানোর জন্য যথেষ্ট code যোগ করব, যেটি সব সময় একটি empty vector return করে। তারপরে test টি compile হয়ে fail করা উচিত, কারণ একটি empty vector "safe, fast, productive." line-যুক্ত একটি vector-এর সাথে মেলে না।
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}লক্ষ্য করুন যে আমাদের search-এর signature-এ একটি explicit lifetime 'a define করতে হবে এবং সেই lifetime-টি contents argument এবং return value-এর সাথে ব্যবহার করতে হবে। Chapter 10-এ স্মরণ করুন যে lifetime parameter গুলো specify করে যে কোন argument lifetime, return value-এর lifetime-এর সাথে connected। এই ক্ষেত্রে, আমরা indicate করছি যে returned vector-টিতে string slice থাকা উচিত যা contents argument-এর slice-গুলোকে reference করে ( query argument-এর নয়)।
অন্য কথায়, আমরা Rust-কে বলি যে search function দ্বারা returned data ততদিন live থাকবে যতদিন contents argument-এ search function-এ pass করা data live থাকে। এটা গুরুত্বপূর্ণ! একটি slice দ্বারা referenced data-টিকে valid হতে হবে যাতে reference-টি valid হয়; যদি compiler ধরে নেয় যে আমরা contents-এর পরিবর্তে query-এর string slice তৈরি করছি, তাহলে এটি তার safety checking ভুলভাবে করবে।
যদি আমরা lifetime annotation গুলো ভুলে যাই এবং এই function টি compile করার চেষ্টা করি, তাহলে আমরা এই error পাব:
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:28:51
|
28 | pub fn search(query: &str, contents: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
28 | pub fn search<'a>(query: &'a str, contents: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
Rust-এর পক্ষে জানা সম্ভব নয় যে আমাদের দুটি argument-এর মধ্যে কোনটি প্রয়োজন, তাই আমাদের এটি explicit ভাবে বলতে হবে। যেহেতু contents হল সেই argument যাতে আমাদের সমস্ত text রয়েছে এবং আমরা সেই text-এর যে অংশগুলো match করে সেগুলো return করতে চাই, তাই আমরা জানি contents হল সেই argument যাকে lifetime syntax ব্যবহার করে return value-এর সাথে connect করা উচিত।
অন্যান্য programming language-গুলোতে আপনাকে signature-এ argument গুলোকে return value-এর সাথে connect করতে হয় না, কিন্তু এই practice টি সময়ের সাথে সহজ হয়ে যাবে। আপনি এই example টিকে Chapter 10-এর "লাইফটাইম সহ রেফারেন্স ভ্যালিডেট করা" বিভাগের উদাহরণগুলোর সাথে তুলনা করতে পারেন।
এখন আসুন test টি run করি:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.97s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... FAILED
failures:
---- tests::one_result stdout ----
thread 'tests::one_result' panicked at src/lib.rs:44:9:
assertion `left == right` failed
left: ["safe, fast, productive."]
right: []
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::one_result
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
দারুণ, test fail করেছে, ঠিক যেমনটি আমরা আশা করেছিলাম। আসুন test টিকে pass করাই!
Test Pass করার জন্য Code লেখা
বর্তমানে, আমাদের test fail করছে কারণ আমরা সব সময় একটি empty vector return করি। সেটি ঠিক করতে এবং search implement করতে, আমাদের প্রোগ্রামকে নিম্নলিখিত step গুলো follow করতে হবে:
- Contents-এর প্রতিটি line-এর মধ্যে iterate করা।
- Line-টিতে আমাদের query string আছে কিনা তা check করা।
- যদি থাকে, তাহলে আমরা যে value-গুলোর list return করছি তাতে এটি যোগ করা।
- যদি না থাকে, তাহলে কিছু না করা।
- Match করা result-গুলোর list return করা।
আসুন প্রতিটি step-এর মধ্যে দিয়ে কাজ করি, line-গুলোর মধ্যে iterate করা দিয়ে শুরু করি।
lines Method-এর সাহায্যে Line-গুলোর মধ্যে Iterate করা
Rust-এ string-গুলোর line-by-line iteration handle করার জন্য একটি সহায়ক method রয়েছে, যার সুবিধাজনকভাবে নাম দেওয়া হয়েছে lines, যেটি Listing 12-17-এ দেখানো পদ্ধতিতে কাজ করে। মনে রাখবেন এটি এখনও compile হবে না।
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}lines method টি একটি iterator return করে। আমরা Chapter 13-এ iterator সম্পর্কে গভীরভাবে আলোচনা করব, কিন্তু স্মরণ করুন যে আপনি Listing 3-5-এ iterator ব্যবহার করার এই উপায়টি দেখেছিলেন, যেখানে আমরা একটি collection-এর প্রতিটি item-এ কিছু code run করার জন্য একটি iterator-এর সাথে একটি for loop ব্যবহার করেছিলাম।
প্রতিটি Line-এ Query-র জন্য Search করা
এরপরে, আমরা check করব যে current line-টিতে আমাদের query string রয়েছে কিনা। সৌভাগ্যবশত, string-গুলোতে contains নামক একটি সহায়ক method রয়েছে যা আমাদের জন্য এটি করে! Listing 12-18-এ দেখানো search function-এ contains method-টিতে একটি call যোগ করুন। মনে রাখবেন এটি এখনও compile হবে না।
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
if line.contains(query) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}এই মুহূর্তে, আমরা functionality তৈরি করছি। Code-টিকে compile করাতে, আমাদের body থেকে একটি value return করতে হবে যেমনটি আমরা function signature-এ indicate করেছিলাম।
Matching Line গুলো Store করা
এই function টি শেষ করতে, আমাদের matching line গুলো store করার একটি উপায় প্রয়োজন যা আমরা return করতে চাই। এর জন্য, আমরা for loop-এর আগে একটি mutable vector তৈরি করতে পারি এবং vector-এ একটি line store করার জন্য push method call করতে পারি। for loop-এর পরে, আমরা vector টি return করি, যেমনটি Listing 12-19-এ দেখানো হয়েছে।
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}এখন search function-টির শুধুমাত্র সেই line গুলো return করা উচিত যেগুলোতে query রয়েছে এবং আমাদের test pass করা উচিত। আসুন test টি run করি:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
আমাদের test pass করেছে, তাই আমরা জানি এটি কাজ করছে!
এই সময়ে, আমরা search function-এর implementation refactor করার সুযোগগুলো বিবেচনা করতে পারি, test গুলোকে pass করিয়ে একই functionality বজায় রেখে। Search function-এর code খুব খারাপ নয়, কিন্তু এটি iterator-এর কিছু useful feature-এর সুবিধা নেয় না। আমরা Chapter 13-এ এই example-এ ফিরে আসব, যেখানে আমরা iterator-গুলো বিস্তারিতভাবে explore করব এবং দেখব কীভাবে এটিকে improve করা যায়।
run Function-এ search Function ব্যবহার করা
এখন যেহেতু search function টি কাজ করছে এবং tested, তাই আমাদের run function থেকে search call করতে হবে। আমাদের config.query value এবং contents যা run file থেকে read করে, সেটিকে search function-এ pass করতে হবে। তারপর run, search থেকে returned প্রতিটি line প্রিন্ট করবে:
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}আমরা এখনও search থেকে প্রতিটি line return করতে এবং print করতে একটি for loop ব্যবহার করছি।
এখন পুরো প্রোগ্রামটি কাজ করা উচিত! আসুন এটি পরীক্ষা করে দেখি, প্রথমে এমন একটি শব্দ দিয়ে যেটি Emily Dickinson-এর কবিতা থেকে ঠিক একটি line return করবে: frog।
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
দারুণ! এখন আসুন এমন একটি শব্দ try করি যা multiple line-এর সাথে match করবে, যেমন body:
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
এবং অবশেষে, আসুন নিশ্চিত করি যে আমরা যখন এমন একটি শব্দের জন্য search করি যা কবিতার কোথাও নেই, যেমন monomorphization, তখন আমরা কোনো line পাই না:
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
চমৎকার! আমরা একটি classic tool-এর নিজস্ব mini version তৈরি করেছি এবং application গুলোকে কীভাবে structure করতে হয় সে সম্পর্কে অনেক কিছু শিখেছি। আমরা file input এবং output, lifetime, testing এবং command line parsing সম্পর্কেও কিছুটা শিখেছি।
এই project-টি সম্পূর্ণ করার জন্য, আমরা সংক্ষেপে দেখাব কীভাবে environment variable-গুলোর সাথে কাজ করতে হয় এবং কীভাবে standard error-এ print করতে হয়, উভয়ই দরকারী যখন আপনি command line program লেখেন।
Environment Variable-দের সাথে কাজ করা
আমরা minigrep-কে আরও উন্নত করব একটি extra feature যোগ করে: case-insensitive searching-এর জন্য একটি option যা user একটি environment variable-এর মাধ্যমে চালু করতে পারবে। আমরা এই feature-টিকে একটি command line option করতে পারতাম এবং users-দের প্রতিবার এটি apply করতে চাইলে সেটি enter করতে বলতে পারতাম, কিন্তু পরিবর্তে এটিকে একটি environment variable করে, আমরা আমাদের user-দের environment variable-টি একবার set করার অনুমতি দিই এবং সেই terminal session-এ তাদের সমস্ত search case-insensitive হয়।
Case-Insensitive search Function-এর জন্য একটি Failing Test লেখা
আমরা প্রথমে একটি নতুন search_case_insensitive function যোগ করি যেটি environment variable-টির একটি value থাকলে call করা হবে। আমরা TDD process টি follow করা চালিয়ে যাব, তাই প্রথম step টি হল আবার একটি failing test লেখা। আমরা নতুন search_case_insensitive function-এর জন্য একটি নতুন test যোগ করব এবং আমাদের পুরানো test-এর নাম one_result থেকে case_sensitive-এ পরিবর্তন করব যাতে দুটি test-এর মধ্যে পার্থক্য স্পষ্ট হয়, যেমনটি Listing 12-20-তে দেখানো হয়েছে।
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}লক্ষ্য করুন যে আমরা পুরানো test-এর contents-ও edit করেছি। আমরা "Duct tape." text-সহ একটি নতুন line যোগ করেছি যেখানে একটি capital D রয়েছে যা "duct" query-র সাথে match করা উচিত নয় যখন আমরা case-sensitive পদ্ধতিতে search করছি। এইভাবে পুরানো test টি পরিবর্তন করা নিশ্চিত করতে সাহায্য করে যে আমরা accidental ভাবে case-sensitive search functionality break করছি না যা আমরা ইতিমধ্যেই implement করেছি। এই test টি এখন pass করা উচিত এবং case-insensitive search-এ কাজ করার সময় এটি pass করতে থাকা উচিত।
Case-insensitive search-এর জন্য নতুন test টি "rUsT" কে তার query হিসেবে ব্যবহার করে। আমরা যে search_case_insensitive function টি যোগ করতে যাচ্ছি, তাতে "rUsT" query-টি "Rust:"-যুক্ত line-টির সাথে match করা উচিত যেখানে একটি capital R রয়েছে এবং "Trust me." line-টির সাথেও match করা উচিত, যদিও query-র থেকে দুটোতেই আলাদা casing রয়েছে। এটি আমাদের failing test, এবং এটি compile হতে fail করবে কারণ আমরা এখনও search_case_insensitive function টি define করিনি। Listing 12-16-এ search function-এর জন্য যেভাবে করেছিলাম, সেভাবে একটি skeleton implementation যোগ করতে পারেন যেটি সব সময় একটি empty vector return করে, যাতে test compile হয়ে fail করে।
search_case_insensitive Function Implement করা
Listing 12-21-এ দেখানো search_case_insensitive function টি প্রায় search function-এর মতোই হবে। পার্থক্য শুধুমাত্র এই যে আমরা query এবং প্রতিটি line-কে lowercase করব যাতে input argument-গুলোর case যাই হোক না কেন, line-টিতে query আছে কিনা তা check করার সময় সেগুলি একই case-এর হবে।
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}প্রথমে আমরা query string-টিকে lowercase করি এবং এটিকে একই নামের একটি নতুন variable-এ store করি, original টিকে shadowing করে। Query-তে to_lowercase call করা প্রয়োজন যাতে user-এর query "rust", "RUST", "Rust", বা "rUsT" যাই হোক না কেন, আমরা query-টিকে "rust" হিসেবে treat করব এবং case-এর প্রতি insensitive হব। যদিও to_lowercase basic Unicode handle করবে, এটি 100% accurate হবে না। যদি আমরা একটি real application লিখতাম, তাহলে আমাদের এখানে আরও কিছু কাজ করতে হত, কিন্তু এই section টি environment variable সম্পর্কে, Unicode সম্পর্কে নয়, তাই আমরা এটিকে এখানেই ছেড়ে দেব।
লক্ষ্য করুন যে query এখন একটি string slice-এর পরিবর্তে একটি String, কারণ to_lowercase call করা existing data-কে reference করার পরিবর্তে new data create করে। উদাহরণস্বরূপ, ধরা যাক query হল "rUsT": সেই string slice-টিতে আমাদের ব্যবহার করার জন্য কোনো lowercase u বা t নেই, তাই আমাদের "rust" ধারণকারী একটি নতুন String allocate করতে হবে। আমরা যখন এখন contains method-এ argument হিসেবে query pass করি, তখন আমাদের একটি ampersand যোগ করতে হবে কারণ contains-এর signature একটি string slice নেওয়ার জন্য define করা হয়েছে।
এরপরে, আমরা প্রতিটি line-এ to_lowercase-এ একটি call যোগ করি সমস্ত character lowercase করার জন্য। এখন যেহেতু আমরা line এবং query কে lowercase-এ convert করেছি, তাই query-র case যাই হোক না কেন আমরা match খুঁজে পাব।
আসুন দেখি এই implementation টি test গুলো pass করে কিনা:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
দারুণ! সেগুলো pass করেছে। এখন, আসুন run function থেকে নতুন search_case_insensitive function টি call করি। প্রথমে আমরা Config struct-এ একটি configuration option যোগ করব case-sensitive এবং case-insensitive search-এর মধ্যে switch করার জন্য। এই field টি যোগ করলে compiler error হবে কারণ আমরা এখনও এই field টি কোথাও initialize করিনি:
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}আমরা ignore_case field টি যোগ করেছি যেটিতে একটি Boolean রয়েছে। এরপরে, আমাদের run function-এর ignore_case field-এর value check করতে হবে এবং search function বা search_case_insensitive function call করতে হবে কিনা তা decide করতে সেটি ব্যবহার করতে হবে, যেমনটি Listing 12-22-তে দেখানো হয়েছে। এটি এখনও compile হবে না।
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}অবশেষে, আমাদের environment variable-টি check করতে হবে। Environment variable-গুলোর সাথে কাজ করার function গুলো standard library-এর env module-এ রয়েছে, তাই আমরা src/lib.rs-এর উপরের দিকে সেই module-টিকে scope-এ আনি। তারপর আমরা env module থেকে var function টি ব্যবহার করব এটা দেখতে যে IGNORE_CASE নামের একটি environment variable-এর জন্য কোনো value set করা হয়েছে কিনা, যেমনটি Listing 12-23-এ দেখানো হয়েছে।
use std::env;
// --snip--
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}এখানে, আমরা একটি নতুন variable, ignore_case তৈরি করি। এর value set করার জন্য, আমরা env::var function call করি এবং এতে IGNORE_CASE environment variable-এর নাম pass করি। env::var function একটি Result return করে যেটি successful Ok variant হবে যাতে environment variable-টির value থাকবে যদি environment variable-টি কোনো value-তে set করা থাকে। Environment variable-টি set করা না থাকলে এটি Err variant return করবে।
আমরা Result-এর উপর is_ok method টি ব্যবহার করছি এটা check করার জন্য যে environment variable-টি set করা আছে কিনা, যার অর্থ হল প্রোগ্রামটির case-insensitive search করা উচিত। যদি IGNORE_CASE environment variable-টি কোনো কিছুতে set করা না থাকে, তাহলে is_ok, false return করবে এবং প্রোগ্রামটি case-sensitive search করবে। Environment variable-টির value নিয়ে আমাদের মাথা ঘামানোর দরকার নেই, শুধুমাত্র এটি set করা আছে নাকি unset, তাই আমরা unwrap, expect, বা Result-এ দেখা অন্যান্য method-গুলোর পরিবর্তে is_ok check করছি।
আমরা ignore_case variable-এর value-টি Config instance-এ pass করি যাতে run function সেই value টি read করতে পারে এবং Listing 12-22-এ implement করা search_case_insensitive বা search call করতে হবে কিনা তা decide করতে পারে।
আসুন চেষ্টা করে দেখা যাক! প্রথমে আমরা environment variable set না করে এবং to query দিয়ে আমাদের প্রোগ্রামটি run করব, যেটি lowercase-এ to শব্দযুক্ত যেকোনো line-এর সাথে match করা উচিত:
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
মনে হচ্ছে এটা এখনও কাজ করছে! এখন আসুন IGNORE_CASE কে 1-এ set করে কিন্তু একই query to দিয়ে প্রোগ্রামটি run করি:
$ IGNORE_CASE=1 cargo run -- to poem.txt
আপনি যদি PowerShell ব্যবহার করেন, তাহলে আপনাকে environment variable set করতে হবে এবং প্রোগ্রামটিকে আলাদা command হিসেবে run করতে হবে:
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
এটি আপনার shell session-এর বাকি অংশের জন্য IGNORE_CASE-কে স্থায়ী করবে। এটিকে Remove-Item cmdlet দিয়ে unset করা যেতে পারে:
PS> Remove-Item Env:IGNORE_CASE
আমাদের to যুক্ত line গুলো পাওয়া উচিত যেগুলিতে uppercase letter থাকতে পারে:
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
চমৎকার, আমরা To যুক্ত line-ও পেয়েছি! আমাদের minigrep প্রোগ্রামটি এখন একটি environment variable দ্বারা নিয়ন্ত্রিত case-insensitive searching করতে পারে। এখন আপনি জানেন কীভাবে command line argument বা environment variable ব্যবহার করে set করা option গুলো manage করতে হয়।
কিছু প্রোগ্রাম একই configuration-এর জন্য argument এবং environment variable উভয়কেই অনুমতি দেয়। সেই ক্ষেত্রগুলোতে, প্রোগ্রামগুলো decide করে যে কোনটি প্রাধান্য পাবে। নিজে থেকে আরেকটি exercise-এর জন্য, একটি command line argument বা একটি environment variable-এর মাধ্যমে case sensitivity নিয়ন্ত্রণ করার চেষ্টা করুন। প্রোগ্রামটি case sensitive-এ set করা একটি এবং ignore case-এ set করা একটি দিয়ে run করা হলে command line argument বা environment variable-এর মধ্যে কোনটি প্রাধান্য পাওয়া উচিত তা ঠিক করুন।
std::env module-টিতে environment variable-গুলোর সাথে কাজ করার জন্য আরও অনেক useful feature রয়েছে: কী কী available তা দেখতে এর documentation দেখুন।
Standard Output-এর পরিবর্তে Standard Error-এ Error Message লেখা
এখন আমরা println! macro ব্যবহার করে আমাদের সমস্ত output terminal-এ লিখছি। বেশিরভাগ terminal-এ, দুই ধরনের output রয়েছে: সাধারণ তথ্যের জন্য standard output (stdout) এবং error message-এর জন্য standard error (stderr।)। এই পার্থক্য users-দের প্রোগ্রামের successful output-কে একটি file-এ direct করা বেছে নিতে সক্ষম করে, কিন্তু তবুও error message গুলো screen-এ print করে।
println! macro শুধুমাত্র standard output-এ print করতে সক্ষম, তাই standard error-এ print করার জন্য আমাদের অন্য কিছু ব্যবহার করতে হবে।
Error গুলো কোথায় লেখা হচ্ছে তা Check করা
প্রথমে আসুন দেখি কীভাবে minigrep দ্বারা printed content বর্তমানে standard output-এ লেখা হচ্ছে, সেইসাথে যে কোনও error message-ও যা আমরা পরিবর্তে standard error-এ লিখতে চাই। আমরা standard output stream-কে একটি file-এ redirect করার সময় ইচ্ছাকৃতভাবে একটি error সৃষ্টি করে তা করব। আমরা standard error stream redirect করব না, তাই standard error-এ পাঠানো যেকোনো content screen-এ প্রদর্শিত হতে থাকবে।
Command line program গুলো standard error stream-এ error message পাঠাবে বলে আশা করা হয় যাতে আমরা standard output stream-কে একটি file-এ redirect করলেও screen-এ error message দেখতে পাই। আমাদের প্রোগ্রামটি বর্তমানে ভালোভাবে আচরণ করছে না: আমরা দেখতে পাব যে এটি পরিবর্তে error message output-টি একটি file-এ save করে!
এই behavior টি প্রদর্শন করার জন্য, আমরা > এবং file path, output.txt দিয়ে প্রোগ্রামটি run করব, যেখানে আমরা standard output stream-টি redirect করতে চাই। আমরা কোনো argument pass করব না, যার ফলে একটি error হওয়া উচিত:
$ cargo run > output.txt
> syntax টি shell-কে screen-এর পরিবর্তে standard output-এর contents output.txt-এ লিখতে বলে। আমরা যে error message-টি আশা করছিলাম সেটি screen-এ printed হতে দেখিনি, তার মানে এটি file-এ চলে গেছে। output.txt-তে এটি রয়েছে:
Problem parsing arguments: not enough arguments
হ্যাঁ, আমাদের error message টি standard output-এ print করা হচ্ছে। এই ধরনের error message-গুলো standard error-এ print করা আরও বেশি useful, যাতে successful run-এর data শুধুমাত্র file-টিতে থাকে। আমরা সেটা পরিবর্তন করব।
Standard Error-এ Error Print করা
Error message গুলো কীভাবে print করা হয় তা পরিবর্তন করতে আমরা Listing 12-24-এর code ব্যবহার করব। এই chapter-এ আগে করা refactoring-এর কারণে, error message print করে এমন সমস্ত code একটি function, main-এ রয়েছে। Standard library eprintln! macro provide করে যা standard error stream-এ print করে, তাই আসুন দুটি জায়গা পরিবর্তন করি যেখানে আমরা error print করার জন্য println! call করছিলাম, পরিবর্তে eprintln! ব্যবহার করার জন্য।
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}আসুন এখন কোনো argument ছাড়াই এবং > দিয়ে standard output redirect করে একইভাবে প্রোগ্রামটি আবার run করি:
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
এখন আমরা screen-এ error দেখতে পাচ্ছি এবং output.txt-তে কিছুই নেই, যা command line program-গুলোর ক্ষেত্রে আমাদের প্রত্যাশিত behavior।
আসুন প্রোগ্রামটি আবার এমন argument দিয়ে run করি যা কোনো error সৃষ্টি করে না কিন্তু তবুও standard output-কে একটি file-এ redirect করে, এইভাবে:
$ cargo run -- to poem.txt > output.txt
আমরা terminal-এ কোনো output দেখতে পাব না, এবং output.txt-তে আমাদের result গুলো থাকবে:
Filename: output.txt
Are you nobody, too?
How dreary to be somebody!
এটি প্রদর্শন করে যে আমরা এখন successful output-এর জন্য standard output এবং error output-এর জন্য standard error ব্যবহার করছি।
সারসংক্ষেপ
এই chapter-এ ఇప్పటి পর্যন্ত শেখা কিছু major concept-এর পুনরাবৃত্তি করা হয়েছে এবং Rust-এ common I/O operation গুলো কীভাবে perform করতে হয় তা আলোচনা করা হয়েছে। Command line argument, file, environment variable, এবং error print করার জন্য eprintln! macro ব্যবহার করে, আপনি এখন command line application লেখার জন্য প্রস্তুত। পূর্ববর্তী chapter-গুলোর concept-গুলোর সাথে মিলিত হয়ে, আপনার code ভালোভাবে organized হবে, উপযুক্ত data structure-গুলোতে data কার্যকরভাবে store করবে, error-গুলোকে সুন্দরভাবে handle করবে এবং ভালোভাবে tested হবে।
এরপরে, আমরা functional language দ্বারা প্রভাবিত Rust-এর কিছু feature explore করব: closure এবং iterator।
Functional Language Features: Iterators and Closures
Rust-এর design অনেক existing language এবং technique থেকে inspiration নিয়েছে, এবং একটি significant influence হল functional programming। Functional style-এ Programming-এ প্রায়শই function-গুলোকে value হিসেবে ব্যবহার করা হয় সেগুলোকে argument হিসেবে pass করে, অন্য function থেকে return করে, পরে execution-এর জন্য variable-এ assign করে, এবং আরও অনেক কিছু।
এই chapter-এ, আমরা functional programming কী বা কী নয় সে বিষয়ে বিতর্ক করব না, বরং Rust-এর কিছু feature নিয়ে আলোচনা করব যেগুলো functional হিসেবে refer করা অনেক language-এর feature-গুলোর মতো।
আরও specifically, আমরা আলোচনা করব:
- Closures, একটি function-এর মতো construct যাকে আপনি একটি variable-এ store করতে পারেন
- Iterators, element-এর একটি series process করার একটি উপায়
- Chapter 12-এর I/O project-কে improve করতে closure এবং iterator কীভাবে ব্যবহার করবেন
- Closure এবং iterator-এর performance (Spoiler alert: আপনি যতটা ভাবছেন সেগুলি তার চেয়ে দ্রুত!)
আমরা ইতিমধ্যেই pattern matching এবং enum-এর মতো আরও কিছু Rust feature cover করেছি, যেগুলোও functional style দ্বারা প্রভাবিত। যেহেতু idiomatic, fast Rust code লেখার জন্য closure এবং iterator-এ দক্ষতা অর্জন করা গুরুত্বপূর্ণ, তাই আমরা এই পুরো chapter-টি এগুলোর জন্য উৎসর্গ করব।
ক্লোজার: Anonymous Function যারা তাদের Environment Capture করতে পারে
Rust-এর closure গুলো হল anonymous function যাদেরকে আপনি একটি variable-এ save করতে পারেন অথবা অন্য function-গুলোতে argument হিসেবে pass করতে পারেন। আপনি একটি জায়গায় closure তৈরি করতে পারেন এবং তারপর অন্য কোনো context-এ evaluate করার জন্য closure টিকে অন্য কোথাও call করতে পারেন। Function-এর বিপরীতে, closure গুলো যে scope-এ define করা হয়েছে সেখান থেকে value capture করতে পারে। আমরা দেখাব কীভাবে এই closure feature গুলো code reuse এবং behavior customization-এর অনুমতি দেয়।
Closure-এর সাহায্যে Environment Capture করা
আমরা প্রথমে পরীক্ষা করব কীভাবে আমরা closure ব্যবহার করে যে environment-এ সেগুলোকে define করা হয়েছে সেখান থেকে value capture করে পরে ব্যবহার করতে পারি। এখানে scenario টি হল: মাঝে মাঝে, আমাদের টি-শার্ট কোম্পানি প্রচারের অংশ হিসেবে আমাদের মেইলিং লিস্টের কাউকে একটি exclusive, limited-edition শার্ট উপহার দেয়। মেইলিং লিস্টের লোকেরা চাইলে তাদের প্রোফাইলে তাদের প্রিয় রং যোগ করতে পারে। যদি বিনামূল্যে শার্টের জন্য নির্বাচিত ব্যক্তির প্রিয় রং set করা থাকে, তাহলে তারা সেই রঙের শার্ট পায়। যদি ব্যক্তিটি প্রিয় রং specify না করে থাকে, তাহলে কোম্পানির কাছে বর্তমানে যে রঙের শার্ট সবচেয়ে বেশি আছে সেটি তারা পায়।
এটি implement করার অনেক উপায় রয়েছে। এই উদাহরণের জন্য, আমরা ShirtColor নামক একটি enum ব্যবহার করব যাতে Red এবং Blue variant রয়েছে (সরলতার জন্য available রং-এর সংখ্যা সীমিত করা হচ্ছে)। আমরা কোম্পানির inventory-কে একটি Inventory struct দিয়ে represent করি যার shirts নামে একটি field রয়েছে যাতে বর্তমানে stock-এ থাকা শার্টের রং represent করে এমন একটি Vec<ShirtColor> রয়েছে। Inventory-তে defined giveaway method টি বিনামূল্যে শার্ট বিজয়ীর optional শার্টের রং preference পায় এবং ব্যক্তিটি যে শার্টের রং পাবে তা return করে। এই setup টি Listing 13-1-এ দেখানো হয়েছে:
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
}
struct Inventory {
shirts: Vec<ShirtColor>,
}
impl Inventory {
fn giveaway(&self, user_preference: Option<ShirtColor>) -> ShirtColor {
user_preference.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
fn main() {
let store = Inventory {
shirts: vec![ShirtColor::Blue, ShirtColor::Red, ShirtColor::Blue],
};
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"The user with preference {:?} gets {:?}",
user_pref1, giveaway1
);
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"The user with preference {:?} gets {:?}",
user_pref2, giveaway2
);
}main-এ defined store-এ এই limited-edition প্রচারের জন্য বিতরণ করার জন্য দুটি নীল শার্ট এবং একটি লাল শার্ট অবশিষ্ট রয়েছে। আমরা লাল শার্টের preference-সহ একজন user এবং কোনো preference ছাড়া একজন user-এর জন্য giveaway method টি call করি।
আবারও, এই code টি অনেকভাবে implement করা যেতে পারে, এবং এখানে, closure-গুলোর উপর focus করার জন্য, আমরা সেই concept গুলোতেই সীমাবদ্ধ রয়েছি যেগুলো আপনি ইতিমধ্যেই শিখেছেন, শুধুমাত্র giveaway method-এর body ছাড়া যেটি একটি closure ব্যবহার করে। Giveaway method-এ, আমরা user preference-টিকে Option<ShirtColor> type-এর একটি parameter হিসেবে পাই এবং user_preference-এ unwrap_or_else method call করি। unwrap_or_else method on Option<T> standard library দ্বারা define করা হয়েছে। এটি একটি argument নেয়: কোনো argument ছাড়া একটি closure যা একটি value T return করে ( Option<T>-এর Some variant-এ stored একই type, এক্ষেত্রে ShirtColor।)। যদি Option<T> হল Some variant, unwrap_or_else, Some-এর ভেতরের value return করে। যদি Option<T> হল None variant, unwrap_or_else closure-টিকে call করে এবং closure দ্বারা returned value-টি return করে।
আমরা unwrap_or_else-এ argument হিসেবে closure expression || self.most_stocked() specify করি। এটি এমন একটি closure যা নিজে কোনো parameter নেয় না (যদি closure-টির parameter থাকত, তাহলে সেগুলো দুটি vertical bar-এর মধ্যে থাকত)। Closure-এর body self.most_stocked() call করে। আমরা এখানে closure টি define করছি, এবং যদি result-এর প্রয়োজন হয় তাহলে unwrap_or_else-এর implementation পরে closure-টিকে evaluate করবে।
এই code run করলে print হবে:
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
The user with preference Some(Red) gets Red
The user with preference None gets Blue
এখানে একটি interesting বিষয় হল যে আমরা একটি closure pass করেছি যেটি current Inventory instance-এ self.most_stocked() call করে। Standard library-র আমাদের defined Inventory বা ShirtColor type, বা এই scenario-তে আমরা যে logic ব্যবহার করতে চাই সে সম্পর্কে কিছু জানার প্রয়োজন ছিল না। Closure টি self Inventory instance-এর একটি immutable reference capture করে এবং আমরা যে code specify করি তার সাথে এটিকে unwrap_or_else method-এ pass করে। অন্যদিকে, function-গুলো এইভাবে তাদের environment capture করতে পারে না।
ক্লোজার টাইপ ইনফারেন্স এবং অ্যানোটেশন
Function এবং closure-এর মধ্যে আরও পার্থক্য রয়েছে। Closure-গুলোতে সাধারণত parameter-গুলোর type বা return value annotate করার প্রয়োজন হয় না, যেমনটা fn function-গুলোতে করতে হয়। Function-গুলোতে type annotation প্রয়োজন কারণ type গুলো আপনার user-দের কাছে exposed একটি explicit interface-এর অংশ। এই interface-টিকে rigidly define করা important যাতে সবাই একমত হতে পারে যে একটি function কী type-এর value ব্যবহার করে এবং return করে। অন্যদিকে, closure-গুলোকে এভাবে exposed interface-এ ব্যবহার করা হয় না: এগুলো variable-এ store করা হয় এবং সেগুলোর নাম না দিয়ে এবং আমাদের library-র user-দের কাছে expose না করে ব্যবহার করা হয়।
Closure গুলো সাধারণত ছোট হয় এবং যেকোনো arbitrary scenario-তে নয়, শুধুমাত্র একটি narrow context-এর মধ্যেই relevant। এই limited context-গুলোর মধ্যে, compiler parameter-গুলোর type এবং return type infer করতে পারে, একইভাবে এটি বেশিরভাগ variable-এর type infer করতে সক্ষম (এমন কিছু বিরল ক্ষেত্র রয়েছে যেখানে compiler-এর closure type annotation-ও প্রয়োজন)।
Variable-গুলোর মতোই, আমরা যদি strictly প্রয়োজনের চেয়ে বেশি verbose না হয়ে explicitness এবং clarity বাড়াতে চাই তাহলে type annotation যোগ করতে পারি। একটি closure-এর জন্য type গুলো annotate করা Listing 13-2-তে দেখানো definition-এর মতো হবে। এই উদাহরণে, আমরা একটি closure define করছি এবং এটিকে একটি variable-এ store করছি, Listing 13-1-এ আমরা যেভাবে argument হিসেবে pass করার জায়গায় closure define করেছিলাম সেভাবে না করে।
use std::thread; use std::time::Duration; fn generate_workout(intensity: u32, random_number: u32) { let expensive_closure = |num: u32| -> u32 { println!("calculating slowly..."); thread::sleep(Duration::from_secs(2)); num }; if intensity < 25 { println!("Today, do {} pushups!", expensive_closure(intensity)); println!("Next, do {} situps!", expensive_closure(intensity)); } else { if random_number == 3 { println!("Take a break today! Remember to stay hydrated!"); } else { println!( "Today, run for {} minutes!", expensive_closure(intensity) ); } } } fn main() { let simulated_user_specified_value = 10; let simulated_random_number = 7; generate_workout(simulated_user_specified_value, simulated_random_number); }
Type annotation যোগ করার সাথে, closure-গুলোর syntax function-গুলোর syntax-এর সাথে আরও সাদৃশ্যপূর্ণ দেখায়। এখানে আমরা একটি function define করি যেটি তার parameter-এর সাথে 1 যোগ করে এবং একটি closure যার একই behavior রয়েছে, তুলনা করার জন্য। আমরা relevant অংশগুলোকে line up করার জন্য কিছু space যোগ করেছি। এটি তুলে ধরে যে কীভাবে closure syntax function syntax-এর মতোই, শুধুমাত্র pipe ব্যবহার করা এবং syntax-এর amount যা optional তা ছাড়া:
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;প্রথম line-টি একটি function definition দেখায়, এবং দ্বিতীয় line-টি একটি fully annotated closure definition দেখায়। তৃতীয় line-এ, আমরা closure definition থেকে type annotation গুলো সরিয়ে দিই। চতুর্থ line-এ, আমরা bracket গুলো সরিয়ে দিই, যেগুলো optional কারণ closure body-তে শুধুমাত্র একটি expression রয়েছে। এগুলি সবই valid definition যা call করা হলে একই behavior তৈরি করবে। add_one_v3 এবং add_one_v4 line-গুলোতে closure গুলোকে evaluated হতে হবে compile হতে পারার জন্য কারণ type গুলো তাদের usage থেকে infer করা হবে। এটি let v = Vec::new();-এর মতোই, যেখানে Rust-এর type infer করতে পারার জন্য type annotation বা কোনো type-এর value Vec-এ insert করা প্রয়োজন।
Closure definition-গুলোর জন্য, compiler তাদের প্রতিটি parameter এবং তাদের return value-এর জন্য একটি concrete type infer করবে। উদাহরণস্বরূপ, Listing 13-3 একটি short closure-এর definition দেখায় যেটি শুধুমাত্র parameter হিসেবে পাওয়া value টি return করে। এই closure টি এই উদাহরণের উদ্দেশ্য ছাড়া খুব বেশি useful নয়। লক্ষ্য করুন যে আমরা definition-এ কোনো type annotation যোগ করিনি। যেহেতু কোনো type annotation নেই, তাই আমরা closure-টিকে যেকোনো type দিয়ে call করতে পারি, যা আমরা এখানে প্রথমবার String দিয়ে করেছি। যদি আমরা তারপর একটি integer দিয়ে example_closure call করার চেষ্টা করি, তাহলে আমরা একটি error পাব।
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}Compiler আমাদের এই error দেয়:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| --------------- ^- help: try using a conversion method: `.to_string()`
| | |
| | expected `String`, found integer
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:4:29
|
4 | let s = example_closure(String::from("hello"));
| --------------- ^^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let example_closure = |x| x;
| ^
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` (bin "closure-example") due to 1 previous error
প্রথমবার যখন আমরা String value দিয়ে example_closure call করি, compiler x-এর type এবং closure-টির return type String হিসেবে infer করে। সেই type গুলো তারপর example_closure-এ closure-টিতে lock হয়ে যায়, এবং আমরা যখন একই closure-এর সাথে অন্য type ব্যবহার করার চেষ্টা করি তখন আমরা একটি type error পাই।
Reference Capture করা বা Ownership Move করা
Closure-গুলো তাদের environment থেকে তিনটি উপায়ে value capture করতে পারে, যা function-এর তিনটি parameter নেওয়ার উপায়কে সরাসরি map করে: immutably borrow করা, mutably borrow করা এবং ownership নেওয়া। Function-এর body captured value-গুলোর সাথে কী করে তার উপর ভিত্তি করে closure ঠিক করবে কোনটি ব্যবহার করতে হবে।
Listing 13-4-এ, আমরা একটি closure define করি যা list নামের vector-টিতে একটি immutable reference capture করে কারণ value print করার জন্য এটির শুধুমাত্র একটি immutable reference প্রয়োজন:
fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); let only_borrows = || println!("From closure: {list:?}"); println!("Before calling closure: {list:?}"); only_borrows(); println!("After calling closure: {list:?}"); }
এই উদাহরণটি আরও তুলে ধরে যে একটি variable একটি closure definition-এর সাথে bind হতে পারে, এবং আমরা পরে variable-এর নাম এবং parentheses ব্যবহার করে closure-টিকে call করতে পারি যেন variable-এর নামটি একটি function-এর নাম।
যেহেতু আমরা একই সময়ে list-এ multiple immutable reference রাখতে পারি, তাই closure definition-এর আগে, closure definition-এর পরে কিন্তু closure call করার আগে এবং closure call করার পরে code থেকে list এখনও accessible। এই code compile, run এবং print করে:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
Before calling closure: [1, 2, 3]
From closure: [1, 2, 3]
After calling closure: [1, 2, 3]
এরপরে, Listing 13-5-এ, আমরা closure body পরিবর্তন করি যাতে এটি list vector-এ একটি element যোগ করে। Closure টি এখন একটি mutable reference capture করে:
fn main() { let mut list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); let mut borrows_mutably = || list.push(7); borrows_mutably(); println!("After calling closure: {list:?}"); }
এই code compile, run এবং print করে:
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
After calling closure: [1, 2, 3, 7]
লক্ষ্য করুন যে borrows_mutably closure-এর definition এবং call-এর মধ্যে আর কোনো println! নেই: যখন borrows_mutably define করা হয়, তখন এটি list-এ একটি mutable reference capture করে। Closure call করার পরে আমরা আবার closure টি ব্যবহার করি না, তাই mutable borrow শেষ হয়ে যায়। Closure definition এবং closure call-এর মধ্যে, print করার জন্য একটি immutable borrow-এর অনুমতি নেই কারণ mutable borrow থাকলে অন্য কোনো borrow-এর অনুমতি নেই। সেখানে একটি println! যোগ করে দেখুন আপনি কী error message পান!
এমনকি closure-এর body-র ownership-এর strictly প্রয়োজন না হলেও, আপনি যদি closure-টিকে environment-এ ব্যবহৃত value-গুলোর ownership নিতে বাধ্য করতে চান, তাহলে আপনি parameter list-এর আগে move keyword টি ব্যবহার করতে পারেন।
এই technique টি বেশিরভাগ ক্ষেত্রে उपयोगी হয় যখন একটি closure-কে একটি নতুন thread-এ pass করা হয় যাতে data-টিকে move করা যায় যাতে এটি new thread-এর owned হয়। আমরা Chapter 16-এ thread নিয়ে বিস্তারিত আলোচনা করব এবং concurrency নিয়ে কথা বলার সময় আপনি কেন সেগুলো ব্যবহার করতে চাইবেন, কিন্তু আপাতত, আসুন সংক্ষেপে একটি new thread spawn করা explore করি একটি closure ব্যবহার করে যেখানে move keyword-এর প্রয়োজন। Listing 13-6, Listing 13-4-কে modify করে main thread-এর পরিবর্তে একটি new thread-এ vector print করার জন্য:
use std::thread; fn main() { let list = vec![1, 2, 3]; println!("Before defining closure: {list:?}"); thread::spawn(move || println!("From thread: {list:?}")) .join() .unwrap(); }
আমরা একটি new thread spawn করি, thread-টিকে argument হিসেবে run করার জন্য একটি closure দিই। Closure body list-টি print করে। Listing 13-4-এ, closure টি শুধুমাত্র একটি immutable reference ব্যবহার করে list capture করেছিল কারণ এটি print করার জন্য list-এ least amount-এর access-এর প্রয়োজন ছিল। এই উদাহরণে, যদিও closure body-র এখনও শুধুমাত্র একটি immutable reference প্রয়োজন, তবুও আমাদের specify করতে হবে যে list-কে closure-এ move করা উচিত closure definition-এর শুরুতে move keyword টি বসিয়ে। New thread টি main thread-এর বাকি অংশ শেষ হওয়ার আগে শেষ হয়ে যেতে পারে, অথবা main thread টি প্রথমে শেষ হতে পারে। যদি main thread list-এর ownership বজায় রাখত কিন্তু new thread-এর আগে শেষ হয়ে যেত এবং list drop করত, তাহলে thread-এর immutable reference টি invalid হয়ে যেত। অতএব, compiler-এর প্রয়োজন যে list-কে new thread-এ দেওয়া closure-টিতে move করা হোক যাতে reference টি valid হয়। Move keyword টি সরিয়ে বা closure define করার পরে main thread-এ list ব্যবহার করে দেখুন আপনি কী compiler error পান!
Closure থেকে Captured Value-গুলোকে সরানো এবং Fn Traits
Closure টি যে environment-এ define করা হয়েছে সেখান থেকে একটি reference capture করার পরে বা ownership নেওয়ার পরে (এইভাবে closure-এর মধ্যে কী move করা হয়েছে, যদি কিছু move করা হয়ে থাকে, তাকে প্রভাবিত করে), closure-এর body-র code define করে যে closure-টি পরে evaluate করা হলে reference বা value-গুলোর কী হবে (এইভাবে closure-এর বাইরে কী move করা হয়েছে, যদি কিছু move করা হয়ে থাকে, তাকে প্রভাবিত করে)। একটি closure body নিম্নলিখিত যেকোনো একটি কাজ করতে পারে: একটি captured value-কে closure-এর বাইরে move করা, captured value-কে mutate করা, value-টিকে move বা mutate কোনোটিই না করা, অথবা শুরুতেই environment থেকে কিছুই capture না করা।
একটি closure যেভাবে environment থেকে value capture করে এবং handle করে তা প্রভাবিত করে closure টি কোন trait গুলো implement করে, এবং trait-গুলোর মাধ্যমেই function এবং struct গুলো specify করতে পারে যে তারা কোন ধরনের closure ব্যবহার করতে পারে। Closure-গুলো স্বয়ংক্রিয়ভাবে এই তিনটি Fn trait-এর মধ্যে একটি, দুটি, অথবা তিনটিই implement করবে, একটি additive পদ্ধতিতে, closure-এর body কীভাবে value-গুলো handle করে তার উপর নির্ভর করে:
FnOnceসেই closure-গুলোর ক্ষেত্রে প্রযোজ্য যাদেরকে একবার call করা যেতে পারে। সমস্ত closure অন্তত এই trait টি implement করে, কারণ সমস্ত closure-কেই call করা যেতে পারে। একটি closure যেটি captured value-গুলোকে তার body-র বাইরে move করে সেটি শুধুমাত্রFnOnceimplement করবে এবং অন্য কোনোFntrait implement করবে না, কারণ এটিকে শুধুমাত্র একবার call করা যেতে পারে।FnMutসেই closure-গুলোর ক্ষেত্রে প্রযোজ্য যেগুলো captured value-গুলোকে তাদের body-র বাইরে move করে না, কিন্তু captured value-গুলোকে mutate করতে পারে। এই closure-গুলোকে একাধিকবার call করা যেতে পারে।Fnসেই closure-গুলোর ক্ষেত্রে প্রযোজ্য যেগুলো captured value-গুলোকে তাদের body-র বাইরে move করে না এবং captured value-গুলোকে mutate করে না, সেইসাথে সেই closure-গুলোর ক্ষেত্রেও যেগুলো তাদের environment থেকে কিছুই capture করে না। এই closure-গুলোকে তাদের environment-কে mutate না করে একাধিকবার call করা যেতে পারে, যা এমন পরিস্থিতিতে important যেখানে একটি closure-কে একাধিকবার concurrently call করা হয়।
আসুন Option<T>-তে unwrap_or_else method-টির definition দেখি যেটি আমরা Listing 13-1-এ ব্যবহার করেছি:
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}মনে রাখবেন যে T হল generic type যা Option-এর Some variant-এ value-টির type represent করে। সেই type T, unwrap_or_else function-টির return type-ও: উদাহরণস্বরূপ, যে code Option<String>-এ unwrap_or_else call করে সেটি একটি String পাবে।
এরপরে, লক্ষ্য করুন যে unwrap_or_else function-টিতে অতিরিক্ত generic type parameter F রয়েছে। F type হল f নামের parameter-টির type, যেটি হল সেই closure যা আমরা unwrap_or_else call করার সময় provide করি।
Generic type F-এ specified trait bound হল FnOnce() -> T, যার মানে F অবশ্যই একবার call করা যেতে হবে, কোনো argument নেবে না এবং একটি T return করবে। Trait bound-এ FnOnce ব্যবহার করা এই constraint-টি প্রকাশ করে যে unwrap_or_else শুধুমাত্র f-কে সর্বাধিক একবার call করবে। Unwrap_or_else-এর body-তে, আমরা দেখতে পাচ্ছি যে যদি Option টি Some হয়, তাহলে f call করা হবে না। যদি Option টি None হয়, তাহলে f একবার call করা হবে। যেহেতু সমস্ত closure FnOnce implement করে, তাই unwrap_or_else সমস্ত তিনটি closure-এর প্রকারভেদ accept করে এবং যতটা সম্ভব flexible।
দ্রষ্টব্য: যদি আমাদের যা করতে হবে তার জন্য environment থেকে value capture করার প্রয়োজন না হয়, তাহলে আমরা closure-এর পরিবর্তে একটি function-এর নাম ব্যবহার করতে পারি। উদাহরণস্বরূপ, যদি value
Noneহয় তাহলে একটি নতুন, empty vector পেতে আমরা একটিOption<Vec<T>>value-তেunwrap_or_else(Vec::new)কল করতে পারতাম। Compiler স্বয়ংক্রিয়ভাবে function definition-এর জন্য প্রযোজ্যFntrait-গুলোর মধ্যে যেটি প্রযোজ্য সেটি implement করে।
এখন আসুন slice-গুলোতে defined standard library method sort_by_key দেখি, এটি unwrap_or_else থেকে কীভাবে আলাদা এবং কেন sort_by_key trait bound-এর জন্য FnOnce-এর পরিবর্তে FnMut ব্যবহার করে। Closure-টি consider করা slice-এর current item-এর একটি reference-এর আকারে একটি argument পায় এবং type K-এর একটি value return করে যেটিকে order করা যেতে পারে। এই function টি useful যখন আপনি প্রতিটি item-এর একটি particular attribute-এর উপর ভিত্তি করে একটি slice sort করতে চান। Listing 13-7-এ, আমাদের কাছে Rectangle instance-এর একটি list রয়েছে এবং আমরা সেগুলোকে তাদের width attribute-এর উপর ভিত্তি করে low থেকে high-তে order করার জন্য sort_by_key ব্যবহার করি:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let mut list = [ Rectangle { width: 10, height: 1 }, Rectangle { width: 3, height: 5 }, Rectangle { width: 7, height: 12 }, ]; list.sort_by_key(|r| r.width); println!("{list:#?}"); }
এই code print করে:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
width: 3,
height: 5,
},
Rectangle {
width: 7,
height: 12,
},
Rectangle {
width: 10,
height: 1,
},
]
Sort_by_key-কে একটি FnMut closure নেওয়ার জন্য define করার কারণ হল এটি closure-টিকে একাধিকবার call করে: slice-এর প্রতিটি item-এর জন্য একবার। Closure |r| r.width তার environment থেকে কোনো কিছু capture, mutate বা move করে না, তাই এটি trait bound requirement গুলো পূরণ করে।
বিপরীতে, Listing 13-8 একটি closure-এর উদাহরণ দেখায় যেটি শুধুমাত্র FnOnce trait implement করে, কারণ এটি environment থেকে একটি value move করে। Compiler আমাদের এই closure-টিকে sort_by_key-এর সাথে ব্যবহার করতে দেবে না:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("closure called");
list.sort_by_key(|r| {
sort_operations.push(value);
r.width
});
println!("{list:#?}");
}List sort করার সময় sort_by_key closure-টিকে কতবার call করে তা count করার এটি একটি contrived, জটিল উপায় (যা কাজ করে না)। এই code টি value—closure-এর environment থেকে একটি String—sort_operations vector-এ push করে এই counting করার চেষ্টা করে। Closure টি value capture করে তারপর value-এর ownership sort_operations vector-এ transfer করে closure-এর বাইরে value move করে। এই closure-টিকে একবার call করা যেতে পারে; এটিকে দ্বিতীয়বার call করার চেষ্টা কাজ করবে না কারণ value আর environment-এ থাকবে না যাতে এটিকে আবার sort_operations-এ push করা যায়! অতএব, এই closure টি শুধুমাত্র FnOnce implement করে। যখন আমরা এই code টি compile করার চেষ্টা করি, তখন আমরা এই error পাই যে closure-টি FnMut implement করতে হবে বলে value কে closure-এর বাইরে move করা যাবে না:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let value = String::from("closure called");
| ----- captured outer variable
16 |
17 | list.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | sort_operations.push(value);
| ^^^^^ move occurs because `value` has type `String`, which does not implement the `Copy` trait
|
help: consider cloning the value if the performance cost is acceptable
|
18 | sort_operations.push(value.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` (bin "rectangles") due to 1 previous error
Error টি closure body-র সেই line-টির দিকে নির্দেশ করে যেটি environment-এর বাইরে value move করে। এটি ঠিক করার জন্য, আমাদের closure body পরিবর্তন করতে হবে যাতে এটি environment-এর বাইরে value move না করে। Closure-টি কতবার call করা হয়েছে তা count করার জন্য, environment-এ একটি counter রাখা এবং closure body-তে এর value increment করা এটি calculate করার আরও straightforward উপায়। Listing 13-9-এর closure-টি sort_by_key-এর সাথে কাজ করে কারণ এটি শুধুমাত্র num_sort_operations counter-এ একটি mutable reference capture করছে এবং তাই একাধিকবার call করা যেতে পারে:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let mut list = [ Rectangle { width: 10, height: 1 }, Rectangle { width: 3, height: 5 }, Rectangle { width: 7, height: 12 }, ]; let mut num_sort_operations = 0; list.sort_by_key(|r| { num_sort_operations += 1; r.width }); println!("{list:#?}, sorted in {num_sort_operations} operations"); }
Closure-গুলোর ব্যবহার করে এমন function বা type define বা ব্যবহার করার সময় Fn trait গুলো important। পরবর্তী section-এ, আমরা iterator নিয়ে আলোচনা করব। অনেক iterator method closure argument নেয়, তাই আমরা যখন continue করব তখন এই closure-এর details গুলো মনে রাখবেন!
Iterator-এর সাহায্যে Item-গুলোর একটি Series-কে Process করা
Iterator pattern আপনাকে item-গুলোর একটি sequence-এর উপর পর্যায়ক্রমে কিছু task perform করার অনুমতি দেয়। একটি iterator প্রতিটি item-এর উপর iterate করার logic এবং sequence কখন শেষ হয়েছে তা নির্ধারণ করার জন্য responsible। আপনি যখন iterator ব্যবহার করেন, তখন আপনাকে সেই logic নিজে reimplement করতে হবে না।
Rust-এ, iterator-গুলো lazy, অর্থাৎ যতক্ষণ না আপনি iterator-কে consume করার জন্য method call করেন ততক্ষণ পর্যন্ত সেগুলোর কোনো effect নেই। উদাহরণস্বরূপ, Listing 13-10-এর code Vec<T>-তে defined iter method-টিকে call করে vector v1-এর item-গুলোর উপর একটি iterator create করে। এই code নিজে থেকে কোনো useful কাজ করে না।
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); }
Iterator-টি v1_iter variable-এ store করা হয়। একবার আমরা একটি iterator create করার পরে, আমরা এটিকে বিভিন্ন উপায়ে ব্যবহার করতে পারি। Chapter 3-এর Listing 3-5-এ, আমরা একটি array-এর উপর একটি for loop ব্যবহার করে iterate করেছিলাম যাতে এর প্রতিটি item-এ কিছু code execute করা যায়। এর ভেতরে এটি implicitly একটি iterator create করে consume করেছিল, কিন্তু এখন পর্যন্ত আমরা ঠিক কীভাবে এটি কাজ করে তা এড়িয়ে গেছি।
Listing 13-11-এর উদাহরণে, আমরা iterator create করাকে for loop-এ iterator ব্যবহার করা থেকে আলাদা করি। যখন v1_iter-এর iterator ব্যবহার করে for loop-টি call করা হয়, তখন iterator-এর প্রতিটি element loop-এর একটি iteration-এ ব্যবহৃত হয়, যেটি প্রতিটি value print করে।
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); for val in v1_iter { println!("Got: {val}"); } }
যেসব language-এ তাদের standard library দ্বারা iterator provide করা হয় না, সেগুলোতে আপনি সম্ভবত index 0-তে একটি variable শুরু করে, একটি value পাওয়ার জন্য সেই variable-টি ব্যবহার করে vector-এ index করে, এবং loop-এ variable value-টি increment করে যতক্ষণ না এটি vector-এর মোট item সংখ্যার সমান হয়, এভাবে একই functionality লিখতেন।
Iterator-গুলো আপনার জন্য সেই সমস্ত logic handle করে, repetitive code কমিয়ে দেয় যেখানে আপনার ভুল হওয়ার সম্ভাবনা থাকতে পারে। Iterator-গুলো আপনাকে একই logic বিভিন্ন ধরনের sequence-এর সাথে ব্যবহার করার flexibility দেয়, শুধুমাত্র vector-এর মতো data structure-গুলোতেই নয় যেগুলোতে আপনি index করতে পারেন। আসুন পরীক্ষা করি কীভাবে iterator-গুলো তা করে।
Iterator Trait এবং next Method
সমস্ত iterator Iterator নামক একটি trait implement করে যা standard library-তে define করা হয়েছে। Trait-টির definition এইরকম:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // default implementation সহ method গুলো সরানো হয়েছে } }
লক্ষ্য করুন এই definition-এ কিছু new syntax ব্যবহার করা হয়েছে: type Item এবং Self::Item, যেগুলো এই trait-এর সাথে একটি associated type define করছে। আমরা Chapter 20-এ associated type সম্পর্কে বিস্তারিত আলোচনা করব। আপাতত, আপনার যা জানা দরকার তা হল এই code বলছে যে Iterator trait implement করার জন্য আপনাকে একটি Item type-ও define করতে হবে, এবং এই Item type-টি next method-এর return type-এ ব্যবহৃত হয়। অন্য কথায়, Item type-টি হবে iterator থেকে returned type।
Iterator trait-টির implementor-দের শুধুমাত্র একটি method define করতে হয়: next method, যেটি iterator-এর একটি item প্রতিবারে Some-এ wrap করে return করে এবং iteration শেষ হয়ে গেলে None return করে।
আমরা সরাসরি iterator-গুলোতে next method call করতে পারি; Listing 13-12 প্রদর্শন করে vector থেকে create করা iterator-এ next-এর repeated call থেকে কী value return করা হয়।
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}লক্ষ্য করুন যে আমাদের v1_iter-কে mutable করতে হয়েছিল: একটি iterator-এ next method call করা internal state পরিবর্তন করে যা iterator ব্যবহার করে track রাখে যে এটি sequence-এ কোথায় আছে। অন্য কথায়, এই code টি iterator-কে consume করে, বা ব্যবহার করে। Next-এর প্রতিটি call iterator থেকে একটি item খেয়ে ফেলে। যখন আমরা একটি for loop ব্যবহার করি তখন আমাদের v1_iter-কে mutable করতে হয়নি কারণ loop টি v1_iter-এর ownership নিয়েছিল এবং এটিকে behind the scenes mutable করেছিল।
আরও লক্ষ্য করুন যে next-এ call থেকে আমরা যে value-গুলো পাই সেগুলো হল vector-এর value-গুলোর immutable reference। Iter method immutable reference-গুলোর উপর একটি iterator produce করে। যদি আমরা এমন একটি iterator create করতে চাই যেটি v1-এর ownership নেয় এবং owned value return করে, তাহলে আমরা iter-এর পরিবর্তে into_iter call করতে পারি। একইভাবে, যদি আমরা mutable reference-গুলোর উপর iterate করতে চাই, তাহলে আমরা iter-এর পরিবর্তে iter_mut call করতে পারি।
যে Method-গুলো Iterator-কে Consume করে
Iterator trait-টিতে standard library দ্বারা provide করা default implementation সহ আরও বেশ কয়েকটি method রয়েছে; আপনি Iterator trait-এর জন্য standard library API documentation দেখে এই method গুলো সম্পর্কে জানতে পারেন। এই method-গুলোর মধ্যে কিছু তাদের definition-এ next method call করে, যে কারণে Iterator trait implement করার সময় আপনাকে next method implement করতে হয়।
যে method গুলো next কল করে তাদের consuming adapter বলা হয়, কারণ সেগুলোকে call করলে iterator টি ব্যবহৃত হয়ে যায়। একটি উদাহরণ হল sum method, যেটি iterator-এর ownership নেয় এবং repeatedly next call করে item-গুলোর মধ্যে iterate করে, এইভাবে iterator-টিকে consume করে। এটি iterate করার সময়, এটি প্রতিটি item-কে একটি running total-এর সাথে যোগ করে এবং iteration সম্পূর্ণ হলে total টি return করে। Listing 13-13 sum method-এর ব্যবহারের চিত্র তুলে ধরে এমন একটি test ধারণ করে:
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}Sum-এ call করার পরে আমরা v1_iter ব্যবহার করতে পারি না কারণ sum যে iterator-এ call করা হয় সেটির ownership নেয়।
যে Method-গুলো অন্যান্য Iterator Produce করে
Iterator adapter হল Iterator trait-এ defined method যেগুলো iterator-কে consume করে না। পরিবর্তে, সেগুলো original iterator-এর কিছু aspect পরিবর্তন করে different iterator produce করে।
Listing 13-14 iterator adapter method map-এ call করার একটি উদাহরণ দেখায়, যেটি item-গুলোর মধ্যে iterate করার সময় প্রতিটি item-এ call করার জন্য একটি closure নেয়। Map method টি একটি new iterator return করে যেটি modified item গুলো produce করে। এখানে closure টি একটি new iterator create করে যেখানে vector-এর প্রতিটি item-এর সাথে 1 যোগ করা হবে:
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; v1.iter().map(|x| x + 1); }
তবে, এই code একটি warning produce করে:
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
4 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iterators` (bin "iterators") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
Listing 13-14-এর code কিছুই করে না; আমরা যে closure টি specify করেছি সেটি কখনও call করা হয় না। Warning টি আমাদের মনে করিয়ে দেয় কেন: iterator adapter গুলো lazy, এবং আমাদের এখানে iterator-টিকে consume করতে হবে।
এই warning টি ঠিক করতে এবং iterator-টিকে consume করতে, আমরা collect method টি ব্যবহার করব, যেটি আমরা Chapter 12-তে Listing 12-1-এ env::args-এর সাথে ব্যবহার করেছি। এই method টি iterator-টিকে consume করে এবং resulting value গুলোকে একটি collection data type-এ collect করে।
Listing 13-15-এ, আমরা map-এ call থেকে returned iterator-এর উপর iterate করার result গুলোকে একটি vector-এ collect করি। এই vector-টিতে original vector-এর প্রতিটি item-এর সাথে 1 যোগ করা থাকবে।
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; let v2: Vec<_> = v1.iter().map(|x| x + 1).collect(); assert_eq!(v2, vec![2, 3, 4]); }
যেহেতু map একটি closure নেয়, তাই আমরা প্রতিটি item-এ perform করতে চাই এমন যেকোনো operation specify করতে পারি। এটি একটি দুর্দান্ত উদাহরণ যে কীভাবে closure গুলো আপনাকে কিছু behavior customize করতে দেয়, সেইসাথে Iterator trait provide করা iteration behavior-টিকে reuse করতে দেয়।
আপনি readable উপায়ে complex action perform করার জন্য iterator adapter-এ multiple call chain করতে পারেন। কিন্তু যেহেতু সমস্ত iterator lazy, তাই আপনাকে iterator adapter-গুলোতে call থেকে result পেতে consuming adapter method গুলোর মধ্যে একটিকে call করতে হবে।
তাদের Environment Capture করে এমন Closure ব্যবহার করা
অনেক iterator adapter argument হিসেবে closure নেয়, এবং commonly iterator adapter-গুলোতে argument হিসেবে আমরা যে closure গুলো specify করব সেগুলো হবে এমন closure যেগুলো তাদের environment capture করে।
এই উদাহরণের জন্য, আমরা filter method টি ব্যবহার করব যেটি একটি closure নেয়। Closure টি iterator থেকে একটি item পায় এবং একটি bool return করে। যদি closure টি true return করে, তাহলে value টি filter দ্বারা produced iteration-এ include করা হবে। যদি closure টি false return করে, তাহলে value টি include করা হবে না।
Listing 13-16-এ, আমরা Shoe struct instance-গুলোর একটি collection-এর উপর iterate করার জন্য shoe_size variable-টিকে তার environment থেকে capture করে এমন একটি closure-এর সাথে filter ব্যবহার করি। এটি শুধুমাত্র specified size-এর জুতাগুলো return করবে।
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}Shoes_in_size function টি parameter হিসেবে জুতাগুলোর একটি vector এবং একটি জুতার size-এর ownership নেয়। এটি specified size-এর শুধুমাত্র জুতাগুলো ধারণকারী একটি vector return করে।
Shoes_in_size-এর body-তে, আমরা vector-টির ownership নেয় এমন একটি iterator create করার জন্য into_iter call করি। তারপর আমরা সেই iterator-টিকে একটি new iterator-এ adapt করার জন্য filter call করি যেটিতে শুধুমাত্র সেই element গুলো থাকে যেগুলোর জন্য closure টি true return করে।
Closure টি environment থেকে shoe_size parameter টি capture করে এবং প্রতিটি জুতার size-এর সাথে value-টিকে compare করে, শুধুমাত্র specified size-এর জুতাগুলো রাখে। অবশেষে, collect call করা adapted iterator দ্বারা returned value গুলোকে gather করে function দ্বারা returned একটি vector-এ রাখে।
Test টি দেখায় যে যখন আমরা shoes_in_size call করি, তখন আমরা শুধুমাত্র সেই জুতাগুলো ফেরত পাই যেগুলোর size আমাদের specified value-এর সমান।
আমাদের I/O প্রোজেক্টকে উন্নত করা
Iterator সম্পর্কে এই নতুন জ্ঞান দিয়ে, আমরা Chapter 12-এর I/O প্রোজেক্টকে improve করতে পারি iterator ব্যবহার করে code-এর জায়গাগুলোকে আরও clear এবং concise করতে। আসুন দেখি কীভাবে iterator গুলো Config::build ফাংশন এবং search ফাংশনের আমাদের implementation-কে improve করতে পারে।
একটি clone সরানো Iterator ব্যবহার করে
Listing 12-6-এ, আমরা code যোগ করেছিলাম যেটি String value-গুলোর একটি slice নিত এবং slice-এ index করে এবং value গুলোকে clone করে Config struct-এর একটি instance create করত, Config struct-কে সেই value-গুলোর owner হওয়ার অনুমতি দিত। Listing 13-17-এ, আমরা Config::build ফাংশনের implementation-টিকে পুনরায় লিখেছি যেমনটি Listing 12-23-এ ছিল:
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}তখন, আমরা বলেছিলাম inefficient clone কলগুলো নিয়ে চিন্তা না করতে কারণ আমরা ভবিষ্যতে সেগুলোকে সরিয়ে দেব। এখন সেই সময়!
আমাদের এখানে clone-এর প্রয়োজন ছিল কারণ parameter args-এ String element-সহ একটি slice রয়েছে, কিন্তু build ফাংশনটি args-এর owner নয়। একটি Config instance-এর ownership return করার জন্য, আমাদের Config-এর query এবং file_path field থেকে value গুলোকে clone করতে হয়েছিল যাতে Config instance টি তার value-গুলোর owner হতে পারে।
Iterator সম্পর্কে আমাদের নতুন জ্ঞান দিয়ে, আমরা build ফাংশনটিকে পরিবর্তন করতে পারি একটি slice borrow করার পরিবর্তে argument হিসেবে একটি iterator-এর ownership নেওয়ার জন্য। আমরা slice-এর length check করা এবং specific location-গুলোতে index করার code-এর পরিবর্তে iterator functionality ব্যবহার করব। এটি Config::build ফাংশনটি কী করছে তা স্পষ্ট করবে কারণ iterator টি value গুলো access করবে।
একবার Config::build iterator-এর ownership নেওয়ার পরে এবং borrow করা indexing operation গুলো ব্যবহার করা বন্ধ করে দিলে, আমরা clone কল না করে এবং একটি new allocation তৈরি না করে iterator থেকে String value গুলোকে Config-এ move করতে পারি।
Returned Iterator সরাসরি ব্যবহার করা
আপনার I/O প্রোজেক্টের src/main.rs ফাইলটি খুলুন, যেটি এইরকম হওয়া উচিত:
Filename: src/main.rs
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}আমরা প্রথমে main ফাংশনের শুরু পরিবর্তন করব যা Listing 12-24-এ ছিল Listing 13-18-এর code-এ, যেটি এবার একটি iterator ব্যবহার করে। আমরা যতক্ষণ Config::build update না করি ততক্ষণ এটি compile হবে না।
use std::env;
use std::process;
use minigrep::Config;
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = minigrep::run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}Env::args ফাংশন একটি iterator return করে! Iterator value গুলোকে একটি vector-এ collect করে তারপর Config::build-এ একটি slice pass করার পরিবর্তে, এখন আমরা env::args থেকে returned iterator-এর ownership সরাসরি Config::build-এ pass করছি।
এরপরে, আমাদের Config::build-এর definition update করতে হবে। আপনার I/O প্রোজেক্টের src/lib.rs ফাইলে, আসুন Config::build-এর signature পরিবর্তন করে Listing 13-19-এর মতো করি। এটি এখনও compile হবে না কারণ আমাদের function body update করতে হবে।
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Env::args ফাংশনের জন্য standard library documentation দেখায় যে এটি যে iterator return করে তার type হল std::env::Args, এবং সেই type টি Iterator trait implement করে এবং String value return করে।
আমরা Config::build ফাংশনের signature আপডেট করেছি যাতে parameter args-এর একটি generic type থাকে trait bound impl Iterator<Item = String> সহ, &[String]-এর পরিবর্তে। Chapter 10-এর “প্যারামিটার হিসেবে Traits” বিভাগে আলোচনা করা impl Trait syntax-এর এই ব্যবহারটির অর্থ হল args যেকোনো type হতে পারে যেটি Iterator trait implement করে এবং String item return করে।
যেহেতু আমরা args-এর ownership নিচ্ছি এবং এটিকে iterate করে args কে mutate করব, তাই আমরা এটিকে mutable করতে args parameter-এর specification-এ mut keyword যোগ করতে পারি।
Indexing-এর পরিবর্তে Iterator Trait Method ব্যবহার করা
এরপরে, আমরা Config::build-এর body ঠিক করব। যেহেতু args, Iterator trait implement করে, তাই আমরা জানি যে আমরা এটিতে next method কল করতে পারি! Listing 13-20, Listing 12-23 থেকে code update করে next method ব্যবহার করার জন্য:
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}মনে রাখবেন যে env::args-এর return value-এর প্রথম value টি হল প্রোগ্রামের নাম। আমরা সেটিকে ignore করতে চাই এবং পরবর্তী value-তে যেতে চাই, তাই প্রথমে আমরা next কল করি এবং return value-এর সাথে কিছুই করি না। দ্বিতীয়ত, আমরা Config-এর query field-এ যে value টি রাখতে চাই সেটি পেতে next কল করি। যদি next একটি Some return করে, তাহলে আমরা value টি extract করতে একটি match ব্যবহার করি। যদি এটি None return করে, তাহলে এর অর্থ হল পর্যাপ্ত argument দেওয়া হয়নি এবং আমরা একটি Err value দিয়ে তাড়াতাড়ি return করি। আমরা file_path value-এর জন্য একই কাজ করি।
Iterator Adapter দিয়ে Code আরও Clear করা
আমরা আমাদের I/O প্রোজেক্টের search ফাংশনেও iterator-গুলোর সুবিধা নিতে পারি, যেটি Listing 13-21-এ পুনরায় লেখা হয়েছে যেমনটি Listing 12-19-এ ছিল:
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}আমরা iterator adapter method ব্যবহার করে এই code-টিকে আরও concise উপায়ে লিখতে পারি। এটি আমাদের একটি mutable intermediate results vector থাকাও এড়াতে দেয়। Functional programming style code-কে আরও clear করতে mutable state-এর পরিমাণ minimize করা prefer করে। Mutable state সরিয়ে দেওয়া future-এ searching-কে parallel-এ ঘটানোর enhancement enable করতে পারে, কারণ আমাদের results vector-এ concurrent access manage করতে হবে না। Listing 13-22 এই পরিবর্তনটি দেখায়:
use std::env;
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
pub fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}মনে রাখবেন যে search ফাংশনের উদ্দেশ্য হল contents-এর সমস্ত line return করা যেগুলোতে query রয়েছে। Listing 13-16-এর filter উদাহরণের মতোই, এই code টি শুধুমাত্র সেই line গুলো রাখতে filter adapter ব্যবহার করে যেগুলোর জন্য line.contains(query) true return করে। তারপর আমরা matching line গুলোকে collect-এর সাহায্যে অন্য একটি vector-এ collect করি। অনেক সহজ! Search_case_insensitive ফাংশনেও iterator method ব্যবহার করতে একই পরিবর্তন করতে পারেন।
Loop বা Iterator-এর মধ্যে বেছে নেওয়া
পরবর্তী logical প্রশ্ন হল আপনার নিজের code-এ আপনার কোন style বেছে নেওয়া উচিত এবং কেন: Listing 13-21-এর original implementation নাকি Listing 13-22-এ iterator ব্যবহার করা version। বেশিরভাগ Rust programmer iterator style ব্যবহার করা prefer করেন। এটি প্রথমে আয়ত্ত করা একটু কঠিন, কিন্তু একবার আপনি বিভিন্ন iterator adapter এবং সেগুলো কী করে সে সম্পর্কে ধারণা পেলে, iterator গুলো বুঝতে সহজ হতে পারে। Looping-এর বিভিন্ন অংশ নিয়ে ঘাঁটাঘাঁটি করার এবং new vector তৈরি করার পরিবর্তে, code loop-এর high-level objective-এর উপর focus করে। এটি কিছু commonplace code-কে abstract করে যাতে এই code-এর unique concept গুলো দেখা সহজ হয়, যেমন iterator-এর প্রতিটি element-কে যে filtering condition টি pass করতে হবে।
কিন্তু দুটি implementation কি truly equivalent? স্বজ্ঞাত অনুমান হতে পারে যে আরও low-level loop টি দ্রুততর হবে। আসুন performance নিয়ে কথা বলি।
পারফরম্যান্স তুলনা: লুপ বনাম ইটারেটর
লুপ ব্যবহার করবেন নাকি ইটারেটর ব্যবহার করবেন তা নির্ধারণ করতে, আপনাকে জানতে হবে কোন ইমপ্লিমেন্টেশনটি দ্রুততর: search ফাংশনের explicit for লুপ সহ ভার্সন নাকি ইটারেটর সহ ভার্সন।
আমরা স্যার আর্থার কোনান ডয়েলের লেখা The Adventures of Sherlock Holmes-এর সম্পূর্ণ বিষয়বস্তু একটি String-এ লোড করে এবং contents-এর মধ্যে the শব্দটি খুঁজে বের করে একটি বেঞ্চমার্ক চালিয়েছি। For লুপ ব্যবহার করে search-এর ভার্সন এবং ইটারেটর ব্যবহার করা ভার্সনের বেঞ্চমার্কের ফলাফল এখানে দেওয়া হল:
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
দুটি implementation-এর performance প্রায় একই! আমরা এখানে বেঞ্চমার্ক কোড ব্যাখ্যা করব না, কারণ উদ্দেশ্য এটা প্রমাণ করা নয় যে দুটি ভার্সন equivalent, বরং এই দুটি implementation কীভাবে performance-এর দিক থেকে compare করে তার একটি general sense পাওয়া।
আরও comprehensive বেঞ্চমার্কের জন্য, আপনার contents হিসেবে বিভিন্ন আকারের various text, query হিসেবে ভিন্ন শব্দ এবং ভিন্ন দৈর্ঘ্যের শব্দ এবং অন্যান্য সমস্ত variation ব্যবহার করে পরীক্ষা করা উচিত। মূল বিষয়টি হল: ইটারেটরগুলো, যদিও একটি high-level abstraction, তবুও মোটামুটি একই কোডে compile হয় যেমনটি আপনি নিজে lower-level কোড লিখলে হত। ইটারেটর হল Rust-এর zero-cost abstraction-গুলোর মধ্যে একটি, যার অর্থ হল abstraction ব্যবহার করলে কোনো additional runtime overhead যুক্ত হয় না। এটি C++-এর original designer এবং implementor, Bjarne Stroustrup-এর "Foundations of C++" (2012)-এ zero-overhead-কে যেভাবে define করেছেন তার অনুরূপ:
সাধারণভাবে, C++ implementation গুলো zero-overhead নীতি মেনে চলে: আপনি যা ব্যবহার করেন না, তার জন্য আপনাকে মূল্য দিতে হবে না। এবং আরও: আপনি যা ব্যবহার করেন, আপনি নিজে এর চেয়ে ভালো কোড করতে পারতেন না।
আরেকটি উদাহরণ হিসেবে, নিম্নলিখিত কোডটি একটি অডিও ডিকোডার থেকে নেওয়া হয়েছে। ডিকোডিং অ্যালগরিদম previous sample-গুলোর একটি linear function-এর উপর ভিত্তি করে future value গুলো estimate করতে linear prediction mathematical operation ব্যবহার করে। এই কোডটি scope-এর তিনটি variable-এর উপর কিছু math করার জন্য একটি ইটারেটর চেইন ব্যবহার করে: ডেটার একটি buffer স্লাইস, 12টি coefficients-এর একটি অ্যারে এবং qlp_shift-এ ডেটা shift করার একটি পরিমাণ। আমরা এই উদাহরণের মধ্যে variable গুলো declare করেছি কিন্তু সেগুলোকে কোনো value দিইনি; যদিও এই কোডটির context-এর বাইরে খুব বেশি অর্থ নেই, তবুও এটি একটি concise, real-world উদাহরণ যে কীভাবে Rust high-level idea গুলোকে low-level কোডে translate করে।
let buffer: &mut [i32];
let coefficients: [i64; 12];
let qlp_shift: i16;
for i in 12..buffer.len() {
let prediction = coefficients.iter()
.zip(&buffer[i - 12..i])
.map(|(&c, &s)| c * s as i64)
.sum::<i64>() >> qlp_shift;
let delta = buffer[i];
buffer[i] = prediction as i32 + delta;
}Prediction-এর value calculate করার জন্য, এই কোডটি coefficients-এর 12টি value-এর প্রতিটির উপর iterate করে এবং zip মেথড ব্যবহার করে coefficient value গুলোর সাথে buffer-এর previous 12টি value-এর pair তৈরি করে। তারপর, প্রতিটি pair-এর জন্য, আমরা value গুলোকে একসাথে গুণ করি, সমস্ত result যোগ করি এবং যোগফলের বিটগুলোকে qlp_shift বিট ডানদিকে shift করি।
অডিও ডিকোডারের মতো অ্যাপ্লিকেশনগুলোতে প্রায়শই calculation-গুলো performance-কে সবচেয়ে বেশি priority দেয়। এখানে, আমরা একটি ইটারেটর তৈরি করছি, দুটি অ্যাডাপ্টার ব্যবহার করছি এবং তারপর value টি consume করছি। এই Rust কোডটি কোন অ্যাসেম্বলি কোডে compile হবে? আচ্ছা, এই লেখার সময় পর্যন্ত, এটি সেই একই অ্যাসেম্বলিতে compile হয় যা আপনি নিজে লিখতেন। Coefficients-এর value-গুলোর উপর iteration-এর সাথে সম্পর্কিত কোনো লুপ নেই: Rust জানে যে 12টি iteration রয়েছে, তাই এটি লুপটিকে "আনরোল" করে। Unrolling হল একটি অপ্টিমাইজেশন যা লুপ কন্ট্রোলিং কোডের overhead সরিয়ে দেয় এবং পরিবর্তে লুপের প্রতিটি পুনরাবৃত্তির জন্য repetitive কোড তৈরি করে।
সমস্ত coefficient গুলো register-এ store করা হয়, যার মানে value গুলো অ্যাক্সেস করা খুব দ্রুত। Runtime-এ অ্যারে অ্যাক্সেসে কোনো সীমা পরীক্ষা নেই। Rust যে সমস্ত অপ্টিমাইজেশন প্রয়োগ করতে সক্ষম সেগুলো resulting কোডকে অত্যন্ত efficient করে তোলে। এখন আপনি এটা জানেন, আপনি ভয় ছাড়াই ইটারেটর এবং ক্লোজার ব্যবহার করতে পারেন! সেগুলো কোডকে এমনভাবে দেখায় যেন এটি higher level-এর, কিন্তু এটি করার জন্য runtime performance penalty আরোপ করে না।
সারসংক্ষেপ
ক্লোজার এবং ইটারেটর হল Rust-এর feature যা functional programming language-এর idea দ্বারা অনুপ্রাণিত। Low-level performance-এ high-level idea গুলোকে clearly express করার জন্য Rust-এর సామর্থ্যে এরা অবদান রাখে। ক্লোজার এবং ইটারেটরগুলোর implementation এমন যে runtime performance প্রভাবিত হয় না। এটি Rust-এর zero-cost abstraction provide করার প্রচেষ্টার লক্ষ্যের অংশ।
এখন যেহেতু আমরা আমাদের I/O প্রোজেক্টের expressiveness improve করেছি, আসুন cargo-এর আরও কিছু feature দেখি যা আমাদের প্রোজেক্টটিকে বিশ্বের সাথে share করতে সাহায্য করবে।
Cargo এবং Crates.io সম্পর্কে আরও
এখন পর্যন্ত আমরা আমাদের কোড build, run এবং test করার জন্য Cargo-র শুধুমাত্র সবচেয়ে basic feature গুলো ব্যবহার করেছি, কিন্তু এটি আরও অনেক কিছু করতে পারে। এই chapter-এ, আমরা এর আরও কিছু advanced feature নিয়ে আলোচনা করব যাতে আপনাকে নিম্নলিখিত কাজগুলো কীভাবে করতে হয় তা দেখানো যায়:
- Release profile-এর মাধ্যমে আপনার build customize করা
- crates.io-তে library publish করা
- Workspaces-এর সাহায্যে large project organize করা
- crates.io থেকে binary install করা
- Custom command ব্যবহার করে Cargo extend করা
Cargo এই chapter-এ আমরা যা আলোচনা করেছি তার চেয়েও বেশি functionality করতে পারে, তাই এর সমস্ত feature-এর complete explanation-এর জন্য, এর ডকুমেন্টেশন দেখুন।
Release Profile-এর সাহায্যে Build Customize করা
Rust-এ, release profile গুলো হল predefined এবং customizable profile যেগুলোতে different configuration থাকে, যা একজন programmer-কে কোড compile করার জন্য বিভিন্ন option-এর উপর আরও বেশি control রাখার সুযোগ দেয়। প্রতিটি profile একে অপরের থেকে independently configure করা হয়।
Cargo-র দুটি প্রধান profile রয়েছে: dev প্রোফাইল যা Cargo ব্যবহার করে যখন আপনি cargo build চালান এবং release প্রোফাইল যা Cargo ব্যবহার করে যখন আপনি cargo build --release চালান। Dev প্রোফাইলটি development-এর জন্য ভালো default সহ define করা হয়েছে, এবং release প্রোফাইলে release build-গুলোর জন্য ভালো default রয়েছে।
এই profile-গুলোর নাম আপনার build-গুলোর output থেকে পরিচিত হতে পারে:
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
Dev এবং release হল compiler-এর ব্যবহৃত এই different profile গুলো।
Cargo-র প্রতিটি profile-এর জন্য default setting রয়েছে যা প্রযোজ্য হয় যখন আপনি project-এর Cargo.toml ফাইলে explicitly কোনো [profile.*] section যোগ করেননি। আপনি যে কোনো profile customize করতে চান তার জন্য [profile.*] section যোগ করে, আপনি default setting গুলোর যেকোনো subset override করেন। উদাহরণস্বরূপ, dev এবং release profile-গুলোর জন্য opt-level setting-এর default value গুলো এখানে দেওয়া হল:
Filename: Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
Opt-level setting টি আপনার কোডে Rust যে সংখ্যক optimization apply করবে তা নিয়ন্ত্রণ করে, যার range হল 0 থেকে 3। আরও optimization apply করলে compiling time বাড়ে, তাই আপনি যদি development-এ থাকেন এবং প্রায়শই আপনার কোড compile করেন, তাহলে resulting code ধীরে চললেও আপনি দ্রুত compile করার জন্য কম optimization চাইবেন। তাই dev-এর জন্য default opt-level হল 0। যখন আপনি আপনার কোড release করার জন্য প্রস্তুত হন, তখন compile করতে আরও বেশি সময় ব্যয় করা সবচেয়ে ভালো। আপনি release mode-এ শুধুমাত্র একবার compile করবেন, কিন্তু আপনি compiled program টি বহুবার চালাবেন, তাই release mode দ্রুততর কোডের জন্য দীর্ঘতর compile time-এর trade-off করে। সেই কারণেই release প্রোফাইলের জন্য ডিফল্ট opt-level হল 3।
আপনি Cargo.toml-এ এটির জন্য একটি different value যোগ করে একটি default setting override করতে পারেন। উদাহরণস্বরূপ, যদি আমরা development profile-এ optimization level 1 ব্যবহার করতে চাই, তাহলে আমরা আমাদের প্রোজেক্টের Cargo.toml ফাইলে এই দুটি লাইন যোগ করতে পারি:
Filename: Cargo.toml
[profile.dev]
opt-level = 1
এই কোডটি 0-এর default setting টিকে override করে। এখন যখন আমরা cargo build চালাই, তখন Cargo dev প্রোফাইলের জন্য default গুলো ব্যবহার করবে এবং তার সাথে opt-level-এ আমাদের customization যোগ করবে। যেহেতু আমরা opt-level কে 1-এ set করেছি, তাই Cargo default-এর চেয়ে বেশি optimization apply করবে, কিন্তু release build-এর মতো ততটা নয়।
প্রতিটি প্রোফাইলের জন্য configuration option এবং default-গুলোর complete list-এর জন্য, Cargo’s documentation দেখুন।
Crates.io-তে একটি Crate পাবলিশ করা
আমরা আমাদের প্রোজেক্টের dependencies হিসেবে crates.io থেকে প্যাকেজ ব্যবহার করেছি, কিন্তু আপনি আপনার নিজের প্যাকেজ publish করে অন্যদের সাথে আপনার কোড share করতে পারেন। Crates.io-এর crate registry আপনার প্যাকেজগুলোর source code distribute করে, তাই এটি primarily open source কোড হোস্ট করে।
Rust এবং Cargo-তে এমন feature রয়েছে যা আপনার published package-কে অন্যদের জন্য খুঁজে পাওয়া এবং ব্যবহার করা সহজ করে তোলে। আমরা এরপরে এই feature গুলোর মধ্যে কয়েকটি নিয়ে আলোচনা করব এবং তারপর একটি package কীভাবে publish করতে হয় তা ব্যাখ্যা করব।
প্রয়োজনীয় ডকুমেন্টেশন কমেন্ট তৈরি করা
আপনার প্যাকেজগুলো সঠিকভাবে document করা অন্যান্য user-দের জানতে সাহায্য করবে যে সেগুলো কীভাবে এবং কখন ব্যবহার করতে হবে, তাই ডকুমেন্টেশন লেখার জন্য সময় ব্যয় করা উচিত। Chapter 3-তে, আমরা আলোচনা করেছি কীভাবে দুটি স্ল্যাশ, // ব্যবহার করে Rust কোডে comment করতে হয়। Rust-এ ডকুমেন্টেশনের জন্য একটি বিশেষ ধরনের comment-ও রয়েছে, সুবিধাজনকভাবে ডকুমেন্টেশন কমেন্ট নামে পরিচিত, যা HTML ডকুমেন্টেশন generate করবে। HTML ডকুমেন্টেশন public API item-গুলোর জন্য ডকুমেন্টেশন কমেন্টের contents প্রদর্শন করে, যা সেইসব প্রোগ্রামারদের জন্য উদ্দিষ্ট যারা আপনার crate কীভাবে ব্যবহার করতে হয় তা জানতে আগ্রহী, আপনার crate কীভাবে ইমপ্লিমেন্ট করা হয়েছে তার বিপরীতে।
ডকুমেন্টেশন কমেন্টগুলো দুটির পরিবর্তে তিনটি স্ল্যাশ, /// ব্যবহার করে এবং text format করার জন্য Markdown notation সাপোর্ট করে। ডকুমেন্টেশন কমেন্টগুলো যে item-গুলোকে ডকুমেন্ট করছে তার ঠিক আগে রাখুন। Listing 14-1 my_crate নামের একটি ক্রেটে add_one ফাংশনের জন্য ডকুমেন্টেশন কমেন্ট দেখায়।
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}এখানে, আমরা add_one ফাংশনটি কী করে তার একটি description দিই, Examples heading দিয়ে একটি section শুরু করি এবং তারপর add_one ফাংশনটি কীভাবে ব্যবহার করতে হয় তা প্রদর্শন করে এমন কোড provide করি। আমরা cargo doc চালিয়ে এই ডকুমেন্টেশন কমেন্ট থেকে HTML ডকুমেন্টেশন generate করতে পারি। এই কমান্ডটি Rust-এর সাথে distribute করা rustdoc টুলটি চালায় এবং generated HTML ডকুমেন্টেশনটি target/doc ডিরেক্টরিতে রাখে।
সুবিধার জন্য, cargo doc --open চালালে আপনার current crate-এর ডকুমেন্টেশনের জন্য HTML build হবে (সেইসাথে আপনার crate-এর সমস্ত dependency-এর ডকুমেন্টেশনও) এবং result টি একটি ওয়েব ব্রাউজারে open হবে। Add_one ফাংশনে নেভিগেট করুন এবং আপনি দেখতে পাবেন কীভাবে ডকুমেন্টেশন কমেন্টের text গুলো render করা হয়েছে, যেমনটি Figure 14-1-এ দেখানো হয়েছে:
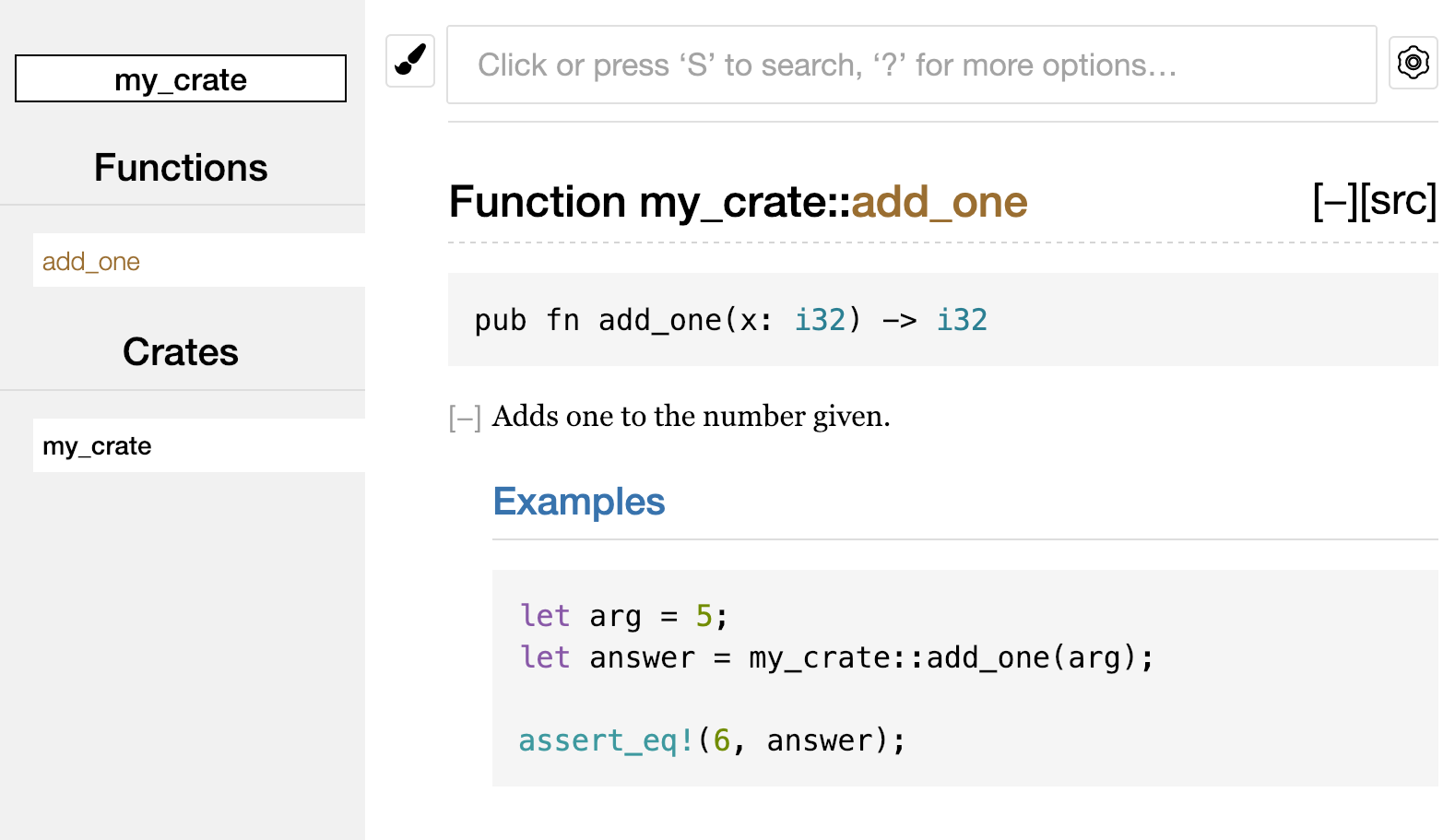
Figure 14-1: add_one ফাংশনের জন্য HTML ডকুমেন্টেশন
সাধারণভাবে ব্যবহৃত Section গুলো
আমরা Listing 14-1-এ # Examples Markdown heading টি ব্যবহার করেছি HTML-এ "Examples" শিরোনাম সহ একটি section তৈরি করতে। এখানে আরও কয়েকটি section রয়েছে যা crate author-রা তাদের ডকুমেন্টেশনে সাধারণত ব্যবহার করেন:
- Panics: যে পরিস্থিতিতে document করা ফাংশনটি প্যানিক করতে পারে। ফাংশনের কলাররা যারা চান না যে তাদের প্রোগ্রামগুলো প্যানিক করুক, তাদের নিশ্চিত করা উচিত যে তারা এই পরিস্থিতিতে ফাংশনটিকে কল করবে না।
- Errors: যদি ফাংশনটি একটি
Resultরিটার্ন করে, তাহলে কী ধরনের error ঘটতে পারে এবং কোন পরিস্থিতিতে সেই error গুলো রিটার্ন হতে পারে তার description কলারদের জন্য সহায়ক হতে পারে যাতে তারা different উপায়ে different ধরনের error হ্যান্ডেল করার জন্য কোড লিখতে পারে। - Safety: যদি ফাংশনটি কল করা
unsafeহয় (আমরা Chapter 20-এ unsafety নিয়ে আলোচনা করব), তাহলে কেন ফাংশনটি unsafe এবং ফাংশনটি আশা করে যে কলাররা কোন invariant গুলো বজায় রাখবে তা ব্যাখ্যা করে একটি section থাকা উচিত।
বেশিরভাগ ডকুমেন্টেশন কমেন্টের এই সমস্ত section-গুলোর প্রয়োজন নেই, তবে এটি একটি ভালো চেকলিস্ট যা আপনাকে আপনার কোডের সেই দিকগুলো মনে করিয়ে দেবে যেগুলোর বিষয়ে user-রা জানতে আগ্রহী হবে।
ডকুমেন্টেশন কমেন্টগুলো টেস্ট হিসেবে
আপনার ডকুমেন্টেশন কমেন্টগুলোতে example code block যোগ করা আপনার লাইব্রেরি কীভাবে ব্যবহার করতে হয় তা প্রদর্শন করতে সাহায্য করতে পারে, এবং এটি করার একটি additional bonus রয়েছে: cargo test চালালে আপনার ডকুমেন্টেশনের code example গুলো test হিসেবে চলবে! Example সহ ডকুমেন্টেশনের চেয়ে ভালো কিছু নেই। কিন্তু উদাহরণের চেয়ে খারাপ কিছু নেই যা কাজ করে না কারণ ডকুমেন্টেশন লেখার পর থেকে কোড পরিবর্তন হয়েছে। যদি আমরা Listing 14-1 থেকে add_one ফাংশনের জন্য ডকুমেন্টেশন সহ cargo test চালাই, তাহলে আমরা test result-এ এইরকম একটি section দেখতে পাব:
Doc-tests my_crate
running 1 test
test src/lib.rs - add_one (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
এখন যদি আমরা ফাংশন বা example পরিবর্তন করি যাতে example-এর assert_eq! প্যানিক করে এবং আবার cargo test চালাই, তাহলে আমরা দেখতে পাব যে doc test গুলো ধরবে যে example এবং code একে অপরের সাথে out of sync!
কন্টেইন করা Item গুলোতে কমেন্ট করা
Doc comment-এর //! স্টাইলটি comment-এর পরে থাকা item-গুলোর পরিবর্তে comment গুলো ধারণ করা item-টিতে ডকুমেন্টেশন যোগ করে। আমরা সাধারণত এই doc comment গুলো crate root ফাইলের ভিতরে (src/lib.rs convention অনুযায়ী) বা একটি module-এর ভিতরে ব্যবহার করি crate বা module-টিকে সামগ্রিকভাবে document করার জন্য।
উদাহরণস্বরূপ, add_one ফাংশন ধারণকারী my_crate crate-টির purpose বর্ণনা করে এমন ডকুমেন্টেশন যোগ করার জন্য, আমরা Listing 14-2-তে দেখানো src/lib.rs ফাইলের শুরুতে //! দিয়ে শুরু হওয়া ডকুমেন্টেশন কমেন্ট যোগ করি:
//! # My Crate
//!
//! `my_crate` is a collection of utilities to make performing certain
//! calculations more convenient.
/// Adds one to the number given.
// --snip--
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}লক্ষ্য করুন //! দিয়ে শুরু হওয়া শেষ লাইনের পরে কোনো কোড নেই। যেহেতু আমরা ///-এর পরিবর্তে //! দিয়ে comment গুলো শুরু করেছি, তাই আমরা এই comment-এর পরে থাকা কোনো item-এর পরিবর্তে এই comment ধারণ করা item-টিকে document করছি। এই ক্ষেত্রে, সেই item টি হল src/lib.rs ফাইল, যেটি হল crate root। এই comment গুলো সম্পূর্ণ crate বর্ণনা করে।
যখন আমরা cargo doc --open চালাই, তখন এই comment গুলো crate-এর public item-গুলোর list-এর উপরে my_crate-এর ডকুমেন্টেশনের front page-এ প্রদর্শিত হবে, যেমনটি Figure 14-2-তে দেখানো হয়েছে:
Figure 14-2: my_crate-এর জন্য Rendered ডকুমেন্টেশন, সামগ্রিকভাবে crate বর্ণনা করে এমন মন্তব্য সহ
Item-গুলোর ভেতরের ডকুমেন্টেশন কমেন্টগুলো বিশেষ করে crate এবং module গুলো describe করার জন্য useful। আপনার user-দের crate-এর organization বুঝতে সাহায্য করার জন্য container-এর overall purpose ব্যাখ্যা করতে এগুলো ব্যবহার করুন।
pub use-এর সাহায্যে একটি সুবিধাজনক Public API এক্সপোর্ট করা
আপনার public API-এর structure একটি crate publish করার সময় একটি major consideration। আপনার crate ব্যবহার করা লোকেরা structure-টির সাথে আপনার চেয়ে কম পরিচিত এবং আপনার crate-এ একটি large module hierarchy থাকলে তারা যে অংশগুলো ব্যবহার করতে চায় সেগুলো খুঁজে পেতে অসুবিধা হতে পারে।
Chapter 7-এ, আমরা pub keyword ব্যবহার করে কীভাবে item গুলোকে public করতে হয় এবং use keyword-এর সাহায্যে item গুলোকে scope-এ আনতে হয় তা দেখেছি। যাইহোক, আপনি যখন একটি crate develop করছেন তখন যে structure টি আপনার কাছে যুক্তিসঙ্গত মনে হয় সেটি আপনার user-দের জন্য খুব সুবিধাজনক নাও হতে পারে। আপনি আপনার struct গুলোকে multiple level ধারণকারী একটি hierarchy-তে organize করতে চাইতে পারেন, কিন্তু তারপর যারা hierarchy-এর গভীরে define করা একটি type ব্যবহার করতে চান তারা হয়তো সেই type-টি existing কিনা তা খুঁজে পেতে সমস্যায় পড়তে পারেন। তাদের use my_crate::some_module::another_module::UsefulType;-এর পরিবর্তে use my_crate::UsefulType; লিখতে হতে পারে।
ভাল খবর হল যদি structure-টি অন্য library থেকে ব্যবহার করার জন্য সুবিধাজনক না হয়, তাহলে আপনাকে আপনার internal organization rearrange করতে হবে না: এর পরিবর্তে, আপনি pub use ব্যবহার করে আপনার private structure থেকে different একটি public structure তৈরি করতে item গুলোকে re-export করতে পারেন। Re-exporting একটি public item-কে এক জায়গায় নেয় এবং এটিকে অন্য জায়গায় public করে, যেন এটি অন্য জায়গার পরিবর্তে সেখানেই define করা হয়েছিল।
উদাহরণস্বরূপ, ধরা যাক আমরা artistic concept গুলো model করার জন্য art নামে একটি লাইব্রেরি তৈরি করেছি। এই লাইব্রেরির মধ্যে দুটি module রয়েছে: kinds module যাতে PrimaryColor এবং SecondaryColor নামে দুটি enum রয়েছে এবং utils module যাতে mix নামে একটি ফাংশন রয়েছে, যেমনটি Listing 14-3-তে দেখানো হয়েছে:
//! # Art
//!
//! A library for modeling artistic concepts.
pub mod kinds {
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
unimplemented!();
}
}Figure 14-3 দেখায় যে cargo doc দ্বারা generate করা এই crate-এর ডকুমেন্টেশনের front page-টি কেমন হবে:
Figure 14-3: art-এর ডকুমেন্টেশনের Front page যা kinds এবং utils module-গুলোর তালিকা করে
লক্ষ্য করুন যে PrimaryColor এবং SecondaryColor type গুলো front page-এ list করা হয়নি, mix ফাংশনটিও নয়। সেগুলো দেখতে আমাদের kinds এবং utils-এ ক্লিক করতে হবে।
অন্য একটি crate যেটি এই লাইব্রেরির উপর নির্ভর করে, সেটির use statement প্রয়োজন হবে যা art থেকে item গুলোকে scope-এ আনে, বর্তমানে define করা module structure টি specify করে। Listing 14-4 একটি crate-এর উদাহরণ দেখায় যেটি art crate থেকে PrimaryColor এবং mix item গুলো ব্যবহার করে:
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}Listing 14-4-এর code-এর author, যিনি art crate ব্যবহার করেন, তাকে খুঁজে বের করতে হয়েছিল যে PrimaryColor kinds module-এ রয়েছে এবং mix utils module-এ রয়েছে। Art crate-এর module structure টি art crate-এ কাজ করা developer-দের জন্য এটি ব্যবহারকারীদের চেয়ে বেশি relevant। Internal structure-টিতে art crate কীভাবে ব্যবহার করতে হয় তা বোঝার চেষ্টা করা কারও জন্য কোনো useful information নেই, বরং বিভ্রান্তির কারণ হয় কারণ যারা এটি ব্যবহার করেন তাদের খুঁজে বের করতে হবে কোথায় খুঁজতে হবে এবং use statement-গুলোতে module-এর নাম specify করতে হবে।
Public API থেকে internal organization সরানোর জন্য, আমরা Listing 14-3-এর art crate code modify করে top level-এ item গুলোকে re-export করতে pub use statement যোগ করতে পারি, যেমনটি Listing 14-5-এ দেখানো হয়েছে:
//! # Art
//!
//! A library for modeling artistic concepts.
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
// --snip--
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Orange
}
}Cargo doc এই crate-এর জন্য যে API ডকুমেন্টেশন generate করে সেটি এখন front page-এ re-export গুলোকে list করবে এবং লিঙ্ক করবে, যেমনটি Figure 14-4-এ দেখানো হয়েছে, PrimaryColor এবং SecondaryColor type গুলো এবং mix ফাংশনটিকে খুঁজে পাওয়া সহজ করে তুলবে।
Figure 14-4: art-এর ডকুমেন্টেশনের Front page যা re-export-গুলোর তালিকা করে
Art crate user-রা এখনও Listing 14-3 থেকে internal structure দেখতে এবং ব্যবহার করতে পারে যেমনটি Listing 14-4-এ দেখানো হয়েছে, অথবা তারা Listing 14-5-এর আরও সুবিধাজনক structure টি ব্যবহার করতে পারে, যেমনটি Listing 14-6-এ দেখানো হয়েছে:
use art::PrimaryColor;
use art::mix;
fn main() {
// --snip--
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}যেসব ক্ষেত্রে অনেকগুলি nested module রয়েছে, সেখানে pub use-এর সাহায্যে top level-এ type গুলোকে re-export করা crate ব্যবহার করা লোকেদের অভিজ্ঞতায় significant difference আনতে পারে। Pub use-এর আরেকটি সাধারণ ব্যবহার হল current crate-এ একটি dependency-এর definition গুলোকে re-export করা যাতে সেই crate-এর definition গুলো আপনার crate-এর public API-এর অংশ হয়।
একটি useful public API structure তৈরি করা বিজ্ঞানের চেয়ে একটি শিল্প বেশি, এবং আপনি আপনার user-দের জন্য সবচেয়ে উপযুক্ত API খুঁজে বের করার জন্য iterate করতে পারেন। Pub use বেছে নেওয়া আপনাকে flexibility দেয় যে আপনি কীভাবে আপনার crate-কে internally structure করবেন এবং আপনার user-দের কাছে যা present করবেন তা থেকে সেই internal structure-কে decouple করবেন। আপনি যে crate গুলো install করেছেন সেগুলোর মধ্যে কয়েকটির code দেখুন যাতে বোঝা যায় যে তাদের internal structure তাদের public API থেকে আলাদা কিনা।
একটি Crates.io অ্যাকাউন্ট সেট আপ করা
আপনি কোনো crate publish করার আগে, আপনাকে crates.io-তে একটি অ্যাকাউন্ট তৈরি করতে হবে এবং একটি API টোকেন পেতে হবে। এটি করার জন্য, crates.io-এ হোম পেজে যান এবং একটি GitHub অ্যাকাউন্টের মাধ্যমে লগ ইন করুন। (GitHub অ্যাকাউন্টটি বর্তমানে একটি requirement, কিন্তু site-টি ভবিষ্যতে অ্যাকাউন্ট তৈরি করার অন্য উপায় support করতে পারে।) একবার আপনি লগ ইন করার পরে, https://crates.io/me/-এ আপনার অ্যাকাউন্ট সেটিংসে যান এবং আপনার API key পান। তারপর cargo login কমান্ডটি চালান এবং prompt করা হলে আপনার API key টি পেস্ট করুন, এইভাবে:
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
এই কমান্ডটি Cargo-কে আপনার API টোকেন সম্পর্কে জানাবে এবং এটিকে locally ~/.cargo/credentials-এ store করবে। মনে রাখবেন যে এই টোকেনটি একটি গোপনীয়তা: এটি অন্য কারও সাথে share করবেন না। আপনি যদি কোনো কারণে এটি কারও সাথে share করেন, তাহলে আপনার এটি revoke করা উচিত এবং crates.io-তে একটি new token generate করা উচিত।
একটি নতুন Crate-এ মেটাডেটা যোগ করা
ধরা যাক আপনার কাছে একটি crate আছে যা আপনি publish করতে চান। Publish করার আগে, আপনাকে crate-এর Cargo.toml ফাইলের [package] section-এ কিছু metadata যোগ করতে হবে।
আপনার crate-এর একটি unique name প্রয়োজন হবে। আপনি locally একটি crate-এ কাজ করার সময়, আপনি একটি crate-এর নাম যা খুশি রাখতে পারেন। যাইহোক, crates.io-তে crate-এর নামগুলো first-come, first-served ভিত্তিতে বরাদ্দ করা হয়। একবার একটি crate-এর নাম নেওয়া হলে, অন্য কেউ সেই নামে একটি crate publish করতে পারবে না। একটি crate publish করার চেষ্টা করার আগে, আপনি যে নামটি ব্যবহার করতে চান সেটি search করুন। যদি নামটি ব্যবহার করা হয়ে থাকে, তাহলে আপনাকে অন্য একটি নাম খুঁজে বের করতে হবে এবং publish করার জন্য new name টি ব্যবহার করতে Cargo.toml ফাইলের [package] section-এর অধীনে name field টি edit করতে হবে, এইভাবে:
Filename: Cargo.toml
[package]
name = "guessing_game"
এমনকি যদি আপনি একটি unique name বেছে নিয়ে থাকেন, তাহলেও আপনি যখন এই সময়ে crate publish করার জন্য cargo publish চালান, তখন আপনি একটি warning এবং তারপর একটি error পাবেন:
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error (status 400 Bad Request): missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for more information on configuring these fields
এই error-টির কারণ হল আপনি কিছু crucial information missing রেখেছেন: একটি description এবং license প্রয়োজন যাতে লোকেরা জানতে পারে আপনার crate কী করে এবং কোন শর্তে তারা এটি ব্যবহার করতে পারে। Cargo.toml-এ, একটি description যোগ করুন যা শুধুমাত্র একটি বা দুটি বাক্য, কারণ এটি আপনার crate-এর সাথে search result-এ প্রদর্শিত হবে। License field-এর জন্য, আপনাকে একটি লাইসেন্স শনাক্তকারী মান দিতে হবে। Linux Foundation’s Software Package Data Exchange (SPDX) আপনি এই value-টির জন্য যে identifier গুলো ব্যবহার করতে পারেন সেগুলোর তালিকা করে। উদাহরণস্বরূপ, আপনি যদি specify করতে চান যে আপনি MIT লাইসেন্স ব্যবহার করে আপনার crate লাইসেন্স করেছেন, তাহলে MIT identifier যোগ করুন:
Filename: Cargo.toml
[package]
name = "guessing_game"
license = "MIT"
আপনি যদি এমন একটি লাইসেন্স ব্যবহার করতে চান যা SPDX-এ নেই, তাহলে আপনাকে সেই লাইসেন্সের text একটি ফাইলে রাখতে হবে, ফাইলটিকে আপনার প্রোজেক্টে include করতে হবে এবং তারপর license key ব্যবহার করার পরিবর্তে সেই ফাইলের নাম specify করতে license-file ব্যবহার করতে হবে।
আপনার প্রোজেক্টের জন্য কোন লাইসেন্স উপযুক্ত সে সম্পর্কে গাইডেন্স এই বইয়ের সুযোগের বাইরে। Rust community-র অনেকে MIT OR Apache-2.0-এর dual license ব্যবহার করে Rust-এর মতোই তাদের প্রোজেক্ট লাইসেন্স করে। এই practice টি প্রদর্শন করে যে আপনি আপনার প্রোজেক্টের জন্য multiple license রাখতে OR দ্বারা separated multiple license identifier-ও specify করতে পারেন।
একটি unique name, version, আপনার description এবং একটি লাইসেন্স যোগ করার সাথে, publish করার জন্য প্রস্তুত একটি প্রোজেক্টের জন্য Cargo.toml ফাইলটি এইরকম হতে পারে:
Filename: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
description = "A fun game where you guess what number the computer has chosen."
license = "MIT OR Apache-2.0"
[dependencies]
অন্যরা যাতে আপনার crate আরও সহজে খুঁজে পেতে এবং ব্যবহার করতে পারে তা নিশ্চিত করতে আপনি যে অন্যান্য metadata specify করতে পারেন Cargo-এর ডকুমেন্টেশন তা describe করে।
Crates.io-তে পাবলিশ করা
এখন যেহেতু আপনি একটি অ্যাকাউন্ট তৈরি করেছেন, আপনার API টোকেন save করেছেন, আপনার crate-এর জন্য একটি নাম বেছে নিয়েছেন এবং প্রয়োজনীয় metadata specify করেছেন, আপনি publish করার জন্য প্রস্তুত! একটি crate publish করা অন্যদের ব্যবহারের জন্য crates.io-তে একটি specific version আপলোড করে।
সতর্ক থাকুন, কারণ একটি publish হল স্থায়ী। Version টি কখনই overwrite করা যাবে না এবং code delete করা যাবে না। Crates.io-এর একটি প্রধান লক্ষ্য হল code-এর একটি permanent archive হিসেবে কাজ করা যাতে crates.io থেকে crate-গুলোর উপর নির্ভর করে এমন সমস্ত প্রোজেক্টের build গুলো কাজ করতে থাকে। Version deletion-এর অনুমতি দিলে সেই লক্ষ্য পূরণ করা অসম্ভব হয়ে যেত। তবে, আপনি কতগুলো crate version publish করতে পারবেন তার কোনো limit নেই।
আবার cargo publish কমান্ডটি চালান। এটি এখন সফল হওয়া উচিত:
$ cargo publish
Updating crates.io index
Packaging guessing_game v0.1.0 (file:///projects/guessing_game)
Verifying guessing_game v0.1.0 (file:///projects/guessing_game)
Compiling guessing_game v0.1.0
(file:///projects/guessing_game/target/package/guessing_game-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
Uploading guessing_game v0.1.0 (file:///projects/guessing_game)
অভিনন্দন! আপনি এখন Rust community-র সাথে আপনার কোড share করেছেন এবং যে কেউ সহজেই তাদের প্রোজেক্টের dependency হিসেবে আপনার crate যোগ করতে পারে।
একটি বিদ্যমান Crate-এর একটি নতুন Version পাবলিশ করা
আপনি যখন আপনার crate-এ পরিবর্তন করেছেন এবং একটি new version release করার জন্য প্রস্তুত, তখন আপনি আপনার Cargo.toml ফাইলে specified version value পরিবর্তন করুন এবং পুনরায় publish করুন। আপনি কী ধরনের পরিবর্তন করেছেন তার উপর ভিত্তি করে একটি উপযুক্ত পরবর্তী version number কী তা decide করতে Semantic Versioning নিয়ম ব্যবহার করুন। তারপর new version আপলোড করতে cargo publish চালান।
cargo yank-এর সাহায্যে Crates.io থেকে Version Deprecate করা
যদিও আপনি একটি crate-এর previous version গুলো remove করতে পারবেন না, আপনি future-এর কোনো প্রোজেক্টকে সেগুলোকে new dependency হিসেবে যোগ করা থেকে আটকাতে পারেন। এটি useful যখন একটি crate version কোনো না কোনো কারণে broken থাকে। এই ধরনের পরিস্থিতিতে, Cargo একটি crate version yank করা support করে।
একটি version yank করা new project গুলোকে সেই version-টির উপর নির্ভর করা থেকে বিরত রাখে এবং সেইসাথে এটির উপর নির্ভর করে এমন সমস্ত existing project গুলোকে continue রাখার অনুমতি দেয়। মূলত, একটি yank-এর অর্থ হল Cargo.lock সহ সমস্ত প্রোজেক্ট break করবে না এবং future-এ generate করা কোনো Cargo.lock ফাইল yank করা version টি ব্যবহার করবে না।
একটি crate-এর একটি version yank করতে, আপনি পূর্বে publish করেছেন এমন crate-টির ডিরেক্টরিতে, cargo yank চালান এবং কোন version টি yank করতে চান তা specify করুন। উদাহরণস্বরূপ, যদি আমরা guessing_game নামের একটি crate-এর version 1.0.1 publish করে থাকি এবং আমরা এটিকে yank করতে চাই, তাহলে guessing_game-এর প্রোজেক্ট ডিরেক্টরিতে আমরা চালাব:
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank guessing_game@1.0.1
কমান্ডে --undo যোগ করে, আপনি একটি yank undo করতে পারেন এবং প্রোজেক্টগুলোকে আবার একটি version-এর উপর নির্ভর করা শুরু করার অনুমতি দিতে পারেন:
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank guessing_game@1.0.1
একটি yank কোনো কোড delete করে না। উদাহরণস্বরূপ, এটি accidentally আপলোড করা গোপনীয়তা delete করতে পারে না। যদি সেটি ঘটে, তাহলে আপনাকে অবশ্যই সেই গোপনীয়তাগুলো immediately reset করতে হবে।
Cargo Workspaces
Chapter 12-এ, আমরা একটি প্যাকেজ তৈরি করেছি যাতে একটি বাইনারি ক্রেট এবং একটি লাইব্রেরি ক্রেট অন্তর্ভুক্ত ছিল। আপনার প্রোজেক্ট develop হওয়ার সাথে সাথে, আপনি হয়তো দেখতে পাবেন যে লাইব্রেরি ক্রেটটি আরও বড় হচ্ছে এবং আপনি আপনার প্যাকেজটিকে আরও multiple library crate-এ split করতে চান। Cargo workspaces নামক একটি feature offer করে যা একসাথে develop করা multiple related package গুলোকে manage করতে সাহায্য করতে পারে।
একটি ওয়ার্কস্পেস তৈরি করা
একটি ওয়ার্কস্পেস হল প্যাকেজগুলোর একটি set যা একই Cargo.lock এবং আউটপুট ডিরেক্টরি share করে। আসুন একটি ওয়ার্কস্পেস ব্যবহার করে একটি প্রোজেক্ট তৈরি করি—আমরা trivial কোড ব্যবহার করব যাতে আমরা ওয়ার্কস্পেসের structure-এর উপর মনোযোগ দিতে পারি। একটি ওয়ার্কস্পেসকে structure করার একাধিক উপায় রয়েছে, তাই আমরা শুধুমাত্র একটি common উপায় দেখাব। আমাদের কাছে একটি বাইনারি এবং দুটি লাইব্রেরি ধারণকারী একটি ওয়ার্কস্পেস থাকবে। বাইনারি, যেটি main functionality provide করবে, দুটি লাইব্রেরির উপর নির্ভর করবে। একটি লাইব্রেরি একটি add_one ফাংশন provide করবে, এবং দ্বিতীয় লাইব্রেরি একটি add_two ফাংশন provide করবে। এই তিনটি crate একই ওয়ার্কস্পেসের অংশ হবে। আমরা ওয়ার্কস্পেসের জন্য একটি নতুন ডিরেক্টরি তৈরি করে শুরু করব:
$ mkdir add
$ cd add
এরপরে, add ডিরেক্টরিতে, আমরা Cargo.toml ফাইলটি তৈরি করি যা সম্পূর্ণ ওয়ার্কস্পেস configure করবে। এই ফাইলটিতে একটি [package] section থাকবে না। পরিবর্তে, এটি একটি [workspace] section দিয়ে শুরু হবে যা আমাদের ওয়ার্কস্পেসে member যোগ করার অনুমতি দেবে। আমরা আমাদের ওয়ার্কস্পেসে Cargo-এর resolver algorithm-এর latest and greatest version ব্যবহার করার জন্য resolver কে "2"-তে set করে রাখি।
Filename: Cargo.toml
[workspace]
resolver = "2"
এরপরে, আমরা add ডিরেক্টরির মধ্যে cargo new চালিয়ে adder বাইনারি ক্রেট তৈরি করব:
$ cargo new adder
Creating binary (application) `adder` package
Adding `adder` as member of workspace at `file:///projects/add`
ওয়ার্কস্পেসের ভিতরে cargo new চালানো স্বয়ংক্রিয়ভাবে newly created প্যাকেজটিকে ওয়ার্কস্পেস Cargo.toml-এর [workspace] ডেফিনিশনে members কী-তে যোগ করে, এইভাবে:
[workspace]
resolver = "2"
members = ["adder"]
এই সময়ে, আমরা cargo build চালিয়ে ওয়ার্কস্পেস build করতে পারি। আপনার add ডিরেক্টরির ফাইলগুলো এইরকম হওয়া উচিত:
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
ওয়ার্কস্পেসের top level-এ একটি target ডিরেক্টরি রয়েছে যেখানে compiled artifact গুলো রাখা হবে; adder প্যাকেজের নিজস্ব target ডিরেক্টরি নেই। এমনকি যদি আমরা adder ডিরেক্টরির ভেতর থেকে cargo build চালাই, তাহলেও compiled artifact গুলো add/adder/target-এর পরিবর্তে add/target-এ থাকবে। Cargo এইভাবে একটি ওয়ার্কস্পেসে target ডিরেক্টরিকে structure করে কারণ একটি ওয়ার্কস্পেসের crate গুলো একে অপরের উপর নির্ভর করে। যদি প্রতিটি crate-এর নিজস্ব target ডিরেক্টরি থাকত, তাহলে প্রতিটি crate-কে তার নিজস্ব target ডিরেক্টরিতে artifact গুলো রাখার জন্য ওয়ার্কস্পেসের প্রতিটি অন্য crate-কে recompile করতে হত। একটি target ডিরেক্টরি share করে, crate গুলো অপ্রয়োজনীয় rebuilding এড়াতে পারে।
ওয়ার্কস্পেসে দ্বিতীয় প্যাকেজ তৈরি করা
এরপরে, আসুন ওয়ার্কস্পেসে আরেকটি মেম্বার প্যাকেজ তৈরি করি এবং এটিকে add_one নাম দিই। Top-level Cargo.toml পরিবর্তন করে members লিস্টে add_one পাথ specify করুন:
Filename: Cargo.toml
[workspace]
resolver = "2"
members = ["adder", "add_one"]
তারপর add_one নামের একটি নতুন লাইব্রেরি ক্রেট generate করুন:
$ cargo new add_one --lib
Creating library `add_one` package
Adding `add_one` as member of workspace at `file:///projects/add`
আপনার add ডিরেক্টরিতে এখন এই ডিরেক্টরি এবং ফাইলগুলো থাকা উচিত:
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Add_one/src/lib.rs ফাইলে, আসুন একটি add_one ফাংশন যোগ করি:
Filename: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}এখন আমরা আমাদের বাইনারি সহ adder প্যাকেজটিকে add_one প্যাকেজের উপর নির্ভর করাতে পারি যেটিতে আমাদের লাইব্রেরি রয়েছে। প্রথমে, আমাদের adder/Cargo.toml-এ add_one-এর উপর একটি পাথ নির্ভরতা যোগ করতে হবে।
Filename: adder/Cargo.toml
[dependencies]
add_one = { path = "../add_one" }
Cargo ধরে নেয় না যে একটি ওয়ার্কস্পেসের crate গুলো একে অপরের উপর নির্ভর করবে, তাই আমাদের dependency relationship গুলো সম্পর্কে explicit হতে হবে।
এরপরে, আসুন adder ক্রেটে add_one ক্রেট থেকে add_one ফাংশনটি ব্যবহার করি। Adder/src/main.rs ফাইলটি খুলুন এবং main ফাংশন পরিবর্তন করে add_one ফাংশনটিকে কল করুন, যেমনটি Listing 14-7-এ রয়েছে।
{{#rustdoc_include ../listings/ch14-more-about-cargo/listing-14-7/add/adder/src/main.rs}}Top-level add ডিরেক্টরিতে cargo build চালিয়ে ওয়ার্কস্পেস build করি!
$ cargo build
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.22s
Add ডিরেক্টরি থেকে বাইনারি ক্রেট চালানোর জন্য, আমরা -p আর্গুমেন্ট এবং প্যাকেজের নাম cargo run-এর সাথে ব্যবহার করে ওয়ার্কস্পেসের কোন প্যাকেজটি চালাতে চাই তা specify করতে পারি:
$ cargo run -p adder
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/adder`
Hello, world! 10 plus one is 11!
এটি adder/src/main.rs-এর কোড চালায়, যেটি add_one ক্রেটের উপর নির্ভর করে।
ওয়ার্কস্পেসে একটি External Package-এর উপর নির্ভর করা
লক্ষ্য করুন যে ওয়ার্কস্পেসের top level-এ শুধুমাত্র একটি Cargo.lock ফাইল রয়েছে, প্রতিটি crate-এর ডিরেক্টরিতে Cargo.lock থাকার পরিবর্তে। এটি নিশ্চিত করে যে সমস্ত crate সমস্ত dependency-এর একই version ব্যবহার করছে। যদি আমরা adder/Cargo.toml এবং add_one/Cargo.toml ফাইলগুলোতে rand প্যাকেজ যোগ করি, তাহলে Cargo সেগুলোর উভয়কেই rand-এর একটি version-এ resolve করবে এবং সেটিকে একটি Cargo.lock-এ record করবে। ওয়ার্কস্পেসের সমস্ত crate-কে একই dependency ব্যবহার করা মানে হল crate গুলো সব সময় একে অপরের সাথে compatible হবে। আসুন add_one/Cargo.toml ফাইলের [dependencies] section-এ rand crate যোগ করি যাতে আমরা add_one crate-এ rand crate ব্যবহার করতে পারি:
Filename: add_one/Cargo.toml
[dependencies]
rand = "0.8.5"
আমরা এখন add_one/src/lib.rs ফাইলে use rand; যোগ করতে পারি, এবং add ডিরেক্টরিতে cargo build চালিয়ে সম্পূর্ণ ওয়ার্কস্পেস build করলে rand crate টি আসবে এবং compile হবে। আমরা একটি warning পাব কারণ আমরা scope-এ আনা rand-কে refer করছি না:
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling add_one v0.1.0 (file:///projects/add/add_one)
warning: unused import: `rand`
--> add_one/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `add_one` (lib) generated 1 warning (run `cargo fix --lib -p add_one` to apply 1 suggestion)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.95s
Top-level Cargo.lock-এ এখন add_one-এর rand-এর উপর dependency সম্পর্কে তথ্য রয়েছে। যাইহোক, যদিও rand ওয়ার্কস্পেসের কোথাও ব্যবহার করা হয়েছে, তবুও আমরা ওয়ার্কস্পেসের অন্যান্য crate-গুলোতে এটি ব্যবহার করতে পারব না যতক্ষণ না আমরা তাদের Cargo.toml ফাইলগুলোতেও rand যোগ করি। উদাহরণস্বরূপ, যদি আমরা adder প্যাকেজের জন্য adder/src/main.rs ফাইলে use rand; যোগ করি, তাহলে আমরা একটি error পাব:
$ cargo build
--snip--
Compiling adder v0.1.0 (file:///projects/add/adder)
error[E0432]: unresolved import `rand`
--> adder/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
এটি ঠিক করতে, adder প্যাকেজের জন্য Cargo.toml ফাইলটি edit করুন এবং indicate করুন যে rand এটির জন্যও একটি dependency। Adder প্যাকেজ build করলে Cargo.lock-এ adder-এর জন্য dependency-এর list-এ rand যোগ হবে, কিন্তু rand-এর কোনো additional copy ডাউনলোড হবে না। Cargo নিশ্চিত করবে যে ওয়ার্কস্পেসের প্রতিটি প্যাকেজের প্রতিটি crate rand প্যাকেজ ব্যবহার করে একই version ব্যবহার করবে যতক্ষণ না তারা rand-এর compatible version specify করে, আমাদের জায়গা বাঁচাবে এবং নিশ্চিত করবে যে ওয়ার্কস্পেসের crate গুলো একে অপরের সাথে compatible হবে।
যদি ওয়ার্কস্পেসের crate গুলো একই dependency-এর incompatible version specify করে, তাহলে Cargo সেগুলোর প্রত্যেকটিকে resolve করবে, কিন্তু তবুও যতটা সম্ভব কম version resolve করার চেষ্টা করবে।
ওয়ার্কস্পেসে একটি টেস্ট যোগ করা
আরেকটি enhancement-এর জন্য, আসুন add_one crate-এর মধ্যে add_one::add_one ফাংশনের একটি test যোগ করি:
Filename: add_one/src/lib.rs
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}এখন top-level add ডিরেক্টরিতে cargo test চালান। এইরকম structure করা একটি ওয়ার্কস্পেসে cargo test চালালে ওয়ার্কস্পেসের সমস্ত crate-এর জন্য test গুলো চলবে:
$ cargo test
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.20s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/adder-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
আউটপুটের প্রথম section টি দেখায় যে add_one ক্রেটের it_works test টি pass করেছে। পরবর্তী section টি দেখায় যে adder ক্রেটে zero test পাওয়া গেছে, এবং তারপর শেষ section টি দেখায় add_one ক্রেটে zero ডকুমেন্টেশন test পাওয়া গেছে।
আমরা top-level ডিরেক্টরি থেকে -p flag ব্যবহার করে এবং যে crate-টি test করতে চাই তার নাম specify করে একটি ওয়ার্কস্পেসের একটি particular crate-এর জন্য test চালাতে পারি:
$ cargo test -p add_one
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
এই আউটপুটটি দেখায় cargo test শুধুমাত্র add_one ক্রেটের জন্য test গুলো চালিয়েছে এবং adder ক্রেটের test গুলো চালায়নি।
আপনি যদি ওয়ার্কস্পেসের crate গুলোকে crates.io-তে publish করেন, তাহলে ওয়ার্কস্পেসের প্রতিটি crate-কে আলাদাভাবে publish করতে হবে। Cargo test-এর মতোই, আমরা -p flag ব্যবহার করে এবং যে crate-টি publish করতে চাই তার নাম specify করে আমাদের ওয়ার্কস্পেসের একটি particular crate publish করতে পারি।
অতিরিক্ত practice-এর জন্য, add_one crate-এর মতোই এই ওয়ার্কস্পেসে একটি add_two crate যোগ করুন!
আপনার প্রোজেক্ট যত বাড়বে, ওয়ার্কস্পেস ব্যবহার করার কথা বিবেচনা করুন: কোডের একটি বড় অংশের চেয়ে ছোট, individual component গুলো বোঝা সহজ। উপরন্তু, crate গুলোকে একটি ওয়ার্কস্পেসে রাখলে crate-গুলোর মধ্যে coordination সহজতর হতে পারে যদি সেগুলো প্রায়শই একই সময়ে পরিবর্তন করা হয়।
cargo install-এর সাহায্যে Crates.io থেকে বাইনারি ইন্সটল করা
Cargo install কমান্ড আপনাকে locally বাইনারি ক্রেট ইন্সটল এবং ব্যবহার করার অনুমতি দেয়। এটি সিস্টেম প্যাকেজগুলোকে replace করার উদ্দেশ্যে নয়; এটি Rust ডেভেলপারদের জন্য crates.io-তে অন্যদের share করা টুল ইন্সটল করার একটি সুবিধাজনক উপায়। মনে রাখবেন যে আপনি শুধুমাত্র সেই প্যাকেজগুলো ইন্সটল করতে পারবেন যেগুলোর বাইনারি টার্গেট রয়েছে। একটি বাইনারি টার্গেট হল রানযোগ্য প্রোগ্রাম যা তৈরি হয় যদি ক্রেটটিতে একটি src/main.rs ফাইল বা বাইনারি হিসেবে specified অন্য কোনো ফাইল থাকে, লাইব্রেরি টার্গেটের বিপরীতে যা নিজে থেকে রানযোগ্য নয় কিন্তু অন্যান্য প্রোগ্রামের মধ্যে include করার জন্য উপযুক্ত। সাধারণত, crate গুলোতে README ফাইলে তথ্য থাকে যে একটি crate লাইব্রেরি, বাইনারি টার্গেট আছে, নাকি দুটোই।
Cargo install দিয়ে ইন্সটল করা সমস্ত বাইনারিগুলো ইন্সটলেশন রুটের bin ফোল্ডারে store করা হয়। আপনি যদি rustup.rs ব্যবহার করে Rust ইন্সটল করে থাকেন এবং কোনো কাস্টম কনফিগারেশন না থাকে, তাহলে এই ডিরেক্টরি হবে $HOME/.cargo/bin। আপনি cargo install দিয়ে ইন্সটল করা প্রোগ্রামগুলো চালাতে সক্ষম হওয়ার জন্য নিশ্চিত করুন যে ডিরেক্টরিটি আপনার $PATH-এ রয়েছে।
উদাহরণস্বরূপ, Chapter 12-এ আমরা উল্লেখ করেছি যে ফাইল সার্চ করার জন্য ripgrep নামক grep টুলের একটি Rust ইমপ্লিমেন্টেশন রয়েছে। Ripgrep ইন্সটল করতে, আমরা নিম্নলিখিতটি চালাতে পারি:
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v14.1.1
Downloaded 1 crate (213.6 KB) in 0.40s
Installing ripgrep v14.1.1
--snip--
Compiling grep v0.3.2
Finished `release` profile [optimized + debuginfo] target(s) in 6.73s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v14.1.1` (executable `rg`)
আউটপুটের শেষের দিক থেকে দ্বিতীয় লাইনটি ইন্সটল করা বাইনারির location এবং নাম দেখায়, যেটি ripgrep-এর ক্ষেত্রে rg। যতক্ষণ ইন্সটলেশন ডিরেক্টরি আপনার $PATH-এ রয়েছে, যেমনটি আগে উল্লেখ করা হয়েছে, ততক্ষণ আপনি rg --help চালাতে পারেন এবং ফাইল সার্চ করার জন্য একটি দ্রুততর, rustier টুল ব্যবহার করা শুরু করতে পারেন!
কাস্টম কমান্ড সহ Cargo-কে প্রসারিত করা
Cargo এমনভাবে ডিজাইন করা হয়েছে যাতে আপনি Cargo-কে modify না করে নতুন সাবকমান্ড দিয়ে এটিকে প্রসারিত করতে পারেন। যদি আপনার $PATH-এ cargo-something নামের একটি বাইনারি থাকে, তাহলে আপনি এটিকে এমনভাবে চালাতে পারেন যেন এটি একটি Cargo সাবকমান্ড, cargo something চালিয়ে। আপনি যখন cargo --list চালান তখন এইরকম কাস্টম কমান্ডগুলোও list করা হয়। Cargo install ব্যবহার করে extension গুলো ইন্সটল করতে এবং তারপর বিল্ট-ইন Cargo টুলগুলোর মতোই চালাতে পারা Cargo-র ডিজাইনের একটি অত্যন্ত সুবিধাজনক সুবিধা!
সারসংক্ষেপ
Cargo এবং crates.io-এর সাথে কোড share করা হল Rust ইকোসিস্টেমকে অনেকগুলি different task-এর জন্য useful করে তোলার অংশ। Rust-এর standard library ছোট এবং stable, কিন্তু crate গুলো share করা, ব্যবহার করা এবং improve করা সহজ, language-এর চেয়ে আলাদা টাইমলাইনে। Crates.io-তে আপনার কাছে useful কোড share করতে দ্বিধা করবেন না; সম্ভবত এটি অন্য কারও জন্যও useful হবে!
Smart Pointers
একটি পয়েন্টার হল একটি variable-এর জন্য একটি general concept যাতে মেমরির একটি address থাকে। এই address টি অন্য কোনো ডেটাকে refer করে, বা "পয়েন্ট করে"। Rust-এ সবচেয়ে common ধরনের পয়েন্টার হল একটি reference, যেটি সম্পর্কে আপনি Chapter 4-এ শিখেছেন। Reference গুলো & চিহ্ন দ্বারা নির্দেশিত হয় এবং যে value-টিকে point করে সেটিকে borrow করে। ডেটা refer করা ছাড়া এগুলোর অন্য কোনো special capabilities নেই এবং কোনো overhead নেই।
অন্যদিকে, স্মার্ট পয়েন্টারগুলো হল ডেটা স্ট্রাকচার যা পয়েন্টারের মতো কাজ করে কিন্তু অতিরিক্ত মেটাডেটা এবং capabilities-ও রাখে। স্মার্ট পয়েন্টারের concept টি Rust-এর জন্য unique নয়: স্মার্ট পয়েন্টারগুলোর উৎপত্তি C++-এ এবং অন্যান্য language-এও রয়েছে। Rust-এর standard library-তে বিভিন্ন ধরনের স্মার্ট পয়েন্টার define করা আছে যা reference-এর মাধ্যমে provide করা functionality-এর চেয়েও বেশি কিছু provide করে। General concept টি explore করার জন্য, আমরা স্মার্ট পয়েন্টারের কয়েকটি ভিন্ন উদাহরণ দেখব, যার মধ্যে একটি reference counting স্মার্ট পয়েন্টার type রয়েছে। এই পয়েন্টারটি আপনাকে ডেটার একাধিক owner রাখার অনুমতি দেয় owner-এর সংখ্যা ট্র্যাক করে এবং যখন কোনো owner অবশিষ্ট থাকে না, তখন ডেটা clean up করে।
Rust-এর, ownership এবং borrowing-এর concept সহ, reference এবং স্মার্ট পয়েন্টারের মধ্যে একটি additional পার্থক্য রয়েছে: যেখানে reference গুলো শুধুমাত্র ডেটা borrow করে, সেখানে অনেক ক্ষেত্রে স্মার্ট পয়েন্টারগুলো যে ডেটা point করে তার owner হয়।
যদিও আমরা সেগুলোকে সেই সময়ে সেই নামে ডাকিনি, আমরা ইতিমধ্যেই এই বইয়ে কয়েকটি স্মার্ট পয়েন্টারের সম্মুখীন হয়েছি, যার মধ্যে Chapter 8-এর String এবং Vec<T> রয়েছে। এই দুটি type-কেই স্মার্ট পয়েন্টার হিসেবে গণ্য করা হয় কারণ তারা কিছু মেমরির owner এবং আপনাকে এটিকে manipulate করার অনুমতি দেয়। এগুলোর metadata এবং extra capabilities বা guarantee-ও রয়েছে। উদাহরণস্বরূপ, String তার capacity-কে metadata হিসেবে store করে এবং এর ডেটা সব সময় valid UTF-8 হবে তা নিশ্চিত করার additional ability রাখে।
স্মার্ট পয়েন্টারগুলো সাধারণত struct ব্যবহার করে implement করা হয়। একটি ordinary struct-এর বিপরীতে, স্মার্ট পয়েন্টারগুলো Deref এবং Drop trait গুলোকে implement করে। Deref trait-টি স্মার্ট পয়েন্টার struct-এর একটি instance-কে একটি reference-এর মতো আচরণ করার অনুমতি দেয় যাতে আপনি আপনার কোড লিখতে পারেন reference বা স্মার্ট পয়েন্টার উভয়ের সাথেই কাজ করার জন্য। Drop trait আপনাকে সেই কোডটি কাস্টমাইজ করার অনুমতি দেয় যা স্মার্ট পয়েন্টারের একটি instance scope-এর বাইরে চলে গেলে run হয়। এই chapter-এ, আমরা এই দুটি trait নিয়ে আলোচনা করব এবং প্রদর্শন করব কেন সেগুলো স্মার্ট পয়েন্টারগুলোর জন্য important।
যেহেতু স্মার্ট পয়েন্টার প্যাটার্নটি Rust-এ প্রায়শই ব্যবহৃত একটি general design pattern, তাই এই chapter-এ existing সমস্ত স্মার্ট পয়েন্টার cover করা হবে না। অনেক লাইব্রেরির নিজস্ব স্মার্ট পয়েন্টার রয়েছে এবং আপনি নিজেও লিখতে পারেন। আমরা standard library-এর সবচেয়ে common স্মার্ট পয়েন্টারগুলো cover করব:
Box<T>heap-এ value allocate করার জন্যRc<T>, একটি reference counting type যা multiple ownership-এর অনুমতি দেয়Ref<T>এবংRefMut<T>,RefCell<T>-এর মাধ্যমে অ্যাক্সেস করা হয়, এমন একটি type যা compile time-এর পরিবর্তে runtime-এ borrowing rule গুলো enforce করে
এছাড়াও, আমরা ইন্টেরিয়র মিউটেবিলিটি প্যাটার্নটি কভার করব যেখানে একটি immutable type একটি ভেতরের value mutate করার জন্য একটি API expose করে। আমরা reference cycle নিয়েও আলোচনা করব: কীভাবে সেগুলো মেমরি লিক করতে পারে এবং কীভাবে সেগুলো প্রতিরোধ করা যায়।
আসুন শুরু করা যাক!
Box<T> ব্যবহার করে Heap-এর ডেটার দিকে পয়েন্ট করা
সবচেয়ে straightforward স্মার্ট পয়েন্টার হল একটি box, যার টাইপ লেখা হয় Box<T>। Box গুলো আপনাকে stack-এর পরিবর্তে heap-এ ডেটা store করার অনুমতি দেয়। Stack-এ যা অবশিষ্ট থাকে তা হল heap ডেটার পয়েন্টার। Stack এবং heap-এর মধ্যে পার্থক্য পর্যালোচনা করতে Chapter 4 দেখুন।
Box-গুলোর পারফরম্যান্স ওভারহেড নেই, stack-এর পরিবর্তে heap-এ তাদের ডেটা store করা ছাড়া। কিন্তু সেগুলোর অনেক extra capabilities-ও নেই। আপনি সেগুলোকে প্রায়শই এই পরিস্থিতিতে ব্যবহার করবেন:
- যখন আপনার কাছে এমন একটি টাইপ থাকে যার আকার compile time-এ জানা যায় না এবং আপনি সেই টাইপের একটি value এমন একটি context-এ ব্যবহার করতে চান যার জন্য একটি exact আকারের প্রয়োজন
- যখন আপনার কাছে প্রচুর পরিমাণে ডেটা থাকে এবং আপনি ownership transfer করতে চান কিন্তু নিশ্চিত করতে চান যে ডেটা copy করা হবে না
- যখন আপনি একটি value-র owner হতে চান এবং আপনি শুধুমাত্র এটি একটি particular trait implement করে এমন একটি টাইপ কিনা তা নিয়ে চিন্তা করেন, specific টাইপের কিনা তা নয়
আমরা প্রথম পরিস্থিতিটি "বক্স সহ পুনরাবৃত্তিমূলক প্রকারগুলিকে সক্ষম করা" বিভাগে প্রদর্শন করব। দ্বিতীয় ক্ষেত্রে, প্রচুর পরিমাণে ডেটার ownership transfer করতে দীর্ঘ সময় লাগতে পারে কারণ ডেটা stack-এর চারপাশে copy করা হয়। এই পরিস্থিতিতে পারফরম্যান্স improve করার জন্য, আমরা box-এ heap-এর উপর প্রচুর পরিমাণে ডেটা store করতে পারি। তারপর, stack-এর চারপাশে শুধুমাত্র অল্প পরিমাণ পয়েন্টার ডেটা copy করা হয়, যেখানে এটি যে ডেটা refer করে তা heap-এর একটি স্থানে থাকে। তৃতীয় ক্ষেত্রটি trait object নামে পরিচিত, এবং Chapter 18-এ একটি সম্পূর্ণ বিভাগ, "ভিন্ন প্রকারের মানের জন্য অনুমতি দেয় এমন Trait অবজেক্ট ব্যবহার করা," শুধুমাত্র সেই বিষয়ে আলোচনা করা হয়েছে। তাই আপনি এখানে যা শিখবেন তা Chapter 18-এ আবার প্রয়োগ করবেন!
Heap-এ ডেটা Store করার জন্য একটি Box<T> ব্যবহার করা
আমরা Box<T>-এর জন্য heap storage use case নিয়ে আলোচনা করার আগে, আমরা syntax এবং Box<T>-এর মধ্যে stored value-গুলোর সাথে কীভাবে ইন্টারঅ্যাক্ট করতে হয় তা দেখব।
Listing 15-1 দেখানো হয়েছে কিভাবে heap-এ একটি i32 value store করতে একটি box ব্যবহার করতে হয়:
fn main() { let b = Box::new(5); println!("b = {b}"); }
আমরা b variable-টিকে একটি Box-এর value হিসেবে define করি যা 5 value-টির দিকে point করে, যেটি heap-এ allocate করা হয়েছে। এই প্রোগ্রামটি b = 5 প্রিন্ট করবে; এই ক্ষেত্রে, আমরা box-এর ডেটা অ্যাক্সেস করতে পারি একইভাবে যেভাবে আমরা করতাম যদি এই ডেটা stack-এ থাকত। যেকোনো owned value-এর মতোই, যখন একটি box scope-এর বাইরে চলে যায়, যেমন b main-এর শেষে করে, তখন এটিকে deallocate করা হবে। Deallocation টি box (স্ট্যাকে সংরক্ষিত) এবং এটি যে ডেটার দিকে point করে (heap-এ সংরক্ষিত) উভয়ের জন্যই ঘটে।
Heap-এ একটি single value রাখা খুব useful নয়, তাই আপনি এভাবে প্রায়শই নিজে থেকে box ব্যবহার করবেন না। Stack-এ একটি single i32-এর মতো value থাকা, যেখানে সেগুলো default ভাবে store করা হয়, বেশিরভাগ পরিস্থিতিতে বেশি উপযুক্ত। আসুন এমন একটি ক্ষেত্র দেখি যেখানে box গুলো আমাদের এমন type define করার অনুমতি দেয় যেগুলো আমাদের কাছে box না থাকলে define করার অনুমতি থাকত না।
Box-এর সাহায্যে Recursive Type গুলো Enable করা
একটি recursive type-এর value-র অংশ হিসেবে একই type-এর অন্য value থাকতে পারে। Recursive type গুলো একটি সমস্যা তৈরি করে কারণ, compile time-এ, Rust-কে জানতে হবে একটি type কতটুকু জায়গা নেয়। যাইহোক, recursive type-এর value-গুলোর nesting তাত্ত্বিকভাবে অসীমভাবে চলতে পারে, তাই Rust জানতে পারে না value-টির জন্য কতটুকু জায়গা প্রয়োজন। যেহেতু box-গুলোর একটি known আকার রয়েছে, তাই আমরা recursive type definition-এ একটি box insert করে recursive type গুলোকে enable করতে পারি।
Recursive type-এর একটি উদাহরণ হিসেবে, আসুন cons list explore করি। এটি functional programming language-গুলোতে commonly পাওয়া একটি ডেটা টাইপ। আমরা যে cons list type টি define করব সেটি recursion ছাড়া straightforward; অতএব, আমরা যে উদাহরণের সাথে কাজ করব তার concept গুলো useful হবে যে কোনো সময় আপনি recursive type-এর সাথে জড়িত আরও complex পরিস্থিতিতে পড়লে।
Cons List সম্পর্কে আরও তথ্য
একটি cons list হল একটি ডেটা স্ট্রাকচার যা Lisp প্রোগ্রামিং ভাষা এবং এর উপভাষাগুলো থেকে এসেছে এবং এটি nested pair দিয়ে তৈরি, এবং এটি Lisp-এর linked list-এর সংস্করণ। এর নামটি Lisp-এর cons ফাংশন (সংক্ষেপে "construct ফাংশন") থেকে এসেছে যা তার দুটি আর্গুমেন্ট থেকে একটি new pair তৈরি করে। একটি value এবং অন্য একটি pair নিয়ে গঠিত একটি pair-এ cons কল করে, আমরা recursive pair দিয়ে তৈরি cons list তৈরি করতে পারি।
উদাহরণস্বরূপ, এখানে 1, 2, 3 তালিকা ধারণকারী একটি cons list-এর একটি pseudocode উপস্থাপনা রয়েছে যেখানে প্রতিটি pair বন্ধনীতে রয়েছে:
(1, (2, (3, Nil)))
একটি cons list-এর প্রতিটি item-এ দুটি element রয়েছে: current item-এর value এবং next item। List-এর শেষ item-টিতে শুধুমাত্র Nil নামক একটি value রয়েছে যেখানে কোনো next item নেই। একটি cons list recursively cons ফাংশন কল করে তৈরি করা হয়। Recursion-এর base case বোঝানোর জন্য canonical নামটি হল Nil। মনে রাখবেন যে এটি Chapter 6-এ আলোচিত "null" বা "nil" concept-এর মতো নয়, যেটি একটি invalid বা অনুপস্থিত value।
Cons list Rust-এ commonly ব্যবহৃত ডেটা স্ট্রাকচার নয়। বেশিরভাগ সময় যখন আপনার Rust-এ item-গুলোর একটি list থাকে, তখন Vec<T> ব্যবহার করা একটি ভাল পছন্দ। অন্যান্য, আরও complex recursive data type গুলো বিভিন্ন পরিস্থিতিতে useful, কিন্তু এই chapter-এ cons list দিয়ে শুরু করে, আমরা explore করতে পারি কীভাবে box গুলো আমাদের খুব বেশি বিভ্রান্তি ছাড়াই একটি recursive data type define করতে দেয়।
Listing 15-2 একটি cons list-এর জন্য একটি enum definition ধারণ করে। মনে রাখবেন যে এই কোডটি এখনও compile হবে না কারণ List type-টির একটি known আকার নেই, যা আমরা প্রদর্শন করব।
enum List {
Cons(i32, List),
Nil,
}
fn main() {}দ্রষ্টব্য: আমরা এই উদাহরণের উদ্দেশ্যে শুধুমাত্র
i32value ধারণ করে এমন একটি cons list implement করছি। আমরা এটিকে জেনেরিক ব্যবহার করে implement করতে পারতাম, যেমনটি আমরা Chapter 10-এ আলোচনা করেছি, একটি cons list type define করতে যা যেকোনো type-এর value store করতে পারে।
1, 2, 3 তালিকা store করার জন্য List type ব্যবহার করা Listing 15-3-এর কোডের মতো হবে:
enum List {
Cons(i32, List),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}প্রথম Cons value-টিতে 1 এবং আরেকটি List value রয়েছে। এই List value-টি হল আরেকটি Cons value যাতে 2 এবং আরেকটি List value রয়েছে। এই List value-টি আরও একটি Cons value যাতে 3 এবং একটি List value রয়েছে, যেটি অবশেষে Nil, non-recursive variant যা list-এর শেষ নির্দেশ করে।
যদি আমরা Listing 15-3-এর কোড compile করার চেষ্টা করি, তাহলে আমরা Listing 15-4-এ দেখানো error টি পাব:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
error[E0391]: cycle detected when computing when `List` needs drop
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `List` needs drop again
= note: cycle used when computing whether `List` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
Error টি দেখায় যে এই type-টির "অসীম আকার" রয়েছে। কারণ হল যে আমরা List-কে এমন একটি variant দিয়ে define করেছি যেটি recursive: এটি সরাসরি নিজের আরেকটি value ধারণ করে। ফলস্বরূপ, Rust বুঝতে পারে না যে একটি List value store করার জন্য তার কতটুকু জায়গা প্রয়োজন। আসুন ভেঙে দেখি কেন আমরা এই error টি পাই। প্রথমে, আমরা দেখব কিভাবে Rust decide করে যে এটি একটি non-recursive type-এর value store করার জন্য কতটুকু জায়গা প্রয়োজন।
একটি Non-Recursive Type-এর আকার গণনা করা
Chapter 6-এ enum definition নিয়ে আলোচনা করার সময় আমরা Listing 6-2-তে define করা Message enum-টি স্মরণ করি:
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() {}
একটি Message value-এর জন্য কতটা জায়গা allocate করতে হবে তা নির্ধারণ করতে, Rust প্রতিটি variant-এর মধ্যে দিয়ে যায় এটা দেখতে যে কোন variant-টির সবচেয়ে বেশি জায়গা প্রয়োজন। Rust দেখে যে Message::Quit-এর কোনো জায়গার প্রয়োজন নেই, Message::Move-এর দুটি i32 value store করার জন্য যথেষ্ট জায়গা প্রয়োজন, ইত্যাদি। যেহেতু শুধুমাত্র একটি variant ব্যবহার করা হবে, তাই একটি Message value-এর জন্য সবচেয়ে বেশি যে জায়গার প্রয়োজন হবে তা হল এর largest variant store করার জন্য যে জায়গা লাগবে।
Listing 15-2-এর List enum-এর মতো recursive type-এর জন্য Rust কতটা জায়গা প্রয়োজন তা নির্ধারণ করার চেষ্টা করলে কী ঘটে তার সাথে এটি contrast করুন। Compiler Cons variant দেখে শুরু করে, যেটিতে type i32-এর একটি value এবং type List-এর একটি value রয়েছে। অতএব, Cons-এর একটি i32-এর আকারের সমান amount জায়গা এবং একটি List-এর আকারের প্রয়োজন। List type-টির জন্য কতটা মেমরির প্রয়োজন তা বের করতে, compiler variant গুলো দেখে, Cons variant দিয়ে শুরু করে। Cons variant-এ type i32-এর একটি value এবং type List-এর একটি value রয়েছে এবং এই প্রক্রিয়াটি অনির্দিষ্টকালের জন্য চলতে থাকে, যেমনটি Figure 15-1-এ দেখানো হয়েছে।

Figure 15-1: অসীম Cons ভেরিয়েন্ট নিয়ে গঠিত একটি অসীম List
একটি পরিচিত আকারের Recursive Type পেতে Box<T> ব্যবহার করা
যেহেতু Rust recursively define করা type-গুলোর জন্য কতটা জায়গা allocate করতে হবে তা বের করতে পারে না, তাই compiler এই সহায়ক পরামর্শ সহ একটি error দেয়:
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
এই পরামর্শে, "indirection"-এর অর্থ হল সরাসরি একটি value store করার পরিবর্তে, আমাদের data structure পরিবর্তন করে value-টিকে পরোক্ষভাবে store করা উচিত value-টির একটি pointer store করে।
যেহেতু একটি Box<T> হল একটি পয়েন্টার, তাই Rust সব সময় জানে একটি Box<T>-এর জন্য কতটা জায়গা প্রয়োজন: একটি পয়েন্টারের আকার এটি যে ডেটার দিকে point করছে তার পরিমাণের উপর ভিত্তি করে পরিবর্তিত হয় না। এর মানে হল আমরা সরাসরি অন্য একটি List value-এর পরিবর্তে Cons variant-এর ভিতরে একটি Box<T> রাখতে পারি। Box<T> পরবর্তী List value-টির দিকে point করবে যা Cons variant-এর ভিতরে থাকার পরিবর্তে heap-এ থাকবে। ধারণাগতভাবে, আমাদের এখনও একটি list রয়েছে, যা অন্যান্য list ধারণকারী list দিয়ে তৈরি, কিন্তু এই implementation টি এখন item গুলোকে একে অপরের ভিতরে রাখার পরিবর্তে একে অপরের পাশে রাখার মতো।
আমরা Listing 15-2-তে List enum-এর definition এবং Listing 15-3-এ List-এর usage পরিবর্তন করে Listing 15-5-এর কোডে পরিবর্তন করতে পারি, যেটি compile হবে:
enum List { Cons(i32, Box<List>), Nil, } use crate::List::{Cons, Nil}; fn main() { let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil)))))); }
Cons variant-টির একটি i32-এর আকার এবং box-এর পয়েন্টার ডেটা store করার জায়গার প্রয়োজন। Nil variant কোনো value store করে না, তাই এটির Cons variant-এর চেয়ে কম জায়গার প্রয়োজন। আমরা এখন জানি যে কোনো List value একটি i32-এর আকার এবং একটি box-এর পয়েন্টার ডেটার আকার নেবে। একটি box ব্যবহার করে, আমরা অসীম, recursive chain ভেঙে দিয়েছি, তাই compiler একটি List value store করার জন্য প্রয়োজনীয় আকার বের করতে পারে। Figure 15-2 দেখায় এখন Cons variant-টি কেমন দেখাচ্ছে।

Figure 15-2: একটি List যা অসীম আকারের নয় কারণ Cons একটি Box ধারণ করে
Box গুলো শুধুমাত্র indirection এবং heap allocation provide করে; সেগুলোর অন্য কোনো special capabilities নেই, যেমনটি আমরা অন্য স্মার্ট পয়েন্টার টাইপগুলোর সাথে দেখব। সেগুলোর এই special capability গুলোর কারণে হওয়া পারফরম্যান্স ওভারহেডও নেই, তাই cons list-এর মতো ক্ষেত্রগুলোতে সেগুলো useful হতে পারে যেখানে indirection হল একমাত্র feature যা আমাদের প্রয়োজন। আমরা Chapter 18-এ box-গুলোর আরও use case দেখব।
Box<T> type টি একটি স্মার্ট পয়েন্টার কারণ এটি Deref trait implement করে, যা Box<T> value গুলোকে reference-এর মতো treat করার অনুমতি দেয়। যখন একটি Box<T> value scope-এর বাইরে চলে যায়, তখন box যে heap ডেটার দিকে point করছে সেটিও clean up করা হয় Drop trait implementation-এর কারণে। এই দুটি trait আমরা এই chapter-এর বাকি অংশে আলোচনা করব এমন অন্যান্য স্মার্ট পয়েন্টার টাইপগুলোর দ্বারা provide করা functionality-এর জন্য আরও গুরুত্বপূর্ণ হবে। আসুন এই দুটি trait আরও বিশদভাবে explore করি।
Deref Trait-এর সাহায্যে Smart Pointer-গুলোকে সাধারণ রেফারেন্সের মতো ব্যবহার করা
Deref trait implement করার মাধ্যমে আপনি dereference operator *-এর behavior কাস্টমাইজ করতে পারবেন (গুণ বা glob অপারেটরের সাথে বিভ্রান্ত হবেন না)। একটি স্মার্ট পয়েন্টারকে সাধারণ রেফারেন্সের মতো ব্যবহার করার জন্য Deref implement করে, আপনি এমন কোড লিখতে পারেন যা রেফারেন্সে operate করে এবং সেই কোডটি স্মার্ট পয়েন্টারগুলোর সাথেও ব্যবহার করতে পারেন।
আসুন প্রথমে দেখি কিভাবে dereference operator টি regular reference-এর সাথে কাজ করে। তারপর আমরা Box<T>-এর মতো আচরণ করে এমন একটি custom type define করার চেষ্টা করব এবং দেখব কেন dereference operator টি আমাদের newly defined type-এ reference-এর মতো কাজ করে না। আমরা explore করব কিভাবে Deref trait implement করা smart pointer গুলোকে reference-এর মতোই কাজ করতে সক্ষম করে। তারপর আমরা Rust-এর deref coercion feature দেখব এবং এটি কীভাবে আমাদের reference বা smart pointer-এর সাথে কাজ করতে দেয়।
দ্রষ্টব্য: আমরা যে
MyBox<T>টাইপটি তৈরি করতে যাচ্ছি এবং realBox<T>-এর মধ্যে একটি বড় পার্থক্য রয়েছে: আমাদের version-টি heap-এ ডেটা store করবে না। আমরা এই উদাহরণটিকেDeref-এর উপর ফোকাস করছি, তাই ডেটা আসলে কোথায় store করা হয়েছে তা পয়েন্টারের মতো আচরণের চেয়ে কম গুরুত্বপূর্ণ।
পয়েন্টারকে অনুসরণ করে Value-তে যাওয়া
একটি regular reference হল এক ধরনের পয়েন্টার, এবং একটি পয়েন্টারকে অন্য কোথাও store করা একটি value-এর একটি তীরচিহ্ন হিসেবে ভাবা যেতে পারে। Listing 15-6-এ, আমরা একটি i32 value-এর একটি reference তৈরি করি এবং তারপর value-এর reference-টিকে follow করতে dereference operator ব্যবহার করি:
#![allow(unused)] fn main() { {{#rustdoc_include ../listings/ch15-smart-pointers/listing-15-6/src/main.rs}} }
X variable-টি একটি i32 value 5 ধারণ করে। আমরা y-কে x-এর একটি reference-এর সমান set করি। আমরা assert করতে পারি যে x, 5-এর সমান। যাইহোক, যদি আমরা y-এর value সম্পর্কে একটি assertion করতে চাই, তাহলে আমাদের *y ব্যবহার করতে হবে reference-টিকে follow করে যে value-টির দিকে এটি point করছে (তাই dereference) যাতে compiler actual value-টি compare করতে পারে। একবার আমরা y কে dereference করলে, আমরা integer value-টিতে অ্যাক্সেস পাই যেখানে y point করছে যা আমরা 5-এর সাথে compare করতে পারি।
যদি আমরা assert_eq!(5, y); লেখার চেষ্টা করতাম, তাহলে আমরা এই compilation error পেতাম:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider dereferencing here
--> file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/macros/mod.rs:46:35
|
46| if !(*left_val == **right_val) {
| +
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
একটি সংখ্যা এবং একটি সংখ্যার reference-এর মধ্যে তুলনা করার অনুমতি নেই কারণ সেগুলো different type। আমাদের অবশ্যই dereference operator ব্যবহার করতে হবে reference-টিকে follow করে যে value-টির দিকে এটি point করছে।
Box<T>-কে রেফারেন্সের মতো ব্যবহার করা
আমরা Listing 15-6-এর কোডটিকে একটি reference-এর পরিবর্তে একটি Box<T> ব্যবহার করার জন্য পুনরায় লিখতে পারি; Listing 15-7-এ Box<T>-তে ব্যবহৃত dereference operator টি Listing 15-6-এ reference-এ ব্যবহৃত dereference operator-এর মতোই কাজ করে:
fn main() { let x = 5; let y = Box::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Listing 15-7 এবং Listing 15-6-এর মধ্যে প্রধান পার্থক্য হল এখানে আমরা y-কে set করি x-এর value-এর দিকে point করা একটি reference-এর পরিবর্তে x-এর একটি copied value-এর দিকে point করা একটি Box<T>-এর instance হিসেবে। শেষ assertion-এ, আমরা Box<T>-এর পয়েন্টারকে follow করতে dereference operator ব্যবহার করতে পারি একইভাবে যেভাবে আমরা করতাম যখন y একটি reference ছিল। এরপরে, আমরা explore করব Box<T>-এর মধ্যে কী special যা আমাদের dereference operator ব্যবহার করতে সক্ষম করে, আমাদের নিজস্ব type define করে।
আমাদের নিজস্ব Smart Pointer Define করা
আসুন standard library দ্বারা provide করা Box<T> type-এর মতো একটি স্মার্ট পয়েন্টার তৈরি করি যাতে experience করা যায় কীভাবে স্মার্ট পয়েন্টারগুলো default ভাবে reference থেকে ভিন্ন আচরণ করে। তারপর আমরা দেখব কিভাবে dereference operator ব্যবহার করার ক্ষমতা যোগ করতে হয়।
Box<T> type-টি ultimately একটি element সহ একটি tuple struct হিসাবে define করা হয়, তাই Listing 15-8 একই ভাবে একটি MyBox<T> type define করে। আমরা Box<T>-তে define করা new ফাংশনের সাথে মেলানোর জন্য একটি new ফাংশনও define করব।
#![allow(unused)] fn main() { {{#rustdoc_include ../listings/ch15-smart-pointers/listing-15-8/src/main.rs:here}} }
আমরা MyBox নামক একটি struct define করি এবং একটি জেনেরিক প্যারামিটার T declare করি, কারণ আমরা চাই আমাদের type যেকোনো type-এর value ধারণ করুক। MyBox type হল type T-এর একটি element সহ একটি tuple struct। MyBox::new ফাংশনটি type T-এর একটি প্যারামিটার নেয় এবং একটি MyBox ইন্সট্যান্স রিটার্ন করে যা passed করা value ধারণ করে।
আসুন Listing 15-8-এ Listing 15-7-এর main ফাংশনটি যোগ করার চেষ্টা করি এবং Box<T>-এর পরিবর্তে আমরা define করা MyBox<T> type ব্যবহার করার জন্য এটিকে পরিবর্তন করি। Listing 15-9-এর কোডটি compile হবে না কারণ Rust জানে না কিভাবে MyBox-কে dereference করতে হয়।
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}এখানে resulting compilation error রয়েছে:
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
আমাদের MyBox<T> type-টিকে dereference করা যাবে না কারণ আমরা আমাদের type-এ সেই ক্ষমতা implement করিনি। * অপারেটরের সাহায্যে dereferencing enable করতে, আমরা Deref trait implement করি।
Deref Trait Implement করা
Chapter 10-এর “একটি Type-এ একটি Trait Implement করা”-এ আলোচনা করা হয়েছে, একটি trait implement করার জন্য, আমাদের trait-এর প্রয়োজনীয় method গুলোর জন্য implementation provide করতে হবে। Standard library দ্বারা provide করা Deref trait-এর জন্য আমাদের deref নামক একটি method implement করতে হবে যা self borrow করে এবং ভেতরের ডেটার একটি reference রিটার্ন করে। Listing 15-10 MyBox<T>-এর definition-এ যোগ করার জন্য Deref-এর একটি implementation রয়েছে:
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &Self::Target { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn main() { let x = 5; let y = MyBox::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
Type Target = T; syntax টি Deref trait-এর ব্যবহার করার জন্য একটি associated type define করে। Associated type গুলো হল একটি জেনেরিক প্যারামিটার declare করার একটি সামান্য ভিন্ন উপায়, কিন্তু আপাতত আপনাকে সেগুলো নিয়ে চিন্তা করতে হবে না; আমরা সেগুলো Chapter 20-এ আরও বিশদে আলোচনা করব।
আমরা deref method-এর body-কে &self.0 দিয়ে পূরণ করি যাতে deref সেই value-টির একটি reference রিটার্ন করে যাকে আমরা * অপারেটর দিয়ে অ্যাক্সেস করতে চাই; Chapter 5-এর “বিভিন্ন Type তৈরি করতে Named Field ছাড়া Tuple Struct ব্যবহার করা” বিভাগ থেকে স্মরণ করুন যে .0 একটি tuple struct-এর প্রথম value অ্যাক্সেস করে। Listing 15-9-এর main ফাংশনটি যেটি MyBox<T> value-তে * কল করে এখন compile হয় এবং assertion গুলো pass করে!
Deref trait ছাড়া, compiler শুধুমাত্র & reference গুলোকে dereference করতে পারে। Deref method compiler-কে Deref implement করে এমন যেকোনো type-এর value নেওয়ার এবং deref method call করে একটি & reference পাওয়ার ক্ষমতা দেয় যা এটি কীভাবে dereference করতে হয় তা জানে।
যখন আমরা Listing 15-9-এ *y enter করেছিলাম, তখন behind the scenes-এ Rust আসলে এই কোডটি চালিয়েছিল:
*(y.deref())Rust * operator-টিকে deref method-এ একটি call এবং তারপর একটি plain dereference দিয়ে প্রতিস্থাপন করে যাতে আমাদের ভাবতে না হয় যে আমাদের deref method call করতে হবে কিনা। এই Rust feature টি আমাদের এমন কোড লিখতে দেয় যা identically function করে, আমাদের কাছে একটি regular reference থাকুক বা Deref implement করে এমন একটি type থাকুক।
Deref method-টি কেন একটি value-এর reference রিটার্ন করে এবং *(y.deref())-এর বন্ধনীর বাইরের plain dereference টি কেন এখনও প্রয়োজনীয়, তার কারণ হল ownership system। যদি deref method টি value-এর reference-এর পরিবর্তে সরাসরি value টি রিটার্ন করত, তাহলে value টি self-এর বাইরে move করা হত। আমরা এই ক্ষেত্রে বা বেশিরভাগ ক্ষেত্রে যেখানে আমরা dereference operator ব্যবহার করি সেখানে MyBox<T>-এর ভেতরের value-টির ownership নিতে চাই না।
মনে রাখবেন যে * operator টি deref method-এ একটি call এবং তারপর * operator-এ একটি call দিয়ে প্রতিস্থাপিত হয় শুধুমাত্র একবার, প্রতিবার যখন আমরা আমাদের কোডে একটি * ব্যবহার করি। যেহেতু * operator-এর substitution infinitely recurse করে না, তাই আমরা i32 type-এর ডেটা পাই, যেটি Listing 15-9-এর assert_eq!-এর 5-এর সাথে মেলে।
Function এবং Method-এর সাথে Implicit Deref Coercion
Deref coercion Deref trait implement করে এমন একটি type-এর reference-কে অন্য type-এর reference-এ convert করে। উদাহরণস্বরূপ, deref coercion &String-কে &str-এ convert করতে পারে কারণ String Deref trait implement করে যাতে এটি &str রিটার্ন করে। Deref coercion হল একটি সুবিধা যা Rust function এবং method-গুলোতে argument-এর উপর perform করে এবং শুধুমাত্র সেই type-গুলোতে কাজ করে যেগুলো Deref trait implement করে। এটি স্বয়ংক্রিয়ভাবে ঘটে যখন আমরা একটি particular type-এর value-এর একটি reference একটি function বা method-এ argument হিসেবে pass করি যা function বা method definition-এর parameter type-এর সাথে মেলে না। Deref method-এ call-গুলোর একটি sequence আমরা provide করা type-টিকে parameter-এর প্রয়োজনীয় type-এ convert করে।
Deref coercion Rust-এ যোগ করা হয়েছিল যাতে function এবং method call লেখার প্রোগ্রামারদের & এবং * দিয়ে অনেকগুলি explicit reference এবং dereference যোগ করার প্রয়োজন না হয়। Deref coercion feature টি আমাদের আরও কোড লিখতে দেয় যা reference বা smart pointer উভয়ের জন্যই কাজ করতে পারে।
Deref coercion কীভাবে কাজ করে তা দেখতে, আসুন Listing 15-8-এ define করা MyBox<T> type-টি এবং Listing 15-10-এ যোগ করা Deref-এর implementation ব্যবহার করি। Listing 15-11 একটি ফাংশনের definition দেখায় যার একটি string slice প্যারামিটার রয়েছে:
fn hello(name: &str) { println!("Hello, {name}!"); } fn main() {}
আমরা hello ফাংশনটিকে argument হিসেবে একটি string slice দিয়ে কল করতে পারি, যেমন উদাহরণস্বরূপ hello("Rust");। Deref coercion MyBox<String> type-এর value-এর reference দিয়ে hello কল করা সম্ভব করে, যেমনটি Listing 15-12-তে দেখানো হয়েছে:
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn hello(name: &str) { println!("Hello, {name}!"); } fn main() { let m = MyBox::new(String::from("Rust")); hello(&m); }
এখানে আমরা hello ফাংশনটিকে &m আর্গুমেন্ট দিয়ে কল করছি, যেটি একটি MyBox<String> value-এর reference। যেহেতু আমরা Listing 15-10-এ MyBox<T>-তে Deref trait implement করেছি, তাই Rust deref কল করে &MyBox<String>-কে &String-এ পরিণত করতে পারে। Standard library String-এ Deref-এর একটি implementation provide করে যা একটি string slice রিটার্ন করে এবং এটি Deref-এর জন্য API ডকুমেন্টেশনে রয়েছে। Rust &String-কে &str-এ পরিণত করতে আবার deref কল করে, যেটি hello ফাংশনের definition-এর সাথে মেলে।
যদি Rust deref coercion implement না করত, তাহলে &MyBox<String> type-এর value দিয়ে hello কল করার জন্য আমাদের Listing 15-12-এর কোডের পরিবর্তে Listing 15-13-এর কোড লিখতে হত।
use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &T { &self.0 } } struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } fn hello(name: &str) { println!("Hello, {name}!"); } fn main() { let m = MyBox::new(String::from("Rust")); hello(&(*m)[..]); }
(*m) MyBox<String>-কে একটি String-এ dereference করে। তারপর & এবং [..] String-এর একটি string slice নেয় যা hello-এর signature-এর সাথে মেলানোর জন্য সম্পূর্ণ string-এর সমান। Deref coercion ছাড়া এই কোডটি এই সমস্ত symbol জড়িত থাকার কারণে পড়তে, লিখতে এবং বুঝতে আরও কঠিন। Deref coercion Rust-কে আমাদের জন্য স্বয়ংক্রিয়ভাবে এই conversion গুলো handle করার অনুমতি দেয়।
যখন জড়িত type গুলোর জন্য Deref trait define করা হয়, তখন Rust type গুলোকে analyze করবে এবং parameter-এর type-এর সাথে মেলানোর জন্য একটি reference পেতে যতবার প্রয়োজন ততবার Deref::deref ব্যবহার করবে। কতবার Deref::deref insert করতে হবে তা compile time-এ resolve করা হয়, তাই deref coercion-এর সুবিধা নেওয়ার জন্য কোনো runtime penalty নেই!
Deref Coercion কীভাবে Mutability-র সাথে ইন্টারঅ্যাক্ট করে
আপনি যেভাবে immutable reference-গুলোতে * operator override করতে Deref trait ব্যবহার করেন, একইভাবে আপনি mutable reference-গুলোতে * operator override করতে DerefMut trait ব্যবহার করতে পারেন।
Rust তিনটি ক্ষেত্রে type এবং trait implementation খুঁজে পেলে deref coercion করে:
&Tথেকে&U-তে যখনT: Deref<Target=U>&mut Tথেকে&mut U-তে যখনT: DerefMut<Target=U>&mut Tথেকে&U-তে যখনT: Deref<Target=U>
প্রথম দুটি ক্ষেত্র একে অপরের মতোই, শুধুমাত্র দ্বিতীয়টি mutability implement করে। প্রথম ক্ষেত্রটি বলে যে যদি আপনার কাছে একটি &T থাকে এবং T কোনো type U-তে Deref implement করে, তাহলে আপনি transparently একটি &U পেতে পারেন। দ্বিতীয় ক্ষেত্রটি বলে যে mutable reference-গুলোর জন্যও একই deref coercion ঘটে।
তৃতীয় ক্ষেত্রটি আরও জটিল: Rust একটি mutable reference-কে একটি immutable reference-এ coerce করবে। কিন্তু এর বিপরীতটি সম্ভব নয়: immutable reference গুলো কখনই mutable reference-এ coerce হবে না। Borrowing rule-গুলোর কারণে, যদি আপনার কাছে একটি mutable reference থাকে, তাহলে সেই mutable reference-টি অবশ্যই সেই ডেটার একমাত্র reference হতে হবে (অন্যথায়, প্রোগ্রামটি compile হবে না)। একটি mutable reference-কে একটি immutable reference-এ convert করা কখনই borrowing rule গুলো ভাঙবে না। একটি immutable reference-কে একটি mutable reference-এ convert করার জন্য প্রয়োজন হবে যে initial immutable reference-টি সেই ডেটার একমাত্র immutable reference, কিন্তু borrowing rule গুলো সেটির গ্যারান্টি দেয় না। অতএব, Rust এই assumption করতে পারে না যে একটি immutable reference-কে একটি mutable reference-এ convert করা সম্ভব।
Drop Trait-এর সাহায্যে Cleanup-এর সময় কোড চালানো
স্মার্ট পয়েন্টার প্যাটার্নের জন্য গুরুত্বপূর্ণ দ্বিতীয় trait টি হল Drop, যা আপনাকে কাস্টমাইজ করতে দেয় যখন একটি value scope-এর বাইরে চলে যেতে চলেছে তখন কী ঘটবে। আপনি যেকোনো টাইপের জন্য Drop trait-এর একটি implementation provide করতে পারেন এবং সেই কোডটি ফাইল বা নেটওয়ার্ক কানেকশনের মতো রিসোর্স release করতে ব্যবহার করা যেতে পারে।
আমরা স্মার্ট পয়েন্টারগুলোর context-এ Drop introduce করছি কারণ Drop trait-এর functionality প্রায় সব সময় একটি স্মার্ট পয়েন্টার implement করার সময় ব্যবহার করা হয়। উদাহরণস্বরূপ, যখন একটি Box<T> ড্রপ করা হয়, তখন এটি heap-এর সেই space-টি deallocate করবে যেখানে box টি point করছে।
কিছু language-এ, কিছু type-এর জন্য, প্রোগ্রামারকে প্রতিবার সেই type-গুলোর একটি instance ব্যবহার করা শেষ হলে মেমরি বা রিসোর্স free করার জন্য কোড কল করতে হয়। উদাহরণের মধ্যে রয়েছে ফাইল হ্যান্ডেল, সকেট বা লক। যদি তারা ভুলে যায়, তাহলে সিস্টেম ওভারলোড হয়ে যেতে পারে এবং ক্র্যাশ করতে পারে। Rust-এ, আপনি specify করতে পারেন যে একটি value scope-এর বাইরে চলে গেলে একটি particular code-এর অংশ run হবে এবং compiler স্বয়ংক্রিয়ভাবে এই কোডটি insert করবে। ফলস্বরূপ, আপনাকে একটি প্রোগ্রামের সর্বত্র cleanup কোড রাখার বিষয়ে সতর্ক থাকতে হবে না যেখানে একটি particular type-এর instance-এর কাজ শেষ হয়েছে—তবুও আপনি রিসোর্স লিক করবেন না!
আপনি Drop trait implement করে একটি value scope-এর বাইরে চলে গেলে যে কোডটি run হবে তা specify করেন। Drop trait-এর জন্য আপনাকে drop নামক একটি method implement করতে হবে যা self-এর একটি mutable reference নেয়। Rust কখন drop কল করে তা দেখতে, আসুন আপাতত println! স্টেটমেন্ট দিয়ে drop implement করি।
Listing 15-14 একটি CustomSmartPointer struct দেখায় যার একমাত্র কাস্টম functionality হল যে instance টি scope-এর বাইরে চলে গেলে এটি Dropping CustomSmartPointer! প্রিন্ট করবে, এটা দেখানোর জন্য যে Rust কখন drop ফাংশনটি চালায়।
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("my stuff"), }; let d = CustomSmartPointer { data: String::from("other stuff"), }; println!("CustomSmartPointers created."); }
Drop trait টি prelude-এ অন্তর্ভুক্ত, তাই আমাদের এটিকে scope-এ আনার প্রয়োজন নেই। আমরা CustomSmartPointer-এ Drop trait implement করি এবং drop method-এর জন্য একটি implementation provide করি যা println! কল করে। Drop ফাংশনের body হল সেই জায়গা যেখানে আপনি আপনার type-এর একটি instance scope-এর বাইরে চলে গেলে আপনি যে লজিকটি চালাতে চান সেটি রাখবেন। Rust কখন drop কল করবে তা visually প্রদর্শন করার জন্য আমরা এখানে কিছু text প্রিন্ট করছি।
Main-এ, আমরা CustomSmartPointer-এর দুটি instance তৈরি করি এবং তারপর CustomSmartPointers created প্রিন্ট করি। Main-এর শেষে, CustomSmartPointer-এর আমাদের instance গুলো scope-এর বাইরে চলে যাবে এবং Rust আমাদের drop method-এ রাখা কোডটিকে কল করবে, আমাদের final message প্রিন্ট করবে। মনে রাখবেন যে আমাদের explicit ভাবে drop method কল করার প্রয়োজন ছিল না।
যখন আমরা এই প্রোগ্রামটি চালাই, তখন আমরা নিম্নলিখিত আউটপুট দেখতে পাব:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created.
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
Rust স্বয়ংক্রিয়ভাবে আমাদের instance গুলো scope-এর বাইরে চলে গেলে আমাদের জন্য drop কল করেছে, আমরা যে কোড specify করেছি সেটি কল করে। Variable গুলো তাদের তৈরির বিপরীত ক্রমে ড্রপ করা হয়, তাই d-কে c-এর আগে ড্রপ করা হয়েছিল। এই উদাহরণের উদ্দেশ্য হল আপনাকে drop method কীভাবে কাজ করে তার একটি visual guide দেওয়া; সাধারণত আপনি একটি print message-এর পরিবর্তে আপনার type-এর যে cleanup কোড চালানো দরকার তা specify করবেন।
std::mem::drop দিয়ে একটি Value-কে তাড়াতাড়ি Drop করা
দুর্ভাগ্যবশত, স্বয়ংক্রিয় drop functionality disable করা straightforward নয়। Drop disable করা সাধারণত প্রয়োজন হয় না; Drop trait-এর মূল বিষয় হল এটি স্বয়ংক্রিয়ভাবে handle করা হয়। যাইহোক, মাঝে মাঝে, আপনি একটি value তাড়াতাড়ি clean up করতে চাইতে পারেন। একটি উদাহরণ হল যখন স্মার্ট পয়েন্টার ব্যবহার করা হয় যা লক manage করে: আপনি হয়তো drop method-কে force করতে চাইতে পারেন যা লক release করে যাতে একই scope-এর অন্যান্য কোড লকটি acquire করতে পারে। Rust আপনাকে Drop trait-এর drop method ম্যানুয়ালি কল করতে দেয় না; পরিবর্তে আপনাকে standard library দ্বারা provide করা std::mem::drop ফাংশনটি কল করতে হবে যদি আপনি একটি value-কে তার scope-এর শেষের আগে ড্রপ করতে বাধ্য করতে চান।
যদি আমরা Listing 15-14 থেকে main ফাংশনটিকে modify করে Drop trait-এর drop method ম্যানুয়ালি কল করার চেষ্টা করি, যেমনটি Listing 15-15-এ দেখানো হয়েছে, তাহলে আমরা একটি compiler error পাব:
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created.");
c.drop();
println!("CustomSmartPointer dropped before the end of main.");
}যখন আমরা এই কোডটি compile করার চেষ্টা করি, তখন আমরা এই error টি পাব:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 | drop(c);
| +++++ ~
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` (bin "drop-example") due to 1 previous error
এই error message টি বলে যে আমাদের explicit ভাবে drop কল করার অনুমতি নেই। Error message টি destructor শব্দটি ব্যবহার করে, যেটি একটি instance clean up করে এমন একটি ফাংশনের general programming term। একটি destructor একটি constructor-এর অনুরূপ, যা একটি instance তৈরি করে। Rust-এর drop ফাংশনটি হল একটি particular destructor।
Rust আমাদের explicit ভাবে drop কল করতে দেয় না কারণ Rust এখনও স্বয়ংক্রিয়ভাবে main-এর শেষে value-টিতে drop কল করবে। এটি একটি double free error-এর কারণ হবে কারণ Rust একই value দুবার clean up করার চেষ্টা করবে।
আমরা যখন একটি value scope-এর বাইরে চলে যায় তখন drop-এর স্বয়ংক্রিয় insertion disable করতে পারি না এবং আমরা explicit ভাবে drop method কল করতে পারি না। সুতরাং, যদি আমাদের একটি value-কে তাড়াতাড়ি clean up করতে বাধ্য করতে হয়, তাহলে আমরা std::mem::drop ফাংশনটি ব্যবহার করি।
Std::mem::drop ফাংশনটি Drop trait-এর drop method থেকে আলাদা। আমরা এটিকে argument হিসেবে যে value-টিকে force drop করতে চাই সেটি pass করে কল করি। ফাংশনটি prelude-এ রয়েছে, তাই আমরা Listing 15-15-এর main-কে modify করে drop ফাংশনটিকে কল করতে পারি, যেমনটি Listing 15-16-এ দেখানো হয়েছে:
struct CustomSmartPointer { data: String, } impl Drop for CustomSmartPointer { fn drop(&mut self) { println!("Dropping CustomSmartPointer with data `{}`!", self.data); } } fn main() { let c = CustomSmartPointer { data: String::from("some data"), }; println!("CustomSmartPointer created."); drop(c); println!("CustomSmartPointer dropped before the end of main."); }
এই কোডটি run করলে নিম্নলিখিতগুলো প্রিন্ট হবে:
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created.
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main.
Dropping CustomSmartPointer with data `some data`! text টি CustomSmartPointer created. এবং CustomSmartPointer dropped before the end of main. text-এর মধ্যে প্রিন্ট করা হয়েছে, এটি দেখায় যে drop method code-টি সেই সময়ে c-কে drop করার জন্য কল করা হয়েছে।
আপনি cleanup-কে সুবিধাজনক এবং নিরাপদ করতে Drop trait implementation-এ specify করা কোডটি বিভিন্ন উপায়ে ব্যবহার করতে পারেন: উদাহরণস্বরূপ, আপনি এটি ব্যবহার করে আপনার নিজের মেমরি অ্যালোকেটর তৈরি করতে পারেন! Drop trait এবং Rust-এর ownership system-এর সাহায্যে, আপনাকে clean up করার কথা মনে রাখতে হবে না কারণ Rust এটি স্বয়ংক্রিয়ভাবে করে।
ভুলবশত এখনও ব্যবহৃত value গুলো clean up করার ফলে ഉണ്ടാ হওয়া সমস্যাগুলো নিয়ে আপনাকে চিন্তা করতে হবে না: ownership system যা নিশ্চিত করে যে reference গুলো সব সময় valid, তাও নিশ্চিত করে যে drop শুধুমাত্র একবার কল করা হবে যখন value টি আর ব্যবহার করা হবে না।
এখন যেহেতু আমরা Box<T> এবং স্মার্ট পয়েন্টারগুলোর কিছু বৈশিষ্ট্য পরীক্ষা করেছি, আসুন standard library-তে define করা আরও কয়েকটি স্মার্ট পয়েন্টার দেখি।
Rc<T>, Reference Counted Smart Pointer
বেশিরভাগ ক্ষেত্রে, ownership স্পষ্ট: আপনি জানেন কোন variable একটি নির্দিষ্ট value-র owner। যাইহোক, এমন কিছু ক্ষেত্র আছে যখন একটি single value-র একাধিক owner থাকতে পারে। উদাহরণস্বরূপ, graph ডেটা স্ট্রাকচারে, multiple edge একই node-এর দিকে point করতে পারে এবং সেই node-টি conceptually সেই সমস্ত edge-এর owned যেগুলো সেটির দিকে point করে। একটি node-কে clean up করা উচিত নয় যতক্ষণ না এটির দিকে point করা কোনো edge না থাকে এবং তাই কোনো owner না থাকে।
আপনাকে Rust টাইপ Rc<T> ব্যবহার করে explicitly multiple ownership enable করতে হবে, যেটি reference counting-এর জন্য একটি abbreviation। Rc<T> টাইপ একটি value-তে reference-এর সংখ্যা ট্র্যাক করে যাতে value টি এখনও ব্যবহারে আছে কিনা তা নির্ধারণ করা যায়। যদি একটি value-তে zero reference থাকে, তাহলে কোনো reference invalid না করে value টি clean up করা যেতে পারে।
Rc<T>-কে একটি family room-এর একটি TV-র মতো কল্পনা করুন। যখন একজন ব্যক্তি TV দেখার জন্য প্রবেশ করেন, তখন তারা এটি চালু করেন। অন্যরা ঘরে এসে TV দেখতে পারে। যখন শেষ ব্যক্তি ঘর ছেড়ে চলে যায়, তখন তারা TV বন্ধ করে দেয় কারণ এটি আর ব্যবহার করা হচ্ছে না। যদি অন্য কেউ TV দেখার সময় কেউ TV বন্ধ করে দেয়, তাহলে অবশিষ্ট TV দর্শকদের মধ্যে হট্টগোল হবে!
আমরা Rc<T> টাইপ ব্যবহার করি যখন আমরা আমাদের প্রোগ্রামের multiple part-এর read করার জন্য heap-এ কিছু ডেটা allocate করতে চাই এবং আমরা compile time-এ নির্ধারণ করতে পারি না যে কোন অংশটি ডেটা ব্যবহার করা শেষ করবে। যদি আমরা জানতাম যে কোন অংশটি শেষে শেষ করবে, তাহলে আমরা সেই অংশটিকে ডেটার owner বানাতে পারতাম এবং compile time-এ প্রযোজ্য normal ownership নিয়মগুলো কার্যকর হত।
মনে রাখবেন যে Rc<T> শুধুমাত্র single-threaded scenario-তে ব্যবহারের জন্য। যখন আমরা Chapter 16-এ concurrency নিয়ে আলোচনা করব, তখন আমরা দেখব কিভাবে multithreaded প্রোগ্রামগুলোতে reference counting করতে হয়।
ডেটা Share করার জন্য Rc<T> ব্যবহার করা
আসুন Listing 15-5-এ আমাদের cons list-এর উদাহরণে ফিরে যাই। মনে রাখবেন যে আমরা এটিকে Box<T> ব্যবহার করে define করেছি। এবার, আমরা দুটি list তৈরি করব যারা উভয়ই একটি third list-এর ownership share করবে। ধারণাগতভাবে, এটি Figure 15-3-এর মতো:

Figure 15-3: দুটি তালিকা, b এবং c, একটি তৃতীয় তালিকা, a-এর ownership share করছে
আমরা list a তৈরি করব যাতে 5 এবং তারপর 10 থাকবে। তারপর আমরা আরও দুটি list তৈরি করব: b যেটি 3 দিয়ে শুরু হবে এবং c যেটি 4 দিয়ে শুরু হবে। B এবং c উভয় list-ই তারপর প্রথম a list-এ continue করবে যেখানে 5 এবং 10 রয়েছে। অন্য কথায়, উভয় list প্রথম list টি share করবে যেখানে 5 এবং 10 রয়েছে।
Box<T> দিয়ে List-এর আমাদের definition ব্যবহার করে এই scenario টি implement করার চেষ্টা করলে কাজ করবে না, যেমনটি Listing 15-17-তে দেখানো হয়েছে:
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}যখন আমরা এই কোডটি compile করি, তখন আমরা এই error টি পাই:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
Cons variant গুলো তাদের ধারণ করা ডেটার owner, তাই যখন আমরা b list তৈরি করি, তখন a-কে b-তে move করা হয় এবং b, a-এর owner হয়। তারপর, যখন আমরা c তৈরি করার সময় আবার a ব্যবহার করার চেষ্টা করি, তখন আমাদের অনুমতি দেওয়া হয় না কারণ a move করা হয়েছে।
আমরা পরিবর্তে reference ধারণ করার জন্য Cons-এর definition পরিবর্তন করতে পারি, কিন্তু তারপর আমাদের lifetime parameter গুলো specify করতে হবে। Lifetime parameter গুলো specify করে, আমরা specify করব যে list-এর প্রতিটি element পুরো list-এর অন্তত যতদিন বাঁচবে ততদিন বাঁচবে। Listing 15-17-এর element এবং list-গুলোর ক্ষেত্রে এটি প্রযোজ্য, কিন্তু প্রতিটি scenario-তে নয়।
পরিবর্তে, আমরা Listing 15-18-এ দেখানো Box<T>-এর জায়গায় Rc<T> ব্যবহার করার জন্য List-এর আমাদের definition পরিবর্তন করব। প্রতিটি Cons variant-এ এখন একটি value এবং একটি List-এর দিকে point করা একটি Rc<T> থাকবে। যখন আমরা b তৈরি করি, তখন a-এর ownership নেওয়ার পরিবর্তে, আমরা a যে Rc<List> ধারণ করছে সেটিকে clone করব, এইভাবে reference-এর সংখ্যা এক থেকে দুই-এ বৃদ্ধি করব এবং a ও b-কে সেই Rc<List>-এর ডেটার ownership share করার অনুমতি দেব। C তৈরি করার সময় আমরা a-কে clone করব, reference-এর সংখ্যা দুই থেকে তিনে বাড়িয়ে দেব। প্রতিবার যখন আমরা Rc::clone কল করি, Rc<List>-এর ভেতরের ডেটার reference count বাড়বে এবং ডেটা clean up করা হবে না যতক্ষণ না এটির zero reference থাকে।
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); let b = Cons(3, Rc::clone(&a)); let c = Cons(4, Rc::clone(&a)); }
আমাদের একটি use স্টেটমেন্ট যোগ করতে হবে Rc<T>-কে scope-এ আনার জন্য কারণ এটি prelude-এ নেই। Main-এ, আমরা 5 এবং 10 ধারণকারী list তৈরি করি এবং এটিকে a-তে একটি new Rc<List>-এ store করি। তারপর যখন আমরা b এবং c তৈরি করি, তখন আমরা Rc::clone ফাংশনটি কল করি এবং a-তে Rc<List>-এর একটি reference argument হিসেবে pass করি।
আমরা Rc::clone(&a)-এর পরিবর্তে a.clone() কল করতে পারতাম, কিন্তু Rust-এর convention হল এই ক্ষেত্রে Rc::clone ব্যবহার করা। Rc::clone-এর implementation সমস্ত ডেটার deep copy তৈরি করে না যেমন বেশিরভাগ type-এর clone-এর implementation করে। Rc::clone-এ কল শুধুমাত্র reference count বাড়ায়, যেটিতে বেশি সময় লাগে না। ডেটার Deep copy-তে অনেক সময় লাগতে পারে। Reference counting-এর জন্য Rc::clone ব্যবহার করে, আমরা visually deep-copy ধরনের clone এবং reference count বাড়ায় এমন clone-এর মধ্যে পার্থক্য করতে পারি। কোডে performance-এর সমস্যাগুলো খোঁজার সময়, আমাদের শুধুমাত্র deep-copy clone গুলো বিবেচনা করতে হবে এবং Rc::clone-এ কলগুলো উপেক্ষা করতে পারি।
একটি Rc<T> ক্লোন করা Reference Count বাড়ায়
আসুন Listing 15-18-এ আমাদের working example পরিবর্তন করি যাতে আমরা a-তে Rc<List>-এর reference তৈরি এবং drop করার সাথে সাথে reference count-এর পরিবর্তনগুলো দেখতে পারি।
Listing 15-19-এ, আমরা main পরিবর্তন করব যাতে এটির list c-এর চারপাশে একটি ভেতরের scope থাকে; তারপর আমরা দেখতে পাব কিভাবে reference count পরিবর্তিত হয় যখন c scope-এর বাইরে চলে যায়।
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); println!("count after creating a = {}", Rc::strong_count(&a)); let b = Cons(3, Rc::clone(&a)); println!("count after creating b = {}", Rc::strong_count(&a)); { let c = Cons(4, Rc::clone(&a)); println!("count after creating c = {}", Rc::strong_count(&a)); } println!("count after c goes out of scope = {}", Rc::strong_count(&a)); }
প্রোগ্রামের প্রতিটি পয়েন্টে যেখানে reference count পরিবর্তিত হয়, আমরা reference count প্রিন্ট করি, যেটি আমরা Rc::strong_count ফাংশন কল করে পাই। এই ফাংশনটির নাম count-এর পরিবর্তে strong_count রাখা হয়েছে কারণ Rc<T> type-এ একটি weak_count-ও রয়েছে; আমরা "Reference Cycle প্রতিরোধ করা: একটি Rc<T>-কে একটি Weak<T>-তে পরিণত করা"-এ দেখব weak_count কীসের জন্য ব্যবহৃত হয়।
এই কোডটি নিম্নলিখিতগুলো প্রিন্ট করে:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
আমরা দেখতে পাচ্ছি যে a-তে Rc<List>-এর initial reference count হল 1; তারপর প্রতিবার যখন আমরা clone কল করি, count 1 করে বাড়ে। যখন c scope-এর বাইরে চলে যায়, তখন count 1 কমে যায়। Reference count বাড়ানোর জন্য আমাদের Rc::clone কল করতে হবে, সেরকম reference count কমাতে আমাদের কোনো ফাংশন কল করতে হবে না: Drop trait-এর implementation স্বয়ংক্রিয়ভাবে reference count কমিয়ে দেয় যখন একটি Rc<T> value scope-এর বাইরে চলে যায়।
এই উদাহরণে আমরা যা দেখতে পাচ্ছি না তা হল যখন b এবং তারপর a main-এর শেষে scope-এর বাইরে চলে যায়, তখন count 0 হয় এবং Rc<List> সম্পূর্ণরূপে clean up করা হয়। Rc<T> ব্যবহার করা একটি single value-কে multiple owner রাখার অনুমতি দেয় এবং count নিশ্চিত করে যে value-টি valid থাকবে যতক্ষণ পর্যন্ত owner-দের মধ্যে কেউ একজন existing থাকে।
Immutable reference-এর মাধ্যমে, Rc<T> আপনাকে আপনার প্রোগ্রামের multiple part-এর মধ্যে শুধুমাত্র read করার জন্য ডেটা share করার অনুমতি দেয়। যদি Rc<T> আপনাকে multiple mutable reference রাখার অনুমতি দিত, তাহলে আপনি Chapter 4-এ আলোচনা করা borrowing rule-গুলোর মধ্যে একটি লঙ্ঘন করতে পারতেন: একই স্থানে multiple mutable borrow ডেটা রেস এবং অসঙ্গতি সৃষ্টি করতে পারে। কিন্তু ডেটা mutate করতে পারা খুব useful! পরবর্তী section-এ, আমরা interior mutability pattern এবং RefCell<T> type নিয়ে আলোচনা করব যা আপনি এই immutability restriction-এর সাথে কাজ করার জন্য একটি Rc<T>-এর সাথে ব্যবহার করতে পারেন।
RefCell<T> এবং ইন্টেরিয়র মিউটেবিলিটি প্যাটার্ন
ইন্টেরিয়র মিউটেবিলিটি হল Rust-এর একটি ডিজাইন প্যাটার্ন যা আপনাকে ডেটা মিউটেট করার অনুমতি দেয়, এমনকি যখন সেই ডেটার ইমিউটেবল রেফারেন্স থাকে; সাধারণত, এই কাজটি borrowing rule দ্বারা অনুমোদিত নয়। ডেটা মিউটেট করার জন্য, প্যাটার্নটি ডেটা স্ট্রাকচারের ভিতরে unsafe কোড ব্যবহার করে Rust-এর সাধারণ নিয়মগুলোকে বাঁকিয়ে দেয় যা মিউটেশন এবং borrowing নিয়ন্ত্রণ করে। Unsafe কোড কম্পাইলারকে নির্দেশ করে যে আমরা ম্যানুয়ালি নিয়মগুলো পরীক্ষা করছি কম্পাইলারের উপর নির্ভর না করে; আমরা Chapter 20-এ unsafe কোড নিয়ে আরও আলোচনা করব।
আমরা ইন্টেরিয়র মিউটেবিলিটি প্যাটার্ন ব্যবহার করে এমন type গুলো তখনই ব্যবহার করতে পারি যখন আমরা নিশ্চিত করতে পারি যে borrowing rule গুলো runtime-এ follow করা হবে, যদিও কম্পাইলার সেটি guarantee করতে পারে না। জড়িত unsafe কোডটি তখন একটি safe API-তে wrap করা হয় এবং বাইরের type টি এখনও immutable থাকে।
আসুন RefCell<T> টাইপটি দেখে এই concept টি explore করি যা ইন্টেরিয়র মিউটেবিলিটি প্যাটার্ন follow করে।
RefCell<T> দিয়ে Runtime-এ Borrowing Rule গুলো Enforce করা
Rc<T>-এর বিপরীতে, RefCell<T> টাইপটি এটি ধারণ করা ডেটার উপর single ownership represent করে। তাহলে, RefCell<T>-কে Box<T>-এর মতো টাইপ থেকে কী আলাদা করে? Chapter 4-এ শেখা borrowing rule গুলো স্মরণ করুন:
- যেকোনো সময়ে, আপনার কাছে হয় (কিন্তু দুটোই নয়) একটি mutable reference অথবা যেকোনো সংখ্যক immutable reference থাকতে পারে।
- Reference গুলো সব সময় valid হতে হবে।
Reference এবং Box<T>-এর ক্ষেত্রে, borrowing rule-গুলোর invariant গুলো compile time-এ enforce করা হয়। RefCell<T>-এর ক্ষেত্রে, এই invariant গুলো runtime-এ enforce করা হয়। Reference-এর ক্ষেত্রে, আপনি যদি এই নিয়মগুলো ভাঙেন, তাহলে আপনি একটি compiler error পাবেন। RefCell<T>-এর ক্ষেত্রে, আপনি যদি এই নিয়মগুলো ভাঙেন, তাহলে আপনার প্রোগ্রাম panic করবে এবং exit করবে।
Compile time-এ borrowing rule গুলো check করার সুবিধা হল development process-এ error গুলো আরও তাড়াতাড়ি ধরা পড়বে এবং runtime performance-এর উপর কোনো প্রভাব পড়বে না কারণ সমস্ত analysis আগেই সম্পন্ন করা হয়েছে। সেই কারণে, বেশিরভাগ ক্ষেত্রে compile time-এ borrowing rule গুলো check করা হল সেরা পছন্দ, যে কারণে এটি Rust-এর default।
পরিবর্তে runtime-এ borrowing rule গুলো check করার সুবিধা হল যে certain memory-safe scenario গুলোর অনুমতি দেওয়া হয়, যেখানে সেগুলো compile-time check দ্বারা অনুমোদিত হত না। Static analysis, যেমন Rust compiler, সহজাতভাবে রক্ষণশীল। কোডের কিছু বৈশিষ্ট্য কোড analyze করে detect করা অসম্ভব: সবচেয়ে বিখ্যাত উদাহরণ হল Halting Problem, যা এই বইয়ের সুযোগের বাইরে কিন্তু research করার জন্য একটি interesting বিষয়।
যেহেতু কিছু analysis অসম্ভব, তাই যদি Rust compiler নিশ্চিত না হতে পারে যে কোডটি ownership rule গুলো মেনে চলছে, তাহলে এটি একটি সঠিক প্রোগ্রামকে reject করতে পারে; এইভাবে, এটি রক্ষণশীল। যদি Rust একটি incorrect প্রোগ্রাম accept করত, তাহলে user-রা Rust যে guarantee গুলো দেয় তাতে বিশ্বাস রাখতে পারত না। যাইহোক, যদি Rust একটি সঠিক প্রোগ্রাম reject করে, তাহলে প্রোগ্রামার অসুবিধার সম্মুখীন হবেন, কিন্তু কোনো catastrophic ঘটনা ঘটতে পারে না। RefCell<T> টাইপটি useful যখন আপনি নিশ্চিত যে আপনার কোড borrowing rule গুলো follow করে কিন্তু compiler সেটি বুঝতে এবং guarantee করতে অক্ষম।
Rc<T>-এর মতোই, RefCell<T> শুধুমাত্র single-threaded scenario-তে ব্যবহারের জন্য এবং আপনি যদি এটিকে multithreaded context-এ ব্যবহার করার চেষ্টা করেন তাহলে আপনাকে একটি compile-time error দেবে। আমরা Chapter 16-এ আলোচনা করব কিভাবে একটি multithreaded প্রোগ্রামে RefCell<T>-এর কার্যকারিতা পাওয়া যায়।
Box<T>, Rc<T>, বা RefCell<T> বেছে নেওয়ার কারণগুলোর একটি সংক্ষেপ এখানে দেওয়া হল:
Rc<T>একই ডেটার multiple owner-এর অনুমতি দেয়;Box<T>এবংRefCell<T>-এর single owner রয়েছে।Box<T>compile time-এ check করা immutable বা mutable borrow-এর অনুমতি দেয়;Rc<T>শুধুমাত্র compile time-এ check করা immutable borrow-এর অনুমতি দেয়;RefCell<T>runtime-এ check করা immutable বা mutable borrow-এর অনুমতি দেয়।- যেহেতু
RefCell<T>runtime-এ check করা mutable borrow-এর অনুমতি দেয়, তাই আপনিRefCell<T>-এর ভেতরের value-কে mutate করতে পারেন যদিওRefCell<T>immutable হয়।
একটি immutable value-এর ভেতরের value-কে mutate করা হল ইন্টেরিয়র মিউটেবিলিটি প্যাটার্ন। আসুন এমন একটি পরিস্থিতি দেখি যেখানে ইন্টেরিয়র মিউটেবিলিটি useful এবং পরীক্ষা করি কীভাবে এটি সম্ভব।
ইন্টেরিয়র মিউটেবিলিটির জন্য একটি Use Case: Mock অবজেক্ট
কখনও কখনও testing-এর সময় একজন প্রোগ্রামার অন্য type-এর জায়গায় একটি type ব্যবহার করেন, particular behavior পর্যবেক্ষণ করতে এবং assert করতে যে এটি সঠিকভাবে implement করা হয়েছে। এই placeholder type-টিকে test double বলা হয়। এটিকে ফিল্মমেকিং-এ "স্টান্ট ডাবল"-এর মতো ভাবুন, যেখানে একজন ব্যক্তি একটি particular tricky scene করার জন্য একজন অভিনেতার পরিবর্তে আসেন এবং substitute করেন। Test double গুলো অন্য type-এর জন্য দাঁড়ায় যখন আমরা test চালাই। Mock object হল test double-এর specific type যা একটি test চলাকালীন কী ঘটে তা record করে যাতে আপনি assert করতে পারেন যে সঠিক action গুলো ঘটেছে।
Rust-এ অন্যান্য language-এর মতো একই অর্থে অবজেক্ট নেই এবং Rust-এর standard library-তে অন্য কিছু language-এর মতো mock object functionality বিল্ট-ইন নেই। যাইহোক, আপনি निश्चितভাবে একটি struct তৈরি করতে পারেন যা একটি mock object-এর মতোই একই উদ্দেশ্যে কাজ করবে।
এখানে সেই scenario টি রয়েছে যা আমরা test করব: আমরা একটি লাইব্রেরি তৈরি করব যা একটি maximum value-এর বিপরীতে একটি value ট্র্যাক করে এবং current value টি maximum value-এর কতটা কাছাকাছি তার উপর ভিত্তি করে message পাঠায়। এই লাইব্রেরিটি ব্যবহার করা যেতে পারে একজন user-এর API call-এর সংখ্যার কোটা ট্র্যাক রাখতে, উদাহরণস্বরূপ।
আমাদের লাইব্রেরি শুধুমাত্র একটি value maximum-এর কতটা কাছাকাছি এবং কোন সময়ে কী message হওয়া উচিত তা ট্র্যাক করার কার্যকারিতা provide করবে। যে অ্যাপ্লিকেশনগুলো আমাদের লাইব্রেরি ব্যবহার করে সেগুলো message পাঠানোর mechanism provide করবে বলে আশা করা হচ্ছে: অ্যাপ্লিকেশনটি অ্যাপ্লিকেশনে একটি message রাখতে পারে, একটি email পাঠাতে পারে, একটি text message পাঠাতে পারে বা অন্য কিছু করতে পারে। লাইব্রেরির সেই detail জানার প্রয়োজন নেই। এটির যা প্রয়োজন তা হল এমন কিছু যা আমরা provide করব এমন একটি trait implement করে, যার নাম Messenger। Listing 15-20 লাইব্রেরির কোড দেখায়:
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}এই কোডের একটি গুরুত্বপূর্ণ অংশ হল Messenger trait-এ send নামক একটি method রয়েছে যা self-এর একটি immutable reference এবং message-এর text নেয়। এই trait টি হল সেই ইন্টারফেস যা আমাদের মক অবজেক্টকে implement করতে হবে যাতে মকটিকে একটি real object-এর মতোই ব্যবহার করা যায়। আরেকটি গুরুত্বপূর্ণ অংশ হল যে আমরা LimitTracker-এ set_value method-এর behavior test করতে চাই। আমরা value parameter-এর জন্য যা pass করি তা পরিবর্তন করতে পারি, কিন্তু set_value আমাদের জন্য কোনো কিছু return করে না যার উপর আমরা assertion করতে পারি। আমরা বলতে চাই যে যদি আমরা Messenger trait implement করে এমন কিছু এবং max-এর জন্য একটি particular value দিয়ে একটি LimitTracker তৈরি করি, যখন আমরা value-এর জন্য different number pass করি, তখন messenger-কে উপযুক্ত message গুলো পাঠাতে বলা হয়।
আমাদের এমন একটি মক অবজেক্ট দরকার যা, যখন আমরা send কল করি, তখন একটি email বা text message পাঠানোর পরিবর্তে, শুধুমাত্র সেই message গুলো ট্র্যাক রাখবে যেগুলো পাঠানোর কথা। আমরা মক অবজেক্টের একটি new instance তৈরি করতে পারি, মক অবজেক্ট ব্যবহার করে একটি LimitTracker তৈরি করতে পারি, LimitTracker-এ set_value method কল করতে পারি এবং তারপর চেক করতে পারি যে মক অবজেক্টে আমাদের প্রত্যাশিত message গুলো আছে কিনা। Listing 15-21 ঠিক এটি করার জন্য একটি মক অবজেক্ট implement করার একটি প্রচেষ্টা দেখায়, কিন্তু borrow checker এটির অনুমতি দেবে না:
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}এই test code-টি একটি MockMessenger struct define করে যাতে sent_messages field রয়েছে message গুলো ট্র্যাক রাখার জন্য String value-গুলোর একটি Vec সহ। আমরা একটি associated function new ও define করি যাতে new MockMessenger value তৈরি করা সুবিধাজনক হয় যেগুলো message-এর একটি empty list দিয়ে শুরু হয়। তারপর আমরা MockMessenger-এর জন্য Messenger trait implement করি যাতে আমরা একটি LimitTracker-কে একটি MockMessenger দিতে পারি। Send method-এর definition-এ, আমরা parameter হিসেবে pass করা message টি নিই এবং এটিকে MockMessenger-এর sent_messages-এর list-এ store করি।
Test-এ, আমরা test করছি যখন LimitTracker-কে value set করতে বলা হয় এমন কিছুতে যা max value-এর 75 শতাংশের বেশি। প্রথমে, আমরা একটি new MockMessenger তৈরি করি, যেটি message-এর একটি empty list দিয়ে শুরু হবে। তারপর আমরা একটি new LimitTracker তৈরি করি এবং এটিকে new MockMessenger-এর একটি reference এবং 100-এর একটি max value দিই। আমরা LimitTracker-এ set_value method-টিকে 80 value দিয়ে কল করি, যেটি 100-এর 75 শতাংশের বেশি। তারপর আমরা assert করি যে MockMessenger যে message গুলোর ট্র্যাক রাখছে তার list-এ এখন একটি message থাকা উচিত।
যাইহোক, এই test-এর একটি সমস্যা আছে, যেমনটি এখানে দেখানো হয়েছে:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn send(&mut self, msg: &str);
3 | }
...
56 | impl Messenger for MockMessenger {
57 ~ fn send(&mut self, message: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` (lib test) due to 1 previous error
warning: build failed, waiting for other jobs to finish...
আমরা message-গুলোর ট্র্যাক রাখার জন্য MockMessenger-কে modify করতে পারি না, কারণ send method টি self-এর একটি immutable reference নেয়। আমরা error text থেকে &mut self ব্যবহার করার পরামর্শও নিতে পারি না impl method এবং trait definition-এ। আমরা শুধুমাত্র testing-এর স্বার্থে Messenger trait পরিবর্তন করতে চাই না। পরিবর্তে, আমাদের বিদ্যমান ডিজাইনের সাথে আমাদের test code-কে সঠিকভাবে কাজ করার একটি উপায় খুঁজে বের করতে হবে।
এটি এমন একটি পরিস্থিতি যেখানে ইন্টেরিয়র মিউটেবিলিটি সাহায্য করতে পারে! আমরা sent_messages-কে একটি RefCell<T>-এর মধ্যে store করব এবং তারপর send method টি sent_messages modify করে আমরা যে message গুলো দেখেছি সেগুলো store করতে সক্ষম হবে। Listing 15-22 দেখায় যে এটি দেখতে কেমন:
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}Sent_messages field-টি এখন Vec<String>-এর পরিবর্তে RefCell<Vec<String>> type-এর। New ফাংশনে, আমরা empty vector-এর চারপাশে একটি new RefCell<Vec<String>> instance তৈরি করি।
Send method-এর implementation-এর জন্য, প্রথম parameter টি এখনও self-এর একটি immutable borrow, যেটি trait definition-এর সাথে মেলে। আমরা self.sent_messages-এ RefCell<Vec<String>>-এ borrow_mut কল করি RefCell<Vec<String>>-এর ভেতরের value-টির একটি mutable reference পেতে, যেটি হল vector। তারপর আমরা test চলাকালীন পাঠানো message গুলোর ট্র্যাক রাখতে vector-এ mutable reference-এ push কল করতে পারি।
আমাদের শেষ যে পরিবর্তনটি করতে হবে তা হল assertion-এ: ভেতরের vector-এ কতগুলো item আছে তা দেখতে, আমরা vector-টির একটি immutable reference পেতে RefCell<Vec<String>>-এ borrow কল করি।
এখন আপনি দেখেছেন কিভাবে RefCell<T> ব্যবহার করতে হয়, আসুন এটি কীভাবে কাজ করে তা দেখি!
RefCell<T>-এর সাহায্যে Runtime-এ Borrow-এর ট্র্যাক রাখা
Immutable এবং mutable reference তৈরি করার সময়, আমরা যথাক্রমে & এবং &mut syntax ব্যবহার করি। RefCell<T>-এর ক্ষেত্রে, আমরা borrow এবং borrow_mut method ব্যবহার করি, যেগুলো RefCell<T>-এর অন্তর্গত safe API-এর অংশ। Borrow method টি স্মার্ট পয়েন্টার টাইপ Ref<T> রিটার্ন করে এবং borrow_mut স্মার্ট পয়েন্টার টাইপ RefMut<T> রিটার্ন করে। উভয় type-ই Deref implement করে, তাই আমরা সেগুলোকে regular reference-এর মতো treat করতে পারি।
RefCell<T> ট্র্যাক রাখে কতগুলো Ref<T> এবং RefMut<T> স্মার্ট পয়েন্টার বর্তমানে active রয়েছে। প্রতিবার যখন আমরা borrow কল করি, RefCell<T> active থাকা immutable borrow-এর সংখ্যা বাড়িয়ে দেয়। যখন একটি Ref<T> value scope-এর বাইরে চলে যায়, তখন immutable borrow-এর সংখ্যা এক কমে যায়। Compile-time borrowing rule-গুলোর মতোই, RefCell<T> আমাদের যেকোনো সময়ে অনেকগুলো immutable borrow বা একটি mutable borrow রাখার অনুমতি দেয়।
যদি আমরা এই নিয়মগুলো লঙ্ঘন করার চেষ্টা করি, তাহলে reference-এর মতো compiler error পাওয়ার পরিবর্তে, RefCell<T>-এর implementation runtime-এ panic করবে। Listing 15-23, Listing 15-22-এ send-এর implementation-এর একটি modification দেখায়। আমরা ইচ্ছাকৃতভাবে একই scope-এর জন্য দুটি active mutable borrow তৈরি করার চেষ্টা করছি এটা বোঝানোর জন্য যে RefCell<T> আমাদের runtime-এ এটি করা থেকে বিরত রাখে।
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}আমরা borrow_mut থেকে returned RefMut<T> স্মার্ট পয়েন্টারের জন্য একটি variable one_borrow তৈরি করি। তারপর আমরা একই ভাবে variable two_borrow-তে আরেকটি mutable borrow তৈরি করি। এটি একই scope-এ দুটি mutable reference তৈরি করে, যার অনুমতি নেই। যখন আমরা আমাদের লাইব্রেরির জন্য test চালাই, তখন Listing 15-23-এর কোডটি কোনো error ছাড়াই compile হবে, কিন্তু test fail করবে:
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at src/lib.rs:60:53:
already borrowed: BorrowMutError
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
লক্ষ্য করুন যে কোডটি already borrowed: BorrowMutError message দিয়ে panic করেছে। এইভাবে RefCell<T> runtime-এ borrowing rule-গুলোর violation গুলো handle করে।
এখানে যেমনটি করেছি, compile time-এর পরিবর্তে runtime-এ borrowing error গুলো ধরার অর্থ হল আপনি development process-এ আপনার কোডের ভুলগুলো আরও পরে খুঁজে পাবেন: সম্ভবত আপনার কোড production-এ deploy না হওয়া পর্যন্ত নয়। এছাড়াও, compile time-এর পরিবর্তে runtime-এ borrow-গুলোর ট্র্যাক রাখার ফলে আপনার কোড সামান্য runtime performance penalty বহন করবে। যাইহোক, RefCell<T> ব্যবহার করা একটি মক অবজেক্ট লেখা সম্ভব করে যা নিজেকে modify করে সেই message গুলোর ট্র্যাক রাখতে পারে যেগুলো এটি দেখেছে যখন আপনি এটিকে এমন একটি context-এ ব্যবহার করছেন যেখানে শুধুমাত্র immutable value-গুলোর অনুমতি রয়েছে। আপনি regular reference-এর চেয়ে বেশি functionality পেতে RefCell<T> ব্যবহার করতে পারেন এর trade-off গুলো থাকা সত্ত্বেও।
Rc<T> এবং RefCell<T> একত্রিত করে Mutable ডেটার Multiple Owner থাকা
RefCell<T> ব্যবহার করার একটি সাধারণ উপায় হল Rc<T>-এর সাথে। স্মরণ করুন যে Rc<T> আপনাকে কিছু ডেটার multiple owner রাখার অনুমতি দেয়, কিন্তু এটি শুধুমাত্র সেই ডেটাতে immutable অ্যাক্সেস দেয়। যদি আপনার কাছে একটি Rc<T> থাকে যা একটি RefCell<T> ধারণ করে, তাহলে আপনি এমন একটি value পেতে পারেন যার multiple owner থাকতে পারে এবং যাকে আপনি mutate করতে পারেন!
উদাহরণস্বরূপ, Listing 15-18-এর cons list উদাহরণটি স্মরণ করুন যেখানে আমরা multiple list-কে অন্য list-এর ownership share করার অনুমতি দেওয়ার জন্য Rc<T> ব্যবহার করেছি। যেহেতু Rc<T> শুধুমাত্র immutable value ধারণ করে, তাই আমরা list-গুলো তৈরি করার পরে সেগুলোর কোনো value পরিবর্তন করতে পারি না। আসুন RefCell<T> যোগ করি list-গুলোর value পরিবর্তন করার ক্ষমতা অর্জন করতে। Listing 15-24 দেখায় যে Cons definition-এ একটি RefCell<T> ব্যবহার করে, আমরা সমস্ত list-এ stored value-কে modify করতে পারি:
#[derive(Debug)] enum List { Cons(Rc<RefCell<i32>>, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; fn main() { let value = Rc::new(RefCell::new(5)); let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil))); let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a)); let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a)); *value.borrow_mut() += 10; println!("a after = {a:?}"); println!("b after = {b:?}"); println!("c after = {c:?}"); }
আমরা Rc<RefCell<i32>>-এর একটি instance-এর একটি value তৈরি করি এবং এটিকে value নামক একটি variable-এ store করি যাতে আমরা পরে এটিকে সরাসরি অ্যাক্সেস করতে পারি। তারপর আমরা a-তে একটি List তৈরি করি একটি Cons variant দিয়ে যা value ধারণ করে। আমাদের value clone করতে হবে যাতে a এবং value উভয়েরই ভেতরের 5 value-টির ownership থাকে, value থেকে a-তে ownership transfer করার পরিবর্তে বা a-এর value থেকে borrow করার পরিবর্তে।
আমরা list a-কে একটি Rc<T>-তে wrap করি যাতে আমরা যখন list b এবং c তৈরি করি, তখন তারা উভয়েই a-কে refer করতে পারে, যেটি আমরা Listing 15-18-এ করেছিলাম।
A, b এবং c-তে list গুলো তৈরি করার পরে, আমরা value-এর value-তে 10 যোগ করতে চাই। আমরা value-তে borrow_mut কল করে এটি করি, যেটি স্বয়ংক্রিয় ডিরেফারেন্সিং feature ব্যবহার করে যা আমরা Chapter 5-এ আলোচনা করেছি (“-> অপারেটরটি কোথায়?” বিভাগটি দেখুন) Rc<T>-কে ভেতরের RefCell<T> value-তে dereference করতে। Borrow_mut method টি একটি RefMut<T> স্মার্ট পয়েন্টার রিটার্ন করে এবং আমরা এটিতে dereference operator ব্যবহার করি এবং ভেতরের value পরিবর্তন করি।
যখন আমরা a, b এবং c প্রিন্ট করি, তখন আমরা দেখতে পাই যে সেগুলোর সবগুলোর modified value রয়েছে 5-এর পরিবর্তে 15:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
এই technique টি বেশ neat! RefCell<T> ব্যবহার করে, আমাদের কাছে একটি বাহ্যিকভাবে immutable List value রয়েছে। কিন্তু আমরা RefCell<T>-এর method গুলো ব্যবহার করতে পারি যা এটির ইন্টেরিয়র মিউটেবিলিটিতে অ্যাক্সেস provide করে যাতে আমাদের প্রয়োজনের সময় আমরা আমাদের ডেটা modify করতে পারি। Borrowing rule-গুলোর runtime check গুলো আমাদের ডেটা রেস থেকে রক্ষা করে এবং আমাদের ডেটা স্ট্রাকচারে এই নমনীয়তার জন্য কখনও কখনও কিছুটা গতি trade করা সার্থক। মনে রাখবেন যে RefCell<T> মাল্টিথ্রেডেড কোডের জন্য কাজ করে না! Mutex<T> হল RefCell<T>-এর থ্রেড-নিরাপদ সংস্করণ এবং আমরা Chapter 16-এ Mutex<T> নিয়ে আলোচনা করব।
রেফারেন্স সাইকেল মেমরি লিক করতে পারে
Rust-এর মেমরি সুরক্ষার গ্যারান্টিগুলো অ্যাক্সিডেন্টালি মেমরি তৈরি করা কঠিন করে তোলে, যা কখনও clean up করা হয় না (মেমরি লিক নামে পরিচিত)। মেমরি লিক সম্পূর্ণরূপে প্রতিরোধ করা Rust-এর গ্যারান্টিগুলোর মধ্যে একটি নয়, অর্থাৎ Rust-এ মেমরি লিক মেমরি নিরাপদ। আমরা Rc<T> এবং RefCell<T> ব্যবহার করে দেখতে পারি যে Rust মেমরি লিকের অনুমতি দেয়: এমন রেফারেন্স তৈরি করা সম্ভব যেখানে আইটেমগুলো একে অপরের দিকে একটি চক্রে নির্দেশ করে। এটি মেমরি লিক তৈরি করে কারণ চক্রের প্রতিটি আইটেমের রেফারেন্স গণনা কখনও 0-এ পৌঁছাবে না এবং value গুলো কখনও ড্রপ হবে না।
একটি রেফারেন্স সাইকেল তৈরি করা
আসুন দেখি কিভাবে একটি রেফারেন্স সাইকেল ঘটতে পারে এবং কিভাবে এটি প্রতিরোধ করা যায়, List enum-এর definition এবং Listing 15-25-এর একটি tail মেথড দিয়ে শুরু করি:
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() {}
আমরা Listing 15-5 থেকে List definition-এর আরেকটি variation ব্যবহার করছি। Cons variant-এর দ্বিতীয় element টি এখন RefCell<Rc<List>>, অর্থাৎ Listing 15-24-এর মতো i32 value modify করার ক্ষমতা থাকার পরিবর্তে, আমরা List value-টিকে modify করতে চাই যেটি একটি Cons variant point করছে। আমরা একটি tail মেথডও যোগ করছি যাতে আমাদের জন্য দ্বিতীয় item অ্যাক্সেস করা সুবিধাজনক হয় যদি আমাদের কাছে একটি Cons variant থাকে।
Listing 15-26-এ, আমরা একটি main ফাংশন যোগ করছি যা Listing 15-25-এর definition গুলো ব্যবহার করে। এই কোডটি a-তে একটি list এবং b-তে একটি list তৈরি করে যা a-এর list-এর দিকে point করে। তারপর এটি a-এর list-টিকে b-এর দিকে point করার জন্য modify করে, একটি রেফারেন্স সাইকেল তৈরি করে। এই প্রক্রিয়ার বিভিন্ন পয়েন্টে reference count গুলো কী তা দেখানোর জন্য পথের মধ্যে println! স্টেটমেন্ট রয়েছে।
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() { let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil)))); println!("a initial rc count = {}", Rc::strong_count(&a)); println!("a next item = {:?}", a.tail()); let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); println!("a rc count after b creation = {}", Rc::strong_count(&a)); println!("b initial rc count = {}", Rc::strong_count(&b)); println!("b next item = {:?}", b.tail()); if let Some(link) = a.tail() { *link.borrow_mut() = Rc::clone(&b); } println!("b rc count after changing a = {}", Rc::strong_count(&b)); println!("a rc count after changing a = {}", Rc::strong_count(&a)); // Uncomment the next line to see that we have a cycle; // it will overflow the stack. // println!("a next item = {:?}", a.tail()); }
আমরা a variable-এ একটি List value ধারণকারী একটি Rc<List> ইন্সট্যান্স তৈরি করি, 5, Nil-এর একটি initial list সহ। তারপর আমরা b variable-এ আরেকটি List value ধারণকারী একটি Rc<List> ইন্সট্যান্স তৈরি করি যাতে 10 value রয়েছে এবং a-এর list-এর দিকে point করে।
আমরা a-কে modify করি যাতে এটি Nil-এর পরিবর্তে b-এর দিকে point করে, একটি cycle তৈরি করে। আমরা tail মেথড ব্যবহার করে a-তে RefCell<Rc<List>>-এর একটি reference পেতে করি, যেটি আমরা link variable-এ রাখি। তারপর আমরা RefCell<Rc<List>>-এ borrow_mut মেথড ব্যবহার করে ভেতরের value-টিকে একটি Rc<List> থেকে পরিবর্তন করি যা একটি Nil value ধারণ করে b-এর Rc<List>-এ।
যখন আমরা এই কোডটি চালাই, আপাতত শেষ println! টিকে commented out রেখে, আমরা এই আউটপুট পাব:
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
A এবং b উভয়ের Rc<List> ইন্সট্যান্সের reference count 2 হয় a-এর list-টিকে b-এর দিকে point করার জন্য পরিবর্তন করার পরে। Main-এর শেষে, Rust b variable টি ড্রপ করে, যা b Rc<List> ইন্সট্যান্সের reference count 2 থেকে 1-এ কমিয়ে দেয়। Rc<List>-এর মেমরি heap-এ এই সময়ে ড্রপ করা হবে না, কারণ এর reference count 1, 0 নয়। তারপর Rust a ড্রপ করে, যা a Rc<List> ইন্সট্যান্সের reference count-ও 2 থেকে 1-এ কমিয়ে দেয়। এই ইন্সট্যান্সের মেমরিও ড্রপ করা যাবে না, কারণ অন্য Rc<List> ইন্সট্যান্স এখনও এটির দিকে refer করছে। List-এর জন্য allocate করা মেমরি চিরতরে uncollected থাকবে। এই reference cycle টি visualize করার জন্য, আমরা Figure 15-4-এ ডায়াগ্রামটি তৈরি করেছি।

Figure 15-4: List a এবং b-এর একটি reference cycle একে অপরের দিকে point করছে
আপনি যদি শেষ println! টিকে un-comment করেন এবং প্রোগ্রামটি চালান, তাহলে Rust a থেকে b থেকে a-এর দিকে point করে এই cycle-টি প্রিন্ট করার চেষ্টা করবে, এবং এভাবে, যতক্ষণ না এটি stack overflow করে।
একটি real-world প্রোগ্রামের তুলনায়, এই উদাহরণে একটি reference cycle তৈরি করার পরিণতিগুলো খুব ভয়াবহ নয়: আমরা reference cycle তৈরি করার পরপরই, প্রোগ্রামটি শেষ হয়ে যায়। যাইহোক, যদি একটি আরও complex প্রোগ্রাম একটি চক্রে প্রচুর মেমরি allocate করত এবং দীর্ঘ সময় ধরে রাখত, তাহলে প্রোগ্রামটি প্রয়োজনের চেয়ে বেশি মেমরি ব্যবহার করত এবং সিস্টেমকে overwhelm করতে পারত, যার ফলে available মেমরি শেষ হয়ে যেত।
Reference cycle তৈরি করা সহজে করা যায় না, তবে এটি অসম্ভবও নয়। যদি আপনার কাছে RefCell<T> value থাকে যাতে Rc<T> value বা interior mutability এবং reference counting সহ type-গুলোর similar nested combination থাকে, তাহলে আপনাকে নিশ্চিত করতে হবে যে আপনি cycle তৈরি করবেন না; আপনি সেগুলোকে ধরার জন্য Rust-এর উপর নির্ভর করতে পারবেন না। একটি reference cycle তৈরি করা আপনার প্রোগ্রামের একটি logic bug হবে যা minimize করার জন্য আপনার automated test, code review এবং অন্যান্য software development practice ব্যবহার করা উচিত।
Reference cycle এড়ানোর আরেকটি সমাধান হল আপনার ডেটা স্ট্রাকচারগুলোকে এমনভাবে reorganize করা যাতে কিছু reference ownership প্রকাশ করে এবং কিছু reference না করে। ফলস্বরূপ, আপনি কিছু ownership relationship এবং কিছু non-ownership relationship দিয়ে তৈরি cycle পেতে পারেন এবং শুধুমাত্র ownership relationship গুলোই প্রভাবিত করে যে একটি value ড্রপ করা যেতে পারে কিনা। Listing 15-25-এ, আমরা সব সময় চাই যে Cons variant গুলো তাদের list-এর owner হোক, তাই ডেটা স্ট্রাকচার reorganize করা সম্ভব নয়। আসুন parent node এবং child node দিয়ে তৈরি graph ব্যবহার করে একটি উদাহরণ দেখি এটা দেখার জন্য কখন non-ownership relationship গুলো reference cycle প্রতিরোধ করার একটি উপযুক্ত উপায়।
Reference Cycle প্রতিরোধ করা: একটি Rc<T>-কে একটি Weak<T>-তে পরিণত করা
এখন পর্যন্ত, আমরা প্রদর্শন করেছি যে Rc::clone কল করা একটি Rc<T> ইন্সট্যান্সের strong_count বাড়ায় এবং একটি Rc<T> ইন্সট্যান্স শুধুমাত্র তখনই clean up করা হয় যদি এর strong_count 0 হয়। আপনি Rc::downgrade কল করে এবং Rc<T>-এর একটি reference pass করে একটি Rc<T> ইন্সট্যান্সের মধ্যে value-টির একটি weak reference-ও তৈরি করতে পারেন। Strong reference হল কিভাবে আপনি একটি Rc<T> ইন্সট্যান্সের ownership share করতে পারেন। Weak reference গুলো ownership relationship প্রকাশ করে না এবং সেগুলোর count Rc<T> ইন্সট্যান্স কখন clean up করা হবে তা প্রভাবিত করে না। সেগুলো একটি reference cycle-এর কারণ হবে না কারণ কিছু weak reference জড়িত যেকোনো cycle ভেঙে যাবে একবার জড়িত value-গুলোর strong reference count 0 হলে।
আপনি যখন Rc::downgrade কল করেন, তখন আপনি Weak<T> type-এর একটি স্মার্ট পয়েন্টার পান। Rc<T> ইন্সট্যান্সে strong_count 1 বাড়ানোর পরিবর্তে, Rc::downgrade কল করলে weak_count 1 বাড়ে। Rc<T> টাইপটি strong_count-এর মতোই কতগুলো Weak<T> রেফারেন্স বিদ্যমান তা ট্র্যাক রাখতে weak_count ব্যবহার করে। পার্থক্য হল Rc<T> ইন্সট্যান্স clean up করার জন্য weak_count-এর 0 হওয়ার প্রয়োজন নেই।
যেহেতু Weak<T> যে value-টিকে refer করে সেটি ড্রপ করা হতে পারে, তাই Weak<T> যে value-টির দিকে point করছে সেটি দিয়ে কিছু করতে, আপনাকে নিশ্চিত করতে হবে যে value টি এখনও বিদ্যমান। এটি একটি Weak<T> ইন্সট্যান্সে upgrade method কল করে করুন, যেটি একটি Option<Rc<T>> রিটার্ন করবে। যদি Rc<T> value টি এখনও ড্রপ করা না হয়ে থাকে তাহলে আপনি Some-এর একটি result পাবেন এবং যদি Rc<T> value টি ড্রপ করা হয়ে থাকে তাহলে None-এর একটি result পাবেন। যেহেতু upgrade একটি Option<Rc<T>> রিটার্ন করে, তাই Rust নিশ্চিত করবে যে Some case এবং None case handle করা হয়েছে এবং কোনো invalid pointer থাকবে না।
একটি উদাহরণ হিসেবে, যে item গুলো শুধুমাত্র next item সম্পর্কে জানে এমন একটি list ব্যবহার করার পরিবর্তে, আমরা একটি tree তৈরি করব যার item গুলো তাদের children item এবং তাদের parent item গুলো সম্পর্কে জানে।
একটি Tree ডেটা স্ট্রাকচার তৈরি করা: চাইল্ড নোড সহ একটি Node
শুরু করার জন্য, আমরা এমন node দিয়ে একটি tree তৈরি করব যা তাদের child node গুলো সম্পর্কে জানে। আমরা Node নামক একটি struct তৈরি করব যা তার নিজস্ব i32 value এবং সেইসাথে এর children Node value-গুলোর reference ধারণ করে:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
আমরা চাই একটি Node তার children-দের owner হোক এবং আমরা সেই ownership variable গুলোর সাথে share করতে চাই যাতে আমরা tree-এর প্রতিটি Node সরাসরি অ্যাক্সেস করতে পারি। এটি করার জন্য, আমরা Vec<T> item গুলোকে Rc<Node> type-এর value হিসেবে define করি। আমরা এটাও চাই যে কোন node গুলো অন্য node-এর child তা modify করতে, তাই children-এ Vec<Rc<Node>>-এর চারপাশে আমাদের একটি RefCell<T> আছে।
এরপরে, আমরা আমাদের struct definition ব্যবহার করব এবং value 3 এবং কোনো child ছাড়া leaf নামক একটি Node ইন্সট্যান্স এবং value 5 এবং leaf-কে তার children-দের মধ্যে একটি হিসেবে নিয়ে branch নামক আরেকটি ইন্সট্যান্স তৈরি করব, যেমনটি Listing 15-27-এ দেখানো হয়েছে:
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { value: i32, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, children: RefCell::new(vec![]), }); let branch = Rc::new(Node { value: 5, children: RefCell::new(vec![Rc::clone(&leaf)]), }); }
আমরা leaf-এ Rc<Node> clone করি এবং branch-এ store করি, অর্থাৎ leaf-এর Node-এর এখন দুটি owner রয়েছে: leaf এবং branch। আমরা branch.children-এর মাধ্যমে branch থেকে leaf-এ যেতে পারি, কিন্তু leaf থেকে branch-এ যাওয়ার কোনো উপায় নেই। কারণ হল leaf-এর branch-এর কোনো reference নেই এবং জানে না যে তারা related। আমরা চাই leaf জানুক যে branch হল এর parent। আমরা এরপরে সেটি করব।
একটি Child থেকে তার Parent-এর একটি Reference যোগ করা
Child node-টিকে তার parent সম্পর্কে অবগত করতে, আমাদের Node struct definition-এ একটি parent field যোগ করতে হবে। সমস্যা হল parent-এর type কী হওয়া উচিত তা decide করা। আমরা জানি এতে একটি Rc<T> থাকতে পারে না, কারণ এটি leaf.parent-এর branch-এর দিকে point করা এবং branch.children-এর leaf-এর দিকে point করা একটি reference cycle তৈরি করবে, যার ফলে তাদের strong_count value গুলো কখনও 0 হবে না।
অন্যভাবে relationship গুলো সম্পর্কে চিন্তা করলে, একটি parent node-এর তার children-দের owner হওয়া উচিত: যদি একটি parent node ড্রপ করা হয়, তাহলে তার child node গুলোও ড্রপ করা উচিত। যাইহোক, একটি child-এর তার parent-এর owner হওয়া উচিত নয়: যদি আমরা একটি child node ড্রপ করি, তাহলে parent-এর এখনও existing থাকা উচিত। এটি weak reference-এর জন্য একটি case!
তাই Rc<T>-এর পরিবর্তে, আমরা parent-এর type-টিকে Weak<T> ব্যবহার করব, specifically একটি RefCell<Weak<Node>>। এখন আমাদের Node struct definition দেখতে এরকম:
Filename: src/main.rs
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
একটি node তার parent node-কে refer করতে সক্ষম হবে কিন্তু তার parent-এর owner নয়। Listing 15-28-এ, আমরা main update করি এই new definition ব্যবহার করার জন্য যাতে leaf node-এর তার parent, branch-কে refer করার একটি উপায় থাকে:
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); }
Leaf node তৈরি করা Listing 15-27-এর মতোই, parent field ছাড়া: leaf কোনো parent ছাড়াই শুরু হয়, তাই আমরা একটি new, empty Weak<Node> reference instance তৈরি করি।
এই সময়ে, যখন আমরা upgrade method ব্যবহার করে leaf-এর parent-এর একটি reference পাওয়ার চেষ্টা করি, তখন আমরা একটি None value পাই। আমরা প্রথম println! স্টেটমেন্ট থেকে আউটপুটে এটি দেখতে পাই:
leaf parent = None
যখন আমরা branch node তৈরি করি, তখন এটির parent field-এ একটি new Weak<Node> reference থাকবে, কারণ branch-এর কোনো parent node নেই। আমাদের কাছে এখনও branch-এর children-দের মধ্যে একটি হিসেবে leaf রয়েছে। একবার আমাদের কাছে branch-এ Node ইন্সট্যান্স থাকলে, আমরা leaf-কে modify করে এটিকে তার parent-এর একটি Weak<Node> reference দিতে পারি। আমরা leaf-এর parent field-এ RefCell<Weak<Node>>-এ borrow_mut method ব্যবহার করি এবং তারপর branch-এ Rc<Node> থেকে branch-এর একটি Weak<Node> reference তৈরি করতে Rc::downgrade ফাংশনটি ব্যবহার করি।
যখন আমরা leaf-এর parent-কে আবার প্রিন্ট করি, তখন এবার আমরা branch ধারণকারী একটি Some variant পাব: এখন leaf তার parent অ্যাক্সেস করতে পারে! যখন আমরা leaf প্রিন্ট করি, তখন আমরা Listing 15-26-এর মতো একটি stack overflow-তে শেষ হওয়া cycle-টিও এড়াই; Weak<Node> reference গুলো (Weak) হিসেবে প্রিন্ট করা হয়:
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
অসীম আউটপুটের অভাব নির্দেশ করে যে এই কোডটি একটি reference cycle তৈরি করেনি। আমরা Rc::strong_count এবং Rc::weak_count কল করে পাওয়া value গুলো দেখেও এটি বলতে পারি।
strong_count এবং weak_count-এর পরিবর্তনগুলো Visualizing করা
আসুন দেখি কিভাবে Rc<Node> ইন্সট্যান্সগুলোর strong_count এবং weak_count value গুলো পরিবর্তিত হয় একটি new inner scope তৈরি করে এবং branch-এর creation-কে সেই scope-এ move করে। এটি করার মাধ্যমে, আমরা দেখতে পাব branch তৈরি হলে এবং তারপর scope-এর বাইরে চলে গেলে drop হলে কী ঘটে। Modification গুলো Listing 15-29-এ দেখানো হয়েছে:
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); { let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!( "branch strong = {}, weak = {}", Rc::strong_count(&branch), Rc::weak_count(&branch), ); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); } println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); }
Leaf তৈরি হওয়ার পরে, এর Rc<Node>-এর strong count 1 এবং weak count 0 থাকে। ভেতরের scope-এ, আমরা branch তৈরি করি এবং এটিকে leaf-এর সাথে associate করি, সেই সময়ে, যখন আমরা count গুলো প্রিন্ট করি, তখন branch-এ Rc<Node>-এর strong count 1 এবং weak count 1 থাকবে (leaf.parent-এর জন্য branch-এর দিকে Weak<Node> দিয়ে point করা)। যখন আমরা leaf-এ count গুলো প্রিন্ট করি, তখন আমরা দেখব এটির strong count 2 হবে, কারণ branch-এ এখন leaf-এর Rc<Node>-এর একটি clone রয়েছে যা branch.children-এ store করা আছে, কিন্তু এখনও 0-এর একটি weak count থাকবে।
যখন ভেতরের scope শেষ হয়, তখন branch scope-এর বাইরে চলে যায় এবং Rc<Node>-এর strong count কমে 0 হয়, তাই এর Node ড্রপ করা হয়। Leaf.parent থেকে 1-এর weak count-এর Node ড্রপ করা হবে কিনা তার উপর কোনো প্রভাব নেই, তাই আমরা কোনো মেমরি লিক পাই না!
যদি আমরা scope-এর শেষের পরে leaf-এর parent অ্যাক্সেস করার চেষ্টা করি, তাহলে আমরা আবার None পাব। প্রোগ্রামের শেষে, leaf-এ Rc<Node>-এর strong count 1 এবং weak count 0 থাকে, কারণ variable leaf এখন আবার Rc<Node>-এর একমাত্র reference।
Count এবং value dropping manage করে এমন সমস্ত logic Rc<T> এবং Weak<T> এবং তাদের Drop trait-এর implementation-গুলোতে তৈরি করা হয়েছে। Node-এর definition-এ child থেকে তার parent-এর relationship একটি Weak<T> reference হওয়া উচিত specify করে, আপনি parent node-গুলোকে child node-গুলোর দিকে point করাতে পারবেন এবং এর বিপরীতে একটি reference cycle এবং মেমরি লিক তৈরি না করে।
সারসংক্ষেপ
এই chapter-এ আলোচনা করা হয়েছে কিভাবে স্মার্ট পয়েন্টার ব্যবহার করে regular reference-এর সাথে Rust default ভাবে যে গ্যারান্টি এবং trade-off গুলো করে সেগুলো থেকে আলাদা গ্যারান্টি এবং trade-off করা যায়। Box<T> type-টির একটি known আকার রয়েছে এবং heap-এ allocate করা ডেটার দিকে point করে। Rc<T> type টি heap-এর ডেটার reference-এর সংখ্যা ট্র্যাক রাখে যাতে ডেটার multiple owner থাকতে পারে। RefCell<T> type তার ইন্টেরিয়র মিউটেবিলিটি সহ আমাদের এমন একটি type দেয় যা আমরা ব্যবহার করতে পারি যখন আমাদের একটি immutable type প্রয়োজন কিন্তু সেই type-এর একটি ভেতরের value পরিবর্তন করতে হবে; এটি compile time-এর পরিবর্তে runtime-এ borrowing rule গুলোও enforce করে।
এছাড়াও Deref এবং Drop trait নিয়ে আলোচনা করা হয়েছে, যেগুলো স্মার্ট পয়েন্টারগুলোর অনেক functionality enable করে। আমরা reference cycle গুলো explore করেছি যা মেমরি লিক করতে পারে এবং কিভাবে Weak<T> ব্যবহার করে সেগুলো প্রতিরোধ করা যায়।
যদি এই chapter টি আপনার আগ্রহ জাগিয়ে তোলে এবং আপনি আপনার নিজের স্মার্ট পয়েন্টার implement করতে চান, তাহলে আরও useful তথ্যের জন্য "The Rustonomicon" দেখুন।
এরপরে, আমরা Rust-এ concurrency নিয়ে আলোচনা করব। আপনি কয়েকটি new smart pointer সম্পর্কেও জানতে পারবেন।
নির্ভীক Concurrency
Concurrent প্রোগ্রামিং নিরাপদে এবং দক্ষতার সাথে হ্যান্ডেল করা Rust-এর অন্যতম প্রধান লক্ষ্য। Concurrent প্রোগ্রামিং, যেখানে একটি প্রোগ্রামের বিভিন্ন অংশ স্বাধীনভাবে execute করে, এবং parallel প্রোগ্রামিং, যেখানে একটি প্রোগ্রামের বিভিন্ন অংশ একই সময়ে execute করে, এগুলি ক্রমশ গুরুত্বপূর্ণ হয়ে উঠছে কারণ আরও বেশি সংখ্যক কম্পিউটার তাদের multiple প্রসেসরগুলোর সুবিধা নিচ্ছে। ঐতিহাসিকভাবে, এই প্রেক্ষাপটগুলোতে প্রোগ্রামিং কঠিন এবং ত্রুটিপ্রবণ ছিল। Rust এই situation পরিবর্তন করতে চায়।
প্রাথমিকভাবে, Rust টিম ভেবেছিল যে মেমরি নিরাপত্তা নিশ্চিত করা এবং concurrency সমস্যা প্রতিরোধ করা দুটি আলাদা চ্যালেঞ্জ যা different method দিয়ে সমাধান করতে হবে। সময়ের সাথে সাথে, টিম আবিষ্কার করেছে যে ownership এবং type system হল মেমরি নিরাপত্তা এবং concurrency সমস্যাগুলো manage করার জন্য একটি powerful tool-এর set! Ownership এবং type checking-এর সুবিধা নিয়ে, অনেক concurrency error Rust-এ compile-time error, runtime error নয়। অতএব, আপনাকে একটি runtime concurrency bug ঘটার exact circumstances গুলো reproduce করার চেষ্টা করার জন্য প্রচুর সময় ব্যয় করার পরিবর্তে, incorrect কোড compile হতে অস্বীকার করবে এবং সমস্যাটি ব্যাখ্যা করে একটি error উপস্থাপন করবে। ফলস্বরূপ, আপনি আপনার কোডটি production-এ পাঠানোর পরে potentially ঠিক করার পরিবর্তে এটিতে কাজ করার সময় ঠিক করতে পারেন। আমরা Rust-এর এই দিকটির নাম দিয়েছি নির্ভীক concurrency। নির্ভীক concurrency আপনাকে এমন কোড লিখতে দেয় যা সূক্ষ্ম ত্রুটিমুক্ত এবং নতুন বাগ প্রবর্তন না করে refactor করা সহজ।
দ্রষ্টব্য: সরলতার জন্য, আমরা অনেক সমস্যাকে আরও সুনির্দিষ্টভাবে concurrent এবং/অথবা parallel বলার পরিবর্তে concurrent হিসাবে refer করব। যদি এই বইটি concurrency এবং/অথবা parallelism সম্পর্কে হত, তাহলে আমরা আরও specific হতাম। এই chapter-এর জন্য, অনুগ্রহ করে মানসিকভাবে concurrent ব্যবহার করার সময় concurrent এবং/অথবা parallel substitute করুন।
অনেক language concurrent সমস্যাগুলো হ্যান্ডেল করার জন্য যে সমাধানগুলো offer করে সে সম্পর্কে dogmatic। উদাহরণস্বরূপ, Erlang-এর message-passing concurrency-র জন্য elegant functionality রয়েছে কিন্তু thread-গুলোর মধ্যে state share করার জন্য শুধুমাত্র অস্পষ্ট উপায় রয়েছে। Possible solution গুলোর শুধুমাত্র একটি subset-কে support করা higher-level language গুলোর জন্য একটি যুক্তিসঙ্গত কৌশল, কারণ একটি higher-level language কিছু control ত্যাগ করে abstraction অর্জনের সুবিধাগুলোর প্রতিশ্রুতি দেয়। যাইহোক, lower-level language গুলো থেকে যেকোনো পরিস্থিতিতে best performance সহ সমাধান provide করার আশা করা হয় এবং hardware-এর উপর কম abstraction থাকে। অতএব, Rust আপনার পরিস্থিতি এবং requirement-এর জন্য উপযুক্ত যেকোনো উপায়ে problem গুলো model করার জন্য বিভিন্ন ধরনের tool offer করে।
এই chapter-এ আমরা যে বিষয়গুলো cover করব সেগুলো হল:
- কিভাবে একই সময়ে multiple code-এর অংশ run করার জন্য thread তৈরি করতে হয়
- Message-passing concurrency, যেখানে channel গুলো thread-গুলোর মধ্যে message পাঠায়
- Shared-state concurrency, যেখানে multiple thread-এর কিছু ডেটার অ্যাক্সেস থাকে
SyncএবংSendtrait, যেগুলো Rust-এর concurrency গ্যারান্টিগুলোকে user-defined type-এর পাশাপাশি standard library দ্বারা provide করা type গুলোতেও extend করে
থ্রেড ব্যবহার করে একই সাথে কোড চালানো
বেশিরভাগ current অপারেটিং সিস্টেমে, একটি executed প্রোগ্রামের কোড একটি প্রসেস-এ run হয় এবং অপারেটিং সিস্টেম একসাথে multiple প্রসেস manage করবে। একটি প্রোগ্রামের মধ্যে, আপনার independent অংশগুলোও থাকতে পারে যেগুলো simultaneously চলে। এই independent অংশগুলো run করে এমন feature গুলোকে থ্রেড বলা হয়। উদাহরণস্বরূপ, একটি ওয়েব সার্ভারে multiple থ্রেড থাকতে পারে যাতে এটি একই সময়ে একাধিক অনুরোধে respond করতে পারে।
আপনার প্রোগ্রামের computation-কে multiple থ্রেডে বিভক্ত করে একই সময়ে multiple task চালানো পারফরম্যান্স improve করতে পারে, তবে এটি complexity-ও বাড়িয়ে দেয়। যেহেতু থ্রেডগুলো simultaneously চলতে পারে, তাই বিভিন্ন থ্রেডে আপনার কোডের অংশগুলো কোন ক্রমে চলবে সে সম্পর্কে কোনো inherent গ্যারান্টি নেই। এটি সমস্যার দিকে নিয়ে যেতে পারে, যেমন:
- রেস কন্ডিশন, যেখানে থ্রেডগুলো একটি অসঙ্গত ক্রমে ডেটা বা রিসোর্স অ্যাক্সেস করছে
- ডেডলক, যেখানে দুটি থ্রেড একে অপরের জন্য অপেক্ষা করছে, উভয় থ্রেডকে continue করা থেকে বিরত রাখছে
- বাগ যেগুলো শুধুমাত্র certain পরিস্থিতিতে ঘটে এবং reliably reproduce এবং ঠিক করা কঠিন
Rust থ্রেড ব্যবহারের negative effect গুলো প্রশমিত করার চেষ্টা করে, কিন্তু একটি multithreaded context-এ প্রোগ্রামিং করার জন্য এখনও careful thought প্রয়োজন এবং এর জন্য একটি কোড স্ট্রাকচার প্রয়োজন যা single thread-এ চলা প্রোগ্রামগুলোর থেকে আলাদা।
প্রোগ্রামিং ল্যাঙ্গুয়েজগুলো কয়েকটি different উপায়ে থ্রেড implement করে এবং অনেক অপারেটিং সিস্টেম একটি API provide করে যা ল্যাঙ্গুয়েজ new থ্রেড তৈরি করার জন্য কল করতে পারে। Rust standard library থ্রেড ইমপ্লিমেন্টেশনের একটি 1:1 মডেল ব্যবহার করে, যেখানে একটি প্রোগ্রাম প্রতি language থ্রেডের জন্য একটি অপারেটিং সিস্টেম থ্রেড ব্যবহার করে। এমন কিছু crate রয়েছে যেগুলো থ্রেডিংয়ের অন্যান্য মডেল implement করে যা 1:1 মডেলের সাথে different trade-off করে। (Rust-এর async সিস্টেম, যা আমরা அடுத்த chapter-এ দেখব, concurrency-র জন্য আরেকটি অ্যাপ্রোচ প্রদান করে।)
spawn-এর সাহায্যে একটি New Thread তৈরি করা
একটি new thread তৈরি করতে, আমরা thread::spawn ফাংশনটি কল করি এবং এটিকে একটি ক্লোজার (আমরা Chapter 13-এ ক্লোজার নিয়ে আলোচনা করেছি) pass করি যেখানে new thread-এ আমরা যে কোডটি চালাতে চাই তা থাকে। Listing 16-1-এর উদাহরণটি একটি main thread থেকে কিছু text এবং একটি new thread থেকে অন্য text প্রিন্ট করে:
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { for i in 1..10 { println!("hi number {i} from the spawned thread!"); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {i} from the main thread!"); thread::sleep(Duration::from_millis(1)); } }
লক্ষ্য করুন যে যখন একটি Rust প্রোগ্রামের main thread complete হয়, তখন সমস্ত spawned thread গুলো বন্ধ হয়ে যায়, সেগুলো running শেষ করুক বা না করুক। এই প্রোগ্রাম থেকে আউটপুট প্রতিবার একটু ভিন্ন হতে পারে, তবে এটি নিম্নলিখিতগুলোর মতো দেখাবে:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the main thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
Thread::sleep-এর কলগুলো একটি থ্রেডকে অল্প সময়ের জন্য তার execution stop করতে বাধ্য করে, অন্য একটি থ্রেডকে চলতে দেয়। থ্রেডগুলো সম্ভবত পালাক্রমে চলবে, তবে এটির গ্যারান্টি নেই: এটি নির্ভর করে আপনার অপারেটিং সিস্টেম কীভাবে থ্রেডগুলোকে schedule করে তার উপর। এই run-এ, main thread টি প্রথমে প্রিন্ট করেছে, যদিও spawned thread থেকে প্রিন্ট স্টেটমেন্টটি কোডে প্রথমে appear করে। এবং যদিও আমরা spawned thread-টিকে i 9 না হওয়া পর্যন্ত প্রিন্ট করতে বলেছিলাম, main thread বন্ধ হওয়ার আগে এটি শুধুমাত্র 5-এ পৌঁছেছে।
যদি আপনি এই কোডটি চালান এবং শুধুমাত্র main thread থেকে আউটপুট দেখেন, অথবা কোনো overlap না দেখেন, তাহলে range-গুলোতে সংখ্যা বাড়ানোর চেষ্টা করুন যাতে অপারেটিং সিস্টেমের থ্রেডগুলোর মধ্যে switch করার আরও সুযোগ তৈরি হয়।
join Handle ব্যবহার করে সমস্ত Thread শেষ হওয়ার জন্য অপেক্ষা করা
Listing 16-1-এর কোডটি শুধুমাত্র main thread শেষ হওয়ার কারণে বেশিরভাগ সময় spawned thread-টিকে prematurely থামিয়ে দেয় না, কিন্তু যেহেতু থ্রেডগুলো কোন ক্রমে run করে সে সম্পর্কে কোনো গ্যারান্টি নেই, তাই আমরা এটাও গ্যারান্টি দিতে পারি না যে spawned thread টি আদৌ run করতে পারবে!
আমরা thread::spawn-এর return value একটি variable-এ save করে spawned thread-টি না চলা বা prematurely শেষ হওয়ার সমস্যাটি সমাধান করতে পারি। Thread::spawn-এর return type হল JoinHandle। একটি JoinHandle হল একটি owned value যা, যখন আমরা এটিতে join method কল করি, তখন এর থ্রেড শেষ হওয়ার জন্য অপেক্ষা করবে। Listing 16-2 দেখায় কিভাবে Listing 16-1-এ তৈরি করা থ্রেডের JoinHandle ব্যবহার করতে হয় এবং main exit করার আগে spawned thread টি শেষ হয়েছে তা নিশ্চিত করতে join কল করতে হয়:
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {i} from the spawned thread!"); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {i} from the main thread!"); thread::sleep(Duration::from_millis(1)); } handle.join().unwrap(); }
হ্যান্ডেলে join কল করা currently running থ্রেডটিকে ব্লক করে যতক্ষণ না হ্যান্ডেল দ্বারা represented থ্রেডটি terminate হয়। একটি থ্রেডকে ব্লক করার অর্থ হল সেই থ্রেডটিকে কাজ করা বা exit করা থেকে বিরত রাখা। যেহেতু আমরা main thread-এর for লুপের পরে join-এর কলটি রেখেছি, তাই Listing 16-2 চালালে এইরকম আউটপুট produce হওয়া উচিত:
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 1 from the spawned thread!
hi number 3 from the main thread!
hi number 2 from the spawned thread!
hi number 4 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
দুটি থ্রেড alternating ভাবে চলতে থাকে, কিন্তু main thread টি handle.join()-এ কলের কারণে অপেক্ষা করে এবং spawned thread শেষ না হওয়া পর্যন্ত শেষ হয় না।
কিন্তু আসুন দেখি কি হয় যখন আমরা পরিবর্তে main-এ for লুপের আগে handle.join() move করি, এইভাবে:
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {i} from the spawned thread!"); thread::sleep(Duration::from_millis(1)); } }); handle.join().unwrap(); for i in 1..5 { println!("hi number {i} from the main thread!"); thread::sleep(Duration::from_millis(1)); } }
Main thread টি spawned thread শেষ হওয়ার জন্য অপেক্ষা করবে এবং তারপর তার for লুপ চালাবে, তাই আউটপুটটি আর interleaved হবে না, যেমনটি এখানে দেখানো হয়েছে:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
ছোট details, যেমন join কোথায় কল করা হয়েছে, তা আপনার থ্রেডগুলো একই সময়ে run করবে কিনা তা প্রভাবিত করতে পারে।
থ্রেডগুলোর সাথে move ক্লোজার ব্যবহার করা
আমরা প্রায়শই thread::spawn-এ pass করা closure-গুলোর সাথে move keyword ব্যবহার করব কারণ closure টি তখন environment থেকে ব্যবহৃত value গুলোর ownership নেবে, এইভাবে সেই value গুলোর ownership এক থ্রেড থেকে অন্য থ্রেডে transfer করবে। Chapter 13-এ “Reference Capture করা বা Ownership Move করা”-এ, আমরা closure-এর context-এ move নিয়ে আলোচনা করেছি। এখন, আমরা move এবং thread::spawn-এর মধ্যে interaction-এর উপর বেশি concentrate করব।
Listing 16-1-এ লক্ষ্য করুন যে আমরা thread::spawn-এ যে closure টি pass করি সেটি কোনো argument নেয় না: আমরা spawned thread-এর কোডে main thread থেকে কোনো ডেটা ব্যবহার করছি না। Spawned thread-এ main thread থেকে ডেটা ব্যবহার করার জন্য, spawned thread-এর closure-এর প্রয়োজনীয় value গুলো capture করতে হবে। Listing 16-3 main thread-এ একটি vector তৈরি করার এবং অন্য thread-এ এটি ব্যবহার করার একটি প্রচেষ্টা দেখায়। যাইহোক, এটি এখনও কাজ করবে না, যেমনটি আপনি একটু পরেই দেখতে পাবেন।
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}Closure টি v ব্যবহার করে, তাই এটি v ক্যাপচার করবে এবং এটিকে closure-এর environment-এর অংশ করে তুলবে। যেহেতু thread::spawn এই closure-টিকে একটি new thread-এ চালায়, তাই আমাদের সেই new thread-এর মধ্যে v অ্যাক্সেস করতে সক্ষম হওয়া উচিত। কিন্তু যখন আমরা এই উদাহরণটি compile করি, তখন আমরা নিম্নলিখিত error টি পাই:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {v:?}");
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {v:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Rust infer করে কিভাবে v ক্যাপচার করতে হবে, এবং যেহেতু println!-এর শুধুমাত্র v-এর একটি reference প্রয়োজন, তাই closure টি v borrow করার চেষ্টা করে। যাইহোক, একটি সমস্যা আছে: Rust বলতে পারে না spawned thread টি কতক্ষণ চলবে, তাই এটি জানে না যে v-এর reference সব সময় valid থাকবে কিনা।
Listing 16-4 এমন একটি scenario provide করে যেখানে v-এর একটি reference থাকার সম্ভাবনা বেশি যা valid হবে না:
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
drop(v); // oh no!
handle.join().unwrap();
}যদি Rust আমাদের এই কোডটি চালানোর অনুমতি দিত, তাহলে spawned thread-টি immediately background-এ চলে যাওয়ার সম্ভাবনা থাকত, আদৌ না চলে। Spawned thread-টির ভিতরে v-এর একটি reference রয়েছে, কিন্তু main thread অবিলম্বে v ড্রপ করে, Chapter 15-এ আলোচনা করা drop ফাংশনটি ব্যবহার করে। তারপর, যখন spawned thread execute করা শুরু করে, তখন v আর valid থাকে না, তাই এটির একটি reference-ও invalid। ওহ না!
Listing 16-3-এর compiler error ঠিক করতে, আমরা error message-এর পরামর্শ ব্যবহার করতে পারি:
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
Closure-এর আগে move keyword যোগ করে, আমরা closure-টিকে এটি যে value গুলো ব্যবহার করছে সেগুলোর ownership নিতে বাধ্য করি, Rust-কে infer করার অনুমতি দেওয়ার পরিবর্তে যে এটির value গুলো borrow করা উচিত। Listing 16-5-এ দেখানো Listing 16-3-এর modification টি compile হবে এবং আমরা যেভাবে চাই সেভাবে চলবে:
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(move || { println!("Here's a vector: {v:?}"); }); handle.join().unwrap(); }
আমরা Listing 16-4-এর কোডটি ঠিক করার জন্য একই কাজ করার চেষ্টা করতে প্রলুব্ধ হতে পারি যেখানে main thread একটি move closure ব্যবহার করে drop কল করেছে। যাইহোক, এই fix কাজ করবে না কারণ Listing 16-4 যা করার চেষ্টা করছে তা একটি ভিন্ন কারণে অনুমোদিত নয়। যদি আমরা closure-এ move যোগ করি, তাহলে আমরা v-কে closure-এর environment-এ move করব এবং আমরা main thread-এ এটিতে আর drop কল করতে পারব না। পরিবর্তে আমরা এই compiler error টি পাব:
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {v:?}");
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Rust-এর ownership rule গুলো আবার আমাদের বাঁচিয়েছে! আমরা Listing 16-3-এর কোড থেকে একটি error পেয়েছি কারণ Rust রক্ষণশীল ছিল এবং thread-এর জন্য শুধুমাত্র v ধার করছিল, যার অর্থ main thread তাত্ত্বিকভাবে spawned thread-এর reference-কে invalidate করতে পারত। Rust-কে v-এর ownership spawned thread-এ move করতে বলে, আমরা Rust-কে গ্যারান্টি দিচ্ছি যে main thread আর v ব্যবহার করবে না। যদি আমরা Listing 16-4-কে একইভাবে পরিবর্তন করি, তাহলে আমরা ownership rule গুলো লঙ্ঘন করছি যখন আমরা main thread-এ v ব্যবহার করার চেষ্টা করি। Move keyword Rust-এর borrowing-এর রক্ষণশীল default-কে override করে; এটি আমাদের ownership rule গুলো লঙ্ঘন করতে দেয় না।
থ্রেড এবং থ্রেড API-এর একটি basic understanding-এর সাথে, আসুন দেখি আমরা থ্রেড দিয়ে কী করতে পারি।
থ্রেডগুলোর মধ্যে ডেটা ট্রান্সফার করতে Message Passing ব্যবহার করা
নিরাপদ concurrency নিশ্চিত করার জন্য একটি ক্রমবর্ধমান জনপ্রিয় অ্যাপ্রোচ হল মেসেজ পাসিং, যেখানে থ্রেড বা অ্যাক্টররা একে অপরের কাছে ডেটাযুক্ত মেসেজ পাঠিয়ে communicate করে। Go ল্যাঙ্গুয়েজ ডকুমেন্টেশন থেকে একটি স্লোগানে এই ধারণাটি হল: “মেমরি শেয়ার করে communicate করবেন না; পরিবর্তে, communicate করে মেমরি শেয়ার করুন।”
মেসেজ-সেন্ডিং concurrency সম্পন্ন করার জন্য, Rust-এর standard library চ্যানেলগুলোর একটি ইমপ্লিমেন্টেশন provide করে। একটি চ্যানেল হল একটি general প্রোগ্রামিং কনসেপ্ট যার মাধ্যমে ডেটা এক থ্রেড থেকে অন্য থ্রেডে পাঠানো হয়।
আপনি প্রোগ্রামিং-এ একটি চ্যানেলকে জলের একটি দিকনির্দেশক চ্যানেলের মতো কল্পনা করতে পারেন, যেমন একটি স্রোত বা একটি নদী। আপনি যদি একটি রাবার হাঁসের মতো কিছু নদীতে রাখেন তবে এটি জলপথের শেষ পর্যন্ত downstream-এ চলে যাবে।
একটি চ্যানেলের দুটি অংশ রয়েছে: একটি ট্রান্সমিটার এবং একটি রিসিভার। ট্রান্সমিটার অংশটি হল upstream location যেখানে আপনি নদীতে রাবার হাঁস রাখেন এবং রিসিভার অংশটি হল যেখানে রাবার হাঁসটি downstream-এ শেষ হয়। আপনার কোডের একটি অংশ ডেটা সহ ট্রান্সমিটারে মেথড কল করে যা আপনি পাঠাতে চান এবং অন্য অংশটি আগত মেসেজগুলোর জন্য রিসিভিং প্রান্তটি চেক করে। একটি চ্যানেলকে বন্ধ বলা হয় যদি ট্রান্সমিটার বা রিসিভার অংশের যেকোনো একটি ড্রপ করা হয়।
এখানে, আমরা একটি প্রোগ্রাম তৈরি করব যেখানে value generate করতে এবং সেগুলোকে একটি চ্যানেলের নিচে পাঠানোর জন্য একটি থ্রেড থাকবে এবং অন্য একটি থ্রেড value গুলো receive করবে এবং সেগুলো প্রিন্ট করবে। ফিচারটি বোঝানোর জন্য আমরা একটি চ্যানেল ব্যবহার করে থ্রেডগুলোর মধ্যে simple value পাঠাব। একবার আপনি technique-টির সাথে পরিচিত হয়ে গেলে, আপনি যেকোনো থ্রেডের মধ্যে communicate করার জন্য চ্যানেলগুলো ব্যবহার করতে পারেন, যেমন একটি চ্যাট সিস্টেম বা এমন একটি সিস্টেম যেখানে অনেক থ্রেড একটি calculation-এর অংশগুলো সম্পাদন করে এবং অংশগুলো একটি থ্রেডে পাঠায় যা result গুলোকে একত্রিত করে।
প্রথমে, Listing 16-6-এ, আমরা একটি চ্যানেল তৈরি করব কিন্তু এটি দিয়ে কিছু করব না। মনে রাখবেন যে এটি এখনও compile হবে না কারণ Rust বলতে পারে না আমরা চ্যানেলের মাধ্যমে কী ধরনের value পাঠাতে চাই।
Filename: src/main.rs
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}Listing 16-6: একটি চ্যানেল তৈরি করা এবং দুটি অংশকে tx এবং rx-এ assign করা
আমরা mpsc::channel ফাংশন ব্যবহার করে একটি new চ্যানেল তৈরি করি; mpsc মানে multiple producer, single consumer। সংক্ষেপে, Rust-এর standard library যেভাবে চ্যানেলগুলো implement করে তার মানে হল একটি চ্যানেলের একাধিক সেন্ডিং প্রান্ত থাকতে পারে যেগুলো value produce করে কিন্তু শুধুমাত্র একটি রিসিভিং প্রান্ত থাকতে পারে যা সেই value গুলোকে consume করে। কল্পনা করুন multiple stream একসাথে একটি বড় নদীতে প্রবাহিত হচ্ছে: যেকোনো stream-এর নিচে পাঠানো সবকিছু শেষে একটি নদীতে শেষ হবে। আমরা আপাতত একটি single producer দিয়ে শুরু করব, কিন্তু যখন আমরা এই উদাহরণটি কাজ করাব তখন আমরা multiple producer যোগ করব।
Mpsc::channel ফাংশনটি একটি tuple রিটার্ন করে, যার প্রথম element টি হল sending end—ট্রান্সমিটার—এবং দ্বিতীয় element টি হল receiving end—রিসিভার। Tx এবং rx abbreviation গুলো traditionally অনেক ক্ষেত্রে যথাক্রমে ট্রান্সমিটার এবং রিসিভার-এর জন্য ব্যবহৃত হয়, তাই আমরা আমাদের variable গুলোর নাম সেই অনুযায়ী রাখি প্রতিটি প্রান্ত নির্দেশ করার জন্য। আমরা একটি let স্টেটমেন্ট ব্যবহার করছি একটি প্যাটার্নের সাথে যা tuple গুলোকে destructure করে; আমরা Chapter 19-এ let স্টেটমেন্ট এবং destructuring-এ প্যাটার্নের ব্যবহার নিয়ে আলোচনা করব। আপাতত, জেনে রাখুন যে এইভাবে একটি let স্টেটমেন্ট ব্যবহার করা mpsc::channel দ্বারা returned tuple-এর অংশগুলো extract করার একটি সুবিধাজনক উপায়।
আসুন ট্রান্সমিটিং প্রান্তটিকে একটি spawned thread-এ move করি এবং এটিকে একটি string পাঠাতে দিই যাতে spawned thread টি main thread-এর সাথে communicate করে, যেমনটি Listing 16-7-এ দেখানো হয়েছে। এটি নদীতে upstream-এ একটি রাবার হাঁস রাখার বা এক থ্রেড থেকে অন্য থ্রেডে একটি চ্যাট মেসেজ পাঠানোর মতো।
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); }); }
আবারও, আমরা একটি new thread তৈরি করতে thread::spawn ব্যবহার করছি এবং তারপর tx-কে closure-এ move করতে move ব্যবহার করছি যাতে spawned thread-টি tx-এর owner হয়। Spawned thread-টির চ্যানেলের মাধ্যমে message পাঠাতে সক্ষম হওয়ার জন্য transmitter-এর owner হওয়া প্রয়োজন।
ট্রান্সমিটারের একটি send method রয়েছে যা আমরা যে value টি পাঠাতে চাই সেটি নেয়। Send method টি একটি Result<T, E> টাইপ রিটার্ন করে, তাই যদি রিসিভারটি ইতিমধ্যেই ড্রপ করা হয়ে থাকে এবং একটি value পাঠানোর কোনো জায়গা না থাকে, তাহলে send operation টি একটি error রিটার্ন করবে। এই উদাহরণে, আমরা error-এর ক্ষেত্রে panic করার জন্য unwrap কল করছি। কিন্তু একটি real application-এ, আমরা এটিকে সঠিকভাবে হ্যান্ডেল করব: proper error handling-এর জন্য strategy গুলো পর্যালোচনা করতে Chapter 9-এ ফিরে যান।
Listing 16-8-এ, আমরা main thread-এ রিসিভার থেকে value টি পাব। এটি নদীর শেষে জল থেকে রাবার হাঁস retrieve করা বা একটি চ্যাট মেসেজ receive করার মতো।
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); }); let received = rx.recv().unwrap(); println!("Got: {received}"); }
রিসিভারের দুটি useful method রয়েছে: recv এবং try_recv। আমরা recv ব্যবহার করছি, receive-এর সংক্ষিপ্ত, যেটি main thread-এর execution-কে ব্লক করবে এবং চ্যানেলের নিচে একটি value পাঠানো না হওয়া পর্যন্ত অপেক্ষা করবে। একবার একটি value পাঠানো হলে, recv এটিকে একটি Result<T, E>-তে রিটার্ন করবে। যখন ট্রান্সমিটার বন্ধ হয়ে যায়, তখন recv একটি error রিটার্ন করবে এটা বোঝাতে যে আর কোনো value আসবে না।
Try_recv method টি ব্লক করে না, কিন্তু পরিবর্তে অবিলম্বে একটি Result<T, E> রিটার্ন করবে: যদি একটি message available থাকে তাহলে একটি Ok value যাতে message টি থাকবে এবং যদি এই মুহূর্তে কোনো message না থাকে তাহলে একটি Err value। Try_recv ব্যবহার করা useful যদি এই থ্রেডের message-এর জন্য অপেক্ষা করার সময় অন্য কাজ করার থাকে: আমরা একটি লুপ লিখতে পারি যা প্রতি কিছুক্ষণ অন্তর try_recv কল করে, যদি একটি message available থাকে তাহলে সেটিকে handle করে এবং অন্যথায় কিছুক্ষণ অন্য কাজ করে আবার check করে।
আমরা এই উদাহরণে সরলতার জন্য recv ব্যবহার করেছি; main thread-এর message-এর জন্য অপেক্ষা করা ছাড়া অন্য কোনো কাজ করার নেই, তাই main thread-কে ব্লক করা উপযুক্ত।
যখন আমরা Listing 16-8-এর কোডটি চালাই, তখন আমরা main thread থেকে প্রিন্ট করা value টি দেখতে পাব:
Got: hi
দারুণ!
চ্যানেল এবং Ownership Transference
Ownership rule গুলো message পাঠানোর ক্ষেত্রে একটি গুরুত্বপূর্ণ ভূমিকা পালন করে কারণ সেগুলো আপনাকে নিরাপদ, concurrent কোড লিখতে সাহায্য করে। Concurrent প্রোগ্রামিং-এ error প্রতিরোধ করা হল আপনার Rust প্রোগ্রামগুলো জুড়ে ownership সম্পর্কে চিন্তা করার সুবিধা। আসুন একটি experiment করি এটা দেখাতে যে কীভাবে চ্যানেল এবং ownership সমস্যা প্রতিরোধ করতে একসাথে কাজ করে: আমরা spawned thread-এ একটি val value ব্যবহার করার চেষ্টা করব পরে যখন আমরা এটিকে চ্যানেলের নিচে পাঠিয়েছি। Listing 16-9-এর কোডটি compile করার চেষ্টা করুন এটা দেখতে যে কেন এই কোডটির অনুমতি নেই:
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {val}");
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}এখানে, আমরা tx.send-এর মাধ্যমে চ্যানেলের নিচে পাঠানোর পরে val প্রিন্ট করার চেষ্টা করি। এটির অনুমতি দেওয়া একটি খারাপ ধারণা হবে: একবার value টি অন্য থ্রেডে পাঠানো হলে, সেই থ্রেডটি value টি আবার ব্যবহার করার চেষ্টা করার আগে এটিকে modify বা ড্রপ করতে পারে। সম্ভাব্যভাবে, অন্য থ্রেডের modification গুলো অসঙ্গত বা অস্তিত্বহীন ডেটার কারণে error বা unexpected result-এর কারণ হতে পারে। যাইহোক, আমরা যদি Listing 16-9-এর কোড compile করার চেষ্টা করি তাহলে Rust আমাদের একটি error দেয়:
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:26
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {val}");
| ^^^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` (bin "message-passing") due to 1 previous error
আমাদের concurrency-জনিত ভুল একটি compile time error ঘটিয়েছে। Send ফাংশনটি তার parameter-এর ownership নেয় এবং যখন value টি move করা হয়, তখন receiver এটির ownership নেয়। এটি আমাদের পাঠানো value টি accidental ভাবে আবার ব্যবহার করা থেকে বিরত রাখে; ownership system পরীক্ষা করে যে সবকিছু ঠিক আছে।
একাধিক Value পাঠানো এবং Receiver-এর অপেক্ষা দেখা
Listing 16-8-এর কোডটি compile এবং run হয়েছিল, কিন্তু এটি আমাদের স্পষ্টভাবে দেখায়নি যে দুটি আলাদা থ্রেড চ্যানেলের মাধ্যমে একে অপরের সাথে কথা বলছে। Listing 16-10-এ আমরা কিছু modification করেছি যা প্রমাণ করবে যে Listing 16-8-এর কোডটি concurrently চলছে: spawned thread টি এখন multiple message পাঠাবে এবং প্রতিটি message-এর মধ্যে এক সেকেন্ডের জন্য pause করবে।
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
}এইবার, spawned thread-টিতে string-গুলোর একটি vector রয়েছে যা আমরা main thread-এ পাঠাতে চাই। আমরা সেগুলোর উপর iterate করি, প্রতিটি individually পাঠাই এবং প্রতিটি পাঠানোর মধ্যে thread::sleep ফাংশনটিকে Duration value 1 সেকেন্ড দিয়ে কল করে pause করি।
Main thread-এ, আমরা আর explicit ভাবে recv ফাংশনটি কল করছি না: পরিবর্তে, আমরা rx-কে একটি iterator হিসেবে treat করছি। প্রতিটি value receive করার জন্য, আমরা এটিকে প্রিন্ট করছি। যখন চ্যানেলটি বন্ধ হয়ে যায়, তখন iteration শেষ হয়ে যাবে।
Listing 16-10-এর কোডটি চালানোর সময়, আপনি প্রতিটি লাইনের মধ্যে 1-সেকেন্ড pause সহ নিম্নলিখিত আউটপুট দেখতে পাবেন:
Got: hi
Got: from
Got: the
Got: thread
যেহেতু main thread-এর for লুপে আমাদের কোনো কোড নেই যা pause বা delay করে, তাই আমরা বলতে পারি যে main thread টি spawned thread থেকে value receive করার জন্য অপেক্ষা করছে।
ট্রান্সমিটারকে ক্লোন করে একাধিক Producer তৈরি করা
আগে আমরা উল্লেখ করেছি যে mpsc হল multiple producer, single consumer-এর জন্য একটি acronym। আসুন mpsc ব্যবহার করি এবং Listing 16-10-এর কোড expand করি multiple thread তৈরি করতে যেগুলো সবই একই receiver-এ value পাঠায়। আমরা ট্রান্সমিটারকে ক্লোন করে এটি করতে পারি, যেমনটি Listing 16-11-তে দেখানো হয়েছে:
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
// --snip--
}এইবার, আমরা প্রথম spawned thread তৈরি করার আগে, আমরা ট্রান্সমিটারে clone কল করি। এটি আমাদের একটি new transmitter দেবে যা আমরা প্রথম spawned thread-এ pass করতে পারি। আমরা original transmitter-টিকে একটি second spawned thread-এ pass করি। এটি আমাদের দুটি থ্রেড দেয়, প্রতিটি এক রিসিভারে different message পাঠায়।
যখন আপনি কোডটি চালান, তখন আপনার আউটপুট এইরকম হওয়া উচিত:
Got: hi
Got: more
Got: from
Got: messages
Got: for
Got: the
Got: thread
Got: you
আপনি হয়তো value গুলো অন্য ক্রমে দেখতে পারেন, আপনার সিস্টেমের উপর নির্ভর করে। এটিই concurrency-কে interesting এবং সেইসাথে কঠিন করে তোলে। আপনি যদি thread::sleep নিয়ে experiment করেন, এটিকে different thread-এ বিভিন্ন value দেন, তাহলে প্রতিটি run আরও nondeterministic হবে এবং প্রতিবার different আউটপুট তৈরি করবে।
এখন আমরা দেখেছি কিভাবে চ্যানেলগুলো কাজ করে, আসুন concurrency-র একটি different method দেখি।
শেয়ারড-স্টেট কনকারেন্সি (Shared-State Concurrency)
মেসেজ পাসিং কনকারেন্সি পরিচালনার একটি চমৎকার উপায়, কিন্তু এটিই একমাত্র উপায় নয়। আরেকটি পদ্ধতি হল একাধিক থ্রেড একই শেয়ার করা ডেটা অ্যাক্সেস করবে। Go ল্যাংগুয়েজ ডকুমেন্টেশনের স্লোগানের এই অংশটি আবার বিবেচনা করুন: "মেমরি শেয়ার করে যোগাযোগ করবেন না।" ("do not communicate by sharing memory.")
মেমরি শেয়ার করে যোগাযোগ দেখতে কেমন হবে? এছাড়াও, মেসেজ-পাসিং উৎসাহীরা কেন মেমরি শেয়ারিং ব্যবহার না করার জন্য সতর্ক করেন?
একভাবে, যেকোনো প্রোগ্রামিং ল্যাংগুয়েজের চ্যানেলগুলি single ownership এর মতো, কারণ একবার আপনি একটি চ্যানেলের মাধ্যমে একটি value পাঠিয়ে দিলে, আপনার আর সেই value টি ব্যবহার করা উচিত নয়। শেয়ারড মেমরি কনকারেন্সি অনেকটা multiple ownership এর মতো: একাধিক থ্রেড একই সময়ে একই মেমরি লোকেশন অ্যাক্সেস করতে পারে। আপনি যেমনটি Chapter 15 এ দেখেছেন, যেখানে smart pointer গুলি multiple ownership সম্ভব করেছে, multiple ownership জটিলতা বাড়াতে পারে কারণ এই বিভিন্ন owner দের পরিচালনা করতে হয়। Rust এর type system এবং ownership নিয়ম এই পরিচালনা সঠিকভাবে করতে ব্যাপকভাবে সহায়তা করে। একটি উদাহরণের জন্য, আসুন mutex দেখি, শেয়ারড মেমরির জন্য আরও সাধারণ কনকারেন্সি প্রিমিটিভগুলির মধ্যে একটি।
ডেটাতে একবারে একটি থ্রেড থেকে অ্যাক্সেসের অনুমতি দিতে Mutex ব্যবহার করা
Mutex হল mutual exclusion এর সংক্ষিপ্ত রূপ, যেমন, একটি mutex যেকোনো সময়ে শুধুমাত্র একটি থ্রেডকে কিছু ডেটা অ্যাক্সেস করার অনুমতি দেয়। একটি mutex-এর ডেটা অ্যাক্সেস করার জন্য, একটি থ্রেডকে প্রথমে mutex এর lock অ্যাকোয়ার করার জন্য অনুরোধ করে অ্যাক্সেসের ইচ্ছা জানাতে হবে। lock হল একটি ডেটা স্ট্রাকচার যা mutex-এর অংশ, যা বর্তমানে ডেটাতে কার exclusive access আছে তার ট্র্যাক রাখে। অতএব, mutex কে বর্ণনা করা হয় লকিং সিস্টেমের মাধ্যমে ডেটা guard (রক্ষা) করছে।
Mutex ব্যবহারের ক্ষেত্রে দুটি নিয়ম মনে রাখতে হয়, তাই এগুলি ব্যবহার করা কঠিন:
- ডেটা ব্যবহার করার আগে আপনাকে lock অ্যাকোয়ার করার চেষ্টা করতে হবে।
- যখন আপনার mutex দ্বারা সুরক্ষিত ডেটার কাজ শেষ হয়ে যাবে, তখন আপনাকে অবশ্যই ডেটা unlock করতে হবে যাতে অন্য থ্রেডগুলি lock অ্যাকোয়ার করতে পারে।
বাস্তব দুনিয়ায় mutex-এর একটি উদাহরণ হিসেবে, একটি কনফারেন্সে একটি প্যানেল আলোচনা কল্পনা করুন যেখানে কেবল একটি মাইক্রোফোন রয়েছে। কোনও প্যানেলিস্ট কথা বলার আগে, তাদের জিজ্ঞাসা করতে হবে বা সংকেত দিতে হবে যে তারা মাইক্রোফোনটি ব্যবহার করতে চায়। যখন তারা মাইক্রোফোনটি পায়, তারা যতক্ষণ চায় ততক্ষণ কথা বলতে পারে এবং তারপরে পরবর্তী প্যানেলিস্ট যিনি কথা বলতে অনুরোধ করেছেন তাকে মাইক্রোফোনটি দিতে পারে। যদি কোনও প্যানেলিস্ট তার কাজ শেষ হয়ে গেলে মাইক্রোফোনটি দিতে ভুলে যায়, তবে অন্য কেউ কথা বলতে পারবে না। যদি শেয়ার্ড মাইক্রোফোনের পরিচালনা ভুল হয়ে যায়, তাহলে প্যানেলটি পরিকল্পনা অনুযায়ী কাজ করবে না!
Mutex-এর পরিচালনা সঠিকভাবে করা অবিশ্বাস্যভাবে কঠিন হতে পারে, যে কারণে অনেকেই চ্যানেলের প্রতি উৎসাহী। যাইহোক, Rust-এর type system এবং ownership নিয়মের কারণে, আপনি locking এবং unlocking ভুল করতে পারবেন না।
Mutex<T> এর API
কিভাবে একটি mutex ব্যবহার করতে হয় তার উদাহরণ হিসাবে, আসুন Listing 16-12 এ দেখানো single-threaded প্রসঙ্গে একটি mutex ব্যবহার করে শুরু করি:
use std::sync::Mutex; fn main() { let m = Mutex::new(5); { let mut num = m.lock().unwrap(); *num = 6; } println!("m = {m:?}"); }
অনেক type এর মতোই, আমরা new অ্যাসোসিয়েটেড ফাংশন ব্যবহার করে একটি Mutex<T> তৈরি করি। mutex এর ভেতরের ডেটা অ্যাক্সেস করতে, আমরা lock অ্যাকোয়ার করার জন্য lock মেথড ব্যবহার করি। এই কলটি current thread কে ব্লক করবে যাতে lock পাওয়ার আগ পর্যন্ত এটি কোনও কাজ করতে না পারে।
যদি lock ধরে রাখা অন্য কোনো থ্রেড প্যানিক করে তাহলে lock-এ কল fail করবে। সেক্ষেত্রে, কেউই কখনও lock টি পেতে সক্ষম হবে না, তাই আমরা unwrap বেছে নিয়েছি এবং যদি আমরা সেই পরিস্থিতিতে থাকি তবে এই থ্রেডটিকে প্যানিক করাব।
আমরা lock অ্যাকোয়ার করার পরে, আমরা return value টিকে, এক্ষেত্রে num নামের, ভেতরের ডেটার একটি mutable reference হিসাবে ব্যবহার করতে পারি। type system নিশ্চিত করে যে আমরা m-এর value ব্যবহার করার আগে একটি lock অ্যাকোয়ার করি। m-এর type হল Mutex<i32>, i32 নয়, তাই i32 value ব্যবহার করতে সক্ষম হওয়ার জন্য আমাদের অবশ্যই lock কল করতে হবে। আমরা ভুলতে পারি না; type system অন্যথায় আমাদের ভেতরের i32 অ্যাক্সেস করতে দেবে না।
আপনি যেমন সন্দেহ করতে পারেন, Mutex<T> একটি smart pointer। আরও সঠিকভাবে বলতে গেলে, lock-এর কলটি MutexGuard নামক একটি smart pointer রিটার্ন করে, একটি LockResult-এর মধ্যে wrap করা যা আমরা unwrap-এর কলের মাধ্যমে হ্যান্ডেল করেছি। MutexGuard smart pointer টি আমাদের ভেতরের ডেটার দিকে পয়েন্ট করার জন্য Deref ইমপ্লিমেন্ট করে; smart pointer-টিতে একটি Drop ইমপ্লিমেন্টেশনও রয়েছে যা MutexGuard scope-এর বাইরে চলে গেলে স্বয়ংক্রিয়ভাবে lock ছেড়ে দেয়, যা inner scope-এর শেষে ঘটে। ফলস্বরূপ, আমরা lock ছেড়ে দিতে ভুলে যাওয়ার এবং mutex-কে অন্য থ্রেড দ্বারা ব্যবহৃত হওয়া থেকে ব্লক করার ঝুঁকি নেই, কারণ lock রিলিজ স্বয়ংক্রিয়ভাবে ঘটে।
lock ড্রপ করার পরে, আমরা mutex value প্রিন্ট করতে পারি এবং দেখতে পারি যে আমরা ভেতরের i32 কে 6-এ পরিবর্তন করতে সক্ষম হয়েছি।
একাধিক থ্রেডের মধ্যে একটি Mutex<T> শেয়ার করা
এখন, আসুন Mutex<T> ব্যবহার করে একাধিক থ্রেডের মধ্যে একটি value শেয়ার করার চেষ্টা করি। আমরা 10 টি থ্রেড চালু করব এবং তাদের প্রত্যেককে একটি counter value 1 করে বৃদ্ধি করতে বলব, যাতে counter-টি 0 থেকে 10 পর্যন্ত যায়। Listing 16-13-এর পরবর্তী উদাহরণে একটি compiler error থাকবে এবং আমরা সেই error-টি Mutex<T> ব্যবহার সম্পর্কে আরও জানতে এবং কীভাবে Rust আমাদের এটি সঠিকভাবে ব্যবহার করতে সহায়তা করে তা শিখতে ব্যবহার করব।
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}আমরা Listing 16-12 এর মতো একটি Mutex<T> এর ভিতরে একটি i32 রাখার জন্য একটি counter variable তৈরি করি। এরপর, আমরা সংখ্যার একটি range-এর উপর iterate করে 10 টি থ্রেড তৈরি করি। আমরা thread::spawn ব্যবহার করি এবং সমস্ত থ্রেডকে একই ক্লোজার দিই: একটি যা counter-টিকে থ্রেডের মধ্যে move করে, lock মেথড কল করে Mutex<T>-তে একটি lock অ্যাকোয়ার করে এবং তারপর mutex-এর value-তে 1 যোগ করে। যখন একটি থ্রেড তার ক্লোজার চালানো শেষ করে, num scope-এর বাইরে চলে যাবে এবং lock ছেড়ে দেবে যাতে অন্য থ্রেড এটি অ্যাকোয়ার করতে পারে।
main থ্রেডে, আমরা সমস্ত join handle সংগ্রহ করি। তারপর, Listing 16-2-তে যেমন করেছি, আমরা প্রতিটি হ্যান্ডেলে join কল করি যাতে সমস্ত থ্রেড শেষ হয়। সেই সময়ে, main থ্রেড lock অ্যাকোয়ার করবে এবং এই program-এর result প্রিন্ট করবে।
আমরা ইঙ্গিত দিয়েছিলাম যে এই উদাহরণটি compile হবে না। এখন দেখা যাক কেন!
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: borrow of moved value: `counter`
--> src/main.rs:21:29
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let handle = thread::spawn(move || {
| ------- value moved into closure here, in previous iteration of loop
...
21 | println!("Result: {}", *counter.lock().unwrap());
| ^^^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = counter.lock();
9 ~ for _ in 0..10 {
10 | let handle = thread::spawn(move || {
11 ~ let mut num = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Error মেসেজ বলছে যে counter value-টি লুপের পূর্ববর্তী ইটারেশনে move করা হয়েছিল। Rust আমাদের বলছে যে আমরা counter-এর ownership একাধিক থ্রেডে move করতে পারি না। আসুন Chapter 15-এ আলোচনা করা একটি multiple-ownership পদ্ধতি দিয়ে compiler error ঠিক করি।
একাধিক থ্রেড সহ Multiple Ownership
Chapter 15-এ, আমরা একটি reference counted value তৈরি করতে smart pointer Rc<T> ব্যবহার করে একটি value-কে একাধিক owner দিয়েছিলাম। আসুন এখানে একই কাজ করি এবং দেখি কী হয়। আমরা Listing 16-14-তে Mutex<T>-কে Rc<T>-তে wrap করব এবং ownership থ্রেডে move করার আগে Rc<T> ক্লোন করব।
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}আবার, আমরা compile করি এবং… ভিন্ন error পাই! compiler আমাদের অনেক কিছু শেখাচ্ছে।
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/std/src/thread/mod.rs:731:8
|
728 | pub fn spawn<F, T>(f: F) -> JoinHandle<T>
| ----- required by a bound in this function
...
731 | F: Send + 'static,
| ^^^^ required by this bound in `spawn`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
বাহ, সেই error মেসেজটি খুব শব্দবহুল! ফোকাস করার জন্য এখানে গুরুত্বপূর্ণ অংশটি হল: `Rc<Mutex<i32>>` cannot be sent between threads safely। compiler আমাদের কারণটিও বলছে: the trait `Send` is not implemented for `Rc<Mutex<i32>>`। আমরা পরবর্তী বিভাগে Send সম্পর্কে কথা বলব: এটি এমন একটি trait যা নিশ্চিত করে যে আমরা থ্রেডের সাথে যে type গুলি ব্যবহার করি সেগুলি concurrent পরিস্থিতিতে ব্যবহারের জন্য উপযুক্ত।
দুর্ভাগ্যবশত, Rc<T> থ্রেড জুড়ে শেয়ার করা নিরাপদ নয়। যখন Rc<T> reference count পরিচালনা করে, তখন এটি প্রতিটি clone কলের জন্য count-এ যোগ করে এবং প্রতিটি ক্লোন ড্রপ হওয়ার সময় count থেকে বিয়োগ করে। কিন্তু এটি count-এর পরিবর্তনগুলি অন্য থ্রেড দ্বারা বাধাগ্রস্ত হতে পারে না তা নিশ্চিত করার জন্য কোনও concurrency প্রিমিটিভ ব্যবহার করে না। এটি ভুল count-এর দিকে পরিচালিত করতে পারে—সূক্ষ্ম বাগ যা memory leak বা আমাদের কাজ শেষ হওয়ার আগেই একটি value ড্রপ হওয়ার কারণ হতে পারে। আমাদের যা দরকার তা হল একটি type যা Rc<T>-এর মতোই কিন্তু যা reference count-এ পরিবর্তনগুলি thread-safe উপায়ে করে।
Arc<T> এর সাথে অ্যাটমিক রেফারেন্স কাউন্টিং
সৌভাগ্যবশত, Arc<T> হল Rc<T> এর মতো একটি type যা concurrent পরিস্থিতিতে ব্যবহার করা নিরাপদ। a মানে atomic, অর্থাৎ এটি একটি atomically reference-counted type। অ্যাটমিক হল এক ধরনের concurrency প্রিমিটিভ যা আমরা এখানে বিস্তারিতভাবে আলোচনা করব না: আরও বিস্তারিত জানার জন্য std::sync::atomic এর স্ট্যান্ডার্ড লাইব্রেরি ডকুমেন্টেশন দেখুন। এই সময়ে, আপনাকে শুধু জানতে হবে যে অ্যাটমিকগুলি primitive type-এর মতো কাজ করে তবে থ্রেড জুড়ে শেয়ার করা নিরাপদ।
আপনি তখন ভাবতে পারেন কেন সমস্ত primitive type অ্যাটমিক নয় এবং কেন স্ট্যান্ডার্ড লাইব্রেরি type গুলি ডিফল্টভাবে Arc<T> ব্যবহার করার জন্য ইমপ্লিমেন্ট করা হয় না। কারণ হল থ্রেড নিরাপত্তার সাথে একটি পারফরম্যান্স পেনাল্টি আসে যা আপনি তখনই দিতে চান যখন আপনার সত্যিই প্রয়োজন হয়। আপনি যদি শুধুমাত্র একটি single thread-এর মধ্যে value-গুলির উপর অপারেশন সম্পাদন করেন, তাহলে আপনার কোড আরও দ্রুত চলতে পারে যদি এটিকে অ্যাটমিকদের দেওয়া গ্যারান্টিগুলি প্রয়োগ করতে না হয়।
আসুন আমাদের উদাহরণে ফিরে আসি: Arc<T> এবং Rc<T>-এর একই API রয়েছে, তাই আমরা use লাইন, new-এর কল এবং clone-এর কল পরিবর্তন করে আমাদের program ঠিক করি। Listing 16-15-এর কোডটি অবশেষে compile এবং রান করবে:
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let counter = Arc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
এই কোডটি নিম্নলিখিতগুলি প্রিন্ট করবে:
Result: 10
আমরা পেরেছি! আমরা 0 থেকে 10 পর্যন্ত গণনা করেছি, যা খুব চিত্তাকর্ষক নাও মনে হতে পারে, তবে এটি আমাদের Mutex<T> এবং থ্রেড নিরাপত্তা সম্পর্কে অনেক কিছু শিখিয়েছে। আপনি একটি counter বৃদ্ধি করার চেয়ে আরও জটিল অপারেশন করার জন্য এই program-এর গঠন ব্যবহার করতে পারেন। এই কৌশলটি ব্যবহার করে, আপনি একটি calculation-কে স্বাধীন অংশে বিভক্ত করতে পারেন, সেই অংশগুলিকে থ্রেড জুড়ে বিভক্ত করতে পারেন এবং তারপর প্রতিটি থ্রেডকে তার অংশ দিয়ে final result আপডেট করার জন্য একটি Mutex<T> ব্যবহার করতে পারেন।
মনে রাখবেন যে আপনি যদি সাধারণ numerical অপারেশন করেন, তাহলে স্ট্যান্ডার্ড লাইব্রেরির std::sync::atomic মডিউল দ্বারা প্রদত্ত Mutex<T> type-এর চেয়ে সহজ type রয়েছে। এই type গুলি primitive type গুলিতে নিরাপদ, concurrent, অ্যাটমিক অ্যাক্সেস সরবরাহ করে। আমরা এই উদাহরণের জন্য একটি primitive type-এর সাথে Mutex<T> ব্যবহার করতে বেছে নিয়েছি যাতে আমরা Mutex<T> কীভাবে কাজ করে তাতে মনোযোগ দিতে পারি।
RefCell<T>/Rc<T> এবং Mutex<T>/Arc<T> এর মধ্যে মিল
আপনি হয়তো লক্ষ্য করেছেন যে counter হল immutable, কিন্তু আমরা এর ভেতরের value-তে একটি mutable reference পেতে পারি; এর মানে হল Mutex<T> ইন্টেরিয়র mutability প্রদান করে, যেমন Cell পরিবার করে। একইভাবে আমরা Chapter 15-এ Rc<T>-এর ভেতরের contents পরিবর্তন করার অনুমতি দেওয়ার জন্য RefCell<T> ব্যবহার করেছি, আমরা Arc<T>-এর ভেতরের contents পরিবর্তন করতে Mutex<T> ব্যবহার করি।
আরেকটি বিষয় লক্ষণীয় যে Rust আপনাকে Mutex<T> ব্যবহার করার সময় সব ধরনের লজিক error থেকে রক্ষা করতে পারে না। Chapter 15 থেকে মনে রাখবেন যে Rc<T> ব্যবহার করার সময় রেফারেন্স সাইকেল তৈরি হওয়ার ঝুঁকি ছিল, যেখানে দুটি Rc<T> value একে অপরকে রেফার করে, যার ফলে memory leak হয়। একইভাবে, Mutex<T>-এর deadlock তৈরি হওয়ার ঝুঁকি রয়েছে। এগুলি ঘটে যখন একটি অপারেশনের দুটি রিসোর্স lock করা প্রয়োজন হয় এবং দুটি থ্রেড প্রতিটি একটি করে lock অ্যাকোয়ার করে, যার ফলে তারা একে অপরের জন্য চিরকাল অপেক্ষা করে। আপনি যদি ডেডলকগুলিতে আগ্রহী হন তবে একটি Rust program তৈরি করার চেষ্টা করুন যাতে একটি ডেডলক রয়েছে; তারপর যেকোনো ল্যাংগুয়েজের জন্য mutex-এর ডেডলক প্রশমন কৌশলগুলি নিয়ে রিসার্চ করুন এবং Rust-এ সেগুলি ইমপ্লিমেন্ট করার চেষ্টা করুন। Mutex<T> এবং MutexGuard-এর জন্য স্ট্যান্ডার্ড লাইব্রেরি API ডকুমেন্টেশন দরকারী তথ্য সরবরাহ করে।
আমরা এই চ্যাপ্টারটি Send এবং Sync trait এবং কীভাবে আমরা সেগুলি custom type-এর সাথে ব্যবহার করতে পারি সে সম্পর্কে কথা বলে শেষ করব।
Sync এবং Send Trait-এর সাহায্যে প্রসারণযোগ্য কনকারেন্সি (Extensible Concurrency)
আগ্রহজনকভাবে, Rust ল্যাংগুয়েজে কনকারেন্সির বৈশিষ্ট্য খুবই কম। এই চ্যাপ্টারে আমরা இதுவரை কনকারেন্সির প্রায় প্রতিটি বৈশিষ্ট্য নিয়ে আলোচনা করেছি সেগুলি standard library-এর অংশ, ল্যাংগুয়েজের নয়। কনকারেন্সি পরিচালনার জন্য আপনার বিকল্পগুলি কেবল ল্যাংগুয়েজ বা standard library-তে সীমাবদ্ধ নয়; আপনি নিজের কনকারেন্সি বৈশিষ্ট্য লিখতে পারেন বা অন্যদের লেখা বৈশিষ্ট্যগুলি ব্যবহার করতে পারেন।
যাইহোক, দুটি কনকারেন্সি ধারণা ল্যাংগুয়েজে এমবেড করা আছে: std::marker-এর Sync এবং Send trait।
Send-এর মাধ্যমে থ্রেডগুলির মধ্যে Ownership স্থানান্তর করার অনুমতি
Send মার্কার trait টি নির্দেশ করে যে Send ইমপ্লিমেন্ট করা type-এর value-গুলির ownership থ্রেডগুলির মধ্যে স্থানান্তর করা যেতে পারে। প্রায় প্রতিটি Rust টাইপ Send, তবে কিছু ব্যতিক্রম রয়েছে, যার মধ্যে Rc<T> অন্তর্ভুক্ত: এটি Send হতে পারে না কারণ আপনি যদি একটি Rc<T> value ক্লোন করেন এবং ক্লোনের ownership অন্য থ্রেডে স্থানান্তর করার চেষ্টা করেন, তাহলে উভয় থ্রেড একই সময়ে reference count আপডেট করতে পারে। এই কারণে, Rc<T> single-threaded পরিস্থিতিতে ব্যবহারের জন্য ইমপ্লিমেন্ট করা হয়েছে যেখানে আপনি thread-safe পারফরম্যান্স পেনাল্টি দিতে চান না।
অতএব, Rust-এর type system এবং trait bound গুলি নিশ্চিত করে যে আপনি কখনই ভুল করে অনিরাপদভাবে থ্রেড জুড়ে একটি Rc<T> value পাঠাতে পারবেন না। Listing 16-14-এ যখন আমরা এটি করার চেষ্টা করেছি, তখন আমরা error পেয়েছিলাম the trait Send is not implemented for Rc<Mutex<i32>>। যখন আমরা Arc<T>-এ পরিবর্তন করেছি, যেটি Send, কোডটি compile হয়েছে।
Send type গুলি দ্বারা সম্পূর্ণরূপে গঠিত যেকোনো type স্বয়ংক্রিয়ভাবে Send হিসাবে চিহ্নিত হয়। Raw pointer গুলি বাদে প্রায় সমস্ত primitive type হল Send, যা নিয়ে আমরা Chapter 20-এ আলোচনা করব।
Sync-এর মাধ্যমে একাধিক থ্রেড থেকে অ্যাক্সেসের অনুমতি
Sync মার্কার trait টি নির্দেশ করে যে Sync ইমপ্লিমেন্ট করা type-টিকে একাধিক থ্রেড থেকে রেফারেন্স করা নিরাপদ। অন্য কথায়, যেকোনো type T হল Sync যদি &T ( T-তে একটি immutable reference) Send হয়, অর্থাৎ reference টি নিরাপদে অন্য থ্রেডে পাঠানো যেতে পারে। Send-এর মতোই, primitive type গুলি Sync, এবং সম্পূর্ণরূপে Sync type গুলি দ্বারা গঠিত type গুলিও Sync।
smart pointer Rc<T>-ও Sync নয়, একই কারণে এটি Send নয়। RefCell<T> type (যা নিয়ে আমরা Chapter 15-এ আলোচনা করেছি) এবং সম্পর্কিত Cell<T> type-এর পরিবার Sync নয়। RefCell<T> runtime-এ যে borrow চেকিং করে তার ইমপ্লিমেন্টেশন thread-safe নয়। smart pointer Mutex<T> হল Sync এবং একাধিক থ্রেডের সাথে অ্যাক্সেস শেয়ার করতে ব্যবহার করা যেতে পারে যেমনটি আপনি “Sharing a Mutex<T> Between Multiple Threads”-এ দেখেছেন।
ম্যানুয়ালি Send এবং Sync ইমপ্লিমেন্ট করা Unsafe
যেহেতু Send এবং Sync trait দ্বারা গঠিত type গুলি স্বয়ংক্রিয়ভাবে Send এবং Sync হয়, তাই আমাদের ম্যানুয়ালি সেই trait গুলি ইমপ্লিমেন্ট করার প্রয়োজন নেই। মার্কার trait হিসাবে, তাদের ইমপ্লিমেন্ট করার জন্য কোনও মেথডও নেই। এগুলি কেবল কনকারেন্সি সম্পর্কিত ইনভেরিয়েন্টগুলি প্রয়োগ করার জন্য দরকারী।
এই trait গুলি ম্যানুয়ালি ইমপ্লিমেন্ট করার মধ্যে unsafe Rust কোড ইমপ্লিমেন্ট করা জড়িত। আমরা Chapter 20-এ unsafe Rust কোড ব্যবহার সম্পর্কে কথা বলব; আপাতত, গুরুত্বপূর্ণ তথ্য হল যে Send এবং Sync অংশ দ্বারা গঠিত নয় এমন নতুন concurrent type তৈরি করার জন্য safety গ্যারান্টিগুলি বজায় রাখার জন্য সতর্ক চিন্তাভাবনার প্রয়োজন। “The Rustonomicon”-এ এই গ্যারান্টিগুলি এবং কীভাবে সেগুলি বজায় রাখা যায় সে সম্পর্কে আরও তথ্য রয়েছে।
সারাংশ
এই বইয়ে আপনি কনকারেন্সির শেষ দেখা পাবেন না: সম্পূর্ণ পরবর্তী চ্যাপ্টারটি অ্যাসিঙ্ক্রোনাস প্রোগ্রামিংয়ের উপর ফোকাস করে এবং Chapter 21-এর প্রোজেক্টটি এখানে আলোচিত ছোট উদাহরণগুলির চেয়ে আরও বাস্তব পরিস্থিতিতে এই চ্যাপ্টারের ধারণাগুলি ব্যবহার করবে।
আগেই উল্লেখ করা হয়েছে, যেহেতু Rust কীভাবে কনকারেন্সি পরিচালনা করে তার খুব সামান্য অংশই ল্যাংগুয়েজের অংশ, তাই অনেক কনকারেন্সি সমাধান crate হিসাবে ইমপ্লিমেন্ট করা হয়। এগুলি standard library-এর চেয়ে দ্রুত বিকশিত হয়, তাই multithreaded পরিস্থিতিতে ব্যবহার করার জন্য বর্তমান, state-of-the-art crate-গুলির জন্য অনলাইনে সার্চ করতে ভুলবেন না।
Rust standard library মেসেজ পাসিংয়ের জন্য চ্যানেল এবং smart pointer type, যেমন Mutex<T> এবং Arc<T>, সরবরাহ করে যা concurrent পরিস্থিতিতে ব্যবহার করা নিরাপদ। type system এবং borrow চেকার নিশ্চিত করে যে এই সমাধানগুলি ব্যবহার করা কোডে ডেটা রেস বা অবৈধ রেফারেন্স থাকবে না। একবার আপনি আপনার কোড compile করতে পারলে, আপনি নিশ্চিন্ত থাকতে পারেন যে এটি অন্যান্য ল্যাংগুয়েজের সাধারণ hard-to-track-down বাগগুলি ছাড়াই আনন্দের সাথে একাধিক থ্রেডে চলবে। Concurrent প্রোগ্রামিং আর ভয় পাওয়ার মতো কোনও ধারণা নয়: এগিয়ে যান এবং আপনার program গুলিকে নির্ভয়ে concurrent করুন!
অ্যাসিঙ্ক্রোনাস প্রোগ্রামিং-এর মূল বিষয়: Async, Await, Futures, এবং Streams
আমরা কম্পিউটারকে যে কাজগুলি করতে বলি তার অনেকগুলি শেষ হতে বেশ কিছুটা সময় নিতে পারে। এই দীর্ঘ-চলমান প্রক্রিয়াগুলি সম্পূর্ণ হওয়ার জন্য অপেক্ষা করার সময় আমরা যদি অন্য কিছু করতে পারতাম তবে ভাল হত। আধুনিক কম্পিউটারগুলি একবারে একাধিক অপারেশনে কাজ করার জন্য দুটি কৌশল সরবরাহ করে: প্যারালেলিজম (parallelism) এবং কনকারেন্সি (concurrency)। একবার যখন আমরা প্যারালাল বা কনকারেন্ট অপারেশন যুক্ত প্রোগ্রাম লেখা শুরু করি, তখন আমরা দ্রুত অ্যাসিঙ্ক্রোনাস প্রোগ্রামিং-এর অন্তর্নিহিত নতুন চ্যালেঞ্জগুলির সম্মুখীন হই, যেখানে অপারেশনগুলি শুরু হওয়ার ক্রমে ধারাবাহিকভাবে শেষ নাও হতে পারে। এই চ্যাপ্টারটি প্যারালেলিজম এবং কনকারেন্সির জন্য থ্রেড ব্যবহারের বিষয়ে Chapter 16-এর উপর ভিত্তি করে তৈরি হয়েছে এবং অ্যাসিঙ্ক্রোনাস প্রোগ্রামিং-এর একটি বিকল্প পদ্ধতির পরিচয় দেয়: Rust-এর Futures, Streams, সেগুলিকে সমর্থন করে এমন async এবং await সিনট্যাক্স এবং অ্যাসিঙ্ক্রোনাস অপারেশনগুলির মধ্যে পরিচালনা ও সমন্বয় করার টুল।
আসুন একটি উদাহরণ বিবেচনা করা যাক। ধরুন আপনি একটি পারিবারিক উদযাপনের একটি ভিডিও এক্সপোর্ট করছেন, এমন একটি অপারেশন যা কয়েক মিনিট থেকে কয়েক ঘন্টা পর্যন্ত সময় নিতে পারে। ভিডিও এক্সপোর্ট যতটা সম্ভব CPU এবং GPU পাওয়ার ব্যবহার করবে। যদি আপনার কেবল একটি CPU কোর থাকত এবং আপনার অপারেটিং সিস্টেম সেই এক্সপোর্টটি সম্পূর্ণ না হওয়া পর্যন্ত এটিকে স্থগিত না করত—অর্থাৎ, যদি এটি এক্সপোর্টটিকে synchronously এক্সিকিউট করত—তাহলে সেই কাজটি চলার সময় আপনি আপনার কম্পিউটারে অন্য কিছু করতে পারতেন না। এটি একটি হতাশাজনক অভিজ্ঞতা হত। সৌভাগ্যবশত, আপনার কম্পিউটারের অপারেটিং সিস্টেম অন্যান্য কাজগুলিকে যুগপতভাবে সম্পন্ন করার সুযোগ দিতে যথেষ্ট পরিমাণে এক্সপোর্টকে অদৃশ্যভাবে বাধা দিতে পারে এবং দেয়।
এখন ধরুন আপনি অন্য কারও শেয়ার করা একটি ভিডিও ডাউনলোড করছেন, যেটিতেও কিছুক্ষণ সময় লাগতে পারে কিন্তু এটি CPU-এর বেশি সময় নেয় না। এই ক্ষেত্রে, CPU-কে নেটওয়ার্ক থেকে ডেটা আসার জন্য অপেক্ষা করতে হবে। আপনি ডেটা আসা শুরু করার সাথে সাথেই পড়া শুরু করতে পারলেও, সমস্ত ডেটা আসতে কিছুটা সময় লাগতে পারে। এমনকি সমস্ত ডেটা উপস্থিত থাকলেও, যদি ভিডিওটি বেশ বড় হয়, তবে এটি লোড হতে কমপক্ষে এক বা দুই সেকেন্ড সময় লাগতে পারে। এটি খুব বেশি মনে নাও হতে পারে, তবে এটি একটি আধুনিক প্রসেসরের জন্য অনেক দীর্ঘ সময়, যা প্রতি সেকেন্ডে কয়েক বিলিয়ন অপারেশন সম্পাদন করতে পারে। আবারও, আপনার অপারেটিং সিস্টেম নেটওয়ার্ক কলের কাজ শেষ হওয়ার অপেক্ষার সময় CPU-কে অন্য কাজ করার অনুমতি দেওয়ার জন্য আপনার প্রোগ্রামটিকে অদৃশ্যভাবে বাধা দেবে।
ভিডিও এক্সপোর্ট হল একটি CPU-bound বা compute-bound অপারেশনের উদাহরণ। এটি CPU বা GPU-এর মধ্যে কম্পিউটারের সম্ভাব্য ডেটা প্রসেসিং গতি এবং সেই গতির কতটা এটি অপারেশনে ডেডিকেট করতে পারে তার দ্বারা সীমাবদ্ধ। ভিডিও ডাউনলোড হল একটি IO-bound অপারেশনের উদাহরণ, কারণ এটি কম্পিউটারের input এবং output-এর গতির দ্বারা সীমাবদ্ধ; এটি কেবল ততটাই দ্রুত চলতে পারে যতটা দ্রুত নেটওয়ার্ক জুড়ে ডেটা পাঠানো যায়।
এই উভয় উদাহরণেই, অপারেটিং সিস্টেমের অদৃশ্য বাধাগুলি এক ধরনের কনকারেন্সি সরবরাহ করে। সেই কনকারেন্সি অবশ্য কেবল সম্পূর্ণ প্রোগ্রামের স্তরে ঘটে: অপারেটিং সিস্টেম অন্য প্রোগ্রামগুলিকে কাজ করার সুযোগ দেওয়ার জন্য একটি প্রোগ্রামকে বাধা দেয়। অনেক ক্ষেত্রে, যেহেতু আমরা অপারেটিং সিস্টেমের চেয়ে অনেক বেশি সুক্ষ্ম স্তরে আমাদের প্রোগ্রামগুলি বুঝতে পারি, তাই আমরা কনকারেন্সির এমন সুযোগগুলি দেখতে পাই যা অপারেটিং সিস্টেম দেখতে পায় না।
উদাহরণস্বরূপ, যদি আমরা ফাইল ডাউনলোড পরিচালনা করার জন্য একটি টুল তৈরি করি, তাহলে আমাদের প্রোগ্রামটি এমনভাবে লিখতে পারা উচিত যাতে একটি ডাউনলোড শুরু করলে UI লক না হয় এবং ব্যবহারকারীরা একই সাথে একাধিক ডাউনলোড শুরু করতে পারে। নেটওয়ার্কের সাথে ইন্টারঅ্যাক্ট করার জন্য অনেকগুলি অপারেটিং সিস্টেম API blocking, যদিও; অর্থাৎ, তারা প্রোগ্রামের অগ্রগতি ব্লক করে যতক্ষণ না তারা যে ডেটা প্রসেস করছে তা সম্পূর্ণরূপে প্রস্তুত হয়।
Note: আপনি যদি এটি সম্পর্কে চিন্তা করেন তবে বেশিরভাগ ফাংশন কল এইভাবে কাজ করে। যাইহোক, blocking শব্দটি সাধারণত ফাইল, নেটওয়ার্ক বা কম্পিউটারের অন্যান্য রিসোর্সের সাথে ইন্টারঅ্যাক্ট করা ফাংশন কলগুলির জন্য সংরক্ষিত থাকে, কারণ সেই ক্ষেত্রগুলিতে একটি individual প্রোগ্রাম non-blocking অপারেশনে উপকৃত হবে।
আমরা প্রতিটি ফাইল ডাউনলোড করার জন্য একটি ডেডিকেটেড থ্রেড স্পন করে আমাদের main থ্রেডকে ব্লক করা এড়াতে পারি। যাইহোক, সেই থ্রেডগুলির ওভারহেড অবশেষে একটি সমস্যা হয়ে দাঁড়াবে। কলের শুরুতেই যদি ব্লক না করে তবে সেটি আরও ভাল হত। আমরা যদি ব্লকিং কোডে ব্যবহার করা একই ডিরেক্ট স্টাইলে লিখতে পারতাম, তাহলে আরও ভাল হত, অনেকটা এইরকম:
let data = fetch_data_from(url).await;
println!("{data}");Rust-এর async ( asynchronous-এর সংক্ষিপ্ত) অ্যাবস্ট্রাকশন আমাদের ঠিক সেটাই দেয়। এই চ্যাপ্টারে, আপনি নিম্নলিখিত বিষয়গুলি কভার করার সাথে সাথে async সম্পর্কে সমস্ত কিছু শিখবেন:
- কীভাবে Rust-এর
asyncএবংawaitসিনট্যাক্স ব্যবহার করবেন - Chapter 16-এ আমরা যে চ্যালেঞ্জগুলি দেখেছিলাম তার কিছু সমাধান করতে কীভাবে async মডেল ব্যবহার করবেন
- কীভাবে multithreading এবং async একে অপরের পরিপূরক সমাধান সরবরাহ করে, যা আপনি অনেক ক্ষেত্রে একত্রিত করতে পারেন
বাস্তবে async কীভাবে কাজ করে তা দেখার আগে, আমাদের প্যারালেলিজম এবং কনকারেন্সির মধ্যে পার্থক্যগুলি নিয়ে আলোচনা করার জন্য একটি সংক্ষিপ্ত বিরতি নিতে হবে।
প্যারালেলিজম এবং কনকারেন্সি (Parallelism and Concurrency)
আমরা ఇప్పటి পর্যন্ত প্যারালেলিজম এবং কনকারেন্সিকে বেশিরভাগ ক্ষেত্রে বিনিময়যোগ্য হিসাবে বিবেচনা করেছি। এখন আমাদের তাদের মধ্যে আরও সুনির্দিষ্টভাবে পার্থক্য করতে হবে, কারণ আমরা কাজ শুরু করার সাথে সাথে পার্থক্যগুলি দেখা যাবে।
একটি সফ্টওয়্যার প্রোজেক্টে একটি দল কীভাবে কাজ ভাগ করতে পারে তার বিভিন্ন উপায় বিবেচনা করুন। আপনি একজন individual সদস্যকে একাধিক কাজ বরাদ্দ করতে পারেন, প্রতিটি সদস্যকে একটি কাজ বরাদ্দ করতে পারেন, বা দুটি পদ্ধতির মিশ্রণ ব্যবহার করতে পারেন।
যখন একজন ব্যক্তি কোনও কাজ সম্পূর্ণ হওয়ার আগেই বেশ কয়েকটি ভিন্ন কাজ নিয়ে কাজ করেন, তখন এটি হল কনকারেন্সি। হতে পারে আপনার কম্পিউটারে দুটি ভিন্ন প্রোজেক্ট চেক আউট করা আছে, এবং যখন আপনি একটি প্রোজেক্টে বিরক্ত হন বা আটকে যান, তখন আপনি অন্যটিতে স্যুইচ করেন। আপনি কেবল একজন ব্যক্তি, তাই আপনি একই সময়ে উভয় কাজেই অগ্রগতি করতে পারবেন না, তবে আপনি মাল্টি-টাস্ক করতে পারেন, তাদের মধ্যে স্যুইচ করে একবারে একটিতে অগ্রগতি করতে পারেন (চিত্র 17-1 দেখুন)।

যখন দলটি প্রতিটি সদস্যকে একটি করে কাজ নেয় এবং একা একা কাজ করে, তখন এটি প্যারালেলিজম। দলের প্রত্যেকে একই সময়ে অগ্রগতি করতে পারে (চিত্র 17-2 দেখুন)।

এই উভয় ওয়ার্কফ্লোতেই, আপনাকে বিভিন্ন কাজের মধ্যে সমন্বয় করতে হতে পারে। হতে পারে আপনি ভেবেছিলেন একজন ব্যক্তিকে দেওয়া কাজটি অন্য সবার কাজ থেকে সম্পূর্ণ স্বাধীন, কিন্তু আসলে এটির জন্য দলের অন্য একজন ব্যক্তির প্রথমে তাদের কাজটি শেষ করা প্রয়োজন। কিছু কাজ প্যারালালে করা যেতে পারে, তবে এর মধ্যে কিছু আসলে সিরিয়াল: এটি কেবল একটি সিরিজে ঘটতে পারে, একের পর এক কাজ, যেমন চিত্র 17-3-এ।

একইভাবে, আপনি বুঝতে পারেন যে আপনার নিজের একটি কাজ আপনার অন্য একটি কাজের উপর নির্ভরশীল। এখন আপনার কনকারেন্ট কাজও সিরিয়াল হয়ে গেছে।
প্যারালেলিজম এবং কনকারেন্সি একে অপরের সাথে ছেদ করতে পারে। আপনি যদি জানতে পারেন যে আপনার একজন সহকর্মী আপনার একটি কাজ শেষ না করা পর্যন্ত আটকে আছেন, তাহলে আপনি সম্ভবত আপনার সহকর্মীকে "আনব্লক" করার জন্য সেই কাজের উপর সমস্ত মনোযোগ দেবেন। আপনি এবং আপনার সহকর্মী আর প্যারালালে কাজ করতে পারবেন না, এবং আপনি আপনার নিজের কাজগুলিতেও আর কনকারেন্টলি কাজ করতে পারবেন না।
সফ্টওয়্যার এবং হার্ডওয়্যারের ক্ষেত্রেও একই বেসিক ডায়নামিকগুলি কার্যকর হয়। একটি single CPU কোর সহ একটি মেশিনে, CPU একবারে কেবল একটি অপারেশন সম্পাদন করতে পারে, তবে এটি এখনও কনকারেন্টলি কাজ করতে পারে। থ্রেড, প্রসেস এবং async-এর মতো টুল ব্যবহার করে, কম্পিউটার একটি অ্যাক্টিভিটি পজ করতে পারে এবং অন্যগুলিতে স্যুইচ করতে পারে, অবশেষে আবার সেই প্রথম অ্যাক্টিভিটিতে ফিরে আসার আগে। একাধিক CPU কোর সহ একটি মেশিনে, এটি প্যারালালে কাজও করতে পারে। একটি কোর একটি কাজ সম্পাদন করতে পারে যখন অন্য কোর সম্পূর্ণ সম্পর্কহীন একটি কাজ সম্পাদন করে এবং সেই অপারেশনগুলি আসলে একই সময়ে ঘটে।
Rust-এ async নিয়ে কাজ করার সময়, আমরা সবসময় কনকারেন্সির সাথে কাজ করি। হার্ডওয়্যার, অপারেটিং সিস্টেম এবং আমরা যে async রানটাইম ব্যবহার করছি তার উপর নির্ভর করে (async রানটাইম সম্পর্কে শীঘ্রই আরও আলোচনা করা হবে), সেই কনকারেন্সি হুডের নিচে প্যারালেলিজমও ব্যবহার করতে পারে।
এখন, আসুন Rust-এ অ্যাসিঙ্ক্রোনাস প্রোগ্রামিং কীভাবে কাজ করে তাতে ডুব দেওয়া যাক।
ফিউচার এবং Async সিনট্যাক্স (Futures and the Async Syntax)
Rust-এ অ্যাসিঙ্ক্রোনাস প্রোগ্রামিং-এর মূল উপাদানগুলি হল ফিউচার এবং Rust-এর async এবং await কীওয়ার্ড।
একটি ফিউচার হল এমন একটি মান যা এখনই প্রস্তুত নাও হতে পারে কিন্তু ভবিষ্যতে কোনো এক সময়ে প্রস্তুত হবে। (এই একই ধারণাটি অনেক ভাষায় দেখা যায়, কখনও কখনও অন্য নামে যেমন টাস্ক বা প্রমিজ)। Rust একটি Future trait সরবরাহ করে একটি বিল্ডিং ব্লক হিসাবে যাতে বিভিন্ন অ্যাসিঙ্ক্রোনাস অপারেশনগুলি বিভিন্ন ডেটা স্ট্রাকচার কিন্তু একটি সাধারণ ইন্টারফেসের সাথে ইমপ্লিমেন্ট করা যায়। Rust-এ, ফিউচার হল এমন টাইপ যা Future trait ইমপ্লিমেন্ট করে। প্রতিটি ফিউচার তার নিজস্ব তথ্য রাখে যে কতটা অগ্রগতি হয়েছে এবং "প্রস্তুত" মানে কী।
আপনি ব্লক এবং ফাংশনগুলিতে async কীওয়ার্ড প্রয়োগ করতে পারেন এটা বোঝাতে যে সেগুলিকে বাধা দেওয়া এবং পুনরায় শুরু করা যেতে পারে। একটি async ব্লক বা async ফাংশনের মধ্যে, আপনি await কীওয়ার্ড ব্যবহার করতে পারেন একটি ফিউচারের জন্য অপেক্ষা করার জন্য (অর্থাৎ, এটি প্রস্তুত হওয়ার জন্য অপেক্ষা করা)। একটি async ব্লক বা ফাংশনের মধ্যে আপনি যেখানেই একটি ফিউচারের জন্য অপেক্ষা করেন সেটি হল সেই async ব্লক বা ফাংশনের বিরতি এবং পুনরায় শুরু করার একটি সম্ভাব্য স্থান। একটি ফিউচারের সাথে তার মান এখনও উপলব্ধ কিনা তা দেখার জন্য পরীক্ষা করার প্রক্রিয়াটিকে পোলিং বলা হয়।
অন্যান্য কিছু ভাষা, যেমন C# এবং JavaScript-ও অ্যাসিঙ্ক্রোনাস প্রোগ্রামিংয়ের জন্য async এবং await কীওয়ার্ড ব্যবহার করে। আপনি যদি সেই ভাষাগুলির সাথে পরিচিত হন তবে আপনি Rust কীভাবে কাজ করে, সিনট্যাক্স কীভাবে পরিচালনা করে সহ বেশ কয়েকটি উল্লেখযোগ্য পার্থক্য লক্ষ্য করতে পারেন। এর যথেষ্ট কারণ আছে, যেমনটি আমরা দেখতে পাব!
অ্যাসিঙ্ক্রোনাস Rust লেখার সময়, আমরা বেশিরভাগ সময় async এবং await কীওয়ার্ড ব্যবহার করি। Rust সেগুলিকে Future trait ব্যবহার করে সমতুল্য কোডে কম্পাইল করে, অনেকটা যেভাবে এটি for লুপগুলিকে Iterator trait ব্যবহার করে সমতুল্য কোডে কম্পাইল করে। যেহেতু Rust Future trait সরবরাহ করে, তাই প্রয়োজনে আপনি আপনার নিজের ডেটা টাইপের জন্যও এটি ইমপ্লিমেন্ট করতে পারেন। আমরা এই চ্যাপ্টার জুড়ে যে ফাংশনগুলি দেখব তার অনেকগুলি Future-এর নিজস্ব ইমপ্লিমেন্টেশন সহ টাইপ রিটার্ন করে। আমরা চ্যাপ্টারের শেষে trait-এর সংজ্ঞায় ফিরে যাব এবং এটি কীভাবে কাজ করে সে সম্পর্কে আরও গভীরে আলোচনা করব, তবে এটি আমাদের এগিয়ে যাওয়ার জন্য যথেষ্ট বিশদ।
এই সমস্ত কিছু বিমূর্ত মনে হতে পারে, তাই আসুন আমাদের প্রথম অ্যাসিঙ্ক্রোনাস প্রোগ্রামটি লিখি: একটি ছোট ওয়েব স্ক্র্যাপার। আমরা কমান্ড লাইন থেকে দুটি URL পাস করব, উভয়কেই কনকারেন্টলি ফেচ করব এবং যেটি প্রথমে শেষ হবে তার ফলাফল রিটার্ন করব। এই উদাহরণে বেশ কিছুটা নতুন সিনট্যাক্স থাকবে, তবে চিন্তা করবেন না—আমরা যাওয়ার পথে আপনার যা জানা দরকার তা ব্যাখ্যা করব।
আমাদের প্রথম অ্যাসিঙ্ক্রোনাস প্রোগ্রাম (Our First Async Program)
এই চ্যাপ্টারের ফোকাস ইকোসিস্টেমের বিভিন্ন অংশ নিয়ে কাজ করার পরিবর্তে অ্যাসিঙ্ক্রোনাস শেখার উপর রাখার জন্য, আমরা trpl ক্রেট তৈরি করেছি (trpl হল “The Rust Programming Language”-এর সংক্ষিপ্ত)। এটি আপনার প্রয়োজনীয় সমস্ত টাইপ, trait এবং ফাংশনগুলিকে পুনরায় এক্সপোর্ট করে, প্রাথমিকভাবে futures এবং tokio ক্রেটগুলি থেকে। futures ক্রেটটি অ্যাসিঙ্ক্রোনাস কোডের জন্য Rust এক্সপেরিমেন্টেশনের একটি অফিশিয়াল হোম, এবং এটি আসলে যেখানে Future trait মূলত ডিজাইন করা হয়েছিল। Tokio হল আজকের Rust-এ সর্বাধিক ব্যবহৃত অ্যাসিঙ্ক্রোনাস রানটাইম, বিশেষ করে ওয়েব অ্যাপ্লিকেশনগুলির জন্য। অন্যান্য দুর্দান্ত রানটাইম রয়েছে এবং সেগুলি আপনার উদ্দেশ্যের জন্য আরও উপযুক্ত হতে পারে। আমরা trpl-এর জন্য হুডের নিচে tokio ক্রেট ব্যবহার করি কারণ এটি ভালভাবে পরীক্ষিত এবং ব্যাপকভাবে ব্যবহৃত।
কিছু ক্ষেত্রে, trpl এই চ্যাপ্টারের সাথে প্রাসঙ্গিক বিশদগুলিতে আপনাকে ফোকাস রাখতে মূল API-গুলিকে রিনেম বা র্যাপ করে। আপনি যদি ক্রেটটি কী করে তা বুঝতে চান তবে আমরা আপনাকে এর সোর্স কোড দেখার জন্য উৎসাহিত করি। আপনি দেখতে পারবেন প্রতিটি রি-এক্সপোর্ট কোন ক্রেট থেকে আসে এবং আমরা ক্রেটটি কী করে তা ব্যাখ্যা করে বিস্তৃত মন্তব্য রেখেছি।
hello-async নামে একটি নতুন বাইনারি প্রোজেক্ট তৈরি করুন এবং trpl ক্রেটটিকে একটি ডিপেন্ডেন্সি হিসাবে যুক্ত করুন:
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
এখন আমরা আমাদের প্রথম অ্যাসিঙ্ক্রোনাস প্রোগ্রামটি লিখতে trpl দ্বারা প্রদত্ত বিভিন্ন অংশ ব্যবহার করতে পারি। আমরা একটি ছোট কমান্ড লাইন টুল তৈরি করব যা দুটি ওয়েব পেজ ফেচ করে, প্রতিটি থেকে <title> এলিমেন্ট টেনে আনে এবং যে পেজটি প্রথমে সেই পুরো প্রক্রিয়াটি শেষ করে তার টাইটেল প্রিন্ট করে।
page_title ফাংশন সংজ্ঞায়িত করা (Defining the page_title Function)
আসুন একটি ফাংশন লিখে শুরু করি যা একটি প্যারামিটার হিসাবে একটি পেজ URL নেয়, এটিতে একটি রিকোয়েস্ট করে এবং টাইটেল এলিমেন্টের টেক্সট রিটার্ন করে (লিস্টিং 17-1 দেখুন)।
extern crate trpl; // required for mdbook test fn main() { // TODO: we'll add this next! } use trpl::Html; async fn page_title(url: &str) -> Option<String> { let response = trpl::get(url).await; let response_text = response.text().await; Html::parse(&response_text) .select_first("title") .map(|title_element| title_element.inner_html()) }
প্রথমে, আমরা page_title নামে একটি ফাংশন সংজ্ঞায়িত করি এবং এটিকে async কীওয়ার্ড দিয়ে চিহ্নিত করি। তারপর আমরা trpl::get ফাংশন ব্যবহার করি যে URL পাস করা হয়েছে সেটি ফেচ করতে এবং রেসপন্সের জন্য অপেক্ষা করতে await কীওয়ার্ড যুক্ত করি। রেসপন্সের টেক্সট পেতে, আমরা এর text মেথড কল করি এবং আবারও await কীওয়ার্ড দিয়ে এটির জন্য অপেক্ষা করি। এই দুটি ধাপই অ্যাসিঙ্ক্রোনাস। get ফাংশনের জন্য, আমাদের সার্ভারের রেসপন্সের প্রথম অংশটি ফেরত পাঠানোর জন্য অপেক্ষা করতে হবে, যার মধ্যে HTTP হেডার, কুকি ইত্যাদি অন্তর্ভুক্ত থাকবে এবং রেসপন্স বডি থেকে আলাদাভাবে ডেলিভার করা যেতে পারে। বিশেষ করে যদি বডি খুব বড় হয়, তবে এটির সমস্তটা আসতে কিছুটা সময় লাগতে পারে। যেহেতু আমাদের রেসপন্সের সম্পূর্ণতা আসার জন্য অপেক্ষা করতে হবে, তাই text মেথডটিও অ্যাসিঙ্ক্রোনাস।
আমাদের এই দুটি ফিউচারের জন্যই স্পষ্টভাবে অপেক্ষা করতে হবে, কারণ Rust-এ ফিউচারগুলি লেজি: await কীওয়ার্ড দিয়ে আপনি তাদের না বলা পর্যন্ত তারা কিছুই করে না। (আসলে, আপনি যদি একটি ফিউচার ব্যবহার না করেন তবে Rust একটি কম্পাইলার সতর্কতা দেখাবে।) এটি আপনাকে Chapter 13-এর Processing a Series of Items With Iterators বিভাগের ইটারেটর নিয়ে আলোচনার কথা মনে করিয়ে দিতে পারে। ইটারেটরগুলি যতক্ষণ না আপনি তাদের next মেথড কল করেন ততক্ষণ কিছুই করে না—সরাসরি বা for লুপ বা map-এর মতো মেথড ব্যবহার করে যা হুডের নিচে next ব্যবহার করে। একইভাবে, ফিউচারগুলি আপনি তাদের স্পষ্টভাবে করতে না বললে কিছুই করে না। এই লেজিনেস Rust-কে অ্যাসিঙ্ক্রোনাস কোড চালানো এড়াতে দেয় যতক্ষণ না এটির আসলেই প্রয়োজন হয়।
Note: এটি Creating a New Thread with spawn-এ
thread::spawnব্যবহার করার সময় আমরা আগের চ্যাপ্টারে যে আচরণ দেখেছি তার থেকে আলাদা, যেখানে আমরা অন্য থ্রেডে যে ক্লোজারটি পাস করেছি সেটি অবিলম্বে চলতে শুরু করে। এটি অন্যান্য অনেক ভাষা যেভাবে অ্যাসিঙ্ক্রোনাস অ্যাপ্রোচ করে তার থেকেও আলাদা। কিন্তু Rust-এর জন্য তার পারফরম্যান্স গ্যারান্টি সরবরাহ করতে সক্ষম হওয়া গুরুত্বপূর্ণ, যেমনটি ইটারেটরের ক্ষেত্রে।
একবার আমাদের কাছে response_text থাকলে, আমরা এটিকে Html::parse ব্যবহার করে Html টাইপের একটি ইনস্ট্যান্সে পার্স করতে পারি। একটি raw string-এর পরিবর্তে, আমাদের কাছে এখন একটি ডেটা টাইপ রয়েছে যা আমরা HTML-এর সাথে একটি সমৃদ্ধ ডেটা স্ট্রাকচার হিসাবে কাজ করতে ব্যবহার করতে পারি। বিশেষ করে, আমরা একটি প্রদত্ত CSS নির্বাচকের প্রথম ইনস্ট্যান্স খুঁজে বের করতে select_first মেথড ব্যবহার করতে পারি। স্ট্রিং "title" পাস করে, আমরা ডকুমেন্টের প্রথম <title> এলিমেন্টটি পাব, যদি থাকে। যেহেতু কোনও ম্যাচিং এলিমেন্ট নাও থাকতে পারে, তাই select_first একটি Option<ElementRef> রিটার্ন করে। অবশেষে, আমরা Option::map মেথড ব্যবহার করি, যা আমাদের Option-এর মধ্যে থাকা আইটেমটির সাথে কাজ করতে দেয় যদি এটি উপস্থিত থাকে এবং যদি না থাকে তবে কিছুই করে না। (আমরা এখানে একটি match এক্সপ্রেশনও ব্যবহার করতে পারতাম, কিন্তু map আরও বেশি প্রচলিত।) আমরা map-কে যে ফাংশন সরবরাহ করি তার বডিতে, আমরা title_element-এ inner_html কল করি তার কনটেন্ট পেতে, যা একটি String। সবশেষে, আমাদের কাছে একটি Option<String> থাকে।
লক্ষ্য করুন যে Rust-এর await কীওয়ার্ডটি আপনি যে এক্সপ্রেশনের জন্য অপেক্ষা করছেন তার পরে বসে, আগে নয়। অর্থাৎ, এটি একটি পোস্টফিক্স কীওয়ার্ড। আপনি যদি অন্যান্য ভাষায় async ব্যবহার করে থাকেন তবে এটি আপনার অভ্যস্ত হওয়ার থেকে আলাদা হতে পারে, তবে Rust-এ এটি মেথডের চেইনগুলির সাথে কাজ করা অনেক সুন্দর করে তোলে। ফলস্বরূপ, আমরা page_url_for-এর বডি পরিবর্তন করতে পারি trpl::get এবং text ফাংশন কলগুলিকে একসাথে চেইন করতে এবং তাদের মধ্যে await ব্যবহার করতে, যেমনটি Listing 17-2-এ দেখানো হয়েছে।
extern crate trpl; // required for mdbook test use trpl::Html; fn main() { // TODO: we'll add this next! } async fn page_title(url: &str) -> Option<String> { let response_text = trpl::get(url).await.text().await; Html::parse(&response_text) .select_first("title") .map(|title_element| title_element.inner_html()) }
এর সাথে, আমরা সফলভাবে আমাদের প্রথম অ্যাসিঙ্ক্রোনাস ফাংশনটি লিখেছি! main-এ এটি কল করার জন্য কিছু কোড যুক্ত করার আগে, আসুন আমরা যা লিখেছি এবং এর অর্থ কী সে সম্পর্কে আরও একটু কথা বলি।
যখন Rust async কীওয়ার্ড দিয়ে চিহ্নিত একটি ব্লক দেখে, তখন এটি এটিকে একটি অনন্য, বেনামী ডেটা টাইপে কম্পাইল করে যা Future trait ইমপ্লিমেন্ট করে। যখন Rust async দিয়ে চিহ্নিত একটি ফাংশন দেখে, তখন এটি এটিকে একটি non-async ফাংশনে কম্পাইল করে যার বডি একটি অ্যাসিঙ্ক্রোনাস ব্লক। একটি অ্যাসিঙ্ক্রোনাস ফাংশনের রিটার্ন টাইপ হল কম্পাইলার সেই অ্যাসিঙ্ক্রোনাস ব্লকের জন্য যে বেনামী ডেটা টাইপ তৈরি করে তার টাইপ।
সুতরাং, async fn লেখা একটি ফাংশন লেখার সমতুল্য যা রিটার্ন টাইপের একটি ফিউচার রিটার্ন করে। কম্পাইলারের কাছে, Listing 17-1-এর async fn page_title-এর মতো একটি ফাংশন সংজ্ঞা এইরকমভাবে সংজ্ঞায়িত একটি non-async ফাংশনের সমতুল্য:
#![allow(unused)] fn main() { extern crate trpl; // required for mdbook test use std::future::Future; use trpl::Html; fn page_title(url: &str) -> impl Future<Output = Option<String>> { async move { let text = trpl::get(url).await.text().await; Html::parse(&text) .select_first("title") .map(|title| title.inner_html()) } } }
আসুন রূপান্তরিত সংস্করণের প্রতিটি অংশের মধ্য দিয়ে যাই:
- এটি
impl Traitসিনট্যাক্স ব্যবহার করে যা আমরা Chapter 10-এর “Traits as Parameters” বিভাগে আলোচনা করেছি। - রিটার্ন করা trait হল একটি
Futureযার সাথে একটিOutputটাইপ যুক্ত। লক্ষ্য করুন যেOutputটাইপটি হলOption<String>, যাpage_title-এরasync fnসংস্করণের মূল রিটার্ন টাইপের মতোই। - মূল ফাংশনের বডিতে কল করা সমস্ত কোড একটি
async moveব্লকের মধ্যে র্যাপ করা হয়েছে। মনে রাখবেন যে ব্লকগুলি হল এক্সপ্রেশন। এই সম্পূর্ণ ব্লকটি হল ফাংশন থেকে রিটার্ন করা এক্সপ্রেশন। - এই অ্যাসিঙ্ক্রোনাস ব্লকটি
Option<String>টাইপের একটি মান তৈরি করে, যেমনটি বর্ণনা করা হয়েছে। এই মানটি রিটার্ন টাইপেরOutputটাইপের সাথে মেলে। এটি আপনার দেখা অন্যান্য ব্লকের মতোই। - নতুন ফাংশন বডিটি একটি
async moveব্লক কারণ এটিurlপ্যারামিটারটি কীভাবে ব্যবহার করে। (আমরা এই চ্যাপ্টারে পরেasyncবনামasync moveসম্পর্কে আরও অনেক কিছু আলোচনা করব।)
এখন আমরা main-এ page_title কল করতে পারি।
একটি একক পেজের টাইটেল নির্ধারণ করা (Determining a Single Page’s Title)
শুরু করার জন্য, আমরা কেবল একটি একক পেজের জন্য টাইটেল পাব। Listing 17-3-এ, আমরা Accepting Command Line Arguments বিভাগে কমান্ড লাইনের আর্গুমেন্ট পেতে Chapter 12-এ ব্যবহৃত একই প্যাটার্ন অনুসরণ করি। তারপর আমরা প্রথম URL page_title-এ পাস করি এবং ফলাফলের জন্য অপেক্ষা করি। যেহেতু ফিউচার দ্বারা উৎপাদিত মানটি একটি Option<String>, তাই পেজটিতে একটি <title> আছে কিনা তা বিবেচনা করার জন্য আমরা বিভিন্ন মেসেজ প্রিন্ট করতে একটি match এক্সপ্রেশন ব্যবহার করি।
extern crate trpl; // required for mdbook test
use trpl::Html;
async fn main() {
let args: Vec<String> = std::env::args().collect();
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title_element| title_element.inner_html())
}দুর্ভাগ্যবশত, এই কোডটি কম্পাইল হয় না। আমরা await কীওয়ার্ডটি শুধুমাত্র অ্যাসিঙ্ক্রোনাস ফাংশন বা ব্লকে ব্যবহার করতে পারি এবং Rust আমাদের বিশেষ main ফাংশনটিকে async হিসাবে চিহ্নিত করতে দেবে না।
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
| ^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
main কে async হিসাবে চিহ্নিত করা যায় না তার কারণ হল অ্যাসিঙ্ক্রোনাস কোডের একটি রানটাইম প্রয়োজন: একটি Rust ক্রেট যা অ্যাসিঙ্ক্রোনাস কোড এক্সিকিউট করার বিশদ পরিচালনা করে। একটি প্রোগ্রামের main ফাংশন একটি রানটাইম ইনিশিয়ালাইজ করতে পারে, কিন্তু এটি নিজে একটি রানটাইম নয়। (আমরা একটু পরেই দেখব কেন এটি এইরকম।) প্রতিটি Rust প্রোগ্রাম যা অ্যাসিঙ্ক্রোনাস কোড এক্সিকিউট করে সেখানে অন্তত একটি স্থান রয়েছে যেখানে এটি একটি রানটাইম সেট আপ করে এবং ফিউচারগুলি এক্সিকিউট করে।
বেশিরভাগ ভাষা যারা অ্যাসিঙ্ক্রোনাস সমর্থন করে তারা একটি রানটাইম বান্ডেল করে, কিন্তু Rust তা করে না। পরিবর্তে, অনেকগুলি বিভিন্ন অ্যাসিঙ্ক্রোনাস রানটাইম উপলব্ধ রয়েছে, যার প্রতিটি যে ব্যবহারের ক্ষেত্রে টার্গেট করে তার জন্য উপযুক্ত বিভিন্ন ট্রেডঅফ তৈরি করে। উদাহরণস্বরূপ, অনেকগুলি CPU কোর এবং প্রচুর পরিমাণে RAM সহ একটি high-throughput ওয়েব সার্ভারের একটি single কোর, অল্প পরিমাণে RAM এবং কোনও হিপ অ্যালোকেশন ক্ষমতা নেই এমন একটি মাইক্রোকন্ট্রোলারের চেয়ে খুব আলাদা চাহিদা রয়েছে। সেই রানটাইমগুলি সরবরাহ করা ক্রেটগুলি প্রায়শই ফাইল বা নেটওয়ার্ক I/O-এর মতো সাধারণ কার্যকারিতার অ্যাসিঙ্ক্রোনাস সংস্করণও সরবরাহ করে।
এখানে, এবং এই চ্যাপ্টারের বাকি অংশ জুড়ে, আমরা trpl ক্রেট থেকে run ফাংশনটি ব্যবহার করব, যা একটি আর্গুমেন্ট হিসাবে একটি ফিউচার নেয় এবং এটি সম্পূর্ণ হওয়া পর্যন্ত চালায়। পর্দার আড়ালে, run কল করা একটি রানটাইম সেট আপ করে যা পাস করা ফিউচারটি চালানোর জন্য ব্যবহৃত হয়। ফিউচারটি সম্পূর্ণ হয়ে গেলে, run ফিউচারটি যে মান তৈরি করেছে তা রিটার্ন করে।
আমরা page_title দ্বারা রিটার্ন করা ফিউচারটি সরাসরি run-এ পাস করতে পারি এবং এটি সম্পূর্ণ হয়ে গেলে, আমরা Listing 17-3-এ করার চেষ্টা করার মতো ফলাফলের Option<String>-এ ম্যাচ করতে পারি। যাইহোক, চ্যাপ্টারের বেশিরভাগ উদাহরণের জন্য (এবং বাস্তব বিশ্বের বেশিরভাগ অ্যাসিঙ্ক্রোনাস কোডের জন্য), আমরা শুধুমাত্র একটি অ্যাসিঙ্ক্রোনাস ফাংশন কলের চেয়ে আরও বেশি কিছু করব, তাই পরিবর্তে আমরা একটি async ব্লক পাস করব এবং Listing 17-4-এর মতো page_title কলের ফলাফলের জন্য স্পষ্টভাবে অপেক্ষা করব।
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::run(async {
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
})
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title_element| title_element.inner_html())
}যখন আমরা এই কোডটি চালাই, তখন আমরা প্রাথমিকভাবে প্রত্যাশিত আচরণটি পাই:
$ cargo run -- https://www.rust-lang.org
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
The title for https://www.rust-lang.org was
Rust Programming Language
উফ—অবশেষে আমাদের কাছে কিছু কার্যকরী অ্যাসিঙ্ক্রোনাস কোড আছে! কিন্তু দুটি সাইট একে অপরের বিরুদ্ধে রেস করানোর কোড যুক্ত করার আগে, আসুন সংক্ষেপে ফিউচারগুলি কীভাবে কাজ করে সেদিকে আমাদের মনোযোগ ফিরিয়ে দিই।
প্রতিটি অ্যাওয়েট পয়েন্ট—অর্থাৎ, কোডটি যেখানেই await কীওয়ার্ড ব্যবহার করে—এমন একটি স্থানকে উপস্থাপন করে যেখানে কন্ট্রোল রানটাইমে ফিরে যায়। এটি কাজ করার জন্য, Rust-কে অ্যাসিঙ্ক্রোনাস ব্লকের সাথে জড়িত স্টেট ট্র্যাক রাখতে হবে যাতে রানটাইম অন্য কিছু কাজ শুরু করতে পারে এবং তারপর প্রথমটিকে আবার অগ্রসর করার চেষ্টা করার জন্য প্রস্তুত হলে ফিরে আসতে পারে। এটি একটি অদৃশ্য স্টেট মেশিন, যেন আপনি প্রতিটি অ্যাওয়েট পয়েন্টে বর্তমান স্টেট সংরক্ষণ করার জন্য এইরকম একটি enum লিখেছেন:
#![allow(unused)] fn main() { extern crate trpl; // required for mdbook test enum PageTitleFuture<'a> { Initial { url: &'a str }, GetAwaitPoint { url: &'a str }, TextAwaitPoint { response: trpl::Response }, } }
প্রতিটি স্টেটের মধ্যে ট্রানজিশন করার জন্য হাতে কোড লেখা ক্লান্তিকর এবং ত্রুটি-প্রবণ হবে, বিশেষ করে যখন আপনাকে পরে কোডে আরও কার্যকারিতা এবং আরও স্টেট যুক্ত করতে হবে। সৌভাগ্যবশত, Rust কম্পাইলার অ্যাসিঙ্ক্রোনাস কোডের জন্য স্টেট মেশিন ডেটা স্ট্রাকচারগুলি স্বয়ংক্রিয়ভাবে তৈরি এবং পরিচালনা করে। ডেটা স্ট্রাকচারের চারপাশে স্বাভাবিক borrowing এবং ownership-এর নিয়মগুলি এখনও প্রযোজ্য, এবং আনন্দের বিষয়, কম্পাইলার আমাদের জন্য সেগুলিও পরীক্ষা করে এবং দরকারী error মেসেজ সরবরাহ করে। আমরা চ্যাপ্টারে পরে সেগুলির কয়েকটির মধ্য দিয়ে কাজ করব।
অবশেষে, কিছুকে এই স্টেট মেশিনটি এক্সিকিউট করতে হবে এবং সেই কিছু হল একটি রানটাইম। (এই কারণেই আপনি রানটাইমগুলি দেখার সময় এক্সিকিউটর-এর রেফারেন্স দেখতে পারেন: একজন এক্সিকিউটর হল একটি রানটাইমের অংশ যা অ্যাসিঙ্ক্রোনাস কোড এক্সিকিউট করার জন্য দায়ী।)
এখন আপনি দেখতে পাচ্ছেন কেন কম্পাইলার আমাদের Listing 17-3-এ main কেই একটি অ্যাসিঙ্ক্রোনাস ফাংশন করতে দেয়নি। যদি main একটি অ্যাসিঙ্ক্রোনাস ফাংশন হত, তাহলে অন্য কিছুকে main যে ফিউচার রিটার্ন করেছে তার স্টেট মেশিন পরিচালনা করতে হত, কিন্তু main হল প্রোগ্রামের শুরুর পয়েন্ট! পরিবর্তে, আমরা একটি রানটাইম সেট আপ করতে এবং async ব্লক দ্বারা রিটার্ন করা ফিউচারটি শেষ না হওয়া পর্যন্ত চালানোর জন্য main-এ trpl::run ফাংশনটি কল করেছি।
Note: কিছু রানটাইম ম্যাক্রো সরবরাহ করে যাতে আপনি একটি অ্যাসিঙ্ক্রোনাস
mainফাংশন লিখতে পারেন। সেই ম্যাক্রোগুলিasync fn main() { ... }কে একটি সাধারণfn main-এ পুনর্লিখন করে, যা Listing 17-5-এ আমরা হাতে যা করেছি তাই করে: একটি ফাংশন কল করে যাtrpl::run-এর মতো ফিউচারটি সম্পূর্ণ হওয়া পর্যন্ত চালায়।
এখন আসুন এই টুকরোগুলি একসাথে রাখি এবং দেখি কীভাবে আমরা কনকারেন্ট কোড লিখতে পারি।
আমাদের দুটি URL একে অপরের বিরুদ্ধে রেস করানো (Racing Our Two URLs Against Each Other)
Listing 17-5-এ, আমরা কমান্ড লাইন থেকে পাস করা দুটি ভিন্ন URL সহ page_title কল করি এবং তাদের রেস করাই।
extern crate trpl; // required for mdbook test
use trpl::{Either, Html};
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::run(async {
let title_fut_1 = page_title(&args[1]);
let title_fut_2 = page_title(&args[2]);
let (url, maybe_title) =
match trpl::race(title_fut_1, title_fut_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
println!("{url} returned first");
match maybe_title {
Some(title) => println!("Its page title is: '{title}'"),
None => println!("Its title could not be parsed."),
}
})
}
async fn page_title(url: &str) -> (&str, Option<String>) {
let text = trpl::get(url).await.text().await;
let title = Html::parse(&text)
.select_first("title")
.map(|title| title.inner_html());
(url, title)
}আমরা ব্যবহারকারী-সরবরাহকৃত URL-গুলির প্রত্যেকটির জন্য page_title কল করে শুরু করি। আমরা ফলাফলের ফিউচারগুলিকে title_fut_1 এবং title_fut_2 হিসাবে সংরক্ষণ করি। মনে রাখবেন, এগুলি এখনও কিছুই করে না, কারণ ফিউচারগুলি অলস এবং আমরা এখনও তাদের জন্য অপেক্ষা করিনি। তারপর আমরা ফিউচারগুলিকে trpl::race-এ পাস করি, যা এটিতে পাস করা ফিউচারগুলির মধ্যে কোনটি প্রথমে শেষ হয় তা নির্দেশ করার জন্য একটি মান রিটার্ন করে।
Note: হুডের নিচে,
raceএকটি আরও সাধারণ ফাংশন,select-এর উপর নির্মিত, যা আপনি বাস্তব-বিশ্বের Rust কোডে আরও ঘন ঘন দেখতে পাবেন। একটিselectফাংশন এমন অনেক কিছু করতে পারে যাtrpl::raceফাংশন পারে না, তবে এটির কিছু অতিরিক্ত জটিলতাও রয়েছে যা আমরা আপাতত এড়িয়ে যেতে পারি।
যেকোনো ফিউচার বৈধভাবে “জিততে” পারে, তাই একটি Result রিটার্ন করা অর্থবোধক নয়। পরিবর্তে, race এমন একটি টাইপ রিটার্ন করে যা আমরা আগে দেখিনি, trpl::Either। Either টাইপটি কিছুটা Result-এর মতো যে এটির দুটি কেস রয়েছে। Result-এর মতো, যদিও, Either-এ সাফল্য বা ব্যর্থতার কোনও ধারণা নেই। পরিবর্তে, এটি "একটি বা অন্যটি" বোঝাতে Left এবং Right ব্যবহার করে:
#![allow(unused)] fn main() { enum Either<A, B> { Left(A), Right(B), } }
race ফাংশনটি প্রথম আর্গুমেন্ট জিতলে সেই ফিউচারের আউটপুট সহ Left এবং দ্বিতীয় ফিউচার আর্গুমেন্টের আউটপুট সহ Right রিটার্ন করে যদি সেটি জেতে। এটি ফাংশনটি কল করার সময় আর্গুমেন্টগুলি যে ক্রমে প্রদর্শিত হয় তার সাথে মেলে: প্রথম আর্গুমেন্টটি দ্বিতীয় আর্গুমেন্টের বাম দিকে।
আমরা page_title আপডেটও করি যাতে পাস করা একই URL রিটার্ন করা হয়। এইভাবে, যদি যে পেজটি প্রথমে রিটার্ন করে তাতে একটি <title> সমাধান করার মতো না থাকে, তাহলেও আমরা একটি অর্থপূর্ণ মেসেজ প্রিন্ট করতে পারি। সেই তথ্য উপলব্ধ থাকায়, আমরা আমাদের println! আউটপুট আপডেট করে শেষ করি যাতে কোন URLটি প্রথমে শেষ হয়েছে এবং সেই URL-এর ওয়েব পেজের জন্য <title> কী, যদি থাকে, তা নির্দেশ করা যায়।
আপনি এখন একটি ছোট কার্যকরী ওয়েব স্ক্র্যাপার তৈরি করেছেন! কয়েকটি URL বেছে নিন এবং কমান্ড লাইন টুলটি চালান। আপনি আবিষ্কার করতে পারেন যে কিছু সাইট ধারাবাহিকভাবে অন্যদের চেয়ে দ্রুত, আবার অন্য ক্ষেত্রে দ্রুত সাইটটি রান থেকে রানে পরিবর্তিত হয়। আরও গুরুত্বপূর্ণ, আপনি ফিউচারগুলির সাথে কাজ করার বেসিকগুলি শিখেছেন, তাই এখন আমরা অ্যাসিঙ্ক্রোনাস দিয়ে আমরা কী করতে পারি তার গভীরে ডুব দিতে পারি।
অ্যাসিঙ্ক্রোনাস ব্যবহার করে কনকারেন্সি প্রয়োগ করা (Applying Concurrency with Async)
এই বিভাগে, আমরা Chapter 16-এ থ্রেড দিয়ে মোকাবিলা করা একই কনকারেন্সি চ্যালেঞ্জগুলির মধ্যে কয়েকটিতে অ্যাসিঙ্ক্রোনাস প্রয়োগ করব। যেহেতু আমরা ইতিমধ্যে সেখানে মূল ধারণাগুলির অনেকগুলি নিয়ে কথা বলেছি, তাই এই বিভাগে আমরা থ্রেড এবং ফিউচারের মধ্যে কী আলাদা তার উপর ফোকাস করব।
অনেক ক্ষেত্রে, অ্যাসিঙ্ক্রোনাস ব্যবহার করে কনকারেন্সির সাথে কাজ করার জন্য API গুলি থ্রেড ব্যবহার করার API-গুলির মতোই। অন্য ক্ষেত্রে, সেগুলি বেশ ভিন্ন হয়। এমনকি যখন API গুলি থ্রেড এবং অ্যাসিঙ্ক্রোনাসের মধ্যে দেখতে একই রকম দেখায়, তখনও তাদের প্রায়শই আলাদা আচরণ থাকে—এবং তাদের প্রায় সবসময়ই আলাদা পারফরম্যান্স বৈশিষ্ট্য থাকে।
spawn_task দিয়ে একটি নতুন টাস্ক তৈরি করা (Creating a New Task with spawn_task)
আমরা Creating a New Thread with Spawn-এ যে প্রথম অপারেশনটি মোকাবেলা করেছি তা হল দুটি পৃথক থ্রেডে গণনা করা। আসুন অ্যাসিঙ্ক্রোনাস ব্যবহার করে একই কাজ করি। trpl ক্রেট একটি spawn_task ফাংশন সরবরাহ করে যা thread::spawn API-এর মতোই এবং একটি sleep ফাংশন যা thread::sleep API-এর একটি অ্যাসিঙ্ক্রোনাস সংস্করণ। আমরা এইগুলিকে একসাথে ব্যবহার করে গণনার উদাহরণটি ইমপ্লিমেন্ট করতে পারি, যেমনটি Listing 17-6-এ দেখানো হয়েছে।
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::run(async { trpl::spawn_task(async { for i in 1..10 { println!("hi number {i} from the first task!"); trpl::sleep(Duration::from_millis(500)).await; } }); for i in 1..5 { println!("hi number {i} from the second task!"); trpl::sleep(Duration::from_millis(500)).await; } }); }
আমাদের শুরুর পয়েন্ট হিসাবে, আমরা আমাদের main ফাংশনটিকে trpl::run দিয়ে সেট আপ করি যাতে আমাদের টপ-লেভেল ফাংশনটি অ্যাসিঙ্ক্রোনাস হতে পারে।
Note: এই চ্যাপ্টারের এখন থেকে সামনের দিকে, প্রতিটি উদাহরণে
main-এtrpl::runসহ এই একই র্যাপিং কোড অন্তর্ভুক্ত থাকবে, তাই আমরা প্রায়শই এটিকে বাদ দেব যেমনটি আমরাmain-এর সাথে করি। আপনার কোডে এটি অন্তর্ভুক্ত করতে ভুলবেন না!
তারপর আমরা সেই ব্লকের মধ্যে দুটি লুপ লিখি, প্রত্যেকটিতে একটি trpl::sleep কল রয়েছে, যা পরবর্তী মেসেজ পাঠানোর আগে আধা সেকেন্ড (500 মিলিসেকেন্ড) অপেক্ষা করে। আমরা একটি লুপ trpl::spawn_task-এর বডিতে রাখি এবং অন্যটি একটি টপ-লেভেল for লুপে রাখি। আমরা sleep কলের পরেও একটি await যুক্ত করি।
এই কোডটি থ্রেড-ভিত্তিক ইমপ্লিমেন্টেশনের মতোই আচরণ করে—এই সত্যটি সহ যে আপনি যখন এটি চালাবেন তখন আপনার নিজের টার্মিনালে মেসেজগুলি ভিন্ন ক্রমে প্রদর্শিত হতে পারে:
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
এই সংস্করণটি main অ্যাসিঙ্ক্রোনাস ব্লকের বডির for লুপ শেষ হওয়ার সাথে সাথেই বন্ধ হয়ে যায়, কারণ main ফাংশন শেষ হলে spawn_task দ্বারা স্পন করা টাস্কটি বন্ধ হয়ে যায়। আপনি যদি এটিকে টাস্কটি সম্পূর্ণ হওয়া পর্যন্ত চালাতে চান তবে আপনাকে প্রথম টাস্কটি সম্পূর্ণ হওয়ার জন্য অপেক্ষা করতে একটি join handle ব্যবহার করতে হবে। থ্রেডের সাথে, আমরা থ্রেডটি চালানো শেষ না হওয়া পর্যন্ত “ব্লক” করতে join মেথড ব্যবহার করেছি। Listing 17-7-এ, আমরা একই কাজ করতে await ব্যবহার করতে পারি, কারণ টাস্ক হ্যান্ডেল নিজেই একটি ফিউচার। এর Output টাইপ হল একটি Result, তাই আমরা এটির জন্য অপেক্ষা করার পরেও এটিকে আনর্যাপ করি।
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::run(async { let handle = trpl::spawn_task(async { for i in 1..10 { println!("hi number {i} from the first task!"); trpl::sleep(Duration::from_millis(500)).await; } }); for i in 1..5 { println!("hi number {i} from the second task!"); trpl::sleep(Duration::from_millis(500)).await; } handle.await.unwrap(); }); }
এই আপডেটেড সংস্করণটি উভয় লুপ শেষ না হওয়া পর্যন্ত চলে।
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
এখন পর্যন্ত, মনে হচ্ছে অ্যাসিঙ্ক্রোনাস এবং থ্রেড আমাদের একই বেসিক ফলাফল দেয়, শুধুমাত্র ভিন্ন সিনট্যাক্স সহ: join handle-এ join কল করার পরিবর্তে await ব্যবহার করা এবং sleep কলের জন্য অপেক্ষা করা।
বড় পার্থক্য হল এটি করার জন্য আমাদের অন্য অপারেটিং সিস্টেম থ্রেড স্পন করার প্রয়োজন হয়নি। আসলে, আমাদের এখানে একটি টাস্কও স্পন করার দরকার নেই। যেহেতু অ্যাসিঙ্ক্রোনাস ব্লকগুলি বেনামী ফিউচারে কম্পাইল হয়, তাই আমরা প্রতিটি লুপকে একটি অ্যাসিঙ্ক্রোনাস ব্লকে রাখতে পারি এবং trpl::join ফাংশন ব্যবহার করে রানটাইমকে উভয়কেই সম্পূর্ণ হওয়া পর্যন্ত চালাতে দিতে পারি।
Waiting for All Threads to Finishing Using join Handles বিভাগে, আমরা দেখিয়েছি কিভাবে আপনি std::thread::spawn কল করলে রিটার্ন করা JoinHandle টাইপের join মেথড ব্যবহার করবেন। trpl::join ফাংশনটি একই রকম, কিন্তু ফিউচারের জন্য। আপনি যখন এটিকে দুটি ফিউচার দেন, তখন এটি একটি একক নতুন ফিউচার তৈরি করে যার আউটপুট হল একটি টাপল যাতে আপনি যে প্রতিটি ফিউচার পাস করেছেন তার আউটপুট থাকে একবার সেগুলি উভয়ই সম্পূর্ণ হয়ে গেলে। সুতরাং, Listing 17-8-এ, আমরা fut1 এবং fut2 উভয়ের শেষ হওয়ার জন্য অপেক্ষা করতে trpl::join ব্যবহার করি। আমরা fut1 এবং fut2-এর জন্য অপেক্ষা করি না বরং trpl::join দ্বারা উৎপাদিত নতুন ফিউচারের জন্য অপেক্ষা করি। আমরা আউটপুট উপেক্ষা করি, কারণ এটি কেবল দুটি ইউনিট মান ধারণকারী একটি টাপল।
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::run(async { let fut1 = async { for i in 1..10 { println!("hi number {i} from the first task!"); trpl::sleep(Duration::from_millis(500)).await; } }; let fut2 = async { for i in 1..5 { println!("hi number {i} from the second task!"); trpl::sleep(Duration::from_millis(500)).await; } }; trpl::join(fut1, fut2).await; }); }
যখন আমরা এটি চালাই, তখন আমরা উভয় ফিউচার সম্পূর্ণ হওয়া পর্যন্ত চলতে দেখি:
hi number 1 from the first task!
hi number 1 from the second task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
এখন, আপনি প্রতিবার একই ক্রম দেখতে পাবেন, যা আমরা থ্রেড দিয়ে যা দেখেছি তার থেকে খুব আলাদা। এর কারণ হল trpl::join ফাংশনটি ফেয়ার, অর্থাৎ এটি প্রতিটি ফিউচারকে সমানভাবে প্রায়শই পরীক্ষা করে, তাদের মধ্যে পরিবর্তন করে এবং অন্যটি প্রস্তুত থাকলে কখনই একটিকে এগিয়ে যেতে দেয় না। থ্রেডের সাথে, অপারেটিং সিস্টেম সিদ্ধান্ত নেয় কোন থ্রেডটি পরীক্ষা করতে হবে এবং কতক্ষণ চলতে দিতে হবে। অ্যাসিঙ্ক্রোনাস Rust-এর সাথে, রানটাইম সিদ্ধান্ত নেয় কোন টাস্কটি পরীক্ষা করতে হবে। (বাস্তবে, বিশদগুলি জটিল হয়ে যায় কারণ একটি অ্যাসিঙ্ক্রোনাস রানটাইম হুডের নিচে অপারেটিং সিস্টেম থ্রেডগুলিকে কনকারেন্সি পরিচালনার অংশ হিসাবে ব্যবহার করতে পারে, তাই ফেয়ারনেস গ্যারান্টি দেওয়া একটি রানটাইমের জন্য আরও বেশি কাজ হতে পারে—তবে এটি এখনও সম্ভব!) রানটাইমগুলিকে কোনও প্রদত্ত অপারেশনের জন্য ফেয়ারনেসের গ্যারান্টি দিতে হবে না এবং তারা প্রায়শই বিভিন্ন API সরবরাহ করে যাতে আপনি ফেয়ারনেস চান কিনা তা বেছে নিতে পারেন।
ফিউচারগুলির জন্য অপেক্ষা করার এই কিছু ভেরিয়েশন চেষ্টা করুন এবং দেখুন তারা কী করে:
- যেকোনো একটি বা উভয় লুপের চারপাশ থেকে অ্যাসিঙ্ক্রোনাস ব্লকটি সরিয়ে দিন।
- প্রতিটি অ্যাসিঙ্ক্রোনাস ব্লককে সংজ্ঞায়িত করার পরপরই এটির জন্য অপেক্ষা করুন।
- শুধুমাত্র প্রথম লুপটিকে একটি অ্যাসিঙ্ক্রোনাস ব্লকে র্যাপ করুন এবং দ্বিতীয় লুপের বডির পরে ফলাফলের ফিউচারের জন্য অপেক্ষা করুন।
একটি অতিরিক্ত চ্যালেঞ্জের জন্য, কোড চালানোর আগে প্রতিটি ক্ষেত্রে আউটপুট কী হবে তা বের করার চেষ্টা করুন!
মেসেজ পাসিং ব্যবহার করে দুটি টাস্কে গণনা করা (Counting Up on Two Tasks Using Message Passing)
ফিউচারের মধ্যে ডেটা শেয়ার করাও পরিচিত হবে: আমরা আবার মেসেজ পাসিং ব্যবহার করব, কিন্তু এবার টাইপ এবং ফাংশনের অ্যাসিঙ্ক্রোনাস সংস্করণ সহ। থ্রেড-ভিত্তিক এবং ফিউচার-ভিত্তিক কনকারেন্সির মধ্যে কিছু মূল পার্থক্য বোঝানোর জন্য আমরা Using Message Passing to Transfer Data Between Threads-এ যা করেছি তার থেকে সামান্য ভিন্ন পথ নেব। Listing 17-9-এ, আমরা শুধুমাত্র একটি একক অ্যাসিঙ্ক্রোনাস ব্লক দিয়ে শুরু করব—একটি পৃথক থ্রেড স্পন করার মতো একটি পৃথক টাস্ক স্পন না করে।
extern crate trpl; // required for mdbook test fn main() { trpl::run(async { let (tx, mut rx) = trpl::channel(); let val = String::from("hi"); tx.send(val).unwrap(); let received = rx.recv().await.unwrap(); println!("Got: {received}"); }); }
এখানে, আমরা trpl::channel ব্যবহার করি, যা Chapter 16-এ থ্রেডের সাথে ব্যবহার করা মাল্টিপল-প্রডিউসার, সিঙ্গল-কনজিউমার চ্যানেল API-এর একটি অ্যাসিঙ্ক্রোনাস সংস্করণ। API-এর অ্যাসিঙ্ক্রোনাস সংস্করণটি থ্রেড-ভিত্তিক সংস্করণের থেকে সামান্য আলাদা: এটি একটি ইমিউটেবল রিসিভার rx-এর পরিবর্তে একটি মিউটেবল ব্যবহার করে এবং এর recv মেথড সরাসরি মান তৈরি করার পরিবর্তে আমাদের অপেক্ষা করতে হবে এমন একটি ফিউচার তৈরি করে। এখন আমরা সেন্ডার থেকে রিসিভারে মেসেজ পাঠাতে পারি। লক্ষ্য করুন যে আমাদের একটি পৃথক থ্রেড বা এমনকি একটি টাস্কও স্পন করতে হবে না; আমাদের কেবল rx.recv কলের জন্য অপেক্ষা করতে হবে।
std::mpsc::channel-এর সিঙ্ক্রোনাস Receiver::recv মেথড একটি মেসেজ না পাওয়া পর্যন্ত ব্লক করে। trpl::Receiver::recv মেথডটি তা করে না, কারণ এটি অ্যাসিঙ্ক্রোনাস। ব্লক করার পরিবর্তে, এটি রানটাইমে কন্ট্রোল ফিরিয়ে দেয় যতক্ষণ না হয় একটি মেসেজ রিসিভ করা হয় বা চ্যানেলের সেন্ড সাইড বন্ধ হয়ে যায়। বিপরীতে, আমরা send কলের জন্য অপেক্ষা করি না, কারণ এটি ব্লক করে না। এটির প্রয়োজন নেই, কারণ আমরা যে চ্যানেলে এটি পাঠাচ্ছি সেটি আনবাউন্ডেড।
Note: যেহেতু এই সমস্ত অ্যাসিঙ্ক্রোনাস কোড একটি
trpl::runকলের মধ্যে একটি অ্যাসিঙ্ক্রোনাস ব্লকে চলে, তাই এর ভেতরের সবকিছু ব্লক করা এড়াতে পারে। যাইহোক, এর বাইরের কোডটিrunফাংশন রিটার্ন করার উপর ব্লক করবে।trpl::runফাংশনের মূল উদ্দেশ্য হল এটি: এটি আপনাকে বেছে নিতে দেয় কোথায় অ্যাসিঙ্ক্রোনাস কোডের কিছু সেটের উপর ব্লক করতে হবে এবং এইভাবে কোথায় সিঙ্ক্রোনাস এবং অ্যাসিঙ্ক্রোনাস কোডের মধ্যে ট্রানজিশন করতে হবে। বেশিরভাগ অ্যাসিঙ্ক্রোনাস রানটাইমে,run-এর নাম আসলেblock_onরাখা হয়েছে ঠিক এই কারণেই।
এই উদাহরণ সম্পর্কে দুটি জিনিস লক্ষ্য করুন। প্রথমত, মেসেজটি অবিলম্বে আসবে। দ্বিতীয়ত, যদিও আমরা এখানে একটি ফিউচার ব্যবহার করি, এখনও কোনও কনকারেন্সি নেই। লিস্টিং-এর সবকিছু ক্রমানুসারে ঘটে, ঠিক যেমন কোনও ফিউচার জড়িত না থাকলে হত।
আসুন Listing 17-10-এ দেখানো মতো করে মেসেজের একটি সিরিজ পাঠিয়ে এবং তাদের মধ্যে স্লিপ করে প্রথম অংশটি সমাধান করি।
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::run(async {
let (tx, mut rx) = trpl::channel();
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
}মেসেজ পাঠানোর পাশাপাশি, আমাদের সেগুলি গ্রহণ করতে হবে। এক্ষেত্রে, যেহেতু আমরা জানি কতগুলি মেসেজ আসছে, তাই আমরা rx.recv().await চারবার কল করে ম্যানুয়ালি এটি করতে পারি। বাস্তব জগতে, যদিও, আমরা সাধারণত অজানা সংখ্যক মেসেজের জন্য অপেক্ষা করব, তাই আমাদের অপেক্ষা করতে হবে যতক্ষণ না আমরা নির্ধারণ করি যে আর কোনও মেসেজ নেই।
Listing 16-10-এ, আমরা একটি সিঙ্ক্রোনাস চ্যানেল থেকে প্রাপ্ত সমস্ত আইটেম প্রসেস করতে একটি for লুপ ব্যবহার করেছি। Rust-এ এখনও একটি for লুপ লেখার কোনও উপায় নেই আইটেমগুলির একটি অ্যাসিঙ্ক্রোনাস সিরিজের উপর, যাইহোক, তাই আমাদের একটি লুপ ব্যবহার করতে হবে যা আমরা আগে দেখিনি: while let কন্ডিশনাল লুপ। এটি Concise Control Flow with if let and let else বিভাগে আমরা যে if let গঠন দেখেছি তার লুপ সংস্করণ। এটি যে প্যাটার্নটি নির্দিষ্ট করে তা মানের সাথে মিলতে থাকলে লুপটি এক্সিকিউট করা চালিয়ে যাবে।
rx.recv কলটি একটি ফিউচার তৈরি করে, যার জন্য আমরা অপেক্ষা করি। রানটাইম ফিউচারটি প্রস্তুত না হওয়া পর্যন্ত এটিকে থামিয়ে রাখবে। একবার একটি মেসেজ এলে, ফিউচারটি যতবার একটি মেসেজ আসবে ততবার Some(message)-এ রেজলভ করবে। যখন চ্যানেলটি বন্ধ হয়ে যায়, কোনও মেসেজ এসেছে কিনা তা নির্বিশেষে, ফিউচারটি পরিবর্তে None-এ রেজলভ করবে যাতে নির্দেশ করে যে আর কোনও মান নেই এবং তাই আমাদের পোলিং বন্ধ করা উচিত—অর্থাৎ, অপেক্ষা করা বন্ধ করা উচিত।
while let লুপ এই সমস্ত কিছুকে একত্রিত করে। rx.recv().await কলের ফলাফল যদি Some(message) হয়, তাহলে আমরা মেসেজটিতে অ্যাক্সেস পাব এবং আমরা এটিকে লুপ বডিতে ব্যবহার করতে পারি, ঠিক যেমনটি আমরা if let-এর সাথে করতে পারতাম। যদি ফলাফলটি None হয়, তাহলে লুপটি শেষ হয়। প্রতিবার লুপটি সম্পূর্ণ হলে, এটি আবার অ্যাওয়েট পয়েন্টে আঘাত করে, তাই রানটাইম এটিকে আবার থামিয়ে দেয় যতক্ষণ না অন্য কোনও মেসেজ আসে।
কোডটি এখন সফলভাবে সমস্ত মেসেজ পাঠায় এবং গ্রহণ করে। দুর্ভাগ্যবশত, এখনও কয়েকটি সমস্যা রয়েছে। একটির জন্য, মেসেজগুলি আধা-সেকেন্ডের ব্যবধানে আসে না। সেগুলি আমাদের প্রোগ্রাম শুরু করার 2 সেকেন্ড (2,000 মিলিসেকেন্ড) পরে একবারে আসে। অন্যটির জন্য, এই প্রোগ্রামটিও কখনও শেষ হয় না! পরিবর্তে, এটি নতুন মেসেজের জন্য চিরকাল অপেক্ষা করে। আপনাকে ctrl-c ব্যবহার করে এটি বন্ধ করতে হবে।
আসুন প্রথমে পরীক্ষা করে দেখি কেন মেসেজগুলি প্রতিটিটির মধ্যে বিলম্ব সহ আসার পরিবর্তে সম্পূর্ণ বিলম্বের পরে একবারে আসে। একটি প্রদত্ত অ্যাসিঙ্ক্রোনাস ব্লকের মধ্যে, কোডে await কীওয়ার্ডগুলি যে ক্রমে প্রদর্শিত হয় সেই ক্রমেই প্রোগ্রামটি চলার সময় সেগুলি এক্সিকিউট করা হয়।
Listing 17-10-এ শুধুমাত্র একটি অ্যাসিঙ্ক্রোনাস ব্লক রয়েছে, তাই এর সবকিছু লিনিয়ারভাবে চলে। এখনও কোনও কনকারেন্সি নেই। সমস্ত tx.send কলগুলি ঘটে, সমস্ত trpl::sleep কল এবং তাদের সম্পর্কিত অ্যাওয়েট পয়েন্টগুলির সাথে ইন্টারস্পার্সড। শুধুমাত্র তখনই while let লুপ recv কলের অ্যাওয়েট পয়েন্টগুলির মধ্য দিয়ে যেতে পারে।
আমরা যে আচরণটি চাই তা পেতে, যেখানে প্রতিটি মেসেজের মধ্যে স্লিপ বিলম্ব ঘটে, আমাদের tx এবং rx অপারেশনগুলিকে তাদের নিজস্ব অ্যাসিঙ্ক্রোনাস ব্লকে রাখতে হবে, যেমনটি Listing 17-11-এ দেখানো হয়েছে। তারপর রানটাইম trpl::join ব্যবহার করে তাদের প্রত্যেকটিকে আলাদাভাবে এক্সিকিউট করতে পারে, ঠিক গণনার উদাহরণের মতো। আবারও, আমরা trpl::join কলের ফলাফলের জন্য অপেক্ষা করি, individual ফিউচারগুলির জন্য নয়। আমরা যদি individual ফিউচারগুলির জন্য ক্রমানুসারে অপেক্ষা করতাম, তাহলে আমরা একটি সিকোয়েন্সিয়াল ফ্লো-তে ফিরে যেতাম—ঠিক যা আমরা করার চেষ্টা করছি না।
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::run(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}Listing 17-11-এর আপডেটেড কোডের সাথে, মেসেজগুলি 2 সেকেন্ড পরে তাড়াহুড়ো করে আসার পরিবর্তে 500-মিলিসেকেন্ডের ব্যবধানে প্রিন্ট করা হয়।
প্রোগ্রামটি এখনও শেষ হয় না, যদিও, while let লুপ যেভাবে trpl::join-এর সাথে ইন্টারঅ্যাক্ট করে তার কারণে:
trpl::joinথেকে রিটার্ন করা ফিউচার তখনই সম্পূর্ণ হয় যখন উভয় ফিউচার এটিকে পাস করা হয়েছে সম্পূর্ণ হয়।txফিউচারটিvals-এ শেষ মেসেজ পাঠানোর পরে স্লিপ শেষ করার পরে সম্পূর্ণ হয়।rxফিউচারটিwhile letলুপ শেষ না হওয়া পর্যন্ত সম্পূর্ণ হবে না।while letলুপটি শেষ হবে না যতক্ষণ নাrx.recv-এর জন্য অপেক্ষা করলেNoneপাওয়া যায়।rx.recv-এর জন্য অপেক্ষা করলেNoneরিটার্ন করবে শুধুমাত্র চ্যানেলের অন্য প্রান্তটি বন্ধ হয়ে গেলে।- চ্যানেলটি বন্ধ হবে শুধুমাত্র যদি আমরা
rx.closeকল করি বা যখন সেন্ডার সাইড,tx, ড্রপ করা হয়। - আমরা কোথাও
rx.closeকল করি না এবংtrpl::run-এ পাস করা বাইরের অ্যাসিঙ্ক্রোনাস ব্লকটি শেষ না হওয়া পর্যন্তtxড্রপ করা হবে না। - ব্লকটি শেষ হতে পারে না কারণ এটি
trpl::joinসম্পূর্ণ হওয়ার উপর ব্লক করা, যা আমাদের এই তালিকার শীর্ষে ফিরিয়ে নিয়ে যায়।
আমরা কোথাও rx.close কল করে ম্যানুয়ালি rx বন্ধ করতে পারি, তবে এটি খুব বেশি অর্থবোধক নয়। কিছু arbitrary সংখ্যক মেসেজ হ্যান্ডেল করার পরে বন্ধ করা প্রোগ্রামটি বন্ধ করে দেবে, কিন্তু আমরা মেসেজ মিস করতে পারি। আমাদের অন্য কোনও উপায়ের প্রয়োজন যাতে tx ফাংশনের শেষের আগে ড্রপ করা হয় তা নিশ্চিত করা যায়।
এখন, যে অ্যাসিঙ্ক্রোনাস ব্লকে আমরা মেসেজ পাঠাই সেটি শুধুমাত্র tx ধার করে কারণ একটি মেসেজ পাঠানোর জন্য ownership-এর প্রয়োজন হয় না, কিন্তু আমরা যদি tx কে সেই অ্যাসিঙ্ক্রোনাস ব্লকে move করতে পারতাম, তাহলে সেই ব্লকটি শেষ হয়ে গেলে এটি ড্রপ করা হত। Chapter 13-এর Capturing References or Moving Ownership বিভাগে, আপনি শিখেছেন কিভাবে ক্লোজারের সাথে move কীওয়ার্ড ব্যবহার করতে হয় এবং Chapter 16-এর Using move Closures with Threads বিভাগে আলোচনা করা হয়েছে, থ্রেডের সাথে কাজ করার সময় আমাদের প্রায়শই ডেটা ক্লোজারে move করতে হয়। একই বেসিক ডায়নামিকগুলি অ্যাসিঙ্ক্রোনাস ব্লকের ক্ষেত্রে প্রযোজ্য, তাই move কীওয়ার্ডটি অ্যাসিঙ্ক্রোনাস ব্লকের সাথে একইভাবে কাজ করে যেমনটি ক্লোজারের সাথে করে।
Listing 17-12-এ, আমরা মেসেজ পাঠানোর জন্য ব্যবহৃত ব্লকটিকে async থেকে async move-এ পরিবর্তন করি। যখন আমরা কোডের এই সংস্করণটি চালাই, তখন শেষ মেসেজটি পাঠানো এবং গ্রহণ করার পরে এটি সুন্দরভাবে বন্ধ হয়ে যায়।
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::run(async { let (tx, mut rx) = trpl::channel(); let tx_fut = async move { let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("future"), ]; for val in vals { tx.send(val).unwrap(); trpl::sleep(Duration::from_millis(500)).await; } }; let rx_fut = async { while let Some(value) = rx.recv().await { println!("received '{value}'"); } }; trpl::join(tx_fut, rx_fut).await; }); }
এই অ্যাসিঙ্ক্রোনাস চ্যানেলটিও একটি মাল্টিপল-প্রডিউসার চ্যানেল, তাই আমরা একাধিক ফিউচার থেকে মেসেজ পাঠাতে চাইলে tx-এ clone কল করতে পারি, যেমনটি Listing 17-13-এ দেখানো হয়েছে।
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::run(async { let (tx, mut rx) = trpl::channel(); let tx1 = tx.clone(); let tx1_fut = async move { let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("future"), ]; for val in vals { tx1.send(val).unwrap(); trpl::sleep(Duration::from_millis(500)).await; } }; let rx_fut = async { while let Some(value) = rx.recv().await { println!("received '{value}'"); } }; let tx_fut = async move { let vals = vec![ String::from("more"), String::from("messages"), String::from("for"), String::from("you"), ]; for val in vals { tx.send(val).unwrap(); trpl::sleep(Duration::from_millis(1500)).await; } }; trpl::join3(tx1_fut, tx_fut, rx_fut).await; }); }
প্রথমে, আমরা প্রথম অ্যাসিঙ্ক্রোনাস ব্লকের বাইরে tx ক্লোন করে tx1 তৈরি করি। আমরা tx1-কে সেই ব্লকে move করি ঠিক যেমনটি আমরা আগে tx-এর সাথে করেছি। তারপর, পরে, আমরা মূল tx-কে একটি নতুন অ্যাসিঙ্ক্রোনাস ব্লকে move করি, যেখানে আমরা সামান্য ধীর বিলম্বের সাথে আরও মেসেজ পাঠাই। আমরা এই নতুন অ্যাসিঙ্ক্রোনাস ব্লকটিকে মেসেজ গ্রহণ করার অ্যাসিঙ্ক্রোনাস ব্লকের পরে রাখি, তবে এটি এর আগেও যেতে পারত। মূল বিষয় হল ফিউচারগুলি যে ক্রমে অপেক্ষা করা হয়, সেগুলি যে ক্রমে তৈরি করা হয় তাতে নয়।
মেসেজ পাঠানোর জন্য উভয় অ্যাসিঙ্ক্রোনাস ব্লককেই async move ব্লক হতে হবে যাতে tx এবং tx1 উভয়ই সেই ব্লকগুলি শেষ হলে ড্রপ করা হয়। অন্যথায়, আমরা একই অসীম লুপে ফিরে যাব যেখানে আমরা শুরু করেছিলাম। অবশেষে, আমরা অতিরিক্ত ফিউচার হ্যান্ডেল করতে trpl::join থেকে trpl::join3-এ পরিবর্তন করি।
এখন আমরা উভয় সেন্ডিং ফিউচার থেকে সমস্ত মেসেজ দেখতে পাই এবং যেহেতু সেন্ডিং ফিউচারগুলি পাঠানোর পরে সামান্য ভিন্ন বিলম্ব ব্যবহার করে, তাই মেসেজগুলিও সেই ভিন্ন ব্যবধানে রিসিভ করা হয়।
received 'hi'
received 'more'
received 'from'
received 'the'
received 'messages'
received 'future'
received 'for'
received 'you'
এটি একটি ভাল শুরু, তবে এটি আমাদের শুধুমাত্র কয়েকটি ফিউচারের মধ্যে সীমাবদ্ধ করে: join-এর সাথে দুটি বা join3-এর সাথে তিনটি। আসুন দেখি কিভাবে আমরা আরও ফিউচারের সাথে কাজ করতে পারি।
যেকোনো সংখ্যক ফিউচারের সাথে কাজ করা (Working with Any Number of Futures)
পূর্ববর্তী বিভাগে যখন আমরা দুটি ফিউচার থেকে তিনটি ফিউচার ব্যবহার করা শুরু করি, তখন আমাদের join ব্যবহার করা থেকে join3 ব্যবহার করাতে পরিবর্তন করতে হয়েছিল। আমরা যতগুলি ফিউচার join করতে চাই তার সংখ্যা পরিবর্তন করার সময় প্রতিবার একটি ভিন্ন ফাংশন কল করা বিরক্তিকর হবে। আনন্দের বিষয়, আমাদের কাছে join-এর একটি ম্যাক্রো ফর্ম রয়েছে যাতে আমরা ইচ্ছামতো সংখ্যক আর্গুমেন্ট পাস করতে পারি। এটি নিজে থেকেই ফিউচারগুলির জন্য অপেক্ষা করার কাজটিও পরিচালনা করে। সুতরাং, আমরা Listing 17-13-এর কোডটিকে join3-এর পরিবর্তে join! ব্যবহার করে পুনরায় লিখতে পারি, যেমনটি Listing 17-14-তে রয়েছে।
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::run(async { let (tx, mut rx) = trpl::channel(); let tx1 = tx.clone(); let tx1_fut = async move { let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("future"), ]; for val in vals { tx1.send(val).unwrap(); trpl::sleep(Duration::from_secs(1)).await; } }; let rx_fut = async { while let Some(value) = rx.recv().await { println!("received '{value}'"); } }; let tx_fut = async move { let vals = vec![ String::from("more"), String::from("messages"), String::from("for"), String::from("you"), ]; for val in vals { tx.send(val).unwrap(); trpl::sleep(Duration::from_secs(1)).await; } }; trpl::join!(tx1_fut, tx_fut, rx_fut); }); }
এটি অবশ্যই join এবং join3 এবং join4 ইত্যাদির মধ্যে অদলবদল করার চেয়ে একটি উন্নতি! যাইহোক, এমনকি এই ম্যাক্রো ফর্মটিও তখনই কাজ করে যখন আমরা আগে থেকে ফিউচারের সংখ্যা জানি। বাস্তব-বিশ্বের Rust-এ, যদিও, ফিউচারগুলিকে একটি কালেকশনে পুশ করা এবং তারপরে তাদের মধ্যে কিছু বা সমস্ত ফিউচার সম্পূর্ণ হওয়ার জন্য অপেক্ষা করা একটি সাধারণ প্যাটার্ন।
কিছু কালেকশনের সমস্ত ফিউচার পরীক্ষা করার জন্য, আমাদের সেগুলির সমস্ত-এর উপর ইটারেট করতে হবে এবং join করতে হবে। trpl::join_all ফাংশনটি যেকোনো টাইপ গ্রহণ করে যা Iterator trait ইমপ্লিমেন্ট করে, যেটি আপনি The Iterator Trait and the next Method Chapter 13-এ শিখেছেন, তাই মনে হচ্ছে এটিই উপযুক্ত। আসুন আমাদের ফিউচারগুলিকে একটি ভেক্টরে রাখি এবং Listing 17-15-এ দেখানো মতো join!-কে join_all দিয়ে প্রতিস্থাপন করি।
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::run(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let futures = vec![tx1_fut, rx_fut, tx_fut];
trpl::join_all(futures).await;
});
}দুর্ভাগ্যবশত, এই কোডটি কম্পাইল হয় না। পরিবর্তে, আমরা এই error টি পাই:
error[E0308]: mismatched types
--> src/main.rs:45:37
|
10 | let tx1_fut = async move {
| ---------- the expected `async` block
...
24 | let rx_fut = async {
| ----- the found `async` block
...
45 | let futures = vec![tx1_fut, rx_fut, tx_fut];
| ^^^^^^ expected `async` block, found a different `async` block
|
= note: expected `async` block `{async block@src/main.rs:10:23: 10:33}`
found `async` block `{async block@src/main.rs:24:22: 24:27}`
= note: no two async blocks, even if identical, have the same type
= help: consider pinning your async block and casting it to a trait object
এটি বিস্ময়কর হতে পারে। সর্বোপরি, অ্যাসিঙ্ক্রোনাস ব্লকগুলির কোনওটিই কিছু রিটার্ন করে না, তাই প্রতিটি একটি Future<Output = ()> তৈরি করে। মনে রাখবেন যে Future হল একটি trait, এবং কম্পাইলার প্রতিটি অ্যাসিঙ্ক্রোনাস ব্লকের জন্য একটি অনন্য enum তৈরি করে। আপনি একটি Vec-এ দুটি ভিন্ন হাতে লেখা স্ট্রাক্ট রাখতে পারবেন না এবং কম্পাইলার দ্বারা তৈরি করা বিভিন্ন enums-এর ক্ষেত্রেও একই নিয়ম প্রযোজ্য।
এটি কাজ করার জন্য, আমাদের trait অবজেক্ট ব্যবহার করতে হবে, ঠিক যেমনটি আমরা Chapter 12-এর “Returning Errors from the run function”-এ করেছি। (আমরা Chapter 18-এ trait অবজেক্টগুলি বিস্তারিতভাবে কভার করব।) trait অবজেক্ট ব্যবহার করা আমাদের এই টাইপগুলি দ্বারা উৎপাদিত প্রতিটি বেনামী ফিউচারকে একই টাইপ হিসাবে বিবেচনা করতে দেয়, কারণ সেগুলি সবই Future trait ইমপ্লিমেন্ট করে।
Note: Chapter 8-এর Using an Enum to Store Multiple Values বিভাগে, আমরা একটি
Vec-এ একাধিক টাইপ অন্তর্ভুক্ত করার আরেকটি উপায় নিয়ে আলোচনা করেছি: ভেক্টরে প্রদর্শিত হতে পারে এমন প্রতিটি টাইপকে উপস্থাপন করার জন্য একটি enum ব্যবহার করা। আমরা এখানে তা করতে পারি না। একটি কারণ হল, আমাদের কাছে বিভিন্ন টাইপের নাম দেওয়ার কোনও উপায় নেই, কারণ সেগুলি বেনামী। অন্যটির জন্য, আমরা যে কারণে একটি ভেক্টর এবংjoin_all-এর কাছে পৌঁছেছি তা হল ফিউচারের একটি ডায়নামিক কালেকশনের সাথে কাজ করতে সক্ষম হওয়া যেখানে আমরা শুধুমাত্র তাদের একই আউটপুট টাইপ আছে কিনা তা নিয়ে চিন্তা করি।
আমরা Listing 17-16-এ দেখানো মতো প্রতিটি ফিউচারকে vec!-এর মধ্যে Box::new-এ র্যাপ করে শুরু করি।
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::run(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let futures =
vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
trpl::join_all(futures).await;
});
}দুর্ভাগ্যবশত, এই কোডটি এখনও কম্পাইল হয় না। আসলে, আমরা দ্বিতীয় এবং তৃতীয় Box::new কলের জন্য আগেও একই বেসিক error পেয়েছি, পাশাপাশি Unpin trait উল্লেখ করে নতুন error-ও পেয়েছি। আমরা একটু পরেই Unpin error-এ ফিরে আসব। প্রথমে, আসুন futures variable-এর টাইপটি স্পষ্টভাবে annotate করে Box::new কলের টাইপ error গুলি ঠিক করি (Listing 17-17 দেখুন)।
extern crate trpl; // required for mdbook test
use std::{future::Future, time::Duration};
fn main() {
trpl::run(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let futures: Vec<Box<dyn Future<Output = ()>>> =
vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
trpl::join_all(futures).await;
});
}এই টাইপ ডিক্লারেশনটি একটু জটিল, তাই আসুন এটি নিয়ে আলোচনা করি:
- ভেতরের টাইপটি হল ফিউচার নিজেই। আমরা স্পষ্টভাবে উল্লেখ করি যে ফিউচারের আউটপুট হল ইউনিট টাইপ
(),Future<Output = ()>লিখে। - তারপর আমরা এটিকে ডায়নামিক হিসাবে চিহ্নিত করতে
dynদিয়ে trait টিকে annotate করি। - সম্পূর্ণ trait রেফারেন্সটি একটি
Box-এর মধ্যে র্যাপ করা হয়েছে। - অবশেষে, আমরা স্পষ্টভাবে বলি যে
futuresহল এই আইটেমগুলি ধারণকারী একটিVec।
এটি ইতিমধ্যেই একটি বড় পার্থক্য তৈরি করেছে। এখন যখন আমরা কম্পাইলার চালাই, তখন আমরা শুধুমাত্র Unpin উল্লেখ করে error গুলি পাই। যদিও তাদের মধ্যে তিনটি রয়েছে, তাদের বিষয়বস্তু খুব একই রকম।
error[E0308]: mismatched types
--> src/main.rs:46:46
|
10 | let tx1_fut = async move {
| ---------- the expected `async` block
...
24 | let rx_fut = async {
| ----- the found `async` block
...
46 | vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
| -------- ^^^^^^ expected `async` block, found a different `async` block
| |
| arguments to this function are incorrect
|
= note: expected `async` block `{async block@src/main.rs:10:23: 10:33}`
found `async` block `{async block@src/main.rs:24:22: 24:27}`
= note: no two async blocks, even if identical, have the same type
= help: consider pinning your async block and casting it to a trait object
note: associated function defined here
--> file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/boxed.rs:252:12
|
252 | pub fn new(x: T) -> Self {
| ^^^
error[E0308]: mismatched types
--> src/main.rs:46:64
|
10 | let tx1_fut = async move {
| ---------- the expected `async` block
...
30 | let tx_fut = async move {
| ---------- the found `async` block
...
46 | vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
| -------- ^^^^^^ expected `async` block, found a different `async` block
| |
| arguments to this function are incorrect
|
= note: expected `async` block `{async block@src/main.rs:10:23: 10:33}`
found `async` block `{async block@src/main.rs:30:22: 30:32}`
= note: no two async blocks, even if identical, have the same type
= help: consider pinning your async block and casting it to a trait object
note: associated function defined here
--> file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/boxed.rs:252:12
|
252 | pub fn new(x: T) -> Self {
| ^^^
error[E0277]: `{async block@src/main.rs:10:23: 10:33}` cannot be unpinned
--> src/main.rs:48:24
|
48 | trpl::join_all(futures).await;
| -------------- ^^^^^^^ the trait `Unpin` is not implemented for `{async block@src/main.rs:10:23: 10:33}`
| |
| required by a bound introduced by this call
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<{async block@src/main.rs:10:23: 10:33}>` to implement `Future`
note: required by a bound in `join_all`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:105:14
|
102 | pub fn join_all<I>(iter: I) -> JoinAll<I::Item>
| -------- required by a bound in this function
...
105 | I::Item: Future,
| ^^^^^^ required by this bound in `join_all`
error[E0277]: `{async block@src/main.rs:10:23: 10:33}` cannot be unpinned
--> src/main.rs:48:9
|
48 | trpl::join_all(futures).await;
| ^^^^^^^^^^^^^^^^^^^^^^^ the trait `Unpin` is not implemented for `{async block@src/main.rs:10:23: 10:33}`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<{async block@src/main.rs:10:23: 10:33}>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
error[E0277]: `{async block@src/main.rs:10:23: 10:33}` cannot be unpinned
--> src/main.rs:48:33
|
48 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `{async block@src/main.rs:10:23: 10:33}`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<{async block@src/main.rs:10:23: 10:33}>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
এটি অনেক কিছু, তাই আসুন এটিকে আলাদা করি। মেসেজের প্রথম অংশটি আমাদের বলে যে প্রথম অ্যাসিঙ্ক্রোনাস ব্লক (src/main.rs:8:23: 20:10) Unpin trait ইমপ্লিমেন্ট করে না এবং এটি সমাধান করার জন্য pin! বা Box::pin ব্যবহার করার পরামর্শ দেয়। চ্যাপ্টারের পরে, আমরা Pin এবং Unpin সম্পর্কে আরও কয়েকটি বিশদ বিবরণে যাব। আপাতত, যদিও, আমরা আটকে যাওয়া থেকে বাঁচতে কম্পাইলারের পরামর্শ অনুসরণ করতে পারি। Listing 17-18-এ, আমরা প্রতিটি Box-এর জন্য Pin র্যাপ করে futures-এর জন্য টাইপ অ্যানোটেশন আপডেট করে শুরু করি। দ্বিতীয়ত, আমরা ফিউচারগুলিকে নিজেরাই পিন করতে Box::pin ব্যবহার করি।
extern crate trpl; // required for mdbook test use std::{ future::Future, pin::{Pin, pin}, time::Duration, }; fn main() { trpl::run(async { let (tx, mut rx) = trpl::channel(); let tx1 = tx.clone(); let tx1_fut = pin!(async move { let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("future"), ]; for val in vals { tx1.send(val).unwrap(); trpl::sleep(Duration::from_secs(1)).await; } }); let rx_fut = pin!(async { while let Some(value) = rx.recv().await { println!("received '{value}'"); } }); let tx_fut = pin!(async move { let vals = vec![ String::from("more"), String::from("messages"), String::from("for"), String::from("you"), ]; for val in vals { tx.send(val).unwrap(); trpl::sleep(Duration::from_secs(1)).await; } }); let futures: Vec<Pin<Box<dyn Future<Output = ()>>>> = vec![Box::pin(tx1_fut), Box::pin(rx_fut), Box::pin(tx_fut)]; trpl::join_all(futures).await; }); }
যদি আমরা এটি কম্পাইল এবং রান করি, তাহলে আমরা অবশেষে সেই আউটপুটটি পাব যার জন্য আমরা আশা করেছিলাম:
received 'hi'
received 'more'
received 'from'
received 'messages'
received 'the'
received 'for'
received 'future'
received 'you'
উফ!
এখানে আরও কিছু বিষয় অন্বেষণ করার আছে। একটির জন্য, Pin<Box<T>> ব্যবহার করা Box-এর সাথে হিপে এই ফিউচারগুলি রাখার কারণে অল্প পরিমাণে ওভারহেড যুক্ত করে—এবং আমরা এটি শুধুমাত্র টাইপগুলিকে সারিবদ্ধ করার জন্য করছি। আমাদের আসলে হিপ অ্যালোকেশনের প্রয়োজন নেই: এই ফিউচারগুলি এই বিশেষ ফাংশনের জন্য লোকাল। যেমনটি আগে উল্লেখ করা হয়েছে, Pin নিজেই একটি র্যাপার টাইপ, তাই আমরা Vec-এ একটি একক টাইপ থাকার সুবিধা পেতে পারি—যে মূল কারণে আমরা Box-এর কাছে পৌঁছেছিলাম—হিপ অ্যালোকেশন না করেই। আমরা প্রতিটি ফিউচারের সাথে সরাসরি Pin ব্যবহার করতে পারি, std::pin::pin ম্যাক্রো ব্যবহার করে।
যাইহোক, আমাদের এখনও পিন করা রেফারেন্সের টাইপ সম্পর্কে স্পষ্ট হতে হবে; অন্যথায়, Rust এখনও জানবে না যে এগুলিকে ডায়নামিক trait অবজেক্ট হিসাবে ব্যাখ্যা করতে হবে, যা আমাদের Vec-এ তাদের হতে হবে। তাই আমরা প্রতিটি ফিউচারকে সংজ্ঞায়িত করার সময় pin! করি এবং futures-কে ডায়নামিক ফিউচার টাইপের পিন করা মিউটেবল রেফারেন্স ধারণকারী একটি Vec হিসাবে সংজ্ঞায়িত করি, যেমনটি Listing 17-19-এ রয়েছে।
extern crate trpl; // required for mdbook test use std::{ future::Future, pin::{Pin, pin}, time::Duration, }; fn main() { trpl::run(async { let (tx, mut rx) = trpl::channel(); let tx1 = tx.clone(); let tx1_fut = pin!(async move { // --snip-- let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("future"), ]; for val in vals { tx1.send(val).unwrap(); trpl::sleep(Duration::from_secs(1)).await; } }); let rx_fut = pin!(async { // --snip-- while let Some(value) = rx.recv().await { println!("received '{value}'"); } }); let tx_fut = pin!(async move { // --snip-- let vals = vec![ String::from("more"), String::from("messages"), String::from("for"), String::from("you"), ]; for val in vals { tx.send(val).unwrap(); trpl::sleep(Duration::from_secs(1)).await; } }); let futures: Vec<Pin<&mut dyn Future<Output = ()>>> = vec![tx1_fut, rx_fut, tx_fut]; trpl::join_all(futures).await; }); }
আমরা এই পর্যন্ত এসেছি এই সত্যটি উপেক্ষা করে যে আমাদের আলাদা Output টাইপ থাকতে পারে। উদাহরণস্বরূপ, Listing 17-20-এ, a-এর জন্য বেনামী ফিউচার Future<Output = u32> ইমপ্লিমেন্ট করে, b-এর জন্য বেনামী ফিউচার Future<Output = &str> ইমপ্লিমেন্ট করে এবং c-এর জন্য বেনামী ফিউচার Future<Output = bool> ইমপ্লিমেন্ট করে।
extern crate trpl; // required for mdbook test fn main() { trpl::run(async { let a = async { 1u32 }; let b = async { "Hello!" }; let c = async { true }; let (a_result, b_result, c_result) = trpl::join!(a, b, c); println!("{a_result}, {b_result}, {c_result}"); }); }
আমরা তাদের জন্য অপেক্ষা করতে trpl::join! ব্যবহার করতে পারি, কারণ এটি আমাদের একাধিক ফিউচার টাইপ পাস করতে দেয় এবং সেই টাইপগুলির একটি টাপল তৈরি করে। আমরা trpl::join_all ব্যবহার করতে পারি না, কারণ এটির জন্য পাস করা সমস্ত ফিউচারের একই টাইপ থাকতে হবে। মনে রাখবেন, সেই error-টিই আমাদের Pin-এর সাথে এই অ্যাডভেঞ্চারে শুরু করিয়েছে!
এটি একটি মৌলিক ট্রেডঅফ: আমরা হয় join_all-এর সাথে একটি ডায়নামিক সংখ্যক ফিউচারের সাথে ডিল করতে পারি, যতক্ষণ না তাদের সবার একই টাইপ থাকে, অথবা আমরা join ফাংশন বা join! ম্যাক্রোর সাথে একটি নির্দিষ্ট সংখ্যক ফিউচারের সাথে ডিল করতে পারি, এমনকি যদি তাদের আলাদা টাইপ থাকে। Rust-এ অন্য কোনও টাইপের সাথে কাজ করার সময় আমরা যে পরিস্থিতির মুখোমুখি হব এটি সেই একই পরিস্থিতি। ফিউচারগুলি বিশেষ নয়, যদিও তাদের সাথে কাজ করার জন্য আমাদের কাছে কিছু চমৎকার সিনট্যাক্স রয়েছে এবং এটি একটি ভাল জিনিস।
রেসিং ফিউচার (Racing Futures)
যখন আমরা join পরিবারের ফাংশন এবং ম্যাক্রোগুলির সাথে ফিউচারগুলিকে “join” করি, তখন আমরা এগিয়ে যাওয়ার আগে তাদের সমস্ত-এর শেষ হওয়ার প্রয়োজন বোধ করি। কখনও কখনও, যদিও, এগিয়ে যাওয়ার আগে আমাদের একটি সেট থেকে কিছু ফিউচার শেষ হওয়ার প্রয়োজন হয়—এক ধরনের ফিউচারকে একে অপরের বিরুদ্ধে রেস করানোর মতো।
Listing 17-21-এ, আমরা আবারও দুটি ফিউচার, slow এবং fast-কে একে অপরের বিরুদ্ধে চালানোর জন্য trpl::race ব্যবহার করি।
extern crate trpl; // required for mdbook test use std::time::Duration; fn main() { trpl::run(async { let slow = async { println!("'slow' started."); trpl::sleep(Duration::from_millis(100)).await; println!("'slow' finished."); }; let fast = async { println!("'fast' started."); trpl::sleep(Duration::from_millis(50)).await; println!("'fast' finished."); }; trpl::race(slow, fast).await; }); }
প্রতিটি ফিউচার যখন চলতে শুরু করে তখন একটি মেসেজ প্রিন্ট করে, sleep কল করে এবং অপেক্ষা করে কিছু সময়ের জন্য বিরতি দেয় এবং তারপর এটি শেষ হলে আরেকটি মেসেজ প্রিন্ট করে। তারপর আমরা slow এবং fast উভয়কেই trpl::race-এ পাস করি এবং তাদের মধ্যে একটি শেষ হওয়ার জন্য অপেক্ষা করি। (এখানে ফলাফলটি খুব আশ্চর্যজনক নয়: fast জিতে।) “Our First Async Program”-এ যখন আমরা race ব্যবহার করেছি তার বিপরীতে, আমরা এখানে এটি যে Either ইনস্ট্যান্স রিটার্ন করে তা উপেক্ষা করি, কারণ সমস্ত আকর্ষণীয় আচরণ অ্যাসিঙ্ক্রোনাস ব্লকের বডিতে ঘটে।
লক্ষ্য করুন যে আপনি যদি race-এ আর্গুমেন্টগুলির ক্রম উল্টে দেন, তাহলে fast ফিউচারটি সর্বদা প্রথমে শেষ হওয়া সত্ত্বেও “started” মেসেজগুলির ক্রম পরিবর্তন হয়। এর কারণ হল এই বিশেষ race ফাংশনের ইমপ্লিমেন্টেশনটি ফেয়ার নয়। এটি সর্বদা আর্গুমেন্ট হিসাবে পাস করা ফিউচারগুলিকে যে ক্রমে পাস করা হয়েছে সেই ক্রমে চালায়। অন্যান্য ইমপ্লিমেন্টেশনগুলি ফেয়ার এবং র্যান্ডমভাবে কোন ফিউচারটি প্রথমে পোল করতে হবে তা বেছে নেবে। আমরা যে রেসের ইমপ্লিমেন্টেশন ব্যবহার করছি সেটি ফেয়ার হোক বা না হোক, অন্য টাস্ক শুরু হওয়ার আগে ফিউচারগুলির একটি তার বডিতে প্রথম await পর্যন্ত চলবে।
Our First Async Program থেকে মনে করুন যে প্রতিটি অ্যাওয়েট পয়েন্টে, Rust একটি রানটাইমকে টাস্কটি থামানোর এবং অন্যটিতে স্যুইচ করার সুযোগ দেয় যদি যে ফিউচারের জন্য অপেক্ষা করা হচ্ছে সেটি প্রস্তুত না হয়। এর বিপরীতটিও সত্য: Rust শুধুমাত্র অ্যাসিঙ্ক্রোনাস ব্লকগুলিকে থামিয়ে দেয় এবং একটি অ্যাওয়েট পয়েন্টে একটি রানটাইমে কন্ট্রোল ফিরিয়ে দেয়। অ্যাওয়েট পয়েন্টগুলির মধ্যে সবকিছু সিঙ্ক্রোনাস।
এর মানে হল যে আপনি যদি কোনও অ্যাওয়েট পয়েন্ট ছাড়াই একটি অ্যাসিঙ্ক্রোনাস ব্লকে অনেকগুলি কাজ করেন, তাহলে সেই ফিউচারটি অন্য কোনও ফিউচারকে অগ্রগতি করতে বাধা দেবে। আপনি কখনও কখনও এটিকে একটি ফিউচার অন্য ফিউচারগুলিকে স্টার্ভ করছে বলে উল্লেখ করতে পারেন। কিছু ক্ষেত্রে, এটি কোনও বড় বিষয় নাও হতে পারে। যাইহোক, আপনি যদি কোনও ব্যয়বহুল সেটআপ বা দীর্ঘ-চলমান কাজ করছেন, অথবা আপনার যদি এমন একটি ফিউচার থাকে যা অনির্দিষ্টকালের জন্য কোনও নির্দিষ্ট কাজ করতে থাকবে, তাহলে আপনাকে কখন এবং কোথায় রানটাইমে কন্ট্রোল ফিরিয়ে দিতে হবে সে সম্পর্কে ভাবতে হবে।
একইভাবে, যদি আপনার দীর্ঘ-চলমান ব্লকিং অপারেশন থাকে, তাহলে অ্যাসিঙ্ক্রোনাস প্রোগ্রামের বিভিন্ন অংশের একে অপরের সাথে সম্পর্কযুক্ত হওয়ার উপায় সরবরাহ করার জন্য একটি দরকারী টুল হতে পারে।
কিন্তু সেই ক্ষেত্রগুলিতে আপনি কীভাবে রানটাইমে কন্ট্রোল ফিরিয়ে দেবেন?
রানটাইমে কন্ট্রোল প্রদান করা (Yielding Control to the Runtime)
আসুন একটি দীর্ঘ-চলমান অপারেশনের সিমুলেশন করি। Listing 17-22 একটি slow ফাংশন প্রবর্তন করে।
extern crate trpl; // required for mdbook test use std::{thread, time::Duration}; fn main() { trpl::run(async { // We will call `slow` here later }); } fn slow(name: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{name}' ran for {ms}ms"); }
এই কোডটি trpl::sleep-এর পরিবর্তে std::thread::sleep ব্যবহার করে যাতে slow কল করলে বর্তমান থ্রেডটি কিছু মিলিসেকেন্ডের জন্য ব্লক হয়ে যায়। আমরা slow ব্যবহার করতে পারি বাস্তব-বিশ্বের অপারেশনগুলির জন্য যা দীর্ঘ-চলমান এবং ব্লকিং উভয়ই।
Listing 17-23-এ, আমরা এক জোড়া ফিউচারে এই ধরনের CPU-বাউন্ড কাজ করার অনুকরণ করতে slow ব্যবহার করি।
extern crate trpl; // required for mdbook test use std::{thread, time::Duration}; fn main() { trpl::run(async { let a = async { println!("'a' started."); slow("a", 30); slow("a", 10); slow("a", 20); trpl::sleep(Duration::from_millis(50)).await; println!("'a' finished."); }; let b = async { println!("'b' started."); slow("b", 75); slow("b", 10); slow("b", 15); slow("b", 350); trpl::sleep(Duration::from_millis(50)).await; println!("'b' finished."); }; trpl::race(a, b).await; }); } fn slow(name: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{name}' ran for {ms}ms"); }
শুরু করার জন্য, প্রতিটি ফিউচার শুধুমাত্র একগুচ্ছ ধীর অপারেশন করার পরে রানটাইমে কন্ট্রোল ফিরিয়ে দেয়। আপনি যদি এই কোডটি চালান তবে আপনি এই আউটপুটটি দেখতে পাবেন:
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
আমাদের আগের উদাহরণের মতোই, a শেষ হওয়ার সাথে সাথেই race শেষ হয়ে যায়। দুটি ফিউচারের মধ্যে কোনও ইন্টারলিভিং নেই, যদিও। a ফিউচার trpl::sleep কলের জন্য অপেক্ষা করার আগ পর্যন্ত তার সমস্ত কাজ করে, তারপর b ফিউচার তার নিজের trpl::sleep কলের জন্য অপেক্ষা করার আগ পর্যন্ত তার সমস্ত কাজ করে এবং অবশেষে a ফিউচার সম্পূর্ণ হয়। তাদের ধীর টাস্কগুলির মধ্যে উভয় ফিউচারকে অগ্রগতি করার অনুমতি দেওয়ার জন্য, আমাদের অ্যাওয়েট পয়েন্টগুলির প্রয়োজন যাতে আমরা রানটাইমে কন্ট্রোল ফিরিয়ে দিতে পারি। এর মানে হল আমাদের এমন কিছুর প্রয়োজন যার জন্য আমরা অপেক্ষা করতে পারি!
আমরা Listing 17-23-এ এই ধরনের হ্যান্ডঅফ ঘটতে দেখতে পাচ্ছি: যদি আমরা a ফিউচারের শেষে trpl::sleep সরিয়ে দিই, তাহলে এটি b ফিউচার মোটেই না চলেই সম্পূর্ণ হয়ে যাবে। আসুন Listing 17-24-এ দেখানো মতো অপারেশনগুলিকে অগ্রগতি বন্ধ করে দেওয়ার জন্য sleep ফাংশনটিকে একটি শুরুর পয়েন্ট হিসাবে ব্যবহার করার চেষ্টা করি।
extern crate trpl; // required for mdbook test use std::{thread, time::Duration}; fn main() { trpl::run(async { let one_ms = Duration::from_millis(1); let a = async { println!("'a' started."); slow("a", 30); trpl::sleep(one_ms).await; slow("a", 10); trpl::sleep(one_ms).await; slow("a", 20); trpl::sleep(one_ms).await; println!("'a' finished."); }; let b = async { println!("'b' started."); slow("b", 75); trpl::sleep(one_ms).await; slow("b", 10); trpl::sleep(one_ms).await; slow("b", 15); trpl::sleep(one_ms).await; slow("b", 35); trpl::sleep(one_ms).await; println!("'b' finished."); }; trpl::race(a, b).await; }); } fn slow(name: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{name}' ran for {ms}ms"); }
Listing 17-24-এ, আমরা slow-এ প্রতিটি কলের মধ্যে অ্যাওয়েট পয়েন্ট সহ trpl::sleep কল যুক্ত করি। এখন দুটি ফিউচারের কাজ ইন্টারলিভড:
'a' started.
'a' ran for 30ms
'b' started.
'b' ran for 75ms
'a' ran for 10ms
'b' ran for 10ms
'a' ran for 20ms
'b' ran for 15ms
'a' finished.
a ফিউচারটি b-তে কন্ট্রোল দেওয়ার আগে কিছুক্ষণ চলে, কারণ এটি trpl::sleep কল করার আগেই slow কল করে, কিন্তু তার পরে ফিউচারগুলি প্রতিবার তাদের মধ্যে একটি অ্যাওয়েট পয়েন্টে আঘাত করার সময় অদলবদল করে। এক্ষেত্রে, আমরা slow-এ প্রতিটি কলের পরে এটি করেছি, কিন্তু আমরা যে কোনও উপায়ে কাজটিকে ভেঙে দিতে পারি যা আমাদের কাছে সবচেয়ে বেশি অর্থবোধক।
আমরা এখানে সত্যিই স্লিপ করতে চাই না: আমরা যতটা পারি তত দ্রুত অগ্রগতি করতে চাই। আমাদের শুধু রানটাইমে কন্ট্রোল ফিরিয়ে দিতে হবে। আমরা সরাসরি yield_now ফাংশন ব্যবহার করে তা করতে পারি। Listing 17-25-এ, আমরা সেই সমস্ত sleep কলগুলিকে yield_now দিয়ে প্রতিস্থাপন করি।
extern crate trpl; // required for mdbook test use std::{thread, time::Duration}; fn main() { trpl::run(async { let a = async { println!("'a' started."); slow("a", 30); trpl::yield_now().await; slow("a", 10); trpl::yield_now().await; slow("a", 20); trpl::yield_now().await; println!("'a' finished."); }; let b = async { println!("'b' started."); slow("b", 75); trpl::yield_now().await; slow("b", 10); trpl::yield_now().await; slow("b", 15); trpl::yield_now().await; slow("b", 35); trpl::yield_now().await; println!("'b' finished."); }; trpl::race(a, b).await; }); } fn slow(name: &str, ms: u64) { thread::sleep(Duration::from_millis(ms)); println!("'{name}' ran for {ms}ms"); }
এই কোডটি প্রকৃত উদ্দেশ্য সম্পর্কে আরও স্পষ্ট এবং sleep ব্যবহার করার চেয়ে উল্লেখযোগ্যভাবে দ্রুত হতে পারে, কারণ sleep দ্বারা ব্যবহৃত টাইমারের মতো টাইমারগুলির প্রায়শই তারা কতটা দানাদার হতে পারে তার উপর সীমাবদ্ধতা থাকে। উদাহরণস্বরূপ, আমরা যে sleep-এর সংস্করণ ব্যবহার করছি, সেটি সর্বদা কমপক্ষে এক মিলিসেকেন্ডের জন্য স্লিপ করবে, এমনকি যদি আমরা এটিকে এক ন্যানোসেকেন্ডের Duration পাস করি। আবারও, আধুনিক কম্পিউটারগুলি দ্রুত: তারা এক মিলিসেকেন্ডে অনেক কিছু করতে পারে!
আপনি Listing 17-26-এ দেখানো একটির মতো একটি ছোট বেঞ্চমার্ক সেট আপ করে এটি নিজে দেখতে পারেন। (এটি পারফরম্যান্স পরীক্ষা করার জন্য বিশেষভাবে কঠোর উপায় নয়, তবে এখানে পার্থক্য দেখানোর জন্য এটি যথেষ্ট।)
extern crate trpl; // required for mdbook test use std::time::{Duration, Instant}; fn main() { trpl::run(async { let one_ns = Duration::from_nanos(1); let start = Instant::now(); async { for _ in 1..1000 { trpl::sleep(one_ns).await; } } .await; let time = Instant::now() - start; println!( "'sleep' version finished after {} seconds.", time.as_secs_f32() ); let start = Instant::now(); async { for _ in 1..1000 { trpl::yield_now().await; } } .await; let time = Instant::now() - start; println!( "'yield' version finished after {} seconds.", time.as_secs_f32() ); }); }
এখানে, আমরা সমস্ত স্ট্যাটাস প্রিন্টিং এড়িয়ে যাই, trpl::sleep-এ একটি এক-ন্যানোসেকেন্ড Duration পাস করি এবং প্রতিটি ফিউচারকে নিজে থেকে চলতে দিই, ফিউচারগুলির মধ্যে কোনও স্যুইচিং ছাড়াই। তারপর আমরা 1,000 বার চালাই এবং দেখি trpl::sleep ব্যবহার করা ফিউচারটি trpl::yield_now ব্যবহার করা ফিউচারের তুলনায় কত সময় নেয়।
yield_now সহ সংস্করণটি অনেক দ্রুত!
এর মানে হল যে অ্যাসিঙ্ক্রোনাস কম্পিউট-বাউন্ড টাস্কগুলির জন্যও দরকারী হতে পারে, আপনার প্রোগ্রাম অন্য কী করছে তার উপর নির্ভর করে, কারণ এটি প্রোগ্রামের বিভিন্ন অংশের মধ্যে সম্পর্কগুলিকে গঠন করার জন্য একটি দরকারী টুল সরবরাহ করে। এটি কোঅপারেটিভ মাল্টিটাস্কিং-এর একটি ফর্ম, যেখানে প্রতিটি ফিউচারের অ্যাওয়েট পয়েন্টের মাধ্যমে কখন এটি কন্ট্রোল হস্তান্তর করবে তা নির্ধারণ করার ক্ষমতা রয়েছে। তাই প্রতিটি ফিউচারেরও খুব বেশি সময় ধরে ব্লক করা এড়াতে দায়িত্ব রয়েছে। কিছু Rust-ভিত্তিক এমবেডেড অপারেটিং সিস্টেমে, এটিই একমাত্র ধরনের মাল্টিটাস্কিং!
বাস্তব-বিশ্বের কোডে, আপনি সাধারণত প্রতিটি লাইনে ফাংশন কলের সাথে অ্যাওয়েট পয়েন্টগুলিকে অল্টারনেট করবেন না। যদিও এইভাবে কন্ট্রোল প্রদান করা তুলনামূলকভাবে সস্তা, এটি বিনামূল্যে নয়। অনেক ক্ষেত্রে, একটি কম্পিউট-বাউন্ড টাস্ককে ভেঙে ফেলার চেষ্টা করলে এটি উল্লেখযোগ্যভাবে ধীর হয়ে যেতে পারে, তাই কখনও কখনও একটি অপারেশনকে সংক্ষিপ্তভাবে ব্লক করতে দেওয়া সামগ্রিক পারফরম্যান্সের জন্য আরও ভাল। আপনার কোডের আসল পারফরম্যান্সের বাধাগুলি কী তা দেখতে সর্বদা পরিমাপ করুন। অন্তর্নিহিত ডায়নামিকটি মনে রাখা গুরুত্বপূর্ণ, যদিও, আপনি যদি দেখেন যে আপনি কনকারেন্টলি ঘটবে বলে আশা করেছিলেন এমন অনেক কাজ সিরিয়ালে ঘটছে!
আমাদের নিজস্ব অ্যাসিঙ্ক্রোনাস অ্যাবস্ট্রাকশন তৈরি করা (Building Our Own Async Abstractions)
আমরা ফিউচারগুলিকে একসাথে কম্পোজ করে নতুন প্যাটার্ন তৈরি করতে পারি। উদাহরণস্বরূপ, আমরা ইতিমধ্যেই আমাদের কাছে থাকা অ্যাসিঙ্ক্রোনাস বিল্ডিং ব্লকগুলির সাথে একটি timeout ফাংশন তৈরি করতে পারি। যখন আমরা শেষ করব, ফলাফলটি হবে আরেকটি বিল্ডিং ব্লক যা আমরা আরও অ্যাসিঙ্ক্রোনাস অ্যাবস্ট্রাকশন তৈরি করতে ব্যবহার করতে পারি।
Listing 17-27 দেখায় কিভাবে আমরা আশা করব এই timeout একটি স্লো ফিউচারের সাথে কাজ করবে।
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::run(async {
let slow = async {
trpl::sleep(Duration::from_millis(100)).await;
"I finished!"
};
match timeout(slow, Duration::from_millis(10)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}আসুন এটি ইমপ্লিমেন্ট করি! শুরু করার জন্য, আসুন timeout-এর জন্য API সম্পর্কে চিন্তা করি:
- এটি নিজেই একটি অ্যাসিঙ্ক্রোনাস ফাংশন হওয়া দরকার যাতে আমরা এটির জন্য অপেক্ষা করতে পারি।
- এর প্রথম প্যারামিটারটি চালানো উচিত একটি ফিউচার। আমরা এটিকে জেনেরিক করতে পারি যাতে এটি যেকোনো ফিউচারের সাথে কাজ করতে পারে।
- এর দ্বিতীয় প্যারামিটারটি হবে অপেক্ষা করার সর্বোচ্চ সময়। যদি আমরা একটি
Durationব্যবহার করি, তাহলে এটিকেtrpl::sleep-এ পাস করা সহজ হবে। - এটি একটি
Resultরিটার্ন করা উচিত। ফিউচার সফলভাবে সম্পন্ন হলে,ResultহবেOkফিউচার দ্বারা উৎপাদিত মান সহ। যদি টাইমআউটটি প্রথমে শেষ হয়ে যায়, তাহলেResultহবেErrটাইমআউট যে সময়কালের জন্য অপেক্ষা করেছে তার সাথে।
Listing 17-28 এই ডিক্লারেশনটি দেখায়।
extern crate trpl; // required for mdbook test
use std::{future::Future, time::Duration};
fn main() {
trpl::run(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_millis(10)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
// Here is where our implementation will go!
}এটি টাইপের জন্য আমাদের লক্ষ্যগুলি পূরণ করে। এখন আসুন আচরণ সম্পর্কে চিন্তা করি যা আমাদের প্রয়োজন: আমরা যে ফিউচারটি পাস করেছি সেটিকে সময়কালের বিরুদ্ধে রেস করাতে চাই। আমরা সময়কাল থেকে একটি টাইমার ফিউচার তৈরি করতে trpl::sleep ব্যবহার করতে পারি এবং কলার যে ফিউচারটি পাস করে তার সাথে সেই টাইমারটি চালানোর জন্য trpl::race ব্যবহার করতে পারি।
আমরা এটাও জানি যে race ফেয়ার নয়, আর্গুমেন্টগুলিকে যে ক্রমে পাস করা হয়েছে সেই ক্রমে পোল করে। সুতরাং, আমরা future_to_try-কে race-এ প্রথমে পাস করি যাতে max_time খুব কম সময় হলেও এটি সম্পূর্ণ হওয়ার সুযোগ পায়। যদি future_to_try প্রথমে শেষ হয়, তাহলে race future_to_try-এর আউটপুট সহ Left রিটার্ন করবে। যদি timer প্রথমে শেষ হয়, তাহলে race টাইমারের () আউটপুট সহ Right রিটার্ন করবে।
Listing 17-29-এ, আমরা trpl::race-এর জন্য অপেক্ষা করার ফলাফলের উপর ম্যাচ করি।
extern crate trpl; // required for mdbook test use std::{future::Future, time::Duration}; use trpl::Either; // --snip-- fn main() { trpl::run(async { let slow = async { trpl::sleep(Duration::from_secs(5)).await; "Finally finished" }; match timeout(slow, Duration::from_secs(2)).await { Ok(message) => println!("Succeeded with '{message}'"), Err(duration) => { println!("Failed after {} seconds", duration.as_secs()) } } }); } async fn timeout<F: Future>( future_to_try: F, max_time: Duration, ) -> Result<F::Output, Duration> { match trpl::race(future_to_try, trpl::sleep(max_time)).await { Either::Left(output) => Ok(output), Either::Right(_) => Err(max_time), } }
যদি future_to_try সফল হয় এবং আমরা একটি Left(output) পাই, তাহলে আমরা Ok(output) রিটার্ন করি। যদি পরিবর্তে স্লিপ টাইমার শেষ হয়ে যায় এবং আমরা একটি Right(()) পাই, তাহলে আমরা _ দিয়ে () উপেক্ষা করি এবং পরিবর্তে Err(max_time) রিটার্ন করি।
এর সাথে, আমাদের কাছে দুটি অন্যান্য অ্যাসিঙ্ক্রোনাস হেল্পার থেকে তৈরি একটি কার্যকরী timeout রয়েছে। আমরা যদি আমাদের কোড চালাই, তাহলে এটি টাইমআউটের পরে ব্যর্থতার মোড প্রিন্ট করবে:
Failed after 2 seconds
যেহেতু ফিউচারগুলি অন্যান্য ফিউচারের সাথে কম্পোজ করে, তাই আপনি ছোট অ্যাসিঙ্ক্রোনাস বিল্ডিং ব্লক ব্যবহার করে সত্যিই শক্তিশালী টুল তৈরি করতে পারেন। উদাহরণস্বরূপ, আপনি টাইমআউটগুলিকে রিট্রাই-এর সাথে একত্রিত করতে এই একই পদ্ধতি ব্যবহার করতে পারেন এবং পরিবর্তে নেটওয়ার্ক কলের মতো অপারেশনগুলির সাথে সেগুলি ব্যবহার করতে পারেন (চ্যাপ্টারের শুরু থেকে একটি উদাহরণ)।
বাস্তবে, আপনি সাধারণত সরাসরি async এবং await-এর সাথে কাজ করবেন এবং গৌণভাবে join, join_all, race ইত্যাদির মতো ফাংশন এবং ম্যাক্রোগুলির সাথে কাজ করবেন। সেই API-গুলির সাথে ফিউচার ব্যবহার করার জন্য আপনাকে কেবল মাঝে মাঝে pin-এর কাছে পৌঁছাতে হবে।
আমরা এখন একই সময়ে একাধিক ফিউচারের সাথে কাজ করার বিভিন্ন উপায় দেখেছি। এরপরে, আমরা দেখব কিভাবে আমরা স্ট্রিম-এর সাহায্যে সময়ের সাথে একটি সিকোয়েন্সে একাধিক ফিউচারের সাথে কাজ করতে পারি। এখানে আরও কয়েকটি বিষয় রয়েছে যা আপনি প্রথমে বিবেচনা করতে চাইতে পারেন:
-
আমরা কিছু গ্রুপের সমস্ত ফিউচার শেষ হওয়ার জন্য অপেক্ষা করতে
join_all-এর সাথে একটিVecব্যবহার করেছি। পরিবর্তে একটি সিকোয়েন্সে ফিউচারের একটি গ্রুপ প্রসেস করতে আপনি কীভাবে একটিVecব্যবহার করতে পারেন? এটি করার ট্রেডঅফগুলি কী কী? -
futuresক্রেট থেকেfutures::stream::FuturesUnorderedটাইপটি দেখুন। এটি ব্যবহার করা একটিVecব্যবহার করার থেকে কীভাবে আলাদা হবে? (চিন্তা করবেন না যে এটি ক্রেটেরstreamঅংশ থেকে এসেছে; এটি ফিউচারের যেকোনো কালেকশনের সাথে ঠিকঠাক কাজ করে।)
স্ট্রিমস: সিকোয়েন্সে ফিউচার (Streams: Futures in Sequence)
এই চ্যাপ্টারে ఇప్పటి পর্যন্ত, আমরা বেশিরভাগ ক্ষেত্রে individual ফিউচারের মধ্যেই আটকে ছিলাম। একটি বড় ব্যতিক্রম ছিল অ্যাসিঙ্ক্রোনাস চ্যানেল যা আমরা ব্যবহার করেছি। এই চ্যাপ্টারের “Message Passing” বিভাগে আমরা কীভাবে আমাদের অ্যাসিঙ্ক্রোনাস চ্যানেলের জন্য রিসিভার ব্যবহার করেছি তা স্মরণ করুন। অ্যাসিঙ্ক্রোনাস recv মেথড সময়ের সাথে আইটেমগুলির একটি সিকোয়েন্স তৈরি করে। এটি স্ট্রিম নামে পরিচিত আরও অনেক সাধারণ প্যাটার্নের একটি উদাহরণ।
আমরা Chapter 13-এর The Iterator Trait and the next Method বিভাগে Iterator trait দেখার সময় আইটেমগুলির একটি সিকোয়েন্স দেখেছিলাম, কিন্তু ইটারেটর এবং অ্যাসিঙ্ক্রোনাস চ্যানেল রিসিভারের মধ্যে দুটি পার্থক্য রয়েছে। প্রথম পার্থক্য হল সময়: ইটারেটরগুলি সিঙ্ক্রোনাস, যেখানে চ্যানেল রিসিভার অ্যাসিঙ্ক্রোনাস। দ্বিতীয়টি হল API। Iterator-এর সাথে সরাসরি কাজ করার সময়, আমরা এর সিঙ্ক্রোনাস next মেথড কল করি। বিশেষ করে trpl::Receiver স্ট্রিমের সাথে, আমরা পরিবর্তে একটি অ্যাসিঙ্ক্রোনাস recv মেথড কল করেছি। অন্যথায়, এই API গুলি খুব একই রকম মনে হয় এবং সেই মিলটি কোনও কাকতালীয় ঘটনা নয়। একটি স্ট্রিম হল ইটারেশনের একটি অ্যাসিঙ্ক্রোনাস ফর্মের মতো। যেখানে trpl::Receiver বিশেষভাবে মেসেজ পাওয়ার জন্য অপেক্ষা করে, যদিও, সাধারণ-উদ্দেশ্যের স্ট্রিম API অনেক বিস্তৃত: এটি Iterator-এর মতোই পরবর্তী আইটেম সরবরাহ করে, কিন্তু অ্যাসিঙ্ক্রোনাসভাবে।
Rust-এ ইটারেটর এবং স্ট্রিমের মধ্যে মিলের অর্থ হল আমরা আসলে যেকোনো ইটারেটর থেকে একটি স্ট্রিম তৈরি করতে পারি। একটি ইটারেটরের মতো, আমরা একটি স্ট্রিমের next মেথড কল করে এবং তারপর আউটপুটের জন্য অপেক্ষা করে একটি স্ট্রিমের সাথে কাজ করতে পারি, যেমনটি Listing 17-30-এ রয়েছে।
extern crate trpl; // required for mdbook test
fn main() {
trpl::run(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}আমরা সংখ্যার একটি অ্যারে দিয়ে শুরু করি, যেটিকে আমরা একটি ইটারেটরে রূপান্তর করি এবং তারপর সমস্ত মান দ্বিগুণ করতে map কল করি। তারপর আমরা trpl::stream_from_iter ফাংশন ব্যবহার করে ইটারেটরটিকে একটি স্ট্রিমে রূপান্তর করি। এরপর, আমরা while let লুপ দিয়ে স্ট্রিমে আইটেমগুলি আসার সাথে সাথে সেগুলির উপর লুপ করি।
দুর্ভাগ্যবশত, যখন আমরা কোডটি চালানোর চেষ্টা করি, তখন এটি কম্পাইল হয় না, তবে পরিবর্তে এটি রিপোর্ট করে যে কোনও next মেথড উপলব্ধ নেই:
error[E0599]: no method named `next` found for struct `Iter` in the current scope
--> src/main.rs:10:40
|
10 | while let Some(value) = stream.next().await {
| ^^^^
|
= note: the full type name has been written to '/Users/chris/dev/rust-lang/book/main/listings/ch17-async-await/listing-17-30/target/debug/deps/async_await-575db3dd3197d257.long-type-14490787947592691573.txt'
= note: consider using `--verbose` to print the full type name to the console
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
1 + use std::iter::Iterator;
|
1 + use std::str::pattern::Searcher;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(value) = stream.try_next().await {
| ~~~~~~~~
এই আউটপুটটি যেমন ব্যাখ্যা করে, কম্পাইলার error-এর কারণ হল next মেথডটি ব্যবহার করতে সক্ষম হওয়ার জন্য আমাদের স্কোপে সঠিক trait-এর প্রয়োজন। আমাদের এখন পর্যন্ত আলোচনা দেওয়া হলে, আপনি যুক্তিসঙ্গতভাবে আশা করতে পারেন যে trait টি হবে Stream, কিন্তু এটি আসলে StreamExt। এক্সটেনশনের জন্য সংক্ষিপ্ত, Ext হল Rust কমিউনিটিতে একটি trait-কে অন্যটির সাথে প্রসারিত করার জন্য একটি সাধারণ প্যাটার্ন।
আমরা চ্যাপ্টারের শেষে Stream এবং StreamExt trait গুলিকে আরও একটু বিশদে ব্যাখ্যা করব, কিন্তু আপাতত আপনার যা জানা দরকার তা হল Stream trait একটি নিম্ন-স্তরের ইন্টারফেস সংজ্ঞায়িত করে যা কার্যকরভাবে Iterator এবং Future trait গুলিকে একত্রিত করে। StreamExt Stream-এর উপরে API-গুলির একটি উচ্চ-স্তরের সেট সরবরাহ করে, যার মধ্যে next মেথড এবং সেইসাথে Iterator trait দ্বারা প্রদত্ত ইউটিলিটি মেথডগুলির অনুরূপ অন্যান্য ইউটিলিটি মেথড রয়েছে। Stream এবং StreamExt এখনও Rust-এর স্ট্যান্ডার্ড লাইব্রেরির অংশ নয়, তবে বেশিরভাগ ইকোসিস্টেম ক্রেট একই সংজ্ঞা ব্যবহার করে।
কম্পাইলার error-এর সমাধান হল trpl::StreamExt-এর জন্য একটি use স্টেটমেন্ট যুক্ত করা, যেমনটি Listing 17-31-এ রয়েছে।
extern crate trpl; // required for mdbook test use trpl::StreamExt; fn main() { trpl::run(async { let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let iter = values.iter().map(|n| n * 2); let mut stream = trpl::stream_from_iter(iter); while let Some(value) = stream.next().await { println!("The value was: {value}"); } }); }
এই সমস্ত টুকরোগুলি একসাথে রাখলে, এই কোডটি আমরা যেভাবে চাই সেভাবে কাজ করে! আরও কী, এখন যেহেতু আমাদের স্কোপে StreamExt রয়েছে, আমরা এর সমস্ত ইউটিলিটি মেথড ব্যবহার করতে পারি, ঠিক ইটারেটরের মতোই। উদাহরণস্বরূপ, Listing 17-32-এ, আমরা তিন এবং পাঁচের গুণিতক ব্যতীত অন্য সবকিছু ফিল্টার করতে filter মেথড ব্যবহার করি।
extern crate trpl; // required for mdbook test use trpl::StreamExt; fn main() { trpl::run(async { let values = 1..101; let iter = values.map(|n| n * 2); let stream = trpl::stream_from_iter(iter); let mut filtered = stream.filter(|value| value % 3 == 0 || value % 5 == 0); while let Some(value) = filtered.next().await { println!("The value was: {value}"); } }); }
অবশ্যই, এটি খুব আকর্ষণীয় নয়, যেহেতু আমরা সাধারণ ইটারেটর দিয়ে এবং কোনও অ্যাসিঙ্ক্রোনাস ছাড়াই একই কাজ করতে পারি। আসুন দেখি আমরা কী করতে পারি যা স্ট্রিমের জন্য অনন্য।
কম্পোজিং স্ট্রিম (Composing Streams)
অনেকগুলি ধারণা স্বাভাবিকভাবেই স্ট্রিম হিসাবে উপস্থাপিত হয়: একটি সারিতে উপলব্ধ হওয়া আইটেম, ফাইল সিস্টেম থেকে ক্রমবর্ধমানভাবে ডেটার অংশগুলি টেনে আনা যখন সম্পূর্ণ ডেটা সেট কম্পিউটারের মেমরির জন্য খুব বড় হয়, অথবা সময়ের সাথে নেটওয়ার্কের মাধ্যমে ডেটা আসা। যেহেতু স্ট্রিমগুলি ফিউচার, তাই আমরা সেগুলিকে অন্য যেকোনো ধরনের ফিউচারের সাথে ব্যবহার করতে পারি এবং সেগুলিকে আকর্ষণীয় উপায়ে একত্রিত করতে পারি। উদাহরণস্বরূপ, আমরা অনেকগুলি নেটওয়ার্ক কল ট্রিগার করা এড়াতে ইভেন্টগুলিকে ব্যাচ আপ করতে পারি, দীর্ঘ-চলমান অপারেশনগুলির সিকোয়েন্সে টাইমআউট সেট করতে পারি, অথবা অপ্রয়োজনীয় কাজ এড়াতে ইউজার ইন্টারফেস ইভেন্টগুলিকে থ্রোটল করতে পারি।
আসুন একটি ওয়েব সকেট বা অন্য রিয়েল-টাইম কমিউনিকেশন প্রোটোকল থেকে আমরা যে ডেটা স্ট্রিম দেখতে পারি তার জন্য একটি স্ট্যান্ড-ইন হিসাবে মেসেজের একটি ছোট স্ট্রিম তৈরি করে শুরু করি, যেমনটি Listing 17-33-এ দেখানো হয়েছে।
extern crate trpl; // required for mdbook test use trpl::{ReceiverStream, Stream, StreamExt}; fn main() { trpl::run(async { let mut messages = get_messages(); while let Some(message) = messages.next().await { println!("{message}"); } }); } fn get_messages() -> impl Stream<Item = String> { let (tx, rx) = trpl::channel(); let messages = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"]; for message in messages { tx.send(format!("Message: '{message}'")).unwrap(); } ReceiverStream::new(rx) }
প্রথমে, আমরা get_messages নামে একটি ফাংশন তৈরি করি যা impl Stream<Item = String> রিটার্ন করে। এর ইমপ্লিমেন্টেশনের জন্য, আমরা একটি অ্যাসিঙ্ক্রোনাস চ্যানেল তৈরি করি, ইংরেজি বর্ণমালার প্রথম 10টি অক্ষরের উপর লুপ করি এবং সেগুলিকে চ্যানেলের মাধ্যমে পাঠাই।
আমরা একটি নতুন টাইপও ব্যবহার করি: ReceiverStream, যা trpl::channel থেকে rx রিসিভারকে একটি next মেথড সহ একটি Stream-এ রূপান্তর করে। main-এ ফিরে, আমরা স্ট্রিম থেকে সমস্ত মেসেজ প্রিন্ট করতে একটি while let লুপ ব্যবহার করি।
যখন আমরা এই কোডটি চালাই, তখন আমরা ঠিক সেই ফলাফলগুলি পাই যা আমরা আশা করব:
Message: 'a'
Message: 'b'
Message: 'c'
Message: 'd'
Message: 'e'
Message: 'f'
Message: 'g'
Message: 'h'
Message: 'i'
Message: 'j'
আবার, আমরা এটি রেগুলার Receiver API বা এমনকি রেগুলার Iterator API দিয়ে করতে পারি, যদিও, তাই আসুন এমন একটি বৈশিষ্ট্য যুক্ত করি যার জন্য স্ট্রিমের প্রয়োজন: স্ট্রীমের প্রতিটি আইটেমে প্রযোজ্য একটি টাইমআউট এবং আমরা যে আইটেমগুলি নির্গত করি তাতে একটি বিলম্ব যোগ করা, যেমনটি Listing 17-34-এ দেখানো হয়েছে।
extern crate trpl; // required for mdbook test use std::{pin::pin, time::Duration}; use trpl::{ReceiverStream, Stream, StreamExt}; fn main() { trpl::run(async { let mut messages = pin!(get_messages().timeout(Duration::from_millis(200))); while let Some(result) = messages.next().await { match result { Ok(message) => println!("{message}"), Err(reason) => eprintln!("Problem: {reason:?}"), } } }) } fn get_messages() -> impl Stream<Item = String> { let (tx, rx) = trpl::channel(); let messages = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"]; for message in messages { tx.send(format!("Message: '{message}'")).unwrap(); } ReceiverStream::new(rx) }
আমরা timeout মেথড দিয়ে স্ট্রিমে একটি টাইমআউট যুক্ত করে শুরু করি, যা StreamExt trait থেকে আসে। তারপর আমরা while let লুপের বডি আপডেট করি, কারণ স্ট্রিমটি এখন একটি Result রিটার্ন করে। Ok ভেরিয়েন্ট নির্দেশ করে যে একটি মেসেজ সময়মতো এসেছে; Err ভেরিয়েন্ট নির্দেশ করে যে কোনও মেসেজ আসার আগেই টাইমআউট শেষ হয়ে গেছে। আমরা সেই ফলাফলের উপর match করি এবং হয় মেসেজটি সফলভাবে পেলে প্রিন্ট করি অথবা টাইমআউট সম্পর্কে একটি নোটিশ প্রিন্ট করি। অবশেষে, লক্ষ্য করুন যে আমরা টাইমআউট প্রয়োগ করার পরে মেসেজগুলিকে পিন করি, কারণ টাইমআউট হেল্পার একটি স্ট্রিম তৈরি করে যেটিকে পোল করার জন্য পিন করা প্রয়োজন।
যাইহোক, যেহেতু মেসেজগুলির মধ্যে কোনও বিলম্ব নেই, তাই এই টাইমআউট প্রোগ্রামের আচরণ পরিবর্তন করে না। আসুন আমরা যে মেসেজগুলি পাঠাই তাতে একটি পরিবর্তনশীল বিলম্ব যুক্ত করি, যেমনটি Listing 17-35-এ দেখানো হয়েছে।
extern crate trpl; // required for mdbook test use std::{pin::pin, time::Duration}; use trpl::{ReceiverStream, Stream, StreamExt}; fn main() { trpl::run(async { let mut messages = pin!(get_messages().timeout(Duration::from_millis(200))); while let Some(result) = messages.next().await { match result { Ok(message) => println!("{message}"), Err(reason) => eprintln!("Problem: {reason:?}"), } } }) } fn get_messages() -> impl Stream<Item = String> { let (tx, rx) = trpl::channel(); trpl::spawn_task(async move { let messages = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"]; for (index, message) in messages.into_iter().enumerate() { let time_to_sleep = if index % 2 == 0 { 100 } else { 300 }; trpl::sleep(Duration::from_millis(time_to_sleep)).await; tx.send(format!("Message: '{message}'")).unwrap(); } }); ReceiverStream::new(rx) }
get_messages-এ, আমরা messages অ্যারের সাথে enumerate ইটারেটর মেথড ব্যবহার করি যাতে আমরা যে প্রতিটি আইটেম পাঠাচ্ছি তার ইনডেক্স এবং সেইসাথে আইটেমটিও পেতে পারি। তারপর আমরা বাস্তব জগতে মেসেজের একটি স্ট্রিম থেকে আমরা যে বিভিন্ন বিলম্ব দেখতে পারি তা অনুকরণ করতে জোড়-ইনডেক্স আইটেমগুলিতে 100-মিলিসেকেন্ড বিলম্ব এবং বিজোড়-ইনডেক্স আইটেমগুলিতে 300-মিলিসেকেন্ড বিলম্ব প্রয়োগ করি। যেহেতু আমাদের টাইমআউট 200 মিলিসেকেন্ডের জন্য, তাই এটি অর্ধেক মেসেজকে প্রভাবিত করবে।
get_messages ফাংশনে মেসেজগুলির মধ্যে স্লিপ করার জন্য ব্লক না করে, আমাদের অ্যাসিঙ্ক্রোনাস ব্যবহার করতে হবে। যাইহোক, আমরা get_messages-কে নিজেই একটি অ্যাসিঙ্ক্রোনাস ফাংশন করতে পারি না, কারণ তাহলে আমরা একটি Stream<Item = String>>-এর পরিবর্তে একটি Future<Output = Stream<Item = String>> রিটার্ন করব। কলারকে স্ট্রিমটিতে অ্যাক্সেস পেতে get_messages-এর জন্য নিজেই অপেক্ষা করতে হবে। কিন্তু মনে রাখবেন: একটি প্রদত্ত ফিউচারের মধ্যে সবকিছু লিনিয়ারভাবে ঘটে; কনকারেন্সি ঘটে ফিউচারগুলির মধ্যে। get_messages-এর জন্য অপেক্ষা করার জন্য এটিকে সমস্ত মেসেজ পাঠাতে হবে, প্রতিটি মেসেজের মধ্যে স্লিপ বিলম্ব সহ, রিসিভার স্ট্রিম রিটার্ন করার আগে। ফলস্বরূপ, টাইমআউটটি অকেজো হবে। স্ট্রীমের মধ্যে কোনও বিলম্ব থাকবে না; সেগুলি স্ট্রিমটি উপলব্ধ হওয়ার আগেই ঘটবে।
পরিবর্তে, আমরা get_messages-কে একটি রেগুলার ফাংশন হিসাবে ছেড়ে দিই যা একটি স্ট্রিম রিটার্ন করে এবং অ্যাসিঙ্ক্রোনাস sleep কলগুলি পরিচালনা করার জন্য আমরা একটি টাস্ক স্পন করি।
Note: এইভাবে
spawn_taskকল করা কাজ করে কারণ আমরা ইতিমধ্যেই আমাদের রানটাইম সেট আপ করেছি; যদি আমরা তা না করতাম, তাহলে এটি একটি প্যানিকের কারণ হত। অন্যান্য ইমপ্লিমেন্টেশনগুলি বিভিন্ন ট্রেডঅফ বেছে নেয়: তারা একটি নতুন রানটাইম স্পন করতে পারে এবং প্যানিক এড়াতে পারে কিন্তু সামান্য অতিরিক্ত ওভারহেড সহ শেষ হতে পারে, অথবা তারা রানটাইমের রেফারেন্স ছাড়াই টাস্ক স্পন করার কোনও স্বতন্ত্র উপায় সরবরাহ নাও করতে পারে। আপনি নিশ্চিত করুন যে আপনার রানটাইম কোন ট্রেডঅফ বেছে নিয়েছে এবং সেই অনুযায়ী আপনার কোড লিখুন!
এখন আমাদের কোডের অনেক বেশি আকর্ষণীয় ফলাফল রয়েছে। অন্য প্রতিটি জোড়া মেসেজের মধ্যে, একটি Problem: Elapsed(()) error।
Message: 'a'
Problem: Elapsed(())
Message: 'b'
Message: 'c'
Problem: Elapsed(())
Message: 'd'
Message: 'e'
Problem: Elapsed(())
Message: 'f'
Message: 'g'
Problem: Elapsed(())
Message: 'h'
Message: 'i'
Problem: Elapsed(())
Message: 'j'
টাইমআউট শেষ পর্যন্ত মেসেজগুলিকে আসা থেকে আটকাতে পারে না। আমরা এখনও সমস্ত মূল মেসেজ পাই, কারণ আমাদের চ্যানেলটি আনবাউন্ডেড: এটি মেমরিতে যতগুলি মেসেজ ফিট করতে পারে ততগুলি ধারণ করতে পারে। যদি মেসেজটি টাইমআউটের আগে না আসে, তাহলে আমাদের স্ট্রিম হ্যান্ডলার সেটি বিবেচনা করবে, কিন্তু যখন এটি আবার স্ট্রিমটি পোল করবে, তখন মেসেজটি এসে যেতে পারে।
প্রয়োজনের ভিত্তিতে আপনি অন্যান্য ধরণের চ্যানেল বা আরও সাধারণভাবে অন্যান্য ধরণের স্ট্রিম ব্যবহার করে আলাদা আচরণ পেতে পারেন। আসুন তাদের মধ্যে একটিকে বাস্তবে দেখি, সময়ের ব্যবধানের একটি স্ট্রিমের সাথে এই মেসেজের স্ট্রিমটিকে একত্রিত করে।
স্ট্রিমগুলিকে মার্জ করা (Merging Streams)
প্রথমে, আসুন আরেকটি স্ট্রিম তৈরি করি, যেটি সরাসরি চলতে দিলে প্রতি মিলি সেকেন্ডে একটি আইটেম নির্গত করবে। সরলতার জন্য, আমরা একটি বিলম্বের সাথে একটি মেসেজ পাঠাতে sleep ফাংশনটি ব্যবহার করতে পারি এবং এটিকে get_messages-এ আমরা যে পদ্ধতি ব্যবহার করেছি তার সাথে একত্রিত করতে পারি একটি চ্যানেল থেকে একটি স্ট্রিম তৈরি করার জন্য। পার্থক্য হল যে এবার, আমরা যে ব্যবধানগুলি অতিক্রান্ত হয়েছে তার সংখ্যা ফেরত পাঠাব, তাই রিটার্ন টাইপ হবে impl Stream<Item = u32>, এবং আমরা ফাংশনটিকে get_intervals বলতে পারি (Listing 17-36 দেখুন)।
extern crate trpl; // required for mdbook test use std::{pin::pin, time::Duration}; use trpl::{ReceiverStream, Stream, StreamExt}; fn main() { trpl::run(async { let mut messages = pin!(get_messages().timeout(Duration::from_millis(200))); while let Some(result) = messages.next().await { match result { Ok(message) => println!("{message}"), Err(reason) => eprintln!("Problem: {reason:?}"), } } }) } fn get_messages() -> impl Stream<Item = String> { let (tx, rx) = trpl::channel(); trpl::spawn_task(async move { let messages = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"]; for (index, message) in messages.into_iter().enumerate() { let time_to_sleep = if index % 2 == 0 { 100 } else { 300 }; trpl::sleep(Duration::from_millis(time_to_sleep)).await; tx.send(format!("Message: '{message}'")).unwrap(); } }); ReceiverStream::new(rx) } fn get_intervals() -> impl Stream<Item = u32> { let (tx, rx) = trpl::channel(); trpl::spawn_task(async move { let mut count = 0; loop { trpl::sleep(Duration::from_millis(1)).await; count += 1; tx.send(count).unwrap(); } }); ReceiverStream::new(rx) }
আমরা টাস্কের মধ্যে একটি count সংজ্ঞায়িত করে শুরু করি। (আমরা এটিকে টাস্কের বাইরেও সংজ্ঞায়িত করতে পারি, তবে যেকোনো প্রদত্ত variable-এর সুযোগ সীমিত করা আরও পরিষ্কার।) তারপর আমরা একটি অসীম লুপ তৈরি করি। লুপের প্রতিটি পুনরাবৃত্তি অ্যাসিঙ্ক্রোনাসভাবে এক মিলি সেকেন্ডের জন্য স্লিপ করে, কাউন্ট বাড়ায় এবং তারপর এটিকে চ্যানেলের মাধ্যমে পাঠায়। যেহেতু এটি spawn_task দ্বারা তৈরি টাস্কের মধ্যে র্যাপ করা হয়েছে, তাই অসীম লুপ সহ এটির সমস্ত কিছুই রানটাইমের সাথে পরিষ্কার হয়ে যাবে।
এই ধরনের অসীম লুপ, যা শুধুমাত্র তখনই শেষ হয় যখন পুরো রানটাইমটি ভেঙে যায়, অ্যাসিঙ্ক্রোনাস Rust-এ বেশ সাধারণ: অনেক প্রোগ্রামের অনির্দিষ্টকালের জন্য চলতে থাকা প্রয়োজন। অ্যাসিঙ্ক্রোনাসের সাথে, এটি অন্য কিছু ব্লক করে না, যতক্ষণ লুপের প্রতিটি পুনরাবৃত্তিতে কমপক্ষে একটি অ্যাওয়েট পয়েন্ট থাকে।
এখন, আমাদের main ফাংশনের অ্যাসিঙ্ক্রোনাস ব্লকে ফিরে, আমরা messages এবং intervals স্ট্রিমগুলিকে মার্জ করার চেষ্টা করতে পারি, যেমনটি Listing 17-37-এ দেখানো হয়েছে।
extern crate trpl; // required for mdbook test
use std::{pin::pin, time::Duration};
use trpl::{ReceiverStream, Stream, StreamExt};
fn main() {
trpl::run(async {
let messages = get_messages().timeout(Duration::from_millis(200));
let intervals = get_intervals();
let merged = messages.merge(intervals);
while let Some(result) = merged.next().await {
match result {
Ok(message) => println!("{message}"),
Err(reason) => eprintln!("Problem: {reason:?}"),
}
}
})
}
fn get_messages() -> impl Stream<Item = String> {
let (tx, rx) = trpl::channel();
trpl::spawn_task(async move {
let messages = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"];
for (index, message) in messages.into_iter().enumerate() {
let time_to_sleep = if index % 2 == 0 { 100 } else { 300 };
trpl::sleep(Duration::from_millis(time_to_sleep)).await;
tx.send(format!("Message: '{message}'")).unwrap();
}
});
ReceiverStream::new(rx)
}
fn get_intervals() -> impl Stream<Item = u32> {
let (tx, rx) = trpl::channel();
trpl::spawn_task(async move {
let mut count = 0;
loop {
trpl::sleep(Duration::from_millis(1)).await;
count += 1;
tx.send(count).unwrap();
}
});
ReceiverStream::new(rx)
}আমরা get_intervals কল করে শুরু করি। তারপর আমরা messages এবং intervals স্ট্রিমগুলিকে merge মেথড দিয়ে মার্জ করি, যা একাধিক স্ট্রিমকে একটি স্ট্রিমে একত্রিত করে যা আইটেমগুলি উপলব্ধ হওয়ার সাথে সাথেই যেকোনো সোর্স স্ট্রিম থেকে আইটেম তৈরি করে, কোনও নির্দিষ্ট ক্রম আরোপ না করে। অবশেষে, আমরা সেই সম্মিলিত স্ট্রিমের উপর লুপ করি messages-এর পরিবর্তে।
এই সময়ে, messages বা intervals কোনওটিরই পিন করা বা মিউটেবল হওয়ার প্রয়োজন নেই, কারণ উভয়কেই একক merged স্ট্রিমে একত্রিত করা হবে। যাইহোক, merge-এ এই কলটি কম্পাইল হয় না! (while let লুপের next কলটিও নয়, তবে আমরা সেটিতে ফিরে আসব।) এর কারণ হল দুটি স্ট্রিমের আলাদা টাইপ রয়েছে। messages স্ট্রিমের টাইপ হল Timeout<impl Stream<Item = String>>, যেখানে Timeout হল সেই টাইপ যা একটি timeout কলের জন্য Stream ইমপ্লিমেন্ট করে। intervals স্ট্রিমের টাইপ হল impl Stream<Item = u32>। এই দুটি স্ট্রিম মার্জ করার জন্য, আমাদের তাদের মধ্যে একটিকে অন্যটির সাথে মেলানোর জন্য রূপান্তর করতে হবে। আমরা intervals স্ট্রিমটিকে পুনরায় কাজ করব, কারণ messages ইতিমধ্যেই আমাদের কাঙ্ক্ষিত বেসিক ফর্ম্যাটে রয়েছে এবং টাইমআউট error গুলিকে হ্যান্ডেল করতে হবে (Listing 17-38 দেখুন)।
extern crate trpl; // required for mdbook test
use std::{pin::pin, time::Duration};
use trpl::{ReceiverStream, Stream, StreamExt};
fn main() {
trpl::run(async {
let messages = get_messages().timeout(Duration::from_millis(200));
let intervals = get_intervals()
.map(|count| format!("Interval: {count}"))
.timeout(Duration::from_secs(10));
let merged = messages.merge(intervals);
let mut stream = pin!(merged);
while let Some(result) = stream.next().await {
match result {
Ok(message) => println!("{message}"),
Err(reason) => eprintln!("Problem: {reason:?}"),
}
}
})
}
fn get_messages() -> impl Stream<Item = String> {
let (tx, rx) = trpl::channel();
trpl::spawn_task(async move {
let messages = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"];
for (index, message) in messages.into_iter().enumerate() {
let time_to_sleep = if index % 2 == 0 { 100 } else { 300 };
trpl::sleep(Duration::from_millis(time_to_sleep)).await;
tx.send(format!("Message: '{message}'")).unwrap();
}
});
ReceiverStream::new(rx)
}
fn get_intervals() -> impl Stream<Item = u32> {
let (tx, rx) = trpl::channel();
trpl::spawn_task(async move {
let mut count = 0;
loop {
trpl::sleep(Duration::from_millis(1)).await;
count += 1;
tx.send(count).unwrap();
}
});
ReceiverStream::new(rx)
}প্রথমে, আমরা intervals-কে একটি স্ট্রিং-এ রূপান্তর করতে map হেল্পার মেথড ব্যবহার করতে পারি। দ্বিতীয়ত, আমাদের messages থেকে Timeout-এর সাথে মেলাতে হবে। যেহেতু আমরা আসলে intervals-এর জন্য একটি টাইমআউট চাই না, যদিও, আমরা কেবল একটি টাইমআউট তৈরি করতে পারি যা আমরা যে অন্যান্য সময়কাল ব্যবহার করছি তার চেয়ে দীর্ঘ। এখানে, আমরা Duration::from_secs(10) দিয়ে একটি 10-সেকেন্ডের টাইমআউট তৈরি করি। অবশেষে, আমাদের stream কে মিউটেবল করতে হবে, যাতে while let লুপের next কলগুলি স্ট্রিমের মধ্য দিয়ে পুনরাবৃত্তি করতে পারে এবং এটিকে পিন করতে হবে যাতে এটি করা নিরাপদ হয়। এটি আমাদের প্রায় যেখানে আমাদের থাকা দরকার সেখানে পৌঁছে দেয়। সবকিছু টাইপ চেক করে। আপনি যদি এটি চালান, যদিও, দুটি সমস্যা হবে। প্রথমত, এটি কখনই বন্ধ হবে না! আপনাকে ctrl-c দিয়ে এটি বন্ধ করতে হবে। দ্বিতীয়ত, ইংরেজি বর্ণমালার মেসেজগুলি সমস্ত ইন্টারভাল কাউন্টার মেসেজের মধ্যে চাপা পড়ে যাবে:
--snip--
Interval: 38
Interval: 39
Interval: 40
Message: 'a'
Interval: 41
Interval: 42
Interval: 43
--snip--
Listing 17-39 এই শেষ দুটি সমস্যা সমাধানের একটি উপায় দেখায়।
extern crate trpl; // required for mdbook test use std::{pin::pin, time::Duration}; use trpl::{ReceiverStream, Stream, StreamExt}; fn main() { trpl::run(async { let messages = get_messages().timeout(Duration::from_millis(200)); let intervals = get_intervals() .map(|count| format!("Interval: {count}")) .throttle(Duration::from_millis(100)) .timeout(Duration::from_secs(10)); let merged = messages.merge(intervals).take(20); let mut stream = pin!(merged); while let Some(result) = stream.next().await { match result { Ok(message) => println!("{message}"), Err(reason) => eprintln!("Problem: {reason:?}"), } } }) } fn get_messages() -> impl Stream<Item = String> { let (tx, rx) = trpl::channel(); trpl::spawn_task(async move { let messages = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"]; for (index, message) in messages.into_iter().enumerate() { let time_to_sleep = if index % 2 == 0 { 100 } else { 300 }; trpl::sleep(Duration::from_millis(time_to_sleep)).await; tx.send(format!("Message: '{message}'")).unwrap(); } }); ReceiverStream::new(rx) } fn get_intervals() -> impl Stream<Item = u32> { let (tx, rx) = trpl::channel(); trpl::spawn_task(async move { let mut count = 0; loop { trpl::sleep(Duration::from_millis(1)).await; count += 1; tx.send(count).unwrap(); } }); ReceiverStream::new(rx) }
প্রথমে, আমরা intervals স্ট্রিমে throttle মেথড ব্যবহার করি যাতে এটি messages স্ট্রিমকে অভিভূত না করে। থ্রটলিং হল একটি ফাংশন কল করার হার সীমিত করার একটি উপায়—অথবা, এক্ষেত্রে, স্ট্রিমটি কত ঘন ঘন পোল করা হবে। প্রতি 100 মিলিসেকেন্ডে একবার যথেষ্ট হওয়া উচিত, কারণ আমাদের মেসেজগুলি প্রায় সেই সময়ে আসে।
আমরা একটি স্ট্রিম থেকে যে আইটেমগুলি গ্রহণ করব তার সংখ্যা সীমিত করতে, আমরা merged স্ট্রিমে take মেথড প্রয়োগ করি, কারণ আমরা চূড়ান্ত আউটপুট সীমিত করতে চাই, শুধুমাত্র একটি স্ট্রিম বা অন্যটি নয়।
এখন যখন আমরা প্রোগ্রামটি চালাই, তখন এটি স্ট্রিম থেকে 20টি আইটেম টানার পরে বন্ধ হয়ে যায় এবং ইন্টারভালগুলি মেসেজগুলিকে অভিভূত করে না। আমরা Interval: 100 বা Interval: 200 বা এই জাতীয় কিছু পাই না, তবে পরিবর্তে Interval: 1, Interval: 2 ইত্যাদি পাই—এমনকি আমাদের একটি সোর্স স্ট্রিম থাকা সত্ত্বেও যা প্রতি মিলি সেকেন্ডে একটি ইভেন্ট তৈরি করতে পারে। এর কারণ হল throttle কলটি একটি নতুন স্ট্রিম তৈরি করে যা মূল স্ট্রিমটিকে র্যাপ করে যাতে মূল স্ট্রিমটি শুধুমাত্র থ্রোটল হারে পোল করা হয়, তার নিজস্ব "নেটিভ" হারে নয়। আমাদের কাছে একগুচ্ছ আনহ্যান্ডেলড ইন্টারভাল মেসেজ নেই যা আমরা উপেক্ষা করতে বেছে নিচ্ছি। পরিবর্তে, আমরা সেই ইন্টারভাল মেসেজগুলি প্রথমেই তৈরি করি না! এটি হল Rust-এর ফিউচারের অন্তর্নিহিত "অলসতা", যা আমাদের পারফরম্যান্সের বৈশিষ্ট্যগুলি বেছে নিতে দেয়।
Interval: 1
Message: 'a'
Interval: 2
Interval: 3
Problem: Elapsed(())
Interval: 4
Message: 'b'
Interval: 5
Message: 'c'
Interval: 6
Interval: 7
Problem: Elapsed(())
Interval: 8
Message: 'd'
Interval: 9
Message: 'e'
Interval: 10
Interval: 11
Problem: Elapsed(())
Interval: 12
আমাদের শেষ একটি জিনিস হ্যান্ডেল করতে হবে: error! এই উভয় চ্যানেল-ভিত্তিক স্ট্রিমের সাথে, চ্যানেলের অন্য দিকটি বন্ধ হয়ে গেলে send কলগুলি ব্যর্থ হতে পারে—এবং এটি কেবল রানটাইম কীভাবে স্ট্রিম তৈরি করা ফিউচারগুলিকে এক্সিকিউট করে তার বিষয়। ఇప్పటి অবধি, আমরা unwrap কল করে এই সম্ভাবনাটিকে উপেক্ষা করেছি, কিন্তু একটি ভাল আচরণ করা অ্যাপে, আমাদের স্পষ্টভাবে error টি হ্যান্ডেল করা উচিত, অন্তত লুপটি শেষ করে যাতে আমরা আর কোনও মেসেজ পাঠানোর চেষ্টা না করি। Listing 17-40 একটি সহজ error কৌশল দেখায়: সমস্যাটি প্রিন্ট করুন এবং তারপর লুপগুলি থেকে break করুন।
extern crate trpl; // required for mdbook test use std::{pin::pin, time::Duration}; use trpl::{ReceiverStream, Stream, StreamExt}; fn main() { trpl::run(async { let messages = get_messages().timeout(Duration::from_millis(200)); let intervals = get_intervals() .map(|count| format!("Interval #{count}")) .throttle(Duration::from_millis(500)) .timeout(Duration::from_secs(10)); let merged = messages.merge(intervals).take(20); let mut stream = pin!(merged); while let Some(result) = stream.next().await { match result { Ok(item) => println!("{item}"), Err(reason) => eprintln!("Problem: {reason:?}"), } } }); } fn get_messages() -> impl Stream<Item = String> { let (tx, rx) = trpl::channel(); trpl::spawn_task(async move { let messages = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"]; for (index, message) in messages.into_iter().enumerate() { let time_to_sleep = if index % 2 == 0 { 100 } else { 300 }; trpl::sleep(Duration::from_millis(time_to_sleep)).await; if let Err(send_error) = tx.send(format!("Message: '{message}'")) { eprintln!("Cannot send message '{message}': {send_error}"); break; } } }); ReceiverStream::new(rx) } fn get_intervals() -> impl Stream<Item = u32> { let (tx, rx) = trpl::channel(); trpl::spawn_task(async move { let mut count = 0; loop { trpl::sleep(Duration::from_millis(1)).await; count += 1; if let Err(send_error) = tx.send(count) { eprintln!("Could not send interval {count}: {send_error}"); break; }; } }); ReceiverStream::new(rx) }
যথারীতি, একটি মেসেজ পাঠানোর error হ্যান্ডেল করার সঠিক উপায়টি ভিন্ন হবে; শুধু নিশ্চিত করুন যে আপনার একটি কৌশল আছে।
এখন যেহেতু আমরা অনেকগুলি অ্যাসিঙ্ক্রোনাস বাস্তবে দেখেছি, আসুন এক ধাপ পিছিয়ে যাই এবং Future, Stream এবং Rust অ্যাসিঙ্ক্রোনাস কাজ করার জন্য যে অন্যান্য মূল trait গুলি ব্যবহার করে তার কয়েকটি বিশদ বিবরণে ডুব দিই।
অ্যাসিঙ্ক্রোনাসের জন্য ব্যবহৃত Trait গুলির আরও গভীর পর্যালোচনা (A Closer Look at the Traits for Async)
এই চ্যাপ্টার জুড়ে, আমরা Future, Pin, Unpin, Stream, এবং StreamExt trait গুলিকে বিভিন্ন উপায়ে ব্যবহার করেছি। এখনও পর্যন্ত, যদিও, আমরা কীভাবে সেগুলি কাজ করে বা কীভাবে সেগুলি একসাথে ফিট করে তার বিশদ বিবরণে খুব বেশি যাওয়া এড়িয়ে গেছি, যা আপনার প্রতিদিনের Rust-এর কাজের জন্য বেশিরভাগ সময় ঠিক আছে। কখনও কখনও, যদিও, আপনি এমন পরিস্থিতির সম্মুখীন হবেন যেখানে আপনাকে এই বিশদগুলির আরও কয়েকটি বুঝতে হবে। এই বিভাগে, আমরা সেই পরিস্থিতিতে সাহায্য করার জন্য যথেষ্ট গভীরে যাব, এখনও অন্যান্য ডকুমেন্টেশনের জন্য সত্যিই গভীর ডাইভ ছেড়ে দেব।
Future Trait
আসুন Future trait কীভাবে কাজ করে তা ঘনিষ্ঠভাবে দেখে শুরু করি। Rust এটিকে কীভাবে সংজ্ঞায়িত করে তা এখানে:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
সেই trait সংজ্ঞায় অনেকগুলি নতুন টাইপ এবং কিছু সিনট্যাক্স রয়েছে যা আমরা আগে দেখিনি, তাই আসুন সংজ্ঞাটি একে একে দেখি।
প্রথমত, Future-এর অ্যাসোসিয়েটেড টাইপ Output বলে যে ফিউচারটি কী-তে রেজলভ করে। এটি Iterator trait-এর জন্য Item অ্যাসোসিয়েটেড টাইপের অনুরূপ। দ্বিতীয়ত, Future-এর poll মেথডও রয়েছে, যা তার self প্যারামিটারের জন্য একটি বিশেষ Pin রেফারেন্স এবং একটি Context টাইপের মিউটেবল রেফারেন্স নেয় এবং একটি Poll<Self::Output> রিটার্ন করে। আমরা একটু পরেই Pin এবং Context সম্পর্কে আরও কথা বলব। আপাতত, আসুন মেথডটি কী রিটার্ন করে, Poll টাইপ, সেদিকে মনোযোগ দিই:
#![allow(unused)] fn main() { enum Poll<T> { Ready(T), Pending, } }
এই Poll টাইপটি একটি Option-এর মতো। এটির একটি ভেরিয়েন্ট রয়েছে যার একটি মান রয়েছে, Ready(T), এবং একটি যার নেই, Pending। Poll মানে Option-এর থেকে বেশ ভিন্ন কিছু! Pending ভেরিয়েন্ট নির্দেশ করে যে ফিউচারের এখনও কাজ করার আছে, তাই কলারকে পরে আবার পরীক্ষা করতে হবে। Ready ভেরিয়েন্ট নির্দেশ করে যে ফিউচারটি তার কাজ শেষ করেছে এবং T মানটি উপলব্ধ।
Note: বেশিরভাগ ফিউচারের সাথে, ফিউচারটি
Readyরিটার্ন করার পরে কলারের আবারpollকল করা উচিত নয়। অনেক ফিউচার প্রস্তুত হওয়ার পরে আবার পোল করা হলে প্যানিক করবে। যে ফিউচারগুলি আবার পোল করা নিরাপদ সেগুলি তাদের ডকুমেন্টেশনে স্পষ্টভাবে তা বলবে। এটিIterator::nextকীভাবে আচরণ করে তার অনুরূপ।
যখন আপনি এমন কোড দেখেন যা await ব্যবহার করে, তখন Rust এটিকে হুডের নিচে poll কল করা কোডে কম্পাইল করে। আপনি যদি Listing 17-4-এ ফিরে তাকান, যেখানে আমরা একটি একক URL-এর জন্য পেজের টাইটেল প্রিন্ট করেছি একবার এটি রেজলভ হয়ে গেলে, Rust এটিকে এইরকম কিছুতে (যদিও ঠিক নয়) কম্পাইল করে:
match page_title(url).poll() {
Ready(page_title) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// But what goes here?
}
}ফিউচারটি এখনও Pending হলে আমাদের কী করা উচিত? আমাদের আবার, এবং আবার, এবং আবার চেষ্টা করার কিছু উপায় দরকার, যতক্ষণ না ফিউচারটি অবশেষে প্রস্তুত হয়। অন্য কথায়, আমাদের একটি লুপ দরকার:
let mut page_title_fut = page_title(url);
loop {
match page_title_fut.poll() {
Ready(value) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// continue
}
}
}যদি Rust এটিকে ঠিক সেই কোডে কম্পাইল করত, যদিও, প্রতিটি await ব্লকিং হত—ঠিক আমরা যা করতে যাচ্ছিলাম তার বিপরীত! পরিবর্তে, Rust নিশ্চিত করে যে লুপটি এমন কিছুতে কন্ট্রোল হস্তান্তর করতে পারে যা এই ফিউচারে কাজ করা বন্ধ করে অন্য ফিউচারগুলিতে কাজ করতে পারে এবং তারপর এটি আবার পরে পরীক্ষা করতে পারে। যেমনটি আমরা দেখেছি, সেই কিছু হল একটি অ্যাসিঙ্ক্রোনাস রানটাইম এবং এই শিডিউলিং এবং সমন্বয় কাজ হল এর প্রধান কাজগুলির মধ্যে একটি।
এই চ্যাপ্টারের শুরুতে, আমরা rx.recv-এর জন্য অপেক্ষা করার বর্ণনা দিয়েছি। recv কলটি একটি ফিউচার রিটার্ন করে এবং ফিউচারের জন্য অপেক্ষা করা এটিকে পোল করে। আমরা উল্লেখ করেছি যে একটি রানটাইম ফিউচারটিকে ততক্ষণ পর্যন্ত থামিয়ে রাখবে যতক্ষণ না এটি হয় Some(message) অথবা চ্যানেলটি বন্ধ হয়ে গেলে None দিয়ে প্রস্তুত হয়। Future trait এবং বিশেষ করে Future::poll সম্পর্কে আমাদের গভীর উপলব্ধির সাথে, আমরা দেখতে পাচ্ছি কীভাবে এটি কাজ করে। রানটাইম জানে যে ফিউচারটি প্রস্তুত নয় যখন এটি Poll::Pending রিটার্ন করে। বিপরীতভাবে, রানটাইম জানে যে ফিউচারটি প্রস্তুত এবং poll যখন Poll::Ready(Some(message)) বা Poll::Ready(None) রিটার্ন করে তখন এটিকে অগ্রসর করে।
একটি রানটাইম কীভাবে এটি করে তার সঠিক বিবরণ এই বইয়ের সুযোগের বাইরে, তবে মূল বিষয় হল ফিউচারের বেসিক মেকানিক্স দেখা: একটি রানটাইম প্রতিটি ফিউচারকে পোল করে যার জন্য এটি দায়ী, ফিউচারটি এখনও প্রস্তুত না হলে এটিকে আবার ঘুমাতে ফিরিয়ে দেয়।
Pin এবং Unpin Trait
আমরা যখন Listing 17-16-এ পিনিং-এর ধারণাটি চালু করি, তখন আমরা একটি খুব জটিল error মেসেজের সম্মুখীন হয়েছিলাম। এখানে এটির প্রাসঙ্গিক অংশটি আবার রয়েছে:
error[E0277]: `{async block@src/main.rs:10:23: 10:33}` cannot be unpinned
--> src/main.rs:48:33
|
48 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `{async block@src/main.rs:10:23: 10:33}`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<{async block@src/main.rs:10:23: 10:33}>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
এই error মেসেজটি আমাদের কেবল বলে না যে আমাদের মানগুলিকে পিন করতে হবে, তবে পিনিং কেন প্রয়োজন তাও বলে। trpl::join_all ফাংশনটি JoinAll নামক একটি স্ট্রাক্ট রিটার্ন করে। সেই স্ট্রাক্টটি একটি টাইপ F-এর উপর জেনেরিক, যা Future trait ইমপ্লিমেন্ট করার জন্য সীমাবদ্ধ। একটি ফিউচারকে সরাসরি await দিয়ে অপেক্ষা করা ফিউচারটিকে অন্তর্নিহিতভাবে পিন করে। তাই আমরা যেখানেই ফিউচারের জন্য অপেক্ষা করতে চাই সেখানেই আমাদের pin! ব্যবহার করার প্রয়োজন নেই।
যাইহোক, আমরা এখানে সরাসরি একটি ফিউচারের জন্য অপেক্ষা করছি না। পরিবর্তে, আমরা join_all ফাংশনে ফিউচারের একটি কালেকশন পাস করে একটি নতুন ফিউচার, JoinAll তৈরি করি। join_all-এর স্বাক্ষরের জন্য কালেকশনের আইটেমগুলির টাইপগুলির প্রত্যেককেই Future trait ইমপ্লিমেন্ট করতে হবে এবং Box<T> শুধুমাত্র তখনই Future ইমপ্লিমেন্ট করে যদি T যেটি এটিকে র্যাপ করে সেটি একটি ফিউচার হয় যা Unpin trait ইমপ্লিমেন্ট করে।
এটি হজম করার জন্য অনেক কিছু! এটিকে সত্যিই বোঝার জন্য, আসুন Future trait কীভাবে কাজ করে, বিশেষ করে পিনিং-এর চারপাশে আরও একটু গভীরে ডুব দিই।
Future trait-এর সংজ্ঞাটি আবার দেখুন:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; // Required method fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
cx প্যারামিটার এবং এর Context টাইপ হল কীভাবে একটি রানটাইম আসলে জানে কখন কোনও প্রদত্ত ফিউচার পরীক্ষা করতে হবে এবং এখনও অলস থাকতে হবে তার মূল বিষয়। আবারও, এটি কীভাবে কাজ করে তার বিশদ বিবরণ এই চ্যাপ্টারের সুযোগের বাইরে এবং আপনি সাধারণত শুধুমাত্র তখনই এটি সম্পর্কে চিন্তা করতে হবে যখন আপনি একটি কাস্টম Future ইমপ্লিমেন্টেশন লিখছেন। পরিবর্তে আমরা self-এর জন্য টাইপের উপর ফোকাস করব, কারণ এটি প্রথমবার যখন আমরা একটি মেথড দেখেছি যেখানে self-এর একটি টাইপ অ্যানোটেশন রয়েছে। self-এর জন্য একটি টাইপ অ্যানোটেশন অন্যান্য ফাংশন প্যারামিটারের জন্য টাইপ অ্যানোটেশনের মতোই কাজ করে, তবে দুটি মূল পার্থক্য সহ:
-
এটি Rust-কে বলে যে মেথডটি কল করার জন্য
selfঅবশ্যই কোন টাইপের হতে হবে। -
এটি কেবল যেকোনো টাইপ হতে পারে না। এটি যে টাইপের উপর মেথডটি ইমপ্লিমেন্ট করা হয়েছে, সেই টাইপের একটি রেফারেন্স বা স্মার্ট পয়েন্টার, অথবা সেই টাইপের একটি রেফারেন্স র্যাপ করা একটি
Pin-এ সীমাবদ্ধ।
আমরা Chapter 18-এ এই সিনট্যাক্স সম্পর্কে আরও দেখব। আপাতত, এটি জানাই যথেষ্ট যে আমরা যদি একটি ফিউচারকে পোল করতে চাই এটি Pending নাকি Ready(Output) তা পরীক্ষা করার জন্য, তাহলে আমাদের টাইপের একটি Pin-এ র্যাপ করা মিউটেবল রেফারেন্স দরকার।
Pin হল পয়েন্টার-জাতীয় টাইপ যেমন &, &mut, Box, এবং Rc-এর জন্য একটি র্যাপার। (টেকনিক্যালি, Pin এমন টাইপের সাথে কাজ করে যা Deref বা DerefMut trait ইমপ্লিমেন্ট করে, কিন্তু এটি কার্যকরভাবে শুধুমাত্র পয়েন্টারগুলির সাথে কাজ করার সমতুল্য।) Pin নিজে কোনও পয়েন্টার নয় এবং Rc এবং Arc-এর রেফারেন্স কাউন্টিংয়ের সাথে যেমন আচরণ করে তেমন কোনও নিজস্ব আচরণ নেই; এটি সম্পূর্ণরূপে একটি টুল যা কম্পাইলার পয়েন্টার ব্যবহারের উপর সীমাবদ্ধতা প্রয়োগ করতে ব্যবহার করতে পারে।
await কে poll-এ কলের পরিপ্রেক্ষিতে ইমপ্লিমেন্ট করা হয় তা স্মরণ করা আমাদের আগে দেখা error মেসেজটি ব্যাখ্যা করতে শুরু করে, কিন্তু সেটি Unpin-এর পরিপ্রেক্ষিতে ছিল, Pin-এর নয়। তাহলে Pin কীভাবে Unpin-এর সাথে সম্পর্কিত এবং Future-এর poll কল করার জন্য self-কে একটি Pin টাইপে থাকা কেন প্রয়োজন?
এই চ্যাপ্টারের শুরুতে মনে করুন একটি ফিউচারের অ্যাওয়েট পয়েন্টগুলির একটি সিরিজ একটি স্টেট মেশিনে কম্পাইল করা হয় এবং কম্পাইলার নিশ্চিত করে যে স্টেট মেশিনটি borrowing এবং ownership সহ Rust-এর নিরাপত্তার চারপাশে সমস্ত স্বাভাবিক নিয়ম অনুসরণ করে। এটি কাজ করার জন্য, Rust দেখে যে একটি অ্যাওয়েট পয়েন্ট এবং হয় পরবর্তী অ্যাওয়েট পয়েন্ট বা অ্যাসিঙ্ক্রোনাস ব্লকের শেষের মধ্যে কোন ডেটার প্রয়োজন। তারপর এটি কম্পাইল করা স্টেট মেশিনে একটি সংশ্লিষ্ট ভেরিয়েন্ট তৈরি করে। প্রতিটি ভেরিয়েন্ট সোর্স কোডের সেই বিভাগে ব্যবহৃত ডেটাতে তার প্রয়োজনীয় অ্যাক্সেস পায়, হয় সেই ডেটার ownership নিয়ে বা সেটিতে একটি মিউটেবল বা ইমিউটেবল রেফারেন্স পেয়ে।
এখন পর্যন্ত, সবকিছু ঠিক আছে: আমরা যদি একটি প্রদত্ত অ্যাসিঙ্ক্রোনাস ব্লকে ownership বা রেফারেন্স সম্পর্কে কিছু ভুল করি, তাহলে borrow চেকার আমাদের বলবে। যখন আমরা সেই ব্লকের সাথে সম্পর্কিত ফিউচারটিকে সরাতে চাই—যেমন এটিকে join_all-এর সাথে ব্যবহার করার জন্য একটি Vec-এ সরানো—জিনিসগুলি আরও কঠিন হয়ে যায়।
যখন আমরা একটি ফিউচারকে সরিয়ে দিই—সেটিকে join_all-এর সাথে ব্যবহার করার জন্য একটি ডেটা স্ট্রাকচারে পুশ করে বা একটি ফাংশন থেকে রিটার্ন করে—তার মানে আসলে আমাদের জন্য Rust যে স্টেট মেশিন তৈরি করে তা সরানো। এবং Rust-এ অন্য বেশিরভাগ টাইপের বিপরীতে, অ্যাসিঙ্ক্রোনাস ব্লকের জন্য Rust যে ফিউচারগুলি তৈরি করে সেগুলি কোনও প্রদত্ত ভেরিয়েন্টের ফিল্ডে নিজেদের রেফারেন্স সহ শেষ হতে পারে, যেমনটি চিত্র 17-4-এ সরলীকৃত চিত্রে দেখানো হয়েছে।

ডিফল্টভাবে, যদিও, যে কোনও অবজেক্ট যার নিজের প্রতি রেফারেন্স রয়েছে সেটি সরানো অনিরাপদ, কারণ রেফারেন্সগুলি সর্বদা তারা যেটিকে রেফার করে তার প্রকৃত মেমরি অ্যাড্রেসের দিকে নির্দেশ করে (চিত্র 17-5 দেখুন)। আপনি যদি ডেটা স্ট্রাকচারটি নিজেই সরিয়ে দেন, তাহলে সেই অভ্যন্তরীণ রেফারেন্সগুলি পুরানো লোকেশনের দিকে নির্দেশ করে থাকবে। যাইহোক, সেই মেমরি লোকেশনটি এখন অবৈধ। একটির জন্য, আপনি যখন ডেটা স্ট্রাকচারে পরিবর্তন করবেন তখন এর মান আপডেট করা হবে না। অন্য—আরও গুরুত্বপূর্ণ—জিনিসের জন্য, কম্পিউটার এখন অন্য উদ্দেশ্যে সেই মেমরিটি পুনরায় ব্যবহার করতে মুক্ত! আপনি পরে সম্পূর্ণ সম্পর্কহীন ডেটা পড়তে পারেন।

তাত্ত্বিকভাবে, Rust কম্পাইলার যখনই কোনও অবজেক্ট সরানো হয় তখনই সেটিতে প্রতিটি রেফারেন্স আপডেট করার চেষ্টা করতে পারে, তবে এটি প্রচুর পারফরম্যান্স ওভারহেড যুক্ত করতে পারে, বিশেষ করে যদি রেফারেন্সের একটি সম্পূর্ণ ওয়েব আপডেট করার প্রয়োজন হয়। পরিবর্তে আমরা যদি নিশ্চিত করতে পারি যে প্রশ্নে থাকা ডেটা স্ট্রাকচারটি মেমরিতে সরানো হচ্ছে না, তাহলে আমাদের কোনও রেফারেন্স আপডেট করতে হবে না। এটিই Rust-এর borrow চেকারের প্রয়োজন: নিরাপদ কোডে, এটি আপনাকে কোনও আইটেমকে সক্রিয় রেফারেন্স সহ সরানোর অনুমতি দেয় না।
Pin আমাদের প্রয়োজনীয় গ্যারান্টি দেওয়ার জন্য এটির উপর ভিত্তি করে তৈরি। যখন আমরা একটি মানকে পিন করি সেই মানের একটি পয়েন্টারকে Pin-এ র্যাপ করে, তখন এটি আর সরতে পারে না। সুতরাং, যদি আপনার কাছে Pin<Box<SomeType>> থাকে, তাহলে আপনি আসলে SomeType মানটিকে পিন করেন, Box পয়েন্টারকে নয়। চিত্র 17-6 এই প্রক্রিয়াটি চিত্রিত করে।

প্রকৃতপক্ষে, Box পয়েন্টারটি এখনও অবাধে ঘোরাফেরা করতে পারে। মনে রাখবেন: আমরা নিশ্চিত করতে চাই যে চূড়ান্তভাবে রেফারেন্স করা ডেটা যথাস্থানে রয়েছে। যদি একটি পয়েন্টার ঘোরাফেরা করে, কিন্তু এটি যে ডেটার দিকে নির্দেশ করে সেটি একই জায়গায় থাকে, যেমনটি চিত্র 17-7-এ রয়েছে, তাহলে কোনও সম্ভাব্য সমস্যা নেই। একটি স্বাধীন অনুশীলন হিসাবে, টাইপগুলির জন্য ডক্স এবং সেইসাথে std::pin মডিউলটি দেখুন এবং Pin র্যাপ করা একটি Box-এর সাথে আপনি এটি কীভাবে করবেন তা বের করার চেষ্টা করুন।) মূল বিষয় হল সেলফ-রেফারেন্সিয়াল টাইপটি নিজেই সরতে পারে না, কারণ এটি এখনও পিন করা আছে।

যাইহোক, বেশিরভাগ টাইপ ঘোরাফেরা করা সম্পূর্ণ নিরাপদ, এমনকি যদি সেগুলি একটি Pin র্যাপারের পিছনে থাকে। আইটেমগুলির অভ্যন্তরীণ রেফারেন্স থাকলে আমাদের কেবল পিনিং সম্পর্কে চিন্তা করতে হবে। সংখ্যা এবং বুলিয়ানের মতো প্রিমিটিভ মানগুলিতে স্পষ্টতই কোনও অভ্যন্তরীণ রেফারেন্স নেই, তাই সেগুলি নিরাপদ। Rust-এ আপনি সাধারণত যেগুলির সাথে কাজ করেন তার বেশিরভাগ টাইপও নিরাপদ। উদাহরণস্বরূপ, আপনি কোনও চিন্তা ছাড়াই একটি Vec ঘোরাফেরা করতে পারেন। শুধুমাত্র আমরা যা দেখেছি তা দেওয়া হলে, যদি আপনার কাছে একটি Pin<Vec<String>> থাকে, তাহলে আপনাকে Pin দ্বারা প্রদত্ত নিরাপদ কিন্তু সীমাবদ্ধ API-গুলির মাধ্যমে সবকিছু করতে হবে, যদিও একটি Vec<String> সর্বদা সরানো নিরাপদ যদি সেটিতে অন্য কোনও রেফারেন্স না থাকে। আমাদের কম্পাইলারকে বলার একটি উপায় দরকার যে এই ধরনের ক্ষেত্রে আইটেমগুলিকে ঘোরাফেরা করা ঠিক আছে—এবং সেখানেই Unpin কার্যকর হয়।
Unpin হল একটি মার্কার trait, Chapter 16-এ আমরা যে Send এবং Sync trait গুলি দেখেছি তার মতোই এবং এইভাবে এর নিজস্ব কোনও কার্যকারিতা নেই। মার্কার trait গুলি শুধুমাত্র কম্পাইলারকে বলার জন্য বিদ্যমান যে একটি প্রদত্ত trait ইমপ্লিমেন্ট করা টাইপটি একটি নির্দিষ্ট প্রসঙ্গে ব্যবহার করা নিরাপদ। Unpin কম্পাইলারকে জানায় যে একটি প্রদত্ত টাইপ প্রশ্নে থাকা মানটি নিরাপদে সরানো যেতে পারে কিনা সে সম্পর্কে কোনও গ্যারান্টি বহাল রাখার প্রয়োজন নেই।
Send এবং Sync-এর মতোই, কম্পাইলার স্বয়ংক্রিয়ভাবে সমস্ত টাইপের জন্য Unpin ইমপ্লিমেন্ট করে যেখানে এটি প্রমাণ করতে পারে যে এটি নিরাপদ। আবারও Send এবং Sync-এর মতো একটি বিশেষ ক্ষেত্র হল যেখানে একটি টাইপের জন্য Unpin ইমপ্লিমেন্ট করা হয় না। এর জন্য নোটেশন হল impl !Unpin for SomeType, যেখানে SomeType হল এমন একটি টাইপের নাম যা প্রয়োজন সেই গ্যারান্টিগুলি বহাল রাখা নিরাপদ হতে যখন সেই টাইপের একটি পয়েন্টার একটি Pin-এ ব্যবহার করা হয়।
অন্য কথায়, Pin এবং Unpin-এর মধ্যে সম্পর্ক সম্পর্কে মনে রাখার মতো দুটি জিনিস রয়েছে। প্রথমত, Unpin হল “স্বাভাবিক” ক্ষেত্র এবং !Unpin হল বিশেষ ক্ষেত্র। দ্বিতীয়ত, একটি টাইপ Unpin ইমপ্লিমেন্ট করে নাকি !Unpin শুধুমাত্র তখনই গুরুত্বপূর্ণ যখন আপনি সেই টাইপের একটি পিন করা পয়েন্টার ব্যবহার করছেন যেমন Pin<&mut SomeType>।
এটিকে কংক্রিট করতে, একটি String সম্পর্কে চিন্তা করুন: এটির একটি দৈর্ঘ্য এবং ইউনিকোড অক্ষর রয়েছে যা এটিকে তৈরি করে। আমরা একটি String কে Pin-এ র্যাপ করতে পারি, যেমনটি চিত্র 17-8-এ দেখা গেছে। যাইহোক, String স্বয়ংক্রিয়ভাবে Unpin ইমপ্লিমেন্ট করে, যেমনটি Rust-এর বেশিরভাগ অন্যান্য টাইপ করে।

ফলস্বরূপ, আমরা এমন কিছু করতে পারি যা অবৈধ হবে যদি String পরিবর্তে !Unpin ইমপ্লিমেন্ট করত, যেমন মেমরিতে ঠিক একই স্থানে একটি স্ট্রিংকে অন্য একটি দিয়ে প্রতিস্থাপন করা যেমনটি চিত্র 17-9-এ রয়েছে। এটি Pin চুক্তি লঙ্ঘন করে না, কারণ String-এর কোনও অভ্যন্তরীণ রেফারেন্স নেই যা এটিকে ঘোরাফেরা করা অনিরাপদ করে তোলে! ঠিক এই কারণেই এটি !Unpin-এর পরিবর্তে Unpin ইমপ্লিমেন্ট করে।

এখন আমরা Listing 17-17 থেকে সেই join_all কলের জন্য রিপোর্ট করা error গুলি বোঝার জন্য যথেষ্ট জানি। আমরা মূলত অ্যাসিঙ্ক্রোনাস ব্লক দ্বারা উৎপাদিত ফিউচারগুলিকে একটি Vec<Box<dyn Future<Output = ()>>>-এ সরানোর চেষ্টা করেছি, কিন্তু যেমনটি আমরা দেখেছি, সেই ফিউচারগুলিতে অভ্যন্তরীণ রেফারেন্স থাকতে পারে, তাই সেগুলি Unpin ইমপ্লিমেন্ট করে না। তাদের পিন করা দরকার এবং তারপর আমরা Pin টাইপটিকে Vec-এ পাস করতে পারি, এই আত্মবিশ্বাসের সাথে যে ফিউচারের অন্তর্নিহিত ডেটা সরানো হবে না।
Pin এবং Unpin বেশিরভাগ ক্ষেত্রে নিম্ন-স্তরের লাইব্রেরি তৈরি করার জন্য গুরুত্বপূর্ণ, অথবা যখন আপনি নিজেই একটি রানটাইম তৈরি করছেন, প্রতিদিনের Rust কোডের জন্য নয়। যখন আপনি error মেসেজে এই trait গুলি দেখেন, যদিও, এখন আপনার কোড কীভাবে ঠিক করবেন সে সম্পর্কে আপনার আরও ভাল ধারণা থাকবে!
Note:
PinএবংUnpin-এর এই সংমিশ্রণটি Rust-এ এক সম্পূর্ণ শ্রেণীর জটিল টাইপ নিরাপদে ইমপ্লিমেন্ট করা সম্ভব করে যা অন্যথায় চ্যালেঞ্জিং প্রমাণিত হবে কারণ সেগুলি সেলফ-রেফারেন্সিয়াল। যে টাইপগুলিরPinপ্রয়োজন সেগুলি আজ অ্যাসিঙ্ক্রোনাস Rust-এ সবচেয়ে বেশি দেখা যায়, কিন্তু মাঝে মাঝে, আপনি সেগুলিকে অন্যান্য প্রসঙ্গেও দেখতে পারেন।
PinএবংUnpinকীভাবে কাজ করে এবং তাদের যে নিয়মগুলি বহাল রাখতে হবে তার সুনির্দিষ্ট বিবরণstd::pin-এর জন্য API ডকুমেন্টেশনে ব্যাপকভাবে কভার করা হয়েছে, তাই আপনি যদি আরও জানতে আগ্রহী হন তবে এটি শুরু করার জন্য একটি দুর্দান্ত জায়গা।আপনি যদি আরও বিশদে হুডের নিচে কীভাবে জিনিসগুলি কাজ করে তা বুঝতে চান তবে Asynchronous Programming in Rust-এর চ্যাপ্টার 2 এবং 4 দেখুন।
Stream Trait
এখন আপনার Future, Pin, এবং Unpin trait গুলির উপর গভীর উপলব্ধি রয়েছে, আমরা Stream trait-এর দিকে আমাদের মনোযোগ দিতে পারি। আপনি যেমন চ্যাপ্টারের শুরুতে শিখেছেন, স্ট্রিমগুলি অ্যাসিঙ্ক্রোনাস ইটারেটরের মতো। Iterator এবং Future-এর বিপরীতে, যদিও, এই লেখার সময় স্ট্যান্ডার্ড লাইব্রেরিতে Stream-এর কোনও সংজ্ঞা নেই, তবে futures ক্রেট থেকে একটি খুব সাধারণ সংজ্ঞা রয়েছে যা ইকোসিস্টেম জুড়ে ব্যবহৃত হয়।
আসুন একটি Stream trait কীভাবে সেগুলিকে একত্রিত করতে পারে তা দেখার আগে Iterator এবং Future trait-এর সংজ্ঞাগুলি পর্যালোচনা করি। Iterator থেকে, আমাদের একটি সিকোয়েন্সের ধারণা রয়েছে: এর next মেথড একটি Option<Self::Item> সরবরাহ করে। Future থেকে, আমাদের সময়ের সাথে প্রস্তুতির ধারণা রয়েছে: এর poll মেথড একটি Poll<Self::Output> সরবরাহ করে। সময়ের সাথে প্রস্তুত হওয়া আইটেমগুলির একটি সিকোয়েন্স উপস্থাপন করতে, আমরা একটি Stream trait সংজ্ঞায়িত করি যা সেই বৈশিষ্ট্যগুলিকে একত্রিত করে:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Option<Self::Item>>; } }
Stream trait স্ট্রিম দ্বারা উৎপাদিত আইটেমগুলির টাইপের জন্য Item নামে একটি অ্যাসোসিয়েটেড টাইপ সংজ্ঞায়িত করে। এটি Iterator-এর অনুরূপ, যেখানে শূন্য থেকে অনেকগুলি আইটেম থাকতে পারে এবং Future-এর বিপরীতে, যেখানে সর্বদা একটি একক Output থাকে, এমনকি যদি এটি ইউনিট টাইপ () হয়।
Stream সেই আইটেমগুলি পাওয়ার জন্য একটি মেথডও সংজ্ঞায়িত করে। আমরা এটিকে poll_next বলি, এটি স্পষ্ট করতে যে এটি Future::poll-এর মতোই পোল করে এবং Iterator::next-এর মতোই আইটেমগুলির একটি সিকোয়েন্স তৈরি করে। এর রিটার্ন টাইপ Poll-কে Option-এর সাথে একত্রিত করে। বাইরের টাইপটি হল Poll, কারণ এটিকে প্রস্তুতির জন্য পরীক্ষা করতে হবে, ঠিক যেমন একটি ফিউচার করে। ভেতরের টাইপটি হল Option, কারণ এটিকে সংকেত দিতে হবে যে আরও মেসেজ আছে কিনা, ঠিক যেমন একটি ইটারেটর করে।
এরকম একটি সংজ্ঞা সম্ভবত Rust-এর স্ট্যান্ডার্ড লাইব্রেরির অংশ হিসাবে শেষ হবে। ইতিমধ্যে, এটি বেশিরভাগ রানটাইমের টুলকিটের অংশ, তাই আপনি এটির উপর নির্ভর করতে পারেন এবং আমরা পরবর্তীতে যা কভার করব তা সাধারণত প্রযোজ্য হওয়া উচিত!
আমরা স্ট্রিমিং-এর বিভাগে যে উদাহরণটি দেখেছি, যদিও, আমরা poll_next বা Stream ব্যবহার করিনি, তবে পরিবর্তে next এবং StreamExt ব্যবহার করেছি। আমরা অবশ্যই poll_next API-এর পরিপ্রেক্ষিতে সরাসরি আমাদের নিজস্ব Stream স্টেট মেশিন হাতে লিখে কাজ করতে পারতাম, ঠিক যেমনটি আমরা তাদের poll মেথডের মাধ্যমে ফিউচারের সাথে সরাসরি কাজ করতে পারতাম। await ব্যবহার করা অনেক সুন্দর, যদিও, এবং StreamExt trait next মেথড সরবরাহ করে যাতে আমরা ঠিক তাই করতে পারি:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_>, ) -> Poll<Option<Self::Item>>; } trait StreamExt: Stream { async fn next(&mut self) -> Option<Self::Item> where Self: Unpin; // other methods... } }
Note: আমরা চ্যাপ্টারে আগে যে প্রকৃত সংজ্ঞাটি ব্যবহার করেছি তা এর থেকে সামান্য আলাদা দেখায়, কারণ এটি Rust-এর সংস্করণগুলিকে সমর্থন করে যেগুলি এখনও trait-এ অ্যাসিঙ্ক্রোনাস ফাংশন ব্যবহার করা সমর্থন করে না। ফলস্বরূপ, এটি এইরকম দেখায়:
fn next(&mut self) -> Next<'_, Self> where Self: Unpin;সেই
Nextটাইপটি হল একটিstructযাFutureইমপ্লিমেন্ট করে এবং আমাদেরself-এ রেফারেন্সের লাইফটাইমকেNext<'_, Self>দিয়ে নাম দিতে দেয়, যাতেawaitএই মেথডের সাথে কাজ করতে পারে।
StreamExt trait হল স্ট্রিমগুলির সাথে ব্যবহার করার জন্য উপলব্ধ সমস্ত আকর্ষণীয় মেথডের হোম। StreamExt স্বয়ংক্রিয়ভাবে প্রতিটি টাইপের জন্য ইমপ্লিমেন্ট করা হয় যা Stream ইমপ্লিমেন্ট করে, কিন্তু এই trait গুলিকে আলাদাভাবে সংজ্ঞায়িত করা হয়েছে যাতে কমিউনিটি বেস trait-কে প্রভাবিত না করে সুবিধার API-গুলিতে পুনরাবৃত্তি করতে পারে।
trpl ক্রেটে ব্যবহৃত StreamExt-এর সংস্করণে, trait টি কেবল next মেথড সংজ্ঞায়িত করে না, তবে next-এর একটি ডিফল্ট ইমপ্লিমেন্টেশনও সরবরাহ করে যা Stream::poll_next কল করার বিশদগুলি সঠিকভাবে পরিচালনা করে। এর মানে হল যে এমনকি যখন আপনাকে আপনার নিজের স্ট্রিমিং ডেটা টাইপ লিখতে হবে, তখনও আপনাকে শুধুমাত্র Stream ইমপ্লিমেন্ট করতে হবে এবং তারপর যে কেউ আপনার ডেটা টাইপ ব্যবহার করে সে স্বয়ংক্রিয়ভাবে StreamExt এবং এর মেথডগুলি ব্যবহার করতে পারবে।
এগুলিই আমরা এই trait গুলির নিম্ন-স্তরের বিশদ বিবরণের জন্য কভার করতে যাচ্ছি। শেষ করতে, আসুন বিবেচনা করি কিভাবে ফিউচার (স্ট্রিম সহ), টাস্ক এবং থ্রেডগুলি একসাথে ফিট করে!
সবকিছু একসাথে: ফিউচার, টাস্ক এবং থ্রেড (Putting It All Together: Futures, Tasks, and Threads)
আমরা যেমনটি Chapter 16-এ দেখেছি, থ্রেডগুলি কনকারেন্সির একটি পদ্ধতি সরবরাহ করে। আমরা এই চ্যাপ্টারে আরেকটি পদ্ধতি দেখেছি: ফিউচার এবং স্ট্রিম সহ অ্যাসিঙ্ক্রোনাস ব্যবহার করা। আপনি যদি ভাবছেন কখন অন্যটির চেয়ে কোন পদ্ধতি বেছে নেবেন, তাহলে উত্তর হল: এটি নির্ভর করে! এবং অনেক ক্ষেত্রে, পছন্দটি থ্রেড বা অ্যাসিঙ্ক্রোনাস নয়, বরং থ্রেড এবং অ্যাসিঙ্ক্রোনাস।
অনেক অপারেটিং সিস্টেম এখন কয়েক দশক ধরে থ্রেডিং-ভিত্তিক কনকারেন্সি মডেল সরবরাহ করে আসছে এবং ফলস্বরূপ অনেক প্রোগ্রামিং ভাষা তাদের সমর্থন করে। যাইহোক, এই মডেলগুলি তাদের ট্রেডঅফ ছাড়া নয়। অনেক অপারেটিং সিস্টেমে, তারা প্রতিটি থ্রেডের জন্য বেশ কিছুটা মেমরি ব্যবহার করে এবং সেগুলি শুরু এবং বন্ধ করার জন্য কিছু ওভারহেড সহ আসে। থ্রেডগুলি তখনই একটি অপশন যখন আপনার অপারেটিং সিস্টেম এবং হার্ডওয়্যার তাদের সমর্থন করে। মূলধারার ডেস্কটপ এবং মোবাইল কম্পিউটারগুলির বিপরীতে, কিছু এমবেডেড সিস্টেমে কোনও OS নেই, তাই তাদের থ্রেডও নেই।
অ্যাসিঙ্ক্রোনাস মডেলটি ট্রেডঅফের একটি ভিন্ন—এবং চূড়ান্তভাবে পরিপূরক—সেট সরবরাহ করে। অ্যাসিঙ্ক্রোনাস মডেলে, কনকারেন্ট অপারেশনগুলির জন্য তাদের নিজস্ব থ্রেডের প্রয়োজন হয় না। পরিবর্তে, তারা টাস্কগুলিতে চলতে পারে, যেমনটি আমরা স্ট্রিম বিভাগে একটি সিঙ্ক্রোনাস ফাংশন থেকে কাজ শুরু করতে trpl::spawn_task ব্যবহার করার সময় দেখেছি। একটি টাস্ক একটি থ্রেডের মতোই, কিন্তু অপারেটিং সিস্টেম দ্বারা পরিচালিত হওয়ার পরিবর্তে, এটি লাইব্রেরি-লেভেল কোড দ্বারা পরিচালিত হয়: রানটাইম।
পূর্ববর্তী বিভাগে, আমরা দেখেছি যে আমরা একটি অ্যাসিঙ্ক্রোনাস চ্যানেল ব্যবহার করে এবং একটি অ্যাসিঙ্ক্রোনাস টাস্ক স্পন করে একটি স্ট্রিম তৈরি করতে পারি যেটিকে আমরা সিঙ্ক্রোনাস কোড থেকে কল করতে পারি। আমরা একটি থ্রেড দিয়ে ঠিক একই কাজ করতে পারি। Listing 17-40-এ, আমরা trpl::spawn_task এবং trpl::sleep ব্যবহার করেছি। Listing 17-41-এ, আমরা সেগুলিকে get_intervals ফাংশনে স্ট্যান্ডার্ড লাইব্রেরি থেকে thread::spawn এবং thread::sleep API দিয়ে প্রতিস্থাপন করি।
extern crate trpl; // required for mdbook test use std::{pin::pin, thread, time::Duration}; use trpl::{ReceiverStream, Stream, StreamExt}; fn main() { trpl::run(async { let messages = get_messages().timeout(Duration::from_millis(200)); let intervals = get_intervals() .map(|count| format!("Interval #{count}")) .throttle(Duration::from_millis(500)) .timeout(Duration::from_secs(10)); let merged = messages.merge(intervals).take(20); let mut stream = pin!(merged); while let Some(result) = stream.next().await { match result { Ok(item) => println!("{item}"), Err(reason) => eprintln!("Problem: {reason:?}"), } } }); } fn get_messages() -> impl Stream<Item = String> { let (tx, rx) = trpl::channel(); trpl::spawn_task(async move { let messages = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"]; for (index, message) in messages.into_iter().enumerate() { let time_to_sleep = if index % 2 == 0 { 100 } else { 300 }; trpl::sleep(Duration::from_millis(time_to_sleep)).await; if let Err(send_error) = tx.send(format!("Message: '{message}'")) { eprintln!("Cannot send message '{message}': {send_error}"); break; } } }); ReceiverStream::new(rx) } fn get_intervals() -> impl Stream<Item = u32> { let (tx, rx) = trpl::channel(); // This is *not* `trpl::spawn` but `std::thread::spawn`! thread::spawn(move || { let mut count = 0; loop { // Likewise, this is *not* `trpl::sleep` but `std::thread::sleep`! thread::sleep(Duration::from_millis(1)); count += 1; if let Err(send_error) = tx.send(count) { eprintln!("Could not send interval {count}: {send_error}"); break; }; } }); ReceiverStream::new(rx) }
আপনি যদি এই কোডটি চালান, তাহলে আউটপুটটি Listing 17-40-এর মতোই হবে। এবং লক্ষ্য করুন কলিং কোডের দৃষ্টিকোণ থেকে এখানে কতটা সামান্য পরিবর্তন হয়েছে। আরও কী, যদিও আমাদের ফাংশনগুলির মধ্যে একটি রানটাইমে একটি অ্যাসিঙ্ক্রোনাস টাস্ক স্পন করেছে এবং অন্যটি একটি OS থ্রেড স্পন করেছে, ফলাফলের স্ট্রিমগুলি পার্থক্য দ্বারা প্রভাবিত হয়নি।
তাদের মিল থাকা সত্ত্বেও, এই দুটি পদ্ধতির আচরণ খুব আলাদা, যদিও আমরা এই খুব সহজ উদাহরণে এটি পরিমাপ করতে কঠিন সময় পেতে পারি। আমরা যেকোনো আধুনিক ব্যক্তিগত কম্পিউটারে কয়েক মিলিয়ন অ্যাসিঙ্ক্রোনাস টাস্ক স্পন করতে পারি। আমরা যদি থ্রেড দিয়ে এটি করার চেষ্টা করতাম, তাহলে আমরা আক্ষরিক অর্থে মেমরির বাইরে চলে যেতাম!
যাইহোক, এই API গুলি এত মিল থাকার একটি কারণ রয়েছে। থ্রেডগুলি সিঙ্ক্রোনাস অপারেশনের সেটগুলির জন্য একটি সীমানা হিসাবে কাজ করে; থ্রেডগুলির মধ্যে কনকারেন্সি সম্ভব। টাস্কগুলি অ্যাসিঙ্ক্রোনাস অপারেশনের সেটগুলির জন্য একটি সীমানা হিসাবে কাজ করে; টাস্কগুলির মধ্যে এবং ভিতরে উভয় ক্ষেত্রেই কনকারেন্সি সম্ভব, কারণ একটি টাস্ক তার বডিতে ফিউচারগুলির মধ্যে স্যুইচ করতে পারে। অবশেষে, ফিউচারগুলি হল Rust-এর কনকারেন্সির সবচেয়ে দানাদার একক এবং প্রতিটি ফিউচার অন্য ফিউচারের একটি গাছকে উপস্থাপন করতে পারে। রানটাইম—বিশেষ করে, এর এক্সিকিউটর—টাস্কগুলি পরিচালনা করে এবং টাস্কগুলি ফিউচারগুলি পরিচালনা করে। সেই ক্ষেত্রে, টাস্কগুলি হল হালকা, রানটাইম-পরিচালিত থ্রেডের মতো, অপারেটিং সিস্টেমের পরিবর্তে একটি রানটাইম দ্বারা পরিচালিত হওয়ার কারণে অতিরিক্ত ক্ষমতা সহ।
এর মানে এই নয় যে অ্যাসিঙ্ক্রোনাস টাস্কগুলি সর্বদা থ্রেডের চেয়ে ভাল (বা এর বিপরীত)। থ্রেডের সাথে কনকারেন্সি কিছু উপায়ে async-এর সাথে কনকারেন্সির চেয়ে একটি সহজ প্রোগ্রামিং মডেল। এটি একটি শক্তি বা দুর্বলতা হতে পারে। থ্রেডগুলি কিছুটা “ফায়ার অ্যান্ড ফরগেট”; তাদের একটি ফিউচারের কোনও নেটিভ সমতুল্য নেই, তাই অপারেটিং সিস্টেম নিজেই বাধা না দেওয়া পর্যন্ত সেগুলি সম্পূর্ণ হওয়া পর্যন্ত চলে। অর্থাৎ, তাদের ইন্ট্রাটাস্ক কনকারেন্সির জন্য কোনও অন্তর্নির্মিত সমর্থন নেই যেভাবে ফিউচারগুলি করে। Rust-এ থ্রেডগুলির কোনও বাতিলকরণ প্রক্রিয়াও নেই—এমন একটি বিষয় যা আমরা এই চ্যাপ্টারে স্পষ্টভাবে কভার করিনি কিন্তু এই সত্য দ্বারা বোঝানো হয়েছিল যে আমরা যখনই একটি ফিউচার শেষ করেছি, তার স্টেট সঠিকভাবে পরিষ্কার হয়ে গেছে।
এই সীমাবদ্ধতাগুলি থ্রেডগুলিকে ফিউচারের চেয়ে কম্পোজ করা আরও কঠিন করে তোলে। উদাহরণস্বরূপ, থ্রেড ব্যবহার করে এই চ্যাপ্টারে আমরা আগে তৈরি করা timeout এবং throttle মেথডগুলির মতো হেল্পার তৈরি করা আরও কঠিন। ফিউচারগুলি আরও সমৃদ্ধ ডেটা স্ট্রাকচার হওয়ার অর্থ হল সেগুলিকে আরও স্বাভাবিকভাবে একসাথে কম্পোজ করা যেতে পারে, যেমনটি আমরা দেখেছি।
টাস্কগুলি, তাহলে, আমাদের ফিউচারগুলির উপর অতিরিক্ত নিয়ন্ত্রণ দেয়, যা আমাদের কোথায় এবং কীভাবে সেগুলিকে গ্রুপ করতে হবে তা বেছে নিতে দেয়। এবং এটি দেখা যাচ্ছে যে থ্রেড এবং টাস্কগুলি প্রায়শই একসাথে খুব ভাল কাজ করে, কারণ টাস্কগুলি (অন্তত কিছু রানটাইমে) থ্রেডগুলির মধ্যে ঘোরাফেরা করা যেতে পারে। প্রকৃতপক্ষে, হুডের নিচে, আমরা যে রানটাইমটি ব্যবহার করে আসছি—spawn_blocking এবং spawn_task ফাংশন সহ—ডিফল্টভাবে মাল্টিথ্রেডেড! অনেকগুলি রানটাইম সিস্টেমের সামগ্রিক পারফরম্যান্স উন্নত করতে, থ্রেডগুলি বর্তমানে কীভাবে ব্যবহার করা হচ্ছে তার উপর ভিত্তি করে থ্রেডগুলির মধ্যে স্বচ্ছভাবে টাস্কগুলিকে সরানোর জন্য ওয়ার্ক স্টিলিং নামক একটি পদ্ধতি ব্যবহার করে। সেই পদ্ধতির জন্য আসলে থ্রেড এবং টাস্ক এবং সেইজন্য ফিউচারের প্রয়োজন।
কখন কোন পদ্ধতি ব্যবহার করবেন তা নিয়ে চিন্তা করার সময়, এই নিয়মগুলি বিবেচনা করুন:
- যদি কাজটি খুব প্যারালাইজেবল হয়, যেমন প্রচুর ডেটা প্রসেস করা যেখানে প্রতিটি অংশ আলাদাভাবে প্রসেস করা যায়, তাহলে থ্রেডগুলি একটি ভাল পছন্দ।
- যদি কাজটি খুব কনকারেন্ট হয়, যেমন বিভিন্ন উৎস থেকে মেসেজ হ্যান্ডেল করা যা বিভিন্ন বিরতিতে বা বিভিন্ন হারে আসতে পারে, তাহলে অ্যাসিঙ্ক্রোনাস একটি ভাল পছন্দ।
এবং যদি আপনার প্যারালেলিজম এবং কনকারেন্সি উভয়েরই প্রয়োজন হয়, তাহলে আপনাকে থ্রেড এবং অ্যাসিঙ্ক্রোনাসের মধ্যে বেছে নিতে হবে না। আপনি সেগুলিকে অবাধে একসাথে ব্যবহার করতে পারেন, প্রত্যেকটিকে তার সেরা অংশটি করতে দিয়ে। উদাহরণস্বরূপ, Listing 17-42 বাস্তব-বিশ্বের Rust কোডে এই ধরনের মিশ্রণের একটি মোটামুটি সাধারণ উদাহরণ দেখায়।
extern crate trpl; // for mdbook test use std::{thread, time::Duration}; fn main() { let (tx, mut rx) = trpl::channel(); thread::spawn(move || { for i in 1..11 { tx.send(i).unwrap(); thread::sleep(Duration::from_secs(1)); } }); trpl::run(async { while let Some(message) = rx.recv().await { println!("{message}"); } }); }
আমরা একটি অ্যাসিঙ্ক্রোনাস চ্যানেল তৈরি করে শুরু করি, তারপর একটি থ্রেড স্পন করি যা চ্যানেলের সেন্ডার সাইডের ownership নেয়। থ্রেডের মধ্যে, আমরা 1 থেকে 10 পর্যন্ত সংখ্যাগুলি পাঠাই, প্রতিটিটির মধ্যে এক সেকেন্ডের জন্য স্লিপ করি। অবশেষে, আমরা একটি অ্যাসিঙ্ক্রোনাস ব্লক সহ তৈরি একটি ফিউচার চালাই যা trpl::run-এ পাস করা হয় ঠিক যেমনটি আমরা চ্যাপ্টার জুড়ে করেছি। সেই ফিউচারে, আমরা সেই মেসেজগুলির জন্য অপেক্ষা করি, ঠিক যেমনটি আমরা দেখেছি অন্য মেসেজ-পাসিং উদাহরণগুলিতে।
আমরা যে দৃশ্যটি দিয়ে চ্যাপ্টারটি শুরু করেছি তাতে ফিরে যেতে, একটি ডেডিকেটেড থ্রেড ব্যবহার করে ভিডিও এনকোডিং টাস্কগুলির একটি সেট চালানোর কথা কল্পনা করুন (কারণ ভিডিও এনকোডিং কম্পিউট-বাউন্ড) কিন্তু সেই অপারেশনগুলি একটি অ্যাসিঙ্ক্রোনাস চ্যানেলের সাথে UI-কে জানানো হচ্ছে। বাস্তব-বিশ্বের ব্যবহারের ক্ষেত্রে এই ধরনের কম্বিনেশনের অসংখ্য উদাহরণ রয়েছে।
সারাংশ (Summary)
এই বইয়ে আপনি কনকারেন্সির শেষ দেখা পাবেন না। Chapter 21-এর প্রোজেক্টটি এখানে আলোচিত সহজ উদাহরণগুলির চেয়ে আরও বাস্তব পরিস্থিতিতে এই ধারণাগুলি প্রয়োগ করবে এবং থ্রেডিং বনাম টাস্কগুলির সাথে সমস্যা সমাধানের তুলনা আরও সরাসরি করবে।
আপনি এই পদ্ধতির মধ্যে কোনটি বেছে নিন না কেন, Rust আপনাকে নিরাপদ, দ্রুত, কনকারেন্ট কোড লেখার জন্য প্রয়োজনীয় টুল সরবরাহ করে—হোক সেটি একটি high-throughput ওয়েব সার্ভার বা একটি এমবেডেড অপারেটিং সিস্টেমের জন্য।
এরপর, আমরা আপনার Rust প্রোগ্রামগুলি বড় হওয়ার সাথে সাথে সমস্যাগুলি মডেল করার এবং সমাধানগুলিকে গঠন করার প্রচলিত উপায়গুলি সম্পর্কে কথা বলব। এছাড়াও, আমরা আলোচনা করব কিভাবে Rust-এর প্রচলিত পদ্ধতিগুলি অবজেক্ট-ওরিয়েন্টেড প্রোগ্রামিং থেকে আপনার পরিচিত পদ্ধতিগুলির সাথে সম্পর্কিত।
Rust-এর অবজেক্ট-ওরিয়েন্টেড প্রোগ্রামিং বৈশিষ্ট্য
অবজেক্ট-ওরিয়েন্টেড প্রোগ্রামিং (OOP) হল প্রোগ্রাম মডেল করার একটি উপায়। ১৯৬০-এর দশকে সিমুলা (Simula) নামক প্রোগ্রামিং ভাষায় প্রোগ্রামিং ধারণা হিসাবে অবজেক্টের প্রচলন ঘটে। সেই অবজেক্টগুলি অ্যালান কে-এর প্রোগ্রামিং আর্কিটেকচারকে প্রভাবিত করেছিল, যেখানে অবজেক্টগুলি একে অপরের কাছে মেসেজ পাঠায়। এই আর্কিটেকচার বর্ণনা করার জন্য, তিনি ১৯৬৭ সালে অবজেক্ট-ওরিয়েন্টেড প্রোগ্রামিং শব্দটি তৈরি করেন। OOP কী, তা নিয়ে অনেক পরস্পরবিরোধী সংজ্ঞা রয়েছে, এবং এই সংজ্ঞাগুলির মধ্যে কিছু অনুযায়ী Rust অবজেক্ট-ওরিয়েন্টেড, কিন্তু অন্য সংজ্ঞা অনুযায়ী তা নয়। এই চ্যাপ্টারে, আমরা সাধারণত অবজেক্ট-ওরিয়েন্টেড হিসাবে বিবেচিত কিছু বৈশিষ্ট্য এবং সেই বৈশিষ্ট্যগুলি কীভাবে প্রচলিত Rust-এ রূপান্তরিত হয় তা অন্বেষণ করব। তারপরে আমরা আপনাকে দেখাব কীভাবে Rust-এ একটি অবজেক্ট-ওরিয়েন্টেড ডিজাইন প্যাটার্ন বাস্তবায়ন করা যায় এবং এর পরিবর্তে Rust-এর কিছু শক্তির ব্যবহার করে সমাধান বাস্তবায়নের সুবিধা-অসুবিধা নিয়ে আলোচনা করব।
অবজেক্ট-ওরিয়েন্টেড ভাষাগুলির বৈশিষ্ট্য (Characteristics of Object-Oriented Languages)
প্রোগ্রামিং কমিউনিটিতে কোনো ভাষা অবজেক্ট-ওরিয়েন্টেড হওয়ার জন্য কী কী বৈশিষ্ট্য থাকা আবশ্যক, সে সম্পর্কে কোনো সর্বসম্মত মতামত নেই। Rust অনেক প্রোগ্রামিং প্যারাডাইম দ্বারা প্রভাবিত, যার মধ্যে OOP অন্তর্ভুক্ত; উদাহরণস্বরূপ, আমরা Chapter 13-এ ফাংশনাল প্রোগ্রামিং থেকে আসা বৈশিষ্ট্যগুলি অন্বেষণ করেছি। তর্কসাপেক্ষে, OOP ভাষাগুলি কিছু সাধারণ বৈশিষ্ট্য শেয়ার করে, যেমন অবজেক্ট, এনক্যাপসুলেশন এবং ইনহেরিটেন্স। আসুন দেখি সেই বৈশিষ্ট্যগুলির প্রত্যেকটির অর্থ কী এবং Rust সেগুলিকে সমর্থন করে কিনা।
অবজেক্ট ডেটা এবং আচরণ ধারণ করে (Objects Contain Data and Behavior)
এরিক গামা, রিচার্ড হেলম, রালফ জনসন এবং জন ভ্লিসাইডস-এর লেখা Design Patterns: Elements of Reusable Object-Oriented Software বইটি (অ্যাডিসন-ওয়েসলি প্রফেশনাল, ১৯৯৪), যাকে সাধারণত The Gang of Four বই বলা হয়, অবজেক্ট-ওরিয়েন্টেড ডিজাইন প্যাটার্নের একটি ক্যাটালগ। এটি OOP-কে এইভাবে সংজ্ঞায়িত করে:
অবজেক্ট-ওরিয়েন্টেড প্রোগ্রামগুলি অবজেক্ট দিয়ে গঠিত। একটি অবজেক্ট ডেটা এবং সেই ডেটার উপর কাজ করে এমন পদ্ধতি উভয়কেই প্যাকেজ করে। পদ্ধতিগুলিকে সাধারণত মেথড বা অপারেশন বলা হয়।
এই সংজ্ঞা ব্যবহার করে, Rust অবজেক্ট-ওরিয়েন্টেড: স্ট্রাক্ট এবং এনাম-এর ডেটা রয়েছে এবং impl ব্লকগুলি স্ট্রাক্ট এবং এনাম-এ মেথড সরবরাহ করে। যদিও মেথড সহ স্ট্রাক্ট এবং এনামগুলিকে অবজেক্ট বলা হয় না, তারা Gang of Four-এর অবজেক্টের সংজ্ঞা অনুযায়ী একই কার্যকারিতা প্রদান করে।
এনক্যাপসুলেশন যা ইমপ্লিমেন্টেশনের বিবরণ লুকায় (Encapsulation that Hides Implementation Details)
OOP-এর সাথে সাধারণত যুক্ত আরেকটি দিক হল এনক্যাপসুলেশন-এর ধারণা, যার অর্থ হল একটি অবজেক্টের ইমপ্লিমেন্টেশনের বিবরণ সেই অবজেক্ট ব্যবহার করা কোডের কাছে অ্যাক্সেসযোগ্য নয়। অতএব, একটি অবজেক্টের সাথে ইন্টারঅ্যাক্ট করার একমাত্র উপায় হল এর পাবলিক API-এর মাধ্যমে; অবজেক্ট ব্যবহার করা কোড অবজেক্টের অভ্যন্তরে প্রবেশ করে ডেটা বা আচরণ সরাসরি পরিবর্তন করতে সক্ষম হওয়া উচিত নয়। এটি প্রোগ্রামারকে অবজেক্ট ব্যবহার করা কোড পরিবর্তন না করেই একটি অবজেক্টের অভ্যন্তরীণ পরিবর্তন এবং রিফ্যাক্টর করতে সক্ষম করে।
আমরা Chapter 7-এ এনক্যাপসুলেশন কীভাবে নিয়ন্ত্রণ করতে হয় তা নিয়ে আলোচনা করেছি: আমরা pub কীওয়ার্ড ব্যবহার করে সিদ্ধান্ত নিতে পারি যে আমাদের কোডের কোন মডিউল, টাইপ, ফাংশন এবং মেথডগুলি পাবলিক হওয়া উচিত এবং ডিফল্টরূপে অন্য সবকিছু প্রাইভেট। উদাহরণস্বরূপ, আমরা একটি AveragedCollection স্ট্রাক্ট সংজ্ঞায়িত করতে পারি যাতে i32 মানের একটি ভেক্টর রয়েছে এমন একটি ফিল্ড থাকে। স্ট্রাক্টে একটি ফিল্ডও থাকতে পারে যাতে ভেক্টরের মানগুলির গড় থাকে, অর্থাৎ যখনই কারও এটির প্রয়োজন হয় তখনই গড় গণনা করার প্রয়োজন হয় না। অন্য কথায়, AveragedCollection আমাদের জন্য গণনা করা গড় ক্যাশে করবে। Listing 18-1-এ AveragedCollection স্ট্রাক্টের সংজ্ঞা রয়েছে:
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}স্ট্রাক্টটিকে pub হিসাবে চিহ্নিত করা হয়েছে যাতে অন্য কোড এটি ব্যবহার করতে পারে, কিন্তু স্ট্রাক্টের ভেতরের ফিল্ডগুলি প্রাইভেট থাকে। এটি এই ক্ষেত্রে গুরুত্বপূর্ণ কারণ আমরা নিশ্চিত করতে চাই যে যখনই তালিকাটিতে কোনও মান যোগ করা বা সরানো হয়, তখনও গড় আপডেট করা হয়। আমরা Listing 18-2-এ দেখানো স্ট্রাক্টে add, remove এবং average মেথড ইমপ্লিমেন্ট করে এটি করি:
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}পাবলিক মেথড add, remove এবং average হল AveragedCollection-এর একটি ইনস্ট্যান্সের ডেটা অ্যাক্সেস বা পরিবর্তন করার একমাত্র উপায়। যখন add মেথড ব্যবহার করে list-এ কোনও আইটেম যোগ করা হয় বা remove মেথড ব্যবহার করে সরানো হয়, তখন প্রত্যেকটির ইমপ্লিমেন্টেশন প্রাইভেট update_average মেথডকে কল করে যা average ফিল্ড আপডেট করার কাজটিও পরিচালনা করে।
আমরা list এবং average ফিল্ডগুলিকে প্রাইভেট রেখেছি যাতে বাইরের কোডের জন্য সরাসরি list ফিল্ডে আইটেম যোগ বা সরানোর কোনও উপায় না থাকে; অন্যথায়, list পরিবর্তন হলে average ফিল্ডটি সিঙ্কের বাইরে চলে যেতে পারে। average মেথডটি average ফিল্ডের মান রিটার্ন করে, বাইরের কোডকে average পড়তে দেয় কিন্তু পরিবর্তন করতে দেয় না।
যেহেতু আমরা AveragedCollection স্ট্রাক্টের ইমপ্লিমেন্টেশনের বিবরণ এনক্যাপসুলেট করেছি, তাই আমরা ভবিষ্যতে ডেটা স্ট্রাকচারের মতো দিকগুলি সহজেই পরিবর্তন করতে পারি। উদাহরণস্বরূপ, আমরা list ফিল্ডের জন্য Vec<i32>-এর পরিবর্তে একটি HashSet<i32> ব্যবহার করতে পারি। যতক্ষণ add, remove এবং average পাবলিক মেথডগুলির স্বাক্ষর একই থাকে, ততক্ষণ AveragedCollection ব্যবহার করা কোড কম্পাইল করার জন্য পরিবর্তন করার প্রয়োজন হবে না। পরিবর্তে যদি আমরা list-কে পাবলিক করতাম, তাহলে এটি নাও হতে পারত: HashSet<i32> এবং Vec<i32>-এর আইটেম যোগ এবং সরানোর জন্য ভিন্ন মেথড রয়েছে, তাই বাইরের কোডটি যদি সরাসরি list পরিবর্তন করত তাহলে সম্ভবত পরিবর্তন করতে হত।
যদি কোনও ভাষাকে অবজেক্ট-ওরিয়েন্টেড হিসাবে বিবেচনা করার জন্য এনক্যাপসুলেশন একটি প্রয়োজনীয় দিক হয়, তাহলে Rust সেই প্রয়োজনীয়তা পূরণ করে। কোডের বিভিন্ন অংশের জন্য pub ব্যবহার করার বা না করার বিকল্পটি ইমপ্লিমেন্টেশনের বিবরণের এনক্যাপসুলেশন সক্ষম করে।
টাইপ সিস্টেম এবং কোড শেয়ারিং হিসাবে ইনহেরিটেন্স (Inheritance as a Type System and as Code Sharing)
ইনহেরিটেন্স হল এমন একটি মেকানিজম যার মাধ্যমে একটি অবজেক্ট অন্য অবজেক্টের সংজ্ঞা থেকে উপাদানগুলি ইনহেরিট করতে পারে, এইভাবে আপনাকে আবার সেগুলি সংজ্ঞায়িত না করেই প্যারেন্ট অবজেক্টের ডেটা এবং আচরণ লাভ করতে পারে।
যদি কোনও ভাষা অবজেক্ট-ওরিয়েন্টেড হওয়ার জন্য ইনহেরিটেন্স থাকা আবশ্যক হয়, তাহলে Rust তা নয়। কোনও ম্যাক্রো ব্যবহার না করে এমন একটি স্ট্রাক্ট সংজ্ঞায়িত করার কোনও উপায় নেই যা প্যারেন্ট স্ট্রাক্টের ফিল্ড এবং মেথড ইমপ্লিমেন্টেশন ইনহেরিট করে।
যাইহোক, আপনি যদি আপনার প্রোগ্রামিং টুলবক্সে ইনহেরিটেন্স রাখতে অভ্যস্ত হন, তাহলে আপনি Rust-এ অন্যান্য সমাধান ব্যবহার করতে পারেন, প্রাথমিকভাবে ইনহেরিটেন্সের জন্য আপনার কারণের উপর নির্ভর করে।
আপনি দুটি প্রধান কারণে ইনহেরিটেন্স বেছে নেবেন। একটি হল কোড পুনঃব্যবহারের জন্য: আপনি একটি টাইপের জন্য নির্দিষ্ট আচরণ ইমপ্লিমেন্ট করতে পারেন এবং ইনহেরিটেন্স আপনাকে সেই ইমপ্লিমেন্টেশনটি অন্য টাইপের জন্য পুনরায় ব্যবহার করতে সক্ষম করে। আপনি Rust কোডে ডিফল্ট trait মেথড ইমপ্লিমেন্টেশন ব্যবহার করে সীমিত উপায়ে এটি করতে পারেন, যেটি আপনি Listing 10-14-এ দেখেছিলেন যখন আমরা Summary trait-এ summarize মেথডের একটি ডিফল্ট ইমপ্লিমেন্টেশন যোগ করেছি। Summary trait ইমপ্লিমেন্ট করা যেকোনো টাইপের জন্য কোনও অতিরিক্ত কোড ছাড়াই summarize মেথড উপলব্ধ থাকবে। এটি একটি প্যারেন্ট ক্লাসের একটি মেথডের ইমপ্লিমেন্টেশন থাকার এবং একটি ইনহেরিটিং চাইল্ড ক্লাসেরও মেথডের ইমপ্লিমেন্টেশন থাকার অনুরূপ। আমরা যখন Summary trait ইমপ্লিমেন্ট করি তখনও আমরা summarize মেথডের ডিফল্ট ইমপ্লিমেন্টেশন ওভাররাইড করতে পারি, যা একটি চাইল্ড ক্লাস প্যারেন্ট ক্লাস থেকে ইনহেরিট করা একটি মেথডের ইমপ্লিমেন্টেশন ওভাররাইড করার অনুরূপ।
ইনহেরিটেন্স ব্যবহার করার অন্য কারণটি টাইপ সিস্টেমের সাথে সম্পর্কিত: একটি চাইল্ড টাইপকে প্যারেন্ট টাইপের মতো একই জায়গায় ব্যবহার করতে সক্ষম করা। এটিকে _পলিমরফিজম_ও বলা হয়, যার অর্থ হল আপনি যদি কিছু বৈশিষ্ট্য শেয়ার করেন তবে রানটাইমে একাধিক অবজেক্ট একে অপরের জন্য প্রতিস্থাপন করতে পারেন।
পলিমরফিজম (Polymorphism)
অনেকের কাছে, পলিমরফিজম ইনহেরিটেন্সের সমার্থক। কিন্তু এটি আসলে একটি আরও সাধারণ ধারণা যা একাধিক টাইপের ডেটা নিয়ে কাজ করতে পারে এমন কোডকে বোঝায়। ইনহেরিটেন্সের জন্য, সেই টাইপগুলি সাধারণত সাবক্লাস।
Rust পরিবর্তে বিভিন্ন সম্ভাব্য টাইপের উপর অ্যাবস্ট্রাক্ট করতে জেনেরিক ব্যবহার করে এবং সেই টাইপগুলিকে কী সরবরাহ করতে হবে তার উপর সীমাবদ্ধতা আরোপ করতে trait bound ব্যবহার করে। এটিকে কখনও কখনও বাউন্ডেড প্যারামেট্রিক পলিমরফিজম বলা হয়।
ইনহেরিটেন্স সম্প্রতি অনেক প্রোগ্রামিং ভাষায় একটি প্রোগ্রামিং ডিজাইন সমাধান হিসাবে অনুগ্রহ হারিয়েছে কারণ এটি প্রায়শই প্রয়োজনের চেয়ে বেশি কোড শেয়ার করার ঝুঁকিতে থাকে। সাবক্লাসগুলির সর্বদা তাদের প্যারেন্ট ক্লাসের সমস্ত বৈশিষ্ট্য শেয়ার করা উচিত নয় তবে ইনহেরিটেন্সের সাথে তা করবে। এটি একটি প্রোগ্রামের ডিজাইনকে কম নমনীয় করে তুলতে পারে। এটি সাবক্লাসগুলিতে এমন মেথড কল করার সম্ভাবনাও তৈরি করে যা অর্থবোধক নয় বা ত্রুটির কারণ হয় কারণ মেথডগুলি সাবক্লাসে প্রযোজ্য নয়। এছাড়াও, কিছু ভাষা শুধুমাত্র একক ইনহেরিটেন্স-এর অনুমতি দেবে (অর্থাৎ একটি সাবক্লাস শুধুমাত্র একটি ক্লাস থেকে ইনহেরিট করতে পারে), যা একটি প্রোগ্রামের ডিজাইনের নমনীয়তাকে আরও সীমাবদ্ধ করে।
এই কারণগুলির জন্য, Rust ইনহেরিটেন্সের পরিবর্তে trait অবজেক্ট ব্যবহার করার ভিন্ন পদ্ধতি গ্রহণ করে। আসুন দেখি কিভাবে trait অবজেক্ট Rust-এ পলিমরফিজম সক্ষম করে।
বিভিন্ন টাইপের ভ্যালুর জন্য ট্রেইট অবজেক্ট ব্যবহার করা (Using Trait Objects That Allow for Values of Different Types)
আমরা Chapter 8-এ উল্লেখ করেছি যে ভেক্টরের একটি সীমাবদ্ধতা হল যে তারা শুধুমাত্র একটি টাইপের এলিমেন্ট সংরক্ষণ করতে পারে। আমরা Listing 8-9-এ একটি ওয়ার্কঅ্যারাউন্ড তৈরি করেছি যেখানে আমরা একটি SpreadsheetCell এনাম সংজ্ঞায়িত করেছি যাতে ইন্টিজার, ফ্লোট এবং টেক্সট ধারণ করার জন্য ভেরিয়েন্ট ছিল। এর মানে হল যে আমরা প্রতিটি সেলে বিভিন্ন ধরনের ডেটা সংরক্ষণ করতে পারি এবং তবুও একটি ভেক্টর রাখতে পারি যা সারির সেলগুলিকে উপস্থাপন করে। এটি একটি উপযুক্ত সমাধান যখন আমাদের বিনিময়যোগ্য আইটেমগুলি টাইপের একটি নির্দিষ্ট সেট হয় যা আমাদের কোড কম্পাইল করার সময় আমরা জানি।
যাইহোক, কখনও কখনও আমরা চাই যে আমাদের লাইব্রেরি ব্যবহারকারী কোনও নির্দিষ্ট পরিস্থিতিতে বৈধ টাইপের সেট প্রসারিত করতে সক্ষম হোক। এটি কীভাবে অর্জন করা যেতে পারে তা দেখানোর জন্য, আমরা একটি গ্রাফিক্যাল ইউজার ইন্টারফেস (GUI) টুলের উদাহরণ তৈরি করব যা আইটেমগুলির একটি তালিকার মধ্যে পুনরাবৃত্তি করে, প্রতিটি আইটেমকে স্ক্রিনে আঁকার জন্য একটি draw মেথড কল করে—GUI টুলগুলির জন্য এটি একটি সাধারণ কৌশল। আমরা gui নামে একটি লাইব্রেরি ক্রেট তৈরি করব যাতে একটি GUI লাইব্রেরির গঠন থাকবে। এই ক্রেটে ব্যবহারকারীদের ব্যবহারের জন্য কিছু টাইপ থাকতে পারে, যেমন Button বা TextField। এছাড়াও, gui ব্যবহারকারীরা তাদের নিজস্ব টাইপ তৈরি করতে চাইবে যা আঁকা যায়: উদাহরণস্বরূপ, একজন প্রোগ্রামার একটি Image যোগ করতে পারে এবং অন্যজন একটি SelectBox যোগ করতে পারে।
আমরা এই উদাহরণের জন্য সম্পূর্ণরূপে বিকশিত GUI লাইব্রেরি বাস্তবায়ন করব না কিন্তু দেখাব কিভাবে অংশগুলি একসাথে ফিট হবে। লাইব্রেরি লেখার সময়, আমরা জানতে এবং সংজ্ঞায়িত করতে পারি না যে অন্য প্রোগ্রামাররা কী কী টাইপ তৈরি করতে চাইতে পারে। কিন্তু আমরা জানি যে gui-কে বিভিন্ন টাইপের অনেকগুলি মানের ট্র্যাক রাখতে হবে এবং এই ভিন্ন টাইপের মানগুলির প্রত্যেকটিতে একটি draw মেথড কল করতে হবে। আমরা যখন draw মেথড কল করি তখন ঠিক কী ঘটবে তা জানার দরকার নেই, শুধুমাত্র এইটুকু জানলেই হবে যে মানটিতে সেই মেথডটি আমাদের কল করার জন্য উপলব্ধ থাকবে।
ইনহেরিটেন্স সহ একটি ভাষায় এটি করার জন্য, আমরা Component নামে একটি ক্লাস সংজ্ঞায়িত করতে পারি যার উপর draw নামে একটি মেথড রয়েছে। অন্যান্য ক্লাস, যেমন Button, Image, এবং SelectBox, Component থেকে ইনহেরিট করবে এবং এইভাবে draw মেথড ইনহেরিট করবে। তারা প্রত্যেকে তাদের নিজস্ব আচরণ সংজ্ঞায়িত করতে draw মেথডটিকে ওভাররাইড করতে পারে, কিন্তু ফ্রেমওয়ার্কটি সমস্ত টাইপকে Component ইনস্ট্যান্সের মতো আচরণ করতে পারে এবং তাদের উপর draw কল করতে পারে। কিন্তু যেহেতু Rust-এ ইনহেরিটেন্স নেই, তাই আমাদের gui লাইব্রেরিটিকে গঠন করার জন্য অন্য একটি উপায় প্রয়োজন যাতে ব্যবহারকারীরা এটিকে নতুন টাইপ দিয়ে প্রসারিত করতে পারে।
সাধারণ আচরণের জন্য একটি ট্রেইট সংজ্ঞায়িত করা (Defining a Trait for Common Behavior)
আমরা gui-এর যে আচরণ চাই তা বাস্তবায়ন করতে, আমরা Draw নামে একটি ট্রেইট সংজ্ঞায়িত করব যাতে draw নামে একটি মেথড থাকবে। তারপর আমরা একটি ভেক্টর সংজ্ঞায়িত করতে পারি যা একটি ট্রেইট অবজেক্ট নেয়। একটি ট্রেইট অবজেক্ট আমাদের নির্দিষ্ট করা trait ইমপ্লিমেন্ট করা টাইপের একটি ইনস্ট্যান্স এবং রানটাইমে সেই টাইপের ট্রেইট মেথডগুলি সন্ধান করার জন্য ব্যবহৃত একটি টেবিল উভয়ের দিকে নির্দেশ করে। আমরা কিছু ধরনের পয়েন্টার, যেমন একটি & রেফারেন্স বা একটি Box<T> স্মার্ট পয়েন্টার, তারপর dyn কীওয়ার্ড এবং তারপর প্রাসঙ্গিক trait উল্লেখ করে একটি ট্রেইট অবজেক্ট তৈরি করি। (আমরা Chapter 20-এর “Dynamically Sized Types and the Sized Trait”-এ ট্রেইট অবজেক্টগুলিকে কেন একটি পয়েন্টার ব্যবহার করতে হবে সে সম্পর্কে কথা বলব।) আমরা জেনেরিক বা কংক্রিট টাইপের পরিবর্তে ট্রেইট অবজেক্ট ব্যবহার করতে পারি। আমরা যেখানেই একটি ট্রেইট অবজেক্ট ব্যবহার করি, Rust-এর টাইপ সিস্টেম কম্পাইল করার সময় নিশ্চিত করবে যে সেই প্রসঙ্গে ব্যবহৃত যেকোনো মান ট্রেইট অবজেক্টের trait ইমপ্লিমেন্ট করবে। ফলস্বরূপ, আমাদের কম্পাইল করার সময় সমস্ত সম্ভাব্য টাইপ জানার প্রয়োজন নেই।
আমরা উল্লেখ করেছি যে, Rust-এ, আমরা স্ট্রাক্ট এবং এনামগুলিকে “অবজেক্ট” বলা থেকে বিরত থাকি যাতে সেগুলিকে অন্যান্য ভাষার অবজেক্ট থেকে আলাদা করা যায়। একটি স্ট্রাক্ট বা এনামে, স্ট্রাক্ট ফিল্ডের ডেটা এবং impl ব্লকের আচরণ আলাদা করা হয়, যেখানে অন্য ভাষাগুলিতে, ডেটা এবং আচরণকে একত্রিত করে একটি ধারণাকে প্রায়শই অবজেক্ট লেবেল করা হয়। যাইহোক, ট্রেইট অবজেক্টগুলি অন্যান্য ভাষার অবজেক্টের মতো, এই অর্থে যে তারা ডেটা এবং আচরণকে একত্রিত করে। কিন্তু ট্রেইট অবজেক্টগুলি ঐতিহ্যগত অবজেক্ট থেকে আলাদা যে আমরা একটি ট্রেইট অবজেক্টে ডেটা যোগ করতে পারি না। ট্রেইট অবজেক্টগুলি অন্যান্য ভাষার অবজেক্টের মতো সাধারণভাবে দরকারী নয়: তাদের নির্দিষ্ট উদ্দেশ্য হল সাধারণ আচরণ জুড়ে অ্যাবস্ট্রাকশনকে অনুমতি দেওয়া।
Listing 18-3 দেখায় কিভাবে draw নামে একটি মেথড সহ Draw নামে একটি ট্রেইট সংজ্ঞায়িত করতে হয়:
pub trait Draw {
fn draw(&self);
}এই সিনট্যাক্সটি Chapter 10-এ ট্রেইট সংজ্ঞায়িত করার বিষয়ে আমাদের আলোচনার মতোই পরিচিত। এরপর কিছু নতুন সিনট্যাক্স আসে: Listing 18-4 Screen নামক একটি স্ট্রাক্ট সংজ্ঞায়িত করে যাতে components নামক একটি ভেক্টর থাকে। এই ভেক্টরটি Box<dyn Draw> টাইপের, যা একটি ট্রেইট অবজেক্ট; এটি একটি Box-এর ভিতরের যেকোনো টাইপের জন্য একটি স্ট্যান্ড-ইন যা Draw trait ইমপ্লিমেন্ট করে।
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}Screen স্ট্রাক্টে, আমরা run নামে একটি মেথড সংজ্ঞায়িত করব যা তার প্রতিটি components-এ draw মেথড কল করবে, যেমনটি Listing 18-5-এ দেখানো হয়েছে:
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}এটি ট্রেইট বাউন্ড সহ একটি জেনেরিক টাইপ প্যারামিটার ব্যবহার করে এমন একটি স্ট্রাক্ট সংজ্ঞায়িত করার চেয়ে আলাদাভাবে কাজ করে। একটি জেনেরিক টাইপ প্যারামিটার একবারে শুধুমাত্র একটি কংক্রিট টাইপ দিয়ে প্রতিস্থাপিত করা যেতে পারে, যেখানে ট্রেইট অবজেক্টগুলি রানটাইমে ট্রেইট অবজেক্টের জন্য একাধিক কংক্রিট টাইপ পূরণ করার অনুমতি দেয়। উদাহরণস্বরূপ, আমরা Listing 18-6-এর মতো একটি জেনেরিক টাইপ এবং একটি ট্রেইট বাউন্ড ব্যবহার করে Screen স্ট্রাক্ট সংজ্ঞায়িত করতে পারতাম:
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}এটি আমাদের একটি Screen ইনস্ট্যান্সে সীমাবদ্ধ করে যেখানে সমস্ত কম্পোনেন্ট হয় Button টাইপের অথবা সমস্ত TextField টাইপের। আপনি যদি শুধুমাত্র হোমোজিনিয়াস কালেকশন রাখতে চান, তাহলে জেনেরিক এবং ট্রেইট বাউন্ড ব্যবহার করা বাঞ্ছনীয় কারণ সংজ্ঞাগুলি কংক্রিট টাইপ ব্যবহার করার জন্য কম্পাইল করার সময় মনোমরফাইজ করা হবে।
অন্যদিকে, ট্রেইট অবজেক্ট ব্যবহার করে মেথডের সাহায্যে, একটি Screen ইনস্ট্যান্স একটি Vec<T> ধারণ করতে পারে যাতে একটি Box<Button> এবং সেইসাথে একটি Box<TextField> থাকে। আসুন দেখি এটি কীভাবে কাজ করে এবং তারপরে আমরা রানটাইম পারফরম্যান্সের প্রভাব সম্পর্কে কথা বলব।
ট্রেইট ইমপ্লিমেন্ট করা (Implementing the Trait)
এখন আমরা কিছু টাইপ যোগ করব যা Draw trait ইমপ্লিমেন্ট করে। আমরা Button টাইপ সরবরাহ করব। আবারও, একটি GUI লাইব্রেরি বাস্তবায়ন করা এই বইয়ের সুযোগের বাইরে, তাই draw মেথডের বডিতে কোনও দরকারী ইমপ্লিমেন্টেশন থাকবে না। ইমপ্লিমেন্টেশনটি দেখতে কেমন হতে পারে তা কল্পনা করার জন্য, একটি Button স্ট্রাক্টে width, height এবং label-এর জন্য ফিল্ড থাকতে পারে, যেমনটি Listing 18-7-এ দেখানো হয়েছে:
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// code to actually draw a button
}
}Button-এর width, height এবং label ফিল্ডগুলি অন্যান্য কম্পোনেন্টের ফিল্ড থেকে আলাদা হবে; উদাহরণস্বরূপ, একটি TextField টাইপের সেই একই ফিল্ড এবং একটি placeholder ফিল্ড থাকতে পারে। আমরা স্ক্রিনে যে টাইপগুলি আঁকতে চাই তার প্রত্যেকটি Draw trait ইমপ্লিমেন্ট করবে কিন্তু সেই নির্দিষ্ট টাইপটি কীভাবে আঁকতে হয় তা সংজ্ঞায়িত করতে draw মেথডে ভিন্ন কোড ব্যবহার করবে, যেমনটি Button এখানে করেছে (উল্লেখিত প্রকৃত GUI কোড ছাড়া)। উদাহরণস্বরূপ, Button টাইপের একটি অতিরিক্ত impl ব্লক থাকতে পারে যাতে একজন ব্যবহারকারী বাটনে ক্লিক করলে কী ঘটে তার সাথে সম্পর্কিত মেথড থাকতে পারে। এই ধরনের মেথড TextField-এর মতো টাইপের ক্ষেত্রে প্রযোজ্য হবে না।
যদি আমাদের লাইব্রেরি ব্যবহার করে এমন কেউ SelectBox স্ট্রাক্ট ইমপ্লিমেন্ট করার সিদ্ধান্ত নেয় যাতে width, height এবং options ফিল্ড থাকে, তাহলে তারা SelectBox টাইপেও Draw trait ইমপ্লিমেন্ট করে, যেমনটি Listing 18-8-এ দেখানো হয়েছে:
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}আমাদের লাইব্রেরির ব্যবহারকারী এখন একটি Screen ইনস্ট্যান্স তৈরি করতে তাদের main ফাংশন লিখতে পারে। Screen ইনস্ট্যান্সে, তারা প্রতিটি Box<T>-তে রেখে একটি SelectBox এবং একটি Button যোগ করতে পারে যাতে সেগুলি ট্রেইট অবজেক্টে পরিণত হয়। তারপর তারা Screen ইনস্ট্যান্সে run মেথড কল করতে পারে, যা প্রতিটি কম্পোনেন্টে draw কল করবে। Listing 18-9 এই ইমপ্লিমেন্টেশনটি দেখায়:
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}যখন আমরা লাইব্রেরিটি লিখেছিলাম, তখন আমরা জানতাম না যে কেউ SelectBox টাইপ যোগ করতে পারে, কিন্তু আমাদের Screen ইমপ্লিমেন্টেশন নতুন টাইপের উপর কাজ করতে এবং এটিকে আঁকতে সক্ষম হয়েছিল কারণ SelectBox Draw trait ইমপ্লিমেন্ট করে, যার মানে এটি draw মেথড ইমপ্লিমেন্ট করে।
এই ধারণা—একটি মানের কংক্রিট টাইপের পরিবর্তে শুধুমাত্র সেই মানটি যে মেসেজগুলির প্রতিক্রিয়া জানায় সেগুলির প্রতি যত্নশীল হওয়া—ডায়নামিকালি টাইপ করা ভাষাগুলিতে ডাক টাইপিং-এর ধারণার অনুরূপ: যদি এটি হাঁসের মতো হাঁটে এবং হাঁসের মতো ডাকে, তাহলে এটি অবশ্যই একটি হাঁস! Listing 18-5-এ Screen-এ run-এর ইমপ্লিমেন্টেশনে, run-এর প্রতিটি কম্পোনেন্টের কংক্রিট টাইপ কী তা জানার প্রয়োজন নেই। এটি পরীক্ষা করে না যে কোনও কম্পোনেন্ট একটি Button বা একটি SelectBox-এর ইনস্ট্যান্স কিনা, এটি কেবল কম্পোনেন্টের draw মেথড কল করে। components ভেক্টরের মানগুলির টাইপ হিসাবে Box<dyn Draw> উল্লেখ করে, আমরা Screen-কে এমন মানগুলির প্রয়োজন হিসাবে সংজ্ঞায়িত করেছি যেগুলিতে আমরা draw মেথড কল করতে পারি।
ট্রেইট অবজেক্ট এবং Rust-এর টাইপ সিস্টেম ব্যবহার করে ডাক টাইপিং ব্যবহার করে কোডের মতো কোড লেখার সুবিধা হল যে আমাদের কখনই রানটাইমে কোনও মান কোনও নির্দিষ্ট মেথড ইমপ্লিমেন্ট করে কিনা তা পরীক্ষা করতে হবে না বা কোনও মান একটি মেথড ইমপ্লিমেন্ট না করলে এবং আমরা এটি কল করলেও error পাওয়ার বিষয়ে চিন্তা করতে হবে না। যদি মানগুলি ট্রেইট অবজেক্টের প্রয়োজনীয় ট্রেইটগুলি ইমপ্লিমেন্ট না করে তবে Rust আমাদের কোড কম্পাইল করবে না।
উদাহরণস্বরূপ, Listing 18-10 দেখায় যে আমরা যদি একটি কম্পোনেন্ট হিসাবে একটি String সহ একটি Screen তৈরি করার চেষ্টা করি তাহলে কী ঘটে:
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
screen.run();
}আমরা এই error টি পাব কারণ String Draw trait ইমপ্লিমেন্ট করে না:
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `Box<String>` to `Box<dyn Draw>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` (bin "gui") due to 1 previous error
এই error টি আমাদের জানায় যে হয় আমরা Screen-এ এমন কিছু পাস করছি যা পাস করার কথা ছিল না এবং তাই অন্য একটি টাইপ পাস করা উচিত অথবা আমাদের String-এ Draw ইমপ্লিমেন্ট করা উচিত যাতে Screen এটিতে draw কল করতে পারে।
ট্রেইট অবজেক্ট ডায়নামিক ডিসপ্যাচ সম্পাদন করে (Trait Objects Perform Dynamic Dispatch)
Chapter 10-এর “Performance of Code Using Generics”-এ জেনেরিক্সে সম্পাদিত মনোমরফাইজেশন প্রক্রিয়া সম্পর্কে আমাদের আলোচনা স্মরণ করুন: কম্পাইলার প্রতিটি কংক্রিট টাইপের জন্য ফাংশন এবং মেথডগুলির ননজেনরিক ইমপ্লিমেন্টেশন তৈরি করে যা আমরা জেনেরিক টাইপ প্যারামিটারের পরিবর্তে ব্যবহার করি। মনোমরফাইজেশন থেকে প্রাপ্ত কোডটি স্ট্যাটিক ডিসপ্যাচ করে, যখন কম্পাইলার কম্পাইল করার সময় জানে আপনি কোন মেথড কল করছেন। এটি ডায়নামিক ডিসপ্যাচ-এর বিপরীত, যখন কম্পাইলার কম্পাইল করার সময় বলতে পারে না আপনি কোন মেথড কল করছেন। ডায়নামিক ডিসপ্যাচের ক্ষেত্রে, কম্পাইলার এমন কোড নির্গত করে যা রানটাইমে কোন মেথড কল করতে হবে তা নির্ধারণ করবে।
যখন আমরা ট্রেইট অবজেক্ট ব্যবহার করি, তখন Rust-কে অবশ্যই ডায়নামিক ডিসপ্যাচ ব্যবহার করতে হবে। কম্পাইলার সমস্ত টাইপ জানে না যা ট্রেইট অবজেক্ট ব্যবহার করা কোডের সাথে ব্যবহার করা যেতে পারে, তাই এটি জানে না কোন টাইপে ইমপ্লিমেন্ট করা কোন মেথড কল করতে হবে। পরিবর্তে, রানটাইমে, Rust কোন মেথড কল করতে হবে তা জানতে ট্রেইট অবজেক্টের ভিতরের পয়েন্টারগুলি ব্যবহার করে। এই লুকআপে একটি রানটাইম খরচ হয় যা স্ট্যাটিক ডিসপ্যাচের সাথে ঘটে না। ডায়নামিক ডিসপ্যাচ কম্পাইলারকে একটি মেথডের কোড ইনলাইন করা থেকে বিরত রাখে, যা ফলস্বরূপ কিছু অপটিমাইজেশন প্রতিরোধ করে এবং Rust-এর কিছু নিয়ম রয়েছে যে আপনি কোথায় এবং কোথায় ডায়নামিক ডিসপ্যাচ ব্যবহার করতে পারবেন এবং পারবেন না, যাকে ডাইন কম্প্যাটিবিলিটি বলা হয়। যাইহোক, আমরা Listing 18-5-এ যে কোডটি লিখেছিলাম এবং Listing 18-9-এ সমর্থন করতে সক্ষম হয়েছিলাম তাতে অতিরিক্ত নমনীয়তা পেয়েছি, তাই এটি বিবেচনা করার মতো একটি ট্রেড-অফ।
অবজেক্ট-ওরিয়েন্টেড ডিজাইন প্যাটার্ন বাস্তবায়ন করা (Implementing an Object-Oriented Design Pattern)
স্টেট প্যাটার্ন হল একটি অবজেক্ট-ওরিয়েন্টেড ডিজাইন প্যাটার্ন। এই প্যাটার্নের মূল বিষয় হল, আমরা স্টেটগুলির একটি সেট সংজ্ঞায়িত করি যা একটি ভ্যালুর অভ্যন্তরীণভাবে থাকতে পারে। স্টেটগুলি স্টেট অবজেক্ট-এর একটি সেট দ্বারা উপস্থাপিত হয় এবং ভ্যালুর আচরণ তার স্টেটের উপর ভিত্তি করে পরিবর্তিত হয়। আমরা একটি ব্লগ পোস্ট স্ট্রাক্টের উদাহরণ নিয়ে কাজ করব যাতে একটি ফিল্ড থাকবে যা তার স্টেট ধারণ করবে, যেটি "ড্রাফট", "রিভিউ" বা "পাবলিশড" সেট থেকে একটি স্টেট অবজেক্ট হবে।
স্টেট অবজেক্টগুলি কার্যকারিতা শেয়ার করে: অবশ্যই, Rust-এ আমরা অবজেক্ট এবং ইনহেরিটেন্সের পরিবর্তে স্ট্রাক্ট এবং ট্রেইট ব্যবহার করি। প্রতিটি স্টেট অবজেক্ট তার নিজস্ব আচরণের জন্য এবং কখন এটি অন্য স্টেটে পরিবর্তিত হওয়া উচিত তা নিয়ন্ত্রণ করার জন্য দায়ী। যে ভ্যালুটি একটি স্টেট অবজেক্ট ধারণ করে সেটি স্টেটগুলির বিভিন্ন আচরণ বা কখন স্টেটগুলির মধ্যে ট্রানজিশন করতে হবে সে সম্পর্কে কিছুই জানে না।
স্টেট প্যাটার্ন ব্যবহারের সুবিধা হল, যখন প্রোগ্রামের ব্যবসার প্রয়োজনীয়তা পরিবর্তন হয়, তখন আমাদের স্টেট ধারণ করা ভ্যালুর কোড বা ভ্যালু ব্যবহার করা কোড পরিবর্তন করার প্রয়োজন হবে না। আমাদের কেবল স্টেট অবজেক্টগুলির মধ্যে একটির ভিতরের কোড আপডেট করতে হবে যাতে এর নিয়মগুলি পরিবর্তন করা যায় বা সম্ভবত আরও স্টেট অবজেক্ট যুক্ত করা যায়।
প্রথমে, আমরা আরও ঐতিহ্যবাহী অবজেক্ট-ওরিয়েন্টেড উপায়ে স্টেট প্যাটার্নটি বাস্তবায়ন করব, তারপর আমরা এমন একটি পদ্ধতি ব্যবহার করব যা Rust-এ আরও কিছুটা স্বাভাবিক। আসুন স্টেট প্যাটার্ন ব্যবহার করে একটি ব্লগ পোস্ট ওয়ার্কফ্লো ক্রমবর্ধমানভাবে বাস্তবায়ন করি।
চূড়ান্ত কার্যকারিতা দেখতে এইরকম হবে:
- একটি ব্লগ পোস্ট একটি খালি ড্রাফট হিসাবে শুরু হয়।
- যখন ড্রাফট সম্পন্ন হয়, তখন পোস্টের একটি রিভিউ রিকোয়েস্ট করা হয়।
- যখন পোস্টটি অ্যাপ্রুভ করা হয়, তখন এটি পাবলিশ করা হয়।
- শুধুমাত্র পাবলিশড ব্লগ পোস্টগুলি প্রিন্ট করার জন্য কনটেন্ট রিটার্ন করে, তাই আনঅ্যাপ্রুভড পোস্টগুলি দুর্ঘটনাক্রমে পাবলিশ করা যায় না।
একটি পোস্টে অন্য কোনো পরিবর্তন করার চেষ্টা করা হলে তার কোনো প্রভাব থাকা উচিত নয়। উদাহরণস্বরূপ, যদি আমরা একটি রিভিউ রিকোয়েস্ট করার আগে একটি ড্রাফ্ট ব্লগ পোস্ট অ্যাপ্রুভ করার চেষ্টা করি, তাহলে পোস্টটি আনপাবলিশড ড্রাফ্ট থাকা উচিত।
Listing 18-11 কোড আকারে এই ওয়ার্কফ্লো দেখায়: এটি blog নামক একটি লাইব্রেরি ক্রেটে আমরা যে API বাস্তবায়ন করব তার একটি ব্যবহারের উদাহরণ। এটি এখনও কম্পাইল হবে না কারণ আমরা blog ক্রেটটি বাস্তবায়ন করিনি।
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}আমরা ব্যবহারকারীকে Post::new দিয়ে একটি নতুন ড্রাফ্ট ব্লগ পোস্ট তৈরি করার অনুমতি দিতে চাই। আমরা ব্লগ পোস্টে টেক্সট যোগ করার অনুমতি দিতে চাই। যদি আমরা অ্যাপ্রুভালের আগে অবিলম্বে পোস্টের কনটেন্ট পাওয়ার চেষ্টা করি, তাহলে আমাদের কোনও টেক্সট পাওয়া উচিত নয় কারণ পোস্টটি এখনও একটি ড্রাফ্ট। আমরা প্রদর্শনের উদ্দেশ্যে কোডে assert_eq! যোগ করেছি। এর জন্য একটি চমৎকার ইউনিট টেস্ট হবে একটি ড্রাফ্ট ব্লগ পোস্ট content মেথড থেকে একটি খালি স্ট্রিং রিটার্ন করে কিনা তা পরীক্ষা করা, কিন্তু আমরা এই উদাহরণের জন্য পরীক্ষা লিখব না।
এরপর, আমরা পোস্টের একটি রিভিউয়ের জন্য একটি রিকোয়েস্ট সক্রিয় করতে চাই, এবং আমরা চাই অ্যাপ্রুভালের অপেক্ষায় থাকার সময় content যেন একটি খালি স্ট্রিং রিটার্ন করে। যখন পোস্টটি অ্যাপ্রুভাল পায়, তখন এটি পাবলিশ হওয়া উচিত, যার মানে হল content কল করা হলে পোস্টের টেক্সট রিটার্ন করা হবে।
লক্ষ্য করুন যে ক্রেট থেকে আমরা যে একমাত্র টাইপের সাথে ইন্টারঅ্যাক্ট করছি তা হল Post টাইপ। এই টাইপটি স্টেট প্যাটার্ন ব্যবহার করবে এবং একটি ভ্যালু ধারণ করবে যা তিনটি স্টেট অবজেক্টের মধ্যে একটি হবে যা একটি পোস্টের বিভিন্ন স্টেটকে উপস্থাপন করে—ড্রাফ্ট, রিভিউয়ের জন্য অপেক্ষা করা, বা পাবলিশড। এক স্টেট থেকে অন্য স্টেটে পরিবর্তন Post টাইপের মধ্যে অভ্যন্তরীণভাবে পরিচালিত হবে। স্টেটগুলি আমাদের লাইব্রেরির ব্যবহারকারীদের দ্বারা Post ইনস্ট্যান্সে কল করা মেথডগুলির প্রতিক্রিয়ায় পরিবর্তিত হয়, কিন্তু তাদের সরাসরি স্টেট পরিবর্তনগুলি পরিচালনা করতে হবে না। এছাড়াও, ব্যবহারকারীরা স্টেটগুলির সাথে কোনও ভুল করতে পারে না, যেমন রিভিউ করার আগে একটি পোস্ট পাবলিশ করা।
Post সংজ্ঞায়িত করা এবং ড্রাফ্ট স্টেটে একটি নতুন ইনস্ট্যান্স তৈরি করা (Defining Post and Creating a New Instance in the Draft State)
আসুন লাইব্রেরির ইমপ্লিমেন্টেশন শুরু করি! আমরা জানি যে আমাদের একটি পাবলিক Post স্ট্রাক্ট দরকার যা কিছু কনটেন্ট ধারণ করে, তাই আমরা স্ট্রাক্টের সংজ্ঞা এবং একটি অ্যাসোসিয়েটেড পাবলিক new ফাংশন দিয়ে শুরু করব যাতে Post-এর একটি ইনস্ট্যান্স তৈরি করা যায়, যেমনটি Listing 18-12-এ দেখানো হয়েছে। আমরা একটি প্রাইভেট State ট্রেইটও তৈরি করব যা সেই আচরণকে সংজ্ঞায়িত করবে যা একটি Post-এর সমস্ত স্টেট অবজেক্টের অবশ্যই থাকতে হবে।
তারপর Post একটি state নামক প্রাইভেট ফিল্ডে একটি Option<T>-এর ভিতরে Box<dyn State>-এর একটি ট্রেইট অবজেক্ট ধারণ করবে স্টেট অবজেক্ট রাখার জন্য। আপনি একটু পরেই দেখতে পাবেন কেন Option<T> প্রয়োজন।
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}State ট্রেইট বিভিন্ন পোস্ট স্টেট দ্বারা শেয়ার করা আচরণ সংজ্ঞায়িত করে। স্টেট অবজেক্টগুলি হল Draft, PendingReview, এবং Published, এবং তারা সকলেই State ট্রেইট ইমপ্লিমেন্ট করবে। আপাতত, ট্রেইটের কোনও মেথড নেই, এবং আমরা শুধুমাত্র Draft স্টেট সংজ্ঞায়িত করে শুরু করব কারণ আমরা চাই একটি পোস্ট সেই স্টেটে শুরু হোক।
যখন আমরা একটি নতুন Post তৈরি করি, তখন আমরা এর state ফিল্ডটিকে একটি Some মান সেট করি যা একটি Box ধারণ করে। এই Box টি Draft স্ট্রাক্টের একটি নতুন ইনস্ট্যান্সের দিকে নির্দেশ করে। এটি নিশ্চিত করে যে যখনই আমরা Post-এর একটি নতুন ইনস্ট্যান্স তৈরি করি, এটি একটি ড্রাফ্ট হিসাবে শুরু হবে। যেহেতু Post-এর state ফিল্ডটি প্রাইভেট, তাই অন্য কোনো স্টেটে Post তৈরি করার কোনো উপায় নেই! Post::new ফাংশনে, আমরা content ফিল্ডটিকে একটি নতুন, খালি String-এ সেট করি।
পোস্ট কনটেন্টের টেক্সট সংরক্ষণ করা (Storing the Text of the Post Content)
আমরা Listing 18-11-এ দেখেছি যে আমরা add_text নামে একটি মেথড কল করতে এবং এটিকে একটি &str পাস করতে সক্ষম হতে চাই যা তারপর ব্লগ পোস্টের টেক্সট কনটেন্ট হিসাবে যুক্ত করা হয়। আমরা এটিকে content ফিল্ডটিকে pub হিসাবে প্রকাশ করার পরিবর্তে একটি মেথড হিসাবে ইমপ্লিমেন্ট করি, যাতে পরে আমরা একটি মেথড ইমপ্লিমেন্ট করতে পারি যা content ফিল্ডের ডেটা কীভাবে পড়া হয় তা নিয়ন্ত্রণ করবে। add_text মেথডটি বেশ সহজবোধ্য, তাই আসুন Listing 18-13-এ impl Post ব্লকে ইমপ্লিমেন্টেশন যোগ করি:
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}add_text মেথডটি self-এর একটি মিউটেবল রেফারেন্স নেয়, কারণ আমরা Post ইনস্ট্যান্স পরিবর্তন করছি যার উপর আমরা add_text কল করছি। তারপর আমরা content-এ String-এ push_str কল করি এবং সংরক্ষিত content-এ যোগ করার জন্য text আর্গুমেন্ট পাস করি। এই আচরণটি পোস্টটি কোন স্টেটে আছে তার উপর নির্ভর করে না, তাই এটি স্টেট প্যাটার্নের অংশ নয়। add_text মেথডটি state ফিল্ডের সাথে মোটেও ইন্টারঅ্যাক্ট করে না, তবে এটি আমাদের সমর্থন করতে চাওয়া আচরণের অংশ।
একটি ড্রাফ্ট পোস্টের কনটেন্ট খালি তা নিশ্চিত করা (Ensuring the Content of a Draft Post Is Empty)
এমনকি আমরা add_text কল করার পরে এবং আমাদের পোস্টে কিছু কনটেন্ট যোগ করার পরেও, আমরা চাই যে content মেথডটি একটি খালি স্ট্রিং স্লাইস রিটার্ন করুক কারণ পোস্টটি এখনও ড্রাফ্ট স্টেটে রয়েছে, যেমনটি Listing 18-11-এর 7 লাইনে দেখানো হয়েছে। আপাতত, আসুন content মেথডটিকে সবচেয়ে সহজ জিনিস দিয়ে ইমপ্লিমেন্ট করি যা এই প্রয়োজনীয়তা পূরণ করবে: সর্বদা একটি খালি স্ট্রিং স্লাইস রিটার্ন করা। আমরা পরে এটি পরিবর্তন করব যখন আমরা একটি পোস্টের স্টেট পরিবর্তন করার ক্ষমতা ইমপ্লিমেন্ট করব যাতে এটি পাবলিশ করা যায়। এখন পর্যন্ত, পোস্টগুলি শুধুমাত্র ড্রাফ্ট স্টেটে থাকতে পারে, তাই পোস্টের কনটেন্ট সবসময় খালি হওয়া উচিত। Listing 18-14 এই প্লেসহোল্ডার ইমপ্লিমেন্টেশন দেখায়:
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}এই যোগ করা content মেথড সহ, Listing 18-11-এর 7 লাইন পর্যন্ত সবকিছু উদ্দেশ্য অনুযায়ী কাজ করে।
পোস্টের একটি রিভিউয়ের অনুরোধ করা তার স্টেট পরিবর্তন করে (Requesting a Review of the Post Changes Its State)
এরপর, আমাদের একটি পোস্টের রিভিউয়ের জন্য অনুরোধ করার কার্যকারিতা যোগ করতে হবে, যা এর স্টেট Draft থেকে PendingReview-তে পরিবর্তন করবে। Listing 18-15 এই কোডটি দেখায়:
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}আমরা Post-কে request_review নামে একটি পাবলিক মেথড দিই যা self-এর একটি মিউটেবল রেফারেন্স নেবে। তারপর আমরা Post-এর বর্তমান স্টেটে একটি অভ্যন্তরীণ request_review মেথড কল করি এবং এই দ্বিতীয় request_review মেথডটি বর্তমান স্টেটটিকে কনজিউম করে এবং একটি নতুন স্টেট রিটার্ন করে।
আমরা State ট্রেইটে request_review মেথড যোগ করি; যে সমস্ত টাইপ ট্রেইট ইমপ্লিমেন্ট করে তাদের এখন request_review মেথড ইমপ্লিমেন্ট করতে হবে। লক্ষ্য করুন যে মেথডের প্রথম প্যারামিটার হিসাবে self, &self, বা &mut self থাকার পরিবর্তে, আমাদের কাছে self: Box<Self> রয়েছে। এই সিনট্যাক্সের অর্থ হল মেথডটি শুধুমাত্র তখনই বৈধ যখন একটি Box-এ টাইপটি ধারণ করে কল করা হয়। এই সিনট্যাক্সটি Box<Self>-এর ownership নেয়, পুরানো স্টেটটিকে অকার্যকর করে যাতে Post-এর স্টেট ভ্যালু একটি নতুন স্টেটে রূপান্তরিত হতে পারে।
পুরানো স্টেটটি কনজিউম করার জন্য, request_review মেথডের স্টেট ভ্যালুর ownership নেওয়া প্রয়োজন। এখানেই Post-এর state ফিল্ডের Option আসে: আমরা state ফিল্ড থেকে Some মানটি বের করে নিতে take মেথড কল করি এবং এর জায়গায় একটি None রেখে যাই, কারণ Rust আমাদের স্ট্রাক্টগুলিতে জনবসতিহীন ফিল্ড রাখতে দেয় না। এটি আমাদের state ভ্যালুকে Post থেকে সরানোর অনুমতি দেয়, ধার করার পরিবর্তে। তারপর আমরা পোস্টের state ভ্যালুকে এই অপারেশনের ফলাফলে সেট করব।
আমাদের state-কে সাময়িকভাবে None-এ সেট করতে হবে, সরাসরি self.state = self.state.request_review();-এর মতো কোড দিয়ে সেট করার পরিবর্তে, স্টেট ভ্যালুর ownership পেতে। এটি নিশ্চিত করে যে Post পুরানো state ভ্যালুটি ব্যবহার করতে পারবে না যখন আমরা এটিকে একটি নতুন স্টেটে রূপান্তরিত করব।
Draft-এ request_review মেথড একটি নতুন PendingReview স্ট্রাক্টের একটি নতুন, বক্সড ইনস্ট্যান্স রিটার্ন করে, যা সেই স্টেটকে উপস্থাপন করে যখন একটি পোস্ট রিভিউয়ের জন্য অপেক্ষা করছে। PendingReview স্ট্রাক্টটিও request_review মেথড ইমপ্লিমেন্ট করে কিন্তু কোনও রূপান্তর করে না। বরং, এটি নিজেই রিটার্ন করে, কারণ যখন আমরা ইতিমধ্যে PendingReview স্টেটে থাকা একটি পোস্টে একটি রিভিউয়ের অনুরোধ করি, তখন এটি PendingReview স্টেটে থাকা উচিত।
এখন আমরা স্টেট প্যাটার্নের সুবিধাগুলি দেখতে শুরু করতে পারি: Post-এ request_review মেথডটি তার state ভ্যালু যাই হোক না কেন একই। প্রতিটি স্টেট তার নিজস্ব নিয়মের জন্য দায়ী।
আমরা Post-এ content মেথডটিকে যেমন আছে তেমনই রাখব, একটি খালি স্ট্রিং স্লাইস রিটার্ন করব। আমরা এখন Draft স্টেটের পাশাপাশি PendingReview স্টেটেও একটি Post রাখতে পারি, কিন্তু আমরা PendingReview স্টেটে একই আচরণ চাই। Listing 18-11 এখন 10 লাইন পর্যন্ত কাজ করে!
content-এর আচরণ পরিবর্তন করতে approve যোগ করা (Adding approveto Change the Behavior ofcontent`)
approve মেথডটি request_review মেথডের মতোই হবে: এটি state-কে সেই মানে সেট করবে যা বর্তমান স্টেটের বলা উচিত যখন সেই স্টেটটি অ্যাপ্রুভ করা হয়, যেমনটি Listing 18-16-এ দেখানো হয়েছে:
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}আমরা State ট্রেইটে approve মেথড যোগ করি এবং একটি নতুন স্ট্রাক্ট যোগ করি যা State ইমপ্লিমেন্ট করে, Published স্টেট।
PendingReview-তে request_review যেভাবে কাজ করে, আমরা যদি একটি Draft-এ approve মেথড কল করি, তাহলে এর কোনো প্রভাব থাকবে না কারণ approve self রিটার্ন করবে। যখন আমরা PendingReview-তে approve কল করি, তখন এটি Published স্ট্রাক্টের একটি নতুন, বক্সড ইনস্ট্যান্স রিটার্ন করে। Published স্ট্রাক্টটি State ট্রেইট ইমপ্লিমেন্ট করে এবং request_review মেথড এবং approve মেথড উভয়ের জন্য, এটি নিজেই রিটার্ন করে, কারণ সেই ক্ষেত্রগুলিতে পোস্টটি Published স্টেটে থাকা উচিত।
এখন আমাদের Post-এ content মেথড আপডেট করতে হবে। আমরা চাই content থেকে রিটার্ন করা মান Post-এর বর্তমান স্টেটের উপর নির্ভর করুক, তাই আমরা Post-কে তার state-এ সংজ্ঞায়িত একটি content মেথডে অর্পণ করব, যেমনটি Listing 18-17-এ দেখানো হয়েছে:
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// --snip--
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}যেহেতু লক্ষ্য হল এই সমস্ত নিয়মগুলিকে স্ট্রাক্টগুলির মধ্যে রাখা যা State ইমপ্লিমেন্ট করে, তাই আমরা state-এ একটি content মেথড কল করি এবং পোস্ট ইনস্ট্যান্সটি (অর্থাৎ, self) একটি আর্গুমেন্ট হিসাবে পাস করি। তারপর আমরা state ভ্যালুতে content মেথড ব্যবহার করে যে মানটি রিটার্ন করা হয়েছে তা রিটার্ন করি।
আমরা Option-এ as_ref মেথড কল করি কারণ আমরা Option-এর ভিতরের মানের একটি রেফারেন্স চাই, মানের ownership নয়। যেহেতু state হল একটি Option<Box<dyn State>>, যখন আমরা as_ref কল করি, তখন একটি Option<&Box<dyn State>> রিটার্ন করা হয়। যদি আমরা as_ref কল না করতাম, তাহলে আমরা একটি error পেতাম কারণ আমরা ফাংশন প্যারামিটারের ধার করা &self থেকে state সরাতে পারি না।
তারপর আমরা unwrap মেথড কল করি, যা আমরা জানি কখনই প্যানিক করবে না, কারণ আমরা জানি যে Post-এর মেথডগুলি নিশ্চিত করে যে সেই মেথডগুলি সম্পন্ন হলে state-এ সর্বদা একটি Some মান থাকবে। এটি সেই ক্ষেত্রগুলির মধ্যে একটি যা আমরা Chapter 9-এর “Cases In Which You Have More Information Than the Compiler” বিভাগে আলোচনা করেছি যখন আমরা জানি যে একটি None মান কখনই সম্ভব নয়, যদিও কম্পাইলার সেটি বুঝতে সক্ষম নয়।
এই মুহুর্তে, যখন আমরা &Box<dyn State>-এ content কল করি, তখন & এবং Box-এ ডিরেফ কোয়েরশন কার্যকর হবে যাতে content মেথডটি শেষ পর্যন্ত সেই টাইপে কল করা হয় যা State ট্রেইট ইমপ্লিমেন্ট করে। তার মানে আমাদের State ট্রেইটের সংজ্ঞায় content যোগ করতে হবে, এবং সেখানেই আমরা কোন কনটেন্ট রিটার্ন করতে হবে তার লজিক রাখব, আমরা কোন স্টেটে আছি তার উপর নির্ভর করে, যেমনটি Listing 18-18-এ দেখানো হয়েছে:
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --snip--
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}আমরা content মেথডের জন্য একটি ডিফল্ট ইমপ্লিমেন্টেশন যোগ করি যা একটি খালি স্ট্রিং স্লাইস রিটার্ন করে। এর মানে হল যে আমাদের Draft এবং PendingReview স্ট্রাক্টগুলিতে content ইমপ্লিমেন্ট করার দরকার নেই। Published স্ট্রাক্টটি content মেথডটিকে ওভাররাইড করবে এবং post.content-এর মান রিটার্ন করবে।
লক্ষ্য করুন যে আমাদের এই মেথডে লাইফটাইম অ্যানোটেশন প্রয়োজন, যেমনটি আমরা Chapter 10-এ আলোচনা করেছি। আমরা একটি আর্গুমেন্ট হিসাবে একটি post-এর রেফারেন্স নিচ্ছি এবং সেই post-এর অংশের একটি রেফারেন্স রিটার্ন করছি, তাই রিটার্ন করা রেফারেন্সের লাইফটাইম post আর্গুমেন্টের লাইফটাইমের সাথে সম্পর্কিত।
এবং আমরা সম্পন্ন করেছি—Listing 18-11-এর সমস্ত কিছুই এখন কাজ করে! আমরা ব্লগ পোস্ট ওয়ার্কফ্লোর নিয়ম সহ স্টেট প্যাটার্নটি ইমপ্লিমেন্ট করেছি। নিয়ম সম্পর্কিত লজিক Post-এর মধ্যে ছড়িয়ে ছিটিয়ে না থেকে স্টেট অবজেক্টগুলিতে থাকে।
কেন একটি এনাম (Enum) নয়?
আপনি হয়তো ভাবছেন কেন আমরা বিভিন্ন সম্ভাব্য পোস্ট স্টেট ভেরিয়েন্ট সহ একটি
enumব্যবহার করিনি। এটি অবশ্যই একটি সম্ভাব্য সমাধান, এটি চেষ্টা করুন এবং শেষ ফলাফলগুলি তুলনা করে দেখুন কোনটি আপনি পছন্দ করেন! এনাম ব্যবহারের একটি অসুবিধা হল প্রতিটি স্থান যেখানে এনামের মান পরীক্ষা করা হয় সেখানে প্রতিটি সম্ভাব্য ভেরিয়েন্ট পরিচালনা করার জন্য একটিmatchএক্সপ্রেশন বা অনুরূপ প্রয়োজন হবে। এটি এই ট্রেইট অবজেক্ট সমাধানের চেয়ে বেশি পুনরাবৃত্তিমূলক হতে পারে।
স্টেট প্যাটার্নের ট্রেড-অফ (Trade-offs of the State Pattern)
আমরা দেখিয়েছি যে Rust অবজেক্ট-ওরিয়েন্টেড স্টেট প্যাটার্ন ইমপ্লিমেন্ট করতে সক্ষম যাতে প্রতিটি স্টেটে একটি পোস্টের যে ভিন্ন ধরনের আচরণ থাকা উচিত তা এনক্যাপসুলেট করা যায়। Post-এর মেথডগুলি বিভিন্ন আচরণ সম্পর্কে কিছুই জানে না। আমরা যেভাবে কোডটি সংগঠিত করেছি, তাতে আমাদের শুধুমাত্র একটি জায়গায় দেখতে হবে একটি পাবলিশড পোস্টের বিভিন্ন উপায়গুলি জানার জন্য: Published স্ট্রাক্টে State ট্রেইটের ইমপ্লিমেন্টেশন।
আমরা যদি এমন একটি বিকল্প ইমপ্লিমেন্টেশন তৈরি করতাম যা স্টেট প্যাটার্ন ব্যবহার করে না, তাহলে আমরা পরিবর্তে Post-এর মেথডগুলিতে বা এমনকি main কোডে match এক্সপ্রেশন ব্যবহার করতে পারতাম যা পোস্টের স্টেট পরীক্ষা করে এবং সেই স্থানগুলিতে আচরণ পরিবর্তন করে। এর মানে হল যে একটি পোস্ট পাবলিশড স্টেটে থাকার সমস্ত প্রভাব বোঝার জন্য আমাদের বেশ কয়েকটি জায়গায় দেখতে হবে! এটি শুধুমাত্র আরও বাড়বে যত বেশি স্টেট আমরা যোগ করব: সেই match এক্সপ্রেশনগুলির প্রত্যেকটির জন্য অন্য একটি আর্ম প্রয়োজন হবে।
স্টেট প্যাটার্নের সাথে, Post মেথড এবং আমরা যেখানে Post ব্যবহার করি সেখানে match এক্সপ্রেশনের প্রয়োজন নেই এবং একটি নতুন স্টেট যোগ করার জন্য, আমাদের কেবল একটি নতুন স্ট্রাক্ট যুক্ত করতে হবে এবং সেই একটি স্ট্রাক্টে ট্রেইট মেথডগুলি ইমপ্লিমেন্ট করতে হবে।
স্টেট প্যাটার্ন ব্যবহার করে ইমপ্লিমেন্টেশনটি আরও কার্যকারিতা যোগ করার জন্য প্রসারিত করা সহজ। স্টেট প্যাটার্ন ব্যবহার করে এমন কোড বজায় রাখার সরলতা দেখতে, এই কয়েকটি পরামর্শ চেষ্টা করুন:
- একটি
rejectমেথড যুক্ত করুন যা পোস্টের স্টেটকেPendingReviewথেকেDraft-এ পরিবর্তন করে। - স্টেটটিকে
Published-এ পরিবর্তন করার আগেapprove-এ দুটি কল প্রয়োজন। - ব্যবহারকারীদের শুধুমাত্র তখনই টেক্সট কনটেন্ট যোগ করার অনুমতি দিন যখন একটি পোস্ট
Draftস্টেটে থাকে। ইঙ্গিত: স্টেট অবজেক্টকে কনটেন্ট সম্পর্কে কী পরিবর্তন হতে পারে তার জন্য দায়ী করুন কিন্তুPostপরিবর্তন করার জন্য দায়ী নয়।
স্টেট প্যাটার্নের একটি অসুবিধা হল, যেহেতু স্টেটগুলি স্টেটগুলির মধ্যে ট্রানজিশন ইমপ্লিমেন্ট করে, তাই কিছু স্টেট একে অপরের সাথে কাপল্ড। যদি আমরা PendingReview এবং Published-এর মধ্যে আরেকটি স্টেট যোগ করি, যেমন Scheduled, তাহলে আমাদের PendingReview-এর কোড পরিবর্তন করতে হবে যাতে পরিবর্তে Scheduled-এ ট্রানজিশন করা যায়। একটি নতুন স্টেট যোগ করার সাথে PendingReview-এর পরিবর্তন করার প্রয়োজন না হলে এটি কম কাজ হত, কিন্তু তার মানে অন্য একটি ডিজাইন প্যাটার্নে স্যুইচ করা।
আরেকটি অসুবিধা হল যে আমরা কিছু লজিক ডুপ্লিকেট করেছি। কিছু ডুপ্লিকেশন দূর করতে, আমরা State ট্রেইটে request_review এবং approve মেথডগুলির জন্য ডিফল্ট ইমপ্লিমেন্টেশন তৈরি করার চেষ্টা করতে পারি যা self রিটার্ন করে; যাইহোক, এটি ডাইন কম্প্যাটিবল হবে না, কারণ ট্রেইটটি জানে না যে কংক্রিট self ঠিক কী হবে। আমরা State-কে একটি ট্রেইট অবজেক্ট হিসাবে ব্যবহার করতে চাই, তাই আমাদের এর মেথডগুলি ডাইন কম্প্যাটিবল হওয়া দরকার।
অন্যান্য ডুপ্লিকেশনের মধ্যে রয়েছে Post-এ request_review এবং approve মেথডগুলির অনুরূপ ইমপ্লিমেন্টেশন। উভয় মেথডই Option-এর state ফিল্ডের মানের উপর একই মেথডের ইমপ্লিমেন্টেশনে অর্পণ করে এবং state ফিল্ডের নতুন মানটিকে ফলাফলে সেট করে। যদি আমাদের Post-এ অনেকগুলি মেথড থাকত যা এই প্যাটার্ন অনুসরণ করে, তাহলে আমরা পুনরাবৃত্তি দূর করতে একটি ম্যাক্রো সংজ্ঞায়িত করার কথা বিবেচনা করতে পারি (Chapter 20-এর “Macros” বিভাগটি দেখুন)।
অবজেক্ট-ওরিয়েন্টেড ভাষাগুলির জন্য যেমন সংজ্ঞায়িত করা হয়েছে ঠিক তেমনই স্টেট প্যাটার্নটি ইমপ্লিমেন্ট করার মাধ্যমে, আমরা Rust-এর শক্তির পূর্ণ সুবিধা নিচ্ছি না যতটা আমরা পারতাম। আসুন blog ক্রেটে আমরা কিছু পরিবর্তন দেখি যা অবৈধ স্টেট এবং ট্রানজিশনগুলিকে কম্পাইল টাইমের error-এ পরিণত করতে পারে।
টাইপের মধ্যে স্টেট এবং আচরণ এনকোড করা (Encoding States and Behavior as Types)
আমরা আপনাকে দেখাব কীভাবে স্টেট প্যাটার্নটিকে পুনরায় চিন্তা করে ট্রেড-অফের একটি ভিন্ন সেট পাওয়া যায়। স্টেট এবং ট্রানজিশনগুলিকে সম্পূর্ণরূপে এনক্যাপসুলেট করার পরিবর্তে যাতে বাইরের কোডের সেগুলির সম্পর্কে কোনও জ্ঞান না থাকে, আমরা স্টেটগুলিকে বিভিন্ন টাইপের মধ্যে এনকোড করব। ফলস্বরূপ, Rust-এর টাইপ চেকিং সিস্টেম যেখানে শুধুমাত্র পাবলিশড পোস্ট অনুমোদিত সেখানে ড্রাফ্ট পোস্ট ব্যবহার করার প্রচেষ্টাকে কম্পাইলার error ইস্যু করে প্রতিরোধ করবে।
আসুন Listing 18-11-এর main-এর প্রথম অংশটি বিবেচনা করি:
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}আমরা এখনও Post::new ব্যবহার করে ড্রাফ্ট স্টেটে নতুন পোস্ট তৈরি করা এবং পোস্টে টেক্সট যুক্ত করার ক্ষমতা সক্রিয় করি। কিন্তু একটি ড্রাফ্ট পোস্টে একটি content মেথড থাকার পরিবর্তে যা একটি খালি স্ট্রিং রিটার্ন করে, আমরা এমন করব যাতে ড্রাফ্ট পোস্টগুলিতে content মেথড না থাকে। এইভাবে, যদি আমরা একটি ড্রাফ্ট পোস্টের কনটেন্ট পেতে চেষ্টা করি, তাহলে আমরা একটি কম্পাইলার error পাব যা আমাদের বলবে যে মেথডটি বিদ্যমান নেই। ফলস্বরূপ, আমাদের জন্য দুর্ঘটনাক্রমে প্রোডাকশনে ড্রাফ্ট পোস্টের কনটেন্ট প্রদর্শন করা অসম্ভব হবে, কারণ সেই কোডটি কম্পাইলই হবে না। Listing 18-19 একটি Post স্ট্রাক্ট এবং একটি DraftPost স্ট্রাক্টের সংজ্ঞা দেখায়, সেইসাথে প্রত্যেকটির মেথডগুলি:
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}Post এবং DraftPost উভয় স্ট্রাক্টের একটি প্রাইভেট content ফিল্ড রয়েছে যা ব্লগ পোস্টের টেক্সট সংরক্ষণ করে। স্ট্রাক্টগুলিতে আর state ফিল্ড নেই কারণ আমরা স্টেটের এনকোডিংকে স্ট্রাক্টগুলির টাইপে স্থানান্তরিত করছি। Post স্ট্রাক্টটি একটি পাবলিশড পোস্টকে উপস্থাপন করবে এবং এতে একটি content মেথড রয়েছে যা content রিটার্ন করে।
আমাদের এখনও একটি Post::new ফাংশন রয়েছে, কিন্তু Post-এর একটি ইনস্ট্যান্স রিটার্ন করার পরিবর্তে, এটি DraftPost-এর একটি ইনস্ট্যান্স রিটার্ন করে। যেহেতু content প্রাইভেট এবং এমন কোনও ফাংশন নেই যা Post রিটার্ন করে, তাই এই মুহূর্তে Post-এর একটি ইনস্ট্যান্স তৈরি করা সম্ভব নয়।
DraftPost স্ট্রাক্টের একটি add_text মেথড রয়েছে, তাই আমরা আগের মতোই content-এ টেক্সট যোগ করতে পারি, কিন্তু লক্ষ্য করুন যে DraftPost-এ একটি content মেথড সংজ্ঞায়িত করা নেই! তাই এখন প্রোগ্রামটি নিশ্চিত করে যে সমস্ত পোস্ট ড্রাফ্ট পোস্ট হিসাবে শুরু হয় এবং ড্রাফ্ট পোস্টগুলির কনটেন্ট প্রদর্শনের জন্য উপলব্ধ নেই। এই সীমাবদ্ধতাগুলি এড়ানোর যেকোনো প্রচেষ্টা কম্পাইলার error-এর কারণ হবে।
বিভিন্ন টাইপে রূপান্তর হিসাবে ট্রানজিশন বাস্তবায়ন করা (Implementing Transitions as Transformations into Different Types)
তাহলে আমরা কীভাবে একটি পাবলিশড পোস্ট পাব? আমরা এই নিয়মটি প্রয়োগ করতে চাই যে একটি ড্রাফ্ট পোস্ট পাবলিশ করার আগে অবশ্যই রিভিউ এবং অ্যাপ্রুভ করতে হবে। পেন্ডিং রিভিউ স্টেটের একটি পোস্টের এখনও কোনও কনটেন্ট প্রদর্শন করা উচিত নয়। আসুন Listing 18-20-এ দেখানো আরেকটি স্ট্রাক্ট, PendingReviewPost যোগ করে, DraftPost-এ request_review মেথড সংজ্ঞায়িত করে একটি PendingReviewPost রিটার্ন করার জন্য এবং PendingReviewPost-এ একটি approve মেথড সংজ্ঞায়িত করে একটি Post রিটার্ন করার জন্য এই সীমাবদ্ধতাগুলি বাস্তবায়ন করি:
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// --snip--
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}request_review এবং approve মেথডগুলি self-এর ownership নেয়, এইভাবে DraftPost এবং PendingReviewPost ইনস্ট্যান্সগুলিকে গ্রাস করে এবং সেগুলিকে যথাক্রমে একটি PendingReviewPost এবং একটি পাবলিশড Post-এ রূপান্তরিত করে। এইভাবে, আমরা তাদের উপর request_review কল করার পরে আমাদের কাছে কোনও অবশিষ্ট DraftPost ইনস্ট্যান্স থাকবে না, ইত্যাদি। PendingReviewPost স্ট্রাক্টটিতে একটি content মেথড সংজ্ঞায়িত করা নেই, তাই এর কনটেন্ট পড়ার চেষ্টা করলে DraftPost-এর মতো কম্পাইলার error হবে। যেহেতু একটি পাবলিশড Post ইনস্ট্যান্স পাওয়ার একমাত্র উপায় যার একটি content মেথড সংজ্ঞায়িত করা হয়েছে তা হল একটি PendingReviewPost-এ approve মেথড কল করা এবং একটি PendingReviewPost পাওয়ার একমাত্র উপায় হল একটি DraftPost-এ request_review মেথড কল করা, তাই আমরা এখন ব্লগ পোস্ট ওয়ার্কফ্লোটিকে টাইপ সিস্টেমে এনকোড করেছি।
কিন্তু আমাদের main-এও কিছু ছোট পরিবর্তন করতে হবে। request_review এবং approve মেথডগুলি যে স্ট্রাক্টগুলিতে কল করা হয় সেগুলিকে পরিবর্তন করার পরিবর্তে নতুন ইনস্ট্যান্স রিটার্ন করে, তাই আমাদের রিটার্ন করা ইনস্ট্যান্সগুলি সংরক্ষণ করার জন্য আরও let post = শ্যাডোয়িং অ্যাসাইনমেন্ট যোগ করতে হবে। আমরা ড্রাফ্ট এবং পেন্ডিং রিভিউ পোস্টের কনটেন্ট খালি স্ট্রিং হওয়ার অ্যাসারশনগুলিও রাখতে পারি না, বা আমাদের সেগুলি প্রয়োজনও নেই: আমরা আর সেই স্টেটগুলিতে পোস্টের কনটেন্ট ব্যবহার করার চেষ্টা করে এমন কোড কম্পাইল করতে পারি না। main-এর আপডেটেড কোড Listing 18-21-এ দেখানো হয়েছে:
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}post পুনরায় অ্যাসাইন করার জন্য আমাদের main-এ যে পরিবর্তনগুলি করতে হয়েছিল তার মানে হল যে এই ইমপ্লিমেন্টেশনটি আর অবজেক্ট-ওরিয়েন্টেড স্টেট প্যাটার্নকে সম্পূর্ণরূপে অনুসরণ করে না: স্টেটগুলির মধ্যে রূপান্তরগুলি আর সম্পূর্ণরূপে Post ইমপ্লিমেন্টেশনের মধ্যে এনক্যাপসুলেট করা হয় না। যাইহোক, আমাদের লাভ হল যে অবৈধ স্টেটগুলি এখন টাইপ সিস্টেম এবং কম্পাইল করার সময় টাইপ চেকিংয়ের কারণে অসম্ভব! এটি নিশ্চিত করে যে কিছু বাগ, যেমন একটি আনপাবলিশড পোস্টের কনটেন্ট প্রদর্শন, প্রোডাকশনে যাওয়ার আগেই ধরা পড়বে।
Listing 18-21-এর পরে blog ক্রেটে এই বিভাগের শুরুতে প্রস্তাবিত কাজগুলি চেষ্টা করুন যাতে আপনি কোডের এই সংস্করণের ডিজাইন সম্পর্কে কী ভাবেন তা দেখতে পারেন। লক্ষ্য করুন যে এই ডিজাইনে কিছু কাজ ইতিমধ্যেই সম্পন্ন হতে পারে।
আমরা দেখেছি যে যদিও Rust অবজেক্ট-ওরিয়েন্টেড ডিজাইন প্যাটার্নগুলি ইমপ্লিমেন্ট করতে সক্ষম, টাইপ সিস্টেমে স্টেট এনকোড করার মতো অন্যান্য প্যাটার্নগুলিও Rust-এ উপলব্ধ। এই প্যাটার্নগুলির বিভিন্ন ট্রেড-অফ রয়েছে। যদিও আপনি অবজেক্ট-ওরিয়েন্টেড প্যাটার্নগুলির সাথে খুব পরিচিত হতে পারেন, Rust-এর বৈশিষ্ট্যগুলির সুবিধা নেওয়ার জন্য সমস্যাটিকে পুনরায় চিন্তা করা সুবিধা প্রদান করতে পারে, যেমন কম্পাইল করার সময় কিছু বাগ প্রতিরোধ করা। অবজেক্ট-ওরিয়েন্টেড প্যাটার্নগুলি সর্বদা Rust-এর শক্তির সুবিধা নেওয়ার সর্বোত্তম উপায় হবে না, তবে এটি একটি উপলব্ধ বিকল্প।
এরপর, আমরা প্যাটার্নগুলি দেখব, যা Rust-এর আরেকটি বৈশিষ্ট্য যা প্রচুর নমনীয়তা সক্ষম করে। আমরা পুরো বই জুড়ে সংক্ষেপে সেগুলি দেখেছি কিন্তু এখনও তাদের সম্পূর্ণ ক্ষমতা দেখিনি। চলুন শুরু করা যাক!
প্যাটার্ন এবং ম্যাচিং (Patterns and Matching)
প্যাটার্ন হল Rust-এ টাইপের স্ট্রাকচারের সাথে মেলানোর জন্য একটি বিশেষ সিনট্যাক্স, যা জটিল এবং সরল উভয় ধরনের হতে পারে। match এক্সপ্রেশন এবং অন্যান্য গঠনের সাথে প্যাটার্ন ব্যবহার করলে আপনি একটি প্রোগ্রামের কন্ট্রোল ফ্লো-এর উপর আরও বেশি নিয়ন্ত্রণ পাবেন। একটি প্যাটার্ন নিম্নলিখিতগুলির মধ্যে কয়েকটির সমন্বয়ে গঠিত:
- লিটারেল (Literals)
- ডিস্ট্রাকচার্ড অ্যারে, এনাম, স্ট্রাক্ট বা টাপল
- ভেরিয়েবল
- ওয়াইল্ডকার্ড
- প্লেসহোল্ডার
কিছু উদাহরণ প্যাটার্নের মধ্যে রয়েছে x, (a, 3), এবং Some(Color::Red)। যে প্রসঙ্গগুলিতে প্যাটার্নগুলি বৈধ, এই উপাদানগুলি ডেটার আকার বর্ণনা করে। আমাদের প্রোগ্রাম তারপর কোডের একটি নির্দিষ্ট অংশ চালানো চালিয়ে যাওয়ার জন্য ডেটার সঠিক আকার আছে কিনা তা নির্ধারণ করতে মানগুলিকে প্যাটার্নের সাথে মেলায়।
একটি প্যাটার্ন ব্যবহার করার জন্য, আমরা এটিকে কিছু মানের সাথে তুলনা করি। যদি প্যাটার্নটি মানের সাথে মেলে, তাহলে আমরা আমাদের কোডে মানের অংশগুলি ব্যবহার করি। Chapter 6-এর match এক্সপ্রেশনগুলি স্মরণ করুন যা প্যাটার্ন ব্যবহার করে, যেমন মুদ্রা-বাছাই মেশিনের উদাহরণ। যদি মানটি প্যাটার্নের আকারের সাথে খাপ খায়, তাহলে আমরা নামযুক্ত অংশগুলি ব্যবহার করতে পারি। যদি তা না হয়, তাহলে প্যাটার্নের সাথে সম্পর্কিত কোড চলবে না।
এই চ্যাপ্টারটি প্যাটার্ন সম্পর্কিত সমস্ত কিছুর একটি রেফারেন্স। আমরা প্যাটার্ন ব্যবহার করার বৈধ স্থান, রিফিউটেবল এবং ইরিফিউটেবল প্যাটার্নের মধ্যে পার্থক্য এবং বিভিন্ন ধরনের প্যাটার্ন সিনট্যাক্স যা আপনি দেখতে পারেন তা কভার করব। চ্যাপ্টারের শেষে, আপনি পরিষ্কারভাবে অনেক ধারণা প্রকাশ করার জন্য কীভাবে প্যাটার্ন ব্যবহার করবেন তা জানতে পারবেন।
যেখানে যেখানে প্যাটার্ন ব্যবহার করা যেতে পারে (All the Places Patterns Can Be Used)
Rust-এ প্যাটার্নগুলি বেশ কয়েকটি জায়গায় ব্যবহৃত হয়, এবং আপনি না জেনেই সেগুলি অনেক ব্যবহার করেছেন! এই বিভাগে সেই সমস্ত স্থান নিয়ে আলোচনা করা হয়েছে যেখানে প্যাটার্ন বৈধ।
match আর্ম (Arms)
Chapter 6-এ আলোচনা করা হয়েছে, আমরা match এক্সপ্রেশনের আর্ম-এ প্যাটার্ন ব্যবহার করি। আনুষ্ঠানিকভাবে, match এক্সপ্রেশনগুলিকে match কীওয়ার্ড, ম্যাচ করার জন্য একটি মান এবং এক বা একাধিক ম্যাচ আর্ম হিসাবে সংজ্ঞায়িত করা হয় যা একটি প্যাটার্ন এবং মানটি সেই আর্মের প্যাটার্নের সাথে মিললে চালানোর জন্য একটি এক্সপ্রেশন নিয়ে গঠিত, এইরকম:
match VALUE {
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
}
উদাহরণস্বরূপ, Listing 6-5 থেকে match এক্সপ্রেশনটি এখানে দেওয়া হল, যা x ভেরিয়েবলের একটি Option<i32> মানের উপর ম্যাচ করে:
match x {
None => None,
Some(i) => Some(i + 1),
}এই match এক্সপ্রেশনের প্যাটার্নগুলি হল প্রতিটি তীর চিহ্নের বাম দিকের None এবং Some(i)।
match এক্সপ্রেশনের একটি প্রয়োজনীয়তা হল যে মানটির জন্য match এক্সপ্রেশন ব্যবহার করা হচ্ছে, তার সমস্ত সম্ভাবনা অবশ্যই বিবেচনায় রাখতে হবে। এটিকে এক্সহসটিভ (exhaustive) হতে হবে। প্রতিটি সম্ভাবনা কভার করা হয়েছে তা নিশ্চিত করার একটি উপায় হল শেষ আর্মের জন্য একটি ক্যাচ-অল প্যাটার্ন থাকা: উদাহরণস্বরূপ, যেকোনো মানের সাথে মেলে এমন একটি ভেরিয়েবলের নাম কখনই ব্যর্থ হতে পারে না এবং এইভাবে প্রতিটি অবশিষ্ট কেস কভার করে।
_ নামক বিশেষ প্যাটার্নটি যেকোনো কিছুর সাথে মিলবে, কিন্তু এটি কখনই কোনো ভেরিয়েবলের সাথে বাইন্ড করে না, তাই এটি প্রায়শই শেষ ম্যাচ আর্মে ব্যবহৃত হয়। _ প্যাটার্নটি দরকারী হতে পারে যখন আপনি নির্দিষ্ট করা হয়নি এমন কোনো মান উপেক্ষা করতে চান। আমরা এই চ্যাপ্টারের পরে “Ignoring Values in a Pattern” বিভাগে _ প্যাটার্নটি আরও বিশদে কভার করব।
কন্ডিশনাল if let এক্সপ্রেশন (Conditional if let Expressions)
Chapter 6-এ আমরা আলোচনা করেছি কিভাবে if let এক্সপ্রেশনগুলিকে মূলত একটি match-এর সমতুল্য লেখার সংক্ষিপ্ত উপায় হিসাবে ব্যবহার করতে হয় যা শুধুমাত্র একটি কেসের সাথে মেলে। ঐচ্ছিকভাবে, if let-এ একটি সংশ্লিষ্ট else থাকতে পারে যাতে কোড চালানোর জন্য থাকে যদি if let-এর প্যাটার্নটি না মেলে।
Listing 19-1 দেখায় যে if let, else if, এবং else if let এক্সপ্রেশনগুলিকে মিশ্রিত করা এবং মেলানোও সম্ভব। এটি আমাদের একটি match এক্সপ্রেশনের চেয়ে বেশি নমনীয়তা দেয় যেখানে আমরা প্যাটার্নগুলির সাথে তুলনা করার জন্য শুধুমাত্র একটি মান প্রকাশ করতে পারি। এছাড়াও, Rust-এর প্রয়োজন নেই যে if let, else if, else if let আর্মের একটি সিরিজের শর্তগুলি একে অপরের সাথে সম্পর্কিত হোক।
Listing 19-1-এর কোডটি বেশ কয়েকটি শর্তের জন্য একটি সিরিজের চেকের উপর ভিত্তি করে আপনার ব্যাকগ্রাউন্ডের রং কী হবে তা নির্ধারণ করে। এই উদাহরণের জন্য, আমরা হার্ডকোডেড মান সহ ভেরিয়েবল তৈরি করেছি যা একটি বাস্তব প্রোগ্রাম ব্যবহারকারীর ইনপুট থেকে পেতে পারে।
fn main() { let favorite_color: Option<&str> = None; let is_tuesday = false; let age: Result<u8, _> = "34".parse(); if let Some(color) = favorite_color { println!("Using your favorite color, {color}, as the background"); } else if is_tuesday { println!("Tuesday is green day!"); } else if let Ok(age) = age { if age > 30 { println!("Using purple as the background color"); } else { println!("Using orange as the background color"); } } else { println!("Using blue as the background color"); } }
যদি ব্যবহারকারী একটি প্রিয় রঙ নির্দিষ্ট করে, তাহলে সেই রঙটি ব্যাকগ্রাউন্ড হিসাবে ব্যবহৃত হয়। যদি কোনও প্রিয় রঙ নির্দিষ্ট করা না থাকে এবং আজ মঙ্গলবার হয়, তাহলে ব্যাকগ্রাউন্ডের রং সবুজ হবে। অন্যথায়, যদি ব্যবহারকারী তাদের বয়স একটি স্ট্রিং হিসাবে নির্দিষ্ট করে এবং আমরা এটিকে সফলভাবে একটি সংখ্যা হিসাবে পার্স করতে পারি, তাহলে সংখ্যার মানের উপর নির্ভর করে রংটি হয় বেগুনী বা কমলা হবে। যদি এই শর্তগুলির কোনওটিই প্রযোজ্য না হয়, তাহলে ব্যাকগ্রাউন্ডের রং নীল হবে।
এই কন্ডিশনাল স্ট্রাকচারটি আমাদের জটিল প্রয়োজনীয়তাগুলি সমর্থন করতে দেয়। এখানে আমাদের কাছে থাকা হার্ডকোডেড মানগুলির সাথে, এই উদাহরণটি Using purple as the background color প্রিন্ট করবে।
আপনি দেখতে পাচ্ছেন যে if let নতুন ভেরিয়েবলও প্রবর্তন করতে পারে যা বিদ্যমান ভেরিয়েবলগুলিকে শ্যাডো করে, একইভাবে যেভাবে match আর্মগুলি পারে: if let Ok(age) = age লাইনটি একটি নতুন age ভেরিয়েবল প্রবর্তন করে যাতে Ok ভেরিয়েন্টের ভিতরের মানটি থাকে, বিদ্যমান age ভেরিয়েবলটিকে শ্যাডো করে। এর মানে হল আমাদের if age > 30 শর্তটি সেই ব্লকের মধ্যে রাখতে হবে: আমরা এই দুটি শর্তকে if let Ok(age) = age && age > 30-তে একত্রিত করতে পারি না। নতুন age যা আমরা 30-এর সাথে তুলনা করতে চাই তা কোঁকড়া বন্ধনী দিয়ে শুরু হওয়া নতুন স্কোপ শুরু না হওয়া পর্যন্ত বৈধ নয়।
if let এক্সপ্রেশন ব্যবহারের অসুবিধা হল কম্পাইলার এক্সহসটিভনেস পরীক্ষা করে না, যেখানে match এক্সপ্রেশনের সাথে এটি করে। যদি আমরা শেষ else ব্লকটি বাদ দিতাম এবং সেইজন্য কিছু কেস হ্যান্ডেল করতে মিস করতাম, তাহলে কম্পাইলার আমাদের সম্ভাব্য লজিক বাগ সম্পর্কে সতর্ক করত না।
while let কন্ডিশনাল লুপ (while let Conditional Loops)
if let-এর গঠনের অনুরূপ, while let কন্ডিশনাল লুপ একটি while লুপকে ততক্ষণ চলতে দেয় যতক্ষণ একটি প্যাটার্ন মিলতে থাকে। আমরা প্রথমবার Chapter 17-এ একটি while let লুপ দেখেছিলাম, যেখানে আমরা এটিকে ততক্ষণ লুপ করতে ব্যবহার করেছি যতক্ষণ একটি স্ট্রিম নতুন মান তৈরি করে। একইভাবে, Listing 19-2-তে আমরা একটি while let লুপ দেখাই যা থ্রেডগুলির মধ্যে পাঠানো মেসেজগুলির জন্য অপেক্ষা করে, কিন্তু এক্ষেত্রে একটি Option-এর পরিবর্তে একটি Result পরীক্ষা করে।
fn main() { let (tx, rx) = std::sync::mpsc::channel(); std::thread::spawn(move || { for val in [1, 2, 3] { tx.send(val).unwrap(); } }); while let Ok(value) = rx.recv() { println!("{value}"); } }
এই উদাহরণটি 1, 2 এবং 3 প্রিন্ট করে। যখন আমরা Chapter 16-এ recv দেখেছিলাম, তখন আমরা সরাসরি error টি আনর্যাপ করেছি, অথবা একটি for লুপ ব্যবহার করে একটি ইটারেটর হিসাবে এটির সাথে ইন্টারঅ্যাক্ট করেছি। Listing 19-2 যেমন দেখায়, যদিও, আমরা while let ব্যবহার করতে পারি, কারণ recv মেথডটি যতক্ষণ সেন্ডার মেসেজ তৈরি করছে ততক্ষণ Ok রিটার্ন করে এবং তারপর সেন্ডার সাইড ডিসকানেক্ট হয়ে গেলে একটি Err তৈরি করে।
for লুপ (for Loops)
একটি for লুপে, for কীওয়ার্ডের ঠিক পরে যে মানটি আসে সেটি হল একটি প্যাটার্ন। উদাহরণস্বরূপ, for x in y-তে x হল প্যাটার্ন। Listing 19-3 প্রদর্শন করে কিভাবে একটি for লুপে একটি প্যাটার্ন ব্যবহার করে একটি টাপলকে ডিস্ট্রাকচার বা ভেঙে আলাদা করা যায়, for লুপের অংশ হিসাবে।
fn main() { let v = vec!['a', 'b', 'c']; for (index, value) in v.iter().enumerate() { println!("{value} is at index {index}"); } }
Listing 19-3-এর কোডটি নিম্নলিখিতগুলি প্রিন্ট করবে:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
আমরা enumerate মেথড ব্যবহার করে একটি ইটারেটরকে অ্যাডাপ্ট করি যাতে এটি একটি মান এবং সেই মানের জন্য ইনডেক্স তৈরি করে, একটি টাপলে স্থাপন করা হয়। উৎপাদিত প্রথম মান হল (0, 'a') টাপল। যখন এই মানটি (index, value) প্যাটার্নের সাথে মেলানো হয়, তখন index হবে 0 এবং value হবে 'a', আউটপুটের প্রথম লাইনটি প্রিন্ট করবে।
let স্টেটমেন্ট (let Statements)
এই চ্যাপ্টারের আগে, আমরা শুধুমাত্র match এবং if let-এর সাথে প্যাটার্ন ব্যবহার করার বিষয়ে স্পষ্টভাবে আলোচনা করেছি, কিন্তু আসলে, আমরা অন্যান্য জায়গাতেও প্যাটার্ন ব্যবহার করেছি, যার মধ্যে let স্টেটমেন্টও রয়েছে। উদাহরণস্বরূপ, let সহ এই সরল ভেরিয়েবল অ্যাসাইনমেন্টটি বিবেচনা করুন:
#![allow(unused)] fn main() { let x = 5; }
আপনি যখনই এইরকম একটি let স্টেটমেন্ট ব্যবহার করেছেন তখনই আপনি প্যাটার্ন ব্যবহার করছেন, যদিও আপনি এটি উপলব্ধি নাও করতে পারেন! আরও আনুষ্ঠানিকভাবে, একটি let স্টেটমেন্ট এইরকম দেখায়:
let PATTERN = EXPRESSION;
let x = 5;-এর মতো স্টেটমেন্টে PATTERN স্লটে একটি ভেরিয়েবলের নাম সহ, ভেরিয়েবলের নামটি কেবল একটি প্যাটার্নের একটি বিশেষ সরল রূপ। Rust এক্সপ্রেশনটিকে প্যাটার্নের সাথে তুলনা করে এবং যে কোনও নাম খুঁজে পায় তা অ্যাসাইন করে। তাই let x = 5; উদাহরণে, x হল একটি প্যাটার্ন যার অর্থ “এখানে যা মেলে তাকে x ভেরিয়েবলের সাথে বাইন্ড করুন।” যেহেতু x নামটি সম্পূর্ণ প্যাটার্ন, তাই এই প্যাটার্নটির কার্যকরী অর্থ হল “মান যাই হোক না কেন, সবকিছুকে x ভেরিয়েবলের সাথে বাইন্ড করুন।”
let-এর প্যাটার্ন ম্যাচিং দিকটি আরও স্পষ্টভাবে দেখতে, Listing 19-4 বিবেচনা করুন, যা একটি টাপল ডিস্ট্রাকচার করতে let-এর সাথে একটি প্যাটার্ন ব্যবহার করে।
fn main() { let (x, y, z) = (1, 2, 3); }
এখানে, আমরা একটি টাপলকে একটি প্যাটার্নের সাথে মেলাই। Rust (1, 2, 3) মানটিকে (x, y, z) প্যাটার্নের সাথে তুলনা করে এবং দেখে যে মানটি প্যাটার্নের সাথে মেলে, তাই Rust 1-কে x-এর সাথে, 2-কে y-এর সাথে এবং 3-কে z-এর সাথে বাইন্ড করে। আপনি এই টাপল প্যাটার্নটিকে এর মধ্যে তিনটি পৃথক ভেরিয়েবল প্যাটার্ন নেস্ট করার মতো ভাবতে পারেন।
যদি প্যাটার্নের এলিমেন্টের সংখ্যা টাপলের এলিমেন্টের সংখ্যার সাথে না মেলে, তাহলে সামগ্রিক টাইপ মিলবে না এবং আমরা একটি কম্পাইলার error পাব। উদাহরণস্বরূপ, Listing 19-5 দুটি ভেরিয়েবলের মধ্যে তিনটি এলিমেন্ট সহ একটি টাপল ডিস্ট্রাকচার করার একটি প্রচেষ্টা দেখায়, যা কাজ করবে না।
fn main() {
let (x, y) = (1, 2, 3);
}এই কোডটি কম্পাইল করার চেষ্টা করলে এই টাইপ error পাওয়া যায়:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Error টি ঠিক করার জন্য, আমরা _ বা .. ব্যবহার করে টাপলের এক বা একাধিক মান উপেক্ষা করতে পারি, যেমনটি আপনি “Ignoring Values in a Pattern” বিভাগে দেখতে পাবেন। যদি সমস্যাটি হয় যে প্যাটার্নে আমাদের অনেকগুলি ভেরিয়েবল রয়েছে, তাহলে সমাধান হল ভেরিয়েবলগুলি সরিয়ে টাইপগুলিকে মেলানো যাতে ভেরিয়েবলের সংখ্যা টাপলের এলিমেন্টের সংখ্যার সমান হয়।
ফাংশন প্যারামিটার (Function Parameters)
ফাংশন প্যারামিটারগুলিও প্যাটার্ন হতে পারে। Listing 19-6-এর কোড, যা foo নামে একটি ফাংশন ঘোষণা করে যা i32 টাইপের x নামে একটি প্যারামিটার নেয়, এখন আপনার কাছে পরিচিত হওয়া উচিত।
fn foo(x: i32) { // code goes here } fn main() {}
x অংশটি একটি প্যাটার্ন! যেমনটি আমরা let-এর সাথে করেছি, আমরা একটি ফাংশনের আর্গুমেন্টে একটি টাপলকে প্যাটার্নের সাথে মেলাতে পারি। Listing 19-7 একটি ফাংশনে পাস করার সময় একটি টাপলের মানগুলিকে বিভক্ত করে।
fn print_coordinates(&(x, y): &(i32, i32)) { println!("Current location: ({x}, {y})"); } fn main() { let point = (3, 5); print_coordinates(&point); }
এই কোডটি Current location: (3, 5) প্রিন্ট করে। &(3, 5) মানগুলি &(x, y) প্যাটার্নের সাথে মেলে, তাই x হল 3 মান এবং y হল 5 মান।
আমরা ক্লোজার প্যারামিটার তালিকাতেও একইভাবে প্যাটার্ন ব্যবহার করতে পারি যেমনটি ফাংশন প্যারামিটার তালিকায় করা হয়, কারণ ক্লোজারগুলি ফাংশনের মতোই, যেমনটি Chapter 13-এ আলোচনা করা হয়েছে।
এই সময়ে, আপনি প্যাটার্ন ব্যবহার করার বেশ কয়েকটি উপায় দেখেছেন, কিন্তু প্যাটার্নগুলি আমরা যেখানে ব্যবহার করতে পারি সেখানে সব জায়গায় একই কাজ করে না। কিছু জায়গায়, প্যাটার্নগুলিকে অবশ্যই ইরিফিউটেবল হতে হবে; অন্য পরিস্থিতিতে, সেগুলি রিফিউটেবল হতে পারে। আমরা পরবর্তীতে এই দুটি ধারণা নিয়ে আলোচনা করব।
রিফিউটেবিলিটি: একটি প্যাটার্ন মেলে কিনা (Refutability: Whether a Pattern Might Fail to Match)
প্যাটার্ন দুটি রূপে আসে: রিফিউটেবল (refutable) এবং ইরিফিউটেবল (irrefutable)। যে প্যাটার্নগুলি যে কোনও সম্ভাব্য মানের জন্য মিলবে সেগুলি হল ইরিফিউটেবল। একটি উদাহরণ হবে let x = 5; স্টেটমেন্টের x, কারণ x যেকোনো কিছুর সাথে মেলে এবং তাই মেলতে ব্যর্থ হতে পারে না। যে প্যাটার্নগুলি কিছু সম্ভাব্য মানের জন্য মেলতে ব্যর্থ হতে পারে সেগুলি হল রিফিউটেবল। একটি উদাহরণ হবে if let Some(x) = a_value এক্সপ্রেশনের Some(x), কারণ যদি a_value ভেরিয়েবলের মান Some-এর পরিবর্তে None হয়, তাহলে Some(x) প্যাটার্নটি মিলবে না।
ফাংশন প্যারামিটার, let স্টেটমেন্ট এবং for লুপগুলি কেবল ইরিফিউটেবল প্যাটার্ন গ্রহণ করতে পারে, কারণ মানগুলি না মিললে প্রোগ্রামটি অর্থপূর্ণ কিছু করতে পারে না। if let এবং while let এক্সপ্রেশন এবং let-else স্টেটমেন্ট রিফিউটেবল এবং ইরিফিউটেবল প্যাটার্ন গ্রহণ করে, কিন্তু কম্পাইলার ইরিফিউটেবল প্যাটার্নের বিরুদ্ধে সতর্ক করে কারণ সংজ্ঞা অনুসারে সেগুলি সম্ভাব্য ব্যর্থতা পরিচালনা করার উদ্দেশ্যে তৈরি: একটি কন্ডিশনালের কার্যকারিতা হল সফলতা বা ব্যর্থতার উপর নির্ভর করে ভিন্নভাবে কাজ করার ক্ষমতা।
সাধারণভাবে, রিফিউটেবল এবং ইরিফিউটেবল প্যাটার্নের মধ্যে পার্থক্য নিয়ে আপনার চিন্তা করার দরকার নেই; যাইহোক, আপনাকে রিফিউটেবিলিটির ধারণার সাথে পরিচিত হতে হবে যাতে আপনি কোনও error মেসেজে এটি দেখলে প্রতিক্রিয়া জানাতে পারেন। সেই ক্ষেত্রগুলিতে, আপনাকে কোডের অভিপ্রেত আচরণের উপর নির্ভর করে প্যাটার্ন বা আপনি যে গঠনের সাথে প্যাটার্নটি ব্যবহার করছেন সেটি পরিবর্তন করতে হবে।
আসুন একটি উদাহরণের দিকে তাকাই যেখানে আমরা একটি রিফিউটেবল প্যাটার্ন ব্যবহার করার চেষ্টা করি যেখানে Rust-এর একটি ইরিফিউটেবল প্যাটার্ন প্রয়োজন এবং এর বিপরীতে কী ঘটে। Listing 19-8 একটি let স্টেটমেন্ট দেখায়, কিন্তু প্যাটার্নের জন্য আমরা Some(x) নির্দিষ্ট করেছি, একটি রিফিউটেবল প্যাটার্ন। আপনি যেমন আশা করতে পারেন, এই কোডটি কম্পাইল হবে না।
{{#rustdoc_include ../listings/ch19-patterns-and-matching/listing-19-8/src/main.rs:here}}যদি some_option_value একটি None মান হয়, তাহলে এটি Some(x) প্যাটার্নের সাথে মিলতে ব্যর্থ হবে, অর্থাৎ প্যাটার্নটি রিফিউটেবল। যাইহোক, let স্টেটমেন্ট শুধুমাত্র একটি ইরিফিউটেবল প্যাটার্ন গ্রহণ করতে পারে কারণ None মান দিয়ে কোডটি বৈধভাবে কিছুই করতে পারে না। কম্পাইল করার সময়, Rust অভিযোগ করবে যে আমরা একটি রিফিউটেবল প্যাটার্ন ব্যবহার করার চেষ্টা করেছি যেখানে একটি ইরিফিউটেবল প্যাটার্ন প্রয়োজন:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let else` to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
যেহেতু আমরা Some(x) প্যাটার্ন দিয়ে প্রতিটি বৈধ মান কভার করিনি (এবং করতেও পারিনি!), তাই Rust সঙ্গতভাবেই একটি কম্পাইলার error তৈরি করে।
যদি আমাদের কাছে একটি রিফিউটেবল প্যাটার্ন থাকে যেখানে একটি ইরিফিউটেবল প্যাটার্ন প্রয়োজন, তাহলে আমরা প্যাটার্ন ব্যবহার করা কোড পরিবর্তন করে এটিকে ঠিক করতে পারি: let ব্যবহার করার পরিবর্তে, আমরা if let ব্যবহার করতে পারি। তারপর যদি প্যাটার্নটি না মেলে, তাহলে কোডটি কেবল কোঁকড়া বন্ধনীর ভিতরের কোডটি এড়িয়ে যাবে, এটিকে বৈধভাবে চালিয়ে যাওয়ার একটি উপায় দেবে। Listing 19-9 দেখায় কিভাবে Listing 19-8-এর কোড ঠিক করা যায়।
fn main() { let some_option_value: Option<i32> = None; if let Some(x) = some_option_value { println!("{x}"); } }
আমরা কোডটিকে একটি আউট দিয়েছি! এই কোডটি এখন সম্পূর্ণরূপে বৈধ। যাইহোক, যদি আমরা if let-কে একটি ইরিফিউটেবল প্যাটার্ন (এমন একটি প্যাটার্ন যা সর্বদা মিলবে), যেমন x, দিই, যেমনটি Listing 19-10-এ দেখানো হয়েছে, তাহলে কম্পাইলার একটি সতর্কতা দেবে।
fn main() { if let x = 5 { println!("{x}"); }; }
Rust অভিযোগ করে যে একটি ইরিফিউটেবল প্যাটার্নের সাথে if let ব্যবহার করার কোনও মানে হয় না:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `if let` pattern
--> src/main.rs:2:8
|
2 | if let x = 5 {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `if let` is useless
= help: consider replacing the `if let` with a `let`
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
5
এই কারণে, ম্যাচ আর্মগুলিকে অবশ্যই রিফিউটেবল প্যাটার্ন ব্যবহার করতে হবে, শেষ আর্মটি বাদে, যেটি একটি ইরিফিউটেবল প্যাটার্ন দিয়ে অবশিষ্ট সমস্ত মানের সাথে মেলানো উচিত। Rust আমাদের শুধুমাত্র একটি আর্ম সহ একটি match-এ একটি ইরিফিউটেবল প্যাটার্ন ব্যবহার করার অনুমতি দেয়, কিন্তু এই সিনট্যাক্সটি বিশেষভাবে দরকারী নয় এবং এটি একটি সরল let স্টেটমেন্ট দিয়ে প্রতিস্থাপিত করা যেতে পারে।
এখন আপনি জানেন যে কোথায় প্যাটার্ন ব্যবহার করতে হবে এবং রিফিউটেবল এবং ইরিফিউটেবল প্যাটার্নের মধ্যে পার্থক্য কী, আসুন প্যাটার্ন তৈরি করতে আমরা যে সমস্ত সিনট্যাক্স ব্যবহার করতে পারি তা কভার করি।
প্যাটার্ন সিনট্যাক্স (Pattern Syntax)
এই বিভাগে, আমরা প্যাটার্নে ব্যবহৃত সমস্ত বৈধ সিনট্যাক্স সংগ্রহ করব এবং আলোচনা করব কেন এবং কখন আপনি তাদের প্রতিটি ব্যবহার করতে চাইতে পারেন।
লিটারেল ম্যাচিং (Matching Literals)
আপনি যেমন Chapter 6-এ দেখেছেন, আপনি সরাসরি লিটারেলের সাথে প্যাটার্ন মেলাতে পারেন। নিম্নলিখিত কোড কিছু উদাহরণ দেয়:
fn main() { let x = 1; match x { 1 => println!("one"), 2 => println!("two"), 3 => println!("three"), _ => println!("anything"), } }
এই কোডটি one প্রিন্ট করবে কারণ x-এর মান হল 1। এই সিনট্যাক্সটি দরকারী যখন আপনি চান যে আপনার কোডটি যদি কোনও নির্দিষ্ট কংক্রিট মান পায় তাহলে একটি অ্যাকশন নেবে।
নামযুক্ত ভেরিয়েবল ম্যাচিং (Matching Named Variables)
নামযুক্ত ভেরিয়েবলগুলি হল ইরিফিউটেবল প্যাটার্ন যা যেকোনো মানের সাথে মেলে এবং আমরা বইটিতে সেগুলি অনেকবার ব্যবহার করেছি। যাইহোক, যখন আপনি match, if let, বা while let এক্সপ্রেশনে নামযুক্ত ভেরিয়েবল ব্যবহার করেন তখন একটি জটিলতা দেখা দেয়। যেহেতু এই ধরনের প্রতিটি এক্সপ্রেশন একটি নতুন স্কোপ শুরু করে, তাই এক্সপ্রেশনের ভিতরে একটি প্যাটার্নের অংশ হিসাবে ঘোষিত ভেরিয়েবলগুলি বাইরের একই নামের ভেরিয়েবলগুলিকে শ্যাডো করবে, যেমনটি সমস্ত ভেরিয়েবলের ক্ষেত্রে হয়। Listing 19-11-এ, আমরা x নামে একটি ভেরিয়েবল ঘোষণা করি যার মান Some(5) এবং একটি ভেরিয়েবল y যার মান 10। তারপর আমরা x মানের উপর একটি match এক্সপ্রেশন তৈরি করি। ম্যাচ আর্মের প্যাটার্নগুলি এবং শেষে println! দেখুন এবং এই কোডটি চালানোর আগে বা আরও পড়ার আগে কোডটি কী প্রিন্ট করবে তা বোঝার চেষ্টা করুন।
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(y) => println!("Matched, y = {y}"), _ => println!("Default case, x = {x:?}"), } println!("at the end: x = {x:?}, y = {y}"); }
আসুন match এক্সপ্রেশনটি চলার সময় কী ঘটে তা দেখি। প্রথম ম্যাচ আর্মের প্যাটার্নটি x-এর সংজ্ঞায়িত মানের সাথে মেলে না, তাই কোড চলতে থাকে।
দ্বিতীয় ম্যাচ আর্মের প্যাটার্নটি y নামে একটি নতুন ভেরিয়েবল প্রবর্তন করে যা একটি Some মানের ভিতরের যেকোনো মানের সাথে মিলবে। যেহেতু আমরা match এক্সপ্রেশনের ভিতরের একটি নতুন স্কোপে আছি, তাই এটি একটি নতুন y ভেরিয়েবল, শুরুতে ঘোষিত y নয় যার মান 10। এই নতুন y বাইন্ডিং একটি Some-এর ভিতরের যেকোনো মানের সাথে মিলবে, যা আমাদের x-এ রয়েছে। অতএব, এই নতুন y, x-এর Some-এর ভিতরের মানের সাথে বাইন্ড করে। সেই মানটি হল 5, তাই সেই আর্মের জন্য এক্সপ্রেশনটি এক্সিকিউট হয় এবং Matched, y = 5 প্রিন্ট করে।
যদি x Some(5)-এর পরিবর্তে একটি None মান হত, তাহলে প্রথম দুটি আর্মের প্যাটার্নগুলি মিলত না, তাই মানটি আন্ডারস্কোরের সাথে মিলত। আমরা আন্ডারস্কোর আর্মের প্যাটার্নে x ভেরিয়েবলটি প্রবর্তন করিনি, তাই এক্সপ্রেশনের x এখনও বাইরের x যা শ্যাডো করা হয়নি। এই অনুমানমূলক ক্ষেত্রে, match প্রিন্ট করত Default case, x = None।
যখন match এক্সপ্রেশনটি শেষ হয়, তখন এর স্কোপ শেষ হয়, এবং সেইসাথে ভিতরের y-এর স্কোপও শেষ হয়। শেষ println! at the end: x = Some(5), y = 10 তৈরি করে।
একটি match এক্সপ্রেশন তৈরি করতে যা বাইরের x এবং y-এর মানগুলির তুলনা করে, বিদ্যমান y ভেরিয়েবলটিকে শ্যাডো করে এমন একটি নতুন ভেরিয়েবল প্রবর্তন করার পরিবর্তে, আমাদের পরিবর্তে একটি ম্যাচ গার্ড কন্ডিশনাল ব্যবহার করতে হবে। আমরা পরে “Extra Conditionals with Match Guards” বিভাগে ম্যাচ গার্ড সম্পর্কে কথা বলব।
একাধিক প্যাটার্ন (Multiple Patterns)
আপনি | সিনট্যাক্স ব্যবহার করে একাধিক প্যাটার্ন মেলাতে পারেন, যেটি হল প্যাটার্ন অথবা অপারেটর। উদাহরণস্বরূপ, নিম্নলিখিত কোডে আমরা x-এর মানকে ম্যাচ আর্মগুলির সাথে মেলাই, যার প্রথমটিতে একটি অথবা বিকল্প রয়েছে, যার অর্থ হল যদি x-এর মান সেই আর্মের যেকোনো মানের সাথে মেলে, তাহলে সেই আর্মের কোড চলবে:
fn main() { let x = 1; match x { 1 | 2 => println!("one or two"), 3 => println!("three"), _ => println!("anything"), } }
এই কোডটি one or two প্রিন্ট করবে।
..= দিয়ে মানের রেঞ্জ ম্যাচিং (Matching Ranges of Values with ..=)
..= সিনট্যাক্স আমাদের মানগুলির একটি অন্তর্ভুক্তিমূলক রেঞ্জের সাথে মেলাতে দেয়। নিম্নলিখিত কোডে, যখন একটি প্যাটার্ন প্রদত্ত রেঞ্জের যেকোনো মানের সাথে মেলে, তখন সেই আর্মটি এক্সিকিউট হবে:
fn main() { let x = 5; match x { 1..=5 => println!("one through five"), _ => println!("something else"), } }
যদি x 1, 2, 3, 4, বা 5 হয়, তাহলে প্রথম আর্মটি মিলবে। এই সিনট্যাক্সটি একই ধারণা প্রকাশ করার জন্য | অপারেটর ব্যবহার করার চেয়ে একাধিক ম্যাচ মানের জন্য আরও সুবিধাজনক; যদি আমরা | ব্যবহার করতাম তাহলে আমাদের 1 | 2 | 3 | 4 | 5 নির্দিষ্ট করতে হত। একটি রেঞ্জ নির্দিষ্ট করা অনেক ছোট, বিশেষ করে যদি আমরা, উদাহরণস্বরূপ, 1 থেকে 1,000-এর মধ্যে যেকোনো সংখ্যার সাথে মেলাতে চাই!
কম্পাইলার কম্পাইল করার সময় পরীক্ষা করে যে রেঞ্জটি খালি নয় এবং যেহেতু Rust শুধুমাত্র char এবং সাংখ্যিক মানের জন্য বলতে পারে যে একটি রেঞ্জ খালি কিনা, তাই রেঞ্জগুলি শুধুমাত্র সাংখ্যিক বা char মানের সাথে অনুমোদিত।
এখানে char মানের রেঞ্জ ব্যবহার করার একটি উদাহরণ দেওয়া হল:
fn main() { let x = 'c'; match x { 'a'..='j' => println!("early ASCII letter"), 'k'..='z' => println!("late ASCII letter"), _ => println!("something else"), } }
Rust বলতে পারে যে 'c' প্রথম প্যাটার্নের রেঞ্জের মধ্যে রয়েছে এবং early ASCII letter প্রিন্ট করে।
মানগুলিকে ভেঙে আলাদা করতে ডিস্ট্রাকচারিং (Destructuring to Break Apart Values)
আমরা স্ট্রাক্ট, এনাম এবং টাপলগুলিকে ডিস্ট্রাকচার করতে প্যাটার্ন ব্যবহার করতে পারি যাতে এই মানগুলির বিভিন্ন অংশ ব্যবহার করা যায়। আসুন প্রতিটি মানের মধ্য দিয়ে যাই।
ডিস্ট্রাকচারিং স্ট্রাক্ট (Destructuring Structs)
Listing 19-12 দুটি ফিল্ড, x এবং y সহ একটি Point স্ট্রাক্ট দেখায়, যাকে আমরা একটি let স্টেটমেন্ট সহ একটি প্যাটার্ন ব্যবহার করে আলাদা করতে পারি।
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x: a, y: b } = p; assert_eq!(0, a); assert_eq!(7, b); }
এই কোডটি a এবং b ভেরিয়েবল তৈরি করে যা p স্ট্রাক্টের x এবং y ফিল্ডের মানের সাথে মেলে। এই উদাহরণটি দেখায় যে প্যাটার্নের ভেরিয়েবলের নামগুলি স্ট্রাক্টের ফিল্ডের নামের সাথে মিলতে হবে না। যাইহোক, কোন ভেরিয়েবলগুলি কোন ফিল্ড থেকে এসেছে তা মনে রাখা সহজ করার জন্য ভেরিয়েবলের নামগুলিকে ফিল্ডের নামের সাথে মেলানো সাধারণ। এই সাধারণ ব্যবহারের কারণে এবং let Point { x: x, y: y } = p; লেখায় অনেক ডুপ্লিকেশন থাকার কারণে, Rust-এর স্ট্রাক্ট ফিল্ডগুলির সাথে মেলে এমন প্যাটার্নগুলির জন্য একটি সংক্ষিপ্ত রূপ রয়েছে: আপনাকে শুধুমাত্র স্ট্রাক্ট ফিল্ডের নাম তালিকাভুক্ত করতে হবে এবং প্যাটার্ন থেকে তৈরি হওয়া ভেরিয়েবলগুলির একই নাম থাকবে। Listing 19-13, Listing 19-12-এর কোডের মতোই আচরণ করে, কিন্তু let প্যাটার্নে তৈরি হওয়া ভেরিয়েবলগুলি a এবং b-এর পরিবর্তে x এবং y।
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x, y } = p; assert_eq!(0, x); assert_eq!(7, y); }
এই কোডটি x এবং y ভেরিয়েবল তৈরি করে যা p ভেরিয়েবলের x এবং y ফিল্ডের সাথে মেলে। ফলাফল হল যে x এবং y ভেরিয়েবলগুলিতে p স্ট্রাক্টের মান রয়েছে।
আমরা সমস্ত ফিল্ডের জন্য ভেরিয়েবল তৈরি করার পরিবর্তে স্ট্রাক্ট প্যাটার্নের অংশ হিসাবে আক্ষরিক মানগুলির সাথেও ডিস্ট্রাকচার করতে পারি। এটি করার ফলে আমাদের অন্য ফিল্ডগুলিকে ডিস্ট্রাকচার করার জন্য ভেরিয়েবল তৈরি করার সময় নির্দিষ্ট মানগুলির জন্য কিছু ফিল্ড পরীক্ষা করার অনুমতি দেয়।
Listing 19-14-এ, আমাদের একটি match এক্সপ্রেশন রয়েছে যা Point মানগুলিকে তিনটি ক্ষেত্রে পৃথক করে: যে পয়েন্টগুলি সরাসরি x অক্ষের উপর থাকে (y = 0 হলে এটি সত্য), y অক্ষের উপর (x = 0), বা কোনওটিতেই নয়।
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; match p { Point { x, y: 0 } => println!("On the x axis at {x}"), Point { x: 0, y } => println!("On the y axis at {y}"), Point { x, y } => { println!("On neither axis: ({x}, {y})"); } } }
প্রথম আর্মটি x অক্ষের উপর অবস্থিত যেকোনো পয়েন্টের সাথে মিলবে, এটি নির্দিষ্ট করে যে y ফিল্ডটি মিলবে যদি এর মান আক্ষরিক 0-এর সাথে মেলে। প্যাটার্নটি এখনও একটি x ভেরিয়েবল তৈরি করে যা আমরা এই আর্মের কোডের জন্য ব্যবহার করতে পারি।
একইভাবে, দ্বিতীয় আর্মটি y অক্ষের যেকোনো পয়েন্টের সাথে মেলে, এটি নির্দিষ্ট করে যে x ফিল্ডটি মিলবে যদি এর মান 0 হয় এবং y ফিল্ডের মানের জন্য একটি ভেরিয়েবল y তৈরি করে। তৃতীয় আর্মটি কোনও আক্ষরিক নির্দিষ্ট করে না, তাই এটি অন্য যেকোনো Point-এর সাথে মেলে এবং x এবং y উভয় ফিল্ডের জন্য ভেরিয়েবল তৈরি করে।
এই উদাহরণে, x-এ একটি 0 থাকার কারণে p মানটি দ্বিতীয় আর্মের সাথে মেলে, তাই এই কোডটি On the y axis at 7 প্রিন্ট করবে।
মনে রাখবেন যে একটি match এক্সপ্রেশন প্রথম ম্যাচিং প্যাটার্নটি খুঁজে পাওয়ার পরে আর্মগুলি পরীক্ষা করা বন্ধ করে দেয়, তাই যদিও Point { x: 0, y: 0} x অক্ষ এবং y অক্ষের উপর রয়েছে, তবুও এই কোডটি শুধুমাত্র On the x axis at 0 প্রিন্ট করবে।
ডিস্ট্রাকচারিং এনাম (Destructuring Enums)
আমরা এই বইটিতে এনামগুলিকে ডিস্ট্রাকচার করেছি (উদাহরণস্বরূপ, Chapter 6-এর Listing 6-5), কিন্তু এখনও স্পষ্টভাবে আলোচনা করিনি যে একটি এনামকে ডিস্ট্রাকচার করার প্যাটার্নটি এনামের মধ্যে সংরক্ষিত ডেটা যেভাবে সংজ্ঞায়িত করা হয়েছে তার সাথে সঙ্গতিপূর্ণ। একটি উদাহরণ হিসাবে, Listing 19-15-এ আমরা Listing 6-2 থেকে Message এনাম ব্যবহার করি এবং প্যাটার্নগুলির সাথে একটি match লিখি যা প্রতিটি অভ্যন্তরীণ মানকে ডিস্ট্রাকচার করবে।
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() { let msg = Message::ChangeColor(0, 160, 255); match msg { Message::Quit => { println!("The Quit variant has no data to destructure."); } Message::Move { x, y } => { println!("Move in the x direction {x} and in the y direction {y}"); } Message::Write(text) => { println!("Text message: {text}"); } Message::ChangeColor(r, g, b) => { println!("Change the color to red {r}, green {g}, and blue {b}"); } } }
এই কোডটি Change the color to red 0, green 160, and blue 255 প্রিন্ট করবে। অন্যান্য আর্ম থেকে কোড চালানোর জন্য msg-এর মান পরিবর্তন করার চেষ্টা করুন।
কোনও ডেটা ছাড়া এনাম ভেরিয়েন্টগুলির জন্য, যেমন Message::Quit, আমরা মানটিকে আরও ডিস্ট্রাকচার করতে পারি না। আমরা শুধুমাত্র আক্ষরিক Message::Quit মানের উপর মেলাতে পারি এবং সেই প্যাটার্নে কোনও ভেরিয়েবল নেই।
স্ট্রাক্ট-জাতীয় এনাম ভেরিয়েন্টগুলির জন্য, যেমন Message::Move, আমরা স্ট্রাক্টগুলির সাথে মেলানোর জন্য নির্দিষ্ট করা প্যাটার্নের অনুরূপ একটি প্যাটার্ন ব্যবহার করতে পারি। ভেরিয়েন্টের নামের পরে, আমরা কোঁকড়া বন্ধনী রাখি এবং তারপর ভেরিয়েবল সহ ফিল্ডগুলি তালিকাভুক্ত করি যাতে আমরা এই আর্মের কোডে ব্যবহার করার জন্য টুকরোগুলি ভেঙে ফেলতে পারি। এখানে আমরা Listing 19-13-এ যেমন করেছি তেমনই সংক্ষিপ্ত রূপ ব্যবহার করি।
টাপল-জাতীয় এনাম ভেরিয়েন্টগুলির জন্য, যেমন Message::Write যা একটি এলিমেন্ট সহ একটি টাপল ধারণ করে এবং Message::ChangeColor যা তিনটি এলিমেন্ট সহ একটি টাপল ধারণ করে, প্যাটার্নটি টাপলগুলির সাথে মেলানোর জন্য আমরা যে প্যাটার্নটি নির্দিষ্ট করি তার অনুরূপ। প্যাটার্নের ভেরিয়েবলের সংখ্যা অবশ্যই আমরা যে ভেরিয়েন্টের সাথে মেলাচ্ছি তার এলিমেন্টের সংখ্যার সাথে মিলতে হবে।
নেস্টেড স্ট্রাক্ট এবং এনাম ডিস্ট্রাকচার করা (Destructuring Nested Structs and Enums)
এখন পর্যন্ত, আমাদের সমস্ত উদাহরণ এক লেভেল গভীরতার স্ট্রাক্ট বা এনামগুলির সাথে মিলছিল, কিন্তু ম্যাচিং নেস্টেড আইটেমগুলিতেও কাজ করতে পারে! উদাহরণস্বরূপ, আমরা Listing 19-16-এ দেখানো ChangeColor মেসেজে RGB এবং HSV রং সমর্থন করার জন্য Listing 19-15-এর কোডটি রিফ্যাক্টর করতে পারি।
enum Color { Rgb(i32, i32, i32), Hsv(i32, i32, i32), } enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(Color), } fn main() { let msg = Message::ChangeColor(Color::Hsv(0, 160, 255)); match msg { Message::ChangeColor(Color::Rgb(r, g, b)) => { println!("Change color to red {r}, green {g}, and blue {b}"); } Message::ChangeColor(Color::Hsv(h, s, v)) => { println!("Change color to hue {h}, saturation {s}, value {v}"); } _ => (), } }
match এক্সপ্রেশনের প্রথম আর্মের প্যাটার্নটি একটি Message::ChangeColor এনাম ভেরিয়েন্টের সাথে মেলে যাতে একটি Color::Rgb ভেরিয়েন্ট থাকে; তারপর প্যাটার্নটি তিনটি অভ্যন্তরীণ i32 মানের সাথে বাইন্ড করে। দ্বিতীয় আর্মের প্যাটার্নটিও একটি Message::ChangeColor এনাম ভেরিয়েন্টের সাথে মেলে, কিন্তু অভ্যন্তরীণ এনামটি পরিবর্তে Color::Hsv-এর সাথে মেলে। আমরা এই জটিল শর্তগুলি একটি match এক্সপ্রেশনে নির্দিষ্ট করতে পারি, এমনকি যদি দুটি এনাম জড়িত থাকে।
স্ট্রাক্ট এবং টাপল ডিস্ট্রাকচার করা (Destructuring Structs and Tuples)
আমরা আরও জটিল উপায়ে ডিস্ট্রাকচারিং প্যাটার্নগুলিকে মিশ্রিত করতে, মেলাতে এবং নেস্ট করতে পারি। নিম্নলিখিত উদাহরণটি একটি জটিল ডিস্ট্রাকচার দেখায় যেখানে আমরা একটি টাপলের ভিতরে স্ট্রাক্ট এবং টাপলগুলিকে নেস্ট করি এবং সমস্ত প্রিমিটিভ মানগুলিকে ডিস্ট্রাকচার করি:
fn main() { struct Point { x: i32, y: i32, } let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 }); }
এই কোডটি আমাদের জটিল টাইপগুলিকে তাদের উপাদান অংশে ভেঙে দিতে দেয় যাতে আমরা যে মানগুলিতে আগ্রহী সেগুলি আলাদাভাবে ব্যবহার করতে পারি।
প্যাটার্নগুলির সাথে ডিস্ট্রাকচারিং হল মানগুলির টুকরোগুলি ব্যবহার করার একটি সুবিধাজনক উপায়, যেমন একটি স্ট্রাক্টের প্রতিটি ফিল্ডের মান, একে অপরের থেকে আলাদাভাবে।
একটি প্যাটার্নের মান উপেক্ষা করা (Ignoring Values in a Pattern)
আপনি দেখেছেন যে কখনও কখনও একটি প্যাটার্নের মান উপেক্ষা করা দরকারী, যেমন একটি match-এর শেষ আর্মে, একটি ক্যাচ-অল পেতে যা আসলে কিছুই করে না কিন্তু অবশিষ্ট সমস্ত সম্ভাব্য মান বিবেচনা করে। একটি প্যাটার্নে সম্পূর্ণ মান বা মানের অংশ উপেক্ষা করার কয়েকটি উপায় রয়েছে: _ প্যাটার্ন ব্যবহার করে (যা আপনি দেখেছেন), অন্য প্যাটার্নের মধ্যে _ প্যাটার্ন ব্যবহার করে, একটি নাম ব্যবহার করে যা একটি আন্ডারস্কোর দিয়ে শুরু হয়, বা একটি মানের অবশিষ্ট অংশগুলি উপেক্ষা করতে .. ব্যবহার করে। আসুন এই প্যাটার্নগুলির প্রত্যেকটি কীভাবে এবং কেন ব্যবহার করতে হয় তা অন্বেষণ করি।
_ দিয়ে একটি সম্পূর্ণ মান উপেক্ষা করা (Ignoring an Entire Value with _)
আমরা একটি ওয়াইল্ডকার্ড প্যাটার্ন হিসাবে আন্ডারস্কোর ব্যবহার করেছি যা যেকোনো মানের সাথে মিলবে কিন্তু মানের সাথে বাইন্ড করবে না। এটি একটি match এক্সপ্রেশনের শেষ আর্ম হিসাবে বিশেষভাবে দরকারী, তবে আমরা এটিকে ফাংশন প্যারামিটার সহ যেকোনো প্যাটার্নে ব্যবহার করতে পারি, যেমনটি Listing 19-17-এ দেখানো হয়েছে।
fn foo(_: i32, y: i32) { println!("This code only uses the y parameter: {y}"); } fn main() { foo(3, 4); }
এই কোডটি প্রথম আর্গুমেন্ট হিসাবে পাস করা মান 3-কে সম্পূর্ণরূপে উপেক্ষা করবে এবং This code only uses the y parameter: 4 প্রিন্ট করবে।
বেশিরভাগ ক্ষেত্রে যখন আপনার আর কোনও নির্দিষ্ট ফাংশন প্যারামিটারের প্রয়োজন হয় না, তখন আপনি স্বাক্ষর পরিবর্তন করবেন যাতে এটি অব্যবহৃত প্যারামিটার অন্তর্ভুক্ত না করে। একটি ফাংশন প্যারামিটার উপেক্ষা করা বিশেষভাবে দরকারী হতে পারে যখন, উদাহরণস্বরূপ, আপনি একটি ট্রেইট ইমপ্লিমেন্ট করছেন যখন আপনার একটি নির্দিষ্ট টাইপ স্বাক্ষরের প্রয়োজন কিন্তু আপনার ইমপ্লিমেন্টেশনের ফাংশন বডিতে একটি প্যারামিটারের প্রয়োজন নেই। আপনি তখন অব্যবহৃত ফাংশন প্যারামিটার সম্পর্কে কম্পাইলার সতর্কতা পাওয়া এড়াতে পারবেন, যেমনটি আপনি একটি নাম ব্যবহার করলে করতেন।
একটি মানের অংশবিশেষ উপেক্ষা করতে নেস্টেড _ ব্যবহার করা (Ignoring Parts of a Value with a Nested _)
আমরা একটি মানের শুধুমাত্র একটি অংশ পরীক্ষা করতে চাইলে এবং অন্য অংশগুলি ব্যবহার করতে না চাইলে, অন্য একটি প্যাটার্নের ভিতরে _ ব্যবহার করতে পারি। Listing 19-18 এমন কোড দেখায় যা একটি সেটিং-এর মান পরিচালনার জন্য দায়ী। ব্যবসার প্রয়োজনীয়তা হল যে ব্যবহারকারীকে একটি সেটিং-এর বিদ্যমান কাস্টমাইজেশন ওভাররাইট করার অনুমতি দেওয়া উচিত নয়, তবে সেটিং আনসেট করতে এবং বর্তমানে আনসেট থাকলে এটিকে একটি মান দিতে পারে।
fn main() { let mut setting_value = Some(5); let new_setting_value = Some(10); match (setting_value, new_setting_value) { (Some(_), Some(_)) => { println!("Can't overwrite an existing customized value"); } _ => { setting_value = new_setting_value; } } println!("setting is {setting_value:?}"); }
এই কোডটি Can't overwrite an existing customized value প্রিন্ট করবে এবং তারপর setting is Some(5) প্রিন্ট করবে। প্রথম ম্যাচ আর্মে, আমাদের Some ভেরিয়েন্টের ভিতরের মানগুলির সাথে মেলানো বা ব্যবহার করার প্রয়োজন নেই, তবে আমাদের setting_value এবং new_setting_value যখন Some ভেরিয়েন্ট হয় তখন সেই ক্ষেত্রটির জন্য পরীক্ষা করতে হবে। সেই ক্ষেত্রে, আমরা setting_value পরিবর্তন না করার কারণ প্রিন্ট করি এবং এটি পরিবর্তন হয় না।
অন্যান্য সমস্ত ক্ষেত্রে (যদি setting_value বা new_setting_value None হয়) দ্বিতীয় আর্মের _ প্যাটার্ন দ্বারা প্রকাশিত, আমরা new_setting_value-কে setting_value হতে দিতে চাই।
আমরা একটি প্যাটার্নের মধ্যে একাধিক স্থানে আন্ডারস্কোর ব্যবহার করে নির্দিষ্ট মান উপেক্ষা করতে পারি। Listing 19-19 পাঁচটি আইটেমের একটি টাপলের দ্বিতীয় এবং চতুর্থ মান উপেক্ষা করার একটি উদাহরণ দেখায়।
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, _, third, _, fifth) => { println!("Some numbers: {first}, {third}, {fifth}") } } }
এই কোডটি Some numbers: 2, 8, 32 প্রিন্ট করবে এবং 4 এবং 16 মানগুলি উপেক্ষা করা হবে।
একটি অব্যবহৃত ভেরিয়েবল উপেক্ষা করতে এর নামের শুরুতে _ ব্যবহার করা (Ignoring an Unused Variable by Starting Its Name with _)
যদি আপনি একটি ভেরিয়েবল তৈরি করেন কিন্তু কোথাও ব্যবহার না করেন, তাহলে Rust সাধারণত একটি সতর্কতা জারি করবে কারণ একটি অব্যবহৃত ভেরিয়েবল একটি বাগ হতে পারে। যাইহোক, কখনও কখনও একটি ভেরিয়েবল তৈরি করা দরকারী হতে পারে যা আপনি এখনও ব্যবহার করবেন না, যেমন যখন আপনি প্রোটোটাইপিং করছেন বা সবেমাত্র একটি প্রোজেক্ট শুরু করছেন। এই পরিস্থিতিতে, আপনি Rust-কে অব্যবহৃত ভেরিয়েবল সম্পর্কে সতর্ক না করতে বলতে পারেন ভেরিয়েবলের নাম একটি আন্ডারস্কোর দিয়ে শুরু করে। Listing 19-20-এ, আমরা দুটি অব্যবহৃত ভেরিয়েবল তৈরি করি, কিন্তু যখন আমরা এই কোডটি কম্পাইল করি, তখন আমাদের কেবল একটি সম্পর্কে সতর্কতা পাওয়া উচিত।
fn main() { let _x = 5; let y = 10; }
এখানে আমরা y ভেরিয়েবলটি ব্যবহার না করার বিষয়ে একটি সতর্কতা পাই, কিন্তু _x ব্যবহার না করার বিষয়ে আমরা কোনও সতর্কতা পাই না।
লক্ষ্য করুন যে শুধুমাত্র _ ব্যবহার করা এবং একটি আন্ডারস্কোর দিয়ে শুরু হওয়া একটি নাম ব্যবহারের মধ্যে একটি সূক্ষ্ম পার্থক্য রয়েছে। সিনট্যাক্স _x এখনও মানটিকে ভেরিয়েবলের সাথে বাইন্ড করে, যেখানে _ মোটেও বাইন্ড করে না। এই পার্থক্যটি গুরুত্বপূর্ণ এমন একটি ক্ষেত্র দেখানোর জন্য, Listing 19-21 আমাদের একটি error দেবে।
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{s:?}");
}আমরা একটি error পাব কারণ s-এর মান এখনও _s-এ সরানো হবে, যা আমাদের আবার s ব্যবহার করতে বাধা দেয়। যাইহোক, নিজে থেকে আন্ডারস্কোর ব্যবহার করা কখনই মানের সাথে বাইন্ড করে না। Listing 19-22 কোনও error ছাড়াই কম্পাইল হবে কারণ s, _-তে সরানো হয় না।
fn main() { let s = Some(String::from("Hello!")); if let Some(_) = s { println!("found a string"); } println!("{s:?}"); }
এই কোডটি ঠিকঠাক কাজ করে কারণ আমরা কখনই s-কে কোনও কিছুর সাথে বাইন্ড করি না; এটি সরানো হয় না।
.. দিয়ে একটি মানের অবশিষ্ট অংশগুলি উপেক্ষা করা (Ignoring Remaining Parts of a Value with ..)
অনেকগুলি অংশ সহ মানগুলির সাথে, আমরা নির্দিষ্ট অংশগুলি ব্যবহার করতে এবং বাকিগুলি উপেক্ষা করতে .. সিনট্যাক্স ব্যবহার করতে পারি, প্রতিটি উপেক্ষিত মানের জন্য আন্ডারস্কোর তালিকাভুক্ত করার প্রয়োজন এড়াতে। .. প্যাটার্নটি একটি মানের যে কোনও অংশকে উপেক্ষা করে যা আমরা প্যাটার্নের বাকি অংশে স্পষ্টভাবে মেলিনি। Listing 19-23-এ, আমাদের একটি Point স্ট্রাক্ট রয়েছে যা ত্রিমাত্রিক স্থানে একটি স্থানাঙ্ক ধারণ করে। match এক্সপ্রেশনে, আমরা শুধুমাত্র x স্থানাঙ্কের উপর কাজ করতে চাই এবং y এবং z ফিল্ডের মানগুলি উপেক্ষা করতে চাই।
fn main() { struct Point { x: i32, y: i32, z: i32, } let origin = Point { x: 0, y: 0, z: 0 }; match origin { Point { x, .. } => println!("x is {x}"), } }
আমরা x মান তালিকাভুক্ত করি এবং তারপর শুধু .. প্যাটার্ন অন্তর্ভুক্ত করি। এটি y: _ এবং z: _ তালিকাভুক্ত করার চেয়ে দ্রুততর, বিশেষ করে যখন আমরা এমন স্ট্রাক্টগুলির সাথে কাজ করছি যেখানে প্রচুর ফিল্ড রয়েছে এবং শুধুমাত্র একটি বা দুটি ফিল্ড প্রাসঙ্গিক।
.. সিনট্যাক্সটি যতগুলি মানের প্রয়োজন ততগুলিতে প্রসারিত হবে। Listing 19-24 একটি টাপলের সাথে .. ব্যবহার করার উপায় দেখায়।
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, .., last) => { println!("Some numbers: {first}, {last}"); } } }
এই কোডে, প্রথম এবং শেষ মান first এবং last দিয়ে মেলানো হয়। .. মাঝের সবকিছু মেলবে এবং উপেক্ষা করবে।
যাইহোক, .. ব্যবহার করা অবশ্যই দ্ব্যর্থহীন হতে হবে। যদি এটি অস্পষ্ট হয় যে কোন মানগুলি মেলানোর জন্য উদ্দিষ্ট এবং কোনটি উপেক্ষা করা উচিত, Rust আমাদের একটি error দেবে। Listing 19-25 দ্ব্যর্থহীনভাবে .. ব্যবহারের একটি উদাহরণ দেখায়, তাই এটি কম্পাইল হবে না।
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {second}")
},
}
}আমরা যখন এই উদাহরণটি কম্পাইল করি, তখন আমরা এই error টি পাই:
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Rust-এর পক্ষে নির্ধারণ করা অসম্ভব যে second-এর সাথে একটি মান মেলানোর আগে টাপলের কতগুলি মান উপেক্ষা করতে হবে এবং তারপর আরও কতগুলি মান উপেক্ষা করতে হবে। এই কোডটির অর্থ হতে পারে যে আমরা 2 উপেক্ষা করতে চাই, second-কে 4-এর সাথে বাইন্ড করতে চাই এবং তারপর 8, 16 এবং 32 উপেক্ষা করতে চাই; অথবা আমরা 2 এবং 4 উপেক্ষা করতে চাই, second-কে 8-এর সাথে বাইন্ড করতে চাই এবং তারপর 16 এবং 32 উপেক্ষা করতে চাই; এবং আরও অনেক কিছু। second ভেরিয়েবলের নামটি Rust-এর কাছে বিশেষ কিছু বোঝায় না, তাই আমরা একটি কম্পাইলার error পাই কারণ এইভাবে দুটি জায়গায় .. ব্যবহার করা দ্ব্যর্থহীন।
ম্যাচ গার্ড সহ অতিরিক্ত শর্ত (Extra Conditionals with Match Guards)
একটি ম্যাচ গার্ড হল একটি অতিরিক্ত if শর্ত, যা একটি match আর্মের প্যাটার্নের পরে নির্দিষ্ট করা হয়, যেটি সেই আর্মটি বেছে নেওয়ার জন্য অবশ্যই মিলতে হবে। ম্যাচ গার্ডগুলি এমন আরও জটিল ধারণা প্রকাশ করার জন্য দরকারী যা একটি প্যাটার্ন একা অনুমতি দেয়। এগুলি শুধুমাত্র match এক্সপ্রেশনেই পাওয়া যায়, if let বা while let এক্সপ্রেশনে নয়।
শর্তটি প্যাটার্নে তৈরি করা ভেরিয়েবল ব্যবহার করতে পারে। Listing 19-26 একটি match দেখায় যেখানে প্রথম আর্মের প্যাটার্ন Some(x) এবং একটি ম্যাচ গার্ড if x % 2 == 0 রয়েছে (যা সংখ্যাটি জোড় হলে সত্য হবে)।
fn main() { let num = Some(4); match num { Some(x) if x % 2 == 0 => println!("The number {x} is even"), Some(x) => println!("The number {x} is odd"), None => (), } }
এই উদাহরণটি The number 4 is even প্রিন্ট করবে। যখন num-কে প্রথম আর্মের প্যাটার্নের সাথে তুলনা করা হয়, তখন এটি মেলে, কারণ Some(4) Some(x)-এর সাথে মেলে। তারপর ম্যাচ গার্ড পরীক্ষা করে যে x-কে 2 দ্বারা ভাগ করার অবশিষ্টাংশ 0-এর সমান কিনা এবং যেহেতু এটি, তাই প্রথম আর্মটি নির্বাচন করা হয়।
যদি num Some(5) হত, তাহলে প্রথম আর্মের ম্যাচ গার্ডটি মিথ্যা হত কারণ 5 কে 2 দ্বারা ভাগ করার অবশিষ্টাংশ হল 1, যা 0-এর সমান নয়। Rust তারপর দ্বিতীয় আর্মে যেত, যেটি মিলত কারণ দ্বিতীয় আর্মের কোনও ম্যাচ গার্ড নেই এবং তাই এটি যেকোনো Some ভেরিয়েন্টের সাথে মেলে।
if x % 2 == 0 শর্তটি একটি প্যাটার্নের মধ্যে প্রকাশ করার কোনও উপায় নেই, তাই ম্যাচ গার্ড আমাদের এই লজিকটি প্রকাশ করার ক্ষমতা দেয়। এই অতিরিক্ত অভিব্যক্তির নেতিবাচক দিক হল যে কম্পাইলার ম্যাচ গার্ড এক্সপ্রেশন জড়িত থাকলে এক্সহসটিভনেস পরীক্ষা করার চেষ্টা করে না।
Listing 19-11-এ, আমরা উল্লেখ করেছি যে আমরা আমাদের প্যাটার্ন-শ্যাডোয়িং সমস্যা সমাধানের জন্য ম্যাচ গার্ড ব্যবহার করতে পারি। মনে রাখবেন যে আমরা match এক্সপ্রেশনের প্যাটার্নের ভিতরে একটি নতুন ভেরিয়েবল তৈরি করেছি, match-এর বাইরের ভেরিয়েবলটি ব্যবহার করার পরিবর্তে। সেই নতুন ভেরিয়েবলটির অর্থ হল আমরা বাইরের ভেরিয়েবলের মানের বিরুদ্ধে পরীক্ষা করতে পারিনি। Listing 19-27 দেখায় কিভাবে আমরা এই সমস্যাটি সমাধান করতে একটি ম্যাচ গার্ড ব্যবহার করতে পারি।
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(n) if n == y => println!("Matched, n = {n}"), _ => println!("Default case, x = {x:?}"), } println!("at the end: x = {x:?}, y = {y}"); }
এই কোডটি এখন Default case, x = Some(5) প্রিন্ট করবে। দ্বিতীয় ম্যাচ আর্মের প্যাটার্নটি একটি নতুন ভেরিয়েবল y প্রবর্তন করে না যা বাইরের y-কে শ্যাডো করবে, মানে আমরা ম্যাচ গার্ডে বাইরের y ব্যবহার করতে পারি। Some(y) হিসাবে প্যাটার্নটি নির্দিষ্ট করার পরিবর্তে, যা বাইরের y-কে শ্যাডো করত, আমরা Some(n) নির্দিষ্ট করি। এটি একটি নতুন ভেরিয়েবল n তৈরি করে যা কোনও কিছুকে শ্যাডো করে না কারণ match-এর বাইরে কোনও n ভেরিয়েবল নেই।
ম্যাচ গার্ড if n == y একটি প্যাটার্ন নয় এবং তাই নতুন ভেরিয়েবল প্রবর্তন করে না। এই y হল বাইরের y, একটি নতুন শ্যাডো করা y নয় এবং আমরা n-কে y-এর সাথে তুলনা করে বাইরের y-এর মতো একই মান আছে এমন একটি মান খুঁজতে পারি।
আপনি একটি ম্যাচ গার্ডে অথবা অপারেটর | ব্যবহার করে একাধিক প্যাটার্ন নির্দিষ্ট করতে পারেন; ম্যাচ গার্ড শর্তটি সমস্ত প্যাটার্নের ক্ষেত্রে প্রযোজ্য হবে। Listing 19-28 | ব্যবহার করে একটি প্যাটার্নকে একটি ম্যাচ গার্ডের সাথে একত্রিত করার সময় অগ্রাধিকার দেখায়। এই উদাহরণের গুরুত্বপূর্ণ অংশ হল if y ম্যাচ গার্ডটি 4, 5, এবং 6-এর ক্ষেত্রে প্রযোজ্য, যদিও এটি দেখতে এমন হতে পারে যে if y শুধুমাত্র 6-এর ক্ষেত্রে প্রযোজ্য।
fn main() { let x = 4; let y = false; match x { 4 | 5 | 6 if y => println!("yes"), _ => println!("no"), } }
ম্যাচ শর্তটি বলে যে আর্মটি শুধুমাত্র তখনই মেলে যদি x-এর মান 4, 5, বা 6-এর সমান হয় এবং যদি y true হয়। যখন এই কোডটি চালানো হয়, তখন প্রথম আর্মের প্যাটার্নটি মেলে কারণ x হল 4, কিন্তু ম্যাচ গার্ড if y মিথ্যা, তাই প্রথম আর্মটি বেছে নেওয়া হয় না। কোডটি দ্বিতীয় আর্মে চলে যায়, যেটি মেলে এবং এই প্রোগ্রামটি no প্রিন্ট করে। এর কারণ হল if শর্তটি শুধুমাত্র শেষ মান 6-এর ক্ষেত্রে নয়, বরং সম্পূর্ণ প্যাটার্ন 4 | 5 | 6-এর ক্ষেত্রে প্রযোজ্য। অন্য কথায়, একটি প্যাটার্নের সাথে একটি ম্যাচ গার্ডের অগ্রাধিকার এইভাবে আচরণ করে:
(4 | 5 | 6) if y => ...
এইটার পরিবর্তে:
4 | 5 | (6 if y) => ...
কোডটি চালানোর পরে, অগ্রাধিকারের আচরণটি স্পষ্ট হয়: যদি ম্যাচ গার্ডটি শুধুমাত্র | অপারেটর ব্যবহার করে নির্দিষ্ট করা মানগুলির তালিকার চূড়ান্ত মানের ক্ষেত্রে প্রয়োগ করা হত, তাহলে আর্মটি মিলত এবং প্রোগ্রামটি yes প্রিন্ট করত।
@ বাইন্ডিং (@ Bindings)
অ্যাট অপারেটর @ আমাদের একটি ভেরিয়েবল তৈরি করতে দেয় যা একটি মান ধারণ করে একই সাথে আমরা সেই মানটিকে একটি প্যাটার্ন ম্যাচের জন্য পরীক্ষা করছি। Listing 19-29-এ, আমরা পরীক্ষা করতে চাই যে একটি Message::Hello id ফিল্ড 3..=7 রেঞ্জের মধ্যে আছে কিনা। আমরা ভেরিয়েবল id_variable-এর সাথে মানটিও বাইন্ড করতে চাই যাতে আমরা আর্মের সাথে সম্পর্কিত কোডে এটি ব্যবহার করতে পারি। আমরা এই ভেরিয়েবলটির নাম id দিতে পারি, ফিল্ডের মতোই, কিন্তু এই উদাহরণের জন্য আমরা একটি ভিন্ন নাম ব্যবহার করব।
fn main() { enum Message { Hello { id: i32 }, } let msg = Message::Hello { id: 5 }; match msg { Message::Hello { id: id_variable @ 3..=7, } => println!("Found an id in range: {id_variable}"), Message::Hello { id: 10..=12 } => { println!("Found an id in another range") } Message::Hello { id } => println!("Found some other id: {id}"), } }
এই উদাহরণটি Found an id in range: 5 প্রিন্ট করবে। রেঞ্জ 3..=7-এর আগে id_variable @ নির্দিষ্ট করে, আমরা রেঞ্জের সাথে মিলে যাওয়া যেকোনো মান ক্যাপচার করছি এবং একই সাথে পরীক্ষা করছি যে মানটি রেঞ্জ প্যাটার্নের সাথে মেলে কিনা।
দ্বিতীয় আর্মে, যেখানে আমাদের প্যাটার্নে শুধুমাত্র একটি রেঞ্জ নির্দিষ্ট করা আছে, আর্মের সাথে সম্পর্কিত কোডে এমন একটি ভেরিয়েবল নেই যাতে id ফিল্ডের প্রকৃত মান রয়েছে। id ফিল্ডের মান 10, 11, বা 12 হতে পারত, কিন্তু সেই প্যাটার্নের সাথে থাকা কোডটি জানে না কোনটি। প্যাটার্ন কোডটি id ফিল্ড থেকে মান ব্যবহার করতে সক্ষম নয়, কারণ আমরা একটি ভেরিয়েবলে id মান সংরক্ষণ করিনি।
শেষ আর্মে, যেখানে আমরা একটি রেঞ্জ ছাড়া একটি ভেরিয়েবল নির্দিষ্ট করেছি, আমাদের কাছে আর্মের কোডে ব্যবহারের জন্য একটি ভেরিয়েবল রয়েছে যার নাম id। এর কারণ হল আমরা স্ট্রাক্ট ফিল্ড শর্টহ্যান্ড সিনট্যাক্স ব্যবহার করেছি। কিন্তু আমরা এই আর্মে id ফিল্ডের মানের উপর কোনও পরীক্ষা প্রয়োগ করিনি, যেমনটি আমরা প্রথম দুটি আর্মের সাথে করেছি: যেকোনো মান এই প্যাটার্নের সাথে মিলবে।
@ ব্যবহার করা আমাদের একটি মানের পরীক্ষা করতে এবং এটিকে একটি প্যাটার্নের মধ্যে একটি ভেরিয়েবলে সংরক্ষণ করতে দেয়।
সারসংক্ষেপ (Summary)
Rust-এর প্যাটার্নগুলি বিভিন্ন ধরণের ডেটার মধ্যে পার্থক্য করতে খুব দরকারী। যখন match এক্সপ্রেশনে ব্যবহার করা হয়, Rust নিশ্চিত করে যে আপনার প্যাটার্নগুলি প্রতিটি সম্ভাব্য মান কভার করে, অথবা আপনার প্রোগ্রাম কম্পাইল হবে না। let স্টেটমেন্ট এবং ফাংশন প্যারামিটারের প্যাটার্নগুলি সেই গঠনগুলিকে আরও দরকারী করে তোলে, মানগুলিকে ছোট অংশে ডিস্ট্রাকচার করা এবং সেই অংশগুলিকে ভেরিয়েবলের সাথে যুক্ত করা সক্ষম করে। আমরা আমাদের প্রয়োজনের সাথে মানানসই সহজ বা জটিল প্যাটার্ন তৈরি করতে পারি।
এরপর, বইটির শেষ চ্যাপ্টারের আগে, আমরা Rust-এর বিভিন্ন বৈশিষ্ট্যের কিছু উন্নত দিক দেখব।
উন্নত বৈশিষ্ট্য (Advanced Features)
এখন পর্যন্ত, আপনি Rust প্রোগ্রামিং ভাষার সর্বাধিক ব্যবহৃত অংশগুলি শিখেছেন। Chapter 21-এ আরও একটি প্রোজেক্ট করার আগে, আমরা ভাষার কয়েকটি দিক দেখব যেগুলির সাথে আপনি হয়তো মাঝেমধ্যে পরিচিত হবেন, কিন্তু প্রতিদিন ব্যবহার নাও করতে পারেন। আপনি যখন কোনও অজানা বিষয়ের সম্মুখীন হন তখন এই চ্যাপ্টারটিকে একটি রেফারেন্স হিসাবে ব্যবহার করতে পারেন। এখানে আলোচিত বৈশিষ্ট্যগুলি খুব নির্দিষ্ট পরিস্থিতিতে দরকারী। যদিও আপনি প্রায়শই এগুলি ব্যবহার নাও করতে পারেন, আমরা নিশ্চিত করতে চাই যে Rust-এর সমস্ত বৈশিষ্ট্য সম্পর্কে আপনার ধারণা রয়েছে।
এই চ্যাপ্টারে, আমরা যা যা কভার করব:
- আনসেফ রাস্ট (Unsafe Rust): কীভাবে Rust-এর কিছু গ্যারান্টি থেকে বেরিয়ে আসা যায় এবং ম্যানুয়ালি সেই গ্যারান্টিগুলি বহাল রাখার দায়িত্ব নেওয়া যায়।
- অ্যাডভান্সড ট্রেইট (Advanced traits): অ্যাসোসিয়েটেড টাইপ, ডিফল্ট টাইপ প্যারামিটার, ফুললি কোয়ালিফাইড সিনট্যাক্স, সুপারট্রেইট এবং ট্রেইটের সাথে সম্পর্কিত নিউটাইপ প্যাটার্ন।
- অ্যাডভান্সড টাইপ (Advanced types): নিউটাইপ প্যাটার্ন, টাইপ অ্যালিয়াস, নেভার টাইপ এবং ডায়নামিকালি সাইজড টাইপ সম্পর্কে আরও অনেক কিছু।
- অ্যাডভান্সড ফাংশন এবং ক্লোজার (Advanced functions and closures): ফাংশন পয়েন্টার এবং রিটার্নিং ক্লোজার।
- ম্যাক্রো (Macros): কম্পাইল করার সময় আরও কোড সংজ্ঞায়িত করে এমন কোড সংজ্ঞায়িত করার উপায়।
এটি সবার জন্য Rust-এর বৈশিষ্ট্যগুলির একটি সমাহার! চলুন শুরু করা যাক!
আনসেফ রাস্ট (Unsafe Rust)
এখন পর্যন্ত আমরা যে সমস্ত কোড নিয়ে আলোচনা করেছি, কম্পাইল করার সময় সেগুলিতে Rust-এর মেমরি সুরক্ষার গ্যারান্টি প্রয়োগ করা হয়েছে। যাইহোক, Rust-এর ভিতরে একটি লুকানো দ্বিতীয় ভাষা রয়েছে যা এই মেমরি সুরক্ষার গ্যারান্টিগুলি প্রয়োগ করে না: এটিকে আনসেফ রাস্ট বলা হয় এবং এটি সাধারণ Rust-এর মতোই কাজ করে, কিন্তু আমাদের অতিরিক্ত সুপারপাওয়ার দেয়।
আনসেফ রাস্ট বিদ্যমান কারণ, স্বভাবতই, স্ট্যাটিক বিশ্লেষণ রক্ষণশীল। কম্পাইলার যখন নির্ধারণ করার চেষ্টা করে যে কোড গ্যারান্টিগুলি সমর্থন করে কিনা, তখন কিছু অবৈধ প্রোগ্রাম গ্রহণ করার চেয়ে কিছু বৈধ প্রোগ্রাম প্রত্যাখ্যান করা ভাল। যদিও কোডটি ঠিক হতে পারে, যদি Rust কম্পাইলারের কাছে আত্মবিশ্বাসী হওয়ার জন্য পর্যাপ্ত তথ্য না থাকে, তাহলে এটি কোডটি প্রত্যাখ্যান করবে। এই ক্ষেত্রগুলিতে, আপনি কম্পাইলারকে বলতে আনসেফ কোড ব্যবহার করতে পারেন, “আমাকে বিশ্বাস করুন, আমি জানি আমি কী করছি।” তবে সতর্ক থাকুন, আপনি নিজের ঝুঁকিতে আনসেফ রাস্ট ব্যবহার করেন: যদি আপনি আনসেফ কোডটি ভুলভাবে ব্যবহার করেন, তাহলে মেমরি অসুরক্ষার কারণে সমস্যা দেখা দিতে পারে, যেমন নাল পয়েন্টার ডিরেফারেন্সিং।
Rust-এর একটি আনসেফ অল্টার ইগো থাকার আরেকটি কারণ হল অন্তর্নিহিত কম্পিউটার হার্ডওয়্যার স্বভাবতই আনসেফ। যদি Rust আপনাকে আনসেফ অপারেশন করতে না দেয়, তাহলে আপনি কিছু কাজ করতে পারবেন না। Rust-এর আপনাকে নিম্ন-স্তরের সিস্টেম প্রোগ্রামিং করার অনুমতি দিতে হবে, যেমন সরাসরি অপারেটিং সিস্টেমের সাথে ইন্টারঅ্যাক্ট করা বা এমনকি আপনার নিজের অপারেটিং সিস্টেম লেখা। নিম্ন-স্তরের সিস্টেম প্রোগ্রামিং নিয়ে কাজ করা এই ভাষার অন্যতম লক্ষ্য। আসুন আমরা আনসেফ রাস্ট দিয়ে কী করতে পারি এবং কীভাবে এটি করতে পারি তা অন্বেষণ করি।
আনসেফ সুপারপাওয়ার (Unsafe Superpowers)
আনসেফ রাস্টে স্যুইচ করতে, unsafe কীওয়ার্ড ব্যবহার করুন এবং তারপর একটি নতুন ব্লক শুরু করুন যা আনসেফ কোড ধারণ করে। আপনি আনসেফ রাস্টে পাঁচটি কাজ করতে পারেন যা আপনি নিরাপদ রাস্টে করতে পারবেন না, যেগুলিকে আমরা আনসেফ সুপারপাওয়ার বলি। সেই সুপারপাওয়ারগুলির মধ্যে এই ক্ষমতাগুলি অন্তর্ভুক্ত রয়েছে:
- একটি র' পয়েন্টার ডিরেফারেন্স করা
- একটি আনসেফ ফাংশন বা মেথড কল করা
- একটি মিউটেবল স্ট্যাটিক ভেরিয়েবল অ্যাক্সেস বা পরিবর্তন করা
- একটি আনসেফ ট্রেইট ইমপ্লিমেন্ট করা।
- একটি
union-এর ফিল্ড অ্যাক্সেস করা।
এটি বোঝা গুরুত্বপূর্ণ যে unsafe বড় হাতের অক্ষর নয় বা Rust-এর অন্য কোনো নিরাপত্তা পরীক্ষাকে অক্ষম করে না: আপনি যদি আনসেফ কোডে একটি রেফারেন্স ব্যবহার করেন, তাহলেও সেটি পরীক্ষা করা হবে। unsafe কীওয়ার্ডটি শুধুমাত্র আপনাকে এই পাঁচটি বৈশিষ্ট্যে অ্যাক্সেস দেয় যা তখন কম্পাইলার মেমরি সুরক্ষার জন্য পরীক্ষা করে না। আপনি এখনও একটি আনসেফ ব্লকের ভিতরে কিছুটা নিরাপত্তা পাবেন।
এছাড়াও, unsafe-এর মানে এই নয় যে ব্লকের ভিতরের কোডটি অবশ্যই বিপজ্জনক বা এটিতে অবশ্যই মেমরি নিরাপত্তার সমস্যা থাকবে: উদ্দেশ্য হল যে প্রোগ্রামার হিসাবে, আপনি নিশ্চিত করবেন যে একটি unsafe ব্লকের ভিতরের কোড মেমরিকে বৈধ উপায়ে অ্যাক্সেস করবে।
মানুষ ত্রুটিপ্রবণ, এবং ভুল ঘটবে, কিন্তু এই পাঁচটি আনসেফ অপারেশনকে unsafe দিয়ে চিহ্নিত ব্লকের ভিতরে রাখার প্রয়োজন করে আপনি জানতে পারবেন যে মেমরি নিরাপত্তা সম্পর্কিত কোনও ত্রুটি অবশ্যই একটি unsafe ব্লকের মধ্যে থাকবে। unsafe ব্লকগুলিকে ছোট রাখুন; আপনি পরে যখন মেমরি বাগগুলি তদন্ত করবেন তখন আপনি কৃতজ্ঞ হবেন।
আনসেফ কোডকে যতটা সম্ভব আলাদা করতে, আনসেফ কোডকে একটি নিরাপদ অ্যাবস্ট্রাকশনের মধ্যে আবদ্ধ করা এবং একটি নিরাপদ API সরবরাহ করা ভাল, যা আমরা এই চ্যাপ্টারে পরে আলোচনা করব যখন আমরা আনসেফ ফাংশন এবং মেথডগুলি পরীক্ষা করব। স্ট্যান্ডার্ড লাইব্রেরির অংশগুলি আনসেফ কোডের উপর নিরাপদ অ্যাবস্ট্রাকশন হিসাবে প্রয়োগ করা হয় যা অডিট করা হয়েছে। একটি নিরাপদ অ্যাবস্ট্রাকশনের মধ্যে আনসেফ কোড র্যাপ করা unsafe-এর ব্যবহারগুলিকে সেই সমস্ত জায়গায় ছড়িয়ে যাওয়া থেকে আটকায় যেখানে আপনি বা আপনার ব্যবহারকারীরা unsafe কোড দিয়ে ইমপ্লিমেন্ট করা কার্যকারিতা ব্যবহার করতে চাইতে পারেন, কারণ একটি নিরাপদ অ্যাবস্ট্রাকশন ব্যবহার করা নিরাপদ।
আসুন একে একে পাঁচটি আনসেফ সুপারপাওয়ারের দিকে তাকাই। আমরা কিছু অ্যাবস্ট্রাকশনও দেখব যা আনসেফ কোডের জন্য একটি নিরাপদ ইন্টারফেস সরবরাহ করে।
একটি র' পয়েন্টার ডিরেফারেন্স করা (Dereferencing a Raw Pointer)
Chapter 4-এর “Dangling References”-এ, আমরা উল্লেখ করেছি যে কম্পাইলার নিশ্চিত করে যে রেফারেন্সগুলি সর্বদা বৈধ। আনসেফ রাস্ট-এ র' পয়েন্টার নামে দুটি নতুন টাইপ রয়েছে যা রেফারেন্সের মতো। রেফারেন্সের মতো, র' পয়েন্টারগুলি ইমিউটেবল বা মিউটেবল হতে পারে এবং যথাক্রমে *const T এবং *mut T হিসাবে লেখা হয়। এখানে তারকাচিহ্নটি ডিরেফারেন্স অপারেটর নয়; এটি টাইপের নামের অংশ। র' পয়েন্টারের প্রসঙ্গে, ইমিউটেবল-এর অর্থ হল পয়েন্টারটি ডিরেফারেন্স করার পরে সরাসরি অ্যাসাইন করা যাবে না।
রেফারেন্স এবং স্মার্ট পয়েন্টার থেকে ভিন্ন, র' পয়েন্টার:
- ইমিউটেবল এবং মিউটেবল উভয় পয়েন্টার বা একই লোকেশনে একাধিক মিউটেবল পয়েন্টার রেখে বরোয়িং-এর নিয়ম উপেক্ষা করার অনুমতি দেওয়া হয়।
- বৈধ মেমরির দিকে নির্দেশ করার গ্যারান্টি দেওয়া হয় না
- নাল (null) হওয়ার অনুমতি দেওয়া হয়
- কোনও স্বয়ংক্রিয় ক্লিনিং ইমপ্লিমেন্ট করে না
Rust-কে এই গ্যারান্টিগুলি প্রয়োগ করা থেকে বিরত রেখে, আপনি আরও ভাল পারফরম্যান্স বা অন্য ভাষা বা হার্ডওয়্যারের সাথে ইন্টারফেস করার ক্ষমতার বিনিময়ে গ্যারান্টিযুক্ত নিরাপত্তা ছেড়ে দিতে পারেন যেখানে Rust-এর গ্যারান্টি প্রযোজ্য নয়।
Listing 20-1-এ দেখানো হয়েছে কিভাবে একটি ইমিউটেবল এবং একটি মিউটেবল র' পয়েন্টার তৈরি করা যায়।
fn main() { let mut num = 5; let r1 = &raw const num; let r2 = &raw mut num; }
লক্ষ্য করুন যে আমরা এই কোডে unsafe কীওয়ার্ডটি অন্তর্ভুক্ত করিনি। আমরা নিরাপদ কোডে র' পয়েন্টার তৈরি করতে পারি; আমরা কেবল একটি আনসেফ ব্লকের বাইরে র' পয়েন্টার ডিরেফারেন্স করতে পারি না, যেমনটি আপনি একটু পরেই দেখতে পাবেন।
আমরা র' বরো অপারেটর ব্যবহার করে র' পয়েন্টার তৈরি করেছি: &raw const num একটি *const i32 ইমিউটেবল র' পয়েন্টার তৈরি করে এবং &raw mut num একটি *mut i32 মিউটেবল র' পয়েন্টার তৈরি করে। যেহেতু আমরা সেগুলি সরাসরি একটি লোকাল ভেরিয়েবল থেকে তৈরি করেছি, তাই আমরা জানি যে এই বিশেষ র' পয়েন্টারগুলি বৈধ, কিন্তু আমরা কোনও র' পয়েন্টার সম্পর্কে সেই অনুমান করতে পারি না।
এটি প্রদর্শন করার জন্য, পরবর্তীতে আমরা একটি র' পয়েন্টার তৈরি করব যার বৈধতা সম্পর্কে আমরা এতটা নিশ্চিত হতে পারি না, র' রেফারেন্স অপারেটর ব্যবহার করার পরিবর্তে একটি মান কাস্ট করতে as ব্যবহার করে। Listing 20-2 দেখায় কিভাবে মেমরির একটি নির্বিচারে লোকেশনে একটি র' পয়েন্টার তৈরি করতে হয়। নির্বিচারে মেমরি ব্যবহার করার চেষ্টা করা অনির্ধারিত: সেই অ্যাড্রেসে ডেটা থাকতে পারে বা নাও থাকতে পারে, কম্পাইলার কোডটিকে অপ্টিমাইজ করতে পারে যাতে কোনও মেমরি অ্যাক্সেস না থাকে, অথবা প্রোগ্রামটি একটি সেগমেন্টেশন ফল্ট সহ error করতে পারে। সাধারণত, এইরকম কোড লেখার কোনও ভাল কারণ নেই, বিশেষ করে এমন ক্ষেত্রে যেখানে আপনি পরিবর্তে একটি র' বরো অপারেটর ব্যবহার করতে পারেন, তবে এটি সম্ভব।
fn main() { let address = 0x012345usize; let r = address as *const i32; }
মনে রাখবেন যে আমরা নিরাপদ কোডে র' পয়েন্টার তৈরি করতে পারি, কিন্তু আমরা র' পয়েন্টারগুলিকে ডিরেফারেন্স করতে পারি না এবং যে ডেটার দিকে নির্দেশ করা হচ্ছে তা পড়তে পারি না। Listing 20-3-এ, আমরা একটি র' পয়েন্টারে ডিরেফারেন্স অপারেটর * ব্যবহার করি যার জন্য একটি unsafe ব্লক প্রয়োজন।
fn main() { let mut num = 5; let r1 = &raw const num; let r2 = &raw mut num; unsafe { println!("r1 is: {}", *r1); println!("r2 is: {}", *r2); } }
একটি পয়েন্টার তৈরি করা কোনও ক্ষতি করে না; শুধুমাত্র তখনই যখন আমরা এটির নির্দেশিত মানটি অ্যাক্সেস করার চেষ্টা করি তখনই আমরা একটি অবৈধ মানের সম্মুখীন হতে পারি।
এছাড়াও লক্ষ্য করুন যে Listing 20-1 এবং 20-3-এ, আমরা *const i32 এবং *mut i32 র' পয়েন্টার তৈরি করেছি যেগুলি উভয়ই একই মেমরি লোকেশনের দিকে নির্দেশ করে, যেখানে num সংরক্ষণ করা হয়। যদি আমরা পরিবর্তে num-এ একটি ইমিউটেবল এবং একটি মিউটেবল রেফারেন্স তৈরি করার চেষ্টা করতাম, তাহলে কোডটি কম্পাইল হত না কারণ Rust-এর ownership নিয়মগুলি একই সময়ে কোনও ইমিউটেবল রেফারেন্সের সাথে একটি মিউটেবল রেফারেন্সের অনুমতি দেয় না। র' পয়েন্টারগুলির সাহায্যে, আমরা একই লোকেশনে একটি মিউটেবল পয়েন্টার এবং একটি ইমিউটেবল পয়েন্টার তৈরি করতে পারি এবং মিউটেবল পয়েন্টারের মাধ্যমে ডেটা পরিবর্তন করতে পারি, সম্ভাব্যভাবে একটি ডেটা রেস তৈরি করতে পারি। সাবধান!
এই সমস্ত বিপদ থাকা সত্ত্বেও, আপনি কেন কখনও র' পয়েন্টার ব্যবহার করবেন? একটি প্রধান ব্যবহারের ক্ষেত্র হল C কোডের সাথে ইন্টারফেস করার সময়, যেমনটি আপনি পরবর্তী বিভাগে দেখতে পাবেন, “Calling an Unsafe Function or Method.” আরেকটি ক্ষেত্র হল নিরাপদ অ্যাবস্ট্রাকশন তৈরি করা যা বরো চেকার বুঝতে পারে না। আমরা আনসেফ ফাংশনগুলির পরিচয় দেব এবং তারপরে একটি নিরাপদ অ্যাবস্ট্রাকশনের উদাহরণ দেখব যা আনসেফ কোড ব্যবহার করে।
একটি আনসেফ ফাংশন বা মেথড কল করা (Calling an Unsafe Function or Method)
আপনি একটি আনসেফ ব্লকে যে দ্বিতীয় ধরনের অপারেশন করতে পারেন তা হল আনসেফ ফাংশন কল করা। আনসেফ ফাংশন এবং মেথডগুলি দেখতে হুবহু রেগুলার ফাংশন এবং মেথডের মতোই, তবে সংজ্ঞার বাকি অংশের আগে তাদের একটি অতিরিক্ত unsafe রয়েছে। এই প্রসঙ্গে unsafe কীওয়ার্ডটি নির্দেশ করে যে ফাংশনটির প্রয়োজনীয়তা রয়েছে যা আমাদের এই ফাংশনটি কল করার সময় অবশ্যই বজায় রাখতে হবে, কারণ Rust গ্যারান্টি দিতে পারে না যে আমরা এই প্রয়োজনীয়তাগুলি পূরণ করেছি। একটি unsafe ব্লকের মধ্যে একটি আনসেফ ফাংশন কল করে, আমরা বলছি যে আমরা এই ফাংশনের ডকুমেন্টেশন পড়েছি এবং ফাংশনের শর্তাবলী বহাল রাখার দায়িত্ব নিচ্ছি।
এখানে dangerous নামে একটি আনসেফ ফাংশন রয়েছে যা তার বডিতে কিছুই করে না:
fn main() { unsafe fn dangerous() {} unsafe { dangerous(); } }
আমাদের অবশ্যই একটি পৃথক unsafe ব্লকের মধ্যে dangerous ফাংশনটি কল করতে হবে। যদি আমরা unsafe ব্লক ছাড়া dangerous কল করার চেষ্টা করি, তাহলে আমরা একটি error পাব:
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function `dangerous` is unsafe and requires unsafe block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
unsafe ব্লকের মাধ্যমে, আমরা Rust-এর কাছে দাবী করছি যে আমরা ফাংশনের ডকুমেন্টেশন পড়েছি, আমরা কীভাবে এটি সঠিকভাবে ব্যবহার করতে হয় তা বুঝি এবং আমরা যাচাই করেছি যে আমরা ফাংশনের কন্ট্রাক্ট পূরণ করছি।
একটি আনসেফ ফাংশনের বডিতে আনসেফ অপারেশনগুলি সম্পাদন করতে, আপনাকে এখনও একটি রেগুলার ফাংশনের মতোই একটি unsafe ব্লক ব্যবহার করতে হবে এবং কম্পাইলার আপনাকে সতর্ক করবে যদি আপনি ভুলে যান। এটি unsafe ব্লকগুলিকে যতটা সম্ভব ছোট রাখতে সাহায্য করে, কারণ পুরো ফাংশন বডিতে আনসেফ অপারেশনের প্রয়োজন নাও হতে পারে।
আনসেফ কোডের উপর একটি নিরাপদ অ্যাবস্ট্রাকশন তৈরি করা (Creating a Safe Abstraction over Unsafe Code)
শুধুমাত্র একটি ফাংশনে আনসেফ কোড থাকার মানে এই নয় যে আমাদের পুরো ফাংশনটিকে আনসেফ হিসাবে চিহ্নিত করতে হবে। প্রকৃতপক্ষে, একটি নিরাপদ ফাংশনে আনসেফ কোড র্যাপ করা একটি সাধারণ অ্যাবস্ট্রাকশন। উদাহরণস্বরূপ, আসুন স্ট্যান্ডার্ড লাইব্রেরি থেকে split_at_mut ফাংশনটি অধ্যয়ন করি, যার জন্য কিছু আনসেফ কোড প্রয়োজন। আমরা অন্বেষণ করব কিভাবে আমরা এটি ইমপ্লিমেন্ট করতে পারি। এই নিরাপদ মেথডটি মিউটেবল স্লাইসের উপর সংজ্ঞায়িত করা হয়েছে: এটি একটি স্লাইস নেয় এবং আর্গুমেন্ট হিসাবে দেওয়া ইনডেক্সে স্লাইসটিকে বিভক্ত করে দুটি করে। Listing 20-4 দেখায় কিভাবে split_at_mut ব্যবহার করতে হয়।
#![allow(unused)] fn main() { {{#rustdoc_include ../listings/ch20-advanced-features/listing-20-4/src/main.rs:here}} }
আমরা শুধুমাত্র নিরাপদ Rust ব্যবহার করে এই ফাংশনটি ইমপ্লিমেন্ট করতে পারি না। একটি প্রচেষ্টা Listing 20-5-এর মতো দেখতে হতে পারে, যা কম্পাইল হবে না। সরলতার জন্য, আমরা split_at_mut-কে একটি মেথডের পরিবর্তে একটি ফাংশন হিসাবে এবং শুধুমাত্র i32 মানের স্লাইসের জন্য ইমপ্লিমেন্ট করব, জেনেরিক টাইপ T-এর জন্য নয়।
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}এই ফাংশনটি প্রথমে স্লাইসের মোট দৈর্ঘ্য পায়। তারপর এটি নিশ্চিত করে যে প্যারামিটার হিসাবে দেওয়া ইনডেক্সটি স্লাইসের মধ্যে রয়েছে কিনা তা পরীক্ষা করে যে এটি দৈর্ঘ্যের চেয়ে কম বা সমান কিনা। এই দাবীটির অর্থ হল যে আমরা যদি স্লাইসটিকে বিভক্ত করার জন্য দৈর্ঘ্যের চেয়ে বড় একটি ইনডেক্স পাস করি, তাহলে ফাংশনটি সেই ইনডেক্সটি ব্যবহার করার চেষ্টা করার আগেই প্যানিক করবে।
তারপর আমরা একটি টাপলে দুটি মিউটেবল স্লাইস রিটার্ন করি: একটি মূল স্লাইসের শুরু থেকে mid ইনডেক্স পর্যন্ত এবং অন্যটি mid থেকে স্লাইসের শেষ পর্যন্ত।
আমরা যখন Listing 20-5-এর কোড কম্পাইল করার চেষ্টা করি, তখন আমরা একটি error পাব।
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Rust-এর বরো চেকার বুঝতে পারে না যে আমরা স্লাইসের বিভিন্ন অংশ বরো করছি; এটি শুধুমাত্র জানে যে আমরা একই স্লাইস থেকে দুবার বরো করছি। একটি স্লাইসের বিভিন্ন অংশ বরো করা মৌলিকভাবে ঠিক আছে কারণ দুটি স্লাইস ওভারল্যাপ করছে না, কিন্তু Rust এটি বোঝার মতো যথেষ্ট স্মার্ট নয়। যখন আমরা জানি কোড ঠিক আছে, কিন্তু Rust জানে না, তখন আনসেফ কোডের কাছে পৌঁছানোর সময়।
Listing 20-6 দেখায় কিভাবে একটি unsafe ব্লক, একটি র' পয়েন্টার এবং কিছু আনসেফ ফাংশন কল ব্যবহার করে split_at_mut-এর ইমপ্লিমেন্টেশন কাজ করানো যায়।
use std::slice; fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = values.len(); let ptr = values.as_mut_ptr(); assert!(mid <= len); unsafe { ( slice::from_raw_parts_mut(ptr, mid), slice::from_raw_parts_mut(ptr.add(mid), len - mid), ) } } fn main() { let mut vector = vec![1, 2, 3, 4, 5, 6]; let (left, right) = split_at_mut(&mut vector, 3); }
Chapter 4-এর “The Slice Type” থেকে মনে করুন যে স্লাইসগুলি হল কিছু ডেটার একটি পয়েন্টার এবং স্লাইসের দৈর্ঘ্য। আমরা একটি স্লাইসের দৈর্ঘ্য পেতে len মেথড এবং একটি স্লাইসের র' পয়েন্টার অ্যাক্সেস করতে as_mut_ptr মেথড ব্যবহার করি। এক্ষেত্রে, যেহেতু আমাদের কাছে i32 মানের একটি মিউটেবল স্লাইস রয়েছে, তাই as_mut_ptr *mut i32 টাইপের একটি র' পয়েন্টার রিটার্ন করে, যা আমরা ptr ভেরিয়েবলে সংরক্ষণ করেছি।
আমরা এই দাবীটি রাখি যে mid ইনডেক্সটি স্লাইসের মধ্যে রয়েছে। তারপর আমরা আনসেফ কোডে আসি: slice::from_raw_parts_mut ফাংশনটি একটি র' পয়েন্টার এবং একটি দৈর্ঘ্য নেয় এবং এটি একটি স্লাইস তৈরি করে। আমরা এই ফাংশনটি ব্যবহার করে একটি স্লাইস তৈরি করি যা ptr থেকে শুরু হয় এবং mid সংখ্যক আইটেম দীর্ঘ। তারপর আমরা ptr-এ mid কে আর্গুমেন্ট হিসাবে দিয়ে add মেথড কল করি যাতে একটি র' পয়েন্টার পাওয়া যায় যা mid থেকে শুরু হয় এবং আমরা সেই পয়েন্টার এবং mid-এর পরের অবশিষ্ট সংখ্যক আইটেম ব্যবহার করে একটি স্লাইস তৈরি করি দৈর্ঘ্যের জন্য।
slice::from_raw_parts_mut ফাংশনটি আনসেফ কারণ এটি একটি র' পয়েন্টার নেয় এবং অবশ্যই বিশ্বাস করতে হবে যে এই পয়েন্টারটি বৈধ। র' পয়েন্টারগুলিতে add মেথডটিও আনসেফ, কারণ এটিকে অবশ্যই বিশ্বাস করতে হবে যে অফসেট লোকেশনটিও একটি বৈধ পয়েন্টার। অতএব, আমাদের slice::from_raw_parts_mut এবং add-এর চারপাশে একটি unsafe ব্লক রাখতে হয়েছিল যাতে আমরা সেগুলি কল করতে পারি। কোডটি দেখে এবং mid অবশ্যই len-এর থেকে কম বা সমান হতে হবে এই দাবী যোগ করে, আমরা বলতে পারি যে unsafe ব্লকের মধ্যে ব্যবহৃত সমস্ত র' পয়েন্টারগুলি স্লাইসের মধ্যে ডেটার বৈধ পয়েন্টার হবে। এটি unsafe-এর একটি গ্রহণযোগ্য এবং উপযুক্ত ব্যবহার।
লক্ষ্য করুন যে আমাদের ফলস্বরূপ split_at_mut ফাংশনটিকে unsafe হিসাবে চিহ্নিত করার প্রয়োজন নেই এবং আমরা নিরাপদ Rust থেকে এই ফাংশনটিকে কল করতে পারি। আমরা ফাংশনের একটি ইমপ্লিমেন্টেশন সহ আনসেফ কোডের একটি নিরাপদ অ্যাবস্ট্রাকশন তৈরি করেছি যা নিরাপদ উপায়ে unsafe কোড ব্যবহার করে, কারণ এটি শুধুমাত্র সেই ডেটা থেকে বৈধ পয়েন্টার তৈরি করে যাতে এই ফাংশনটির অ্যাক্সেস রয়েছে।
বিপরীতে, Listing 20-7-এ slice::from_raw_parts_mut-এর ব্যবহার সম্ভবত ক্র্যাশ করবে যখন স্লাইসটি ব্যবহার করা হবে। এই কোডটি একটি নির্বিচারে মেমরি লোকেশন নেয় এবং 10,000 আইটেম দীর্ঘ একটি স্লাইস তৈরি করে।
fn main() { use std::slice; let address = 0x01234usize; let r = address as *mut i32; let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) }; }
আমরা এই নির্বিচারে লোকেশনে মেমরির মালিক নই এবং এই কোডটি যে স্লাইস তৈরি করে তাতে বৈধ i32 মান রয়েছে তার কোনও গ্যারান্টি নেই। values ব্যবহার করার চেষ্টা করা যেন এটি একটি বৈধ স্লাইস, এটি অনির্ধারিত আচরণের দিকে পরিচালিত করে।
এক্সটার্ন ফাংশন ব্যবহার করে বাহ্যিক কোড কল করা (Using extern` Functions to Call External Code)
কখনও কখনও, আপনার Rust কোডের অন্য ভাষায় লেখা কোডের সাথে ইন্টারঅ্যাক্ট করার প্রয়োজন হতে পারে। এর জন্য, Rust-এর extern কীওয়ার্ড রয়েছে যা একটি ফরেন ফাংশন ইন্টারফেস (FFI) তৈরি এবং ব্যবহারে সহায়তা করে। একটি FFI হল একটি প্রোগ্রামিং ভাষার জন্য ফাংশন সংজ্ঞায়িত করার এবং একটি ভিন্ন (বিদেশী) প্রোগ্রামিং ভাষাকে সেই ফাংশনগুলিকে কল করার অনুমতি দেওয়ার একটি উপায়।
Listing 20-8 C স্ট্যান্ডার্ড লাইব্রেরি থেকে abs ফাংশনের সাথে একটি ইন্টিগ্রেশন কীভাবে সেট আপ করতে হয় তা প্রদর্শন করে। extern ব্লকের মধ্যে ঘোষিত ফাংশনগুলি সাধারণত Rust কোড থেকে কল করা অনিরাপদ, তাই তাদের অবশ্যই unsafe হিসাবে চিহ্নিত করতে হবে। এর কারণ হল অন্য ভাষাগুলি Rust-এর নিয়ম এবং গ্যারান্টিগুলি প্রয়োগ করে না এবং Rust সেগুলি পরীক্ষা করতে পারে না, তাই নিরাপত্তা নিশ্চিত করার দায়িত্ব প্রোগ্রামারের উপর বর্তায়।
unsafe extern "C" { fn abs(input: i32) -> i32; } fn main() { unsafe { println!("Absolute value of -3 according to C: {}", abs(-3)); } }
unsafe extern "C" ব্লকের মধ্যে, আমরা অন্য ভাষা থেকে যে বাহ্যিক ফাংশনগুলিকে কল করতে চাই তাদের নাম এবং স্বাক্ষর তালিকাভুক্ত করি। "C" অংশটি সংজ্ঞায়িত করে যে বাহ্যিক ফাংশনটি কোন অ্যাপ্লিকেশন বাইনারি ইন্টারফেস (ABI) ব্যবহার করে: ABI সংজ্ঞায়িত করে কিভাবে অ্যাসেম্বলি স্তরে ফাংশনটিকে কল করতে হয়। "C" ABI হল সবচেয়ে সাধারণ এবং C প্রোগ্রামিং ভাষার ABI অনুসরণ করে।
এই বিশেষ ফাংশনটির কোন মেমরি নিরাপত্তা বিবেচনা নেই। আসলে, আমরা জানি যে abs-এ যেকোনো কল সর্বদাই যেকোনো i32-এর জন্য নিরাপদ হবে, তাই আমরা safe কীওয়ার্ড ব্যবহার করে বলতে পারি যে এই নির্দিষ্ট ফাংশনটি কল করা নিরাপদ, যদিও এটি একটি unsafe extern ব্লকে রয়েছে। একবার আমরা সেই পরিবর্তনটি করলে, এটিকে কল করার জন্য আর একটি unsafe ব্লকের প্রয়োজন হয় না, যেমনটি Listing 20-9-এ দেখানো হয়েছে।
unsafe extern "C" { safe fn abs(input: i32) -> i32; } fn main() { println!("Absolute value of -3 according to C: {}", abs(-3)); }
একটি ফাংশনকে safe হিসাবে চিহ্নিত করা এটিকে সহজাতভাবে নিরাপদ করে না! পরিবর্তে, এটি এমন একটি প্রতিশ্রুতির মতো যা আপনি Rust-কে দিচ্ছেন যে এটি নিরাপদ। সেই প্রতিশ্রুতি রাখা হয়েছে কিনা তা নিশ্চিত করা এখনও আপনার দায়িত্ব!
অন্যান্য ভাষা থেকে Rust ফাংশন কল করা (Calling Rust Functions from Other Languages)
আমরা
externব্যবহার করে একটি ইন্টারফেস তৈরি করতে পারি যা অন্যান্য ভাষাগুলিকে Rust ফাংশন কল করার অনুমতি দেয়। একটি সম্পূর্ণexternব্লক তৈরি করার পরিবর্তে, আমরাexternকীওয়ার্ড যোগ করি এবং প্রাসঙ্গিক ফাংশনের জন্যfnকীওয়ার্ডের ঠিক আগে ব্যবহার করার জন্য ABI নির্দিষ্ট করি। আমাদের এই ফাংশনের নাম ম্যাংগল না করার জন্য Rust কম্পাইলারকে বলার জন্য একটি#[unsafe(no_mangle)]অ্যানোটেশনও যোগ করতে হবে। ম্যাংলিং হল যখন একটি কম্পাইলার আমাদের দেওয়া একটি ফাংশনের নাম পরিবর্তন করে একটি ভিন্ন নামে পরিবর্তন করে যাতে কম্পাইলেশন প্রক্রিয়ার অন্যান্য অংশগুলির জন্য আরও তথ্য থাকে কিন্তু মানুষের পাঠযোগ্যতা কম থাকে। প্রতিটি প্রোগ্রামিং ভাষার কম্পাইলার নামগুলিকে সামান্য ভিন্নভাবে ম্যাংগল করে, তাই অন্য ভাষাগুলির দ্বারা একটি Rust ফাংশনকে নামযোগ্য করার জন্য, আমাদের অবশ্যই Rust কম্পাইলারের নাম ম্যাংলিং অক্ষম করতে হবে। এটি আনসেফ কারণ বিল্ট-ইন ম্যাংলিং ছাড়াই লাইব্রেরি জুড়ে নামের সংঘর্ষ হতে পারে, তাই আমরা যে নামটি এক্সপোর্ট করেছি তা ম্যাংলিং ছাড়াই এক্সপোর্ট করা নিরাপদ কিনা তা নিশ্চিত করা আমাদের দায়িত্ব।নিম্নলিখিত উদাহরণে, আমরা
call_from_cফাংশনটিকে C কোড থেকে অ্যাক্সেসযোগ্য করে তুলি, এটিকে একটি শেয়ার্ড লাইব্রেরিতে কম্পাইল করার এবং C থেকে লিঙ্ক করার পরে:#![allow(unused)] fn main() { #[unsafe(no_mangle)] pub extern "C" fn call_from_c() { println!("Just called a Rust function from C!"); } }
extern-এর এই ব্যবহারের জন্যunsafeপ্রয়োজন হয় না।
একটি মিউটেবল স্ট্যাটিক ভেরিয়েবল অ্যাক্সেস বা পরিবর্তন করা (Accessing or Modifying a Mutable Static Variable)
এই বইটিতে, আমরা এখনও গ্লোবাল ভেরিয়েবল সম্পর্কে কথা বলিনি, যা Rust সমর্থন করে কিন্তু Rust-এর ownership নিয়মের সাথে সমস্যাযুক্ত হতে পারে। যদি দুটি থ্রেড একই মিউটেবল গ্লোবাল ভেরিয়েবল অ্যাক্সেস করে, তাহলে এটি একটি ডেটা রেসের কারণ হতে পারে।
Rust-এ, গ্লোবাল ভেরিয়েবলগুলিকে স্ট্যাটিক ভেরিয়েবল বলা হয়। Listing 20-10 একটি স্ট্যাটিক ভেরিয়েবলের উদাহরণ ঘোষণা এবং ব্যবহার দেখায় যার মান একটি স্ট্রিং স্লাইস।
static HELLO_WORLD: &str = "Hello, world!"; fn main() { println!("name is: {HELLO_WORLD}"); }
স্ট্যাটিক ভেরিয়েবলগুলি কনস্ট্যান্টের মতোই, যা আমরা Chapter 3-এর “Constants”-এ আলোচনা করেছি। স্ট্যাটিক ভেরিয়েবলের নামগুলি রীতি অনুযায়ী SCREAMING_SNAKE_CASE-এ থাকে। স্ট্যাটিক ভেরিয়েবলগুলি শুধুমাত্র 'static লাইফটাইম সহ রেফারেন্স সংরক্ষণ করতে পারে, যার অর্থ হল Rust কম্পাইলার লাইফটাইম বের করতে পারে এবং আমাদের এটিকে স্পষ্টভাবে অ্যানোটেট করার প্রয়োজন নেই। একটি অপরিবর্তনীয় স্ট্যাটিক ভেরিয়েবল অ্যাক্সেস করা নিরাপদ।
কনস্ট্যান্ট এবং অপরিবর্তনীয় স্ট্যাটিক ভেরিয়েবলের মধ্যে একটি সূক্ষ্ম পার্থক্য হল যে একটি স্ট্যাটিক ভেরিয়েবলের মানগুলির মেমরিতে একটি নির্দিষ্ট ঠিকানা থাকে। মান ব্যবহার করা সর্বদা একই ডেটা অ্যাক্সেস করবে। অন্যদিকে, কনস্ট্যান্টগুলিকে যখনই ব্যবহার করা হয় তখনই তাদের ডেটা ডুপ্লিকেট করার অনুমতি দেওয়া হয়। আরেকটি পার্থক্য হল স্ট্যাটিক ভেরিয়েবলগুলি মিউটেবল হতে পারে। মিউটেবল স্ট্যাটিক ভেরিয়েবল অ্যাক্সেস এবং পরিবর্তন করা আনসেফ। Listing 20-11 দেখায় কিভাবে COUNTER নামে একটি মিউটেবল স্ট্যাটিক ভেরিয়েবল ঘোষণা, অ্যাক্সেস এবং পরিবর্তন করতে হয়।
static mut COUNTER: u32 = 0; /// SAFETY: Calling this from more than a single thread at a time is undefined /// behavior, so you *must* guarantee you only call it from a single thread at /// a time. unsafe fn add_to_count(inc: u32) { unsafe { COUNTER += inc; } } fn main() { unsafe { // SAFETY: This is only called from a single thread in `main`. add_to_count(3); println!("COUNTER: {}", *(&raw const COUNTER)); } }
নিয়মিত ভেরিয়েবলের মতো, আমরা mut কীওয়ার্ড ব্যবহার করে মিউটেবিলিটি নির্দিষ্ট করি। যে কোনও কোড যা COUNTER থেকে পড়ে বা লেখে তা অবশ্যই একটি unsafe ব্লকের মধ্যে থাকতে হবে। Listing 20-11-এর কোডটি কম্পাইল করে এবং আমরা যেমন আশা করি COUNTER: 3 প্রিন্ট করে কারণ এটি সিঙ্গেল থ্রেডেড। একাধিক থ্রেড COUNTER অ্যাক্সেস করলে সম্ভবত ডেটা রেস হবে, তাই এটি অনির্ধারিত আচরণ। অতএব, আমাদের সম্পূর্ণ ফাংশনটিকে unsafe হিসাবে চিহ্নিত করতে হবে এবং নিরাপত্তার সীমাবদ্ধতা নথিভুক্ত করতে হবে, যাতে ফাংশনটিকে কল করা যে কেউ জানে যে তারা কী করতে পারে এবং কী করতে পারে না।
যখনই আমরা একটি আনসেফ ফাংশন লিখি, তখন SAFETY দিয়ে শুরু করে একটি মন্তব্য লেখা এবং কলারকে ফাংশনটি নিরাপদে কল করার জন্য কী করতে হবে তা ব্যাখ্যা করা প্রথাগত। একইভাবে, যখনই আমরা একটি আনসেফ অপারেশন করি, তখন নিরাপত্তার নিয়মগুলি কীভাবে বহাল রাখা হয় তা ব্যাখ্যা করার জন্য SAFETY দিয়ে শুরু করে একটি মন্তব্য লেখা প্রথাগত।
অতিরিক্তভাবে, কম্পাইলার আপনাকে একটি মিউটেবল স্ট্যাটিক ভেরিয়েবলের রেফারেন্স তৈরি করার অনুমতি দেবে না। আপনি শুধুমাত্র একটি র' পয়েন্টারের মাধ্যমে এটি অ্যাক্সেস করতে পারেন, যা র' বরো অপারেটরগুলির মধ্যে একটি দিয়ে তৈরি করা হয়। এর মধ্যে এমন ক্ষেত্রগুলিও রয়েছে যেখানে রেফারেন্সটি অদৃশ্যভাবে তৈরি করা হয়, যেমন যখন এটি এই কোড লিস্টিং-এর println!-এ ব্যবহৃত হয়। স্ট্যাটিক মিউটেবল ভেরিয়েবলের রেফারেন্স শুধুমাত্র র' পয়েন্টারের মাধ্যমে তৈরি করা যেতে পারে এমন প্রয়োজনীয়তা তাদের ব্যবহারের জন্য নিরাপত্তার প্রয়োজনীয়তাগুলিকে আরও স্পষ্ট করতে সহায়তা করে।
মিউটেবল ডেটা যা বিশ্বব্যাপী অ্যাক্সেসযোগ্য, সেখানে কোনও ডেটা রেস নেই তা নিশ্চিত করা কঠিন, যে কারণে Rust মিউটেবল স্ট্যাটিক ভেরিয়েবলগুলিকে আনসেফ বলে মনে করে। যেখানে সম্ভব, সেখানে কনকারেন্সি কৌশল এবং থ্রেড-নিরাপদ স্মার্ট পয়েন্টারগুলি ব্যবহার করা বাঞ্ছনীয় যা আমরা Chapter 16-এ আলোচনা করেছি যাতে কম্পাইলার পরীক্ষা করে যে বিভিন্ন থ্রেড থেকে অ্যাক্সেস করা ডেটা নিরাপদে করা হয়েছে।
একটি আনসেফ ট্রেইট ইমপ্লিমেন্ট করা (Implementing an Unsafe Trait)
আমরা একটি আনসেফ ট্রেইট ইমপ্লিমেন্ট করতে unsafe ব্যবহার করতে পারি। একটি ট্রেইট আনসেফ হয় যখন এর অন্তত একটি মেথডের কিছু ইনভেরিয়েন্ট থাকে যা কম্পাইলার যাচাই করতে পারে না। আমরা trait-এর আগে unsafe কীওয়ার্ড যোগ করে এবং ট্রেইটের ইমপ্লিমেন্টেশনকেও unsafe হিসাবে চিহ্নিত করে ঘোষণা করি যে একটি ট্রেইট unsafe, যেমনটি Listing 20-12-এ দেখানো হয়েছে।
unsafe trait Foo { // methods go here } unsafe impl Foo for i32 { // method implementations go here } fn main() {}
unsafe impl ব্যবহার করে, আমরা প্রতিশ্রুতি দিচ্ছি যে আমরা সেই ইনভেরিয়েন্টগুলি বহাল রাখব যা কম্পাইলার যাচাই করতে পারে না।
একটি উদাহরণ হিসাবে, “Extensible Concurrency with the Sync and Send Traits” in Chapter 16-এ আমরা যে Sync এবং Send মার্কার ট্রেইটগুলি নিয়ে আলোচনা করেছি তা স্মরণ করুন: কম্পাইলার এই ট্রেইটগুলি স্বয়ংক্রিয়ভাবে ইমপ্লিমেন্ট করে যদি আমাদের টাইপগুলি সম্পূর্ণরূপে Send এবং Sync টাইপ দ্বারা গঠিত হয়। যদি আমরা এমন একটি টাইপ ইমপ্লিমেন্ট করি যাতে এমন একটি টাইপ থাকে যা Send বা Sync নয়, যেমন র' পয়েন্টার, এবং আমরা সেই টাইপটিকে Send বা Sync হিসাবে চিহ্নিত করতে চাই, তাহলে আমাদের অবশ্যই unsafe ব্যবহার করতে হবে। Rust যাচাই করতে পারে না যে আমাদের টাইপটি এই গ্যারান্টিগুলি বহাল রাখে যে এটি নিরাপদে থ্রেড জুড়ে পাঠানো যেতে পারে বা একাধিক থ্রেড থেকে অ্যাক্সেস করা যেতে পারে; অতএব, আমাদের সেই পরীক্ষাগুলি ম্যানুয়ালি করতে হবে এবং সেই অনুযায়ী unsafe দিয়ে নির্দেশ করতে হবে।
একটি ইউনিয়নের ক্ষেত্রগুলি অ্যাক্সেস করা (Accessing Fields of a Union)
unsafe দিয়ে কাজ করে এমন চূড়ান্ত অ্যাকশন হল একটি ইউনিয়ন-এর ক্ষেত্রগুলি অ্যাক্সেস করা। একটি union একটি struct-এর মতোই, কিন্তু একটি নির্দিষ্ট দৃষ্টান্তে একবারে শুধুমাত্র একটি ঘোষিত ক্ষেত্র ব্যবহার করা হয়। ইউনিয়নগুলি প্রাথমিকভাবে C কোডের ইউনিয়নগুলির সাথে ইন্টারফেস করতে ব্যবহৃত হয়। ইউনিয়ন ক্ষেত্রগুলি অ্যাক্সেস করা অনিরাপদ কারণ Rust বর্তমানে ইউনিয়ন ইনস্ট্যান্সে সংরক্ষিত ডেটার টাইপ গ্যারান্টি দিতে পারে না। আপনি Rust Reference-এ ইউনিয়ন সম্পর্কে আরও জানতে পারেন।
আনসেফ কোড পরীক্ষা করার জন্য Miri ব্যবহার করা (Using Miri to check unsafe code)
আনসেফ কোড লেখার সময়, আপনি পরীক্ষা করতে চাইতে পারেন যে আপনি যা লিখেছেন তা আসলে নিরাপদ এবং সঠিক কিনা। এটি করার অন্যতম সেরা উপায় হল Miri ব্যবহার করা, যা অনির্ধারিত আচরণ সনাক্ত করার জন্য একটি অফিশিয়াল Rust টুল। যেখানে বরো চেকার একটি স্ট্যাটিক টুল যা কম্পাইল করার সময় কাজ করে, Miri হল একটি ডায়নামিক টুল যা রানটাইমে কাজ করে। এটি আপনার প্রোগ্রাম বা এর টেস্ট স্যুট চালানোর মাধ্যমে আপনার কোড পরীক্ষা করে এবং আপনি যখন Rust কীভাবে কাজ করা উচিত সে সম্পর্কে এটি যে নিয়মগুলি বোঝে তা লঙ্ঘন করেন তখন সনাক্ত করে।
Miri ব্যবহার করার জন্য Rust-এর একটি নাইটলি বিল্ড প্রয়োজন (যা আমরা Appendix G: How Rust is Made and “Nightly Rust”)-এ আরও আলোচনা করব)। আপনি rustup +nightly component add miri টাইপ করে Rust-এর একটি নাইটলি ভার্সন এবং Miri টুল উভয়ই ইনস্টল করতে পারেন। এটি আপনার প্রোজেক্ট যে Rust ভার্সন ব্যবহার করে তা পরিবর্তন করে না; এটি শুধুমাত্র আপনার সিস্টেমে টুলটি যোগ করে যাতে আপনি যখন চান তখন এটি ব্যবহার করতে পারেন। আপনি cargo +nightly miri run বা cargo +nightly miri test টাইপ করে একটি প্রোজেক্টে Miri চালাতে পারেন।
এটি কতটা সহায়ক হতে পারে তার একটি উদাহরণ হিসাবে, Listing 20-11-এর বিরুদ্ধে আমরা যখন এটি চালাই তখন কী ঘটে তা বিবেচনা করুন:
$ cargo +nightly miri run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.01s
Running `/Users/chris/.rustup/toolchains/nightly-aarch64-apple-darwin/bin/cargo-miri runner target/miri/aarch64-apple-darwin/debug/unsafe-example`
COUNTER: 3
এটি সহায়কভাবে এবং সঠিকভাবে লক্ষ্য করে যে আমাদের কাছে মিউটেবল ডেটার শেয়ার্ড রেফারেন্স রয়েছে এবং এটি সম্পর্কে সতর্ক করে। এক্ষেত্রে, এটি আমাদের বলে না কিভাবে সমস্যাটি ঠিক করতে হয়, তবে এর মানে হল যে আমরা জানি যে একটি সম্ভাব্য সমস্যা রয়েছে এবং কীভাবে এটি নিরাপদ তা নিশ্চিত করতে হবে সে সম্পর্কে ভাবতে পারি। অন্যান্য ক্ষেত্রে, এটি আসলে আমাদের বলতে পারে যে কিছু কোড অবশ্যই ভুল এবং এটি কীভাবে ঠিক করতে হবে সে সম্পর্কে সুপারিশ করতে পারে।
Miri আনসেফ কোড লেখার সময় আপনি যা ভুল করতে পারেন তার সবকিছু ধরে না। একটি জিনিসের জন্য, যেহেতু এটি একটি ডায়নামিক চেক, এটি শুধুমাত্র সেই কোডের সাথে সমস্যাগুলি ধরে যা আসলে চালানো হয়। এর মানে হল যে আপনি যে আনসেফ কোড লিখেছেন সে সম্পর্কে আপনার আত্মবিশ্বাস বাড়ানোর জন্য আপনাকে এটিকে ভাল পরীক্ষার কৌশলগুলির সাথে ব্যবহার করতে হবে। অন্য একটি জিনিসের জন্য, এটি আপনার কোডটি আনসাউন্ড হতে পারে এমন প্রতিটি সম্ভাব্য উপায় কভার করে না। যদি Miri একটি সমস্যা ধরে, তাহলে আপনি জানেন যে একটি বাগ আছে, কিন্তু শুধু এই কারণে যে Miri একটি বাগ ধরে না তার মানে এই নয় যে কোনও সমস্যা নেই। Miri অনেক কিছু ধরতে পারে, যদিও। এই চ্যাপ্টারের আনসেফ কোডের অন্যান্য উদাহরণগুলিতে এটি চালানোর চেষ্টা করুন এবং দেখুন এটি কী বলে!
কখন আনসেফ কোড ব্যবহার করবেন (When to Use Unsafe Code)
এইমাত্র আলোচিত পাঁচটি অ্যাকশন (সুপারপাওয়ার) নেওয়ার জন্য unsafe ব্যবহার করা ভুল বা এমনকি ভ্রুকুটি করাও নয়। তবে কম্পাইলার মেমরি নিরাপত্তা বহাল রাখতে সাহায্য করতে পারে না বলে unsafe কোড সঠিক করা আরও কঠিন। যখন আপনার unsafe কোড ব্যবহার করার একটি কারণ থাকে, তখন আপনি তা করতে পারেন এবং একটি স্পষ্ট unsafe অ্যানোটেশন থাকা সমস্যাগুলি দেখা দিলে সমস্যার উৎস ট্র্যাক করা সহজ করে তোলে। আপনি যখনই আনসেফ কোড লেখেন, আপনি Miri ব্যবহার করে আরও আত্মবিশ্বাসী হতে পারেন যে আপনি যে কোডটি লিখেছেন সেটি Rust-এর নিয়মগুলি বহাল রাখে।
আনসেফ রাস্ট-এর সাথে কার্যকরভাবে কীভাবে কাজ করতে হয় তার আরও গভীর অনুসন্ধানের জন্য, Rust-এর এই বিষয়ের উপর অফিশিয়াল গাইড, Rustonomicon পড়ুন।
অ্যাডভান্সড ট্রেইট (Advanced Traits)
আমরা দশম অধ্যায়ে "ট্রেইট: শেয়ার্ড বিহেভিয়ার নির্ধারণ" অংশে ট্রেইট নিয়ে আলোচনা করেছিলাম, কিন্তু এর আরও advanced বিষয়গুলো আলোচনা করিনি। এখন যেহেতু আপনি Rust সম্পর্কে আরও জানেন, তাই আমরা গভীরে যেতে পারি।
অ্যাসোসিয়েটেড টাইপ ব্যবহার করে ট্রেইট সংজ্ঞায় প্লেসহোল্ডার টাইপ নির্দিষ্ট করা
অ্যাসোসিয়েটেড টাইপ (Associated types) একটি টাইপ প্লেসহোল্ডারের সাথে ট্রেইটকে সংযুক্ত করে, যাতে ট্রেইট মেথডের সংজ্ঞাগুলো তাদের সিগনেচারে এই প্লেসহোল্ডার টাইপগুলো ব্যবহার করতে পারে। একটি ট্রেইটের implementor, প্লেসহোল্ডার টাইপের পরিবর্তে ব্যবহৃত হওয়ার জন্য একটি concrete টাইপ নির্দিষ্ট করবে। এইভাবে, আমরা এমন একটি ট্রেইট সংজ্ঞায়িত করতে পারি যা কিছু টাইপ ব্যবহার করে, কিন্তু ট্রেইটটি ইমপ্লিমেন্ট করার আগ পর্যন্ত সেই টাইপগুলো আসলে কী, তা জানার প্রয়োজন নেই।
এই অধ্যায়ের বেশিরভাগ advanced ফিচারকে আমরা বলেছি কদাচিৎ প্রয়োজন হয়। অ্যাসোসিয়েটেড টাইপগুলি মাঝখানে কোথাও রয়েছে: এগুলি বইয়ের বাকি অংশে বর্ণিত ফিচারগুলোর চেয়ে কম ব্যবহৃত হয়, তবে এই অধ্যায়ে আলোচিত অন্যান্য অনেক ফিচারের চেয়ে বেশি ব্যবহৃত হয়।
অ্যাসোসিয়েটেড টাইপ সহ একটি ট্রেইটের উদাহরণ হল Iterator ট্রেইট, যা standard library সরবরাহ করে। অ্যাসোসিয়েটেড টাইপটির নাম Item এবং এটি Iterator ট্রেইট ইমপ্লিমেন্ট করা টাইপের ভ্যালুগুলোর টাইপের প্রতিনিধিত্ব করে, যার উপর ইটারেশন করা হচ্ছে। Iterator ট্রেইটের সংজ্ঞাটি লিস্টিং ২০-১৩-তে দেখানো হয়েছে।
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Item টাইপটি একটি প্লেসহোল্ডার, এবং next মেথডের সংজ্ঞা দেখায় যে এটি Option<Self::Item> টাইপের ভ্যালু রিটার্ন করবে। Iterator ট্রেইটের ইমপ্লিমেন্টররা Item-এর জন্য concrete টাইপ নির্দিষ্ট করবে এবং next মেথড সেই concrete টাইপের একটি ভ্যালু ধারণকারী একটি Option রিটার্ন করবে।
অ্যাসোসিয়েটেড টাইপগুলো জেনেরিকের মতোই মনে হতে পারে, কারণ জেনেরিক আমাদের কোন টাইপ হ্যান্ডেল করতে পারে তা নির্দিষ্ট না করেই একটি ফাংশন সংজ্ঞায়িত করার অনুমতি দেয়। দুটি ধারণার মধ্যে পার্থক্য পরীক্ষা করার জন্য, আমরা Counter নামক একটি টাইপে Iterator ট্রেইটের একটি ইমপ্লিমেন্টেশন দেখব, যেখানে Item টাইপটি u32 হিসেবে নির্দিষ্ট করা হয়েছে:
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}এই সিনট্যাক্সটি জেনেরিকের সিনট্যাক্সের মতোই। তাহলে কেন জেনেরিক ব্যবহার করে Iterator ট্রেইটকে সংজ্ঞায়িত করা হয় না, যেমনটি লিস্টিং ২০-১৪-তে দেখানো হয়েছে?
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}পার্থক্য হল, লিস্টিং ২০-১৪ এর মতো জেনেরিক ব্যবহার করার সময়, আমাদের প্রতিটি ইমপ্লিমেন্টেশনে টাইপ annotate করতে হবে; কারণ আমরা Iterator<String> for Counter বা অন্য কোনো টাইপের জন্যও ইমপ্লিমেন্ট করতে পারি, তাই Counter-এর জন্য Iterator-এর একাধিক ইমপ্লিমেন্টেশন থাকতে পারে। অন্য কথায়, যখন একটি ট্রেইটের একটি জেনেরিক প্যারামিটার থাকে, তখন এটি একটি টাইপের জন্য একাধিকবার ইমপ্লিমেন্ট করা যেতে পারে, প্রতিবার জেনেরিক টাইপ প্যারামিটারের concrete টাইপ পরিবর্তন করে। যখন আমরা Counter-এ next মেথড ব্যবহার করি, তখন আমাদের টাইপ অ্যানোটেশন দিতে হবে, যাতে বোঝা যায় Iterator-এর কোন ইমপ্লিমেন্টেশনটি আমরা ব্যবহার করতে চাই।
অ্যাসোসিয়েটেড টাইপের সাথে, আমাদের টাইপ annotate করার দরকার নেই, কারণ আমরা একটি টাইপের উপর একটি ট্রেইট একাধিকবার ইমপ্লিমেন্ট করতে পারি না। লিস্টিং ২০-১৩-তে অ্যাসোসিয়েটেড টাইপ ব্যবহার করা সংজ্ঞার সাথে, আমরা কেবল একবার বেছে নিতে পারি Item-এর টাইপ কী হবে, কারণ impl Iterator for Counter কেবল একবারই থাকতে পারে। Counter-এ next কল করার সময় আমাদের প্রতিবার উল্লেখ করতে হবে না যে আমরা u32 ভ্যালুর একটি ইটারেটর চাই।
অ্যাসোসিয়েটেড টাইপগুলি ট্রেইটের কন্ট্রাক্টের অংশ হয়ে ওঠে: ট্রেইটের ইমপ্লিমেন্টরদের অবশ্যই অ্যাসোসিয়েটেড টাইপ প্লেসহোল্ডারের জন্য একটি টাইপ সরবরাহ করতে হবে। অ্যাসোসিয়েটেড টাইপগুলির প্রায়শই এমন একটি নাম থাকে যা বর্ণনা করে কিভাবে টাইপটি ব্যবহার করা হবে, এবং API ডকুমেন্টেশনে অ্যাসোসিয়েটেড টাইপটি ডকুমেন্ট করা ভাল প্র্যাকটিস।
ডিফল্ট জেনেরিক টাইপ প্যারামিটার এবং অপারেটর ওভারলোডিং
যখন আমরা জেনেরিক টাইপ প্যারামিটার ব্যবহার করি, তখন আমরা জেনেরিক টাইপের জন্য একটি ডিফল্ট concrete টাইপ নির্দিষ্ট করতে পারি। এটি ট্রেইটের ইমপ্লিমেন্টরদের জন্য একটি concrete টাইপ নির্দিষ্ট করার প্রয়োজনীয়তা দূর করে, যদি ডিফল্ট টাইপটি কাজ করে। আপনি <PlaceholderType=ConcreteType> সিনট্যাক্স দিয়ে জেনেরিক টাইপ ঘোষণা করার সময় একটি ডিফল্ট টাইপ নির্দিষ্ট করতে পারেন।
এই কৌশলটি যেখানে দরকারী তার একটি দুর্দান্ত উদাহরণ হল অপারেটর ওভারলোডিং, যেখানে আপনি নির্দিষ্ট পরিস্থিতিতে একটি অপারেটরের (যেমন +) আচরণ কাস্টমাইজ করেন।
Rust আপনাকে আপনার নিজের অপারেটর তৈরি করতে বা নির্বিচারে অপারেটর ওভারলোড করার অনুমতি দেয় না। কিন্তু আপনি std::ops-এ তালিকাভুক্ত অপারেটর এবং সংশ্লিষ্ট ট্রেইটগুলিকে ইমপ্লিমেন্ট করে সেই অপারেশনগুলি ওভারলোড করতে পারেন। উদাহরণস্বরূপ, লিস্টিং ২০-১৫-তে আমরা দুটি Point ইন্সট্যান্সকে একসাথে যোগ করতে + অপারেটরকে ওভারলোড করি। আমরা একটি Point স্ট্রাকটে Add ট্রেইট ইমপ্লিমেন্ট করে এটি করি:
use std::ops::Add; #[derive(Debug, Copy, Clone, PartialEq)] struct Point { x: i32, y: i32, } impl Add for Point { type Output = Point; fn add(self, other: Point) -> Point { Point { x: self.x + other.x, y: self.y + other.y, } } } fn main() { assert_eq!( Point { x: 1, y: 0 } + Point { x: 2, y: 3 }, Point { x: 3, y: 3 } ); }
add মেথড দুটি Point ইন্সট্যান্সের x ভ্যালু এবং দুটি Point ইন্সট্যান্সের y ভ্যালু যোগ করে একটি নতুন Point তৈরি করে। Add ট্রেইটের Output নামে একটি অ্যাসোসিয়েটেড টাইপ রয়েছে যা add মেথড থেকে রিটার্ন করা টাইপ নির্ধারণ করে।
এই কোডের ডিফল্ট জেনেরিক টাইপটি Add ট্রেইটের মধ্যে রয়েছে। এখানে এর সংজ্ঞা দেওয়া হল:
#![allow(unused)] fn main() { trait Add<Rhs=Self> { type Output; fn add(self, rhs: Rhs) -> Self::Output; } }
এই কোডটি সাধারণভাবে পরিচিত হওয়া উচিত: একটি মেথড এবং একটি অ্যাসোসিয়েটেড টাইপ সহ একটি ট্রেইট। নতুন অংশটি হল Rhs=Self: এই সিনট্যাক্সটিকে ডিফল্ট টাইপ প্যারামিটার বলা হয়। Rhs জেনেরিক টাইপ প্যারামিটারটি (সংক্ষেপে "right hand side") add মেথডের rhs প্যারামিটারের টাইপ সংজ্ঞায়িত করে। যদি আমরা Add ট্রেইট ইমপ্লিমেন্ট করার সময় Rhs-এর জন্য একটি concrete টাইপ নির্দিষ্ট না করি, তাহলে Rhs-এর টাইপ ডিফল্টভাবে Self হবে, যেটি হবে সেই টাইপ যার উপর আমরা Add ইমপ্লিমেন্ট করছি।
যখন আমরা Point-এর জন্য Add ইমপ্লিমেন্ট করেছি, তখন আমরা Rhs-এর জন্য ডিফল্ট ব্যবহার করেছি কারণ আমরা দুটি Point ইন্সট্যান্স যোগ করতে চেয়েছিলাম। আসুন Add ট্রেইট ইমপ্লিমেন্ট করার একটি উদাহরণ দেখি যেখানে আমরা ডিফল্ট ব্যবহার না করে Rhs টাইপ কাস্টমাইজ করতে চাই।
আমাদের দুটি স্ট্রাক্ট রয়েছে, Millimeters এবং Meters, যা বিভিন্ন ইউনিটে ভ্যালু ধারণ করে। অন্য একটি স্ট্রাকটে বিদ্যমান টাইপের এই পাতলা র্যাপিংটি নিউটাইপ প্যাটার্ন নামে পরিচিত, যা আমরা “Using the Newtype Pattern to Implement External Traits on External Types” বিভাগে আরও বিশদভাবে বর্ণনা করি। আমরা মিলিমিটারের ভ্যালুগুলিকে মিটারের ভ্যালুতে যোগ করতে চাই এবং Add-এর ইমপ্লিমেন্টেশনকে সঠিকভাবে কনভার্সন করতে চাই। আমরা Millimeters-এর জন্য Add ইমপ্লিমেন্ট করতে পারি Meters কে Rhs হিসেবে রেখে, যেমনটি লিস্টিং ২০-১৬-তে দেখানো হয়েছে।
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}Millimeters এবং Meters যোগ করার জন্য, আমরা Self-এর ডিফল্ট ব্যবহার না করে Rhs টাইপ প্যারামিটারের ভ্যালু সেট করতে impl Add<Meters> নির্দিষ্ট করি।
আপনি দুটি প্রধান উপায়ে ডিফল্ট টাইপ প্যারামিটার ব্যবহার করবেন:
- বিদ্যমান কোড না ভেঙে একটি টাইপ প্রসারিত করতে।
- নির্দিষ্ট ক্ষেত্রে কাস্টমাইজেশনের অনুমতি দিতে, যা বেশিরভাগ ব্যবহারকারীর প্রয়োজন হবে না।
স্ট্যান্ডার্ড লাইব্রেরির Add ট্রেইটটি দ্বিতীয় উদ্দেশ্যের একটি উদাহরণ: সাধারণত, আপনি দুটি একই রকম টাইপ যোগ করবেন, কিন্তু Add ট্রেইট এর বাইরেও কাস্টমাইজ করার ক্ষমতা প্রদান করে। Add ট্রেইট সংজ্ঞায় ডিফল্ট টাইপ প্যারামিটার ব্যবহার করার অর্থ হল আপনাকে বেশিরভাগ সময় অতিরিক্ত প্যারামিটারটি নির্দিষ্ট করতে হবে না। অন্য কথায়, সামান্য ইমপ্লিমেন্টেশন বয়লারপ্লেটের প্রয়োজন নেই, যা ট্রেইট ব্যবহার করা সহজ করে তোলে।
প্রথম উদ্দেশ্যটি দ্বিতীয়টির মতোই, কিন্তু বিপরীত: আপনি যদি একটি বিদ্যমান ট্রেইটে একটি টাইপ প্যারামিটার যুক্ত করতে চান, তাহলে আপনি বিদ্যমান ইমপ্লিমেন্টেশন কোড না ভেঙে ট্রেইটের কার্যকারিতা প্রসারিত করার অনুমতি দিতে একটি ডিফল্ট দিতে পারেন।
ডিসঅ্যাম্বিগুইয়েশন এর জন্য সম্পূর্ণ Qualified সিনট্যাক্স: একই নামের মেথড কল করা
Rust-এ এমন কিছু নেই যা একটি ট্রেইটের অন্য একটি ট্রেইটের মেথডের মতো একই নামের একটি মেথড থাকতে বাধা দেয়, এবং Rust আপনাকে একটি টাইপের উপর উভয় ট্রেইট ইমপ্লিমেন্ট করা থেকেও আটকায় না। টাইপের উপর সরাসরি ট্রেইটের মেথডগুলোর মতো একই নামের একটি মেথড ইমপ্লিমেন্ট করাও সম্ভব।
একই নামের মেথড কল করার সময়, আপনাকে Rust-কে জানাতে হবে আপনি কোনটি ব্যবহার করতে চান। লিস্টিং ২০-১৭-এর কোডটি বিবেচনা করুন, যেখানে আমরা দুটি ট্রেইট সংজ্ঞায়িত করেছি, Pilot এবং Wizard, উভয়েরই fly নামে একটি মেথড রয়েছে। তারপর আমরা উভয় ট্রেইটকে একটি Human টাইপের উপর ইমপ্লিমেন্ট করি, যার ইতিমধ্যেই fly নামে একটি মেথড ইমপ্লিমেন্ট করা আছে। প্রতিটি fly মেথড আলাদা কিছু করে।
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() {}
যখন আমরা Human-এর একটি ইন্সট্যান্সে fly কল করি, তখন কম্পাইলার ডিফল্টভাবে সেই মেথডটিকে কল করে যা সরাসরি টাইপের উপর ইমপ্লিমেন্ট করা হয়েছে, যেমনটি লিস্টিং ২০-১৮-তে দেখানো হয়েছে।
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() { let person = Human; person.fly(); }
এই কোডটি চালালে *waving arms furiously* প্রিন্ট হবে, এটি দেখায় যে Rust সরাসরি Human-এর উপর ইমপ্লিমেন্ট করা fly মেথডটিকে কল করেছে।
Pilot ট্রেইট বা Wizard ট্রেইট থেকে fly মেথডগুলিকে কল করার জন্য, আমরা কোন fly মেথড বোঝাতে চাই তা নির্দিষ্ট করতে আমাদের আরও স্পষ্ট সিনট্যাক্স ব্যবহার করতে হবে। লিস্টিং ২০-১৯ এই সিনট্যাক্স প্রদর্শন করে।
trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } fn main() { let person = Human; Pilot::fly(&person); Wizard::fly(&person); person.fly(); }
মেথডের নামের আগে ট্রেইটের নাম নির্দিষ্ট করা Rust-এর কাছে স্পষ্ট করে যে আমরা fly-এর কোন ইমপ্লিমেন্টেশনটি কল করতে চাই। আমরা Human::fly(&person) লিখতে পারতাম, যা লিস্টিং ২০-১৯-এ ব্যবহৃত person.fly()-এর সমতুল্য, কিন্তু আমাদের যদি ডিসঅ্যাম্বিগুইয়েট করার প্রয়োজন না হয় তবে এটি লিখতে একটু বেশি সময় লাগবে।
এই কোডটি চালালে নিম্নলিখিতগুলি প্রিন্ট হবে:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
যেহেতু fly মেথড একটি self প্যারামিটার নেয়, যদি আমাদের দুটি টাইপ থাকে যারা উভয়েই একটি ট্রেইট ইমপ্লিমেন্ট করে, তাহলে Rust self-এর টাইপের উপর ভিত্তি করে একটি ট্রেইটের কোন ইমপ্লিমেন্টেশন ব্যবহার করতে হবে তা নির্ধারণ করতে পারে।
যাইহোক, অ্যাসোসিয়েটেড ফাংশন যেগুলি মেথড নয়, সেগুলির একটি self প্যারামিটার নেই। যখন একাধিক টাইপ বা ট্রেইট থাকে যা একই ফাংশন নাম সহ নন-মেথড ফাংশন সংজ্ঞায়িত করে, তখন Rust সব সময় জানে না আপনি কোন টাইপটি বোঝাতে চেয়েছেন, যদি না আপনি সম্পূর্ণ qualified সিনট্যাক্স ব্যবহার করেন। উদাহরণস্বরূপ, লিস্টিং ২০-২০-তে আমরা একটি পশু আশ্রয়ের জন্য একটি ট্রেইট তৈরি করি, যারা সমস্ত বাচ্চা কুকুরকে Spot নাম দিতে চায়। আমরা একটি Animal ট্রেইট তৈরি করি, যার সাথে একটি অ্যাসোসিয়েটেড নন-মেথড ফাংশন baby_name রয়েছে। Animal ট্রেইটটি Dog স্ট্রাক্টের জন্য ইমপ্লিমেন্ট করা হয়েছে, যার উপর আমরা সরাসরি baby_name নামে একটি অ্যাসোসিয়েটেড নন-মেথড ফাংশনও সরবরাহ করি।
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", Dog::baby_name()); }
আমরা সমস্ত কুকুরছানাকে Spot নামকরণের কোডটি Dog-এর উপর সংজ্ঞায়িত baby_name অ্যাসোসিয়েটেড ফাংশনে ইমপ্লিমেন্ট করি। Dog টাইপটি Animal ট্রেইটও ইমপ্লিমেন্ট করে, যা সমস্ত প্রাণীর বৈশিষ্ট্য বর্ণনা করে। বাচ্চা কুকুরদের কুকুরছানা বলা হয়, এবং এটি Dog-এর উপর Animal ট্রেইটের ইমপ্লিমেন্টেশনে Animal ট্রেইটের সাথে অ্যাসোসিয়েটেড baby_name ফাংশনে প্রকাশ করা হয়েছে।
main-এ, আমরা Dog::baby_name ফাংশনটি কল করি, যা সরাসরি Dog-এর উপর সংজ্ঞায়িত অ্যাসোসিয়েটেড ফাংশনকে কল করে। এই কোডটি নিম্নলিখিতগুলি প্রিন্ট করে:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
এই আউটপুটটি আমরা যা চেয়েছিলাম তা নয়। আমরা baby_name ফাংশনটি কল করতে চাই যা Animal ট্রেইটের অংশ, যা আমরা Dog-এর উপর ইমপ্লিমেন্ট করেছি, যাতে কোডটি A baby dog is called a puppy প্রিন্ট করে। লিস্টিং ২০-১৯-এ আমরা যে ট্রেইটের নাম নির্দিষ্ট করার কৌশল ব্যবহার করেছি তা এখানে সাহায্য করে না; যদি আমরা main কে লিস্টিং ২০-২১-এর কোডে পরিবর্তন করি, তাহলে আমরা একটি কম্পাইলেশন ত্রুটি পাব।
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Animal::baby_name());
}যেহেতু Animal::baby_name-এর একটি self প্যারামিটার নেই, এবং অন্যান্য টাইপ থাকতে পারে যা Animal ট্রেইট ইমপ্লিমেন্ট করে, তাই Rust নির্ধারণ করতে পারে না যে আমরা Animal::baby_name-এর কোন ইমপ্লিমেন্টেশনটি চাই। আমরা এই কম্পাইলার ত্রুটি পাব:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` (bin "traits-example") due to 1 previous error
ডিসঅ্যাম্বিগুইয়েট করতে এবং Rust-কে জানাতে যে আমরা অন্য কোনো টাইপের জন্য Animal-এর ইমপ্লিমেন্টেশনের পরিবর্তে Dog-এর জন্য Animal-এর ইমপ্লিমেন্টেশন ব্যবহার করতে চাই, আমাদের সম্পূর্ণ qualified সিনট্যাক্স ব্যবহার করতে হবে। লিস্টিং ২০-২২ প্রদর্শন করে কিভাবে সম্পূর্ণ qualified সিনট্যাক্স ব্যবহার করতে হয়।
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", <Dog as Animal>::baby_name()); }
আমরা অ্যাঙ্গেল ব্র্যাকেটের মধ্যে Rust-কে একটি টাইপ অ্যানোটেশন সরবরাহ করছি, যা নির্দেশ করে যে আমরা এই ফাংশন কলের জন্য Dog টাইপটিকে Animal হিসেবে বিবেচনা করতে চাই, এটি বলে Dog-এর উপর ইমপ্লিমেন্ট করা Animal ট্রেইট থেকে baby_name মেথডটিকে কল করতে চাই। এই কোডটি এখন আমরা যা চাই তা প্রিন্ট করবে:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
সাধারণভাবে, সম্পূর্ণ qualified সিনট্যাক্স নিম্নরূপ সংজ্ঞায়িত করা হয়েছে:
<Type as Trait>::function(receiver_if_method, next_arg, ...);অ্যাসোসিয়েটেড ফাংশন যেগুলি মেথড নয়, সেগুলির জন্য কোনও receiver থাকবে না: কেবল অন্যান্য আর্গুমেন্টের তালিকা থাকবে। আপনি সর্বত্র সম্পূর্ণ qualified সিনট্যাক্স ব্যবহার করতে পারেন যেখানে আপনি ফাংশন বা মেথড কল করেন। যাইহোক, আপনি এই সিনট্যাক্সের যেকোনো অংশ বাদ দিতে পারেন যা Rust প্রোগ্রামের অন্যান্য তথ্য থেকে বের করতে পারে। আপনাকে এই আরও ভারবোস সিনট্যাক্সটি কেবল সেই ক্ষেত্রেই ব্যবহার করতে হবে যেখানে একই নাম ব্যবহার করে একাধিক ইমপ্লিমেন্টেশন রয়েছে এবং Rust-কে সনাক্ত করতে সাহায্যের প্রয়োজন হয় আপনি কোন ইমপ্লিমেন্টেশনটি কল করতে চান।
একটি ট্রেইটের মধ্যে অন্য ট্রেইটের কার্যকারিতা প্রয়োজন করতে Supertrait ব্যবহার
কখনও কখনও, আপনি এমন একটি ট্রেইট সংজ্ঞা লিখতে পারেন যা অন্য ট্রেইটের উপর নির্ভরশীল: একটি টাইপের জন্য প্রথম ট্রেইটটি ইমপ্লিমেন্ট করতে, আপনি চাইতে পারেন যে টাইপটি দ্বিতীয় ট্রেইটটিও ইমপ্লিমেন্ট করুক। আপনি এটি করবেন যাতে আপনার ট্রেইট সংজ্ঞাটি দ্বিতীয় ট্রেইটের অ্যাসোসিয়েটেড আইটেমগুলি ব্যবহার করতে পারে। যে ট্রেইটের উপর আপনার ট্রেইট সংজ্ঞা নির্ভর করে তাকে আপনার ট্রেইটের supertrait বলা হয়।
উদাহরণস্বরূপ, ধরা যাক আমরা একটি OutlinePrint ট্রেইট তৈরি করতে চাই, যেখানে outline_print নামে একটি মেথড থাকবে, যা প্রদত্ত একটি ভ্যালুকে এমনভাবে ফর্ম্যাট করে প্রিন্ট করবে যেন এটি অ্যাস্টেরিস্ক (*) এর মধ্যে আবদ্ধ থাকে। অর্থাৎ, একটি Point স্ট্রাক্ট দেওয়া হল যা স্ট্যান্ডার্ড লাইব্রেরির Display ট্রেইট ইমপ্লিমেন্ট করে (x, y) আউটপুট দেয়, যখন আমরা x-এর জন্য 1 এবং y-এর জন্য 3 আছে এমন একটি Point ইন্সট্যান্সে outline_print কল করি, তখন এটি নিম্নলিখিতগুলি প্রিন্ট করবে:
**********
* *
* (1, 3) *
* *
**********
outline_print মেথডের ইমপ্লিমেন্টেশনে, আমরা Display ট্রেইটের কার্যকারিতা ব্যবহার করতে চাই। অতএব, আমাদের নির্দিষ্ট করতে হবে যে OutlinePrint ট্রেইটটি কেবল সেই সমস্ত টাইপের জন্য কাজ করবে যারা Display ইমপ্লিমেন্ট করে এবং OutlinePrint-এর প্রয়োজনীয় কার্যকারিতা সরবরাহ করে। আমরা ট্রেইট সংজ্ঞায় OutlinePrint: Display নির্দিষ্ট করে এটি করতে পারি। এই কৌশলটি ট্রেইটে একটি ট্রেইট বাউন্ড যোগ করার মতোই। লিস্টিং ২০-২৩ OutlinePrint ট্রেইটের একটি ইমপ্লিমেন্টেশন দেখায়।
use std::fmt; trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {output} *"); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } fn main() {}
যেহেতু আমরা নির্দিষ্ট করেছি যে OutlinePrint-এর Display ট্রেইট প্রয়োজন, তাই আমরা to_string ফাংশনটি ব্যবহার করতে পারি, যা Display ইমপ্লিমেন্ট করে এমন যেকোনো টাইপের জন্য স্বয়ংক্রিয়ভাবে ইমপ্লিমেন্ট করা হয়। যদি আমরা একটি কোলন যোগ না করে এবং ট্রেইটের নামের পরে Display ট্রেইট নির্দিষ্ট না করে to_string ব্যবহার করার চেষ্টা করতাম, তাহলে আমরা একটি এরর পেতাম, যেখানে বলা হত যে বর্তমান স্কোপে &Self টাইপের জন্য to_string নামে কোনো মেথড পাওয়া যায়নি।
আসুন দেখি কী ঘটে যখন আমরা OutlinePrint কে এমন একটি টাইপে ইমপ্লিমেন্ট করার চেষ্টা করি যা Display ইমপ্লিমেন্ট করে না, যেমন Point স্ট্রাক্ট:
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}আমরা একটি এরর পাই যেখানে বলা হয়েছে যে Display প্রয়োজন কিন্তু ইমপ্লিমেন্ট করা হয়নি:
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:23
|
20 | impl OutlinePrint for Point {}
| ^^^^^ `Point` cannot be formatted with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `Point`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:24:7
|
24 | p.outline_print();
| ^^^^^^^^^^^^^ `Point` cannot be formatted with the default formatter
|
= help: the trait `std::fmt::Display` is not implemented for `Point`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
note: required by a bound in `OutlinePrint::outline_print`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint::outline_print`
4 | fn outline_print(&self) {
| ------------- required by a bound in this associated function
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` (bin "traits-example") due to 2 previous errors
এটি ঠিক করার জন্য, আমরা Point-এ Display ইমপ্লিমেন্ট করি এবং OutlinePrint-এর প্রয়োজনীয় শর্ত পূরণ করি, এইভাবে:
trait OutlinePrint: fmt::Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {output} *"); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } struct Point { x: i32, y: i32, } impl OutlinePrint for Point {} use std::fmt; impl fmt::Display for Point { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) } } fn main() { let p = Point { x: 1, y: 3 }; p.outline_print(); }
তারপর Point-এ OutlinePrint ট্রেইট ইমপ্লিমেন্ট করা সফলভাবে কম্পাইল হবে, এবং আমরা একটি Point ইন্সট্যান্সে outline_print কল করে অ্যাস্টেরিস্কের আউটলাইনের মধ্যে এটি প্রদর্শন করতে পারি।
বাহ্যিক টাইপের উপর বাহ্যিক ট্রেইট ইমপ্লিমেন্ট করতে নিউটাইপ প্যাটার্ন ব্যবহার
দশম অধ্যায়ের “একটি টাইপের উপর একটি ট্রেইট ইমপ্লিমেন্ট করা” অংশে, আমরা অরফান নিয়ম (orphan rule) উল্লেখ করেছি, যেখানে বলা হয়েছে যে আমরা কেবল তখনই একটি টাইপের উপর একটি ট্রেইট ইমপ্লিমেন্ট করতে পারি যদি ট্রেইট বা টাইপ উভয়ই আমাদের ক্রেটের লোকাল হয়। নিউটাইপ প্যাটার্ন ব্যবহার করে এই সীমাবদ্ধতা অতিক্রম করা সম্ভব, যেখানে একটি টাপল স্ট্রাকটে একটি নতুন টাইপ তৈরি করা হয়। (আমরা পঞ্চম অধ্যায়ে “নামযুক্ত ফিল্ড ছাড়া টাপল স্ট্রাক্ট ব্যবহার করে ভিন্ন টাইপ তৈরি করা” অংশে টাপল স্ট্রাক্ট নিয়ে আলোচনা করেছি।) টাপল স্ট্রাক্টটিতে একটি ফিল্ড থাকবে এবং এটি যে টাইপের জন্য আমরা একটি ট্রেইট ইমপ্লিমেন্ট করতে চাই তার চারপাশে একটি পাতলা র্যাপার হবে। তারপর র্যাপার টাইপটি আমাদের ক্রেটের লোকাল হবে, এবং আমরা র্যাপারের উপর ট্রেইটটি ইমপ্লিমেন্ট করতে পারি। Newtype হল একটি শব্দ যা হ্যাসকেল (Haskell) প্রোগ্রামিং ভাষা থেকে এসেছে। এই প্যাটার্নটি ব্যবহার করার জন্য কোনো রানটাইম পারফরম্যান্স পেনাল্টি নেই, এবং কম্পাইল করার সময় র্যাপার টাইপটি বাদ দেওয়া হয়।
উদাহরণস্বরূপ, ধরা যাক আমরা Vec<T>-এর উপর Display ইমপ্লিমেন্ট করতে চাই, যা অরফান নিয়ম আমাদের সরাসরি করতে বাধা দেয় কারণ Display ট্রেইট এবং Vec<T> টাইপ উভয়ই আমাদের ক্রেটের বাইরে সংজ্ঞায়িত। আমরা একটি Wrapper স্ট্রাক্ট তৈরি করতে পারি যা Vec<T>-এর একটি ইন্সট্যান্স ধারণ করে; তারপর আমরা Wrapper-এর উপর Display ইমপ্লিমেন্ট করতে পারি এবং Vec<T> ভ্যালু ব্যবহার করতে পারি, যেমনটি লিস্টিং ২০-২৪-এ দেখানো হয়েছে।
use std::fmt; struct Wrapper(Vec<String>); impl fmt::Display for Wrapper { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "[{}]", self.0.join(", ")) } } fn main() { let w = Wrapper(vec![String::from("hello"), String::from("world")]); println!("w = {w}"); }
Display-এর ইমপ্লিমেন্টেশন ভেতরের Vec<T> অ্যাক্সেস করতে self.0 ব্যবহার করে, কারণ Wrapper হল একটি টাপল স্ট্রাক্ট এবং Vec<T> হল টাপলের 0 ইনডেক্সের আইটেম। তারপর আমরা Wrapper-এর উপর Display ট্রেইটের কার্যকারিতা ব্যবহার করতে পারি।
এই কৌশলটি ব্যবহারের অসুবিধা হল Wrapper একটি নতুন টাইপ, তাই এটির ধারণ করা ভ্যালুর মেথডগুলি নেই। আমাদের Vec<T>-এর সমস্ত মেথড সরাসরি Wrapper-এর উপর ইমপ্লিমেন্ট করতে হবে যাতে মেথডগুলি self.0-তে ডেলিগেট করে, যা আমাদের Wrapper-কে অবিকল Vec<T>-এর মতো আচরণ করার অনুমতি দেবে। আমরা যদি চাইতাম যে নতুন টাইপটির ভেতরের টাইপের প্রতিটি মেথড থাকুক, তাহলে ভেতরের টাইপটি রিটার্ন করার জন্য Wrapper-এর উপর Deref ট্রেইট (পঞ্চদশ অধ্যায়ের “Deref ট্রেইট ব্যবহার করে স্মার্ট পয়েন্টারগুলিকে সাধারণ রেফারেন্সের মতো ব্যবহার করা” অংশে আলোচিত) ইমপ্লিমেন্ট করা একটি সমাধান হবে। যদি আমরা না চাই যে Wrapper টাইপটির ভেতরের টাইপের সমস্ত মেথড থাকুক—উদাহরণস্বরূপ, Wrapper টাইপের আচরণ সীমাবদ্ধ করতে—তাহলে আমাদের কেবল সেই মেথডগুলি ইমপ্লিমেন্ট করতে হবে যা আমরা ম্যানুয়ালি চাই।
এই নিউটাইপ প্যাটার্নটি তখনও দরকারী, যখন ট্রেইট জড়িত থাকে না। আসুন ফোকাস পরিবর্তন করি এবং Rust-এর টাইপ সিস্টেমের সাথে ইন্টারঅ্যাক্ট করার কিছু advanced উপায় দেখি।
অ্যাডভান্সড টাইপস (Advanced Types)
Rust-এর টাইপ সিস্টেমে কিছু বৈশিষ্ট্য রয়েছে যা আমরা ఇప్పటి পর্যন্ত উল্লেখ করেছি কিন্তু এখনও আলোচনা করিনি। টাইপ হিসাবে নিউটাইপগুলি কেন দরকারী তা পরীক্ষা করার সময় আমরা সাধারণভাবে নিউটাইপ নিয়ে আলোচনা শুরু করব। তারপর আমরা টাইপ অ্যালিয়াস-এ যাব, যা নিউটাইপের মতোই একটি বৈশিষ্ট্য কিন্তু সামান্য ভিন্ন শব্দার্থ সহ। আমরা ! টাইপ এবং ডায়নামিকভাবে সাইজড টাইপ নিয়েও আলোচনা করব।
টাইপ নিরাপত্তা এবং অ্যাবস্ট্রাকশনের জন্য নিউটাইপ প্যাটার্ন ব্যবহার করা (Using the Newtype Pattern for Type Safety and Abstraction)
এই অংশটি ধরে নিচ্ছে যে আপনি আগের অংশটি পড়েছেন “Using the Newtype Pattern to Implement External Traits on External Types.” নিউটাইপ প্যাটার্নটি আমরা இதுவரை যে কাজগুলি নিয়ে আলোচনা করেছি তার বাইরেও দরকারী, যার মধ্যে রয়েছে স্ট্যাটিকালি এনফোর্স করা যে মানগুলি কখনও বিভ্রান্ত হয় না এবং একটি মানের একক নির্দেশ করা। আপনি Listing 20-16-এ ইউনিট নির্দেশ করার জন্য নিউটাইপ ব্যবহারের একটি উদাহরণ দেখেছেন: মনে রাখবেন যে Millimeters এবং Meters স্ট্রাক্টগুলি একটি নিউটাইপে u32 মানগুলিকে র্যাপ করেছে। যদি আমরা Millimeters টাইপের একটি প্যারামিটার সহ একটি ফাংশন লিখি, তাহলে আমরা এমন একটি প্রোগ্রাম কম্পাইল করতে পারব না যেটি ভুলবশত Meters টাইপের মান বা একটি সাধারণ u32 দিয়ে সেই ফাংশনটিকে কল করার চেষ্টা করে।
আমরা একটি টাইপের কিছু ইমপ্লিমেন্টেশন বিবরণ অ্যাবস্ট্রাক্ট করার জন্য নিউটাইপ প্যাটার্নটিও ব্যবহার করতে পারি: নতুন টাইপটি একটি পাবলিক API প্রকাশ করতে পারে যা প্রাইভেট ইনার টাইপের API থেকে ভিন্ন।
নিউটাইপগুলি অভ্যন্তরীণ ইমপ্লিমেন্টেশনও লুকাতে পারে। উদাহরণস্বরূপ, আমরা একটি People টাইপ সরবরাহ করতে পারি যা একটি HashMap<i32, String> র্যাপ করে যা একজন ব্যক্তির ID-কে তার নামের সাথে যুক্ত করে সংরক্ষণ করে। People ব্যবহার করা কোড শুধুমাত্র আমাদের দেওয়া পাবলিক API-এর সাথে ইন্টারঅ্যাক্ট করবে, যেমন People কালেকশনে একটি নামের স্ট্রিং যোগ করার একটি মেথড; সেই কোডটির জানার প্রয়োজন হবে না যে আমরা অভ্যন্তরীণভাবে নামগুলিতে একটি i32 ID অ্যাসাইন করি। নিউটাইপ প্যাটার্ন হল ইমপ্লিমেন্টেশনের বিশদ বিবরণ লুকানোর জন্য এনক্যাপসুলেশন অর্জনের একটি হালকা উপায়, যা আমরা Chapter 18-এর “Encapsulation that Hides Implementation Details”-এ আলোচনা করেছি।
টাইপ অ্যালিয়াস দিয়ে টাইপ সিনোনিম তৈরি করা (Creating Type Synonyms with Type Aliases)
Rust একটি বিদ্যমান টাইপকে অন্য নাম দেওয়ার জন্য একটি টাইপ অ্যালিয়াস ঘোষণা করার ক্ষমতা প্রদান করে। এর জন্য আমরা type কীওয়ার্ড ব্যবহার করি। উদাহরণস্বরূপ, আমরা i32-এর জন্য Kilometers অ্যালিয়াস তৈরি করতে পারি এভাবে:
fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
এখন, Kilometers অ্যালিয়াসটি i32-এর জন্য একটি সমার্থক শব্দ; Listing 20-16-এ আমরা যে Millimeters এবং Meters টাইপ তৈরি করেছি তার বিপরীতে, Kilometers একটি পৃথক, নতুন টাইপ নয়। Kilometers টাইপের মানগুলিকে i32 টাইপের মানগুলির মতোই বিবেচনা করা হবে:
fn main() { type Kilometers = i32; let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); }
যেহেতু Kilometers এবং i32 একই টাইপ, তাই আমরা উভয় টাইপের মান যোগ করতে পারি এবং আমরা Kilometers মানগুলিকে এমন ফাংশনগুলিতে পাস করতে পারি যা i32 প্যারামিটার নেয়। যাইহোক, এই পদ্ধতি ব্যবহার করে, আমরা টাইপ চেকিং সুবিধা পাই না যা আমরা আগে আলোচনা করা নিউটাইপ প্যাটার্ন থেকে পাই। অন্য কথায়, আমরা যদি কোথাও Kilometers এবং i32 মানগুলিকে মিশিয়ে ফেলি, তাহলে কম্পাইলার আমাদের কোনও error দেবে না।
টাইপ সিনোনিমের প্রধান ব্যবহারের ক্ষেত্র হল পুনরাবৃত্তি কমানো। উদাহরণস্বরূপ, আমাদের কাছে এইরকম একটি দীর্ঘ টাইপ থাকতে পারে:
Box<dyn Fn() + Send + 'static>ফাংশন স্বাক্ষর এবং টাইপ অ্যানোটেশন হিসাবে এই দীর্ঘ টাইপটি কোডের সর্বত্র লেখা ক্লান্তিকর এবং ত্রুটিপ্রবণ হতে পারে। Listing 20-25-এর মতো কোডে পূর্ণ একটি প্রোজেক্ট থাকার কল্পনা করুন।
fn main() { let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi")); fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) { // --snip-- } fn returns_long_type() -> Box<dyn Fn() + Send + 'static> { // --snip-- Box::new(|| ()) } }
একটি টাইপ অ্যালিয়াস পুনরাবৃত্তি কমিয়ে এই কোডটিকে আরও পরিচালনাযোগ্য করে তোলে। Listing 20-26-এ, আমরা ভারবোস টাইপের জন্য Thunk নামে একটি অ্যালিয়াস চালু করেছি এবং টাইপের সমস্ত ব্যবহারকে ছোট অ্যালিয়াস Thunk দিয়ে প্রতিস্থাপন করতে পারি।
fn main() { type Thunk = Box<dyn Fn() + Send + 'static>; let f: Thunk = Box::new(|| println!("hi")); fn takes_long_type(f: Thunk) { // --snip-- } fn returns_long_type() -> Thunk { // --snip-- Box::new(|| ()) } }
এই কোডটি পড়া এবং লেখা অনেক সহজ! একটি টাইপ অ্যালিয়াসের জন্য একটি অর্থপূর্ণ নাম নির্বাচন করা আপনার অভিপ্রায় জানাতে সাহায্য করতে পারে (thunk হল এমন কোডের জন্য একটি শব্দ যা পরবর্তীতে মূল্যায়ন করা হবে, তাই এটি একটি ক্লোজারের জন্য একটি উপযুক্ত নাম যা সংরক্ষণ করা হয়)।
টাইপ অ্যালিয়াসগুলি পুনরাবৃত্তি কমানোর জন্য Result<T, E> টাইপের সাথেও সাধারণত ব্যবহৃত হয়। স্ট্যান্ডার্ড লাইব্রেরির std::io মডিউলটি বিবেচনা করুন। I/O অপারেশনগুলি প্রায়শই Result<T, E> রিটার্ন করে এমন পরিস্থিতিগুলি পরিচালনা করার জন্য যখন অপারেশনগুলি কাজ করতে ব্যর্থ হয়। এই লাইব্রেরিতে একটি std::io::Error স্ট্রাক্ট রয়েছে যা সমস্ত সম্ভাব্য I/O ত্রুটিগুলিকে উপস্থাপন করে। std::io-এর অনেকগুলি ফাংশন Result<T, E> রিটার্ন করবে যেখানে E হল std::io::Error, যেমন Write ট্রেইটের এই ফাংশনগুলি:
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}Result<..., Error> অনেক পুনরাবৃত্তি হয়। যেমন, std::io-এর এই টাইপ অ্যালিয়াস ডিক্লারেশন রয়েছে:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}যেহেতু এই ডিক্লারেশনটি std::io মডিউলে রয়েছে, তাই আমরা সম্পূর্ণরূপে যোগ্যতাসম্পন্ন অ্যালিয়াস std::io::Result<T> ব্যবহার করতে পারি; অর্থাৎ, একটি Result<T, E> যেখানে E পূরণ করা হয়েছে std::io::Error হিসাবে। Write ট্রেইট ফাংশন স্বাক্ষরগুলি দেখতে এইরকম হয়:
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}টাইপ অ্যালিয়াস দুটি উপায়ে সাহায্য করে: এটি কোড লেখা সহজ করে এবং এটি আমাদের std::io জুড়ে একটি সামঞ্জস্যপূর্ণ ইন্টারফেস দেয়। কারণ এটি একটি অ্যালিয়াস, এটি শুধুমাত্র আরেকটি Result<T, E>, যার মানে হল যে আমরা এটির সাথে Result<T, E>-তে কাজ করে এমন কোনও মেথড ব্যবহার করতে পারি, সেইসাথে ? অপারেটরের মতো বিশেষ সিনট্যাক্সও ব্যবহার করতে পারি।
নেভার টাইপ যা কখনও রিটার্ন করে না (The Never Type that Never Returns)
Rust-এর একটি বিশেষ টাইপ রয়েছে যার নাম ! যা টাইপ থিওরির পরিভাষায় এম্পটি টাইপ নামে পরিচিত কারণ এর কোনও মান নেই। আমরা এটিকে নেভার টাইপ বলতে পছন্দ করি কারণ এটি ফাংশনের রিটার্ন টাইপের জায়গায় ব্যবহৃত হয় যখন একটি ফাংশন কখনও রিটার্ন করবে না। এখানে একটি উদাহরণ:
fn bar() -> ! {
// --snip--
panic!();
}এই কোডটি এভাবে পড়া হয় “bar ফাংশনটি কখনও রিটার্ন করে না।” যে ফাংশনগুলি কখনও রিটার্ন করে না তাদের ডাইভার্জিং ফাংশন বলা হয়। আমরা ! টাইপের মান তৈরি করতে পারি না তাই bar কখনও রিটার্ন করতে পারে না।
কিন্তু যে টাইপের জন্য আপনি কখনই মান তৈরি করতে পারবেন না তার ব্যবহার কী? Listing 2-5-এর কোডটি স্মরণ করুন, সংখ্যা অনুমান করার গেমের অংশ; আমরা এখানে Listing 20-27-এ এর একটি অংশ পুনরুত্পাদন করেছি।
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}সেই সময়ে, আমরা এই কোডের কিছু বিবরণ এড়িয়ে গেছি। “The match Control Flow Operator” in Chapter 6-এ, আমরা আলোচনা করেছি যে match আর্মগুলিকে অবশ্যই একই টাইপ রিটার্ন করতে হবে। সুতরাং, উদাহরণস্বরূপ, নিম্নলিখিত কোডটি কাজ করে না:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}এই কোডে guess-এর টাইপটি অবশ্যই একটি পূর্ণসংখ্যা এবং একটি স্ট্রিং হতে হবে এবং Rust-এর প্রয়োজন যে guess-এর শুধুমাত্র একটি টাইপ থাকুক। তাহলে continue কী রিটার্ন করে? Listing 20-27-এ আমরা কীভাবে একটি আর্ম থেকে একটি u32 রিটার্ন করতে পেরেছিলাম এবং অন্য একটি আর্ম যা continue দিয়ে শেষ হয়েছিল?
আপনি যেমন অনুমান করতে পারেন, continue-এর একটি ! মান রয়েছে। অর্থাৎ, যখন Rust guess-এর টাইপ গণনা করে, তখন এটি উভয় ম্যাচ আর্মের দিকে তাকায়, পূর্বেরটি u32 মান সহ এবং পরেরটি ! মান সহ। যেহেতু !-এর কখনও কোনও মান থাকতে পারে না, তাই Rust সিদ্ধান্ত নেয় যে guess-এর টাইপ হল u32।
এই আচরণের আনুষ্ঠানিক উপায় হল যে ! টাইপের এক্সপ্রেশনগুলিকে অন্য কোনও টাইপে জোর করে আনা যেতে পারে। আমাদের এই match আর্মটিকে continue দিয়ে শেষ করার অনুমতি দেওয়া হয়েছে কারণ continue কোনও মান রিটার্ন করে না; পরিবর্তে, এটি কন্ট্রোলটিকে লুপের শীর্ষে ফিরিয়ে নিয়ে যায়, তাই Err ক্ষেত্রে, আমরা কখনই guess-এ কোনও মান অ্যাসাইন করি না।
নেভার টাইপটি panic! ম্যাক্রোর সাথেও দরকারী। Option<T> মানগুলিতে আমরা যে unwrap ফাংশনটি কল করি তা একটি মান তৈরি করতে বা প্যানিক করতে এই সংজ্ঞা সহ:
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}এই কোডে, Listing 20-27-এর match-এর মতোই একই জিনিস ঘটে: Rust দেখে যে val-এর টাইপ T এবং panic!-এর টাইপ !, তাই সামগ্রিক match এক্সপ্রেশনের ফলাফল হল T। এই কোডটি কাজ করে কারণ panic! কোনও মান তৈরি করে না; এটি প্রোগ্রামটি শেষ করে দেয়। None ক্ষেত্রে, আমরা unwrap থেকে কোনও মান রিটার্ন করব না, তাই এই কোডটি বৈধ।
! টাইপের একটি চূড়ান্ত এক্সপ্রেশন হল একটি loop:
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}এখানে, লুপটি কখনই শেষ হয় না, তাই ! হল এক্সপ্রেশনের মান। যাইহোক, আমরা যদি একটি break অন্তর্ভুক্ত করি তবে এটি সত্য হবে না, কারণ লুপটি যখন break-এ পৌঁছাবে তখন শেষ হবে।
ডায়নামিকভাবে সাইজড টাইপ এবং Sized ট্রেইট (Dynamically Sized Types and the Sized Trait)
Rust-কে তার টাইপ সম্পর্কে কিছু বিশদ জানতে হবে, যেমন একটি নির্দিষ্ট টাইপের মানের জন্য কতটা জায়গা বরাদ্দ করতে হবে। এটি তার টাইপ সিস্টেমের একটি কোণকে প্রথমে একটু বিভ্রান্তিকর করে তোলে: ডায়নামিকালি সাইজড টাইপের ধারণা। কখনও কখনও DST বা আনসাইজড টাইপ হিসাবে উল্লেখ করা হয়, এই টাইপগুলি আমাদের এমন মান ব্যবহার করে কোড লিখতে দেয় যার আকার আমরা শুধুমাত্র রানটাইমে জানতে পারি।
আসুন str নামক একটি ডায়নামিকালি সাইজড টাইপের বিশদ বিবরণে ডুব দিই, যা আমরা পুরো বইটি জুড়ে ব্যবহার করে আসছি। ঠিক আছে, &str নয়, শুধুমাত্র str, একটি DST। আমরা রানটাইম পর্যন্ত জানতে পারি না স্ট্রিংটি কত লম্বা, মানে আমরা str টাইপের একটি ভেরিয়েবল তৈরি করতে পারি না, বা আমরা str টাইপের একটি আর্গুমেন্ট নিতে পারি না। নিম্নলিখিত কোডটি বিবেচনা করুন, যা কাজ করে না:
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}Rust-কে জানতে হবে একটি নির্দিষ্ট টাইপের যেকোনো মানের জন্য কতটা মেমরি বরাদ্দ করতে হবে এবং একটি টাইপের সমস্ত মানের অবশ্যই একই পরিমাণ মেমরি ব্যবহার করতে হবে। যদি Rust আমাদের এই কোডটি লেখার অনুমতি দিত, তাহলে এই দুটি str মানকে একই পরিমাণ জায়গা নিতে হত। কিন্তু তাদের দৈর্ঘ্য ভিন্ন: s1-এর 12 বাইট স্টোরেজ প্রয়োজন এবং s2-এর 15 বাইট প্রয়োজন। এই কারণেই ডায়নামিকালি সাইজড টাইপ ধারণকারী একটি ভেরিয়েবল তৈরি করা সম্ভব নয়।
তাহলে আমরা কি করব? এই ক্ষেত্রে, আপনি ইতিমধ্যেই উত্তরটি জানেন: আমরা s1 এবং s2-এর টাইপ str-এর পরিবর্তে &str করি। “String Slices” in Chapter 4 থেকে স্মরণ করুন যে স্লাইস ডেটা স্ট্রাকচারটি শুধুমাত্র স্লাইসের শুরুর অবস্থান এবং দৈর্ঘ্য সংরক্ষণ করে। সুতরাং যদিও একটি &T হল একটি একক মান যা মেমরির ঠিকানা সংরক্ষণ করে যেখানে T অবস্থিত, একটি &str হল দুটি মান: str-এর ঠিকানা এবং এর দৈর্ঘ্য। যেমন, আমরা কম্পাইল করার সময় একটি &str মানের আকার জানতে পারি: এটি একটি usize-এর দৈর্ঘ্যের দ্বিগুণ। অর্থাৎ, আমরা সবসময় একটি &str-এর আকার জানি, এটি যে স্ট্রিংটিকে নির্দেশ করে সেটি যতই দীর্ঘ হোক না কেন। সাধারণভাবে, এইভাবেই Rust-এ ডায়নামিকালি সাইজড টাইপগুলি ব্যবহার করা হয়: তাদের কাছে অতিরিক্ত মেটাডেটা থাকে যা ডায়নামিক তথ্যের আকার সংরক্ষণ করে। ডায়নামিকালি সাইজড টাইপের গোল্ডেন রুল হল যে আমাদের অবশ্যই ডায়নামিকালি সাইজড টাইপের মানগুলিকে কোনও ধরণের পয়েন্টারের পিছনে রাখতে হবে।
আমরা str-কে সব ধরনের পয়েন্টারের সাথে একত্রিত করতে পারি: উদাহরণস্বরূপ, Box<str> বা Rc<str>। প্রকৃতপক্ষে, আপনি এটি আগেও দেখেছেন কিন্তু একটি ভিন্ন ডায়নামিকালি সাইজড টাইপের সাথে: ট্রেইট। প্রতিটি ট্রেইট হল একটি ডায়নামিকালি সাইজড টাইপ যা আমরা ট্রেইটের নাম ব্যবহার করে উল্লেখ করতে পারি। “Using Trait Objects That Allow for Values of Different Types” in Chapter 18-এ, আমরা উল্লেখ করেছি যে ট্রেইটগুলিকে ট্রেইট অবজেক্ট হিসাবে ব্যবহার করার জন্য, আমাদের অবশ্যই সেগুলিকে একটি পয়েন্টারের পিছনে রাখতে হবে, যেমন &dyn Trait বা Box<dyn Trait> (Rc<dyn Trait>-ও কাজ করবে)।
DST-গুলির সাথে কাজ করার জন্য, Rust কম্পাইল করার সময় কোনও টাইপের আকার জানা আছে কিনা তা নির্ধারণ করতে Sized ট্রেইট সরবরাহ করে। এই ট্রেইটটি স্বয়ংক্রিয়ভাবে সবকিছুর জন্য ইমপ্লিমেন্ট করা হয় যার আকার কম্পাইল করার সময় জানা যায়। এছাড়াও, Rust স্পষ্টভাবে প্রতিটি জেনেরিক ফাংশনে Sized-এর উপর একটি বাউন্ড যোগ করে। অর্থাৎ, এইরকম একটি জেনেরিক ফাংশন সংজ্ঞা:
fn generic<T>(t: T) {
// --snip--
}আসলে এমনভাবে আচরণ করে যেন আমরা এটি লিখেছি:
fn generic<T: Sized>(t: T) {
// --snip--
}ডিফল্টরূপে, জেনেরিক ফাংশনগুলি শুধুমাত্র সেই টাইপগুলিতে কাজ করবে যেগুলির কম্পাইল করার সময় একটি পরিচিত আকার রয়েছে। যাইহোক, আপনি এই সীমাবদ্ধতা শিথিল করতে নিম্নলিখিত বিশেষ সিনট্যাক্স ব্যবহার করতে পারেন:
fn generic<T: ?Sized>(t: &T) {
// --snip--
}?Sized-এর উপর একটি ট্রেইট বাউন্ড মানে "T Sized হতে পারে বা নাও হতে পারে" এবং এই নোটেশনটি ডিফল্টকে ওভাররাইড করে যে জেনেরিক টাইপগুলির কম্পাইল করার সময় একটি পরিচিত আকার থাকতে হবে। এই অর্থ সহ ?Trait সিনট্যাক্স শুধুমাত্র Sized-এর জন্য উপলব্ধ, অন্য কোনও ট্রেইটের জন্য নয়।
এছাড়াও লক্ষ্য করুন যে আমরা t প্যারামিটারের টাইপ T থেকে &T-তে পরিবর্তন করেছি। কারণ টাইপটি Sized নাও হতে পারে, আমাদের এটিকে কোনও ধরণের পয়েন্টারের পিছনে ব্যবহার করতে হবে। এক্ষেত্রে, আমরা একটি রেফারেন্স বেছে নিয়েছি।
এরপর, আমরা ফাংশন এবং ক্লোজার সম্পর্কে কথা বলব!
অ্যাডভান্সড ফাংশন এবং ক্লোজার (Advanced Functions and Closures)
এই বিভাগে ফাংশন এবং ক্লোজার সম্পর্কিত কিছু উন্নত বৈশিষ্ট্য অন্বেষণ করা হয়েছে, যার মধ্যে রয়েছে ফাংশন পয়েন্টার এবং রিটার্নিং ক্লোজার।
ফাংশন পয়েন্টার (Function Pointers)
আমরা ফাংশনে ক্লোজার পাস করার বিষয়ে কথা বলেছি; আপনি ফাংশনে রেগুলার ফাংশনও পাস করতে পারেন! এই কৌশলটি দরকারী যখন আপনি একটি নতুন ক্লোজার সংজ্ঞায়িত করার পরিবর্তে ইতিমধ্যে সংজ্ঞায়িত একটি ফাংশন পাস করতে চান। ফাংশনগুলি fn টাইপে কোয়ার্স করে (ছোট হাতের f দিয়ে), Fn ক্লোজার ট্রেইটের সাথে বিভ্রান্ত হবেন না। fn টাইপকে ফাংশন পয়েন্টার বলা হয়। ফাংশন পয়েন্টার সহ ফাংশন পাস করা আপনাকে অন্য ফাংশনের আর্গুমেন্ট হিসাবে ফাংশন ব্যবহার করার অনুমতি দেবে।
একটি প্যারামিটার যে একটি ফাংশন পয়েন্টার, তা নির্দিষ্ট করার সিনট্যাক্স ক্লোজারের মতোই, যেমনটি Listing 20-28-এ দেখানো হয়েছে, যেখানে আমরা add_one নামে একটি ফাংশন সংজ্ঞায়িত করেছি যা তার প্যারামিটারে এক যোগ করে। do_twice ফাংশনটি দুটি প্যারামিটার নেয়: একটি ফাংশন পয়েন্টার যে কোনও ফাংশনে যা একটি i32 প্যারামিটার নেয় এবং একটি i32 রিটার্ন করে এবং একটি i32 মান। do_twice ফাংশনটি f ফাংশনটিকে দুবার কল করে, এটিকে arg মান পাস করে, তারপর দুটি ফাংশন কলের ফলাফল একসাথে যোগ করে। main ফাংশনটি add_one এবং 5 আর্গুমেন্ট সহ do_twice কল করে।
fn add_one(x: i32) -> i32 { x + 1 } fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 { f(arg) + f(arg) } fn main() { let answer = do_twice(add_one, 5); println!("The answer is: {answer}"); }
এই কোডটি The answer is: 12 প্রিন্ট করে। আমরা নির্দিষ্ট করি যে do_twice-এ f প্যারামিটারটি হল একটি fn যা i32 টাইপের একটি প্যারামিটার নেয় এবং একটি i32 রিটার্ন করে। তারপর আমরা do_twice-এর বডিতে f কল করতে পারি। main-এ, আমরা ফাংশনের নাম add_one-কে do_twice-এর প্রথম আর্গুমেন্ট হিসাবে পাস করতে পারি।
ক্লোজারের বিপরীতে, fn হল একটি টাইপ, ট্রেইট নয়, তাই আমরা সরাসরি প্যারামিটার টাইপ হিসাবে fn নির্দিষ্ট করি, ট্রেইট বাউন্ড হিসাবে Fn ট্রেইটগুলির মধ্যে একটি সহ একটি জেনেরিক টাইপ প্যারামিটার ঘোষণা করার পরিবর্তে।
ফাংশন পয়েন্টারগুলি ক্লোজারের তিনটি ট্রেইটই (Fn, FnMut এবং FnOnce) ইমপ্লিমেন্ট করে, যার মানে আপনি সবসময় একটি ফাংশন পয়েন্টারকে একটি ফাংশনের আর্গুমেন্ট হিসাবে পাস করতে পারেন যা একটি ক্লোজার আশা করে। জেনেরিক টাইপ এবং ক্লোজার ট্রেইটগুলির মধ্যে একটি ব্যবহার করে ফাংশন লেখা ভাল যাতে আপনার ফাংশনগুলি ফাংশন বা ক্লোজার উভয়ই গ্রহণ করতে পারে।
বলা বাহুল্য, আপনি যেখানে শুধুমাত্র fn গ্রহণ করতে চান এবং ক্লোজার নয়, তার একটি উদাহরণ হল বাহ্যিক কোডের সাথে ইন্টারফেস করার সময় যেখানে ক্লোজার নেই: C ফাংশনগুলি আর্গুমেন্ট হিসাবে ফাংশন গ্রহণ করতে পারে, কিন্তু C-তে ক্লোজার নেই।
আপনি কোথায় ইনলাইনে সংজ্ঞায়িত একটি ক্লোজার বা একটি নামযুক্ত ফাংশন ব্যবহার করতে পারেন তার একটি উদাহরণ হিসাবে, আসুন স্ট্যান্ডার্ড লাইব্রেরিতে Iterator ট্রেইট দ্বারা সরবরাহ করা map মেথডের একটি ব্যবহার দেখি। সংখ্যার একটি ভেক্টরকে স্ট্রিং-এর ভেক্টরে পরিণত করতে map ফাংশনটি ব্যবহার করার জন্য, আমরা একটি ক্লোজার ব্যবহার করতে পারি, এইভাবে:
fn main() { let list_of_numbers = vec![1, 2, 3]; let list_of_strings: Vec<String> = list_of_numbers.iter().map(|i| i.to_string()).collect(); }
অথবা আমরা ক্লোজারের পরিবর্তে map-এর আর্গুমেন্ট হিসাবে একটি ফাংশনের নাম দিতে পারি, এইভাবে:
fn main() { let list_of_numbers = vec![1, 2, 3]; let list_of_strings: Vec<String> = list_of_numbers.iter().map(ToString::to_string).collect(); }
লক্ষ্য করুন যে আমাদের অবশ্যই সম্পূর্ণ যোগ্য সিনট্যাক্স ব্যবহার করতে হবে যা আমরা “Advanced Traits”-এ আলোচনা করেছি কারণ to_string নামে একাধিক ফাংশন উপলব্ধ রয়েছে। এখানে, আমরা ToString ট্রেইটে সংজ্ঞায়িত to_string ফাংশনটি ব্যবহার করছি, যা স্ট্যান্ডার্ড লাইব্রেরি যেকোনো টাইপের জন্য ইমপ্লিমেন্ট করেছে যা Display ইমপ্লিমেন্ট করে।
Chapter 6-এর “Enum values” থেকে স্মরণ করুন যে আমরা যে প্রতিটি এনাম ভেরিয়েন্টের নাম সংজ্ঞায়িত করি সেটিও একটি ইনিশিয়ালাইজার ফাংশন হয়ে ওঠে। আমরা এই ইনিশিয়ালাইজার ফাংশনগুলিকে ফাংশন পয়েন্টার হিসাবে ব্যবহার করতে পারি যা ক্লোজার ট্রেইটগুলি ইমপ্লিমেন্ট করে, যার অর্থ হল আমরা ইনিশিয়ালাইজার ফাংশনগুলিকে মেথডগুলির আর্গুমেন্ট হিসাবে নির্দিষ্ট করতে পারি যা ক্লোজার নেয়, এইভাবে:
fn main() { enum Status { Value(u32), Stop, } let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect(); }
এখানে আমরা Status::Value-এর ইনিশিয়ালাইজার ফাংশন ব্যবহার করে map-এ কল করা প্রতিটি u32 মানের জন্য Status::Value ইনস্ট্যান্স তৈরি করি। কিছু লোক এই স্টাইলটি পছন্দ করে এবং কিছু লোক ক্লোজার ব্যবহার করতে পছন্দ করে। এগুলি একই কোডে কম্পাইল হয়, তাই আপনার কাছে যেটি পরিষ্কার মনে হয় সেটি ব্যবহার করুন।
ক্লোজার রিটার্ন করা (Returning Closures)
ক্লোজারগুলি ট্রেইট দ্বারা উপস্থাপিত হয়, যার মানে আপনি সরাসরি ক্লোজার রিটার্ন করতে পারবেন না। বেশিরভাগ ক্ষেত্রে যেখানে আপনি একটি ট্রেইট রিটার্ন করতে চাইতে পারেন, আপনি পরিবর্তে ফাংশনের রিটার্ন মান হিসাবে ট্রেইটটি ইমপ্লিমেন্ট করে এমন কংক্রিট টাইপ ব্যবহার করতে পারেন। যাইহোক, আপনি সাধারণত ক্লোজারের সাথে এটি করতে পারবেন না কারণ তাদের সাধারণত একটি কংক্রিট টাইপ থাকে না যা রিটার্নযোগ্য। উদাহরণস্বরূপ, আপনি যদি ক্লোজারটি তার স্কোপ থেকে কোনও মান ক্যাপচার করে তবে ফাংশন পয়েন্টার fn-কে রিটার্ন টাইপ হিসাবে ব্যবহার করার অনুমতি নেই।
পরিবর্তে, আপনি সাধারণত impl Trait সিনট্যাক্স ব্যবহার করবেন যা আমরা Chapter 10-এ শিখেছি। আপনি Fn, FnOnce এবং FnMut ব্যবহার করে যেকোনো ফাংশন টাইপ রিটার্ন করতে পারেন। উদাহরণস্বরূপ, এই কোডটি ঠিকঠাক কাজ করবে:
#![allow(unused)] fn main() { fn returns_closure(init: i32) -> impl Fn(i32) -> i32 { move |x| x + init } }
যাইহোক, আমরা যেমন Chapter 13-এর “Closure Type Inference and Annotation” বিভাগে উল্লেখ করেছি, প্রতিটি ক্লোজারও তার নিজস্ব স্বতন্ত্র টাইপ। যদি আপনাকে একই স্বাক্ষর কিন্তু ভিন্ন ইমপ্লিমেন্টেশন সহ একাধিক ফাংশনের সাথে কাজ করতে হয়, তাহলে আপনাকে তাদের জন্য একটি ট্রেইট অবজেক্ট ব্যবহার করতে হবে:
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
fn returns_initialized_closure(init: i32) -> Box<dyn Fn(i32) -> i32> {
Box::new(move |x| x + init)
}এই কোডটি ঠিকঠাক কম্পাইল হবে—কিন্তু আমরা যদি impl Fn(i32) -> i32 নিয়ে কাজ করার চেষ্টা করতাম তাহলে হত না। ট্রেইট অবজেক্ট সম্পর্কে আরও জানতে, Chapter 18-এর “Using Trait Objects That Allow for Values of Different Types” বিভাগটি দেখুন।
এরপর, আসুন ম্যাক্রোগুলির দিকে তাকাই!
ম্যাক্রো (Macros)
আমরা এই বই জুড়ে println! এর মতো ম্যাক্রো ব্যবহার করেছি, কিন্তু ম্যাক্রো কী এবং এটি কীভাবে কাজ করে তা আমরা পুরোপুরি অনুসন্ধান করিনি। ম্যাক্রো শব্দটি Rust-এর একগুচ্ছ ফিচারকে বোঝায়: macro_rules! দিয়ে ডিক্লেয়ারেটিভ ম্যাক্রো এবং তিন ধরনের প্রোসিডিউরাল ম্যাক্রো:
- কাস্টম
#[derive]ম্যাক্রো, যা স্ট্রাক্ট এবং এনামে ব্যবহৃতderiveঅ্যাট্রিবিউটের সাথে যোগ করা কোড নির্দিষ্ট করে। - অ্যাট্রিবিউট-এর মতো ম্যাক্রো, যা যেকোনো আইটেমে ব্যবহারযোগ্য কাস্টম অ্যাট্রিবিউট সংজ্ঞায়িত করে।
- ফাংশন-এর মতো ম্যাক্রো, যা ফাংশন কলের মতো দেখায় কিন্তু তাদের আর্গুমেন্ট হিসাবে নির্দিষ্ট টোকেনগুলির উপর কাজ করে।
আমরা এগুলির প্রতিটি নিয়ে একে একে আলোচনা করব, কিন্তু প্রথমে দেখা যাক, আমাদের ফাংশন থাকা সত্ত্বেও কেন ম্যাক্রোর প্রয়োজন।
ম্যাক্রো এবং ফাংশনের মধ্যে পার্থক্য
মৌলিকভাবে, ম্যাক্রো হল কোড লেখার একটি উপায় যা অন্য কোড লেখে, যা মেটাপ্রোগ্রামিং নামে পরিচিত। অ্যাপেন্ডিক্স C-তে, আমরা derive অ্যাট্রিবিউট নিয়ে আলোচনা করি, যা আপনার জন্য বিভিন্ন ট্রেইটের ইমপ্লিমেন্টেশন তৈরি করে। আমরা বই জুড়ে println! এবং vec! ম্যাক্রোও ব্যবহার করেছি। এই সমস্ত ম্যাক্রো ম্যানুয়ালি লেখা কোডের চেয়ে বেশি কোড তৈরি করতে বিস্তৃত হয়।
মেটাপ্রোগ্রামিং আপনার লেখা এবং রক্ষণাবেক্ষণ করা কোডের পরিমাণ কমাতে দরকারী, যা ফাংশনেরও অন্যতম ভূমিকা। তবে, ম্যাক্রোগুলির কিছু অতিরিক্ত ক্ষমতা রয়েছে যা ফাংশনগুলির নেই।
একটি ফাংশন সিগনেচারকে অবশ্যই ফাংশনটির প্যারামিটারের সংখ্যা এবং টাইপ ঘোষণা করতে হবে। অন্যদিকে, ম্যাক্রোগুলি পরিবর্তনশীল সংখ্যক প্যারামিটার নিতে পারে: আমরা println!("hello") কে একটি আর্গুমেন্ট সহ বা println!("hello {}", name) কে দুটি আর্গুমেন্ট সহ কল করতে পারি। এছাড়াও, কম্পাইলার কোডের অর্থ ব্যাখ্যা করার আগেই ম্যাক্রোগুলি এক্সপান্ড করা হয়, তাই একটি ম্যাক্রো, উদাহরণস্বরূপ, একটি প্রদত্ত টাইপের উপর একটি ট্রেইট ইমপ্লিমেন্ট করতে পারে। একটি ফাংশন তা পারে না, কারণ এটি রানটাইমে কল করা হয় এবং একটি ট্রেইট কম্পাইল করার সময় ইমপ্লিমেন্ট করা প্রয়োজন।
একটি ফাংশনের পরিবর্তে একটি ম্যাক্রো ইমপ্লিমেন্ট করার অসুবিধা হল ম্যাক্রো সংজ্ঞাগুলি ফাংশন সংজ্ঞার চেয়ে বেশি জটিল কারণ আপনি Rust কোড লিখছেন যা Rust কোড লেখে। এই পরোক্ষতার কারণে, ম্যাক্রো সংজ্ঞাগুলি সাধারণত ফাংশন সংজ্ঞার চেয়ে পড়া, বোঝা এবং রক্ষণাবেক্ষণ করা আরও কঠিন।
ম্যাক্রো এবং ফাংশনের মধ্যে আরেকটি গুরুত্বপূর্ণ পার্থক্য হল, আপনি একটি ফাইলে ম্যাক্রো কল করার আগে আপনাকে অবশ্যই ম্যাক্রো ডিফাইন করতে হবে অথবা সেগুলিকে স্কোপের মধ্যে আনতে হবে, যেখানে ফাংশনের ক্ষেত্রে আপনি যেকোনো জায়গায় ডিফাইন করতে এবং যেকোনো জায়গা থেকে কল করতে পারেন।
সাধারণ মেটাপ্রোগ্রামিংয়ের জন্য macro_rules! সহ ডিক্লেয়ারেটিভ ম্যাক্রো
Rust-এ ম্যাক্রোর সর্বাধিক ব্যবহৃত রূপটি হল ডিক্লেয়ারেটিভ ম্যাক্রো। এগুলিকে কখনও কখনও "ম্যাক্রোস বাই এক্সাম্পল," "macro_rules! ম্যাক্রো," বা কেবল "ম্যাক্রো" হিসাবেও উল্লেখ করা হয়। তাদের মূলে, ডিক্লেয়ারেটিভ ম্যাক্রোগুলি আপনাকে Rust-এর match এক্সপ্রেশনের মতো কিছু লিখতে দেয়। ষষ্ঠ অধ্যায়ে আলোচনা করা হয়েছে, match এক্সপ্রেশন হল কন্ট্রোল স্ট্রাকচার যা একটি এক্সপ্রেশন নেয়, এক্সপ্রেশনের ফলস্বরূপ ভ্যালুটিকে প্যাটার্নের সাথে তুলনা করে এবং তারপর ম্যাচিং প্যাটার্নের সাথে অ্যাসোসিয়েটেড কোডটি চালায়। ম্যাক্রোও একটি ভ্যালুকে প্যাটার্নের সাথে তুলনা করে যা নির্দিষ্ট কোডের সাথে অ্যাসোসিয়েটেড: এই পরিস্থিতিতে, ভ্যালুটি হল ম্যাক্রোতে পাস করা আক্ষরিক Rust সোর্স কোড; প্যাটার্নগুলি সেই সোর্স কোডের কাঠামোর সাথে তুলনা করা হয়; এবং প্রতিটি প্যাটার্নের সাথে অ্যাসোসিয়েটেড কোড, যখন ম্যাচ করে, তখন ম্যাক্রোতে পাস করা কোডটিকে প্রতিস্থাপন করে। এই সব কম্পাইলেশনের সময় ঘটে।
একটি ম্যাক্রো সংজ্ঞায়িত করতে, আপনি macro_rules! কনস্ট্রাক্ট ব্যবহার করেন। vec! ম্যাক্রোটি কীভাবে সংজ্ঞায়িত করা হয়েছে তা দেখে macro_rules! কীভাবে ব্যবহার করতে হয় তা অন্বেষণ করা যাক। অষ্টম অধ্যায়ে আলোচনা করা হয়েছে কিভাবে আমরা নির্দিষ্ট ভ্যালু সহ একটি নতুন ভেক্টর তৈরি করতে vec! ম্যাক্রো ব্যবহার করতে পারি। উদাহরণস্বরূপ, নিম্নলিখিত ম্যাক্রো তিনটি ইন্টিজার ধারণকারী একটি নতুন ভেক্টর তৈরি করে:
#![allow(unused)] fn main() { let v: Vec<u32> = vec![1, 2, 3]; }
আমরা দুটি ইন্টিজারের একটি ভেক্টর বা পাঁচটি স্ট্রিং স্লাইসের একটি ভেক্টর তৈরি করতেও vec! ম্যাক্রো ব্যবহার করতে পারি। আমরা একই কাজ করার জন্য একটি ফাংশন ব্যবহার করতে পারব না, কারণ আমরা আগে থেকে ভ্যালুগুলির সংখ্যা বা টাইপ জানতে পারব না।
লিস্টিং ২০-২৯ vec! ম্যাক্রোর একটি সামান্য সরলীকৃত সংজ্ঞা দেখায়।
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}দ্রষ্টব্য: স্ট্যান্ডার্ড লাইব্রেরিতে
vec!ম্যাক্রোর প্রকৃত সংজ্ঞায় মেমরির সঠিক পরিমাণ আগে থেকে বরাদ্দ করার কোড অন্তর্ভুক্ত রয়েছে। সেই কোডটি একটি অপ্টিমাইজেশন যা উদাহরণটিকে সহজ করার জন্য আমরা এখানে অন্তর্ভুক্ত করিনি।
#[macro_export] অ্যানোটেশন নির্দেশ করে যে এই ম্যাক্রোটি যখনই ম্যাক্রো সংজ্ঞায়িত করা ক্রেটটি স্কোপে আনা হয় তখনই উপলব্ধ করা উচিত। এই অ্যানোটেশন ছাড়া, ম্যাক্রোটিকে স্কোপে আনা যাবে না।
তারপর আমরা macro_rules! এবং ম্যাক্রোর নাম_বিস্ময়বোধক চিহ্ন ছাড়া_ দিয়ে ম্যাক্রো সংজ্ঞা শুরু করি। নামটি, এই ক্ষেত্রে vec, এর পরে ম্যাক্রো সংজ্ঞার বডি নির্দেশ করে কোঁকড়া ধনুর্বন্ধনী রয়েছে।
vec! বডির গঠনটি match এক্সপ্রেশনের গঠনের অনুরূপ। এখানে আমাদের একটি আর্ম রয়েছে যার প্যাটার্ন ( $( $x:expr ),* ), তার পরে => এবং এই প্যাটার্নের সাথে অ্যাসোসিয়েটেড কোডের ব্লক রয়েছে। যদি প্যাটার্নটি ম্যাচ করে, তাহলে অ্যাসোসিয়েটেড কোডের ব্লকটি নির্গত হবে। যেহেতু এই ম্যাক্রোতে এটিই একমাত্র প্যাটার্ন, তাই ম্যাচ করার কেবল একটি বৈধ উপায় রয়েছে; অন্য কোনো প্যাটার্ন এরর দেবে। আরও জটিল ম্যাক্রোগুলির একাধিক আর্ম থাকবে।
ম্যাক্রো সংজ্ঞায় বৈধ প্যাটার্ন সিনট্যাক্স ঊনবিংশ অধ্যায়ে আলোচিত প্যাটার্ন সিনট্যাক্সের চেয়ে আলাদা কারণ ম্যাক্রো প্যাটার্নগুলি ভ্যালুগুলির পরিবর্তে Rust কোড কাঠামোর সাথে মেলানো হয়। আসুন লিস্টিং ২০-২৯-এর প্যাটার্নের অংশগুলির অর্থ কী তা নিয়ে আলোচনা করি; সম্পূর্ণ ম্যাক্রো প্যাটার্ন সিনট্যাক্সের জন্য, Rust রেফারেন্স দেখুন।
প্রথমে, আমরা সম্পূর্ণ প্যাটার্নটিকে আবদ্ধ করতে এক সেট প্যারেন্থেসিস ব্যবহার করি। ম্যাক্রো সিস্টেমে একটি ভেরিয়েবল ঘোষণা করতে আমরা একটি ডলার চিহ্ন ($) ব্যবহার করি, যেখানে প্যাটার্নের সাথে ম্যাচ করা Rust কোড থাকবে। ডলার চিহ্নটি স্পষ্ট করে দেয় যে এটি একটি সাধারণ Rust ভেরিয়েবলের পরিবর্তে একটি ম্যাক্রো ভেরিয়েবল। এরপরে প্যারেন্থেসিসের একটি সেট আসে যা প্রতিস্থাপন কোডে ব্যবহারের জন্য প্যারেন্থেসিসের মধ্যে থাকা প্যাটার্নের সাথে মেলে এমন মানগুলিকে ক্যাপচার করে। $()-এর মধ্যে $x:expr রয়েছে, যা যেকোনো Rust এক্সপ্রেশনের সাথে মেলে এবং এক্সপ্রেশনটিকে $x নাম দেয়।
$()-এর পরের কমা নির্দেশ করে যে $()-এর মধ্যে থাকা কোডের সাথে মেলে এমন কোডের প্রতিটি উদাহরণের মধ্যে একটি আক্ষরিক কমা বিভাজক অক্ষর উপস্থিত থাকতে হবে। * নির্দিষ্ট করে যে প্যাটার্নটি *-এর আগে যা কিছু আছে তার শূন্য বা তার বেশি উদাহরণের সাথে মেলে।
যখন আমরা vec![1, 2, 3]; দিয়ে এই ম্যাক্রোটিকে কল করি, তখন $x প্যাটার্নটি তিনটি এক্সপ্রেশন 1, 2 এবং 3-এর সাথে তিনবার মেলে।
এখন আসুন এই আর্মের সাথে অ্যাসোসিয়েটেড কোডের বডির প্যাটার্নটি দেখি: $()*-এর মধ্যে temp_vec.push() প্যাটার্নের সাথে $()-এর সাথে মেলে এমন প্রতিটি অংশের জন্য শূন্য বা তার বেশি বার তৈরি করা হয়, প্যাটার্নটি কতবার মেলে তার উপর নির্ভর করে। $x প্রতিটি মিলে যাওয়া এক্সপ্রেশন দিয়ে প্রতিস্থাপিত হয়। যখন আমরা vec![1, 2, 3]; দিয়ে এই ম্যাক্রোটিকে কল করি, তখন এই ম্যাক্রো কলটিকে প্রতিস্থাপন করা জেনারেট করা কোডটি নিম্নলিখিত হবে:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}আমরা একটি ম্যাক্রো সংজ্ঞায়িত করেছি যা যেকোনো টাইপের যেকোনো সংখ্যক আর্গুমেন্ট নিতে পারে এবং নির্দিষ্ট উপাদানগুলি ধারণকারী একটি ভেক্টর তৈরি করার জন্য কোড তৈরি করতে পারে।
ম্যাক্রো কীভাবে লিখতে হয় সে সম্পর্কে আরও জানতে, অনলাইন ডকুমেন্টেশন বা অন্যান্য সংস্থানগুলি দেখুন, যেমন ড্যানিয়েল কিপ দ্বারা শুরু করা এবং লুকাস ওয়ার্থ দ্বারা অবিরত “The Little Book of Rust Macros”।
অ্যাট্রিবিউট থেকে কোড তৈরির জন্য প্রোসিডিউরাল ম্যাক্রো
ম্যাক্রোর দ্বিতীয় রূপটি হল প্রোসিডিউরাল ম্যাক্রো, যা একটি ফাংশনের মতো আরও কাজ করে (এবং এটি এক ধরনের procedure)। প্রোসিডিউরাল ম্যাক্রোগুলি কিছু কোডকে ইনপুট হিসাবে গ্রহণ করে, সেই কোডের উপর কাজ করে এবং কিছু কোডকে আউটপুট হিসাবে তৈরি করে, যেখানে ডিক্লেয়ারেটিভ ম্যাক্রোগুলি প্যাটার্নের সাথে মেলে এবং কোডটিকে অন্য কোড দিয়ে প্রতিস্থাপন করে। তিন ধরনের প্রোসিডিউরাল ম্যাক্রো হল কাস্টম ডিরাইভ, অ্যাট্রিবিউট-এর মতো এবং ফাংশন-এর মতো, এবং সবই একইভাবে কাজ করে।
প্রোসিডিউরাল ম্যাক্রো তৈরি করার সময়, সংজ্ঞাগুলি অবশ্যই তাদের নিজস্ব ক্রেটে একটি বিশেষ ক্রেট টাইপ সহ থাকতে হবে। এটি জটিল প্রযুক্তিগত কারণে, যা আমরা ভবিষ্যতে দূর করার আশা করি। লিস্টিং ২০-৩০-এ, আমরা দেখাই কিভাবে একটি প্রোসিডিউরাল ম্যাক্রো সংজ্ঞায়িত করতে হয়, যেখানে some_attribute হল একটি নির্দিষ্ট ম্যাক্রো বৈচিত্র্য ব্যবহারের জন্য একটি প্লেসহোল্ডার।
use proc_macro;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}যে ফাংশনটি একটি প্রোসিডিউরাল ম্যাক্রো সংজ্ঞায়িত করে সেটি একটি TokenStream কে ইনপুট হিসাবে নেয় এবং একটি TokenStream কে আউটপুট হিসাবে তৈরি করে। TokenStream টাইপটি proc_macro ক্রেট দ্বারা সংজ্ঞায়িত করা হয়েছে যা Rust-এর সাথে অন্তর্ভুক্ত এবং টোকেনগুলির একটি ক্রম উপস্থাপন করে। এটি ম্যাক্রোর মূল: ম্যাক্রো যে সোর্স কোডের উপর কাজ করছে সেটি ইনপুট TokenStream তৈরি করে এবং ম্যাক্রো যে কোড তৈরি করে তা হল আউটপুট TokenStream। ফাংশনটির সাথে একটি অ্যাট্রিবিউটও সংযুক্ত রয়েছে যা নির্দিষ্ট করে যে আমরা কোন ধরনের প্রোসিডিউরাল ম্যাক্রো তৈরি করছি। আমরা একই ক্রেটে একাধিক ধরনের প্রোসিডিউরাল ম্যাক্রো রাখতে পারি।
আসুন বিভিন্ন ধরনের প্রোসিডিউরাল ম্যাক্রো দেখি। আমরা একটি কাস্টম ডিরাইভ ম্যাক্রো দিয়ে শুরু করব এবং তারপরে ছোটখাটো অমিলগুলি ব্যাখ্যা করব যা অন্য ফর্মগুলিকে আলাদা করে তোলে।
কীভাবে একটি কাস্টম derive ম্যাক্রো লিখবেন
আসুন hello_macro নামে একটি ক্রেট তৈরি করি যা HelloMacro নামে একটি ট্রেইট সংজ্ঞায়িত করে, যার সাথে hello_macro নামে একটি অ্যাসোসিয়েটেড ফাংশন রয়েছে। আমাদের ব্যবহারকারীদের তাদের প্রতিটি টাইপের জন্য HelloMacro ট্রেইট ইমপ্লিমেন্ট করার পরিবর্তে, আমরা একটি প্রোসিডিউরাল ম্যাক্রো সরবরাহ করব যাতে ব্যবহারকারীরা তাদের টাইপকে #[derive(HelloMacro)] দিয়ে অ্যানোটেট করতে পারে এবং hello_macro ফাংশনের একটি ডিফল্ট ইমপ্লিমেন্টেশন পেতে পারে। ডিফল্ট ইমপ্লিমেন্টেশনটি Hello, Macro! My name is TypeName! প্রিন্ট করবে, যেখানে TypeName হল সেই টাইপের নাম যার উপর এই ট্রেইটটি সংজ্ঞায়িত করা হয়েছে। অন্য কথায়, আমরা একটি ক্রেট লিখব যা অন্য একজন প্রোগ্রামারকে আমাদের ক্রেট ব্যবহার করে লিস্টিং ২০-৩১-এর মতো কোড লিখতে সক্ষম করে।
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}আমরা কাজ শেষ করার পর এই কোডটি Hello, Macro! My name is Pancakes! প্রিন্ট করবে। প্রথম ধাপ হল একটি নতুন লাইব্রেরি ক্রেট তৈরি করা, এইভাবে:
$ cargo new hello_macro --lib
এরপরে, আমরা HelloMacro ট্রেইট এবং এর অ্যাসোসিয়েটেড ফাংশন সংজ্ঞায়িত করব:
pub trait HelloMacro {
fn hello_macro();
}আমাদের একটি ট্রেইট এবং এর ফাংশন রয়েছে। এই মুহুর্তে, আমাদের ক্রেট ব্যবহারকারী পছন্দসই কার্যকারিতা অর্জনের জন্য ট্রেইটটি ইমপ্লিমেন্ট করতে পারে, এইভাবে:
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}যাইহোক, তাদের প্রতিটি টাইপের জন্য ইমপ্লিমেন্টেশন ব্লক লিখতে হবে যা তারা hello_macro-এর সাথে ব্যবহার করতে চায়; আমরা তাদের এই কাজটি করা থেকে বিরত রাখতে চাই।
অতিরিক্তভাবে, আমরা এখনও hello_macro ফাংশনটিকে ডিফল্ট ইমপ্লিমেন্টেশন সহ সরবরাহ করতে পারি না যা সেই টাইপের নাম প্রিন্ট করবে যার উপর ট্রেইটটি ইমপ্লিমেন্ট করা হয়েছে: Rust-এর রিফ্লেকশন ক্ষমতা নেই, তাই এটি রানটাইমে টাইপের নাম দেখতে পারে না। আমাদের কম্পাইল করার সময় কোড তৈরি করার জন্য একটি ম্যাক্রো প্রয়োজন।
পরবর্তী ধাপ হল প্রোসিডিউরাল ম্যাক্রো সংজ্ঞায়িত করা। এই লেখার সময়, প্রোসিডিউরাল ম্যাক্রোগুলি তাদের নিজস্ব ক্রেটে থাকা দরকার। অবশেষে, এই সীমাবদ্ধতা তুলে নেওয়া হতে পারে। ক্রেট এবং ম্যাক্রো ক্রেট গঠনের নিয়ম নিম্নরূপ: foo নামের একটি ক্রেটের জন্য, একটি কাস্টম ডিরাইভ প্রোসিডিউরাল ম্যাক্রো ক্রেটকে foo_derive বলা হয়। আসুন আমাদের hello_macro প্রকল্পের ভিতরে hello_macro_derive নামে একটি নতুন ক্রেট শুরু করি:
$ cargo new hello_macro_derive --lib
আমাদের দুটি ক্রেট ঘনিষ্ঠভাবে সম্পর্কিত, তাই আমরা আমাদের hello_macro ক্রেটের ডিরেক্টরির মধ্যে প্রোসিডিউরাল ম্যাক্রো ক্রেট তৈরি করি। যদি আমরা hello_macro-তে ট্রেইট সংজ্ঞা পরিবর্তন করি, তাহলে আমাদের hello_macro_derive-এ প্রোসিডিউরাল ম্যাক্রোর ইমপ্লিমেন্টেশনও পরিবর্তন করতে হবে। দুটি ক্রেট আলাদাভাবে প্রকাশ করতে হবে, এবং প্রোগ্রামারদের এই ক্রেটগুলি ব্যবহার করার জন্য উভয়কেই নির্ভরতা হিসাবে যুক্ত করতে হবে এবং উভয়কেই স্কোপে আনতে হবে। আমরা পরিবর্তে hello_macro ক্রেটটিকে hello_macro_derive কে নির্ভরতা হিসাবে ব্যবহার করতে এবং প্রোসিডিউরাল ম্যাক্রো কোড পুনরায় এক্সপোর্ট করতে পারতাম। যাইহোক, আমরা যেভাবে প্রকল্পটি গঠন করেছি তা প্রোগ্রামারদের জন্য hello_macro ব্যবহার করা সম্ভব করে তোলে, এমনকি যদি তারা derive কার্যকারিতা না চায়।
আমাদের hello_macro_derive ক্রেটটিকে একটি প্রোসিডিউরাল ম্যাক্রো ক্রেট হিসাবে ঘোষণা করতে হবে। আমাদের syn এবং quote ক্রেট থেকে কার্যকারিতারও প্রয়োজন হবে, যেমনটি আপনি একটু পরেই দেখতে পাবেন, তাই আমাদের সেগুলিকে নির্ভরতা হিসাবে যুক্ত করতে হবে। hello_macro_derive-এর জন্য Cargo.toml ফাইলে নিম্নলিখিতগুলি যুক্ত করুন:
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
প্রোসিডিউরাল ম্যাক্রো সংজ্ঞায়িত করা শুরু করতে, লিস্টিং ২০-৩২-এর কোডটি hello_macro_derive ক্রেটের জন্য আপনার src/lib.rs ফাইলে রাখুন। মনে রাখবেন যে impl_hello_macro ফাংশনের জন্য একটি সংজ্ঞা যোগ না করা পর্যন্ত এই কোডটি কম্পাইল হবে না।
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate.
let ast = syn::parse(input).unwrap();
// Build the trait implementation.
impl_hello_macro(&ast)
}লক্ষ্য করুন যে আমরা কোডটিকে hello_macro_derive ফাংশনে বিভক্ত করেছি, যেটি TokenStream পার্স করার জন্য দায়ী, এবং impl_hello_macro ফাংশন, যেটি সিনট্যাক্স ট্রি রূপান্তর করার জন্য দায়ী: এটি একটি প্রোসিডিউরাল ম্যাক্রো লেখা আরও সুবিধাজনক করে তোলে। বাইরের ফাংশনের কোড (এই ক্ষেত্রে hello_macro_derive) আপনি যে প্রোসিডিউরাল ম্যাক্রো ক্রেট দেখেন বা তৈরি করেন তার প্রায় সবগুলির জন্যই একই হবে। ভিতরের ফাংশনের বডিতে আপনি যে কোডটি নির্দিষ্ট করেন (এই ক্ষেত্রে impl_hello_macro) আপনার প্রোসিডিউরাল ম্যাক্রোর উদ্দেশ্যের উপর নির্ভর করে আলাদা হবে।
আমরা তিনটি নতুন ক্রেট চালু করেছি: proc_macro, syn, এবং quote। proc_macro ক্রেটটি Rust-এর সাথে আসে, তাই আমাদের এটিকে Cargo.toml-এ নির্ভরতাগুলিতে যুক্ত করার দরকার ছিল না। proc_macro ক্রেটটি হল কম্পাইলারের API যা আমাদের কোড থেকে Rust কোড পড়তে এবং ম্যানিপুলেট করার অনুমতি দেয়।
syn ক্রেট একটি স্ট্রিং থেকে Rust কোডকে একটি ডেটা স্ট্রাকচারে পার্স করে যার উপর আমরা অপারেশন করতে পারি। quote ক্রেট syn ডেটা স্ট্রাকচারগুলিকে আবার Rust কোডে পরিণত করে। এই ক্রেটগুলি আমাদের হ্যান্ডেল করতে হতে পারে এমন যেকোনো ধরনের Rust কোড পার্স করা অনেক সহজ করে তোলে: Rust কোডের জন্য একটি সম্পূর্ণ পার্সার লেখা কোনো সহজ কাজ নয়।
যখন আমাদের লাইব্রেরির একজন ব্যবহারকারী একটি টাইপের উপর #[derive(HelloMacro)] নির্দিষ্ট করে তখন hello_macro_derive ফাংশনটিকে কল করা হবে। এটি সম্ভব কারণ আমরা এখানে hello_macro_derive ফাংশনটিকে proc_macro_derive দিয়ে অ্যানোটেট করেছি এবং HelloMacro নামটি নির্দিষ্ট করেছি, যা আমাদের ট্রেইটের নামের সাথে মেলে; এটি সেই নিয়ম যা বেশিরভাগ প্রোসিডিউরাল ম্যাক্রো অনুসরণ করে।
hello_macro_derive ফাংশন প্রথমে input কে TokenStream থেকে এমন একটি ডেটা স্ট্রাকচারে রূপান্তর করে যা আমরা ব্যাখ্যা করতে এবং অপারেশন করতে পারি। এখানেই syn কাজে আসে। syn-এর parse ফাংশনটি একটি TokenStream নেয় এবং পার্স করা Rust কোডকে উপস্থাপন করে এমন একটি DeriveInput স্ট্রাক্ট রিটার্ন করে। লিস্টিং ২০-৩৩ struct Pancakes; স্ট্রিং পার্স করে আমরা যে DeriveInput স্ট্রাক্ট পাই তার প্রাসঙ্গিক অংশগুলি দেখায়:
DeriveInput {
// --snip--
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}এই স্ট্রাক্টের ফিল্ডগুলি দেখায় যে আমরা যে Rust কোডটি পার্স করেছি সেটি হল Pancakes-এর ident (আইডেন্টিফায়ার, অর্থাৎ নাম) সহ একটি ইউনিট স্ট্রাক্ট। এই স্ট্রাক্টের উপর সব ধরনের Rust কোড বর্ণনা করার জন্য আরও ফিল্ড রয়েছে; আরও তথ্যের জন্য syn ডকুমেন্টেশন DeriveInput-এর জন্য দেখুন।
শীঘ্রই আমরা impl_hello_macro ফাংশনটি সংজ্ঞায়িত করব, যেখানে আমরা নতুন Rust কোড তৈরি করব যা আমরা অন্তর্ভুক্ত করতে চাই। কিন্তু তার আগে, মনে রাখবেন যে আমাদের ডিরাইভ ম্যাক্রোর আউটপুটও একটি TokenStream। রিটার্ন করা TokenStream আমাদের ক্রেট ব্যবহারকারীদের লেখা কোডে যোগ করা হয়, তাই যখন তারা তাদের ক্রেট কম্পাইল করে, তখন তারা অতিরিক্ত কার্যকারিতা পাবে যা আমরা পরিবর্তিত TokenStream-এ সরবরাহ করি।
আপনি হয়তো লক্ষ্য করেছেন যে আমরা syn::parse ফাংশনে কল ব্যর্থ হলে hello_macro_derive ফাংশনটিকে প্যানিক করার জন্য unwrap কল করছি। প্রোসিডিউরাল ম্যাক্রো API-এর সাথে সঙ্গতি রাখতে proc_macro_derive ফাংশনগুলিকে Result-এর পরিবর্তে TokenStream রিটার্ন করতে হবে বলে এরর-এ আমাদের প্রোসিডিউরাল ম্যাক্রো প্যানিক করা প্রয়োজন। আমরা unwrap ব্যবহার করে এই উদাহরণটিকে সরল করেছি; প্রোডাকশন কোডে, আপনার panic! বা expect ব্যবহার করে কী ভুল হয়েছে সে সম্পর্কে আরও নির্দিষ্ট এরর মেসেজ সরবরাহ করা উচিত।
এখন আমাদের কাছে অ্যানোটেটেড Rust কোডকে TokenStream থেকে DeriveInput ইন্সট্যান্সে পরিণত করার কোড রয়েছে, আসুন সেই কোডটি তৈরি করি যা অ্যানোটেটেড টাইপের উপর HelloMacro ট্রেইট ইমপ্লিমেন্ট করে, যেমনটি লিস্টিং ২০-৩৪-এ দেখানো হয়েছে।
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let generated = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
generated.into()
}আমরা ast.ident ব্যবহার করে অ্যানোটেটেড টাইপের নাম (আইডেন্টিফায়ার) ধারণকারী একটি Ident স্ট্রাক্ট ইন্সট্যান্স পাই। লিস্টিং ২০-৩৩-এর স্ট্রাক্টটি দেখায় যে যখন আমরা লিস্টিং ২০-৩১-এর কোডে impl_hello_macro ফাংশনটি চালাই, তখন আমরা যে ident পাব তার ident ফিল্ডে "Pancakes"-এর একটি ভ্যালু থাকবে। এইভাবে, লিস্টিং ২০-৩৪-এর name ভেরিয়েবলটিতে একটি Ident স্ট্রাক্ট ইন্সট্যান্স থাকবে যা প্রিন্ট করার সময় "Pancakes" স্ট্রিং হবে, লিস্টিং ২০-৩১-এর স্ট্রাক্টের নাম।
quote! ম্যাক্রো আমাদের Rust কোড সংজ্ঞায়িত করতে দেয় যা আমরা রিটার্ন করতে চাই। কম্পাইলার quote! ম্যাক্রোর সরাসরি ফলাফলের থেকে আলাদা কিছু আশা করে, তাই আমাদের এটিকে একটি TokenStream-এ রূপান্তর করতে হবে। আমরা এটি into মেথড কল করে করি, যা এই মধ্যবর্তী উপস্থাপনাকে গ্রাস করে এবং প্রয়োজনীয় TokenStream টাইপের একটি ভ্যালু রিটার্ন করে।
quote! ম্যাক্রো কিছু খুব সুন্দর টেমপ্লেটিং মেকানিক্সও সরবরাহ করে: আমরা #name লিখতে পারি, এবং quote! এটিকে name ভেরিয়েবলের ভ্যালু দিয়ে প্রতিস্থাপন করবে। আপনি নিয়মিত ম্যাক্রোর মতো একইভাবে কিছু পুনরাবৃত্তিও করতে পারেন। একটি পুঙ্খানুপুঙ্খ ভূমিকার জন্য quote ক্রেটের ডক্স দেখুন।
আমরা চাই আমাদের প্রোসিডিউরাল ম্যাক্রো ব্যবহারকারীর অ্যানোটেটেড টাইপের জন্য আমাদের HelloMacro ট্রেইটের একটি ইমপ্লিমেন্টেশন তৈরি করুক, যা আমরা #name ব্যবহার করে পেতে পারি। ট্রেইট ইমপ্লিমেন্টেশনে hello_macro নামে একটি ফাংশন রয়েছে, যার বডিতে আমরা যে কার্যকারিতা সরবরাহ করতে চাই তা রয়েছে: Hello, Macro! My name is এবং তারপর অ্যানোটেটেড টাইপের নাম প্রিন্ট করা।
এখানে ব্যবহৃত stringify! ম্যাক্রোটি Rust-এ বিল্ট-ইন। এটি 1 + 2-এর মতো একটি Rust এক্সপ্রেশন নেয় এবং কম্পাইল করার সময় এক্সপ্রেশনটিকে "1 + 2"-এর মতো একটি স্ট্রিং লিটারেলে পরিণত করে। এটি format! বা println! থেকে আলাদা, ম্যাক্রো যা এক্সপ্রেশনটিকে মূল্যায়ন করে এবং তারপর ফলাফলটিকে একটি String-এ পরিণত করে। এমন একটি সম্ভাবনা রয়েছে যে #name ইনপুটটি আক্ষরিকভাবে প্রিন্ট করার জন্য একটি এক্সপ্রেশন হতে পারে, তাই আমরা stringify! ব্যবহার করি। stringify! ব্যবহার করা কম্পাইল করার সময় #name কে একটি স্ট্রিং লিটারেলে রূপান্তর করে একটি অ্যালোকেশনও বাঁচায়।
এই মুহুর্তে, cargo build hello_macro এবং hello_macro_derive উভয় ক্ষেত্রেই সফলভাবে সম্পন্ন হওয়া উচিত। আসুন প্রোসিডিউরাল ম্যাক্রোটিকে অ্যাকশনে দেখতে লিস্টিং ২০-৩১-এর কোডের সাথে এই ক্রেটগুলিকে সংযুক্ত করি! আপনার projects ডিরেক্টরিতে cargo new pancakes ব্যবহার করে একটি নতুন বাইনারি প্রোজেক্ট তৈরি করুন। আমাদের pancakes ক্রেটের Cargo.toml-এ নির্ভরতা হিসাবে hello_macro এবং hello_macro_derive যোগ করতে হবে। আপনি যদি crates.io-তে hello_macro এবং hello_macro_derive-এর আপনার সংস্করণ প্রকাশ করেন, তাহলে সেগুলি নিয়মিত নির্ভরতা হবে; যদি না হয়, আপনি সেগুলিকে path নির্ভরতা হিসাবে নিম্নরূপ নির্দিষ্ট করতে পারেন:
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
লিস্টিং ২০-৩১-এর কোডটি src/main.rs-এ রাখুন এবং cargo run চালান: এটি Hello, Macro! My name is Pancakes! প্রিন্ট করবে। প্রোসিডিউরাল ম্যাক্রো থেকে HelloMacro ট্রেইটের ইমপ্লিমেন্টেশনটি pancakes ক্রেটকে এটি ইমপ্লিমেন্ট করার প্রয়োজন ছাড়াই অন্তর্ভুক্ত করা হয়েছিল; #[derive(HelloMacro)] ট্রেইট ইমপ্লিমেন্টেশন যোগ করেছে।
এরপরে, আসুন অন্বেষণ করি কিভাবে অন্যান্য ধরনের প্রোসিডিউরাল ম্যাক্রোগুলি কাস্টম ডিরাইভ ম্যাক্রোগুলি থেকে আলাদা।
অ্যাট্রিবিউট-এর মতো ম্যাক্রো
অ্যাট্রিবিউট-এর মতো ম্যাক্রো কাস্টম ডিরাইভ ম্যাক্রোর মতোই, কিন্তু derive অ্যাট্রিবিউটের জন্য কোড তৈরি করার পরিবর্তে, তারা আপনাকে নতুন অ্যাট্রিবিউট তৈরি করতে দেয়। এগুলি আরও flexible: derive শুধুমাত্র স্ট্রাক্ট এবং এনামের জন্য কাজ করে; অ্যাট্রিবিউটগুলি অন্যান্য আইটেমগুলিতেও প্রয়োগ করা যেতে পারে, যেমন ফাংশন। অ্যাট্রিবিউট-এর মতো ম্যাক্রো ব্যবহারের একটি উদাহরণ এখানে দেওয়া হল: ধরুন আপনার কাছে route নামে একটি অ্যাট্রিবিউট রয়েছে যা একটি ওয়েব অ্যাপ্লিকেশন ফ্রেমওয়ার্ক ব্যবহার করার সময় ফাংশনগুলিকে অ্যানোটেট করে:
#[route(GET, "/")]
fn index() {এই #[route] অ্যাট্রিবিউটটি ফ্রেমওয়ার্ক দ্বারা একটি প্রোসিডিউরাল ম্যাক্রো হিসাবে সংজ্ঞায়িত করা হবে। ম্যাক্রো সংজ্ঞা ফাংশনের স্বাক্ষরটি এইরকম দেখতে হবে:
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {এখানে, আমাদের TokenStream টাইপের দুটি প্যারামিটার রয়েছে। প্রথমটি অ্যাট্রিবিউটের কনটেন্টের জন্য: GET, "/" অংশ। দ্বিতীয়টি অ্যাট্রিবিউটটি যে আইটেমের সাথে সংযুক্ত তার বডির জন্য: এই ক্ষেত্রে, fn index() {} এবং ফাংশনের বডির বাকি অংশ।
এছাড়া, অ্যাট্রিবিউট-এর মতো ম্যাক্রো কাস্টম ডিরাইভ ম্যাক্রোর মতোই কাজ করে: আপনি proc-macro ক্রেট টাইপ সহ একটি ক্রেট তৈরি করেন এবং একটি ফাংশন ইমপ্লিমেন্ট করেন যা আপনার ইচ্ছামতো কোড তৈরি করে!
ফাংশন-এর মতো ম্যাক্রো
ফাংশন-এর মতো ম্যাক্রো সেই ম্যাক্রোগুলিকে সংজ্ঞায়িত করে যা ফাংশন কলের মতো দেখায়। macro_rules! ম্যাক্রোর মতোই, এগুলি ফাংশনের চেয়ে বেশি flexible; উদাহরণস্বরূপ, তারা অজানা সংখ্যক আর্গুমেন্ট নিতে পারে। যাইহোক, macro_rules! ম্যাক্রোগুলি শুধুমাত্র সেই ম্যাচ-এর মতো সিনট্যাক্স ব্যবহার করে সংজ্ঞায়িত করা যেতে পারে যা আমরা আগে “সাধারণ মেটাপ্রোগ্রামিংয়ের জন্য macro_rules! সহ ডিক্লেয়ারেটিভ ম্যাক্রো” তে আলোচনা করেছি। ফাংশন-এর মতো ম্যাক্রোগুলি একটি TokenStream প্যারামিটার নেয় এবং তাদের সংজ্ঞা অন্য দুটি ধরণের প্রোসিডিউরাল ম্যাক্রোর মতোই Rust কোড ব্যবহার করে সেই TokenStream-কে ম্যানিপুলেট করে। একটি ফাংশন-এর মতো ম্যাক্রোর একটি উদাহরণ হল একটি sql! ম্যাক্রো, যাকে এইভাবে কল করা যেতে পারে:
let sql = sql!(SELECT * FROM posts WHERE id=1);এই ম্যাক্রোটি এর ভিতরের SQL স্টেটমেন্টটিকে পার্স করবে এবং এটি সিনট্যাক্টিকভাবে সঠিক কিনা তা পরীক্ষা করবে, যা macro_rules! ম্যাক্রো যা করতে পারে তার চেয়ে অনেক বেশি জটিল প্রসেসিং। sql! ম্যাক্রোটিকে এইভাবে সংজ্ঞায়িত করা হবে:
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {এই সংজ্ঞাটি কাস্টম ডিরাইভ ম্যাক্রোর স্বাক্ষরের মতোই: আমরা প্যারেন্থেসিসের ভিতরের টোকেনগুলি পাই এবং আমরা যে কোড তৈরি করতে চেয়েছিলাম তা রিটার্ন করি।
সারসংক্ষেপ
বাহ! এখন আপনার টুলবক্সে কিছু Rust ফিচার রয়েছে যা আপনি সম্ভবত প্রায়শই ব্যবহার করবেন না, তবে আপনি জানবেন যে সেগুলি খুব বিশেষ পরিস্থিতিতে উপলব্ধ। আমরা বেশ কয়েকটি জটিল বিষয় উপস্থাপন করেছি যাতে আপনি যখন এরর মেসেজের সাজেশনগুলিতে বা অন্য লোকেদের কোডে এগুলির মুখোমুখি হন, তখন আপনি এই ধারণা এবং সিনট্যাক্সগুলি চিনতে পারবেন। সমাধানগুলিতে আপনাকে গাইড করতে এই অধ্যায়টিকে একটি রেফারেন্স হিসাবে ব্যবহার করুন।
এরপরে, আমরা বই জুড়ে যা আলোচনা করেছি তার সবকিছু অনুশীলনে প্রয়োগ করব এবং আরও একটি প্রোজেক্ট করব!
ফাইনাল প্রোজেক্ট: একটি মাল্টিথ্রেডেড ওয়েব সার্ভার তৈরি করা (Final Project: Building a Multithreaded Web Server)
এটি একটি দীর্ঘ যাত্রা ছিল, কিন্তু আমরা বইটির শেষে পৌঁছেছি। এই চ্যাপ্টারে, আমরা শেষ অধ্যায়গুলিতে আলোচিত কিছু ধারণা প্রদর্শন করার জন্য এবং পূর্ববর্তী কিছু পাঠ পুনরালোচনা করার জন্য একসাথে আরও একটি প্রোজেক্ট তৈরি করব।
আমাদের ফাইনাল প্রোজেক্টের জন্য, আমরা একটি ওয়েব সার্ভার তৈরি করব যা "hello" বলে এবং একটি ওয়েব ব্রাউজারে চিত্র 21-1 এর মতো দেখায়।
চিত্র 21-1: আমাদের ফাইনাল শেয়ার্ড প্রোজেক্ট
ওয়েব সার্ভার তৈরির জন্য আমাদের পরিকল্পনাটি এখানে দেওয়া হল:
- TCP এবং HTTP সম্পর্কে কিছু শিখুন।
- একটি সকেটে TCP কানেকশন শুনুন।
- অল্প সংখ্যক HTTP রিকোয়েস্ট পার্স করুন।
- একটি সঠিক HTTP রেসপন্স তৈরি করুন।
- একটি থ্রেড পুল দিয়ে আমাদের সার্ভারের থ্রুপুট উন্নত করুন।
শুরু করার আগে, আমাদের দুটি বিষয় উল্লেখ করা উচিত: প্রথমত, আমরা যে পদ্ধতিটি ব্যবহার করব সেটি Rust-এর সাথে একটি ওয়েব সার্ভার তৈরি করার সর্বোত্তম উপায় হবে না। কমিউনিটির সদস্যরা crates.io-এ উপলব্ধ অনেকগুলি প্রোডাকশন-রেডি ক্রেট প্রকাশ করেছেন যা আমাদের তৈরি করা ওয়েব সার্ভার এবং থ্রেড পুল ইমপ্লিমেন্টেশনের চেয়ে আরও সম্পূর্ণ। যাইহোক, এই চ্যাপ্টারে আমাদের উদ্দেশ্য হল আপনাকে শিখতে সাহায্য করা, সহজ পথ নেওয়া নয়। যেহেতু Rust একটি সিস্টেম প্রোগ্রামিং ভাষা, তাই আমরা যে অ্যাবস্ট্রাকশন লেভেলে কাজ করতে চাই তা বেছে নিতে পারি এবং অন্য ভাষাগুলিতে সম্ভব বা ব্যবহারিক নয় এমন নিম্ন স্তরে যেতে পারি।
দ্বিতীয়ত, আমরা এখানে অ্যাসিঙ্ক এবং অ্যাওয়েট ব্যবহার করব না। একটি থ্রেড পুল তৈরি করা নিজেই একটি যথেষ্ট বড় চ্যালেঞ্জ, এর সাথে অ্যাসিঙ্ক রানটাইম যুক্ত না করেই! যাইহোক, আমরা লক্ষ্য করব কিভাবে অ্যাসিঙ্ক এবং অ্যাওয়েট এই চ্যাপ্টারে আমরা দেখতে পাব এমন কিছু সমস্যার ক্ষেত্রে প্রযোজ্য হতে পারে। চূড়ান্তভাবে, যেমনটি আমরা Chapter 17-এ উল্লেখ করেছি, অনেক অ্যাসিঙ্ক রানটাইম তাদের কাজ পরিচালনার জন্য থ্রেড পুল ব্যবহার করে।
তাই আমরা বেসিক HTTP সার্ভার এবং থ্রেড পুল ম্যানুয়ালি লিখব যাতে আপনি ভবিষ্যতে ব্যবহার করতে পারেন এমন ক্রেটগুলির পিছনের সাধারণ ধারণা এবং কৌশলগুলি শিখতে পারেন।
একটি সিঙ্গেল-থ্রেডেড ওয়েব সার্ভার তৈরি করা (Building a Single-Threaded Web Server)
আমরা একটি সিঙ্গেল-থ্রেডেড ওয়েব সার্ভার চালু করে শুরু করব। শুরু করার আগে, ওয়েব সার্ভার তৈরিতে জড়িত প্রোটোকলগুলির একটি সংক্ষিপ্ত বিবরণ দেখা যাক। এই প্রোটোকলগুলির বিশদ বিবরণ এই বইয়ের সুযোগের বাইরে, তবে একটি সংক্ষিপ্ত বিবরণ আপনাকে প্রয়োজনীয় তথ্য দেবে।
ওয়েব সার্ভারগুলিতে জড়িত দুটি প্রধান প্রোটোকল হল হাইপারটেক্সট ট্রান্সফার প্রোটোকল (HTTP) এবং ট্রান্সমিশন কন্ট্রোল প্রোটোকল (TCP)। উভয় প্রোটোকলই রিকোয়েস্ট-রেসপন্স প্রোটোকল, অর্থাৎ একজন ক্লায়েন্ট রিকোয়েস্ট শুরু করে এবং একজন সার্ভার রিকোয়েস্টগুলি শোনে এবং ক্লায়েন্টকে একটি রেসপন্স প্রদান করে। সেই রিকোয়েস্ট এবং রেসপন্সগুলির বিষয়বস্তু প্রোটোকল দ্বারা সংজ্ঞায়িত করা হয়।
TCP হল নিম্ন-স্তরের প্রোটোকল যা বর্ণনা করে কিভাবে তথ্য এক সার্ভার থেকে অন্য সার্ভারে যায়, কিন্তু সেই তথ্যটি কী তা নির্দিষ্ট করে না। HTTP, TCP-এর উপরে তৈরি হয়ে রিকোয়েস্ট এবং রেসপন্সগুলির বিষয়বস্তু সংজ্ঞায়িত করে। টেকনিক্যালি HTTP অন্যান্য প্রোটোকলের সাথে ব্যবহার করা সম্ভব, কিন্তু বেশিরভাগ ক্ষেত্রে, HTTP তার ডেটা TCP-এর মাধ্যমে পাঠায়। আমরা TCP এবং HTTP রিকোয়েস্ট এবং রেসপন্সের raw bytes নিয়ে কাজ করব।
TCP কানেকশন শোনা (Listening to the TCP Connection)
আমাদের ওয়েব সার্ভারকে একটি TCP কানেকশন শুনতে হবে, তাই এটিই প্রথম অংশ যা নিয়ে আমরা কাজ করব। স্ট্যান্ডার্ড লাইব্রেরি একটি std::net মডিউল সরবরাহ করে যা আমাদের এটি করতে দেয়। চলুন যথারীতি একটি নতুন প্রোজেক্ট তৈরি করি:
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
এখন শুরু করার জন্য src/main.rs-এ Listing 21-1-এর কোডটি লিখুন। এই কোডটি লোকাল অ্যাড্রেস 127.0.0.1:7878-এ আগত TCP স্ট্রিমগুলির জন্য শুনবে। যখন এটি একটি আগত স্ট্রিম পাবে, তখন এটি Connection established! প্রিন্ট করবে।
use std::net::TcpListener; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); println!("Connection established!"); } }
TcpListener ব্যবহার করে, আমরা 127.0.0.1:7878 অ্যাড্রেসে TCP কানেকশন শুনতে পারি। অ্যাড্রেসে, কোলনের আগের অংশটি আপনার কম্পিউটারকে উপস্থাপন করে এমন একটি IP অ্যাড্রেস (এটি প্রতিটি কম্পিউটারে একই এবং লেখকদের কম্পিউটারের প্রতিনিধিত্ব করে না), এবং 7878 হল পোর্ট। আমরা দুটি কারণে এই পোর্টটি বেছে নিয়েছি: HTTP সাধারণত এই পোর্টে গৃহীত হয় না তাই আমাদের সার্ভারটি আপনার মেশিনে চলমান অন্য কোনও ওয়েব সার্ভারের সাথে বিরোধ করার সম্ভাবনা কম, এবং 7878 হল টেলিফোনে rust টাইপ করা।
এই পরিস্থিতিতে bind ফাংশনটি new ফাংশনের মতোই কাজ করে, যেখানে এটি একটি নতুন TcpListener ইনস্ট্যান্স রিটার্ন করবে। ফাংশনটির নাম bind কারণ, নেটওয়ার্কিং-এ, শোনার জন্য একটি পোর্টের সাথে কানেক্ট করাকে "বাইন্ডিং টু এ পোর্ট" বলা হয়।
bind ফাংশনটি একটি Result<T, E> রিটার্ন করে, যা নির্দেশ করে যে বাইন্ডিং ব্যর্থ হওয়া সম্ভব। উদাহরণস্বরূপ, পোর্ট 80-তে কানেক্ট করার জন্য অ্যাডমিনিস্ট্রেটরের বিশেষাধিকার প্রয়োজন (নন-অ্যাডমিনিস্ট্রেটররা শুধুমাত্র 1023-এর চেয়ে বেশি পোর্টে শুনতে পারে), তাই আমরা যদি অ্যাডমিনিস্ট্রেটর না হয়ে পোর্ট 80-তে কানেক্ট করার চেষ্টা করি, তাহলে বাইন্ডিং কাজ করবে না। উদাহরণস্বরূপ, বাইন্ডিং কাজ করবে না যদি আমরা আমাদের প্রোগ্রামের দুটি ইনস্ট্যান্স চালাই এবং তাই একই পোর্টে দুটি প্রোগ্রাম শুনি। যেহেতু আমরা শুধুমাত্র শেখার উদ্দেশ্যে একটি বেসিক সার্ভার লিখছি, তাই আমরা এই ধরণের ত্রুটিগুলি পরিচালনা করার বিষয়ে চিন্তা করব না; পরিবর্তে, ত্রুটি ঘটলে প্রোগ্রাম বন্ধ করতে আমরা unwrap ব্যবহার করি।
TcpListener-এর incoming মেথড একটি ইটারেটর রিটার্ন করে যা আমাদের স্ট্রিমের একটি সিকোয়েন্স দেয় (আরও নির্দিষ্টভাবে, TcpStream টাইপের স্ট্রিম)। একটি একক স্ট্রিম ক্লায়েন্ট এবং সার্ভারের মধ্যে একটি খোলা কানেকশন উপস্থাপন করে। একটি কানেকশন হল সম্পূর্ণ রিকোয়েস্ট এবং রেসপন্স প্রক্রিয়ার নাম যেখানে একজন ক্লায়েন্ট সার্ভারের সাথে কানেক্ট করে, সার্ভার একটি রেসপন্স তৈরি করে এবং সার্ভার কানেকশন বন্ধ করে দেয়। যেমন, ক্লায়েন্ট কী পাঠিয়েছে তা দেখতে আমরা TcpStream থেকে পড়ব এবং তারপর ক্লায়েন্টের কাছে ডেটা ফেরত পাঠাতে স্ট্রিমে আমাদের রেসপন্স লিখব। সামগ্রিকভাবে, এই for লুপটি প্রতিটি কানেকশনকে একে একে প্রসেস করবে এবং পরিচালনা করার জন্য আমাদের স্ট্রিমের একটি সিরিজ তৈরি করবে।
আপাতত, স্ট্রিম পরিচালনার মধ্যে রয়েছে unwrap কল করা যাতে আমাদের প্রোগ্রামটি বন্ধ হয়ে যায় যদি স্ট্রীমে কোনও ত্রুটি থাকে; যদি কোনও ত্রুটি না থাকে, তাহলে প্রোগ্রামটি একটি মেসেজ প্রিন্ট করে। আমরা পরবর্তী লিস্টিং-এ সাফল্যের ক্ষেত্রের জন্য আরও কার্যকারিতা যুক্ত করব। যখন কোনও ক্লায়েন্ট সার্ভারের সাথে কানেক্ট করে তখন আমরা incoming মেথড থেকে ত্রুটিগুলি পেতে পারি তার কারণ হল আমরা আসলে কানেকশনগুলির উপর পুনরাবৃত্তি করছি না। পরিবর্তে, আমরা কানেকশন প্রচেষ্টার উপর পুনরাবৃত্তি করছি। কানেকশনটি বিভিন্ন কারণে সফল নাও হতে পারে, যার অনেকগুলি অপারেটিং সিস্টেম নির্দিষ্ট। উদাহরণস্বরূপ, অনেক অপারেটিং সিস্টেমে তারা সমর্থন করতে পারে এমন যুগপত খোলা কানেকশনের সংখ্যার একটি সীমা রয়েছে; সেই সংখ্যার বাইরের নতুন কানেকশন প্রচেষ্টা একটি ত্রুটি তৈরি করবে যতক্ষণ না কিছু খোলা কানেকশন বন্ধ করা হয়।
আসুন এই কোডটি চালানোর চেষ্টা করি! টার্মিনালে cargo run চালান এবং তারপর একটি ওয়েব ব্রাউজারে 127.0.0.1:7878 লোড করুন। ব্রাউজারটি "Connection reset"-এর মতো একটি ত্রুটি মেসেজ দেখানো উচিত কারণ সার্ভারটি বর্তমানে কোনও ডেটা ফেরত পাঠাচ্ছে না। কিন্তু যখন আপনি আপনার টার্মিনালের দিকে তাকাবেন, তখন আপনি বেশ কয়েকটি মেসেজ দেখতে পাবেন যা ব্রাউজারটি সার্ভারের সাথে কানেক্ট করার সময় প্রিন্ট করা হয়েছিল!
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
কখনও কখনও আপনি একটি ব্রাউজার রিকোয়েস্টের জন্য একাধিক মেসেজ প্রিন্ট হতে দেখবেন; এর কারণ হতে পারে যে ব্রাউজারটি পেজের জন্য একটি রিকোয়েস্ট করছে এবং সেইসাথে অন্যান্য রিসোর্সের জন্য একটি রিকোয়েস্ট করছে, যেমন ব্রাউজার ট্যাবে প্রদর্শিত favicon.ico আইকন।
এছাড়াও এটি হতে পারে যে ব্রাউজারটি সার্ভারের সাথে একাধিকবার কানেক্ট করার চেষ্টা করছে কারণ সার্ভার কোনও ডেটা দিয়ে রেসপন্স করছে না। যখন লুপের শেষে stream স্কোপের বাইরে চলে যায় এবং ড্রপ করা হয়, তখন কানেকশনটি drop ইমপ্লিমেন্টেশনের অংশ হিসাবে বন্ধ হয়ে যায়। ব্রাউজারগুলি কখনও কখনও বন্ধ কানেকশনগুলিকে পুনরায় চেষ্টা করে পরিচালনা করে, কারণ সমস্যাটি অস্থায়ী হতে পারে। গুরুত্বপূর্ণ বিষয় হল যে আমরা সফলভাবে একটি TCP কানেকশনের হ্যান্ডেল পেয়েছি!
আপনি যখন কোডের একটি নির্দিষ্ট সংস্করণ চালানো শেষ করবেন তখন ctrl-c টিপে প্রোগ্রামটি বন্ধ করতে ভুলবেন না। তারপর আপনি প্রতিটি কোড পরিবর্তনের সেট করার পরে cargo run কমান্ডটি ব্যবহার করে প্রোগ্রামটি পুনরায় চালু করুন যাতে আপনি নতুন কোড চালাচ্ছেন তা নিশ্চিত করতে পারেন।
রিকোয়েস্ট পড়া (Reading the Request)
আসুন ব্রাউজার থেকে রিকোয়েস্ট পড়ার কার্যকারিতা ইমপ্লিমেন্ট করি! প্রথমে একটি কানেকশন পাওয়া এবং তারপর কানেকশনের সাথে কিছু কাজ করার বিষয়গুলিকে আলাদা করার জন্য, আমরা কানেকশন প্রসেস করার জন্য একটি নতুন ফাংশন শুরু করব। এই নতুন handle_connection ফাংশনে, আমরা TCP স্ট্রিম থেকে ডেটা পড়ব এবং ব্রাউজার থেকে পাঠানো ডেটা দেখতে এটি প্রিন্ট করব। কোডটিকে Listing 21-2-এর মতো দেখতে পরিবর্তন করুন।
use std::{ io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); println!("Request: {http_request:#?}"); }
আমরা std::io::prelude এবং std::io::BufReader-কে স্কোপে নিয়ে আসি যাতে আমরা স্ট্রিম থেকে পড়তে এবং লিখতে পারি এমন ট্রেইট এবং টাইপগুলিতে অ্যাক্সেস পেতে পারি। main ফাংশনের for লুপে, আমরা একটি কানেকশন তৈরি করেছি এমন একটি মেসেজ প্রিন্ট করার পরিবর্তে, এখন আমরা নতুন handle_connection ফাংশনটি কল করি এবং stream পাস করি।
handle_connection ফাংশনে, আমরা একটি নতুন BufReader ইনস্ট্যান্স তৈরি করি যা stream-এর একটি রেফারেন্সকে র্যাপ করে। BufReader আমাদের জন্য std::io::Read ট্রেইট মেথডগুলিতে কল পরিচালনা করে বাফারিং যোগ করে।
আমরা ব্রাউজার আমাদের সার্ভারে যে রিকোয়েস্ট পাঠায় তার লাইনগুলি সংগ্রহ করার জন্য http_request নামে একটি ভেরিয়েবল তৈরি করি। আমরা নির্দেশ করি যে আমরা এই লাইনগুলিকে একটি ভেক্টরে সংগ্রহ করতে চাই Vec<_> টাইপ অ্যানোটেশন যোগ করে।
BufReader, std::io::BufRead ট্রেইট ইমপ্লিমেন্ট করে, যা lines মেথড সরবরাহ করে। lines মেথড ডেটার স্ট্রিমটিকে যখনই একটি নতুন লাইনের বাইট দেখতে পায় তখনই বিভক্ত করে Result<String, std::io::Error>-এর একটি ইটারেটর রিটার্ন করে। প্রতিটি String পেতে, আমরা প্রতিটি Result-কে ম্যাপ করি এবং unwrap করি। ডেটা বৈধ UTF-8 না হলে বা স্ট্রিম থেকে পড়তে সমস্যা হলে Result একটি error হতে পারে। আবারও, একটি প্রোডাকশন প্রোগ্রামের এই ত্রুটিগুলিকে আরও সুন্দরভাবে পরিচালনা করা উচিত, কিন্তু আমরা সরলতার জন্য ত্রুটির ক্ষেত্রে প্রোগ্রামটি বন্ধ করা বেছে নিচ্ছি।
ব্রাউজার পরপর দুটি নতুন লাইন অক্ষর পাঠিয়ে একটি HTTP রিকোয়েস্টের সমাপ্তি নির্দেশ করে, তাই স্ট্রিম থেকে একটি রিকোয়েস্ট পেতে, আমরা লাইনগুলি ততক্ষণ নিই যতক্ষণ না আমরা একটি লাইন পাই যা খালি স্ট্রিং। একবার আমরা লাইনগুলিকে ভেক্টরে সংগ্রহ করার পরে, আমরা সেগুলিকে সুন্দর ডিবাগ ফরম্যাটিং ব্যবহার করে প্রিন্ট করি যাতে আমরা ওয়েব ব্রাউজার আমাদের সার্ভারে যে নির্দেশাবলী পাঠাচ্ছে তা দেখতে পারি।
আসুন এই কোডটি চেষ্টা করি! প্রোগ্রামটি শুরু করুন এবং আবার একটি ওয়েব ব্রাউজারে একটি রিকোয়েস্ট করুন। লক্ষ্য করুন যে আমরা এখনও ব্রাউজারে একটি error পেজ পাব, কিন্তু টার্মিনালে আমাদের প্রোগ্রামের আউটপুট এখন এইরকম দেখতে হবে:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
আপনার ব্রাউজারের উপর নির্ভর করে, আপনি সামান্য ভিন্ন আউটপুট পেতে পারেন। এখন যে আমরা রিকোয়েস্ট ডেটা প্রিন্ট করছি, আমরা রিকোয়েস্টের প্রথম লাইনে GET-এর পরে পাথটি দেখে বুঝতে পারি কেন আমরা একটি ব্রাউজার রিকোয়েস্ট থেকে একাধিক কানেকশন পাচ্ছি। যদি পুনরাবৃত্ত কানেকশনগুলি সবই / রিকোয়েস্ট করে, তাহলে আমরা জানি যে ব্রাউজারটি বারবার / ফেচ করার চেষ্টা করছে কারণ এটি আমাদের প্রোগ্রাম থেকে কোনও রেসপন্স পাচ্ছে না।
আসুন এই রিকোয়েস্ট ডেটা ভেঙে দেখি যাতে বোঝা যায় ব্রাউজার আমাদের প্রোগ্রামের কাছে কী চাইছে।
একটি HTTP রিকোয়েস্টের আরও বিশদ পর্যালোচনা (A Closer Look at an HTTP Request)
HTTP হল একটি টেক্সট-ভিত্তিক প্রোটোকল, এবং একটি রিকোয়েস্ট এই ফর্ম্যাট নেয়:
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
প্রথম লাইনটি হল রিকোয়েস্ট লাইন যা ক্লায়েন্ট কী রিকোয়েস্ট করছে সে সম্পর্কে তথ্য রাখে। রিকোয়েস্ট লাইনের প্রথম অংশটি ব্যবহৃত মেথড, যেমন GET বা POST নির্দেশ করে, যা বর্ণনা করে যে ক্লায়েন্ট কীভাবে এই রিকোয়েস্টটি করছে। আমাদের ক্লায়েন্ট একটি GET রিকোয়েস্ট ব্যবহার করেছে, যার মানে এটি তথ্য চাইছে।
রিকোয়েস্ট লাইনের পরবর্তী অংশটি হল /, যা ক্লায়েন্ট যে ইউনিফর্ম রিসোর্স আইডেন্টিফায়ার (URI) রিকোয়েস্ট করছে তা নির্দেশ করে: একটি URI প্রায়, কিন্তু সম্পূর্ণরূপে নয়, একটি ইউনিফর্ম রিসোর্স লোকেটর (URL)-এর মতোই। URI এবং URL-এর মধ্যে পার্থক্য এই চ্যাপ্টারে আমাদের উদ্দেশ্যের জন্য গুরুত্বপূর্ণ নয়, তবে HTTP স্পেক URI শব্দটি ব্যবহার করে, তাই আমরা এখানে URI-এর জন্য মানসিকভাবে URL প্রতিস্থাপন করতে পারি।
শেষ অংশটি হল ক্লায়েন্ট যে HTTP ভার্সন ব্যবহার করছে এবং তারপর রিকোয়েস্ট লাইনটি একটি CRLF সিকোয়েন্স দিয়ে শেষ হয়। (CRLF মানে ক্যারেজ রিটার্ন এবং লাইন ফিড, যা টাইপরাইটারের দিনের শব্দ!) CRLF সিকোয়েন্সটিকে \r\n হিসাবেও লেখা যেতে পারে, যেখানে \r হল একটি ক্যারেজ রিটার্ন এবং \n হল একটি লাইন ফিড। CRLF সিকোয়েন্স রিকোয়েস্ট লাইনটিকে রিকোয়েস্টের বাকি ডেটা থেকে আলাদা করে। লক্ষ্য করুন যে যখন CRLF প্রিন্ট করা হয়, তখন আমরা \r\n-এর পরিবর্তে একটি নতুন লাইন শুরু হতে দেখি।
এখন পর্যন্ত আমাদের প্রোগ্রাম চালানোর ফলে প্রাপ্ত রিকোয়েস্ট লাইনের ডেটা দেখলে, আমরা দেখতে পাই যে GET হল মেথড, / হল রিকোয়েস্ট URI এবং HTTP/1.1 হল ভার্সন।
রিকোয়েস্ট লাইনের পরে, Host: থেকে শুরু করে বাকি লাইনগুলি হল হেডার। GET রিকোয়েস্টের কোনও বডি নেই।
একটি ভিন্ন ব্রাউজার থেকে একটি রিকোয়েস্ট করার চেষ্টা করুন বা একটি ভিন্ন অ্যাড্রেস, যেমন 127.0.0.1:7878/test, রিকোয়েস্ট করার চেষ্টা করুন যাতে রিকোয়েস্ট ডেটা কীভাবে পরিবর্তিত হয় তা দেখা যায়।
এখন আমরা জানি ব্রাউজার কী চাইছে, আসুন কিছু ডেটা ফেরত পাঠানো যাক!
একটি রেসপন্স লেখা (Writing a Response)
ক্লায়েন্ট রিকোয়েস্টের রেসপন্সে ডেটা পাঠানোর কাজটি আমরা ইমপ্লিমেন্ট করব। রেসপন্সগুলির নিম্নলিখিত ফর্ম্যাট রয়েছে:
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
প্রথম লাইনটি হল একটি স্ট্যাটাস লাইন যাতে রেসপন্সে ব্যবহৃত HTTP ভার্সন, রিকোয়েস্টের ফলাফলের সংক্ষিপ্ত বিবরণ দেয় এমন একটি সংখ্যাসূচক স্ট্যাটাস কোড এবং স্ট্যাটাস কোডের একটি টেক্সট বিবরণ প্রদান করে এমন একটি কারণ বাক্যাংশ রয়েছে। CRLF সিকোয়েন্সের পরে যেকোনও হেডার, আরেকটি CRLF সিকোয়েন্স এবং রেসপন্সের বডি থাকে।
এখানে একটি উদাহরণ রেসপন্স রয়েছে যা HTTP ভার্সন 1.1 ব্যবহার করে এবং যার স্ট্যাটাস কোড 200, একটি OK কারণ বাক্যাংশ, কোনও হেডার নেই এবং কোনও বডি নেই:
HTTP/1.1 200 OK\r\n\r\n
স্ট্যাটাস কোড 200 হল স্ট্যান্ডার্ড সাফল্যের রেসপন্স। টেক্সটটি একটি ক্ষুদ্র সফল HTTP রেসপন্স। আসুন এটিকে একটি সফল রিকোয়েস্টের রেসপন্স হিসাবে স্ট্রীমে লিখি! handle_connection ফাংশন থেকে, println! সরিয়ে দিন যা রিকোয়েস্ট ডেটা প্রিন্ট করছিল এবং এটিকে Listing 21-3-এর কোড দিয়ে প্রতিস্থাপন করুন।
use std::{ io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let response = "HTTP/1.1 200 OK\r\n\r\n"; stream.write_all(response.as_bytes()).unwrap(); }
প্রথম নতুন লাইনটি response ভেরিয়েবলটিকে সংজ্ঞায়িত করে যা সাফল্যের মেসেজের ডেটা ধারণ করে। তারপর আমরা আমাদের response-এ as_bytes কল করি যাতে স্ট্রিং ডেটাকে বাইটে রূপান্তর করা যায়। stream-এর write_all মেথডটি একটি &[u8] নেয় এবং সেই বাইটগুলিকে সরাসরি কানেকশনে পাঠায়। যেহেতু write_all অপারেশনটি ব্যর্থ হতে পারে, তাই আমরা আগের মতোই যেকোনো error ফলাফলের উপর unwrap ব্যবহার করি। আবারও, একটি বাস্তব অ্যাপ্লিকেশনে আপনি এখানে error হ্যান্ডলিং যুক্ত করবেন।
এই পরিবর্তনগুলির সাথে, আসুন আমাদের কোডটি চালাই এবং একটি রিকোয়েস্ট করি। আমরা আর টার্মিনালে কোনও ডেটা প্রিন্ট করছি না, তাই আমরা Cargo থেকে আউটপুট ছাড়া অন্য কোনও আউটপুট দেখতে পাব না। আপনি যখন একটি ওয়েব ব্রাউজারে 127.0.0.1:7878 লোড করবেন, তখন আপনি একটি error-এর পরিবর্তে একটি ফাঁকা পেজ পাবেন। আপনি এইমাত্র একটি HTTP রিকোয়েস্ট গ্রহণ এবং একটি রেসপন্স পাঠানোর হ্যান্ডকোড করেছেন!
রিয়েল HTML রিটার্ন করা (Returning Real HTML)
আসুন একটি ফাঁকা পেজের চেয়ে বেশি কিছু রিটার্ন করার কার্যকারিতা ইমপ্লিমেন্ট করি। আপনার প্রোজেক্ট ডিরেক্টরির রুটে, src ডিরেক্টরিতে নয়, hello.html নামে নতুন ফাইল তৈরি করুন। আপনি যেকোনো HTML ইনপুট করতে পারেন; Listing 21-4 একটি সম্ভাবনা দেখায়।
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
এটি একটি হেডিং এবং কিছু টেক্সট সহ একটি ন্যূনতম HTML5 ডকুমেন্ট। একটি রিকোয়েস্ট পেলে সার্ভার থেকে এটি রিটার্ন করার জন্য, আমরা Listing 21-5-এ দেখানো handle_connection পরিবর্তন করব যাতে HTML ফাইলটি পড়া যায়, এটিকে রেসপন্সে একটি বডি হিসাবে যুক্ত করা যায় এবং পাঠানো যায়।
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; // --snip-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let http_request: Vec<_> = buf_reader .lines() .map(|result| result.unwrap()) .take_while(|line| !line.is_empty()) .collect(); let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
আমরা use স্টেটমেন্টে fs যোগ করেছি যাতে স্ট্যান্ডার্ড লাইব্রেরির ফাইল সিস্টেম মডিউলটিকে স্কোপে আনা যায়। একটি ফাইলের বিষয়বস্তু একটি স্ট্রিং-এ পড়ার কোডটি পরিচিত হওয়া উচিত; Listing 12-4-এ আমরা আমাদের I/O প্রোজেক্টের জন্য একটি ফাইলের বিষয়বস্তু পড়ার সময় এটি ব্যবহার করেছি।
এরপর, আমরা ফাইলের বিষয়বস্তু সাফল্যের রেসপন্সের বডি হিসাবে যুক্ত করতে format! ব্যবহার করি। একটি বৈধ HTTP রেসপন্স নিশ্চিত করতে, আমরা Content-Length হেডার যুক্ত করি যা আমাদের রেসপন্স বডির আকারে সেট করা হয়, এক্ষেত্রে hello.html-এর আকার।
cargo run দিয়ে এই কোডটি চালান এবং আপনার ব্রাউজারে 127.0.0.1:7878 লোড করুন; আপনি আপনার HTML রেন্ডার করা দেখতে পাবেন!
বর্তমানে, আমরা http_request-এর রিকোয়েস্ট ডেটা উপেক্ষা করছি এবং শর্তহীনভাবে HTML ফাইলের বিষয়বস্তু ফেরত পাঠাচ্ছি। তার মানে আপনি যদি আপনার ব্রাউজারে 127.0.0.1:7878/something-else রিকোয়েস্ট করেন, তাহলেও আপনি এই একই HTML রেসপন্স ফিরে পাবেন। এই মুহূর্তে, আমাদের সার্ভার খুব সীমিত এবং বেশিরভাগ ওয়েব সার্ভার যা করে তা করে না। আমরা রিকোয়েস্টের উপর নির্ভর করে আমাদের রেসপন্সগুলি কাস্টমাইজ করতে চাই এবং শুধুমাত্র / -তে একটি ভাল-ফর্ম্যাট করা রিকোয়েস্টের জন্য HTML ফাইলটি ফেরত পাঠাতে চাই।
রিকোয়েস্ট ভ্যালিডেট করা এবং বেছে বেছে রেসপন্স করা (Validating the Request and Selectively Responding)
এই মুহূর্তে, আমাদের ওয়েব সার্ভার ক্লায়েন্ট যাই রিকোয়েস্ট করুক না কেন ফাইলের HTML রিটার্ন করবে। আসুন ব্রাউজারটি / রিকোয়েস্ট করছে কিনা তা পরীক্ষা করার জন্য কার্যকারিতা যুক্ত করি এবং HTML ফাইলটি রিটার্ন করার আগে এবং ব্রাউজার অন্য কিছু রিকোয়েস্ট করলে একটি error রিটার্ন করি। এর জন্য আমাদের handle_connection পরিবর্তন করতে হবে, যেমনটি Listing 21-6-এ দেখানো হয়েছে। এই নতুন কোডটি প্রাপ্ত রিকোয়েস্টের বিষয়বস্তু পরীক্ষা করে / -এর জন্য একটি রিকোয়েস্ট দেখতে কেমন হওয়া উচিত এবং রিকোয়েস্টগুলিকে ভিন্নভাবে আচরণ করার জন্য if এবং else ব্লক যুক্ত করে।
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } // --snip-- fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } else { // some other request } }
আমরা শুধুমাত্র HTTP রিকোয়েস্টের প্রথম লাইনটি দেখতে যাচ্ছি, তাই পুরো রিকোয়েস্টটিকে একটি ভেক্টরে পড়ার পরিবর্তে, আমরা ইটারেটর থেকে প্রথম আইটেমটি পেতে next কল করছি। প্রথম unwrap টি Option-এর যত্ন নেয় এবং ইটারেটরের কোনও আইটেম না থাকলে প্রোগ্রামটি বন্ধ করে দেয়। দ্বিতীয় unwrap টি Result হ্যান্ডেল করে এবং Listing 21-2-এ যোগ করা map-এর unwrap-এর মতোই এর প্রভাব রয়েছে।
এরপর, আমরা request_line পরীক্ষা করে দেখি যে এটি / পাথের একটি GET রিকোয়েস্ট লাইনের সমান কিনা। যদি তাই হয়, তাহলে if ব্লকটি আমাদের HTML ফাইলের বিষয়বস্তু রিটার্ন করে।
যদি request_line / পাথের GET রিকোয়েস্টের সমান না হয়, তাহলে এর মানে হল যে আমরা অন্য কোনও রিকোয়েস্ট পেয়েছি। অন্য সব রিকোয়েস্টের রেসপন্স করার জন্য আমরা একটু পরেই else ব্লকে কোড যুক্ত করব।
এখন এই কোডটি চালান এবং 127.0.0.1:7878 রিকোয়েস্ট করুন; আপনি hello.html-এর HTML পাওয়া উচিত। আপনি যদি অন্য কোনো রিকোয়েস্ট করেন, যেমন 127.0.0.1:7878/something-else, তাহলে আপনি Listing 21-1 এবং Listing 21-2-এর কোড চালানোর সময় যে কানেকশন error গুলি দেখেছিলেন সেরকম একটি error পাবেন।
এখন আসুন Listing 21-7-এর কোডটি else ব্লকে যুক্ত করি যাতে স্ট্যাটাস কোড 404 সহ একটি রেসপন্স রিটার্ন করা যায়, যা নির্দেশ করে যে রিকোয়েস্টের জন্য কনটেন্ট পাওয়া যায়নি। আমরা শেষ ব্যবহারকারীর কাছে রেসপন্স নির্দেশ করে ব্রাউজারে রেন্ডার করার জন্য একটি পেজের জন্য কিছু HTML-ও রিটার্ন করব।
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); if request_line == "GET / HTTP/1.1" { let status_line = "HTTP/1.1 200 OK"; let contents = fs::read_to_string("hello.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); // --snip-- } else { let status_line = "HTTP/1.1 404 NOT FOUND"; let contents = fs::read_to_string("404.html").unwrap(); let length = contents.len(); let response = format!( "{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}" ); stream.write_all(response.as_bytes()).unwrap(); } }
এখানে, আমাদের রেসপন্সের স্ট্যাটাস কোড 404 এবং কারণ বাক্যাংশ NOT FOUND সহ একটি স্ট্যাটাস লাইন রয়েছে। রেসপন্সের বডি হবে 404.html ফাইলের HTML। আপনাকে error পেজের জন্য hello.html-এর পাশে একটি 404.html ফাইল তৈরি করতে হবে; আবার আপনার ইচ্ছামতো যেকোনো HTML ব্যবহার করতে পারেন বা Listing 21-8-এর উদাহরণ HTML ব্যবহার করতে পারেন।
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
এই পরিবর্তনগুলির সাথে, আপনার সার্ভার আবার চালান। 127.0.0.1:7878 রিকোয়েস্ট করলে hello.html-এর কনটেন্ট রিটার্ন করা উচিত এবং অন্য কোনো রিকোয়েস্ট, যেমন 127.0.0.1:7878/foo, 404.html থেকে error HTML রিটার্ন করা উচিত।
রিফ্যাক্টরিং-এর একটি ছোঁয়া (A Touch of Refactoring)
এই মুহূর্তে, if এবং else ব্লকগুলিতে অনেক পুনরাবৃত্তি রয়েছে: উভয়ই ফাইল পড়ছে এবং ফাইলের কনটেন্টগুলি স্ট্রীমে লিখছে। শুধুমাত্র পার্থক্য হল স্ট্যাটাস লাইন এবং ফাইলের নাম। আসুন সেই পার্থক্যগুলিকে আলাদা if এবং else লাইনে বের করে কোডটিকে আরও সংক্ষিপ্ত করি যা স্ট্যাটাস লাইন এবং ফাইলের নামের মানগুলিকে ভেরিয়েবলে অ্যাসাইন করবে; তারপর আমরা ফাইলটি পড়তে এবং রেসপন্স লিখতে কোডে শর্তহীনভাবে সেই ভেরিয়েবলগুলি ব্যবহার করতে পারি। Listing 21-9 বড় if এবং else ব্লকগুলি প্রতিস্থাপন করার পরে ফলাফল কোড দেখায়।
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } // --snip-- fn handle_connection(mut stream: TcpStream) { // --snip-- let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = if request_line == "GET / HTTP/1.1" { ("HTTP/1.1 200 OK", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
এখন if এবং else ব্লকগুলি শুধুমাত্র একটি টাপলে স্ট্যাটাস লাইন এবং ফাইলের নামের উপযুক্ত মানগুলি রিটার্ন করে; তারপর আমরা Chapter 19-এ আলোচনা করা let স্টেটমেন্টের একটি প্যাটার্ন ব্যবহার করে এই দুটি মানকে status_line এবং filename-এ অ্যাসাইন করতে ডিস্ট্রাকচারিং ব্যবহার করি।
পূর্বে ডুপ্লিকেট করা কোডটি এখন if এবং else ব্লকের বাইরে এবং status_line এবং filename ভেরিয়েবল ব্যবহার করে। এটি দুটি ক্ষেত্রের মধ্যে পার্থক্য দেখা সহজ করে তোলে এবং এর মানে হল যে আমরা যদি ফাইল রিডিং এবং রেসপন্স রাইটিং কীভাবে কাজ করে তা পরিবর্তন করতে চাই তবে আমাদের কোড আপডেট করার জন্য শুধুমাত্র একটি জায়গা রয়েছে। Listing 21-9-এর কোডের আচরণ Listing 21-7-এর মতোই হবে।
অসাধারণ! আমাদের কাছে এখন প্রায় 40 লাইনের Rust কোডে একটি সহজ ওয়েব সার্ভার রয়েছে যা একটি কনটেন্টের পেজ সহ একটি রিকোয়েস্টের রেসপন্স করে এবং অন্য সমস্ত রিকোয়েস্টের জন্য একটি 404 রেসপন্স করে।
বর্তমানে, আমাদের সার্ভার একটি একক থ্রেডে চলে, অর্থাৎ এটি একবারে শুধুমাত্র একটি রিকোয়েস্ট পরিবেশন করতে পারে। আসুন কিছু স্লো রিকোয়েস্ট সিমুলেট করে পরীক্ষা করি কিভাবে এটি একটি সমস্যা হতে পারে। তারপর আমরা এটিকে ঠিক করব যাতে আমাদের সার্ভার একবারে একাধিক রিকোয়েস্ট হ্যান্ডেল করতে পারে।
আমাদের সিঙ্গেল-থ্রেডেড সার্ভারকে মাল্টিথ্রেডেড সার্ভারে পরিণত করা
এখন, সার্ভার প্রতিটি অনুরোধ একে একে প্রক্রিয়া করবে, মানে এটি প্রথমটির প্রসেসিং শেষ না হওয়া পর্যন্ত দ্বিতীয় কানেকশনটি প্রক্রিয়া করবে না। যদি সার্ভার আরও বেশি সংখ্যক অনুরোধ গ্রহণ করে, তাহলে এই সিরিয়াল এক্সিকিউশন ক্রমশ কম অপ্টিমাল হবে। যদি সার্ভার এমন একটি অনুরোধ পায় যা প্রক্রিয়া করতে বেশি সময় নেয়, তাহলে পরবর্তী অনুরোধগুলিকে দীর্ঘ অনুরোধটি শেষ না হওয়া পর্যন্ত অপেক্ষা করতে হবে, এমনকি যদি নতুন অনুরোধগুলি দ্রুত প্রক্রিয়া করা যায় তাহলেও। আমাদের এটি ঠিক করতে হবে, কিন্তু প্রথমে আমরা সমস্যাটি কার্যকর অবস্থায় দেখব।
বর্তমান সার্ভার ইমপ্লিমেন্টেশনে একটি স্লো রিকোয়েস্ট সিমুলেট করা
আমরা দেখব কিভাবে একটি স্লো-প্রসেসিং অনুরোধ আমাদের বর্তমান সার্ভার ইমপ্লিমেন্টেশনে করা অন্যান্য অনুরোধগুলিকে প্রভাবিত করতে পারে। লিস্টিং ২১-১০ /sleep-এ একটি অনুরোধ হ্যান্ডেল করা ইমপ্লিমেন্ট করে, যেখানে একটি সিমুলেটেড স্লো রেসপন্স থাকবে যা সার্ভারকে প্রতিক্রিয়া জানানোর আগে পাঁচ সেকেন্ডের জন্য স্লিপিং মোডে রাখবে।
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, thread, time::Duration, }; // --snip-- fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { // --snip-- let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; // --snip-- let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
আমরা if থেকে match-এ পরিবর্তন করেছি, কারণ এখন আমাদের তিনটি কেস রয়েছে। স্ট্রিং লিটারেল ভ্যালুগুলির সাথে প্যাটার্ন ম্যাচ করার জন্য আমাদের request_line-এর একটি স্লাইসের উপর স্পষ্টভাবে ম্যাচ করতে হবে; match স্বয়ংক্রিয়ভাবে রেফারেন্সিং এবং ডিরেফারেন্সিং করে না, যেমনটি ইকুয়ালিটি মেথড করে।
প্রথম আর্মটি লিস্টিং ২১-৯ এর if ব্লকের মতোই। দ্বিতীয় আর্মটি /sleep-এর অনুরোধের সাথে মেলে। যখন সেই অনুরোধটি গৃহীত হয়, সার্ভার সফল HTML পেজটি রেন্ডার করার আগে পাঁচ সেকেন্ডের জন্য স্লিপ করবে। তৃতীয় আর্মটি লিস্টিং ২১-৯ এর else ব্লকের মতোই।
আপনি দেখতে পাচ্ছেন কিভাবে আমাদের সার্ভারটি প্রাথমিক: প্রকৃত লাইব্রেরিগুলি একাধিক অনুরোধের স্বীকৃতি আরও কম ভারবোস উপায়ে হ্যান্ডেল করবে!
cargo run ব্যবহার করে সার্ভার শুরু করুন। তারপর দুটি ব্রাউজার উইন্ডো খুলুন: একটি http://127.0.0.1:7878/ এর জন্য এবং অন্যটি http://127.0.0.1:7878/sleep এর জন্য। আপনি যদি আগের মতো কয়েকবার / URI-তে প্রবেশ করেন, তাহলে আপনি দেখতে পাবেন এটি দ্রুত প্রতিক্রিয়া জানাচ্ছে। কিন্তু আপনি যদি /sleep-এ প্রবেশ করেন এবং তারপর / লোড করেন, তাহলে আপনি দেখতে পাবেন যে / লোড হওয়ার আগে sleep তার পুরো পাঁচ সেকেন্ডের জন্য ঘুমিয়েছে।
একটি স্লো অনুরোধের পিছনে অন্যান্য অনুরোধগুলি আটকে যাওয়া এড়াতে আমরা একাধিক কৌশল ব্যবহার করতে পারি, যার মধ্যে একটি হল async ব্যবহার করা যেমনটি আমরা ১৭ অধ্যায়ে করেছি; আমরা যেটি ইমপ্লিমেন্ট করব সেটি হল একটি থ্রেড পুল।
থ্রেড পুল দিয়ে থ্রুপুট উন্নত করা
একটি থ্রেড পুল হল স্পন করা থ্রেডগুলির একটি গ্রুপ যা অপেক্ষা করছে এবং একটি কাজ হ্যান্ডেল করার জন্য প্রস্তুত। যখন প্রোগ্রামটি একটি নতুন কাজ পায়, তখন এটি পুলের একটি থ্রেডকে কাজটি অর্পণ করে এবং সেই থ্রেডটি কাজটি প্রক্রিয়া করবে। পুলের অবশিষ্ট থ্রেডগুলি অন্য কোনো কাজ হ্যান্ডেল করার জন্য উপলব্ধ থাকে, যখন প্রথম থ্রেডটি প্রসেসিং করছে। যখন প্রথম থ্রেডটি তার কাজ প্রক্রিয়া করা শেষ করে, তখন সেটি অলস থ্রেডগুলির পুলে ফিরে আসে, একটি নতুন কাজ হ্যান্ডেল করার জন্য প্রস্তুত। একটি থ্রেড পুল আপনাকে কানেকশনগুলি কনকারেন্টলি প্রক্রিয়া করার অনুমতি দেয়, আপনার সার্ভারের থ্রুপুট বৃদ্ধি করে।
DoS অ্যাটাক থেকে আমাদের রক্ষা করার জন্য আমরা পুলের থ্রেডের সংখ্যা একটি ছোট সংখ্যায় সীমাবদ্ধ করব; যদি আমাদের প্রোগ্রাম প্রতিটি অনুরোধ আসার সাথে সাথে একটি নতুন থ্রেড তৈরি করত, তাহলে কেউ আমাদের সার্ভারে ১০ মিলিয়ন অনুরোধ করলে আমাদের সার্ভারের সমস্ত সংস্থান ব্যবহার করে এবং অনুরোধগুলির প্রসেসিং বন্ধ করে দিয়ে বিপর্যয় সৃষ্টি করতে পারত।
আনলিমিটেড থ্রেড স্পন করার পরিবর্তে, আমাদের পুলে একটি নির্দিষ্ট সংখ্যক থ্রেড অপেক্ষা করবে। আসা অনুরোধগুলি প্রসেসিংয়ের জন্য পুলে পাঠানো হয়। পুলটি আগত অনুরোধগুলির একটি কিউ বজায় রাখবে। পুলের প্রতিটি থ্রেড এই কিউ থেকে একটি অনুরোধ তুলে নেবে, অনুরোধটি হ্যান্ডেল করবে এবং তারপর কিউ-কে অন্য একটি অনুরোধের জন্য জিজ্ঞাসা করবে। এই ডিজাইনের সাহায্যে, আমরা N পর্যন্ত অনুরোধ কনকারেন্টলি প্রক্রিয়া করতে পারি, যেখানে N হল থ্রেডের সংখ্যা। যদি প্রতিটি থ্রেড একটি দীর্ঘ-চলমান অনুরোধের প্রতিক্রিয়া জানায়, তাহলে পরবর্তী অনুরোধগুলি এখনও কিউতে ব্যাক আপ করতে পারে, কিন্তু আমরা সেই পয়েন্টে পৌঁছানোর আগে আমরা যে দীর্ঘ-চলমান অনুরোধগুলি হ্যান্ডেল করতে পারি তার সংখ্যা বাড়িয়েছি।
এই কৌশলটি একটি ওয়েব সার্ভারের থ্রুপুট উন্নত করার অনেকগুলি উপায়ের মধ্যে একটি। আপনি যে অন্যান্য অপশনগুলি দেখতে পারেন সেগুলি হল ফর্ক/জয়েন মডেল, সিঙ্গেল-থ্রেডেড অ্যাসিঙ্ক্রোনাস I/O মডেল এবং মাল্টি-থ্রেডেড অ্যাসিঙ্ক্রোনাস I/O মডেল। আপনি যদি এই বিষয়ে আগ্রহী হন, তাহলে আপনি অন্যান্য সমাধান সম্পর্কে আরও পড়তে পারেন এবং সেগুলি ইমপ্লিমেন্ট করার চেষ্টা করতে পারেন; Rust-এর মতো একটি নিম্ন-স্তরের ভাষার সাথে, এই সমস্ত অপশন সম্ভব।
আমরা একটি থ্রেড পুল ইমপ্লিমেন্ট করা শুরু করার আগে, আসুন পুলটি ব্যবহার করা কেমন হওয়া উচিত সে সম্পর্কে কথা বলি। যখন আপনি কোড ডিজাইন করার চেষ্টা করছেন, তখন ক্লায়েন্ট ইন্টারফেসটি প্রথমে লেখা আপনার ডিজাইনকে গাইড করতে সাহায্য করতে পারে। কোডের API এমনভাবে লিখুন যাতে আপনি যেভাবে এটি কল করতে চান সেইভাবে এটি গঠিত হয়; তারপর কার্যকারিতা ইমপ্লিমেন্ট করে এবং তারপর পাবলিক API ডিজাইন করার পরিবর্তে সেই কাঠামোর মধ্যে কার্যকারিতা ইমপ্লিমেন্ট করুন।
১২ অধ্যায়ের প্রোজেক্টে আমরা যেভাবে টেস্ট-চালিত ডেভেলপমেন্ট ব্যবহার করেছি, আমরা এখানে কম্পাইলার-চালিত ডেভেলপমেন্ট ব্যবহার করব। আমরা সেই কোডটি লিখব যা আমাদের ইচ্ছামতো ফাংশনগুলিকে কল করে এবং তারপর কম্পাইলার থেকে এররগুলি দেখে আমরা নির্ধারণ করব যে কোডটি কাজ করার জন্য আমাদের পরবর্তীতে কী পরিবর্তন করা উচিত। তবে, আমরা এটি করার আগে, আমরা সেই কৌশলটি অন্বেষণ করব যা আমরা শুরুর পয়েন্ট হিসাবে ব্যবহার করব না।
প্রতিটি অনুরোধের জন্য একটি থ্রেড স্পন করা
প্রথমে, আসুন দেখি আমাদের কোডটি কেমন হতে পারে যদি এটি প্রতিটি কানেকশনের জন্য একটি নতুন থ্রেড তৈরি করে। আগেই যেমন উল্লেখ করা হয়েছে, এটি আমাদের চূড়ান্ত প্ল্যান নয় কারণ আনলিমিটেড সংখ্যক থ্রেড স্পন করার সমস্যা রয়েছে, তবে প্রথমে একটি কার্যকরী মাল্টিথ্রেডেড সার্ভার পাওয়ার জন্য এটি একটি শুরুর পয়েন্ট। তারপর আমরা থ্রেড পুলটিকে একটি উন্নতি হিসাবে যুক্ত করব এবং দুটি সমাধানের মধ্যে পার্থক্য করা সহজ হবে। লিস্টিং ২১-১১ for লুপের মধ্যে প্রতিটি স্ট্রিম হ্যান্ডেল করার জন্য একটি নতুন থ্রেড স্পন করতে main-এ যে পরিবর্তনগুলি করতে হবে তা দেখায়।
use std::{ fs, io::{BufReader, prelude::*}, net::{TcpListener, TcpStream}, thread, time::Duration, }; fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); thread::spawn(|| { handle_connection(stream); }); } } fn handle_connection(mut stream: TcpStream) { let buf_reader = BufReader::new(&stream); let request_line = buf_reader.lines().next().unwrap().unwrap(); let (status_line, filename) = match &request_line[..] { "GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"), "GET /sleep HTTP/1.1" => { thread::sleep(Duration::from_secs(5)); ("HTTP/1.1 200 OK", "hello.html") } _ => ("HTTP/1.1 404 NOT FOUND", "404.html"), }; let contents = fs::read_to_string(filename).unwrap(); let length = contents.len(); let response = format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}"); stream.write_all(response.as_bytes()).unwrap(); }
আপনি যেমন ১৬ অধ্যায়ে শিখেছেন, thread::spawn একটি নতুন থ্রেড তৈরি করবে এবং তারপর নতুন থ্রেডে ক্লোজারের কোডটি চালাবে। আপনি যদি এই কোডটি চালান এবং আপনার ব্রাউজারে /sleep লোড করেন, তারপর আরও দুটি ব্রাউজার ট্যাবে / লোড করেন, তাহলে আপনি দেখবেন যে / এর অনুরোধগুলিকে /sleep শেষ হওয়ার জন্য অপেক্ষা করতে হবে না। তবে, যেমনটি আমরা উল্লেখ করেছি, এটি অবশেষে সিস্টেমটিকে অভিভূত করবে কারণ আপনি কোনো সীমা ছাড়াই নতুন থ্রেড তৈরি করবেন।
আপনি হয়তো ১৭ অধ্যায় থেকেও মনে করতে পারেন যে এটি ঠিক সেই ধরনের পরিস্থিতি যেখানে async এবং await সত্যিই উজ্জ্বল! থ্রেড পুল তৈরি করার সময় এটি মনে রাখবেন এবং চিন্তা করুন যে async-এর সাথে জিনিসগুলি কীভাবে আলাদা বা একই রকম দেখাবে।
সীমিত সংখ্যক থ্রেড তৈরি করা
আমরা চাই আমাদের থ্রেড পুলটি একই রকম, পরিচিত উপায়ে কাজ করুক যাতে থ্রেড থেকে থ্রেড পুলে পরিবর্তন করার জন্য আমাদের API ব্যবহার করা কোডে বড় পরিবর্তনের প্রয়োজন না হয়। লিস্টিং ২১-১২ একটি ThreadPool স্ট্রাক্টের জন্য অনুমানমূলক ইন্টারফেস দেখায় যা আমরা thread::spawn-এর পরিবর্তে ব্যবহার করতে চাই।
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}আমরা ThreadPool::new ব্যবহার করে একটি কনফিগারযোগ্য সংখ্যক থ্রেড সহ একটি নতুন থ্রেড পুল তৈরি করি, এই ক্ষেত্রে চারটি। তারপর, for লুপে, pool.execute-এর thread::spawn-এর মতোই একটি ইন্টারফেস রয়েছে, যেখানে এটি পুলের প্রতিটি স্ট্রিমের জন্য চালানো উচিত এমন একটি ক্লোজার নেয়। আমাদের pool.execute ইমপ্লিমেন্ট করতে হবে যাতে এটি ক্লোজারটি নেয় এবং চালানোর জন্য পুলের একটি থ্রেডকে দেয়। এই কোডটি এখনও কম্পাইল হবে না, কিন্তু আমরা চেষ্টা করব যাতে কম্পাইলার আমাদের এটি কীভাবে ঠিক করতে হয় সে সম্পর্কে গাইড করতে পারে।
কম্পাইলার ড্রাইভেন ডেভেলপমেন্ট ব্যবহার করে ThreadPool তৈরি করা
লিস্টিং 21-12-এ src/main.rs-এ পরিবর্তন করুন, এবং তারপর cargo check থেকে কম্পাইলার এররগুলিকে আমাদের ডেভেলপমেন্ট ড্রাইভ করার জন্য ব্যবহার করি। আমরা যে প্রথম এররটি পাই তা এখানে:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` (bin "hello") due to 1 previous error
দারুণ! এই এররটি আমাদের বলে যে আমাদের একটি ThreadPool টাইপ বা মডিউল প্রয়োজন, তাই আমরা এখন একটি তৈরি করব। আমাদের ThreadPool ইমপ্লিমেন্টেশন আমাদের ওয়েব সার্ভার যে ধরনের কাজ করছে তার থেকে স্বাধীন হবে। তাই আসুন hello ক্রেটটিকে একটি বাইনারি ক্রেট থেকে একটি লাইব্রেরি ক্রেটে পরিবর্তন করি যাতে আমাদের ThreadPool ইমপ্লিমেন্টেশন থাকে। আমরা একটি লাইব্রেরি ক্রেটে পরিবর্তন করার পরে, আমরা ওয়েব অনুরোধগুলি পরিবেশন করার জন্য নয়, থ্রেড পুল ব্যবহার করে আমরা যে কোনও কাজ করতে চাই তার জন্যও পৃথক থ্রেড পুল লাইব্রেরি ব্যবহার করতে পারি।
একটি src/lib.rs ফাইল তৈরি করুন যাতে নিম্নলিখিতগুলি রয়েছে, যা একটি ThreadPool স্ট্রাক্টের সবচেয়ে সহজ সংজ্ঞা যা আমরা আপাতত রাখতে পারি:
pub struct ThreadPool;তারপর লাইব্রেরি ক্রেট থেকে ThreadPool কে স্কোপে আনতে src/main.rs ফাইলের শীর্ষে নিম্নলিখিত কোড যোগ করে main.rs ফাইলটি এডিট করুন:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}এই কোডটি এখনও কাজ করবে না, তবে আসুন এটিকে আবার চেক করি যাতে আমাদের পরবর্তী এররটি পাওয়া যায়, যেটিকে আমাদের অ্যাড্রেস করতে হবে:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
এই এররটি ইঙ্গিত দেয় যে এরপরে আমাদের ThreadPool-এর জন্য new নামে একটি অ্যাসোসিয়েটেড ফাংশন তৈরি করতে হবে। আমরা জানি যে new-এর একটি প্যারামিটার থাকতে হবে যা 4 কে আর্গুমেন্ট হিসাবে গ্রহণ করতে পারে এবং একটি ThreadPool ইন্সট্যান্স রিটার্ন করা উচিত। আসুন সবচেয়ে সহজ new ফাংশনটি ইমপ্লিমেন্ট করি যার এই বৈশিষ্ট্যগুলি থাকবে:
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}আমরা size প্যারামিটারের টাইপ হিসাবে usize বেছে নিয়েছি কারণ আমরা জানি যে নেগেটিভ সংখ্যক থ্রেডের কোনো অর্থ নেই। আমরা জানি যে আমরা এই 4 কে থ্রেডগুলির একটি কালেকশনের এলিমেন্টের সংখ্যা হিসাবে ব্যবহার করব, যেটি usize টাইপের কাজ, যেমনটি তৃতীয় অধ্যায়ের “পূর্ণসংখ্যার প্রকারভেদ” এ আলোচনা করা হয়েছে।
আসুন আবার কোডটি চেক করি:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| -----^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
এখন এররটি ঘটেছে কারণ ThreadPool-এ আমাদের কোনো execute মেথড নেই। “সীমাবদ্ধ সংখ্যক থ্রেড তৈরি করা” থেকে মনে করুন যে আমরা সিদ্ধান্ত নিয়েছি আমাদের থ্রেড পুলের thread::spawn-এর মতোই একটি ইন্টারফেস থাকা উচিত। এছাড়াও, আমরা execute ফাংশনটি ইমপ্লিমেন্ট করব যাতে এটি যে ক্লোজারটি পায় সেটি নেয় এবং চালানোর জন্য পুলের একটি অলস থ্রেডকে দেয়।
আমরা ThreadPool-এ execute মেথডটিকে সংজ্ঞায়িত করব যাতে এটি একটি প্যারামিটার হিসাবে একটি ক্লোজার নেয়। ত্রয়োদশ অধ্যায়ের “ক্লোজার থেকে ক্যাপচার করা ভ্যালুগুলিকে সরানো এবং Fn ট্রেইট” থেকে মনে করুন যে আমরা তিনটি ভিন্ন ট্রেইট সহ ক্লোজারগুলিকে প্যারামিটার হিসাবে নিতে পারি: Fn, FnMut এবং FnOnce। আমাদের এখানে কোন ধরনের ক্লোজার ব্যবহার করতে হবে তা নির্ধারণ করতে হবে। আমরা জানি যে আমরা শেষ পর্যন্ত স্ট্যান্ডার্ড লাইব্রেরির thread::spawn ইমপ্লিমেন্টেশনের মতোই কিছু করব, তাই আমরা দেখতে পারি thread::spawn-এর সিগনেচারের তার প্যারামিটারের উপর কী কী বাউন্ড রয়েছে। ডকুমেন্টেশন আমাদের নিম্নলিখিতগুলি দেখায়:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,F টাইপ প্যারামিটারটি হল যেটি নিয়ে আমরা এখানে চিন্তিত; T টাইপ প্যারামিটারটি রিটার্ন ভ্যালুর সাথে সম্পর্কিত এবং আমরা সেটি নিয়ে চিন্তিত নই। আমরা দেখতে পাচ্ছি যে spawn FnOnce কে F-এর উপর ট্রেইট বাউন্ড হিসাবে ব্যবহার করে। এটি সম্ভবত আমরাও চাই, কারণ আমরা অবশেষে execute-এ যে আর্গুমেন্টটি পাই সেটি spawn-এ পাস করব। আমরা আরও নিশ্চিত হতে পারি যে FnOnce হল সেই ট্রেইট যা আমরা ব্যবহার করতে চাই কারণ একটি অনুরোধ চালানোর থ্রেডটি শুধুমাত্র সেই অনুরোধের ক্লোজারটি একবার চালাবে, যা FnOnce-এর Once-এর সাথে মেলে।
F টাইপ প্যারামিটারের Send ট্রেইট বাউন্ড এবং 'static লাইফটাইম বাউন্ডও রয়েছে, যা আমাদের পরিস্থিতিতে দরকারী: আমাদের ক্লোজারটিকে একটি থ্রেড থেকে অন্য থ্রেডে স্থানান্তর করার জন্য Send প্রয়োজন এবং 'static কারণ আমরা জানি না থ্রেডটি এক্সিকিউট হতে কতক্ষণ সময় নেবে। আসুন ThreadPool-এ একটি execute মেথড তৈরি করি যা এই বাউন্ডগুলি সহ F টাইপের একটি জেনেরিক প্যারামিটার নেবে:
pub struct ThreadPool;
impl ThreadPool {
// --snip--
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}আমরা এখনও FnOnce-এর পরে () ব্যবহার করি কারণ এই FnOnce এমন একটি ক্লোজারকে উপস্থাপন করে যা কোনো প্যারামিটার নেয় না এবং ইউনিট টাইপ () রিটার্ন করে। ফাংশন সংজ্ঞার মতোই, রিটার্ন টাইপটি সিগনেচার থেকে বাদ দেওয়া যেতে পারে, কিন্তু আমাদের কোনো প্যারামিটার না থাকলেও, আমাদের এখনও প্যারেন্থেসিস প্রয়োজন।
আবারও, এটি execute মেথডের সবচেয়ে সহজ ইমপ্লিমেন্টেশন: এটি কিছুই করে না, তবে আমরা কেবল আমাদের কোড কম্পাইল করার চেষ্টা করছি। আসুন এটি আবার চেক করি:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.24s
এটি কম্পাইল হয়! তবে মনে রাখবেন যে আপনি যদি cargo run চেষ্টা করেন এবং ব্রাউজারে একটি অনুরোধ করেন, তাহলে আপনি ব্রাউজারে সেই এররগুলি দেখতে পাবেন যা আমরা এই অধ্যায়ের শুরুতে দেখেছিলাম। আমাদের লাইব্রেরি এখনও execute-এ পাস করা ক্লোজারটিকে কল করছে না!
দ্রষ্টব্য: কঠোর কম্পাইলার সহ ভাষাগুলি, যেমন হাস্কেল (Haskell) এবং Rust সম্পর্কে আপনি যে উক্তিটি শুনতে পারেন তা হল "যদি কোড কম্পাইল হয়, তাহলে এটি কাজ করে।" কিন্তু এই উক্তিটি সর্বজনীনভাবে সত্য নয়। আমাদের প্রোজেক্ট কম্পাইল হয়, কিন্তু এটি একেবারে কিছুই করে না! যদি আমরা একটি বাস্তব, সম্পূর্ণ প্রোজেক্ট তৈরি করতাম, তাহলে কোডটি কম্পাইল হয় এবং আমাদের ইচ্ছামতো আচরণ করে কিনা তা পরীক্ষা করার জন্য ইউনিট টেস্ট লেখা শুরু করার জন্য এটি একটি ভাল সময় হবে।
বিবেচনা করুন: আমরা যদি ক্লোজারের পরিবর্তে একটি ফিউচার এক্সিকিউট করতাম তবে এখানে কী আলাদা হত?
new-এ থ্রেডের সংখ্যা ভ্যালিডেট করা
আমরা new এবং execute-এর প্যারামিটারগুলির সাথে কিছুই করছি না। আসুন এই ফাংশনগুলির বডিগুলিকে আমাদের ইচ্ছামতো আচরণ দিয়ে ইমপ্লিমেন্ট করি। শুরু করতে, আসুন new সম্পর্কে চিন্তা করি। এর আগে আমরা size প্যারামিটারের জন্য একটি আনসাইনড টাইপ বেছে নিয়েছিলাম কারণ নেগেটিভ সংখ্যক থ্রেড সহ একটি পুলের কোনো মানে হয় না। যাইহোক, শূন্য থ্রেড সহ একটি পুলেরও কোনো মানে হয় না, তবুও শূন্য একটি সম্পূর্ণ বৈধ usize। আমরা কোড যোগ করব যাতে size শূন্যের চেয়ে বড় কিনা তা পরীক্ষা করার জন্য আমরা একটি ThreadPool ইন্সট্যান্স রিটার্ন করার আগে এবং assert! ম্যাক্রো ব্যবহার করে শূন্য পেলে প্রোগ্রামটি প্যানিক করে, যেমনটি লিস্টিং ২১-১৩-তে দেখানো হয়েছে।
pub struct ThreadPool;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}আমরা এখানে যেভাবে assert! ম্যাক্রো যোগ করেছি, তার পরিবর্তে, আমরা new কে build-এ পরিবর্তন করতে পারতাম এবং একটি Result রিটার্ন করতে পারতাম, যেমনটি আমরা I/O প্রোজেক্টে লিস্টিং ১২-৯-এ Config::build-এর সাথে করেছি। কিন্তু আমরা এই ক্ষেত্রে সিদ্ধান্ত নিয়েছি যে কোনো থ্রেড ছাড়াই একটি থ্রেড পুল তৈরি করার চেষ্টা একটি পুনরুদ্ধার অযোগ্য এরর হওয়া উচিত। আপনি যদি উচ্চাকাঙ্ক্ষী হন, তাহলে new ফাংশনের সাথে তুলনা করার জন্য নিম্নলিখিত সিগনেচার সহ build নামে একটি ফাংশন লেখার চেষ্টা করুন:
pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> {থ্রেড স্টোর করার জন্য জায়গা তৈরি করা
এখন যেহেতু পুলটিতে স্টোর করার জন্য আমাদের কাছে বৈধ সংখ্যক থ্রেড আছে, তাই আমরা সেই থ্রেডগুলি তৈরি করতে পারি এবং স্ট্রাক্টটি রিটার্ন করার আগে ThreadPool স্ট্রাক্টে সেগুলি স্টোর করতে পারি। কিন্তু আমরা কীভাবে একটি থ্রেড "স্টোর" করব? আসুন thread::spawn-এর সিগনেচারটি আবার দেখি:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,spawn ফাংশনটি একটি JoinHandle<T> রিটার্ন করে, যেখানে T হল সেই টাইপ যা ক্লোজারটি রিটার্ন করে। আসুন JoinHandle ব্যবহার করার চেষ্টা করি এবং দেখি কী হয়। আমাদের ক্ষেত্রে, থ্রেড পুলে আমরা যে ক্লোজারগুলি পাস করছি সেগুলি কানেকশন হ্যান্ডেল করবে এবং কিছুই রিটার্ন করবে না, তাই T হবে ইউনিট টাইপ ()।
লিস্টিং ২১-১৪-এর কোডটি কম্পাইল হবে কিন্তু এখনও কোনো থ্রেড তৈরি করে না। আমরা ThreadPool-এর সংজ্ঞা পরিবর্তন করে thread::JoinHandle<()> ইন্সট্যান্সের একটি ভেক্টর রেখেছি, size ক্যাপাসিটি সহ ভেক্টরটিকে ইনিশিয়ালাইজ করেছি, একটি for লুপ সেট আপ করেছি যা থ্রেড তৈরি করার জন্য কিছু কোড চালাবে এবং সেগুলি ধারণকারী একটি ThreadPool ইন্সট্যান্স রিটার্ন করেছি।
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// create some threads and store them in the vector
}
ThreadPool { threads }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}আমরা লাইব্রেরি ক্রেটে std::thread কে স্কোপে এনেছি কারণ আমরা ThreadPool-এর ভেক্টরের আইটেমগুলির টাইপ হিসাবে thread::JoinHandle ব্যবহার করছি।
একবার একটি বৈধ সাইজ পাওয়া গেলে, আমাদের ThreadPool একটি নতুন ভেক্টর তৈরি করে যা size সংখ্যক আইটেম ধারণ করতে পারে। with_capacity ফাংশনটি Vec::new-এর মতোই কাজ করে, কিন্তু একটি গুরুত্বপূর্ণ পার্থক্য সহ: এটি ভেক্টরে আগে থেকে জায়গা বরাদ্দ করে। যেহেতু আমরা জানি যে আমাদের ভেক্টরে size সংখ্যক এলিমেন্ট স্টোর করতে হবে, তাই আগে থেকে এই অ্যালোকেশন করা Vec::new ব্যবহার করার চেয়ে কিছুটা বেশি কার্যকর, যা এলিমেন্ট যোগ করার সাথে সাথে নিজে থেকেই রিসাইজ হয়।
আপনি যখন আবার cargo check চালাবেন, তখন এটি সফল হওয়া উচিত।
ThreadPool থেকে একটি থ্রেডে কোড পাঠানোর জন্য দায়িত্বশীল একটি Worker স্ট্রাক্ট
আমরা লিস্টিং ২১-১৪-তে থ্রেড তৈরির বিষয়ে for লুপে একটি কমেন্ট রেখেছিলাম। এখানে, আমরা দেখব কিভাবে আমরা আসলে থ্রেড তৈরি করি। স্ট্যান্ডার্ড লাইব্রেরি থ্রেড তৈরি করার উপায় হিসাবে thread::spawn সরবরাহ করে এবং thread::spawn আশা করে যে থ্রেডটি তৈরি হওয়ার সাথে সাথেই চালানোর জন্য কিছু কোড পাবে। যাইহোক, আমাদের ক্ষেত্রে, আমরা থ্রেডগুলি তৈরি করতে চাই এবং তাদের অপেক্ষা করাতে চাই সেই কোডের জন্য যা আমরা পরে পাঠাব। থ্রেডের স্ট্যান্ডার্ড লাইব্রেরির ইমপ্লিমেন্টেশনে এটি করার কোনো উপায় নেই; আমাদের এটি ম্যানুয়ালি ইমপ্লিমেন্ট করতে হবে।
আমরা ThreadPool এবং থ্রেডগুলির মধ্যে একটি নতুন ডেটা স্ট্রাকচার উপস্থাপন করে এই আচরণটি ইমপ্লিমেন্ট করব যা এই নতুন আচরণটি পরিচালনা করবে। আমরা এই ডেটা স্ট্রাকচারটিকে Worker বলব, যা পুলিং ইমপ্লিমেন্টেশনে একটি সাধারণ শব্দ। Worker সেই কোডটি তুলে নেয় যা চালানো দরকার এবং Worker এর থ্রেডে কোডটি চালায়।
একটি রেস্তোরাঁর রান্নাঘরে কাজ করা লোকেদের কথা ভাবুন: কর্মীরা গ্রাহকদের কাছ থেকে অর্ডার আসার জন্য অপেক্ষা করে এবং তারপর সেই অর্ডারগুলি নেওয়া এবং সেগুলি পূরণ করার জন্য তারা দায়ী থাকে।
থ্রেড পুলে JoinHandle<()> ইন্সট্যান্সের একটি ভেক্টর সংরক্ষণ করার পরিবর্তে, আমরা Worker স্ট্রাক্টের ইন্সট্যান্স সংরক্ষণ করব। প্রতিটি Worker একটি একক JoinHandle<()> ইন্সট্যান্স সংরক্ষণ করবে। তারপর আমরা Worker-এ একটি মেথড ইমপ্লিমেন্ট করব যা চালানোর জন্য কোডের একটি ক্লোজার নেবে এবং এক্সিকিউশনের জন্য ইতিমধ্যে চলমান থ্রেডে পাঠাবে। লগিং বা ডিবাগিং করার সময় আমরা পুলের বিভিন্ন Worker ইন্সট্যান্সের মধ্যে পার্থক্য করার জন্য প্রতিটি Worker-কে একটি id দেব।
এখানে নতুন প্রক্রিয়াটি রয়েছে যা ঘটবে যখন আমরা একটি ThreadPool তৈরি করব। আমরা এইভাবে Worker সেট আপ করার পরে থ্রেডে ক্লোজার পাঠানোর কোডটি ইমপ্লিমেন্ট করব:
- একটি
Workerস্ট্রাক্ট সংজ্ঞায়িত করুন যা একটিidএবং একটিJoinHandle<()>ধারণ করে। Workerইন্সট্যান্সের একটি ভেক্টর ধারণ করতেThreadPoolপরিবর্তন করুন।- একটি
Worker::newফাংশন সংজ্ঞায়িত করুন যা একটিidনম্বর নেয় এবং একটিWorkerইন্সট্যান্স রিটার্ন করে যাidএবং একটি খালি ক্লোজার দিয়ে স্পন করা থ্রেড ধারণ করে। ThreadPool::new-তে, একটিidজেনারেট করতেforলুপ কাউন্টার ব্যবহার করুন, সেইidদিয়ে একটি নতুনWorkerতৈরি করুন এবং ভেক্টরে worker-কে স্টোর করুন।
আপনি যদি চ্যালেঞ্জের জন্য প্রস্তুত হন, তাহলে লিস্টিং ২১-১৫-এর কোড দেখার আগে নিজে থেকে এই পরিবর্তনগুলি ইমপ্লিমেন্ট করার চেষ্টা করুন।
প্রস্তুত? পূর্ববর্তী পরিবর্তনগুলি করার একটি উপায় সহ লিস্টিং ২১-১৫ এখানে রয়েছে।
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}আমরা ThreadPool-এ ফিল্ডের নাম threads থেকে workers-এ পরিবর্তন করেছি কারণ এটি এখন JoinHandle<()> ইন্সট্যান্সের পরিবর্তে Worker ইন্সট্যান্স ধারণ করছে। আমরা Worker::new-তে আর্গুমেন্ট হিসাবে for লুপের কাউন্টার ব্যবহার করি এবং আমরা প্রতিটি নতুন Worker কে workers নামের ভেক্টরে সংরক্ষণ করি।
বাহ্যিক কোড (যেমন src/main.rs-এ আমাদের সার্ভার) ThreadPool-এর মধ্যে একটি Worker স্ট্রাক্ট ব্যবহার সম্পর্কিত ইমপ্লিমেন্টেশনের বিবরণ জানার প্রয়োজন নেই, তাই আমরা Worker স্ট্রাক্ট এবং এর new ফাংশনকে প্রাইভেট করি। Worker::new ফাংশনটি আমরা যে id দিই সেটি ব্যবহার করে এবং একটি খালি ক্লোজার ব্যবহার করে একটি নতুন থ্রেড স্পন করে তৈরি করা একটি JoinHandle<()> ইন্সট্যান্স সংরক্ষণ করে।
দ্রষ্টব্য: যদি অপারেটিং সিস্টেম পর্যাপ্ত সিস্টেম রিসোর্সের অভাবে একটি থ্রেড তৈরি করতে না পারে, তাহলে
thread::spawnপ্যানিক করবে। এটি আমাদের পুরো সার্ভারকে প্যানিক করে তুলবে, যদিও কিছু থ্রেড তৈরি করা সফল হতে পারে। সরলতার খাতিরে, এই আচরণটি ঠিক আছে, কিন্তু একটি প্রোডাকশন থ্রেড পুল ইমপ্লিমেন্টেশনে, আপনি সম্ভবতstd::thread::Builderএবং এরspawnমেথড ব্যবহার করতে চাইবেন যাResultরিটার্ন করে।
এই কোডটি কম্পাইল হবে এবং ThreadPool::new-তে আর্গুমেন্ট হিসাবে নির্দিষ্ট করা Worker ইন্সট্যান্সের সংখ্যা স্টোর করবে। কিন্তু আমরা এখনও execute-এ পাওয়া ক্লোজারটি প্রক্রিয়া করছি না। আসুন দেখি কিভাবে এটি করতে হয়।
চ্যানেলগুলির মাধ্যমে থ্রেডগুলিতে অনুরোধ পাঠানো
আমরা যে পরবর্তী সমস্যাটির সমাধান করব তা হল thread::spawn-কে দেওয়া ক্লোজারগুলি কিছুই করে না। বর্তমানে, আমরা execute মেথডে যে ক্লোজারটি এক্সিকিউট করতে চাই সেটি পাই। কিন্তু ThreadPool তৈরির সময় প্রতিটি Worker তৈরি করার সময় আমাদের thread::spawn-কে চালানোর জন্য একটি ক্লোজার দিতে হবে।
আমরা চাই যে Worker স্ট্রাক্টগুলি যা আমরা এইমাত্র তৈরি করেছি সেগুলি ThreadPool-এ থাকা একটি কিউ থেকে চালানোর জন্য কোড ফেচ করুক এবং সেই কোডটি চালানোর জন্য তার থ্রেডে পাঠাক।
ষোড়শ অধ্যায়ে আমরা যে চ্যানেলগুলি সম্পর্কে শিখেছি—দুটি থ্রেডের মধ্যে যোগাযোগের একটি সহজ উপায়—এই ব্যবহারের ক্ষেত্রে উপযুক্ত হবে। আমরা কাজের কিউ হিসাবে কাজ করার জন্য একটি চ্যানেল ব্যবহার করব, এবং execute ThreadPool থেকে Worker ইন্সট্যান্সে একটি কাজ পাঠাবে, যা কাজটি তার থ্রেডে পাঠাবে। এখানে পরিকল্পনাটি রয়েছে:
ThreadPoolএকটি চ্যানেল তৈরি করবে এবং সেন্ডারকে ধরে রাখবে।- প্রতিটি
Workerরিসিভারকে ধরে রাখবে। - আমরা একটি নতুন
Jobস্ট্রাক্ট তৈরি করব যা চ্যানেলটিতে পাঠাতে চাওয়া ক্লোজারগুলিকে ধারণ করবে। executeমেথডটি যে কাজটি এক্সিকিউট করতে চায় সেটি সেন্ডারের মাধ্যমে পাঠাবে।- তার থ্রেডে,
Workerতার রিসিভারের উপর লুপ করবে এবং প্রাপ্ত যেকোনো কাজের ক্লোজার এক্সিকিউট করবে।
আসুন ThreadPool::new-তে একটি চ্যানেল তৈরি করে এবং ThreadPool ইন্সট্যান্সে সেন্ডারটিকে ধরে রেখে শুরু করি, যেমনটি লিস্টিং ২১-১৬-তে দেখানো হয়েছে। Job স্ট্রাক্ট আপাতত কিছুই ধারণ করে না তবে এটি চ্যানেলে পাঠানো আইটেমটির টাইপ হবে।
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}ThreadPool::new-তে, আমরা আমাদের নতুন চ্যানেল তৈরি করি এবং পুলটিকে সেন্ডার ধরে রাখতে দিই। এটি সফলভাবে কম্পাইল হবে।
আসুন থ্রেড পুল চ্যানেল তৈরি করার সাথে সাথে প্রতিটি Worker-এ চ্যানেলের একটি রিসিভার পাস করার চেষ্টা করি। আমরা জানি যে আমরা Worker ইন্সট্যান্সগুলি যে থ্রেড স্পন করে তাতে রিসিভারটি ব্যবহার করতে চাই, তাই আমরা ক্লোজারে receiver প্যারামিটারটি রেফারেন্স করব। লিস্টিং ২১-১৭-এর কোডটি এখনও পুরোপুরি কম্পাইল হবে না।
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}আমরা কিছু ছোট এবং সহজবোধ্য পরিবর্তন করেছি: আমরা Worker::new-তে রিসিভারটি পাস করি এবং তারপর আমরা এটি ক্লোজারের ভিতরে ব্যবহার করি।
যখন আমরা এই কোডটি চেক করার চেষ্টা করি, তখন আমরা এই এররটি পাই:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
25 | for id in 0..size {
| ----------------- inside of this loop
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
|
note: consider changing this parameter type in method `new` to borrow instead if owning the value isn't necessary
--> src/lib.rs:47:33
|
47 | fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
| --- in this method ^^^^^^^^^^^^^^^^^^^ this parameter takes ownership of the value
help: consider moving the expression out of the loop so it is only moved once
|
25 ~ let mut value = Worker::new(id, receiver);
26 ~ for id in 0..size {
27 ~ workers.push(value);
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` (lib) due to 1 previous error
কোডটি একাধিক Worker ইন্সট্যান্সে receiver পাস করার চেষ্টা করছে। এটি কাজ করবে না, যেমনটি আপনি ষোড়শ অধ্যায় থেকে মনে করবেন: Rust যে চ্যানেল ইমপ্লিমেন্টেশন সরবরাহ করে তা হল মাল্টিপল প্রোডিউসার, সিঙ্গেল কনজিউমার। এর মানে হল আমরা এই কোডটি ঠিক করার জন্য চ্যানেলের কনজিউমিং প্রান্তটি ক্লোন করতে পারি না। আমরা একাধিক কনজিউমারের কাছে একাধিকবার একটি মেসেজ পাঠাতে চাই না; আমরা একাধিক Worker ইন্সট্যান্স সহ মেসেজের একটি তালিকা চাই যাতে প্রতিটি মেসেজ একবার প্রক্রিয়া করা হয়।
অতিরিক্তভাবে, চ্যানেল কিউ থেকে একটি কাজ নেওয়া receiver-কে মিউটেট করে, তাই থ্রেডগুলির receiver শেয়ার এবং মডিফাই করার একটি নিরাপদ উপায় প্রয়োজন; অন্যথায়, আমরা রেস কন্ডিশন পেতে পারি (যেমনটি ষোড়শ অধ্যায়ে আলোচনা করা হয়েছে)।
ষোড়শ অধ্যায়ে আলোচিত থ্রেড-নিরাপদ স্মার্ট পয়েন্টারগুলির কথা মনে করুন: একাধিক থ্রেড জুড়ে ওনারশিপ শেয়ার করতে এবং থ্রেডগুলিকে ভ্যালু মিউটেট করার অনুমতি দেওয়ার জন্য, আমাদের Arc<Mutex<T>> ব্যবহার করতে হবে। Arc টাইপ একাধিক Worker ইন্সট্যান্সকে রিসিভারের মালিক হতে দেবে এবং Mutex নিশ্চিত করবে যে একবারে শুধুমাত্র একটি Worker রিসিভার থেকে একটি কাজ পায়। লিস্টিং ২১-১৮ আমাদের যে পরিবর্তনগুলি করতে হবে তা দেখায়।
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
// --snip--
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}ThreadPool::new-তে, আমরা রিসিভারটিকে একটি Arc এবং একটি Mutex-এ রাখি। প্রতিটি নতুন Worker-এর জন্য, আমরা Arc ক্লোন করি যাতে রেফারেন্স কাউন্ট বাড়ে, যাতে Worker ইন্সট্যান্সগুলি রিসিভারের ওনারশিপ শেয়ার করতে পারে।
এই পরিবর্তনগুলির সাথে, কোড কম্পাইল হয়! আমরা সেখানে পৌঁছে যাচ্ছি!
execute মেথড ইমপ্লিমেন্ট করা
আসুন অবশেষে ThreadPool-এ execute মেথডটি ইমপ্লিমেন্ট করি। আমরা execute যে ধরনের ক্লোজার পায় সেটি ধারণ করে এমন একটি ট্রেইট অবজেক্টের জন্য Job-কে একটি স্ট্রাক্ট থেকে একটি টাইপ অ্যালিয়াসে পরিবর্তন করব। যেমনটি বিংশ অধ্যায়ের “টাইপ অ্যালিয়াস সহ টাইপ সিনোনিম তৈরি করা” তে আলোচনা করা হয়েছে, টাইপ অ্যালিয়াসগুলি আমাদের ব্যবহারের সুবিধার জন্য দীর্ঘ টাইপগুলিকে ছোট করার অনুমতি দেয়। লিস্টিং ২১-১৯ দেখুন।
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}execute-এ পাওয়া ক্লোজারটি ব্যবহার করে একটি নতুন Job ইন্সট্যান্স তৈরি করার পরে, আমরা সেই কাজটি চ্যানেলের পাঠানোর প্রান্তে পাঠাই। পাঠানোর ক্ষেত্রে ব্যর্থ হলে আমরা send-এ unwrap কল করছি। উদাহরণস্বরূপ, যদি আমরা আমাদের সমস্ত থ্রেড এক্সিকিউট করা বন্ধ করে দিই, তাহলে এটি ঘটতে পারে, যার অর্থ রিসিভিং প্রান্তটি নতুন মেসেজ গ্রহণ করা বন্ধ করে দিয়েছে। এই মুহূর্তে, আমরা আমাদের থ্রেডগুলিকে এক্সিকিউট করা বন্ধ করতে পারি না: পুলটি যতদিন বিদ্যমান থাকে ততদিন আমাদের থ্রেডগুলি এক্সিকিউট করতে থাকে। আমরা unwrap ব্যবহার করার কারণ হল আমরা জানি যে ব্যর্থতার ঘটনা ঘটবে না, কিন্তু কম্পাইলার তা জানে না।
কিন্তু আমরা এখনও পুরোপুরি শেষ করিনি! Worker-এ, thread::spawn-কে পাস করা আমাদের ক্লোজারটি এখনও চ্যানেলের রিসিভিং প্রান্তটিকে রেফারেন্স করে। পরিবর্তে, আমাদের ক্লোজারটিকে চিরতরে লুপ করতে হবে, চ্যানেলের রিসিভিং প্রান্তটিকে একটি কাজের জন্য জিজ্ঞাসা করতে হবে এবং যখন এটি একটি কাজ পাবে তখন সেটি চালাতে হবে। আসুন Worker::new-তে লিস্টিং ২১-২০-তে দেখানো পরিবর্তনটি করি।
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}এখানে, আমরা প্রথমে মিউটেক্স অর্জন করতে receiver-এ lock কল করি এবং তারপর কোনো এরর-এ প্যানিক করার জন্য unwrap কল করি। যদি মিউটেক্সটি একটি পয়জনড অবস্থায় থাকে তবে লক অর্জন করা ব্যর্থ হতে পারে, যা ঘটতে পারে যদি অন্য কোনো থ্রেড লকটি রিলিজ করার পরিবর্তে লকটি ধরে রাখার সময় প্যানিক করে। এই পরিস্থিতিতে, এই থ্রেডটিকে প্যানিক করার জন্য unwrap কল করা হল সঠিক কাজ। আপনার জন্য অর্থপূর্ণ একটি এরর মেসেজ সহ এই unwrap কে একটি expect-এ পরিবর্তন করতে পারেন।
যদি আমরা মিউটেক্সের উপর লক পাই, তাহলে আমরা চ্যানেল থেকে একটি Job রিসিভ করার জন্য recv কল করি। একটি ফাইনাল unwrap এখানেও যেকোনো এরর অতিক্রম করে, যা ঘটতে পারে যদি সেন্ডার ধারণ করা থ্রেডটি বন্ধ হয়ে যায়, একইভাবে send মেথড Err রিটার্ন করে যদি রিসিভার বন্ধ হয়ে যায়।
recv-তে কলটি ব্লক করে, তাই যদি এখনও কোনো কাজ না থাকে, তাহলে বর্তমান থ্রেডটি একটি কাজ উপলব্ধ না হওয়া পর্যন্ত অপেক্ষা করবে। Mutex<T> নিশ্চিত করে যে একবারে শুধুমাত্র একটি Worker থ্রেড একটি কাজের অনুরোধ করার চেষ্টা করছে।
আমাদের থ্রেড পুলটি এখন একটি কার্যকরী অবস্থায় রয়েছে! এটিকে একটি cargo run দিন এবং কিছু অনুরোধ করুন:
$ cargo run
Compiling hello v.1.0 (file:///projects/hello)
warning: field `workers` is never read
--> src/lib.rs:7:5
|
6 | pub struct ThreadPool {
| ---------- field in this struct
7 | workers: Vec<Worker>,
| ^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: fields `id` and `thread` are never read
--> src/lib.rs:48:5
|
47 | struct Worker {
| ------ fields in this struct
48 | id: usize,
| ^^
49 | thread: thread::JoinHandle<()>,
| ^^^^^^
warning: `hello` (lib) generated 2 warnings
Finished `dev` profile [unoptimized + debuginfo] target(s) in 4.91s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
সফল! আমাদের এখন একটি থ্রেড পুল রয়েছে যা অ্যাসিঙ্ক্রোনাসভাবে কানেকশন এক্সিকিউট করে। কখনও চারটির বেশি থ্রেড তৈরি হয় না, তাই সার্ভার প্রচুর অনুরোধ পেলেও আমাদের সিস্টেম ওভারলোড হবে না। যদি আমরা /sleep-এ একটি অনুরোধ করি, তাহলে সার্ভার অন্য থ্রেড চালিয়ে অন্য অনুরোধগুলি পরিবেশন করতে সক্ষম হবে।
দ্রষ্টব্য: আপনি যদি একই সাথে একাধিক ব্রাউজার উইন্ডোতে /sleep খোলেন, তাহলে সেগুলি পাঁচ সেকেন্ডের ব্যবধানে একবারে একটি লোড হতে পারে। কিছু ওয়েব ব্রাউজার ক্যাশিংয়ের কারণে একই অনুরোধের একাধিক ইন্সট্যান্স ক্রমানুসারে এক্সিকিউট করে। এই সীমাবদ্ধতা আমাদের ওয়েব সার্ভারের কারণে নয়।
এখানে থামার এবং লিস্টিং 21-18, 21-19 এবং 21-20-এর কোডগুলি কীভাবে আলাদা হত তা বিবেচনা করার জন্য এটি একটি ভাল সময়, যদি আমরা কাজ করার জন্য ক্লোজারের পরিবর্তে ফিউচার ব্যবহার করতাম। কোন টাইপগুলি পরিবর্তন হবে? মেথড স্বাক্ষরগুলি কীভাবে আলাদা হবে, যদি আদৌ হয়? কোডের কোন অংশগুলি একই থাকবে?
17 এবং 18 অধ্যায়ে while let লুপ সম্পর্কে জানার পরে, আপনি হয়ত ভাবছেন কেন আমরা লিস্টিং 21-21-এ দেখানো ওয়ার্কার থ্রেড কোডটি লিখিনি।
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}এই কোডটি কম্পাইল এবং রান করে কিন্তু কাঙ্ক্ষিত থ্রেডিং আচরণ দেয় না: একটি স্লো অনুরোধ এখনও অন্যান্য অনুরোধগুলিকে প্রসেস হওয়ার জন্য অপেক্ষা করাবে। কারণটি কিছুটা সূক্ষ্ম: Mutex স্ট্রাক্টের কোনো পাবলিক unlock মেথড নেই কারণ লকের ওনারশিপ lock মেথড রিটার্ন করা LockResult<MutexGuard<T>>-এর মধ্যে MutexGuard<T>-এর লাইফটাইমের উপর ভিত্তি করে। কম্পাইল করার সময়, বরো চেকার তখন এই নিয়মটি প্রয়োগ করতে পারে যে একটি Mutex দ্বারা সুরক্ষিত একটি রিসোর্স অ্যাক্সেস করা যাবে না যদি না আমরা লকটি ধরে রাখি। যাইহোক, যদি আমরা MutexGuard<T>-এর লাইফটাইম সম্পর্কে সচেতন না হই, তাহলে এই ইমপ্লিমেন্টেশনটি ইচ্ছার চেয়ে বেশি সময় ধরে লক ধরে রাখতে পারে।
লিস্টিং 21-20-এর কোডটি let job = receiver.lock().unwrap().recv().unwrap(); ব্যবহার করে কাজ করে কারণ let-এর সাথে, সমান চিহ্নের ডান পাশের এক্সপ্রেশনে ব্যবহৃত যেকোনো টেম্পোরারি ভ্যালু let স্টেটমেন্ট শেষ হওয়ার সাথে সাথেই ড্রপ হয়ে যায়। যাইহোক, while let (এবং if let এবং match) অ্যাসোসিয়েটেড ব্লকের শেষ না হওয়া পর্যন্ত টেম্পোরারি ভ্যালু ড্রপ করে না। লিস্টিং 21-21-এ, job()-তে কলের সময়কাল ধরে লকটি ধরে রাখা হয়, যার অর্থ অন্য Worker ইন্সট্যান্সগুলি কাজ পেতে পারে না।
গ্রেসফুল শাটডাউন এবং ক্লিনআপ (Graceful Shutdown and Cleanup)
Listing 21-20-এর কোডটি থ্রেড পুল ব্যবহার করে অ্যাসিঙ্ক্রোনাসভাবে রিকোয়েস্টগুলির প্রতিক্রিয়া জানাচ্ছে, যেমনটি আমরা চেয়েছিলাম। আমরা workers, id, এবং thread ফিল্ড সম্পর্কে কিছু সতর্কতা পাচ্ছি যা আমরা সরাসরি ব্যবহার করছি না, যা আমাদের মনে করিয়ে দেয় যে আমরা কোনও কিছু পরিষ্কার করছি না। যখন আমরা main থ্রেড বন্ধ করার জন্য কম মার্জিত ctrl-c পদ্ধতি ব্যবহার করি, তখন অন্যান্য সমস্ত থ্রেডও অবিলম্বে বন্ধ হয়ে যায়, এমনকি যদি তারা কোনও রিকোয়েস্ট প্রক্রিয়া করার মাঝখানে থাকে তাহলেও।
এরপর, আমরা পুলের প্রতিটি থ্রেডে join কল করার জন্য Drop ট্রেইট ইমপ্লিমেন্ট করব যাতে সেগুলি বন্ধ হওয়ার আগে যে রিকোয়েস্টগুলিতে কাজ করছে সেগুলি শেষ করতে পারে। তারপর আমরা থ্রেডগুলিকে নতুন রিকোয়েস্ট গ্রহণ করা বন্ধ করতে এবং বন্ধ করার একটি উপায় ইমপ্লিমেন্ট করব। এই কোডটি কার্যকর অবস্থায় দেখতে, আমরা আমাদের সার্ভারকে পরিবর্তন করব যাতে এটি তার থ্রেড পুলটি সুন্দরভাবে বন্ধ করার আগে কেবল দুটি রিকোয়েস্ট গ্রহণ করে।
এখানে একটি লক্ষণীয় বিষয়: এগুলোর কোনোটিই কোডের সেই অংশগুলিকে প্রভাবিত করে না যা ক্লোজার এক্সিকিউট করে, তাই আমরা যদি অ্যাসিঙ্ক রানটাইমের জন্য একটি থ্রেড পুল ব্যবহার করতাম তাহলেও এখানে সবকিছু একই থাকত।
ThreadPool-এ Drop ট্রেইট ইমপ্লিমেন্ট করা (Implementing the DropTrait onThreadPool`)
আসুন আমাদের থ্রেড পুলে Drop ইমপ্লিমেন্ট করে শুরু করি। পুলটি ড্রপ করা হলে, আমাদের থ্রেডগুলি সব join করা উচিত যাতে তারা তাদের কাজ শেষ করতে পারে। Listing 21-22 Drop-এর একটি প্রথম প্রচেষ্টা দেখায়; এই কোডটি এখনও ঠিকঠাক কাজ করবে না।
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}প্রথমে, আমরা থ্রেড পুলের প্রতিটি workers-এর মধ্যে লুপ করি। আমরা এর জন্য &mut ব্যবহার করি কারণ self হল একটি মিউটেবল রেফারেন্স, এবং আমাদের worker-কেও মিউটেট করতে হবে। প্রতিটি কর্মীর জন্য, আমরা একটি মেসেজ প্রিন্ট করি যে এই নির্দিষ্ট Worker ইনস্ট্যান্সটি বন্ধ হচ্ছে এবং তারপর আমরা সেই Worker ইনস্ট্যান্সের থ্রেডে join কল করি। যদি join-এ কল ব্যর্থ হয়, তাহলে Rust-কে প্যানিক করতে এবং একটি অমার্জিত শাটডাউনে যেতে আমরা unwrap ব্যবহার করি।
আমরা যখন এই কোডটি কম্পাইল করি তখন এই error টি পাই:
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: `JoinHandle::<T>::join` takes ownership of the receiver `self`, which moves `worker.thread`
--> file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/std/src/thread/mod.rs:1876:17
|
1876 | pub fn join(self) -> Result<T> {
| ^^^^
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` (lib) due to 1 previous error
Error টি আমাদের বলে যে আমরা join কল করতে পারি না কারণ আমাদের কাছে প্রতিটি worker-এর শুধুমাত্র একটি মিউটেবল বরো রয়েছে এবং join তার আর্গুমেন্টের ownership নেয়। এই সমস্যাটি সমাধান করার জন্য, আমাদের thread-কে Worker ইনস্ট্যান্স থেকে সরিয়ে নিতে হবে যা thread-এর মালিক, যাতে join থ্রেডটিকে ব্যবহার করতে পারে। Listing 18-15-এ আমরা যেমন করেছিলাম, তেমন একটি উপায় ব্যবহার করা যেতে পারে। যদি Worker একটি Option<thread::JoinHandle<()>> রাখত, তাহলে আমরা Option-এ take মেথড কল করে Some ভেরিয়েন্ট থেকে মানটি সরিয়ে নিতে পারতাম এবং এর জায়গায় একটি None ভেরিয়েন্ট রেখে যেতে পারতাম। অন্য কথায়, একটি Worker যেটি চলছে তার thread-এ একটি Some ভেরিয়েন্ট থাকবে এবং যখন আমরা একটি Worker পরিষ্কার করতে চাইব, তখন আমরা Some-কে None দিয়ে প্রতিস্থাপন করব যাতে Worker-এর চালানোর জন্য কোনও থ্রেড না থাকে।
যাইহোক, এটি শুধুমাত্র তখনই আসবে যখন Worker ড্রপ করা হবে। বিনিময়ে, আমরা যেখানেই worker.thread অ্যাক্সেস করি সেখানেই আমাদের একটি Option<thread::JoinHandle<()>> নিয়ে কাজ করতে হবে। ইডিওমেটিক রাস্ট Option বেশ কিছুটা ব্যবহার করে, কিন্তু আপনি যখন নিজেকে এমন কিছু র্যাপ করতে দেখবেন যা আপনি জানেন যে Option-এ সবসময় উপস্থিত থাকবে, তখন এটি একটি বিকল্প পদ্ধতির সন্ধান করার জন্য একটি ভাল ধারণা। সেগুলি আপনার কোডকে আরও পরিষ্কার এবং কম ত্রুটি-প্রবণ করে তুলতে পারে।
এই ক্ষেত্রে, একটি ভাল বিকল্প বিদ্যমান: Vec::drain মেথড। এটি Vec থেকে কোন আইটেমগুলি সরাতে হবে তা নির্দিষ্ট করার জন্য একটি রেঞ্জ প্যারামিটার গ্রহণ করে এবং সেই আইটেমগুলির একটি ইটারেটর রিটার্ন করে। .. রেঞ্জ সিনট্যাক্স পাস করলে Vec থেকে সমস্ত মান সরানো হবে।
সুতরাং আমাদের ThreadPool-এর drop ইমপ্লিমেন্টেশন এইভাবে আপডেট করতে হবে:
#![allow(unused)] fn main() { use std::{ sync::{Arc, Mutex, mpsc}, thread, }; pub struct ThreadPool { workers: Vec<Worker>, sender: mpsc::Sender<Job>, } type Job = Box<dyn FnOnce() + Send + 'static>; impl ThreadPool { /// Create a new ThreadPool. /// /// The size is the number of threads in the pool. /// /// # Panics /// /// The `new` function will panic if the size is zero. pub fn new(size: usize) -> ThreadPool { assert!(size > 0); let (sender, receiver) = mpsc::channel(); let receiver = Arc::new(Mutex::new(receiver)); let mut workers = Vec::with_capacity(size); for id in 0..size { workers.push(Worker::new(id, Arc::clone(&receiver))); } ThreadPool { workers, sender } } pub fn execute<F>(&self, f: F) where F: FnOnce() + Send + 'static, { let job = Box::new(f); self.sender.send(job).unwrap(); } } impl Drop for ThreadPool { fn drop(&mut self) { for worker in self.workers.drain(..) { println!("Shutting down worker {}", worker.id); worker.thread.join().unwrap(); } } } struct Worker { id: usize, thread: thread::JoinHandle<()>, } impl Worker { fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker { let thread = thread::spawn(move || { loop { let job = receiver.lock().unwrap().recv().unwrap(); println!("Worker {id} got a job; executing."); job(); } }); Worker { id, thread } } } }
এটি কম্পাইলার error সমাধান করে এবং আমাদের কোডে অন্য কোনও পরিবর্তনের প্রয়োজন হয় না।
থ্রেডগুলিকে সংকেত দেওয়া যাতে কাজের জন্য শোনা বন্ধ করা যায় (Signaling to the Threads to Stop Listening for Jobs)
আমরা যে সমস্ত পরিবর্তন করেছি, তাতে আমাদের কোড কোনও সতর্কতা ছাড়াই কম্পাইল হয়। যাইহোক, খারাপ খবর হল এই কোডটি এখনও আমাদের ইচ্ছামতো কাজ করে না। মূল বিষয় হল Worker ইনস্ট্যান্সগুলির থ্রেড দ্বারা চালানো ক্লোজারগুলির লজিক: এই মুহূর্তে, আমরা join কল করি, কিন্তু সেটি থ্রেডগুলিকে বন্ধ করবে না কারণ তারা কাজের জন্য চিরকাল loop করে। আমরা যদি আমাদের বর্তমান drop-এর ইমপ্লিমেন্টেশন দিয়ে আমাদের ThreadPool ড্রপ করার চেষ্টা করি, তাহলে main থ্রেড চিরকাল ব্লক হয়ে থাকবে, প্রথম থ্রেডটি শেষ হওয়ার জন্য অপেক্ষা করবে।
এই সমস্যাটি সমাধান করার জন্য, আমাদের ThreadPool-এর drop ইমপ্লিমেন্টেশনে একটি পরিবর্তন এবং তারপর Worker লুপে একটি পরিবর্তন প্রয়োজন।
প্রথমে আমরা থ্রেডগুলি শেষ হওয়ার জন্য অপেক্ষা করার আগে sender ড্রপ করার জন্য ThreadPool-এর drop ইমপ্লিমেন্টেশন পরিবর্তন করব। Listing 21-23 ThreadPool-এ sender কে স্পষ্টভাবে ড্রপ করার পরিবর্তনগুলি দেখায়। থ্রেডের বিপরীতে, এখানে আমাদের Option::take দিয়ে ThreadPool থেকে sender-কে সরানোর জন্য একটি Option ব্যবহার করতে হবে।
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
// --snip--
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}sender ড্রপ করা চ্যানেলটি বন্ধ করে দেয়, যা নির্দেশ করে যে আর কোনও মেসেজ পাঠানো হবে না। যখন এটি ঘটে, তখন Worker ইনস্ট্যান্সগুলি অসীম লুপে যে সমস্ত recv কল করে সেগুলি একটি error রিটার্ন করবে। Listing 21-24-এ, আমরা সেই ক্ষেত্রে লুপ থেকে সুন্দরভাবে বেরিয়ে আসার জন্য Worker লুপ পরিবর্তন করি, যার মানে থ্রেডগুলি শেষ হবে যখন ThreadPool-এর drop ইমপ্লিমেন্টেশন তাদের উপর join কল করবে।
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker { id, thread }
}
}এই কোডটি কার্যকর অবস্থায় দেখতে, আসুন Listing 21-25-এ দেখানো মতো দুটি রিকোয়েস্ট পরিবেশন করার পরে সার্ভারটিকে সুন্দরভাবে বন্ধ করার জন্য main পরিবর্তন করি।
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}আপনি একটি বাস্তব-বিশ্বের ওয়েব সার্ভারকে শুধুমাত্র দুটি রিকোয়েস্ট পরিবেশন করার পরে বন্ধ করতে চাইবেন না। এই কোডটি কেবল দেখায় যে গ্রেসফুল শাটডাউন এবং ক্লিনআপ কাজ করছে।
take মেথডটি Iterator ট্রেইটে সংজ্ঞায়িত করা হয়েছে এবং পুনরাবৃত্তিকে সর্বাধিক প্রথম দুটি আইটেমের মধ্যে সীমাবদ্ধ করে। main-এর শেষে ThreadPool স্কোপের বাইরে চলে যাবে এবং drop ইমপ্লিমেন্টেশন চলবে।
cargo run দিয়ে সার্ভার শুরু করুন এবং তিনটি রিকোয়েস্ট করুন। তৃতীয় রিকোয়েস্টটিতে error হওয়া উচিত এবং আপনার টার্মিনালে আপনি এইরকম আউটপুট দেখতে পাবেন:
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
আপনি Worker আইডি এবং প্রিন্ট করা মেসেজগুলির একটি ভিন্ন ক্রম দেখতে পারেন। আমরা দেখতে পাচ্ছি কিভাবে এই কোডটি মেসেজগুলি থেকে কাজ করে: Worker ইনস্ট্যান্স 0 এবং 3 প্রথম দুটি রিকোয়েস্ট পেয়েছে। সার্ভারটি দ্বিতীয় কানেকশনের পরে কানেকশন গ্রহণ করা বন্ধ করে দিয়েছে এবং Worker 3 এমনকি তার কাজ শুরু করার আগেই ThreadPool-এ Drop ইমপ্লিমেন্টেশন চলতে শুরু করে। sender ড্রপ করা সমস্ত Worker ইনস্ট্যান্সকে ডিসকানেক্ট করে এবং তাদের বন্ধ করতে বলে। Worker ইনস্ট্যান্সগুলি প্রত্যেকে ডিসকানেক্ট করার সময় একটি মেসেজ প্রিন্ট করে এবং তারপর থ্রেড পুল প্রতিটি Worker থ্রেড শেষ হওয়ার জন্য অপেক্ষা করতে join কল করে।
এই বিশেষ এক্সিকিউশনের একটি আকর্ষণীয় দিক লক্ষ্য করুন: ThreadPool sender-কে ড্রপ করেছে এবং কোনও Worker ত্রুটি পাওয়ার আগে, আমরা Worker 0-তে join করার চেষ্টা করেছি। Worker 0 এখনও recv থেকে কোনও ত্রুটি পায়নি, তাই main থ্রেড Worker 0 শেষ হওয়ার জন্য অপেক্ষা করতে ব্লক করে। ইতিমধ্যে, Worker 3 একটি কাজ পেয়েছে এবং তারপর সমস্ত থ্রেড একটি ত্রুটি পেয়েছে। যখন Worker 0 শেষ হয়, তখন main থ্রেড বাকি Worker ইনস্ট্যান্সগুলি শেষ হওয়ার জন্য অপেক্ষা করে। সেই সময়ে, তারা সবাই তাদের লুপ থেকে বেরিয়ে এসেছে এবং বন্ধ হয়ে গেছে।
অভিনন্দন! আমরা এখন আমাদের প্রোজেক্ট সম্পন্ন করেছি; আমাদের কাছে একটি বেসিক ওয়েব সার্ভার রয়েছে যা অ্যাসিঙ্ক্রোনাসভাবে প্রতিক্রিয়া জানাতে একটি থ্রেড পুল ব্যবহার করে। আমরা সার্ভারের একটি গ্রেসফুল শাটডাউন করতে সক্ষম, যা পুলের সমস্ত থ্রেড পরিষ্কার করে।
রেফারেন্সের জন্য এখানে সম্পূর্ণ কোড রয়েছে:
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r\nContent-Length: {length}\r\n\r\n{contents}");
stream.write_all(response.as_bytes()).unwrap();
}use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}আমরা এখানে আরও কিছু করতে পারি! আপনি যদি এই প্রোজেক্টটি উন্নত করতে চান তবে এখানে কিছু ধারণা রয়েছে:
ThreadPoolএবং এর পাবলিক মেথডগুলিতে আরও ডকুমেন্টেশন যুক্ত করুন।- লাইব্রেরির কার্যকারিতার পরীক্ষা যুক্ত করুন।
unwrapকলগুলিকে আরও শক্তিশালী ত্রুটি হ্যান্ডলিংয়ে পরিবর্তন করুন।- ওয়েব রিকোয়েস্ট পরিবেশন করা ছাড়া অন্য কোনও কাজ সম্পাদন করতে
ThreadPoolব্যবহার করুন। - crates.io-এ একটি থ্রেড পুল ক্রেট খুঁজুন এবং পরিবর্তে ক্রেট ব্যবহার করে একটি অনুরূপ ওয়েব সার্ভার ইমপ্লিমেন্ট করুন। তারপর এর API এবং দৃঢ়তা আমরা ইমপ্লিমেন্ট করা থ্রেড পুলের সাথে তুলনা করুন।
সারসংক্ষেপ (Summary)
সাবাশ! আপনি বইটির শেষে পৌঁছে গেছেন! Rust-এর এই সফরে আমাদের সাথে যোগ দেওয়ার জন্য আমরা আপনাকে ধন্যবাদ জানাতে চাই। আপনি এখন আপনার নিজের Rust প্রোজেক্টগুলি ইমপ্লিমেন্ট করতে এবং অন্য লোকেদের প্রোজেক্টে সাহায্য করতে প্রস্তুত। মনে রাখবেন যে অন্যান্য Rustaceans-দের একটি স্বাগত জানানোর মতো কমিউনিটি রয়েছে যারা আপনার Rust যাত্রায় আপনার সম্মুখীন হওয়া যেকোনো চ্যালেঞ্জে আপনাকে সাহায্য করতে পারলে খুশি হবে।
পরিশিষ্ট (Appendix)
নিম্নলিখিত বিভাগগুলিতে রেফারেন্স সামগ্রী রয়েছে যা আপনার Rust যাত্রায় সহায়ক হতে পারে।
পরিশিষ্ট A: কিওয়ার্ড (Keywords)
নিম্নলিখিত তালিকায় এমন কীওয়ার্ডগুলি রয়েছে যা Rust ভাষা দ্বারা বর্তমান বা ভবিষ্যতের ব্যবহারের জন্য সংরক্ষিত। ফলস্বরূপ, এগুলিকে আইডেন্টিফায়ার হিসাবে ব্যবহার করা যাবে না (তবে কাঁচা আইডেন্টিফায়ার হিসাবে ব্যবহার করা যেতে পারে, যেমনটি আমরা “Raw Identifiers” বিভাগে আলোচনা করব)। আইডেন্টিফায়ার হল ফাংশন, ভেরিয়েবল, প্যারামিটার, স্ট্রাক্ট ফিল্ড, মডিউল, ক্রেট, কনস্ট্যান্ট, ম্যাক্রো, স্ট্যাটিক ভ্যালু, অ্যাট্রিবিউট, টাইপ, ট্রেইট বা লাইফটাইমের নাম।
বর্তমানে ব্যবহৃত কিওয়ার্ডগুলো
নিম্নে বর্তমানে ব্যবহৃত কিওয়ার্ডগুলোর একটি তালিকা এবং তাদের কার্যাবলী বর্ণনা করা হলো।
as- প্রিমিটিভ কাস্টিং সম্পাদন করে, কোনো আইটেমের নির্দিষ্ট ট্রেইটকে দ্ব্যর্থহীন করে, অথবাuseস্টেটমেন্টে আইটেমগুলোর নাম পরিবর্তন করে।async- বর্তমান থ্রেডকে ব্লক করার পরিবর্তে একটিFutureরিটার্ন করে।await- একটিFuture-এর ফলাফল প্রস্তুত না হওয়া পর্যন্ত এক্সিকিউশন স্থগিত রাখে।break- একটি লুপ থেকে অবিলম্বে বের হয়ে যায়।const- কনস্ট্যান্ট আইটেম বা কনস্ট্যান্ট র-পয়েন্টার সংজ্ঞায়িত করে।continue- লুপের পরবর্তী ইটারেশনে চলে যায়।crate- একটি মডিউল পাথে, ক্রেইট রুটকে বোঝায়।dyn- একটি ট্রেইট অবজেক্টে ডাইনামিক ডিসপ্যাচ।else-ifএবংif letকন্ট্রোল ফ্লো কনস্ট্রাক্টের জন্য ফলব্যাক।enum- একটি এনিউমারেশন সংজ্ঞায়িত করে।extern- একটি বাহ্যিক ফাংশন বা ভেরিয়েবল লিঙ্ক করে।false- বুলিয়ান ফলস লিটারেল।fn- একটি ফাংশন বা ফাংশন পয়েন্টার টাইপ সংজ্ঞায়িত করে।for- একটি ইটারেটর থেকে আইটেমগুলির উপর লুপ করে, একটি ট্রেইট ইমপ্লিমেন্ট করে, অথবা একটি উচ্চ-র্যাঙ্কড লাইফটাইম নির্দিষ্ট করে।if- একটি কন্ডিশনাল এক্সপ্রেশনের ফলাফলের উপর ভিত্তি করে ব্রাঞ্চ করে।impl- ইনহেরেন্ট বা ট্রেইট কার্যকারিতা ইমপ্লিমেন্ট করে।in-forলুপ সিনট্যাক্সের অংশ।let- একটি ভেরিয়েবল বাইন্ড করে।loop- শর্তহীনভাবে লুপ করে।match- একটি ভ্যালুকে প্যাটার্নের সাথে ম্যাচ করে।mod- একটি মডিউল সংজ্ঞায়িত করে।move- একটি ক্লোজারকে তার সমস্ত ক্যাপচারের ওনারশিপ নিতে বাধ্য করে।mut- রেফারেন্স, র-পয়েন্টার বা প্যাটার্ন বাইন্ডিংয়ে মিউটেবিলিটি নির্দেশ করে।pub- স্ট্রাক্ট ফিল্ড,implব্লক বা মডিউলে পাবলিক ভিজিবিলিটি নির্দেশ করে।ref- রেফারেন্স দ্বারা বাইন্ড করে।return- ফাংশন থেকে রিটার্ন করে।Self- আমরা যে টাইপটি সংজ্ঞায়িত করছি বা ইমপ্লিমেন্ট করছি তার জন্য একটি টাইপ অ্যালিয়াস।self- মেথড সাবজেক্ট বা বর্তমান মডিউল।static- গ্লোবাল ভেরিয়েবল বা সম্পূর্ণ প্রোগ্রাম এক্সিকিউশন স্থায়ী লাইফটাইম।struct- একটি স্ট্রাকচার সংজ্ঞায়িত করে।super- বর্তমান মডিউলের প্যারেন্ট মডিউল।trait- একটি ট্রেইট সংজ্ঞায়িত করে।true- বুলিয়ান ট্রু লিটারেল।type- একটি টাইপ অ্যালিয়াস বা অ্যাসোসিয়েটেড টাইপ সংজ্ঞায়িত করে।union- একটি ইউনিয়ন সংজ্ঞায়িত করে; শুধুমাত্র ইউনিয়ন ডিক্লেয়ারেশন-এ ব্যবহৃত হলেই কীওয়ার্ড।unsafe- আনসেইফ কোড, ফাংশন, ট্রেইট বা ইমপ্লিমেন্টেশন নির্দেশ করে।use- স্কোপে সিম্বল আনে; জেনেরিক এবং লাইফটাইম বাউন্ডের জন্য সুনির্দিষ্ট ক্যাপচারগুলি নির্দিষ্ট করে।where- একটি টাইপকে সীমাবদ্ধ করে এমন ক্লজগুলি নির্দেশ করে।while- একটি এক্সপ্রেশনের ফলাফলের উপর ভিত্তি করে শর্তসাপেক্ষে লুপ করে।
ভবিষ্যতের জন্য সংরক্ষিত কিওয়ার্ডগুলো
নিম্নলিখিত কিওয়ার্ডগুলোর এখনও কোনো কার্যকারিতা নেই তবে ভবিষ্যতের সম্ভাব্য ব্যবহারের জন্য Rust দ্বারা সংরক্ষিত।
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
কাঁচা আইডেন্টিফায়ার (Raw Identifiers)
কাঁচা আইডেন্টিফায়ার হল সিনট্যাক্স যা আপনাকে এমন জায়গায় কীওয়ার্ড ব্যবহার করতে দেয় যেখানে সাধারণত তাদের অনুমতি দেওয়া হয় না। আপনি r# দিয়ে একটি কীওয়ার্ড প্রিফিক্স করে একটি কাঁচা আইডেন্টিফায়ার ব্যবহার করেন।
উদাহরণস্বরূপ, match একটি কীওয়ার্ড। আপনি যদি নিম্নলিখিত ফাংশনটি কম্পাইল করার চেষ্টা করেন যা match কে তার নাম হিসাবে ব্যবহার করে:
Filename: src/main.rs
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}আপনি এই এররটি পাবেন:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
এররটি দেখায় যে আপনি ফাংশন আইডেন্টিফায়ার হিসাবে match কীওয়ার্ডটি ব্যবহার করতে পারবেন না। match কে ফাংশনের নাম হিসাবে ব্যবহার করতে, আপনাকে কাঁচা আইডেন্টিফায়ার সিনট্যাক্স ব্যবহার করতে হবে, যেমন:
Filename: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool { haystack.contains(needle) } fn main() { assert!(r#match("foo", "foobar")); }
এই কোডটি কোনো এরর ছাড়াই কম্পাইল হবে। main-এ ফাংশনটিকে যেখানে কল করা হয়েছে এবং যেখানে এটিকে ডিফাইন করা হয়েছে, উভয় জায়গাতেই ফাংশনের নামের আগে r# প্রিফিক্সটি মনে রাখবেন।
কাঁচা আইডেন্টিফায়ারগুলি আপনাকে আইডেন্টিফায়ার হিসাবে আপনার পছন্দের যেকোনো শব্দ ব্যবহার করার অনুমতি দেয়, এমনকি যদি সেই শব্দটি একটি সংরক্ষিত কীওয়ার্ড হয়। এটি আমাদেরকে আইডেন্টিফায়ারের নাম চয়ন করার আরও স্বাধীনতা দেয়, পাশাপাশি এমন একটি ভাষায় লেখা প্রোগ্রামগুলির সাথে ইন্টিগ্রেট করতে দেয় যেখানে এই শব্দগুলি কীওয়ার্ড নয়। এছাড়াও, কাঁচা আইডেন্টিফায়ারগুলি আপনাকে আপনার ক্রেট যে Rust এডিশন ব্যবহার করে তার থেকে ভিন্ন একটি এডিশনে লেখা লাইব্রেরিগুলি ব্যবহার করার অনুমতি দেয়। উদাহরণস্বরূপ, try 2015 এডিশনে একটি কীওয়ার্ড নয় তবে 2018, 2021 এবং 2024 এডিশনে একটি কীওয়ার্ড। আপনি যদি 2015 এডিশন ব্যবহার করে লেখা একটি লাইব্রেরির উপর নির্ভরশীল হন এবং একটি try ফাংশন থাকে, তাহলে আপনার 2018 এডিশনের কোড থেকে সেই ফাংশনটিকে কল করার জন্য আপনাকে কাঁচা আইডেন্টিফায়ার সিনট্যাক্স, এই ক্ষেত্রে r#try, ব্যবহার করতে হবে। এডিশন সম্পর্কে আরও তথ্যের জন্য পরিশিষ্ট E দেখুন।
পরিশিষ্ট B: অপারেটর এবং প্রতীক
এই পরিশিষ্টে Rust-এর সিনট্যাক্সের একটি শব্দকোষ রয়েছে, যার মধ্যে অপারেটর এবং অন্যান্য প্রতীক রয়েছে যা নিজে থেকে বা পাথ, জেনেরিক, ট্রেইট বাউন্ড, ম্যাক্রো, অ্যাট্রিবিউট, কমেন্ট, টাপল এবং ব্র্যাকেটের প্রসঙ্গে প্রদর্শিত হয়।
অপারেটর
সারণি B-1-এ Rust-এর অপারেটরগুলো, অপারেটরটি কীভাবে প্রসঙ্গে প্রদর্শিত হবে তার একটি উদাহরণ, একটি সংক্ষিপ্ত ব্যাখ্যা এবং সেই অপারেটরটি ওভারলোডযোগ্য কিনা তা রয়েছে। যদি একটি অপারেটর ওভারলোডযোগ্য হয়, তাহলে সেই অপারেটরটিকে ওভারলোড করতে ব্যবহৃত প্রাসঙ্গিক ট্রেইটটি তালিকাভুক্ত করা হয়েছে।
সারণি B-1: অপারেটর
| অপারেটর | উদাহরণ | ব্যাখ্যা | ওভারলোডযোগ্য? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | ম্যাক্রো এক্সপ্যানশন | |
! | !expr | বিটওয়াইজ বা লজিক্যাল কমপ্লিমেন্ট | Not |
!= | expr != expr | অসমতা তুলনা | PartialEq |
% | expr % expr | অ্যারিথমেটিক রিমেইন্ডার | Rem |
%= | var %= expr | অ্যারিথমেটিক রিমেইন্ডার এবং অ্যাসাইনমেন্ট | RemAssign |
& | &expr, &mut expr | বোরো | |
& | &type, &mut type, &'a type, &'a mut type | বোরোড পয়েন্টার টাইপ | |
& | expr & expr | বিটওয়াইজ AND | BitAnd |
&= | var &= expr | বিটওয়াইজ AND এবং অ্যাসাইনমেন্ট | BitAndAssign |
&& | expr && expr | শর্ট-সার্কিটিং লজিক্যাল AND | |
* | expr * expr | অ্যারিথমেটিক গুণ | Mul |
*= | var *= expr | অ্যারিথমেটিক গুণ এবং অ্যাসাইনমেন্ট | MulAssign |
* | *expr | ডিরেফারেন্স | Deref |
* | *const type, *mut type | র-পয়েন্টার | |
+ | trait + trait, 'a + trait | কম্পাউন্ড টাইপ কনস্ট্রেইন্ট | |
+ | expr + expr | অ্যারিথমেটিক যোগ | Add |
+= | var += expr | অ্যারিথমেটিক যোগ এবং অ্যাসাইনমেন্ট | AddAssign |
, | expr, expr | আর্গুমেন্ট এবং এলিমেন্ট বিভাজক | |
- | - expr | অ্যারিথমেটিক নেগেশন | Neg |
- | expr - expr | অ্যারিথমেটিক বিয়োগ | Sub |
-= | var -= expr | অ্যারিথমেটিক বিয়োগ এবং অ্যাসাইনমেন্ট | SubAssign |
-> | fn(...) -> type, |...| -> type | ফাংশন এবং ক্লোজার রিটার্ন টাইপ | |
. | expr.ident | ফিল্ড অ্যাক্সেস | |
. | expr.ident(expr, ...) | মেথড কল | |
. | expr.0, expr.1, ইত্যাদি | টাপল ইনডেক্সিং | |
.. | .., expr.., ..expr, expr..expr | রাইট-এক্সক্লুসিভ রেঞ্জ লিটারেল | PartialOrd |
..= | ..=expr, expr..=expr | রাইট-ইনক্লুসিভ রেঞ্জ লিটারেল | PartialOrd |
.. | ..expr | স্ট্রাক্ট লিটারেল আপডেট সিনট্যাক্স | |
.. | variant(x, ..), struct_type { x, .. } | "এবং বাকি" প্যাটার্ন বাইন্ডিং | |
... | expr...expr | (বাতিল, পরিবর্তে ..= ব্যবহার করুন) একটি প্যাটার্নে: ইনক্লুসিভ রেঞ্জ প্যাটার্ন | |
/ | expr / expr | অ্যারিথমেটিক ভাগ | Div |
/= | var /= expr | অ্যারিথমেটিক ভাগ এবং অ্যাসাইনমেন্ট | DivAssign |
: | pat: type, ident: type | কনস্ট্রেইন্ট | |
: | ident: expr | স্ট্রাক্ট ফিল্ড ইনিশিয়ালাইজার | |
: | 'a: loop {...} | লুপ লেবেল | |
; | expr; | স্টেটমেন্ট এবং আইটেম টার্মিনেটর | |
; | [...; len] | ফিক্সড-সাইজ অ্যারে সিনট্যাক্সের অংশ | |
<< | expr << expr | লেফট-শিফট | Shl |
<<= | var <<= expr | লেফট-শিফট এবং অ্যাসাইনমেন্ট | ShlAssign |
< | expr < expr | তুলনামূলকভাবে ছোট | PartialOrd |
<= | expr <= expr | তুলনামূলকভাবে ছোট বা সমান | PartialOrd |
= | var = expr, ident = type | অ্যাসাইনমেন্ট/সমতা | |
== | expr == expr | সমতা তুলনা | PartialEq |
=> | pat => expr | ম্যাচ আর্ম সিনট্যাক্সের অংশ | |
> | expr > expr | তুলনামূলকভাবে বড় | PartialOrd |
>= | expr >= expr | তুলনামূলকভাবে বড় বা সমান | PartialOrd |
>> | expr >> expr | রাইট-শিফট | Shr |
>>= | var >>= expr | রাইট-শিফট এবং অ্যাসাইনমেন্ট | ShrAssign |
@ | ident @ pat | প্যাটার্ন বাইন্ডিং | |
^ | expr ^ expr | বিটওয়াইজ এক্সক্লুসিভ OR | BitXor |
^= | var ^= expr | বিটওয়াইজ এক্সক্লুসিভ OR এবং অ্যাসাইনমেন্ট | BitXorAssign |
| | pat | pat | প্যাটার্ন অল্টারনেটিভ | |
| | expr | expr | বিটওয়াইজ OR | BitOr |
|= | var |= expr | বিটওয়াইজ OR এবং অ্যাসাইনমেন্ট | BitOrAssign |
|| | expr || expr | শর্ট-সার্কিটিং লজিক্যাল OR | |
? | expr? | এরর প্রোপাগেশন |
অপারেটর-বিহীন প্রতীক
নিম্নলিখিত তালিকায় সমস্ত প্রতীক রয়েছে যা অপারেটর হিসাবে কাজ করে না; অর্থাৎ, তারা একটি ফাংশন বা মেথড কলের মতো আচরণ করে না।
সারণি B-2 সেই প্রতীকগুলিকে দেখায় যা নিজে থেকে প্রদর্শিত হয় এবং বিভিন্ন স্থানে বৈধ।
সারণি B-2: স্ট্যান্ড-অ্যালোন সিনট্যাক্স
| প্রতীক | ব্যাখ্যা |
|---|---|
'ident | নামযুক্ত লাইফটাইম বা লুপ লেবেল |
...u8, ...i32, ...f64, ...usize, ইত্যাদি | নির্দিষ্ট টাইপের সাংখ্যিক লিটারেল |
"..." | স্ট্রিং লিটারেল |
r"...", r#"..."#, r##"..."##, ইত্যাদি | কাঁচা স্ট্রিং লিটারেল, এস্কেপ অক্ষরগুলি প্রক্রিয়া করা হয় না |
b"..." | বাইট স্ট্রিং লিটারেল; একটি স্ট্রিংয়ের পরিবর্তে বাইটের একটি অ্যারে তৈরি করে |
br"...", br#"..."#, br##"..."##, ইত্যাদি | কাঁচা বাইট স্ট্রিং লিটারেল, কাঁচা এবং বাইট স্ট্রিং লিটারেলের সংমিশ্রণ |
'...' | অক্ষর লিটারেল |
b'...' | ASCII বাইট লিটারেল |
|...| expr | ক্লোজার |
! | ডাইভার্জিং ফাংশনের জন্য সর্বদা খালি বটম টাইপ |
_ | "উপেক্ষিত" প্যাটার্ন বাইন্ডিং; পূর্ণসংখ্যা লিটারেলগুলিকে পঠনযোগ্য করতেও ব্যবহৃত হয় |
সারণি B-3 সেই প্রতীকগুলিকে দেখায় যা মডিউল হায়ারার্কির মাধ্যমে একটি আইটেমের পাথের প্রসঙ্গে প্রদর্শিত হয়।
সারণি B-3: পাথ-সম্পর্কিত সিনট্যাক্স
| প্রতীক | ব্যাখ্যা |
|---|---|
ident::ident | নেমস্পেস পাথ |
::path | এক্সটার্ন প্রি-লুডের সাপেক্ষে পাথ, যেখানে অন্য সমস্ত ক্রেট রুটেড (অর্থাৎ, ক্রেটের নাম সহ একটি স্পষ্টতই অ্যাবসোলিউট পাথ) |
self::path | বর্তমান মডিউলের সাপেক্ষে পাথ (অর্থাৎ, একটি স্পষ্টতই রিলেটিভ পাথ)। |
super::path | বর্তমান মডিউলের প্যারেন্টের সাপেক্ষে পাথ |
type::ident, <type as trait>::ident | অ্যাসোসিয়েটেড কনস্ট্যান্ট, ফাংশন এবং টাইপ |
<type>::... | এমন একটি টাইপের জন্য অ্যাসোসিয়েটেড আইটেম যা সরাসরি নামকরণ করা যায় না (যেমন, <&T>::..., <[T]>::..., ইত্যাদি) |
trait::method(...) | যে ট্রেইট এটিকে সংজ্ঞায়িত করে তার নামকরণের মাধ্যমে একটি মেথড কলকে দ্ব্যর্থহীন করা |
type::method(...) | যে টাইপের জন্য এটি সংজ্ঞায়িত করা হয়েছে তার নামকরণের মাধ্যমে একটি মেথড কলকে দ্ব্যর্থহীন করা |
<type as trait>::method(...) | ট্রেইট এবং টাইপের নামকরণের মাধ্যমে একটি মেথড কলকে দ্ব্যর্থহীন করা |
সারণি B-4 সেই প্রতীকগুলিকে দেখায় যা জেনেরিক টাইপ প্যারামিটার ব্যবহারের প্রসঙ্গে প্রদর্শিত হয়।
সারণি B-4: জেনেরিক
| প্রতীক | ব্যাখ্যা |
|---|---|
path<...> | একটি টাইপে জেনেরিক টাইপের প্যারামিটার নির্দিষ্ট করে (যেমন, Vec<u8>) |
path::<...>, method::<...> | একটি এক্সপ্রেশনে জেনেরিক টাইপ, ফাংশন বা মেথডের প্যারামিটার নির্দিষ্ট করে; প্রায়শই টার্বোফিশ হিসাবে উল্লেখ করা হয় (যেমন, "42".parse::<i32>()) |
fn ident<...> ... | জেনেরিক ফাংশন সংজ্ঞায়িত করুন |
struct ident<...> ... | জেনেরিক স্ট্রাকচার সংজ্ঞায়িত করুন |
enum ident<...> ... | জেনেরিক এনিউমারেশন সংজ্ঞায়িত করুন |
impl<...> ... | জেনেরিক ইমপ্লিমেন্টেশন সংজ্ঞায়িত করুন |
for<...> type | উচ্চ-র্যাঙ্কড লাইফটাইম বাউন্ড |
type<ident=type> | একটি জেনেরিক টাইপ যেখানে এক বা একাধিক অ্যাসোসিয়েটেড টাইপের নির্দিষ্ট অ্যাসাইনমেন্ট রয়েছে (যেমন, Iterator<Item=T>) |
সারণি B-5 সেই প্রতীকগুলিকে দেখায় যা ট্রেইট বাউন্ড সহ জেনেরিক টাইপ প্যারামিটারগুলিকে সীমাবদ্ধ করার প্রসঙ্গে প্রদর্শিত হয়।
সারণি B-5: ট্রেইট বাউন্ড কনস্ট্রেইন্ট
| প্রতীক | ব্যাখ্যা |
|---|---|
T: U | জেনেরিক প্যারামিটার T এমন টাইপগুলিতে সীমাবদ্ধ যা U ইমপ্লিমেন্ট করে |
T: 'a | জেনেরিক টাইপ T-কে অবশ্যই লাইফটাইম 'a থেকে বেশি সময় বাঁচতে হবে (অর্থাৎ টাইপটি ট্রানজিটিভভাবে 'a-এর চেয়ে কম লাইফটাইম সহ কোনো রেফারেন্স ধারণ করতে পারে না) |
T: 'static | জেনেরিক টাইপ T-তে 'static ছাড়া অন্য কোনো বোরোড রেফারেন্স নেই |
'b: 'a | জেনেরিক লাইফটাইম 'b-কে অবশ্যই লাইফটাইম 'a থেকে বেশি সময় বাঁচতে হবে |
T: ?Sized | জেনেরিক টাইপ প্যারামিটারকে ডায়নামিকভাবে সাইজ করা টাইপ হওয়ার অনুমতি দিন |
'a + trait, trait + trait | কম্পাউন্ড টাইপ কনস্ট্রেইন্ট |
সারণি B-6 সেই প্রতীকগুলিকে দেখায় যা ম্যাক্রো কল করা বা সংজ্ঞায়িত করার এবং একটি আইটেমে অ্যাট্রিবিউট নির্দিষ্ট করার প্রসঙ্গে প্রদর্শিত হয়।
সারণি B-6: ম্যাক্রো এবং অ্যাট্রিবিউট
| প্রতীক | ব্যাখ্যা |
|---|---|
#[meta] | আউটার অ্যাট্রিবিউট |
#![meta] | ইনার অ্যাট্রিবিউট |
$ident | ম্যাক্রো সাবস্টিটিউশন |
$ident:kind | ম্যাক্রো ক্যাপচার |
$(…)… | ম্যাক্রো রিপিটেশন |
ident!(...), ident!{...}, ident![...] | ম্যাক্রো ইনভোকেশন |
সারণি B-7 সেই প্রতীকগুলিকে দেখায় যা কমেন্ট তৈরি করে।
সারণি B-7: কমেন্ট
| প্রতীক | ব্যাখ্যা |
|---|---|
// | লাইন কমেন্ট |
//! | ইনার লাইন ডক কমেন্ট |
/// | আউটার লাইন ডক কমেন্ট |
/*...*/ | ব্লক কমেন্ট |
/*!...*/ | ইনার ব্লক ডক কমেন্ট |
/**...*/ | আউটার ব্লক ডক কমেন্ট |
সারণি B-8-এ দেখানো হয়েছে কোন কোন পরিস্থিতিতে গোলাকার বন্ধনী ব্যবহার করা হয়।
সারণি B-8: গোলাকার বন্ধনী
| প্রতীক | ব্যাখ্যা |
|---|---|
() | খালি টাপল (ইউনিট হিসাবেও পরিচিত), লিটারেল এবং টাইপ উভয়ই |
(expr) | প্যারেনথেসাইজড এক্সপ্রেশন |
(expr,) | একক-উপাদান টাপল এক্সপ্রেশন |
(type,) | একক-উপাদান টাপল টাইপ |
(expr, ...) | টাপল এক্সপ্রেশন |
(type, ...) | টাপল টাইপ |
expr(expr, ...) | ফাংশন কল এক্সপ্রেশন; টাপল struct এবং টাপল enum ভেরিয়েন্ট ইনিশিয়ালাইজ করতেও ব্যবহৃত হয় |
সারণি B-9-এ সেই প্রেক্ষাপটগুলি দেখানো হয়েছে যেখানে কোঁকড়া ধনুর্বন্ধনী ব্যবহার করা হয়।
সারণি B-9: কোঁকড়া বন্ধনী
| প্রসঙ্গ | ব্যাখ্যা |
|---|---|
{...} | ব্লক এক্সপ্রেশন |
Type {...} | struct লিটারেল |
সারণি B-10 সেই প্রেক্ষাপটগুলি দেখায় যেখানে বর্গাকার বন্ধনী ব্যবহার করা হয়।
সারণি B-10: বর্গাকার বন্ধনী
| প্রসঙ্গ | ব্যাখ্যা |
|---|---|
[...] | অ্যারে লিটারেল |
[expr; len] | expr-এর len সংখ্যক কপি ধারণকারী অ্যারে লিটারেল |
[type; len] | type-এর len সংখ্যক ইন্সট্যান্স ধারণকারী অ্যারে টাইপ |
expr[expr] | কালেকশন ইনডেক্সিং। ওভারলোডযোগ্য (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | কালেকশন স্লাইসিং ভান করে কালেকশন ইনডেক্সিং, "সূচক" হিসাবে Range, RangeFrom, RangeTo, বা RangeFull ব্যবহার করে |
পরিশিষ্ট C: ডিরাইভেবল ট্রেইট (Derivable Traits)
বইয়ের বিভিন্ন স্থানে, আমরা derive অ্যাট্রিবিউট নিয়ে আলোচনা করেছি, যা আপনি একটি স্ট্রাক্ট বা এনাম সংজ্ঞায় প্রয়োগ করতে পারেন। derive অ্যাট্রিবিউট কোড তৈরি করে যা derive সিনট্যাক্স দিয়ে আপনি যে টাইপটিকে অ্যানোটেট করেছেন তার উপর নিজস্ব ডিফল্ট ইমপ্লিমেন্টেশন সহ একটি ট্রেইট ইমপ্লিমেন্ট করবে।
এই পরিশিষ্টে, আমরা স্ট্যান্ডার্ড লাইব্রেরির সমস্ত ট্রেইটের একটি রেফারেন্স সরবরাহ করি যা আপনি derive-এর সাথে ব্যবহার করতে পারেন। প্রতিটি বিভাগে কভার করা হয়েছে:
- এই ট্রেইট ডিরাইভ করলে কোন অপারেটর এবং মেথডগুলি সক্রিয় হবে
deriveদ্বারা প্রদত্ত ট্রেইটের ইমপ্লিমেন্টেশন কী করে- ট্রেইট ইমপ্লিমেন্ট করা টাইপ সম্পর্কে কী বোঝায়
- কোন পরিস্থিতিতে আপনাকে ট্রেইট ইমপ্লিমেন্ট করার অনুমতি দেওয়া হয়েছে বা নেই
- অপারেশনের উদাহরণ যার জন্য ট্রেইট প্রয়োজন
আপনি যদি derive অ্যাট্রিবিউট দ্বারা প্রদত্ত আচরণ থেকে ভিন্ন আচরণ চান, তাহলে ম্যানুয়ালি কীভাবে সেগুলি ইমপ্লিমেন্ট করবেন তার বিশদ বিবরণের জন্য প্রতিটি ট্রেইটের জন্য স্ট্যান্ডার্ড লাইব্রেরি ডকুমেন্টেশন দেখুন।
এখানে তালিকাভুক্ত এই ট্রেইটগুলি হল স্ট্যান্ডার্ড লাইব্রেরি দ্বারা সংজ্ঞায়িত একমাত্র ট্রেইট যা derive ব্যবহার করে আপনার টাইপগুলিতে ইমপ্লিমেন্ট করা যেতে পারে। স্ট্যান্ডার্ড লাইব্রেরিতে সংজ্ঞায়িত অন্যান্য ট্রেইটগুলির যুক্তিসঙ্গত ডিফল্ট আচরণ নেই, তাই আপনি যা অর্জন করার চেষ্টা করছেন তার জন্য উপযুক্ত উপায়ে সেগুলি ইমপ্লিমেন্ট করা আপনার উপর নির্ভর করে।
একটি ট্রেইটের উদাহরণ যা ডিরাইভ করা যায় না তা হল Display, যা শেষ ব্যবহারকারীদের জন্য ফরম্যাটিং পরিচালনা করে। আপনার সর্বদা একজন শেষ ব্যবহারকারীর কাছে একটি টাইপ প্রদর্শনের উপযুক্ত উপায় বিবেচনা করা উচিত। টাইপের কোন অংশগুলি শেষ ব্যবহারকারীর দেখার অনুমতি দেওয়া উচিত? কোন অংশগুলি তারা প্রাসঙ্গিক বলে মনে করবে? ডেটার কোন ফরম্যাট তাদের জন্য সবচেয়ে প্রাসঙ্গিক হবে? Rust কম্পাইলারের এই অন্তর্দৃষ্টি নেই, তাই এটি আপনার জন্য উপযুক্ত ডিফল্ট আচরণ সরবরাহ করতে পারে না।
এই পরিশিষ্টে প্রদত্ত ডিরাইভেবল ট্রেইটগুলির তালিকা ব্যাপক নয়: লাইব্রেরিগুলি তাদের নিজস্ব ট্রেইটগুলির জন্য derive ইমপ্লিমেন্ট করতে পারে, যার ফলে আপনি যে ট্রেইটগুলির সাথে derive ব্যবহার করতে পারেন তার তালিকা সত্যিই উন্মুক্ত। derive ইমপ্লিমেন্ট করার সাথে একটি প্রসিডিউরাল ম্যাক্রো ব্যবহার করা জড়িত, যা বিশ অধ্যায়ের “ম্যাক্রো” বিভাগে কভার করা হয়েছে।
প্রোগ্রামার আউটপুটের জন্য Debug
Debug ট্রেইট ফরম্যাট স্ট্রিংগুলিতে ডিবাগ ফরম্যাটিং সক্রিয় করে, যা আপনি {} প্লেসহোল্ডারগুলির মধ্যে :? যোগ করে নির্দেশ করেন।
Debug ট্রেইট আপনাকে ডিবাগিংয়ের উদ্দেশ্যে একটি টাইপের ইন্সট্যান্স প্রিন্ট করার অনুমতি দেয়, যাতে আপনি এবং আপনার টাইপ ব্যবহারকারী অন্যান্য প্রোগ্রামাররা প্রোগ্রামের এক্সিকিউশনের একটি নির্দিষ্ট পয়েন্টে একটি ইন্সট্যান্স পরিদর্শন করতে পারেন।
উদাহরণস্বরূপ, assert_eq! ম্যাক্রো ব্যবহারে Debug ট্রেইট প্রয়োজন। যদি সমতা অ্যাসারশন ব্যর্থ হয় তবে এই ম্যাক্রো আর্গুমেন্ট হিসাবে দেওয়া ইন্সট্যান্সগুলির ভ্যালু প্রিন্ট করে যাতে প্রোগ্রামাররা দেখতে পারে কেন দুটি ইন্সট্যান্স সমান ছিল না।
সমতা তুলনার জন্য PartialEq এবং Eq
PartialEq ট্রেইট আপনাকে সমতা পরীক্ষা করার জন্য একটি টাইপের ইন্সট্যান্সগুলির তুলনা করার অনুমতি দেয় এবং == এবং != অপারেটরগুলির ব্যবহার সক্রিয় করে।
PartialEq ডিরাইভ করা eq মেথড ইমপ্লিমেন্ট করে। যখন স্ট্রাক্টগুলিতে PartialEq ডিরাইভ করা হয়, তখন দুটি ইন্সট্যান্স শুধুমাত্র তখনই সমান হয় যদি সমস্ত ফিল্ড সমান হয় এবং ইন্সট্যান্সগুলি সমান হয় না যদি কোনও ফিল্ড সমান না হয়। যখন এনামগুলিতে ডিরাইভ করা হয়, তখন প্রতিটি ভেরিয়েন্ট নিজের সাথে সমান এবং অন্য ভেরিয়েন্টগুলির সাথে সমান নয়।
উদাহরণস্বরূপ, assert_eq! ম্যাক্রোর ব্যবহারের সাথে PartialEq ট্রেইট প্রয়োজন, যেটি সমতার জন্য একটি টাইপের দুটি ইন্সট্যান্সের তুলনা করতে সক্ষম হওয়া প্রয়োজন।
Eq ট্রেইটের কোনো মেথড নেই। এর উদ্দেশ্য হল সংকেত দেওয়া যে অ্যানোটেটেড টাইপের প্রতিটি ভ্যালুর জন্য, ভ্যালুটি নিজের সমান। Eq ট্রেইট শুধুমাত্র সেই টাইপগুলিতে প্রয়োগ করা যেতে পারে যা PartialEq ইমপ্লিমেন্ট করে, যদিও PartialEq ইমপ্লিমেন্ট করে এমন সমস্ত টাইপ Eq ইমপ্লিমেন্ট করতে পারে না। এর একটি উদাহরণ হল ফ্লোটিং পয়েন্ট নম্বর টাইপ: ফ্লোটিং পয়েন্ট সংখ্যার ইমপ্লিমেন্টেশন বলে যে নট-এ-নাম্বার (NaN) ভ্যালুর দুটি ইন্সট্যান্স একে অপরের সমান নয়।
কখন Eq প্রয়োজন তার একটি উদাহরণ হল HashMap<K, V>-তে key-এর জন্য, যাতে HashMap<K, V> বলতে পারে দুটি key একই কিনা।
অর্ডারিং তুলনার জন্য PartialOrd এবং Ord
PartialOrd ট্রেইট আপনাকে সর্টিংয়ের উদ্দেশ্যে একটি টাইপের ইন্সট্যান্সগুলির তুলনা করার অনুমতি দেয়। যে টাইপ PartialOrd ইমপ্লিমেন্ট করে সেটি <, >, <=, এবং >= অপারেটরগুলির সাথে ব্যবহার করা যেতে পারে। আপনি শুধুমাত্র সেই টাইপগুলিতে PartialOrd ট্রেইট প্রয়োগ করতে পারেন যা PartialEq ইমপ্লিমেন্ট করে।
PartialOrd ডিরাইভ করা partial_cmp মেথড ইমপ্লিমেন্ট করে, যা একটি Option<Ordering> রিটার্ন করে যা None হবে যখন প্রদত্ত ভ্যালুগুলি কোনো অর্ডারিং তৈরি করে না। একটি ভ্যালুর উদাহরণ যা কোনো অর্ডারিং তৈরি করে না, যদিও সেই টাইপের বেশিরভাগ ভ্যালু তুলনা করা যায়, তা হল NaN ফ্লোটিং পয়েন্ট ভ্যালু। যেকোনো ফ্লোটিং পয়েন্ট নম্বর এবং NaN ফ্লোটিং পয়েন্ট ভ্যালু দিয়ে partial_cmp কল করলে None রিটার্ন করবে।
যখন স্ট্রাক্টগুলিতে ডিরাইভ করা হয়, তখন PartialOrd স্ট্রাক্ট সংজ্ঞায় ফিল্ডগুলি যে ক্রমে প্রদর্শিত হয় সেই ক্রমে প্রতিটি ফিল্ডের ভ্যালু তুলনা করে দুটি ইন্সট্যান্সের তুলনা করে। যখন এনামগুলিতে ডিরাইভ করা হয়, তখন এনাম সংজ্ঞায় আগে ঘোষিত এনামের ভেরিয়েন্টগুলিকে পরে তালিকাভুক্ত ভেরিয়েন্টগুলির চেয়ে কম বলে মনে করা হয়।
উদাহরণস্বরূপ, rand ক্রেট থেকে gen_range মেথডের জন্য PartialOrd ট্রেইট প্রয়োজন, যা একটি রেঞ্জ এক্সপ্রেশন দ্বারা নির্দিষ্ট করা রেঞ্জে একটি র্যান্ডম ভ্যালু জেনারেট করে।
Ord ট্রেইট আপনাকে জানতে দেয় যে অ্যানোটেটেড টাইপের যেকোনো দুটি ভ্যালুর জন্য, একটি বৈধ অর্ডারিং বিদ্যমান থাকবে। Ord ট্রেইট cmp মেথড ইমপ্লিমেন্ট করে, যা একটি Option<Ordering>-এর পরিবর্তে একটি Ordering রিটার্ন করে কারণ একটি বৈধ অর্ডারিং সর্বদা সম্ভব হবে। আপনি শুধুমাত্র সেই টাইপগুলিতে Ord ট্রেইট প্রয়োগ করতে পারেন যা PartialOrd এবং Eq ইমপ্লিমেন্ট করে (এবং Eq-এর জন্য PartialEq প্রয়োজন)। যখন স্ট্রাক্ট এবং এনামগুলিতে ডিরাইভ করা হয়, তখন cmp, PartialOrd-এর সাথে partial_cmp-এর জন্য ডিরাইভ করা ইমপ্লিমেন্টেশনের মতোই আচরণ করে।
কখন Ord প্রয়োজন তার একটি উদাহরণ হল BTreeSet<T>-তে ভ্যালু সংরক্ষণ করার সময়, একটি ডেটা স্ট্রাকচার যা ভ্যালুগুলির সর্ট অর্ডারের উপর ভিত্তি করে ডেটা সংরক্ষণ করে।
ভ্যালু ডুপ্লিকেট করার জন্য Clone এবং Copy
Clone ট্রেইট আপনাকে একটি ভ্যালুর একটি ডিপ কপি তৈরি করার অনুমতি দেয় এবং ডুপ্লিকেশন প্রক্রিয়ায় নির্বিচারে কোড চালানো এবং হিপ ডেটা কপি করা জড়িত থাকতে পারে। Clone সম্পর্কে আরও তথ্যের জন্য চতুর্থ অধ্যায়ের “ভেরিয়েবল এবং ডেটার সাথে ক্লোনের মিথস্ক্রিয়া” দেখুন।
Clone ডিরাইভ করা clone মেথড ইমপ্লিমেন্ট করে, যা সম্পূর্ণ টাইপের জন্য ইমপ্লিমেন্ট করা হলে, টাইপের প্রতিটি অংশে clone কল করে। এর মানে হল Clone ডিরাইভ করার জন্য টাইপের সমস্ত ফিল্ড বা ভ্যালুগুলিকে অবশ্যই Clone ইমপ্লিমেন্ট করতে হবে।
কখন Clone প্রয়োজন তার একটি উদাহরণ হল একটি স্লাইসে to_vec মেথড কল করার সময়। স্লাইসটি এতে থাকা টাইপ ইন্সট্যান্সগুলির মালিক নয়, কিন্তু to_vec থেকে রিটার্ন করা ভেক্টরটির তার ইন্সট্যান্সগুলির মালিক হতে হবে, তাই to_vec প্রতিটি আইটেমে clone কল করে। সুতরাং, স্লাইসে সংরক্ষিত টাইপটিকে অবশ্যই Clone ইমপ্লিমেন্ট করতে হবে।
Copy ট্রেইট আপনাকে শুধুমাত্র স্ট্যাকে সংরক্ষিত বিটগুলি কপি করে একটি ভ্যালু ডুপ্লিকেট করার অনুমতি দেয়; কোনো নির্বিচারে কোডের প্রয়োজন নেই। Copy সম্পর্কে আরও তথ্যের জন্য চতুর্থ অধ্যায়ের “শুধুমাত্র স্ট্যাক ডেটা: কপি” দেখুন।
Copy ট্রেইট প্রোগ্রামারদের সেই মেথডগুলিকে ওভারলোড করা এবং কোনও নির্বিচারে কোড চালানো হচ্ছে না সেই অনুমান লঙ্ঘন করা থেকে বিরত রাখতে কোনও মেথড সংজ্ঞায়িত করে না। এইভাবে, সমস্ত প্রোগ্রামার অনুমান করতে পারে যে একটি ভ্যালু কপি করা খুব দ্রুত হবে।
আপনি যেকোনো টাইপের উপর Copy ডিরাইভ করতে পারেন যার সমস্ত অংশ Copy ইমপ্লিমেন্ট করে। যে টাইপ Copy ইমপ্লিমেন্ট করে তাকে অবশ্যই Clone ইমপ্লিমেন্ট করতে হবে, কারণ যে টাইপ Copy ইমপ্লিমেন্ট করে তার Clone-এর একটি তুচ্ছ ইমপ্লিমেন্টেশন রয়েছে যা Copy-এর মতোই কাজ করে।
Copy ট্রেইট খুব কমই প্রয়োজন হয়; যে টাইপগুলি Copy ইমপ্লিমেন্ট করে তাদের অপ্টিমাইজেশন উপলব্ধ থাকে, যার অর্থ আপনাকে clone কল করতে হবে না, যা কোডটিকে আরও সংক্ষিপ্ত করে তোলে।
Copy দিয়ে যা কিছু সম্ভব তা আপনি Clone দিয়েও সম্পন্ন করতে পারেন, তবে কোডটি ধীর হতে পারে বা জায়গায় clone ব্যবহার করতে হতে পারে।
একটি নির্দিষ্ট আকারের ভ্যালুতে একটি ভ্যালু ম্যাপ করার জন্য Hash
Hash ট্রেইট আপনাকে নির্বিচারে আকারের একটি টাইপের ইন্সট্যান্স নিতে এবং একটি হ্যাশ ফাংশন ব্যবহার করে সেই ইন্সট্যান্সটিকে নির্দিষ্ট আকারের একটি ভ্যালুতে ম্যাপ করার অনুমতি দেয়। Hash ডিরাইভ করা hash মেথড ইমপ্লিমেন্ট করে। hash মেথডের ডিরাইভ করা ইমপ্লিমেন্টেশন টাইপের প্রতিটি অংশে hash কল করার ফলাফলকে একত্রিত করে, যার অর্থ Hash ডিরাইভ করার জন্য সমস্ত ফিল্ড বা ভ্যালুগুলিকে অবশ্যই Hash ইমপ্লিমেন্ট করতে হবে।
কখন Hash প্রয়োজন তার একটি উদাহরণ হল ডেটা দক্ষতার সাথে সংরক্ষণ করার জন্য HashMap<K, V>-তে key সংরক্ষণ করার সময়।
ডিফল্ট ভ্যালুর জন্য Default
Default ট্রেইট আপনাকে একটি টাইপের জন্য একটি ডিফল্ট ভ্যালু তৈরি করার অনুমতি দেয়। Default ডিরাইভ করা default ফাংশন ইমপ্লিমেন্ট করে। default ফাংশনের ডিরাইভ করা ইমপ্লিমেন্টেশন টাইপের প্রতিটি অংশে default ফাংশন কল করে, যার অর্থ Default ডিরাইভ করার জন্য টাইপের সমস্ত ফিল্ড বা ভ্যালুগুলিকে অবশ্যই Default ইমপ্লিমেন্ট করতে হবে।
Default::default ফাংশনটি সাধারণত পঞ্চম অধ্যায়ের “স্ট্রাক্ট আপডেট সিনট্যাক্স সহ অন্যান্য ইন্সট্যান্স থেকে ইন্সট্যান্স তৈরি করা” তে আলোচিত স্ট্রাক্ট আপডেট সিনট্যাক্সের সাথে ব্যবহার করা হয়। আপনি একটি স্ট্রাক্টের কয়েকটি ফিল্ড কাস্টমাইজ করতে পারেন এবং তারপর ..Default::default() ব্যবহার করে বাকি ফিল্ডগুলির জন্য একটি ডিফল্ট ভ্যালু সেট এবং ব্যবহার করতে পারেন।
উদাহরণস্বরূপ, আপনি যখন Option<T> ইন্সট্যান্সে unwrap_or_default মেথড ব্যবহার করেন তখন Default ট্রেইট প্রয়োজন। যদি Option<T> None হয়, তাহলে unwrap_or_default মেথড Option<T>-তে সংরক্ষিত টাইপ T-এর জন্য Default::default-এর ফলাফল রিটার্ন করবে।
পরিশিষ্ট D - দরকারী ডেভেলপমেন্ট টুল (Useful Development Tools)
এই পরিশিষ্টে, আমরা কিছু দরকারী ডেভেলপমেন্ট টুল নিয়ে আলোচনা করব যা Rust প্রোজেক্ট সরবরাহ করে। আমরা স্বয়ংক্রিয় ফরম্যাটিং, ওয়ার্নিং ফিক্স প্রয়োগ করার দ্রুত উপায়, একটি লিন্টার এবং IDE-এর সাথে ইন্টিগ্রেশন দেখব।
rustfmt দিয়ে স্বয়ংক্রিয় ফরম্যাটিং (Automatic Formatting)
rustfmt টুলটি কমিউনিটি কোড স্টাইল অনুযায়ী আপনার কোড রিফরম্যাট করে। অনেক সহযোগিতামূলক প্রোজেক্ট Rust লেখার সময় কোন স্টাইল ব্যবহার করতে হবে তা নিয়ে তর্ক এড়াতে rustfmt ব্যবহার করে: প্রত্যেকে টুল ব্যবহার করে তাদের কোড ফরম্যাট করে।
rustfmt ইনস্টল করতে, নিম্নলিখিতটি লিখুন:
$ rustup component add rustfmt
এই কমান্ডটি আপনাকে rustfmt এবং cargo-fmt দেয়, একইভাবে Rust আপনাকে rustc এবং cargo উভয়ই দেয়। যেকোনো Cargo প্রোজেক্ট ফরম্যাট করতে, নিম্নলিখিতটি লিখুন:
$ cargo fmt
এই কমান্ডটি চালানো বর্তমান ক্রেটের সমস্ত Rust কোডকে রিফরম্যাট করে। এটি শুধুমাত্র কোড স্টাইল পরিবর্তন করবে, কোড শব্দার্থ নয়। rustfmt সম্পর্কে আরও তথ্যের জন্য, এর ডকুমেন্টেশন দেখুন।
rustfix দিয়ে আপনার কোড ঠিক করুন (Fix Your Code)
rustfix টুলটি Rust ইনস্টলেশনের সাথে অন্তর্ভুক্ত এবং স্বয়ংক্রিয়ভাবে কম্পাইলার ওয়ার্নিংগুলি ঠিক করতে পারে যেগুলির সমস্যা সমাধানের একটি পরিষ্কার উপায় রয়েছে যা সম্ভবত আপনি চান। সম্ভবত আপনি আগেও কম্পাইলার ওয়ার্নিং দেখেছেন। উদাহরণস্বরূপ, এই কোডটি বিবেচনা করুন:
Filename: src/main.rs
fn main() { let mut x = 42; println!("{x}"); }
এখানে, আমরা x ভেরিয়েবলটিকে মিউটেবল হিসাবে সংজ্ঞায়িত করছি, কিন্তু আমরা আসলে এটিকে কখনই মিউটেট করি না। Rust আমাদের সেই সম্পর্কে সতর্ক করে:
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: variable does not need to be mutable
--> src/main.rs:2:9
|
2 | let mut x = 0;
| ----^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
ওয়ার্নিংটি সাজেস্ট করে যে আমরা mut কীওয়ার্ডটি সরিয়ে দিই। আমরা cargo fix কমান্ডটি চালিয়ে rustfix টুল ব্যবহার করে স্বয়ংক্রিয়ভাবে সেই সাজেশনটি প্রয়োগ করতে পারি:
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
আমরা যখন আবার src/main.rs দেখি, তখন আমরা দেখতে পাব যে cargo fix কোড পরিবর্তন করেছে:
Filename: src/main.rs
fn main() { let x = 42; println!("{x}"); }
x ভেরিয়েবলটি এখন ইমিউটেবল, এবং ওয়ার্নিংটি আর দেখা যায় না।
আপনি বিভিন্ন Rust এডিশনের মধ্যে আপনার কোড পরিবর্তন করতে cargo fix কমান্ডটিও ব্যবহার করতে পারেন। এডিশনগুলি পরিশিষ্ট E-এ কভার করা হয়েছে।
Clippy-র সাথে আরও লিন্ট (More Lints with Clippy)
Clippy টুলটি আপনার কোড অ্যানালাইজ করার জন্য লিন্টের একটি সংগ্রহ, যাতে আপনি সাধারণ ভুলগুলি ধরতে পারেন এবং আপনার Rust কোড উন্নত করতে পারেন।
Clippy ইনস্টল করতে, নিম্নলিখিতটি লিখুন:
$ rustup component add clippy
যেকোনো Cargo প্রোজেক্টে Clippy-র লিন্ট চালানোর জন্য, নিম্নলিখিতটি লিখুন:
$ cargo clippy
উদাহরণস্বরূপ, ধরুন আপনি এমন একটি প্রোগ্রাম লেখেন যা একটি গাণিতিক কনস্ট্যান্টের আসন্ন মান ব্যবহার করে, যেমন pi, যেমনটি এই প্রোগ্রামটি করে:
Filename: src/main.rs
fn main() { let x = 3.1415; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
এই প্রোজেক্টে cargo clippy চালালে এই এররটি আসে:
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
এই এররটি আপনাকে জানায় যে Rust-এ ইতিমধ্যেই একটি আরও সুনির্দিষ্ট PI কনস্ট্যান্ট সংজ্ঞায়িত করা হয়েছে এবং আপনি যদি কনস্ট্যান্টটি ব্যবহার করেন তবে আপনার প্রোগ্রামটি আরও সঠিক হবে। তারপর আপনি PI কনস্ট্যান্ট ব্যবহার করার জন্য আপনার কোড পরিবর্তন করবেন। নিম্নলিখিত কোডটি Clippy থেকে কোনো এরর বা ওয়ার্নিং দেয় না:
Filename: src/main.rs
fn main() { let x = std::f64::consts::PI; let r = 8.0; println!("the area of the circle is {}", x * r * r); }
Clippy সম্পর্কে আরও তথ্যের জন্য, এর ডকুমেন্টেশন দেখুন।
rust-analyzer ব্যবহার করে IDE ইন্টিগ্রেশন
IDE ইন্টিগ্রেশনে সাহায্য করার জন্য, Rust কমিউনিটি rust-analyzer ব্যবহার করার পরামর্শ দেয়। এই টুলটি কম্পাইলার-কেন্দ্রিক ইউটিলিটিগুলির একটি সেট যা ল্যাঙ্গুয়েজ সার্ভার প্রোটোকল-এ কথা বলে, যা IDE এবং প্রোগ্রামিং ভাষাগুলির একে অপরের সাথে যোগাযোগ করার জন্য একটি স্পেসিফিকেশন। বিভিন্ন ক্লায়েন্ট rust-analyzer ব্যবহার করতে পারে, যেমন Visual Studio Code-এর জন্য Rust analyzer প্লাগ-ইন।
ইনস্টলেশন নির্দেশাবলীর জন্য rust-analyzer প্রকল্পের হোম পেজ দেখুন, তারপর আপনার নির্দিষ্ট IDE-তে ল্যাঙ্গুয়েজ সার্ভার সাপোর্ট ইনস্টল করুন। আপনার IDE অটোকমপ্লিশন, জাম্প টু ডেফিনিশন এবং ইনলাইন এরর-এর মতো ক্ষমতা অর্জন করবে।
পরিশিষ্ট E - এডিশন (Editions)
প্রথম অধ্যায়ে, আপনি দেখেছেন যে cargo new আপনার Cargo.toml ফাইলে এডিশন সম্পর্কে কিছু মেটাডেটা যুক্ত করে। এই পরিশিষ্টে এটি কী বোঝায় তা নিয়ে আলোচনা করা হয়েছে।
Rust ভাষা এবং কম্পাইলারের ছয় সপ্তাহের একটি রিলিজ চক্র রয়েছে, যার অর্থ ব্যবহারকারীরা ক্রমাগত নতুন ফিচারের একটি ধারা পান। অন্যান্য প্রোগ্রামিং ভাষাগুলি কম ঘন ঘন বড় পরিবর্তন প্রকাশ করে; Rust আরও ঘন ঘন ছোট আপডেট প্রকাশ করে। কিছুক্ষণ পর, এই সমস্ত ক্ষুদ্র পরিবর্তনগুলি যোগ হয়ে যায়। কিন্তু রিলিজ থেকে রিলিজে ফিরে তাকানো এবং বলা কঠিন হতে পারে, "বাহ, Rust 1.10 এবং Rust 1.31-এর মধ্যে, Rust অনেক পরিবর্তিত হয়েছে!"
প্রতি দুই বা তিন বছরে, Rust টিম একটি নতুন Rust এডিশন তৈরি করে। প্রতিটি এডিশন সম্পূর্ণ আপডেটেড ডকুমেন্টেশন এবং টুলিং সহ একটি পরিষ্কার প্যাকেজে যে ফিচারগুলি এসেছে সেগুলিকে একত্রিত করে। নতুন এডিশনগুলি সাধারণ ছয় সপ্তাহের রিলিজ প্রক্রিয়ার অংশ হিসাবে পাঠানো হয়।
এডিশনগুলি বিভিন্ন লোকের জন্য বিভিন্ন উদ্দেশ্যে কাজ করে:
- সক্রিয় Rust ব্যবহারকারীদের জন্য, একটি নতুন এডিশন ক্রমবর্ধমান পরিবর্তনগুলিকে সহজে বোঝা যায় এমন একটি প্যাকেজে একত্রিত করে।
- অ-ব্যবহারকারীদের জন্য, একটি নতুন এডিশন সংকেত দেয় যে কিছু বড় অগ্রগতি এসেছে, যা Rust-কে পুনরায় দেখার যোগ্য করে তুলতে পারে।
- যারা Rust ডেভেলপ করছেন তাদের জন্য, একটি নতুন এডিশন সমগ্র প্রোজেক্টের জন্য একটি র্যালিং পয়েন্ট প্রদান করে।
এই লেখার সময়, চারটি Rust এডিশন উপলব্ধ: Rust 2015, Rust 2018, Rust 2021, এবং Rust 2024। এই বইটি Rust 2024 এডিশনের ইডিয়ম ব্যবহার করে লেখা হয়েছে।
Cargo.toml-এর edition কী নির্দেশ করে যে কম্পাইলার আপনার কোডের জন্য কোন এডিশন ব্যবহার করবে। যদি কী-টি বিদ্যমান না থাকে, তাহলে পশ্চাৎগামী সামঞ্জস্যতার কারণে Rust 2015 কে এডিশন ভ্যালু হিসাবে ব্যবহার করে।
প্রতিটি প্রোজেক্ট ডিফল্ট 2015 এডিশন ছাড়া অন্য কোনো এডিশন বেছে নিতে পারে। এডিশনগুলিতে বেমানান পরিবর্তন থাকতে পারে, যেমন একটি নতুন কীওয়ার্ড অন্তর্ভুক্ত করা যা কোডের আইডেন্টিফায়ারের সাথে বিরোধ করে। যাইহোক, আপনি যদি সেই পরিবর্তনগুলিতে অপ্ট ইন না করেন, তাহলে আপনি যে Rust কম্পাইলার ভার্সন ব্যবহার করছেন তা আপগ্রেড করলেও আপনার কোড কম্পাইল হতে থাকবে।
সমস্ত Rust কম্পাইলার ভার্সন সেই কম্পাইলারের প্রকাশের আগে বিদ্যমান যেকোনো এডিশনকে সমর্থন করে এবং তারা যেকোনো সমর্থিত এডিশনের ক্রেটগুলিকে একসাথে লিঙ্ক করতে পারে। এডিশন পরিবর্তনগুলি শুধুমাত্র কম্পাইলার প্রাথমিকভাবে কোড পার্স করার পদ্ধতিকে প্রভাবিত করে। অতএব, আপনি যদি Rust 2015 ব্যবহার করেন এবং আপনার একটি ডিপেন্ডেন্সি Rust 2018 ব্যবহার করে, তাহলে আপনার প্রোজেক্ট কম্পাইল হবে এবং সেই ডিপেন্ডেন্সি ব্যবহার করতে পারবে। বিপরীত পরিস্থিতি, যেখানে আপনার প্রোজেক্ট Rust 2018 ব্যবহার করে এবং একটি ডিপেন্ডেন্সি Rust 2015 ব্যবহার করে, তাও কাজ করে।
স্পষ্ট করার জন্য: বেশিরভাগ ফিচার সমস্ত এডিশনে উপলব্ধ থাকবে। যেকোনো Rust এডিশন ব্যবহারকারী ডেভেলপাররা নতুন স্থিতিশীল রিলিজ হওয়ার সাথে সাথে উন্নতি দেখতে থাকবেন। যাইহোক, কিছু ক্ষেত্রে, প্রধানত যখন নতুন কীওয়ার্ড যোগ করা হয়, কিছু নতুন ফিচার শুধুমাত্র পরবর্তী এডিশনগুলিতে উপলব্ধ হতে পারে। আপনি যদি এই ধরনের ফিচারগুলির সুবিধা নিতে চান তবে আপনাকে এডিশন পরিবর্তন করতে হবে।
আরও বিশদ বিবরণের জন্য, Edition Guide হল এডিশন সম্পর্কে একটি সম্পূর্ণ বই যা এডিশনগুলির মধ্যে পার্থক্য গণনা করে এবং cargo fix-এর মাধ্যমে কীভাবে স্বয়ংক্রিয়ভাবে আপনার কোডকে একটি নতুন এডিশনে আপগ্রেড করবেন তা ব্যাখ্যা করে।
পরিশিষ্ট F: বইটির অনুবাদ (Translations of the Book)
ইংরেজি ছাড়া অন্য ভাষাগুলির রিসোর্সের জন্য। বেশিরভাগই এখনও প্রক্রিয়াধীন; সাহায্য করতে বা একটি নতুন অনুবাদ সম্পর্কে আমাদের জানাতে অনুবাদ লেবেল দেখুন!
- Português (BR)
- Português (PT)
- 简体中文: KaiserY/trpl-zh-cn, gnu4cn/rust-lang-Zh_CN
- 正體中文
- Українська
- Español, alternate, Español por RustLangES
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi, Persian (FA)
- Deutsch
- हिंदी
- ไทย
- Danske
পরিশিষ্ট G - কীভাবে Rust তৈরি হয় এবং "নাইটলি Rust" (How Rust is Made and "Nightly Rust")
এই পরিশিষ্টটি Rust কীভাবে তৈরি হয় এবং এটি আপনাকে একজন Rust ডেভেলপার হিসেবে কীভাবে প্রভাবিত করে সে সম্পর্কে।
স্থবিরতা ছাড়া স্থিতিশীলতা (Stability Without Stagnation)
একটি ভাষা হিসাবে, Rust আপনার কোডের স্থায়িত্ব সম্পর্কে অত্যন্ত যত্নশীল। আমরা চাই Rust এমন একটি মজবুত ভিত্তি হোক যার উপর আপনি নির্মাণ করতে পারেন, এবং যদি জিনিসগুলি ক্রমাগত পরিবর্তিত হতে থাকে, তবে সেটি অসম্ভব হবে। একই সময়ে, যদি আমরা নতুন ফিচার নিয়ে পরীক্ষা-নিরীক্ষা করতে না পারি, তাহলে আমরা গুরুত্বপূর্ণ ত্রুটিগুলি রিলিজের আগে জানতে পারব না, যখন আমরা আর কোনো পরিবর্তন করতে পারব না।
এই সমস্যার সমাধানে আমরা যাকে বলি "স্থবিরতা ছাড়া স্থিতিশীলতা", এবং আমাদের গাইডলাইন হল: আপনার কখনই স্থিতিশীল Rust-এর একটি নতুন ভার্সনে আপগ্রেড করতে ভয় পাওয়া উচিত নয়। প্রতিটি আপগ্রেড যন্ত্রণাহীন হওয়া উচিত, তবে আপনাকে নতুন ফিচার, কম বাগ এবং দ্রুত কম্পাইল করার সময় এনে দেবে।
ছু-ছু! রিলিজ চ্যানেল এবং ট্রেনে চড়া (Choo, Choo! Release Channels and Riding the Trains)
Rust ডেভেলপমেন্ট একটি ট্রেন সময়সূচীতে কাজ করে। অর্থাৎ, সমস্ত ডেভেলপমেন্ট Rust রিপোজিটরির master ব্রাঞ্চে করা হয়। রিলিজগুলি একটি সফটওয়্যার রিলিজ ট্রেন মডেল অনুসরণ করে, যা Cisco IOS এবং অন্যান্য সফটওয়্যার প্রোজেক্ট দ্বারা ব্যবহৃত হয়েছে। Rust-এর জন্য তিনটি রিলিজ চ্যানেল রয়েছে:
- নাইটলি (Nightly)
- বিটা (Beta)
- স্থিতিশীল (Stable)
বেশিরভাগ Rust ডেভেলপার প্রাথমিকভাবে স্থিতিশীল চ্যানেল ব্যবহার করেন, তবে যারা পরীক্ষামূলক নতুন ফিচারগুলি ব্যবহার করতে চান তারা নাইটলি বা বিটা ব্যবহার করতে পারেন।
ডেভেলপমেন্ট এবং রিলিজ প্রক্রিয়া কীভাবে কাজ করে তার একটি উদাহরণ এখানে দেওয়া হল: ধরা যাক Rust টিম Rust 1.5-এর রিলিজে কাজ করছে। সেই রিলিজটি ২০১৫ সালের ডিসেম্বরে হয়েছিল, তবে এটি আমাদের বাস্তবসম্মত ভার্সন নম্বর সরবরাহ করবে। Rust-এ একটি নতুন ফিচার যোগ করা হয়েছে: master ব্রাঞ্চে একটি নতুন কমিট আসে। প্রতি রাতে, Rust-এর একটি নতুন নাইটলি ভার্সন তৈরি করা হয়। প্রতিটি দিন একটি রিলিজের দিন, এবং এই রিলিজগুলি আমাদের রিলিজ পরিকাঠামো দ্বারা স্বয়ংক্রিয়ভাবে তৈরি করা হয়। সুতরাং সময় অতিবাহিত হওয়ার সাথে সাথে, আমাদের রিলিজগুলি প্রতি রাতে এইরকম দেখায়:
nightly: * - - * - - *
প্রতি ছয় সপ্তাহে, একটি নতুন রিলিজ প্রস্তুত করার সময়! Rust রিপোজিটরির beta ব্রাঞ্চটি নাইটলি দ্বারা ব্যবহৃত master ব্রাঞ্চ থেকে শাখা তৈরি করে। এখন, দুটি রিলিজ রয়েছে:
nightly: * - - * - - *
|
beta: *
বেশিরভাগ Rust ব্যবহারকারী সক্রিয়ভাবে বিটা রিলিজ ব্যবহার করেন না, তবে সম্ভাব্য রিগ্রেশন আবিষ্কার করতে Rust-কে সাহায্য করার জন্য তাদের CI সিস্টেমে বিটার বিরুদ্ধে পরীক্ষা করেন। ইতিমধ্যে, এখনও প্রতি রাতে একটি নাইটলি রিলিজ রয়েছে:
nightly: * - - * - - * - - * - - *
|
beta: *
ধরা যাক একটি রিগ্রেশন পাওয়া গেছে। ভালো যে রিগ্রেশনটি একটি স্থিতিশীল রিলিজে লুকিয়ে যাওয়ার আগে আমাদের বিটা রিলিজটি পরীক্ষা করার জন্য কিছু সময় ছিল! ফিক্সটি master-এ প্রয়োগ করা হয়েছে, যাতে নাইটলি ঠিক করা হয় এবং তারপর ফিক্সটি beta ব্রাঞ্চে ব্যাকপোর্ট করা হয় এবং বিটার একটি নতুন রিলিজ তৈরি করা হয়:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
প্রথম বিটা তৈরি হওয়ার ছয় সপ্তাহ পরে, একটি স্থিতিশীল রিলিজের সময়! stable ব্রাঞ্চটি beta ব্রাঞ্চ থেকে তৈরি করা হয়:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
হুররে! Rust 1.5 সম্পন্ন হয়েছে! যাইহোক, আমরা একটি জিনিস ভুলে গেছি: যেহেতু ছয় সপ্তাহ চলে গেছে, তাই আমাদের Rust-এর পরবর্তী ভার্সন, 1.6-এর একটি নতুন বিটাও প্রয়োজন। তাই stable beta থেকে শাখা তৈরি করার পরে, beta-এর পরবর্তী ভার্সনটি আবার nightly থেকে শাখা তৈরি করে:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
এটিকে "ট্রেন মডেল" বলা হয় কারণ প্রতি ছয় সপ্তাহে, একটি রিলিজ "স্টেশন ছেড়ে যায়", কিন্তু একটি স্থিতিশীল রিলিজ হিসাবে পৌঁছানোর আগে এটিকে এখনও বিটা চ্যানেলের মধ্য দিয়ে একটি যাত্রা করতে হয়।
Rust প্রতি ছয় সপ্তাহে ঘড়ির কাঁটার মতো রিলিজ হয়। আপনি যদি একটি Rust রিলিজের তারিখ জানেন, তাহলে আপনি পরবর্তীটির তারিখ জানতে পারবেন: এটি ছয় সপ্তাহ পরে। প্রতি ছয় সপ্তাহে রিলিজ নির্ধারিত হওয়ার একটি সুন্দর দিক হল যে পরবর্তী ট্রেন শীঘ্রই আসছে। যদি কোনো ফিচার কোনো নির্দিষ্ট রিলিজ মিস করে, তাহলে চিন্তার কিছু নেই: অল্প সময়ের মধ্যেই আরেকটি আসছে! এটি রিলিজের সময়সীমার কাছাকাছি সম্ভবত অপালিশ করা ফিচারগুলিকে লুকিয়ে রাখার চাপ কমাতে সাহায্য করে।
এই প্রক্রিয়ার জন্য ধন্যবাদ, আপনি সর্বদা Rust-এর পরবর্তী বিল্ডটি পরীক্ষা করে দেখতে পারেন এবং নিজে যাচাই করতে পারেন যে আপগ্রেড করা সহজ কিনা: যদি একটি বিটা রিলিজ প্রত্যাশা অনুযায়ী কাজ না করে, তাহলে আপনি টিমের কাছে রিপোর্ট করতে পারেন এবং পরবর্তী স্থিতিশীল রিলিজ হওয়ার আগে এটি ঠিক করাতে পারেন! একটি বিটা রিলিজে ভাঙ্গন তুলনামূলকভাবে বিরল, কিন্তু rustc এখনও একটি সফটওয়্যারের অংশ, এবং বাগ বিদ্যমান থাকে।
রক্ষণাবেক্ষণের সময়
Rust প্রোজেক্ট সবচেয়ে সাম্প্রতিক স্থিতিশীল ভার্সনটিকে সমর্থন করে। যখন একটি নতুন স্থিতিশীল ভার্সন প্রকাশিত হয়, তখন পুরানো ভার্সনটি তার জীবনকালের শেষে (EOL) পৌঁছে যায়। এর মানে প্রতিটি ভার্সন ছয় সপ্তাহের জন্য সমর্থিত।
অস্থির ফিচার (Unstable Features)
এই রিলিজ মডেলের সাথে আরও একটি বিষয় রয়েছে: অস্থির ফিচার। Rust একটি "ফিচার ফ্ল্যাগ" নামক কৌশল ব্যবহার করে, যা নির্ধারণ করে যে একটি প্রদত্ত রিলিজে কোন ফিচারগুলি সক্রিয় করা হয়েছে। যদি একটি নতুন ফিচার সক্রিয় ডেভেলপমেন্টের অধীনে থাকে, তবে সেটি master-এ আসে এবং সেইজন্য, নাইটলিতে, কিন্তু একটি ফিচার ফ্ল্যাগের পিছনে। আপনি যদি একজন ব্যবহারকারী হিসাবে, কাজের অগ্রগতিতে থাকা ফিচারটি ব্যবহার করতে চান, তাহলে আপনি তা করতে পারেন, কিন্তু আপনাকে অবশ্যই Rust-এর একটি নাইটলি রিলিজ ব্যবহার করতে হবে এবং অপ্ট ইন করার জন্য উপযুক্ত ফ্ল্যাগ দিয়ে আপনার সোর্স কোড অ্যানোটেট করতে হবে।
আপনি যদি Rust-এর বিটা বা স্থিতিশীল রিলিজ ব্যবহার করেন, তাহলে আপনি কোনো ফিচার ফ্ল্যাগ ব্যবহার করতে পারবেন না। এটি হল মূল বিষয় যা আমাদের নতুন ফিচারগুলিকে চিরতরে স্থিতিশীল ঘোষণা করার আগে ব্যবহারিক ব্যবহারের সুযোগ দেয়। যারা ব্লিডিং এজ-এ থাকতে চান তারা তা করতে পারেন, এবং যারা একটি রক-সলিড অভিজ্ঞতা চান তারা স্থিতিশীল থাকতে পারেন এবং জানতে পারেন যে তাদের কোড ভাঙবে না। স্থবিরতা ছাড়া স্থিতিশীলতা।
এই বইটিতে শুধুমাত্র স্থিতিশীল ফিচার সম্পর্কে তথ্য রয়েছে, কারণ অগ্রগতির ফিচারগুলি এখনও পরিবর্তনশীল, এবং নিশ্চিতভাবেই এই বইটি লেখার সময় এবং স্থিতিশীল বিল্ডগুলিতে সক্রিয় হওয়ার মধ্যে সেগুলি আলাদা হবে। আপনি অনলাইন-এ নাইটলি-অনলি ফিচারগুলির জন্য ডকুমেন্টেশন খুঁজে পেতে পারেন।
Rustup এবং Rust Nightly-র ভূমিকা
Rustup গ্লোবাল বা প্রোজেক্ট-ভিত্তিক ভিত্তিতে Rust-এর বিভিন্ন রিলিজ চ্যানেলের মধ্যে পরিবর্তন করা সহজ করে তোলে। ডিফল্টরূপে, আপনার স্থিতিশীল Rust ইনস্টল করা থাকবে। উদাহরণস্বরূপ, নাইটলি ইনস্টল করতে:
$ rustup toolchain install nightly
আপনি rustup দিয়ে আপনার ইনস্টল করা সমস্ত টুলচেইন (Rust-এর রিলিজ এবং সংশ্লিষ্ট কম্পোনেন্ট) দেখতে পারেন। আপনার একজন লেখকের উইন্ডোজ কম্পিউটারে এখানে একটি উদাহরণ রয়েছে:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
আপনি দেখতে পাচ্ছেন, স্থিতিশীল টুলচেইন হল ডিফল্ট। বেশিরভাগ Rust ব্যবহারকারী বেশিরভাগ সময় স্থিতিশীল ব্যবহার করেন। আপনি হয়তো বেশিরভাগ সময় স্থিতিশীল ব্যবহার করতে চাইতে পারেন, কিন্তু একটি নির্দিষ্ট প্রোজেক্টে নাইটলি ব্যবহার করতে পারেন, কারণ আপনি একটি কাটিং-এজ ফিচার সম্পর্কে আগ্রহী। এটি করার জন্য, আপনি সেই প্রোজেক্টের ডিরেক্টরিতে rustup override ব্যবহার করে নাইটলি টুলচেইন সেট করতে পারেন, যেটি rustup ব্যবহার করবে যখন আপনি সেই ডিরেক্টরিতে থাকবেন:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
এখন, প্রতিবার আপনি ~/projects/needs-nightly-এর ভিতরে rustc বা cargo কল করবেন, rustup নিশ্চিত করবে যে আপনি আপনার স্থিতিশীল Rust-এর ডিফল্টের পরিবর্তে নাইটলি Rust ব্যবহার করছেন। আপনার যখন অনেক Rust প্রোজেক্ট থাকে তখন এটি কাজে আসে!
RFC প্রক্রিয়া এবং টিম (The RFC Process and Teams)
তাহলে আপনি এই নতুন ফিচারগুলি সম্পর্কে কীভাবে জানবেন? Rust-এর ডেভেলপমেন্ট মডেল একটি রিকোয়েস্ট ফর কমেন্টস (RFC) প্রক্রিয়া অনুসরণ করে। আপনি যদি Rust-এ কোনো উন্নতি চান, তাহলে আপনি একটি প্রস্তাব লিখতে পারেন, যাকে RFC বলা হয়।
যেকোনো ব্যক্তি Rust উন্নত করার জন্য RFC লিখতে পারেন, এবং প্রস্তাবগুলি Rust টিম দ্বারা পর্যালোচনা ও আলোচনা করা হয়, যা অনেক বিষয়ভিত্তিক সাবটিম নিয়ে গঠিত। Rust-এর ওয়েবসাইটে টিমগুলির একটি সম্পূর্ণ তালিকা রয়েছে, যার মধ্যে প্রোজেক্টের প্রতিটি ক্ষেত্রের জন্য টিম রয়েছে: ভাষা ডিজাইন, কম্পাইলার ইমপ্লিমেন্টেশন, পরিকাঠামো, ডকুমেন্টেশন এবং আরও অনেক কিছু। উপযুক্ত টিম প্রস্তাব এবং কমেন্টগুলি পড়ে, তাদের নিজস্ব কিছু কমেন্ট লেখে এবং অবশেষে, ফিচারটি গ্রহণ বা প্রত্যাখ্যান করার জন্য একটি ঐক্যমত হয়।
যদি ফিচারটি গৃহীত হয়, তাহলে Rust রিপোজিটরিতে একটি ইস্যু খোলা হয় এবং কেউ এটি ইমপ্লিমেন্ট করতে পারে। যিনি এটি ইমপ্লিমেন্ট করেন তিনি খুব সম্ভবত সেই ব্যক্তি নাও হতে পারেন যিনি প্রথমে ফিচারটির প্রস্তাব করেছিলেন! যখন ইমপ্লিমেন্টেশন প্রস্তুত হয়, তখন এটি একটি ফিচার গেটের পিছনে master ব্রাঞ্চে আসে, যেমনটি আমরা “অস্থির ফিচার” বিভাগে আলোচনা করেছি।
কিছু সময় পরে, যখন নাইটলি রিলিজ ব্যবহারকারী Rust ডেভেলপাররা নতুন ফিচারটি ব্যবহার করার সুযোগ পান, তখন টিমের সদস্যরা ফিচারটি নিয়ে আলোচনা করবেন, এটি নাইটলিতে কীভাবে কাজ করেছে এবং এটি স্থিতিশীল Rust-এ যাওয়া উচিত কিনা তা নিয়ে সিদ্ধান্ত নেবেন। যদি সিদ্ধান্ত হয় এগিয়ে যাওয়ার, তাহলে ফিচার গেটটি সরিয়ে ফেলা হয় এবং ফিচারটি এখন স্থিতিশীল বলে বিবেচিত হয়! এটি ট্রেনে চড়ে Rust-এর একটি নতুন স্থিতিশীল রিলিজে যায়।